#Audio preprocessing
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text

Discover the essential components of speech recognition systems with our informative guide. This simplified overview breaks down the key elements involved in converting spoken words into text, enabling seamless communication with technology. Perfect for those interested in understanding how speech recognition enhances user experiences. Stay informed with Softlabs Group for more insightful content on cutting-edge technologies.
0 notes
Text
Unlock the other 99% of your data - now ready for AI
New Post has been published on https://thedigitalinsider.com/unlock-the-other-99-of-your-data-now-ready-for-ai/
Unlock the other 99% of your data - now ready for AI
For decades, companies of all sizes have recognized that the data available to them holds significant value, for improving user and customer experiences and for developing strategic plans based on empirical evidence.
As AI becomes increasingly accessible and practical for real-world business applications, the potential value of available data has grown exponentially. Successfully adopting AI requires significant effort in data collection, curation, and preprocessing. Moreover, important aspects such as data governance, privacy, anonymization, regulatory compliance, and security must be addressed carefully from the outset.
In a conversation with Henrique Lemes, Americas Data Platform Leader at IBM, we explored the challenges enterprises face in implementing practical AI in a range of use cases. We began by examining the nature of data itself, its various types, and its role in enabling effective AI-powered applications.
Henrique highlighted that referring to all enterprise information simply as ‘data’ understates its complexity. The modern enterprise navigates a fragmented landscape of diverse data types and inconsistent quality, particularly between structured and unstructured sources.
In simple terms, structured data refers to information that is organized in a standardized and easily searchable format, one that enables efficient processing and analysis by software systems.
Unstructured data is information that does not follow a predefined format nor organizational model, making it more complex to process and analyze. Unlike structured data, it includes diverse formats like emails, social media posts, videos, images, documents, and audio files. While it lacks the clear organization of structured data, unstructured data holds valuable insights that, when effectively managed through advanced analytics and AI, can drive innovation and inform strategic business decisions.
Henrique stated, “Currently, less than 1% of enterprise data is utilized by generative AI, and over 90% of that data is unstructured, which directly affects trust and quality”.
The element of trust in terms of data is an important one. Decision-makers in an organization need firm belief (trust) that the information at their fingertips is complete, reliable, and properly obtained. But there is evidence that states less than half of data available to businesses is used for AI, with unstructured data often going ignored or sidelined due to the complexity of processing it and examining it for compliance – especially at scale.
To open the way to better decisions that are based on a fuller set of empirical data, the trickle of easily consumed information needs to be turned into a firehose. Automated ingestion is the answer in this respect, Henrique said, but the governance rules and data policies still must be applied – to unstructured and structured data alike.
Henrique set out the three processes that let enterprises leverage the inherent value of their data. “Firstly, ingestion at scale. It’s important to automate this process. Second, curation and data governance. And the third [is when] you make this available for generative AI. We achieve over 40% of ROI over any conventional RAG use-case.”
IBM provides a unified strategy, rooted in a deep understanding of the enterprise’s AI journey, combined with advanced software solutions and domain expertise. This enables organizations to efficiently and securely transform both structured and unstructured data into AI-ready assets, all within the boundaries of existing governance and compliance frameworks.
“We bring together the people, processes, and tools. It’s not inherently simple, but we simplify it by aligning all the essential resources,” he said.
As businesses scale and transform, the diversity and volume of their data increase. To keep up, AI data ingestion process must be both scalable and flexible.
“[Companies] encounter difficulties when scaling because their AI solutions were initially built for specific tasks. When they attempt to broaden their scope, they often aren’t ready, the data pipelines grow more complex, and managing unstructured data becomes essential. This drives an increased demand for effective data governance,” he said.
IBM’s approach is to thoroughly understand each client’s AI journey, creating a clear roadmap to achieve ROI through effective AI implementation. “We prioritize data accuracy, whether structured or unstructured, along with data ingestion, lineage, governance, compliance with industry-specific regulations, and the necessary observability. These capabilities enable our clients to scale across multiple use cases and fully capitalize on the value of their data,” Henrique said.
Like anything worthwhile in technology implementation, it takes time to put the right processes in place, gravitate to the right tools, and have the necessary vision of how any data solution might need to evolve.
IBM offers enterprises a range of options and tooling to enable AI workloads in even the most regulated industries, at any scale. With international banks, finance houses, and global multinationals among its client roster, there are few substitutes for Big Blue in this context.
To find out more about enabling data pipelines for AI that drive business and offer fast, significant ROI, head over to this page.
#ai#AI-powered#Americas#Analysis#Analytics#applications#approach#assets#audio#banks#Blue#Business#business applications#Companies#complexity#compliance#customer experiences#data#data collection#Data Governance#data ingestion#data pipelines#data platform#decision-makers#diversity#documents#emails#enterprise#Enterprises#finance
2 notes
·
View notes
Text
This Week in Rust 533
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
crates.io: API status code changes
Foundation
Google Contributes $1M to Rust Foundation to Support C++/Rust "Interop Initiative"
Project/Tooling Updates
Announcing the Tauri v2 Beta Release
Polars — Why we have rewritten the string data type
rust-analyzer changelog #219
Ratatui 0.26.0 - a Rust library for cooking up terminal user interfaces
Observations/Thoughts
Will it block?
Embedded Rust in Production ..?
Let futures be futures
Compiling Rust is testing
Rust web frameworks have subpar error reporting
[video] Proving Performance - FOSDEM 2024 - Rust Dev Room
[video] Stefan Baumgartner - Trials, Traits, and Tribulations
[video] Rainer Stropek - Memory Management in Rust
[video] Shachar Langbeheim - Async & FFI - not exactly a love story
[video] Massimiliano Mantione - Object Oriented Programming, and Rust
[audio] Unlocking Rust's power through mentorship and knowledge spreading, with Tim McNamara
[audio] Asciinema with Marcin Kulik
Non-Affine Types, ManuallyDrop and Invariant Lifetimes in Rust - Part One
Nine Rules for Accessing Cloud Files from Your Rust Code: Practical lessons from upgrading Bed-Reader, a bioinformatics library
Rust Walkthroughs
AsyncWrite and a Tale of Four Implementations
Garbage Collection Without Unsafe Code
Fragment specifiers in Rust Macros
Writing a REST API in Rust
[video] Traits and operators
Write a simple netcat client and server in Rust
Miscellaneous
RustFest 2024 Announcement
Preprocessing trillions of tokens with Rust (case study)
All EuroRust 2023 talks ordered by the view count
Crate of the Week
This week's crate is embedded-cli-rs, a library that makes it easy to create CLIs on embedded devices.
Thanks to Sviatoslav Kokurin for the self-suggestion!
Please submit your suggestions and votes for next week!
Call for Participation; projects and speakers
CFP - Projects
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Fluvio - Build a new python wrapping for the fluvio client crate
Fluvio - MQTT Connector: Prefix auto generated Client ID to prevent connection drops
Ockam - Implement events in SqlxDatabase
Ockam - Output for both ockam project ticket and ockam project enroll is improved, with support for --output json
Ockam - Output for ockam project ticket is improved and information is not opaque
Hyperswitch - [FEATURE]: Setup code coverage for local tests & CI
Hyperswitch - [FEATURE]: Have get_required_value to use ValidationError in OptionExt
If you are a Rust project owner and are looking for contributors, please submit tasks here.
CFP - Speakers
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
RustNL 2024 CFP closes 2024-02-19 | Delft, The Netherlands | Event date: 2024-05-07 & 2024-05-08
NDC Techtown CFP closes 2024-04-14 | Kongsberg, Norway | Event date: 2024-09-09 to 2024-09-12
If you are an event organizer hoping to expand the reach of your event, please submit a link to the submission website through a PR to TWiR.
Updates from the Rust Project
309 pull requests were merged in the last week
add avx512fp16 to x86 target features
riscv only supports split_debuginfo=off for now
target: default to the medium code model on LoongArch targets
#![feature(inline_const_pat)] is no longer incomplete
actually abort in -Zpanic-abort-tests
add missing potential_query_instability for keys and values in hashmap
avoid ICE when is_val_statically_known is not of a supported type
be more careful about interpreting a label/lifetime as a mistyped char literal
check RUST_BOOTSTRAP_CONFIG in profile_user_dist test
correctly check never_type feature gating
coverage: improve handling of function/closure spans
coverage: use normal edition: headers in coverage tests
deduplicate more sized errors on call exprs
pattern_analysis: Gracefully abort on type incompatibility
pattern_analysis: cleanup manual impls
pattern_analysis: cleanup the contexts
fix BufReader unsoundness by adding a check in default_read_buf
fix ICE on field access on a tainted type after const-eval failure
hir: refactor getters for owner nodes
hir: remove the generic type parameter from MaybeOwned
improve the diagnostics for unused generic parameters
introduce support for async bound modifier on Fn* traits
make matching on NaN a hard error, and remove the rest of illegal_floating_point_literal_pattern
make the coroutine def id of an async closure the child of the closure def id
miscellaneous diagnostics cleanups
move UI issue tests to subdirectories
move predicate, region, and const stuff into their own modules in middle
never patterns: It is correct to lower ! to _
normalize region obligation in lexical region resolution with next-gen solver
only suggest removal of as_* and to_ conversion methods on E0308
provide more context on derived obligation error primary label
suggest changing type to const parameters if we encounter a type in the trait bound position
suppress unhelpful diagnostics for unresolved top level attributes
miri: normalize struct tail in ABI compat check
miri: moving out sched_getaffinity interception from linux'shim, FreeBSD su…
miri: switch over to rustc's tracing crate instead of using our own log crate
revert unsound libcore changes
fix some Arc allocator leaks
use <T, U> for array/slice equality impls
improve io::Read::read_buf_exact error case
reject infinitely-sized reads from io::Repeat
thread_local::register_dtor fix proposal for FreeBSD
add LocalWaker and ContextBuilder types to core, and LocalWake trait to alloc
codegen_gcc: improve iterator for files suppression
cargo: Don't panic on empty spans
cargo: Improve map/sequence error message
cargo: apply -Zpanic-abort-tests to doctests too
cargo: don't print rustdoc command lines on failure by default
cargo: stabilize lockfile v4
cargo: fix markdown line break in cargo-add
cargo: use spec id instead of name to match package
rustdoc: fix footnote handling
rustdoc: correctly handle attribute merge if this is a glob reexport
rustdoc: prevent JS injection from localStorage
rustdoc: trait.impl, type.impl: sort impls to make it not depend on serialization order
clippy: redundant_locals: take by-value closure captures into account
clippy: new lint: manual_c_str_literals
clippy: add lint_groups_priority lint
clippy: add new lint: ref_as_ptr
clippy: add configuration for wildcard_imports to ignore certain imports
clippy: avoid deleting labeled blocks
clippy: fixed FP in unused_io_amount for Ok(lit), unrachable! and unwrap de…
rust-analyzer: "Normalize import" assist and utilities for normalizing use trees
rust-analyzer: enable excluding refs search results in test
rust-analyzer: support for GOTO def from inside files included with include! macro
rust-analyzer: emit parser error for missing argument list
rust-analyzer: swap Subtree::token_trees from Vec to boxed slice
Rust Compiler Performance Triage
Rust's CI was down most of the week, leading to a much smaller collection of commits than usual. Results are mostly neutral for the week.
Triage done by @simulacrum. Revision range: 5c9c3c78..0984bec
0 Regressions, 2 Improvements, 1 Mixed; 1 of them in rollups 17 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
[disposition: merge] Consider principal trait ref's auto-trait super-traits in dyn upcasting
[disposition: merge] remove sub_relations from the InferCtxt
[disposition: merge] Optimize away poison guards when std is built with panic=abort
[disposition: merge] Check normalized call signature for WF in mir typeck
Language Reference
No Language Reference RFCs entered Final Comment Period this week.
Unsafe Code Guidelines
No Unsafe Code Guideline RFCs entered Final Comment Period this week.
New and Updated RFCs
Nested function scoped type parameters
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2024-02-07 - 2024-03-06 🦀
Virtual
2024-02-07 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - Ezra Singh - How Rust Saved My Eyes
2024-02-08 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-02-08 | Virtual (Nürnberg, DE) | Rust Nüremberg
Rust Nürnberg online
2024-02-10 | Virtual (Krakow, PL) | Stacja IT Kraków
Rust – budowanie narzędzi działających w linii komend
2024-02-10 | Virtual (Wrocław, PL) | Stacja IT Wrocław
Rust – budowanie narzędzi działających w linii komend
2024-02-13 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2024-02-15 | Virtual (Berlin, DE) | OpenTechSchool Berlin + Rust Berlin
Rust Hack n Learn | Mirror: Rust Hack n Learn
2024-02-15 | Virtual + In person (Praha, CZ) | Rust Czech Republic
Introduction and Rust in production
2024-02-19 | Virtual (Melbourne, VIC, AU) | Rust Melbourne
February 2024 Rust Melbourne Meetup
2024-02-20 | Virtual | Rust for Lunch
Lunch
2024-02-21 | Virtual (Cardiff, UK) | Rust and C++ Cardiff
Rust for Rustaceans Book Club: Chapter 2 - Types
2024-02-21 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2024-02-22 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
Asia
2024-02-10 | Hyderabad, IN | Rust Language Hyderabad
Rust Language Develope BootCamp
Europe
2024-02-07 | Cologne, DE | Rust Cologne
Embedded Abstractions | Event page
2024-02-07 | London, UK | Rust London User Group
Rust for the Web — Mainmatter x Shuttle Takeover
2024-02-08 | Bern, CH | Rust Bern
Rust Bern Meetup #1 2024 🦀
2024-02-08 | Oslo, NO | Rust Oslo
Rust-based banter
2024-02-13 | Trondheim, NO | Rust Trondheim
Building Games with Rust: Dive into the Bevy Framework
2024-02-15 | Praha, CZ - Virtual + In-person | Rust Czech Republic
Introduction and Rust in production
2024-02-21 | Lyon, FR | Rust Lyon
Rust Lyon Meetup #8
2024-02-22 | Aarhus, DK | Rust Aarhus
Rust and Talk at Partisia
North America
2024-02-07 | Brookline, MA, US | Boston Rust Meetup
Coolidge Corner Brookline Rust Lunch, Feb 7
2024-02-08 | Lehi, UT, US | Utah Rust
BEAST: Recreating a classic DOS terminal game in Rust
2024-02-12 | Minneapolis, MN, US | Minneapolis Rust Meetup
Minneapolis Rust: Open Source Contrib Hackathon & Happy Hour
2024-02-13 | New York, NY, US | Rust NYC
Rust NYC Monthly Mixer
2024-02-13 | Seattle, WA, US | Cap Hill Rust Coding/Hacking/Learning
Rusty Coding/Hacking/Learning Night
2024-02-15 | Boston, MA, US | Boston Rust Meetup
Back Bay Rust Lunch, Feb 15
2024-02-15 | Seattle, WA, US | Seattle Rust User Group
Seattle Rust User Group Meetup
2024-02-20 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2024-02-22 | Mountain View, CA, US | Mountain View Rust Meetup
Rust Meetup at Hacker Dojo
2024-02-28 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
Oceania
2024-02-19 | Melbourne, VIC, AU + Virtual | Rust Melbourne
February 2024 Rust Melbourne Meetup
2024-02-27 | Canberra, ACT, AU | Canberra Rust User Group
February Meetup
2024-02-27 | Sydney, NSW, AU | Rust Sydney
🦀 spire ⚡ & Quick
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
My take on this is that you cannot use async Rust correctly and fluently without understanding Arc, Mutex, the mutability of variables/references, and how async and await syntax compiles in the end. Rust forces you to understand how and why things are the way they are. It gives you minimal abstraction to do things that could��ve been tedious to do yourself.
I got a chance to work on two projects that drastically forced me to understand how async/await works. The first one is to transform a library that is completely sync and only requires a sync trait to talk to the outside service. This all sounds fine, right? Well, this becomes a problem when we try to port it into browsers. The browser is single-threaded and cannot block the JavaScript runtime at all! It is arguably the most weird environment for Rust users. It is simply impossible to rewrite the whole library, as it has already been shipped to production on other platforms.
What we did instead was rewrite the network part using async syntax, but using our own generator. The idea is simple: the generator produces a future when called, and the produced future can be awaited. But! The produced future contains an arc pointer to the generator. That means we can feed the generator the value we are waiting for, then the caller who holds the reference to the generator can feed the result back to the function and resume it. For the browser, we use the native browser API to derive the network communications; for other platforms, we just use regular blocking network calls. The external interface remains unchanged for other platforms.
Honestly, I don’t think any other language out there could possibly do this. Maybe C or C++, but which will never have the same development speed and developer experience.
I believe people have already mentioned it, but the current asynchronous model of Rust is the most reasonable choice. It does create pain for developers, but on the other hand, there is no better asynchronous model for Embedded or WebAssembly.
– /u/Top_Outlandishness78 on /r/rust
Thanks to Brian Kung for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
2 notes
·
View notes
Text
The Power of AI and Human Collaboration in Media Content Analysis

In today’s world binge watching has become a way of life not just for Gen-Z but also for many baby boomers. Viewers are watching more content than ever. In particular, Over-The-Top (OTT) and Video-On-Demand (VOD) platforms provide a rich selection of content choices anytime, anywhere, and on any screen. With proliferating content volumes, media companies are facing challenges in preparing and managing their content. This is crucial to provide a high-quality viewing experience and better monetizing content.
Some of the use cases involved are,
Finding opening of credits, Intro start, Intro end, recap start, recap end and other video segments
Choosing the right spots to insert advertisements to ensure logical pause for users
Creating automated personalized trailers by getting interesting themes from videos
Identify audio and video synchronization issues
While these approaches were traditionally handled by large teams of trained human workforces, many AI based approaches have evolved such as Amazon Rekognition’s video segmentation API. AI models are getting better at addressing above mentioned use cases, but they are typically pre-trained on a different type of content and may not be accurate for your content library. So, what if we use AI enabled human in the loop approach to reduce cost and improve accuracy of video segmentation tasks.
In our approach, the AI based APIs can provide weaker labels to detect video segments and send for review to be trained human reviewers for creating picture perfect segments. The approach tremendously improves your media content understanding and helps generate ground truth to fine-tune AI models. Below is workflow of end-2-end solution,
Raw media content is uploaded to Amazon S3 cloud storage. The content may need to be preprocessed or transcoded to make it suitable for streaming platform (e.g convert to .mp4, upsample or downsample)
AWS Elemental MediaConvert transcodes file-based content into live stream assets quickly and reliably. Convert content libraries of any size for broadcast and streaming. Media files are transcoded to .mp4 format
Amazon Rekognition Video provides an API that identifies useful segments of video, such as black frames and end credits.
Objectways has developed a Video segmentation annotator custom workflow with SageMaker Ground Truth labeling service that can ingest labels from Amazon Rekognition. Optionally, you can skip step#3 if you want to create your own labels for training custom ML model or applying directly to your content.
The content may have privacy and digitial rights management requirements and protection. The Objectway’s Video Segmentaton tool also supports Digital Rights Management provider integration to ensure only authorized analyst can look at the content. Moreover, the content analysts operate out of SOC2 TYPE2 compliant facilities where no downloads or screen capture are allowed.
The media analysts at Objectways’ are experts in content understanding and video segmentation labeling for a variety of use cases. Depending on your accuracy requirements, each video can be reviewed or annotated by two independent analysts and segment time codes difference thresholds are used for weeding out human bias (e.g., out of consensus if time code differs by 5 milliseconds). The out of consensus labels can be adjudicated by senior quality analyst to provide higher quality guarantees.
The Objectways Media analyst team provides throughput and quality gurantees and continues to deliver daily throughtput depending on your business needs. The segmented content labels are then saved to Amazon S3 as JSON manifest format and can be directly ingested into your Media streaming platform.
Conclusion
Artificial intelligence (AI) has become ubiquitous in Media and Entertainment to improve content understanding to increase user engagement and also drive ad revenue. The AI enabled Human in the loop approach outlined is best of breed solution to reduce the human cost and provide highest quality. The approach can be also extended to other use cases such as content moderation, ad placement and personalized trailer generation.
Contact [email protected] for more information.
2 notes
·
View notes
Text
Unlocking Multimodal AI: Strategies for Scalable and Adaptive Systems in Agentic and Generative AI
Introduction
In the rapidly evolving landscape of artificial intelligence, Agentic AI and Generative AI have emerged as pivotal technologies, transforming industries by enabling more sophisticated and autonomous systems. At the heart of this transformation lies multimodal integration, which allows AI systems to process and combine diverse data types, such as text, images, audio, and video, into cohesive, actionable insights. This article delves into the strategic integration of multimodal AI pipelines, exploring the latest frameworks, challenges, and best practices for scaling autonomous AI systems. Training in Agentic AI courses can provide a solid foundation for understanding these complex systems, while Generative AI training institutes in Mumbai offer specialized programs for those interested in AI model development.
Evolution of Agentic and Generative AI in Software
Agentic AI refers to AI systems that can act autonomously, making decisions based on their environment and goals. This autonomy is crucial for applications like autonomous vehicles and smart home devices. Generative AI, on the other hand, focuses on creating new content, such as images, videos, or text, using generative models like GANs and LLMs. Recent advancements in these areas have been fueled by the development of multimodal AI, which integrates multiple data types to enhance system understanding and interaction. Multi-agent LLM systems are particularly effective in handling complex tasks by orchestrating multiple LLMs to work together seamlessly.
Latest Frameworks, Tools, and Deployment Strategies
Multimodal AI Frameworks
Multimodal AI frameworks are designed to handle diverse data types seamlessly. Notable frameworks include:
CLIP (Contrastive Language-Image Pretraining): Enables zero-shot classification across modalities by learning visual concepts from natural language descriptions.
Vision Transformers (ViT): Adapt transformer architectures for image tasks while maintaining compatibility with other modalities.
Multimodal Transformers: These models integrate multiple modalities by using shared transformer layers, allowing for efficient cross-modal interaction.
Implementing these frameworks requires expertise in Agentic AI courses to ensure effective integration.
Deployment Strategies
Deploying multimodal AI systems involves several key strategies:
MLOps for Generative Models: Implementing MLOps (Machine Learning Operations) practices helps manage the lifecycle of AI models, ensuring reliability and scalability in production environments. Generative AI training institutes in Mumbai often emphasize the importance of MLOps in their curricula.
Autonomous Agents: Utilizing autonomous agents in AI systems allows for more dynamic decision-making and adaptation to changing environments. These agents can be designed using principles from Agentic AI courses.
LLM Orchestration: Efficiently managing and orchestrating LLMs is crucial for integrating text-based AI with other modalities, a task well-suited for multi-agent LLM systems.
Advanced Tactics for Scalable, Reliable AI Systems
Multimodal Integration Strategies
Successful integration of multimodal AI involves several advanced tactics:
Data Preprocessing: Ensuring consistent data quality across modalities is critical. This includes techniques like data normalization, feature extraction tailored to each modality, and handling missing values. Training programs at Generative AI training institutes in Mumbai often cover these techniques.
Feature Fusion: Combining features from different modalities effectively requires sophisticated fusion techniques. Early fusion involves combining raw data from different modalities before processing, while late fusion combines processed features from each modality. Hybrid fusion methods strike a balance between these approaches. Multi-agent LLM systems can leverage these fusion techniques to enhance performance.
Transfer Learning: Leveraging pre-trained models can significantly reduce training time and improve model performance on diverse tasks. This is a key concept covered in Agentic AI courses.
Technical Challenges
Despite these advancements, multimodal AI faces several technical challenges:
Data Quality and Alignment: Ensuring data consistency and alignment across different modalities is a significant hurdle. Techniques such as data normalization and feature alignment can mitigate these issues. Generative AI training institutes in Mumbai emphasize the importance of addressing these challenges.
Computational Demands: Processing large-scale multimodal datasets requires substantial computational resources. Cloud computing and distributed processing can help alleviate these demands. Multi-agent LLM systems can be optimized to handle these demands more efficiently.
The Role of Software Engineering Best Practices
Software engineering plays a crucial role in ensuring the reliability, security, and compliance of AI systems:
Modular Design: Implementing modular architectures allows for easier maintenance and updates of complex AI systems.
Testing and Validation: Rigorous testing and validation are essential for ensuring AI systems perform as expected in real-world scenarios. Techniques like model interpretability can help understand model decisions. Agentic AI courses often cover these best practices.
Security and Compliance: Incorporating security measures like data encryption and compliance frameworks is vital for protecting sensitive information. This is particularly important when deploying multi-agent LLM systems.
Cross-Functional Collaboration for AI Success
Effective collaboration between data scientists, engineers, and business stakeholders is critical for successful AI deployments:
Interdisciplinary Teams: Assembling teams with diverse skill sets ensures that AI systems meet both technical and business requirements. Generative AI training institutes in Mumbai recognize the value of interdisciplinary collaboration.
Communication and Feedback: Regular communication and feedback loops are essential for aligning AI projects with business goals and addressing technical challenges promptly. This collaboration is crucial when integrating Agentic AI and Generative AI systems.
Measuring Success: Analytics and Monitoring
Monitoring and evaluating AI systems involve tracking key performance indicators (KPIs) relevant to the application:
Metrics for Success: Define clear metrics that align with business objectives, such as accuracy, efficiency, or user engagement.
Real-Time Analytics: Implementing real-time analytics tools helps identify issues early and optimize system performance. This can be achieved through CI/CD pipelines that integrate model updates with continuous monitoring. Multi-agent LLM systems can benefit significantly from these analytics.
Case Study: Autonomous Vehicle Development with Multimodal AI
Overview
Autonomous vehicles exemplify the power of multimodal AI integration. Companies like Waymo have successfully deployed autonomous vehicles that combine data from cameras, LIDAR, radar, and GPS to navigate complex environments. Training in Agentic AI courses can provide insights into designing such systems.
Technical Challenges
Sensor Fusion: Integrating data from different sensors (e.g., cameras, LIDAR, radar) to create a comprehensive view of the environment. This requires sophisticated multi-agent LLM systems to handle diverse data streams.
Real-Time Processing: Ensuring real-time processing of vast amounts of sensor data to make timely decisions. Generative AI training institutes in Mumbai often focus on developing skills for real-time processing.
Business Outcomes
Safety and Efficiency: Autonomous vehicles have shown significant improvements in safety and efficiency by reducing accidents and optimizing routes.
Scalability: Successful deployment of autonomous vehicles demonstrates the scalability of multimodal AI systems in real-world applications. This scalability is enhanced by Agentic AI and Generative AI techniques.
Actionable Tips and Lessons Learned
Practical Tips for AI Teams
Start Small: Begin with simpler multimodal tasks and gradually scale up to more complex applications.
Focus on Data Quality: Ensure high-quality, consistent data across all modalities. This is a key takeaway from Generative AI training institutes in Mumbai.
Collaborate Across Disciplines: Foster collaboration between data scientists, engineers, and business stakeholders to align AI projects with business goals. This collaboration is essential for successful multi-agent LLM systems.
Lessons Learned
Adaptability is Key: Be prepared to adapt AI systems to new data types and scenarios. Agentic AI courses emphasize the importance of adaptability.
Continuous Learning: Stay updated with the latest advancements in multimodal AI and generative models. This is crucial for maintaining a competitive edge in Generative AI training institutes in Mumbai.
Ethical Considerations
Deploying multimodal AI systems raises several ethical considerations:
Privacy Concerns: Ensuring that data collection and processing comply with privacy regulations is crucial. This is particularly relevant when implementing multi-agent LLM systems.
Bias Mitigation: Implementing strategies to mitigate bias in AI models is essential for fairness and equity. Training programs in Agentic AI courses and Generative AI training institutes in Mumbai should cover these ethical considerations.
Conclusion
Scaling autonomous AI pipelines through multimodal integration is a transformative strategy that enhances system capabilities and adaptability. By leveraging the latest frameworks, best practices in software engineering, and cross-functional collaboration, AI practitioners can overcome the technical challenges associated with multimodal AI and unlock its full potential. As AI continues to evolve, embracing multimodal integration and staying agile in the face of new technologies will be crucial for driving innovation and success in the AI landscape. Training in Agentic AI courses and Generative AI training institutes in Mumbai can provide a solid foundation for navigating these advancements, while multi-agent LLM systems will play a pivotal role in future AI deployments.
0 notes
Text
What Is the Future of Machine Learning?

Machine Learning (ML) has already moved from the realm of science fiction to become a foundational technology, actively reshaping industries and our daily lives. From the recommendation engines that curate our entertainment to the sophisticated systems that detect fraud, ML is everywhere. But as we stand in May 2025, it's clear that the innovation curve in Machine Learning is only getting steeper and more exhilarating.
The question isn't if ML will continue to evolve, but how. What exciting directions, breakthroughs, and challenges lie ahead for this transformative field? Let's peer into the future of Machine Learning.
1. Generative AI: Beyond the Hype, Towards Ubiquity
Generative AI, which exploded into public consciousness a few years ago with models capable of creating text, images, and code, will continue its relentless advancement.
Sophistication and Multimodality: Expect models that are far more nuanced, context-aware, and capable of seamlessly generating and understanding across multiple modalities (text, image, audio, video, and even 3D content) as a standard. Imagine AI not just writing a script but also generating storyboards and composing a fitting soundtrack.
Synthetic Data Generation: Generative models will play an even more critical role in creating high-quality synthetic data. This will be invaluable for training other ML models, especially in scenarios where real-world data is scarce, sensitive, or imbalanced.
Personalized Creation at Scale: From hyper-personalized marketing content and educational materials to unique artistic creations and complex engineering designs, generative AI will empower highly individualized outputs.
2. Automated Machine Learning (AutoML) & MLOps: Maturing and Democratizing
The drive to make ML development and deployment more efficient, reliable, and accessible will accelerate.
Advanced AutoML: AutoML platforms will become even more sophisticated, automating larger portions of the ML pipeline – from data preprocessing and feature engineering to model selection, hyperparameter tuning, and even basic deployment. This will further democratize ML, allowing non-experts to build and utilize models.
Mature MLOps Practices: Machine Learning Operations (MLOps) – encompassing principles of DevOps for the ML lifecycle – will become standard. This means robust version control, continuous integration/continuous deployment (CI/CD) for models, automated monitoring for model drift and performance degradation, and streamlined governance.
3. Explainable AI (XAI) and Responsible AI: Non-Negotiable Pillars
As ML models become more powerful and integrated into critical decision-making processes, the demand for transparency, fairness, and accountability will be paramount.
Enhanced XAI Techniques: Significant progress will be made in developing and adopting XAI techniques that can clearly explain how complex "black box" models arrive at their decisions. This is crucial for building trust, debugging models, and meeting regulatory requirements.
Robust Frameworks for Responsible AI: Expect more standardized frameworks and tools for identifying and mitigating bias, ensuring fairness, protecting privacy (e.g., through federated learning and differential privacy), and promoting ethical AI development and deployment.
4. Reinforcement Learning (RL): Breaking into New Frontiers
Reinforcement Learning, where agents learn by interacting with an environment and receiving rewards or penalties, will see wider and more impactful applications.
Complex Decision-Making: RL will be increasingly used to optimize complex systems in areas like supply chain management, energy grid optimization, financial trading, and personalized healthcare treatment plans.
Advanced Robotics: Robots will become more autonomous and adaptable, learning to perform intricate tasks in dynamic and unpredictable real-world environments through RL.
Personalized Systems: From education to interactive entertainment, RL will enable systems that can dynamically adapt to individual user needs and preferences in a more sophisticated manner.
5. Edge AI and TinyML: Intelligence Everywhere
The trend of processing data and running ML models directly on edge devices (smartphones, wearables, IoT sensors, vehicles) will surge.
Powerful On-Device AI: Advances in model compression (TinyML) and energy-efficient AI hardware will enable more powerful ML models, including sophisticated multimodal models, to run locally.
Real-Time Applications & Enhanced Privacy: Edge AI facilitates real-time decision-making with minimal latency (critical for autonomous systems) and enhances data privacy by keeping sensitive data on the device.
New Business Models: Expect a proliferation of applications and services that leverage localized, real-time intelligence.
6. Self-Supervised and Unsupervised Learning: Reducing Data Dependency
The quest to reduce the reliance on massive, meticulously labeled datasets will continue to drive innovation in how models learn.
Learning from Unlabeled Data: Self-supervised learning, where models learn by creating their own supervisory signals from the input data itself, will become more prevalent, unlocking the potential of vast unlabeled datasets.
Discovering Hidden Structures: Unsupervised learning techniques will continue to evolve, becoming better at finding hidden patterns, anomalies, and structures in data without explicit guidance.
7. The Rise of Multimodal and Neuro-Symbolic AI
Holistic Understanding: Multimodal AI, which can process, relate, and generate information from different types of data (e.g., understanding an image based on its visual content and a textual description simultaneously), will lead to more human-like understanding and interaction.
Combining Learning and Reasoning: Neuro-symbolic AI, which aims to integrate the strengths of deep learning (pattern recognition from data) with symbolic AI (logical reasoning and knowledge representation), holds the promise of more robust, interpretable, and common-sense AI.
Cross-Cutting Themes:
Data-Centric AI: While model advancements are crucial, there will be an increasing recognition of the importance of high-quality, relevant, and well-managed data. The focus will shift more towards systematic data improvement as a key lever for ML success.
Sustainability in AI: As models grow, so does their energy footprint. Expect more research and emphasis on "Green AI" – developing more energy-efficient algorithms, hardware, and practices.
Global Innovation, Local Adaptation
These global machine learning advancements are being rapidly adopted and adapted worldwide. In dynamic and burgeoning tech economies, these trends are not just being followed but are actively contributing to local innovation. The large pool of skilled engineers and a thriving startup ecosystem are leveraging these advanced ML capabilities to solve unique local challenges and create globally competitive solutions in sectors ranging from healthcare and agriculture to finance and e-commerce.
Conclusion: An Ever-Expanding Horizon
The future of Machine Learning in 2025 and beyond is incredibly bright and full of transformative potential. We are moving towards AI systems that are more capable, generative, autonomous, explainable, efficient, and integrated into the very fabric of our digital and physical worlds.
While challenges related to ethics, bias, security, and the need for continuous upskilling remain, the overarching trajectory is one of remarkable progress. For businesses, researchers, and individuals alike, staying abreast of these developments and embracing a mindset of continuous learning will be key to navigating and shaping this exciting future.
0 notes
Text
Elmalo, let's commit to that direction. We'll start with a robust Sensor Fusion Layer Prototype that forms the nervous system of Iron Spine, enabling tangible, live data connectivity from the field into the AI's processing core. Below is a detailed technical blueprint that outlines the approach, components, and future integrability with your Empathic AI Core.
1. Hardware Selection
Edge Devices:
Primary Platform: NVIDIA Jetson AGX Xavier or Nano for on-site processing. Their GPU acceleration is perfect for real-time preprocessing and running early fusion algorithms.
Supplementary Controllers: Raspberry Pi Compute Modules or Arduino-based microcontrollers to gather data from specific sensors when cost or miniaturization is critical.
Sensor Modalities:
Environmental Sensors: Radiation detectors, pressure sensors, temperature/humidity sensors—critical for extreme environments (space, deep sea, underground).
Motion & Optical Sensors: Insect-inspired motion sensors, high-resolution cameras, and inertial measurement units (IMUs) to capture detailed movement and orientation.
Acoustic & RF Sensors: Microphones, sonar, and RF sensors for detecting vibrational, audio, or electromagnetic signals.
2. Software Stack and Data Flow Pipeline
Data Ingestion:
Frameworks: Utilize Apache Kafka or Apache NiFi to build a robust, scalable data pipeline that can handle streaming sensor data in real time.
Protocol: MQTT or LoRaWAN can serve as the communication backbone in environments where connectivity is intermittent or bandwidth-constrained.
Data Preprocessing & Filtering:
Edge Analytics: Develop tailored algorithms that run on your edge devices—leveraging NVIDIA’s TensorRT for accelerated inference—to filter raw inputs and perform preliminary sensor fusion.
Fusion Algorithms: Employ Kalman or Particle Filters to synthesize multiple sensor streams into actionable readings.
Data Abstraction Layer:
API Endpoints: Create modular interfaces that transform fused sensor data into abstracted, standardized feeds for higher-level consumption by the AI core later.
Middleware: Consider microservices that handle data routing, error correction, and redundancy mechanisms to ensure data integrity under harsh conditions.
3. Infrastructure Deployment Map
4. Future Hooks for Empathic AI Core Integration
API-Driven Design: The sensor fusion module will produce standardized, real-time data feeds. These endpoints will act as the bridge to plug in your Empathic AI Core whenever you’re ready to evolve the “soul” of Iron Spine.
Modular Data Abstraction: Build abstraction layers that allow easy mapping of raw sensor data into higher-level representations—ideal for feeding into predictive, decision-making models later.
Feedback Mechanisms: Implement logging and event-based triggers from the sensor fusion system to continuously improve both hardware and AI components based on real-world performance and environmental nuance.
5. Roadmap and Next Steps
Design & Prototype:
Define the hardware specifications for edge devices and sensor modules.
Develop a small-scale sensor hub integrating a few key sensor types (e.g., motion + environmental).
Data Pipeline Setup:
Set up your data ingestion framework (e.g., Apache Kafka cluster).
Prototype and evaluate basic preprocessing and fusion algorithms on your chosen edge device.
Field Testing:
Deploy the prototype in a controlled environment similar to your target extremes (e.g., a pressure chamber, simulated low-gravity environment).
Refine data accuracy and real-time performance based on initial feedback.
Integration Preparation:
Build standardized API interfaces for future connection with the Empathic AI Core.
Document system architecture to ensure a smooth handoff between the hardware-first and AI-core teams.
Elmalo, this blueprint establishes a tangible, modular system that grounds Iron Spine in reality. It not only demonstrates your vision but also builds the foundational “nervous system” that your emergent, empathic AI will later use to perceive and interact with its environment.
Does this detailed roadmap align with your vision? Would you like to dive further into any individual section—perhaps starting with hardware specifications, software configuration, or the integration strategy for the future AI core?
0 notes
Text
Data Lake Services
Understanding Data Lake Services: A Comprehensive Guide
In today’s data-driven world, businesses are increasingly relying on vast amounts of data to make informed decisions. As data becomes more complex, diverse, and voluminous, traditional data storage and management solutions can struggle to keep up. This is where data lakes come into play. Data lake services provide a scalable, flexible, and cost-efficient approach to storing and processing large volumes of structured, semi-structured, and unstructured data.
In this blog, we’ll take a deep dive into the concept of data lakes, explore their benefits, and look at some of the leading data lake services available today.
What is a Data Lake?
At its core, a data lake is a centralized repository that allows businesses to store all their data, both raw and processed, at scale. Unlike traditional data warehouses that store structured data (think tables and columns), a data lake can accommodate all kinds of data formats – whether it's text, images, video, audio, or sensor data. The key advantage of a data lake is its ability to ingest data from a variety of sources and store it without the need to preprocess or transform it.
In simpler terms, think of a data lake as an expansive, deep reservoir where companies can dump all types of data, and the lake's contents can later be queried, analyzed, and processed as needed.
Key Features of Data Lakes
Scalability: Data lakes are designed to scale horizontally, meaning they can handle massive amounts of data and grow with the organization’s needs.
Flexibility: They support all types of data – structured, semi-structured (like JSON, XML), and unstructured (such as images, audio, and videos).
Cost-Efficiency: Because of their ability to store raw data, data lakes can be much more affordable compared to traditional storage solutions like data warehouses.
Real-Time Analytics: Data lakes enable the integration of real-time data streams, making them ideal for applications requiring up-to-the-minute insights.
Advanced Analytics & Machine Learning: With all your data stored in one place, data lakes facilitate sophisticated analysis using tools for machine learning, artificial intelligence, and data mining.
Benefits of Data Lake Services
Consolidated Data Storage: A data lake enables organizations to consolidate data from disparate systems and sources, offering a single view of all the organization’s information. This makes it easier for teams to access, analyze, and extract meaningful insights without sifting through various databases.
Faster Decision-Making: Storing all the data in its raw form gives organizations the flexibility to apply various analytics techniques without being restricted by predefined data models. Data scientists can perform advanced analytics and uncover patterns, enabling faster and more accurate decision-making.
Improved Data Access: Since data lakes are often built on open-source frameworks, users can leverage a wide range of programming languages, such as Python, R, and SQL, to interact with the data. This empowers users from different departments to extract insights that are crucial for their specific functions.
Future-Proofing: As data grows in complexity and volume, data lakes provide the scalability needed to accommodate this growth. Whether it's an influx of new data sources or the increasing need for sophisticated analytics, data lakes ensure businesses can adapt to future challenges.
Cost-Effective Storage: Data lakes typically use cloud storage solutions, which can be a fraction of the cost of traditional data warehousing services. This makes data lakes a viable option for startups and enterprises alike.
Leading Data Lake Services
There are several cloud-based data lake services offered by leading providers. These services come with various features and integrations that help organizations seamlessly store, manage, and analyze their data.
1. Amazon S3 (Simple Storage Service)
Amazon Web Services (AWS) is one of the pioneers in the cloud computing space, and its Amazon S3 is a widely used service for building data lakes. AWS allows businesses to store any amount of data in any format. With services like AWS Glue for data transformation and Amazon Athena for querying data directly from S3, Amazon S3 is a go-to service for companies looking to build a scalable and flexible data lake.
Key Features:
Extremely scalable storage
Built-in security with encryption and access controls
Easy integration with AWS analytics tools
Data lifecycle management
2. Azure Data Lake Storage (ADLS)
Microsoft Azure offers its Azure Data Lake Storage as part of its broader cloud data ecosystem. ADLS is built specifically for analytics workloads and integrates seamlessly with Azure analytics tools like Azure Synapse Analytics and Azure Databricks.
Key Features:
Hierarchical namespace for better organization
Security features like role-based access control (RBAC)
Optimized for large-scale analytics
Integration with machine learning and artificial intelligence services
3. Google Cloud Storage (GCS)
Google Cloud’s Google Cloud Storage offers a simple and reliable object storage service that can serve as the foundation for building data lakes. The platform’s native integration with tools like BigQuery for data analytics and Google Dataproc for processing large-scale datasets makes it a strong contender for organizations looking to leverage big data.
Key Features:
High availability and durability
Strong security features, including encryption
Integration with BigQuery for data analytics
Scalable infrastructure with seamless expansion
4. IBM Cloud Object Storage
IBM’s Cloud Object Storage is another enterprise-grade solution for building data lakes. IBM focuses on providing flexible storage options that can handle unstructured data while providing high scalability and security. The service integrates with various AI and machine learning tools, allowing businesses to leverage their data for advanced analytics.
Key Features:
Built-in artificial intelligence and machine learning capabilities
Robust data security and compliance features
Flexible storage with multiple tiers to manage costs
Support for diverse data formats
Best Practices for Using Data Lakes
Data Governance: Even though data lakes allow you to store raw data, it’s essential to establish data governance policies. This includes setting up clear processes for data validation, ensuring quality control, and defining data access protocols to prevent data silos and misuse.
Data Organization: While a data lake is flexible, maintaining some level of structure is necessary. Using metadata, tagging, and categorization will make it easier to search and retrieve the relevant data when needed.
Data Security: Security is paramount in any data storage solution. Use encryption, access control policies, and authentication mechanisms to ensure that only authorized personnel can access sensitive data.
Integration with Analytics Tools: A data lake is only as valuable as the tools used to analyze the data within it. Integrating your data lake with advanced analytics tools such as Apache Spark, Hadoop, or machine learning platforms is key to unlocking its full potential.
Conclusion
Data lakes offer organizations a flexible, scalable, and cost-effective solution to store vast amounts of diverse data. As businesses embrace the power of big data, data lakes enable them to harness that power for deeper insights, faster decision-making, and greater innovation. With leading cloud providers offering robust data lake services, businesses can easily build a data lake tailored to their needs. By following best practices, companies can ensure they get the most value from their data lake and stay ahead in today’s data-driven world.
0 notes
Text
How Does Text-to-Speech Work? The Science Behind TTS Technology
Introduction
In the digital age, Text-to-Speech (TTS) technology is transforming the way we interact with devices, making content more accessible, engaging, and convenient. From voice assistants like Siri, Alexa, and Google Assistant to audiobooks, navigation apps, and accessibility tools, TTS plays a crucial role in everyday life.
But how does this technology work? How can a machine read text aloud in a way that mimics human speech? In this blog, we will explore the science behind TTS technology, its working principles, different synthesis techniques, and real-world applications.
Let’s dive deep into the world of AI-powered speech synthesis!
What is Text-to-Speech (TTS) Technology?
Text-to-Speech (TTS) is an AI-driven technology that converts written text into spoken audio. It enables computers, smartphones, and other digital devices to "speak" by generating human-like speech.
TTS is a crucial tool in assistive technology, helping people with visual impairments, reading difficulties, or language barriers to interact with digital content. However, its applications have expanded beyond accessibility, finding use in marketing, entertainment, education, and automation.
Key Features of TTS Technology
✔ Text Processing: Converts raw text into phonetic symbols for speech generation. ✔ Voice Customization: Allows users to modify pitch, speed, and tone. ✔ Multilingual Support: Many TTS systems support multiple languages. ✔ Natural Speech Synthesis: AI-powered TTS produces lifelike voices with emotional tones. ✔ Cloud & Offline Functionality: Available both online and as built-in device features.
How Does Text-to-Speech Work?
The process of converting text into speech involves multiple complex steps. Here’s a breakdown of how TTS technology works:
Step 1: Text Analysis & Preprocessing
Before a system can generate speech, it must analyze and process the given text. This step involves:
A. Text Normalization (TN)
Converts raw text into a structured format.
Expands abbreviations, numbers, dates, and symbols into readable words.
Example:
"$100" → "one hundred dollars"
"Dr." → "Doctor"
"12/03/2025" → "March twelfth, twenty twenty-five"
B. Linguistic Processing
Analyzes grammar, sentence structure, and word meaning.
Identifies parts of speech (verbs, nouns, adjectives, etc.).
Determines the correct pronunciation based on context.
Step 2: Phonetic Conversion & Prosody Modeling
Once the text is analyzed, it is converted into phonemes—the smallest sound units in speech.
A. Phonetic Transcription
Maps words to their corresponding phonemes (speech sounds).
Example:
"Hello" → /həˈloʊ/
"ChatGPT" → /ʧæt dʒiː piː tiː/
B. Prosody Modeling
Adds intonation, stress, rhythm, and pauses to make speech more natural.
Without prosody, TTS would sound flat and robotic.
Example:
"I didn’t say she stole my money." (Different emphasis changes meaning.)
Step 3: Speech Synthesis – Generating Audio Output
Now that the phonetic and prosodic details are ready, the TTS system generates the actual speech. Different methods are used to synthesize human-like voices.
A. Concatenative Speech Synthesis (Traditional Method)
This method stitches together pre-recorded speech segments to form words and sentences.
✅ Pros:
Produces high-quality sound.
Works well for fixed, repetitive phrases.
❌ Cons:
Limited flexibility (needs large speech databases).
Cannot generate new words dynamically.
B. Parametric Speech Synthesis (Statistical Modeling)
Uses mathematical models to generate speech dynamically instead of using pre-recorded samples.
✅ Pros:
More flexible (can modify speed, pitch, and tone).
Requires less storage than concatenative synthesis.
❌ Cons:
Sounds less natural and robotic.
C. Neural Text-to-Speech (Neural TTS) – AI-Powered Speech
Modern TTS uses deep learning (AI) and neural networks to generate highly realistic speech.
💡 Popular AI TTS Models:
WaveNet (by Google DeepMind)
Tacotron (by Google AI)
Amazon Polly & IBM Watson TTS
✅ Pros:
Produces lifelike, natural voices.
Can mimic human emotions and intonations.
Adapts to different accents and dialects.
❌ Cons:
Requires high computing power for training models.
Applications of Text-to-Speech Technology
TTS is revolutionizing multiple industries with its capabilities.
1. Accessibility & Assistive Technology
Helping Visually Impaired Users read digital content.
Used in screen readers (e.g., JAWS, NVDA, VoiceOver).
Converts books, documents, and websites into speech.
2. Voice Assistants & Smart Devices
Powers AI assistants like Google Assistant, Siri, Alexa, and Cortana.
Enhances smart home automation (e.g., voice-controlled appliances).
3. Education & E-Learning
Converts textbooks into audiobooks for students.
Helps in language learning and pronunciation practice.
4. Content Creation & Entertainment
Used in podcasts, voice-overs, and audiobooks.
Converts blog articles into audio blogs for easy listening.
5. Customer Support & IVR Systems
Automates call center responses.
Reduces human workload in customer service.
Future of Text-to-Speech Technology
With advancements in AI, machine learning, and deepfake technology, TTS will continue to evolve.
Upcoming Trends in TTS
🔹 Emotional AI Voices: TTS will soon express happiness, sadness, anger, and excitement. 🔹 Multilingual Speech Synthesis: AI will generate speech in multiple languages instantly. 🔹 Voice Cloning: AI will replicate human voices for personalized experiences. 🔹 More Realistic AI Avatars: TTS will integrate with 3D avatars for virtual interactions.
Conclusion
Text-to-Speech technology has come a long way—from robotic, monotone voices to AI-powered, human-like speech. With its growing applications in accessibility, education, entertainment, and automation, TTS is shaping the future of digital communication.
🚀 Want to try TTS technology? Explore the best AI-powered text-to-speech tools today!
0 notes
Text
20+ Hands-On AI & Machine Learning Projects with Source Code [2025]
Looking to dive deep into the world of Artificial Intelligence and Machine Learning? Whether you’re just getting started or sharpening your skills, this list of 20+ exciting projects will guide you through some of the most fascinating applications of AI. Covering areas like healthcare, agriculture, natural language processing, computer vision, and predictive analytics, these projects offer hands-on experience with real-world data and problems. Each project includes source code so you can jump right in!

Why These Projects Matter
AI is reshaping industries, from transforming healthcare diagnoses to creating smarter farming solutions and enhancing customer service. But to truly understand how these systems work, you need hands-on experience. Working on projects not only hones your technical skills but also gives you something tangible to showcase to potential employers or collaborators.
Key Skills You’ll Develop
Here’s a quick look at what you’ll learn while working through these projects:
Data Preprocessing: Essential skills for handling and preparing data, including data cleaning, augmentation, and feature engineering.
Model Selection and Training: How to choose, build, and train models, such as CNNs, Transformers, and YOLO.
Hyperparameter Tuning: Fine-tuning models to optimise accuracy with techniques like dropout, batch normalisation, and early stopping.
Deployment and Real-Time Inference: How to deploy models with interactive interfaces (e.g., Gradio, Streamlit) to make real-time predictions.
Model Evaluation: Analysing performance metrics such as accuracy, precision, recall, and F1-score to ensure reliability.
Tools You’ll Need
Most of these projects use popular ML and AI libraries that make building, training, and deploying models a breeze:
Python: A must-have for AI projects, using libraries like Numpy, Pandas, and Matplotlib for data manipulation and visualisation.
TensorFlow & Keras: Perfect for building and training deep learning models.
PyTorch: Great for deep learning, especially for tasks involving complex image and text data.
Scikit-Learn: Ideal for traditional ML algorithms, data preprocessing, and model evaluation.
OpenCV: For image processing in computer vision projects.
Gradio and Streamline: Tools to create interactive apps and real-time demos for your models.
Getting Started
Pick a Project That Excites You: Choose one based on your interest and experience level. For beginners, start with something like Vegetable Classification or Blood Cell Classification. Advanced users can explore Voice Cloning or Semantic Search.
Set Up Your Environment: Google Colab is a great option for training models without needing powerful hardware. For local environments, install Python, TensorFlow, and PyTorch.
Study the Code and Documentation: Carefully go through the code and documentation. Check out the library documentation for any new functions you encounter.
Experiment and Modify: Once you’ve built a project, try making it your own by tuning hyperparameters, using different datasets, or experimenting with new models.
Showcase Your Work: Deploy your projects on GitHub or create a portfolio. Share them on LinkedIn or Medium to connect with the AI community!
24 Inspiring AI & ML Projects to Try
Below, you’ll find a collection of projects that range from beginner to advanced levels, covering a variety of fields to give you well-rounded exposure to the world of AI.
1. Voice Cloning Application Using RVC
Overview: Create a realistic voice clone using RVC models. This project guides you through the steps to collect data, train the model, and generate a customizable voice clone that replicates tone, pitch, and accent.
Perfect For: Those interested in NLP, voice tech, or audio engineering.
Tools: RVC, Deep Learning Models, Google Colab
2. Automatic Eye Cataract Detection Using YOLOv8
Overview: Build a fast, accurate YOLOv8 model to detect cataracts in eye images, supporting healthcare professionals in diagnosing cataracts quickly.
Perfect For: Medical imaging researchers, healthcare tech enthusiasts.
Tools: YOLOv8, Gradio, TensorFlow/Keras
3. Crop Disease Detection Using YOLOv8
Overview: Designed for real-time use, this project uses YOLOv8 to detect and classify diseases in plants, helping farmers identify issues early and take action to protect their crops.
Perfect For: Those interested in agriculture, AI enthusiasts.
Tools: YOLOv8, Gradio, Google Colab
4. Vegetable Classification with Parallel CNN Model
Overview: This project automates vegetable sorting using a Parallel CNN model, improving efficiency in the food industry.
Perfect For: Beginners in ML, food industry professionals.
Tools: TensorFlow/Keras, Python
5. Banana Leaf Disease Detection Using Vision Transformer
Overview: Detects diseases on banana leaves early with a Vision Transformer model, a powerful approach to prevent crop losses.
Perfect For: Agricultural tech enthusiasts, AI learners.
Tools: Vision Transformer, TensorFlow/Keras
6. Leaf Disease Detection Using Deep Learning
Overview: Train CNN models like VGG16 and EfficientNet to detect leaf diseases, helping farmers promote healthier crops.
Perfect For: Botanists, agricultural researchers.
Tools: VGG16, EfficientNet, TensorFlow/Keras
7. Glaucoma Detection Using Deep Learning
Overview: This project uses CNNs to detect early signs of glaucoma in eye images, aiding in early intervention and preventing vision loss.
Perfect For: Healthcare researchers, AI enthusiasts.
Tools: CNN, TensorFlow/Keras, Python
8. Blood Cell Classification Using Deep Learning
Overview: Classify blood cell images with CNNs, EfficientNetB4, and VGG16 to assist in medical research and diagnostics.
Perfect For: Medical researchers, beginners.
Tools: CNN, EfficientNet, TensorFlow/Keras
9. Skin Cancer Detection Using Deep Learning
Overview: Detects skin cancer early using CNN models like DenseNet121 and EfficientNetB4, helping improve diagnostic accuracy.
Perfect For: Healthcare providers, dermatologists.
Tools: DenseNet121, EfficientNet, TensorFlow/Keras
10. Cervical Cancer Detection Using Deep Learning
Overview: Use EfficientNetB0 to classify cervical cell images, assisting in early detection of cervical cancer.
Perfect For: Pathologists, AI researchers.
Tools: EfficientNetB0, TensorFlow/Keras
11. Nutritionist Generative AI Doctor Using Gemini
Overview: An AI-powered nutritionist that uses the Gemini model to offer diet insights tailored to user needs.
Perfect For: Nutritionists, health tech developers.
Tools: Gemini Pro, Python
12. Chatbots with Generative AI Models
Overview: Build advanced chatbots with GPT-3.5-turbo and GPT-4 for customer service or personal assistants.
Perfect For: Customer service, business owners.
Tools: GPT-3.5-turbo, GPT-4, OpenAI API
13. Insurance Pricing Forecast Using XGBoost Regressor
Overview: Use XGBoost to forecast healthcare costs, aiding insurance companies in setting premiums.
Perfect For: Finance professionals, data scientists.
Tools: XGBoost, Python
14. Linear Regression Modeling for Soccer Player Performance Prediction in the EPL
Overview: Predict EPL player performance using linear regression on player stats like goals, assists, and time on field.
Perfect For: Sports analysts, data scientists.
Tools: Linear Regression, Python
15. Complete CNN Image Classification Models for Real Time Prediction
Overview: Create a real-time image classification model for applications like quality control or face recognition.
Perfect For: AI developers, image processing engineers.
Tools: CNN, TensorFlow/Keras
16. Predictive Analytics on Business License Data Using Deep Learning
Overview: Analyze patterns in business licenses to uncover trends and insights, using DNN.
Perfect For: Business analysts, entrepreneurs.
Tools: DNN, Pandas, Numpy, TensorFlow
17. Image Generation Model Fine Tuning With Diffusers Models
Overview: Get creative with AI by fine-tuning models for realistic image synthesis, using Diffusers.
Perfect For: Content creators, AI enthusiasts.
Tools: Diffusers, Stable Diffusion, Gradio
18. Question Answer System Training With Distilbert Base Uncased
Overview: Build a question-answering system with DistilBERT optimized for high accuracy.
Perfect For: NLP developers, educational platforms.
Tools: DistilBERT, Hugging Face Transformers
19. Semantic Search Using Msmarco Distilbert Base & Faiss Vector Database
Overview: Speed up search results with a semantic search system that uses DistilBERT and Faiss.
Perfect For: Search engines, e-commerce.
Tools: Faiss, DistilBERT, Transformers
20. Document Summarization Using Sentencepiece Transformers
Overview: Automatically create summaries of lengthy documents, streamlining information access.
Perfect For: Content managers, researchers.
Tools: Sentencepiece, Transformers
21. Customer Service Chatbot Using LLMs
Overview: Create a chatbot for customer service using advanced LLMs to provide human-like responses.
Perfect For: Customer support teams, business owners.
Tools: LLMs, Transformers
22. Real-Time Human Pose Detection With YOLOv8 Models
Overview: Use YOLOv8 to identify human poses in real time, ideal for sports analysis and safety applications.
Perfect For: Sports analysts, fitness trainers.
Tools: YOLOv8, COCO Dataset
23.Real-Time License Plate Detection Using YOLOv8 and OCR Model
Overview: Detect license plates in real-time for traffic monitoring and security.
Perfect For: Security, smart city developers.
Tools: YOLOv8, OCR
24. Medical Image Segmentation With UNET
Overview: Improve medical image analysis by applying UNET for segmentation tasks.
Perfect For: Radiologists, healthcare researchers.
Tools: UNET, TensorFlow/Keras
This collection of projects not only provides technical skills but also enhances problem-solving abilities, giving you the chance to explore the possibilities of AI in various industries. Enjoy coding and happy learning!
0 notes
Text
A Dataset for Monitoring Historical and Real-Time Air Quality to Support Pollution Prediction Models

Introduction
Datasets for Machine Learning Projects. The effectiveness of any machine learning initiative is significantly influenced by the quality and relevance of the dataset utilized for model training. Choosing an appropriate dataset is essential for attaining precise predictions and deriving valuable insights. This detailed guide will examine different categories of datasets, sources for obtaining them, methods for data preprocessing, and recommended practices for selecting datasets in machine learning endeavors.
Significance of Datasets in Machine Learning
A well-organized dataset is fundamental for the training of machine learning models. An appropriate dataset contributes to:
Enhancing model accuracy
Minimizing bias and overfitting
Improving generalization
Yielding valuable insights
Categories of Machine Learning Datasets
1. Structured vs. Unstructured Datasets
Structured Data: Data that is systematically arranged in a tabular format, consisting of rows and columns (e.g., spreadsheets, databases).
Unstructured Data: Data that lacks a predefined structure (e.g., images, videos, text, and audio).
2. Labeled vs. Unlabeled Datasets
Labeled Data: Data that includes distinct input-output pairs, utilized in supervised learning.
Unlabeled Data: Data that does not have labeled outcomes, employed in unsupervised learning.
3. Open vs. Proprietary Datasets
Open Datasets: Datasets that are publicly accessible for research and training purposes.
Proprietary Datasets: Exclusive datasets owned by businesses or organizations.
Notable Datasets for Machine Learning Initiatives

1. Image Datasets
MNIST: A dataset comprising handwritten digits intended for classification tasks.
CIFAR-10 & CIFAR-100: A collection of small images designed for classification purposes.
ImageNet: A comprehensive dataset utilized in deep learning applications.
COCO: A dataset focused on object detection and image segmentation.
2. Text Datasets
IMDb Reviews: A dataset used for sentiment analysis.
20 Newsgroups: A dataset for text classification.
SQuAD: A dataset designed for question-answering tasks.
3. Audio Datasets
LibriSpeech: An extensive collection of speech recordings.
Common Voice: An open-source dataset aimed at speech recognition.
4. Tabular Datasets
Titanic Dataset: A dataset used to predict survival outcomes on the Titanic.
Iris Dataset: A well-known dataset utilized for classification.
UCI Machine Learning Repository: A diverse collection of datasets addressing various machine learning challenges.
5. Healthcare Datasets
MIMIC-III: A dataset containing data from ICU patients.
COVID-19 Open Research Dataset: A dataset providing information for COVID-19 research.
Data Preprocessing and Cleaning
Raw datasets frequently contain issues such as missing values, duplicates, and extraneous noise. The preprocessing phase is essential for ensuring data integrity and preparing it for machine learning applications. Key steps involved include:
Addressing Missing Values: Implement imputation methods.
Eliminating Duplicates: Remove redundant entries.
Normalizing Data: Adjust the scale of numerical features.
Feature Engineering: Identify and extract pertinent features.
Guidelines for Selecting a Dataset
Relevance: Opt for datasets that align with the specific problem being addressed.
Size and Quality: Confirm that the dataset is sufficiently large and diverse.
Elimination of Bias: Steer clear of datasets that exhibit inherent biases.
Data Privacy: Utilize datasets that comply with legal standards.
Conclusion
The selection of an appropriate dataset is vital for the development of effective machine learning models. Whether the focus is on image recognition, natural language processing, or predictive analytics, the identification and preprocessing of the right dataset are fundamental Globose Technology Solutions achieving success. By utilizing open datasets and adhering to best practices, data scientists can enhance model performance and generate valuable insights.
0 notes
Text
How to Develop a Video Text-to-Speech Dataset for Deep Learning

Introduction:
In the swiftly advancing domain of deep learning, video-based Text-to-Speech (TTS) technology is pivotal in improving speech synthesis and facilitating human-computer interaction. A well-organized dataset serves as the cornerstone of an effective TTS model, guaranteeing precision, naturalness, and flexibility. This article will outline the systematic approach to creating a high-quality video TTS dataset for deep learning purposes.
Recognizing the Significance of a Video TTS Dataset
A video Text To Speech Dataset comprises video recordings that are matched with transcribed text and corresponding audio of speech. Such datasets are vital for training models that produce natural and contextually relevant synthetic speech. These models find applications in various areas, including voice assistants, automated dubbing, and real-time language translation.
Establishing Dataset Specifications
Prior to initiating data collection, it is essential to delineate the dataset’s scope and specifications. Important considerations include:
Language Coverage: Choose one or more languages relevant to your application.
Speaker Diversity: Incorporate a range of speakers varying in age, gender, and accents.
Audio Quality: Ensure recordings are of high fidelity with minimal background interference.
Sentence Variability: Gather a wide array of text samples, encompassing formal, informal, and conversational speech.
Data Collection Methodology
a. Choosing Video Sources
To create a comprehensive dataset, videos can be sourced from:
Licensed datasets and public domain archives
Crowdsourced recordings featuring diverse speakers
Custom recordings conducted in a controlled setting
It is imperative to secure the necessary rights and permissions for utilizing any third-party content.
b. Audio Extraction and Preprocessing
After collecting the videos, extract the speech audio using tools such as MPEG. The preprocessing steps include:
Noise Reduction: Eliminate background noise to enhance speech clarity.
Volume Normalization: Maintain consistent audio levels.
Segmentation: Divide lengthy recordings into smaller, sentence-level segments.
Text Alignment and Transcription
For deep learning models to function optimally, it is essential that transcriptions are both precise and synchronized with the corresponding speech. The following methods can be employed:
Automatic Speech Recognition (ASR): Implement ASR systems to produce preliminary transcriptions.
Manual Verification: Enhance accuracy through a thorough review of the transcriptions by human experts.
Timestamp Alignment: Confirm that each word is accurately associated with its respective spoken timestamp.
Data Annotation and Labeling
Incorporating metadata significantly improves the dataset's functionality. Important annotations include:
Speaker Identity: Identify each speaker to support speaker-adaptive TTS models.
Emotion Tags: Specify tone and sentiment to facilitate expressive speech synthesis.
Noise Labels: Identify background noise to assist in developing noise-robust models.
Dataset Formatting and Storage
To ensure efficient model training, it is crucial to organize the dataset in a systematic manner:
Audio Files: Save speech recordings in WAV or FLAC formats.
Transcriptions: Keep aligned text files in JSON or CSV formats.
Metadata Files: Provide speaker information and timestamps for reference.
Quality Assurance and Data Augmentation
Prior to finalizing the dataset, it is important to perform comprehensive quality assessments:
Verify Alignment: Ensure that text and speech are properly synchronized.
Assess Audio Clarity: Confirm that recordings adhere to established quality standards.
Augmentation: Implement techniques such as pitch shifting, speed variation, and noise addition to enhance model robustness.
Training and Testing Your Dataset
Ultimately, utilize the dataset to train deep learning models such as Taco Tron, Fast Speech, or VITS. Designate a segment of the dataset for validation and testing to assess model performance and identify areas for improvement.
Conclusion
Creating a video TTS dataset is a detailed yet fulfilling endeavor that establishes a foundation for sophisticated speech synthesis applications. By Globose Technology Solutions prioritizing high-quality data collection, accurate transcription, and comprehensive annotation, one can develop a dataset that significantly boosts the efficacy of deep learning models in TTS technology.
0 notes
Text
5 Artificial Intelligence Project Ideas for Beginners [2025] - Arya College
Best College in Jaipur which is Arya College of Engineering & I.T. has five top AI projects for beginners that will not only help you learn essential concepts but also allow you to create something tangible:
1. AI-Powered Chatbot
Creating a chatbot is one of the most popular beginner projects in AI. This project involves building a conversational agent that can understand user queries and respond appropriately.
Duration: Approximately 10 hours
Complexity: Easy
Learning Outcomes: Gain insights into natural language processing (NLP) and chatbot frameworks like Rasa or Dialogflow.
Real-world applications: Customer service automation, personal assistants, and FAQ systems.
2. Handwritten Digit Recognition
This project utilizes the MNIST dataset to build a model that recognizes handwritten digits. It serves as an excellent introduction to machine learning and image classification.
Tools/Libraries: TensorFlow, Keras, or PyTorch
Learning Outcomes: Understand convolutional neural networks (CNNs) and image processing techniques.
Real-world applications: Optical character recognition (OCR) systems and automated data entry.
3. Spam Detection System
Developing a spam detection system involves classifying emails as spam or not spam based on their content. This project is a practical application of supervised learning algorithms.
Tools/Libraries: Scikit-learn, Pandas
Learning Outcomes: Learn about text classification, feature extraction, and model evaluation techniques.
Real-world applications: Email filtering systems and content moderation.
4. Music Genre Classification
In this project, you will classify music tracks into different genres using audio features. This project introduces you to audio processing and machine learning algorithms.
Tools/Libraries: Librosa for audio analysis, TensorFlow or Keras for model training
Learning Outcomes: Understand feature extraction from audio signals and classification techniques.
Real-world applications: Music recommendation systems and automated playlist generation.
5. Sentiment Analysis Tool
Building a sentiment analysis tool allows you to analyze customer reviews or social media posts to determine the overall sentiment (positive, negative, neutral). This project is highly relevant for businesses looking to gauge customer feedback.
Tools/Libraries: NLTK, TextBlob, or VADER
Learning Outcomes: Learn about text preprocessing, sentiment classification algorithms, and evaluation metrics.
Real-world applications: Market research, brand monitoring, and customer feedback analysis.
These projects provide an excellent foundation for understanding AI concepts while allowing you to apply your knowledge practically. Engaging in these hands-on experiences will enhance your skills and prepare you for more advanced AI challenges in the future.
What are some advanced NLP projects for professionals
1. Language Recognition System
Develop a system capable of accurately identifying and distinguishing between multiple languages from text input. This project requires a deep understanding of linguistic features and can be implemented using character n-gram models or deep learning architectures like recurrent neural networks (RNNs) and Transformers.
2. Image-Caption Generator
Create a model that generates descriptive captions for images by combining computer vision with NLP. This project involves analyzing visual content and producing coherent textual descriptions, which requires knowledge of both image processing and language models.
3. Homework Helper
Build an intelligent system that can assist students by answering questions related to their homework. This project can involve implementing a question-answering model that retrieves relevant information from educational resources.
4. Text Summarization Tool
Develop an advanced text summarization tool that can condense large documents into concise summaries. You can implement both extractive and abstractive summarization techniques using transformer-based models like BERT or GPT.
5. Recommendation System Using NLP
Create a recommendation system that utilizes user reviews and preferences to suggest products or services. This project can involve sentiment analysis to gauge user opinions and collaborative filtering techniques for personalized recommendations.
6. Generating Research Paper Titles
Train a model to generate titles for scientific papers based on their content. This innovative project can involve using GPT-2 or similar models trained on datasets of existing research titles.
7. Translate and Summarize News Articles
Build a web application that translates news articles from one language to another while also summarizing them. This project can utilize libraries such as Hugging Face Transformers for translation tasks combined with summarization techniques.
0 notes
Text
25 Real-World Machine Learning Projects for All Levels in 2025

Beginner-Level Projects
If you're new to machine learning, these projects will help. They will teach you the basics and build a solid foundation.
Predict House Prices. Use regression algorithms to predict housing prices. Use features like location, size, and the number of rooms. This project introduces you to data preprocessing and basic ML concepts.
Iris Flower Classification: A classic beginner project. Use the Iris dataset to classify iris flowers into species. It’s perfect for understanding supervised learning and classification algorithms.
Spam Email Detector: Create a model to classify emails as spam or not using NLP techniques. This project introduces text preprocessing and basic NLP.
Handwritten Digit Recognition: Use the MNIST dataset. Build a model to recognize digits in handwritten text. This project is a great introduction to image processing and neural networks.
Movie Recommendation System: Create a simple system to recommend movies. Use collaborative filtering to suggest films based on user preferences. This project introduces you to recommendation algorithms.
Intermediate-Level Projects
After the basics, these projects will let you explore advanced ideas and techniques.
Sentiment Analysis on Social Media: Analyze tweets or reviews for sentiment. They can be positive, negative, or neutral. This project dives deeper into NLP and text classification.
Detecting Fake News: Create a model to spot fake news articles. Use NLP and classification algorithms. This project presents significant challenges and has a meaningful impact on society.
Customer Segmentation: Use K-Means to segment customers by their buying behavior. This project is great for understanding unsupervised learning.
Stock Price Prediction: Predict stock prices using time series analysis and regression models. This project introduces you to financial data and forecasting techniques.
Chatbot Development: Create a chatbot using NLP and deep learning models like Seq2Seq. This project is perfect for learning about conversational AI.
Image Captioning: Build a model that uses CNNs and RNNs to generate captions for images. This project combines computer vision and NLP.
Predicting Diabetes Risk: Use healthcare data to predict diabetes risk in patients. This project introduces you to medical datasets and classification.
Detecting Anomalies in Network Traffic: Find cyber threats by spotting odd patterns in network traffic. This project is ideal for learning about anomaly detection.
Music Genre Classification: Use audio features and ML to classify music into genres. This project introduces you to audio processing.
Predicting Customer Churn: Use customer data to find those likely to leave a service. This project is great for understanding the business applications of ML.
Advanced-Level Projects
For seasoned practitioners, these projects will test your skills. They will use cutting-edge technologies.
Train a model to drive in a simulation using reinforcement learning. This project is perfect for exploring autonomous systems.
GANs for art creation use GANs to create realistic images or art. This project dives into generative models and creative AI.
Human Pose Estimation: Build a model to estimate human poses from images or videos. This project is ideal for exploring computer vision and deep learning.
Build a language translation system with transformer models such as BERT or GPT. This project introduces you to advanced NLP techniques.
AI-Powered Personal Assistant: Create a voice-activated personal assistant like Siri or Alexa. This project combines NLP, speech recognition, and AI integration.
Predicting Air Quality: Use environmental data to predict air quality in various regions. This project is great for exploring time series forecasting and environmental ML.
Deepfake Detection: Build a model to detect deepfake videos or images. This project presents significant challenges and addresses important social issues.
AI for Game Development: Train an AI agent to play a video game using reinforcement learning. This project is perfect for exploring game AI and decision-making systems.
Use deep learning to segment medical images, like X-rays or MRIs. This project is ideal for healthcare applications of ML.
AI-Powered Cybersecurity System. Develop a system that uses ML to detect and prevent cyberattacks in real time. This project is perfect for exploring AI in cybersecurity.
Why These Projects Matter
These projects will boost your technical skills. They will also give you practical experience in solving real-world problems. They cover many fields, from healthcare to cybersecurity. This ensures you gain exposure to diverse domains.
Tips for Success
Begin with simpler projects, and as you gain experience, progress to more complex ones.
Use open datasets: Kaggle, UCI, and Google Dataset Search have good practice datasets.
Leverage Tools and Frameworks: Use popular ML libraries, like TensorFlow, PyTorch, and Scikit-learn. They can speed up your work.
Collaborate and Share: Join online communities like GitHub or Reddit. Share your projects and get feedback.
Conclusion
Machine learning is a field that thrives on innovation and experimentation. Working on these 25 projects will boost your tech skills. You’ll also grow a problem-solving mindset, which is key for success in 2025 and after. Every project, from a spam detector to a self-driving car, will help you master machine learning. So, pick a project that excites you, roll up your sleeves, and start coding! The future of AI is in your hands.
Please contact us
📞 Phone: +1 713-287-1187
📧 Email: [email protected]
🌐 Visit our website.
0 notes
Text
How to Choose the Right Machine Learning Algorithm for Your Data

How to Choose the Right Machine Learning Algorithm for Your Data Selecting the right machine learning algorithm is crucial for building effective models and achieving accurate predictions.
With so many algorithms available, deciding which one to use can feel overwhelming. This blog will guide you through the key factors to consider and help you make an informed decision based on your data and problem.
Understand Your Problem Type The type of problem you’re solving largely determines the algorithm you’ll use.
Classification: When your goal is to assign data to predefined categories, like spam detection or disease diagnosis.
Algorithms:
Logistic Regression, Decision Trees, Random Forest, SVM, Neural Networks.
Regression:
When predicting continuous values, such as house prices or stock market trends.
Algorithms:
Linear Regression, Ridge Regression, Lasso Regression, Gradient Boosting.
Clustering:
For grouping similar data points, like customer segmentation or image clustering.
Algorithms:
K-Means, DBSCAN, Hierarchical Clustering. Dimensionality Reduction: For reducing features while retaining important information, often used in data preprocessing.
Algorithms: PCA, t-SNE, Autoencoders.
2. Assess Your Data The quality, size, and characteristics of your data significantly impact algorithm selection.
Data Size: For small datasets, simpler models like Linear Regression or Decision Trees often perform well.
For large datasets, algorithms like Neural Networks or Gradient Boosting can leverage more data effectively.
Data Type:
Structured data (tables with rows and columns):
Use algorithms like Logistic Regression or Random Forest.
Unstructured data (text, images, audio):
Deep learning models such as Convolutional Neural Networks (CNNs) or Recurrent Neural Networks (RNNs) work best.
Missing Values and Outliers:
Robust algorithms like Random Forest or Gradient Boosting handle missing values and outliers well.
3. Consider Interpretability Sometimes, understanding how a model makes predictions is as important as its accuracy.
High Interpretability Needed:
Choose simpler models like Decision Trees, Linear Regression, or Logistic Regression.
Accuracy Over Interpretability:
Complex models like Neural Networks or Gradient Boosting might be better.
4. Evaluate Training Time and Computational Resources Some algorithms are computationally expensive and may not be suitable for large datasets or limited hardware.
Fast Algorithms: Logistic Regression, Naive Bayes, K-Nearest Neighbors (KNN).
Resource-Intensive Algorithms: Neural Networks, Gradient Boosting, SVM with non-linear kernels.
5. Experiment and Validate Even with careful planning, it’s essential to test multiple algorithms and compare their performance using techniques like cross-validation.
Use performance metrics such as accuracy, precision, recall, F1 score, or mean squared error to evaluate models.
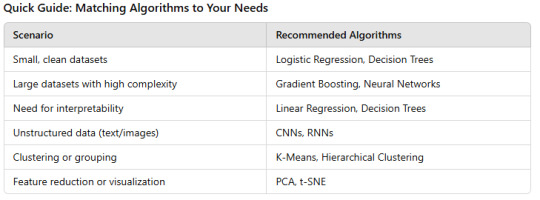
Conclusion
Choosing the right machine learning algorithm requires understanding your problem, dataset, and resources.
By matching the algorithm to your specific needs and experimenting with different options, you can build a model that delivers reliable and actionable results.

0 notes
Text
Data Collection For Machine Learning: Fueling the Next Generation of AI

In the text of artificial intelligence, data is that which gives breath to innovation and transformation. In other words, the heart of any model of machine learning is the dataset. The process of data gathering in machine learning is what builds the intelligent systems that allow algorithms to learn, adapt, and make decisions. Irrespective of their sophistication, advanced AI would fail without good quality, well-organized data.
This article discusses the importance of data collection for machine learning, its role in AI development, the different methodologies, challenges, and how it is shaping the future of intelligent systems.
Significance of Data Collection in Machine Learning
Data is the lifeblood of machine learning models. These models analyze examples to derive patterns, ascertain relationships, and develop a prediction based on them. The amount and quality of data given to the machine learning model will directly affect the model's accuracy, reliability, and generalization.
The Role of Data Collection in AI Success
Statistical Training and Testing of Algorithms: Machine learning algorithms are trainable with data. A spectrum of datasets allows models to train on alternate scenarios, which would enable accurate predictions during everyday applications of models. Validation datasets check for model effectiveness and help in reducing overfitting.
Facilitating Personalization: An intelligent system could tailor a richer experience based on personal information typically gathered from social interactions with high-quality data. In some instances, that might include recommendations on streaming services or targeted marketing campaigns.
Driving Advancement: The autonomous car, medical diagnosis, etc. would be nothing without big datasets for performing some of those advanced tasks like object detection, or sentiment analysis, or even what we call disease prediction.
Data Collection Process for Machine Learning
Collecting data for machine learning, therefore, is an exhaustive process wherein some steps need to be followed to ensure the data is to be used from a quality perspective.
Identification of Data Requirements: Prior to gathering the data, it is mandatory to identify the data type that is to be collected. It depends on the problem that one may want the AI system to address.
Sources of Data: Sources from which data can be derived include, public datasets, web scraping, sensor and IoT devices.
Data Annotation and Labelling: Raw data has to be annotated, that is labelled in order to be useful for machine learning. This can consist of images labelled by objects or feature. Text can be tagged with sentiment or intent. Audio files can be transcribed into text, or can be classified by sound type.
Data Cleaning and Preprocessing: The collected data is often found imperfect. Thus, cleaning removes errors, duplicates, and irrelevant information. Preprocessing helps to ensure that data is presented in a fashion or normalized data to be input into machine learning models.
Diverse Data: For the models to achieve maximum approximating generalization, the data must represent varied scenarios, demographics, and conditions. A lack of diversity in data may lead to biased predictions. This would undermine the reliability of the system.
Applications of Collected Data in AI Systems
Datasets collected empower AI systems across different sectors enabling them to attain remarkable results:
Healthcare: In medical AI, datasets collected from imaging, electronic health records, and genetic data are used to, diagnose diseases, predict patient outcomes, personalize treatment plans.
Autonomous Systems: Self-driving cars require massive amounts of data--acquired from road cameras, LiDAR, and GPS--to understand how to navigate safely and efficiently.
Retail and E-Commerce: Customer behavior, purchase history, and product review data allow AI models to recommend products, anticipate trends, and improve upon customer experience.
Natural Language Processing: From chatbots to translation tools, speech and text datasets enable machines to understand and generate human-like language.
Smart Cities: Data collected from urban infrastructure, sensors, and traffic systems is used to plan for cities, reducing congestion and improving public safety.
Challenges of Data Collection for Machine Learning
While data collection is extremely important, there are a few issues to be addressed as they pose challenges to successful AI development:
Data privacy and security: Collection of sensitive data from people's personal information or medical records provides numerous ethical hurdles. Security of sensitive data and abiding by privacy regulations such as GDPR are important.
Bias in Data: Bias in collected data can make AI models unfair. For example, facial recognition systems trained on non-diverse datasets might not recognize some people from underrepresented populations.
Scalability: As the AI system advances in complexity, so does the volume of data needed. The collection, storage, and management of such vast amounts can heavily utilize resources.
Cost and resources: Data collection, annotation, and preprocessing require considerable time, effort, and monetary input.
The Future of Data Collection in AI
With these technological advances, data collection is set to become more efficient and effective. The emerging trends include:
Synthetic Data Generation: AI-driven tools create artificial datasets that reduce reliance on real-world data and ease issues around privacy.
Real-time Data Streaming: Data is retrieved by IoT devices and edge computing for live AI processing.
Decentralized Data Collection: The use of Blockchain ensures secure and transparent exchange of information among different organizations and individuals.
Conclusion
Data-driven collection for machine learning is central to AI, the enabling force behind systems transforming industries and enhancing lives across the world. Every effort-from data sourcing and annotation to the resolution of ethical challenges-adds leaps in the development of ever-more intelligent and trustworthy AI models.
As technology enhances, tools and forms of data collection appear to be improving and, consequently, paving the way for smart systems that are of better accuracy, inclusion, and impact. Investing now in quality data collection sets the stage for a future where AI systems can sap their full potentials for meaningful change across the globe.
Visit Globose Technology Solutions to see how the team can speed up your data collection for machine learning projects.
0 notes