#python list methods
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Total funding amounts to $125.3M.
Text
Hey everyone!
I know it’s been a minute, but with the recent news that Automattic has laid off a portion of its workforce (including a sizable percent of tumblr's staff), it's a good time to have a quick chat about the future.
Now, as far as we know, tumblr isn't going anywhere just yet. No need to panic! However, I do recommend that you take into consideration a few things.
1: Backup your tumblr! Here's tumblr's official guide to doing so. It's always a good idea to have backups of your data and now is a great time to do so.
*I’ll also be including a handful of other links walking you guys through other backup methods at the end of this post. As I understand it, each of them have different pros and cons, and it might be a good idea to have more than one type of backup depending on what you want to save/how you’d like the backup to look/etc.
2: Have some place your mutuals/friends can find you! A carrd or linktree is a great way to list off anywhere you might find yourself on the internet.
3: Once again, don't panic! We don’t know that anything is happening to tumblr anytime soon—it just doesn’t hurt to have a backup. Better to have a plan now instead of being blindsided later.
*The other backup methods I’ve been able to find:
—First off, someone put together a document with several backup methods & pros and cons for each. (I believe it originated from a tumblr post, but with search being the way it is I haven’t been able to track it down.) This goes over a lot, but I’m adding a few more links to this post in case they might be helpful too.
—This post and this video were a good guide to the older “bbolli tumblr-utils backup for beginners” method mentioned in the doc (I used them during the ban in 2018 to make sure I had my main blog saved).
—I’ve also found a handful of python & python 3 tumblr backup tutorial videos out there, in case those would be helpful for you. (I haven’t personally tried these methods out yet, but the videos seem to go over the updated version of tumblr-utils.
#psa#tumblr backup options#doc rambles#again: don’t panic#we don’t know anything is happening right now#but it’s always handy to have a backup just in case!
749 notes
·
View notes
Text
ATTENTION BELOVED FOLLOWERS
YOU WILL BE AUTOMATICALLY BLOCKED BY MY BOT IF YOU DO NOT READ THIS POST
Now that I have your attention, I will explain the full situation.
I have 36,000 followers. The vast majority of these followers are bots, a fact that annoys me to no end. I realized that I may be able to solve this problem, although considerable effort would be needed in order to execute my plan.
I am currently learning Python in order to made a program that interfaces with the Tumblr API in a process that will retrieve my follower list and block thousands upon thousands of accounts automatically.
In order to filter out exclusively bots, I will provide one method of survival. Reply with a single period on THIS post. Make sure that your are commenting from your main blog, not a side account! I will make a list of users who are capable of engaging with my posts, and remove your names from the list of followers who shall be purged.
COMMENT "." ON THIS POST IN ORDER TO BE SPARED
If all goes to plan, I will run this program on FEBRUARY 10 2025, one month after the creation of this post. If this program takes longer than a month, the deadline for opting in for immunity will be similarly extended.
If you are a long time mutual, if you are a rarely online lurker, if you are a new impulse follower, please comment regardless! Even if we have never spoken, don't feel embarrassed by interacting. My goal is to have an entirely human followerbase, and everyone is welcome to enjoy the post-apocalyptic paradise.
#prepare to see this post a lot#IF YOU HAVE QUESTIONS: Please DM or send an Ask. the replies should ideally just say “.” as that is easy to filter out for my full list#I have no experience with Python but my headmate and I are determined to unravel its mysteries#i have no idea if this can be accomplished in a month. hopefully i guess#IF YOU VOTED KUTZIL RATHER THAN HAZORET THO? Don't even bother. you deserve to be blocked.
372 notes
·
View notes
Text
Welp, I've been using external methods of auto-backing up my tumblr but it seems like it doesn't do static pages, only posts.
So I guess I'll have some manual backing up to do later
Still, it's better than nothing and I'm using the official tumblr backup process for my smaller blogs so hopefully that'll net the static pages and direct messages too. But. My main - starstruckpurpledragon - 'backed up' officially but was undownloadable; either it failed or it'd download a broken, unusable, 'empty' zip. So *shrugs* I'm sure I'm not the only one who is trying to back up everything at once. Wouldn't be shocked if the rest of the backups are borked too when I try to download their zips.
There are two diff ways I've been externally backing up my tumblr.
TumblThree - This one is relatively straight forward in that you can download it and start backing up immediately. It's not pretty, but it gets the job done. Does not get static pages or your direct message conversations, but your posts, gifs, jpegs, etc are all there. You can back up more than just your own blog(s) if you want to as well.
That said, it dumps all your posts into one of three text files which makes them hard to find. That's why I say it's 'not pretty'. It does have a lot of options in there that are useful for tweaking your download experience and it's not bad for if you're unfamiliar with command line solutions and don't have an interest in learning them. (Which is fair, command line can be annoying if you're not used to it.) There are options for converting the output into nicer html files for each post but I haven't tried them and I suspect they require command line anyway.
I got my blogs backed up using this method as of yesterday but wasn't thrilled with the output. Decided that hey, I'm a software engineer, command line doesn't scare me, I'll try this back up thing another way. Leading to today's successful adventures with:
TumblrUtils - This one does take more work to set up but once it's working it'll back up all your posts in pretty html files by default. It does take some additional doing for video/audio but so does TumblThree so I'll probably look into it more later.
First, you have to download and install python. I promise, the code snake isn't dangerous, it's an incredibly useful scripting language. If you have an interest in learning computer languages, it's not a bad one to know. Installing python should go pretty fast and when it's completed, you'll now be able to run python scripts from the command line/terminal.
Next, you'll want to actually download the TumblrUtils zip file and unzip that somewhere. I stuck mine on an external drive, but basically put it where you've got space and can access it easily.
You'll want to open up the tumblr_backup.py file with a text editor and find line 105, which should look like: ''' API_KEY = '' '''
So here's the hard part. Getting a key to stick in there. Go to the tumblr apps page to 'register' an application - which is the fancy way of saying request an API. Hit the register an application button and, oh joy. A form. With required fields. *sigh* All the url fields can be the same url. It just needs to be a valid one. Ostensibly something that interfaces with tumblr fairly nicely. I have an old wordpress blog, so I used it. The rest of the fields should be pretty self explanatory. Only fill in the required ones. It should be approved instantly if everything is filled in right.
And maybe I'll start figuring out wordpress integration if tumblr doesn't die this year, that'd be interesting. *shrug* I've got too many projects to start a new one now, but I like learning things for the sake of learning them sometimes. So it's on my maybe to do list now.
Anywho, all goes well, you should now have an 'OAuth Consumer Key' which is the API key you want. Copy that, put in between the empty single quotes in the python script, and hit save.
Command line time!
It's fairly simple to do. Open your command line (or terminal), navigate to where the script lives, and then run: ''' tumblr_backup.py <blog_name_here> '''
You can also include options before the blog name but after the script filename if you want to get fancy about things. But just let it sit there running until it backs the whole blog up. It can also handle multiple blogs at once if you want. Big blogs will take hours, small blogs will take a few minutes. Which is about on par with TumblThree too, tbh.
The final result is pretty. Individual html files for every post (backdated to the original post date) and anything you reblogged, theme information, a shiny index file organizing everything. It's really quite nice to dig through. Much like TumbleThree, it does not seem to grab direct message conversations or static pages (non-posts) but again it's better than nothing.
And you can back up other blogs too, so if there are fandom blogs you follow and don't want to lose or friends whose blogs you'd like to hang on to for your own re-reading purposes, that's doable with either of these backup options.
I've backed up basically everything all over again today using this method (my main is still backing up, slow going) and it does appear to take less memory than official backups do. So that's a plus.
Anyway, this was me tossing my hat into the 'how to back up your tumblr' ring. Hope it's useful. :D
40 notes
·
View notes
Note
Hi Argumate! I just read about your chinese language learning method, and you inspired me to get back to studying chinese too. I want to do things with big datasets like you did, and I am wondering if that means I should learn to code? Or maybe I just need to know databases or something? I want to structure my deck similar to yours, but instead of taking the most common individual characters and phrases, I want to start with the most common components of characters. The kangxi radicals are a good start, but I guess I want a more evidence-based and continuous approach. I've found a dataset that breaks each hanzi into two principle components, but now I want to use it determine the components of those components so that I have a list of all the meaningful parts of each hanzi. So the dataset I found has 嘲 as composed of 口 and 朝, but not as 口𠦝月, or 口十曰月. So I want to make that full list, then combine it with data about hanzi frequency to determine the most commonly used components of the most commonly used hanzi, and order my memorization that way. I just don't know if what I'm describing is super complicated and unrealistic for a beginner, or too simple to even bother with actual coding. I'm also not far enough into mandarin to know if this is actually a dumb way to order my learning. Should I learn a little python? or sql? or maybe just get super into excel? Is this something I ought to be able to do with bash? Or should I bag the idea and just do something normal? I would really appreciate your advice
I think that's probably a terrible way to learn to read Chinese, but it sounds like a fun coding exercise! one of the dictionaries that comes with Pleco includes this information and you could probably scrape it out of a text file somewhere, but it's going to be a dirty grimy task suited to Python text hacking, not something you would willingly undertake unless you specifically enjoy being Sisyphus as I do.
if you want to actually learn Chinese or learn coding there are probably better ways! but I struggle to turn down the romance of a doomed venture myself.
13 notes
·
View notes
Text
Jan. 16th, 2024
Starting my new position has been insanely busy as of late, and admittedly the only studying I've been doing is about the company. Theres so much more I'd like to learn, especially for this new position so I'm adjusting my "study priorities list" to account for the new changes
The "eat the frog" method needs to be its own category on my list, because there are a lot of impactful items that I'm putting off- but that could be done in a weekend. These for me are quick, high priority and high impact things (ie. a tool that could put me ahead at work)
My frogs:
🐸 Advanced power BI
🐸 Selenium (a tool for automated testing)
High priority (2-3 hours every day):
✒ Python + data structures
Medium priority:
✒ My portfolio (1 hour a day)
✒ GMAT prep (10 minutes a day)
Low priority:
🕰 Azure
#academic assignments#academic burnout#academia aesthetic#academic victim#academic validation#study hard#academic romance#study aesthetic#academic disaster#study blog#studyblr#codeblr#workblr#journaling#new year 2025#classic academia#academic weapon#chaotic academia#chaotic academic aesthetic#dark academic aesthetic#light academia#desi academia#dark academia#Spotify
13 notes
·
View notes
Note
I'm curious: is there something you can share for question number 5 of the author ask game? 😊
Thank you for the ask!
5. Can you share something from researching for a fic?
I don't research a lot for fics besides going back to canon to fact check myself and ensure I'm at least sort of in the character's voice. It's just not something I typically find interesting and I try to keep my fics as something of a hobby, whereas research and fact checking is harder for me.
That being said, I have done extra reading.
Tw for snakes and images/discussion of snake attacks and threat displays.
Idk if I'd call it research since its kinda what I do anyway, but I've spent nights awake on snake Wikipedia and snake reddit and sometimes snake YouTube learning about them because Misumi likes them and Kabuto had a snake summon.
I've learned that there are a few kinds of venomous snakes, elapidae which according to Wikipedia have fangs that don't retract, think black mamba or a king cobra (this seems to be what Orochimaru’s summons are? You might have a better guess than me but they are NOT boas, sorry English dub), Viperidae, and Atractaspididae. I focused mostly on the first group as well as constrictor snakes like pythons and boas.
The threat display of Kabuto's white summon snake in LP is based on a black mamba, in the prison cell chapter it has the same mouth open, s-shape, posture iirc, but it shares little else with that species. I feel like summons have to kind of be their own thing, sharing traits with but separate from conventional snake species.
I'm not expert on them but from what I saw reticulated pythons caught my eye as a Misumi sort of snake. They're the only constrictor that's known to consume people (very very rarely), but they can also be kept as pets (this is not advisable as they have specific care needs few can meet)! They're gorgeous but giant, there's a youtube video of someone interacting with a friend's pet and it was a struggle for them to get it out of the box. Not as big as the biggest constrictors but plenty large. From what I gather they do sometimes attack their handlers if not properly handled, the main method for training them I saw discussed is tap training? Basically to signal to the snake when it's feeding time vs time for handling. I've heard toothpaste is a method to get them off if they latch on (they don't like the smell?) but you mostly would need a second person to untangle the snake. I love them deeply and truly, absolutely beautiful animal.
Despite this I do not own snakes and unlike Sasuke I'm not a snake expert so I try to keep discussion of them to a minimum. What I show of the handling is very subject to errors because for all the research I can do I'm not someone who has the experience to actually confirm any of what I read. Very happy to be corrected when I get things about snake care wrong, especially with how demonized snakes are. It's a line of not wanting to downplay it when they can be a threat and need to be properly cared for but also not making them sound like they hunt people for sport and pleasure.
Some sources but not an exhaustive list as I didn't want to go hunting down specific reddit posts for this, and a lot of it is wikipedia:
This is the pet reticulated python video, I also used one of a snake in captivity at a zoo to see how handlers interact with them but it shows a snake consuming something (that is already dead) and is easily searchable so I won't share it:
youtube
This is kinda sorta what the mambas threat display looks like (that I know of (first image)) but I didn't want to find a video of it doing the display since I didn't want to show a distressed snake.
This is the ask game if anyone else would like to ask me something
#ask game#snakes#tw snakes#fanfic stuff#some of this may be inaccurate#and idk how much reddit wikipedia and youtube dives count as research#but#that's what I got#thanks for letting me ramble about snakes#I love them
4 notes
·
View notes
Text
The split() function in python
The split() method in Python is used to split a string into a list of strings. It takes an optional separator argument, which is the delimiter that is used to split the string. If the separator is not specified, the string is split at any whitespace characters.
The syntax of the split() method is as follows:
Python
string_name.split(separator)
where:
string_name is the string object that is calling the split() method.
separator is the string that is being used as the separator.
For example, the following code splits the string my_string at the first occurrence of the " character:
Python
my_string = "This is a string with a \"quote\" in it." parts = my_string.split("\"") print(parts)
This code will print the following output:
['This is a string with a ', 'quote', ' in it.']
Here are some additional examples of how to use the split() method:
Python
my_string = "This is a string with multiple separators: -_--_-" parts = my_string.split("--") print(parts)
This code will print the following output:
['This is a string with multiple separators: ', '_', '_-']
Python
my_string = "This is a string without a separator." parts = my_string.split("@") print(parts)
This code will print the following output:
['This is a string without a separator.']
The split() method is a very versatile tool that can be used to split strings into lists of strings in a variety of ways. It is commonly used for tasks such as parsing text files, extracting data from strings, and validating user input.
#programmer#studyblr#learning to code#python#kumar's python study notes#codetober#progblr#coding#codeblr#programming
39 notes
·
View notes
Text
Understanding Outliers in Machine Learning and Data Science

In machine learning and data science, an outlier is like a misfit in a dataset. It's a data point that stands out significantly from the rest of the data. Sometimes, these outliers are errors, while other times, they reveal something truly interesting about the data. Either way, handling outliers is a crucial step in the data preprocessing stage. If left unchecked, they can skew your analysis and even mess up your machine learning models.
In this article, we will dive into:
1. What outliers are and why they matter.
2. How to detect and remove outliers using the Interquartile Range (IQR) method.
3. Using the Z-score method for outlier detection and removal.
4. How the Percentile Method and Winsorization techniques can help handle outliers.
This guide will explain each method in simple terms with Python code examples so that even beginners can follow along.
1. What Are Outliers?
An outlier is a data point that lies far outside the range of most other values in your dataset. For example, in a list of incomes, most people might earn between $30,000 and $70,000, but someone earning $5,000,000 would be an outlier.
Why Are Outliers Important?
Outliers can be problematic or insightful:
Problematic Outliers: Errors in data entry, sensor faults, or sampling issues.
Insightful Outliers: They might indicate fraud, unusual trends, or new patterns.
Types of Outliers
1. Univariate Outliers: These are extreme values in a single variable.
Example: A temperature of 300°F in a dataset about room temperatures.
2. Multivariate Outliers: These involve unusual combinations of values in multiple variables.
Example: A person with an unusually high income but a very low age.
3. Contextual Outliers: These depend on the context.
Example: A high temperature in winter might be an outlier, but not in summer.
2. Outlier Detection and Removal Using the IQR Method
The Interquartile Range (IQR) method is one of the simplest ways to detect outliers. It works by identifying the middle 50% of your data and marking anything that falls far outside this range as an outlier.
Steps:
1. Calculate the 25th percentile (Q1) and 75th percentile (Q3) of your data.
2. Compute the IQR:
{IQR} = Q3 - Q1
Q1 - 1.5 \times \text{IQR}
Q3 + 1.5 \times \text{IQR} ] 4. Anything below the lower bound or above the upper bound is an outlier.
Python Example:
import pandas as pd
# Sample dataset
data = {'Values': [12, 14, 18, 22, 25, 28, 32, 95, 100]}
df = pd.DataFrame(data)
# Calculate Q1, Q3, and IQR
Q1 = df['Values'].quantile(0.25)
Q3 = df['Values'].quantile(0.75)
IQR = Q3 - Q1
# Define the bounds
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# Identify and remove outliers
outliers = df[(df['Values'] < lower_bound) | (df['Values'] > upper_bound)]
print("Outliers:\n", outliers)
filtered_data = df[(df['Values'] >= lower_bound) & (df['Values'] <= upper_bound)]
print("Filtered Data:\n", filtered_data)
Key Points:
The IQR method is great for univariate datasets.
It works well when the data isn’t skewed or heavily distributed.
3. Outlier Detection and Removal Using the Z-Score Method
The Z-score method measures how far a data point is from the mean, in terms of standard deviations. If a Z-score is greater than a certain threshold (commonly 3 or -3), it is considered an outlier.
Formula:
Z = \frac{(X - \mu)}{\sigma}
is the data point,
is the mean of the dataset,
is the standard deviation.
Python Example:
import numpy as np
# Sample dataset
data = {'Values': [12, 14, 18, 22, 25, 28, 32, 95, 100]}
df = pd.DataFrame(data)
# Calculate mean and standard deviation
mean = df['Values'].mean()
std_dev = df['Values'].std()
# Compute Z-scores
df['Z-Score'] = (df['Values'] - mean) / std_dev
# Identify and remove outliers
threshold = 3
outliers = df[(df['Z-Score'] > threshold) | (df['Z-Score'] < -threshold)]
print("Outliers:\n", outliers)
filtered_data = df[(df['Z-Score'] <= threshold) & (df['Z-Score'] >= -threshold)]
print("Filtered Data:\n", filtered_data)
Key Points:
The Z-score method assumes the data follows a normal distribution.
It may not work well with skewed datasets.
4. Outlier Detection Using the Percentile Method and Winsorization
Percentile Method:
In the percentile method, we define a lower percentile (e.g., 1st percentile) and an upper percentile (e.g., 99th percentile). Any value outside this range is treated as an outlier.
Winsorization:
Winsorization is a technique where outliers are not removed but replaced with the nearest acceptable value.
Python Example:
from scipy.stats.mstats import winsorize
import numpy as np
Sample data
data = [12, 14, 18, 22, 25, 28, 32, 95, 100]
Calculate percentiles
lower_percentile = np.percentile(data, 1)
upper_percentile = np.percentile(data, 99)
Identify outliers
outliers = [x for x in data if x < lower_percentile or x > upper_percentile]
print("Outliers:", outliers)
# Apply Winsorization
winsorized_data = winsorize(data, limits=[0.01, 0.01])
print("Winsorized Data:", list(winsorized_data))
Key Points:
Percentile and Winsorization methods are useful for skewed data.
Winsorization is preferred when data integrity must be preserved.
Final Thoughts
Outliers can be tricky, but understanding how to detect and handle them is a key skill in machine learning and data science. Whether you use the IQR method, Z-score, or Wins
orization, always tailor your approach to the specific dataset you’re working with.
By mastering these techniques, you’ll be able to clean your data effectively and improve the accuracy of your models.
#science#skills#programming#bigdata#books#machinelearning#artificial intelligence#python#machine learning#data centers#outliers#big data#data analysis#data analytics#data scientist#database#datascience#data
4 notes
·
View notes
Text

This is the current list of genes with known issues: https://www.morphmarket.com/morphpedia/ball-pythons/...
Note: be sure to look at each gene carefully; some only have issues when combined with certain genes or have a strange method of inheritance (ie banana and coral glow) but have no known health issues.
57 notes
·
View notes
Text
What is Data Structure in Python?
Summary: Explore what data structure in Python is, including built-in types like lists, tuples, dictionaries, and sets, as well as advanced structures such as queues and trees. Understanding these can optimize performance and data handling.

Introduction
Data structures are fundamental in programming, organizing and managing data efficiently for optimal performance. Understanding "What is data structure in Python" is crucial for developers to write effective and efficient code. Python, a versatile language, offers a range of built-in and advanced data structures that cater to various needs.
This blog aims to explore the different data structures available in Python, their uses, and how to choose the right one for your tasks. By delving into Python’s data structures, you'll enhance your ability to handle data and solve complex problems effectively.
What are Data Structures?
Data structures are organizational frameworks that enable programmers to store, manage, and retrieve data efficiently. They define the way data is arranged in memory and dictate the operations that can be performed on that data. In essence, data structures are the building blocks of programming that allow you to handle data systematically.
Importance and Role in Organizing Data
Data structures play a critical role in organizing and managing data. By selecting the appropriate data structure, you can optimize performance and efficiency in your applications. For example, using lists allows for dynamic sizing and easy element access, while dictionaries offer quick lookups with key-value pairs.
Data structures also influence the complexity of algorithms, affecting the speed and resource consumption of data processing tasks.
In programming, choosing the right data structure is crucial for solving problems effectively. It directly impacts the efficiency of algorithms, the speed of data retrieval, and the overall performance of your code. Understanding various data structures and their applications helps in writing optimized and scalable programs, making data handling more efficient and effective.
Read: Importance of Python Programming: Real-Time Applications.
Types of Data Structures in Python
Python offers a range of built-in data structures that provide powerful tools for managing and organizing data. These structures are integral to Python programming, each serving unique purposes and offering various functionalities.
Lists
Lists in Python are versatile, ordered collections that can hold items of any data type. Defined using square brackets [], lists support various operations. You can easily add items using the append() method, remove items with remove(), and extract slices with slicing syntax (e.g., list[1:3]). Lists are mutable, allowing changes to their contents after creation.
Tuples
Tuples are similar to lists but immutable. Defined using parentheses (), tuples cannot be altered once created. This immutability makes tuples ideal for storing fixed collections of items, such as coordinates or function arguments. Tuples are often used when data integrity is crucial, and their immutability helps in maintaining consistent data throughout a program.
Dictionaries
Dictionaries store data in key-value pairs, where each key is unique. Defined with curly braces {}, dictionaries provide quick access to values based on their keys. Common operations include retrieving values with the get() method and updating entries using the update() method. Dictionaries are ideal for scenarios requiring fast lookups and efficient data retrieval.
Sets
Sets are unordered collections of unique elements, defined using curly braces {} or the set() function. Sets automatically handle duplicate entries by removing them, which ensures that each element is unique. Key operations include union (combining sets) and intersection (finding common elements). Sets are particularly useful for membership testing and eliminating duplicates from collections.
Each of these data structures has distinct characteristics and use cases, enabling Python developers to select the most appropriate structure based on their needs.
Explore: Pattern Programming in Python: A Beginner’s Guide.
Advanced Data Structures
In advanced programming, choosing the right data structure can significantly impact the performance and efficiency of an application. This section explores some essential advanced data structures in Python, their definitions, use cases, and implementations.
Queues
A queue is a linear data structure that follows the First In, First Out (FIFO) principle. Elements are added at one end (the rear) and removed from the other end (the front).
This makes queues ideal for scenarios where you need to manage tasks in the order they arrive, such as task scheduling or handling requests in a server. In Python, you can implement a queue using collections.deque, which provides an efficient way to append and pop elements from both ends.
Stacks
Stacks operate on the Last In, First Out (LIFO) principle. This means the last element added is the first one to be removed. Stacks are useful for managing function calls, undo mechanisms in applications, and parsing expressions.
In Python, you can implement a stack using a list, with append() and pop() methods to handle elements. Alternatively, collections.deque can also be used for stack operations, offering efficient append and pop operations.
Linked Lists
A linked list is a data structure consisting of nodes, where each node contains a value and a reference (or link) to the next node in the sequence. Linked lists allow for efficient insertions and deletions compared to arrays.
A singly linked list has nodes with a single reference to the next node. Basic operations include traversing the list, inserting new nodes, and deleting existing ones. While Python does not have a built-in linked list implementation, you can create one using custom classes.
Trees
Trees are hierarchical data structures with a root node and child nodes forming a parent-child relationship. They are useful for representing hierarchical data, such as file systems or organizational structures.
Common types include binary trees, where each node has up to two children, and binary search trees, where nodes are arranged in a way that facilitates fast lookups, insertions, and deletions.
Graphs
Graphs consist of nodes (or vertices) connected by edges. They are used to represent relationships between entities, such as social networks or transportation systems. Graphs can be represented using an adjacency matrix or an adjacency list.
The adjacency matrix is a 2D array where each cell indicates the presence or absence of an edge, while the adjacency list maintains a list of edges for each node.
See: Types of Programming Paradigms in Python You Should Know.
Choosing the Right Data Structure
Selecting the appropriate data structure is crucial for optimizing performance and ensuring efficient data management. Each data structure has its strengths and is suited to different scenarios. Here’s how to make the right choice:
Factors to Consider
When choosing a data structure, consider performance, complexity, and specific use cases. Performance involves understanding time and space complexity, which impacts how quickly data can be accessed or modified. For example, lists and tuples offer quick access but differ in mutability.
Tuples are immutable and thus faster for read-only operations, while lists allow for dynamic changes.
Use Cases for Data Structures:
Lists are versatile and ideal for ordered collections of items where frequent updates are needed.
Tuples are perfect for fixed collections of items, providing an immutable structure for data that doesn’t change.
Dictionaries excel in scenarios requiring quick lookups and key-value pairs, making them ideal for managing and retrieving data efficiently.
Sets are used when you need to ensure uniqueness and perform operations like intersections and unions efficiently.
Queues and stacks are used for scenarios needing FIFO (First In, First Out) and LIFO (Last In, First Out) operations, respectively.
Choosing the right data structure based on these factors helps streamline operations and enhance program efficiency.
Check: R Programming vs. Python: A Comparison for Data Science.
Frequently Asked Questions
What is a data structure in Python?
A data structure in Python is an organizational framework that defines how data is stored, managed, and accessed. Python offers built-in structures like lists, tuples, dictionaries, and sets, each serving different purposes and optimizing performance for various tasks.
Why are data structures important in Python?
Data structures are crucial in Python as they impact how efficiently data is managed and accessed. Choosing the right structure, such as lists for dynamic data or dictionaries for fast lookups, directly affects the performance and efficiency of your code.
What are advanced data structures in Python?
Advanced data structures in Python include queues, stacks, linked lists, trees, and graphs. These structures handle complex data management tasks and improve performance for specific operations, such as managing tasks or representing hierarchical relationships.
Conclusion
Understanding "What is data structure in Python" is essential for effective programming. By mastering Python's data structures, from basic lists and dictionaries to advanced queues and trees, developers can optimize data management, enhance performance, and solve complex problems efficiently.
Selecting the appropriate data structure based on your needs will lead to more efficient and scalable code.
#What is Data Structure in Python?#Data Structure in Python#data structures#data structure in python#python#python frameworks#python programming#data science
6 notes
·
View notes
Text
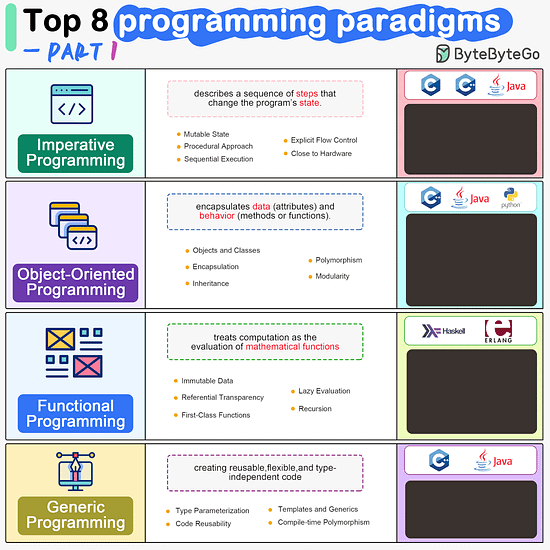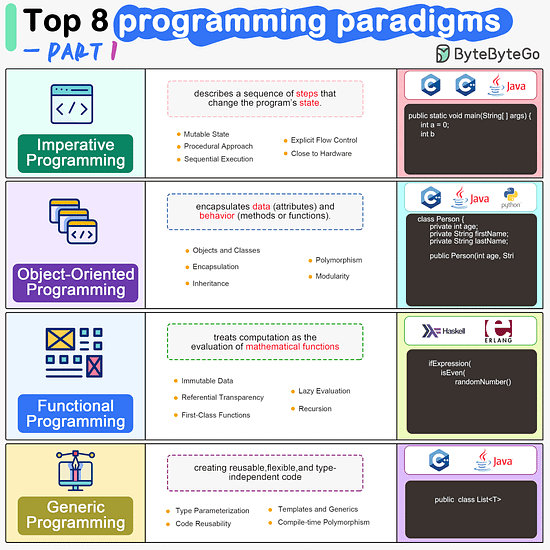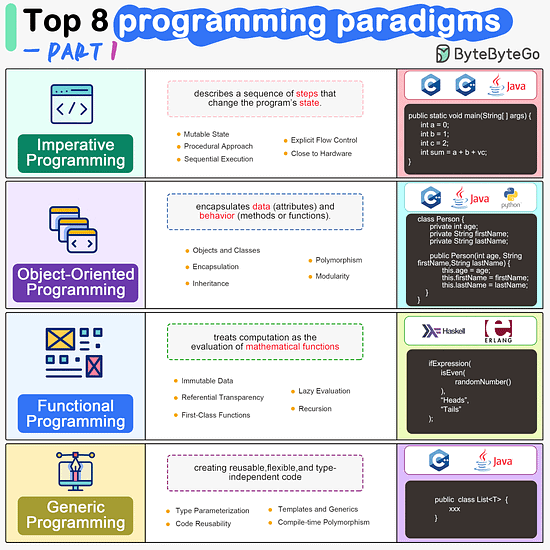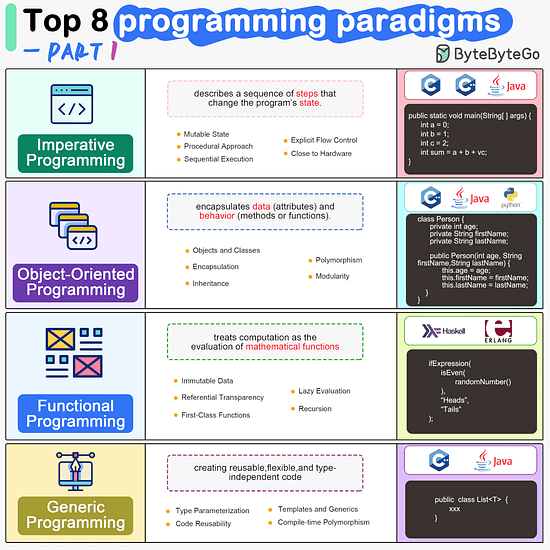
ByteByteGo | Newsletter/Blog
From the newsletter:
Imperative Programming Imperative programming describes a sequence of steps that change the program’s state. Languages like C, C++, Java, Python (to an extent), and many others support imperative programming styles.
Declarative Programming Declarative programming emphasizes expressing logic and functionalities without describing the control flow explicitly. Functional programming is a popular form of declarative programming.
Object-Oriented Programming (OOP) Object-oriented programming (OOP) revolves around the concept of objects, which encapsulate data (attributes) and behavior (methods or functions). Common object-oriented programming languages include Java, C++, Python, Ruby, and C#.
Aspect-Oriented Programming (AOP) Aspect-oriented programming (AOP) aims to modularize concerns that cut across multiple parts of a software system. AspectJ is one of the most well-known AOP frameworks that extends Java with AOP capabilities.
Functional Programming Functional Programming (FP) treats computation as the evaluation of mathematical functions and emphasizes the use of immutable data and declarative expressions. Languages like Haskell, Lisp, Erlang, and some features in languages like JavaScript, Python, and Scala support functional programming paradigms.
Reactive Programming Reactive Programming deals with asynchronous data streams and the propagation of changes. Event-driven applications, and streaming data processing applications benefit from reactive programming.
Generic Programming Generic Programming aims at creating reusable, flexible, and type-independent code by allowing algorithms and data structures to be written without specifying the types they will operate on. Generic programming is extensively used in libraries and frameworks to create data structures like lists, stacks, queues, and algorithms like sorting, searching.
Concurrent Programming Concurrent Programming deals with the execution of multiple tasks or processes simultaneously, improving performance and resource utilization. Concurrent programming is utilized in various applications, including multi-threaded servers, parallel processing, concurrent web servers, and high-performance computing.
#bytebytego#resource#programming#concurrent#generic#reactive#funtional#aspect#oriented#aop#fp#object#oop#declarative#imperative
8 notes
·
View notes
Text
Infrastructure for Disaster Control, a.k.a. Automatic Builds
We all know the feeling of pure and utter stress when, ten minutes before the deadline, you finally click the Build And Export in your game engine and then it fails to build for some reason.
To prevent issues like this, people invented automated builds, also sometimes referred to as CI/CD.
This is a mechanism that tests the project every single time a change is made (a git commit is pushed, or a Perforce changelist is submitted). Because of this, we very quickly know whenever a change broke the build, which means we can fix it immediately, instead of having to fix it at the end.
It is also useful whenever a regression happens that doesn't break the build. We can go back to a previous build, and see if the issue is there or not. By checking a few builds by way of binary search, we can very quickly pinpoint the exact change that caused the regression. We have used this a few times, in fact. Once, the weaving machines stopped showing up in the build, and with this method, we were able to pinpoint the exact change that caused it, and then we submitted a fix!
It's very useful to have an archive of builds for every change we made to the project.
There are multiple different softwares that do this kind of thing, but Jenkins is by and far the most used. Both by indies, but also large AAA studios! So knowing how it works is very useful, so that's why I picked Jenkins for the job. Again, like with Perforce, it was pretty easy to install!
Here is a list of every build run that Jenkins did, including a neat little graph :)

Configuring it was quite tricky, though. I had to create a console terminal CLI command that makes Unreal Engine build project. Resources used: (one) (two)
It took many days of constant iteration, but in the end, I got it to work very well!
I also wrote some explanations of what Jenkins is and how to use it on the Jenkins pages themselves, for my teammates to read:
Dashboard (The Home Page):

Project Page:

Now, it is of course very useful to build the project and catch errors when they happen, but if no-one looks on the Jenkins page, then no-one will see the status! Even if the website is accessible to everyone, people won't really look there very often. Which kind of makes the whole thing useless… So to solve that issue, I implemented Discord pings! There is a Jenkins plugin that automatically sends messages to a specific Discord channel once the build is done. This lets everyone know when the build succeeded or failed.

We of course already had a discord server that we used to discuss everything in, and to hold out online meetings with. So this #build-status channel fit in perfectly, and it was super helpful in catching and solving issues.
Whenever a build failed, people could click on the link, and see the console output that Unreal Engine gave during the build, so we could instantly see where the issue was coming from. And because it rebuilds for every change that is made, we know for certain that the issue can only have come from the change that was just made! This meant that keeping every change small, made it easier to find and fix problems!
Whenever a build succeeds, it gets stored on the server, in the build archive.

But storing it on the server alone is nice and all, but people can't really do anything with them there. I could personally access them by remotely connecting to the server, but I cannot make my teammates go through all that. So I needed to make them more accessible for the whole team, to download whenever they please.
For this, I wanted to create a small website, from which they can download them. Just by going to the link, they could scroll through every build and download it immediately.
I already knew of multiple ways of easily doing this, so I tried out a few.
The Python programming language actually ships with a built-in webserver module that can be used very easily with a single command. But Python wasn't installed, and installing Python on Windows is kind of annoying, so I wanted something else. Something simpler.
I often use the program "darkhttpd" whenever I want a simple webserver, so I tried to download that, but I couldn't get it to work on Windows. Seems like it only really supports Linux…
So I went looking for other, single-executable, webserver programs that do support Windows.
And so I stumbled on "caddy". I'd actually heard of it before, but never used it, as I never had a need for it before then. For actual full websites, I've always used nginx. After some time of looking at the official documentation of caddy's various configuration file formats and command-line arguments, and tweaking things, I had it working like I wanted! It now even automatically starts when the computer boots up, which is something that Perforce and Jenkins set up automatically. Resources used: (one) (two) (three) (four)

And I think that's it! Unfortunately, none of this will roll over to the next team that has to work on this project, because none of this is code that is inside our project folder.
Here’s a summary of the setup, drawn as a network map:

Future
There is a concept called IAC, Infrastructure As Code, which I would like to look into, in the future. It seems very useful for these kinds of situations where other people have to be able to take over, and reproduce the setups.
4 notes
·
View notes
Text

Econometrics Demystified: The Ultimate Compilation of Top 10 Study Aids
Welcome to the world of econometrics, where economic theories meet statistical methods to analyze and interpret data. If you're a student navigating through the complexities of econometrics, you know how challenging it can be to grasp the intricacies of this field. Fear not! This blog is your ultimate guide to the top 10 study aids that will demystify econometrics and make your academic journey smoother.
Economicshomeworkhelper.com – Your Go-To Destination
Let's kick off our list with the go-to destination for all your econometrics homework and exam needs – https://www.economicshomeworkhelper.com/. With a team of experienced experts, this website is dedicated to providing high-quality assistance tailored to your specific requirements. Whether you're struggling with regression analysis or hypothesis testing, the experts at Economicshomeworkhelper.com have got you covered. When in doubt, remember to visit the website and say, "Write My Econometrics Homework."
Econometrics Homework Help: Unraveling the Basics
Before delving into the intricacies, it's crucial to build a strong foundation in the basics of econometrics. Websites offering econometrics homework help, such as Khan Academy and Coursera, provide comprehensive video tutorials and interactive lessons to help you grasp fundamental concepts like linear regression, correlation, and statistical inference.
The Econometrics Academy: Online Courses for In-Depth Learning
For those seeking a more immersive learning experience, The Econometrics Academy offers online courses that cover a wide range of econometrics topics. These courses, often led by seasoned professors, provide in-depth insights into advanced econometric methods, ensuring you gain a deeper understanding of the subject.
"Mastering Metrics" by Joshua D. Angrist and Jörn-Steffen Pischke
No compilation of study aids would be complete without mentioning authoritative books, and "Mastering Metrics" is a must-read for econometrics enthusiasts. Authored by two renowned economists, Joshua D. Angrist and Jörn-Steffen Pischke, this book breaks down complex concepts into digestible chapters, making it an invaluable resource for both beginners and advanced learners.
Econometrics Forums: Join the Conversation
Engaging in discussions with fellow econometrics students and professionals can enhance your understanding of the subject. Platforms like Econometrics Stack Exchange and Reddit's econometrics community provide a space for asking questions, sharing insights, and gaining valuable perspectives. Don't hesitate to join the conversation and expand your econometrics network.
Gretl: Your Free Econometrics Software
Practical application is key in econometrics, and Gretl is the perfect tool for hands-on learning. This free and open-source software allows you to perform a wide range of econometric analyses, from simple regressions to advanced time-series modeling. Download Gretl and take your econometrics skills to the next level.
Econometrics Journal Articles: Stay Updated
Staying abreast of the latest developments in econometrics is essential for academic success. Explore journals such as the "Journal of Econometrics" and "Econometrica" to access cutting-edge research and gain insights from scholars in the field. Reading journal articles not only enriches your knowledge but also equips you with the latest methodologies and approaches.
Econometrics Bloggers: Learn from the Pros
Numerous econometrics bloggers share their expertise and experiences online, offering valuable insights and practical tips. Follow blogs like "The Unassuming Economist" and "Econometrics by Simulation" to benefit from the expertise of professionals who simplify complex econometric concepts through real-world examples and applications.
Econometrics Software Manuals: Master the Tools
While software like STATA, R, and Python are indispensable for econometric analysis, navigating through them can be challenging. Refer to comprehensive manuals and documentation provided by these software platforms to master their functionalities. Understanding the tools at your disposal will empower you to apply econometric techniques with confidence.
Econometrics Webinars and Workshops: Continuous Learning
Finally, take advantage of webinars and workshops hosted by academic institutions and industry experts. These events provide opportunities to deepen your knowledge, ask questions, and engage with professionals in the field. Check out platforms like Econometric Society and DataCamp for upcoming events tailored to econometrics enthusiasts.
Conclusion
Embarking on your econometrics journey doesn't have to be daunting. With the right study aids, you can demystify the complexities of this field and excel in your academic pursuits. Remember to leverage online resources, engage with the econometrics community, and seek assistance when needed. And when the workload becomes overwhelming, don't hesitate to visit Economicshomeworkhelper.com and say, "Write My Econometrics Homework" – your trusted partner in mastering econometrics. Happy studying!
13 notes
·
View notes
Note
how are you downloading Ici tout commence?
From the official site!
First, I use a VPN to get a French IP (or Belgian--I'm not sure which they accept, I just know these two work) so I can access the network's streaming site, TF1+. You should be able to sign up for a free account without issue. This is the page for the season 4 eps:
https://www.tf1.fr/tf1/ici-tout-commence/videos/saison-4
Apparently there are always two eps in advance available for the premium subscribers but I'm not caught up plus I think it'd be a little harder to sign up for an actual paid account so I probably won't be able to do that.
So normally I would use youtube-dl/yt-dlp to download the eps but that won't work here, or at least not without some extra steps, because these are DRMed. This is where it gets a little tricky and the whole process isn't super well documented both because it changes a lot and it makes more sense to teach people to learn how to do it than how to do it and also because, well, the more these methods are spread, the more networks change things up and make things harder.
This thread can help you get started: https://forum.videohelp.com/threads/412113-MYTF1-Help-needed-New-DRM-system-can-t-download
The whole forum is quite useful and I've only had to post for help a couple of times, mostly I just search my issue and read through.
That provided command in the second post, that's something to be used in your command line, on Windows in Start you can open that by typing in cmd or PowerShell or just google what you'll need for your computer.
These are the things you'll need to get to run the command:
N_m3u8DL-RE is a tool you can google and download, and also ffmpeg and mp4decrypt. You'll want them in the same folder for convenience. (I think you might need to install python too? If it says you do, then go ahead, lol.)
The way to get the key, this is the most gatekept part, probably. The various streamers out there use different methods of encryption and increasing security levels, and if you read up on it, you'll see stuff about kid and pssh and cdm and L3, it can be overwhelming, but in this case, the things you need are relatively easily accessible.
I'll tell you how to get the pssh and the license URL and you'll be able to use those to get the key. There are several tools you can use them on, one is public and easy, one is private but still easy-ish, and one is pretty complex and not a route I've gone down myself yet (it's the pinned thread in that particular forum). I don't want to link any of them myself, but I'll link to a thread that mentions the easy public one. It does go down at times which is why the hardcore people recommend that last method.
First, before you click on an ep, open up your browser's Developer Tools, usually Ctrl+Shift+i will do the trick. Go over to your Network tab, this shows all the requests your browser makes when you go to a site.
Then click on the episode in the actual browser. You'll see a flood of requests in the Network tab, filter on mpd.
Select the mpd result and the details for it show on the side, click on Preview. Scroll down until you see <!-- Widevine -->. A couple of lines below it, you'll see something like <cenc:pssh>AAA[a bunch of characters]</cenc:pssh>
Grab that whoooole part that starts with AAA, that's the pssh. Go to the Headers detail tab while you're there and grab the Request URL, this is the mpd link we're going to use later.
Now to get the license. Usually you can filter in your Devtools Network tab on license or, in this case, widevine. Since we're already on the Headers detail tab, grab this Request URL now, it should start with https://widevine-proxy-m.prod.p.tf1.fr/proxy?
Now go back to that easy public tool linked in that thread I linked, lol, and just fill in the PSSH and the License. Hit Send and you get a list of three keys at the bottom. I've always gone for the one in the middle and not bothered with all three, but you can try them all.
So at this point, you should be able to fully create and use the command in the first forum link above. If you read the documentation for N_m3u8DL-RE, there are various flags you can use, --save-name "Outputname" will let you name the output what you want, -sv best defaults to the best video quality, -sa best is best audio quality, and so on.
The way to get the subtitle is to turn on subtitles on the video player on the site and to go back to the DevTools box and filter on textstream. Grab the first request, the one that ends with =1000.dash and paste it into a new browser address, and change the .dash to .vtt. That's the subtitle. :) You can use the free tool Subtitle Edit to both convert it to srt, which will let most video players play it with your video, and there's also an Auto-translate option that lets you translate to English. It offers several ways but as I don't have a Google API, I just use the normal "slow" method, it's not that bad.
A second way to get the subtitle is to use the same command as when you're downloading the ep but remove the -M format=mp4 at the end, and instead add -ss 'id="textstream_fra=1000":for=all'
This was all figured out through a LOT of trial and error on my part so please do try your own best if you hit some issues, that's the best way to learn. Also, I just don't want to be the helpdesk on this, lol.
#replies#Anonymous#sent on 20240213#whew#that's a lot#but for real unless there's a huge error in what I've said just try to troubleshoot your issues on your own :x#there seems to be increased interest in this show...I wish I was in the mood to catch up#unfortch I've stopped on both this and neighbours for now...#I don't want to waste them on the mood I'm in these days#ici tout commence
17 notes
·
View notes
Text
AI Pollen Project Update 1
Hi everyone! I have a bunch of ongoing projects in honey and other things so I figured I should start documenting them here to help myself and anyone who might be interested. Most of these aren’t for a grade, but just because I’m interested or want to improve something.
One of the projects I’m working on is a machine learning model to help with pollen identification under visual methods. There’s very few people who are specialized to identify the origins of pollens in honey, which is pretty important for research! And the people who do it are super busy because it’s very time consuming. This is meant to be a tool and an aid so they can devote more time to the more important parts of the research, such as hunting down geographical origins, rather than the mundane parts like counting individual pollen and trying to group all the species in a sample.
The model will have 3 goals to aid these researchers:
Count overall pollen and individual species of pollen in a sample of honey
Provide the species of each pollen in a sample
Group pollen species together with a confidence listed per sample
Super luckily there’s pretty large pollen databases out there with different types of imaging techniques being used (SEM, electron microscopy, 40X magnification, etc). I’m kind of stumped on which python AI library to use, right now I’ve settled on using OpenCV to make and train the model, but I don’t know if there’s a better option for what I’m trying to do. If anyone has suggestions please let me know
This project will be open source and completely free once I’m done, and I also intend on making it so more confirmed pollen species samples with confirmed geographical origins can be added by researchers easily. I am a firm believer that ML is a tool that’s supposed to make the mundane parts easier so we have time to do what brings us joy, which is why Im working on this project!
I’m pretty busy with school, so I’ll make the next update once I have more progress! :)
Also a little note: genetic tests are more often used for honey samples since it is more accessible despite being more expensive, but this is still an important part of the research. Genetic testing also leaves a lot to be desired, like not being able to tell the exact species of the pollen which can help pinpoint geographical location or adulteration.
2 notes
·
View notes
Text
"DCA"(DIPLOMA IN COMPUTER APPLICATION)
The best career beginning course....

Golden institute is ISO 9001-2015 certified institute. Here you can get all types of computer courses such as DCA, CFA , Python, Digital marketing, and Tally prime . Diploma in Computer Applications (DCA) is a 1 year "Diploma Course" in the field of Computer Applications which provides specialization in various fields such as Fundamentals & Office Productivity tools, Graphic Design & Multimedia, Programming and Functional application Software.

A few of the popular DCA study subjects are listed below
Basic internet concepts Computer Fundamentals Introduction to programming Programming in C RDBMS & Data Management Multimedia Corel draw Tally ERP 9.0 Photoshop
Benefits of Diploma in Computer Application (DCA)
After completion of the DCA course student will able to join any computer jobs with private and government sectors. The certification of this course is fully valid for any government and private deportment worldwide. DCA is the only best option for the student to learn computer skills with affordable fees.
DCA Computer course : Eligibilities are here... Students aspiring to pursue Diploma in Computer Applications (DCA) course must have completed their higher school/ 10 + 2 from a recognized board. Choosing Computers as their main or optional subject after class 10 will give students an additional edge over others. Apart from this no other eligibility criteria is set for aspirants. No minimum cutoff is required.

"TALLY"
A Tally is accounting software. To pursue Tally Course (Certificate and Diploma) you must have certain educational qualifications to thrive and prosper. The eligibility criteria for the tally course is given below along with all significant details on how to approach learning Tally, and how you can successfully complete the course. Generally, the duration of a Tally course is 6 month to 1 year ,but it varies depending on the tally institution you want to join. Likewise, tally course fees are Rs. 10000-20000 on average but it also varies depending on what type of tally course or college you opt for. accounting – Accounting plays a pivotal role in Tally
Key Benefits of the Course:
Effective lessons (topics are explained through a step-by-step process in a very simple language) The course offers videos and e-books (we have two options Video tutorials in Hindi2. e-book course material in English) It offers a planned curriculum (the entire tally online course is designed to meet the requirements of the industry.) After the completion of the course, they offer certificates to the learners.
Tally Course Syllabus – Subjects To Learn Accounting Payroll Taxation Billing Banking Inventory
Tally Course
Eligibility criteria: 10+2 in commerce stream Educational level: Certificate or Diploma Course fee: INR 2200-5000 Skills required: Accounting, Finance, Taxation, Interpersonal Skills Scope after the course: Accountant, Finance Manager, Chartered Accountant, Executive Assistant, Operations Manager Average salary: INR 5,00,000 – 10,00,000

"In this Python course"
Rapidly develop feature-rich applications using Python's built-in statements, functions, and collection types. Structure code with classes, modules, and packages that leverage object-oriented features. Create multiple data accessors to manage various data storage formats. Access additional features with library modules and packages.
Python for Web Development – Flask Flask is a popular Python API that allows experts to build web applications. Python 2.6 and higher variants must install Flask, and you can import Flask on any Python IDE from the Flask package. This section of the course will help you install Flask and learn how to use the Python Flask Framework.
Subjects covered in Python for Web development using Flask:
Introduction to Python Web Framework Flask Installing Flask Working on GET, POST, PUT, METHODS using the Python Flask Framework Working on Templates, render template function
Python course fees and duration
A Python course costs around ₹2200-5000.This course fees can vary depending on multiple factors. For example, a self-paced online course will cost you less than a live interactive online classroom session, and offline training sessions are usually expensive ones. This is mainly because of the trainers’ costs, lab assistance, and other facilities.
Some other factors that affect the cost of a Python course are its duration, course syllabus, number of practical sessions, institute reputation and location, trainers’ expertise, etc. What is the duration of a Python course? The duration of a basic Python course is generally between 3 month to 6 months, and advanced courses can be 1 year . However, some courses extend up to 1 year and more when they combine multiple other courses or include internship programs.
Advantages of Python Python is easy to learn and put into practice. … Functions are defined. … Python allows for quick coding. … Python is versatile. … Python understands compound data types. … Libraries in data science have Python interfaces. … Python is widely supported.

"GRAPHIC DESIGN"
Graphic design, in simple words, is a means that professional individuals use to communicate their ideas and messages. They make this communication possible through the means of visual media.
A graphic designing course helps aspiring individuals to become professional designers and create visual content for top institutions around the world. These courses are specialized to accommodate the needs and requirements of different people. The course is so popular that one does not even need to do a lot of research to choose their preferred colleges, institutes, or academies for their degrees, as they are almost mainstream now.
A graphic design course have objectives:
To train aspirants to become more creative with their visual approach. To train aspirants to be more efficient with the technical aspects of graphics-related tasks and also to acquaint them with relevant aspects of a computer. To train individuals about the various aspects of 2-D and 3-D graphics. To prepare aspirants to become fit for a professional graphic designing profession.
Which course is best for graphic design? Best graphic design courses after 12th - Graphic … Certificate Courses in Graphic Design: Adobe Photoshop. CorelDraw. InDesign. Illustrator. Sketchbook. Figma, etc.
It is possible to become an amateur Graphic Designer who is well on the road to becoming a professional Graphic Designer in about three months. In short, three months is what it will take to receive the professional training required to start building a set of competitive professional job materials.

THE BEST COMPUTER INSTITUTE GOLDEN EDUCATION,ROPNAGAR "PUNJAB"
The best mega DISCOUNT here for your best course in golden education institute in this year.
HURRY UP! GUYS TO JOIN US...
Don't miss the chance
You should go to our institute website
WWW.GOLDEN EDUCATION
CONTACT US: 98151-63600
VISIT IT:
#GOLDEN EDUCATION#INSTITUTE#COURSE#career#best courses#tallyprime#DCA#GRAPHICAL#python#ALL COURSE#ROOPAR
2 notes
·
View notes