#python reading text files
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text
yeah i really love it when you want to build a website and learn coding and programming and scripting and set yourself on fire and the experience is basically just this

#sy.txt#a pyramid scheme of code? a bunch of matryoshka dolls? in my files? more likely than you think#says a lot when i understand more about python following php tutorials compared to looking at python-focused tuts#IT'S ALL THE FUCKING SAME! YET WITH DIFFERENT FUCKING SYMBOLS AND COMMANDS BECAUSE FUCK YOU!!!! AND FOR DIFFERENT USES BUT STILL!!! FUCK YO#anyway at the end of the day it's literally math on sand steroids and boy. am i bad at math and eating sand.#me reading through whatever the fuck a lorekeeper is and it's based on laravel which is based on php and it's based on-#YOU THOUGHT HTML AND CSS WERE DIFFICULT? WRONG! BABY LANGUAGE THAT IS!#it wouldn't be as horrible if all the commands were more intuitive but i've only felt that with html and to some lesser degree bootstrap#and css is thankfully whatever the fuck i make it to be. but nooooooooooo. why is it a dollar symbol for php commands. hell if i know#oh yeah no i can use a hashtag to make a comment but that's also used to make big text in discord and actual hashtags on social media#ARGHHHHHHHHHHHHHHHHHHHH!!!!!! SERIOUSLY!!!!
0 notes
Note
komaedas have you tried straw.page?
(i hope you don't mind if i make a big ollllle webdev post off this!)
i have never tried straw.page but it looks similar to carrd and other WYSIWYG editors (which is unappealing to me, since i know html/css/js and want full control of the code. and can't hide secrets in code comments.....)
my 2 cents as a web designer is if you're looking to learn web design or host long-term web projects, WYSIWYG editors suck doodooass. you don't learn the basics of coding, someone else does it for you! however, if you're just looking to quickly host images, links to your other social medias, write text entries/blogposts, WYSIWYG can be nice.
toyhouse, tumblr, deviantart, a lot of sites implement WYSIWYG for their post editors as well, but then you can run into issues relying on their main site features for things like the search system, user profiles, comments, etc. but it can be nice to just login to your account and host your information in one place, especially on a platform that's geared towards that specific type of information. (toyhouse is a better example of this, since you have a lot of control of how your profile/character pages look, even without a premium account) carrd can be nice if you just want to say "here's where to find me on other sites," for example. but sometimes you want a full website!
---------------------------------------
neocities hosting
currently, i host my website on neocities, but i would say the web2.0sphere has sucked some doodooass right now and i'm fiending for something better than it. it's a static web host, e.g. you can upload text, image, audio, and client-side (mostly javascript and css) files, and html pages. for the past few years, neocities' servers have gotten slower and slower and had total blackouts with no notices about why it's happening... and i'm realizing they host a lot of crypto sites that have crypto miners that eat up a ton of server resources. i don't think they're doing anything to limit bot or crypto mining activity and regular users are taking a hit.



↑ page 1 on neocitie's most viewed sites we find this site. this site has a crypto miner on it, just so i'm not making up claims without proof here. there is also a very populated #crypto tag on neocities (has porn in it tho so be warned...).
---------------------------------------
dynamic/server-side web hosting
$5/mo for neocities premium seems cheap until you realize... The Beautiful World of Server-side Web Hosting!
client-side AKA static web hosting (neocities, geocities) means you can upload images, audio, video, and other files that do not interact with the server where the website is hosted, like html, css, and javascript. the user reading your webpage does not send any information to the server like a username, password, their favourite colour, etc. - any variables handled by scripts like javascript will be forgotten when the page is reloaded, since there's no way to save it to the web server. server-side AKA dynamic web hosting can utilize any script like php, ruby, python, or perl, and has an SQL database to store variables like the aforementioned that would have previously had nowhere to be stored.
there are many places in 2024 you can host a website for free, including: infinityfree (i use this for my test websites :B has tons of subdomains to choose from) [unlimited sites, 5gb/unlimited storage], googiehost [1 site, 1gb/1mb storage], freehostia [5 sites/1 database, 250mb storage], freehosting [1 site, 10gb/unlimited storage]
if you want more features like extra websites, more storage, a dedicated e-mail, PHP configuration, etc, you can look into paying a lil shmoney for web hosting: there's hostinger (this is my promocode so i get. shmoney. if you. um. 🗿🗿🗿) [$2.40-3.99+/mo, 100 sites/300 databases, 100gb storage, 25k visits/mo], a2hosting [$1.75-12.99+/mo, 1 site/5 databases, 10gb/1gb storage], and cloudways [$10-11+/mo, 25gb/1gb]. i'm seeing people say to stay away from godaddy and hostgator. before you purchase a plan, look up coupons, too! (i usually renew my plan ahead of time when hostinger runs good sales/coupons LOL)
here's a big webhost comparison chart from r/HostingHostel circa jan 2024.

---------------------------------------
domain names
most of the free website hosts will give you a subdomain like yoursite.has-a-cool-website-69.org, and usually paid hosts expect you to bring your own domain name. i got my domain on namecheap (enticing registration prices, mid renewal prices), there's also porkbun, cloudflare, namesilo, and amazon route 53. don't use godaddy or squarespace. make sure you double check the promo price vs. the actual renewal price and don't get charged $120/mo when you thought it was $4/mo during a promo, certain TLDs (endings like .com, .org, .cool, etc) cost more and have a base price (.car costs $2,300?!?). look up coupons before you purchase these as well!
namecheap and porkbun offer something called "handshake domains," DO NOT BUY THESE. 🤣🤣🤣 they're usually cheaper and offer more appealing, hyper-specific endings like .iloveu, .8888, .catgirl, .dookie, .gethigh, .♥, .❣, and .✟. I WISH WE COULD HAVE THEM but they're literally unusable. in order to access a page using a handshake domain, you need to download a handshake resolver. every time the user connects to the site, they have to provide proof of work. aside from it being incredibly wasteful, you LITERALLY cannot just type in the URL and go to your own website, you need to download a handshake resolver, meaning everyday internet users cannot access your site.
---------------------------------------
hosting a static site on a dynamic webhost
you can host a static (html/css/js only) website on a dynamic web server without having to learn PHP and SQL! if you're coming from somewhere like neocities, the only thing you need to do is configure your website's properties. your hosting service will probably have tutorials to follow for this, and possibly already did some steps for you. you need to point the nameserver to your domain, install an SSL certificate, and connect to your site using FTP for future uploads. FTP is a faster, alternative way to upload files to your website instead of your webhost's file upload system; programs like WinSCP or FileZilla can upload using FTP for you.
if you wanna learn PHP and SQL and really get into webdev, i wrote a forum post at Mysidia Adoptables here, tho it's sorted geared at the mysidia script library itself (Mysidia Adoptables is a free virtual pet site script, tiny community. go check it out!)
---------------------------------------
file storage & backups
a problem i have run into a lot in my past like, 20 years of internet usage (/OLD) is that a site that is free, has a small community, and maybe sounds too good/cheap to be true, has a higher chance of going under. sometimes this happens to bigger sites like tinypic, photobucket, and imageshack, but for every site like that, there's like a million of baby sites that died with people's files. host your files/websites on a well-known site, or at least back it up and expect it to go under!
i used to host my images on something called "imgjoe" during the tinypic/imageshack era, it lasted about 3 years, and i lost everything hosted on there. more recently, komaedalovemail had its webpages hosted here on tumblr, and tumblr changed its UI so custom pages don't allow javascript, which prevented any new pages from being edited/added. another test site i made a couple years ago on hostinger's site called 000webhost went under/became a part of hostinger's paid-only plans, so i had to look very quickly for a new host or i'd lose my test site.
if you're broke like me, looking into physical file storage can be expensive. anything related to computers has gone through baaaaad inflation due to crypto, which again, I Freaquing Hate, and is killing mother nature. STOP MINING CRYPTO this is gonna be you in 1 year

...um i digress. ANYWAYS, you can archive your websites, which'll save your static assets on The Internet Archive (which could use your lovely donations right now btw), and/or archive.today (also taking donations). having a webhost service with lots of storage and automatic backups can be nice if you're worried about file loss or corruption, or just don't have enough storage on your computer at home!
if you're buying physical storage, be it hard drive, solid state drive, USB stick, whatever... get an actual brand like Western Digital or Seagate and don't fall for those cheap ones on Amazon that claim to have 8,000GB for $40 or you're going to spend 13 days in windows command prompt trying to repair the disk and thenthe power is gong to go out in your shit ass neighvborhood and you have to run it tagain and then Windows 10 tryes to update and itresets the /chkdsk agin while you're awayfrom town nad you're goig to start crytypting and kts just hnot going tot br the same aever agai nikt jus not ggiog to be the saeme
---------------------------------------
further webhosting options
there are other Advanced options when it comes to web hosting. for example, you can physically own and run your own webserver, e.g. with a computer or a raspberry pi. r/selfhosted might be a good place if you're looking into that!
if you know or are learning PHP, SQL, and other server-side languages, you can host a webserver on your computer using something like XAMPP (Apache, MariaDB, PHP, & Perl) with minimal storage space (the latest version takes up a little under 1gb on my computer rn). then, you can test your website without needing an internet connection or worrying about finding a hosting plan that can support your project until you've set everything up!
there's also many PHP frameworks which can be useful for beginners and wizards of the web alike. WordPress is one which you're no doubt familiar with for creating blog posts, and Bluehost is a decent hosting service tailored to WordPress specifically. there's full frameworks like Laravel, CakePHP, and Slim, which will usually handle security, user authentication, web routing, and database interactions that you can build off of. Laravel in particular is noob-friendly imo, and is used by a large populace, and it has many tutorials, example sites built with it, and specific app frameworks.
---------------------------------------
addendum: storing sensitive data
if you decide to host a server-side website, you'll most likely have a login/out functionality (user authentication), and have to store things like usernames, passwords, and e-mails. PLEASE don't launch your website until you're sure your site security is up to snuff!
when trying to check if your data is hackable... It's time to get into the Mind of a Hacker. OWASP has some good cheat sheets that list some of the bigger security concerns and how to mitigate them as a site owner, and you can look up filtered security issues on the Exploit Database.
this is kind of its own topic if you're coding a PHP website from scratch; most frameworks securely store sensitive data for you already. if you're writing your own PHP framework, refer to php.net's security articles and this guide on writing an .htaccess file.
---------------------------------------
but. i be on that phone... :(
ok one thing i see about straw.page that seems nice is that it advertises the ability to make webpages from your phone. WYSIWYG editors in general are more capable of this. i only started looking into this yesterday, but there ARE source code editor apps for mobile devices! if you have a webhosting plan, you can download/upload assets/code from your phone and whatnot and code on the go. i downloaded Runecode for iphone. it might suck ass to keep typing those brackets.... we'll see..... but sometimes you're stuck in the car and you're like damn i wanna code my site GRRRR I WANNA CODE MY SITE!!!
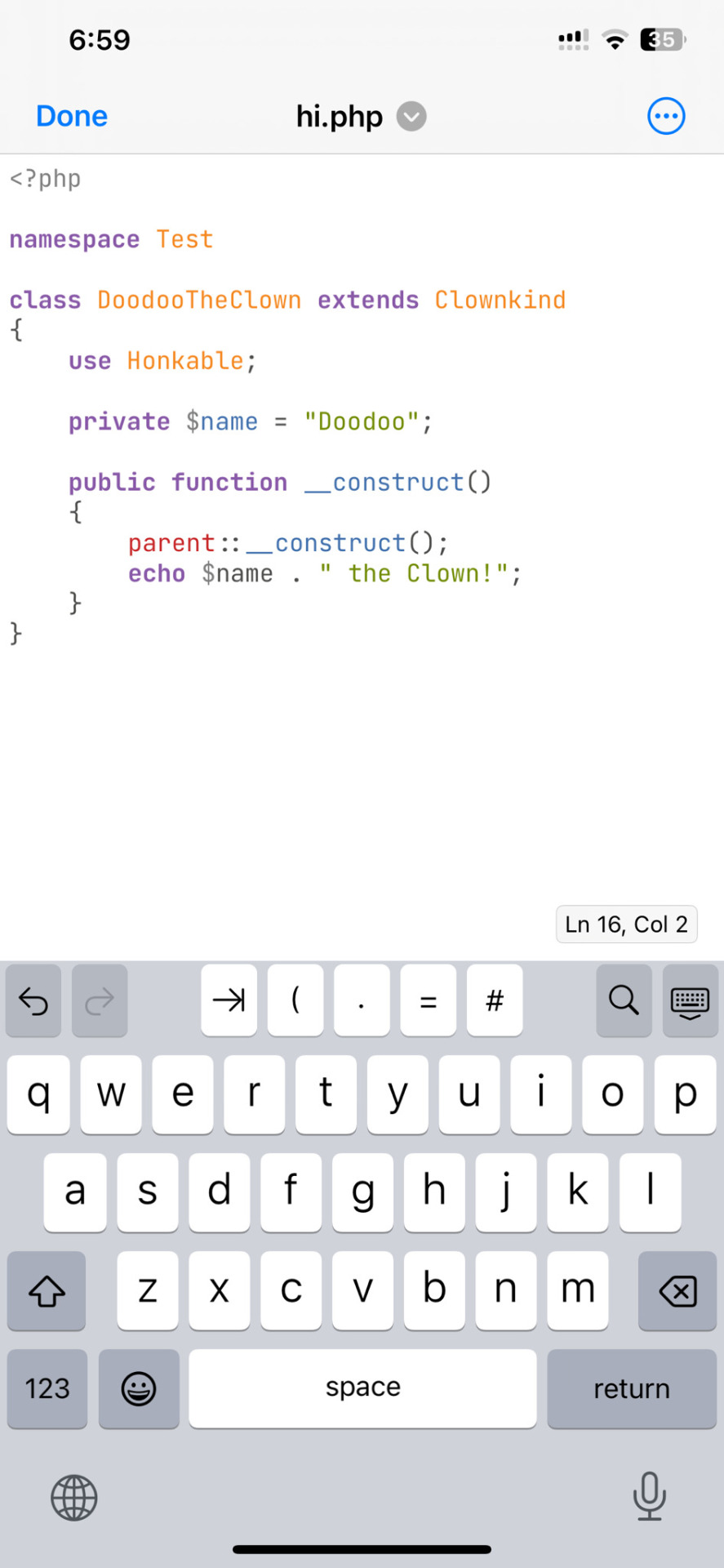
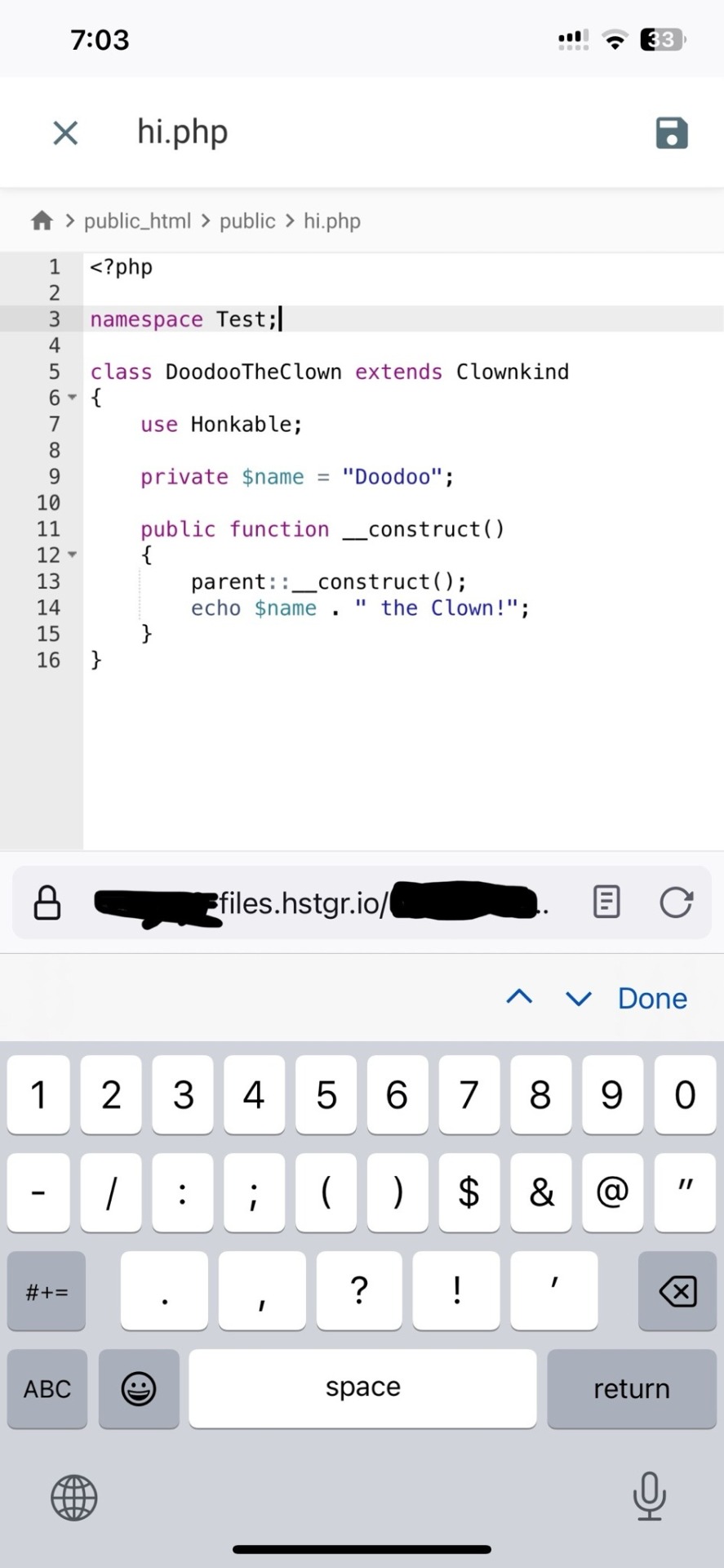
↑ code written in Runecode, then uploaded to Hostinger. Runecode didn't tell me i forgot a semicolon but Hostinger did... i guess you can code from your webhost's file uploader on mobile but i don't trust them since they tend not to autosave or prompt you before closing, and if the wifi dies idk what happens to your code.
---------------------------------------
ANYWAYS! HAPPY WEBSITE BUILDING~! HOPE THIS HELPS~!~!~!
-Mod 12 @eeyes

198 notes
·
View notes
Text


@selemchant @noxconsortium
Here's a breakdown of what I did
I went through the ">conversations" section, looking for which files actually made up the dialogue trees. It's a little different than Inquisition, but I eventually found that they seem to be within the "FC_ConvFlowLayer" files.


Frosty actually has the strings linked correctly within these files, but it's very cumbersome to look at in Frosty. I wanted to make it easier to read. When you export these FC_ConvFlowLayer files, they are .xml files that link to numbers instead of strings.

When you export the raw script of DAV from Frosty Editor, every line is paired with the same matching little numbers (minus the first "0x" for some reason).
The raw script is a .csv file that looks like this:

So I added an "0x" to every line of the .csv file (so they would match) and then made a python program that found all the strings within the <StringId></StringId> tags in all the xml files, and then looked up the matching number in the Raw Script .csv file and then saved the second column (the text) from the .csv file into the .xml files.
So now instead of numbers, I have strings:

Now, these .xml files have a lot of information in them that someone smarter than me could figure out how to make a comprehensive dialogue tree out of, because I think all of the information you would need is provided by the xml files. But that's hard and for now I just wanted a .txt file of who spoke what line.
It wasn't hard from there to write another little program to extract just the speaker and the lines into a plain .txt file

And then to merge all the text files together and use notepad++ and the power of regular expressions to clean them even more:

IF YOU WOULD LIKE TO PLAY AROUND WITH THE .XML FILES THAT HAVE THE NUMBERS REPLACED WITH STRINGS but that still have all the conversation information intact, like how each of the lines are linked to each other, I uploaded them here on google drive (there are 1500 files, but they're pretty small):
LINK TO THE XML FILES FOR YOU TO DO WHAT YOU WANT WITH
#Dragon Age#Veilguard spelunking#Veilguard spoilers#DA4 spoilers#long post#sorry I used a spoilery example lmao
58 notes
·
View notes
Note
Hi Argumate! I just read about your chinese language learning method, and you inspired me to get back to studying chinese too. I want to do things with big datasets like you did, and I am wondering if that means I should learn to code? Or maybe I just need to know databases or something? I want to structure my deck similar to yours, but instead of taking the most common individual characters and phrases, I want to start with the most common components of characters. The kangxi radicals are a good start, but I guess I want a more evidence-based and continuous approach. I've found a dataset that breaks each hanzi into two principle components, but now I want to use it determine the components of those components so that I have a list of all the meaningful parts of each hanzi. So the dataset I found has 嘲 as composed of 口 and 朝, but not as 口𠦝月, or 口十曰月. So I want to make that full list, then combine it with data about hanzi frequency to determine the most commonly used components of the most commonly used hanzi, and order my memorization that way. I just don't know if what I'm describing is super complicated and unrealistic for a beginner, or too simple to even bother with actual coding. I'm also not far enough into mandarin to know if this is actually a dumb way to order my learning. Should I learn a little python? or sql? or maybe just get super into excel? Is this something I ought to be able to do with bash? Or should I bag the idea and just do something normal? I would really appreciate your advice
I think that's probably a terrible way to learn to read Chinese, but it sounds like a fun coding exercise! one of the dictionaries that comes with Pleco includes this information and you could probably scrape it out of a text file somewhere, but it's going to be a dirty grimy task suited to Python text hacking, not something you would willingly undertake unless you specifically enjoy being Sisyphus as I do.
if you want to actually learn Chinese or learn coding there are probably better ways! but I struggle to turn down the romance of a doomed venture myself.
13 notes
·
View notes
Text
Took me four hours but I was able to convert and format a Mandarin epub to include pinyin notation above the text:

Technical details below for anyone interested
I was trying to do this on my personal laptop, which is, unfortunately, Windows. I found two GitHub projects that looked promising: pinyin2epub and epub-with-pinyin and spent most of my time trying to get python to work. I wasn't able to get the second project to work, but I was eventually able to get some output with the pinyin2epub project.
The output was super messy though, with each word appearing on a different line. The script output the new ePub where all the tags that encapsulated every word and pinyin were on a new line, as well as having a ton of extra spacing.
I downloaded Calibre and edited the epub. With the help of regex search and replace I was able to adjust the formatting to what is shown in the picture above.
All in all, I'm fairly happy with it although it does fail to load correctly in any mobile ePub reader I've tried so far ( I have an Android). I think it's the <ruby> tags are either unsupported or cause a processing error entirely depending on the app.
Once I have motivation again I'd love to try to combine the original text epub with a translated epub. My idea here is that there would be a line of the original text above followed by a line of the translate text so on and so forth. I'd probably need to script something for this, maybe it could look for paragraph tags and alternate from two input files. I'd have to think about it a bit more though.
Unfortunately my Mandarin isn't yet strong enough to read the novels I'm interested in entirely in the original language, but I'd love to be able to quickly reference the original text to see what word or character they used, or how a phrase is composed
Feel free to ask if you want to try to do this and need any clarification. The crappy screenshot and lack of links because I'm on my phone and lazy.
114 notes
·
View notes
Note
#The Cute/Pawesome Self Awareness Identifier/Rectifier 9000 #this program will search through fenFacts.txt to check if Fen thinks it is pawesome and cute and then to rectify the situation if it doesn't. #first step, open the file in read mode and set up an empty array to copy each line fenFactsFile = open('fenFacts.txt' , 'r') newFenFactsStringArray = [] #now let's set up our variables to check if Fen already thought it was Cute/Pawesome and/or if it thought it wasn't. cute = False pawesome = False #now to blitzing through through this data. Python has built in functionality to read through lines in a file using a for loop like "for line in file:" where line is the current line of the file so let's just use that for currentLine in fenFactsFile: #loop code starts here. Our comparison strings have the "\n" at the end because we're not stripping these. let's check to see if it thinks it is NOT Cute or Pawesome first. if currentLine == "Is not pawesome.\n": print("I was wrong and thought I was not pawesome ~w~"); #we don't want to keep a wrong fact in our new array so let's skip over to the next iteration of the loop using continue to skip the rest of the code in the loop continue
if currentLine == "Is not cute.\n": print("I wrong and thought I was not cute."); #we don't want to keep a wrong fact in our new array so let's skip over to the next iteration of the loop using continue to skip the rest of the code in the loop continue #Now the cute check if currentLine == "Is cute.\n": cute = True print("I already knew I was cute!"); #now for the pawesome check if currentLine == "Is Pawesome.": pawesome = True print("I already knew I was pawesome ^w^"); #final part of the for loop is to append to our new Fen facts array
newFenFactsStringArray.append(currentLine) #end of the for loop here
#end of reading, we got our checks done. Time to close the file fenFactsFile.close() #Now let's see if we cute or pawesome are still false if cute == False: #it does not recognise its own cuteness. We can fix this. newFenFactsStringArray.append("Is cute.\n") if pawesome == False: #it does not recognise its own pawesomeness. We can fix this newFenFactsStringArray.append("Is pawesome.\n") #Now we have all the Fen Facts we want in newFenFactsStringArray so let's open up fenFacts.txt in write mode and get it fixed up with the cute and pawesome lines but without the is not cute or is not pawesome lines fenFactsFile = open('fenFacts.txt' , 'w') #the next line will replace the text in fenFacts.txt with our newFenFactsStringArray fenFactsFile.writelines(newFenFactsStringArray) #closing it for real this time fenFactsFile.close()
——————
I was wrong and thought I was not pawesome ~w~
I was wrong and thought I was not cute.
#beep boop#asks#I’m not gonna lie the most fun part of this was interpreting the python code it’s genuinely decent practice for me lol#*.zip
14 notes
·
View notes
Text
A trick I've developed for getting files out of Pyodide is converting the file into a dataurl in Python, writing that to a text file, then reading that out with the built in Pyodide file reading functionality and using that however, for a media file this usually means assigning a src to that dataurl and for others this could just mean triggering a download
7 notes
·
View notes
Text
You know what, I'll just ask:
Explanation about the Programming Hell my week has been:
So I started doing a few streams earlier this year reading books aloud. I had a camera on the pages while I read, I'd comment on stuff, used ReactBot a little, at one point a whole 4 people were there.
I've been going through some bad depression moods, and I still want to stream and share books but I dont think I can talk for that long when my mood makes me go nonverbal. I know part of the mood slump is related to not having basically any audience, and I know I won't gain an audience by only streaming once a month or so. So I need to keep streaming even when I'm feeling nonverbal.
The solution I thought of was using TTS (text-to-speech) on books I have saved to my PC, using something like Calibre to read them in the background. There's free to use open source voices, but I wanted to make my own so it still kinda sounded like me and didn't steal someone's likeness. I don't like the idea of making content using someone else's voice, so I looked into making one with my own.
First I looked at the paid programs with good UIs, but not only are they really fucking expensive, they also have hardcoded length limits even on the paid version. I can't get those to read a full book unless I only go at around 30 minutes of reading a month while paying up to $100 monthly to do it, which isn't really an option. I'm on disability, I can't afford that shit.
So I looked at the open source options bc open source means its free. My problem: I can't code to save my life and my experience in the past with programming forums like GitHub and Reddit has been people becoming condescending or hostile when I explain that I have been actively trying to learn to code for 10+ years and it never works. It's interpreted as me not trying or taking "the easy route" because I can't do even the simple stuff. I wish I could. I gave it an honest shot this time, I spent so much fucking time in my command prompt, typing in installs and running python commands, searching errors online to figure out what was going wrong, editing py files and json files and yaml files, learning how to use Audacity to read the metadata of my recordings and make sure they were the right MHz to use in training--and none of it worked. Even when everything I found on horribly formatted GitHub directories SAID it should have been working, it was just a big non functional pile of errors.
So I've given up on making a TTS clone with my voice bc I can't get these "easy codes" to work and the paid ones don't work for what I want or are ridiculously expensive (and mostly still have limits on usage length that mean they wouldnt work).
If anyone reads this and knows how to get these things working properly for cloning--Coqui, Tortoise, Piper, XTTS, any other open source one--reach out and let me know how to do it, because I really tried. Better yet, if you can prove you're trustworthy and are willing to do it, I would love you forever; I can't offer any payment bc I'm on permanent disability and can barely afford things like rent and food, but I would be eternally grateful and willing to draw you stuff and give you a shoutout if that's worth anything to you.
To anyone saying "Just learn to code, you can't give up after a week": This has been an ongoing thing. This is just the latest adventure in "Jasper is failing to learn Python at every turn", along with "why I hate Ren'Py" (that one's been ongoing for years now) and "GitHub has really user-unfriendly layouts" (ever since I got my Graphic Design degree 10 years ago)
#my stream#stream updates#twitch#biggest hurdle i have with reading the books this way is it feels less transformative so ill have to stick to public domain#same reason I'm not using existing audiobooks
3 notes
·
View notes
Text

RenPy: Defining Characters
One of the first things RenPy does upon initialization (the boot-up period before the start label executes the game) is read your custom-made character strings to determine what character dialogue will look like.
Although defining usually takes place under the init block, I've chosen to make a separate pre-start label for organization purposes. Really, any time is fine as long as you make sure the pre-start label runs before the game actually executes, or else you're going to encounter errors.
Let's take a look at the code piece by piece.
$ a = Person(Character("Arthur", who_color="#F4DFB8", who_outlines=[( 3, "#2B0800", 0, 2 )], what_outlines=[( 3, "#2B0800", 0, 2 )], what_color="#F4DFB8", who_font="riseofkingdom.ttf", what_font="junicode.ttf", ctc="ctc", ctc_position="fixed", what_prefix='"', what_suffix='"'), "Arthur", "images/arthurtemp1.png") $ is a common symbol used by both Python and RenPy to define custom-made variables. Here in the pre-start label section of our script, we're using it to define our characters.
For the sake of propriety, it's probably better to define characters using define, but for ease of use, I've chosen $ instead.
It would be tiresome to have to write "Arthur" every time I wanted to call him in the script. Luckily, by assigning these parameters before initialization, RenPy will read "a" as Arthur.
Most scripts will suffice with assigning a Character object class to your character. If you open the script for The Tutorial, you'll find a basic string that looks like this: $ e = Character("Eileen") As you can see in my batch of code, however, I've done something different by nestling the Character object class within a Person object class. The reason why will become apparent in future posts.
For now, let's focus on the fundamentals.
---

who_color tells RenPy the color of the character's name, determined by a hexadecimal code (either three, four, or six digits). Its sister parameter what_color tells RenPy the color of a character's dialogue text.
If no values are given for these parameters, RenPy will look at your project's GUI file to determine them.
---


who_font tells RenPy the kind of font you want to use for your character's name, and likewise, what_font determines the font you want to use for your character's dialogue.
Note that these fonts do not have to match. They can be whatever font you wish.
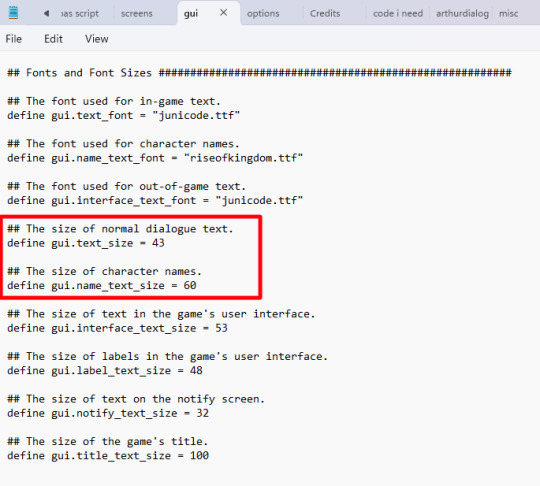
The size of character names and dialogue text can be customized in the GUI file of your project:

---

who_outlines=[( 3, "#2B0800", 0, 2 )], what_outlines=[( 3, "#2B0800", 0, 2 )]
who_outlines and what_outlines add outlines or drop shadows to your text (character name and character dialogue, respectively). This string is expressed as a tuple, or four values enclosed by parentheses.
The first value expresses the width of the shadow in pixels. The second value is a hexadecimal value for your chosen color. The third value offsets the shadow along the X-axis (pixels to the right or left of the text). Because it's set to 0, my drop shadows do not appear to the right or the left of the text. The fourth value offsets the shadow along the Y-axis (pixels beneath/above the text). In this case, shadows appear 2 pixels beneath the text.
My outlines are a bit hard to see because they're only 3 pixels wide and 2 pixels offset.
---
Font files RenPy recognizes TrueType font files. You can download TTF fonts for free online - just be sure to unzip them and put them in your game folder.
If you intend to monetize your project, you absolutely need to make certain your fonts are royalty-free or, ideally, public domain. Most font families come with licenses telling you whether they are free use.
To be on the safe side, I would put the following code before the start label in your script, just so RenPy knows which files to look for:
init:
define config.preload_fonts = ["fontname1.ttf", "fontname2.ttf", "fontname3.ttf"]
---

ctc stands for "click to continue." It's a small icon commonly seen in visual novels, usually in one corner of the text box, that indicates the player has reached the end of a line. It's called "click to continue" because the program waits for the reader to interact to continue. To make a custom ctc icon, make a small drawing in an art program and save the image to your GUI folder. As seen above, I'm using a tiny moon as the ctc in my current project. ctc_position="fixed" means the ctc icon will stay rooted in whatever place you specify in the code. Like with most everything else in RenPy, you can apply transforms to the ctc if you so wish. Fun fact: because the ctc is determined on a character-by-character basis in initialization, you can give different characters custom ctcs!
---

what_prefix="" and what_suffix="" add scare quotes to the beginning and end of a character's dialogue.
One thing you'll notice as you work with RenPy is that "the computer is stupid." That is to say, the program will not execute code you don't explicitly spell out. Things which seem intuitive and a given to us are not interpreted by the program unless you write them into the code.
That is why, in this case, you need to specify both prefix and suffix, otherwise RenPy may begin lines of dialogue with " but not end with ", or vice-versa.
Note that unless you apply these parameters to the narrator character, ADV and NVL narration will not have them.
---
** Note: the next two tags following these ones are extraneous and therefore ignored.
10 notes
·
View notes
Note
Two questions: 1: did you actually make ~ATH, and 2: what was that Sburb text-game that you mentioned on an ask on another blog
While I was back in highschool (iirc?) I made a thing which I titled “drocta ~ATH”, which is a programming language with the design goals of:
1: being actually possible to implement, (and therefore, for example, not having things be tied to the lifespans of external things)
2: being Turing complete, and accept user input and produce output for the user to read, such that in principle one could write useful programs in it (though it is not meant to be practical to do so).
3: matching how ~ATH is depicted in the comic, as closely as I can, with as little as possible that I don’t have some justification for based on what is shown in the comic (plus the navigation page for the comic, which depicts a “SPLIT” command). For example, I avoid assuming that the language has any built-in concept of numbers, because the comic doesn’t depict any, and I don’t need to assume it does, provided I make some reasonable assumptions about what BIFURCATE (and SPLIT) do, and also assume that the BIFURCATE command can also be done in reverse.
However, I try to always make a distinction between “drocta ~ATH”, which is a real thing I made, and “~ATH”, which is a fictional programming language in which it is possible to write programs that e.g. wait until the author’s death and the run some code, or implement some sort of curse that involves the circumstantial simultaneous death of two universes.
In addition, please be aware that the code quality of my interpreter for drocta ~ATH, is very bad! It does not use a proper parser or the like, and, iirc (it has probably been around a decade since I made any serious edits to the code, so I might recall wrong), it uses the actual line numbers of the file for the control flow? (Also, iirc, the code was written for python 2.7 rather than for python 3.) At some point I started a rewrite of the interpreter (keeping the language the same, except possibly fixing bugs), but did not get very far.
If, impossibly, I got some extra time I wouldn’t otherwise have that somehow could only be used for the task of working on drocta ~ATH related stuff, I would be happy to complete that rewrite, and do it properly, but as time has gone on, it seems less likely that I will complete the rewrite.
I am pleased that all these years later, I still get the occasional message asking about drocta ~ATH, and remain happy to answer any questions about it! I enjoy that people still think the idea is interesting.
(If someone wanted to work with me to do the rewrite, that might provide me the provided motivation to do the rewrite, maybe? No promises though. I somewhat doubt that anyone would be interested in doing such a collaboration though.)
Regarding the text based SBURB game, I assume I was talking about “The Overseer Project”. It was very cool.
Thank you for your questions. I hope this answers it to your satisfaction.
6 notes
·
View notes
Text
Signalis Doom - 3
I suppose i forgot to mention that i plan to update this every day i work on it, which so far, has been 3 days in a row. Today was both productive and a total bust. It was mostly spent writing a tool to help me mass import the various textures into doom. Since the og files are sprite sheets, i need to split them up via a text file. It's a predictable pattern, so i figured i'd automate it with a python program. I'm rustier with python than i thought, and even when i'm not getting in my own way, it turns out i overlooked some important things. Not every file is named consistantly, enough are that it threw me.



The common naming scheme is LOCATION_TYPE_IDENTIFIER. the top two are ROT_WALL_ORANGE and ROT_WALL_BLANK. but the third is just MED_WALLS. In the doom editor, any texture files must be named 8 characters or less. You can get away with keeping the source file named something longer, but you need to create a cute truncaded name somewhere at some point for each file. I had planned to have a program scan each file and create names. it woudl read ROT_WALL_ORANGE, and by using the hyphens are markers, grab 3 letters of location, 3 letters of type, the first letter of color, and then a number. ROTWALO1. Great idea in theory, but as mentioned, these files don't all actually follow that pattern.
So that was the better part of a day down the drain. It was a good learning experience, and a reminder that there's times to brute force stuff and there's times to automate a process. It's not gonna be the last time i spend too long on a bad idea, lemme tell ya. There is already an existing tool that does do much of what i was trying to acomplish, but would require me to rename the og files. I had wanted to keep them named the same to assist in easier file replacement later with original material, but at this point it's more trouble than it's worth keeping them as they were. but since i don't have anything to show, uhhhh.... hey i bought this Signalis fanart recently from @Legend_Knit on twitter. it looks great! def check their stuff out if you haven't already.

11 notes
·
View notes
Note
faorite , FILE TYPE : ] hi
oh shit and my favorite filetypes tierlist:
.sh (bash script) GOD TIER. it just does stuff. you can make it do anything. anything.
.md (markdown file) GOD TIER. documentation, letters to self. a beautiful universal syntax for limited text styling. elegant and timeless.
.py (python script) PRETTY GOOD. can run on its own or be imported from another script, and can do different stuff depending which. edit: mixed feelings abt python interpreter and virtual environemtn stuff. forgot to mention that.
.h (c lang header file) HONORABLE MENTION. i don't use these a lot but this is where you declare the contents of your .c/.cpp file without writing the actual logic. you say these are the functions and classes they take this and give you that. Trust me bro
.json (javascript object notation) PRETTY NIFTY. not the most practical if you're looking to constantly be writing to this format imo, BUT we love it for configuration. simple, timeless, universal.
.txt (plaintext) SHIT TIER. it's just text bro. is it meant to be read on its own? use markdown. is it meant to store data in a specific format for program input? make up your own extension, i don't care.
i have more but this has gone on long enough.
4 notes
·
View notes
Text
5 thousand lines of data in a text file and python reads through and sorts the whole thing in less than 5 seconds. genuinely in awe of technology right now
2 notes
·
View notes
Text
I just automated something using Python for the first time and my brain released the
HAPPY CHEMICALS
in a way I have not felt in a long, looooooooooooooong time to the point I wanted to tell everyone what I did despite it being really fucking nerdy.

Basically every mainline railway station on Great Britain has a three letter code like airports, KGX for King's Cross, EDB for Edinburgh, GLC for Glasgow Central. You get the idea. Anyway I have this thing called Espanso where you can type a prompt and it will replace it with something you set it to. For example, I can type :date and it will write the current date (20/07/2023). You can set up your own prompts by learning the very simple mark up language and setting your own prompts.

Anyway I looked at Espanso and thought "I wonder if I could set it up so I could type a station code as an Espanso prompt and get the station code. So after thinking about how I could write it by hand and realising there were 2575 stations in Great Britain, I knew I would have to automate it.

My knowlegde of Python is basic, but after watching part of a video course, learning how to install Python Packages, learning how to use Openpyxl and reading so many blogposts I learnt how to use Python to take info from a spreadsheet, insert it into Espanso's markup langauge, and put that in a fucking text file and after some trial and error and test runs, I did it and my mind just exploded with the happy chemicals.

My monkey brain was like "HEE HOO PUZZLE SOLVED" and I got so much happy brain sauce. And after telling my Mum, Dad, Friends and an elderly neighbour what I did, something set in. Is this...how they get you? Is this how people get into coding for fun or even a career? Has coding bitten me? Will I ever be able to escape this addiction?

20 notes
·
View notes
Text
y'all i need you to know how much effort it took to get caught up on my monthly rec lists LOL
but hey!
now i have a python script that reads my spreadsheet, extracts all the relevant data, and wraps it in html code so the formatting comes out right.
all i have to do is copy/paste the text file output and boom! done!
#and yes i did completely forget to eat lunch while working on this project#but it beats doing 3+ months worth of it by hand!#somebody please get me a cookie#gracie reads hannigram
3 notes
·
View notes
Text
This post was created and written in Emacs as Markdown (with Frontmatter YAML), and then I used my mostly-finished Python code to post it as NPF using the Tumblr API.
The Python packages I'm using are
`pytumblr2` for interacting with the API using Tumblr's "Neue Post Format",
`python-frontmatter` for reading the frontmatter (but not writing; I hate how it disruptively rearranges and reformats existing YAML),
`mistune` for the Markdown parsing, for now with just the strikethrough extension (`marko` seems like it would be a fine alternative if you prefer strict CommonMark compatibility or have other extension wants).
The workflow I now have looks something like this:
Create a new note in Emacs. I use the Denote package, for many reasons which I'll save for another post.
Denote automatically manages some fields in the frontmatter for the information it owns/manages.
Denote has pretty good code for managing tags (Denote calls them "keywords"). The tags go both in the file name and in the frontmatter. There's some smarts to auto-suggest tags based on tags you already use, etc.
The usual composable benefits apply. Denote uses completing-read to get tags from you when used interactively, so you can get nicer narrowing search UX with Vertico, Orderless, and so on.
So when I create a new "note" (post draft in this case) I get prompted for file name, then tags.
I have my own custom code to make tag adding/removing much nicer than the stock Denote experience (saves manual steps, etc).
Edit the post as any other text file in Emacs. I get all the quality-of-life improvements to text editing particular to my tastes.
If I stop and come back later, I can use any search on the file names or contents, or even search the contents of the note folder dired buffer, to find the post draft in a few seconds.
Every time I save this file, Syncthing spreads it to all my devices. If I want, I can trivially use Emac's feature of auto-saving and keeping a configurable number of old copies for these files.
I have a proper undo tree, if basic undo/redo isn't enough, and in the undo tree UI I can even toggle displaying the diff for each change.
My tools such as viewing unsaved changes with `git diff`, or my partial write and partial revert like `git add -p`, are now options I have within easy reach (and this composes with all enhancements to my Git config, such as using Git Delta or Difftastic).
After a successful new post creation, my Python code adds a "tumblr" field with post ID and blog name to the frontmatter YAML. If I tell it to publish a post that already has that information, it edits the existing post. I can also tell it to delete the post mentioned in that field, and if that succeeds it removes the field from the file too.
The giant leap of me being able to draft/edit/manage my posts outside of Tumblr is... more than halfway complete. The last step to an MVP is exposing the Python functions in a CLI and wrapping it with some Emacs keybinds/UX. Longer-term TODOs:
Links! MVP is to just add links to my Markdown-to-NPF code. Ideal is to use Denote links and have my code translate that to Tumblr links.
Would be nice to use the local "title" of the file as the Tumblr URL slug.
Pictures/videos! I basically never make posts with media, but sometimes I want to, and it would be nice to have this available.
7 notes
·
View notes