#DataOps Platform
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
#DataOps Platform#Data Collaboration#Data Security#Data Workflow Automation#Cross-Functional Collaboration#DataOps Tools#Data Insights#Data Quality#DevOps#Data Pipelines
1 note
·
View note
Text
youtube
Power Platform Bootcamp Buenos Aires
Evento de la comunidad Argentina con grandes sesiones.
El Poder de Python y R en Power BI por Mike Ramirez
Transforme datos con buenas prácticas de Power Query por Ignacio Barrau
Agentes en Power Platform: El Futuro de la IA por Andrés Arias Falcón
Power Virtual Agent - Charlando con tu base de datos por Matias Molina y Nicolas Muñoz
¿Por qué deberían los desarrolladores automatizar? por Mauro Gioberti
Microsoft Fabric + Power BI: Arquitecturas y Licenciamiento - Todo lo que necesitas saber por Gonzalo Bissio y Maximiliano Accotto
El auge de los copilotos: De la adopción del low-code a la maestría en análisis de datos por Gaston Cruz y Alex Rostan
Libérate de las Tareas Repetitivas: Potencia tu Talento con Power Apps y Power Automate por Anderson Estrada
Introducción a Microsoft Fabric - Data analytics para la era de al Inteligencia Artificial por Javier Villegas
Tu Primer despliegue con PBIP Power BI Control de versiones CI/CD GIT en GITHUB por Vicente Antonio Juan Magallanes
Espero que lo disfruten
#power bi#power platform#powerbi#power bi argentina#power bi cordoba#power bi jujuy#power bi tips#power bi tutorial#power bi training#fabric#microsoft fabric#dataops#power bi cicd#Youtube
0 notes
Text
#DataOps Platform Market#DataOps Platform Market Scope#DataOps Platform Market Size#DataOps Platform Market Trends#DataOps Platform Market Growth
0 notes
Text
How to Train Your Team to Use a DataOps Platform Effectively

Organizations are depending more and more on massive volumes of data in today’s data-driven world in order to spur innovation, make wise decisions, and gain a competitive edge. Effectively managing and improving data processes is a major difficulty, though. A DataOps platform can be useful in this situation.
A DataOps Platform: What Is It?
A complete solution created to improve and expedite the data management and analytics processes is called a DataOps platform. DataOps is an approach to data management that takes cues from software development processes known as DevOps. Its objective is to ensure high standards of quality, dependability, and compliance while expediting the production and delivery of data products.
Important attributes and advantages
a. Automated Data Pipelines: The automation of data pipelines is a fundamental component of data operations platforms. This entails reducing manual involvement and error-proneness by automating the extraction, transformation, and loading (ETL) procedures. Faster data processing is made possible by automated pipelines, which facilitate the integration and analysis of data from several sources.
b. Enhanced Data Quality: Accurate analytics and reporting depend on high-quality data. Data validation and cleaning techniques are included into DataOps systems to assist find and fix problems with data quality early in the pipeline. As a result, decisions are made more effectively and with more reliability.
c. Enhanced Collaboration: By dismantling silos between data scientists, business analysts, and data engineers, DataOps platform encourages a collaborative approach. The platform facilitates a more integrated and effective workflow by offering features like version control, shared workspaces, and real-time communication capabilities.
d. Flexibility and Scalability: As businesses expand, so do their data requirements. A data operations platform is made to grow with the company, adapting to changing needs and bigger data volumes. Additionally, it supports a broad range of data integration situations by providing flexibility with regard to data sources and destinations.
e. Governance and Compliance: DataOps systems come with strong governance and compliance tools to assist enterprises in following legal obligations and data security guidelines. These characteristics lower the possibility of compliance problems by guaranteeing that data management procedures are open and auditable.
The DataOps Future
With the integration of cutting-edge technologies like artificial intelligence and machine learning into these platforms, the world of data operations is fast changing. More advanced automation features, improved predictive analytics, and deeper interaction with cloud-based services are possible future advances.
A data operations platform will be crucial in guaranteeing that data processes are effective, dependable, and in line with corporate objectives as companies continue to leverage the power of data. In an increasingly data-centric world, companies may preserve a competitive edge and open up new avenues for innovation by using a DataOps strategy.
0 notes
Text
Dry Film Laminator Market 2025 Expected to Reach Significant Rate by 2033
Global “Dry Film Laminator Market” research report is a comprehensive analysis of the current status of the Dry Film Laminator industry worldwide. The report categorizes the global Dry Film Laminator market by top players/brands, region, type, and end-user. It also examines the competition landscape, market share, growth rate, future trends, market drivers, opportunities, and challenges in the global Dry Film Laminator market. The report provides a professional and in-depth study of the industry to help understand its current state and future prospects. What Are The Prominent Key Player Of the Dry Film Laminator Market?
Bungard Elektronik
MITS Electronics
Cipel Italia
Fortex Engineering
Vanguard Electronic
SLN Technologies
The Primary Objectives in This Report Are:
To determine the size of the total market opportunity of global and key countries
To assess the growth potential for Dry Film Laminator
To forecast future growth in each product and end-use market
To assess competitive factors affecting the marketplace
This report also provides key insights about market drivers, restraints, opportunities, new product launches or approvals.
Regional Segment of Dry Film Laminator Market:
Geographically, the report includes research on production, consumption, revenue, market share, and growth rate of the following regions:
United States
Europe (Germany, UK, France, Italy, Spain, Russia, Poland)
China
Japan
India
Southeast Asia (Malaysia, Singapore, Philippines, Indonesia, Thailand, Vietnam)
Latin America (Brazil, Mexico, Colombia)
Middle East and Africa (Saudi Arabia, United Arab Emirates, Turkey, Egypt, South Africa, Nigeria)
The global Dry Film Laminator Market report answers the following questions:
What are the main drivers of the global Dry Film Laminator market? How big will the Dry Film Laminator market and growth rate in upcoming years?
What are the major market trends that affecting the growth of the global Dry Film Laminator market?
Key trend factors affect market share in the world's top regions?
Who are the most important market participants and what strategies being they pursuing in the global Dry Film Laminator market?
What are the market opportunities and threats to which players are exposed in the global Dry Film Laminator market?
Which industry trends, drivers and challenges are driving that growth?
Browse More Details On This Report at - https://www.businessresearchinsights.com/market-reports/dry-film-laminator-market-104435
Contact Us:
Business Research Insights
Phone:
US: (+1) 424 253 0807
UK: (+44) 203 239 8187
Email: [email protected]
Web: https://www.businessresearchinsights.com
Other Reports Here:
DataOps Platform Market
Flower and Ornamental Plants Market
Roller Pumps Device Market Size,
Construction Waste Management Market
Kalimba Market
Smart Inhaler Technology Market
Conductive Flooring Market
Batch and Process Manufacturing ERP Market
Black Pigment Market
Mobile Oxygen Generator Market
Other Reports Here:
3D Dental Scanner Market
Gas Pressure Springs Market
Lobster Market
Beverage Plastic Bottle Market
Baby Prams and Strollers Market
Glass Molding Market
Agarwood Essential Oil Market
Gypsum Centrifuges Market
IT Training Market
Methylglycinediacetic Acid Market
0 notes
Text
Understanding DataOps: The Role of Favoriot
When people talk about DataOps, the spotlight usually falls on data lakes, dashboards, and fancy machine learning pipelines. But as someone who’s spent years building an IoT platform from the ground up, I can tell you this: none of that works if your data source isn’t reliable. That’s where platforms like Favoriot come in — and the often-overlooked connection between IoT and DataOps becomes very…
#dailyprompt#dailyprompt-1960#FAVORIOT#Internet of Things#IoT Platform#Malaysia#Mazlan Abbas#Platform
0 notes
Text
The Future of Data Science: Trends to Watch in 2025
In today's fast-paced digital world, data science continues to be one of the most transformative fields. As we step into 2025, the role of data scientists is evolving rapidly with new technologies, tools, and business demands. Whether you're a budding analyst, a seasoned data professional, or someone curious about the future, these trends will shape the data science landscape in the coming year and beyond.

1. AI and Machine Learning Get Smarter
In 2025, AI and ML models are not just getting more accurate — they’re getting more context-aware. We’ll see a rise in explainable AI (XAI), helping businesses understand why an algorithm made a specific decision. This will be crucial for industries like healthcare, finance, and law where transparency is vital.
2. The Rise of AutoML
Automated Machine Learning (AutoML) will continue to democratize data science by enabling non-experts to build models without deep coding knowledge. This trend will accelerate productivity, reduce human error, and allow data scientists to focus on strategy and interpretation.
3. Data Privacy and Ethics Take Center Stage
With stricter regulations like GDPR and India’s Digital Personal Data Protection Act, data scientists must prioritize ethical data use and privacy compliance. 2025 will see more organizations embedding responsible AI practices in their workflows.
4. Edge Computing + Data Science = Real-Time Intelligence
Expect to see data science moving to the edge — quite literally. With IoT devices generating massive amounts of real-time data, processing this data locally (at the edge) will allow faster decision-making, especially in industries like manufacturing, logistics, and autonomous vehicles.
5. Natural Language Processing (NLP) Reaches New Heights
Thanks to advancements in large language models, NLP will power smarter chatbots, voice assistants, and search systems. Data scientists will increasingly work with unstructured data — text, audio, and video — to uncover deeper insights.
6. Low-Code and No-Code Platforms
Low-code tools will continue to empower business users to perform data analysis and visualization without needing deep technical skills. These platforms bridge the gap between data science and business intelligence, fostering greater collaboration.
7. DataOps and MLOps Maturity
In 2025, organizations are treating data like software. With DataOps and MLOps, companies are streamlining the lifecycle of data pipelines and machine learning models, ensuring version control, monitoring, and scalability across teams.
8. Data Literacy Becomes Essential
As data becomes central to decision-making, data literacy is becoming a key skill across all job roles. Companies are investing in training programs to ensure employees can interpret and use data effectively, not just collect it.
Final Thoughts
Data science in 2025 is more than just crunching numbers — it's about building responsible, scalable, and intelligent systems that can make a real-world impact. Whether you're an aspiring data scientist or an experienced professional, staying updated with these trends is essential.
At Naresh i Technologies, we’re committed to preparing the next generation of data professionals through our industry-focused Data Science and Analytics training programs. Join us and become future-ready!
#datascience#AI#machinelearning#bigdata#analytics#datamining#artificialintelligence#datascientist#technology#dataanalysis#deeplearning#datavisualization#predictiveanalytics#dataengineering#datadriven#datamanagement#datasciencecommunity#AItechnology#datasciencejobs#AIinnovation#datascienceeducation
0 notes
Text
Who’s Setting the Standard for Data Governance? Key Takeaways from the 2025 SPARK Matrix™ As part of our 2025 SPARK Matrix™ research, I recently evaluated the top 21 global vendors in the data governance space—and the findings highlight an exciting shift in how organizations are treating data as a strategic, governed asset. 📊 Download the full sample Blog - https://qksgroup.com/blogs/who-s-setting-the-standard-for-data-governance-insights-from-the-2025-spark-matrix-1182 🔹 Real-Time Data Governance With the rise of IoT and real- time analytics, enterprises are now enforcing governance policies as data is created. AI-powered anomaly detection, streaming pipelines, and event-driven architectures are shaping how businesses secure and validate data in motion—especially in industries like finance, healthcare, and manufacturing. 🔹 Privacy-First, Compliance-Driven From GDPR to emerging global frameworks, privacy-by-design is now fundamental. We’re seeing broad adoption of differential privacy, synthetic data generation, and automated consent management to protect personal data while still enabling insight extraction. 🔹 DataOps Meets Governance CI/CD pipelines are no longer just for code—they’re being used to enforce governance rules throughout the data lifecycle. Integrating governance into DataOps ensures continuous compliance, efficient provisioning, and stronger collaboration between IT, data, and business teams. 🔹 AI Ethics at the Forefront As AI models influence more decisions, explainability and responsible use are becoming non-negotiables. The best vendors now include bias detection, model monitoring, and ethical governance policies to ensure compliance and trust in automated systems. 🔹 Next-Gen Platforms Today’s leading platforms aren’t just cataloging metadata—they’re delivering end-to-end governance. Think: integrated workflows, real-time lineage, automated quality checks, and natural language interfaces powered by GenAI for greater adoption across teams. Become a Client - https://qksgroup.com/become-client 🧭 Where is the market headed? We’re seeing a convergence between data governance and corporate reporting, particularly in ESG and financial disclosures. Cloud-native governance for hybrid/multi-cloud setups is standard. And most importantly, the user experience is being prioritized to make governance everyone’s responsibility—not just IT’s. Let’s continue to drive responsible, secure, and value-driven data ecosystems. #DataGovernance #SPARKMatrix2025 #AI #Compliance #DataOps #RealTimeData #PrivacyByDesign #ResponsibleAI #CloudGovernance #QKSGroup
0 notes
Text
The top Data Engineering trends to look for in 2025

Data engineering is the unsung hero of our data-driven world. It's the critical discipline that builds and maintains the robust infrastructure enabling organizations to collect, store, process, and analyze vast amounts of data. As we navigate mid-2025, this foundational field is evolving at an unprecedented pace, driven by the exponential growth of data, the insatiable demand for real-time insights, and the transformative power of AI.
Staying ahead of these shifts is no longer optional; it's essential for data engineers and the organizations they support. Let's dive into the key data engineering trends that are defining the landscape in 2025.
1. The Dominance of the Data Lakehouse
What it is: The data lakehouse architecture continues its strong upward trajectory, aiming to unify the best features of data lakes (flexible, low-cost storage for raw, diverse data types) and data warehouses (structured data management, ACID transactions, and robust governance). Why it's significant: It offers a single platform for various analytics workloads, from BI and reporting to AI and machine learning, reducing data silos, complexity, and redundancy. Open table formats like Apache Iceberg, Delta Lake, and Hudi are pivotal in enabling lakehouse capabilities. Impact: Greater data accessibility, improved data quality and reliability for analytics, simplified data architecture, and cost efficiencies. Key Technologies: Databricks, Snowflake, Amazon S3, Azure Data Lake Storage, Apache Spark, and open table formats.
2. AI-Powered Data Engineering (Including Generative AI)
What it is: Artificial intelligence, and increasingly Generative AI, are becoming integral to data engineering itself. This involves using AI/ML to automate and optimize various data engineering tasks. Why it's significant: AI can significantly boost efficiency, reduce manual effort, improve data quality, and even help generate code for data pipelines or transformations. Impact: * Automated Data Integration & Transformation: AI tools can now automate aspects of data mapping, cleansing, and pipeline optimization. * Intelligent Data Quality & Anomaly Detection: ML algorithms can proactively identify and flag data quality issues or anomalies in pipelines. * Optimized Pipeline Performance: AI can help in tuning and optimizing the performance of data workflows. * Generative AI for Code & Documentation: LLMs are being used to assist in writing SQL queries, Python scripts for ETL, and auto-generating documentation. Key Technologies: AI-driven ETL/ELT tools, MLOps frameworks integrated with DataOps, platforms with built-in AI capabilities (e.g., Databricks AI Functions, AWS DMS with GenAI).
3. Real-Time Data Processing & Streaming Analytics as the Norm
What it is: The demand for immediate insights and actions based on live data streams continues to grow. Batch processing is no longer sufficient for many use cases. Why it's significant: Businesses across industries like e-commerce, finance, IoT, and logistics require real-time capabilities for fraud detection, personalized recommendations, operational monitoring, and instant decision-making. Impact: A shift towards streaming architectures, event-driven data pipelines, and tools that can handle high-throughput, low-latency data. Key Technologies: Apache Kafka, Apache Flink, Apache Spark Streaming, Apache Pulsar, cloud-native streaming services (e.g., Amazon Kinesis, Google Cloud Dataflow, Azure Stream Analytics), and real-time analytical databases.
4. The Rise of Data Mesh & Data Fabric Architectures
What it is: * Data Mesh: A decentralized sociotechnical approach that emphasizes domain-oriented data ownership, treating data as a product, self-serve data infrastructure, and federated computational governance. * Data Fabric: An architectural approach that automates data integration and delivery across disparate data sources, often using metadata and AI to provide a unified view and access to data regardless of where it resides. Why it's significant: Traditional centralized data architectures struggle with the scale and complexity of modern data. These approaches offer greater agility, scalability, and empower domain teams. Impact: Improved data accessibility and discoverability, faster time-to-insight for domain teams, reduced bottlenecks for central data teams, and better alignment of data with business domains. Key Technologies: Data catalogs, data virtualization tools, API-based data access, and platforms supporting decentralized data management.
5. Enhanced Focus on Data Observability & Governance
What it is: * Data Observability: Going beyond traditional monitoring to provide deep visibility into the health and state of data and data pipelines. It involves tracking data lineage, quality, freshness, schema changes, and distribution. * Data Governance by Design: Integrating robust data governance, security, and compliance practices directly into the data lifecycle and infrastructure from the outset, rather than as an afterthought. Why it's significant: As data volumes and complexity grow, ensuring data quality, reliability, and compliance (e.g., GDPR, CCPA) becomes paramount for building trust and making sound decisions. Regulatory landscapes, like the EU AI Act, are also making strong governance non-negotiable. Impact: Improved data trust and reliability, faster incident resolution, better compliance, and more secure data handling. Key Technologies: AI-powered data observability platforms, data cataloging tools with governance features, automated data quality frameworks, and tools supporting data lineage.
6. Maturation of DataOps and MLOps Practices
What it is: * DataOps: Applying Agile and DevOps principles (automation, collaboration, continuous integration/continuous delivery - CI/CD) to the entire data analytics lifecycle, from data ingestion to insight delivery. * MLOps: Extending DevOps principles specifically to the machine learning lifecycle, focusing on streamlining model development, deployment, monitoring, and retraining. Why it's significant: These practices are crucial for improving the speed, quality, reliability, and efficiency of data and machine learning pipelines. Impact: Faster delivery of data products and ML models, improved data quality, enhanced collaboration between data engineers, data scientists, and IT operations, and more reliable production systems. Key Technologies: Workflow orchestration tools (e.g., Apache Airflow, Kestra), CI/CD tools (e.g., Jenkins, GitLab CI), version control systems (Git), containerization (Docker, Kubernetes), and MLOps platforms (e.g., MLflow, Kubeflow, SageMaker, Azure ML).
The Cross-Cutting Theme: Cloud-Native and Cost Optimization
Underpinning many of these trends is the continued dominance of cloud-native data engineering. Cloud platforms (AWS, Azure, GCP) provide the scalable, flexible, and managed services that are essential for modern data infrastructure. Coupled with this is an increasing focus on cloud cost optimization (FinOps for data), as organizations strive to manage and reduce the expenses associated with large-scale data processing and storage in the cloud.
The Evolving Role of the Data Engineer
These trends are reshaping the role of the data engineer. Beyond building pipelines, data engineers in 2025 are increasingly becoming architects of more intelligent, automated, and governed data systems. Skills in AI/ML, cloud platforms, real-time processing, and distributed architectures are becoming even more crucial.
Global Relevance, Local Impact
These global data engineering trends are particularly critical for rapidly developing digital economies. In countries like India, where the data explosion is immense and the drive for digital transformation is strong, adopting these advanced data engineering practices is key to harnessing data for innovation, improving operational efficiency, and building competitive advantages on a global scale.
Conclusion: Building the Future, One Pipeline at a Time
The field of data engineering is more dynamic and critical than ever. The trends of 2025 point towards more automated, real-time, governed, and AI-augmented data infrastructures. For data engineering professionals and the organizations they serve, embracing these changes means not just keeping pace, but actively shaping the future of how data powers our world.
1 note
·
View note
Text
How Databricks Unity Catalog and Datagaps Automate Governance and Validation

Data quality is the backbone of accurate analytics, regulatory compliance, and efficient business operations. As organizations scale their data ecosystems, maintaining high data integrity becomes more challenging.
The seamless integration between Databricks Unity Catalog and Datagaps DataOps Suite provides a powerful framework for automated governance and validation, ensuring that data remains accurate, complete, and compliant at all times.
In our previous discussion, we highlighted how Datagaps enhances metadata management, lineage tracking, and automation within Unity Catalog. This article takes the next step by diving into data quality assurance – a crucial component of enterprise-wide data governance.
By leveraging Datagaps Data Quality Monitor, organizations can implement automated validation strategies, reduce manual effort, and integrate real-time data quality scores into Unity Catalog for proactive governance. Let’s explore how these technologies work together to ensure high-quality, reliable data that drives better decision-making and compliance.
The Growing Need for Automated Data Quality Assurance
Modern enterprises manage vast amounts of structured and unstructured data across multiple platforms. Ensuring data accuracy, completeness, and consistency is no longer just a best practice – it’s a necessity for regulatory compliance and business intelligence.
Databricks Unity Catalog provides a centralized governance framework for managing metadata, access controls, and data lineage across an organization. By integrating with Datagaps Data Quality Monitor, enterprises can automate data validation, reduce errors, and gain deeper insights into data health and integrity.
6 Key Data Quality Dimensions

Effective data quality management revolves around six fundamental dimensions:
Accuracy – Ensuring data reflects real-world values without discrepancies.
Completeness – Verifying that all required fields and records are present.
Consistency – Maintaining uniformity across multiple data sources and systems.
Timeliness – Ensuring data is up-to-date and available when needed.
Uniqueness – Eliminating duplicate records and redundant data entries.
Validity – Enforcing compliance with defined formats, business rules, and constraints.
By addressing these dimensions, organizations can improve the trustworthiness of their data assets, enhance AI/ML outcomes, and comply with industry regulations.
Automating Data Quality Validation with White-Box and Black-Box Testing
Ensuring data integrity at scale requires a systematic approach to validation. Two widely used methodologies are:
1. White-Box Testing
Examines internal data transformations, lineage, and business rules.
Ensures that every step in the ETL (Extract, Transform, Load) process adheres to defined standards.
Provides deeper insights into data processing logic to catch issues at the source.
2. Black-Box Testing
Focuses on output validation by comparing actual results against expected benchmarks.
Useful for detecting anomalies, missing records, and schema mismatches.
Works well for regulatory compliance and end-to-end data pipeline testing.
A hybrid approach combining both techniques ensures robust validation and proactive anomaly detection.
How Unity Catalog and Datagaps Data Quality Monitor Work Together
1. Unified Governance and Automated Validation
Databricks Unity Catalog centralizes metadata management, access control, and lineage tracking.
Datagaps Data Quality Monitor extends these capabilities with automated quality checks, reducing manual efforts.
2. Mapping Manager Utility: Simplifying Test Case Automation
One of the standout features of Datagaps Data Quality Monitor is the Mapping Manager Utility, which:
Extracts mapping configurations from Databricks Unity Catalog.
Automatically generates white-box and black-box test cases.
Reduces the need for manual intervention, increasing efficiency and scalability.
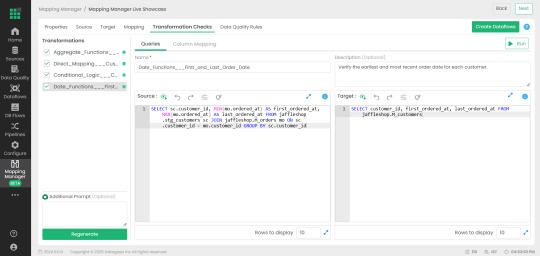
3. Real-Time Data Quality Scores for Proactive Governance
After test execution, a data quality score is generated.
These scores are seamlessly integrated into Databricks Unity Catalog, allowing real-time monitoring.
Organizations can visualize data quality insights through dashboards and take corrective actions before issues impact business operations.
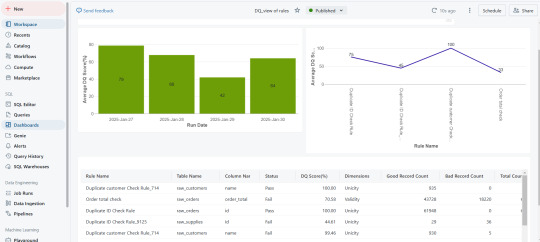
Key Use Cases
ETL and Data Pipeline Validation – Ensuring data transformations adhere to defined business rules.
Regulatory Compliance and Audit Readiness – Mitigating risks associated with inaccurate reporting.
Enterprise Data Lakehouse Governance – Enhancing consistency across distributed datasets.
AI/ML Data Preprocessing – Ensuring clean, high-quality data for better model performance.
Automated Data Quality Checks – Reducing manual data validation efforts for faster, more reliable insights.
Scalability for Large Datasets – Efficiently managing high-volume, high-velocity enterprise data.
Faster QA Cycles – Automating test case execution for rapid turnaround.
Lower Operational Resources – Reducing human intervention, saving time and resources.
The Business Impact: Why This Integration Matters
Enhanced Automation – Eliminates manual quality checks and increases efficiency.
Real-Time Monitoring – Provides instant visibility into data quality metrics.
Stronger Compliance – Supports industry standards and regulations effortlessly.
Scalability – Designed for large-scale, complex data ecosystems.
Cost Efficiency – Reduces operational overhead and improves ROI on data management initiatives.
Ensuring data quality at scale requires a combination of automated governance, real-time monitoring, and seamless integration. The connection between Databricks Unity Catalog and Datagaps Data Quality Monitor provides a comprehensive solution to achieve this goal.
With automated test case generation, continuous data validation, and integrated governance, organizations can ensure their data is always accurate, complete, and compliant—laying the foundation for data-driven decision-making and regulatory confidence.
0 notes
Text
Hewlett Packard Enterprise and Team Computers join Trescon’s Big CIO Show as Co-Powered Sponsors

The 10th edition of the globally acclaimed show virtually connected over 300 online participants from across India, who discussed the emerging tech solutions and strategies for 2021 and beyond. Ranganath Sadasiva, CTO, Hybrid IT, Hewlett Packard Enterprise shared his insights on fueling edge-to-cloud digital transformation and more.
Friday, 06 August 2021: As the leaders in the edge-to-cloud platform, Hewlett Packard Enterprise and Team Computers Co-Powered the 10th edition of Big CIO Show – India. The show virtually connected over 300 online participants from across India, including major stakeholders of India’s technology ecosystem such as government think-tanks, technology experts and leading technology solution providers.
The virtual conference explored sectors of critical infrastructure where Digital Transformation can help the nation boost economic competitiveness with the region’s top technology leaders and the global technology fraternity.
One of the top technology leaders and speakers who joined the conversation was Ranganath Sadasiva, Chief Technology Officer, Hybrid IT, HPE. Ranganath is responsible for bringing in thought leadership across HPE’s Hybrid IT business and delivering the best-in-class technology experience for customers.
He enlightened the audience through the technical session on ‘Fuelling edge to cloud Digital Transformation with Hewlett Packard Enterprise.’
His presentation covered the macro trends leading to accelerated Digital Transformation and Digital Technologies enabling this transition. He spoke of ‘HPE Ezmeral software’ portfolio that enables the transformation of apps, data, and operations by running modern containerized applications and optimally manage their environments from infrastructure up the stack, allowing customers to harness data and turn it into insights with enterprise-grade security, and cost and compliance visibility.
While talking about HPE’s latest announcements, he spoke of how it was time to reimagine Data Management and how this will be a game-changer. HPE’s vision of Unified DataOps empowers customers to break down the silos and complexity to accelerate data-driven transformation. He introduced the audience to their new offerings called Data Storage Cloud Central – a Unified cloud data services and HPE Alletra - cloud-native data infrastructure.
While talking about HPE’s new Compute Launch for the data-driven transformation, he stated, "HPE essentially focuses on workloads that prevail in the marketplace today and ensure that it delivers the right kind of compute resources for everything as a service." He concluded the keynote by stating that, “It is your data, it is your agility, it is your innovation, and we will ensure that you unleash it till the last".
He was also a part of an interesting panel discussion about 'How SDX enables Digital Transformation' where the panellists discussed how the rising customer expectations and global trends are forcing shifts in computing, storage, security, and networking; and how the evolution of the cloud is fuelling the software-defined revolution and driving the need for next-gen, “cloud-first” infrastructures and much more. He remarked “Software-Defined help’s deliver SCALE + AGILE = SCAGILE enterprises”
The panellists who joined him in the discussion include Golok Kumar Simli - CTO, Ministry of External Affairs, Govt of India; Kaushik Majumder - Head of IT, Digital Services & Information Protection Officer, South Asia BASF India Ltd; Milind Khamkar - Group CIO, SUPER-MAX; and Prasanna Lohar - Chief Innovation Officer, DCB Bank.
The show was hosted on the virtual events platform Vmeets to help participants network and conduct business in an interactive and immersive virtual environment. Participants could also engage with speakers in Q&A sessions and network with solution providers in virtual exhibition booths, private consultation rooms and private networking rooms.
Here are a couple of upcoming events you might be interested in attending: Event calendar. About Big CIO Show – India
Big CIO Show is a thought-leadership-driven, business-focused initiative that provides a platform for CIOs who are looking to explore new-age technologies and implementing them in their organisations.
#Big CIO 2025#CIO 2025#Business Events 2025#Business Event#Trescon Global#Business#AI#Artificial Intelligence
0 notes
Text
Data Architect
Designing the target architecture for data platform along with tools and processes by evaluating existing platform and future trends. Azure data stack with fabric and Databricks, open source data stack knowledge Exposure to dataops ecosystem and tools would be plus. The strategy outcome would have target architecture, tools to be implemented, design patterns etc., Apply Now
0 notes
Text
Unlocking the Potential of Your Data: A Guide to Modern Data Engineering Services

In today's digital-first world, data has become the backbone of business success. From enhancing decision-making to driving innovation, the value of data cannot be overstated. But how do businesses ensure that their data is ready to deliver on its promise? Enter data engineering services — the bridge between raw data and actionable insights.
This blog explores the latest trends, best practices, and unique strategies in data engineering, helping organizations leverage data to stay ahead of the curve.
1. The Role of Data Engineering in Modern Businesses
Data engineering is more than just managing databases or building pipelines. It's about creating robust frameworks for data collection, transformation, and storage while ensuring quality and accessibility. Businesses today demand real-time analytics, predictive modeling, and seamless integrations — all of which hinge on well-engineered data systems.
2. Top Trends Transforming Data Engineering Services
a. Rise of Cloud Data Platforms Cloud-native data engineering solutions like Snowflake, Databricks, and BigQuery are revolutionizing how businesses store and process data. They offer scalability, flexibility, and cost efficiency.
b. DataOps for Agile Data Management DataOps combines DevOps principles with data engineering, enabling faster and more reliable data delivery. Automation and CI/CD pipelines for data workflows are becoming the norm.
c. Focus on Data Observability Ensuring data reliability is critical. Tools like Monte Carlo and Datadog are helping organizations proactively monitor and address data quality issues.
d. Integration of AI and Machine Learning Data engineering services now incorporate AI and ML models to automate routine tasks like data mapping, anomaly detection, and schema generation.
3. Benefits of Investing in Data Engineering Services
Improved Decision-Making: Access to clean, structured, and actionable data enables faster and better decisions.
Cost Efficiency: Efficient data pipelines reduce resource wastage and infrastructure costs.
Enhanced Compliance: Modern solutions ensure adherence to data privacy regulations like GDPR and CCPA.
Scalability: With the right data engineering services, businesses can handle growing data volumes seamlessly.
4. Key Components of Effective Data Engineering Solutions
Data Architecture Design: Structuring data ecosystems for optimal performance.
ETL/ELT Processes: Building automated workflows for data extraction, transformation, and loading.
Real-Time Data Processing: Leveraging tools like Apache Kafka and Spark for instantaneous data insights.
Data Governance and Security: Ensuring data integrity, privacy, and compliance with robust frameworks.
5. How to Choose the Right Data Engineering Service Provider
When selecting a data engineering partner, consider:
Their expertise in modern tools and platforms.
Proven case studies and success stories.
Scalability of their solutions.
Focus on data security and governance.
Conclusion The demand for data engineering services is only set to grow as businesses increasingly rely on data-driven strategies. By embracing cutting-edge trends like DataOps, cloud platforms, and AI-driven automation, organizations can unlock the full potential of their data. Investing in the right data engineering solutions today will pave the way for sustained success tomorrow.
0 notes
Text
Approach to Implementing DataOps with Informatica Intelligent Data Management
In today’s data-driven landscape, the ability to manage, integrate, and govern vast amounts of data efficiently is more critical than ever. Informatica’s Intelligent Data Management Cloud (IDMC) is a cutting-edge platform designed to elevate data management, providing organizations with comprehensive solutions for data integration, quality, governance, and privacy. Explore Jade Global’s approach to implementing DataOps with Informatica Intelligent Data Management: https://shorturl.at/1WQ7Y
1 note
·
View note