#- Map: HashMap
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
JavaCollections: Your Data, Your Way
Master the art of data structures:
List: ArrayList, LinkedList
Set: HashSet, TreeSet
Queue: PriorityQueue, Deque
Map: HashMap, TreeMap
Pro tips:
Use generics for type safety
Choose the right collection for your needs
Leverage stream API for elegant data processing
Collections: Because arrays are so last century.
#JavaCollections: Your Data#Your Way#Master the art of data structures:#- List: ArrayList#LinkedList#- Set: HashSet#TreeSet#- Queue: PriorityQueue#Deque#- Map: HashMap#TreeMap#Pro tips:#- Use generics for type safety#- Choose the right collection for your needs#- Leverage stream API for elegant data processing#Collections: Because arrays are so last century.#JavaProgramming#DataStructures#CodingEfficiency
2 notes
·
View notes
Text

What does the JDBC ResultSet interface? . . . . For more questions about Java https://bit.ly/465SkSw Check the above link
#resultset#rowset#drivermanager#preparedstatement#execute#executequery#executeupdate#array#arraylist#jdbc#hashcode#collection#comparator#comparable#blockingqueue#hashSet#treeSet#set#map#hashMap#computersciencemajor#javatpoint
0 notes
Text
Node based coding... in Java. It has taken a few weeks, but I have the system done.
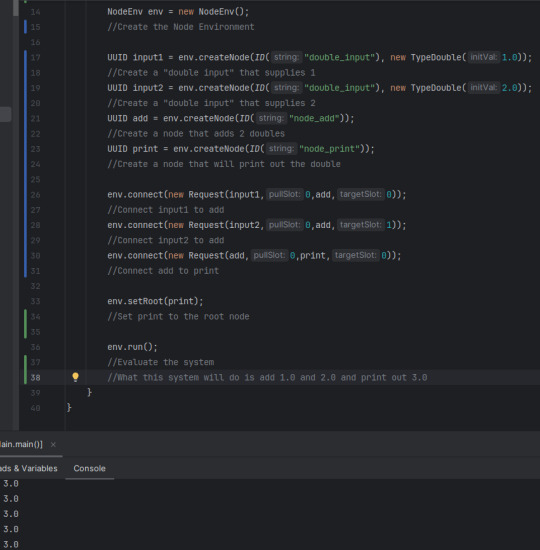
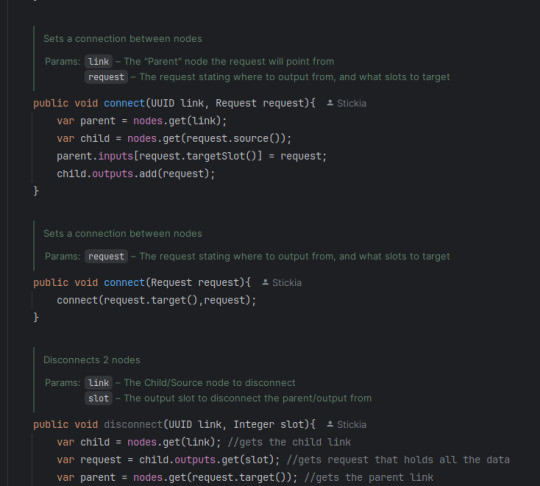
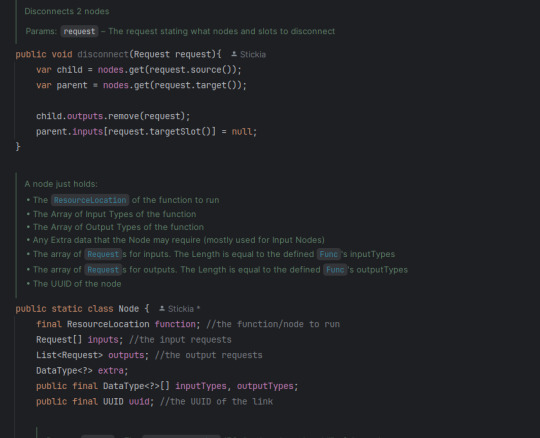
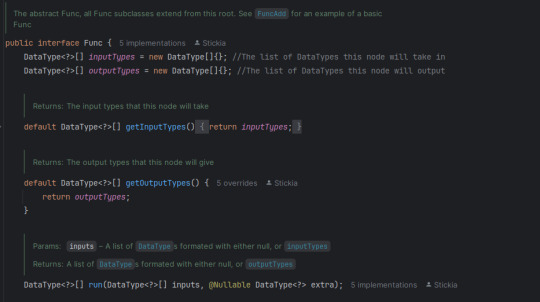
As well, amazingly commented code base that explains what about everything does.
And everything being ran as functions defined in a registry! Hi NeoForge
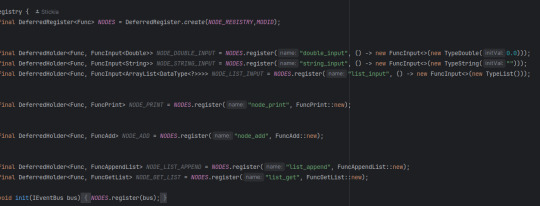
I think the system for reading the graph of nodes is unique also! Since, I have had... a bad time with the JavaStackLimit, I decided to have the core of my system be around avoiding it as much as possible. So instead of recursively asking what node connects to what node, 2 stacks are made, 1 holds what will be running after it is done finding, the other holds a search stack. Meaning it can get any part of the graph, and it should just find the right order of things.
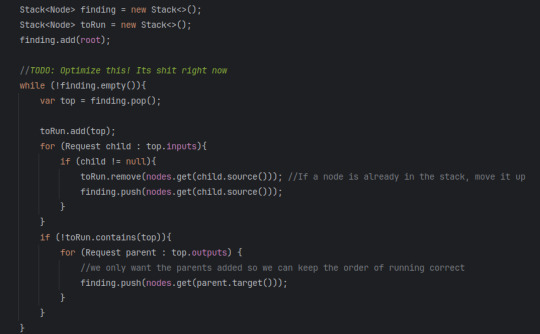
And! Since the read method is different from the run method, I can hypothetically just read and serialize the given node stack, making it persist between restarts.
The running system is a little more complex than just a search.
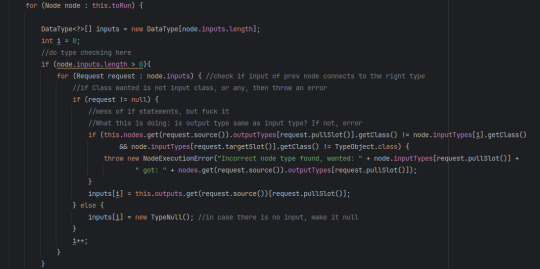
First it starts a `for` loop of the stack of nodes, then it starts making the inputs for the node. It checks if the node has any inputs, if so, check the output type of the previous node, if it is equal to this node's input (or if this node's input takes in ANY) then dont error. After not erroring, add to the input array; or, if the input was not connected to anything, give it null. Repeat the last steps until there are no inputs left for this node.
Next, it runs the node. It does this by getting all the registered nodes (in a HashMap for some extra speed), then finding the associated function with that Key. Then it tries to run the function with the given inputs. If the function does not crash, it checks if the function outputted anything, if so put that into the Environment's HashMap of all node outputs. Finally, repeat the last 2 paragraphs until there are no more nodes. Then clear the output map, so there is no "bleed over"
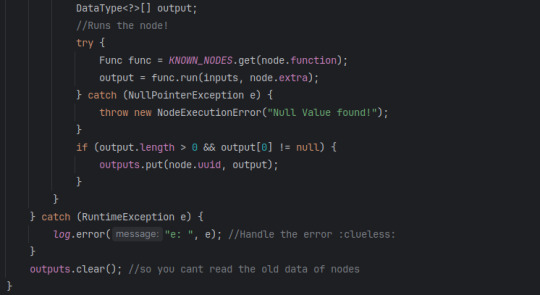
So TLDR: get all nodes into a stack (avoiding duplicates), then run a For Each over that stack, check if the type of inputs/outputs match, if so run the node and put its outputs onto a HashMap of outputs so it only needs to be run once.
And ALL OF THIS just to be put into a silly minecraft mod. But hey, at least I am having fun!
#long post#my art#modded minecraft#coding#Java#minecraft java#minecraft modding#minecraft modding at its finest yall#there is also a lot more in this mod I have not shown in Tumblr yet#If any of yall have any questions#my DMs/Askbox is open!
10 notes
·
View notes
Text
100 days of code - day 10
Hi :)
Today I finished the chapter 7 and 8 from the rust book.
Chapter 7 teaches about modules, that are basically containers that I can use to organize the code, how to use external packages and the conventions for separating modules in different files. It was quite a "boring" chapter, and I get distracted a lot, but I managed to finish.
Chapter 8 show us some useful data structures, that are keep in the std::collections module from rust. They are, Vectors, Strings and HashMap.
Vector is like an array, but with the plus that they are resizable, and can grow and shrink. And also have a lot of useful methods.
Strings are strings. Leaned about some handy methods and macros to manipulate strings.
HashMap is a data structure that maps keys to values with a hashing function. So it is efficient to insert and retrieve data from a hash map.
Also, I did some exercises on rustlings about vectors, ownership and borrowing.
That's it 😊

#day 10#100 days of code#100daysofcode#codeblr#programming#progblr#studyblr#computer science#Rust#1000 hours#code#100 days of productivity#100 days of studying#100 days challenge#tech
26 notes
·
View notes
Text
🚀 Day 1: Kicking Off My Programming & Study Blog!
Welcome to my first post in what I hope will be a long series documenting my journey through programming in Rust, learning algorithms and trying to build some projects. I’ve been learning Rust for couple of weeks and from today I started a course on algorithms MIT's 6.006 Introduction to Algorithms. I felt like sharing my progress here to motivate my self to stay consistent.
🦀 Rust Exercise: Vectors Maps & HashMap
Today, I finished a Rust exercise from the Rust Book form chapter 8. With the use of Hashmap and Vector I had to create create a way for users to add employees to departments (e.g., "Add Sally to Engineering") and retrieve a sorted list of everyone in a department or the whole company.
Core Components: I used a HashMap to store departments and Vec for employee names within each department.
Challenge: I hit a wall when trying to retrieve the list of employees in a department. After an hour of debugging, I finally realized I wasn’t trimming the key string I was using to query the hash map! The newline "\n" was still in the string, causing it not to match any key in the map.
Takeaway: Print the bloody input next time! It would have saved me a lot of time and frustration. I am bad at debugging, Lesson learned.
📘MIT 6.006 Introduction to Algorithms
I also started MIT’s Introduction to Algorithms course and watched Lecture 1. It was an introductory lecture. I have tried learning Algorithms couple of times so I have been through introductions a lot. I hope this time I'll go further.
🔍 What’s Next
Starting both Rust and algorithms simultaneously is exciting, I’m ready for the challenge. For tomorrow, I'm planning to complete more chapters from The Rust Book, Next one is about Error handling and then I'll tackle the next lecture in the MIT series.
Feel free to follow along if you’re on a similar journey, and let’s level up together!
#studyblr#codeblr#coding#programming#rust#computer science#software development#100 days of productivity#100 days of studying#learn to code
2 notes
·
View notes
Text
CS1332 Homework 4: ExternalChainingHashMap
HashMap You are to code an ExternalChainingHashMap, a key-value hash map with an external chaining collision resolution strategy. A HashMap maps unique keys to values and allows O(1) average case lookup of a value when the key is known. The table should not contain duplicate keys, but can contain duplicate values. In the event of trying to add a duplicate key, replace the value in the existing…
0 notes
Text
hi
import java.util.HashMap; import java.util.Map;
public class FrequencyCounter { public static void main(String[] args) { int[] nums = {2, 3, 2, 5, 3, 2}; Map<Integer, Integer> frequencyMap = new HashMap<>(); for (int num : nums) { frequencyMap.put(num, frequencyMap.getOrDefault(num, 0) + 1); } // Print the result for (Map.Entry<Integer, Integer> entry : frequencyMap.entrySet()) { System.out.println("Number " + entry.getKey() + " appears " + entry.getValue() + " times."); } }
} ////////////////////
rray = [2, 1, 5, 1, 3, 2] target = 8 We’ll find the longest subarray where the sum is ≤ 8.
We use left, right, and sum to control and track the window .int left = 0, sum = 0, max = 0;
left: starting point of our sliding window
sum: running total of the current window
count: total number of valid subarrays we find
for (int right = 0; right < array.length; right++) { Expands the window by moving the right pointer forward. sum += array[right]; while (sum > target) { sum -= array[left]; left++; } max = Math.max(max, right - left + 1); }
/// Inheritance Inheritance allows a class to inherit fields and methods from another class. It supports code reuse and method overriding.
🔹 10. Polymorphism Polymorphism lets you perform the same action in different ways. It includes compile-time (overloading) and runtime (overriding) polymorphism.
🔹 11. Encapsulation Encapsulation binds data and methods together, hiding internal details. It’s achieved using private fields and public getters/setters.
🔹 12. Abstraction Abstraction hides complex implementation details and shows only the essentials. It’s achieved using abstract classes or interfaces.
List allows duplicates, Set allows only unique elements, Map stores key-value pairs. They are part of the Java Collections Framework f
Lambdas enable functional-style code using concise syntax. They simplify the implementation of functional interfaces.
🔹 19. Functional Interfaces A functional interface has exactly one abstract method. Examples include Runnable, Callable, and Comparator.
Stream API processes collections in a functional and pipeline-based way. It supports operations like filter(), map(), and collect()
Heap stores objects and is shared, while Stack stores method calls and local variables. Stack is thread-safe; Heap is managed by the garbage collector.
Immutable objects, like String, cannot be changed once created. They are thread-safe and useful in concurrent applications.
int left = 0, right = array.length - 1; while (left < right) { if (array[left] + array[right] == target) { // Found pair } else if (array[left] + array[right] < target) { left++; } else { right--; } } //////////////////
kafka partitions
List inputList = // input data Map uniqueMap = new HashMap<>();
for (Person person : inputList) { String key = person.name + "_" + person.age;if (!uniqueMap.containsKey(key)) { uniqueMap.put(key, person); // first time seeing this name+age } else {
///
List people = Arrays.asList( new Person("Alice", 30), new Person("Bob", 25), new Person("Charlie", 35) ); // Sort by age using lambda people.sort((p1, p2) -> Integer.compare(p1.getAge(), p2.getAge()));
////////////////
public Person(String name, int age) { this.name = name; this.age = age; }@Override public boolean equals(Object o) { if (this == o) return true; if (!(o instanceof Person)) return false; Person person = (Person) o; return age == person.age && Objects.equals(name, person.name); } @Override public int hashCode() { return Objects.hash(name, age); }
}
/////////// hashCode() is used by hash-based collections like HashMap, HashSet, and Hashtable to find the bucket where the object should be placed.
bject.equals() method compares memory addresses
///
List people = Arrays.asList( new Person("Alice", 30), new Person("Bob", 25), new Person("Charlie", 35) ); // Sort by age using lambda people.sort((p1, p2) -> Integer.compare(p1.getAge(), p2.getAge())); // Print sorted list people.forEach(System.out::println); }
///
0 notes
Text
What Are Data Structures and Why Do They Matter in Coding?
If you’ve ever tried to solve a problem in code and felt stuck halfway through, you’re not alone. But here’s a little secret that experienced developers know: success in coding isn’t just about writing lines of code—it’s about organizing your data in a smart way.
That’s where data structures come in. Think of them as tools in a developer’s toolbox. And like any good builder, you need to know which tool to use, when, and why.
So, What Exactly Are Data Structures?
In simple terms, a data structure is a way of organizing and storing data so that it can be used efficiently.
Imagine you’re trying to find a book in a messy pile versus a neatly organized shelf. Data structures are what give you that shelf. They help your code run faster, cleaner, and smarter.
Some common types of data structures include:
Arrays: Lists of items stored in a specific order.
Linked Lists: A series of connected elements, like a chain.
Stacks and Queues: Think of these as the "last in, first out" (LIFO) or "first in, first out" (FIFO) containers.
Trees and Graphs: For organizing data in hierarchical or networked formats.
Hash Tables (or HashMaps): Perfect for fast data lookup.
Why Are Data Structures So Important in Coding?
Here’s why every developer—from beginner to pro—needs to understand data structures:
1. They Make Your Code Efficient
Choosing the right data structure can drastically improve performance. For example, looking up an item in a list might take longer than in a hash map—especially when your app starts handling thousands or millions of records.
2. They Help Solve Complex Problems
Many real-world problems—like navigation systems, recommendation engines, or social media feeds—depend heavily on the right data structures. Without them, building these solutions would be inefficient or even impossible.
3. They’re Essential for Coding Interviews
Tech companies, especially big ones like Google, Amazon, and Meta, often assess your knowledge of data structures and algorithms during interviews. Why? Because they want to know that you can write not just working code, but good code.
4. They Build a Strong Foundation
Learning data structures teaches you how to think like a developer. Once you understand how data flows and interacts, you'll write cleaner, more maintainable code—no matter which language or framework you're using.
When Do You Use Which Data Structure?
That’s the magic question! It depends on what problem you're solving.
Want to process tasks in the order they came in? Use a queue.
Need to undo actions in a program? Use a stack.
Building a directory or hierarchy? Use a tree.
Want lightning-fast lookups? Use a hash table.
The better you understand each data structure, the easier it is to match the right one to the right situation.
Conclusion:
If you're serious about becoming a skilled developer, mastering data structures isn’t optional—it’s essential. Whether you want to ace coding interviews, write efficient software, or build complex applications, understanding how data is structured and accessed is the key.
A structured Data Structures and Algorithms Course can help you build this foundation the right way. It’ll not only teach you the theory behind each concept but also help you apply it in real coding problems—preparing you for real-world development and job opportunities.
1 note
·
View note
Text
Splunk is a popular choice for log analytics. I am a java developer and really love to use splunk for production analytics. I have used splunk for more than 5 years and like its simplicity. This article is a list of best practices that I have learned from good splunk books and over my splunk usage in everyday software projects. Most of the learnings are common for any software architect however it becomes important to document them for new developers. This makes our life easier in maintaining the software after it goes live in production. Almost any software becomes difficult change after its live in production. There are some many things you may need to worry about. Using these best practices while implementing splunk in your software will help you in long run. First Thing First : Keep Splunk Logs Separate Keep splunk log separate from debug / error logs. Debug logs can be verbose. Define a separate splunk logging file in your application. This will also save you on licensing cost since you will not index unwanted logs. Use Standard Logging Framework Use existing logging framework to log to splunk log files. Do not invent your own logging framework. Just ensure to keep the log file separate for splunk. I recommend using Asynchronous logger to avoid any performance issues related to too much logging. Some popular choice of logging frameworks in Java are listed below Log4j SLF4J Apache commons logging Logback Log In KEY=VALUE Format Follow Key=Value format in splunk logging - Splunk understands Key=Value format, so your fields are automatically extracted by splunk. This format is also easier to read without splunk too. You may want to follow this for all other logs too. Use Shorter KEY Names Keep the key name short - preferable size should be less than 10 characters. Though you may have plenty of disc space. Its better to keep a tap on how much you log since it may create performance problems in long run. At the same time keep them understandable. Use Enums For Keys Define a Java Enum for SplunkKeys that has Description of each key and uses name field as the splunk key. public enum SplunkKey TXID("Transaction id"); /** * Describes the purpose of field to be splunked - not logged */ private String description; SplunkKey(String description) this.description = description; public String getDescription() return description; Create A Util Class To Log In Splunk Define a SplunkAudit class in project that can do all splunk logging using easy to call methods. public class SplunkAudit private Map values = new HashMap(); private static ThreadLocal auditLocal = new ThreadLocal(); public static SplunkAudit getInstance() SplunkAudit instance = auditLocal.get(); if (instance == null) instance = new SplunkAudit(); auditLocal.set(instance); return instance; private SplunkAudit() public void add(SplunkKey key, String message) values.put(key.name(), message); public void flush() StringBuilder fullMessage = new StringBuilder(); for (Map.Entry val : values.entrySet()) fullMessage.append(val.getKey()); fullMessage.append("="); fullMessage.append(val.getValue()); fullMessage.append(" "); //log the full message now //log.info(fullMessage); Collect the Splunk Parameters (a collection of key,value pairs ) in transaction and log them at the end of transaction to avoid multiple writes. Use Async Log Writer Its recommended to use async logger for splunk logs. Async logging will perform logging in a separate thread. Below are some options Async Logger Appender for Log4j Logback Async Appender Setup Alerts Setup Splunk queries as alerts - get automatic notifications. Index GC Logs in Splunk Index Java Garbage Collection Logs separately in splunk.
The format of GC log is different and it may get mixed with your regular application logs. Therefore its better to keep it separate. Here are some tips to do GC log analytics using splunk. Log These Fields Production logs are key to debug problems in your software. Having following fields may always be useful. This list is just the minimum fields, you may add more based on your application domain. ThreadName Most important field for Java application to debug and identify multithreading related problems. Ensure every thread has a logical name in your application. This way you can differentiate threads. For example transaction threads and background threads may have different prefix in thread name. Ensure to give a unique id for each thread. Its super easy to set thread names in java. One line statement will do it. Thread.currentThread().setName(“NameOfThread-UniqueId”) Thread Count Print count of threads at any point in time in JVM. Below one liner should provide you java active thread count at any point in JVM. java.lang.Thread.activeCount() Server IP Address Logging the server IP address become essential when we are running the application on multiple servers. Most enterprise application run cluster of servers. Its important to be able to differentiate errors specific to a special server. Its easy to get IP address of current server. Below line of code should work for most places (unless the server has multiple ip addresses) InetAddress.getLocalHost().getHostAddress() Version Version of software source from version control is important field. The software keeps changing for various reasons. You need to be able to identify exact version that is currently live on production. You can include your version control details in manifest file of deployable war / ear file. This can be easily done by maven. Once the information is available in your war/ear file, it can be read in application at runtime and logged in splunk log file. API Name Every application performs some tasks. It may be called API or something else. These are the key identifier of actions. Log unique API names for each action in your application. For example API=CREATE_USER API=DELETE_USER API=RESET_PASS Transaction ID Transaction id is a unique identifier of the transaction. This need not be your database transaction id. However you need a unique identifier to be able to trace one full transaction. User ID - Unique Identifier User identification is important to debug many use cases. You may not want to log user emails or sensitive info, however you can alway log a unique identifier that represents a user in your database. Success / Failure of Transaction Ensure you log success or failure of a transaction in the splunk. This will provide you a easy trend of failures in your system. Sample field would look like TXS=S (Success transaction) TXS=F (Failed transaction) Error Code Log error codes whenever there is a failure. Error codes can uniquely identify exact scenario therefore spend time defining them in your application. Best way is to define enum of ErrorCodes like below public enum ErrorCodes INVALID_EMAIL(1); private int id; ErrorCodes(int id) this.id = id; public int getId() return id; Elapsed Time - Time Taken to Finish Transaction Log the total time take by a transaction. It will help you easily identify the transactions that are slow. Elapsed Time of Each Major Component in Transaction If you transaction is made of multiple steps, you must also include time take for each step. This can narrow down your problem to the component that is performing slow. I hope you find these tip useful. Please share with us anything missed in this page.
0 notes
Video
youtube
LEETCODE PROBLEMS 1-100 . C++ SOLUTIONS
Arrays and Two Pointers 1. Two Sum – Use hashmap to find complement in one pass. 26. Remove Duplicates from Sorted Array – Use two pointers to overwrite duplicates. 27. Remove Element – Shift non-target values to front with a write pointer. 80. Remove Duplicates II – Like #26 but allow at most two duplicates. 88. Merge Sorted Array – Merge in-place from the end using two pointers. 283. Move Zeroes – Shift non-zero values forward; fill the rest with zeros.
Sliding Window 3. Longest Substring Without Repeating Characters – Use hashmap and sliding window. 76. Minimum Window Substring – Track char frequency with two maps and a moving window.
Binary Search and Sorted Arrays 33. Search in Rotated Sorted Array – Modified binary search with pivot logic. 34. Find First and Last Position of Element – Binary search for left and right bounds. 35. Search Insert Position – Standard binary search for target or insertion point. 74. Search a 2D Matrix – Binary search treating matrix as a flat array. 81. Search in Rotated Sorted Array II – Extend #33 to handle duplicates.
Subarray Sums and Prefix Logic 53. Maximum Subarray – Kadane’s algorithm to track max current sum. 121. Best Time to Buy and Sell Stock – Track min price and update max profit.
Linked Lists 2. Add Two Numbers – Traverse two lists and simulate digit-by-digit addition. 19. Remove N-th Node From End – Use two pointers with a gap of n. 21. Merge Two Sorted Lists – Recursively or iteratively merge nodes. 23. Merge k Sorted Lists – Use min heap or divide-and-conquer merges. 24. Swap Nodes in Pairs – Recursively swap adjacent nodes. 25. Reverse Nodes in k-Group – Reverse sublists of size k using recursion. 61. Rotate List – Use length and modulo to rotate and relink. 82. Remove Duplicates II – Use dummy head and skip duplicates. 83. Remove Duplicates I – Traverse and skip repeated values. 86. Partition List – Create two lists based on x and connect them.
Stack 20. Valid Parentheses – Use stack to match open and close brackets. 84. Largest Rectangle in Histogram – Use monotonic stack to calculate max area.
Binary Trees 94. Binary Tree Inorder Traversal – DFS or use stack for in-order traversal. 98. Validate Binary Search Tree – Check value ranges recursively. 100. Same Tree – Compare values and structure recursively. 101. Symmetric Tree – Recursively compare mirrored subtrees. 102. Binary Tree Level Order Traversal – Use queue for BFS. 103. Binary Tree Zigzag Level Order – Modify BFS to alternate direction. 104. Maximum Depth of Binary Tree – DFS recursion to track max depth. 105. Build Tree from Preorder and Inorder – Recursively divide arrays. 106. Build Tree from Inorder and Postorder – Reverse of #105. 110. Balanced Binary Tree – DFS checking subtree heights, return early if unbalanced.
Backtracking 17. Letter Combinations of Phone Number – Map digits to letters and recurse. 22. Generate Parentheses – Use counts of open and close to generate valid strings. 39. Combination Sum – Use DFS to explore sum paths. 40. Combination Sum II – Sort and skip duplicates during recursion. 46. Permutations – Swap elements and recurse. 47. Permutations II – Like #46 but sort and skip duplicate values. 77. Combinations – DFS to select combinations of size k. 78. Subsets – Backtrack by including or excluding elements. 90. Subsets II – Sort and skip duplicates during subset generation.
Dynamic Programming 70. Climbing Stairs – DP similar to Fibonacci sequence. 198. House Robber – Track max value including or excluding current house.
Math and Bit Manipulation 136. Single Number – XOR all values to isolate the single one. 169. Majority Element – Use Boyer-Moore voting algorithm.
Hashing and Frequency Maps 49. Group Anagrams – Sort characters and group in hashmap. 128. Longest Consecutive Sequence – Use set to expand sequences. 242. Valid Anagram – Count characters using map or array.
Matrix and Miscellaneous 11. Container With Most Water – Two pointers moving inward. 42. Trapping Rain Water – Track left and right max heights with two pointers. 54. Spiral Matrix – Traverse matrix layer by layer. 73. Set Matrix Zeroes – Use first row and column as markers.
This version is 4446 characters long. Let me know if you want any part turned into code templates, tables, or formatted for PDF or Markdown.
0 notes
Text
HashMap Related Interview Questions And Answers
These are the some best of HashMap related interview questions and answers for both freshers and experienced Java professionals. I hope they will be helpful for your technical interview. Java HashMap Interview Questions And Answers : 1) What is HashMap in Java? HashMap is a class in Java which implements Map interface. It is a data structure which holds the data as key-value pairs for…
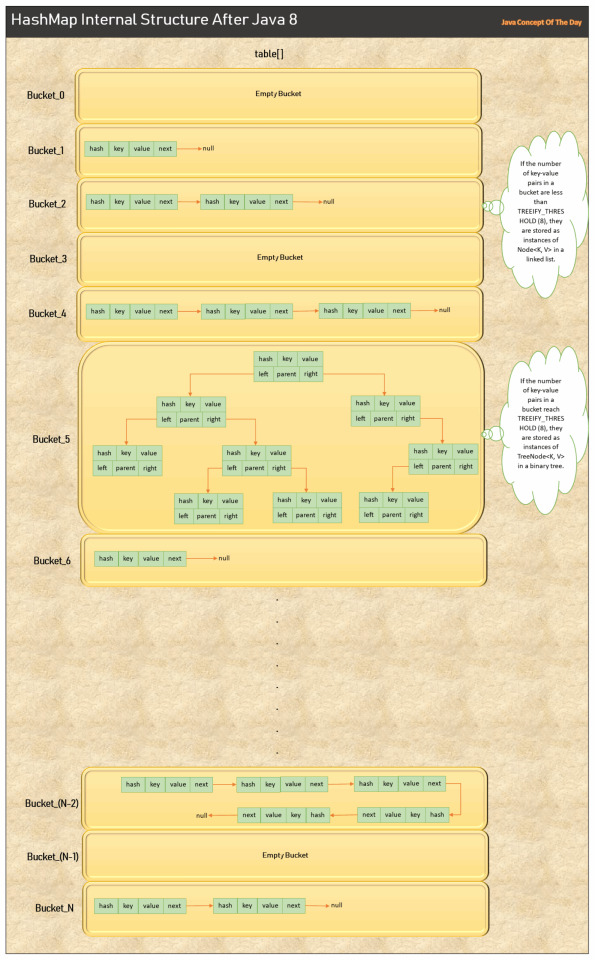
View On WordPress
0 notes
Text

What is the role of the JDBC DriverManager class? . . . . For more questions about Java https://bit.ly/465SkSw Check the above link
#resultset#rowset#drivermanager#preparedstatement#execute#executequery#executeupdate#array#arraylist#jdbc#hashcode#collection#comparator#comparable#blockingqueue#hashSet#treeSet#set#map#hashMap#computersciencemajor#javatpoint
0 notes
Text
📚 Comparing Java Collections: Which Data Structure Should You Use?
If you're diving into Core Java, one thing you'll definitely bump into is the Java Collections Framework. From storing a list of names to mapping users with IDs, collections are everywhere. But with all the options like List, Set, Map, and Queue—how do you know which one to pick? 🤯
Don’t worry, I’ve got you covered. Let’s break it down in simple terms, so you can make smart choices for your next Java project.
🔍 What Are Java Collections, Anyway?
The Java Collection Framework is like a big toolbox. Each tool (or data structure) helps you organize and manage your data in a specific way.
Here's the quick lowdown:
List – Ordered, allows duplicates
Set – Unordered, no duplicates
Map – Key-value pairs, keys are unique
Queue – First-In-First-Out (FIFO), or by priority
📌 When to Use What? Let’s Compare!
📝 List – Perfect for Ordered Data
Wanna keep things in order and allow duplicates? Go with a List.
Popular Types:
ArrayList – Fast for reading, not so much for deleting/inserting
LinkedList – Good for frequent insert/delete
Vector – Thread-safe but kinda slow
Stack – Classic LIFO (Last In, First Out)
Use it when:
You want to access elements by index
Duplicates are allowed
Order matters
Code Snippet:
java

🚫 Set – When You Want Only Unique Stuff
No duplicates allowed here! A Set is your go-to when you want clean, unique data.
Popular Types:
HashSet – Super fast, no order
LinkedHashSet – Keeps order
TreeSet – Sorted, but a bit slower
Use it when:
You care about uniqueness
You don’t mind the order (unless using LinkedHashSet)
You want to avoid duplication issues
Code Snippet:
java

🧭 Map – Key-Value Power Couple
Think of a Map like a dictionary. You look up values by their unique keys.
Popular Types:
HashMap – Fastest, not ordered
LinkedHashMap – Keeps insertion order
TreeMap – Sorted keys
ConcurrentHashMap – Thread-safe (great for multi-threaded apps)
Use it when:
You need to pair keys with values
You want fast data retrieval by key
Each key should be unique
Code Snippet:
java

⏳ Queue – For First-Come-First-Serve Vibes
Need to process tasks or requests in order? Use a Queue. It follows FIFO, unless you're working with priorities.
Popular Types:
LinkedList (as Queue) – Classic FIFO
PriorityQueue – Sorted based on priority
ArrayDeque – No capacity limit, faster than LinkedList
ConcurrentLinkedQueue – Thread-safe version
Use it when:
You’re dealing with task scheduling
You want elements processed in the order they come
You need to simulate real-life queues (like print jobs or tasks)
Code Snippet:
java

🧠 Cheat Sheet: Pick Your Collection Wisely

⚙️ Performance Talk: Behind the Scenes

💡 Real-Life Use Cases
Use ArrayList for menu options or dynamic lists.
Use HashSet for email lists to avoid duplicates.
Use HashMap for storing user profiles with IDs.
Use Queue for task managers or background jobs.
🚀 Final Thoughts: Choose Smart, Code Smarter
When you're working with Java Collections, there’s no one-size-fits-all. Pick your structure based on:
What kind of data you’re working with
Whether duplicates or order matter
Performance needs
The better you match the collection to your use case, the cleaner and faster your code will be. Simple as that. 💥
Got questions? Or maybe a favorite Java collection of your own? Drop a comment or reblog and let’s chat! ☕💻
If you'd like me to write a follow-up on concurrent collections, sorting algorithms, or Java 21 updates, just say the word!
✌️ Keep coding, keep learning! For More Info : Core Java Training in KPHB For UpComing Batches : https://linktr.ee/NIT_Training
#Java#CoreJava#JavaProgramming#JavaCollections#DataStructures#CodingTips#DeveloperLife#LearnJava#ProgrammingBlog#TechBlog#SoftwareEngineering#JavaTutorial#CodeNewbie#JavaList#JavaSet#JavaMap#JavaQueue#CleanCode#ObjectOrientedProgramming#BackendDevelopment#ProgrammingBasics
0 notes
Text
Java Count Character Frequency in String – Different Ways
java count character frequency in string:
Using a HashMap (Traditional approach)
Using Java 8 Streams (Modern approach)
Using Arrays for fixed character sets
Here's the HashMap approach:
java
Copy
Edit
import java.util.HashMap;
import java.util.Map;
public class CharFrequency {
public static void main(String[] args) {
String str = "hello world";
Map<Character, Integer> freqMap = new HashMap<>();
for (char ch : str.toCharArray()) {
freqMap.put(ch, freqMap.getOrDefault(ch, 0) + 1);
}
System.out.println(freqMap);
}
}
It efficiently counts character occurrences using a HashMap. The output would be something like:
Copy
Edit
{h=1, e=1, l=3, o=2, w=1, r=1, d=1}
0 notes
Text
What is the Java collection framework- 2025
The Java Collection Framework is a group of classes and interfaces that provide various data structures and algorithms for storing and manipulating data efficiently. It includes interfaces like List, Set, and Map, and implementations such as ArrayList, HashSet, and HashMap. The framework helps developers handle data more effectively, with built-in methods for searching, sorting, and modifying collections.
0 notes
Text
Assignment 2: HashMap
According to veteran C++ programmers, there are two projects which bring together all the knowledge that a profcient C++ programmer should have: Implementing a STL-compliant template class; and Implement a macro to hash string literals at compile-time. In this assignment, we will be putting #1 on your resume by building a STL-compliant HashMap. Recall that the Map abstract data type stores key…
0 notes