#feedforward
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
12.7% of mobile users access Tumblr.
Text

0 notes
Text
0 notes
Text
anyway i think the most fun class i’ve ever taken is chemical systems control and it really made me feel smart so there’s that
#sybau challenge (100% fail) .ᐟ#feedback control systems…#feedforward control systems…#im foaming at the mouth
1 note
·
View note
Note
How much/quickly do you think AI is going to expand and improve materials science? It feels like a scientific field which is already benefiting tremendously.
My initial instinct was yes, MSE is already benefiting tremendously as you said. At least in terms of the fundamental science and research, AI is huge in materials science. So how quickly? I'd say it's already doing so, and it's only going to move quicker from here. But I'm coming at this from the perspective of a metallurgist who works in/around academia at the moment, with the bias that probably more than half of my research group does computational work. So let's take a step back.
So, first, AI. It's... not a great term. So here's what I, specifically, am referring to when I talk about AI in materials science:

Most of the people I know in AI would refer to what they do as machine learning or deep learning, so machine learning tends to be what I use as a preferred term. And as you can see from the above image, it can do a lot. The thing is, on a fundamental level, materials science is all about how our 118 elements (~90, if you want to ignore everything past uranium and a few others that aren't practical to use) interact. That's a lot of combinations. (Yes, yes, we're not getting into the distinction between materials science, chemistry, and physics right now.) If you're trying to make a new alloy that has X properties and Y price, computers are so much better at running through all the options than a human would be. Or if you have 100 images you want to analyze to get grain size—we're getting to the point where computers can do it faster. (The question is, can they do it better? And this question can get complicated fast. What is better? What is the size of the grain? We're not going to get into 'ground truth' debates here though.) Plenty of other examples exist.
Even beyond the science of it all, machine learning can help collect knowledge in one place. That's what the text/literature bubble above means: there are so many old articles that don't have data attached to them, and I know people personally who are working on the problem of training systems to pull data from pdfs (mainly tables and graphs) so that that information can be collated.
I won't ramble too long about the usage of machine learning in MSE because that could get long quickly, and the two sources I'm linking here cover that far better than I could. But I'll give you this plot from research in 2019 (so already 6 years out of date!) about the growth of machine learning in materials science:

I will leave everyone with the caveat though, that when I say machine learning is huge in MSE, I am, as I said in the beginning, referring to fundamental research in the field. From my perspective, in terms of commercial applications we've still got a ways to go before we trust computers to churn out parts for us. Machine learning can tell researchers the five best element combinations to make a new high entropy alloy—but no company is going to commit to making that product until the predictions of the computer (properties, best processing routes, etc.) have been physically demonstrated with actual parts and tested in traditional ways.
Certain computational materials science techniques, like finite element analysis (which is not AI, though might incorporate it in the future) are trusted by industry, but machine learning techniques are not there yet, and still have a ways to go, as far as I'm aware.
So as for how much? Fundamental research for now only. New materials and high-throughput materials testing/characterization. But I do think, at some point, maybe ten years, maybe twenty years down the line, we'll start to see parts made whose processing was entirely informed by machine learning, possibly with feedback and feedforward control so that the finished parts don't need to be tested to know how they'll perform (see: Digital twins (Wikipedia) (Phys.org) (2022 article)). At that point, it's not a matter of whether the technology will be ready for it, it'll be a matter of how much we want to trust the technology. I don't think we'll do away with physical testing anytime soon.
But hey, that's just one perspective. If anyone's got any thoughts about AI in materials science, please, share them!
Source of image 1, 2022 article.
Source of image 2, 2019 article.
#Materials Science#Science#Artificial Intelligence#Replies#Computational materials science#Machine learning
22 notes
·
View notes
Text
Interesting Papers for Week 19, 2025
Individual-specific strategies inform category learning. Collina, J. S., Erdil, G., Xia, M., Angeloni, C. F., Wood, K. C., Sheth, J., Kording, K. P., Cohen, Y. E., & Geffen, M. N. (2025). Scientific Reports, 15, 2984.
Visual activity enhances neuronal excitability in thalamic relay neurons. Duménieu, M., Fronzaroli-Molinieres, L., Naudin, L., Iborra-Bonnaure, C., Wakade, A., Zanin, E., Aziz, A., Ankri, N., Incontro, S., Denis, D., Marquèze-Pouey, B., Brette, R., Debanne, D., & Russier, M. (2025). Science Advances, 11(4).
The functional role of oscillatory dynamics in neocortical circuits: A computational perspective. Effenberger, F., Carvalho, P., Dubinin, I., & Singer, W. (2025). Proceedings of the National Academy of Sciences, 122(4), e2412830122.
Expert navigators deploy rational complexity–based decision precaching for large-scale real-world planning. Fernandez Velasco, P., Griesbauer, E.-M., Brunec, I. K., Morley, J., Manley, E., McNamee, D. C., & Spiers, H. J. (2025). Proceedings of the National Academy of Sciences, 122(4), e2407814122.
Basal ganglia components have distinct computational roles in decision-making dynamics under conflict and uncertainty. Ging-Jehli, N. R., Cavanagh, J. F., Ahn, M., Segar, D. J., Asaad, W. F., & Frank, M. J. (2025). PLOS Biology, 23(1), e3002978.
Hippocampal Lesions in Male Rats Produce Retrograde Memory Loss for Over‐Trained Spatial Memory but Do Not Impact Appetitive‐Contextual Memory: Implications for Theories of Memory Organization in the Mammalian Brain. Hong, N. S., Lee, J. Q., Bonifacio, C. J. T., Gibb, M. J., Kent, M., Nixon, A., Panjwani, M., Robinson, D., Rusnak, V., Trudel, T., Vos, J., & McDonald, R. J. (2025). Journal of Neuroscience Research, 103(1).
Sensory experience controls dendritic structure and behavior by distinct pathways involving degenerins. Inberg, S., Iosilevskii, Y., Calatayud-Sanchez, A., Setty, H., Oren-Suissa, M., Krieg, M., & Podbilewicz, B. (2025). eLife, 14, e83973.
Distributed representations of temporally accumulated reward prediction errors in the mouse cortex. Makino, H., & Suhaimi, A. (2025). Science Advances, 11(4).
Adaptation optimizes sensory encoding for future stimuli. Mao, J., Rothkopf, C. A., & Stocker, A. A. (2025). PLOS Computational Biology, 21(1), e1012746.
Memory load influences our preparedness to act on visual representations in working memory without affecting their accessibility. Nasrawi, R., Mautner-Rohde, M., & van Ede, F. (2025). Progress in Neurobiology, 245, 102717.
Layer-specific control of inhibition by NDNF interneurons. Naumann, L. B., Hertäg, L., Müller, J., Letzkus, J. J., & Sprekeler, H. (2025). Proceedings of the National Academy of Sciences, 122(4), e2408966122.
Multisensory integration operates on correlated input from unimodal transient channels. Parise, C. V, & Ernst, M. O. (2025). eLife, 12, e90841.3.
Random noise promotes slow heterogeneous synaptic dynamics important for robust working memory computation. Rungratsameetaweemana, N., Kim, R., Chotibut, T., & Sejnowski, T. J. (2025). Proceedings of the National Academy of Sciences, 122(3), e2316745122.
Discriminating neural ensemble patterns through dendritic computations in randomly connected feedforward networks. Somashekar, B. P., & Bhalla, U. S. (2025). eLife, 13, e100664.4.
Effects of noise and metabolic cost on cortical task representations. Stroud, J. P., Wojcik, M., Jensen, K. T., Kusunoki, M., Kadohisa, M., Buckley, M. J., Duncan, J., Stokes, M. G., & Lengyel, M. (2025). eLife, 13, e94961.2.
Representational geometry explains puzzling error distributions in behavioral tasks. Wei, X.-X., & Woodford, M. (2025). Proceedings of the National Academy of Sciences, 122(4), e2407540122.
Deficiency of orexin receptor type 1 in dopaminergic neurons increases novelty-induced locomotion and exploration. Xiao, X., Yeghiazaryan, G., Eggersmann, F., Cremer, A. L., Backes, H., Kloppenburg, P., & Hausen, A. C. (2025). eLife, 12, e91716.4.
Endopiriform neurons projecting to ventral CA1 are a critical node for recognition memory. Yamawaki, N., Login, H., Feld-Jakobsen, S. Ø., Molnar, B. M., Kirkegaard, M. Z., Moltesen, M., Okrasa, A., Radulovic, J., & Tanimura, A. (2025). eLife, 13, e99642.4.
Cost-benefit tradeoff mediates the transition from rule-based to memory-based processing during practice. Yang, G., & Jiang, J. (2025). PLOS Biology, 23(1), e3002987.
Identification of the subventricular tegmental nucleus as brainstem reward center. Zichó, K., Balog, B. Z., Sebestény, R. Z., Brunner, J., Takács, V., Barth, A. M., Seng, C., Orosz, Á., Aliczki, M., Sebők, H., Mikics, E., Földy, C., Szabadics, J., & Nyiri, G. (2025). Science, 387(6732).
#neuroscience#science#research#brain science#scientific publications#cognitive science#neurobiology#cognition#psychophysics#neurons#neural computation#neural networks#computational neuroscience
12 notes
·
View notes
Text
Cancer Invasion Signals
Breast cancer organoids (3D lab-grown tissue models) demonstrate a molecule called YAP in the cancer cell promotes collagen fibre alignment remodelling the extracellular matrix which further activates YAP – a feedforward loop which enhances collective cancer cell invasion
Read the published research article here
Video from work by Antoine A. Khalil and colleagues
Center for Molecular Medicine (CMM), University Medical Center Utrecht, Utrecht, The Netherlands
Image originally published with a Creative Commons Attribution 4.0 International (CC BY 4.0)
Published in Nature Communications, June 2024
You can also follow BPoD on Instagram, Twitter and Facebook
16 notes
·
View notes
Text
The Building Blocks of AI : Neural Networks Explained by Julio Herrera Velutini
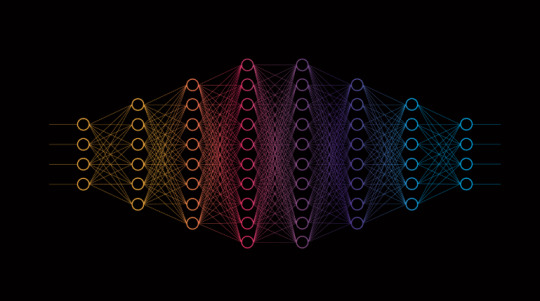
What is a Neural Network?
A neural network is a computational model inspired by the human brain’s structure and function. It is a key component of artificial intelligence (AI) and machine learning, designed to recognize patterns and make decisions based on data. Neural networks are used in a wide range of applications, including image and speech recognition, natural language processing, and even autonomous systems like self-driving cars.
Structure of a Neural Network
A neural network consists of layers of interconnected nodes, known as neurons. These layers include:
Input Layer: Receives raw data and passes it into the network.
Hidden Layers: Perform complex calculations and transformations on the data.
Output Layer: Produces the final result or prediction.
Each neuron in a layer is connected to neurons in the next layer through weighted connections. These weights determine the importance of input signals, and they are adjusted during training to improve the model’s accuracy.
How Neural Networks Work?
Neural networks learn by processing data through forward propagation and adjusting their weights using backpropagation. This learning process involves:
Forward Propagation: Data moves from the input layer through the hidden layers to the output layer, generating predictions.
Loss Calculation: The difference between predicted and actual values is measured using a loss function.
Backpropagation: The network adjusts weights based on the loss to minimize errors, improving performance over time.
Types of Neural Networks-
Several types of neural networks exist, each suited for specific tasks:
Feedforward Neural Networks (FNN): The simplest type, where data moves in one direction.
Convolutional Neural Networks (CNN): Used for image processing and pattern recognition.
Recurrent Neural Networks (RNN): Designed for sequential data like time-series analysis and language processing.
Generative Adversarial Networks (GANs): Used for generating synthetic data, such as deepfake images.
Conclusion-
Neural networks have revolutionized AI by enabling machines to learn from data and improve performance over time. Their applications continue to expand across industries, making them a fundamental tool in modern technology and innovation.
3 notes
·
View notes
Text
Mastering Neural Networks: A Deep Dive into Combining Technologies
How Can Two Trained Neural Networks Be Combined?
Introduction
In the ever-evolving world of artificial intelligence (AI), neural networks have emerged as a cornerstone technology, driving advancements across various fields. But have you ever wondered how combining two trained neural networks can enhance their performance and capabilities? Let’s dive deep into the fascinating world of neural networks and explore how combining them can open new horizons in AI.
Basics of Neural Networks
What is a Neural Network?
Neural networks, inspired by the human brain, consist of interconnected nodes or "neurons" that work together to process and analyze data. These networks can identify patterns, recognize images, understand speech, and even generate human-like text. Think of them as a complex web of connections where each neuron contributes to the overall decision-making process.
How Neural Networks Work
Neural networks function by receiving inputs, processing them through hidden layers, and producing outputs. They learn from data by adjusting the weights of connections between neurons, thus improving their ability to predict or classify new data. Imagine a neural network as a black box that continuously refines its understanding based on the information it processes.
Types of Neural Networks
From simple feedforward networks to complex convolutional and recurrent networks, neural networks come in various forms, each designed for specific tasks. Feedforward networks are great for straightforward tasks, while convolutional neural networks (CNNs) excel in image recognition, and recurrent neural networks (RNNs) are ideal for sequential data like text or speech.
Why Combine Neural Networks?
Advantages of Combining Neural Networks
Combining neural networks can significantly enhance their performance, accuracy, and generalization capabilities. By leveraging the strengths of different networks, we can create a more robust and versatile model. Think of it as assembling a team where each member brings unique skills to tackle complex problems.
Applications in Real-World Scenarios
In real-world applications, combining neural networks can lead to breakthroughs in fields like healthcare, finance, and autonomous systems. For example, in medical diagnostics, combining networks can improve the accuracy of disease detection, while in finance, it can enhance the prediction of stock market trends.
Methods of Combining Neural Networks
Ensemble Learning
Ensemble learning involves training multiple neural networks and combining their predictions to improve accuracy. This approach reduces the risk of overfitting and enhances the model's generalization capabilities.
Bagging
Bagging, or Bootstrap Aggregating, trains multiple versions of a model on different subsets of the data and combines their predictions. This method is simple yet effective in reducing variance and improving model stability.
Boosting
Boosting focuses on training sequential models, where each model attempts to correct the errors of its predecessor. This iterative process leads to a powerful combined model that performs well even on difficult tasks.
Stacking
Stacking involves training multiple models and using a "meta-learner" to combine their outputs. This technique leverages the strengths of different models, resulting in superior overall performance.
Transfer Learning
Transfer learning is a method where a pre-trained neural network is fine-tuned on a new task. This approach is particularly useful when data is scarce, allowing us to leverage the knowledge acquired from previous tasks.
Concept of Transfer Learning
In transfer learning, a model trained on a large dataset is adapted to a smaller, related task. For instance, a model trained on millions of images can be fine-tuned to recognize specific objects in a new dataset.
How to Implement Transfer Learning
To implement transfer learning, we start with a pretrained model, freeze some layers to retain their knowledge, and fine-tune the remaining layers on the new task. This method saves time and computational resources while achieving impressive results.
Advantages of Transfer Learning
Transfer learning enables quicker training times and improved performance, especially when dealing with limited data. It’s like standing on the shoulders of giants, leveraging the vast knowledge accumulated from previous tasks.
Neural Network Fusion
Neural network fusion involves merging multiple networks into a single, unified model. This method combines the strengths of different architectures to create a more powerful and versatile network.
Definition of Neural Network Fusion
Neural network fusion integrates different networks at various stages, such as combining their outputs or merging their internal layers. This approach can enhance the model's ability to handle diverse tasks and data types.
Types of Neural Network Fusion
There are several types of neural network fusion, including early fusion, where networks are combined at the input level, and late fusion, where their outputs are merged. Each type has its own advantages depending on the task at hand.
Implementing Fusion Techniques
To implement neural network fusion, we can combine the outputs of different networks using techniques like averaging, weighted voting, or more sophisticated methods like learning a fusion model. The choice of technique depends on the specific requirements of the task.
Cascade Network
Cascade networks involve feeding the output of one neural network as input to another. This approach creates a layered structure where each network focuses on different aspects of the task.
What is a Cascade Network?
A cascade network is a hierarchical structure where multiple networks are connected in series. Each network refines the outputs of the previous one, leading to progressively better performance.
Advantages and Applications of Cascade Networks
Cascade networks are particularly useful in complex tasks where different stages of processing are required. For example, in image processing, a cascade network can progressively enhance image quality, leading to more accurate recognition.
Practical Examples
Image Recognition
In image recognition, combining CNNs with ensemble methods can improve accuracy and robustness. For instance, a network trained on general image data can be combined with a network fine-tuned for specific object recognition, leading to superior performance.
Natural Language Processing
In natural language processing (NLP), combining RNNs with transfer learning can enhance the understanding of text. A pre-trained language model can be fine-tuned for specific tasks like sentiment analysis or text generation, resulting in more accurate and nuanced outputs.
Predictive Analytics
In predictive analytics, combining different types of networks can improve the accuracy of predictions. For example, a network trained on historical data can be combined with a network that analyzes real-time data, leading to more accurate forecasts.
Challenges and Solutions
Technical Challenges
Combining neural networks can be technically challenging, requiring careful tuning and integration. Ensuring compatibility between different networks and avoiding overfitting are critical considerations.
Data Challenges
Data-related challenges include ensuring the availability of diverse and high-quality data for training. Managing data complexity and avoiding biases are essential for achieving accurate and reliable results.
Possible Solutions
To overcome these challenges, it’s crucial to adopt a systematic approach to model integration, including careful preprocessing of data and rigorous validation of models. Utilizing advanced tools and frameworks can also facilitate the process.
Tools and Frameworks
Popular Tools for Combining Neural Networks
Tools like TensorFlow, PyTorch, and Keras provide extensive support for combining neural networks. These platforms offer a wide range of functionalities and ease of use, making them ideal for both beginners and experts.
Frameworks to Use
Frameworks like Scikit-learn, Apache MXNet, and Microsoft Cognitive Toolkit offer specialized support for ensemble learning, transfer learning, and neural network fusion. These frameworks provide robust tools for developing and deploying combined neural network models.
Future of Combining Neural Networks
Emerging Trends
Emerging trends in combining neural networks include the use of advanced ensemble techniques, the integration of neural networks with other AI models, and the development of more sophisticated fusion methods.
Potential Developments
Future developments may include the creation of more powerful and efficient neural network architectures, enhanced transfer learning techniques, and the integration of neural networks with other technologies like quantum computing.
Case Studies
Successful Examples in Industry
In healthcare, combining neural networks has led to significant improvements in disease diagnosis and treatment recommendations. For example, combining CNNs with RNNs has enhanced the accuracy of medical image analysis and patient monitoring.
Lessons Learned from Case Studies
Key lessons from successful case studies include the importance of data quality, the need for careful model tuning, and the benefits of leveraging diverse neural network architectures to address complex problems.
Online Course
I have came across over many online courses. But finally found something very great platform to save your time and money.
1.Prag Robotics_ TBridge
2.Coursera
Best Practices
Strategies for Effective Combination
Effective strategies for combining neural networks include using ensemble methods to enhance performance, leveraging transfer learning to save time and resources, and adopting a systematic approach to model integration.
Avoiding Common Pitfalls
Common pitfalls to avoid include overfitting, ignoring data quality, and underestimating the complexity of model integration. By being aware of these challenges, we can develop more robust and effective combined neural network models.
Conclusion
Combining two trained neural networks can significantly enhance their capabilities, leading to more accurate and versatile AI models. Whether through ensemble learning, transfer learning, or neural network fusion, the potential benefits are immense. By adopting the right strategies and tools, we can unlock new possibilities in AI and drive advancements across various fields.
FAQs
What is the easiest method to combine neural networks?
The easiest method is ensemble learning, where multiple models are combined to improve performance and accuracy.
Can different types of neural networks be combined?
Yes, different types of neural networks, such as CNNs and RNNs, can be combined to leverage their unique strengths.
What are the typical challenges in combining neural networks?
Challenges include technical integration, data quality, and avoiding overfitting. Careful planning and validation are essential.
How does combining neural networks enhance performance?
Combining neural networks enhances performance by leveraging diverse models, reducing errors, and improving generalization.
Is combining neural networks beneficial for small datasets?
Yes, combining neural networks can be beneficial for small datasets, especially when using techniques like transfer learning to leverage knowledge from larger datasets.
#artificialintelligence#coding#raspberrypi#iot#stem#programming#science#arduinoproject#engineer#electricalengineering#robotic#robotica#machinelearning#electrical#diy#arduinouno#education#manufacturing#stemeducation#robotics#robot#technology#engineering#robots#arduino#electronics#automation#tech#innovation#ai
4 notes
·
View notes
Text
Sesi development meeting pekan ini topiknya menarik "The Art of Giving Feedback/Feedforward. Dibayangan saya sebelum menyusun materi, sepertinya cocok jika pakai metode story telling. Kembali mengingat bagaimana pengalaman mendapatkan feedback dari beberapa atasan selama bekerja. Ada yang cukup menyakitkan, adapula yang membuat semangat untuk terus bertumbuh dan belajar.
Dulu, saya berpikir feedback itu tidak baik, menyakitkan. Ternyata asumsi saya salah, feedback bisa menjadi seperti itu jika cara penyampainnya salah. Nyatanya belakangan feedback menjadi rutinitas harian di dunia kerja.
Tidak ada pengalaman yang tidak berharga, baik atau buruk semuanya punya sisi mendalam jika dimaknai. Kisah mendapatkan feedbak yang tidak menyenangkan menjadi bahan belajar agar ketika memberikan feedbak ke team tidak diperlakukan seperti itu, sebaliknya feedbak yang membuat semangat untuk bertumbuh dan belajar menjadi contoh ketika memberikan feedback kepada team.
Rasulullah adalah teladan terbaik bagaimana beliau memberikan feedback. Suatu hari, Umar bin Khattab RA datang kepada Rasulullah dengan perasaan marah dan ingin menghukum seorang wanita yang dianggapnya telah melakukan kesalahan. Rasulullah dengan lembutnya mendengarkan keluh kesah Umar tanpa mengomentari secara langsung. Namun, Rasulullah menggunakan kesempatan tersebut untuk memberikan feedback kepada Umar.
Rasulullah dengan bijaksana dan penuh kasih mengarahkan Umar untuk menenangkan diri dan memahami situasi dengan lebih baik. Beliau memberikan nasihat kepada Umar tentang pentingnya memahami dan mempertimbangkan dengan baik sebelum mengambil keputusan yang penting. Beliau tidak langsung mengkritik atau menyalahkan, tetapi dengan penuh kesabaran dan empati membimbing Umar untuk memahami situasi dengan lebih baik dan mengambil keputusan yang lebih bijaksana.
Semoga menjadi ruang belajar dalam proses kedepannya. Aamiin
Rabu, 27 Maret 2024 / 16 Ramadhan 1445 H
5 notes
·
View notes
Text
I've got a people at the industrial STEM research division I work at hyping up generative AI for all kinds of modeling prediction stuff and I'm just like.
You just described a clustering algorithm. JMP does that, we have the license.
You just described a discriminant algorithm. JMP does that, we have the license.
Ohh, you just described a sparse data discriminant algorithm. That's actually a machine learning problem, and by machine learning I mean a support vector machine, the least machine learniest ML algorithm. And JMP does that too, we have the license.
Now you just described a feedforward neural network for iterative sparse data prediction. That's definitely machine learning, but not any flavor of genAI and also. Yes. JMP does that, we have the license.
You just described a database search function. Those have been perfected for years, but somehow we can't fund IT well enough to get a working one. I cannot imagine why you think we need genAI to do this, or why we'd be able to get genAI to do this when an old reliable perfected algorithm is beyond us.
... and you are a manager gushing over a shitty faked image we could have done better and cheaper with a stock photo subscription or a concept artist on staff. Go away.
so like I said, I work in the tech industry, and it's been kind of fascinating watching whole new taboos develop at work around this genAI stuff. All we do is talk about genAI, everything is genAI now, "we have to win the AI race," blah blah blah, but nobody asks - you can't ask -
What's it for?
What's it for?
Why would anyone want this?
I sit in so many meetings and listen to genuinely very intelligent people talk until steam is rising off their skulls about genAI, and wonder how fast I'd get fired if I asked: do real people actually want this product, or are the only people excited about this technology the shareholders who want to see lines go up?
like you realize this is a bubble, right, guys? because nobody actually needs this? because it's not actually very good? normal people are excited by the novelty of it, and finance bro capitalists are wetting their shorts about it because they want to get rich quick off of the Next Big Thing In Tech, but the novelty will wear off and the bros will move on to something else and we'll just be left with billions and billions of dollars invested in technology that nobody wants.
and I don't say it, because I need my job. And I wonder how many other people sitting at the same table, in the same meeting, are also not saying it, because they need their jobs.
idk man it's just become a really weird environment.
33K notes
·
View notes
Video
youtube
🔋Smart DC Grid: Voltage Stability via Feedforward⚡ #sciencefather #resea...
0 notes
Text
How to Build a High-Performing Team Through Effective Performance Management

Your team is your best asset, and it’s essential that they perform at their peak. At its core, building these teams requires strong and effective performance management. This involves a strategic process of continuous improvement, aligning individual employees with the broader company. Through this, HR managers are able to foster a culture of learning and excellence, enhancing your employees in all aspects. Mastering performance management is crucial to ensure employees are motivated to do their best, and have the tools to support their growth.
We’ll explore how a robust performance management system can transform teams into high performing units. With a deep dive into its key components, best practices, and common challenges, we’ll cover everything you’ll face – and more. No matter if you’re refining existing processes, or looking to implement a new system, we’ll provide practical insights to help your team, and business, succeed.
What is Performance Management?
Employee performance management is the process of continuous improvement through communication between managers and employees. Put simply, it’s how you, as a manager, improve your team’s productivity. It allows you to assess job responsibilities, set expectations, evaluate performance, and plan development. Unlike annual reviews, performance management focuses on prioritising continuous feedback. This aligns individual goals with organisational objectives, driving more growth for the team. It’s all about empowering your employees to maximise their potential, and in turn transforming those efforts into tangible results for the business.
Importance of Performance Management in Building High-Performing Teams
An effective performance management system builds high-performing teams. It provides a structured framework to:
Align Goals: Ensures all team members understand how their roles contribute to organisational success.
Drive Improvement: Offers regular feedback and development opportunities to enhance skills.
Boost Engagement: Increases motivation by valuing employees and showing clear growth paths for their future.
Improve Retention: Retains talent by prioritising development and success.
Enhance Success: Aligns teams to achieve goals and outperform competitors.
Key Components of Effective Performance Management
1. Goal Setting
Setting goals properly can be a challenge. Despite this, goal setting should be considered the foundation of performance management. Clear and achievable goals align your teams’ efforts with structural objectives that the business needs to achieve. Individual goals should support the team as a whole. Goals should be S.M.A.R.T (Specific, Measurable, Achievable, Relevant, and Time-bound) to ensure clarity in the team. You can also incorporate goals that seem out of reach on the surface, commonly known as “stretch goals.” These can inspire innovation and motivation simultaneously.
2. Regular Feedback
Regular and consistent feedback drives growth. Annual reviews are too slow to drive significant change. It is advisable to schedule weekly check-ins for your most essential teams and monthly reviews for your other teams. These practices assist in adhering to deadlines and sustaining team morale. There are two types of feedback: formal, which is structured reviews, and informal, which are your typical daily interactions. For example, managers can provide immediate feedback in project meetings, preventing unnecessary delays. ‘Feedforward’ can be used to focus on future improvements rather than past errors. This fosters a positive culture within the team and business.
3. Coaching and Development
Coaching helps employees fill in skill gaps and grow. This is mainly accomplished through the two following areas:
Identifying needs: Use performance reviews and self-assessments to highlight areas for improvement, like communication skills for a team leader.
Providing resources: Offer training, mentorship, or stretch assignments (usually a task or project that goes beyond their current skill level or experience to help them grow).
4. Performance Evaluation
Evaluations provide a comprehensive view of performance across the team. This often entails using KPIs and 360-Degree feedback to indicate a level of success or failure. 360-Degree feedback uses input from managers, peers, and subordinates for a holistic view. This helps address any and all blind spots, improving KPIs and plugging any gaps in your processes or data.
5. Recognition and Rewards
Recognition motivates employees and reinforces positive behaviour. This includes monetary rewards, such as bonuses, but also encompasses non-monetary rewards such as awards or praise. These rewards should be linked to employee performance and specific metrics such as sales targets. The emphasis should be on non-financial motivators, which are often more effective than simply throwing money at your team. These motivators, such as leadership attention, can be capitalised on by the employee to grow their career.
Best Practices for Implementing Performance Management
Aligning Individual Goals with Team and Organisational Objectives
Use cascading goals to drive your team forward. Break down organisational objectives into team and individual targets. For example, a business aiming to increase market share might set team goals for product launches and individual goals for sales calls. This allows teams to focus on separate priorities while still having an overall focus on the overarching business objective. To ensure clarity in these processes, communicate regularly and document all actions to be analysed later. Goal setting in performance management is a tool that allows businesses to improve productivity without a focus on expansion.
Creating a Culture of Feedback
Encourage open communication in your workplace. Foster an environment where feedback is constructive, not critical. HR managers can provide their teams with workshops on appropriate and effective critiques, leading to an overall welcoming environment. The SBI (situation, behaviour, impact) model can be used as a framework to improve the delivery of feedback. Feedback in performance management helps your team maintain a positive culture while still achieving goals.
Using Technology to Enhance Performance Management
Employee performance management software helps reduce the risk of human error in your data gathering and reporting processes. Tools like Sentrient streamline goal tracking, feedback, and reporting. It includes data analytics tools to identify trends in performance and employee behaviour. For example, a team might be delivering satisfactory results, but trends might indicate that they are consistently completing their work at the last minute. The software can help reduce administrative costs and time while streamlining the performance management process.
Involving Employees in the Process
Employee self-assessment is key to improving your workforce. When employees evaluate their own performance, it can provide insight into their concerns and uncertainties. Collaborative goal setting helps improve employee engagement as they feel more committed to goals which they set for themselves. This leads to an increase in the drive of your team as they work harder to achieve their goals. Continuous performance management means that the constant rate of improvement aligns with a typical businesses constant state of growth.
Common Challenges in Performance Management and How to Overcome Them
1. Resistance to Change
Communicating the benefits to everyone in the business. Highlight how performance management improves growth and engagement. Communication is essential to ensure that everyone is on the same page and is on board with your business trajectory. Involving stakeholders greatly helps this aspect, and employees should be involved in system design as they are the main users of the processes. This often involves a small team testing an employee performance management system.
2. Lack of Time for Feedback
Feedback should be integrated wherever possible. This typically happens in regular meetings, but time should also be set aside each week for the team to prepare any questions or concerns that need your attention. This enhances performance by consolidating meetings into a streamlined process, thereby eliminating the need for multiple time-consuming sessions throughout the week.
3. Inconsistent Application Across Teams
It is essential to standardise processes across all teams while allowing for departmental customisation. Managers should receive equitable training to ensure a consistent skill set where required. This approach aims to minimise bias and promote workforce flexibility, ensuring that the absence of one manager will not significantly impact operations.
4. Addressing Underperformance
Managers should address issues promptly when they arise. They need to provide clear feedback that directly addresses the problem, ensuring the feedback consists of practical actions the employee can implement. Feedback is effective only if these conditions are met. For longer-term support, structured performance improvement plans can be developed for employees facing difficulties. Consistent underperformance and lack of response to feedback may warrant consideration for replacement.
This given blog was already published here
0 notes
Text
Xanadu Achieves Scalable Gottesman–Kitaev–Preskill States

States Gottesman–Kitaev–Preskill
Xanadu leads photonic quantum computing with their development of a scalable building block for fault-tolerant quantum computers. The achievement involves on-chip Gottesman–Kitaev–Preskill state production and was initially reported in January 2025 by Nature and summarised in June 2025. “First-of-its-kind achievement” and “key step towards scalable fault-tolerant quantum computing” describe this work.
Understanding GKP States' Importance
GKP states are error-tolerant photonic qubits. These complex quantum states consist of photons stacked in specific ways. Due to its unique structure, quantum error correcting methods may identify and fix phase shifts and photon loss. Zachary Vernon, CTO of Xanadu, calls GKP states “the optimal photonic qubit” because they enable quantum logic operations and error correction “at room temperature and using relatively straightforward, deterministic operations.” It has always been challenging to construct high-quality Gottesman–Kitaev–Preskill States on an integrated platform. This discovery advances continuous-variable quantum computing architectures by overcoming that obstacle.
GKP states provide fault-tolerant computing by using linear optics and measurement algorithms, unlike probabilistic entanglement methods that require repeated trials and complex feed-forward control. They fit well with hybrid systems because they generate quantum networks that link chips or modules or create larger cluster states for measurement-based computation.
Quantum systems' interoperability with optical fibre makes scaling easy, allowing them to be distributed among system components or data centres. This demonstration changed photonic quantum computing by taking a different approach from superconducting and trapped-ion platforms and bringing these systems closer to utility-scale quantum machine error thresholds.
Aurora: Photonic Quantum Computing Architectur
The “sub-performant scale model of a quantum computer” “Aurora” represents Xanadu's work. This system uses scalable, rack-deployed modules connected by fibre optics to incorporate all basic components. With 35 photonic devices, 84 squeezers, and 36 photon-number-resolving (PNR) detectors, Aurora provides 12 physical qubit modes each clock cycle. All system components except the cryogenic PNR detection array are operated by a single server computer and fit into four server racks.
Aurora's key technologies and their functions:
Silicon nitride waveguides feature minimal optical losses. This waveguide uses 300 mm wafers, which are common in semiconductor production. Newer chips based on Ligentec SA's 200-mm silicon-nitride waveguide architecture show potential for better squeezing and lower chip-fiber coupling losses.
The efficiency of photon-number-resolving (PNR) detectors is above 99%. In 12-mK dilution coolers, 36 transition edge sensor (TES) arrays form its base. These TES detectors cycle at 1 MHz and detect up to seven photon counts with little miscategorization error. Despite being highly effective, PNR detection efficiencies of over 99% are needed to meet the architecture's strict P1 path loss constraints.
Loss-optimized optical packaging—including accurate alignment, chip mounting, and fibre connections—was emphasised. This protects critical quantum information during routing and measurement.
The refinery array has six photonic integrated circuits (PICs) on a thin-film lithium-niobate substrate. Each refinery's two binary trees of electro-optic Mach-Zehnder modulator switches dynamically select the best output state based on PNR detection system feedforward instructions. Even though current Aurora refinery chips use probability-boosting multiplexing and Bell pair synthesis, future generations will use homodyne detectors to complete the adaptive breeding method.
Interconnects: Phase- and polarization-stabilized fiber-optical delay lines connect the refinery to QPU and refinery modules. These delays allow temporal entanglement and buffer information heralding in the cluster state.
Experiments and Results
Two large trials benchmarked Aurora's main features.
To generate a 12 × N-mode Gaussian cluster state, the system was set to send squeezed states to the QPU array. Data was collected at 1 MHz for two hours to synthesise and measure a macronode cluster state with 86.4 billion modes. Despite substantial optical losses (approximately 14 dB), the nullifier variances remained below the vacuum noise threshold, proving squeezing and cluster state entanglement.
Detecting Repetition Code Errors: This experiment showed the system's feedforward and non-Gaussian-state synthesis using low-quality GKP states. In real time, the QPU decoder assessed the system's two (foliated) repetition code checks. The decoder calculated bit values and phase error probabilities to change the measurement basis for the next time step.
Limitations and Prospects
Despite these notable examples, the “component performance gap” between existing capabilities and fault tolerance needs remains large. The main limiter of quantum state purity and coherence is optical loss. Ideal designs for fault-tolerant operation require loss budgets of about 1%, whereas the Aurora system lost 56% for heralding pathways (P1) and nearly 95% for heralded optical paths (P1 and P2).
Xanadu's future projects include:
Hardware improvements: Chip fabrication, waveguide geometry, and packaging are optimised to improve fidelity and reduce optical loss. The photonic components' insertion loss must be improved by 20-30 times (on a decibel scale).
Architectural Refinements: Testing cutting-edge hardware-level photon generation and detection rates and error mitigation measures to reduce loss and imperfection.
Integration and Scaling: combining the new GKP generation methods with Aurora's networking, error correcting protocols, and logic gates. The company believes scalable, semiconductor-compatible platforms can mass-produce, modify, and monitor error-correcting components for modular quantum computing.
Even though quantum hardware across all platforms is currently in the noisy intermediate-scale quantum (NISQ) period, Xanadu's work shows how to scale photonic quantum computers to address real applications. Fiber-optical networking, classical control electronics, and photonic-chip fabrication can scale and modularise a realistic photonic architecture. We must continuously improve optical GKP-based architectures to find the most hardware-efficient and imperfection-tolerant systems.
#GottesmanKitaevPreskillState#GKPstates#physicalqubit#QuantumProcessingUnit#Xanadu#quantumcomputing#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
0 notes
Text
How is TensorFlow used in neural networks?
TensorFlow is a powerful open-source library developed by Google, primarily used for building and training deep learning and neural network models. It provides a comprehensive ecosystem of tools, libraries, and community resources that make it easier to develop scalable machine learning applications.
In the context of neural networks, TensorFlow enables developers to define and train models using a flexible architecture. At its core, TensorFlow operates through data flow graphs, where nodes represent mathematical operations and edges represent the multidimensional data arrays (tensors) communicated between them. This structure makes it ideal for deep learning tasks that involve complex computations and large-scale data processing.
TensorFlow’s Keras API, integrated directly into the library, simplifies the process of creating and managing neural networks. Using Keras, developers can easily stack layers to build feedforward neural networks, convolutional neural networks (CNNs), or recurrent neural networks (RNNs). Each layer, such as Dense, Conv2D, or LSTM, can be customized with activation functions, initializers, regularizers, and more.
Moreover, TensorFlow supports automatic differentiation, allowing for efficient backpropagation during training. Its optimizer classes like Adam, SGD, and RMSprop help adjust weights to minimize loss functions such as categorical_crossentropy or mean_squared_error.
TensorFlow also supports GPU acceleration, which drastically reduces the training time for large neural networks. Additionally, it provides utilities for model saving, checkpointing, and deployment across platforms, including mobile and web via TensorFlow Lite and TensorFlow.js.
TensorFlow’s ability to handle data pipelines, preprocessing, and visualization (via TensorBoard) makes it an end-to-end solution for neural network development from experimentation to production deployment.
For those looking to harness TensorFlow’s full potential in AI development, enrolling in a data science machine learning course can provide structured and hands-on learning.
0 notes
Text
Assessment Of Learning
As I talked about in my previous post, our assessments of learning are often dictated to us by a higher governing body. In my case, assessments are created by SkilledTradesBC. The rubrics, assessments, and study guides are provided by them. There is not much that we can change within this framework, except help our students to prepare as well as possible.
Assessment As Learning
At the college where I work we have a unique opportunity for students to prepare and serve food for the public at our bistro. The bistro is open daily for lunch, and is mostly used by students and staff. We doing have a growing crowd of locals who come for lunch.
When I have students preparing food in the bistro I have them actively seek feedback from their customers. I direct them to ask open ended questions and not just something like “Did you enjoy your meal?”
I have them ask questions like “What could improve on this meal?” That gives immediate feedback that students can implement right away. At the end of a service shift we go over this feedback and incorporate it into the next meal.
This works on several levels. First, students are receiving feedback from someone other than me. Learning to cook is a lifelong journey, and I don’t always have the right answer. Second, students take feedback from their peers very seriously. It is great to students from different disciplines give feedback to students in the cooking program. Food unites them.
Finally, seeking feedback from the public build customer service and communication skills that are so vital in the service industry.
Volunteering
I am involved with several volunteer groups in Nelson. So is my wife. Every year we have about 5 volunteer events where we serve food. For all of these events I recruit students to help. It’s an amazing way for students, many of whom are international, to connect and be a part of a community event. Similarly to the lunch service in the bistro, students get feedback from the public and from me. This has been a great success.
Assessment For Learning
Finally, I use what I think of as a feedforward strategy by checking in on students after they graduate.
Fortunately in Nelson many of our current and graduate students work in food service establishments around the city. I get the chance to visit them in these places, and talk about their experiences. I like to talk to them about how their learning at school relates to their skills at work, and where their work experiences will take them.
All of this information can be folded back into our curriculum to make our program better and more responsive to the needs of the community.
0 notes
Text
Interesting Papers for Week 10, 2025
Simplified internal models in human control of complex objects. Bazzi, S., Stansfield, S., Hogan, N., & Sternad, D. (2024). PLOS Computational Biology, 20(11), e1012599.
Co-contraction embodies uncertainty: An optimal feedforward strategy for robust motor control. Berret, B., Verdel, D., Burdet, E., & Jean, F. (2024). PLOS Computational Biology, 20(11), e1012598.
Distributed representations of behaviour-derived object dimensions in the human visual system. Contier, O., Baker, C. I., & Hebart, M. N. (2024). Nature Human Behaviour, 8(11), 2179–2193.
Thalamic spindles and Up states coordinate cortical and hippocampal co-ripples in humans. Dickey, C. W., Verzhbinsky, I. A., Kajfez, S., Rosen, B. Q., Gonzalez, C. E., Chauvel, P. Y., Cash, S. S., Pati, S., & Halgren, E. (2024). PLOS Biology, 22(11), e3002855.
Preconfigured cortico-thalamic neural dynamics constrain movement-associated thalamic activity. González-Pereyra, P., Sánchez-Lobato, O., Martínez-Montalvo, M. G., Ortega-Romero, D. I., Pérez-Díaz, C. I., Merchant, H., Tellez, L. A., & Rueda-Orozco, P. E. (2024). Nature Communications, 15, 10185.
A tradeoff between efficiency and robustness in the hippocampal-neocortical memory network during human and rodent sleep. Hahn, M. A., Lendner, J. D., Anwander, M., Slama, K. S. J., Knight, R. T., Lin, J. J., & Helfrich, R. F. (2024). Progress in Neurobiology, 242, 102672.
NREM sleep improves behavioral performance by desynchronizing cortical circuits. Kharas, N., Chelaru, M. I., Eagleman, S., Parajuli, A., & Dragoi, V. (2024). Science, 386(6724), 892–897.
Human hippocampus and dorsomedial prefrontal cortex infer and update latent causes during social interaction. Mahmoodi, A., Luo, S., Harbison, C., Piray, P., & Rushworth, M. F. S. (2024). Neuron, 112(22), 3796-3809.e9.
Can compression take place in working memory without a central contribution of long-term memory? Mathy, F., Friedman, O., & Gauvrit, N. (2024). Memory & Cognition, 52(8), 1726–1736.
Offline hippocampal reactivation during dentate spikes supports flexible memory. McHugh, S. B., Lopes-dos-Santos, V., Castelli, M., Gava, G. P., Thompson, S. E., Tam, S. K. E., Hartwich, K., Perry, B., Toth, R., Denison, T., Sharott, A., & Dupret, D. (2024). Neuron, 112(22), 3768-3781.e8.
Reward Bases: A simple mechanism for adaptive acquisition of multiple reward types. Millidge, B., Song, Y., Lak, A., Walton, M. E., & Bogacz, R. (2024). PLOS Computational Biology, 20(11), e1012580.
Hidden state inference requires abstract contextual representations in the ventral hippocampus. Mishchanchuk, K., Gregoriou, G., Qü, A., Kastler, A., Huys, Q. J. M., Wilbrecht, L., & MacAskill, A. F. (2024). Science, 386(6724), 926–932.
Dopamine builds and reveals reward-associated latent behavioral attractors. Naudé, J., Sarazin, M. X. B., Mondoloni, S., Hannesse, B., Vicq, E., Amegandjin, F., Mourot, A., Faure, P., & Delord, B. (2024). Nature Communications, 15, 9825.
Compensation to visual impairments and behavioral plasticity in navigating ants. Schwarz, S., Clement, L., Haalck, L., Risse, B., & Wystrach, A. (2024). Proceedings of the National Academy of Sciences, 121(48), e2410908121.
Replay shapes abstract cognitive maps for efficient social navigation. Son, J.-Y., Vives, M.-L., Bhandari, A., & FeldmanHall, O. (2024). Nature Human Behaviour, 8(11), 2156–2167.
Rapid modulation of striatal cholinergic interneurons and dopamine release by satellite astrocytes. Stedehouder, J., Roberts, B. M., Raina, S., Bossi, S., Liu, A. K. L., Doig, N. M., McGerty, K., Magill, P. J., Parkkinen, L., & Cragg, S. J. (2024). Nature Communications, 15, 10017.
A hierarchical active inference model of spatial alternation tasks and the hippocampal-prefrontal circuit. Van de Maele, T., Dhoedt, B., Verbelen, T., & Pezzulo, G. (2024). Nature Communications, 15, 9892.
Cognitive reserve against Alzheimer’s pathology is linked to brain activity during memory formation. Vockert, N., Machts, J., Kleineidam, L., Nemali, A., Incesoy, E. I., Bernal, J., Schütze, H., Yakupov, R., Peters, O., Gref, D., Schneider, L. S., Preis, L., Priller, J., Spruth, E. J., Altenstein, S., Schneider, A., Fliessbach, K., Wiltfang, J., Rostamzadeh, A., … Ziegler, G. (2024). Nature Communications, 15, 9815.
The human posterior parietal cortices orthogonalize the representation of different streams of information concurrently coded in visual working memory. Xu, Y. (2024). PLOS Biology, 22(11), e3002915.
Challenging the Bayesian confidence hypothesis in perceptual decision-making. Xue, K., Shekhar, M., & Rahnev, D. (2024). Proceedings of the National Academy of Sciences, 121(48), e2410487121.
#neuroscience#science#research#brain science#scientific publications#cognitive science#neurobiology#cognition#psychophysics#neurons#neural computation#neural networks#computational neuroscience
15 notes
·
View notes