#DataOps Tools
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
US Tumblr user growth rate is estimated to slow down to 4.1%.
Text
#DataOps Platform#Data Collaboration#Data Security#Data Workflow Automation#Cross-Functional Collaboration#DataOps Tools#Data Insights#Data Quality#DevOps#Data Pipelines
1 note
·
View note
Text
DataOps is a set of practices, processes, and technologies that combines an integrated and process-oriented perspective on data with automation and methods from agile software engineering to improve quality, speed, and collaboration and promote a culture of continuous improvement in the area of data analytics.
0 notes
Text
Beyond the Pipeline: Choosing the Right Data Engineering Service Providers for Long-Term Scalability
Introduction: Why Choosing the Right Data Engineering Service Provider is More Critical Than Ever
In an age where data is more valuable than oil, simply having pipelines isn’t enough. You need refineries, infrastructure, governance, and agility. Choosing the right data engineering service providers can make or break your enterprise’s ability to extract meaningful insights from data at scale. In fact, Gartner predicts that by 2025, 80% of data initiatives will fail due to poor data engineering practices or provider mismatches.
If you're already familiar with the basics of data engineering, this article dives deeper into why selecting the right partner isn't just a technical decision—it’s a strategic one. With rising data volumes, regulatory changes like GDPR and CCPA, and cloud-native transformations, companies can no longer afford to treat data engineering service providers as simple vendors. They are strategic enablers of business agility and innovation.
In this post, we’ll explore how to identify the most capable data engineering service providers, what advanced value propositions you should expect from them, and how to build a long-term partnership that adapts with your business.
Section 1: The Evolving Role of Data Engineering Service Providers in 2025 and Beyond
What you needed from a provider in 2020 is outdated today. The landscape has changed:
📌 Real-time data pipelines are replacing batch processes
📌 Cloud-native architectures like Snowflake, Databricks, and Redshift are dominating
📌 Machine learning and AI integration are table stakes
📌 Regulatory compliance and data governance have become core priorities
Modern data engineering service providers are not just builders—they are data architects, compliance consultants, and even AI strategists. You should look for:
📌 End-to-end capabilities: From ingestion to analytics
📌 Expertise in multi-cloud and hybrid data ecosystems
📌 Proficiency with data mesh, lakehouse, and decentralized architectures
📌 Support for DataOps, MLOps, and automation pipelines
Real-world example: A Fortune 500 retailer moved from Hadoop-based systems to a cloud-native lakehouse model with the help of a modern provider, reducing their ETL costs by 40% and speeding up analytics delivery by 60%.
Section 2: What to Look for When Vetting Data Engineering Service Providers
Before you even begin consultations, define your objectives. Are you aiming for cost efficiency, performance, real-time analytics, compliance, or all of the above?
Here’s a checklist when evaluating providers:
📌 Do they offer strategic consulting or just hands-on coding?
📌 Can they support data scaling as your organization grows?
📌 Do they have domain expertise (e.g., healthcare, finance, retail)?
📌 How do they approach data governance and privacy?
📌 What automation tools and accelerators do they provide?
📌 Can they deliver under tight deadlines without compromising quality?
Quote to consider: "We don't just need engineers. We need architects who think two years ahead." – Head of Data, FinTech company
Avoid the mistake of over-indexing on cost or credentials alone. A cheaper provider might lack scalability planning, leading to massive rework costs later.
Section 3: Red Flags That Signal Poor Fit with Data Engineering Service Providers
Not all providers are created equal. Some red flags include:
📌 One-size-fits-all data pipeline solutions
📌 Poor documentation and handover practices
📌 Lack of DevOps/DataOps maturity
📌 No visibility into data lineage or quality monitoring
📌 Heavy reliance on legacy tools
A real scenario: A manufacturing firm spent over $500k on a provider that delivered rigid ETL scripts. When the data source changed, the whole system collapsed.
Avoid this by asking your provider to walk you through previous projects, particularly how they handled pivots, scaling, and changing data regulations.
Section 4: Building a Long-Term Partnership with Data Engineering Service Providers
Think beyond the first project. Great data engineering service providers work iteratively and evolve with your business.
Steps to build strong relationships:
📌 Start with a proof-of-concept that solves a real pain point
📌 Use agile methodologies for faster, collaborative execution
📌 Schedule quarterly strategic reviews—not just performance updates
📌 Establish shared KPIs tied to business outcomes, not just delivery milestones
📌 Encourage co-innovation and sandbox testing for new data products
Real-world story: A healthcare analytics company co-developed an internal patient insights platform with their provider, eventually spinning it into a commercial SaaS product.
Section 5: Trends and Technologies the Best Data Engineering Service Providers Are Already Embracing
Stay ahead by partnering with forward-looking providers who are ahead of the curve:
📌 Data contracts and schema enforcement in streaming pipelines
📌 Use of low-code/no-code orchestration (e.g., Apache Airflow, Prefect)
📌 Serverless data engineering with tools like AWS Glue, Azure Data Factory
📌 Graph analytics and complex entity resolution
📌 Synthetic data generation for model training under privacy laws
Case in point: A financial institution cut model training costs by 30% by using synthetic data generated by its engineering provider, enabling robust yet compliant ML workflows.
Conclusion: Making the Right Choice for Long-Term Data Success
The right data engineering service providers are not just technical executioners—they’re transformation partners. They enable scalable analytics, data democratization, and even new business models.
To recap:
📌 Define goals and pain points clearly
📌 Vet for strategy, scalability, and domain expertise
📌 Watch out for rigidity, legacy tools, and shallow implementations
📌 Build agile, iterative relationships
📌 Choose providers embracing the future
Your next provider shouldn’t just deliver pipelines—they should future-proof your data ecosystem. Take a step back, ask the right questions, and choose wisely. The next few quarters of your business could depend on it.
#DataEngineering#DataEngineeringServices#DataStrategy#BigDataSolutions#ModernDataStack#CloudDataEngineering#DataPipeline#MLOps#DataOps#DataGovernance#DigitalTransformation#TechConsulting#EnterpriseData#AIandAnalytics#InnovationStrategy#FutureOfData#SmartDataDecisions#ScaleWithData#AnalyticsLeadership#DataDrivenInnovation
0 notes
Text
The Data Value Chain: Integrating DataOps, MLOps, and AI for Enterprise Growth
Unlocking Enterprise Value: Maximizing Data Potential with DataOps, MLOps, and AI
In today’s digital-first economy, data has emerged as the most valuable asset for enterprises striving to gain competitive advantage, improve operational efficiency, and foster innovation. However, the sheer volume, velocity, and variety of data generated by modern organizations create complex challenges around management, integration, and actionable insights. To truly harness the potential of enterprise data, businesses are increasingly turning to integrated frameworks such as DataOps, MLOps, and Artificial Intelligence (AI). These methodologies enable streamlined data workflows, robust machine learning lifecycle management, and intelligent automation — together transforming raw data into powerful business outcomes.

The Data Challenge in Modern Enterprises
The explosion of data from sources like IoT devices, customer interactions, social media, and internal systems has overwhelmed traditional data management practices. Enterprises struggle with:
Data silos causing fragmented information and poor collaboration.
Inconsistent data quality leading to unreliable insights.
Slow, manual data pipeline processes delaying analytics.
Difficulty deploying, monitoring, and scaling machine learning models.
Limited ability to automate decision-making in real-time.
To overcome these barriers and unlock data-driven innovation, enterprises must adopt holistic frameworks that combine process automation, governance, and advanced analytics at scale. This is where DataOps, MLOps, and AI converge as complementary approaches to maximize data potential.
DataOps: Accelerating Reliable Data Delivery
DataOps, short for Data Operations, is an emerging discipline inspired by DevOps principles in software engineering. It emphasizes collaboration, automation, and continuous improvement to manage data pipelines efficiently and reliably.
Key aspects of DataOps include:
Automation: Automating data ingestion, cleansing, transformation, and delivery pipelines to reduce manual effort and errors.
Collaboration: Bridging gaps between data engineers, analysts, scientists, and business teams for seamless workflows.
Monitoring & Quality: Implementing real-time monitoring and testing of data pipelines to ensure quality and detect anomalies early.
Agility: Enabling rapid iterations and continuous deployment of data workflows to adapt to evolving business needs.
By adopting DataOps, enterprises can shorten the time-to-insight and create trust in the data that powers analytics and machine learning. This foundation is critical for building advanced AI capabilities that depend on high-quality, timely data.
MLOps: Operationalizing Machine Learning at Scale
Machine learning (ML) has become a vital tool for enterprises to extract predictive insights and automate decision-making. However, managing the entire ML lifecycle — from model development and training to deployment, monitoring, and retraining — is highly complex.
MLOps (Machine Learning Operations) extends DevOps principles to ML systems, offering a standardized approach to operationalize ML models effectively.
Core components of MLOps include:
Model Versioning and Reproducibility: Tracking different model versions, datasets, and training parameters to ensure reproducibility.
Continuous Integration and Delivery (CI/CD): Automating model testing and deployment pipelines for faster, reliable updates.
Monitoring and Governance: Continuously monitoring model performance and detecting data drift or bias for compliance and accuracy.
Collaboration: Facilitating cooperation between data scientists, engineers, and IT teams to streamline model lifecycle management.
Enterprises employing MLOps frameworks can accelerate model deployment from weeks to days or hours, improving responsiveness to market changes. MLOps also helps maintain trust in AI-powered decisions by ensuring models perform reliably in production environments.
AI: The Catalyst for Intelligent Enterprise Transformation
Artificial Intelligence acts as the strategic layer that extracts actionable insights and automates complex tasks using data and ML models. AI capabilities range from natural language processing and computer vision to predictive analytics and recommendation systems.
When powered by DataOps and MLOps, AI solutions become more scalable, trustworthy, and business-aligned.
Examples of AI-driven enterprise benefits include:
Enhanced Customer Experiences: AI chatbots, personalized marketing, and sentiment analysis deliver tailored, responsive interactions.
Operational Efficiency: Predictive maintenance, process automation, and intelligent workflows reduce costs and downtime.
Innovation Enablement: AI uncovers new business opportunities, optimizes supply chains, and supports data-driven product development.
By integrating AI into enterprise processes with the support of disciplined DataOps and MLOps practices, businesses unlock transformative potential from their data assets.
Synergizing DataOps, MLOps, and AI for Maximum Impact
While each discipline delivers unique value, the real power lies in combining DataOps, MLOps, and AI into a cohesive strategy.
Reliable Data Pipelines with DataOps: Provide high-quality, timely data needed for model training and real-time inference.
Scalable ML Model Management via MLOps: Ensure AI models are robust, continuously improved, and safely deployed.
Intelligent Automation with AI: Drive business outcomes by embedding AI insights into workflows, products, and customer experiences.
Together, these frameworks enable enterprises to build a continuous intelligence loop — where data fuels AI models that automate decisions, generating new data and insights in turn. This virtuous cycle accelerates innovation, operational agility, and competitive differentiation.
Practical Steps for Enterprises to Maximize Data Potential
To implement an effective strategy around DataOps, MLOps, and AI, enterprises should consider the following:
Assess Current Data Maturity: Understand existing data infrastructure, pipeline bottlenecks, and analytics capabilities.
Define Business Objectives: Align data and AI initiatives with measurable goals like reducing churn, increasing revenue, or improving operational metrics.
Invest in Automation Tools: Adopt data pipeline orchestration platforms, ML lifecycle management tools, and AI frameworks that support automation and collaboration.
Build Cross-functional Teams: Foster collaboration between data engineers, scientists, IT, and business stakeholders.
Implement Governance and Compliance: Establish data quality standards, security controls, and model audit trails to maintain trust.
Focus on Continuous Improvement: Use metrics and feedback loops to iterate on data pipelines, model performance, and AI outcomes.
The Future Outlook
As enterprises continue their digital transformation journeys, the convergence of DataOps, MLOps, and AI will be essential for unlocking the full value of data. Organizations that successfully adopt these integrated frameworks will benefit from faster insights, higher quality models, and more impactful AI applications. This foundation will enable them to adapt rapidly in a dynamic market landscape and pioneer new data-driven innovations.
Read Full Article : https://businessinfopro.com/maximize-enterprise-data-potential-with-dataops-mlops-and-ai/
Visit Now: https://businessinfopro.com/
0 notes
Text
The Future of Data Science: Trends to Watch in 2025
In today's fast-paced digital world, data science continues to be one of the most transformative fields. As we step into 2025, the role of data scientists is evolving rapidly with new technologies, tools, and business demands. Whether you're a budding analyst, a seasoned data professional, or someone curious about the future, these trends will shape the data science landscape in the coming year and beyond.

1. AI and Machine Learning Get Smarter
In 2025, AI and ML models are not just getting more accurate — they’re getting more context-aware. We’ll see a rise in explainable AI (XAI), helping businesses understand why an algorithm made a specific decision. This will be crucial for industries like healthcare, finance, and law where transparency is vital.
2. The Rise of AutoML
Automated Machine Learning (AutoML) will continue to democratize data science by enabling non-experts to build models without deep coding knowledge. This trend will accelerate productivity, reduce human error, and allow data scientists to focus on strategy and interpretation.
3. Data Privacy and Ethics Take Center Stage
With stricter regulations like GDPR and India’s Digital Personal Data Protection Act, data scientists must prioritize ethical data use and privacy compliance. 2025 will see more organizations embedding responsible AI practices in their workflows.
4. Edge Computing + Data Science = Real-Time Intelligence
Expect to see data science moving to the edge — quite literally. With IoT devices generating massive amounts of real-time data, processing this data locally (at the edge) will allow faster decision-making, especially in industries like manufacturing, logistics, and autonomous vehicles.
5. Natural Language Processing (NLP) Reaches New Heights
Thanks to advancements in large language models, NLP will power smarter chatbots, voice assistants, and search systems. Data scientists will increasingly work with unstructured data — text, audio, and video — to uncover deeper insights.
6. Low-Code and No-Code Platforms
Low-code tools will continue to empower business users to perform data analysis and visualization without needing deep technical skills. These platforms bridge the gap between data science and business intelligence, fostering greater collaboration.
7. DataOps and MLOps Maturity
In 2025, organizations are treating data like software. With DataOps and MLOps, companies are streamlining the lifecycle of data pipelines and machine learning models, ensuring version control, monitoring, and scalability across teams.
8. Data Literacy Becomes Essential
As data becomes central to decision-making, data literacy is becoming a key skill across all job roles. Companies are investing in training programs to ensure employees can interpret and use data effectively, not just collect it.
Final Thoughts
Data science in 2025 is more than just crunching numbers — it's about building responsible, scalable, and intelligent systems that can make a real-world impact. Whether you're an aspiring data scientist or an experienced professional, staying updated with these trends is essential.
At Naresh i Technologies, we’re committed to preparing the next generation of data professionals through our industry-focused Data Science and Analytics training programs. Join us and become future-ready!
#datascience#AI#machinelearning#bigdata#analytics#datamining#artificialintelligence#datascientist#technology#dataanalysis#deeplearning#datavisualization#predictiveanalytics#dataengineering#datadriven#datamanagement#datasciencecommunity#AItechnology#datasciencejobs#AIinnovation#datascienceeducation
0 notes
Text
The top Data Engineering trends to look for in 2025

Data engineering is the unsung hero of our data-driven world. It's the critical discipline that builds and maintains the robust infrastructure enabling organizations to collect, store, process, and analyze vast amounts of data. As we navigate mid-2025, this foundational field is evolving at an unprecedented pace, driven by the exponential growth of data, the insatiable demand for real-time insights, and the transformative power of AI.
Staying ahead of these shifts is no longer optional; it's essential for data engineers and the organizations they support. Let's dive into the key data engineering trends that are defining the landscape in 2025.
1. The Dominance of the Data Lakehouse
What it is: The data lakehouse architecture continues its strong upward trajectory, aiming to unify the best features of data lakes (flexible, low-cost storage for raw, diverse data types) and data warehouses (structured data management, ACID transactions, and robust governance). Why it's significant: It offers a single platform for various analytics workloads, from BI and reporting to AI and machine learning, reducing data silos, complexity, and redundancy. Open table formats like Apache Iceberg, Delta Lake, and Hudi are pivotal in enabling lakehouse capabilities. Impact: Greater data accessibility, improved data quality and reliability for analytics, simplified data architecture, and cost efficiencies. Key Technologies: Databricks, Snowflake, Amazon S3, Azure Data Lake Storage, Apache Spark, and open table formats.
2. AI-Powered Data Engineering (Including Generative AI)
What it is: Artificial intelligence, and increasingly Generative AI, are becoming integral to data engineering itself. This involves using AI/ML to automate and optimize various data engineering tasks. Why it's significant: AI can significantly boost efficiency, reduce manual effort, improve data quality, and even help generate code for data pipelines or transformations. Impact: * Automated Data Integration & Transformation: AI tools can now automate aspects of data mapping, cleansing, and pipeline optimization. * Intelligent Data Quality & Anomaly Detection: ML algorithms can proactively identify and flag data quality issues or anomalies in pipelines. * Optimized Pipeline Performance: AI can help in tuning and optimizing the performance of data workflows. * Generative AI for Code & Documentation: LLMs are being used to assist in writing SQL queries, Python scripts for ETL, and auto-generating documentation. Key Technologies: AI-driven ETL/ELT tools, MLOps frameworks integrated with DataOps, platforms with built-in AI capabilities (e.g., Databricks AI Functions, AWS DMS with GenAI).
3. Real-Time Data Processing & Streaming Analytics as the Norm
What it is: The demand for immediate insights and actions based on live data streams continues to grow. Batch processing is no longer sufficient for many use cases. Why it's significant: Businesses across industries like e-commerce, finance, IoT, and logistics require real-time capabilities for fraud detection, personalized recommendations, operational monitoring, and instant decision-making. Impact: A shift towards streaming architectures, event-driven data pipelines, and tools that can handle high-throughput, low-latency data. Key Technologies: Apache Kafka, Apache Flink, Apache Spark Streaming, Apache Pulsar, cloud-native streaming services (e.g., Amazon Kinesis, Google Cloud Dataflow, Azure Stream Analytics), and real-time analytical databases.
4. The Rise of Data Mesh & Data Fabric Architectures
What it is: * Data Mesh: A decentralized sociotechnical approach that emphasizes domain-oriented data ownership, treating data as a product, self-serve data infrastructure, and federated computational governance. * Data Fabric: An architectural approach that automates data integration and delivery across disparate data sources, often using metadata and AI to provide a unified view and access to data regardless of where it resides. Why it's significant: Traditional centralized data architectures struggle with the scale and complexity of modern data. These approaches offer greater agility, scalability, and empower domain teams. Impact: Improved data accessibility and discoverability, faster time-to-insight for domain teams, reduced bottlenecks for central data teams, and better alignment of data with business domains. Key Technologies: Data catalogs, data virtualization tools, API-based data access, and platforms supporting decentralized data management.
5. Enhanced Focus on Data Observability & Governance
What it is: * Data Observability: Going beyond traditional monitoring to provide deep visibility into the health and state of data and data pipelines. It involves tracking data lineage, quality, freshness, schema changes, and distribution. * Data Governance by Design: Integrating robust data governance, security, and compliance practices directly into the data lifecycle and infrastructure from the outset, rather than as an afterthought. Why it's significant: As data volumes and complexity grow, ensuring data quality, reliability, and compliance (e.g., GDPR, CCPA) becomes paramount for building trust and making sound decisions. Regulatory landscapes, like the EU AI Act, are also making strong governance non-negotiable. Impact: Improved data trust and reliability, faster incident resolution, better compliance, and more secure data handling. Key Technologies: AI-powered data observability platforms, data cataloging tools with governance features, automated data quality frameworks, and tools supporting data lineage.
6. Maturation of DataOps and MLOps Practices
What it is: * DataOps: Applying Agile and DevOps principles (automation, collaboration, continuous integration/continuous delivery - CI/CD) to the entire data analytics lifecycle, from data ingestion to insight delivery. * MLOps: Extending DevOps principles specifically to the machine learning lifecycle, focusing on streamlining model development, deployment, monitoring, and retraining. Why it's significant: These practices are crucial for improving the speed, quality, reliability, and efficiency of data and machine learning pipelines. Impact: Faster delivery of data products and ML models, improved data quality, enhanced collaboration between data engineers, data scientists, and IT operations, and more reliable production systems. Key Technologies: Workflow orchestration tools (e.g., Apache Airflow, Kestra), CI/CD tools (e.g., Jenkins, GitLab CI), version control systems (Git), containerization (Docker, Kubernetes), and MLOps platforms (e.g., MLflow, Kubeflow, SageMaker, Azure ML).
The Cross-Cutting Theme: Cloud-Native and Cost Optimization
Underpinning many of these trends is the continued dominance of cloud-native data engineering. Cloud platforms (AWS, Azure, GCP) provide the scalable, flexible, and managed services that are essential for modern data infrastructure. Coupled with this is an increasing focus on cloud cost optimization (FinOps for data), as organizations strive to manage and reduce the expenses associated with large-scale data processing and storage in the cloud.
The Evolving Role of the Data Engineer
These trends are reshaping the role of the data engineer. Beyond building pipelines, data engineers in 2025 are increasingly becoming architects of more intelligent, automated, and governed data systems. Skills in AI/ML, cloud platforms, real-time processing, and distributed architectures are becoming even more crucial.
Global Relevance, Local Impact
These global data engineering trends are particularly critical for rapidly developing digital economies. In countries like India, where the data explosion is immense and the drive for digital transformation is strong, adopting these advanced data engineering practices is key to harnessing data for innovation, improving operational efficiency, and building competitive advantages on a global scale.
Conclusion: Building the Future, One Pipeline at a Time
The field of data engineering is more dynamic and critical than ever. The trends of 2025 point towards more automated, real-time, governed, and AI-augmented data infrastructures. For data engineering professionals and the organizations they serve, embracing these changes means not just keeping pace, but actively shaping the future of how data powers our world.
1 note
·
View note
Text
The Ultimate Tableau Dashboard Testing Checklist

Ensuring the quality of a Tableau dashboard goes beyond building. It requires thorough testing to validate its reliability and usability. This tableau dashboard testing checklist focuses on essential aspects like verifying data accuracy, evaluating functionality, security testing to protect sensitive data, stress testing for performance under load, and visual testing to maintain clarity and design standards.
Aspects Involved in Testing the Tableau Dashboard

Testing Data Sources:
Ensure the dashboard is connected to the correct data sources and that credentials are set up properly.
Checking Data Accuracy:
1. Check whether the source data is reflected in the dashboard. This involves cross-checking the data on the dashboard with the data from the sources.
2. Verify that the calculated fields, aggregates, and measures are as expected.
Functionality Testing:
1. Report or dashboard design check.
2. Filters and parameters testing to see if they work as expected and do not display incorrect data. Also, if the dynamic changes to data visuals are applied and reflected.
3. Drilldown reports checking.
4. Ease of navigation, interactivity, and responsiveness in terms of usability.
Security Testing:
1. To check the security for report access and Row Level Security Permissions.
2. Integration of Single Sign On (SSO) security.
3. Multi-factor authentication.
Regression Testing:
Any change to the BI Dashboard/Model can impact the existing reports. It is important to perform regression testing so that after updates or modifications, the data/visuals shown in the dashboard remain the same before and after the changes.
youtube
Stress Testing:
To test the load time, run time, filter application time, and to simulate the access of reports and user behavior.
Visual Testing:
To check alignments, layouts, consistencies in terms of texts, visuals, or images to ensure all the elements are properly aligned.
How Does DataOps Suite BI Validator Enable Testing of Tableau Dashboards?

BI Validator is a no-code testing tool to automate the regression, stress, and functional testing of Tableau reports and dashboards.
Checking Data Accuracy:
DataOps Suite allows users to validate the data from the visuals of the report to be compared to the source databases. On connecting to Tableau and selecting a report, the datasets underlying the visuals of the reports are accessible through the suite as well. Each Visual has its own dataset, which can be compared to a source database used to build the tableau report.
This is possible with the help of the Data Compare component in the suite, which can compare the aggregated data from the databases and the datasets of the visuals. The differences are captured, thus allowing users to check the data accuracy between the reports and databases.
Functionality Testing and Visual Testing:
Once the connection is established, the users can access the reports and the exact workspace to work with. The specific workbook/report is accessible. The report will be loaded without any changes, and the visuals and filters of the report can be accessed from the BI Validator itself, thus verifying the responsiveness of the visuals and filters and verifying whether the dynamic changes are reflected.
The BI Validator comes with the Tableau Upgrade component to compare two reports, which can be the same or different from one or different data sources.
A common use case is the comparison of views and worksheets across multiple environments. Comparison can be done in terms of both text and appearance, where the differences are captured and pointed out wherever mismatch occurs in both reports. Also, BI Validator allows the differences in the filters of both reports to be pointed out on enabling “Capture filters after applying.”.
youtube
Security Testing:
BI Validator connects with Tableau Testing through direct trust authentication, default authentication, or personal access token, where the users must provide their respective Tableau credentials, secret key, and secret ID (in direct trust connection) and the necessary web login commands (for default or personal access token connection). Thus, ensuring the authentication is secure so that only the users with valid credentials are accessing their reports to be validated.
BI Validator restricts the users from downloading the testing results when it comes to BI Reports to prevent the sensitive information from being downloaded.
The DataOps suite also has user-based access through roles and containers to prevent access to reports for everyone. The BI Validator can only allow users with defined roles and permissions to access reports.
Regression Testing:
BI Validator supports regression testing of the reports through the Tableau Regression component, which automates the testing of Tableau reports during any in-place upgrades and workbook deployments. This testing happens by comparing a benchmarked/baseline version of the dashboard/report with the live version. The filters can be changed accordingly if needed before/after the benchmarking. These filter changes can be bookmarked as the latest checkpoint before running the test.
Similar to upgrades, regression test runs can validate the differences in terms of appearance or text. Also, differences in the filters can be pointed out on enabling “capture filters after applying.”
Stress Testing:
BI Validator comes with a stress test plan to simulate concurrent users accessing reports to evaluate how reports and dashboards perform under heavy load. The plan typically involves running multiple users through different types of interactions, such as viewing reports, applying filters, refreshing data, and interacting with custom visuals.
The stress test plan allows the users to select the pages/dashboards from required workspaces to perform stress testing. These pages can be either from the same or different report.
Users can run the stress test plan on specific run options like number of parallel users, time spent on each page, total simulation run time, number of seconds to reach parallel users, refresh time, and other options to run the stress test plan.
The runs will result in showing metrics like Average Open Time and Max Open Time, Average Filter Apply Time, SLA Failures.
#datagaps#Tableau#Tableau Testing#Tableau dashboard#Tableau Testing Checklist#BI Validator#BI#Youtube
0 notes
Text
Data Architect
Designing the target architecture for data platform along with tools and processes by evaluating existing platform and future trends. Azure data stack with fabric and Databricks, open source data stack knowledge Exposure to dataops ecosystem and tools would be plus. The strategy outcome would have target architecture, tools to be implemented, design patterns etc., Apply Now
0 notes
Text
Unlocking the Potential of Your Data: A Guide to Modern Data Engineering Services

In today's digital-first world, data has become the backbone of business success. From enhancing decision-making to driving innovation, the value of data cannot be overstated. But how do businesses ensure that their data is ready to deliver on its promise? Enter data engineering services — the bridge between raw data and actionable insights.
This blog explores the latest trends, best practices, and unique strategies in data engineering, helping organizations leverage data to stay ahead of the curve.
1. The Role of Data Engineering in Modern Businesses
Data engineering is more than just managing databases or building pipelines. It's about creating robust frameworks for data collection, transformation, and storage while ensuring quality and accessibility. Businesses today demand real-time analytics, predictive modeling, and seamless integrations — all of which hinge on well-engineered data systems.
2. Top Trends Transforming Data Engineering Services
a. Rise of Cloud Data Platforms Cloud-native data engineering solutions like Snowflake, Databricks, and BigQuery are revolutionizing how businesses store and process data. They offer scalability, flexibility, and cost efficiency.
b. DataOps for Agile Data Management DataOps combines DevOps principles with data engineering, enabling faster and more reliable data delivery. Automation and CI/CD pipelines for data workflows are becoming the norm.
c. Focus on Data Observability Ensuring data reliability is critical. Tools like Monte Carlo and Datadog are helping organizations proactively monitor and address data quality issues.
d. Integration of AI and Machine Learning Data engineering services now incorporate AI and ML models to automate routine tasks like data mapping, anomaly detection, and schema generation.
3. Benefits of Investing in Data Engineering Services
Improved Decision-Making: Access to clean, structured, and actionable data enables faster and better decisions.
Cost Efficiency: Efficient data pipelines reduce resource wastage and infrastructure costs.
Enhanced Compliance: Modern solutions ensure adherence to data privacy regulations like GDPR and CCPA.
Scalability: With the right data engineering services, businesses can handle growing data volumes seamlessly.
4. Key Components of Effective Data Engineering Solutions
Data Architecture Design: Structuring data ecosystems for optimal performance.
ETL/ELT Processes: Building automated workflows for data extraction, transformation, and loading.
Real-Time Data Processing: Leveraging tools like Apache Kafka and Spark for instantaneous data insights.
Data Governance and Security: Ensuring data integrity, privacy, and compliance with robust frameworks.
5. How to Choose the Right Data Engineering Service Provider
When selecting a data engineering partner, consider:
Their expertise in modern tools and platforms.
Proven case studies and success stories.
Scalability of their solutions.
Focus on data security and governance.
Conclusion The demand for data engineering services is only set to grow as businesses increasingly rely on data-driven strategies. By embracing cutting-edge trends like DataOps, cloud platforms, and AI-driven automation, organizations can unlock the full potential of their data. Investing in the right data engineering solutions today will pave the way for sustained success tomorrow.
0 notes
Text

DataOps is a set of practices, processes, and technologies that combines an integrated and process-oriented perspective on data with automation and methods from agile software engineering to improve quality, speed, and collaboration and promote a culture of continuous improvement in the area of data analytics.
0 notes
Text
IBM Watsonx.data Offers VSCode, DBT & Airflow Dataops Tools
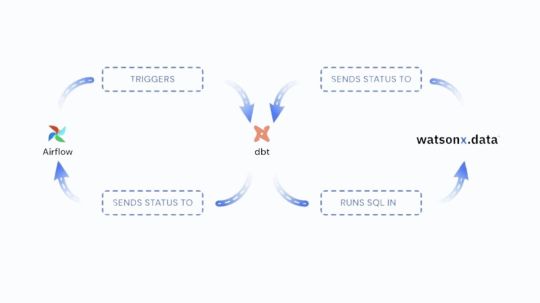
We are happy to inform that VSCode, Apache Airflow, and data-build-tool a potent set of tools for the contemporary dataops stack are now supported by IBM watsonx.data. IBM Watsonx.data delivers a new set of rich capabilities, including data build tool (dbt) compatibility for both Spark and Presto engines, automated orchestration with Apache Airflow, and an integrated development environment via VSCode. These functionalities enable teams to effectively construct, oversee, and coordinate data pipelines.
The difficulty with intricate data pipelines
Building and maintaining complicated data pipelines that depend on several engines and environments is a challenge that organizations must now overcome. Teams must continuously move between different languages and tools, which slows down development and adds complexity.
It can be challenging to coordinate workflows across many platforms, which can result in inefficiencies and bottlenecks. Data delivery slows down in the absence of a smooth orchestration tool, which postpones important decision-making.
A coordinated strategy
Organizations want a unified, efficient solution that manages process orchestration and data transformations in order to meet these issues. Through the implementation of an automated orchestration tool and a single, standardized language for transformations, teams can streamline their workflows, facilitating communication and lowering the difficulty of pipeline maintenance. Here’s where Apache Airflow and DBT come into play.
Teams no longer need to learn more complicated languages like PySpark or Scala because dbt makes it possible to develop modular structured query language (SQL) code for data transformations. The majority of data teams are already familiar with SQL, thus database technology makes it easier to create, manage, and update transformations over time.
Throughout the pipeline, Apache Airflow automates and schedules jobs to minimize manual labor and lower mistake rates. When combined, dbt and Airflow offer a strong framework for easier and more effective management of complicated data pipelines.
Utilizing IBM watsonx.data to tie everything together
Although strong solutions like Apache Airflow and DBT are available, managing a developing data ecosystem calls for more than just a single tool. IBM Watsonx.data adds the scalability, security, and dependability of an enterprise-grade platform to the advantages of these tools. Through the integration of VSCode, Airflow, and DBT within watsonx.data, it has developed a comprehensive solution that makes complex data pipeline management easier:
By making data transformations with SQL simpler, dbt assists teams in avoiding the intricacy of less used languages.
By automating orchestration, Airflow streamlines processes and gets rid of bottlenecks.
VSCode offers developers a comfortable environment that improves teamwork and efficiency.
This combination makes pipeline management easier, freeing your teams to concentrate on what matters most: achieving tangible business results. IBM Watsonx.data‘s integrated solutions enable teams to maintain agility while optimizing data procedures.
Data Build Tool’s Spark adaptor
The data build tool (dbt) adapter dbt-watsonx-spark is intended to link Apache Spark with dbt Core. This adaptor facilitates Spark data model development, testing, and documentation.
FAQs
What is data build tool?
A transformation workflow called dbt enables you to complete more tasks with greater quality. Dbt can help you centralize and modularize your analytics code while giving your data team the kind of checks and balances that are usually seen in software engineering workflows. Before securely delivering data models to production with monitoring and visibility, work together on them, version them, test them, and record your queries.
DBT allows you and your team to work together on a single source of truth for metrics, insights, and business definitions by compiling and running your analytics code against your data platform. Having a single source of truth and the ability to create tests for your data helps to minimize errors when logic shifts and notify you when problems occur.
Read more on govindhtech.com
#IBMWatsonx#dataOffer#VSCode#DBT#data#ApacheSpark#ApacheAirflow#Watsonxdata#DataopsTools#databuildtool#Sparkadaptor#UtilizingIBMwatsonxdata#technology#technews#news#govindhteh
0 notes
Text
Basil Faruqui, BMC Software: How to nail your data and AI strategy - AI News
New Post has been published on https://thedigitalinsider.com/basil-faruqui-bmc-software-how-to-nail-your-data-and-ai-strategy-ai-news/
Basil Faruqui, BMC Software: How to nail your data and AI strategy - AI News
.pp-multiple-authors-boxes-wrapper display:none; img width:100%;
BMC Software’s director of solutions marketing, Basil Faruqui, discusses the importance of DataOps, data orchestration, and the role of AI in optimising complex workflow automation for business success.
What have been the latest developments at BMC?
It’s exciting times at BMC and particularly our Control-M product line, as we are continuing to help some of the largest companies around the world in automating and orchestrating business outcomes that are dependent on complex workflows. A big focus of our strategy has been on DataOps specifically on orchestration within the DataOps practice. During the last twelve months we have delivered over seventy integrations to serverless and PaaS offerings across AWS, Azure and GCP enabling our customers to rapidly bring modern cloud services into their Control-M orchestration patterns. Plus, we are prototyping GenAI based use cases to accelerate workflow development and run-time optimisation.
What are the latest trends you’ve noticed developing in DataOps?
What we are seeing in the Data world in general is continued investment in data and analytics software. Analysts estimate that the spend on Data and Analytics software last year was in the $100 billion plus range. If we look at the Machine Learning, Artificial Intelligence & Data Landscape that Matt Turck at Firstmark publishes every year, its more crowded than ever before. It has 2,011 logos and over five hundred were added since 2023. Given this rapid growth of tools and investment, DataOps is now taking center stage as companies are realising that to successfully operationalise data initiatives, they can no longer just add more engineers. DataOps practices are now becoming the blueprint for scaling these initiatives in production. The recent boom of GenAI is going make this operational model even more important.
What should companies be mindful of when trying to create a data strategy?
As I mentioned earlier that the investment in data initiatives from business executives, CEOs, CMOs, CFOs etc. continues to be strong. This investment is not just for creating incremental efficiencies but for game changing, transformational business outcomes as well. This means that three things become very important. First is clear alignment of the data strategy with the business goals, making sure the technology teams are working on what matters the most to the business. Second, is data quality and accessibility, the quality of the data is critical. Poor data quality will lead to inaccurate insights. Equally important is ensuring data accessibility – making the right data available to the right people at the right time. Democratising data access, while maintaining appropriate controls, empowers teams across the organisation to make data-driven decisions. Third is achieving scale in production. The strategy must ensure that Ops readiness is baked into the data engineering practices so its not something that gets considered after piloting only.
How important is data orchestration as part of a company’s overall strategy?
Data Orchestration is arguably the most important pillar of DataOps. Most organisations have data spread across multiple systems – cloud, on-premises, legacy databases, and third-party applications. The ability to integrate and orchestrate these disparate data sources into a unified system is critical. Proper data orchestration ensures seamless data flow between systems, minimising duplication, latency, and bottlenecks, while supporting timely decision-making.
What do your customers tell you are their biggest difficulties when it comes to data orchestration?
Organisations continue to face the challenge of delivering data products fast and then scaling quickly in production. GenAI is a good example of this. CEOs and boards around the world are asking for quick results as they sense that this could majorly disrupt those who cannot harness its power. GenAI is mainstreaming practices such as prompt engineering, prompt chaining etc. The challenge is how do we take LLMs and vector databases, bots etc and fit them into the larger data pipeline which traverses a very hybrid architecture from multiple-clouds to on-prem including mainframes for many. This just reiterates the need for a strategic approach to orchestration which would allow folding new technologies and practices for scalable automation of data pipelines. One customer described Control-M as a power strip of orchestration where they can plug in new technologies and patterns as they emerge without having to rewire every time they swap older technologies for newer ones.
What are your top tips for ensuring optimum data orchestration?
There can be a number of top tips but I will focus on one, interoperability between application and data workflows which I believe is critical for achieving scale and speed in production. Orchestrating data pipelines is important, but it is vital to keep in mind that these pipelines are part of a larger ecosystem in the enterprise. Let’s consider an ML pipeline is deployed to predict the customers that are likely to switch to a competitor. The data that comes into such a pipeline is a result of workflows that ran in the ERP/CRM and combination of other applications. Successful completion of the application workflows is often a pre-requisite to triggering the data workflows. Once the model identifies customers that are likely to switch, the next step perhaps is to send them a promotional offer which means that we will need to go back to the application layer in the ERP and CRM. Control-M is uniquely positioned to solve this challenge as our customers use it to orchestrate and manage intricate dependencies between the application and the data layer.
What do you see as being the main opportunities and challenges when deploying AI?
AI and specifically GenAI is rapidly increasing the technologies involved in the data ecosystem. Lots of new models, vector databases and new automation patterns around prompt chaining etc. This challenge is not new to the data world, but the pace of change is picking up. From an orchestration perspective we see tremendous opportunities with our customers because we offer a highly adaptable platform for orchestration where they can fold these tools and patterns into their existing workflows versus going back to drawing board.
Do you have any case studies you could share with us of companies successfully utilising AI?
Domino’s Pizza leverages Control-M for orchestrating its vast and complex data pipelines. With over 20,000 stores globally, Domino’s manages more than 3,000 data pipelines that funnel data from diverse sources such as internal supply chain systems, sales data, and third-party integrations. This data from applications needs to go through complex transformation patterns and models before its available for driving decisions related to food quality, customer satisfaction, and operational efficiency across its franchise network.
Control-M plays a crucial role in orchestrating these data workflows, ensuring seamless integration across a wide range of technologies like MicroStrategy, AMQ, Apache Kafka, Confluent, GreenPlum, Couchbase, Talend, SQL Server, and Power BI, to name a few.
Beyond just connecting complex orchestration patterns together Control-M provides them with end-to-end visibility of pipelines, ensuring that they meet strict service-level agreements (SLAs) while handling increasing data volumes. Control-M is helping them generate critical reports faster, deliver insights to franchisees, and scale the roll out new business services.
What can we expect from BMC in the year ahead?
Our strategy for Control-M at BMC will stay focused on a couple of basic principles:
Continue to allow our customers to use Control-M as a single point of control for orchestration as they onboard modern technologies, particularly on the public cloud. This means we will continue to provide new integrations to all major public cloud providers to ensure they can use Control-M to orchestrate workflows across three major cloud infrastructure models of IaaS, Containers and PaaS (Serverless Cloud Services). We plan to continue our strong focus on serverless, and you will see more out-of-the-box integrations from Control-M to support the PaaS model.
We recognise that enterprise orchestration is a team sport, which involves coordination across engineering, operations and business users. And, with this in mind, we plan to bring a user experience and interface that is persona based so that collaboration is frictionless.
Specifically, within DataOps we are looking at the intersection of orchestration and data quality with a specific focus on making data quality a first-class citizen within application and data workflows. Stay tuned for more on this front!
Want to learn more about AI and big data from industry leaders? Check out AI & Big Data Expo taking place in Amsterdam, California, and London. The comprehensive event is co-located with other leading events including Intelligent Automation Conference, BlockX, Digital Transformation Week, and Cyber Security & Cloud Expo.
Explore other upcoming enterprise technology events and webinars powered by TechForge here.
Tags: automation, BMC, data orchestration, DataOps
#000#2023#Accessibility#ADD#ai#ai & big data expo#ai news#AI strategy#amp#Analytics#Apache#apache kafka#application layer#applications#approach#architecture#artificial#Artificial Intelligence#automation#AWS#azure#bi#Big Data#billion#BMC#board#boards#bots#box#Business
0 notes
Text
Simplifying Complex Data Operations with Smart Tools: Match Data Pro LLC Leading the Charge
In the data-driven economy, businesses are increasingly relying on accurate, actionable, and streamlined data to make informed decisions. But as the volume of data grows, so do the challenges: mismatched entries, inconsistent formats, manual data handling, and disconnected systems. That’s where Match Data Pro LLC steps in with robust, user-friendly solutions built to simplify the most complex data tasks.
From intuitive point-and-click data tools to enterprise-ready on-premise data software, Match Data Pro LLC offers a full suite of data ops software that helps businesses regain control of their data environments. Let’s explore how our tools are transforming data workflows and improving business intelligence across industries.
The Challenge of Mismatched Data
Modern businesses often operate across multiple platforms — CRMs, ERPs, marketing suites, accounting software, and more. With so many systems exchanging data, inconsistencies and mismatches are inevitable.
Common mismatched data issues include:
Duplicated records with minor variations
Inconsistent formatting across platforms
Incomplete or outdated entries
Data schema conflicts
These mismatches don’t just clutter your systems — they lead to flawed analytics, poor customer experiences, and inefficient operations. Match Data Pro LLC offers specialized mismatched data solutions that identify, resolve, and prevent these inconsistencies before they impact your business.
Mismatched Data Solutions That Actually Work
Our intelligent matching algorithms use fuzzy logic, pattern recognition, and customizable rules to identify mismatches across large datasets — whether it's customer records, product inventories, or financial transactions.
With our solutions, you can:
Detect and correct field-level mismatches
Merge records with varying structures
Align data formats across multiple systems
Automate reconciliation and cleanup processes
Whether your data is siloed in spreadsheets or flowing through APIs, Match Data Pro LLC helps you achieve consistency and reliability.
Empowering Users with Point-and-Click Data Tools
Not every business has a dedicated IT or data science team. That’s why Match Data Pro LLC designed point-and-click data tools — intuitive interfaces that empower non-technical users to manage, match, and clean data without writing a single line of code.
With our user-friendly dashboard, you can:
Drag and drop datasets for instant processing
Match records with customizable logic
Filter, group, and sort data visually
Schedule automated data operations
Generate real-time reports with one click
These tools are perfect for marketing teams, sales professionals, analysts, and operations managers who need quick results without technical overhead.
Optimize Workflow with Data Ops Software
DataOps, or data operations, is the practice of automating, monitoring, and improving the data pipeline across your organization. Match Data Pro LLC offers scalable data ops software that bridges the gap between IT and business, ensuring that clean, accurate data flows freely across systems.
Our DataOps platform supports:
Data ingestion and transformation
Real-time validation and matching
Workflow automation
Custom pipelines with REST API integration
End-to-end visibility into data flow
By implementing a robust DataOps framework, organizations can break down silos, accelerate decision-making, and reduce the time from data collection to business action.
On-Premise Data Software for Total Control
While cloud-based solutions offer flexibility, some businesses — especially in finance, healthcare, and government — require strict control over their data infrastructure. For these clients, Match Data Pro LLC provides secure, customizable on-premise data software.
With our on-premise solution, you get:
Full ownership of your data and environment
Greater compliance with regulatory standards (GDPR, HIPAA, etc.)
No dependency on third-party cloud providers
Seamless integration with legacy systems
Offline capabilities for remote or secure locations
Whether you're managing sensitive customer data or maintaining a private data warehouse, our on-premise offerings ensure peace of mind and operational integrity.
How Match Data Pro LLC Delivers Value
We understand that every organization’s data landscape is unique. That’s why we offer flexible configurations, expert support, and scalable features that grow with your business.
Key benefits of our platform:
Accurate data matching and cleaning
Automation that saves hours of manual effort
Tools accessible to both technical and non-technical users
API integration for seamless system connectivity
On-premise and cloud deployment options
Whether you’re a startup seeking better customer segmentation or a multinational enterprise trying to unify datasets across geographies, Match Data Pro LLC has a solution that fits.
Real-World Use Cases
Marketing: Clean up and deduplicate lead lists from multiple sources using point-and-click tools
Finance: Reconcile transactions across multiple ledgers with automated workflows
Retail: Align product data across warehouses, stores, and e-commerce platforms
Healthcare: Match patient records across systems while complying with data privacy regulations
Government: Maintain accurate citizen records with secure on-premise deployment
Our flexible software supports use cases across every industry — because clean, reliable data is a universal need.
Match Data Pro LLC: Your Data, Unified and Simplified
In a world driven by data, the ability to unify and streamline your information is what sets top-performing companies apart. Match Data Pro LLC provides the tools, support, and infrastructure to turn messy, mismatched datasets into clean, actionable intelligence.
With point-and-click data tools, mismatched data solutions, data ops software, and on-premise data software, we give you the power to take control of your data — and your business future.
0 notes
Text
Data Engineering Services Explained: What Lies Ahead for the Industry
In an era where data shapes every aspect of business decision-making, organizations are turning to data engineering to harness its full potential. As data volumes and complexities escalate, the demand for specialized data engineering services has surged. This article delves into the core components of data engineering services and offers insights into the evolving future of this critical field.

What are Data Engineering Services?
Data engineering involves the design, construction, and maintenance of systems and infrastructure that allow for the collection, storage, processing, and analysis of data. Data engineering services encompass a variety of tasks and functions that ensure data is accessible, reliable, and usable for data scientists, analysts, and business stakeholders. Key components of data engineering services include:
1. Data Architecture
Data engineers are responsible for designing data architectures that define how data is collected, stored, and accessed. This includes selecting appropriate databases, data lakes, and data warehouses to optimize performance and scalability.
2. Data Integration
Data often comes from multiple sources, including transactional systems, external APIs, and sensor data. Data engineering services involve creating ETL (Extract, Transform, Load) processes that integrate data from these various sources into a unified format.
3. Data Quality and Governance
Ensuring data quality is critical for accurate analysis. Data engineers implement data validation and cleansing processes to identify and rectify errors. They also establish governance frameworks to maintain data integrity and compliance with regulations.
4. Data Pipeline Development
Data pipelines automate the flow of data from its source to storage and processing systems. Data engineering services focus on building efficient pipelines that can handle large volumes of data while ensuring minimal latency.
5. Performance Optimization
As organizations scale, performance becomes a crucial consideration. Data engineers optimize databases and pipelines for speed and efficiency, enabling faster data retrieval and processing.
6. Collaboration with Data Teams
Data engineers work closely with data scientists, analysts, and other stakeholders to understand their data needs. This collaboration ensures that the data infrastructure supports analytical initiatives effectively.
The Future of Data Engineering
As the field of data engineering evolves, several trends are shaping its future:
1. Increased Automation
Automation is set to revolutionize data engineering. Tools and platforms are emerging that automate repetitive tasks such as data cleansing, pipeline management, and monitoring. This will allow data engineers to focus on more strategic initiatives rather than manual processes.
2. Real-time Data Processing
With the rise of IoT devices and streaming applications, the demand for real-time data processing is growing. Future data engineering services will increasingly incorporate technologies like Apache Kafka and Apache Flink to facilitate real-time data ingestion and analytics.
3. Cloud-based Solutions
Cloud computing is becoming the norm for data storage and processing. Data engineering services will continue to leverage cloud platforms like AWS, Google Cloud, and Azure, offering greater scalability, flexibility, and cost-effectiveness.
4. DataOps
DataOps is an emerging discipline that applies agile methodologies to data management. It emphasizes collaboration, continuous integration, and automation in data pipelines. As organizations adopt DataOps, the role of data engineers will shift toward ensuring seamless collaboration across data teams.
5. Focus on Data Security and Privacy
With growing concerns about data security and privacy, data engineers will play a vital role in implementing security measures and ensuring compliance with regulations like GDPR and CCPA. Future services will prioritize data protection as a foundational element of data architecture.
6. Integration of AI and Machine Learning
Data engineering will increasingly intersect with artificial intelligence and machine learning. Data engineers will need to build infrastructures that support machine learning models, ensuring they have access to clean, structured data for training and inference.
Conclusion
Data engineering services are essential for organizations seeking to harness the power of data. As technology continues to advance, the future of data engineering promises to be dynamic and transformative. With a focus on automation, real-time processing, cloud solutions, and security, data engineers will be at the forefront of driving data strategy and innovation. Embracing these trends will enable organizations to make informed decisions, optimize operations, and ultimately gain a competitive edge in their respective industries.
#Data Engineering Services#Data Security#Data Privacy#Future of Data Engineering#Data Architecture#Data Governance
0 notes
Text
Data Science with Generative AI Training Hyderabad | Data Science Training
The Future of Data Science? Key Trends to Watch
Introduction Data Science with Generative AI Course continues to transform industries, driving decision-making, innovation, and efficiency. With the rapid advancement of technology, the field is evolving at a breakneck pace. From automation to ethical AI, data science is entering an exciting new era. This article highlights the key trends shaping the future of data science and what to expect as the discipline continues to grow. Data Science Course in Hyderabad

AI and Machine Learning Integration AI and machine learning (ML) are at the heart of data science advancements. The ability to automate complex tasks and generate insights is driving innovation in various sectors.
Automated Data Processing: AI can streamline data cleaning and preparation, reducing the manual labor required by data scientists.
Predictive Analytics: ML models will become even more sophisticated, leading to better forecasting and real-time decision-making.
AI-Powered Applications: Expect more integration of AI into everyday software and business processes, improving productivity.
Augmented Analytics Augmented analytics leverages AI to enhance data analysis. This trend democratizes data science by making analytics accessible to a broader range of users.
Self-Service Tools: Businesses will see an increase in user-friendly platforms that allow non-technical users to generate insights without needing a data scientist.
AI-Driven Insights: Automation will help uncover hidden patterns in data, speeding up the decision-making process.
Ethical Ai and Responsible Data Usage As AI grows in prominence, ethical concerns around data privacy, bias, and transparency are gaining attention.
Bias Mitigation: Efforts to reduce algorithmic bias will intensify, ensuring AI models are fair and inclusive.
Privacy Protection: Stricter regulations will push companies to prioritize data privacy and security, promoting responsible use of data.
The Rise of DataOps DataOps, the data-focused counterpart to DevOps, will become central to managing data pipelines efficiently.
Automation: Expect greater automation in data workflows, from data integration to deployment.
Collaboration: DataOps encourages better collaboration between data scientists, engineers, and operations teams, improving the speed and quality of data-driven projects.
Real-Time Analytics As businesses demand faster insights, real-time analytics is set to become a significant focus in data science.
Streaming Data: The rise of IoT devices and social media increases the demand for systems that can process and analyze data in real time. Data Science Training Institute in Hyderabad
Faster Decision-Making: Real-time analytics will enable organizations to make more immediate and informed decisions, improving responsiveness to market changes.
Conclusion The future of data science is promising, with trends like AI integration, ethical practices, and real-time analytics reshaping the field. These innovations will empower businesses to harness data's full potential while navigating the challenges that come with responsible and effective data management.
Visualpath is the Leading and Best Institute for learning in Hyderabad. We provide Data Science with Generative AI Training Hyderabad you will get the best course at an affordable cost.
Attend Free Demo
Call on – +91-9989971070
Visit blog: https://visualpathblogs.com/
WhatsApp: https://www.whatsapp.com/catalog/919989971070/
Visit: https://visualpath.in/data-science-with-generative-ai-online-training.html
#Data Science with Generative AI Course#Data Science with Generative AI Training Hyderabad#Data Science Training in Hyderabad#Data Science Training in Ameerpet#Data Science Training Institute in Hyderabad#Data Science Course Training in Hyderabad#Data Science with Generative AI Online Training#Data Science with Generative AI Training#Data Science with Generative AI Course Ameerpet#Data Science with Generative AI Course Hyderabad#Data Science Course in Hyderabad
0 notes
Text
How to Train Your Team to Use a DataOps Platform Effectively

Organizations are depending more and more on massive volumes of data in today’s data-driven world in order to spur innovation, make wise decisions, and gain a competitive edge. Effectively managing and improving data processes is a major difficulty, though. A DataOps platform can be useful in this situation.
A DataOps Platform: What Is It?
A complete solution created to improve and expedite the data management and analytics processes is called a DataOps platform. DataOps is an approach to data management that takes cues from software development processes known as DevOps. Its objective is to ensure high standards of quality, dependability, and compliance while expediting the production and delivery of data products.
Important attributes and advantages
a. Automated Data Pipelines: The automation of data pipelines is a fundamental component of data operations platforms. This entails reducing manual involvement and error-proneness by automating the extraction, transformation, and loading (ETL) procedures. Faster data processing is made possible by automated pipelines, which facilitate the integration and analysis of data from several sources.
b. Enhanced Data Quality: Accurate analytics and reporting depend on high-quality data. Data validation and cleaning techniques are included into DataOps systems to assist find and fix problems with data quality early in the pipeline. As a result, decisions are made more effectively and with more reliability.
c. Enhanced Collaboration: By dismantling silos between data scientists, business analysts, and data engineers, DataOps platform encourages a collaborative approach. The platform facilitates a more integrated and effective workflow by offering features like version control, shared workspaces, and real-time communication capabilities.
d. Flexibility and Scalability: As businesses expand, so do their data requirements. A data operations platform is made to grow with the company, adapting to changing needs and bigger data volumes. Additionally, it supports a broad range of data integration situations by providing flexibility with regard to data sources and destinations.
e. Governance and Compliance: DataOps systems come with strong governance and compliance tools to assist enterprises in following legal obligations and data security guidelines. These characteristics lower the possibility of compliance problems by guaranteeing that data management procedures are open and auditable.
The DataOps Future
With the integration of cutting-edge technologies like artificial intelligence and machine learning into these platforms, the world of data operations is fast changing. More advanced automation features, improved predictive analytics, and deeper interaction with cloud-based services are possible future advances.
A data operations platform will be crucial in guaranteeing that data processes are effective, dependable, and in line with corporate objectives as companies continue to leverage the power of data. In an increasingly data-centric world, companies may preserve a competitive edge and open up new avenues for innovation by using a DataOps strategy.
0 notes