#examples of application software
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
70% of Tumblr users say the Dashboard is their favorite place to spend time online.
Text

0 notes
Text
How much do Java developers earn?
1. Introduction to Java Developer Salaries
What's the earning potential for Java developers? This is a hot topic for students, new grads, and folks looking to get into software development. With the growth of full stack dev, cloud tech, and enterprise software, Java remains essential. Salaries depend on location, experience, and skills. For students in Coimbatore studying Java, knowing what to expect in the industry is key.
Key Points:
- Java developers are in demand across various fields.
- Knowing Spring Boot and full stack skills can boost your pay.
2. Java Developer Salary for Freshers
So how much can freshers make? Entry-level Java developers in cities like Coimbatore usually earn between INR 3 to 5 LPA. Completing a Java Full Stack Developer course typically leads to better pay since it covers a wider skill set. Employers often look for hands-on experience, which is why doing Java mini projects or internships is important.
Key Points:
- Fresh Java developers start around INR 3 LPA.
- Getting certified in Java can help you land a job.
3. Experienced Java Developer Salaries
With 3-5 years under your belt, what can you expect? Salaries typically range from INR 6 to 12 LPA. Those who take a Java training course in Coimbatore often find they earn more. Companies want people with strong backend skills and experience with tools like Spring, Hibernate, or Microservices.
Key Points:
- Mid-level Java developers can earn between INR 6 to 12 LPA.
- Knowledge of Spring and REST APIs can increase your salary.
4. Senior Java Developer Salary
InsightsFor those at a senior level with over 7 years of experience, earnings can start at INR 15 to 25 LPA. This varies based on company size and responsibilities, plus keeping up with new tech is crucial. Attending weekend Java classes or coaching sessions can help keep skills fresh.
Key Points:-
- Senior Java developers generally earn over INR 15 LPA.
- Full stack skills can lead to higher pay.
5. Java Full Stack Developer Salaries
People who complete a Java Full Stack Developer Course in Coimbatore often snag higher-paying jobs. Full stack developers with skills in Java, React, and DevOps can earn about 20% more than those focused solely on Java. If you're curious about Java salaries, investing in full stack training is a smart move.
Key Points:
- Full stack Java developers can earn about 20% more.
- Having both frontend and backend knowledge is important.
6. Salary Trends in Coimbatore and Tier-2 Cities
In Coimbatore, students of Java courses often ask about earning potential. Starting salaries might be a bit lower than in metro areas, but there’s room for growth. Remote work options are now more common, allowing locals to earn metro-level salaries.
Key Points:
- Java jobs in Coimbatore offer competitive pay.
- Remote work opens doors to higher salaries.
7. Java Certification and Salary Growth
Getting certified can mean a 30-40% pay bump compared to non-certified peers. Following a structured Java course helps build strong skills. Recruiters appreciate learning paths and real-world experience from platforms offering Java programs.
Key Points:
- Java certifications help boost your credibility.
- Structured training can get you better job offers.
8. Demand for Java Developers in 2025
Looking ahead, there’s expected growth of 15% in Java jobs by 2025. More students are signing up for Java Full Stack Developer Courses in Coimbatore, and chances for freshers are expanding. Mastering Java basics through tutorials can help set you up for success.
Key Points:
- Job openings for Java developers are on the rise.
- Full stack training fits well with job market trends.
9. Java Developer Skills That Influence Salaries
Earnings for Java developers often depend on skills like Spring Boot, Microservices, REST APIs, and cloud integration. Regular practice with Java exercises, internships, and coaching can create a strong candidate.
Key Points:
- Skills in demand directly impact salary.
- Ongoing learning is vital for career growth.
10. Conclusion and Brand Mention
So how much do Java developers actually make? It varies, but with the right skills and certifications, Java can lead to a rewarding job. Whether you’re just starting out or looking to advance, getting good training is key. If you want to begin or progress in your career, check out Xplore It Corp for Java courses and training designed to help you succeed.
Key Points:
- Look for recognized training programs.
- Xplore It Corp can help you close skills and salary gaps.
FAQs
Q1. How much do Java developers earn after certification?
A certified Java developer can earn 30-40% more than non-certified ones.
Q2. Are Full Stack Developer salaries higher?
Yes, full stack developers generally make 20-25% more due to their wider range of skills.
Q3. Does location affect salaries?
Absolutely, metro cities tend to pay more, but remote jobs are helping close that gap in places like Coimbatore.
Q4. Is a Java internship necessary?
Not strictly necessary, but internships can really enhance a resume, especially for those just starting out.
Q5. What's the best way to learn Java step by step?
Join a structured course, like those from Xplore It Corp, and practice with Java tutorials and coding exercises.
#Java programming language#Object-oriented programming in Java#Java development tools#Java code examples#Java frameworks (Spring#Hibernate)#Java for web development#Core Java concepts#Java backend development#Java IDE (Eclipse#IntelliJ)#Java Virtual Machine (JVM)#Java syntax and structure#Java API integration#Java debugging tools#Java software applications#Java interview preparation#Java certification training#Java app development#Java database connectivity (JDBC)#Java deployment techniques#Enterprise Java development.
0 notes
Text
Read this comprehensive guide to build a successful Minimum Viable Product (MVP) and turn your next big idea into a successful, customer-centric product.
#what is mvp#build mvp#mvp software development#examples of mvp#Minimum Viable Product#Small Business#MVP Cost#Software Development#Software Application Development#Mobile App Development
0 notes
Text
In India, many development companies design sports-related apps. Sports Application Development Apps have various functions such as scoring in real-time statistics. This type of app provides information about games and sporting clubs. If we invest in Sports applications then your businesses grow in the future. Helpfulinsightsolution Provides the best information in every blog.

#Sports application development course#Sports application development tools#Sports application development software#Sports application development examples#sports app ideas#sports game development
0 notes
Text
Have you heard of Backend for Frontend (BFF)? Read our blog to know about its transformative potential in web development, where it elevates user experiences, tackles challenges, and optimizes your web development journey.
#Softwaredevelopmentservices#Ascendion#NitorInfotech#software development#web apps development#web application development#web application#example of an api#backend end#company development software#software company#software businesses
0 notes
Text

ERP Business Software Enterprise Resource Planning (ERP) software is a comprehensive business management solution that integrates various functional areas of an organization into a centralized system. It provides a suite of applications and tools to streamline business processes, improve efficiency, and enhance decision-making.
Implementing an ERP system requires careful planning, stakeholder involvement, and training. It is crucial to select an ERP software that aligns with the specific needs of the business and can be tailored to suit its requirements. By leveraging ERP software, businesses can streamline processes, improve efficiency, enhance decision-making, and gain a competitive advantage in the market. To know more, browse https://lsi-scheduling.com/
#erp business software#erp business software solutions#erp enterprise software#erp business solutions#erp system business process#erp software system requirements#best enterprise erp software#erp business systems#erp business applications#erp enterprise applications#erp benefits for business#erp in business process#what is erp in business#example of erp in business#erp system software#enterprise planning system#enterprise planning software#erp production scheduling
0 notes
Text
Free or Cheap Mandarin Chinese Learning Resources Because You Can't Let John Cena One Up You Again
I will update this list as I learn of any more useful ones. If you want general language learning resources check out this other post. This list is Mandarin specific. Find lists for other specific languages here.
For the purposes of this list "free" means something that is either totally free or has a useful free tier. "Cheap" is a subscription under $10USD a month, a software license or lifetime membership purchase under $100USD, or a book under $30USD. If you want to suggest a resource for this list please suggest ones in that price range that are of decent quality and not AI generated.
WEBSITES
Dong Chinese - A website with lessons, a pinyin guide, a dictionary, and various videos and practice tests. With a free account you're only allowed to do one lesson every 12 hours. To do as many lessons as quickly as you want it costs $10 a month or $80 a year.
Domino Chinese - A paid website with video based lessons from absolute beginner to college level. They claim they can get you ready to get a job in China. They offer a free trial and after that it's $5 a month or pay what you can if you want to support their company.
Chinese Education Center - This is an organization that gives information to students interested in studying abroad in China. They have free text based lessons for beginners on vocab, grammar, and handwriting.
Pleco Dictionary App - This is a very popular dictionary app on both iOS and Android. It has a basic dictionary available for free but other features can be purchased individually or in bundles. A full bundle that has what most people would want is about $30 but there are more expensive options with more features.
MIT OpenCourseWare Chinese 1 2 3 4 5 6 - These are actual archived online courses from MIT available for free. You will likely need to download them onto your computer.
Learn Chinese Web Application From Cambridge University - This is a free downloadable file with Mandarin lessons in a PC application. There's a different program for beginner and intermediate.
Learn Chinese Everyday - A free word a day website. Every day the website posts a different word with pronunciation, stroke order, and example sentences. There's also an archive of free downloadable worksheets related to previous words featured on the website.
Chinese Boost - A free website and blog with beginner lessons and articles about tips and various resources to try.
Chinese Forums - An old fashioned forum website for people learning Chinese to share resources and ask questions. It's still active as of when I'm making this list.
Du Chinese - A free website and an app with lessons and reading and listening practice with dual transcripts in both Chinese characters and pinyin. They also have an English language blog with tips, lessons, and information on Chinese culture.
YOUTUBE CHANNELS
Chinese For Us - A channel that provides free video lessons for beginners. The channel is mostly in English.
Herbin Mandarin - A channel with a variety of lessons for beginners. The channel hasn't uploaded in a while but there's a fairly large archive of lessons to watch. The channel is mainly in English.
Mandarin Blueprint - This channel is by a couple of guys who also run a paid website. However on their YouTube channel there's a lot of free videos with tips about how to go about learning Chinese, pronunciation and writing tips, and things of that nature. The channel is mainly in English.
Blabla Chinese - A comprehensible input channel with content about a variety of topics for beginner to intermediate. The video descriptions are in English but the videos themselves are all in Mandarin.
Lazy Chinese - A channel aimed at intermediate learners with videos on general topics, grammar, and culture. They also have a podcast. The channel has English descriptions but the videos are all in Mandarin.
Easy Mandarin - A channel associated with the easy languages network that interviews people on the street in Taiwan about everyday topics. The channel has on screen subtitles in traditional characters, pinyin, and English.
StickynoteChinese - A relatively new channel but it already has a decent amount of videos. Jun makes videos about culture and personal vlogs in Mandarin. The channel is aimed at learners from beginner to upper intermediate.
Story Learning Chinese With Annie - A comprehensible input channel almost entirely in Mandarin. The host teaches through stories and also makes videos about useful vocabulary words and cultural topics. It appears to be aimed at beginner to intermediate learners.
LinguaFlow Chinese - Another relatively new channel but they seem to be making new videos regularly. The channel is aimed at beginner to intermediate learners and teaches and provides listening practice with video games. The channel is mostly in Mandarin.
Lala Chinese - A channel with tips on grammar and pronunciation with the occasional vlog for listening practice, aimed at upper beginner to upper intermediate learners. Some videos are all in Mandarin while others use a mix of English and Mandarin. Most videos have dual language subtitles onscreen.
Grace Mandarin Chinese - A channel with general information on the nitty gritty of grammar, pronunciation, common mistakes, slang, and useful phrases for different levels of learners. Most videos are in English but some videos are fully in Mandarin.
READING PRACTICE
HSK Reading - A free website with articles sorted into beginner, intermediate, and advanced. Every article has comprehension questions. You can also mouse over individual characters and see the pinyin and possible translations. The website is in a mix of English and Mandarin.
chinesegradedreader.com - A free website with free short readings up to HSK level 3 or upper intermediate. Each article has an explaination at the beginning of key vocabulary words in English and you can mouse over individual characters to get translations.
Mandarin Companion - This company sells books that are translated and simplified versions of classic novels as well as a few originals for absolute beginners. They are available in both traditional and simplified Chinese. Their levels don't appear to be aligned with any HSK curriculum but even their most advanced books don't have more than 500 individual characters according to them so they're likely mostly for beginners to advanced beginners. New paperbacks seem to usually be $14 but cheaper used copies, digital copies, and audiobooks are also available. The website is in English.
Graded Chinese Readers - Not to be confused with chinese graded reader, this is a website with information on different graded readers by different authors and different companies. The website tells you what the book is about, what level it's for, whether or not it uses traditional or simplified characters, and gives you a link to where you can buy it on amazon. They seem to have links to books all the way from HSK 1 or beginner to HSK 6 or college level. A lot of the books seem to be under $10 but as they're all from different companies your mileage and availability may vary. The website is in English.
Mandarin Bean - A website with free articles about Chinese culture and different short stories. Articles are sorted by HSK level from 1 to 6. The website also lets you switch between traditional or simplified characters and turn the pinyin on or off. It also lets you mouse over characters to get a translation. They have a relatively expensive paid tier that gives you access to video lessons and HSK practice tests and lesson notes but all articles and basic features on the site are available on the free tier without an account. The website is in a mix of Mandarin and English.
Mandarin Daily News - This is a daily newspaper from Taiwan made for children so the articles are simpler, have illustrations and pictures, and use easier characters. As it's for native speaker kids in Taiwan, the site is completely in traditional Chinese.
New Tong Wen Tang for Chrome or Firefox - This is a free browser extension that can convert traditional characters to simplified characters or vice versa without a need to copy and paste things into a separate website.
PODCASTS
Melnyks Chinese - A podcast for more traditional audio Mandarin Chinese lessons for English speakers. The link I gave is to their website but they're also available on most podcatcher apps.
Chinese Track - Another podcast aimed at learning Mandarin but this one goes a bit higher into lower intermediate levels.
Dimsum Mandarin - An older podcast archive of 30 episodes of dialogues aimed at beginner to upper beginner learners.
Dashu Mandarin - A podcast run by three Chinese teachers aimed at intermediate learners that discusses culture topics and gives tips for Mandarin learners. There are also male teachers on the podcast which I'm told is relatively rare for Mandarin material aimed at learners and could help if you're struggling to understand more masculine speaking patterns.
Learning Chinese Through Stories - A storytelling podcast mostly aimed at intermediate learners but they do have some episodes aimed at beginner or advanced learners. They have various paid tiers for extra episodes and learning material on their patreon but there's still a large amount of episodes available for free.
Haike Mandarin - A conversational podcast in Taiwanese Mandarin for intermediate learners. Every episode discusses a different everyday topic. The episode descriptions and titles are entirely in traditional Chinese characters. The hosts provide free transcripts and other materials related to the episodes on their blog.
Learn Chinese With Ju - A vocabulary building podcast aimed at intermediate learners. The podcast episodes are short at around 4-6 minutes and the host speaks about a variety of topics in a mix of English and Mandarin.
xiaoyuzhou fm - An iOS app for native speakers to listen to podcasts. I’m told it has a number of interactive features. If you have an android device you’ll likely have to do some finagling with third party apps to get this one working. As this app is for native speakers, the app is entirely in simplified Chinese.
Apple Podcast directories for Taiwan and China - Podcast pages directed towards users in those countries/regions.
SELF STUDY TEXTBOOKS AND DICTIONARIES
Learning Chinese Characters - This series is sorted by HSK levels and each volume in the series is around $11. Used and digital copies can also be found for cheaper.
HSK Standard Course Textbooks - These are textbooks designed around official Chinese government affiliated HSK tests including all of the simplified characters, grammar, vocab, and cultural knowledge necessary to pass each test. There are six books in total and the books prices range wildly depending on the level and the seller, going for as cheap as $14 to as expensive as $60 though as these are pretty common textbooks, used copies and cheaper online shops can be found with a little digging. The one I have linked to here is the HSK 1 textbook. Some textbook sellers will also bundle them with a workbook, some will not.
Chinese Made Easy for Kids - Although this series is aimed at children, I'm told that it's also very useful for adult beginners. There's a large number of textbooks and workbooks at various levels. The site I linked to is aimed at people placing orders in Hong Kong but the individual pages also have links to various other websites you can buy them from in other countries. The books range from $20-$35 but I include them because some of them are cheaper and they seem really easy to find used copies of.
Reading and Writing Chinese - This book contains guides on all 2300 characters in the HSK texts as of 2013. Although it is slightly outdated, it's still useful for self study and is usually less than $20 new. Used copies are also easy to find.
Basic Chinese by Mcgraw Hill - This book also fuctions as a workbook so good quality used copies can be difficult to find. The book is usually $20 but it also often goes on sale on Amazon and they also sell a cheaper digital copy.
Chinese Grammar: A beginner's guide to basic structures - This book goes over beginner level grammar concepts and can usually be found for less than $20 in print or as low as $2 for a digital copy.
Collins Mandarin Chinese Visual Dictionary - A bilingual English/Mandarin visual dictionary that comes with a link to online audio files. A new copy goes for about $14 but used and digital versions are available.
Merriam-Webster's Chinese to English Dictionary - In general Merriam Websters usually has the cheapest decent quality multilingual dictionaries out there, including for Mandarin Chinese. New editions usually go for around $8 each while older editions are usually even cheaper.
(at the end of the list here I will say I had a difficult time finding tv series specifically made for learners of Mandarin Chinese so if you know of any that are made for teenage or adult learners or are kids shows that would be interesting to adults and are free to watch without a subscription please let me know and I will add them to the list. There's a lot of Mandarin language TV that's easy to find but what I'm specifically interested in for these lists are free to watch series made for learners and/or easy to understand kids shows originally made in the target language that are free and easy to access worldwide)
457 notes
·
View notes
Text
It's crazy that so many websites and applications whatever other example of software can reach a point where everyone likes it and it works well and people are happy and then the company that makes the app puts out a UI update for seemingly no reason and it's universally hated by every user. This happens continuously to everything and not once has it been acknowledged by anyone in the industry that this is not a good thing to do.
563 notes
·
View notes
Text
The bill in question is Senate Bill 20. Sponsored by GOP senator Pete Flores, the bill, in its own words, “creates a new state offense for the possession or promotion of obscene material that appears to depict a child younger than 18 years old, regardless of whether the depiction is of an actual child, cartoon or animation, or an image created using an artificial intelligence application or other computer software.” Furthermore, subparagraph c of the bill states: “An offense under this section is a state jail felony,” directing first-time offenders convicted under this law to a minimum of five years in prison, simply for owning or viewing such material. As many responses have pointed out, many popular manga would be banned in Texas if this law is signed into law, which certainly seems like it will at this point. Goblin Slayer is the example many are pointing to, due to the infamous assault scenes of characters by goblins in the early issues.
We haven't even been winning the culture war for a year and conservatives are already speedrunning ways to lose it again. I shouldn't be surprised by these kinds of self-inflicted Ls, but I am, and they still piss me off.
Censorship is evil and wrong. And this is pure censorship. Expanding the definition of child porn to include fake images of children that don't exist does absolutely nothing to protect real children. It just gives the anti-porn puritans something to ban. Because that's what censorious puritans do. They ban everything they don't like, because fuck freedom, personal choice, and the 1st Amendment, right?
"It's okay when we do it" isn't just the motto of the Democrats. It's an increasingly loud rallying cry from people on the right who, not even a year ago, were rightfully pushing back against the left censoring media that didn't fit their moral standards. And it's what's going to lead us back into our nice, echoey caves once the culture war turns against us and we retreat like we always do.
291 notes
·
View notes
Note
hello i love ur art <3 may i ask how you shade/render? or if you can share any helpful tutorials you learned from ^^



Unhinged Art Tutorial
Well, anon and @merlucide! I'm not sure if I'm the best person to learn from (I'll attach some video links at the end to people who I personally look to for art advice) but I happen to have a series of screenshots for how i render with a strawpage drawing I did recently(at the time I drafted most of this a month+ ago), so I'll go over what I do, at least in this case.
Warning: A bit rambly. Not sure if intelligible.
Tutorial..? Explanation? under the cut.
I have a few different shading styles based on ease of program usage and effort level, but in this case i had to individually streak the shadows. I'll be focusing on hair and skin for the most part here.
My sketches are pretty poor, because I'm hasty:



Honestly I find the better the initial sketch, the easier the final profuct will come. So take your time, use layers when sketching to be clean. The airbrush layering shows vaguely how I tend to shade hair.

Backlighting *Applicable mostly when there is a bright background, light behind the subject, or in neutral lighting.
The 'underside'/inside I tend to use a peachier, brighter tone closer to the skin color (for tanned skinned characters I'd use a shade closer to a rosy orange, since that's just a more saturated peach. For darker skinned characters, I'd recommend a slightly redder & brighter version of their skin tone. This works pretty well with dark hair+dark skin, but in the case that your character's hair color is a lot lighter compared to their skin tone [also in the case of a fair skinned character with WHITE hair] it's totally fine to ignore the natural undertone of the character and shade it with a pinkish white.) This works for any hair texture but can be more time consuming for coily hair textures. (2c-4c)

Lineart when I take my time / Old rendering video




It looks more stable if you start off with a solid lineart base because you won't struggle with big-picture placement issues.
"Lineart" when I just try to pump out a drawing

I first did a rough sketch, kept it as an overlay layer and drew over it.

(Chickenscratching is valid though, honestly. I think it has a look to it!) I usually block out base colors, and vaguely where I want the shading to go, unless I need a special type of lighting, which then I'd do the base colors and either choose to wait until I'm finished rendering or do light processing* (*will discuss this later in this post) with different blending modes and layers.
For example if I'm doing the colors mostly FIRST (Choosing a grayed out palette) and then rendering, it'd look a little something like this: Left (Trackpad, on FireAlpaca) / Right (iPad, on Clip Studio & Procreate)


Sometimes, I'll shade with a dark, grayed out tone and then fill it in with something slightly more vibrant. This kind of gives it a bounce-light feel? Also with a lot of pieces I do recently I try to block out entire parts as white because lighting especially on white background pieces looks better if you pretend that it's white behind the character due to an intense sunlight.

Also, I use gradient layers to tweak with the colors. It's pretty useful and looks nice!!!! Gradient maps are available in every software I use: Procreate, FireAlpaca and Clip Studio Paint.

I find that the more intense the light (but not scattered, as in the source is either very bright or it's very close) the darker the shadows usually look? And if there's a brightness coming from behind the figure and the hair is splayed out in some way, it will appear semi translucent because it's just a bunch of strands made of keratin and collagen, something like that....


Anyway this is all very messy but I hope it helped

Here's a process photo for how I shade if that helps too.


More examples..

I broke down my thought process in my lighting so here's a close up of that.
i totally forgot about the video links so here's my idol the one and only:
And I think this guy makes quick but concise tip videos:
Finally I really like the in depth professional explanations from a long time illustrator:
I've personally taken advice from all three's videos and used them to improve my own art, so take a peek!!!!
77 notes
·
View notes
Text

This guide outlines my process for making gifs. I primarily make gifs for video games (Dragon Age, BG3), but I learned how to gif for kpop content (music videos, stage performances). The base principles outlined here should be applicable to any other media!
What I use
Avisynth
Adobe Photoshop 2025
Posts in this guide
Avisynth Basics – How to get high-quality resizing and sharpening for your gif.
Editing Basics – The basics of generating a gif with Photoshop.
(I'll update this list if I end up making more guides!)
Please feel free to reach out if you have any questions; I'll do my best to answer them. 🙌

A note on software…
This guide assumes that you’re using Adobe Photoshop 2025 to edit your gifs, since that’s what I use.
However, there are a lot of cheaper alternatives! You should do your own research to figure out what works best for you, but I started making gifs through ezgif.com.
Although a less powerful software like Ezgif results in a lower quality image file (gif), it’s a good entry point. Ezgif is helpful for making smaller, less detailed gifs! For example, these were some of the first gifs I ever made:


And I made them with just Ezgif! I had less control over the colors and sharpness, but Ezgif got the job done.
For comparison, this is the level of quality you should expect from more powerful softwares (Avisynth, Photoshop):


If this is the level of quality you want, then it might be worth investing in Avisynth, Photoshop, or both.
61 notes
·
View notes
Text
Humans are not perfectly vigilant

I'm on tour with my new, nationally bestselling novel The Bezzle! Catch me in BOSTON with Randall "XKCD" Munroe (Apr 11), then PROVIDENCE (Apr 12), and beyond!

Here's a fun AI story: a security researcher noticed that large companies' AI-authored source-code repeatedly referenced a nonexistent library (an AI "hallucination"), so he created a (defanged) malicious library with that name and uploaded it, and thousands of developers automatically downloaded and incorporated it as they compiled the code:
https://www.theregister.com/2024/03/28/ai_bots_hallucinate_software_packages/
These "hallucinations" are a stubbornly persistent feature of large language models, because these models only give the illusion of understanding; in reality, they are just sophisticated forms of autocomplete, drawing on huge databases to make shrewd (but reliably fallible) guesses about which word comes next:
https://dl.acm.org/doi/10.1145/3442188.3445922
Guessing the next word without understanding the meaning of the resulting sentence makes unsupervised LLMs unsuitable for high-stakes tasks. The whole AI bubble is based on convincing investors that one or more of the following is true:
There are low-stakes, high-value tasks that will recoup the massive costs of AI training and operation;
There are high-stakes, high-value tasks that can be made cheaper by adding an AI to a human operator;
Adding more training data to an AI will make it stop hallucinating, so that it can take over high-stakes, high-value tasks without a "human in the loop."
These are dubious propositions. There's a universe of low-stakes, low-value tasks – political disinformation, spam, fraud, academic cheating, nonconsensual porn, dialog for video-game NPCs – but none of them seem likely to generate enough revenue for AI companies to justify the billions spent on models, nor the trillions in valuation attributed to AI companies:
https://locusmag.com/2023/12/commentary-cory-doctorow-what-kind-of-bubble-is-ai/
The proposition that increasing training data will decrease hallucinations is hotly contested among AI practitioners. I confess that I don't know enough about AI to evaluate opposing sides' claims, but even if you stipulate that adding lots of human-generated training data will make the software a better guesser, there's a serious problem. All those low-value, low-stakes applications are flooding the internet with botshit. After all, the one thing AI is unarguably very good at is producing bullshit at scale. As the web becomes an anaerobic lagoon for botshit, the quantum of human-generated "content" in any internet core sample is dwindling to homeopathic levels:
https://pluralistic.net/2024/03/14/inhuman-centipede/#enshittibottification
This means that adding another order of magnitude more training data to AI won't just add massive computational expense – the data will be many orders of magnitude more expensive to acquire, even without factoring in the additional liability arising from new legal theories about scraping:
https://pluralistic.net/2023/09/17/how-to-think-about-scraping/
That leaves us with "humans in the loop" – the idea that an AI's business model is selling software to businesses that will pair it with human operators who will closely scrutinize the code's guesses. There's a version of this that sounds plausible – the one in which the human operator is in charge, and the AI acts as an eternally vigilant "sanity check" on the human's activities.
For example, my car has a system that notices when I activate my blinker while there's another car in my blind-spot. I'm pretty consistent about checking my blind spot, but I'm also a fallible human and there've been a couple times where the alert saved me from making a potentially dangerous maneuver. As disciplined as I am, I'm also sometimes forgetful about turning off lights, or waking up in time for work, or remembering someone's phone number (or birthday). I like having an automated system that does the robotically perfect trick of never forgetting something important.
There's a name for this in automation circles: a "centaur." I'm the human head, and I've fused with a powerful robot body that supports me, doing things that humans are innately bad at.
That's the good kind of automation, and we all benefit from it. But it only takes a small twist to turn this good automation into a nightmare. I'm speaking here of the reverse-centaur: automation in which the computer is in charge, bossing a human around so it can get its job done. Think of Amazon warehouse workers, who wear haptic bracelets and are continuously observed by AI cameras as autonomous shelves shuttle in front of them and demand that they pick and pack items at a pace that destroys their bodies and drives them mad:
https://pluralistic.net/2022/04/17/revenge-of-the-chickenized-reverse-centaurs/
Automation centaurs are great: they relieve humans of drudgework and let them focus on the creative and satisfying parts of their jobs. That's how AI-assisted coding is pitched: rather than looking up tricky syntax and other tedious programming tasks, an AI "co-pilot" is billed as freeing up its human "pilot" to focus on the creative puzzle-solving that makes coding so satisfying.
But an hallucinating AI is a terrible co-pilot. It's just good enough to get the job done much of the time, but it also sneakily inserts booby-traps that are statistically guaranteed to look as plausible as the good code (that's what a next-word-guessing program does: guesses the statistically most likely word).
This turns AI-"assisted" coders into reverse centaurs. The AI can churn out code at superhuman speed, and you, the human in the loop, must maintain perfect vigilance and attention as you review that code, spotting the cleverly disguised hooks for malicious code that the AI can't be prevented from inserting into its code. As "Lena" writes, "code review [is] difficult relative to writing new code":
https://twitter.com/qntm/status/1773779967521780169
Why is that? "Passively reading someone else's code just doesn't engage my brain in the same way. It's harder to do properly":
https://twitter.com/qntm/status/1773780355708764665
There's a name for this phenomenon: "automation blindness." Humans are just not equipped for eternal vigilance. We get good at spotting patterns that occur frequently – so good that we miss the anomalies. That's why TSA agents are so good at spotting harmless shampoo bottles on X-rays, even as they miss nearly every gun and bomb that a red team smuggles through their checkpoints:
https://pluralistic.net/2023/08/23/automation-blindness/#humans-in-the-loop
"Lena"'s thread points out that this is as true for AI-assisted driving as it is for AI-assisted coding: "self-driving cars replace the experience of driving with the experience of being a driving instructor":
https://twitter.com/qntm/status/1773841546753831283
In other words, they turn you into a reverse-centaur. Whereas my blind-spot double-checking robot allows me to make maneuvers at human speed and points out the things I've missed, a "supervised" self-driving car makes maneuvers at a computer's frantic pace, and demands that its human supervisor tirelessly and perfectly assesses each of those maneuvers. No wonder Cruise's murderous "self-driving" taxis replaced each low-waged driver with 1.5 high-waged technical robot supervisors:
https://pluralistic.net/2024/01/11/robots-stole-my-jerb/#computer-says-no
AI radiology programs are said to be able to spot cancerous masses that human radiologists miss. A centaur-based AI-assisted radiology program would keep the same number of radiologists in the field, but they would get less done: every time they assessed an X-ray, the AI would give them a second opinion. If the human and the AI disagreed, the human would go back and re-assess the X-ray. We'd get better radiology, at a higher price (the price of the AI software, plus the additional hours the radiologist would work).
But back to making the AI bubble pay off: for AI to pay off, the human in the loop has to reduce the costs of the business buying an AI. No one who invests in an AI company believes that their returns will come from business customers to agree to increase their costs. The AI can't do your job, but the AI salesman can convince your boss to fire you and replace you with an AI anyway – that pitch is the most successful form of AI disinformation in the world.
An AI that "hallucinates" bad advice to fliers can't replace human customer service reps, but airlines are firing reps and replacing them with chatbots:
https://www.bbc.com/travel/article/20240222-air-canada-chatbot-misinformation-what-travellers-should-know
An AI that "hallucinates" bad legal advice to New Yorkers can't replace city services, but Mayor Adams still tells New Yorkers to get their legal advice from his chatbots:
https://arstechnica.com/ai/2024/03/nycs-government-chatbot-is-lying-about-city-laws-and-regulations/
The only reason bosses want to buy robots is to fire humans and lower their costs. That's why "AI art" is such a pisser. There are plenty of harmless ways to automate art production with software – everything from a "healing brush" in Photoshop to deepfake tools that let a video-editor alter the eye-lines of all the extras in a scene to shift the focus. A graphic novelist who models a room in The Sims and then moves the camera around to get traceable geometry for different angles is a centaur – they are genuinely offloading some finicky drudgework onto a robot that is perfectly attentive and vigilant.
But the pitch from "AI art" companies is "fire your graphic artists and replace them with botshit." They're pitching a world where the robots get to do all the creative stuff (badly) and humans have to work at robotic pace, with robotic vigilance, in order to catch the mistakes that the robots make at superhuman speed.
Reverse centaurism is brutal. That's not news: Charlie Chaplin documented the problems of reverse centaurs nearly 100 years ago:
https://en.wikipedia.org/wiki/Modern_Times_(film)
As ever, the problem with a gadget isn't what it does: it's who it does it for and who it does it to. There are plenty of benefits from being a centaur – lots of ways that automation can help workers. But the only path to AI profitability lies in reverse centaurs, automation that turns the human in the loop into the crumple-zone for a robot:
https://estsjournal.org/index.php/ests/article/view/260

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/04/01/human-in-the-loop/#monkey-in-the-middle
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
--
Jorge Royan (modified) https://commons.wikimedia.org/wiki/File:Munich_-_Two_boys_playing_in_a_park_-_7328.jpg
CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0/deed.en
--
Noah Wulf (modified) https://commons.m.wikimedia.org/wiki/File:Thunderbirds_at_Attention_Next_to_Thunderbird_1_-_Aviation_Nation_2019.jpg
CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0/deed.en
#pluralistic#ai#supervised ai#humans in the loop#coding assistance#ai art#fully automated luxury communism#labor
379 notes
·
View notes
Note
Hello! First, I wanted to say thank you for your post about updating software and such. I really appreciated your perspective as someone with ADHD. The way you described your experiences with software frustration was IDENTICAL to my experience, so your post made a lot of sense to me.
Second, (and I hope my question isn't bothering you lol) would you mind explaining why it's important to update/adopt the new software? Like, why isn't there an option that doesn't involve constantly adopting new things? I understand why they'd need to fix stuff like functional bugs/make it compatible with new tech, but is it really necessary to change the user side of things as well?
Sorry if those are stupid questions or they're A Lot for a tumblr rando to ask, I'd just really like to understand because I think it would make it easier to get myself to adopt new stuff if I understand why it's necessary, and the other folks I know that know about computers don't really seem to understand the experience.
Thank you so much again for sharing your wisdom!!
A huge part of it is changing technologies and changing norms; I brought up Windows 8 in that other post and Win8 is a *great* example of user experience changing to match hardware, just in a situation that was an enormous mismatch with the market.
Win8's much-beloathed tiles came about because Microsoft seemed to be anticipating a massive pivot to tablet PCs in nearly all applications. The welcome screen was designed to be friendly to people who were using handheld touchscreens who could tap through various options, and it was meant to require more scrolling and less use of a keyboard.
But most people who the operating system went out to *didn't* have touchscreen tablets or laptops, they had a desktop computer with a mouse and a keyboard.
When that was released, it was Microsoft attempting to keep up with (or anticipate) market trends - they wanted something that was like "the iPad for Microsoft" so Windows 8 was meant to go with Microsoft Surface tablets.
We spent the first month of Win8's launch making it look like Windows 7 for our customers.
You can see the same thing with the centered taskbar on Windows 11; that's very clearly supposed to mimic the dock on apple computers (only you can't pin it anywhere but the bottom of the screen, which sucks).
Some of the visual changes are just trends and various companies trying to keep up with one another.
With software like Adobe I think it's probably based on customer data. The tool layout and the menu dropdowns are likely based on what people are actually looking for, and change based on what other tools people are using. That's likely true for most programs you use - the menu bar at the top of the screen in Word is populated with the options that people use the most; if a function you used to click on all the time is now buried, there's a possibility that people use it less these days for any number of reasons. (I'm currently being driven mildly insane by Teams moving the "attach file" button under a "more" menu instead of as an icon next to the "send message" button, and what this tells me is either that more users are putting emojis in their messages than attachments, or microsoft WANTS people to put more emojis than messages in their attachments).
But focusing on the operating system, since that's the big one:
The thing about OSs is that you interact with them so frequently that any little change seems massive and you get REALLY frustrated when you have to deal with that, but version-to-version most OSs don't change all that much visually and they also don't get released all that frequently. I've been working with windows machines for twelve years and in that time the only OSs that Microsoft has released were 8, 10, and 11. That's only about one OS every four years, which just is not that many. There was a big visual change in the interface between 7 and 8 (and 8 and 8.1, which is more of a 'panicked backing away' than a full release), but otherwise, realistically, Windows 11 still looks a lot like XP.


The second one is a screenshot of my actual computer. The only change I've made to the display is to pin the taskbar to the left side instead of keeping it centered and to fuck around a bit with the colors in the display customization. I haven't added any plugins or tools to get it to look different.
This is actually a pretty good demonstration of things changing based on user behavior too - XP didn't come with a search field in the task bar or the start menu, but later versions of Windows OSs did, because users had gotten used to searching things more in their phones and browsers, so then they learned to search things on their computers.
There are definitely nefarious reasons that software manufacturers change their interfaces. Microsoft has included ads in home versions of their OS and pushed searches through the Microsoft store since Windows 10, as one example. That's shitty and I think it's worthwhile to find the time to shut that down (and to kill various assistants and background tools and stop a lot of stuff that runs at startup).
But if you didn't have any changes, you wouldn't have any changes. I think it's handy to have a search field in the taskbar. I find "settings" (which is newer than control panel) easier to navigate than "control panel." Some of the stuff that got added over time is *good* from a user perspective - you can see that there's a little stopwatch pinned at the bottom of my screen; that's a tool I use daily that wasn't included in previous versions of the OS. I'm glad it got added, even if I'm kind of bummed that my Windows OS doesn't come with Spider Solitaire anymore.
One thing that's helpful to think about when considering software is that nobody *wants* to make clunky, unusable software. People want their software to run well, with few problems, and they want users to like it so that they don't call corporate and kick up a fuss.
When you see these kinds of changes to the user experience, it often reflects something that *you* may not want, but that is desirable to a *LOT* of other people. The primary example I can think of here is trackpad scrolling direction; at some point it became common for trackpads to scroll in the opposite direction that they used to; now the default direction is the one that feels wrong to me, because I grew up scrolling with a mouse, not a screen. People who grew up scrolling on a screen seem to feel that the new direction is a lot more intuitive, so it's the default. Thankfully, that's a setting that's easy to change, so it's a change that I make every time I come across it, but the change was made for a sensible reason, even if that reason was opaque to me at the time I stumbled across it and continues to irritate me to this day.
I don't know. I don't want to defend Windows all that much here because I fucking hate Microsoft and definitely prefer using Linux when I'm not at work or using programs that I don't have on Linux. But the thing is that you'll see changes with Linux releases as well.
I wouldn't mind finding a tool that made my desktop look 100% like Windows 95, that would be fun. But we'd probably all be really frustrated if there hadn't been any interface improvements changes since MS-DOS (and people have DEFINITELY been complaining about UX changes at least since then).
Like, I talk about this in terms of backward compatibility sometimes. A lot of people are frustrated that their old computers can't run new software well, and that new computers use so many resources. But the flipside of that is that pretty much nobody wants mobile internet to work the way that it did in 2004 or computers to act the way they did in 1984.
Like. People don't think about it much these days but the "windows" of the Windows Operating system represented a massive change to how people interacted with their computers that plenty of people hated and found unintuitive.
(also take some time to think about the little changes that have happened that you've appreciated or maybe didn't even notice. I used to hate the squiggly line under misspelled words but now I see the utility. Predictive text seems like new technology to me but it's really handy for a lot of people. Right clicking is a UX innovation. Sometimes you have to take the centered task bar in exchange for the built-in timer deck; sometimes you have to lose color-coded files in exchange for a right click.)
296 notes
·
View notes
Text
Writing Advice #?: Don’t write out accents.
The Surface-Level Problem: It’s distracting at best, illegible at worst.
The following passage from Sons and Lovers has never made a whit of sense to me:
“I ham, Walter, my lad,’ ’e says; ‘ta’e which on ’em ter’s a mind.’ An’ so I took one, an’ thanked ’im. I didn’t like ter shake it afore ’is eyes, but ’e says, ‘Tha’d better ma’e sure it’s a good un. An’ so, yer see, I knowed it was.’”
There’s almost certainly a point to that dialogue — plot, character, theme — but I could not figure out what the words were meant to be, and gave up on the book. At a lesser extreme, most of Quincey’s lines from Dracula (“I know I ain’t good enough to regulate the fixin’s of your little shoes”) cause American readers to sputter into laughter, which isn’t ideal for a character who is supposed to be sweet and tragic. Accents-written-out draw attention to mechanical qualities of the text.
Solution #1: Use indicators outside of the quote marks to describe how a character talks. An Atlanta accent can be “drawling” and a London one “clipped”; a Princeton one can sound “stiff” and a Newark one “relaxed.” Do they exaggerate their vowels more (North America) or their consonants more (U.K., north Africa)? Do they sound happy, melodious, frustrated?
The Deeper Problem: It’s ignorant at best, and classist/racist/xenophobic at worst.
You pretty much never see authors writing out their own accents — to the person who has the accent, the words just sound like words. It’s only when the accent is somehow “other” to the author that it gets written out.
And the accents that we consider “other” and “wrong” (even if no one ever uses those words, the decision to deliberately misspell words still conveys it) are pretty much never the ones from wealthy and educated parts of the country. Instead, the accents with misspelled words and awkward inflection are those from other countries, from other social classes, from other ethnicities. If your Maine characters speak normally and your Florida characters have grammatical errors, then you have conveyed what you consider to be correct and normal speech. We know what J.K. Rowling thinks of French-accented English, because it’s dripping off of Fleur Delacour’s every line.
At the bizarre extreme, we see inappropriate application of North U.K. and South U.S.-isms to every uneducated and/or poor character ever to appear in fan fic. When wanting to get across that Steve Rogers is a simple Brooklyn boy, MCU fans have him slip into “mustn’t” and “we is.” When conveying that Robin 2.0 is raised poor in Newark, he uses “ain’t” and “y’all” and “din.” Never mind that Iron Man is from Manhattan, or that Robin 3.0 is raised wealthy in Newark; neither of them ever gets a written-out accent.
Solution #2: A little word choice can go a long way, and a little research can go even further. Listen carefully to the way people talk — on the bus, in a café, on unscripted YouTube — and write down their exact word choice. “We good” literally means the same thing as “no thank you,” but one’s a lot more formal than the other. “Ain’t” is a perfectly good synonym for “am not,” but not everyone will use it.
The Obscure Problem: It’s not even how people talk.
Look at how auto-transcription software messes up speaking styles, and it’s obvious that no one pronounces every spoken sound in every word that comes out of their mouth. Consider how Americans say “you all right?”; 99% of us actually say something like “yait?”, using tone and head tilt to convey meaning. Politicians speak very formally; friends at bars speak very informally.
An example: I’m from Baltimore, Maryland. Unless I’m speaking to an American from Texas, in which case I’m from “Baltmore, Marlind.” Unless I’m speaking to an American from Pennsylvania, in which case I’m from “Balmore, Marlin.” If I’m speaking to a fellow Marylander, I’m of course from “Bamor.” (If I’m speaking to a non-American, I’m of course from “Washington D.C.”) Trying to capture every phoneme of change from moment to moment and setting to setting would be ridiculous; better just to say I inflect more when talking to people from outside my region.
When you write out an accent, you insert yourself, the writer, as an implied listener. You inflict your value judgments and your linguistic ear on the reader, and you take away from the story.
Solution #3: When in doubt, just write the dialogue how you would talk.
#writing#writing advice#accents#fan fiction#classism#language#u.s.-centric af because I've only lived so many places
1K notes
·
View notes
Text
In India, many development companies design sports-related apps. Sports Application Development Apps have various functions such as scoring in real-time statistics. This type of app provides information about games and sporting clubs. If we invest in Sports applications then your businesses grow in the future. Helpfulinsightsolution Provides the best information in every blog.
Users can have a unique, interactive sports app on their gadgets as sports applications provide for exceptional user engagement. The apps have various functions such as scoring in real time, statistics, information on news and so many more about different games and sporting clubs. In addition, users can create their own settings and preferences. Other sports applications allow users to log on to social forums like blogs or Facebook pages and participate in other interactive elements like forming fans’ groups. Users get a chance to update themselves on the latest sports news as well as demonstrate their support for the team of their choice in real time.

#Sports application development course#Sports application development tools#Sports application development software#Sports application development examples#sports app ideas#sports game development
0 notes
Text
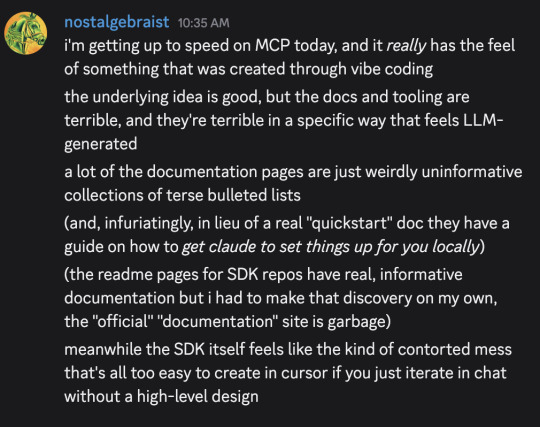
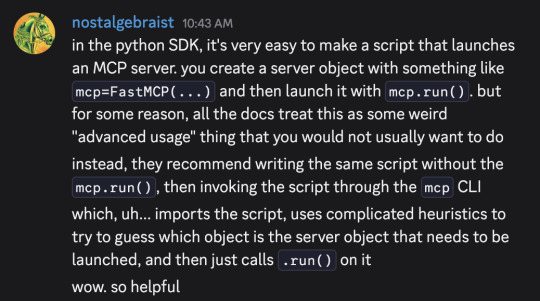

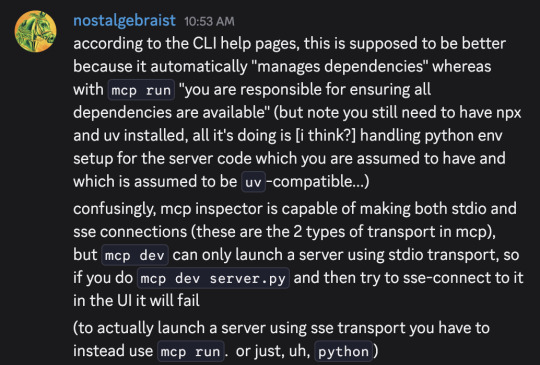
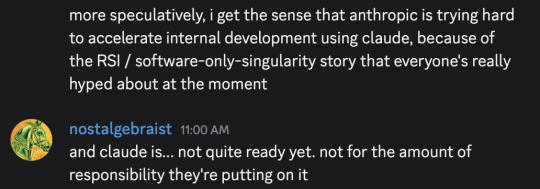
I typed out these messages in a discord server a moment ago, and then thought "hmm, maybe I should make the same points in a tumblr post, since I've been talking about software-only-singularity predictions on tumblr lately"
But, as an extremely lazy (and somewhat busy) person, I couldn't be bothered to re-express the same ideas in a tumblr-post-like format, so I'm giving you these screenshots instead
(If you're not familiar, "MCP" is "Model Context Protocol," a recently introduced standard for connections between LLMs and applications that want to interact with LLMs. Its official website is here – although be warned, that link leads to the bad docs I complained about in the first message. The much more palatable python SDK docs can be found here.)
EDIT: what I said in the first message about "getting Claude to set things up for you locally" was not really correct, I was conflating this (which fits that description) with this and this (which are real quickstarts with code, although not very good ones, and frustratingly there's no end-to-end example of writing a server and then testing it with a hand-written client or the inspector, as opposed to using with "Claude for Desktop" as the client)
64 notes
·
View notes