#Databricks Data Control
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
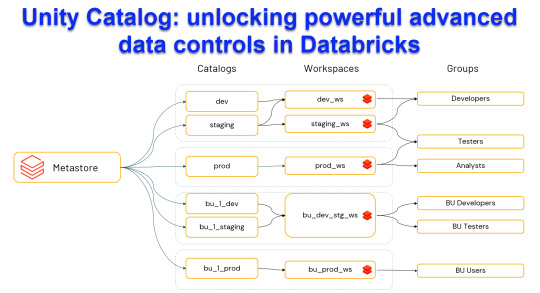
Unity Catalog: Unlocking Powerful Advanced Data Control in Databricks
Harness the power of Unity Catalog within Databricks and elevate your data governance to new heights. Our latest blog post, "Unity Catalog: Unlocking Advanced Data Control in Databricks," delves into the cutting-edge features
View On WordPress
#Advanced Data Security#Automated Data Lineage#Cloud Data Governance#Column Level Masking#Data Discovery and Cataloging#Data Ecosystem Security#Data Governance Solutions#Data Management Best Practices#Data Privacy Compliance#Databricks Data Control#Databricks Delta Sharing#Databricks Lakehouse Platform#Delta Lake Governance#External Data Locations#Managed Data Sources#Row Level Security#Schema Management Tools#Secure Data Sharing#Unity Catalog Databricks#Unity Catalog Features
0 notes
Text
Azure Data Factory Training In Hyderabad
Key Features:
Hybrid Data Integration: Azure Data Factory supports hybrid data integration, allowing users to connect and integrate data from on-premises sources, cloud-based services, and various data stores. This flexibility is crucial for organizations with diverse data ecosystems.
Intuitive Visual Interface: The platform offers a user-friendly, visual interface for designing and managing data pipelines. Users can leverage a drag-and-drop interface to effortlessly create, monitor, and manage complex data workflows without the need for extensive coding expertise.

Data Movement and Transformation: Data movement is streamlined with Azure Data Factory, enabling the efficient transfer of data between various sources and destinations. Additionally, the platform provides a range of data transformation activities, such as cleansing, aggregation, and enrichment, ensuring that data is prepared and optimized for analysis.
Data Orchestration: Organizations can orchestrate complex workflows by chaining together multiple data pipelines, activities, and dependencies. This orchestration capability ensures that data processes are executed in a logical and efficient sequence, meeting business requirements and compliance standards.
Integration with Azure Services: Azure Data Factory seamlessly integrates with other Azure services, including Azure Synapse Analytics, Azure Databricks, Azure Machine Learning, and more. This integration enhances the platform's capabilities, allowing users to leverage additional tools and services to derive deeper insights from their data.
Monitoring and Management: Robust monitoring and management capabilities provide real-time insights into the performance and health of data pipelines. Users can track execution details, diagnose issues, and optimize workflows to enhance overall efficiency.
Security and Compliance: Azure Data Factory prioritizes security and compliance, implementing features such as Azure Active Directory integration, encryption at rest and in transit, and role-based access control. This ensures that sensitive data is handled securely and in accordance with regulatory requirements.
Scalability and Reliability: The platform is designed to scale horizontally, accommodating the growing needs of organizations as their data volumes increase. With built-in reliability features, Azure Data Factory ensures that data processes are executed consistently and without disruptions.
2 notes
·
View notes
Text
PART TWO
The six men are one part of the broader project of Musk allies assuming key government positions. Already, Musk’s lackeys—including more senior staff from xAI, Tesla, and the Boring Company—have taken control of the Office of Personnel Management (OPM) and General Services Administration (GSA), and have gained access to the Treasury Department’s payment system, potentially allowing him access to a vast range of sensitive information about tens of millions of citizens, businesses, and more. On Sunday, CNN reported that DOGE personnel attempted to improperly access classified information and security systems at the US Agency for International Development and that top USAID security officials who thwarted the attempt were subsequently put on leave. The Associated Press reported that DOGE personnel had indeed accessed classified material.“What we're seeing is unprecedented in that you have these actors who are not really public officials gaining access to the most sensitive data in government,” says Don Moynihan, a professor of public policy at the University of Michigan. “We really have very little eyes on what's going on. Congress has no ability to really intervene and monitor what's happening because these aren't really accountable public officials. So this feels like a hostile takeover of the machinery of governments by the richest man in the world.”Bobba has attended UC Berkeley, where he was in the prestigious Management, Entrepreneurship, and Technology program. According to a copy of his now-deleted LinkedIn obtained by WIRED, Bobba was an investment engineering intern at the Bridgewater Associates hedge fund as of last spring and was previously an intern at both Meta and Palantir. He was a featured guest on a since-deleted podcast with Aman Manazir, an engineer who interviews engineers about how they landed their dream jobs, where he talked about those experiences last June.
Coristine, as WIRED previously reported, appears to have recently graduated from high school and to have been enrolled at Northeastern University. According to a copy of his résumé obtained by WIRED, he spent three months at Neuralink, Musk’s brain-computer interface company, last summer.Both Bobba and Coristine are listed in internal OPM records reviewed by WIRED as “experts” at OPM, reporting directly to Amanda Scales, its new chief of staff. Scales previously worked on talent for xAI, Musk’s artificial intelligence company, and as part of Uber’s talent acquisition team, per LinkedIn. Employees at GSA tell WIRED that Coristine has appeared on calls where workers were made to go over code they had written and justify their jobs. WIRED previously reported that Coristine was added to a call with GSA staff members using a nongovernment Gmail address. Employees were not given an explanation as to who he was or why he was on the calls.
Farritor, who per sources has a working GSA email address, is a former intern at SpaceX, Musk’s space company, and currently a Thiel Fellow after, according to his LinkedIn, dropping out of the University of Nebraska—Lincoln. While in school, he was part of an award-winning team that deciphered portions of an ancient Greek scroll.AdvertisementKliger, whose LinkedIn lists him as a special adviser to the director of OPM and who is listed in internal records reviewed by WIRED as a special adviser to the director for information technology, attended UC Berkeley until 2020; most recently, according to his LinkedIn, he worked for the AI company Databricks. His Substack includes a post titled “The Curious Case of Matt Gaetz: How the Deep State Destroys Its Enemies,” as well as another titled “Pete Hegseth as Secretary of Defense: The Warrior Washington Fears.”Killian, also known as Cole Killian, has a working email associated with DOGE, where he is currently listed as a volunteer, according to internal records reviewed by WIRED. According to a copy of his now-deleted résumé obtained by WIRED, he attended McGill University through at least 2021 and graduated high school in 2019. An archived copy of his now-deleted personal website indicates that he worked as an engineer at Jump Trading, which specializes in algorithmic and high-frequency financial trades.Shaotran told Business Insider in September that he was a senior at Harvard studying computer science and also the founder of an OpenAI-backed startup, Energize AI. Shaotran was the runner-up in a hackathon held by xAI, Musk’s AI company. In the Business Insider article, Shaotran says he received a $100,000 grant from OpenAI to build his scheduling assistant, Spark.
Are you a current or former employee with the Office of Personnel Management or another government agency impacted by Elon Musk? We’d like to hear from you. Using a nonwork phone or computer, contact Vittoria Elliott at [email protected] or securely at velliott88.18 on Signal.“To the extent these individuals are exercising what would otherwise be relatively significant managerial control over two very large agencies that deal with very complex topics,” says Nick Bednar, a professor at University of Minnesota’s school of law, “it is very unlikely they have the expertise to understand either the law or the administrative needs that surround these agencies.”Sources tell WIRED that Bobba, Coristine, Farritor, and Shaotran all currently have working GSA emails and A-suite level clearance at the GSA, which means that they work out of the agency’s top floor and have access to all physical spaces and IT systems, according a source with knowledge of the GSA’s clearance protocols. The source, who spoke to WIRED on the condition of anonymity because they fear retaliation, says they worry that the new teams could bypass the regular security clearance protocols to access the agency’s sensitive compartmented information facility, as the Trump administration has already granted temporary security clearances to unvetted people.This is in addition to Coristine and Bobba being listed as “experts” working at OPM. Bednar says that while staff can be loaned out between agencies for special projects or to work on issues that might cross agency lines, it’s not exactly common practice.“This is consistent with the pattern of a lot of tech executives who have taken certain roles of the administration,” says Bednar. “This raises concerns about regulatory capture and whether these individuals may have preferences that don’t serve the American public or the federal government.”

These men just stole the personal information of everyone in America AND control the Treasury. Link to article.
Akash Bobba
Edward Coristine
Luke Farritor
Gautier Cole Killian
Gavin Kliger
Ethan Shaotran
Spread their names!
#freedom of the press#elon musk#elongated muskrat#american politics#politics#news#america#trump administration
149K notes
·
View notes
Text
How to Become a Successful Azure Data Engineer in 2025
In today’s data-driven world, businesses rely on cloud platforms to store, manage, and analyze massive amounts of information. One of the most in-demand roles in this space is that of an Azure Data Engineer. If you're someone looking to build a successful career in the cloud and data domain, Azure Data Engineering in PCMC is quickly becoming a preferred choice among aspiring professionals and fresh graduates.
This blog will walk you through everything you need to know to become a successful Azure Data Engineer in 2025—from required skills to tools, certifications, and career prospects.
Why Choose Azure for Data Engineering?
Microsoft Azure is one of the leading cloud platforms adopted by companies worldwide. With powerful services like Azure Data Factory, Azure Databricks, and Azure Synapse Analytics, it allows organizations to build scalable, secure, and automated data solutions. This creates a huge demand for trained Azure Data Engineers who can design, build, and maintain these systems efficiently.
Key Responsibilities of an Azure Data Engineer
As an Azure Data Engineer, your job is more than just writing code. You will be responsible for:
Designing and implementing data pipelines using Azure services.
Integrating various structured and unstructured data sources.
Managing data storage and security.
Enabling real-time and batch data processing.
Collaborating with data analysts, scientists, and other engineering teams.
Essential Skills to Master in 2025
To succeed as an Azure Data Engineer, you must gain expertise in the following:
1. Strong Programming Knowledge
Languages like SQL, Python, and Scala are essential for data transformation, cleaning, and automation tasks.
2. Understanding of Azure Tools
Azure Data Factory – for data orchestration and transformation.
Azure Synapse Analytics – for big data and data warehousing solutions.
Azure Databricks – for large-scale data processing using Apache Spark.
Azure Storage & Data Lake – for scalable and secure data storage.
3. Data Modeling & ETL Design
Knowing how to model databases and build ETL (Extract, Transform, Load) pipelines is fundamental for any data engineer.
4. Security & Compliance
Understanding Role-Based Access Control (RBAC), Data Encryption, and Data Masking is critical to ensure data integrity and privacy.
Career Opportunities and Growth
With increasing cloud adoption, Azure Data Engineers are in high demand across all industries including finance, healthcare, retail, and IT services. Roles include:
Azure Data Engineer
Data Platform Engineer
Cloud Data Specialist
Big Data Engineer
Salaries range widely depending on skills and experience, but in cities like Pune and PCMC (Pimpri-Chinchwad), entry-level engineers can expect ₹5–7 LPA, while experienced professionals often earn ₹12–20 LPA or more.
Learning from the Right Place Matters
To truly thrive in this field, it’s essential to learn from industry experts. If you’re looking for a trusted Software training institute in Pimpri-Chinchwad, IntelliBI Innovations Technologies offers career-focused Azure Data Engineering programs. Their curriculum is tailored to help students not only understand theory but apply it through real-world projects, resume preparation, and mock interviews.
Conclusion
Azure Data Engineering is not just a job—it’s a gateway to an exciting and future-proof career. With the right skills, certifications, and hands-on experience, you can build powerful data solutions that transform businesses. And with growing opportunities in Azure Data Engineering in PCMC, now is the best time to start your journey.
Whether you’re a fresher or an IT professional looking to upskill, invest in yourself and start building a career that matters.
0 notes
Text
Unlock Business Value with Sombra’s Data & Analytics Services
In today’s data-driven world, smart insights are the difference between a good business and a great one. Sombra https://sombrainc.com/services/data-analytics delivers a full spectrum of data analytics solutions designed to elevate operations, reduce costs, and drive innovation—all while building a lasting data-first culture across your teams.
Key Challenges Addressed
Sombra helps businesses tackle core analytics pain points:
Scaling data operations securely
Ensuring clean, accurate, unified data
Managing growing volumes and disparate sources
Keeping costs under control
Configuring access, governance, and compliance
The Sombra Data Journey
Strategic Alignment – Start with your business goals and map data plans to long-term vision
Data Assessment – Audit current systems, identify gaps, and plan improvements
Solution Design – Architect data lakes, pipelines, dashboards, or AI models tailored for scale
Implementation & Integration – Seamlessly integrate with minimal operational disruption
Deployment & Optimization – Monitor performance and iteratively enhance systems
Ongoing Support – Continuous maintenance and alignment with evolving business needs
Tools & Technologies
Sombra uses a modern, scalable tech stack: Power BI, Tableau, Snowflake, Databricks, AirFlow, DBT, AWS Redshift, BigQuery, Spark, PostgreSQL, MySQL, Python, Talend, Microsoft Fabric, and more.
What You’ll Gain
Data-driven decisions powered by actionable insights
Cost-efficient operations, automated reporting, and better risk management
Faster time to market and higher team productivity
Predictive analytics, AI-based forecasting, and improved operational agility
Sombra’s reputation is backed by over a decade of experience, a team of more than 300 tech professionals, and a high Net Promoter Score well above industry average.
Compliance & Trust
Your data remains secure and compliant. Sombra follows global standards such as GDPR, HIPAA, CCPA, PIPEDA, FISMA, IEC-27001, and others—helping you meet both legal and security expectations.
Proven Results
Clients across finance, healthcare, e-commerce, and other industries report dramatic improvements—from boosting customer satisfaction by 70% to cutting engineering costs by a factor of four.
Final Thoughts
If your goal is to transform scattered data into powerful business intelligence, Sombra offers the experience, strategy, and technical skill to get you there. Their approach doesn’t stop at tools—it’s about building a foundation for smarter, more confident decisions across your entire organization.
Let me know if you'd like this edited down into a short web intro or repurposed for a corporate brochure.
0 notes
Text
Empowering Businesses with Advanced Data Engineering Solutions in Toronto – C Data Insights
In a rapidly digitizing world, companies are swimming in data—but only a few truly know how to harness it. At C Data Insights, we bridge that gap by delivering top-tier data engineering solutions in Toronto designed to transform your raw data into actionable insights. From building robust data pipelines to enabling intelligent machine learning applications, we are your trusted partner in the Greater Toronto Area (GTA).
What Is Data Engineering and Why Is It Critical?
Data engineering involves the design, construction, and maintenance of scalable systems for collecting, storing, and analyzing data. In the modern business landscape, it forms the backbone of decision-making, automation, and strategic planning.
Without a solid data infrastructure, businesses struggle with:
Inconsistent or missing data
Delayed analytics reports
Poor data quality impacting AI/ML performance
Increased operational costs
That’s where our data engineering service in GTA helps. We create a seamless flow of clean, usable, and timely data—so you can focus on growth.
Key Features of Our Data Engineering Solutions
As a leading provider of data engineering solutions in Toronto, C Data Insights offers a full suite of services tailored to your business goals:
1. Data Pipeline Development
We build automated, resilient pipelines that efficiently extract, transform, and load (ETL) data from multiple sources—be it APIs, cloud platforms, or on-premise databases.
2. Cloud-Based Architecture
Need scalable infrastructure? We design data systems on AWS, Azure, and Google Cloud, ensuring flexibility, security, and real-time access.
3. Data Warehousing & Lakehouses
Store structured and unstructured data efficiently with modern data warehousing technologies like Snowflake, BigQuery, and Databricks.
4. Batch & Streaming Data Processing
Process large volumes of data in real-time or at scheduled intervals with tools like Apache Kafka, Spark, and Airflow.
Data Engineering and Machine Learning – A Powerful Duo
Data engineering lays the groundwork, and machine learning unlocks its full potential. Our solutions enable you to go beyond dashboards and reports by integrating data engineering and machine learning into your workflow.
We help you:
Build feature stores for ML models
Automate model training with clean data
Deploy models for real-time predictions
Monitor model accuracy and performance
Whether you want to optimize your marketing spend or forecast inventory needs, we ensure your data infrastructure supports accurate, AI-powered decisions.
Serving the Greater Toronto Area with Local Expertise
As a trusted data engineering service in GTA, we take pride in supporting businesses across:
Toronto
Mississauga
Brampton
Markham
Vaughan
Richmond Hill
Scarborough
Our local presence allows us to offer faster response times, better collaboration, and solutions tailored to local business dynamics.
Why Businesses Choose C Data Insights
✔ End-to-End Support: From strategy to execution, we’re with you every step of the way ✔ Industry Experience: Proven success across retail, healthcare, finance, and logistics ✔ Scalable Systems: Our solutions grow with your business needs ✔ Innovation-Focused: We use the latest tools and best practices to keep you ahead of the curve
Take Control of Your Data Today
Don’t let disorganized or inaccessible data hold your business back. Partner with C Data Insights to unlock the full potential of your data. Whether you need help with cloud migration, real-time analytics, or data engineering and machine learning, we’re here to guide you.
📍 Proudly offering data engineering solutions in Toronto and expert data engineering service in GTA.
📞 Contact us today for a free consultation 🌐 https://cdatainsights.com
C Data Insights – Engineering Data for Smart, Scalable, and Successful Businesses
#data engineering solutions in Toronto#data engineering and machine learning#data engineering service in Gta
0 notes
Text
How Azure Supports Big Data and Real-Time Data Processing

The explosion of digital data in recent years has pushed organizations to look for platforms that can handle massive datasets and real-time data streams efficiently. Microsoft Azure has emerged as a front-runner in this domain, offering robust services for big data analytics and real-time processing. Professionals looking to master this platform often pursue the Azure Data Engineering Certification, which helps them understand and implement data solutions that are both scalable and secure.
Azure not only offers storage and computing solutions but also integrates tools for ingestion, transformation, analytics, and visualization—making it a comprehensive platform for big data and real-time use cases.
Azure’s Approach to Big Data
Big data refers to extremely large datasets that cannot be processed using traditional data processing tools. Azure offers multiple services to manage, process, and analyze big data in a cost-effective and scalable manner.
1. Azure Data Lake Storage
Azure Data Lake Storage (ADLS) is designed specifically to handle massive amounts of structured and unstructured data. It supports high throughput and can manage petabytes of data efficiently. ADLS works seamlessly with analytics tools like Azure Synapse and Azure Databricks, making it a central storage hub for big data projects.
2. Azure Synapse Analytics
Azure Synapse combines big data and data warehousing capabilities into a single unified experience. It allows users to run complex SQL queries on large datasets and integrates with Apache Spark for more advanced analytics and machine learning workflows.
3. Azure Databricks
Built on Apache Spark, Azure Databricks provides a collaborative environment for data engineers and data scientists. It’s optimized for big data pipelines, allowing users to ingest, clean, and analyze data at scale.
Real-Time Data Processing on Azure
Real-time data processing allows businesses to make decisions instantly based on current data. Azure supports real-time analytics through a range of powerful services:
1. Azure Stream Analytics
This fully managed service processes real-time data streams from devices, sensors, applications, and social media. You can write SQL-like queries to analyze the data in real time and push results to dashboards or storage solutions.
2. Azure Event Hubs
Event Hubs can ingest millions of events per second, making it ideal for real-time analytics pipelines. It acts as a front-door for event streaming and integrates with Stream Analytics, Azure Functions, and Apache Kafka.
3. Azure IoT Hub
For businesses working with IoT devices, Azure IoT Hub enables the secure transmission and real-time analysis of data from edge devices to the cloud. It supports bi-directional communication and can trigger workflows based on event data.
Integration and Automation Tools
Azure ensures seamless integration between services for both batch and real-time processing. Tools like Azure Data Factory and Logic Apps help automate the flow of data across the platform.
Azure Data Factory: Ideal for building ETL (Extract, Transform, Load) pipelines. It moves data from sources like SQL, Blob Storage, or even on-prem systems into processing tools like Synapse or Databricks.
Logic Apps: Allows you to automate workflows across Azure services and third-party platforms. You can create triggers based on real-time events, reducing manual intervention.
Security and Compliance in Big Data Handling
Handling big data and real-time processing comes with its share of risks, especially concerning data privacy and compliance. Azure addresses this by providing:
Data encryption at rest and in transit
Role-based access control (RBAC)
Private endpoints and network security
Compliance with standards like GDPR, HIPAA, and ISO
These features ensure that organizations can maintain the integrity and confidentiality of their data, no matter the scale.
Career Opportunities in Azure Data Engineering
With Azure’s growing dominance in cloud computing and big data, the demand for skilled professionals is at an all-time high. Those holding an Azure Data Engineering Certification are well-positioned to take advantage of job roles such as:
Azure Data Engineer
Cloud Solutions Architect
Big Data Analyst
Real-Time Data Engineer
IoT Data Specialist
The certification equips individuals with knowledge of Azure services, big data tools, and data pipeline architecture—all essential for modern data roles.
Final Thoughts
Azure offers an end-to-end ecosystem for both big data analytics and real-time data processing. Whether it’s massive historical datasets or fast-moving event streams, Azure provides scalable, secure, and integrated tools to manage them all.
Pursuing an Azure Data Engineering Certification is a great step for anyone looking to work with cutting-edge cloud technologies in today’s data-driven world. By mastering Azure’s powerful toolset, professionals can design data solutions that are future-ready and impactful.
#Azure#BigData#RealTimeAnalytics#AzureDataEngineer#DataLake#StreamAnalytics#CloudComputing#AzureSynapse#IoTHub#Databricks#CloudZone#AzureCertification#DataPipeline#DataEngineering
0 notes
Text
Unlock Data Governance: Revolutionary Table-Level Access in Modern Platforms
Dive into our latest blog on mastering data governance with Microsoft Fabric & Databricks. Discover key strategies for robust table-level access control and secure your enterprise's data. A must-read for IT pros! #DataGovernance #Security
View On WordPress
#Access Control#Azure Databricks#Big data analytics#Cloud Data Services#Data Access Patterns#Data Compliance#Data Governance#Data Lake Storage#Data Management Best Practices#Data Privacy#Data Security#Enterprise Data Management#Lakehouse Architecture#Microsoft Fabric#pyspark#Role-Based Access Control#Sensitive Data Protection#SQL Data Access#Table-Level Security
0 notes
Text
Enhancing Data Engineering and Business Intelligence with Azure and Power BI
1. Introduction
The world of data engineering and business intelligence is ever-evolving, and professionals today need the right set of skills to harness the potential of vast datasets for decision-making. As a result, platforms like Azure Data Engineering and Power BI have become fundamental tools in modern enterprises. This submission explores my journey through the courses on Azure Data Engineering and Power BI, focusing on how these technologies have transformed my understanding of data management and visualization.
2. Course Overview
Azure Data Engineering
Azure Data Engineering is a specialized course designed for those who want to dive into the world of data solutions within Microsoft Azure. The course covers essential topics such as:
Data storage and management using Azure Storage Accounts, Azure Data Lake, and Azure Blob Storage
Data ingestion and ETL processes using Azure Data Factory
Data transformation and orchestration through Azure Synapse Analytics and Azure Databricks
Data security, governance, and compliance using Azure Purview and Azure Security Center
Real-time analytics with Azure Stream Analytics
Power BI
Power BI is a powerful tool for data visualization and business intelligence. This course teaches how to transform raw data into meaningful insights through interactive dashboards and reports. Key learning areas include:
Data connectivity and transformation using Power Query
Creating relationships between tables and data modeling
Designing interactive dashboards with Power BI Desktop
Publishing and sharing reports through Power BI Service
Implementing data security and role-based access control in Power BI reports
3. Course Objectives and Key Learnings
Azure Data Engineering
The course provided a deep dive into Azure’s ecosystem, equipping me with practical skills in managing and processing large datasets. Some of the key learnings include:
Data Pipeline Automation: How to design and automate ETL pipelines to move data from source systems to Azure data warehouses and lakes.
Advanced Analytics: How to use Azure Machine Learning and Azure Databricks for advanced analytics and AI integration.
Scalability and Performance: Understanding how to optimize storage and processing for large-scale data.
Security and Governance: Ensuring data privacy and compliance with industry regulations using Azure's security tools.
Power BI
The Power BI course was centered around turning data into actionable insights. Some critical takeaways were:
Data Transformation with Power Query: I learned to clean and transform data for better analysis.
Visualization Best Practices: I now understand how to design effective dashboards that convey key business insights.
Real-Time Data Integration: The ability to connect Power BI to real-time data sources and create dynamic reports.
Collaborative Reporting: Publishing and sharing reports in a collaborative environment within organizations.
4. Practical Applications
The skills gained in both courses have direct applicability in various real-world scenarios. Some of the practical applications include:
Business Intelligence and Reporting: Power BI can be used to create interactive dashboards that display key metrics, KPIs, and business trends in real-time.
Data Engineering for Large Enterprises: Azure Data Engineering skills are invaluable for managing massive data pipelines and ensuring data integrity across multiple platforms.
Data-Driven Decision Making: Both tools empower businesses to make data-driven decisions with confidence by providing clean, well-processed data and interactive, insightful reports.
5. Future Outlook
The combination of Azure Data Engineering and Power BI sets a strong foundation for further advancements in data analytics, machine learning, and AI-driven business insights. With Azure's continuous innovations and Power BI's growing ecosystem, I am well-prepared to take on future challenges and deliver high-impact solutions for businesses.
6. Conclusion
In conclusion, both the Azure Data Engineering and Power BI courses have been pivotal in expanding my knowledge in data management, analytics, and business intelligence. These tools are fundamental for any modern data professional looking to work in the cloud and leverage the power of data to make informed decisions.
0 notes
Text
Medallion Architecture: A Scalable Framework for Modern Data Management

In the current big data era, companies must effectively manage data to make data-driven decisions. One such well-known data management architecture is the Medallion Architecture. This architecture offers a structured, scalable, modular approach to building data pipelines, ensuring data quality, and optimizing data operations.
What is Medallion Architecture?
Medallion Architecture is a system for managing and organizing data in stages. Each stage, or “medallion,” improves the quality and usefulness of the data, step by step. The main goal is to transform raw data into meaningful data that is ready for the analysis team.
The Three Layers of Medallion Architecture:
Bronze Layer (Raw Data):This layer stores all raw data exactly as it comes in without any changes or cleaning, preserving a copy of the original data for fixing errors or reprocessing when needed. Example: Logs from a website, sensor data, or files uploaded by users.
Silver Layer (Cleaned and Transformed Data):The Silver Layer involves cleaning, organizing, and validating data by fixing errors such as duplicates or missing values, ensuring the data is consistent and reliable for analysis, such as removing duplicate customer records or standardizing dates in a database Example: Removing duplicate customer records or standardizing dates in a database.
Gold Layer (Business-Ready Data):The Gold Layer contains final, polished data optimized for reports, dashboards, and decision-making, providing businesses with exactly the information they need to make informed decisions Example: A table showing the total monthly sales for each region
Advantages:
Improved Data Quality: Incremental layers progressively refine data quality from raw to business-ready datasets
Scalability: Each layer can be scaled independently based on specific business requirements
Security: If you have a large team to handle, you can separate them by their level
Modularity: The layered approach separates responsibilities, simplifying management and debugging
Traceability: Raw data preserved in the Bronze layer ensures traceability and allows reprocessing when issues arise in downstream layers
Adaptability: The architecture supports diverse data sources and formats, making it suitable for various business needs
Challenges:
Takes Time: Processing through multiple layers can delay results
Storage Costs: Storing raw and processed data requires more space
Requires Skills: Implementing this architecture requires skilled data engineers familiar with ETL/ELT tools, cloud platforms, and distributed systems
Best Practices for Medallion Architecture:
Automate ETL/ELT Processes: Use orchestration tools like Apache Airflow or AWS Step Functions to automate workflows between layers
Enforce Data Quality at Each Layer: Validate schemas, apply deduplication rules, and ensure data consistency as it transitions through layers
Monitor and Optimize Performance: Use monitoring tools to track pipeline performance and optimize transformations for scalability
Leverage Modern Tools: Adopt cloud-native technologies like Databricks, Delta Lake, or Snowflake to simplify the implementation
Plan for Governance: Implement robust data governance policies, including access control, data cataloging, and audit trails
Conclusion
Medallion Architecture is a robust framework for building reliable, scalable, and modular data pipelines. Its layered approach allows businesses to extract maximum value from their data by ensuring quality and consistency at every stage. While it comes with its challenges, the benefits of adopting Medallion Architecture often outweigh the drawbacks, making it a cornerstone for modern data engineering practices.
To learn more about this blog, please click on the link below: https://tudip.com/blog-post/medallion-architecture/.
#Tudip#MedallionArchitecture#BigData#DataPipelines#ETL#DataEngineering#CloudData#TechInnovation#DataQuality#BusinessIntelligence#DataDriven#TudipTechnologies
0 notes
Text
Data Lake Integration with Azure Data Factory: Best Practices and Patterns

As businesses scale their data needs, Azure Data Lake becomes a go-to storage solution — offering massive scalability, low-cost storage, and high performance. When paired with Azure Data Factory (ADF), you get a powerful combo for ingesting, transforming, and orchestrating data pipelines across hybrid environments.
In this blog, we’ll explore best practices and design patterns for integrating Azure Data Lake with ADF, so you can build efficient, secure, and scalable data pipelines.
🔗 Why Use Azure Data Lake with Azure Data Factory?
Cost-effective storage for raw and processed data
Flexible schema support for semi-structured/unstructured data
Seamless integration with Azure Synapse, Databricks, and Power BI
Built-in support in ADF via Copy Activity, Mapping Data Flows, and linked services
🧱 Architecture Overview
A common architecture pattern:pgsqlSource Systems → ADF (Copy/Ingest) → Azure Data Lake (Raw/Curated Zones) ↓ ADF Mapping Data Flows / Databricks ↓ Azure SQL / Synapse Analytics / Reporting Layer
This flow separates ingestion, transformation, and consumption layers for maintainability and performance.
✅ Best Practices for Azure Data Lake Integration
1. Organize Your Data Lake into Zones
Raw Zone: Original source data, untouched
Curated Zone: Cleaned and transformed data
Business/Gold Zone: Finalized datasets for analytics/reporting
Use folder structures like:swift/raw/sales/2025/04/10/ /curated/sales/monthly/ /gold/sales_summary/
💡 Tip: Include metadata such as ingestion date and source system in folder naming.
2. Parameterize Your Pipelines
Make your ADF pipelines reusable by using:
Dataset parameters
Dynamic content for file paths
Pipeline parameters for table/source names
This allows one pipeline to support multiple tables/files with minimal maintenance.
3. Use Incremental Loads Instead of Full Loads
Avoid loading entire datasets repeatedly. Instead:
Use Watermark Columns (e.g., ModifiedDate)
Leverage Last Modified Date or Delta files
Track changes using control tables
4. Secure Your Data Lake Access
Use Managed Identities with RBAC to avoid hardcoded keys
Enable Access Logging and Firewall Rules
Implement Private Endpoints for data lake access inside virtual networks
5. Monitor and Handle Failures Gracefully
Enable Activity-level retries in ADF
Use custom error handling with Web Activities or Logic Apps
Integrate Azure Monitor for alerts on pipeline failures
📐 Common Patterns for Data Lake + ADF
Pattern 1: Landing Zone Ingestion
ADF pulls data from external sources (SQL, API, SFTP) → saves to /raw/ zone. Best for: Initial ingestion, batch processing
Pattern 2: Delta Lake via Data Flows
Use ADF Mapping Data Flows to apply slowly changing dimensions or upserts to data in the curated zone.
Pattern 3: Metadata-Driven Framework
Maintain metadata tables (in SQL or JSON) defining:
Source system
File location
Transformations
Schedul
ADF reads these to dynamically build pipelines — enabling automation and scalability.
Pattern 4: Hierarchical Folder Loading
Design pipelines that traverse folder hierarchies (e.g., /year/month/day) and load data in parallel. Great for partitioned and time-series data.
🚀 Performance Tips
Enable Data Partitioning in Data Flows
Use Staging in Blob if needed for large file ingestion
Tune Data Integration Units (DIUs) for large copy activities
Compress large files (Parquet/Avro) instead of CSVs when possible
🧠 Wrapping Up
When used effectively, Azure Data Factory + Azure Data Lake can become the backbone of your cloud data platform. By following the right patterns and best practices, you’ll ensure your pipelines are not only scalable but also secure, maintainable, and future-ready.
WEBSITE: https://www.ficusoft.in/azure-data-factory-training-in-chennai/
0 notes
Text
youtube
What’s New in Databricks? March 2025 Updates & Features Explained! ### *🚀 What’s New in Databricks? March 2025 Updates & Features Explained!* #databricks #spark #dataengineering #ai #sql #llm Stay ahead with the *latest Databricks updates* for *March 2025.* This month introduces powerful features like: *SQL scripting enhancements, Calling Agents, Genie Files, Lakeflow, Streaming from Views, Secure Access Tokens, Binds, JSON Metadata Exploration, and Automatic Liquid Clustering.* 📌 *Watch the complete breakdown and see how these updates impact your data workflows!* ✨ *🔍 Key Highlights in This Update:* - *0:10* – SQL Scripting Enhancements: More advanced scripting with `BEGIN...END`, `CASE`, and control flow structures - *0:58* – Tabs: Soft tabs for notebooks and files have landed - *1:38* – MLFlow Trae UI: Debug agents with improved tracking - *2:27* – Calling Agents in Databricks: Connect Databricks to external services (e.g., Jira) using *http_request()* function - *5:50* – Volume File Previews: Seamlessly *preview files in volumes* - *6:15* – Genie Files: Easily *join files in Genie conversations* - *7:57* – Genie REST API: Develop your own app using *out-of-the-box Genie capabilities* - *9:15* – Lakeflow Enhancements: New ingestion pipelines, including *Workday & ServiceNow integrations* - *10:40* – Streaming from Views: Learn how to *stream data from SQL views* into live data pipelines - *11:45* – Secure Access Tokens: Manage Databricks *API tokens securely* - *12:24* – Binds: Improve workspace management with *Databricks workspace bindings* for external locations and credentials - *14:22* – DESCRIBE AS JSON: Explore metadata *directly in JSON format* for *more straightforward automation* - *15:50* – Automatic Liquid Clustering: Boost *query performance* with predictive clustering 📚 *Notebooks from the video:* 🔗 [GitHub Repository](https://ift.tt/c3dZYQh) 📝 *More on SQL Enhancements:* 🔗 [Read the full article](https://ift.tt/n9VX6dq) 📝 *More on DESCRIBE AS JSON:* 🔗 [Read the full article](https://ift.tt/sRPU3ik) 📝 *More on Calling GENIE API:* 🔗 [Read the full article](https://ift.tt/6D5fJrQ) ☕ *Enjoyed the video? Could you support me with a coffee?:* 🔗 [Buy Me a Coffee](https://ift.tt/Xv9AmPY) 💡 Whether you're a *data engineer, analyst, or Databricks enthusiast,* these updates will *enhance your workflows* and boost productivity! 🔔 *Subscribe for more Databricks insights & updates:* 📢 [YouTube Channel](https://www.youtube.com/@hubert_dudek/?sub_confirmation=1) 📢 *Stay Connected:* 🔗 [Medium Blog](https://ift.tt/cpeVd0J) --- ### 🎬 *Recommended Videos:* ▶️ [What’s new in January 2025](https://www.youtube.com/watch?v=JJiwSplZmfk)\ ▶️ [What’s new in February 2025](https://www.youtube.com/watch?v=tuKI0sBNbmg) --- ### *🔎 Related Phrases & Keywords:* What’s New In Databricks, March 2025 Updates, Databricks Latest Features, SQL Scripting in Databricks, Calling Agents with HTTP, Genie File Previews, Lakeflow Pipelines, Streaming from Views, Databricks Access Tokens, Databricks Binds, Metadata in JSON, Automatic Liquid Clustering \#databricks #bigdata #dataengineering #machinelearning #sql #cloudcomputing #dataanalytics #ai #azure #googlecloud #aws #etl #python #data #database #datawarehouse via Hubert Dudek https://www.youtube.com/channel/UCR99H9eib5MOHEhapg4kkaQ March 16, 2025 at 09:55PM
#databricks#dataengineering#machinelearning#sql#dataanalytics#ai#databrickstutorial#databrickssql#databricksai#Youtube
0 notes
Text
How Databricks Unity Catalog and Datagaps Automate Governance and Validation

Data quality is the backbone of accurate analytics, regulatory compliance, and efficient business operations. As organizations scale their data ecosystems, maintaining high data integrity becomes more challenging.
The seamless integration between Databricks Unity Catalog and Datagaps DataOps Suite provides a powerful framework for automated governance and validation, ensuring that data remains accurate, complete, and compliant at all times.
In our previous discussion, we highlighted how Datagaps enhances metadata management, lineage tracking, and automation within Unity Catalog. This article takes the next step by diving into data quality assurance – a crucial component of enterprise-wide data governance.
By leveraging Datagaps Data Quality Monitor, organizations can implement automated validation strategies, reduce manual effort, and integrate real-time data quality scores into Unity Catalog for proactive governance. Let’s explore how these technologies work together to ensure high-quality, reliable data that drives better decision-making and compliance.
The Growing Need for Automated Data Quality Assurance
Modern enterprises manage vast amounts of structured and unstructured data across multiple platforms. Ensuring data accuracy, completeness, and consistency is no longer just a best practice – it’s a necessity for regulatory compliance and business intelligence.
Databricks Unity Catalog provides a centralized governance framework for managing metadata, access controls, and data lineage across an organization. By integrating with Datagaps Data Quality Monitor, enterprises can automate data validation, reduce errors, and gain deeper insights into data health and integrity.
6 Key Data Quality Dimensions

Effective data quality management revolves around six fundamental dimensions:
Accuracy – Ensuring data reflects real-world values without discrepancies.
Completeness – Verifying that all required fields and records are present.
Consistency – Maintaining uniformity across multiple data sources and systems.
Timeliness – Ensuring data is up-to-date and available when needed.
Uniqueness – Eliminating duplicate records and redundant data entries.
Validity – Enforcing compliance with defined formats, business rules, and constraints.
By addressing these dimensions, organizations can improve the trustworthiness of their data assets, enhance AI/ML outcomes, and comply with industry regulations.
Automating Data Quality Validation with White-Box and Black-Box Testing
Ensuring data integrity at scale requires a systematic approach to validation. Two widely used methodologies are:
1. White-Box Testing
Examines internal data transformations, lineage, and business rules.
Ensures that every step in the ETL (Extract, Transform, Load) process adheres to defined standards.
Provides deeper insights into data processing logic to catch issues at the source.
2. Black-Box Testing
Focuses on output validation by comparing actual results against expected benchmarks.
Useful for detecting anomalies, missing records, and schema mismatches.
Works well for regulatory compliance and end-to-end data pipeline testing.
A hybrid approach combining both techniques ensures robust validation and proactive anomaly detection.
How Unity Catalog and Datagaps Data Quality Monitor Work Together
1. Unified Governance and Automated Validation
Databricks Unity Catalog centralizes metadata management, access control, and lineage tracking.
Datagaps Data Quality Monitor extends these capabilities with automated quality checks, reducing manual efforts.
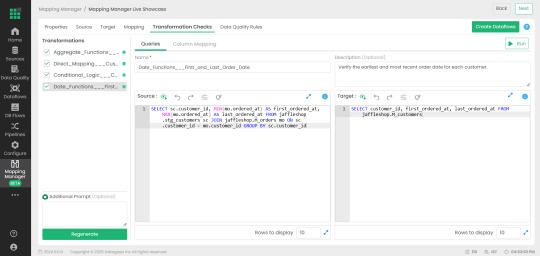
2. Mapping Manager Utility: Simplifying Test Case Automation
One of the standout features of Datagaps Data Quality Monitor is the Mapping Manager Utility, which:
Extracts mapping configurations from Databricks Unity Catalog.
Automatically generates white-box and black-box test cases.
Reduces the need for manual intervention, increasing efficiency and scalability.
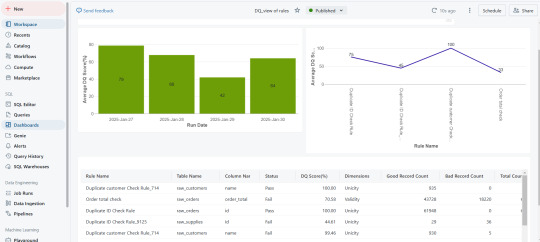
3. Real-Time Data Quality Scores for Proactive Governance
After test execution, a data quality score is generated.
These scores are seamlessly integrated into Databricks Unity Catalog, allowing real-time monitoring.
Organizations can visualize data quality insights through dashboards and take corrective actions before issues impact business operations.
Key Use Cases
ETL and Data Pipeline Validation – Ensuring data transformations adhere to defined business rules.
Regulatory Compliance and Audit Readiness – Mitigating risks associated with inaccurate reporting.
Enterprise Data Lakehouse Governance – Enhancing consistency across distributed datasets.
AI/ML Data Preprocessing – Ensuring clean, high-quality data for better model performance.
Automated Data Quality Checks – Reducing manual data validation efforts for faster, more reliable insights.
Scalability for Large Datasets – Efficiently managing high-volume, high-velocity enterprise data.
Faster QA Cycles – Automating test case execution for rapid turnaround.
Lower Operational Resources – Reducing human intervention, saving time and resources.
The Business Impact: Why This Integration Matters
Enhanced Automation – Eliminates manual quality checks and increases efficiency.
Real-Time Monitoring – Provides instant visibility into data quality metrics.
Stronger Compliance – Supports industry standards and regulations effortlessly.
Scalability – Designed for large-scale, complex data ecosystems.
Cost Efficiency – Reduces operational overhead and improves ROI on data management initiatives.
Ensuring data quality at scale requires a combination of automated governance, real-time monitoring, and seamless integration. The connection between Databricks Unity Catalog and Datagaps Data Quality Monitor provides a comprehensive solution to achieve this goal.
With automated test case generation, continuous data validation, and integrated governance, organizations can ensure their data is always accurate, complete, and compliant—laying the foundation for data-driven decision-making and regulatory confidence.
0 notes
Text
Databricks’ new updates aim to ease gen AI app and agent development
Data lakehouse provider Databricks is introducing four new updates to its portfolio to help enterprises have more control over the development of their agents and other generative AI-based applications. One of the new features launched as part of the updates is Centralized Governance, which is designed to help govern large language models, both open and closed source ones, within Mosaic AI…
0 notes