#Data Deduplication
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
When “GIF” was named word of the year in 2012, Oxford Dictionaries U.S.A. credited Tumblr for pushing the word.
Text
Entity resolution: the detective that solves the mystery of 'Who is this data, really?' 🕵️♀️🔍
#FuzzyMatch #EntityResolution #DataScience #DataAnalytics
https://matasoft.hr/QTrendControl/index.php/41-matasoft-entity-resolution/123-funny-depiction-of-fuzzy-matching-and-entity-resolution-4
https://matasoft.hr/QTrendControl/index.php/41-matasoft-entity-resolution/123-funny-depiction-of-fuzzy-matching-and-entity-resolution-4

#data analytics#data matching#record linkage#fuzzy matching#data science#big data#fuzzy match#entity resolution#data deduplication
0 notes
Text
Video on how to Configure Data Deduplication on Windows Server
Install and Video on how to Configure Data Deduplication on Windows Server Data deduplication eliminates excessive copies of data, significantly reducing storage capacity requirements. The process can run as an inline operation while writing data into the storage system and/or as a background process to eliminate duplicates after writing data to disk. Here is a link to the blogpost. Also, see…

View On WordPress
#Data Deduplication#deduplication#Microsoft Windows#Windows#Windows 10#Windows 11#Windows Server#Windows Server 2012#Windows Server 2016#Windows Server 2019#Windows Server 2022
0 notes
Text
Streamlining Data Accuracy: Match Data Pro LLC’s Cutting-Edge Tools for the Modern Enterprise
In today's data-driven business environment, information is more than just an asset—it's the foundation for critical decision-making, customer engagement, and business growth. However, raw data is rarely perfect. Duplicate entries, missing values, formatting inconsistencies, and outdated information can cause major disruptions across operations. That’s where Match Data Pro LLC comes in—with advanced data cleansing tools, scalable bulk data processing, and seamless SaaS data solutions.
Data deduplication automation
0 notes
Text

Data Cleansing Deduplication | Matchdatapro.com
Discover powerful data deduplication software for effective data cleansing and deduplication. Visit Match Data Pro for solutions. Try it today!
data cleansing deduplication
0 notes
Text
The Ultimate Guide to Data Compression Solutions

Faster data transfers and effective data storage solutions are supported by Data compression. It enhances digital system and network performance as well as data management. Data compression, sometimes referred to as source coding or bit-rate reduction, is the process of changing, encoding, or converting individual data bits to minimize storage space requirements, speed up data transfer, and save operating expenses.
Lossy vs Lossless Data compression
There are basically two types of knowledge compression techniques:
Lossy versus Lossless. Understanding the particular kind of Data compression that works best for your use case is a smart place to start when defining the term.
Poor Data Compression
Higher compression ratios are attained at the expense of some data by lossy Data compression techniques. Multimedia formats like JPEG for images and MP3 for audio frequently employ this kind of compression. Although lossy Data compression significantly reduces file size, some quality is also lost. It works well in scenarios like streaming media where a loss is tolerable.
Compression of Data Without Loss
As the name implies, lossless compression algorithms preserve all of the original data. They are frequently employed in settings like text documents and program files where data integrity is vital. Because data has been compression using lossless methodologies, every last bit of the initial data can be restored with the compressed version without any information being lost.
Data Compression Uses and Examples
For maintaining data availability and recovering in situations of system as failures, data corruption, or emergencies, backup of information has an imperative responsibility. Nonetheless can take a lot of time and resources to back up a lot of data.
Before storing data in backup archives, IT experts utilize file compression techniques to reduce its size. A business might, for instance, have a daily backup schedule that includes moving configuration files, system logs, and sizable databases to a backup server. These kinds of data files have the potential to take up a lot of storage space.
More instances of Data compression and the reasons they are employed in different business contexts are provided below:
Compression of Files: The most common application of Data compression is file compression. By reducing their size, files become easier to manage for storage and transfer more quickly. The ZIP, RAR, and 7z file compression formats are often used.
Consider that you have a PowerPoint presentation that includes a ton of comprehensive charts, embedded movies, and high-resolution photos. It is necessary for you to send this huge file to a colleague via email.
Sending this big file in its original state might have been a hassle. It could be difficult for your colleague to download, take a long time to upload, and use up all of your email storage space. With a popular file compression format like ZIP, these problems are readily resolved.
Compression of Videos: Due to the enormous amount of data needed for each frame, video files are known for being larger files. Video teleconferencing, streaming media, and YouTube video storage all requires compression for video. Following formats for encoding videos are H.265 (HEVC) and H.264 (AVC).
Thinking of an institution that has a comprehensive closed-circuit television, or CCTV, safety system. Various high-definition IP surveillance cameras are positioned deliberately through the estate within the framework of this system’s equipment to continuously record and monitor activity. These cameras continuously record a considerable amount of visual data.
Managing and storing this enormous amount of video material might easily become burdensome and expensive without Data compression. Using Data compression methods designed for security video applications is the answer.
When calculating the amount of storage needed for video surveillance systems that use video compression, Seagate’s Surveillance Storage Calculator is a useful resource.
Compression of Images: In graphic design and photography, picture compression enables quicker digital image loading times and more effective photo storage. JPEG is a popular picture compression format that strikes a compromise between original size and image quality.
The main platform used by an e-commerce company to present its products to customers is its website. High-resolution photographs are featured on the website because the e-commerce market is largely visual. However, the performance of websites, user experience, and operating costs can all be negatively impacted by huge picture file sizes.
The e-commerce company uses picture compression more especially, commonly used formats like JPEG to solve this problem and enhance the functionality of its website. This enhances user experience, lowers operating costs, and optimizes website performance all while enabling the business to display high-quality product photos.
Compression of Audio: Digital music is built on the foundation of audio compression. Lossy compression (LC) has been employed by technologies like MP3, AAC, and OGG in order to minimize the size of music recordings without sacrificing sound quality. Audiophiles who desire uncompromised quality favor lossless audio compression formats like FLAC.
A high-quality audio streaming music service gives customers access to a vast song catalog for listening on several devices. In order to provide a flawless user experience, the service uses audio compression algorithms, mostly lossy ones.
Systems for Computers: Computer systems require Data compression in order to work. Compressed files are frequently used by operating systems to save storage space and enhance system efficiency. By doing this, you can be confident that your computer will function properly even when its storage is full.
Updates are frequently applied to modern computer systems and their operating systems to enhance functionality, security, and performance. Large files including system files, application upgrades, and software fixes may be included in these updates. For users and system administrators, effectively handling these updates can become a difficult undertaking in the absence of Data compression.
Communication: Data compression in telecommunications lowers the bandwidth needed for data transmission. Faster internet connections, effective data movement across networks, and seamless video conferencing are all made possible by it.
The effective transmission of high-quality audio and video data via networks is essential for video conferencing. The bandwidth needs for this real-time communication would be high without Data compression, which would result in lag, dropped connections, and poor call quality.
Things to Think About
When applying Data compression in IT systems or apps, make sure you adhere to best practices specific to the kind of data you’re working with for optimal efficiency. Analyzing your data analytics may also assist your company in maximizing the value of its data.
The Best Methods for Compressing Data
Achieving effective Data compression involves more than just reducing file size. In addition, the compression must guarantee that the data is still accessible when needed and maintain data performance and integrity.
The following are recommended methods to guarantee safe and efficient Data compression:
Ascertain the Compression Level
Prior to applying compression, determine the necessary compression level. You should strive for maximal compression for some file formats and give data integrity preservation priority for others. The secret to achieving the finest outcomes that satisfy your business goals is striking the correct balance.
Imagine a company that handles text documents, such as financial reports and contracts. Maintaining data integrity is critical for these papers. It is ensured that no information is lost during the compression process by using a lower compression level or even lossless compression.
On the other hand, larger compression levels can be used to conserve storage space without causing a major loss of data if the company archives old emails or less important documents.
Type of Compression
Based on the types of data, select the suitable compression technique. While multimedia and video files frequently employ lossy compression, text and program files typically use lossless compression.
A media production company, for example, has a huge collection of high-definition video clips stored. It employs lossy compression algorithms to lower file sizes for distribution and internet streaming while preserving a respectable degree of video quality. Nonetheless, the company ensures that no data is lost during archiving by using lossless compression for their project documentation.
Take Duplication Into Account
The operation of uncovering and eliminating duplicate information from a set of values in order minimize its size is known for data deduplication. This further minimizes the requirement for extra storage devices.
Deduplication can be used in conjunction with compression or independently of it, depending on the particular data management plan. It works best with enterprise storage systems that frequently use data redundancy.
Keep an eye on Compression Efficiency
It’s crucial to keep an eye on your Data compression procedures’ performance to make sure the intended outcomes are being attained without compromising data quality. This may entail routine evaluations of file sizes, decompression speeds, and compression ratios.
For instance, a cloud storage company continuously assesses how well its compression algorithms are working. In order to enhance the process, the corporation may adjust the compression settings or look into different algorithms if it discovers that a certain sort of data is not compressing properly. This continuous assessment guarantees the continued efficacy and efficiency of the Data compression.
Make the most of the task
Various compression techniques may be needed for different activities or projects, depending on the volume and kind of data. For optimal results, you must tailor your compression technique to the unique requirements of your project.
Original Data Backup
Preserve a copy of the original, uncompressed data at all times. In the event that data is lost or corrupted during compression or decompression, you will have a perfect copy to rely on. Frequent original data backups are an essential safety precaution.
For example, a big CAD file containing complex architectural plans is used by an architectural business. To save storage space, they use lossless compression. To avoid any possible data loss owing to unanticipated problems during the compression process, they do, however, maintain stringent backup processes for the original, uncompressed CAD files.
Businesses can efficiently utilize the power of Data compression to ensure data efficiency, cost savings, and data integrity by adhering to these best practices. In data management, Data compression is a tactical advantage that improves performance and data storage methods.
Examine Seagate’s offerings for data backup and recovery
An essential idea in data management and IT is Data compression. It improves the effectiveness and economy of data transfer and storage for your company. Through an awareness of the various compression techniques, when to employ them, and best practices for implementation, IT teams and companies may effectively leverage the power of Data compression.
To protect your data, Seagate provides a variety of data backup and recovery options. Speak with a specialist right now to simplify operations and safeguard your company with strong data protection.
Read more on Govindhtech.com
0 notes
Text
How Large Language Models (LLMs) are Transforming Data Cleaning in 2024
Data is the new oil, and just like crude oil, it needs refining before it can be utilized effectively. Data cleaning, a crucial part of data preprocessing, is one of the most time-consuming and tedious tasks in data analytics. With the advent of Artificial Intelligence, particularly Large Language Models (LLMs), the landscape of data cleaning has started to shift dramatically. This blog delves into how LLMs are revolutionizing data cleaning in 2024 and what this means for businesses and data scientists.
The Growing Importance of Data Cleaning
Data cleaning involves identifying and rectifying errors, missing values, outliers, duplicates, and inconsistencies within datasets to ensure that data is accurate and usable. This step can take up to 80% of a data scientist's time. Inaccurate data can lead to flawed analysis, costing businesses both time and money. Hence, automating the data cleaning process without compromising data quality is essential. This is where LLMs come into play.
What are Large Language Models (LLMs)?
LLMs, like OpenAI's GPT-4 and Google's BERT, are deep learning models that have been trained on vast amounts of text data. These models are capable of understanding and generating human-like text, answering complex queries, and even writing code. With millions (sometimes billions) of parameters, LLMs can capture context, semantics, and nuances from data, making them ideal candidates for tasks beyond text generation—such as data cleaning.
To see how LLMs are also transforming other domains, like Business Intelligence (BI) and Analytics, check out our blog How LLMs are Transforming Business Intelligence (BI) and Analytics.

Traditional Data Cleaning Methods vs. LLM-Driven Approaches
Traditionally, data cleaning has relied heavily on rule-based systems and manual intervention. Common methods include:
Handling missing values: Methods like mean imputation or simply removing rows with missing data are used.
Detecting outliers: Outliers are identified using statistical methods, such as standard deviation or the Interquartile Range (IQR).
Deduplication: Exact or fuzzy matching algorithms identify and remove duplicates in datasets.
However, these traditional approaches come with significant limitations. For instance, rule-based systems often fail when dealing with unstructured data or context-specific errors. They also require constant updates to account for new data patterns.
LLM-driven approaches offer a more dynamic, context-aware solution to these problems.

How LLMs are Transforming Data Cleaning
1. Understanding Contextual Data Anomalies
LLMs excel in natural language understanding, which allows them to detect context-specific anomalies that rule-based systems might overlook. For example, an LLM can be trained to recognize that “N/A” in a field might mean "Not Available" in some contexts and "Not Applicable" in others. This contextual awareness ensures that data anomalies are corrected more accurately.
2. Data Imputation Using Natural Language Understanding
Missing data is one of the most common issues in data cleaning. LLMs, thanks to their vast training on text data, can fill in missing data points intelligently. For example, if a dataset contains customer reviews with missing ratings, an LLM could predict the likely rating based on the review's sentiment and content.
A recent study conducted by researchers at MIT (2023) demonstrated that LLMs could improve imputation accuracy by up to 30% compared to traditional statistical methods. These models were trained to understand patterns in missing data and generate contextually accurate predictions, which proved to be especially useful in cases where human oversight was traditionally required.
3. Automating Deduplication and Data Normalization
LLMs can handle text-based duplication much more effectively than traditional fuzzy matching algorithms. Since these models understand the nuances of language, they can identify duplicate entries even when the text is not an exact match. For example, consider two entries: "Apple Inc." and "Apple Incorporated." Traditional algorithms might not catch this as a duplicate, but an LLM can easily detect that both refer to the same entity.
Similarly, data normalization—ensuring that data is formatted uniformly across a dataset—can be automated with LLMs. These models can normalize everything from addresses to company names based on their understanding of common patterns and formats.
4. Handling Unstructured Data
One of the greatest strengths of LLMs is their ability to work with unstructured data, which is often neglected in traditional data cleaning processes. While rule-based systems struggle to clean unstructured text, such as customer feedback or social media comments, LLMs excel in this domain. For instance, they can classify, summarize, and extract insights from large volumes of unstructured text, converting it into a more analyzable format.
For businesses dealing with social media data, LLMs can be used to clean and organize comments by detecting sentiment, identifying spam or irrelevant information, and removing outliers from the dataset. This is an area where LLMs offer significant advantages over traditional data cleaning methods.
For those interested in leveraging both LLMs and DevOps for data cleaning, see our blog Leveraging LLMs and DevOps for Effective Data Cleaning: A Modern Approach.

Real-World Applications
1. Healthcare Sector
Data quality in healthcare is critical for effective treatment, patient safety, and research. LLMs have proven useful in cleaning messy medical data such as patient records, diagnostic reports, and treatment plans. For example, the use of LLMs has enabled hospitals to automate the cleaning of Electronic Health Records (EHRs) by understanding the medical context of missing or inconsistent information.
2. Financial Services
Financial institutions deal with massive datasets, ranging from customer transactions to market data. In the past, cleaning this data required extensive manual work and rule-based algorithms that often missed nuances. LLMs can assist in identifying fraudulent transactions, cleaning duplicate financial records, and even predicting market movements by analyzing unstructured market reports or news articles.
3. E-commerce
In e-commerce, product listings often contain inconsistent data due to manual entry or differing data formats across platforms. LLMs are helping e-commerce giants like Amazon clean and standardize product data more efficiently by detecting duplicates and filling in missing information based on customer reviews or product descriptions.

Challenges and Limitations
While LLMs have shown significant potential in data cleaning, they are not without challenges.
Training Data Quality: The effectiveness of an LLM depends on the quality of the data it was trained on. Poorly trained models might perpetuate errors in data cleaning.
Resource-Intensive: LLMs require substantial computational resources to function, which can be a limitation for small to medium-sized enterprises.
Data Privacy: Since LLMs are often cloud-based, using them to clean sensitive datasets, such as financial or healthcare data, raises concerns about data privacy and security.

The Future of Data Cleaning with LLMs
The advancements in LLMs represent a paradigm shift in how data cleaning will be conducted moving forward. As these models become more efficient and accessible, businesses will increasingly rely on them to automate data preprocessing tasks. We can expect further improvements in imputation techniques, anomaly detection, and the handling of unstructured data, all driven by the power of LLMs.
By integrating LLMs into data pipelines, organizations can not only save time but also improve the accuracy and reliability of their data, resulting in more informed decision-making and enhanced business outcomes. As we move further into 2024, the role of LLMs in data cleaning is set to expand, making this an exciting space to watch.
Large Language Models are poised to revolutionize the field of data cleaning by automating and enhancing key processes. Their ability to understand context, handle unstructured data, and perform intelligent imputation offers a glimpse into the future of data preprocessing. While challenges remain, the potential benefits of LLMs in transforming data cleaning processes are undeniable, and businesses that harness this technology are likely to gain a competitive edge in the era of big data.
#Artificial Intelligence#Machine Learning#Data Preprocessing#Data Quality#Natural Language Processing#Business Intelligence#Data Analytics#automation#datascience#datacleaning#large language model#ai
2 notes
·
View notes
Text
B2B Database Contacts: Achieving the Precise Harmony Between Quality and Quantity

In the ever-evolving landscape of B2B sales, the tapestry of effective B2B Lead Generation, targeted Sales Leads, and strategic Business Development is intricately woven with the threads of the B2B Contact Database. This comprehensive article embarks on an exploration to unravel the profound interplay between quality and quantity – the pulse that resonates within B2B Database Leads. Join us on this journey as we traverse the pathways, strategies, and insights that guide you towards mastering the equilibrium, steering your Sales Prospecting initiatives towards finesse and success.
DOWNLOAD THE INFOGRAPHIC HERE
The Essence of Quality
Quality emerges as the cornerstone in the realm of B2B Lead Generation, encapsulating the essence of depth, precision, and pertinence that envelops the contact data nestled within the B2B Contact Database. These quality leads, much like jewels in a treasure trove, possess the capacity to metamorphose into valuable clients, etching a definitive impact on your revenue stream. Every contact entry isn't a mere data point; it's a capsule that encapsulates an individual's journey – their role, industry, buying tendencies, and distinctive preferences. Cultivating a repository of such high-caliber contacts is akin to nurturing a reservoir of prospects, where each interaction holds the promise of meaningful outcomes.
Deciphering the Role of Quantity
Yet, even in the pursuit of quality, quantity emerges as a steadfast ally. Quantity embodies the expanse of contacts that populate your B2B Database Leads. Imagine casting a net wide enough to enfold diverse prospects, broadening your scope of engagement. A higher count of contacts translates to an amplified potential for interaction, heightening the probability of uncovering those latent prospects whose untapped potential can blossom into prosperous business alliances. However, it's imperative to acknowledge that quantity, devoid of quality, risks transforming into an exercise in futility – a drain on resources without yielding substantial outcomes.
Quality vs. Quantity: The Artful Balancing Act
In the fervor of database compilation, the allure of sheer quantity can occasionally overshadow the crux of strategic B2B Sales and Sales Prospecting. An extensive, indiscriminate list of contacts can rapidly devolve into a resource drain, sapping efforts and diluting the efficacy of your marketing endeavors. Conversely, an overemphasis on quality might inadvertently curtail your outreach, constraining the potential for growth. The true artistry lies in achieving a symphony – a realization that true success unfolds from the harmonious interaction of quality and quantity.
youtube
Navigating the Equilibrium
This path towards equilibrium demands a continual commitment to vigilance and meticulous recalibration. Consistent audits of your B2B Contact Database serve as the bedrock for maintaining data that is not only up-to-date but also actionable. Removing outdated, duplicated, or erroneous entries becomes a proactive stride towards upholding quality. Simultaneously, infusing your database with fresh, relevant contacts injects vibrancy into your outreach endeavors, widening the avenues for engagement and exploration.
Harnessing Technology for Exemplary Data Management
In this era of technological prowess, an array of tools stands ready to facilitate the intricate choreography between quality and quantity. Step forward Customer Relationship Management (CRM) software – an invaluable ally empowered with features such as data validation, deduplication, and enrichment. Automation, the pinnacle of technological innovation, elevates database management to unparalleled heights of precision, scalability, and efficiency. Embracing these technological marvels forms the bedrock of your B2B Sales and Business Development strategies.
Collaborating with Esteemed B2B Data Providers
In your pursuit of B2B Database Leads, consider forging collaborations with esteemed B2B data providers. These seasoned professionals unlock a treasure trove of verified leads, tailor-made solutions for niche industries, and a portal to global business expansion. By tapping into their expertise, you merge the realms of quality and quantity, securing a comprehensive toolkit poised to reshape your sales landscape.
As we draw the curtains on this exploration, remember that the compass steering your B2B Sales, Sales Prospecting, and Business Development endeavors is calibrated by the delicate interplay of quality and quantity. A B2B Contact Database enriched with high-value leads, accompanied by a robust quantity, stands as the axis upon which your strategic maneuvers pivot. Equipped with insights, tools, and allies like AccountSend, your pursuit to strike this harmonious equilibrium transforms into an enlightening journey that propels your business towards enduring growth and undeniable success.
#AccountSend#B2BLeadGeneration#B2B#LeadGeneration#B2BSales#SalesLeads#B2BDatabases#BusinessDevelopment#SalesFunnel#SalesProspecting#BusinessOwner#Youtube
14 notes
·
View notes
Text
Easy way to get job data from Totaljobs
Totaljobs is one of the largest recruitment websites in the UK. Its mission is to provide job seekers and employers with efficient recruitment solutions and promote the matching of talents and positions. It has an extensive market presence in the UK, providing a platform for professionals across a variety of industries and job types to find jobs and recruit staff.
Introduction to the scraping tool
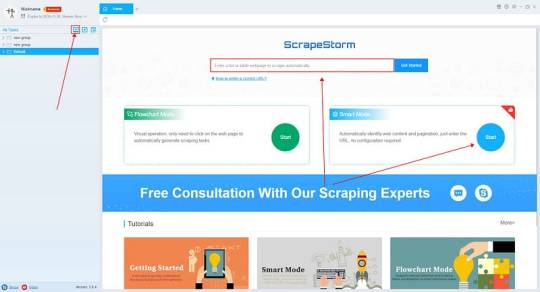
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
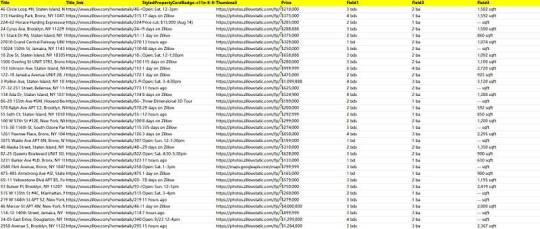
Preview of the scraped result
1. Create a task
(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task
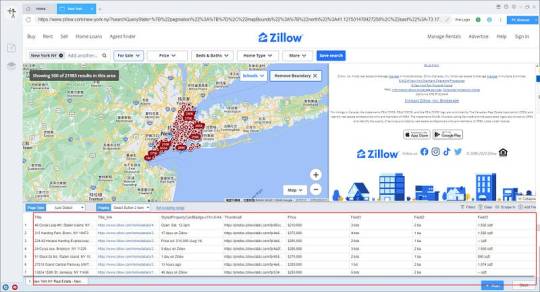
2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.
3. Set up and start the scraping task
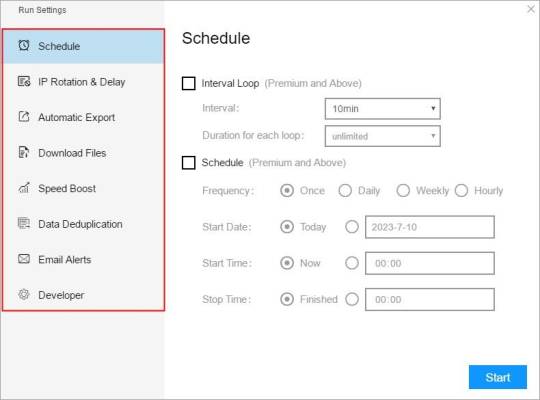
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.
4. Export and view data
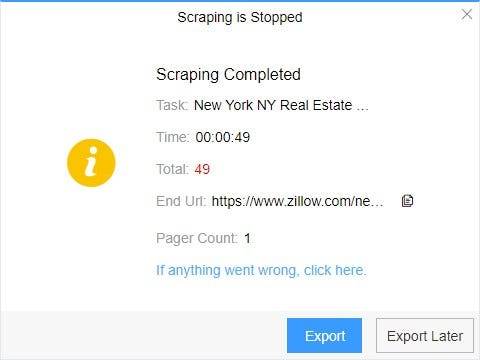
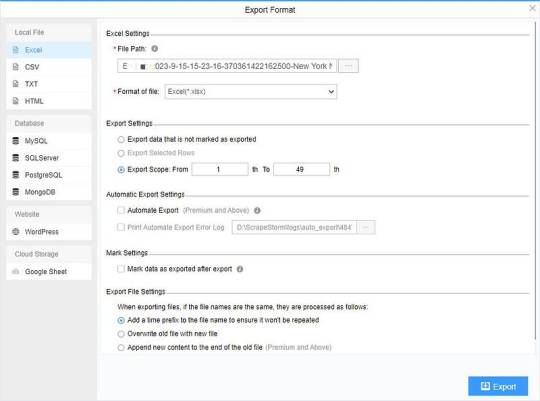
(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data
2 notes
·
View notes
Text
Control Structured Data with Intelligent Archiving

Control Structured Data with Intelligent Archiving
You thought you had your data under control. Spreadsheets, databases, documents all neatly organized in folders and subfolders on the company server. Then the calls started coming in. Where are the 2015 sales figures for the Western region? Do we have the specs for the prototype from two years ago? What was the exact wording of that contract with the supplier who went out of business? Your neatly organized data has turned into a chaotic mess of fragmented information strewn across shared drives, email, file cabinets and the cloud. Before you drown in a sea of unstructured data, it’s time to consider an intelligent archiving solution. A system that can automatically organize, classify and retain your information so you can find what you need when you need it. Say goodbye to frantic searches and inefficiency and hello to the control and confidence of structured data.
The Need for Intelligent Archiving of Structured Data
You’ve got customer info, sales data, HR records – basically anything that can be neatly filed away into rows and columns. At first, it seemed so organized. Now, your databases are overloaded, queries are slow, and finding anything is like searching for a needle in a haystack. An intelligent archiving system can help you regain control of your structured data sprawl. It works by automatically analyzing your data to determine what’s most important to keep active and what can be safely archived. Say goodbye to rigid retention policies and manual data management. This smart system learns your data access patterns and adapts archiving plans accordingly. With less active data clogging up your production systems, queries will run faster, costs will decrease, and your data analysts can actually get work done without waiting hours for results. You’ll also reduce infrastructure demands and risks associated with oversized databases. Compliance and governance are also made easier. An intelligent archiving solution tracks all data movement, providing a clear chain of custody for any information that needs to be retained or deleted to meet regulations. Maybe it’s time to stop treading water and start sailing your data seas with an intelligent archiving solution. Your databases, data analysts and CFO will thank you. Smooth seas ahead, captain!
How Intelligent Archiving Improves Data Management
Intelligent archiving is like a meticulous assistant that helps tame your data chaos. How, you ask? Let’s explore:
Automated file organization
Intelligent archiving software automatically organizes your files into a logical folder structure so you don’t have to spend hours sorting through documents. It’s like having your own personal librarian categorize everything for easy retrieval later.
Efficient storage
This software compresses and deduplicates your data to free up storage space. Duplicate files hog valuable storage, so deduplication removes redundant copies and replaces them with pointers to a single master copy. Your storage costs decrease while data accessibility remains the same.
Compliance made simple
For companies in regulated industries, intelligent archiving simplifies compliance by automatically applying retention policies as data is ingested. There’s no danger of mistakenly deleting information subject to “legal hold” and avoiding potential fines or sanctions. Let the software handle the rules so you can avoid data jail.
Searchability
With intelligent archiving, your data is indexed and searchable, even archived data. You can quickly find that invoice from five years ago or the contract you signed last month. No more digging through piles of folders and boxes. Search and find — it’s that easy. In summary, intelligent archiving brings order to the chaos of your data through automated organization, optimization, compliance enforcement, and searchability. Tame the data beast once and for all!
Implementing an Effective Data Archiving Strategy
So you have a mind-boggling amount of data accumulating and you’re starting to feel like you’re drowning in a sea of unstructured information. Before you decide to throw in the towel, take a deep breath and consider implementing an intelligent archiving strategy.
Get Ruthless
Go through your data and purge anything that’s obsolete or irrelevant. Be brutally honest—if it’s not useful now or in the foreseeable future, delete it. Free up storage space and clear your mind by ditching the digital detritus.
Establish a Filing System
Come up with a logical taxonomy to categorize your data. Group similar types of info together for easy searching and access later on. If you have trouble classifying certain data points, you probably don’t need them. Toss ‘em!
Automate and Delegate
Use tools that can automatically archive data for you based on your taxonomy. Many solutions employ machine learning to categorize and file data accurately without human input. Let technology shoulder the burden so you can focus on more important tasks, like figuring out what to have for lunch.
Review and Refine
Revisit your archiving strategy regularly to make sure it’s still working for your needs. Make adjustments as required to optimize how data is organized and accessed. Get feedback from other users and incorporate their suggestions. An effective archiving approach is always a work in progress. With an intelligent data archiving solution in place, you’ll gain control over your information overload and find the freedom that comes from a decluttered digital space. Tame the data deluge and reclaim your sanity!
Conclusion
So there you have it. The future of data management and control through intelligent archiving is here. No longer do you have to grapple with endless spreadsheets, documents, files and manually track the relationships between them.With AI-powered archiving tools, your data is automatically organized, categorized and connected for you. All that structured data chaos becomes a thing of the past. Your time is freed up to focus on more meaningful work. The possibilities for data-driven insights and optimization seem endless. What are you waiting for? Take back control of your data and unleash its potential with intelligent archiving. The future is now, so hop to it! There’s a whole new world of data-driven opportunity out there waiting for you.
2 notes
·
View notes
Text
No free lunch, but free data matching? Yes please! 🍽️💻 QDeFuZZiner Lite at your service!


#DataScience #FuzzyMatch #EntityResolution #DataAnalytics #BusinessIntelligence #BusinessSoftware #FreeSoftware #QDeFuZZiner #Matasoft #SaaS #DataAnalysis #RecordLinkage #DataMatching #DataMerging #B2B #B2C #MasterData #MasterDataManagement #MDM #ETL #DigitalAgency #DigitalMarketing
https://matasoft.hr/qtrendcontrol/index.php/qdefuzziner-fuzzy-data-matching-software/various-articles/121-qdefuzziner-lite-free
https://matasoft.hr/qtrendcontrol/index.php/qdefuzziner-fuzzy-data-matching-software/various-articles/121-qdefuzziner-lite-free
#data matching#record linkage#fuzzy matching#data science#big data#fuzzy match#entity resolution#data deduplication
0 notes
Text
How to Configure Data Deduplication on Windows Server 2022
Data deduplication is a method or technique that can remove redundant copies of data and reduce data replication on the storage. The data deduplication process ensures that you only have one single unique data on the storage. Deduplication identifies extra copies of data and eliminates them while keeping just a single instance on the storage device. In this article, I will be showing you How to…

View On WordPress
#data#deduplication#Microsoft Windows#Windows#Windows 10#Windows Server#Windows Server 2012#Windows Server 2016#Windows Server 2019#Windows Server 2022
0 notes
Text
The Legal Side of Big Data
What is big data? Big data is a combination of structured and unstructured data collected by businesses to that can be mined for information to use in advance analytical applications. Although big data is important and useful, it does comes with some negatives and one of the big negatives is computer hacking. Sustaining the growth and performance of business while simultaneously protecting sensitive information has become increasingly difficult thanks to the continual rise of cybersecurity threats. Therefore, it’s clear that preventing data breaches is one of the biggest challenges of big data. It is on the company to prevent these hacks and protect their customers while they are at it. If sensitive information gets into the wrong hands, that can be disastrous.
The internet is evolving and what that means is understanding that anything we put on the internet can be found and saved. Anything we put out there can be found, saved, used, and potentially be used against us in the long run. As consumers, we need to take this into consideration when we put anything on the internet. Privacy is an issue when it comes to big data. When dealing with big data, the industry needs to respect and protect privacy by design.
We then comes to our next questions, "What is the best way to balance the opportunities and threats presented by the development of big data?" As mentioned before, big data can serve a purpose, but also pose a threat. Reason for that is lack of proper understanding of massive data. Companies fail in their Big Data initiatives, all thanks to insufficient understanding. Employees might not know what data is, its storage, processing, importance, and sources. Data professionals may know what's happening, but others might not have a transparent picture. So you then address the challenge by taking classes, taking workshops, learning about big data and ways to make it useful. Another issue that can be worked on is storing huge amounts of data in a system application. As data grows, it gets challenging to store and save these amounts of data. Companies choose modern techniques to handle these large data sets, like compression, tiering, and deduplication. Compression is employed to reduce the number of bits within the data, thus reducing its overall size. The two main internet models: advertising and investor story time. Both methods involve large amount of surveillance on people as they use this data for big data.
youtube
2 notes
·
View notes
Text
Data Deduplication Tools | Matchdatapro.com
Discover powerful data deduplication software for effective data cleansing and deduplication. Visit Match Data Pro for solutions. Try it today!
data deduplication tools
0 notes
Text
What is data deduplication and how does it work?

Data deduplication work
Recent years have seen a boom in self-storage facilities. The ordinary individual today has more belongings than they can handle, thus these big warehouse buildings are expanding nationwide.
The IT world has the same issue. The data explosion is underway. Due to IoT capability, even basic items now produce data automatically. Data has never been generated, gathered, or analyzed so much. Never before have more data managers struggled to store so much data.
A corporation may not realize the issue or its size and must find a larger storage solution. Later, the corporation may outgrow that storage system, needing further expenditure. The corporation will eventually tire of this game and seek a cheaper, simpler option data deduplication.
Many firms employ data deduplication (or “dedupe”) as part of their data management system, but few understand it. Tell me how data deduplication works.
How does deduplication work?
First, define your core word. By deleting duplicate data, businesses simplify their data holdings and lower the quantity they archive.
Additionally, when to talk about redundant data, they mean a proliferation of data files at the file level. When discussing data deduplication, while require a file deduplication system.
The primary purpose of deduplication?
Some individuals think data is a commodity to be collected and harvested, like apples from your garden tree.
Each new data file costs money. Such data is frequently expensive to collect. Even organically produced and collected data takes a large financial expenditure for an organization to obtain and analyze. Thus, data sets are investments and must be secured like any other asset.
Data storage space whether on-premises physical servers or cloud storage via a cloud-based data center must be acquired or rented.
Duplicate copies of replicated data reduce the bottom line by adding storage expenses beyond the original storage system and its capacity. Thus, additional storage medium must be used to store new and old data. Duplicate data might become a costly problem for a firm.
To conclude, data deduplication saves money by reducing storage costs.
Additional deduplication advantages
Companies choose data deduplication systems for reasons other than storage capacity, including data preservation and improvement.
Companies optimize deduplicated data workloads to operate more efficiently than duplicated data.
Dedupe also speeds up disaster recovery and reduces data loss. Dedupe makes an organization’s backup system strong enough to handle its backup data. Besides complete backups, dedupe helps retention.
Due to the identical virtual hard drives underpinning VDI remote desktops, data deduplication works well with VDI installations. Microsoft Azure Virtual Desktop and Windows VDI are popular DaaS offerings.
Virtual machines (VMs) are produced during server virtualization by these solutions. These virtual machines power VDI.
Deduplication technique
Most data deduplication uses block deduplication. This approach uses automated methods to find and eliminate data duplications. Block-level analysis may identify distinct data chunks for validation and preservation. Then, when the deduplication program finds a data block repeat, it removes it and replaces it with a reference to the original data.
That’s the major dedupe approach, but not the only one. In other circumstances, file-level data deduplication is used. Single-instance storage compares file server complete copies of data, not segments or blocks. Like its counterpart, file deduplication keeps the original file in the file system and removes copies.
Deduplication approaches function differently from data compression algorithms (e.g., LZ77, LZ78), yet both aim to reduce data redundancy. Deduplication systems do this on a bigger scale than compression methods, which aim to effectively encode data redundancy rather than replace identical files with shared copies.
Data deduplication types
Different methods of data deduplication depend on when it happens:
This kind of data deduplication happens in real time as data moves through the storage system. Because it does not transport or keep duplicate data, inline dedupe reduces data bandwidth. This may reduce the organization’s bandwidth needs. After data is written to a storage device, post-process deduplication occurs.
Data deduplication hash calculations influence both methods of data deduplication. Cryptographic computations are essential for data pattern recognition. In-line deduplications do computations in real time, which might momentarily disable computers. Post-processing deduplications allow hash computations at any moment after data is uploaded without overtaxing the organization’s computer resources.
The small distinctions between deduplication types continue. Another approach to categorize deduplication is by location.
Source deduplication occurs near data generation. The system removes fresh file copies after scanning that region.
Target deduplication is an inversion of source deduplication. Target deduplication removes copies of data in locations other than the original.
Forward-thinking companies must weigh the pros and downsides of each deduplication approach against their demands.
Internal factors like these may determine an organization’s deduplication approach in various usage cases:
Creating how many and what kind of data sets
Organization’s main storage system
Which virtual environments operate?
This firm uses which apps?
Recent data deduplication advances
Data deduplication, like any computer output, will employ AI more as it evolves. Dedupe will get more smart as it uses additional subtleties to discover duplication in scanned data blocks.
In dedupe, reinforcement learning is a trend. This employs incentives and penalties (like reinforcement training) to find the best way to split or merge data.
Ensemble approaches, which combine many models or algorithms to improve dedupe accuracy, are another topic to monitor.
Read more on Govindhtech.com
#datadeduplication#Datadeduplicationwork#deduplication#data#cloudstorage#MicrosoftAzure#VirtualDesktop#deduplicationtypes#technews#technology
0 notes
Text
Don’t forget Amazon is the lovely caring company that gave us Mechanical Turk. From their own site:
While technology continues to improve, there are still many things that human beings can do much more effectively than computers, such as moderating content, performing data deduplication, or research. Traditionally, tasks like this have been accomplished by hiring a large temporary workforce, which is time consuming, expensive and difficult to scale, or have gone undone. Crowdsourcing is a good way to break down a manual, time-consuming project into smaller, more manageable tasks to be completed by distributed workers over the Internet (also known as ‘microtasks’).
The Amazon grocery stores which touted an AI system that tracked what you put in your cart so you didn't have to go through checkout were actually powered by underpaid workers in India.
Just over half of Amazon Fresh stores are equipped with Just Walk Out. The technology allows customers to skip checkout altogether by scanning a QR code when they enter the store. Though it seemed completely automated, Just Walk Out relied on more than 1,000 people in India watching and labeling videos to ensure accurate checkouts. The cashiers were simply moved off-site, and they watched you as you shopped. According to The Information, 700 out of 1,000 Just Walk Out sales required human reviewers as of 2022. This widely missed Amazon’s internal goals of reaching less than 50 reviews per 1,000 sales
A great many AI products are just schemes to shift labor costs to more exploitable workers. There may indeed be a neural net involved in the data processing pipeline, but most products need a vast and underpaid labor force to handle its nearly innumerable errors.
11K notes
·
View notes