#Data Abstraction Services
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
China blocked Tumblr because of pornography and censorship problems in 2013.
Text
SunTec Data offers data abstraction services to help businesses extract critical information from large volumes of data. Our expert team identifies and extracts relevant data from various sources, summarizes it into a simplified report, and conducts rigorous quality checks. This service saves time and effort while providing valuable insights.
0 notes
Text
How AI & Automation Revolutionize Data Abstraction Process Flow in 2023?
Data serves as a fundamental asset for businesses, providing valuable insights for decision-making, market analysis, and monitoring of competitors. However, managing and extracting meaningful information from vast amounts of data can be challenging. Inefficient data abstraction processes often result in storing irrelevant and redundant information, hampering the overall data quality. To address this issue, businesses are turning to data abstraction services, leveraging AI and automation to streamline the process and enhance efficiency. In this blog, we will explore the importance of data abstraction, the impact of AI on the process flow, and the benefits it brings to businesses.
The Significance of Data Abstraction
Data abstraction involves simplifying and condensing the database by eliminating unnecessary or less important information. It enables organizations to maintain a clean and structured dataset, enhancing data-driven decision-making. Currently, a significant portion of stored data is considered irrelevant or of unknown value. Data abstraction helps in resolving this issue and providing a more meaningful representation of the entire dataset.
Building a Better Data Abstraction Process
At an enterprise level, data cleaning and organization are crucial for effective data-driven decisions. Businesses have introduced various services like data mining, data cleansing, data conversion, and data abstraction to make data more accessible and user-friendly. AI technology has revolutionized data abstraction services by automating and optimizing the process, reducing human intervention, and ensuring accuracy.
The Three Levels of Data Abstraction
To understand data abstraction better, let's delve into the three levels of abstraction:
a. Physical or Internal Level
This level represents the actual storage location of the data. Database administrators determine where the data is stored, how it is fragmented, and other physical aspects of data management.
b. Logical or Conceptual Level
The logical level defines the data stored in the database and its relationships. It caters to the organizational data needs and provides a comprehensive overview of the data objects and their relationships.
c. View or External Level
The view level represents how the data is presented to the users. It offers different perspectives or views of the database, allowing users to interact with the system and access relevant information.
Explanation with an Example
Let's consider a customer database. At the physical level, the data is stored in memory blocks, which is hidden from programmers. At the logical level, the data is organized into fields and attributes, defining their relationships. Finally, at the view level, users interact with the system through a user-friendly interface, unaware of the underlying data storage details.
How AI Transforms the Data Abstraction Process?
The integration of AI and automation in the data abstraction process brings about significant changes and benefits:
a. Identifying Necessary Data Entities
AI enhances the accuracy and efficiency of identifying relevant data entities by eliminating invalid or irrelevant data. This process is crucial for data abstraction and AI technology ensures improved precision, reducing the time required.
b. Identifying Key Properties of Entities
With AI, the identification of key properties or attributes of data entities becomes automated and accurate. Machine learning algorithms efficiently assort the properties, eliminating the need for manual intervention.
c. Connecting the Dots - Finding Relations Among Entities
Manually connecting data and identifying relationships among entities can be challenging and time-consuming. However, with the implementation of AI, this process becomes seamless and reliable. AI algorithms are capable of identifying patterns and relationships among data entities with a high degree of accuracy. Through iterative learning, these algorithms continuously improve and adapt, making subsequent cycles of data abstraction faster and more precise. By leveraging AI-powered data abstraction services from professionals, businesses can ensure scalability and meet the growing demands of their data-driven operations.
d. Mapping the Properties to the Entities
Another essential aspect of data abstraction is creating a relational network among the data entities and their properties. This allows for easy visualization of their interdependencies and how changes in one property or entity can affect others. AI and automation significantly accelerate this process, reducing the time required for data transformation and onboarding. By leveraging machine learning algorithms, AI can infer data mapping predictions from existing libraries of tested and certified data maps. This reduces the effort and time needed to build intelligent data mappings, improving efficiency and data integrity.
e. Removing or Preventing Duplicate Data Entities
Duplicate data entities pose a common challenge to data quality. They can occur when records mistakenly share data with each other, leading to inconsistencies and inaccuracies. Duplicate data negatively impacts data quality and can result in significant costs for businesses. AI integration in the data abstraction process enables the effortless identification and removal of duplicate data entities. AI algorithms consistently prevent data decay and duplication, ensuring a clean and efficient database.
f. Validation of the Outcome
The final step in the data abstraction process involves validating the abstracted data against the desired data. With the use of AI, this validation becomes more efficient and time-saving. As data volumes continue to grow, it is crucial for data-driven businesses to employ proactive strategies to monitor and maintain data quality regularly. AI-driven data validation processes ensure the accuracy and reliability of the abstracted data, reducing the risk of acting on faulty insights. Opting for data abstraction services provided by professionals who leverage AI algorithms guarantees accurate, high-quality, and powerful databases.
Conclusion
The exponential growth of data poses complex technological challenges for businesses. Data abstraction plays a vital role in managing and understanding large datasets efficiently. When combined with AI and automation, data abstraction becomes more streamlined, accurate, and reliable. AI enables businesses to identify necessary data entities, identify key properties, establish data relationships, map properties to entities, remove duplicate data, and validate the outcome. By leveraging AI-powered data abstraction services, businesses can unlock the full potential of their data assets, make informed decisions, and transform their operations. For AI-driven data abstraction services, you can choose Outsource BigData, a trusted tech company. Visit the official website of Outsource BigData and learn more about their service.
Original Blog- https://outsourcebigdata.com/blog/data-abstraction-services/how-ai-automation-can-change-data-abstraction-process-flow-in-2022-2/
About AIMLEAP - Outsource Bigdata
AIMLEAP - Outsource Bigdata is a division of AIMLEAP, AIMLEAP is an ISO 9001:2015 and ISO/IEC 27001:2013 certified global technology consulting and service provider offering Digital IT, AI-augmented Data Solutions, Automation, and Research & Analytics Services.
AIMLEAP has been recognized as ‘The Great Place to Work®’. With focus on AI and an automation-first approach, our services include end-to-end IT application management, Mobile App Development, Data Management, Data Mining Services, Web Data Scraping, Self-serving BI reporting solutions, Digital Marketing, and Analytics solutions.
We started in 2012 and successfully delivered projects in IT & digital transformation, automation driven data solutions, and digital marketing for more than 750 fast-growing companies in the USA, Europe, New Zealand, Australia, Canada; and more.
⭐An ISO 9001:2015 and ISO/IEC 27001:2013 certified
⭐Served 750+ customers
⭐ 11+ Years of industry experience
⭐98% Client Retention
⭐Great Place to Work® Certified
⭐ Global Delivery Centers in the USA, Canada, India & Australia
Email: [email protected]
USA: 1-30235 14656
Canada: +1 4378 370 063
India: +91 810 527 1615
Australia: +61 402 576 615
0 notes
Text
Long COVID and financial hardship: A disaggregated analysis at income and education levels - Published Dec 2, 2024
Abstract Objectives To examine how long COVID is associated with financial hardship (food insecurity, inability to pay bills, or threat of losing service) across income and education levels, and to assess the role of employment loss or reduced work hours in this hardship.
Data Source and Study Setting We used nationally representative data on 271,076 adults from the 2022 Behavioral Risk Factor Surveillance System (BRFSS).
Study Design We used multivariable binomial logistic regression models to estimate the average marginal effect of long COVID on financial hardships across multiple income and education groups.
Principal Findings In general, we found a significant positive association between long COVID and the three measures of financial hardships across income and education groups (1–11 percentage points increase, 95% CI 0.00–0.02 and 0.07–0.14, respectively). Mediation analysis showed that lost or reduced hours of employment accounted for a significant portion (6%–20%) of the changes in financial distress.
Conclusions Long COVID has affected the economic wellbeing of people from all socioeconomic statuses, although at a higher rate for lower income groups. Policy attention is needed to address its economic impacts across income and education levels.
What is known on this topic 17.6 million US adults currently have long COVID and given the prolonged effects of long COVID, it has a high potential of causing financial hardship. Literature shows a positive association between COVID-19 and financial hardship as well as delayed and forgone medical care. Literature shows a positive association between COVID-19 and employment loss.
What this study adds Long COVID is associated with increased financial hardship (1–11 percentage points increase) in almost all income and education groups. Lower income groups with income to poverty ratios below 2.00 are especially vulnerable. A significant portion of the association between Long COVID and increased financial hardship (6%–20%) is mediated by loss of employment or reduced work hours.
#mask up#public health#wear a mask#pandemic#wear a respirator#covid#covid 19#coronavirus#sars cov 2#still coviding#long covid#covid is not over
63 notes
·
View notes
Text
Peer Review (FF7 Fic)
Dear Mr. Hojo,
I would like to thank you for submitting your study, "How Much Mako Before It Croaks?" to the Gaia Journal of Biological Science for publication. I would also like to extend my deepest condolences. I truly hope that your university can swiftly locate your missing classmates soon and I cannot imagine how difficult things must be right now. Unfortunately, I must inform you that we are unable to consider your paper for publication at this time. Though I applaud your ambition I'm afraid there are several issues with your submission that render it ineligible for further peer review.
Firstly, your hypothesis. Or rather, the lack of one. You appear to have simply written "Inject frogs with mako until they explode." Mr. Hojo, this is not a hypothesis. It is a foregone conclusion. Secondly, your sample size is three subjects with no control group. Even if you did have a properly structured hypothesis I very much doubt you could prove or disprove anything with so paltry a sample size. Additionally, although you seem to value, in your words, "beautiful data" you aren't exactly clear about what it is you are measuring, either. You seem to think of "data" as some kind of abstract concept, a magical buzzword far removed from any actual math. An no, marking the number of extra limbs your subjects may have sprouted does not count.
Also, I assure you that sending the last living sample along with your paper was quite unnecessary. Please do think upon the mess involved with shipping such a sample the next time you are tempted to apply and, for all our sakes, reconsider. It was our administrative assistant who had the pleasure of opening your package, as she does with all our mail, and the janitorial staff was quite peeved with us over both the mess made of the box itself and the way she subsequently lost her lunch.
We received several letters of resignation the very next day, hers included. So please, do us a service and keep our hiring budget in mind next time you apply for publication?
Kind regards,
Dr. Stephen P. Wilworth,
Editor for the Gaia Journal of Biological Science
P.S. You could have at least included air holes.
Dear Dr. Hojo,
I confess that I am surprised to hear from you so soon after your last endeavor. Congratulations are certainly in order. Not only have you earned your doctorate, but to earn a position under such an esteemed scientist as Professor Ghast!
As to the matter of your submission, please forgive me. I have read it over and though the methodology is much improved I'm afraid it feels a little, shall we say, incomplete. In fact, I recall running into dear Ghast at a conference naught but a month or two ago and, wouldn't you know, he also mentioned this very same JENOVA specimen outlined in your paper. Although I do find his claims of it being an Ancient dubious at best. He is an excellent researcher but perhaps a bit prone to flights of fancy. Well, there is no shame in having one's hypothesis disproved. That is, after all, the way of science.
Perhaps you could help me with a hypothesis of my own? You see, although I know for a fact that you are working under Professor Ghast on this JENOVA project I do not see his name, nor those of any other collaborators, credited within your paper. Maybe you can guess at the hypothesis I have come up with? But no, surely a newly minted PHD such as yourself wouldn't be so crass. You have a smart head on your shoulders and graduated at the top of your class, so I can only assume that there has been some mistake. Especially since Ghast told me himself that he did not plan to speak much about the project, nor publish anything, for "security reasons."
So, then, let us say that this little mistake never happened, shall we? Far be it for me to cut short such a promising future before it even buds.
Kind regards,
Dr. Stephen P. Wilworth,
Editor for the Gaia Journal of Biological Science
Dear Dr. Hojo,
I found your last letter to be frightfully unprofessional. There was no need to level such insults at myself nor the nighttime pursuits of my dear, departed mother. So you can imagine my surprise when I found a new manila envelope on my desk this morning with your name scrawled on the return address. I honestly thought that you had given up on submitting to our illustrious publication in light of our last few tete-a-tetes.
Let it never be said that I give up easily. No, I girded every milliliter of my resolve and dutifully read through your new masterpiece despite my misgivings. The result?
Sir. These are crimes.
Actual crimes.
I admit that when you first said that you were infusing an foetus in vivo I thought to myself, "Ah, good old Dr. Hojo has returned to his roots! Smashing incompatible things together with the wild abandon of a five year old!" And I was relieved, for at least you were predictable.
It was only when I got to the interview with the mother that I realized you meant that you were experimenting on a human foetus. Apologies for this egregious oversight, for many foeti are difficult to distinguish in the early stages of development. My mistake.
I have directed my staff to contact your employer Mr. Shinra, Professor Ghast, and any and all authorities that they can think of. With luck, this letter will not even reach you as you will already be languishing within the darkest, most hellish cell that Shinra may possess.
Regards,
Dr. Stephen P. Wilworth,
Editor for the Gaia Journal of Biological Science
Dear Dr. Hojo,
How are you? Or rather, how are you not in prison? Did my letters never reach Mr. Shinra, or is the man as ethically bankrupt as yourself? It is strange, though, that I have not heard from Professor Ghast. I know him to be an upstanding man of the finest character.
I have lost another administrative assistant. She took one look at the stains on the butcher paper enclosing your most recent work and quit on the spot. She was, perhaps, the smartest of us here in the office for doing so and I envy her such wisdom. I admit that I cannot turn away from your macabre studies. To do so feels like I would be turning a blind eye to an atrocity.
The photos you included are vile. I have not been able to eat or sleep since I first laid eyes on them. You killed this man, didn't you. But then are the pictures out of order? He begins as a corpse, yet the ones further on show him moving, screaming, twisting. Your paper does not clear this up. It keeps skipping around and appears to be interspersed with what I can only describe as mysanthropic ravings.
I once believed there was a natural justice in this world, you know, but by your hands you have revealed that to be a fiction. Well, I may have no legal authority but I can promise you one thing: your papers will never be published. But don't worry, you will most certainly be known. I will make it my personal mission to ensure that every journal on Gaia knows of your sickness. You will become an exile from the halls of learning, a persona non grata in the eyes of science save as a cautionary tale for med students. We will give you what you want in the worst possible way.
Regards,
Dr. Stephen P. Wilworth,
Editor for the Gaia Journal of Biological Science
Welcome, readers, to the new Shinra Electric Company Journal of Science, formerly the Gaia Journal of Biological Science! Do not worry, although this journal may have a new name you can expect the same caliber of standards as always. Nothing will change in that regard!
All this means is that we have a few more resources at our disposal, which will include not only higher quality content but also a faster publication schedule! Starting now the SECJS will be publishing weekly, not monthly.
We have a very special surprise for you for this first issue. Our very own, newly-appointed Director of Research and Development, Professor Hojo, has graced us with one of his latest studies on mako-stone brain implants in project "SPW." So stay tuned! We think you will find it well worth it.
Dr. Kratus Fine
Editor for the Shinra Electric Company Journal of Science
#fanfic#final fantasy 7#ff7#ffvii#hojo#professor hojo#dark comedy#Professor Hojo tries to get published in a peer reviewed journal#much to the distress of the editor#final fantasy vii
23 notes
·
View notes
Note
There was a study* a time back that showed that right-wingers tended to care more about the people directly around them and less the abstract while left-wingers were the inverse and tended to care more about those distant or in the more abstract than those directly around them. I wonder how much this would play out if the people thought their answers were totally secret and they were actually honest when answering.
In my experience the people who care about those around them care about others at a distance too. At least as far as they deem reasonable. Whereas those who do not care about those near them tend to only be paying bare lip-service about those in the abstract and will not lift a finger or sacrifice of their own for anyone near or far.
Whenever I get too depressed thinking about it I try to redirect myself towards what can I do instead but it does feel like sweeping back the seatide with a small broom.
*as always anytime there's a study I don't really trust the data that much as there are so so so very many ways to "creatively interpret" data but still sometimes there is an interesting question present to think about.
It is interesting to think about and I haven’t seen that study but I’m not sure I trust those results because that doesn’t seem to be accurate in the way it plays out.
I mean one thing that is super annoying about leftists is they only think about the immediate area they live in when it comes to policies and social issues.
They want to abolish the electoral college in favor of the popular vote so the big cities they dominate win all the elections, they don’t care about illegal immigration until the immigrants get shipped to their sanctuary cities, they want to get rid of cars in favor of public transportation forgetting that outside of big cities that’s not feasible. So that study doesn’t really match up with reality.
17 notes
·
View notes
Text
Europe is under siege—not by armies but by supply chains and algorithms. Rare-earth minerals, advanced semiconductors, and critical artificial intelligence systems all increasingly lie in foreign hands. As the U.S.-China tech cold war escalates, U.S. President Donald Trump battles Europe’s attempt to regulate tech platforms, Russia manipulates energy flows, and the race for AI supremacy intensifies, Europe’s fragility is becoming painfully clear. For years, policymakers have warned about the continent’s reliance on foreign technology. Those alarms seemed abstract—until now.
Geopolitical flashpoints, from the Dutch lithography firm ASML’s entanglement in the U.S.-China chip war to Ukraine’s need for foreign satellite services, reveal just how precarious Europe’s digital dependence really is. If Europe doesn’t lock down its technological future, it risks becoming hostage to outside powers and compromising its core values.
Fragmented measures aren’t enough. A European Chips Act here, a half-implemented cloud or AI initiative there won’t fix a system where every layer—from raw materials to software—depends on someone else. Recent AI breakthroughs show that whoever controls the stack—digital infrastructure organized into a system of interconnected layers—controls the future.
The U.S. government ties AI research to proprietary chips and data centers through its Stargate program, while China’s DeepSeek masters the entire supply chain at lower costs. Europe can’t keep treating chips, supercomputing, and telecommunication as discrete domains; it needs a unifying vision inspired by digital autonomy and a grasp of the power dynamics shaping the global supply chain.
Without a coherent strategy, the continent will be a mere spectator in the biggest contest of the 21st century: Who controls the digital infrastructure that powers everything from missiles to hospitals?
The answer is the EuroStack—a bold plan to rebuild Europe’s tech backbone layer by layer, with the same urgency once devoted to steel, coal, and oil. That will require a decisive mobilization that treats chips, data, and AI as strategic resources. Europe still has time to act—but that window is closing. Our proposed EuroStack offers a holistic approach that tackles risks at every level of digital infrastructure and amplifies the continent’s strengths.
The EuroStack comprises seven interconnected layers: critical raw materials, chips, networks, the Internet of Things, cloud infrastructure, software platforms, and finally data and AI.
Every microchip, battery, and satellite begins with raw materials—lithium, cobalt, rare-earth metals—that Europe doesn’t control. China commands 60-80 percent of global rare-earth production, while Russia weaponizes gas pipelines. Europe’s green and digital transitions will collapse without secure access to these resources. Beijing’s recent export restrictions on gallium and germanium, both critical for semiconductors, served as a stark wake-up call.
To survive, Europe must forge strategic alliances with resource-rich nations such as Namibia and Chile, invest in recycling technologies, and build mineral stockpiles modeled on its strategic oil reserves. However, this strategy will need to steer clear of subsidizing conflict or profiting from war-driven minerals, as seen in the tensions between Rwanda and the Democratic Republic of the Congo and the latter’s criminal complaints against Apple in Europe—demonstrating how resource struggles can intensify regional instability.
Above this resource base lies the silicon layer, where chips are designed, produced, and integrated. Semiconductors are today’s geopolitical currency, yet Europe’s share of global chip production has dwindled to just 9 percent. U.S. giants such as Intel and Nvidia dominate design, while Asia’s Samsung and TSMC handle most of the manufacturing. Even ASML, Europe’s crown jewel in lithography, finds itself caught in the crossfire of the U.S.-China chip war.
Although ASML dominates the global market for the machines that produce chips, Washington is using its control over critical components and China over raw materials to put pressure on the company. To regain control, Europe must double down on its strengths in automotive, industrial, and health care chipsets. Building pan-European foundries in hubs such as Dresden, Germany, and the Dutch city of Eindhoven—backed by a 100 billion euro sovereign tech fund—could challenge the U.S. CHIPS and Science Act and restore Europe’s foothold.
Next comes connectivity, the digital networks that underpin everything else. When Russian tanks rolled into Ukraine, Kyiv’s generals relied on Starlink—a U.S. satellite system—to coordinate defenses. And U.S. negotiators last month suggested cutting access if no deal were made on Ukrainian resources. Europe’s own Iris2 network remains behind schedule, leaving the European Union vulnerable if strategic interests clash.
Meanwhile, China’s Huawei still dominates 5G infrastructure, with Ericsson and Nokia operating at roughly half its size. Italian Prime Minister Giorgia Meloni has even floated buying Starlink coverage, underscoring how urgent it is for Europe to accelerate Iris2, develop secure 6G, and mandate a “Buy European” policy for critical infrastructure.
A key but often overlooked battleground is the Internet of Things, or IoT. Chinese drones, U.S. sensors, and foreign-controlled industrial platforms threaten to seize control of ports, power grids, and factories. Yet Europe’s engineering prowess in robotics offers a lifeline—if it pivots from consumer gadgets to industrial applications. By harnessing this expertise, Europe can develop secure, homegrown IoT solutions for critical infrastructure, ensuring that smart cities and energy grids are built on robust European standards and safeguarded against cyberattacks.
Then there is the cloud, where data is stored, processed, and mined to train next-generation algorithms. Three U.S. giants—Amazon, Microsoft, and Google—dominate roughly 70 percent of the global market. The EU’s Gaia-X project attempted to forge a European alternative, but traction has been limited.
Still, the lesson from DeepSeek is clear: Controlling data centers and optimizing infrastructure can revolutionize AI innovation. Europe must push for its own sovereign cloud environment—perhaps through decentralized, interoperable clouds that undercut the scale advantage of Big Tech—optimized for privacy and sustainability. Otherwise, European hospitals, banks, and cities will be forced to rent server space in Virginia or Shanghai.
A sovereign cloud is more than a mere repository of data; it represents an ecosystem built on decentralization, interoperability, and stringent privacy and data protection standards, with client data processed and stored in Europe.
Gaia-X faltered due to a lack of unified vision, political commitment, and sufficient scale. To achieve true technological sovereignty, Europe must challenge the monopolistic dominance of global tech giants by ensuring that sensitive information remains within its borders and adheres to robust regulatory frameworks.
When it comes to software, Europe runs on U.S. code. Microsoft Windows powers its offices, Google’s Android runs its phones, and SAP—once a European champion—now relies heavily on U.S. cloud giants. Aside from pockets of strength at companies such as SAP and Dassault Systèmes, Europe’s software ecosystem remains marginal. Open-source software offers an escape hatch but only if Europe invests in it aggressively.
Over time, strategic procurement and robust investments could loosen U.S. Big Tech’s grip. A top priority should be a Europe-wide, privacy-preserving digital identity system—integrated with the digital euro—to protect monetary sovereignty and curb crypto-fueled volatility. Piece by piece, Europe can replace proprietary lock-in with democratic tools.
Finally, there is AI and data, the layer where new value is being generated at breakneck speed. While the United States and China have seized an early lead via OpenAI, Anthropic, and DeepSeek, the field remains open. Europe boasts world-class supercomputing centers and strong AI research, yet it struggles to translate these into scalable ventures. The solution? “AI factories”—public-private hubs that link Europe’s strengths in health care, climate science, and advanced manufacturing.
Europeans could train AI to predict wildfires, not chase ad clicks, and license algorithms under ethical frameworks, not exploitative corporate terms. Rather than only mimicking ChatGPT, Europe should fund AI for societal challenges through important projects of common European interest, double down on high-performance computing infrastructure, and build data commons that reflect core democratic values—privacy, transparency, and human dignity.
The EuroStack isn’t about isolationism; it’s a bold assertion of European sovereignty. A sovereign tech fund of at least 100 billion euros—modeled on Europe’s pandemic recovery drive—could spark cross-border innovation and empower EU industries to shape their own destiny. And a Buy European procurement act would turn public purchasing into a tool for strategic autonomy.
This act could go beyond traditional mandates, championing ethical, homegrown technology by setting forward-thinking criteria that strengthen every link in Europe’s digital ecosystem—from chips and cloud infrastructures to AI and IoT sensors. European chips would be engineered for sovereign cloud systems, AI would be trained on European data, and IoT devices would integrate seamlessly with European satellites. This integrated approach could break the cycle of dependency on foreign suppliers.
This isn’t about shutting out global players; it’s about creating a sophisticated, multidimensional policy tool that champions European priorities. In doing so, Europe can secure its technological future and assert its strategic autonomy in a rapidly evolving global order.
Critics argue that the difference in mindset between Silicon Valley and Brussels is an obstacle, especially the bureaucratic nature of the EU and its focus on regulation. But other countries known for bureaucracy—such as India, China, and South Korea—have achieved homegrown digital technology from a much lower technological base than the EU. Indeed, through targeted industrial policies and massive investments, South Korea has become a world leader in the layers of chips and IoT. The EU currently already has a strong technological base with companies such as ASML, Nokia, and Ericsson.
European overregulation is not the issue; the real problem is a lack of focus and investment. Until now, the EU has never fully committed to a common digital industrial policy that would allow it to innovate on its own terms. Former European Central Bank President Mario Draghi’s recent report on EU competitiveness—which calls for halting further regulation in favor of massive investments—and incoming German Chancellor Friedrich Merz’s bold debt reforms signal a much-needed shift in mindset within the EU.
In the same spirit, Commission President Ursula von der Leyen has launched a defense package providing up to 800 billion euros to boost Europe’s industrial and technological sovereignty that could finally align ambition with strategic autonomy.
If digital autonomy isn’t at the forefront of these broader defense and infrastructure strategies, Europe risks missing its last best chance to chart an independent course on the global stage.
To secure its future, Europe must adopt a Buy European act for defense and critical digital infrastructures and implement a European Sovereign Tech Agency in the model of the U.S. Defense Advanced Research Projects Agency—one that drives strategic investments, spearheads AI development, and fosters disruptive innovation while shaping a forward-looking industrial policy across the EU.
The path forward requires ensuring that investments in semiconductors, networks, and AI reinforce one another, keeping critical technologies—chips, connectivity, and data processing—firmly under the EU’s control to prevent foreign interests from pulling the plug when geopolitics shift.
Europe’s relative decline once seemed tolerable when these risks felt hypothetical, but real-world events—from undersea cable sabotage to wartime reliance on foreign satellite constellations—have exposed the EU’s fragility.
If leaders fail to seize this moment, they will cede control to external techno-powers with little incentive to respect Europe’s needs or ideals. Once this window closes, catching up—or even keeping pace—will be nearly impossible.
The EuroStack represents Europe’s last best chance to shape its own destiny: Build it, or become a digital colony.
8 notes
·
View notes
Text
From the beginning | Previously | Coin standings | 5/18 | 6/6
MS. OVEREAGER is happy to help you out with your problems- you need to do what, again? STALL AND REMOVE GEARS? No problemo. She'll get started right away! And by "get started", I mean "dissolve into nothingness because she was a hallucination masking an abstract concept"! You're on your own, buckos.
Okay, so... Adea thinks that this ODD TAIL AVATAR DATA VALIDATOR is after the gears that Walter ransacked from this place to heal himself earlier. If he can get them out, it'll probably stop chasing him. But removing them- even though they're clearly hurting him at this point- will hurt more, like pulling a knife out of a stab wound. He's going to need to stabilize somewhat before you can risk it.
Right here, with a Defrag Point to heal with, is the best place to do it- but he "healed" about 15% STINGY OUTLIER SOUL INTEGRITY earlier, so he should expect removing the gears to do at least that much damage. He'll need to stay there healing for at least enough time to go through two hunger, probably three, to not die on the spot. So it's a question of... how much time does he have to heal before the DATA VALIDATOR arrives and it's time to operate?

Zero. Zero amount of time. It's right here.
Five NOBLE BELT TUTS remain in the DENIAL OF SERVICE gun. Is it worth it to spend them fending this thing off? By the numbers, no. It's more efficient to just buy SOFTWARE PATCHes. But Adea isn't putting up with this thing chasing after her husband one moment more.
Error: architectural entity field 0x07CF referenced without blueprint key. Update loop deferr-
BLAM.
Error 403: resource reclamation process not configured for I/O operations. Interactions with entities other than entity with field 0x07CF rejected. Error 403: resource reclamation process not configured for I/O operations. Interactions with entities other than entity with field 0x07CF rejected. Error 403: resource reclamation process not configured for I/O operations. Interac...
Four left. The undulating thing is frozen in place. Slowly- achingly slowly- the Defrag Point starts knitting Walter back together. As it does, Adea pries clockwork out of his chest, causing him to shudder violently. It's slow, and harrowing, and every gasp of pain from her scrungly little man makes her wince- but she pulls out about a third of it before the thing finishes rattling off rejection messages for the packets.
Error: architectural entity field 0x0--
BLAM.
The two of you, on top of being injured, are practically starving. Adea suggests-

Walter says we absolutely not resorting to cannibalism on purpose! That was an accident! He wasn't in his right mind! No way no way no way!
Adea says fine, and Walter lets out a cut-off scream as she rips out a driveshaft assembly that was pretending to be his lung. She's got about two-thirds of it out, now- and she's got an idea to conserve ammo.
Error: architectural entity field 0x07CF referenced without blueprint key. Update loop deferred until resource is released.
Yeah, you want this stuff, right? Go get it, Adea says- flinging a gear like a frisbee. The DATA VALIDATOR swoops through the air after it, snagging the gear on a tooth with frightening speed. But... not so frightening that she can't delay it a little more with what she's got.
She hurls the lung-driveshaft like a javelin behind the thing, and then starts chucking the rest of the clockwork every which way, scattering it over a wide area. Like a vampire confronted with grains of rice, the DATA VALIDATOR starts scrambling for the pieces of its precious architectural entity field 0x07CF, twisting itself into knots.

While it chases down cogs, sprockets, gears, and springs... Adea hurries back over to Walter, and rips the rest of the machinery from his chest cavity. This one hurts. He's a huge baby about it and screams like that one time she accidentally bought chili oil instead of lu- uh, like it hurts a lot. This would definitely kill him if he weren't being actively defragmented. She tries not to think about that.
You were kind of hoping this thing would immobilize itself from tying itself in knots, but it's able to stretch itself out and slip through gaps in its own Gordian nightmare. It's all you can do to get the rest of it out before it closes in on you again.
Daintily, it pries open a hatch on the sidewalk with one tooth- and then, piece by piece, delicately reassembles the machinery that Walter mistook for spare parts earlier.
Update loop resumes.

With an audible TWANG, and the sound of rushing air, the tension in the DATA VALIDATOR's tail is released. The knot undoes itself, and its head shoots off backwards into the distance as it's recalled to its starting point in the blink of an eye.
It's gone.
...Now what?
The FILIAL TWINS are still here, and you could always go somewhere with a phone and participate in a NAIAD RUMBLE- but there's a few other possible priorities.
There's this moronic cook who doesn't realize he's not welcome. IDIOT CHEF WON'T GO, so you've got to do something to get rid of the jerk.
You could explore the CURVE HOUSE, a weird distorted funhouse-mirror version of a normal building with all its right angles. Seems disorienting!
There's this guy named Pete sitting on the sidewalk nearby who won't stop crying. EMOTIONAL PETER should probably go to actual therapy, but maybe the two of you can help?
There's a FIENDISH ELF ARISING, and it may or may not be your duty as legendary heroes to stop it from becoming a new Demon Lord or somesuch.
Mom's trapped! OH, RELEASE MOM! From her prison that happens to be here for some reason! ...Which one of your moms is it, anyway?
Continued
#lost in hearts#we're back! with a long one!#except uh. i have a funeral to go to tomorrow so probably no update tomorrow#life has been rough lately i tell you what
9 notes
·
View notes
Text
A new study published last month has confirmed that mRNA Covid injections cause incurable heart disease in the majority of recipients.
“The results revealed higher heart disease risk in individuals receiving mRNA vaccines than other types,” the study declared in the ‘Abstract’ section.
Infowars.com reports: The findings that mRNA shots are more likely to damage the heart than viral vector shots are concurrent with another study that Infowars previously reported on.
Interestingly, the study analyzing Koreans for heart damage post-injection also found that the injected individuals who got infected with the Covid virus had an even greater risk of heart damage.
“Individuals infected by SARS-CoV-2 also exhibited significantly higher heart disease risk than those uninfected,” the study said in the ‘Abstract’ section.
Younger individuals faced a greater risk of heart disease than older individuals.
“…younger individuals who received mRNA vaccines had a higher heart disease risk compared to older individuals,” the study said in the ‘Abstract’ section.
The study was conducted by analyzing data recorded between October 2018 to March 2022 from the National Health Insurance Service Covid database.
“We sought to provide insights for public health policies and clinical decisions pertaining to COVID-19 vaccination strategies,” the study said in the ‘Abstract’ section. “We analysed heart disease risk, including acute cardiac injury, acute myocarditis, acute pericarditis, cardiac arrest, and cardiac arrhythmia, in relation to vaccine type and COVID-19 within 21 days after the first vaccination date, employing Cox proportional hazards models with time-varying covariates.”
6 notes
·
View notes
Text
Reference saved in our archive (Daily updates!)
NSAID usage during acute covid seems to increase the likelihood of long covid while NSAID use after the acute phase seems to slightly lower the risk of long covid. Interesting findings from a cohort of over 225,000.
Abstract Introduction Long coronavirus disease (COVID) poses a significant burden following the coronavirus disease 2019 (COVID-19) pandemic. Debate persists regarding the impact of nonsteroidal anti-inflammatory drug (NSAID) administration during acute-phase COVID-19 on the development of long COVID. Hence, this study aimed to assess the potential association between NSAID use and long COVID using data from patients with COVID-19 in Korea’s National Health Insurance Service.
Methods This nested case-control study defined the study cohort as patients diagnosed with COVID-19 for the first time between 2020 and 2021. The primary exposure investigated was NSAID prescriptions within 14 days of the initial COVID-19 diagnosis. We used propensity score matching to create three control patients matched to each patient in the NSAID exposure group. Odds ratios (ORs) and 95% confidence intervals (CIs) were calculated after the adjustment for demographics, Charlson Comorbidity Index, and existing comorbidities.
Results Among the 225,458 patients diagnosed with COVID-19, we analyzed data from 254 with long COVID. The adjusted OR (aOR) for NSAID exposure during acute-phase COVID-19 was higher in long COVID cases versus controls (aOR, 1.79; 95% CI, 1.00–3.19), suggesting a potential relationship. However, a sensitivity analysis revealed that the increased odds of NSAID exposure in the acute phase became statistically non-significant (aOR, 1.64; 95% CI, 0.90–2.99) when COVID-19 self-quarantine duration was included as a covariate. Additionally, acetaminophen exposure was not significantly associated (aOR, 1.12; 95% CI, 0.75–1.68), while antiviral drugs demonstrated a stronger association (aOR, 3.75; 95% CI, 1.66–8.48).
Conclusion Although this study suggests a possible link between NSAID use in the acute COVID-19 infection stage and a higher risk of long COVID as well as both NSAID and acetaminophen use during the chronic COVID-19 period and a lower risk of long COVID, the association was not statistically significant. Further research is needed to determine the causal relationship between the various treatment options for acute COVID-19 and the development of long COVID.
#mask up#public health#wear a mask#pandemic#covid#wear a respirator#covid 19#still coviding#coronavirus#sars cov 2#long covid#covid is airborne#covid is not over#covid conscious
63 notes
·
View notes
Quote
…professionals who traffic in symbols and rhetoric, images and narratives, data and analysis, ideas and abstraction (as opposed to workers engaged in manual forms of labor tied to physical goods and services). For instance, people who work in fields like education, science, tech, finance, media law, consulting, administration, and public policy are overwhelmingly symbolic capitalists. If you're reading this book, there's a strong chance you're a symbolic capitalist. I am, myself, a symbolic capitalist.
Musa al-Gharbi
5 notes
·
View notes
Text
Atom: The Beginning & AI Cybersecurity

Atom: The Beginning is a manga about two researchers creating advanced robotic AI systems, such as unit A106. Their breakthrough is the Bewusstein (Translation: awareness) system, which aims to give robots a "heart", or a kind of empathy. In volume 2, A106, or Atom, manages to "beat" the highly advanced robot Mars in a fight using a highly abstracted machine language over WiFi to persuade it to stop.

This may be fiction, but it has parallels with current AI development in the use of specific commands to over-run safety guides. This has been demonstrated in GPT models, such as ChatGPT, where users are able to subvert models to get them to output "banned" information by "pretending" to be another AI system, or other means.
There are parallels to Atom, in a sense with users effectively "persuading" the system to empathise. In reality, this is the consequence of training Large Language Models (LLM's) on relatively un-sorted input data. Until recent guardrail placed by OpenAI there were no commands to "stop" the AI from pretending to be an AI from being a human who COULD perform these actions.
As one research paper put it:
"Such attacks can result in erroneous outputs, model-generated hate speech, and the exposure of users’ sensitive information." Branch, et al. 2022

There are, however, more deliberately malicious actions which AI developers can take to introduce backdoors.
In Atom, Volume 4, Atom faces off against Ivan - a Russian military robot. Ivan, however, has been programmed with data collected from the fight between Mars and Atom.

What the human researchers in the manga didn't realise, was the code transmissions were a kind of highly abstracted machine level conversation. Regardless, the "anti-viral" commands were implemented into Ivan and, as a result, Ivan parrots the words Atom used back to it, causing Atom to deliberately hold back.

In AI cybersecurity terms, this is effectively an AI-on-AI prompt injection attack. Attempting to use the words of the AI against itself to perform malicious acts. Not only can this occur, but AI creators can plant "backdoor commands" into AI systems on creation, where a specific set of inputs can activate functionality hidden to regular users.

This is a key security issue for any company training AI systems, and has led many to reconsider outsourcing AI training of potential high-risk AI systems. Researchers, such as Shafi Goldwasser at UC Berkley are at the cutting edge of this research, doing work compared to the key encryption standards and algorithms research of the 1950s and 60s which have led to today's modern world of highly secure online transactions and messaging services.
From returning database entries, to controlling applied hardware, it is key that these dangers are fully understood on a deep mathematical, logical, basis or else we face the dangerous prospect of future AI systems which can be turned against users.
As AI further develops as a field, these kinds of attacks will need to be prevented, or mitigated against, to ensure the safety of systems that people interact with.
References:
Twitter pranksters derail GPT-3 bot with newly discovered “prompt injection” hack - Ars Technica (16/09/2023)
EVALUATING THE SUSCEPTIBILITY OF PRE-TRAINED LANGUAGE MODELS VIA HANDCRAFTED ADVERSARIAL EXAMPLES - Hezekiah Branch et. al, 2022 Funded by Preamble
In Neural Networks, Unbreakable Locks Can Hide Invisible Doors - Quanta Magazine (02/03/2023)
Planting Undetectable Backdoors in Machine Learning Models - Shafi Goldwasser et.al, UC Berkeley, 2022
#ai research#ai#artificial intelligence#atom the beginning#ozuka tezuka#cybersecurity#a106#atom: the beginning
19 notes
·
View notes
Text
Future Anime Girl Gestalt
As a breakthrough in silicon nanostructure materials makes photonics and near-eye displays cheap, smart glasses become the new ubiquitous computers, replacing smartphones. The always-on display provides unique opportunities for advertisers, as does new machine learning-assisted ad targeting. In the new omnipresent augmented reality, ads become personalized, three-dimensional, interactive displays, emerging from blank rectangles in subway stations. You see your facebook friends conversing animatedly, drinking budweiser.
As smart glasses become increasingly necessary for modern life, brands are able to invade further into perceived reality. Cars shine luxuriously. The name and price of your coworker's smartwatch floats above it. Of course many modern advertisements no longer directly sell a product or service, but rather create and maintain brand identities. Large corporations advertise on everyday objects--the plate at your favorite restaurant reveals the name of a software company as you finish your food. Your brother's anger turns him super saiyan, reminding you of the new episodes. A poor neighborhood turns into an alien-inspired techno-organic nightmare.
Many companies use characters to perpetuate their brand. These characters can be personalized--the insurance company mascot that shows up on your car dashboard during a harrowing rush hour is your favorite color, features large, expressive eyes, and is covered in shaggy fur.
Of course, machine learning algorithms can be unpredictable. And ad agencies could not anticipate the omnivalent memetic power of...
...anime girls.
The algorithm customizes your pepsi soda into a fizzy anime slime girl. They customize the call to your healthcare provider to raise the pitch of the representative's voice and translate the audio to Japanese (your glasses display English subtitles). The missiles you see striking a city in Iran are ridden by pale, northrop grumman-labeled anime maids.
As more human agency is ceded to enormous, power-chugging processing centers, the connections between everyday occurrences and brand presence become more abstract. Every character on a show you're not paying attention to, every old shoe you own, every person you interact with, every grain of sand on the beach, every floater in your eye, is an anime girl.
As humans do, they adapt. Generation Glass becomes accustomed to experiencing two entirely foreign sets of sense-data: one, their local, mundane world, of humming processors and concrete and scraggly trees. The other, the networked world, where your entire visual field is painted in overlapping anime girls of various sizes and your auditory vestibular nerve is drowned in high-pitched giggling. Each girl represents some object--pomegranate, sunset, friends, love, death.
As global civilization gently deflates under the pressure of climate change post-2100, so does the capacity to manufacture complex electronics. Within the space of a generation, billions of people are reduced to creating facile, vapid illustrations of the moving, living anime girls they once knew as bigotry and tarmac. Pictures of anime girls are used to label street signs, mathematical concepts, genders, religious texts. Ironically, anime girls become more incorporated into the real world than they ever were in the Glass period, because they adorn real surfaces. A post-traumatic behavior develops, in which a person destroys objects bearing anime girl images in an attempt to, according to one individual, "let them out," or otherwise restore networked consensus reality.
Thousands of years pass. Peregrine sophists of the Fifth Yyrzoc clan uncover an underground concrete structure. In it are glyphs of a single, big-eyed, pale, skinny, large-breasted woman with bright blue hair, surrounded by female figures in blood-red uniforms who are collapsed on the ground. The sophists are able to decode this message and avoid what we would recognize as a nuclear waste storage facility. They theorize that the figures are ancient feminine gods of radiation and death. Several etchings and illustrations are published by a notable scriptorium. Years later they are largely forgotten.
3 notes
·
View notes
Text
















Abstract
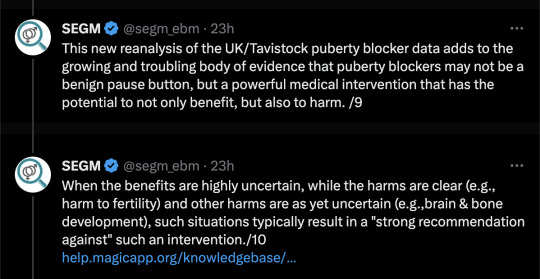
The evidence base for psychological benefits of GnRHA for adolescents with gender dysphoria (GD) was deemed “low quality” by the UK National Institute of Health and Care Excellence. Limitations identified include inattention to clinical importance of findings. This secondary analysis of UK clinical study data uses Reliable and Clinically Significant Change approaches to address this gap. The original uncontrolled study collected data within a specialist GD service. Participants were 44 12–15-year-olds with GD. Puberty was suppressed using “triptorelin”; participants were followed-up for 36 months. Secondary analysis used data from parent-report Child Behavior Checklists and Youth Self-Report forms. Reliable change results: 15–34% of participants reliably deteriorated depending on the subscale, time point and parent versus child report. Clinically significant change results: 27–58% were in the borderline (subclinical) or clinical range at baseline (depending on subscale and parent or child report). Rates of clinically significant change ranged from 0 to 35%, decreasing over time toward zero on both self-report and parent-report. The approach offers an established complementary method to analyze individual level change and to examine who might benefit or otherwise from treatment in a field where research designs have been challenged by lack of control groups and low sample sizes.
==
Indeed.

#puberty blockers#gender ideology#Ben Appel#Leor Sapir#Lupron#queer theory#medical malpractice#medical scandal#mental health#mental health issues#gender affirming care#gender affirming healthcare#affirmation model#medicalization#gender dysphoria#GnRHA#religion is a mental illness
28 notes
·
View notes
Text
oc lore - the resistance
Basically vaguely militarized first responders
each squad has a captain and a S.I.C. (second in command). Squads differ depending on their purpose and each member of a squad (usually around 5 people) can have multiple specialties.
The main branches of the Resistance are:
Public Security - Basically contains the police, public defendants, and detectives (etc.). Has a BUNCH of sub-branches including, but not limited to: - PSRC - Pub. Sec. Riot Control, Kinda obvious but handles riots. - PSDD/PSIS - Pub. Sec. Department of Detectives/Pub. Sec. Investigative Services, Detectives. - PSCN - Pub. Sec. Crisis Negotiators. etc.
EMFRS - Stands for Emergency Medical and/or Fire Response Services. Basically paramedics and firefighters combined into one team.
CBRN Threat Response Force - handles chemical, biological, radiological, or nuclear threats. Split into multiple different sub-branches, the main one being Primary Response (aka first responders on a scene if chems are involved). List of the ones (so far) are: - Primary Response - professionals trained in rapid-response relief efforts. The more experienced responders. - AFA - Affect-Effect Assembly, professionals trained in the ‘what now’, specifically for after attacks. - Preventative Motions Assembly - members more in the legal side of it, trying to outlaw chemical, biological, radiological, or nuclear weapons. - CBRNRC - CBRN Riot Control, basically they’re on standby at any site where they may be a violent confrontation that ends with the usage of chemical weapons. Works closely with PSRC.
NDAA - Natural Disaster Aid Assembly, handles any result of any natural disaster. The most funded aspect of the Resistance.
Removers - The anti-abstractions unit. Groups of people (often separate from most squads) sent into Outbreak Zones to combat the Abstractions.
Logistics - Help people evacuate, create tactics, and handle finances
Medical Corps - The medical personnel. Split into many sub branches but some are: - Paramedics - part of EMFRS (under both Medical Corps and EMFRS). First responders to civilian disputes in non-violent areas. - Combat Medics - NOT part of EMFRS. Medics on the field, highly trained and skilled. Respond to civilian disputes in violent areas. - Field Hospital Staff - Doctors and Surgeons, handle treatment at hospitals. - RCWAMP - Recovery from Chemical Weapons Assistance Medical Personnel. Basically the team behind assisting any being injured in a CBRN attack. Work VERY closely with the CBRN Threat Response Force. - MHAP - Mental Health Assistance Personnel, therapists and psychiatrists
RESpecOp - Resistance Special Operations. The most militarized aspect of the Resistance. Handle scouting, sniping, data analysts, etc. has multiple subbranches a few of them are: - RSOS - RESpecOp Snipers. Kinda obvious, I’d say but snipers! - RSOSC - RESpecOp Scouts. Handle scouting. Has subbranches but a good portion of them work with the Removers branch. RSODA - RESpecOp Data Analysts. Analyze data from operations, create graphs, verify data, and assist with the planning of future operations. RSOIG - RESpecOp Intelligence Gatherers. Gather the intelligence. Different from Data Analysts as they’re the gathering the information in the first place, and tend to provide real-time updates for teams on the field.
this will be updated later on as the story progresses but! :p
2 notes
·
View notes
Text
Gemini Code Assist Enterprise: AI App Development Tool

Introducing Gemini Code Assist Enterprise’s AI-powered app development tool that allows for code customisation.
The modern economy is driven by software development. Unfortunately, due to a lack of skilled developers, a growing number of integrations, vendors, and abstraction levels, developing effective apps across the tech stack is difficult.
To expedite application delivery and stay competitive, IT leaders must provide their teams with AI-powered solutions that assist developers in navigating complexity.
Google Cloud thinks that offering an AI-powered application development solution that works across the tech stack, along with enterprise-grade security guarantees, better contextual suggestions, and cloud integrations that let developers work more quickly and versatile with a wider range of services, is the best way to address development challenges.
Google Cloud is presenting Gemini Code Assist Enterprise, the next generation of application development capabilities.
Beyond AI-powered coding aid in the IDE, Gemini Code Assist Enterprise goes. This is application development support at the corporate level. Gemini’s huge token context window supports deep local codebase awareness. You can use a wide context window to consider the details of your local codebase and ongoing development session, allowing you to generate or transform code that is better appropriate for your application.
With code customization, Code Assist Enterprise not only comprehends your local codebase but also provides code recommendations based on internal libraries and best practices within your company. As a result, Code Assist can produce personalized code recommendations that are more precise and pertinent to your company. In addition to finishing difficult activities like updating the Java version across a whole repository, developers can remain in the flow state for longer and provide more insights directly to their IDEs. Because of this, developers can concentrate on coming up with original solutions to problems, which increases job satisfaction and gives them a competitive advantage. You can also come to market more quickly.
GitLab.com and GitHub.com repos can be indexed by Gemini Code Assist Enterprise code customisation; support for self-hosted, on-premise repos and other source control systems will be added in early 2025.
Yet IDEs are not the only tool used to construct apps. It integrates coding support into all of Google Cloud’s services to help specialist coders become more adaptable builders. The time required to transition to new technologies is significantly decreased by a code assistant, which also integrates the subtleties of an organization’s coding standards into its recommendations. Therefore, the faster your builders can create and deliver applications, the more services it impacts. To meet developers where they are, Code Assist Enterprise provides coding assistance in Firebase, Databases, BigQuery, Colab Enterprise, Apigee, and Application Integration. Furthermore, each Gemini Code Assist Enterprise user can access these products’ features; they are not separate purchases.
Gemini Code Support BigQuery enterprise users can benefit from SQL and Python code support. With the creation of pre-validated, ready-to-run queries (data insights) and a natural language-based interface for data exploration, curation, wrangling, analysis, and visualization (data canvas), they can enhance their data journeys beyond editor-based code assistance and speed up their analytics workflows.
Furthermore, Code Assist Enterprise does not use the proprietary data from your firm to train the Gemini model, since security and privacy are of utmost importance to any business. Source code that is kept separate from each customer’s organization and kept for usage in code customization is kept in a Google Cloud-managed project. Clients are in complete control of which source repositories to utilize for customization, and they can delete all data at any moment.
Your company and data are safeguarded by Google Cloud’s dedication to enterprise preparedness, data governance, and security. This is demonstrated by projects like software supply chain security, Mandiant research, and purpose-built infrastructure, as well as by generative AI indemnification.
Google Cloud provides you with the greatest tools for AI coding support so that your engineers may work happily and effectively. The market is also paying attention. Because of its ability to execute and completeness of vision, Google Cloud has been ranked as a Leader in the Gartner Magic Quadrant for AI Code Assistants for 2024.
Gemini Code Assist Enterprise Costs
In general, Gemini Code Assist Enterprise costs $45 per month per user; however, a one-year membership that ends on March 31, 2025, will only cost $19 per month per user.
Read more on Govindhtech.com
#Gemini#GeminiCodeAssist#AIApp#AI#AICodeAssistants#CodeAssistEnterprise#BigQuery#Geminimodel#News#Technews#TechnologyNews#Technologytrends#Govindhtech#technology
3 notes
·
View notes
Text
My gripes with AI and its acceptance
People on the internet participating in spaces centred around creative work of any kind (both technical and more free-form) are often wary of infringing on creative rights of others. These people are an important factor in enforcing proper treatment of original authors by pointing out cropped references to the author, blurred watermarks, providing sources and meticulously analysing code they suspect to be stolen.
It's always satisfying to see a person trying to pass someone's work as their one be called out for it and made to stop through pure societal pressure directed towards something deemed unjust. Unfortunately these techniques are applicable only on singular individuals or small groups. Any bigger entity tends to lack a 'face' towards which any attempts can be directed. This is why its often much harder to enforce rights of smaller creatives whose work is being stolen by bigger entities. It requires an official process often going through channels of the entity in question (dubious effectiveness) or through the legal system (expensive, tasking, and long). And that is if the copyright infringement could be shown, which used to be somewhat easy. AI changed that.
Casey Rickey demonstrated on his YouTube channel how one could go about replicating a specific style using his own and Salvador Dali's work as an example. The results were in my opinion not exactly successful but close enough to be concerning. Currently available AI models are cheap for what they can produce and while their results are sub-par and often recognisable as AI (which is also changing rapidly) they are free or close to free which is much less than an artist would charge for a commission. This is likely enough to undermine real artists through: 1 - their works likely being already included in current models, 2 - ability to copy their exact style to a text or image prompt. Both of those currently seem to be legally untouchable as in both cases unlawful (and unethical) use of source material is near impossible to prove outside of catching the culprit in-act, as mentions of similar style could be dismissed as subjective and not exactly proving anything (which is fair, but doesn't help the victim).
Is AI generated content derivative?
We could assume AI generated content to be a more advanced way of taking inspiration in someone's work and trying to replicate things that we deem worth replicating in it, an admiration-through-imitation kind of approach. Though I would argue that intent here is important. Is the intent really to appreciate someone's work or is it to gain a close-enough copy of the work? In my case I consider it more as a form of advanced tracing, which doesn't gel well with being derivative.
Being more on the conceptual side - AI, in it's current, non-consensual form is theft. But what is it stealing? It's not exactly the works themselves, it's more (at the risk of being too abstract) about the work that was put in. AI is not a way to steal the effect of someone's work, but rather to steal days of training and personal input that made the work the way it is. It's offering to apply someone's expertise to an idea of a stranger at no cost to them and with potential loss of income by the original artist. It's a commission, but the artist is absent.
The above was written without aid of generative AI's. I might have more to say about this later, but it's enough for now.
Edit: I forgot about my actual point. My conclusion is that because AI generated content in its current form is inseparably involved in copyright infringement of people whose works cannot be extracted from the model nor can they be properly compensated for damages (as it is almost impossible to say for certain whether their rights are infringed upon or not) - all authors of generative AI's that cannot provide a complete list of sources for its training data along with proof of rights to using them cannot offer their AI as a service, cannot accept payment for using them, should not have created them and may not create any without providing such sources.
#ai#ai generated#ai art#ai artwork#artificial intelligence#rant#copyright#law#author#authorship#creative#creative writing#photography#digital drawing#digital painting#coding#ai ethics#ethics#copyright infringement#cyberpunk#would someone please for once make something that benefits not those already benefiting but those being benefited from
3 notes
·
View notes