#kubernetes controller
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
Ingress Controller Kubernetes: A Comprehensive Guide
Ingress controller Kubernetes is a critical component in Kubernetes environments that manages external access to services within a cluster. It acts as a reverse proxy that routes incoming traffic based on defined rules to appropriate backend services. The ingress controller helps in load balancing, SSL termination, and URL-based routing. Understanding how an ingress controller Kubernetes functions is essential for efficiently managing traffic and ensuring smooth communication between services in a Kubernetes cluster.
Key Features of Ingress Controller Kubernetes
The ingress controller Kubernetes offers several key features that enhance the management of network traffic within a Kubernetes environment. These features include path-based routing, host-based routing, SSL/TLS termination, and load balancing. By leveraging these capabilities, an ingress controller Kubernetes helps streamline traffic management, improve security, and ensure high availability of applications. Understanding these features can assist in optimizing your Kubernetes setup and addressing specific traffic management needs.
How to Set Up an Ingress Controller Kubernetes?
Setting up an ingress controller Kubernetes involves several steps to ensure proper configuration and functionality. The process includes deploying the ingress controller using Kubernetes manifests, configuring ingress resources to define routing rules, and applying SSL/TLS certificates for secure communication. Proper setup is crucial for the ingress controller Kubernetes to effectively manage traffic and route requests to the correct services. This section will guide you through the detailed steps to successfully deploy and configure an ingress controller in your Kubernetes cluster.
Comparing Popular Ingress Controllers for Kubernetes
There are several popular ingress controllers Kubernetes available, each with its unique features and capabilities. Common options include NGINX Ingress Controller, Traefik, and HAProxy Ingress. Comparing these ingress controllers involves evaluating factors such as ease of use, performance, scalability, and support for advanced features. Understanding the strengths and limitations of each ingress controller Kubernetes helps in choosing the best solution for your specific use case and requirements.
Troubleshooting Common Issues with Ingress Controller Kubernetes
Troubleshooting issues with an ingress controller Kubernetes can be challenging but is essential for maintaining a functional and efficient Kubernetes environment. Common problems include incorrect routing, SSL/TLS certificate errors, and performance bottlenecks. This section will explore strategies and best practices for diagnosing and resolving these issues, ensuring that your ingress controller Kubernetes operates smoothly and reliably.
Security Considerations for Ingress Controller Kubernetes
Security is a critical aspect of managing an ingress controller Kubernetes. The ingress controller handles incoming traffic, making it a potential target for attacks. Important security considerations include implementing proper access controls, configuring SSL/TLS encryption, and protecting against common vulnerabilities such as cross-site scripting (XSS) and distributed denial-of-service (DDoS) attacks. By addressing these security aspects, you can safeguard your Kubernetes environment and ensure secure access to your services.
Advanced Configuration Techniques for Ingress Controller Kubernetes
Advanced configuration techniques for ingress controller Kubernetes can enhance its functionality and performance. These techniques include custom load balancing algorithms, advanced routing rules, and integration with external authentication providers. By implementing these advanced configurations, you can tailor the ingress controller Kubernetes to meet specific requirements and optimize traffic management based on your application's needs.
Best Practices for Managing Ingress Controller Kubernetes
Managing an ingress controller Kubernetes effectively involves adhering to best practices that ensure optimal performance and reliability. Best practices include regularly updating the ingress controller, monitoring traffic patterns, and implementing efficient resource allocation strategies. By following these practices, you can maintain a well-managed ingress controller that supports the smooth operation of your Kubernetes applications.
The Role of Ingress Controller Kubernetes in Microservices Architectures
In microservices architectures, the ingress controller Kubernetes plays a vital role in managing traffic between various microservices. It enables efficient routing, load balancing, and security for microservices-based applications. Understanding the role of the ingress controller in such architectures helps in designing robust and scalable systems that handle complex traffic patterns and ensure seamless communication between microservices.
Future Trends in Ingress Controller Kubernetes Technology
The field of ingress controller Kubernetes technology is constantly evolving, with new trends and innovations emerging. Future trends may include enhanced support for service meshes, improved integration with cloud-native security solutions, and advancements in automation and observability. Staying informed about these trends can help you leverage the latest advancements in ingress controller technology to enhance your Kubernetes environment.
Conclusion
The ingress controller Kubernetes is a pivotal component in managing traffic within a Kubernetes cluster. By understanding its features, setup processes, and best practices, you can optimize traffic management, enhance security, and improve overall performance. Whether you are troubleshooting common issues or exploring advanced configurations, a well-managed ingress controller is essential for the effective operation of Kubernetes-based applications. Staying updated on future trends and innovations will further enable you to maintain a cutting-edge and efficient Kubernetes environment.
0 notes
Text
Comparing the Best Ingress Controllers for Kubernetes
Comparing the best ingress controllers for Kubernetes involves evaluating key factors such as scalability, performance, and ease of configuration. Popular options like NGINX Ingress Controller offer robust features for managing traffic routing and SSL termination efficiently. Traefik stands out for its simplicity and support for automatic configuration updates, making it ideal for dynamic environments. HAProxy excels in providing advanced load balancing capabilities and extensive configuration options, suitable for complex deployments requiring fine-tuned control. Each controller varies in terms of integration with cloud providers, support for custom routing rules, and community support. Choosing the right ingress controller depends on your specific Kubernetes deployment needs, including workload type, security requirements, and operational preferences, ensuring seamless application delivery and optimal performance across your infrastructure.
Introduction to Kubernetes Ingress Controllers
Ingress controllers are a critical component in Kubernetes architecture, managing external access to services within a cluster. They provide routing rules, SSL termination, and load balancing, ensuring that requests reach the correct service. Selecting the best ingress controller for Kubernetes depends on various factors, including scalability, ease of use, and integration capabilities.
NGINX Ingress Controller: Robust and Reliable
NGINX Ingress Controller is one of the most popular choices for Kubernetes environments. Known for its robustness and reliability, it supports complex configurations and high traffic loads. It offers features like SSL termination, URL rewrites, and load balancing. NGINX is suitable for enterprises that require a powerful and flexible ingress solution capable of handling various traffic management tasks efficiently.
Simplifying Traffic Management in Dynamic Environments
Traefik is praised for its simplicity and ease of configuration, making it ideal for dynamic and fast-paced environments. It automatically discovers services and updates configurations without manual intervention, reducing administrative overhead. Traefik supports various backends, including Kubernetes, Docker, and Consul, providing seamless integration across different platforms. Its dashboard and metrics capabilities offer valuable insights into traffic management.
Mastering Load Balancing with HAProxy
HAProxy is renowned for its advanced load balancing capabilities and high performance. It supports TCP and HTTP load balancing, SSL termination, and extensive configuration options, making it suitable for complex deployments. HAProxy's flexibility allows for fine-tuned control over traffic management, ensuring optimal performance and reliability. Its integration with Kubernetes is strong, providing a powerful ingress solution for demanding environments.
Designed for Simplicity and Performance
Contour, developed by VMware, is an ingress controller designed specifically for Kubernetes. It leverages Envoy Proxy to provide high performance and scalability. Contour is known for its simplicity in setup and use, offering straightforward configuration with powerful features like HTTP/2 and gRPC support. It's a strong contender for environments that prioritize both simplicity and performance.
Comprehensive Service Mesh
Istio goes beyond a traditional ingress controller, offering a comprehensive service mesh solution. It provides advanced traffic management, security features, and observability tools. Istio is ideal for large-scale microservices architectures where detailed control and monitoring of service-to-service communication are essential. Its ingress capabilities are powerful, but it requires more setup and maintenance compared to simpler ingress controllers.
Comparing Ingress Controllers: Which One is Right for You?
When comparing the best ingress controllers for Kubernetes, it's important to consider your specific needs and environment. NGINX is excellent for robust, high-traffic applications; Traefik offers simplicity and automation; HAProxy provides advanced load balancing; Contour is designed for simplicity and performance; and Istio delivers a comprehensive service mesh solution. Evaluate factors such as ease of use, integration with existing tools, scalability, and the level of control required to choose the best ingress controller for your Kubernetes deployment.
Conclusion
Selecting the best ingress controller for Kubernetes is a crucial decision that impacts the performance, scalability, and management of your applications. Each ingress controller offers unique strengths tailored to different use cases. NGINX and HAProxy are suitable for environments needing robust, high-performance solutions. Traefik and Contour are ideal for simpler setups with automation and performance needs. Istio is perfect for comprehensive service mesh requirements in large-scale microservices architectures. By thoroughly evaluating your specific needs and considering the features of each ingress controller, you can ensure an optimal fit for your Kubernetes deployment, enhancing your application's reliability and efficiency.
0 notes
Text
Deploying Large Language Models on Kubernetes: A Comprehensive Guide
New Post has been published on https://thedigitalinsider.com/deploying-large-language-models-on-kubernetes-a-comprehensive-guide/
Deploying Large Language Models on Kubernetes: A Comprehensive Guide
Large Language Models (LLMs) are capable of understanding and generating human-like text, making them invaluable for a wide range of applications, such as chatbots, content generation, and language translation.
However, deploying LLMs can be a challenging task due to their immense size and computational requirements. Kubernetes, an open-source container orchestration system, provides a powerful solution for deploying and managing LLMs at scale. In this technical blog, we’ll explore the process of deploying LLMs on Kubernetes, covering various aspects such as containerization, resource allocation, and scalability.
Understanding Large Language Models
Before diving into the deployment process, let’s briefly understand what Large Language Models are and why they are gaining so much attention.
Large Language Models (LLMs) are a type of neural network model trained on vast amounts of text data. These models learn to understand and generate human-like language by analyzing patterns and relationships within the training data. Some popular examples of LLMs include GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), and XLNet.
LLMs have achieved remarkable performance in various NLP tasks, such as text generation, language translation, and question answering. However, their massive size and computational requirements pose significant challenges for deployment and inference.
Why Kubernetes for LLM Deployment?
Kubernetes is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. It provides several benefits for deploying LLMs, including:
Scalability: Kubernetes allows you to scale your LLM deployment horizontally by adding or removing compute resources as needed, ensuring optimal resource utilization and performance.
Resource Management: Kubernetes enables efficient resource allocation and isolation, ensuring that your LLM deployment has access to the required compute, memory, and GPU resources.
High Availability: Kubernetes provides built-in mechanisms for self-healing, automatic rollouts, and rollbacks, ensuring that your LLM deployment remains highly available and resilient to failures.
Portability: Containerized LLM deployments can be easily moved between different environments, such as on-premises data centers or cloud platforms, without the need for extensive reconfiguration.
Ecosystem and Community Support: Kubernetes has a large and active community, providing a wealth of tools, libraries, and resources for deploying and managing complex applications like LLMs.
Preparing for LLM Deployment on Kubernetes:
Before deploying an LLM on Kubernetes, there are several prerequisites to consider:
Kubernetes Cluster: You’ll need a Kubernetes cluster set up and running, either on-premises or on a cloud platform like Amazon Elastic Kubernetes Service (EKS), Google Kubernetes Engine (GKE), or Azure Kubernetes Service (AKS).
GPU Support: LLMs are computationally intensive and often require GPU acceleration for efficient inference. Ensure that your Kubernetes cluster has access to GPU resources, either through physical GPUs or cloud-based GPU instances.
Container Registry: You’ll need a container registry to store your LLM Docker images. Popular options include Docker Hub, Amazon Elastic Container Registry (ECR), Google Container Registry (GCR), or Azure Container Registry (ACR).
LLM Model Files: Obtain the pre-trained LLM model files (weights, configuration, and tokenizer) from the respective source or train your own model.
Containerization: Containerize your LLM application using Docker or a similar container runtime. This involves creating a Dockerfile that packages your LLM code, dependencies, and model files into a Docker image.
Deploying an LLM on Kubernetes
Once you have the prerequisites in place, you can proceed with deploying your LLM on Kubernetes. The deployment process typically involves the following steps:
Building the Docker Image
Build the Docker image for your LLM application using the provided Dockerfile and push it to your container registry.
Creating Kubernetes Resources
Define the Kubernetes resources required for your LLM deployment, such as Deployments, Services, ConfigMaps, and Secrets. These resources are typically defined using YAML or JSON manifests.
Configuring Resource Requirements
Specify the resource requirements for your LLM deployment, including CPU, memory, and GPU resources. This ensures that your deployment has access to the necessary compute resources for efficient inference.
Deploying to Kubernetes
Use the kubectl command-line tool or a Kubernetes management tool (e.g., Kubernetes Dashboard, Rancher, or Lens) to apply the Kubernetes manifests and deploy your LLM application.
Monitoring and Scaling
Monitor the performance and resource utilization of your LLM deployment using Kubernetes monitoring tools like Prometheus and Grafana. Adjust the resource allocation or scale your deployment as needed to meet the demand.
Example Deployment
Let’s consider an example of deploying the GPT-3 language model on Kubernetes using a pre-built Docker image from Hugging Face. We’ll assume that you have a Kubernetes cluster set up and configured with GPU support.
Pull the Docker Image:
bashCopydocker pull huggingface/text-generation-inference:1.1.0
Create a Kubernetes Deployment:
Create a file named gpt3-deployment.yaml with the following content:
apiVersion: apps/v1 kind: Deployment metadata: name: gpt3-deployment spec: replicas: 1 selector: matchLabels: app: gpt3 template: metadata: labels: app: gpt3 spec: containers: - name: gpt3 image: huggingface/text-generation-inference:1.1.0 resources: limits: nvidia.com/gpu: 1 env: - name: MODEL_ID value: gpt2 - name: NUM_SHARD value: "1" - name: PORT value: "8080" - name: QUANTIZE value: bitsandbytes-nf4
This deployment specifies that we want to run one replica of the gpt3 container using the huggingface/text-generation-inference:1.1.0 Docker image. The deployment also sets the environment variables required for the container to load the GPT-3 model and configure the inference server.
Create a Kubernetes Service:
Create a file named gpt3-service.yaml with the following content:
apiVersion: v1 kind: Service metadata: name: gpt3-service spec: selector: app: gpt3 ports: - port: 80 targetPort: 8080 type: LoadBalancer
This service exposes the gpt3 deployment on port 80 and creates a LoadBalancer type service to make the inference server accessible from outside the Kubernetes cluster.
Deploy to Kubernetes:
Apply the Kubernetes manifests using the kubectl command:
kubectl apply -f gpt3-deployment.yaml kubectl apply -f gpt3-service.yaml
Monitor the Deployment:
Monitor the deployment progress using the following commands:
kubectl get pods kubectl logs <pod_name>
Once the pod is running and the logs indicate that the model is loaded and ready, you can obtain the external IP address of the LoadBalancer service:
kubectl get service gpt3-service
Test the Deployment:
You can now send requests to the inference server using the external IP address and port obtained from the previous step. For example, using curl:
curl -X POST http://<external_ip>:80/generate -H 'Content-Type: application/json' -d '"inputs": "The quick brown fox", "parameters": "max_new_tokens": 50'
This command sends a text generation request to the GPT-3 inference server, asking it to continue the prompt “The quick brown fox” for up to 50 additional tokens.
Advanced topics you should be aware of
While the example above demonstrates a basic deployment of an LLM on Kubernetes, there are several advanced topics and considerations to explore:
_*]:min-w-0″ readability=”131.72387362124″>
1. Autoscaling
Kubernetes supports horizontal and vertical autoscaling, which can be beneficial for LLM deployments due to their variable computational demands. Horizontal autoscaling allows you to automatically scale the number of replicas (pods) based on metrics like CPU or memory utilization. Vertical autoscaling, on the other hand, allows you to dynamically adjust the resource requests and limits for your containers.
To enable autoscaling, you can use the Kubernetes Horizontal Pod Autoscaler (HPA) and Vertical Pod Autoscaler (VPA). These components monitor your deployment and automatically scale resources based on predefined rules and thresholds.
2. GPU Scheduling and Sharing
In scenarios where multiple LLM deployments or other GPU-intensive workloads are running on the same Kubernetes cluster, efficient GPU scheduling and sharing become crucial. Kubernetes provides several mechanisms to ensure fair and efficient GPU utilization, such as GPU device plugins, node selectors, and resource limits.
You can also leverage advanced GPU scheduling techniques like NVIDIA Multi-Instance GPU (MIG) or AMD Memory Pool Remapping (MPR) to virtualize GPUs and share them among multiple workloads.
3. Model Parallelism and Sharding
Some LLMs, particularly those with billions or trillions of parameters, may not fit entirely into the memory of a single GPU or even a single node. In such cases, you can employ model parallelism and sharding techniques to distribute the model across multiple GPUs or nodes.
Model parallelism involves splitting the model architecture into different components (e.g., encoder, decoder) and distributing them across multiple devices. Sharding, on the other hand, involves partitioning the model parameters and distributing them across multiple devices or nodes.
Kubernetes provides mechanisms like StatefulSets and Custom Resource Definitions (CRDs) to manage and orchestrate distributed LLM deployments with model parallelism and sharding.
4. Fine-tuning and Continuous Learning
In many cases, pre-trained LLMs may need to be fine-tuned or continuously trained on domain-specific data to improve their performance for specific tasks or domains. Kubernetes can facilitate this process by providing a scalable and resilient platform for running fine-tuning or continuous learning workloads.
You can leverage Kubernetes batch processing frameworks like Apache Spark or Kubeflow to run distributed fine-tuning or training jobs on your LLM models. Additionally, you can integrate your fine-tuned or continuously trained models with your inference deployments using Kubernetes mechanisms like rolling updates or blue/green deployments.
5. Monitoring and Observability
Monitoring and observability are crucial aspects of any production deployment, including LLM deployments on Kubernetes. Kubernetes provides built-in monitoring solutions like Prometheus and integrations with popular observability platforms like Grafana, Elasticsearch, and Jaeger.
You can monitor various metrics related to your LLM deployments, such as CPU and memory utilization, GPU usage, inference latency, and throughput. Additionally, you can collect and analyze application-level logs and traces to gain insights into the behavior and performance of your LLM models.
6. Security and Compliance
Depending on your use case and the sensitivity of the data involved, you may need to consider security and compliance aspects when deploying LLMs on Kubernetes. Kubernetes provides several features and integrations to enhance security, such as network policies, role-based access control (RBAC), secrets management, and integration with external security solutions like HashiCorp Vault or AWS Secrets Manager.
Additionally, if you’re deploying LLMs in regulated industries or handling sensitive data, you may need to ensure compliance with relevant standards and regulations, such as GDPR, HIPAA, or PCI-DSS.
7. Multi-Cloud and Hybrid Deployments
While this blog post focuses on deploying LLMs on a single Kubernetes cluster, you may need to consider multi-cloud or hybrid deployments in some scenarios. Kubernetes provides a consistent platform for deploying and managing applications across different cloud providers and on-premises data centers.
You can leverage Kubernetes federation or multi-cluster management tools like KubeFed or GKE Hub to manage and orchestrate LLM deployments across multiple Kubernetes clusters spanning different cloud providers or hybrid environments.
These advanced topics highlight the flexibility and scalability of Kubernetes for deploying and managing LLMs.
Conclusion
Deploying Large Language Models (LLMs) on Kubernetes offers numerous benefits, including scalability, resource management, high availability, and portability. By following the steps outlined in this technical blog, you can containerize your LLM application, define the necessary Kubernetes resources, and deploy it to a Kubernetes cluster.
However, deploying LLMs on Kubernetes is just the first step. As your application grows and your requirements evolve, you may need to explore advanced topics such as autoscaling, GPU scheduling, model parallelism, fine-tuning, monitoring, security, and multi-cloud deployments.
Kubernetes provides a robust and extensible platform for deploying and managing LLMs, enabling you to build reliable, scalable, and secure applications.
#access control#Amazon#Amazon Elastic Kubernetes Service#amd#Apache#Apache Spark#app#applications#apps#architecture#Artificial Intelligence#attention#AWS#azure#Behavior#BERT#Blog#Blue#Building#chatbots#Cloud#cloud platform#cloud providers#cluster#clusters#code#command#Community#compliance#comprehensive
0 notes
Photo

Upbound Spaces brings managed control planes to self-hosted computing environments Upbound Inc., the startup behind the popular open-source Crossplane project, today announced a new self-hosting feature for its flagship control plane technology, enabling users to deploy managed control planes in self-managed computing environments. Upbound Spaces enables customers with rigorous compliance and data sovereignty requirements to benefit from the company’s Crossplane control plane technology. The launch of […] The post Upbound Spaces brings managed control planes to self-hosted computing environments appeared first on SiliconANGLE. https://siliconangle.com/2023/09/06/upbound-spaces-brings-managed-control-planes-self-hosted-computing-environments/
#Cloud#NEWS#The-Latest#applications#cloud-native technologies#control plane#Crossplane#internal development platforms#Kubernetes#managed control planes#managed environments#multicloud#self-hosted environments#Upbound#Upbound Spaces#Mike Wheatley#SiliconANGLE
0 notes
Video
youtube
Session 11 Kubernetes Controllers
#youtube#Exploring Kubernetes Controllers! 🌟 📽️ Welcome to our latest video where we delve into the fascinating world of KubernetesControllers! 🚀
1 note
·
View note
Text
#kubernetes controller manager#kubernetes controller golang#kubernetes controller explained#kubernetes controller example#kubernetes controller development
0 notes
Text
What is Argo CD? And When Was Argo CD Established?

What Is Argo CD?
Argo CD is declarative Kubernetes GitOps continuous delivery.
In DevOps, ArgoCD is a Continuous Delivery (CD) technology that has become well-liked for delivering applications to Kubernetes. It is based on the GitOps deployment methodology.
When was Argo CD Established?
Argo CD was created at Intuit and made publicly available following Applatix’s 2018 acquisition by Intuit. The founding developers of Applatix, Hong Wang, Jesse Suen, and Alexander Matyushentsev, made the Argo project open-source in 2017.
Why Argo CD?
Declarative and version-controlled application definitions, configurations, and environments are ideal. Automated, auditable, and easily comprehensible application deployment and lifecycle management are essential.
Getting Started
Quick Start
kubectl create namespace argocd kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
For some features, more user-friendly documentation is offered. Refer to the upgrade guide if you want to upgrade your Argo CD. Those interested in creating third-party connectors can access developer-oriented resources.
How it works
Argo CD defines the intended application state by employing Git repositories as the source of truth, in accordance with the GitOps pattern. There are various approaches to specify Kubernetes manifests:
Applications for Customization
Helm charts
JSONNET files
Simple YAML/JSON manifest directory
Any custom configuration management tool that is set up as a plugin
The deployment of the intended application states in the designated target settings is automated by Argo CD. Deployments of applications can monitor changes to branches, tags, or pinned to a particular manifest version at a Git commit.
Architecture
The implementation of Argo CD is a Kubernetes controller that continually observes active apps and contrasts their present, live state with the target state (as defined in the Git repository). Out Of Sync is the term used to describe a deployed application whose live state differs from the target state. In addition to reporting and visualizing the differences, Argo CD offers the ability to manually or automatically sync the current state back to the intended goal state. The designated target environments can automatically apply and reflect any changes made to the intended target state in the Git repository.
Components
API Server
The Web UI, CLI, and CI/CD systems use the API, which is exposed by the gRPC/REST server. Its duties include the following:
Status reporting and application management
Launching application functions (such as rollback, sync, and user-defined actions)
Cluster credential management and repository (k8s secrets)
RBAC enforcement
Authentication, and auth delegation to outside identity providers
Git webhook event listener/forwarder
Repository Server
An internal service called the repository server keeps a local cache of the Git repository containing the application manifests. When given the following inputs, it is in charge of creating and returning the Kubernetes manifests:
URL of the repository
Revision (tag, branch, commit)
Path of the application
Template-specific configurations: helm values.yaml, parameters
A Kubernetes controller known as the application controller keeps an eye on all active apps and contrasts their actual, live state with the intended target state as defined in the repository. When it identifies an Out Of Sync application state, it may take remedial action. It is in charge of calling any user-specified hooks for lifecycle events (Sync, PostSync, and PreSync).
Features
Applications are automatically deployed to designated target environments.
Multiple configuration management/templating tools (Kustomize, Helm, Jsonnet, and plain-YAML) are supported.
Capacity to oversee and implement across several clusters
Integration of SSO (OIDC, OAuth2, LDAP, SAML 2.0, Microsoft, LinkedIn, GitHub, GitLab)
RBAC and multi-tenancy authorization policies
Rollback/Roll-anywhere to any Git repository-committed application configuration
Analysis of the application resources’ health state
Automated visualization and detection of configuration drift
Applications can be synced manually or automatically to their desired state.
Web user interface that shows program activity in real time
CLI for CI integration and automation
Integration of webhooks (GitHub, BitBucket, GitLab)
Tokens of access for automation
Hooks for PreSync, Sync, and PostSync to facilitate intricate application rollouts (such as canary and blue/green upgrades)
Application event and API call audit trails
Prometheus measurements
To override helm parameters in Git, use parameter overrides.
Read more on Govindhtech.com
#ArgoCD#CD#GitOps#API#Kubernetes#Git#Argoproject#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
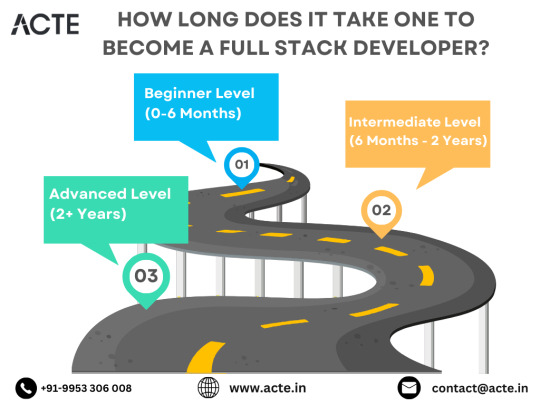
The Roadmap to Full Stack Developer Proficiency: A Comprehensive Guide
Embarking on the journey to becoming a full stack developer is an exhilarating endeavor filled with growth and challenges. Whether you're taking your first steps or seeking to elevate your skills, understanding the path ahead is crucial. In this detailed roadmap, we'll outline the stages of mastering full stack development, exploring essential milestones, competencies, and strategies to guide you through this enriching career journey.

Beginning the Journey: Novice Phase (0-6 Months)
As a novice, you're entering the realm of programming with a fresh perspective and eagerness to learn. This initial phase sets the groundwork for your progression as a full stack developer.
Grasping Programming Fundamentals:
Your journey commences with grasping the foundational elements of programming languages like HTML, CSS, and JavaScript. These are the cornerstone of web development and are essential for crafting dynamic and interactive web applications.
Familiarizing with Basic Data Structures and Algorithms:
To develop proficiency in programming, understanding fundamental data structures such as arrays, objects, and linked lists, along with algorithms like sorting and searching, is imperative. These concepts form the backbone of problem-solving in software development.
Exploring Essential Web Development Concepts:
During this phase, you'll delve into crucial web development concepts like client-server architecture, HTTP protocol, and the Document Object Model (DOM). Acquiring insights into the underlying mechanisms of web applications lays a strong foundation for tackling more intricate projects.
Advancing Forward: Intermediate Stage (6 Months - 2 Years)
As you progress beyond the basics, you'll transition into the intermediate stage, where you'll deepen your understanding and skills across various facets of full stack development.
Venturing into Backend Development:
In the intermediate stage, you'll venture into backend development, honing your proficiency in server-side languages like Node.js, Python, or Java. Here, you'll learn to construct robust server-side applications, manage data storage and retrieval, and implement authentication and authorization mechanisms.
Mastering Database Management:
A pivotal aspect of backend development is comprehending databases. You'll delve into relational databases like MySQL and PostgreSQL, as well as NoSQL databases like MongoDB. Proficiency in database management systems and design principles enables the creation of scalable and efficient applications.
Exploring Frontend Frameworks and Libraries:
In addition to backend development, you'll deepen your expertise in frontend technologies. You'll explore prominent frameworks and libraries such as React, Angular, or Vue.js, streamlining the creation of interactive and responsive user interfaces.
Learning Version Control with Git:
Version control is indispensable for collaborative software development. During this phase, you'll familiarize yourself with Git, a distributed version control system, to manage your codebase, track changes, and collaborate effectively with fellow developers.
Achieving Mastery: Advanced Phase (2+ Years)
As you ascend in your journey, you'll enter the advanced phase of full stack development, where you'll refine your skills, tackle intricate challenges, and delve into specialized domains of interest.
Designing Scalable Systems:
In the advanced stage, focus shifts to designing scalable systems capable of managing substantial volumes of traffic and data. You'll explore design patterns, scalability methodologies, and cloud computing platforms like AWS, Azure, or Google Cloud.
Embracing DevOps Practices:
DevOps practices play a pivotal role in contemporary software development. You'll delve into continuous integration and continuous deployment (CI/CD) pipelines, infrastructure as code (IaC), and containerization technologies such as Docker and Kubernetes.
Specializing in Niche Areas:
With experience, you may opt to specialize in specific domains of full stack development, whether it's frontend or backend development, mobile app development, or DevOps. Specialization enables you to deepen your expertise and pursue career avenues aligned with your passions and strengths.
Conclusion:
Becoming a proficient full stack developer is a transformative journey that demands dedication, resilience, and perpetual learning. By following the roadmap outlined in this guide and maintaining a curious and adaptable mindset, you'll navigate the complexities and opportunities inherent in the realm of full stack development. Remember, mastery isn't merely about acquiring technical skills but also about fostering collaboration, embracing innovation, and contributing meaningfully to the ever-evolving landscape of technology.
#full stack developer#education#information#full stack web development#front end development#frameworks#web development#backend#full stack developer course#technology
9 notes
·
View notes
Text
Ingress Controller Kubernetes: A Comprehensive Guide
Ingress controller Kubernetes is a critical component in Kubernetes environments that manages external access to services within a cluster. It acts as a reverse proxy that routes incoming traffic based on defined rules to appropriate backend services. The ingress controller helps in load balancing, SSL termination, and URL-based routing. Understanding how an ingress controller Kubernetes functions is essential for efficiently managing traffic and ensuring smooth communication between services in a Kubernetes cluster.
Key Features of Ingress Controller Kubernetes
The ingress controller Kubernetes offers several key features that enhance the management of network traffic within a Kubernetes environment. These features include path-based routing, host-based routing, SSL/TLS termination, and load balancing. By leveraging these capabilities, an ingress controller Kubernetes helps streamline traffic management, improve security, and ensure high availability of applications. Understanding these features can assist in optimizing your Kubernetes setup and addressing specific traffic management needs.
How to Set Up an Ingress Controller Kubernetes?
Setting up an ingress controller Kubernetes involves several steps to ensure proper configuration and functionality. The process includes deploying the ingress controller using Kubernetes manifests, configuring ingress resources to define routing rules, and applying SSL/TLS certificates for secure communication. Proper setup is crucial for the **ingress controller Kubernetes** to effectively manage traffic and route requests to the correct services. This section will guide you through the detailed steps to successfully deploy and configure an ingress controller in your Kubernetes cluster.
Comparing Popular Ingress Controllers for Kubernetes
There are several popular **ingress controllers Kubernetes** available, each with its unique features and capabilities. Common options include NGINX Ingress Controller, Traefik, and HAProxy Ingress. Comparing these ingress controllers involves evaluating factors such as ease of use, performance, scalability, and support for advanced features. Understanding the strengths and limitations of each **ingress controller Kubernetes** helps in choosing the best solution for your specific use case and requirements.
Troubleshooting Common Issues with Ingress Controller Kubernetes
Troubleshooting issues with an ingress controller Kubernetes can be challenging but is essential for maintaining a functional and efficient Kubernetes environment. Common problems include incorrect routing, SSL/TLS certificate errors, and performance bottlenecks. This section will explore strategies and best practices for diagnosing and resolving these issues, ensuring that your ingress controller Kubernetes operates smoothly and reliably.
Security Considerations for Ingress Controller Kubernetes
Security is a critical aspect of managing an ingress controller Kubernetes. The ingress controller handles incoming traffic, making it a potential target for attacks. Important security considerations include implementing proper access controls, configuring SSL/TLS encryption, and protecting against common vulnerabilities such as cross-site scripting (XSS) and distributed denial-of-service (DDoS) attacks. By addressing these security aspects, you can safeguard your Kubernetes environment and ensure secure access to your services.
Advanced Configuration Techniques for Ingress Controller Kubernetes
Advanced configuration techniques for **ingress controller Kubernetes** can enhance its functionality and performance. These techniques include custom load balancing algorithms, advanced routing rules, and integration with external authentication providers. By implementing these advanced configurations, you can tailor the **ingress controller Kubernetes** to meet specific requirements and optimize traffic management based on your application's needs.
Best Practices for Managing Ingress Controller Kubernetes
Managing an ingress controller Kubernetes effectively involves adhering to best practices that ensure optimal performance and reliability. Best practices include regularly updating the ingress controller, monitoring traffic patterns, and implementing efficient resource allocation strategies. By following these practices, you can maintain a well-managed ingress controller that supports the smooth operation of your Kubernetes applications.
The Role of Ingress Controller Kubernetes in Microservices Architectures
In microservices architectures, the ingress controller Kubernetes plays a vital role in managing traffic between various microservices. It enables efficient routing, load balancing, and security for microservices-based applications. Understanding the role of the ingress controller in such architectures helps in designing robust and scalable systems that handle complex traffic patterns and ensure seamless communication between microservices.
Future Trends in Ingress Controller Kubernetes Technology
The field of ingress controller Kubernetes technology is constantly evolving, with new trends and innovations emerging. Future trends may include enhanced support for service meshes, improved integration with cloud-native security solutions, and advancements in automation and observability. Staying informed about these trends can help you leverage the latest advancements in ingress controller technology to enhance your Kubernetes environment.
Conclusion
The ingress controller Kubernetes is a pivotal component in managing traffic within a Kubernetes cluster. By understanding its features, setup processes, and best practices, you can optimize traffic management, enhance security, and improve overall performance. Whether you are troubleshooting common issues or exploring advanced configurations, a well-managed ingress controller is essential for the effective operation of Kubernetes-based applications. Staying updated on future trends and innovations will further enable you to maintain a cutting-edge and efficient Kubernetes environment.
0 notes
Text
Load Balancing Web Sockets with K8s/Istio
When load balancing WebSockets in a Kubernetes (K8s) environment with Istio, there are several considerations to ensure persistent, low-latency connections. WebSockets require special handling because they are long-lived, bidirectional connections, which are different from standard HTTP request-response communication. Here’s a guide to implementing load balancing for WebSockets using Istio.
1. Enable WebSocket Support in Istio
By default, Istio supports WebSocket connections, but certain configurations may need tweaking. You should ensure that:
Destination rules and VirtualServices are configured appropriately to allow WebSocket traffic.
Example VirtualService Configuration.
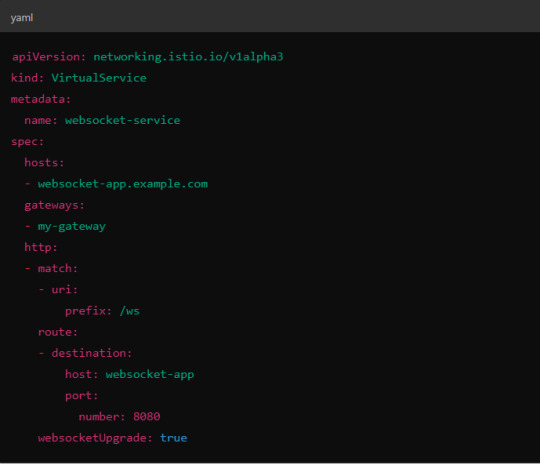
Here, websocketUpgrade: true explicitly allows WebSocket traffic and ensures that Istio won’t downgrade the WebSocket connection to HTTP.
2. Session Affinity (Sticky Sessions)
In WebSocket applications, sticky sessions or session affinity is often necessary to keep long-running WebSocket connections tied to the same backend pod. Without session affinity, WebSocket connections can be terminated if the load balancer routes the traffic to a different pod.
Implementing Session Affinity in Istio.
Session affinity is typically achieved by setting the sessionAffinity field to ClientIP at the Kubernetes service level.
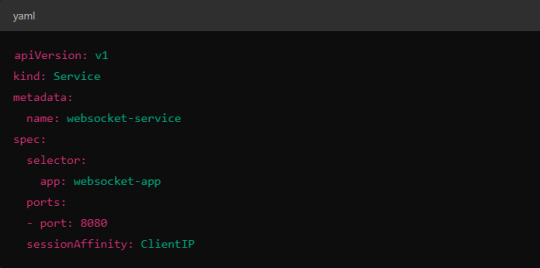
In Istio, you might also control affinity using headers. For example, Istio can route traffic based on headers by configuring a VirtualService to ensure connections stay on the same backend.
3. Load Balancing Strategy
Since WebSocket connections are long-lived, round-robin or random load balancing strategies can lead to unbalanced workloads across pods. To address this, you may consider using least connection or consistent hashing algorithms to ensure that existing connections are efficiently distributed.
Load Balancer Configuration in Istio.
Istio allows you to specify different load balancing strategies in the DestinationRule for your services. For WebSockets, the LEAST_CONN strategy may be more appropriate.
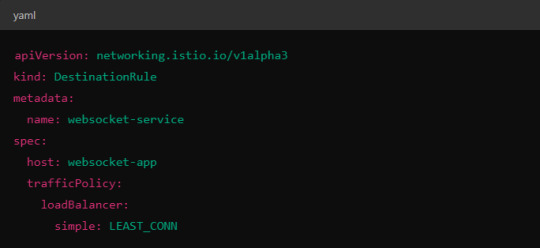
Alternatively, you could use consistent hashing for a more sticky routing based on connection properties like the user session ID.
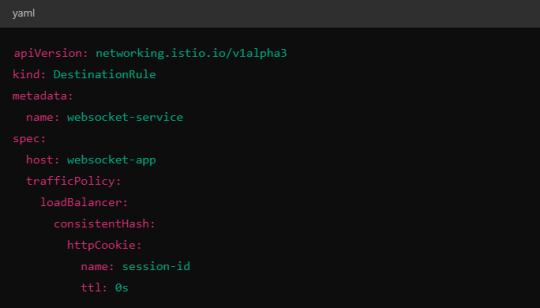
This configuration ensures that connections with the same session ID go to the same pod.
4. Scaling Considerations
WebSocket applications can handle a large number of concurrent connections, so you’ll need to ensure that your Kubernetes cluster can scale appropriately.
Horizontal Pod Autoscaler (HPA): Use an HPA to automatically scale your pods based on metrics like CPU, memory, or custom metrics such as open WebSocket connections.
Istio Autoscaler: You may also scale Istio itself to handle the increased load on the control plane as WebSocket connections increase.
5. Connection Timeouts and Keep-Alive
Ensure that both your WebSocket clients and the Istio proxy (Envoy) are configured for long-lived connections. Some settings that need attention:
Timeouts: In VirtualService, make sure there are no aggressive timeout settings that would prematurely close WebSocket connections.

Keep-Alive Settings: You can also adjust the keep-alive settings at the Envoy level if necessary. Envoy, the proxy used by Istio, supports long-lived WebSocket connections out-of-the-box, but custom keep-alive policies can be configured.
6. Ingress Gateway Configuration
If you're using an Istio Ingress Gateway, ensure that it is configured to handle WebSocket traffic. The gateway should allow for WebSocket connections on the relevant port.
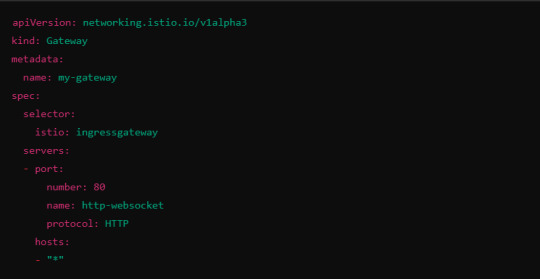
This configuration ensures that the Ingress Gateway can handle WebSocket upgrades and correctly route them to the backend service.
Summary of Key Steps
Enable WebSocket support in Istio’s VirtualService.
Use session affinity to tie WebSocket connections to the same backend pod.
Choose an appropriate load balancing strategy, such as least connection or consistent hashing.
Set timeouts and keep-alive policies to ensure long-lived WebSocket connections.
Configure the Ingress Gateway to handle WebSocket traffic.
By properly configuring Istio, Kubernetes, and your WebSocket service, you can efficiently load balance WebSocket connections in a microservices architecture.
#kubernetes#websockets#Load Balancing#devops#linux#coding#programming#Istio#virtualservices#Load Balancer#Kubernetes cluster#gateway#python#devlog#github#ansible
5 notes
·
View notes
Text
Is cPanel on Its Deathbed? A Tale of Technology, Profits, and a Slow-Moving Train Wreck
Ah, cPanel. The go-to control panel for many web hosting services since the dawn of, well, web hosting. Once the epitome of innovation, it’s now akin to a grizzled war veteran, limping along with a cane and wearing an “I Survived Y2K” t-shirt. So what went wrong? Let’s dive into this slow-moving technological telenovela, rife with corporate greed, security loopholes, and a legacy that may be hanging by a thread.
Chapter 1: A Brief, Glorious History (Or How cPanel Shot to Stardom)
Once upon a time, cPanel was the bee’s knees. Launched in 1996, this software was, for a while, the pinnacle of web management systems. It promised simplicity, reliability, and functionality. Oh, the golden years!
Chapter 2: The Tech Stack Tortoise
In the fast-paced world of technology, being stagnant is synonymous with being extinct. While newer tech stacks are integrating AI, machine learning, and all sorts of jazzy things, cPanel seems to be stuck in a time warp. Why? Because the tech stack is more outdated than a pair of bell-bottom trousers. No Docker, no Kubernetes, and don’t even get me started on the lack of robust API support.
Chapter 3: “The Corpulent Corporate”
In 2018, Oakley Capital, a private equity firm, acquired cPanel. For many, this was the beginning of the end. Pricing structures were jumbled, turning into a monetisation extravaganza. It’s like turning your grandma’s humble pie shop into a mass production line for rubbery, soulless pies. They’ve squeezed every ounce of profit from it, often at the expense of the end-users and smaller hosting companies.
Chapter 4: Security—or the Lack Thereof
Ah, the elephant in the room. cPanel has had its fair share of vulnerabilities. Whether it’s SQL injection flaws, privilege escalation, or simple, plain-text passwords (yes, you heard right), cPanel often appears in the headlines for all the wrong reasons. It’s like that dodgy uncle at family reunions who always manages to spill wine on the carpet; you know he’s going to mess up, yet somehow he’s always invited.
Chapter 5: The (Dis)loyal Subjects—The Hosting Companies
Remember those hosting companies that once swore by cPanel? Well, let’s just say some of them have been seen flirting with competitors at the bar. Newer, shinier control panels are coming to market, offering modern tech stacks and, gasp, lower prices! It’s like watching cPanel’s loyal subjects slowly turn their backs, one by one.
Chapter 6: The Alternatives—Not Just a Rebellion, but a Revolution
Plesk, Webmin, DirectAdmin, oh my! New players are rising, offering updated tech stacks, more customizable APIs, and—wait for it—better security protocols. They’re the Han Solos to cPanel’s Jabba the Hutt: faster, sleeker, and without the constant drooling.
Conclusion: The Twilight Years or a Second Wind?
The debate rages on. Is cPanel merely an ageing actor waiting for its swan song, or can it adapt and evolve, perhaps surprising us all? Either way, the story of cPanel serves as a cautionary tale: adapt or die. And for heaven’s sake, update your tech stack before it becomes a relic in a technology museum, right between floppy disks and dial-up modems.
This outline only scratches the surface, but it’s a start. If cPanel wants to avoid becoming the Betamax of web management systems, it better start evolving—stat. Cheers!
#hosting#wordpress#cpanel#webdesign#servers#websites#webdeveloper#technology#tech#website#developer#digitalagency#uk#ukdeals#ukbusiness#smallbussinessowner
14 notes
·
View notes
Text
Navigating the DevOps Landscape: Opportunities and Roles
DevOps has become a game-changer in the quick-moving world of technology. This dynamic process, whose name is a combination of "Development" and "Operations," is revolutionising the way software is created, tested, and deployed. DevOps is a cultural shift that encourages cooperation, automation, and integration between development and IT operations teams, not merely a set of practises. The outcome? greater software delivery speed, dependability, and effectiveness.

In this comprehensive guide, we'll delve into the essence of DevOps, explore the key technologies that underpin its success, and uncover the vast array of job opportunities it offers. Whether you're an aspiring IT professional looking to enter the world of DevOps or an experienced practitioner seeking to enhance your skills, this blog will serve as your roadmap to mastering DevOps. So, let's embark on this enlightening journey into the realm of DevOps.
Key Technologies for DevOps:
Version Control Systems: DevOps teams rely heavily on robust version control systems such as Git and SVN. These systems are instrumental in managing and tracking changes in code and configurations, promoting collaboration and ensuring the integrity of the software development process.
Continuous Integration/Continuous Deployment (CI/CD): The heart of DevOps, CI/CD tools like Jenkins, Travis CI, and CircleCI drive the automation of critical processes. They orchestrate the building, testing, and deployment of code changes, enabling rapid, reliable, and consistent software releases.
Configuration Management: Tools like Ansible, Puppet, and Chef are the architects of automation in the DevOps landscape. They facilitate the automated provisioning and management of infrastructure and application configurations, ensuring consistency and efficiency.
Containerization: Docker and Kubernetes, the cornerstones of containerization, are pivotal in the DevOps toolkit. They empower the creation, deployment, and management of containers that encapsulate applications and their dependencies, simplifying deployment and scaling.
Orchestration: Docker Swarm and Amazon ECS take center stage in orchestrating and managing containerized applications at scale. They provide the control and coordination required to maintain the efficiency and reliability of containerized systems.
Monitoring and Logging: The observability of applications and systems is essential in the DevOps workflow. Monitoring and logging tools like the ELK Stack (Elasticsearch, Logstash, Kibana) and Prometheus are the eyes and ears of DevOps professionals, tracking performance, identifying issues, and optimizing system behavior.
Cloud Computing Platforms: AWS, Azure, and Google Cloud are the foundational pillars of cloud infrastructure in DevOps. They offer the infrastructure and services essential for creating and scaling cloud-based applications, facilitating the agility and flexibility required in modern software development.
Scripting and Coding: Proficiency in scripting languages such as Shell, Python, Ruby, and coding skills are invaluable assets for DevOps professionals. They empower the creation of automation scripts and tools, enabling customization and extensibility in the DevOps pipeline.
Collaboration and Communication Tools: Collaboration tools like Slack and Microsoft Teams enhance the communication and coordination among DevOps team members. They foster efficient collaboration and facilitate the exchange of ideas and information.
Infrastructure as Code (IaC): The concept of Infrastructure as Code, represented by tools like Terraform and AWS CloudFormation, is a pivotal practice in DevOps. It allows the definition and management of infrastructure using code, ensuring consistency and reproducibility, and enabling the rapid provisioning of resources.

Job Opportunities in DevOps:
DevOps Engineer: DevOps engineers are the architects of continuous integration and continuous deployment (CI/CD) pipelines. They meticulously design and maintain these pipelines to automate the deployment process, ensuring the rapid, reliable, and consistent release of software. Their responsibilities extend to optimizing the system's reliability, making them the backbone of seamless software delivery.
Release Manager: Release managers play a pivotal role in orchestrating the software release process. They carefully plan and schedule software releases, coordinating activities between development and IT teams. Their keen oversight ensures the smooth transition of software from development to production, enabling timely and successful releases.
Automation Architect: Automation architects are the visionaries behind the design and development of automation frameworks. These frameworks streamline deployment and monitoring processes, leveraging automation to enhance efficiency and reliability. They are the engineers of innovation, transforming manual tasks into automated wonders.
Cloud Engineer: Cloud engineers are the custodians of cloud infrastructure. They adeptly manage cloud resources, optimizing their performance and ensuring scalability. Their expertise lies in harnessing the power of cloud platforms like AWS, Azure, or Google Cloud to provide robust, flexible, and cost-effective solutions.
Site Reliability Engineer (SRE): SREs are the sentinels of system reliability. They focus on maintaining the system's resilience through efficient practices, continuous monitoring, and rapid incident response. Their vigilance ensures that applications and systems remain stable and performant, even in the face of challenges.
Security Engineer: Security engineers are the guardians of the DevOps pipeline. They integrate security measures seamlessly into the software development process, safeguarding it from potential threats and vulnerabilities. Their role is crucial in an era where security is paramount, ensuring that DevOps practices are fortified against breaches.
As DevOps continues to redefine the landscape of software development and deployment, gaining expertise in its core principles and technologies is a strategic career move. ACTE Technologies offers comprehensive DevOps training programs, led by industry experts who provide invaluable insights, real-world examples, and hands-on guidance. ACTE Technologies's DevOps training covers a wide range of essential concepts, practical exercises, and real-world applications. With a strong focus on certification preparation, ACTE Technologies ensures that you're well-prepared to excel in the world of DevOps. With their guidance, you can gain mastery over DevOps practices, enhance your skill set, and propel your career to new heights.
11 notes
·
View notes
Text
Journey to Devops
The concept of “DevOps” has been gaining traction in the IT sector for a couple of years. It involves promoting teamwork and interaction, between software developers and IT operations groups to enhance the speed and reliability of software delivery. This strategy has become widely accepted as companies strive to provide software to meet customer needs and maintain an edge, in the industry. In this article we will explore the elements of becoming a DevOps Engineer.
Step 1: Get familiar with the basics of Software Development and IT Operations:
In order to pursue a career as a DevOps Engineer it is crucial to possess a grasp of software development and IT operations. Familiarity with programming languages like Python, Java, Ruby or PHP is essential. Additionally, having knowledge about operating systems, databases and networking is vital.
Step 2: Learn the principles of DevOps:
It is crucial to comprehend and apply the principles of DevOps. Automation, continuous integration, continuous deployment and continuous monitoring are aspects that need to be understood and implemented. It is vital to learn how these principles function and how to carry them out efficiently.
Step 3: Familiarize yourself with the DevOps toolchain:
Git: Git, a distributed version control system is extensively utilized by DevOps teams, for code repository management. It aids in monitoring code alterations facilitating collaboration, among team members and preserving a record of modifications made to the codebase.
Ansible: Ansible is an open source tool used for managing configurations deploying applications and automating tasks. It simplifies infrastructure management. Saves time when performing tasks.
Docker: Docker, on the other hand is a platform for containerization that allows DevOps engineers to bundle applications and dependencies into containers. This ensures consistency and compatibility across environments from development, to production.
Kubernetes: Kubernetes is an open-source container orchestration platform that helps manage and scale containers. It helps automate the deployment, scaling, and management of applications and micro-services.
Jenkins: Jenkins is an open-source automation server that helps automate the process of building, testing, and deploying software. It helps to automate repetitive tasks and improve the speed and efficiency of the software delivery process.
Nagios: Nagios is an open-source monitoring tool that helps us monitor the health and performance of our IT infrastructure. It also helps us to identify and resolve issues in real-time and ensure the high availability and reliability of IT systems as well.
Terraform: Terraform is an infrastructure as code (IAC) tool that helps manage and provision IT infrastructure. It helps us automate the process of provisioning and configuring IT resources and ensures consistency between development and production environments.
Step 4: Gain practical experience:
The best way to gain practical experience is by working on real projects and bootcamps. You can start by contributing to open-source projects or participating in coding challenges and hackathons. You can also attend workshops and online courses to improve your skills.
Step 5: Get certified:
Getting certified in DevOps can help you stand out from the crowd and showcase your expertise to various people. Some of the most popular certifications are:
Certified Kubernetes Administrator (CKA)
AWS Certified DevOps Engineer
Microsoft Certified: Azure DevOps Engineer Expert
AWS Certified Cloud Practitioner
Step 6: Build a strong professional network:
Networking is one of the most important parts of becoming a DevOps Engineer. You can join online communities, attend conferences, join webinars and connect with other professionals in the field. This will help you stay up-to-date with the latest developments and also help you find job opportunities and success.
Conclusion:
You can start your journey towards a successful career in DevOps. The most important thing is to be passionate about your work and continuously learn and improve your skills. With the right skills, experience, and network, you can achieve great success in this field and earn valuable experience.
2 notes
·
View notes
Text
Google Kubernetes Misconfig Lets Any Gmail Account Control Your Clusters
Source: https://thehackernews.com/2024/01/google-kubernetes-misconfig-lets-any.html
More info: https://orca.security/resources/blog/sys-all-google-kubernetes-engine-risk-example/
3 notes
·
View notes
Text
Navigating the DevOps Landscape: A Beginner's Comprehensive
Roadmap In the dynamic realm of software development, the DevOps methodology stands out as a transformative force, fostering collaboration, automation, and continuous enhancement. For newcomers eager to immerse themselves in this revolutionary culture, this all-encompassing guide presents the essential steps to initiate your DevOps expedition.

Grasping the Essence of DevOps Culture: DevOps transcends mere tool usage; it embodies a cultural transformation that prioritizes collaboration and communication between development and operations teams. Begin by comprehending the fundamental principles of collaboration, automation, and continuous improvement.
Immerse Yourself in DevOps Literature: Kickstart your journey by delving into indispensable DevOps literature. "The Phoenix Project" by Gene Kim, Jez Humble, and Kevin Behr, along with "The DevOps Handbook," provides invaluable insights into the theoretical underpinnings and practical implementations of DevOps.
Online Courses and Tutorials: Harness the educational potential of online platforms like Coursera, edX, and Udacity. Seek courses covering pivotal DevOps tools such as Git, Jenkins, Docker, and Kubernetes. These courses will furnish you with a robust comprehension of the tools and processes integral to the DevOps terrain.
Practical Application: While theory is crucial, hands-on experience is paramount. Establish your own development environment and embark on practical projects. Implement version control, construct CI/CD pipelines, and deploy applications to acquire firsthand experience in applying DevOps principles.

Explore the Realm of Configuration Management: Configuration management is a pivotal facet of DevOps. Familiarize yourself with tools like Ansible, Puppet, or Chef, which automate infrastructure provisioning and configuration, ensuring uniformity across diverse environments.
Containerization and Orchestration: Delve into the universe of containerization with Docker and orchestration with Kubernetes. Containers provide uniformity across diverse environments, while orchestration tools automate the deployment, scaling, and management of containerized applications.
Continuous Integration and Continuous Deployment (CI/CD): Integral to DevOps is CI/CD. Gain proficiency in Jenkins, Travis CI, or GitLab CI to automate code change testing and deployment. These tools enhance the speed and reliability of the release cycle, a central objective in DevOps methodologies.
Grasp Networking and Security Fundamentals: Expand your knowledge to encompass networking and security basics relevant to DevOps. Comprehend how security integrates into the DevOps pipeline, embracing the principles of DevSecOps. Gain insights into infrastructure security and secure coding practices to ensure robust DevOps implementations.
Embarking on a DevOps expedition demands a comprehensive strategy that amalgamates theoretical understanding with hands-on experience. By grasping the cultural shift, exploring key literature, and mastering essential tools, you are well-positioned to evolve into a proficient DevOps practitioner, contributing to the triumph of contemporary software development.
2 notes
·
View notes