#Code blocks c compiler
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Note
im good! was just eating dinner (chicken and pasta), and have had a great rest day today with my dogs. i did nothing of note! yippee!
how are you?
echo -n "meo" && while [ 1 ]; do echo -n "w"; done
- @sed-official
MEOWWWWWWWWWWWWWWWW
hi sed how are you
#i say nothing of note#i wrote meowwwwwww....... in a few languages#rust c python bash 3 times haskell (the haskell doesnt work :3) and vim keypresses#@brainfuck-official did it first in. well. brainfuck.#i just stole their idea#... decided to actually test my haskell code. and it works#its just `main = do putStrLn $ “meo” ++ repeat 'w'`#which you think wouldnt be flushed because theres no newlines and no calls to flush.#but apparently ghc decides to pick during compilation if its line or block buffered for some reason#(i only wrote the hask to send to a few friends whose only lang is hask. i didnt think it would actually work!)#im now curious if the ghc optimized hask is faster than my own rust. looks like ive got something to do for the next 10 minutes lol#<edit>dog came by and said hi! the hask took 33.5s to print 1bn chars. the rust took 28.1s.#this is a win for trans girls (rust) and a loss for trans girls (hask)</edit>
8 notes
·
View notes
Text
More Hawkins/Innovations Ball Observations 🔭🎈🧭
+ A Color Theory

I know I’ve already made several posts about this ball, but I have more observations, so I’m going to compile everything here. For the stuff I’ve already made detailed posts about, I’ll just give brief descriptions.
1. Yellow. There’s so much of it here, and in the episode as a whole. Ahead of the part 1 release, I had been thinking a lot about how the color red would be used to signify Colin’s growing love- and it is, particularly in 3x04 (I’ll come back to that)- but in this episode, yellow is used more so, which is even better because it signifies how much Pen, specifically, is haunting Colin (in the romantic way obviously lol). At Stowell House, earlier in the episode, the walls are a very obvious singular yellow tone, and Colin wears a yellow waistcoat. Here at the Innovations Ball, there are a ton of different shades of yellow on the walls, props/furnishings, costumes, and in the lighting.


Also note the blue elements.


AND green!


(I love Marcus repping all the Polin colors. That bodes well.)
So, yeah, lots of Polin-coding, but also, like I said, I have a particular theory about color, which I will return to at the end of this post.
2. Colin’s entrance into the ballroom mirrors the infamously unfortunate Beauty and the Beast scene from 2x04. Both scenes have our leads stopped on staircases in front of grandfather clocks (another surprisingly significant motif of the season). I love the comparison of her being lonely because she’s left alone by him in that moment- and by everyone else as usual- to now him being lonely, despite being surrounded by admirers, because he’s being left alone by the one person who truly knows him and would make that difference for him.




3. I think everyone already knows about this parallel by now, but I have to note it because it’s so in line with my other observations- when Colin says his “it is possible to do anything” line, that scene mirrors the “assuredly, fervently, loudly” scene from 1x08. Pen and Colin are both inspiring each other, encouraging each other to be honest about their feelings.


And I feel like that’s not the only moment where the scenes are mirrored. In 1x08, when Colin sees Pen, the crowd parts so he has (and we have) the full view of her, and he makes his way over to her from the center of the floor to the edge. In 3x03, after Colin almost reveals his feelings (similar to how Pen almost revealed her feelings in 1x08), Pen leaves him at the edge of the floor to go to the center with Debling. And the crowd, which had been parted- giving us a view of Colin behind Pen- now rushes in to block that view.


4. Double meanings. They’re everywhere.
a) Again, the “it is possible to do anything” line. He’s delivering it to the admiring debutantes, but we know he’s really speaking to Pen. He’s really talking to her about his feelings for her. Of course, Pen thinks he’s talking to her about Debling. The hits just keep on coming for Colin in this episode.
b) In another interesting turn of events, considering she’s Whistledown and so much of what she’s said and done in the past seasons has been layered with hidden meanings, Pen goes and speaks the plain singular truth about herself and her intentions to Debling (obviously barring the fact that she’s Whistledown). Of course this is very in line with one of her main journeys for the season, which is to accept and reveal herself.
c) Colin attempts to hide the true meaning of his words to Violet when he asks her about love and friendship. Of course, he’s just so god damn transparent, bless his heart. And Violet, very sweetly, goes along with it.
And btw, after she leaves Colin to let him go approach Pen, she watches them the whole time. 💜

d) Unserious but relevant:

Not only are they literally and metaphorically sick, this pregnancy subplot also fits with the whole theme of nature.
e) The Whistledown narration. As per usual, it applies to multiple characters and their storylines. I’m obsessed with how it’s so intentionally layered onto the shots. The sequence is so incredible and so involved. I’m linking the post I made about it here in case anyone hasn’t seen it yet and is curious about what I mean.
5. I could be totally off about this one, but it looks to me like Miss Malhotra’s hair clip is designed like a compass. If it is, that would make sense because it would be on theme for the ball. But what I particularly love about the idea is that it’s also relevant to Polin. Hardcore Polin fans like to say that Pen is Colin’s compass.

6. At the end of this episode, as Colin has officially fallen in love with Pen, we see the beginning of the next episode’s theme color, red.

Which brings me to my final observation, my color theory.
I’ve said this before and I will continue to say it every time I have an insane prediction or theory: I am probably very wrong. But I’ll say it anyway…
It seems to me that each episode has a different signature color. I think 3x02 is green because Pen and Colin are starting to grow and bloom.


3x03 is yellow because, again, Pen is haunting Colin.


3x04 is red because they’re lovesick for each other.


And 3x01 is everything. It’s an explosion of color.



I think that, in many ways, 3x01 is meant to be a preview of the upcoming episodes, highlighting all of the colors. I mean, wouldn’t the presence of a “Four Seasons” ball indicate that everything is there? Everything that you would see in a year? (Or a full season of Bridgerton?) I think it probably tells us which colors will define the part 2 episodes as well, but I won’t venture to guess.
In speaking about Colin’s garden party waistcoat, the associate costume designer, Dougie Hawkes, said that it has hints about future episodes.


I have to wonder if this color thing has something to do with that. I’m also pretty sure that all of the other waistcoats Colin wears in 3x01 are ones he wears again more obviously in the other part 1 episodes. This seems to indicate, for one thing, that the garden party waistcoat is indeed special, but also that there is so much hiding in plain sight in episode 1 that will come back throughout the season. In other words, there’s probably a lot of stuff in part 2 that’s already been hinted at in 3x01…
But I dunno, I’m probably wrong about this.
Anyway, that’s all for now! ✌️
#i’ve officially become a color conspiracy theorist#it’s ok tho i don’t think i’ll say much more about color for a while after this#i’ve become far more unhinged about mirrors#that batshit post should be ready at the end of the week#anyway#i hope these observations aren’t completely unnecessary#i just love 3x03 so god damn much#polin#bridgerton#bridgerton 3x03#bridgerton analysis#bridgerton parallels#obsessive bridgerton things
55 notes
·
View notes
Text
can an LLM write a demo?
ongoing LLM probing efforts: I tried giving them a challenge to "write code for a 4k demo to render an ocean scene".
note, in demoscene parlance, a '4k demo' refers to a demo that fits in 4 kilobytes, not one that renders to a 4k monitor. this is a stupidly difficult high-context problem and I didn't expect to really get perfect output. well, shocker, the output was largely not all that impressive in human terms.
Here's the best result I was able to get after a fairly extended dialogue with DeepSeek R1 70b, a 300kb demo using opengl:

many wave, very ocean
I'm kind of wondering why I did this at this point, but I think the main reason was that I started to buy a bit of the hype and wanted to reassure myself that LLMs are still a bit daft?
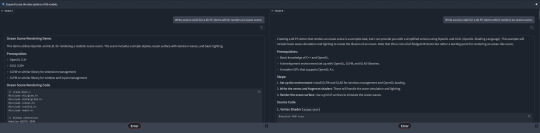
first I tried two LLMs on lmarena.ai but the site bugged out when I rated them rather than tell me which bots I was talking to.
Both generated what looked like a valid OpenGL program (though I did not attempt to compile either), however, looking closer the output was flawed in various ways. The left one decided to do some limited raytracing in the fragment shader rather than displace a mesh. It claimed to be using Gerstner waves, which would be cool, but a closer look at the output showed it was actually just sines. I'm also not sure quite what it thinks it's doing with the projection - it just seems to take the fragment position as if it were the 3D position.
The second AI does better, generating a plausible-looking vertex and fragment shader file with sine-based vertex displacement. There are some oddities, though, like the fact that it doesn't actually use the generated vertex and fragment shaders as external files, writing them out again as strings in the actual program. Overall, I could believe that if I compiled this it would look like a basic sinusoidal ocean with Phong shading. Old-school but reasonable. Unfortunately I closed the tab so I can't actually test it anymore.
Curious about what might be going on inside these models, I tried asking DeepSeek R1:14b the same challenge. Predictably this smaller model did worse. Its chain of thought prompting gave it a pretty coherent description of how you would write a demo like this, but also revealed some interesting confusions, for example multiple times referring to 'example code' that didn't exist, or quoting things I didn't say ('the user mentioned OpenGL and Vulkan').

When it came to output, though, it only gave me a list of steps to follow and omitted actual code:

There is no 'detailed response provided'.
After issuing some clarifications, DeepSeek R1:14b came up with the idea of creating a text-based demo instead, and generated some plausible-looking code in C++. I figured I might actually compile this, but it used a header file conio.h without explanation. Asking it to clarify led to it figuring out this is an old Windows header, replace it with standard library code, and actually spontaneously add a conditional compilation check for a Windows/Linux difference.
I tried compiling the provided code and ran into some missing libraries. A little coaxing gave a lot of blather to tell me 'you need to #include <cmath>'. A little more coaxing got it to tell me what compiler flags would be needed.
Thus I can present to you Deepseek R1:14b's demo:
Beautiful. Sure to win first place. The 'press q to quit' thing doesn't work. And the compiled binary definitely doesn't fit in 4kb (though it might if I stripped it etc.). But... it tried?
For fairness sake, I'll flood my RAM to try the 70b version as well. To its credit, its 'think' block immediately understands what a '4k demo' is supposed to be. Unfortunately it then goes off the rails and decides to do it in pygame, which is... babe you ain't gonna make a 4k demo in pygame lmao. As the output continued, it forgot that 4k referred to binary size rather than resolution, resolving to test the pygame program which is... not something an LLM can do.
Curiously (and this is something I have noticed a couple of times with DeepSeek), the 'actual' answer after the <think> block basically ignored all that Python stuff and wrote me a basic 'hello triangle' OpenGL program in C. So what was the point of all that thinking? Apparently when it maps from the 'think' LLM path to the 'final output' LLM path, DeepSeek can just... ignore what it was thinking about? The shaders it generated were pretty limited, it basically generates one big triangle over the screen with a scrolling sine wave on it, but I decided to see if it would compile anyway.
I tried asking it for advice on setting up GLFW and GLEW with MinGW and its answer was mostly quite good... but garbled some details (suggesting inconsistent places in where to put the libraries), which luckily I know enough to be able to spot. In the end we get this as the resulting demo:
I've lowered my expectations a lot by this point, but I will give DeepSeek a lot of credit for helping me get a working MinGW/OpenGL build environment. Given that it's a long time since I've fucked about with C/C++, and there's nothing so nice as cargo in this ecosystem, it was a lot faster than figuring it out from the docs.
The executable was more like 400kb than 4kb, so I thought I'd see if I could coax DeepSeek R1-70b to make it smaller. The chain of thought generated here was a genuinely solid discussion of sizecoding techniques, but the real proof would be whether DeepSeek could apply the ideas it pulled out concretely. In the end it gave me a list of ideas to try, including a couple of compiler flags - with this I shaved off 100kb, but it's still far too large.
(Ironically it suggested using "minimalistic frameworks often found in demoscene communities".)
I think I've spent as much time investigating this as I want to. Overall, DeepSeek R1 70b did a pretty good job of understanding what I wanted and generating relevant output, and tbh I could definitely imagine a LLM being useful if I needed to quickly reference info while writing a demo, but evaluated on the original question of 'can this LLM write a 4k demo depicting an ocean scene', the answer is a pretty emphatic no.
Running this on my computer, this took ages to generate the full output token by token - the full interaction ended up taking a couple of hours. But if I did this from scratch, having to look up docs and everything with zero experience with the APIs, I think it would probably take me about the same time to get a working OpenGL program.
Could the 'full size' models do better? Quite probably, but I ain't spending money on this shit.
23 notes
·
View notes
Text
22nd Oct || Day 1 of 100 days of code/productivity

today I created a general plan for what I want to accomplish over the next couple months in terms of learning to code. I had a Codeacademy subscription that I had totally forgotten about so I logged in and enrolled into the Learn C Skill Path course - which teaches you the fundamentals of C programming. I chose this course because my university prefers to teach their intro to programming course in C (all Computer Science students _must_ take this course as a prerequisite in order to progress to harder courses that will only build up on the knowledge acquired in here). I've heard it's pretty daunting for a beginner to learn programming in C so let's see how it goes. Just because I've heard scary things does not necessarily mean I should quit so soon. I'm no less than the nerdy guy in class who developed a game at the age of 11 or something, haha.
The course seems to be very beginner-friendly, indeed. and the code environment as well as the terminal are integrated into the website so that we can practice as we learn, so that's good. I'm liking it so far!
The first lesson included the basics of C - everything from:
ensuring you have the correct syntax written down so that the code is able to compile
escape sequences (\n -> add new line and \t -> add new tab)
line comments and block comments that are used to document code as you go
I also learnt how to compile a C program using gcc, yay!
that's it for today, it is now nearly 5:30 am as we speak, and I was not able to get any work done all day because we have a religious festival going on from now through this upcoming month, so needless to say I'll be busy helping my family with preparations. but I really hope to commit to learning how to code for at least 2-3 hours every day, as it would make a massive difference. g'night besties! <3
#100dop#coding#student#stem#code#codeblr#100 days of productivity#programming#100 days of code#student life#study blog#study motivation#studyblr#studyspo#studying#study aesthetic#dark academia#light academia#first post#journal#adhd brain
36 notes
·
View notes
Note
forgive me for the questions & any possible inconsistencies or malformations:
how do we compile our symbolic high/low level code into machine language, and how do we find the most efficient method of conversion from symbolic to machine code?
is it possible to include things from asm in C source code?
why do any of the abstractions in C mean anything? how does the compiler translate them?
would it be possible to write and compile a libc in C on a machine which didn't have a precompiled libc? i think the answer is no, so how much peripheral stuff would you need to pull it off?
are these things i could have figured out by just reading the one compiler book with the dragon on the cover?
thanks and apologies.
these are uhh. these are really good questions. like if you're asking these then i think you know way more than you think you do
how do we compile our symbolic high/low level code into machine language?
we do it the natural (only?) way, using parsers, although a bit more technically involved than just a parser. all programming languages are comprised of just keywords (e.g. int, static, enum, if, etc) and operators(+, -, *, %), those are the only reserved terms. everything between them is an identifier (name of variable, struct, etc), so at some level we can just search for the reserved terms and match them, and match whatever is between them as identifiers (var names or whatever). with this, we can tokenize the raw input put it in the context of a defined grammar.
lex is the name of the program that does this. you have simple, defined keywords, and defined operators, and you group them together a few categories (e.g. int, float, long might all fall under the same "variable qualifier" category"). this is tokenization.
those tokens are given to another program, yacc, which deals with it in the context of some context-free defined grammar you've also provided it. this would be a very strict and unambiguous definition of what C code is, defining things like "qualifiers like int and float always proceed an identifier, the addition (+) operator needs two operands, but the ++ (increment by 1) operator only needs one". yacc processes these tokens in the context of the defined grammar, and since those tokens are defined in broad categories, you can start to converge on a method of generating machine code for them.
how do we find the most efficient method of conversion from symbolic to machine code?
ehehehe. ill save this one for later
is it possible to include things from asm in C source code?
yes:

assembly (which translates directly 1-to-1 to machine code) is the only thing a CPU understands, so there has to be a link between the lowest level programming language and assembly at some point. it works about as you'd expect. that asm() block just gets plopped into the ELF right as it appears in the code. there are some features that allow passing C variables in/out of asm() blocks.
why do any of the abstractions in C mean anything? how does the compiler translate them?
hoping above answers this
would it be possible to write and compile a libc in C on a machine which didn't have a precompiled libc? i think the answer is no, so how much peripheral stuff would you need to pull it off?
yes, and in fact, the litmus test that divides "goofy idea some excited kid thought up and posted all over hacker news" and "real programming language" is whether or not that language is bootstrapped, which is whether or not its compiler is written in "itself". e.g. gcc & clang are both C compilers, and they are written in C. bootstrapping is the process of doing this initially. kind of a chicken-and-egg problem, but you just use external things, other languages, or if it is 1970s, direct assembly itself, to create an initial compiler for that language, and the write a compiler for that language in that language, feed it to the intermediate compiler, and bam.
its really hard to do all of this. really hard. lol
are these things i could have figured out by just reading the one compiler book with the dragon on the cover?
idk which one that is
finally...
how do we find the most efficient method of conversion from symbolic to machine code?
so this is kind of an area of debate lol. starting from the bottom, there are some very simple lines of code that directly map to machine code, e.g
a = b + c;
this would just translate to e.g. sparc
add %L1,%L2,%L3 !
if statements would map to branch instructions, etc, etc. pretty straightforward. but there are higher-order optimizations that modern compilers will do, for example, the compiler might see that you write to a variable but never read from it again, and realize since that memory is never read again, you may as well not even bother writing it in the first place, since it won't matter. and then choose to just not include the now-deemed-unnecessary instructions that store whatever values to memory even though you explicitly wrote it in the source code. some of the times this is fine and yields slightly faster code, but other times it results in the buffer you used for your RSA private key not being bzero'd out and me reading it while wearing a balaclava.
34 notes
·
View notes
Text
This Week in Rust 533
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Official
crates.io: API status code changes
Foundation
Google Contributes $1M to Rust Foundation to Support C++/Rust "Interop Initiative"
Project/Tooling Updates
Announcing the Tauri v2 Beta Release
Polars — Why we have rewritten the string data type
rust-analyzer changelog #219
Ratatui 0.26.0 - a Rust library for cooking up terminal user interfaces
Observations/Thoughts
Will it block?
Embedded Rust in Production ..?
Let futures be futures
Compiling Rust is testing
Rust web frameworks have subpar error reporting
[video] Proving Performance - FOSDEM 2024 - Rust Dev Room
[video] Stefan Baumgartner - Trials, Traits, and Tribulations
[video] Rainer Stropek - Memory Management in Rust
[video] Shachar Langbeheim - Async & FFI - not exactly a love story
[video] Massimiliano Mantione - Object Oriented Programming, and Rust
[audio] Unlocking Rust's power through mentorship and knowledge spreading, with Tim McNamara
[audio] Asciinema with Marcin Kulik
Non-Affine Types, ManuallyDrop and Invariant Lifetimes in Rust - Part One
Nine Rules for Accessing Cloud Files from Your Rust Code: Practical lessons from upgrading Bed-Reader, a bioinformatics library
Rust Walkthroughs
AsyncWrite and a Tale of Four Implementations
Garbage Collection Without Unsafe Code
Fragment specifiers in Rust Macros
Writing a REST API in Rust
[video] Traits and operators
Write a simple netcat client and server in Rust
Miscellaneous
RustFest 2024 Announcement
Preprocessing trillions of tokens with Rust (case study)
All EuroRust 2023 talks ordered by the view count
Crate of the Week
This week's crate is embedded-cli-rs, a library that makes it easy to create CLIs on embedded devices.
Thanks to Sviatoslav Kokurin for the self-suggestion!
Please submit your suggestions and votes for next week!
Call for Participation; projects and speakers
CFP - Projects
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
Fluvio - Build a new python wrapping for the fluvio client crate
Fluvio - MQTT Connector: Prefix auto generated Client ID to prevent connection drops
Ockam - Implement events in SqlxDatabase
Ockam - Output for both ockam project ticket and ockam project enroll is improved, with support for --output json
Ockam - Output for ockam project ticket is improved and information is not opaque
Hyperswitch - [FEATURE]: Setup code coverage for local tests & CI
Hyperswitch - [FEATURE]: Have get_required_value to use ValidationError in OptionExt
If you are a Rust project owner and are looking for contributors, please submit tasks here.
CFP - Speakers
Are you a new or experienced speaker looking for a place to share something cool? This section highlights events that are being planned and are accepting submissions to join their event as a speaker.
RustNL 2024 CFP closes 2024-02-19 | Delft, The Netherlands | Event date: 2024-05-07 & 2024-05-08
NDC Techtown CFP closes 2024-04-14 | Kongsberg, Norway | Event date: 2024-09-09 to 2024-09-12
If you are an event organizer hoping to expand the reach of your event, please submit a link to the submission website through a PR to TWiR.
Updates from the Rust Project
309 pull requests were merged in the last week
add avx512fp16 to x86 target features
riscv only supports split_debuginfo=off for now
target: default to the medium code model on LoongArch targets
#![feature(inline_const_pat)] is no longer incomplete
actually abort in -Zpanic-abort-tests
add missing potential_query_instability for keys and values in hashmap
avoid ICE when is_val_statically_known is not of a supported type
be more careful about interpreting a label/lifetime as a mistyped char literal
check RUST_BOOTSTRAP_CONFIG in profile_user_dist test
correctly check never_type feature gating
coverage: improve handling of function/closure spans
coverage: use normal edition: headers in coverage tests
deduplicate more sized errors on call exprs
pattern_analysis: Gracefully abort on type incompatibility
pattern_analysis: cleanup manual impls
pattern_analysis: cleanup the contexts
fix BufReader unsoundness by adding a check in default_read_buf
fix ICE on field access on a tainted type after const-eval failure
hir: refactor getters for owner nodes
hir: remove the generic type parameter from MaybeOwned
improve the diagnostics for unused generic parameters
introduce support for async bound modifier on Fn* traits
make matching on NaN a hard error, and remove the rest of illegal_floating_point_literal_pattern
make the coroutine def id of an async closure the child of the closure def id
miscellaneous diagnostics cleanups
move UI issue tests to subdirectories
move predicate, region, and const stuff into their own modules in middle
never patterns: It is correct to lower ! to _
normalize region obligation in lexical region resolution with next-gen solver
only suggest removal of as_* and to_ conversion methods on E0308
provide more context on derived obligation error primary label
suggest changing type to const parameters if we encounter a type in the trait bound position
suppress unhelpful diagnostics for unresolved top level attributes
miri: normalize struct tail in ABI compat check
miri: moving out sched_getaffinity interception from linux'shim, FreeBSD su…
miri: switch over to rustc's tracing crate instead of using our own log crate
revert unsound libcore changes
fix some Arc allocator leaks
use <T, U> for array/slice equality impls
improve io::Read::read_buf_exact error case
reject infinitely-sized reads from io::Repeat
thread_local::register_dtor fix proposal for FreeBSD
add LocalWaker and ContextBuilder types to core, and LocalWake trait to alloc
codegen_gcc: improve iterator for files suppression
cargo: Don't panic on empty spans
cargo: Improve map/sequence error message
cargo: apply -Zpanic-abort-tests to doctests too
cargo: don't print rustdoc command lines on failure by default
cargo: stabilize lockfile v4
cargo: fix markdown line break in cargo-add
cargo: use spec id instead of name to match package
rustdoc: fix footnote handling
rustdoc: correctly handle attribute merge if this is a glob reexport
rustdoc: prevent JS injection from localStorage
rustdoc: trait.impl, type.impl: sort impls to make it not depend on serialization order
clippy: redundant_locals: take by-value closure captures into account
clippy: new lint: manual_c_str_literals
clippy: add lint_groups_priority lint
clippy: add new lint: ref_as_ptr
clippy: add configuration for wildcard_imports to ignore certain imports
clippy: avoid deleting labeled blocks
clippy: fixed FP in unused_io_amount for Ok(lit), unrachable! and unwrap de…
rust-analyzer: "Normalize import" assist and utilities for normalizing use trees
rust-analyzer: enable excluding refs search results in test
rust-analyzer: support for GOTO def from inside files included with include! macro
rust-analyzer: emit parser error for missing argument list
rust-analyzer: swap Subtree::token_trees from Vec to boxed slice
Rust Compiler Performance Triage
Rust's CI was down most of the week, leading to a much smaller collection of commits than usual. Results are mostly neutral for the week.
Triage done by @simulacrum. Revision range: 5c9c3c78..0984bec
0 Regressions, 2 Improvements, 1 Mixed; 1 of them in rollups 17 artifact comparisons made in total
Full report here
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
No RFCs were approved this week.
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
[disposition: merge] Consider principal trait ref's auto-trait super-traits in dyn upcasting
[disposition: merge] remove sub_relations from the InferCtxt
[disposition: merge] Optimize away poison guards when std is built with panic=abort
[disposition: merge] Check normalized call signature for WF in mir typeck
Language Reference
No Language Reference RFCs entered Final Comment Period this week.
Unsafe Code Guidelines
No Unsafe Code Guideline RFCs entered Final Comment Period this week.
New and Updated RFCs
Nested function scoped type parameters
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2024-02-07 - 2024-03-06 🦀
Virtual
2024-02-07 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - Ezra Singh - How Rust Saved My Eyes
2024-02-08 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2024-02-08 | Virtual (Nürnberg, DE) | Rust Nüremberg
Rust Nürnberg online
2024-02-10 | Virtual (Krakow, PL) | Stacja IT Kraków
Rust – budowanie narzędzi działających w linii komend
2024-02-10 | Virtual (Wrocław, PL) | Stacja IT Wrocław
Rust – budowanie narzędzi działających w linii komend
2024-02-13 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2024-02-15 | Virtual (Berlin, DE) | OpenTechSchool Berlin + Rust Berlin
Rust Hack n Learn | Mirror: Rust Hack n Learn
2024-02-15 | Virtual + In person (Praha, CZ) | Rust Czech Republic
Introduction and Rust in production
2024-02-19 | Virtual (Melbourne, VIC, AU) | Rust Melbourne
February 2024 Rust Melbourne Meetup
2024-02-20 | Virtual | Rust for Lunch
Lunch
2024-02-21 | Virtual (Cardiff, UK) | Rust and C++ Cardiff
Rust for Rustaceans Book Club: Chapter 2 - Types
2024-02-21 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2024-02-22 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
Asia
2024-02-10 | Hyderabad, IN | Rust Language Hyderabad
Rust Language Develope BootCamp
Europe
2024-02-07 | Cologne, DE | Rust Cologne
Embedded Abstractions | Event page
2024-02-07 | London, UK | Rust London User Group
Rust for the Web — Mainmatter x Shuttle Takeover
2024-02-08 | Bern, CH | Rust Bern
Rust Bern Meetup #1 2024 🦀
2024-02-08 | Oslo, NO | Rust Oslo
Rust-based banter
2024-02-13 | Trondheim, NO | Rust Trondheim
Building Games with Rust: Dive into the Bevy Framework
2024-02-15 | Praha, CZ - Virtual + In-person | Rust Czech Republic
Introduction and Rust in production
2024-02-21 | Lyon, FR | Rust Lyon
Rust Lyon Meetup #8
2024-02-22 | Aarhus, DK | Rust Aarhus
Rust and Talk at Partisia
North America
2024-02-07 | Brookline, MA, US | Boston Rust Meetup
Coolidge Corner Brookline Rust Lunch, Feb 7
2024-02-08 | Lehi, UT, US | Utah Rust
BEAST: Recreating a classic DOS terminal game in Rust
2024-02-12 | Minneapolis, MN, US | Minneapolis Rust Meetup
Minneapolis Rust: Open Source Contrib Hackathon & Happy Hour
2024-02-13 | New York, NY, US | Rust NYC
Rust NYC Monthly Mixer
2024-02-13 | Seattle, WA, US | Cap Hill Rust Coding/Hacking/Learning
Rusty Coding/Hacking/Learning Night
2024-02-15 | Boston, MA, US | Boston Rust Meetup
Back Bay Rust Lunch, Feb 15
2024-02-15 | Seattle, WA, US | Seattle Rust User Group
Seattle Rust User Group Meetup
2024-02-20 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2024-02-22 | Mountain View, CA, US | Mountain View Rust Meetup
Rust Meetup at Hacker Dojo
2024-02-28 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
Oceania
2024-02-19 | Melbourne, VIC, AU + Virtual | Rust Melbourne
February 2024 Rust Melbourne Meetup
2024-02-27 | Canberra, ACT, AU | Canberra Rust User Group
February Meetup
2024-02-27 | Sydney, NSW, AU | Rust Sydney
🦀 spire ⚡ & Quick
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
My take on this is that you cannot use async Rust correctly and fluently without understanding Arc, Mutex, the mutability of variables/references, and how async and await syntax compiles in the end. Rust forces you to understand how and why things are the way they are. It gives you minimal abstraction to do things that could’ve been tedious to do yourself.
I got a chance to work on two projects that drastically forced me to understand how async/await works. The first one is to transform a library that is completely sync and only requires a sync trait to talk to the outside service. This all sounds fine, right? Well, this becomes a problem when we try to port it into browsers. The browser is single-threaded and cannot block the JavaScript runtime at all! It is arguably the most weird environment for Rust users. It is simply impossible to rewrite the whole library, as it has already been shipped to production on other platforms.
What we did instead was rewrite the network part using async syntax, but using our own generator. The idea is simple: the generator produces a future when called, and the produced future can be awaited. But! The produced future contains an arc pointer to the generator. That means we can feed the generator the value we are waiting for, then the caller who holds the reference to the generator can feed the result back to the function and resume it. For the browser, we use the native browser API to derive the network communications; for other platforms, we just use regular blocking network calls. The external interface remains unchanged for other platforms.
Honestly, I don’t think any other language out there could possibly do this. Maybe C or C++, but which will never have the same development speed and developer experience.
I believe people have already mentioned it, but the current asynchronous model of Rust is the most reasonable choice. It does create pain for developers, but on the other hand, there is no better asynchronous model for Embedded or WebAssembly.
– /u/Top_Outlandishness78 on /r/rust
Thanks to Brian Kung for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
2 notes
·
View notes
Text
hmmm…so like in C++(20) I need to do two things right now. ok—I wrote this post and it turned out to be 4! (4. Not 4!. Thankfully.) C++ coding diary/questions/difficulties below:
The recursive function I’m working with is structurally the following:
void f(x) {
if(cond) {
successCode
} else {
code1; f(g(x));
if(cond2) { code2; f(h(x)) }
}
}
So, it can either call itself with different arguments—possibly twice, one after the other—or it can succeed.
The way it works, though, is by having code1 and code2 update entries in a global array. (In fact, code1 is simply a[something] = a[somethingElse], and code2 is simply a[something] = 1. cond2 is a[somethingElse] == 0.) So we do have to proceed sequentially to some extent.
Ideally, successCode initiates a possibly computationally intensive task on, say, one of my CPU cores, but spins that off and continues on with the recursive call. However, successCode needs to only spin that process off after it’s finished reading from that global array. (Maybe that part will be trivial.) Further, it needs to stall in the case too many of these processes have been spun off already, and wait for there to be an opening to start.
I’m wondering if std::thread has what I need for that.
2. one thing I’m doing which feels “bad” is: well, I need to have some local constants accessible to a recursive function. Right now I’m essentially just calling f(a, x) where a is unchanged across recursive calls and x changes. Does the compiler know how to handle this correctly…? Is there a better way? Like making a class or something? (I would typically just define this recursive function f(x) inside an outer function that took a as an argument, but you can’t do that directly in C++…)
3. another which feels bad is using this global array! I just need a block of memory whose length is fixed for the majority of the time, but which must be (rarely) grown. does a std::vector give me just as good performance as a really long array, I wonder? The main thing I’m doing is accessing and setting bits at a bunch of different indices, not inserting or growing…and it never grows too large, so maybe a long array is fine.
4. And that’s the other problem—I’m setting bits. that means I get to choose between:
a long (~100?) (and mostly empty most of the time) global array of bools (current, default choice)
the rumored-to-be-cursed std::vector<bool>, which is overridden to be space-efficient instead of a vector of bools—but at the cost of a bunch of its vector-ness! is it better? who knows! half the things on the manual page say “eh, we leave it up to the implementation to decide how or even whether to do this.”
a long and mostly empty most of the time bitset
a boost::dynamic_bitset, which is like a bitset but…dynamic…and I don’t know if that’s better. Like I said I don’t really need to grow it.
what if I just had as many unsigned ints as I needed and manipulated their bits with bitshifting somehow, as though the concatenation of the ints were my array. what then. would that be far worse?
The weird thing is that I don’t need space efficiency, but I do, on each success, need to transform (and alter) the content of this array (or whatever) into something which is space-efficient, but in a weird and bespoke way (I use the last 6 bits of bytes). that means im either constantly converting integer indices into (whichByte, whichBit) pairs and accessing/setting bit values in bytes at the result, or I’m doing one single translation of the whole array each successCode. hard for me to say which is more efficient without testing…but the second *seems* better somehow. but integer operations might be really fast. idk.
2 notes
·
View notes
Text
Actually that assembly language post reminds me of how I used to write programs that wrote programs back in the Apple II days.
If you've ever had occasion to write programs that output code on a modern OS, you'll know that filenames are now more descriptive than prescriptive. If you can save a text stream, you can just call that block of text "foo.pl" or "foo.py" or "foo.c" and run it through an interpreter or compiler. But Apple DOS didn't save programs in BASIC as text blocks with a .bas extension; it stored them in a tokenized form — sort of a half-compiled format that saved some space and didn't let you store a syntax error. (Each token would be converted back to its text form if you LISTed the program.)
The upshot was that BASIC didn't let you create these tokenized files and save them to disk from inside BASIC programs. However, it did let you create and save text files, and there was a DOS command that treated a text file as if it were being typed into the BASIC interpreter; if you had a BASIC program in memory after that process, the usual save routine worked. It was a real dance of indirection, but I ended up using it a fair amount.
The main example I remember now is a program that wrote random tunes — or rather, a program that, when run, would generate a random tune and then write and save a program to play it over the little beepy speaker. The notes came from a pre-calculated Markov chain table of probable steps — that is, if note N-2 is C and note N-1 is D (up a whole step), then 50% of the time N will be back down a whole step, 22% it'll be up a whole step, et c. — as did their durations, and these pairs got converted into a series of POKE and CALL statements that would sound the speaker at the appropriate frequencies for the appropriate durations when run. The program would write those commands out, along with the block of DATA commands that held the machine language sound routine, to a text file so they could all be loaded back in to be saved and run.
(For those unfamiliar with microcomputer BASICs, POKE put a value directly into a raw memory location, DATA did the same for list of values and a block of locations, and CALL activated a machine language subroutine. Apple II BASIC didn't have any commands for sound, and in fact the machine depended on reading from or writing to a particular memory location to manually move the speaker cone inwards or outwards; doing this at the appropriate frequency was how you generated tones. Add-on cards with real sound hardware existed, but I never knew anybody who had one.)
3 notes
·
View notes
Text
hard to pick a favorite
if i had to it'd probably being able to return and destructure tuples whenever u want. i LOVE returning multiple things from functions without having to declare a new struct every time
but also the enums are so powerful (while not being awful like c unions)
and cargo Just Works
and the documentation is SO GOOD. definitely the best language documentation i've used so far
also using entire blocks of code as an expression in an assignment statement or w/e is really funny and enables some mildly cursed designs (also i like the if-as-expression syntax more than the ? : syntax like in C)
speaking of syntax the syntax in general!!! it's So Explicit which is very nice. makes it very easy to read imo (especially since my IDE autofills the types for let statements)
a lil bit of functional programming is also nice but tbh i dont use that as much as i could
also so many compiler checks!!! helps me to not have to focus as much on the code. if it compiles its probably correct
ALSO THE UNIT TESTING IS SO GOOD ITS SUCH A NICE LIL FRAMEWORK BUILT RIGHT INTO RUST & CARGO
also very nice that if it gets in ur way theres usually a way around it. what with Cells for getting around mutability issues, Rc for multiple ownership, and unsafe blocks for system-level nonsense, stuff like that
lots of things. its my favorite language for a lot of reasons
reblog with your favorite rust feature
352 notes
·
View notes
Text
Unlocking the Basics: A Comprehensive C Programming Language Tutorial for Beginners
Introduction
C programming language is often referred to as the backbone of modern programming. Developed in the early 1970s, C has influenced many other programming languages, including C++, Java, and Python. Its efficiency, flexibility, and powerful features make it a popular choice for system programming, embedded systems, and application development. This tutorial aims to provide beginners with a solid foundation in C programming, covering essential concepts, practical examples, and best practices to help you unlock the basics and start your programming journey.The
Why Learn C?
Before diving into the tutorial, it’s important to understand why learning C is beneficial:
Foundation for Other Languages: C serves as a stepping stone to learning other programming languages. Understanding C concepts will make it easier to grasp languages like C++, Java, and C#.
Performance and Efficiency: C is known for its speed and efficiency, making it ideal for system-level programming and applications where performance is critical.
Portability: C programs can be compiled and run on various platforms with minimal changes, making it a versatile choice for developers.
Rich Libraries: C has a vast collection of libraries that provide pre-written code for common tasks, speeding up the development process.
Strong Community Support: With decades of history, C has a large community of developers, providing ample resources, forums, and documentation for learners.
Getting Started with C Programming
1. Setting Up Your Development Environment
To start programming in C, you need to set up a development environment. Here’s how:
Choose a Compiler: Popular C compilers include GCC (GNU Compiler Collection) for Linux and MinGW for Windows. You can also use IDEs like Code::Blocks, Dev-C++, or Visual Studio.
Install the Compiler: Follow the installation instructions for your chosen compiler. Ensure that the compiler is added to your system’s PATH for easy access.
Choose a Text Editor or IDE: You can write C code in any text editor (like Notepad++ or Sublime Text) or use an Integrated Development Environment (IDE) for a more user-friendly experience.
2. Writing Your First C Program
Let’s start with a simple "Hello, World!" program to familiarize you with the syntax:#include <stdio.h> int main() { printf("Hello, World!\n"); return 0; }
Explanation:
#include <stdio.h>: This line includes the standard input-output library, allowing you to use functions like printf.
int main(): This is the main function where the program execution begins.
printf("Hello, World!\n");: This line prints "Hello, World!" to the console.
return 0;: This indicates that the program has executed successfully.
3. Understanding C Syntax and Structure
C has a specific syntax that you need to understand:
Variables and Data Types: C supports various data types, including int, float, char, and double. You must declare variables before using them.
int age = 25; float salary = 50000.50; char grade = 'A';
Operators: C provides arithmetic, relational, logical, and bitwise operators for performing operations on variables.
Control Structures: Learn about conditional statements (if, else, switch) and loops (for, while, do-while) to control the flow of your program.
4. Functions in C
Functions are essential for organizing code and promoting reusability. Here’s how to define and call a function:#include <stdio.h> void greet() { printf("Welcome to C Programming!\n"); } int main() { greet(); // Calling the function return 0; }
5. Arrays and Strings
Arrays are used to store multiple values of the same type, while strings are arrays of characters. Here’s an example:#include <stdio.h> int main() { int numbers[5] = {1, 2, 3, 4, 5}; char name[20] = "John Doe"; printf("First number: %d\n", numbers[0]); printf("Name: %s\n", name); return 0; }
6. Pointers
Pointers are a powerful feature in C that allows you to directly manipulate memory. Understanding pointers is crucial for dynamic memory allocation and data structures.#include <stdio.h> int main() { int num = 10; int *ptr = # // Pointer to num printf("Value of num: %d\n", *ptr); // Dereferencing the pointer return 0; }
7. Structures and Unions
Structures allow you to group different data types under a single name, while unions enable you to store different data types in the same memory location.#include <stdio.h> struct Student { char name[50]; int age; }; int main() { struct Student student1 = {"Alice", 20}; printf("Student Name: %s, Age: %d\n", student1.name, student1.age); return 0; }
Best Practices for C Programming
Comment Your Code: Use comments to explain complex logic and improve code readability.
Use Meaningful Variable Names: Choose descriptive names for variables and functions to make your code self-explanatory.
Keep Code Organized: Structure your code into functions and modules to enhance maintainability.
Test Your Code: Regularly test your code to catch errors early and ensure it behaves as expected.
Conclusion
Learning C programming is a rewarding journey that opens doors to various fields in software development. By following this comprehensive tutorial, you’ve unlocked the basics of C and gained the foundational knowledge needed to explore more advanced topics.
As you continue your programming journey, practice regularly, build projects, and engage with the C programming community. With dedication and persistence, you’ll become proficient in C programming and be well-equipped to tackle more complex challenges in the world of software development.
Ready to dive deeper? Explore advanced topics like memory management, file handling, and data structures to further enhance your C programming skills! Happy coding with Tpoint-Tech!
0 notes
Text
Improving Python Threading Strategies For AI/ML Workloads
Python Threading Dilemma Solution Python excels at AI and machine learning. CPython, the computer language's reference implementation and byte-code interpreter, needs intrinsic support for parallel processing and multithreading. The notorious Global Interpreter Lock (GIL) “locks” the CPython interpreter into running on one thread at a time, regardless of the context. NumPy, SciPy, and PyTorch provide multi-core processing using C-based implementations.
Python should be approached differently. Imagine GIL as a thread and vanilla Python as a needle. That needle and thread make a clothing. Although high-grade, it might have been made cheaper without losing quality. Therefore, what if Intel could circumvent that “limiter” by parallelising Python programs with Numba or oneAPI libraries? What if a sewing machine replaces a needle and thread to construct that garment? What if dozens or hundreds of sewing machines manufacture several shirts extremely quickly?
Intel Distribution of Python uses robust modules and tools to optimise Intel architecture instruction sets.
Using oneAPI libraries to reduce Python overheads and accelerate math operations, the Intel distribution gives compute-intensive Python numerical and scientific apps like NumPy, SciPy, and Numba C++-like performance. This helps developers provide their applications with excellent multithreading, vectorisation, and memory management while enabling rapid cluster expansion.One Let's look at Intel's Python parallelism and composability technique and how it helps speed up AI/ML processes. Numpy/SciPy Nested Parallelism The Python libraries NumPy and SciPy were designed for scientific computing and numerical computation.
Exposing parallelism on all software levels, such as by parallelising outermost loops or using functional or pipeline parallelism at the application level, can enable multithreading and parallelism in Python applications. This parallelism can be achieved with Dask, Joblib, and the multiprocessing module mproc (with its ThreadPool class).
An optimised math library like the Intel oneAPI Math Kernel Library helps accelerate Python modules like NumPy and SciPy for data parallelism. The high processing needs of huge data for AI and machine learning require this. Multi-threat oneMKL using Python Threading runtimes. Environment variable MKL_THREADING_LAYER adjusts the threading layer. Nested parallelism occurs when one parallel part calls a function that contains another parallel portion. Sync latencies and serial parts—parts that cannot operate in parallel—are common in NumPy and SciPy programs. Parallelism-within-parallelism reduces or hides these areas.
Numba
Even though they offer extensive mathematical and data-focused accelerations, NumPy and SciPy are defined mathematical instruments accelerated with C-extensions. If a developer wants it as fast as C-extensions, they may need unorthodox math. Numba works well here. Just-In-Time compilers Numba and LLVM. Reduce the performance gap between Python and statically typed languages like C and C++. We support Workqueue, OpenMP, and Intel oneAPI Python Threading Building Blocks. The three built-in Python Threading layers represent these runtimes. New threading layers are added using conda commands (e.g., $ conda install tbb). Only workqueue is automatically installed. Numba_threading_layer sets the threading layer. Remember that there are two ways to select this threading layer: (1) picking a layer that is normally safe under diverse parallel processing, or (2) explicitly specifying the suitable threading layer name (e.g., tbb). For Numba threading layer information, see the official documentation.
Threading Composability
The Python Threading composability of an application or component determines the efficiency of co-existing multi-threaded components. A “perfectly composable” component operates efficiently without affecting other system components. To achieve a fully composable Python Threading system, over-subscription must be prevented by ensuring that no parallel piece of code or component requires a specific number of threads (known as “mandatory” parallelism). The alternative is to provide "optional" parallelism in which a work scheduler chooses which user-level threads components are mapped to and automates task coordination across components and parallel areas. The scheduler uses a single thread-pool to arrange the program's components and libraries, hence its threading model must be more efficient than the built-in high-performance library technique. Efficiency is lost otherwise.
Intel's Parallelism and Composability Strategy
Python Threading composability is easier with oneTBB as the work scheduler. The open-source, cross-platform C++ library oneTBB, which supports threading composability, optional parallelism, and layered parallelism, enables multi-core parallel processing. The oneTBB version available at the time of writing includes an experimental module that provides threading composability across libraries, enabling multi-threaded performance enhancements in Python. Acceleration comes from the scheduler's improved Python Threading allocation. OneTBB replaces Python ThreadPool with Pool. By dynamically replacing or updating objects at runtime, monkey patching keeps the thread pool active across modules without code changes. OneTBB also substitutes oneMKL by activating its Python Threading layer, which automates composable parallelism using NumPy and SciPy calls.
Nested parallelism can improve performance, as seen in the following composability example on a system with MKL-enabled NumPy, TBB, and symmetric multiprocessing (SMP) modules and IPython kernels. IPython's command shell interface allows interactive computing in multiple programming languages. The demo was ran in Jupyter Notebook to compare performance quantitatively.
If the kernel is changed in the Jupyter menu, the preceding cell must be run again to construct the ThreadPool and deliver the runtime results below.
With the default Python kernel, the following code runs for all three trials:
This method can find matrix eigenvalues with the default Python kernel. Activating the Python-m SMP kernel improves runtime by an order of magnitude. The Python-m TBB kernel boosts even more.
For this composability example, OneTBB's dynamic task scheduler performs best because it manages code where the innermost parallel sections cannot completely leverage the system's CPU and where work may vary. SMP is still useful, however it works best when workloads are evenly divided and outermost workers have similar loads.
Conclusion
In conclusion, multithreading speeds AI/ML operations. Python AI and machine learning apps can be optimised in several ways. Multithreading and multiprocessing will be crucial to pushing AI/ML software development workflows. See Intel's AI Tools and Framework optimisations and the unified, open, standards-based oneAPI programming architecture that underpins its AI Software Portfolio.
#PythonThreading#Numba#Multithreadingpython#parallelism#nestedparallelism#NumPyandSciPy#Threadingpython#technology#technews#technologynews#news#govindhtech
0 notes
Text
Why Learning Rust Programming is the Best Decision for Your Developer Journey

If you're a beginner exploring which programming language to learn, chances are you've come across Python, JavaScript, and even C++. But have you heard about Rust? Not only is it one of the most modern, fast, and memory-safe programming languages out there, but it’s also quickly climbing the ranks among the developer community.
So why are so many developers – including beginners – switching to Rust? The answer lies in its performance, security, and simplicity, all packed into one elegant language.
In this post, we'll explore the core concepts of Rust programming for beginners, what makes it special, and why you should seriously consider learning it to future-proof your coding career.
🚀 What is Rust, and Why is Everyone Talking About It?
Rust is a statically typed, compiled programming language designed for performance and safety, especially when it comes to concurrent programming. Developed by Mozilla, it's been lauded for combining the power of C and C++ with memory safety without needing a garbage collector.
This means Rust is:
Fast – as fast as C or C++.
Safe – it prevents memory-related bugs before they happen.
Reliable – no more segmentation faults or thread safety issues.
Loved – it’s consistently ranked #1 in Stack Overflow’s Developer Survey as the “most loved programming language.”
The beauty of Rust lies in its balance – high performance without the fear of memory bugs. That's a dream come true for developers, especially those who are just starting.
🔰 Why Rust is Perfect for Beginners
At first glance, Rust might look intimidating. Its syntax is different, its compiler is strict, and the learning curve can feel steep. But that’s actually what makes it so perfect for beginners.
Here's why:
1. Rust Teaches You to Code the Right Way
The Rust compiler doesn’t just throw errors – it guides you. Think of it as a helpful teacher. You'll get suggestions, explanations, and documentation that lead you to write clean, efficient, and safe code.
2. Memory Safety Without Garbage Collection
Unlike languages like Java or Python, Rust does not rely on a garbage collector. Instead, it uses a unique ownership model to manage memory safely and efficiently – a game-changer when it comes to system-level programming.
3. Fantastic Tooling
Tools like cargo (Rust's package manager and build system) and rustfmt (code formatter) make development easier and more organized. Even setting up a project feels seamless and beginner-friendly.
4. Growing Community & Learning Resources
The Rust community is known for being incredibly welcoming. You’ll find tons of resources – documentation, tutorials, forums – and supportive people who are happy to help.
And for those wanting to learn with structure, this Rust Programming for Beginners course is the perfect start. It's beginner-friendly and walks you through everything step-by-step, even if you're totally new to coding.
🧠 Key Concepts You’ll Learn as a Beginner in Rust
Getting started with Rust is more about understanding its core concepts than just memorizing syntax. Here are the most important building blocks you’ll come across:
✅ Ownership & Borrowing
This is Rust’s secret sauce. The ownership system ensures memory is safely managed without needing a garbage collector. Once you understand how variables own their data, you’ll be amazed at how much it simplifies debugging and optimization.
✅ Pattern Matching
Rust has powerful pattern matching using the match keyword. It’s clean, readable, and far more expressive than traditional if/else logic in other languages.
✅ Enums & Option/Result Types
Rust handles errors gracefully and safely with the Result and Option types. No more null references or unexpected crashes!
✅ Lifetimes
They sound scary, but lifetimes are Rust’s way of making sure references live just long enough – not too little, not too long. And yes, the compiler will help you here too.
✅ Traits & Generics
Want to write code that’s flexible and reusable? Traits and generics in Rust help you do just that – without the bloat or confusion.
👩💻 Real-World Applications of Rust
So where can you actually use Rust? Here's where it shines:
Operating Systems – It's being used in parts of Windows and Linux!
WebAssembly – You can compile Rust into WebAssembly to run in browsers.
Game Development – Thanks to its speed and memory safety.
CLI Tools – Many popular command-line tools are written in Rust.
Blockchain & Cryptography – Its memory safety makes it perfect for secure applications.
Embedded Systems – With minimal overhead, Rust works great on microcontrollers.
✨ What Makes Rust Different from Other Languages?
Let’s compare Rust briefly to other popular languages beginners usually learn: LanguagePerformanceMemory SafetyBeginner FriendlyCommunity SupportPython🟡 Moderate🟢 Safe🟢 Very🟢 HighJava🟢 Good🟢 Safe🟢 High🟢 HighC++🟢 Fast🔴 Risky🔴 Steep🟢 HighRust🟢 Fast🟢 Very Safe🟡 Moderate🟢 Growing Fast
Rust finds the perfect middle ground. It gives you the performance of C++ and the safety of Java or Python – with modern tooling and cleaner syntax.
🎯 Who Should Learn Rust?
Rust is ideal for:
Absolute beginners who want to build a solid foundation.
Web developers curious about system-level performance.
Backend developers who want to write faster APIs.
Game developers interested in high-performance engines.
Security-conscious developers working in finance, healthcare, or blockchain.
IoT developers needing low-level control with safety.
In fact, learning Rust gives you an edge in both system-level and application-level programming – something few languages can offer.
🧭 How to Start Learning Rust (Without Feeling Overwhelmed)
Here's a simple roadmap you can follow:
Install Rust using rustup – the official installer.
Learn the basics of ownership, types, and control flow.
Build small CLI projects (like a to-do app or file parser).
Explore crates (Rust’s libraries) and use them in your projects.
Take a structured course, like the Rust Programming for Beginners, which covers all core concepts with practical examples.
Join the community – forums, Discord, Reddit, GitHub.
Keep experimenting – build, fail, learn, repeat!
💡 Tips to Stay Motivated While Learning Rust
Break it down: Rust has a learning curve. Focus on one concept at a time.
Practice > Theory: Build small, real projects to reinforce your learning.
Use online playgrounds: You don’t always need a full setup – try play.rust-lang.org to write and run code in your browser.
Follow Rustaceans (Rust developers) on social platforms to stay updated and inspired.
Celebrate your wins: Even if you understand ownership for the first time – that’s huge!
🧰 Tools and Resources to Support Your Rust Learning Journey
The Rust Book – Free and official Rust guide online.
Rustlings – Hands-on small exercises to practice Rust syntax.
Crates.io – Explore and use open-source libraries.
Rust Analyzer – IDE plugin to make coding in Rust easier and smarter.
VS Code – Pair it with Rust plugins for a smooth dev experience.
But if you want all this knowledge structured and simplified for a beginner, the Rust Programming for Beginners course is hands-down the easiest way to start.
🌐 The Future of Rust: Why You’re Getting in Early
Tech giants like Microsoft, Google, Amazon, and Dropbox are all investing in Rust. Major software like Firefox, Cloudflare, and even parts of Android OS use it under the hood.
Learning Rust today is like learning Python in 2009 – it sets you up to be ahead of the curve. And because so few people truly master it, Rust developers are in high demand.
👏 Final Thoughts: Start Today, Build Smarter Tomorrow
Rust is not just another programming language. It’s a movement toward safer, faster, and more reliable code. Whether you’re aiming to become a system developer, improve your backend skills, or build next-gen applications, Rust will be your secret weapon.
So if you’re a beginner ready to start coding with confidence, explore the Rust Programming for Beginners course and kickstart your journey today.
Remember – every expert was once a beginner. And the best time to start learning Rust is now. 🚀
0 notes
Text
Introduction to Programming

Programming shall be the speech of the next world's future-and here comes the year 2025; with a hope within your heart, you learn it now.
Targeting either website or app or perhaps even game development, it is programming that opens many doors to understanding how the digital world works.
What is a Programming Language?
A set of instructions perfectly understandable by a computer is thus called a programming language. Given, that it consists of human speaking to machines about completing some vital tasks. Such type languages mainly include the beginner kind as well as the powerful kind but for 2025-Python, JavaScript, and Scratch (especially for the more juvenile ones). Each one has its positives depending on what you want to develop.
Major Concepts of Programming
Before jumping into the lines of code, one should know the following:
Syntax and Semantics - consider syntax the rules of grammar for the code and semantics the meaning.
Variables - Labeled containers that hold data.
Control Structures- for example if then else and loops are a way of making decisions or repeating actions.
Functions - Re-usable blocks of code-your future best friends.
Debugging: And while you are learning, you are also fixing errors, so do not fear the bugs!
How Programming Works
Basically, when you write code, you are creating a set of instructions. It is that simple. Some languages need compiling and some don't. That is to say, with C++, for instance, you compile it and then you run it. With Python, you just run them straight through an interpreter. The computer works step-by-step, following your logic to bring about effects you want-whatever it is the case that you're wanting to do: opening a web page, calculating something, or perhaps even moving a character in a game.
Reasons to Learn Programming
More than just a skill, programming is a kind of superpower. It paves the way for high salaries, solves real-world problems, and makes creative visions come to life. Writing code lets you automate those boring tasks and build the next big app.
The Beginning in Programming
The small and inquisitive ones should start with. Identify a language suited to your purpose-Python for all purposes, JavaScript for online work, or Scratch for visuals. Sites like freeCodeCamp, Coursera, and Codecademy are for learning with your own tool, such as VS Code or Thonny, using which you write code on your own. Start small, really: a point here, a point there, mini projects: a calculator, a to-do list, a personal website.
For more information or to join our latest computer courses, contact TCCI – Tririd Computer Coaching Institute
Location: Bopal & Iskcon-Ambli in Ahmedabad, Gujarat
Call now on +91 9825618292
Visit Our Website: http://tccicomputercoaching.com/
#computer classes in bopal Ahmedabad#computer classes near me#Programming Courses in bopal Ahmedabad#software training institute in Iskcon-Ambli Ahmedabad#TCCI - Tririd Computer Coaching Institute
0 notes
Text
So I work as a programmer, and the languages I use and the manner I use them in get kind of weird:
- I use python, but only to program the one robot that internally runs python. The dev environment is “here’s a box you can put text, see if you get runtime errors”. If you want a proper dev environment, you can copy-paste code from the robot program into an editor of your choice. They do have a top-level graphical interface if you want each line of code to take up 10% of your screen.
- There’s a language that’s not quite C++ that we use for a different control box. That one’s dev environment will tell you if you made an error when you try to download. Specifically it tells you the first error, and you have to fix it and try to download again to get the second error. The download process takes 20 seconds. If you try to compile offline you get separate errors.
- On the more normal side of things, we have an SQL/ajax/javascript/html thing for handling some of our internal processes. As a change of pace my problems for this one are self-inflicted, because I never figured out how to set up a proper dev environment and just edit everything in notepad++. Someone else finally showed me how to do local environment testing so I no longer take our internal website down if I miss a close bracket.
- We do a ton of stuff in .NET framework, because 20 years ago my work was using VB6 and we never bothered to migrate to C#. I actually have a real dev environment for this one with autocomplete and syntax checking, so of course it’s my favorite. My boss wants to switch this all over to javascript so we can do android/linux deployment.
- A different robot has an internal language that’s not quite python. This one also has a graphical interface that I won’t use because I want more information to fit on my screen. This one also only tells you about syntax errors during runtime, but the most noteworthy thing about it is that the command to move the robot in a straight line is bugged. I think they fixed it to the point where you can’t reboot the controller by telling it to move in a straight line, but you can make it slowly drift off into space until it faults.
- The ladder logic we use is actually normal (for AB, not Seimen’s), but I did add basically a secondary control layer built out of function blocks to handle sequencing. It is very well-documented, a fact that no one cares about when they ask what the heck I am doing with so many function blocks.
- The ladder logic was a little too normal (expensive) so they also make us use the budget version. It’s very similar except there are no keyboard shortcuts, everything takes more clicks, and instead of changing code live you have to reboot everything and wait about 30 seconds if you want to change something.
- There’s a language we use for one of our internal products that I created over about three days because I didn’t want to worry about malicious external code or figuring out a compiler. The parser is just squashed into an entirely different program so that program can control stuff in the background. It does not have arrays or loops, and I didn’t give it string handling for about a year. There’s no dev environment because it’s not a real language. Something like a quarter of the stuff we sell now uses it.
- One of the robots requires programming via menus. If you want to add an if statement, the menu shortcut is F1 -> 4 -> 8. The end if is F1 -> 4 -> 0 -> 1. The program to let you type is a paid add-on. Exponents and absolute values are also paid add-ons. You get 200 numerical memory registers and can’t have local variables. There is no else if.
#hi I’m Kate#I have had arguments with engineers at three major robot companies#please don’t be too mean about the notepad++ thing#you can be mean about the internal programming language thing#but this post is me bragging#my work is cool and weird and nonsense#I will bite the next time someone advertises their robot as no programming required
1 note
·
View note
Text
Programming Basics for Beginners

If you’re new to programming, you might feel overwhelmed by the terms, languages, and tools out there. Don’t worry! Every expert developer was once a beginner. This post will guide you through the core basics you need to start your coding journey with confidence.
1. What Is Programming?
Programming is the process of writing instructions that a computer can understand and execute. These instructions are written in languages like Python, JavaScript, Java, or C++.
2. Choosing a Programming Language
Start with a beginner-friendly language. Here are some good options:
Python: Easy syntax, great for beginners and used in web development, data science, automation, and more.
JavaScript: The language of the web — used in websites, browsers, and interactive apps.
Scratch: Visual programming language for absolute beginners and kids.
3. Understanding Basic Programming Concepts
Variables: Store data (like numbers or text) for use in your program.
Data Types: Examples include integers, strings (text), booleans (true/false), and lists.
Operators: Symbols like +, -, *, and / used for calculations.
Conditions: Use if statements to make decisions in your code.
Loops: Repeat actions using for or while loops.
Functions: Reusable blocks of code that perform a specific task.
4. Writing Your First Program
Here’s an example in Python:# This is a comment name = input("What is your name? ") print("Hello, " + name + "!")
5. Tools You’ll Need
Text Editor: VS Code, Sublime Text, or Atom
Interpreter/Compiler: To run your code (Python, Node.js, Java SDK, etc.)
Terminal/Command Line: For navigating folders and running code
6. Practice Makes Perfect
The best way to learn programming is by doing. Start small and build up. Try websites like:
Codecademy
freeCodeCamp
W3Schools
Replit – write and run code in your browser
7. Stay Curious and Keep Learning
Programming is always evolving. Learn from tutorials, books, and other developers. Join coding communities and don’t be afraid to ask questions!
Conclusion
Programming might seem complex at first, but once you understand the basics, it becomes a powerful and creative tool. Start slow, be patient, and enjoy the journey — you’re building a skill that can open countless doors.
0 notes
Text
Do you want to know the difference between memcpy and memmove? We’ve got you covered with this guide. Memcpy and memmove are built-in C language functions that work similarly—copying memory blocks from one memory address to another within C. However, the two are not the same, and they have varying, specific functions. It’s crucial to know the difference between the two to understand which function to leverage in specific use cases. After all, you need to determine the best tool and method to use, such as when deciding when to pick Crystal programming language to develop software. This guide covers the main differences between memcpy and memmove to help you understand how each works and when to use them best. Let’s go. Memcpy and memmove: An overview Memcpy is a C function used for copying a specific number of bytes or data (n characters) from a single location or array (source object) to another (destination object). The function helps you copy or move data across memory locations. Memcpy is crucial since memory, which are electronic components, can’t store infinite data, making it necessary to move your data to other locations to free up some space. Consider the following when using memcpy: Ensure you copy data to and from objects that don’t overlap, or the behavior will show as undefined. Include a header file before using the function. Specify the number of bytes before using the memcpy function to copy the memory areas. Copy memory areas or regions that are the same data type. The best way to understand the function is to look at memcpy examples and their use cases. Memcpy syntax: void *memcpy(void * restrict dst ,const void * src ,size_t n); Where: src is the pointer to the source object dst refers to the pointer to the destination object n is the number of bytes you wish to copy. The memmove function also copies data from one location to another. However, memmove copies the data from the source object first and moves it to the temporary array. Then, the function copies the data from the temporary array to the destination object. It allows you to copy between objects that can overlap. The function prevents an undefined behavior when your source and destination objects overlap. Memmove Syntax: void *memmove(void * restrict dst, const void *src, size_t n); Memmove’s basic parameters are the same as memcpy. Implementing memcpy and memmove in C Generally, it’s best not to create your own memcpy since your standard or compiler library likely has a tailored and efficient memcpy implementation. However, some situations call for creating your own memcpy function to work around certain limitations. You can create a memcpy function with a simple memory-transfer algorithm that reads one byte individually, writing the byte before reading the next. While this algorithm is pretty easy to deploy, it doesn’t always offer optimal performance, especially with memory buses that are wider than 8 bits. As you can see in the code below, lines seven and eight handle the scenario so that the source and destination memory is not NULL. Lines 10 to 15 contain a while loop that copies the data from the source to the destination one at a time and increments the source and destination pointer by one. Similar to memcpy, your standard or compiler library will likely have an efficient memmove function implementation. That being said, unless there are special use cases, avoid creating your own memmove function. Implementing memmove is similar to memcpy. The difference is that it can handle an overlapping scenario through a temporary array. The code below copies all the n characters to a temporary array first, then copies the temporary array data to the destination. Key differences between memcpy and memmove Below are the main differences between the memcpy and memmove functions:
Memcpy returns undefined behavior if the memory location that the source and destination pointers point to overlap. On the other hand, memmove has a defined behavior that can handle overlapping scenarios. If you’re unsure if there is overlapping, your safest bet is to use memmove. It’s best to use memcpy when forwarding or duplicating copies and memmove when there is overlapping. Memmove is generally slower than memcpy because the memmove function uses an extra temporary array to copy data before copying the stored data to the destination. Important considerations when using memcpy and memmove While the memcpy and memmove functions work well, it’s best to know their limitations before using them, including the following: The memcpy and memmove functions can show undefined behaviors if you access the source and destination buffer beyond their lengths. Memcpy and memmove don’t check the destination and source buffer’s validity. The memcpy and memmove functions don’t check the terminal null character. Memcpy has limitations. For instance, the memcpy function can fail if the source parameter that is pointed to is in a shared block memory (between processes). Memmove allows memory regions to overlap but can require additional overhead than memcpy, including extra memory, resources, etc. Quick summary: memcpy vs memmove Check out the quick memcpy and memmove comparison below. memcpymemmovePurposeCopies data directly from the source to the destination.Copies data to the temporary buffer or array before copying it to the destination.OverlapShows a wrong output (undefined behavior) when the source and destination overlap. Can handle overlaps by copying to a temporary array first. Performance Faster than memmoveTwo times slower than memmove.Best to useIn general use cases When the source and destination overlap. Memcpy vs memmove: Which is better? Using memcpy or memmove depends on your data and whether the source and destination overlap. While the memcpy and memmove functions give the same results, it’s best to know how each works to ensure you use them correctly and effectively. Both C programming language functions make it easier to move your data but ensure you understand their limitations before you start copying and moving. Doing so helps you minimize potential data loss and avoid using an inefficient method to move large amounts of data.
0 notes