#microarchitecture
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr’s reach among the 26-to-35-year-olds in the US is 11%.
Text

Compact Data Storage (CDS)
#glitch#webcore#glitchart#internetcore#postglitch#processing#databending#abstract#abstract art#generative#generative art#genart#artists on tumblr#experimental art#glitch aesthetic#digital art#aesthetic#glitch art#tech#cybercore#techcore#scifi#cyberpunk#cyberpunk aesthetic#cybernetics#futuristic#microarchitecture#newmedia#multimedia#contemporary art
286 notes
·
View notes
Text
SciTech Chronicles. . . . . . . . .April 17th, 2025
#Donaldjohanson#SwRI#“12.5 light minutes away”#“observation sequence”#raindrops#“plug flow”#10%#“electrically conductive polymer”#“Neurospora crassa”#“Sporosarcina pasteurii”#mineralized#microarchitecture#Hyperadaptor#nickel-based#temperature-insensitive#“sudden or extreme temperature changes”#“high-bed cultivation”#Lidar#disease#pruning
0 notes
Text
Creating a new processor microarchitecture.

Support with your donation an important technology project that will open new opportunities for the entire microprocessor development and manufacturing industry.
Friends, I salute you all.
I am creating a fundamentally new processor microarchitecture and new units of information measurement with a team of like-minded people.
The microarchitecture I am creating will be much faster than the ones we have now. The new microarchitecture will speed up the work of all components of the processor, as well as other devices with which it interacts. New modules and fundamentally new algorithms of operation will be introduced into the work of the processor components.
Why is it important to support with a donation my project to create a new processor microarchitecture? The processors produced today have reached their technological limit in terms of reducing the size of transistors.
Over the past decades, processor performance gains have been largely achieved by reducing the transistor size and, in parallel, increasing the number of transistors on the chip.
Now, further reduction of transistor size is becoming more and more technologically challenging. One way out of this situation is to create a new microprocessor architecture that will use new algorithms. The new microprocessor architecture will make it possible to increase the performance of processors without increasing the number of transistors on the chip or reducing the size of the transistors themselves.
What has been done so far, brief description:
1. Assembled a team of developers with whom I will develop a new processor microarchitecture.
2. Technical specifications of the first samples of the new processor microarchitecture have been approved.
3. A step-by-step scheme of development of the new microarchitecture of the processor is created.
What else needs to be done, a brief description:
1. Acquire lab equipment to be able to design and build a new processor microarchitecture.
2. Purchase lab equipment to test individual compute modules on the new microarchitecture.
3. Develop individual computational modules of the new processor microarchitecture.
4. Test the created computational modules for performance and compliance with the planned specifications.
5. Create fundamentally new operating algorithms for computing modules and blocks.
6. Assemble a new microprocessor architecture from the developed computational modules.
7. Test the new processor microarchitecture against the planned performance.
8. Develop a scheme of interaction of the processor on the new architecture with peripheral devices.
9. Test the interaction of the processor on the new architecture with peripheral devices.
... And much more. The amount of work is huge.
Friends even your minimal donation will help us a lot.
You can help us with your donation through our fundraising platform (link to platform website): https://www.pledge.to/creating-a-new-processor-microarchitecture
or send funds directly to our account:
You can send a donation to the following details:
Bitcoin crypto wallet address:
14bBNxQ8UFtj1WY7QrrUdBwkPYFsvMt2Pw
Bitcoin cash crypto wallet address:
qqn47tcp5xytuj3sp0tkqa9xvdrh5u9lvvhvnsff0v
Ethereum crypto wallet address:
0x653C53216d76a58a3D180519891366D2e61f9985
Polygon (MATIC) crypto wallet address:
0x653C53216d76a58a3D180519891366D2e61f9985
Payment system Payer: Account number: P1108734121
Payment system Webmoney wallet numbers:
US dollar: Z268481228605
Euro: E294954079686
#Donation#donate#donation links#fundraiser#donations#processor#microarchitecture#Creating#technology#computing#research#futurism#microprocessor#microprocessors#project
0 notes
Text
The Intel Core i9-14901KE for Content Creators and Gamers

Intel Raptor Lake processors
Intel stealthily launched the “14001” series of 14th-Gen Raptor Lake Refresh processors. The chips lack Intel’s current microarchitectures‘ Efficiency cores (E-cores) and have just Performance cores (P-cores). This new CPU series is aimed for embedded applications and includes Intel’s first overclockable embedded processor, the Core i9-14901KE.
Intel has stealthily introduced 14th-Gen Raptor Lake Refresh processors ahead of its Arrow Lake-S desktop CPUs. The unusual 14001 series chips have just Performance cores (P-cores) and no Efficiency cores (E-cores) like Intel’s latest architectures. These CPUs, designed for embedded applications, have an intriguing overclockable top model.
The downside is that these CPUs are embedded (soldered-in). They are not user-replaceable and must be purchased with an industrial motherboard. This makes them unattainable for most fans and consumers.
The new E-core-free portfolio from Intel includes three Core i9 models, two Core i7 models, and four Core i5 models. The flagship Core i9-14901KE appears to be an overclockable K-series chip, a rarity for embedded Intel processors.
This series is Intel’s first E-core-free series since the 11th generation, departing from their hybrid architecture plan. Intel can reuse Raptor Lake dies with damaged E-cores but otherwise working components.
New processors have benefits. They eliminate hybrid architecture difficulties like workload scheduling between core types. Many applications don’t need E-cores and work best with six to eight physical cores of any type.
Each Core i9 model has eight Raptor Cove P-cores, 16 threads, and 36MB L3 cache. They differ mostly in clock speeds and power targets. The top-tier Core i9-14901KE has a 5.8GHz turbo clock, 3.8GHz base clock, and 125W long-term TDP. The Core i9-14901E decreases long-term power usage to 65W with a minor performance trade-off, while the 45W variant is the most power-efficient.
Like the i9, the Core i7 has eight cores and 16 threads, but lower speeds and smaller L3 caches. Core i7-14701E and TE run at 65W and 45W, respectively. The worst Core i5 versions have six cores, 12 threads, and 24MB L3 cache. The Core i5-14501 and Core i5-14401 series match their desktop equivalents. Boost clocks and integrated graphics performance differ most.
Intel UHD 770 Graphics with 32 execution units are on all versions except the Core i5-14501. The Core i5-14501 series uses 24 execution units for UHD 730 Graphics.
Intel’s surprising revelation shows its capacity to innovate inside product lines, potentially opening new markets for specialised computer solutions.
The i9-11900K is a good CPU for Intel E-core sceptics. Amazon.com currently sells it for $260.
Intel’s most recent portfolio of 14th-Gen CPUs represents another step forward in chip technology. The overclockable Core i9-14901KE is one of the best of them, providing both pros and hobbyists with great performance and versatility. This post explores the capabilities, features, and potential of the Core i9-14901KE, emphasising the reasons it represents a noteworthy upgrade to Intel’s CPU lineup.
Introducing the Core i9-14901KE
Among Intel’s latest E-core-less CPUs, the Core i9-14901KE delivers optimal performance for demanding applications. Its ability to overclock, which boosts performance, makes it stand out.
Design and Execution
The high-performance Core i9-14901KE uses Intel’s 14nm production process to skip E-cores and use P-cores. Perfect for 3D rendering, video editing, and gaming, this architecture prioritises processing speed and power.
Important details:
Speed of Base Clock: 3.7 GHz
Peak Turbo-Boost Speed: 5.3 GHz
Number of Cores: 10 P-cores
There are 20 threads.
20 MB of L3 cache
Thermal Design Power (TDP): 125 watts
Core i9-14901KE Potential Overclocking
One of the most attractive aspects of the Core i9-14901KE is that it can be overclocked. By adjusting the CPU’s parameters, enthusiasts can unlock more performance by reaching faster clock rates. With the help of its Extreme Tuning Utility (XTU), Intel offers strong overclocking support. Users may tweak voltages, clock rates, and other settings to achieve the ideal compromise between performance and stability.
Cooling Factors
To handle the higher heat output from overclocking the Core i9-14901KE, efficient cooling solutions are needed. It is advised to use specialised water cooling loops or high-quality AIO (All-in-One) liquid coolers to maintain ideal temperatures and guarantee dependable operation during demanding workloads.
E-core-less Design: An Innovative Approach
The Core i9-14901KE‘s decision to forgo E-cores is a reflection of Intel’s strategy emphasis on optimising both single and multi-threaded performance. This CPU provides improved performance for programmes that benefit from higher clock speeds and more core counts by allocating all resources to P-cores.
Benefits of Architecture Without an E-Core:
Better Single-Core Performance
P-cores perform better for single-threaded applications since they are designed for high clock speeds and minimal latency.
Improved Multi-Core Efficiency
Since every core is high-performance, multi-threaded programmes may take advantage of the entire processing capacity without having to deal with the mixed workload that E-cores handle.
Simplified Power Management
Power delivery and thermal management are simplified in the absence of E-cores, which may result in more reliable performance under load.
Comparing and Observing Actual Performance
The Core i9-14901KE has shown considerable performance gains over its predecessors, according to early benchmarks. The CPU shows excellent single-core and multi-core results on artificial benchmarks, indicating its potential in practical applications. Benchmarks for gaming demonstrate notable gains in responsiveness and frame rates, especially in CPU-bound a game.
Productivity and Content Creation:
Professionals and content makers should use the Core i9-14901KE for software development, 3D rendering, and video editing. It reduces rendering times and boosts productivity in demanding processes due to its high clock rates and core count.
Harmony and Prospective-Looking
PCIe 5.0, DDR5 memory , and enhanced networking are supported by Intel’s Z790 chipset in the Core i9-14901KE. Build a cutting-edge system using the newest technology to future-proof your investment.
Upgrade Route and Duration
Users may anticipate continuing compatibility with new technologies and updates because to Intel’s commitment to maintaining the 14th-Gen platform. Because of this, the Core i9-14901KE is a wise option for anyone wishing to construct a high-performance system that will last for many years.
Conclusion: A Novel Standard in High-Efficiency Computing
A new benchmark in high-performance computing is set by the overclockable Core i9-14901KE, which provides unmatched power and versatility. Its E-core-less design and strong overclocking potential set it apart as a top option for professionals, gamers, and enthusiasts looking for extreme performance. With its dramatic advancement in CPU technology, the Core i9-14901KE promises outstanding performance for a variety of demanding workloads, demonstrating Intel’s continued innovation.
Read more on govindhtech.com
#IntelCore#IntelCorei914901KE#microarchitecture#hybridarchitecture#CPU#Corei5models#DDR5memory#news#technews#technologynews#technologytrends#technology#govindhtech
0 notes
Text
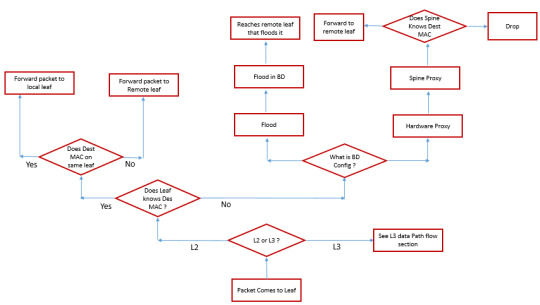
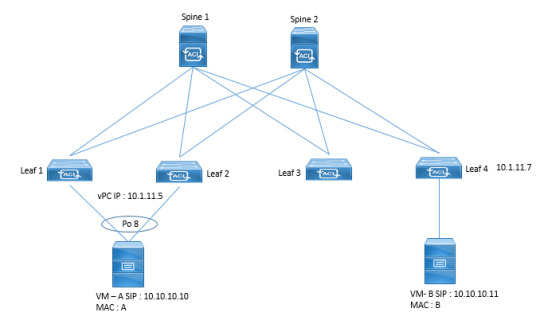
Ready to delve into the world of Layer 2 (L2) Datapath Scenarios and understand how they shape network performance and reliability? DC Lessons offers an engaging course designed for IT professionals, network engineers, and anyone eager to optimize their network infrastructure. https://www.dclessons.com/l2-datapath-scenerios
#DCLessons#DataPath#Learning2Datapath#Scenarios#ComputerArchitecture#DigitalCircuits#LogicDesign#InstructionSetArchitecture#Microarchitecture#ComputerScienceEducation#TechLearning
0 notes
Link
These are specialized solutions for network infrastructure In just a few weeks, Intel will release Meteor Lake processors, which, among other things, will be the company’s first-born, produced using the Intel 4 technical process. However, another company beat Intel itself and was the first to present its chips created using the same technical process. They were Ericsson RAN Compute. [caption id="attachment_84939" align="aligncenter" width="780"] Intel 4 process[/caption] Ericsson announced new RAN Compute These, of course, are not classic CPUs, but specialized solutions for network infrastructure, but the very fact that Ericsson has surpassed Intel is quite interesting. However, for Intel’s IDM 2.0 strategy, within which the processor giant also wants to become a semiconductor manufacturing giant, this is rather a plus. It doesn’t make much sense to say anything about RAN Compute chips from a technical point of view, but it’s still worth noting that, according to the company itself, the high-performance RAN Processor 6672 and Radio Processor 6372 processors provide four times greater performance compared to the previous generation and can support up to six 4G and 5G modes in one device. In addition, the new chips consume 30–60% less energy, which is likely due in large part to the new technical process.
#Advanced_manufacturing#Chip_Manufacturing#CPU_Technology#Intel#Intel_CPU#Intel_processor_lineup.#Intel_processors#manufacturing_process#microarchitecture#Processor_fabrication#semiconductor#semiconductor_industry#semiconductor_technology#Silicon_Technology
0 notes
Text

The people love my insane and ill-informed opinions on microarchitectures.
14 notes
·
View notes
Text
it’s just dawned on me that my exam is NEXT WEEK
ON TUESDAY
NOT EVEN A FULL WEEK AWAY
A COUPLE OF DAYS. OH MY GOD????
chat i’m scared. chat im cooked. chat what is a microarchitecture. chat i still dont know how audio files work. chat. c
5 notes
·
View notes
Note
The ARM microarchitecture (1985)
ARM based processors, it's what powers your phone and most of your beloved mobile devices.
Lower costs, power consumption and heat generation makes them perfect for all types of mobile devices, from a smartwatch to a laptop. Though they are also used on desktop computers, servers and even supercomputers.


Thing Ford Missed #277: The ARM Microarchitecture
18 notes
·
View notes
Text
realising with horror that in the cool chips post I somehow called it P5 microarchitecture instead of P6 microarchitecture and it's just been sitting there for months
9 notes
·
View notes
Text
Computing with Time: Microarchitectural Weird Machines
https://cacm.acm.org/research-highlights/computing-with-time-microarchitectural-weird-machines/
3 notes
·
View notes
Text

DAEMON Database Server
#glitch#webcore#glitchart#internetcore#postglitch#processing#databending#abstract#abstract art#generative#generative art#genart#artists on tumblr#experimental art#glitch aesthetic#digital art#aesthetic#glitch art#tech#cybercore#techcore#scifi#cyberpunk#cyberpunk aesthetic#cybernetics#futuristic#microarchitecture#newmedia#multimedia#contemporary art
147 notes
·
View notes
Text
Resolution Independence, Zoom, Fractional Scaling, Retina Displays, High-DPI: A Minefield
I already explained how CPU dispatch is a minefield: It doesn't cause intermittent bugs. It often doesn't even cause crashes. Badly implemented CPU dispatch means you build something on your machine that runs on your machine, but doesn't perform the dispatch correctly, so it crashes on somebody else's machine, or something build on a worse machine still runs fine on a better machine, but not as well as it could. Some of the bugs only manifest with a different combination of compiler, build system, ABI, and microarchitecture. CPU dispatch is a minefield because it's easy to get wrong in non-obvious ways.
I recently played an old game on Windows 11, with a high-DPI 2560x1600 (WQXGA) monitor. Text was too small to read comfortably read, and the manufacturer had set the zoom level to 150% by default. When I launched the game, it started in fullscreen mode, at 2560x1660, which Windows somehow managed to zoom up to 3840x2400. The window was centered, with all the UI elements hidden behind the edges of the screen. When I switched from fullscreen to windowed, the window still covered the whole desktop and the task bar. I quit the game and switched to another. That game let me choose the resolution before launch. At first I tried 2560x1660, but nothing worked right. Then I started it again, at 1920x1080. It didn't look quite right, and I couldn't understand what was going on. Windows has scaled the game up to 2880x1620, which looked almost correct. At this point I realised what was happening, and I set the zoom to 100%. Both games displayed normally.
The first game was an old pixel art platformer from the early 2000s, with software rendering. The second is a strategy game built with OpenGL around 2015, with high-resolution textures based on vector art, and with a UI that works equally well on an iPad and on a PC.
It was hard to read things on that monitor, so I set the font scaling to 150%, but somehow that made things harder to read. Some applications did not honour the font size defaults, and others did, and still others had tiny UI elements with big letters that were spilling out.
Next, I tried to run a game on Ubuntu, with Sway (based on wayland) as the desktop environment. It's a different machine, a 15.6 inch 1920x1080 laptop with an external 1920x1080 23 inch monitor attached. I zoomed the internal display of the laptop by 150% in order to have windows appear equally sized on both monitors.
What is happening on Windows 11 seems to be that even OpenGL games that don't think in terms of pixels, but in terms of floating point coordinates that go from -1 to +1 in both the x and y dimension, (so 0.1 screen units are different sizes in different dimensions) are treated the same as software rendering games that give a buffer of software-rendered pixels to the operating system/graphics environment. Making an already resolution-independent window bigger feels pointless.
What I would want to happen by default, especially in the case of the software-rendered game, is for the operating system to just tell my game that the desktop is not sized 2560x1600, but 1706x1066 (or just 1600x1000), and to then scale that window up. If the window is scaled up, mouse position coordinates should be automatically scaled down from real pixels to software pixels, unless the mouse cursor is captured: If I am playing a DOOM clone or any first-person game, I do not want relative mouse sensitivity to decrease when I am playing on a 4K monitor or when I am maximising the window (if playing in windowed mode). If I have a retina/zoomed display attached, and a standard definition/unzoomed display, and there is a window overlapping both screens, then only the part of a window that is on the zoomed display should be zoomed in.
What I would want to happen with a "resolution-independent" game is this: The game queries the size of the monitor with a special resolution-independent query function. There is no way to "just make it backward compatible". This is a new thing and needs new API. The query returns
Size of all desktops in hardware pixels
Size of all screens in real-world centimetres
Preferred standard text size in pt/cm (real world) or pixels
Zoom factor (in percent) of all desktops
Which screens are touch or multi-touch screens
Is dark mode enabled?
Which desktop is "currently active"
The "preferred" desktop to open the window
This information would allow an application to create a window that is the appropriate size, and scale all text and UI elements to the appropriate size. We can't assume that a certain size in pixels is big enough for the user to comfortably hit a button.
Even this information might not be enough. What should be the behaviour if a windowed OpenGL application is dragged between a 4K monitor at 200% zoom, and a 640x480 CRT? Should the OS scale the window down the same way it currently scales windows up when they aren't "retina aware"?
I don't really know. All I do know is that Windows, Mac OS, and different wayland compositors all handle high-DPI zoom/retina differently, in a way that breaks sometimes, in some environments. But it looks fine if you don't have scaling set. There are ways to tell the windowing system "I know what I am doing" if you want to disable scaling, but these are easy to abuse. There's a cargo cult of just setting "NSHighResolutionCapable" or "HIGHDPIAWARE" without understanding why and why not. Win32 provides all the information you need, with a very complex API. Wayland has a very different approach. SDL is aware of the issue.
I really hope SDL3 will make this work. If you get this wrong, you'll only realise when somebody on a different operating system with a different monitor tries to get your game to fit on the screen by fiddling with the registry, and it goes from not fitting on the monitor to text being too small read.
8 notes
·
View notes
Text
#Donation#donate#fundraiser#technology#computing#microprocessor#microarchitecture#development#project
1 note
·
View note
Text
10 Key Advantages of Intel Centrino 2 vPro for Power Users

For power users who rely on high-performance computing, the Intel Centrino 2 vPro platform stands out as a top choice. Designed to meet the demanding needs of professionals, this technology integrates advanced features that enhance productivity, security, and connectivity. Here are ten key advantages of Intel Centrino 2 vPro that every power user should know about.
1. Exceptional Processing Power
Intel Centrino 2 vPro utilizes a sophisticated microarchitecture that delivers superior processing capabilities. This means power users can run resource-intensive applications, such as CAD software or data analysis tools, with remarkable speed and efficiency, minimizing delays and enhancing workflow.
2. Comprehensive Security Features
Security is a paramount concern for professionals managing sensitive information. The Centrino 2 vPro platform incorporates advanced security measures, including Intel Trusted Execution Technology (TXT) and Intel Anti-Theft Technology. These features provide hardware-based security, protecting against unauthorized access and potential data breaches.
3. Integrated Wireless Connectivity
With built-in Wi-Fi capabilities, Centrino 2 vPro offers seamless wireless connectivity. This allows users to easily connect to networks without needing additional hardware, ensuring greater flexibility and convenience when working remotely or in varied environments.
4. Longer Battery Life
Centrino 2 vPro is designed with intelligent power management features that optimize battery usage. Power users benefit from extended battery life, allowing for longer periods of productivity without the hassle of frequent recharging, particularly during travel or long meetings.
5. Remote Management Functionality
A standout feature of Centrino 2 vPro is its remote management capabilities. IT departments can remotely manage, update, and troubleshoot devices, reducing downtime and streamlining maintenance processes, which is particularly beneficial for organizations with remote teams.
6. Support for Virtualization
Centrino 2 vPro supports virtualization technology, enabling users to run multiple operating systems and applications simultaneously. This is essential for developers and IT professionals who need to test software across different environments without the need for multiple devices.
7. Enhanced Graphics Performance
The integrated graphics capabilities of Centrino 2 vPro ensure improved visuals for graphics-intensive applications. Power users involved in video editing, graphic design, or gaming can enjoy better performance and visual quality, enhancing their creative and analytical tasks.
8. Rich Multimedia Support
Centrino 2 vPro is designed to support advanced multimedia technologies, providing smoother video playback and superior audio quality. This is particularly advantageous for professionals who create and present multimedia content, ensuring an engaging experience for their audiences.
9. High-Speed Data Transfer
With support for high-speed USB ports and various connectivity options, Centrino 2 vPro ensures quick data transfer rates. This is vital for power users who frequently connect to external drives and devices, enhancing their overall productivity.
10. Compatibility with Legacy Systems
Centrino 2 vPro maintains compatibility with older systems, allowing organizations to transition to newer technologies without losing access to existing resources. This ensures that power users can take advantage of modern features while still leveraging past investments.
Conclusion
Intel Centrino 2 vPro offers a robust suite of features designed specifically for power users who demand high performance, security, and flexibility. By understanding these ten key advantages, professionals can maximize their productivity and enhance their computing experience, making Centrino 2 vPro an invaluable asset in today’s fast-paced work environments. Whether for software development, data analysis, or multimedia creation, this technology empowers users to achieve their goals efficiently and effectively.
Read more: 10 Must-Know Perks of Intel Centrino 2 vPro for Power Users
Read more: 9 Essential Tools in Intel vPro for IT Management Efficiency
Read more: How Is Intel Arc Pushing the Boundaries of Graphics?
Read more: How to Maximize Battery Life on Intel Evo Devices?
2 notes
·
View notes
Text
Intel VTune Profiler For Data Parallel Python Applications

Intel VTune Profiler tutorial
This brief tutorial will show you how to use Intel VTune Profiler to profile the performance of a Python application using the NumPy and Numba example applications.
Analysing Performance in Applications and Systems
For HPC, cloud, IoT, media, storage, and other applications, Intel VTune Profiler optimises system performance, application performance, and system configuration.
Optimise the performance of the entire application not just the accelerated part using the CPU, GPU, and FPGA.
Profile SYCL, C, C++, C#, Fortran, OpenCL code, Python, Google Go, Java,.NET, Assembly, or any combination of languages can be multilingual.
Application or System: Obtain detailed results mapped to source code or coarse-grained system data for a longer time period.
Power: Maximise efficiency without resorting to thermal or power-related throttling.
VTune platform profiler
It has following Features.
Optimisation of Algorithms
Find your code’s “hot spots,” or the sections that take the longest.
Use Flame Graph to see hot code routes and the amount of time spent in each function and with its callees.
Bottlenecks in Microarchitecture and Memory
Use microarchitecture exploration analysis to pinpoint the major hardware problems affecting your application’s performance.
Identify memory-access-related concerns, such as cache misses and difficulty with high bandwidth.
Inductors and XPUs
Improve data transfers and GPU offload schema for SYCL, OpenCL, Microsoft DirectX, or OpenMP offload code. Determine which GPU kernels take the longest to optimise further.
Examine GPU-bound programs for inefficient kernel algorithms or microarchitectural restrictions that may be causing performance problems.
Examine FPGA utilisation and the interactions between CPU and FPGA.
Technical summary: Determine the most time-consuming operations that are executing on the neural processing unit (NPU) and learn how much data is exchanged between the NPU and DDR memory.
In parallelism
Check the threading efficiency of the code. Determine which threading problems are affecting performance.
Examine compute-intensive or throughput HPC programs to determine how well they utilise memory, vectorisation, and the CPU.
Interface and Platform
Find the points in I/O-intensive applications where performance is stalled. Examine the hardware’s ability to handle I/O traffic produced by integrated accelerators or external PCIe devices.
Use System Overview to get a detailed overview of short-term workloads.
Multiple Nodes
Describe the performance characteristics of workloads involving OpenMP and large-scale message passing interfaces (MPI).
Determine any scalability problems and receive suggestions for a thorough investigation.
Intel VTune Profiler
To improve Python performance while using Intel systems, install and utilise the Intel Distribution for Python and Data Parallel Extensions for Python with your applications.
Configure your Python-using VTune Profiler setup.
To find performance issues and areas for improvement, profile three distinct Python application implementations. The pairwise distance calculation algorithm commonly used in machine learning and data analytics will be demonstrated in this article using the NumPy example.
The following packages are used by the three distinct implementations.
Numpy Optimised for Intel
NumPy’s Data Parallel Extension
Extensions for Numba on GPU with Data Parallelism
Python’s NumPy and Data Parallel Extension
By providing optimised heterogeneous computing, Intel Distribution for Python and Intel Data Parallel Extension for Python offer a fantastic and straightforward approach to develop high-performance machine learning (ML) and scientific applications.
Added to the Python Intel Distribution is:
Scalability on PCs, powerful servers, and laptops utilising every CPU core available.
Assistance with the most recent Intel CPU instruction sets.
Accelerating core numerical and machine learning packages with libraries such as the Intel oneAPI Math Kernel Library (oneMKL) and Intel oneAPI Data Analytics Library (oneDAL) allows for near-native performance.
Tools for optimising Python code into instructions with more productivity.
Important Python bindings to help your Python project integrate Intel native tools more easily.
Three core packages make up the Data Parallel Extensions for Python:
The NumPy Data Parallel Extensions (dpnp)
Data Parallel Extensions for Numba, aka numba_dpex
Tensor data structure support, device selection, data allocation on devices, and user-defined data parallel extensions for Python are all provided by the dpctl (Data Parallel Control library).
It is best to obtain insights with comprehensive source code level analysis into compute and memory bottlenecks in order to promptly identify and resolve unanticipated performance difficulties in Machine Learning (ML), Artificial Intelligence ( AI), and other scientific workloads. This may be done with Python-based ML and AI programs as well as C/C++ code using Intel VTune Profiler. The methods for profiling these kinds of Python apps are the main topic of this paper.
Using highly optimised Intel Optimised Numpy and Data Parallel Extension for Python libraries, developers can replace the source lines causing performance loss with the help of Intel VTune Profiler, a sophisticated tool.
Setting up and Installing
1. Install Intel Distribution for Python
2. Create a Python Virtual Environment
python -m venv pyenv
pyenv\Scripts\activate
3. Install Python packages
pip install numpy
pip install dpnp
pip install numba
pip install numba-dpex
pip install pyitt
Make Use of Reference Configuration
The hardware and software components used for the reference example code we use are:
Software Components:
dpnp 0.14.0+189.gfcddad2474
mkl-fft 1.3.8
mkl-random 1.2.4
mkl-service 2.4.0
mkl-umath 0.1.1
numba 0.59.0
numba-dpex 0.21.4
numpy 1.26.4
pyitt 1.1.0
Operating System:
Linux, Ubuntu 22.04.3 LTS
CPU:
Intel Xeon Platinum 8480+
GPU:
Intel Data Center GPU Max 1550
The Example Application for NumPy
Intel will demonstrate how to use Intel VTune Profiler and its Intel Instrumentation and Tracing Technology (ITT) API to optimise a NumPy application step-by-step. The pairwise distance application, a well-liked approach in fields including biology, high performance computing (HPC), machine learning, and geographic data analytics, will be used in this article.
Summary
The three stages of optimisation that we will discuss in this post are summarised as follows:
Step 1: Examining the Intel Optimised Numpy Pairwise Distance Implementation: Here, we’ll attempt to comprehend the obstacles affecting the NumPy implementation’s performance.
Step 2: Profiling Data Parallel Extension for Pairwise Distance NumPy Implementation: We intend to examine the implementation and see whether there is a performance disparity.
Step 3: Profiling Data Parallel Extension for Pairwise Distance Implementation on Numba GPU: Analysing the numba-dpex implementation’s GPU performance
Boost Your Python NumPy Application
Intel has shown how to quickly discover compute and memory bottlenecks in a Python application using Intel VTune Profiler.
Intel VTune Profiler aids in identifying bottlenecks’ root causes and strategies for enhancing application performance.
It can assist in mapping the main bottleneck jobs to the source code/assembly level and displaying the related CPU/GPU time.
Even more comprehensive, developer-friendly profiling results can be obtained by using the Instrumentation and Tracing API (ITT APIs).
Read more on govindhtech.com
#Intel#IntelVTuneProfiler#Python#CPU#GPU#FPGA#Intelsystems#machinelearning#oneMKL#news#technews#technology#technologynews#technologytrends#govindhtech
2 notes
·
View notes