#data-duplicates
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 4 main sources of revenue.
Text
Cleaning Dirty Data in Python: Practical Techniques with Pandas
I. Introduction Hey there! So, let’s talk about a really important step in data analysis: data cleaning. It’s basically like tidying up your room before a big party – you want everything to be neat and organized so you can find what you need, right? Now, when it comes to sorting through a bunch of messy data, you’ll be glad to have a tool like Pandas by your side. It’s like the superhero of…

View On WordPress
#categorical-data#data-cleaning#data-duplicates#data-outliers#inconsistent-data#missing-values#pandas-tutorial#python-data-cleaning-tools#python-data-manipulation#python-pandas#text-cleaning
0 notes
Text


Back in 2022 I started this drawing and it was kinda an overwhelming concept to pull off in scale - just didnt have the right likeness or planes. I had done an adequate drawover for Tella and Atanas last year around this time then left it alone for another year. Glad to finally have it done and match the vision in my head. Included a layer tab-thru under the read more to show how tedious this was with a composition the size of my bathtub...
#myart#myocs#ubetella#atanas#sorry if this double posts i didnt let it process so im trying again and it might send it twice#ill just delete the prev one if i find it duplicated lol#its not a particularly data heavy set of items so idk wtf tumblrs so mad about
46 notes
·
View notes
Text
Science Communication post for school part II: Madagascar hissing cockroaches


This time we looked at light preference and food preference in cockroaches
MHCs are nocturnal detritivores (meaning they eat decaying plant and animal matter). They produce a hissing sound by forcing air out of their spiracles.
The experiment was conducted using choice chambers to give the cockroaches the option to choose between a light and dark area, and later, choose to eat a carrot or slice of pepperoni. They were deprived of food but not moisture for 5 days leading up to the experiment.

The fact they are nocturnal may make it seem like they would prefer the dark. However, at least at time of experimentation (early afternoon) the cockroaches were about an even split on preference.
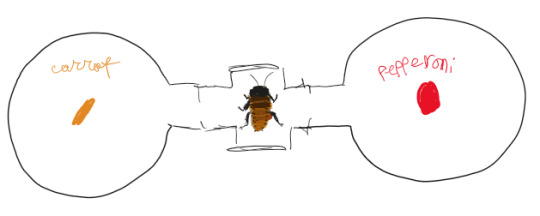
About half of the cockroaches didn't eat. It's unclear if the majority not eating is due to time of day or if they weren't hungry. Those that did eat seemed to have a preference for the carrot, although a few ate the pepperoni.
In order to record data for this experiment we used google sheets. Nearly everyone wrote down data despite working in small groups. The problem with this is that we did not use any tactics to make sure data wouldn't be repeated, perhaps group numbers would have been a good idea. So I ask you, dear random bug people on tumblr, don't do that! Make sure your data makes sense and is accurate. Even ignoring the small sample size this would not be a good study because I don't know if the data is accurate! Good data is important
#upon realizing the issues with the data i did try to sort through and remove duplicates. but i can't be certain that worked#madagascar hissing cockroach#insects#bugblr#entomology#revy the roach#<- this post isnt about him but it contains pictures of him
18 notes
·
View notes
Text
brother I am so cooked... SIX packages. I am going to fucking kill myself
#just thinking thoughts...#THE SHIPPING LABEL SYSTEM IS SO BAD? ? ?#like you have to list everything out on a digital form on your phone... BUT THEN YOU CAN'T JUST LIKE. DUPLICATE IT#AND ADD LIKE A NEW ADDRESS FOR THE SAME PACKAGE CONTENTS#YOU HAVE TO MANUALLY REENTER ALL OF IT. KILLING MYSELF.#including shit like item weights and package dimensions... come on man I am begging you to make a better system.#ONE THAT I DON'T HAVE TO DO ON MY PHONE PLEASE PLEASE PLEASE PLEASE PLEASE AUGHHH#PLEASE HAVE A MACHINE I CAN USE TO ENTER IN MY DATA#I HATE SWAPPING BETWEEN THE FORM AND MY SCREENSHOT OF THE SHIPPING ADDRESSES ON MY PHONE
7 notes
·
View notes
Text
youtube
I'm going back and reuploading my data greeting music videos, starting off with this one! :D
#kingdom hearts#kairi#sora#sokai#data greeting#video#just an fyi#the original video is now set to private on my main channel just so there won't be duplicates 😅#so... rip lol#go give this one some love!
37 notes
·
View notes
Text
Sincerely as a former user of both Excel and sheets, it is nuts how much easier libre office calc is. Not in the typical way that certain things are easier to access but moreso that the formulas and ways things are set up just work with my brain better. I never really had much need to learn formulas in Excel because there were so many and the layout felt over complicated, and don't even get me started on sheets. But with calc, there's a lot more freedom with the formulas and a lot of the skills you have from either of those other programs carries on here. Not a super big point or anything to this post, just simply very appreciative of what calc can do.
#twist rambles#like. obviously i use it a lot to format data. and i was looking into how i wanted to compare two lists bc i need to see the duplicate#issues between them. I don't want to do that manually lol. and there are so many tactics that just work out there.#like. I think in some ways u do have to fight w calc a little bit. i did a school project where we had to do a timeline and where excel has#that feature built in. calc does not. i had to spend an hour familiarizing myself with the formulas and digging on old forums and that is#simply more enjoyable to me bc i walked away with much more knowledge of the program than ok click 2 buttons. i work w spreadsheets often#enough that familiarizing myself w the formulas and different tools honestly is more helpful than it being one of the billion menu options#plus libre is free and has a ton of manuals online. which is great. and it runs better on any machine than office#^ was just thinking about all of this bc i like. didnt have the desire to learn with other sheet programs but i do here. its rewarding
5 notes
·
View notes
Text
MAN, this took a long time. So this could be the migraine talking, but I kept hitting the drop-downs on the left, and not finding it. Apparently, it goes: 1. Find Account (on the left)
2. Find blog name (on left)
3. Find Settings (on left)
4. MOVE TO THE RIGHT and find blog name under Blogs
5. Realize it's not another drop-down, so scroll to the bottom, and find Visibility just above Blocked Tumblrs.
That is devious, underhanded, and deliberately hidden so a ton of folks will just shrug and give up.

They are already selling data to midjourney, and it's very likely your work is already being used to train their models because you have to OPT OUT of this, not opt in. Very scummy of them to roll this out unannounced.
98K notes
·
View notes
Text

Stop Waste: Avoid Paying Twice for Spare Parts and Repeating RFx Procedures Let Data Governance Drive Your Procurement Efficiency
Have you ever wondered how much your company loses by purchasing the same spare parts multiple times or issuing RFx requests to the same supplier repeatedly?
In sectors such as aerospace, defense, and manufacturing, these redundant procurement activities don’t just increase expenses—they also reduce efficiency and introduce avoidable risks.
But the impact doesn’t end there:
Duplicate orders lead to unnecessary capital lock-up and poor inventory control.
Redundant RFx efforts cause wasted time, duplicated labor, and potential confusion for suppliers.
Insufficient visibility into your procurement data and processes can result in costly and time-consuming mistakes.
It’s time to eliminate inefficiencies and make your procurement process more streamlined.
How can you achieve this?
PiLog’s Data Governance solution helps you overcome these challenges by providing:
Centralized, real-time access to procurement data across all systems
Advanced data validation mechanisms that automatically identify duplicate or overlapping supply chain activities
Integrated governance frameworks and workflows that guarantee RFx requests are only sent when necessary—and directed to the right parties at the right time
By utilizing AI-driven data governance combined with intelligent automation, PiLog empowers your team to focus on strategic priorities, reduce costs, and improve operational efficiency.
0 notes
Text
High-Speed Data Transfer Equipment for Fast & Secure Duplication
Discover U-REACH, a leading brand in high-performance data transfer devices and data duplication devices designed for professionals who demand speed, accuracy, and reliability. Our advanced data transfer equipment is engineered to handle large-scale duplication tasks effortlessly, ensuring fast and secure data handling across multiple platforms. Whether you’re duplicating SSDs, HDDs, USBs, or other storage media, U-REACH offers industry-leading performance and support. In addition, our cutting-edge data sanitization devices ensure complete and certified data erasure, meeting global data security standards. Trusted by IT professionals, data centers, and government agencies worldwide, U-REACH solutions help streamline workflows and ensure secure, error-free data duplication and sanitization every time.
#data transfer devices#data transfer equipment#data duplication devices#data Sanitization devices#U-reach India
1 note
·
View note
Text
Description
Empower your website’s visibility with our cutting-edge index monitoring service. Our platform delivers real-time Google indexing insights, automated alerts, and comprehensive technical SEO audits. By optimizing crawl budgets and pinpointing index coverage issues, we help you maintain a robust online presence, ensure high-quality content gets recognized, and drive sustainable organic traffic.
Website
https://searchoptimo.com/
#Google indexing#Website indexing tool#Index monitoring software#Technical SEO audit#Crawl budget optimization#Index coverage#Real-time alerts#Organic traffic growth#Duplicate content management#Canonical tags#Site audit tool#Structured data optimization
1 note
·
View note
Text
youtube
1 note
·
View note
Text
High duplication of HTTP Proxies IPs used for crawling? How to solve it?
With the continuous progress of network technology, crawler technology has been widely used in many fields. In order to avoid being blocked by the website's anti-crawling mechanism, many developers will use Proxies IP to disguise the real identity of the crawler. However, many developers find that the duplication rate of Proxies IP is actually very high when using Proxies IP, which gives them a headache. Today, let's talk about why Proxies have such a high duplication rate? And how to solve this problem?
Why is the Proxies IP duplication rate high?
Have you ever wondered how you can still be "captured" even though you have used Proxies? In fact, the root of the problem lies in the high rate of IP duplication. So, what exactly causes this problem? The following reasons are very critical:
1. Proxies IP resources are scarce and competition is too fierce

2. Free Proxies to "squeeze out" resources
Many developers will choose to use free Proxies IP, but these free service providers often assign the same IP to different usersin order to save resources. Although you don't have to spend money, these IPs tend to bring more trouble, and the crawler effect is instead greatly reduced.
3. Crawling workload and frequent repetitive requests
The job of a crawler usually involves a lot of repetitive crawling. For example, you may need to request the same web page frequently to get the latest data updates. Even if you use multiple Proxies IPs, frequent requests can still result in the same IP appearing over and over again. For certain sensitive websites, this behavior can quickly raise an alarm and cause you to be blocked.
4. Anti-climbing mechanisms are getting smarter
Today's anti-crawling mechanisms are not as simple as they used to be, they are getting "smarter". Websites monitor the frequency and pattern of IP visits to identify crawler behavior. Even if you use Proxies, IPs with a high repetition rate are easily recognized. As a result, you have to keep switching to more IPs, which makes the problem even more complicated.
How to solve the problem of high Proxies IP duplication?
Next, we'll talk about how to solve the problem of high IP duplication to help you better utilize Proxies IP for crawler development.
1. Choose a reliable Proxies IP service provider
The free stuff is good, but the quality often can't keep up. If you want a more stable and reliable Proxies IP, it is best to go with a paid Proxies IP service provider. These service providers usually have a large number of high-quality IP resources and can ensure that these IPs are not heavily reused. For example, IP resources from real home networks are more protected from being blocked than other types of IPs.
2. Rationalization of IP allocation and rotation

3. Regular IP monitoring and updating
Even the best IPs can be blocked after a long time. Therefore, you need to monitor Proxies IPs on a regular basis. Once you find that the duplication rate of a certain IP is too high, or it has begun to show access failure, replace it with a new one in time to ensure continuous and efficient data collection.
4. Use of Proxies IP Pools
To avoid the problem of excessive Proxies IP duplication, you can also create a Proxy IP pool. Proxies IP pool is like an automation tool that helps you manage a large number of IP resources and also check the availability of these IPs on a regular basis. By automating your IP pool management, you can get high-quality Proxies more easily and ensure the diversity and stability of your IP resources.
How to further optimize the use of crawlers with Proxies IP?
You're probably still wondering what else I can do to optimize the crawler beyond these routine operations. Don't worry, here are some useful tips:
Optimize keyword strategy: Use Proxies IP to simulate search behavior in different regions and adjust your keyword strategy in time to cope with changes in different markets.
Detect global page speed: using Proxies IP can test the page loading speed in different regions of the world to optimize the user experience.
Flexible adjustment of strategy: Through Proxies IP data analysis, understand the network environment in different regions, adjust the strategy and improve the efficiency of data collection.
Conclusion
The high duplication rate of Proxies IP does bring a lot of challenges to crawler development, but these problems are completely solvable as long as you choose the right strategy. By choosing a high-quality Proxies IP service provider, using Proxies IPs wisely, monitoring IP status regularly, and establishing an IP pool management mechanism, you can greatly reduce the Proxies IP duplication rate and make your crawler project more efficient and stable.
0 notes
Text

#medical dictionary#criminals calling one time after another essentially supplying them data to elicit the conclusions and actions that they want#attacks by confused legal forces acting upon criminally fabricated data#time travel duplicated the universe
0 notes
Text
A Beginner’s Guide to Data Cleaning Techniques

Data is the lifeblood of any modern organization. However, raw data is rarely ready for analysis. Before it can be used for insights, data must be cleaned, refined, and structured—a process known as data cleaning. This blog will explore essential data-cleaning techniques, why they are important, and how beginners can master them.
#data cleaning techniques#data cleansing#data scrubbing#business intelligence#Data Cleaning Challenges#Removing Duplicate Records#Handling Missing Data#Correcting Inconsistencies#Python#pandas#R#OpenRefine#Microsoft Excel#Tools for Data Cleaning#data cleaning steps#dplyr and tidyr#basic data cleaning features#Data validation
0 notes
Text
Alright boys pack it up no more rain world posting new oni dlc is coming out in less than a week
#rat rambles#oni posting#rain posting#I jest I will probably still be posing some rain world stuff if I get around to designing more guys#but I can already feel the oni brain coming back and am half tempted to do one last comb through the files even tho I know itll be#pointless because the full dlc will be at my fingertips very soon#to be clear I 100% will be combing through the data of the full release too but thats a given#calvin my boy pls make it in pls don't get scrapped pls my boy#oh now that we're getting close Im gonna let myself talk abt this just this once but if you care abt potential spoilers stop reading#anyways so last I checked where the duplicant descriptions and stuff is stored there was an additional new duplicant named calvin#now I wasnt able to find anything else referencing him from my admittedly not super deep digging but he was there#I did thoroughly look through the spritesheets tho and hes definitely not there from what I could yell#or at least he wasnt when I checked idk maybe they put him in during one of the patches for some reason#but yeah I hope he makes it in despite all the specific advertising of them adding one new duplicant#its actually these descriptors that have been making me not wanna talk abt calvin dupe too openly as if he does make it in its probably#going to be a pretty big spoiler for a bit?#ofc if he is a secret of sorts then he wont be for long but if he is meant to be a surprise I don't wanna scream on the rooftop abt it#but I do wanna have proof that I found him before hand it he is a surprise I need to feel cool and special for looking at one file <3#yknow what I think I actually am going to pop open oni and tripple check that I'm not missing anything#I was playing rw a lot to cope with the dlc not being fully out but at this point Ive finished every campaign except saints#and saints is being a buggy bastard for me rn and keeps repeatedly softlocking me so Im giving up on it for now#like just this morning I did the entirety of the hunter campaign in like 2 hours I have so little left to do#if I do decide to replay a campaign tho it's probably going to be either gourmands or spearmasters since theyre my favorites to play as#idc what anyone says Ill always preffer the spearmasters story to rivulets I adore them both but ppl do not appreciate spearmaster enough#like every person Ive seen play it sees the ending as disappointing and I wont stand for it its high-key my favorite ending#now thats entirely because Im a moon enjoyer and a tragedy enjoyer but still I will always lose my mind over moon's final message
0 notes
Text
turns out i can reuse my first spaghetti code function for finding the previous file! now i just use it to find the file before the first entry in the list, so i run it once rather than for every file.
#tütensuppe#this is VERY useful bc like this i can also grab data that was taken while the daq wasnt running!#this was originally a major issue that resulted in the daq having to run ALL the time writing tbs of empty data (a huge waste)#anyway conversion is damn laggy today and jobs keep getting canceled bc 'file too big' smh#also i have to FIGHT the mail client today holy shit#random deletions duplicates and cursor jumps#(and dont forget that the backspace key also has a 'delete message' function that activates at random!)
0 notes