#Dataset Search
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is used by 21% of adults online aged 18-29 years.
Text

Now get the Historical Twitter dataset by using our advanced AI-driven retrieval tool. The RAW Twitter datasets are provided in CSV and JSON formats with information directly lifted from Twitter’s servers.
Visit: www.trackmyhashtag.com
#twitter dataset#download twitter dataset#hashtag analytics#search twitter history#historical twitter dataset#twitter#twitter tool#historical data
2 notes
·
View notes
Text
I've been working on my music library database (finally adding the song-datasets after having completed adding three other kinds of datasets) and wanted to try out the search that had taken quite some work and a bunch of headache to get implemented.
Access crashed when I tried to filter my search.
There are currently 11 song-datasets in my database.
I've tried to somehow get it working and even got some help with it, trying to change the SQL-code but it didn't work.
Soooo...I'm going to make a separate search for every aspect I want to be able to filter my database by. Which means one search is going to turn into at least 4.
At least 4 queries I'll have to fiddle with so it works the way I want it to.
At least 4 sub-forms to make for the search/filter results.
At least 4 forms to make that I can use for filtering the queries.
Don't know if I'm in the mood to untangle and delete the current search and start working on the new system right now. I think not.
#database adventures#fuck it I was so proud of my progress#especially with getting the search done#and especially with making it show datasets that don't have everything filled out
1 note
·
View note
Text
This tool is optional. No one is required to use it, but it's here if you want to know which of your AO3 fics were scraped. Locked works were not 100% protected from this scrape. Currently, I don't know of any next steps you should be taking, so this is all informational.
Most people should use this link to check if they were included in the March 2025 AO3 scrape. This will show up to 2,000 scraped works for most usernames.
Or you can use this version, which is slower but does a better job if your username is a common word. This version also lets you look up works by work ID number, which is useful if you're looking for an orphaned or anonymous fic.
If you have more than 2,000 published works, first off, I am jealous of your motivation to write that much. But second, that won't display right on the public version of the tools. You can send me an ask (preferred) or DM (if you need to) to have me do a custom search for you if you have more than 2,000 total works under 1 username. If you send an ask off-anon asking me to search a name, I'll assume you want a private answer.
In case this post breaches containment: this is a tool that only has access to the work IDs, titles, author names, chapter counts, and hit counts of the scraped fics for this most recent scrape by nyuuzyou discovered in April 2025. There is no other work data in this tool. This never had the content of your works loaded to it, only info to help you check if your works were scraped. If you need additional metadata, I can search my offline copy for you if you share a work ID number and tell me what data you're looking for. I will never search the full work text for anyone, but I can check things like word counts and tags.
Please come yell if the tool stops working, and I'll fix as fast as I can. It's slow as hell, but it does load eventually. Give it up to 10 minutes, and if it seems down after that, please alert me via ask! Anons are on if you're shy. The link at the top is faster and handles most users well.
On mobile, enable screen rotation and turn your phone sideways. It's a litttttle easier to use like that. It works better if you can use desktop.
Some FAQs below the cut:
"What do I need to do now?": At this time, the main place where this dataset was shared is disabled. As far as I'm aware, you don't need to do anything, but I'll update if I hear otherwise. If you're worried about getting scraped again, locking your fics to users only is NOT a guarantee, but it's a little extra protection. There are methods that can protect you more, but those will come at a cost of hiding your works from more potential readers as well.
"I know AO3 will be scraped again, and I'm willing to put a silly amount of effort into making my fics unusable for AI!": Excellent, stick around here. I'm currently trying to keep up with anyone working on solutions to poison our AO3 fics, and I will be reblogging information about doing this as I come across it.
"I want my fics to be unusable for AI, but I wanna be lazy about it.": You're so real for that, bestie. It may take awhile, but I'm on the lookout for data poisoning methods that require less effort, and I will boost posts regarding that once I find anything reputable.
"I don't want to know!": This tool is 100% optional. If you don't want to know, simply don't click the link. You are totally welcome to block me if it makes you feel more comfortable.
"Can I see the exact content they scraped?": Nope, not through me. I don't have the time to vet every single person to make sure they are who they say they are, and I don't want to risk giving a scraped copy of your fic to anyone else. If you really want to see this, you can find the info out there still and look it up yourself, but I can't be the one to do it for you.
"Are locked fics safe?": Not safe, but so far, it appears that locked fics were scraped less often than public fics. The only fics I haven't seen scraped as of right now are fics in unrevealed collections, which even logged-in users can't view without permission from the owner.
"My work wasn't a fic. It was an image/video/podfic.": You're safe! All the scrape got was stuff like the tags you used and your title and author name. The work content itself is a blank gap based on the samples I've checked.
"It's slow.": Unfortunately, a 13 million row data dashboard is going to be on the slow side. I think I've done everything I can to speed it up, but it may still take up to 10 minutes to load if you use the second link. It's faster if you can use desktop or the first link, but it should work on your phone too.
"My fic isn't there.": The cut-off date is around February 15th, 2025 for oneshots, but chapters posted up to March 21st, 2025 have been found in the data so far. I had to remove a few works from the dataset because the data was all skrungly and breaking my tool. (The few fics I removed were NOT in English.) Otherwise, from what I can tell so far, the scraper's code just... wasn't very good, so most likely, your fic was missed by random chance.
Thanks to everyone who helped with the cost to host the tool! I appreciate you so so so much. As of this edit, I've received more donations than what I paid to make this tool so you do NOT need to keep sending money. (But I super appreciate everyone who did help fund this! I just wanna make sure we all know it's all paid for now, so if you send any more that's just going to my savings to fix the electrical problems with my house. I don't have any more costs to support for this project right now.)
(Made some edits to the post on 27-May-2025 to update information!)
5K notes
·
View notes
Text
📚 A List Of Useful Websites When Making An RPG 📚
My timeloop RPG In Stars and Time is done! Which means I can clear all my ISAT gamedev related bookmarks. But I figured I would show them here, in case they can be useful to someone. These range from "useful to write a story/characters/world" to "these are SUPER rpgmaker focused and will help with the terrible math that comes with making a game".
This is what I used to make my RPG game, but it could be useful for writers, game devs of all genres, DMs, artists, what have you. YIPPEE
Writing (Names)
Behind The Name - Why don't you have this bookmarked already. Search for names and their meanings from all over the world!
Medieval Names Archive - Medieval names. Useful. For ME
City and Town Name Generator - Create "fake" names for cities, generated from datasets from any country you desire! I used those for the couple city names in ISAT. I say "fake" in quotes because some of them do end up being actual city names, especially for french generated ones. Don't forget to double check you're not 1. just taking a real city name or 2. using a word that's like, Very Bad, especially if you don't know the country you're taking inspiration from! Don't want to end up with Poopaville, USA
Writing (Words)
Onym - A website full of websites that are full of words. And by that I mean dictionaries, thesauruses, translators, glossaries, ways to mix up words, and way more. HIGHLY recommend checking this website out!!!
Moby Thesaurus - My thesaurus of choice!
Rhyme Zone - Find words that rhyme with others. Perfect for poets, lyricists, punmasters.
In Different Languages - Search for a word, have it translated in MANY different languages in one page.
ASSETS
In general, I will say: just look up what you want on itch.io. There are SO MANY assets for you to buy on itch.io. You want a font? You want a background? You want a sound effect? You want a plugin? A pixel base? An attack animation? A cool UI?!?!?! JUST GO ON ITCH.IO!!!!!!
Visual Assets (General)
Creative Market - Shop for all kinds of assets, from fonts to mockups to templates to brushes to WHATEVER YOU WANT
Velvetyne - Cool and weird fonts
Chevy Ray's Pixel Fonts - They're good fonts.
Contrast Checker - Stop making your text white when your background is lime green no one can read that shit babe!!!!!!
Visual Assets (Game Focused)
Interface In Game - Screenshots of UI (User Interfaces) from SO MANY GAMES. Shows you everything and you can just look at what every single menu in a game looks like. You can also sort them by game genre! GREAT reference!
Game UI Database - Same as above!
Sound Assets
Zapsplat, Freesound - There are many sound effect websites out there but those are the ones I saved. Royalty free!
Shapeforms - Paid packs for music and sounds and stuff.
Other
CloudConvert - Convert files into other files. MAKE THAT .AVI A .MOV
EZGifs - Make those gifs bigger. Smaller. Optimize them. Take a video and make it a gif. The Sky Is The Limit
Marketing
Press Kitty - Did not end up needing this- this will help with creating a press kit! Useful for ANY indie dev. Yes, even if you're making a tiny game, you should have a press kit. You never know!!!
presskit() - Same as above, but a different one.
Itch.io Page Image Guide and Templates - Make your project pages on itch.io look nice.
MOOMANiBE's IGF post - If you're making indie games, you might wanna try and submit your game to the Independent Game Festival at some point. Here are some tips on how, and why you should.
Game Design (General)
An insightful thread where game developers discuss hidden mechanics designed to make games feel more interesting - Title says it all. Check those comments too.
Game Design (RPGs)
Yanfly "Let's Make a Game" Comics - INCREDIBLY useful tips on how to make RPGs, going from dungeons to towns to enemy stats!!!!
Attack Patterns - A nice post on enemy attack patterns, and what attacks you should give your enemies to make them challenging (but not TOO challenging!) A very good starting point.
How To Balance An RPG - Twitter thread on how to balance player stats VS enemy stats.
Nobody Cares About It But It’s The Only Thing That Matters: Pacing And Level Design In JRPGs - a Good Post.
Game Design (Visual Novels)
Feniks Renpy Tutorials - They're good tutorials.
I played over 100 visual novels in one month and here’s my advice to devs. - General VN advice. Also highly recommend this whole blog for help on marketing your games.
I hope that was useful! If it was. Maybe. You'd like to buy me a coffee. Or maybe you could check out my comics and games. Or just my new critically acclaimed game In Stars and Time. If you want. Ok bye
#reference#tutorial#writing#rpgmaker#renpy#video games#game design#i had this in my drafts for a while so you get it now. sorry its so long#long post
8K notes
·
View notes
Note
are there any critiques of AI art or maybe AI in general that you would agree with?
AI art makes it a lot easier to make bad art on a mass production scale which absolutely floods art platforms (sucks). LLMs make it a lot easier to make content slop on a mass production scale which absolutely floods search results (sucks and with much worse consequences). both will be integrated into production pipelines in ways that put people out of jobs or justify lower pay for existing jobs. most AI-produced stuff is bad. the loudest and most emphatic boosters of this shit are soulless venture capital guys with an obvious and profound disdain for the concept of art or creative expression. the current wave of hype around it means that machine learning is being incorporated into workflows and places where it provides no benefit and in fact makes services and production meaningfully worse. it is genuinely terrifying to see people looking to chatGPT for personal and professional advice. the process of training AIs and labelling datasets involves profound exploitation of workers in the global south. the ability of AI tech to automate biases while erasing accountability is chilling. seems unwise to put a lot of our technological eggs in a completely opaque black box basket (mixing my metaphors ab it with that one). bing ai wont let me generate 'tesla CEO meat mistake' because it hates fun
6K notes
·
View notes
Text
Your Meta AI prompts are in a live, public feed

I'm in the home stretch of my 20+ city book tour for my new novel PICKS AND SHOVELS. Catch me in PDX TOMORROW (June 20) at BARNES AND NOBLE with BUNNIE HUANG and at the TUALATIN public library on SUNDAY (June 22). After that, it's LONDON (July 1) with TRASHFUTURE'S RILEY QUINN and then a big finish in MANCHESTER on July 2.

Back in 2006, AOL tried something incredibly bold and even more incredibly stupid: they dumped a data-set of 20,000,000 "anonymized" search queries from 650,000 users (yes, AOL had a search engine – there used to be lots of search engines!):
https://en.wikipedia.org/wiki/AOL_search_log_release
The AOL dump was a catastrophe. In an eyeblink, many of the users in the dataset were de-anonymized. The dump revealed personal, intimate and compromising facts about the lives of AOL search users. The AOL dump is notable for many reasons, not least because it jumpstarted the academic and technical discourse about the limits of "de-identifying" datasets by stripping out personally identifying information prior to releasing them for use by business partners, researchers, or the general public.
It turns out that de-identification is fucking hard. Just a couple of datapoints associated with an "anonymous" identifier can be sufficent to de-anonymize the user in question:
https://www.pnas.org/doi/full/10.1073/pnas.1508081113
But firms stubbornly refuse to learn this lesson. They would love it if they could "safely" sell the data they suck up from our everyday activities, so they declare that they can safely do so, and sell giant data-sets, and then bam, the next thing you know, a federal judge's porn-browsing habits are published for all the world to see:
https://www.theguardian.com/technology/2017/aug/01/data-browsing-habits-brokers
Indeed, it appears that there may be no way to truly de-identify a data-set:
https://pursuit.unimelb.edu.au/articles/understanding-the-maths-is-crucial-for-protecting-privacy
Which is a serious bummer, given the potential insights to be gleaned from, say, population-scale health records:
https://www.nytimes.com/2019/07/23/health/data-privacy-protection.html
It's clear that de-identification is not fit for purpose when it comes to these data-sets:
https://www.cs.princeton.edu/~arvindn/publications/precautionary.pdf
But that doesn't mean there's no safe way to data-mine large data-sets. "Trusted research environments" (TREs) can allow researchers to run queries against multiple sensitive databases without ever seeing a copy of the data, and good procedural vetting as to the research questions processed by TREs can protect the privacy of the people in the data:
https://pluralistic.net/2022/10/01/the-palantir-will-see-you-now/#public-private-partnership
But companies are perennially willing to trade your privacy for a glitzy new product launch. Amazingly, the people who run these companies and design their products seem to have no clue as to how their users use those products. Take Strava, a fitness app that dumped maps of where its users went for runs and revealed a bunch of secret military bases:
https://gizmodo.com/fitness-apps-anonymized-data-dump-accidentally-reveals-1822506098
Or Venmo, which, by default, let anyone see what payments you've sent and received (researchers have a field day just filtering the Venmo firehose for emojis associated with drug buys like "pills" and "little trees"):
https://www.nytimes.com/2023/08/09/technology/personaltech/venmo-privacy-oversharing.html
Then there was the time that Etsy decided that it would publish a feed of everything you bought, never once considering that maybe the users buying gigantic handmade dildos shaped like lovecraftian tentacles might not want to advertise their purchase history:
https://arstechnica.com/information-technology/2011/03/etsy-users-irked-after-buyers-purchases-exposed-to-the-world/
But the most persistent, egregious and consequential sinner here is Facebook (naturally). In 2007, Facebook opted its 20,000,000 users into a new system called "Beacon" that published a public feed of every page you looked at on sites that partnered with Facebook:
https://en.wikipedia.org/wiki/Facebook_Beacon
Facebook didn't just publish this – they also lied about it. Then they admitted it and promised to stop, but that was also a lie. They ended up paying $9.5m to settle a lawsuit brought by some of their users, and created a "Digital Trust Foundation" which they funded with another $6.5m. Mark Zuckerberg published a solemn apology and promised that he'd learned his lesson.
Apparently, Zuck is a slow learner.
Depending on which "submit" button you click, Meta's AI chatbot publishes a feed of all the prompts you feed it:
https://techcrunch.com/2025/06/12/the-meta-ai-app-is-a-privacy-disaster/
Users are clearly hitting this button without understanding that this means that their intimate, compromising queries are being published in a public feed. Techcrunch's Amanda Silberling trawled the feed and found:
"An audio recording of a man in a Southern accent asking, 'Hey, Meta, why do some farts stink more than other farts?'"
"people ask[ing] for help with tax evasion"
"[whether family members would be arrested for their proximity to white-collar crimes"
"how to write a character reference letter for an employee facing legal troubles, with that person’s first and last name included."
While the security researcher Rachel Tobac found "people’s home addresses and sensitive court details, among other private information":
https://twitter.com/racheltobac/status/1933006223109959820
There's no warning about the privacy settings for your AI prompts, and if you use Meta's AI to log in to Meta services like Instagram, it publishes your Instagram search queries as well, including "big booty women."
As Silberling writes, the only saving grace here is that almost no one is using Meta's AI app. The company has only racked up a paltry 6.5m downloads, across its ~3 billion users, after spending tens of billions of dollars developing the app and its underlying technology.
The AI bubble is overdue for a pop:
https://www.wheresyoured.at/measures/
When it does, it will leave behind some kind of residue – cheaper, spin-out, standalone models that will perform many useful functions:
https://locusmag.com/2023/12/commentary-cory-doctorow-what-kind-of-bubble-is-ai/
Those standalone models were released as toys by the companies pumping tens of billions into the unsustainable "foundation models," who bet that – despite the worst unit economics of any technology in living memory – these tools would someday become economically viable, capturing a winner-take-all market with trillions of upside. That bet remains a longshot, but the littler "toy" models are beating everyone's expectations by wide margins, with no end in sight:
https://www.nature.com/articles/d41586-025-00259-0
I can easily believe that one enduring use-case for chatbots is as a kind of enhanced diary-cum-therapist. Journalling is a well-regarded therapeutic tactic:
https://www.charliehealth.com/post/cbt-journaling
And the invention of chatbots was instantly followed by ardent fans who found that the benefits of writing out their thoughts were magnified by even primitive responses:
https://en.wikipedia.org/wiki/ELIZA_effect
Which shouldn't surprise us. After all, divination tools, from the I Ching to tarot to Brian Eno and Peter Schmidt's Oblique Strategies deck have been with us for thousands of years: even random responses can make us better thinkers:
https://en.wikipedia.org/wiki/Oblique_Strategies
I make daily, extensive use of my own weird form of random divination:
https://pluralistic.net/2022/07/31/divination/
The use of chatbots as therapists is not without its risks. Chatbots can – and do – lead vulnerable people into extensive, dangerous, delusional, life-destroying ratholes:
https://www.rollingstone.com/culture/culture-features/ai-spiritual-delusions-destroying-human-relationships-1235330175/
But that's a (disturbing and tragic) minority. A journal that responds to your thoughts with bland, probing prompts would doubtless help many people with their own private reflections. The keyword here, though, is private. Zuckerberg's insatiable, all-annihilating drive to expose our private activities as an attention-harvesting spectacle is poisoning the well, and he's far from alone. The entire AI chatbot sector is so surveillance-crazed that anyone who uses an AI chatbot as a therapist needs their head examined:
https://pluralistic.net/2025/04/01/doctor-robo-blabbermouth/#fool-me-once-etc-etc
AI bosses are the latest and worst offenders in a long and bloody lineage of privacy-hating tech bros. No one should ever, ever, ever trust them with any private or sensitive information. Take Sam Altman, a man whose products routinely barf up the most ghastly privacy invasions imaginable, a completely foreseeable consequence of his totally indiscriminate scraping for training data.
Altman has proposed that conversations with chatbots should be protected with a new kind of "privilege" akin to attorney-client privilege and related forms, such as doctor-patient and confessor-penitent privilege:
https://venturebeat.com/ai/sam-altman-calls-for-ai-privilege-as-openai-clarifies-court-order-to-retain-temporary-and-deleted-chatgpt-sessions/
I'm all for adding new privacy protections for the things we key or speak into information-retrieval services of all types. But Altman is (deliberately) omitting a key aspect of all forms of privilege: they immediately vanish the instant a third party is brought into the conversation. The things you tell your lawyer are priviiliged, unless you discuss them with anyone else, in which case, the privilege disappears.
And of course, all of Altman's products harvest all of our information. Altman is the untrusted third party in every conversation everyone has with one of his chatbots. He is the eternal Carol, forever eavesdropping on Alice and Bob:
https://en.wikipedia.org/wiki/Alice_and_Bob
Altman isn't proposing that chatbots acquire a privilege, in other words – he's proposing that he should acquire this privilege. That he (and he alone) should be able to mine your queries for new training data and other surveillance bounties.
This is like when Zuckerberg directed his lawyers to destroy NYU's "Ad Observer" project, which scraped Facebook to track the spread of paid political misinformation. Zuckerberg denied that this was being done to evade accountability, insisting (with a miraculously straight face) that it was in service to protecting Facebook users' (nonexistent) privacy:
https://pluralistic.net/2021/08/05/comprehensive-sex-ed/#quis-custodiet-ipsos-zuck
We get it, Sam and Zuck – you love privacy.
We just wish you'd share.

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2025/06/19/privacy-invasion-by-design#bringing-home-the-beacon
315 notes
·
View notes
Text
the generative noise reduction artifact experiments that people call "AI Art" were not initially a collage machine, but grew closer to one over time as demands for accuracy and beautiful convincing results without any extra interactions were heeded. overfitting has gotten easier to do accidentally as models have focused more on using smaller datasets efficiently after running into the ceiling of "oops, that's all the data on earth." of course it still can't point you towards the parts of its training data that it "used" because all of it is already in the bread, its just a shit image search now.
394 notes
·
View notes
Text
📊 LANDOSCAR AO3 STATS (may 2025)

notes
sorry this literally took 2 weeks to write... unfortunately the data was retrieved april 28 and it is now may 12.
other work: i previously wrote a stats overview that covered landoscar's fic growth and breakout in 2023 :) i've kept some of the formatting and graphs that i showed there, while other things have been removed or refined because i felt they'd become redundant or unnecessary (aka they were basically just a reflection of fandom growth in general, and not unique or interesting to landoscar as a ship specifically).
methodology: i simply scraped the metadata for every fic in the landoscar tag (until april 28, 2025) and then imported it into google sheets to clean, with most visualizations done in tableau. again, all temporal data is by date updated (not posted) unless noted otherwise. this is because the date that appears on the parent view of the ao3 archives is the updated one, so it's the only feasible datapoint to collect for 3000+ fics.
content: this post does not mention any individual authors or concern itself with kudos, hits, comments, etc. i purely describe archive growth and overall analysis of metadata like word count and tagging metrics.
cleaning: after importing my data, i standardized ship spelling, removed extra "814" or "landoscar" tags, and merged all versions of one-sided, background, implied, past, mentioned etc. into a single "(side)" modifier. i also removed one fic entirely from the dataset because the "loscar" tag was being mistakenly wrangled as landoscar, but otherwise was not actually tagged as landoscar. i also removed extra commentary tags in the ships sets that did not pertain to any ships.
overall stats
before we get into any detailed distributions, let's first look at an overview of the archive as of 2025! in their 2-and-change years as teammates, landoscar have had over 3,409 fics written for them, good enough for 3rd overall in the f1 archives (behind lestappen and maxiel).
most landoscar fics are completed one-shots (although note that a one-shot could easily be 80k words—in fact they have about 30 single-chapter fics that are at least 50k words long), and they also benefit from a lot of first-tagged fic, which is to say 82.3% of landoscar-tagged fics have them as the first ship, implying that they aren't often used as a fleeting side pairing and artificially skewing perception of their popularity. in fact, over half of landoscar fics are PURELY tagged as landoscar (aka otp: true), with no other side pairings tagged at all.

this percentage has actually gone down a bit since 2023 (65.5%), which makes sense since more lando and oscar ships have become established and grown in popularity over the years, but it's also not a very big difference yet...
ship growth
of course, landoscar have grown at a frankly terrifying rate since 2023. remember this annotated graph i posted comparing their growth during the 2023 season to that of carlando and loscar, respectively their other biggest ship at the time? THIS IS HER NOW:

yes... that tiny squished down little rectangle... (wipes away stray tear) they grow up so fast. i also tried to annotate this graph to show other "big" landoscar moments in the timeline since, but i honestly struggled with this because they've just grown SO exponentially and consistently that i don't even feel like i can point to anything as a proper catalyst of production anymore. that is to say, i think landoscar are popular enough now that they have a large amount of dedicated fans/writers who will continuously work on certain drafts and stories regardless of what happens irl, so it's hard to point at certain events as inspiring a meaningful amount of work.
note also that this is all going by date updated, so it's not a true reflection of ~growth~ as a ficdom. thankfully ao3 does have a date_created filter that you can manually enter into the search, but because of this limitation i can't create graphs with the granularity and complexity that scraping an entire archive allows me. nevertheless, i picked a few big ships that landoscar have overtaken over the last 2 years and created this graph using actual date created metrics!!!

this is pretty self-explanatory of course but i think it's fun to look at... :) it's especially satisfying to see how many ships they casually crossed over before the end of 2024.
distributions
some quick graphs this time. rating distribution remains extremely similar to the 2023 graph, with explicit fic coming out on top at 28%:

last time i noted a skew in ratings between the overall f1 rpf tag and the landoscar tag (i.e. landoscar had a higher prevalence of e fic), but looking at it a second time i honestly believe this is more of a cultural shift in (f1? sports rpf? who knows) fandom at large and not specific to landoscar as a ship — filtering the f1 rpf tag to works updated from 2023 onward shows that explicit has since become the most popular rating in general, even when excluding landoscar-tagged fics. is it because fandom is getting more horny in general, or because the etiquette surrounding what constitutes t / m / e has changed, or because people are less afraid to post e fic publicly and no longer quarantine it to locked livejournal posts? or something else altogether? Well i don't know and this is a landoscar stats post so it doesn't matter but that could be something for another thought experiment. regardless because of that i feel like further graphs aren't really necessary 🤷♀️
onto word distribution:

still similar to last time, although i will note that there's a higher representation of longfic now!!! it might not seem like much, but i noted last year that 85% of landoscar fics were under 10k & 97% under 25k — these numbers are now 78% and 92% respectively, which adds up in the grand scheme of a much larger archive. you'll also notice that the prevalence of <1k fic has gone down as well.

for the fun of it here's the wc distribution but with a further rating breakdown; as previously discussed you're more likely to get G ratings in flashfic because there's less wordspace to Make The Porn Happen. of course there are nuances to this but that's just a broad overview
side ships
what other ships are landoscar shippers shipping these days??? a lot of these ships are familiar from last time, but there are two new entries in ham/ros and pia/sai overtaking nor/ric and gas/lec to enter the top 10. ships that include at least one of lando or oscar are highlighted in orange:

of course, i pulled other 814-adjacent ships, but unfortunately i've realized that a lot of them simply aren't that popular/prevalent (context: within the 814 tag specifically) so they didn't make the top 10... because of that, here's a graph with only ships that include lando or oscar and have a minimum of 10 works within the landoscar tag:

eta: other primarily includes oscar & lily and maxf & lando. lando doesn't really have that many popular pairings within landoscar shippers otherwise...
i had wanted to explore these ships further and look at their growth/do some more in depth breakdowns of their popularity, but atm they're simply not popular enough for me to really do anything here. maybe next year?!
that being said, i did make a table comparing the prevalence of side ships within the 814 tag to the global f1 archives, so as to contextualize the popularity of each ship (see 2023). as usually, maxiel is very underrepresented in the landoscar tag, with galex actually receiving quite a boost compared to before!

additional tags
so last time i only had about 400 fics to work with and i did some analysis on additional tags / essentially au tagging. however, the problem is that there are now 3000 fics in my set, and the limitations of web scraping means that i'm not privy to the tag wrangling that happens in Da Backend of ao3. basically i'm being given all the raw versions of these au tags, whereas on ao3 "a/b/o" and "alpha/beta/omega dynamics" and "au - alpha/beta/omega" and "alternate universe - a/b/o" are all being wrangled together. because it would take way too long for me to do all of this manually and i frankly just don't want to clean that many fics after already going through all the ship tags, i've decided to not do any au analysis because i don't think it would be an accurate reflection of the data...
that being said, i had one new little experiment! as landoscar get more and more competitive, i wanted to chart how ~angsty~ they've gotten as a ship on ao3. i wanted to make a cumulative graph that shows how the overall fluff % - angst % difference has shifted over time, but ummmm... tableau and i had a disagreement. so instead here is a graph of the MoM change in angst % (so basically what percentage of the fics updated in that month specifically were tagged angst?):

the overall number is still not very drastic at all and fluff still prevails over angst in the landoscar archive. to be clear, there are 33.2% fics tagged some variation of fluff and 21.4% fics tagged some variation of angst overall, so there's a fluff surplus of 11.8%. but there has definitely been a slight growth in angst metrics over the past few months!
—
i will leave this here for now... if there's anything specific that you're interested in lmk and i can whip it up!!! hehe ty for reading 🧡
#adflkahsdflakhsdlfkahdf i wrote all of this and then lost 80% of my draft. so i had to write it all again#sorry this is a lot shorter than last time too T__T i honestly just felt like a lot of the old graphs were irrelevant#hopefully some of the information is still interesting though even if it's not particularly surprising!!#landoscar#*s
263 notes
·
View notes
Text
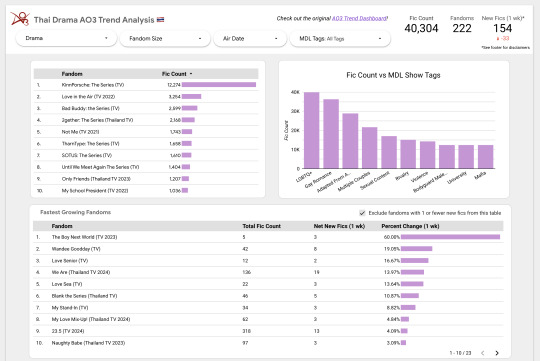
Introducing the Thai Drama AO3 Trends Dashboard! (Beta) 🇹🇭
Over the last several weeks or so I've been building an auto-scraping setup to get AO3 stats on Thai Drama fandoms. Now I finally have it ready to share out!
Take a look if you're interested and let me know what you think :)
(More details and process info under the cut.)
Main Features
This dashboard pulls in data about the quantity of Thai Drama fics over time.
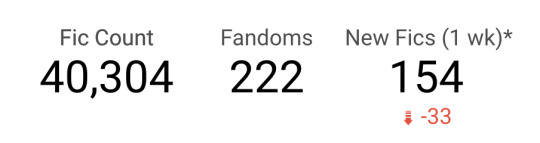
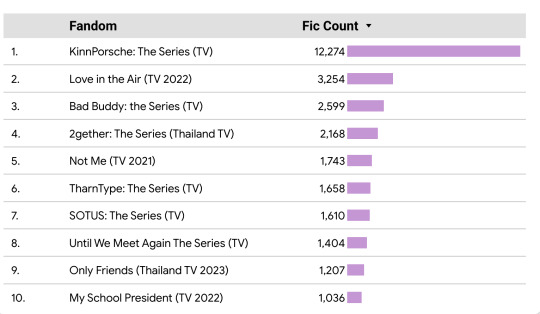
Using filters, it allows you to break that data down by drama, fandom size, air date, and a select number of MyDramaList tags.
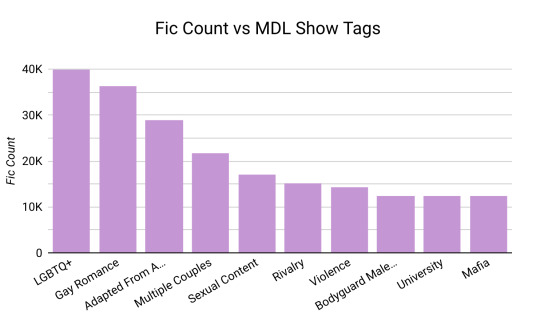
You can also see which fandoms have had the most new fics added on a weekly basis, plus the growth as a percentage of the total.
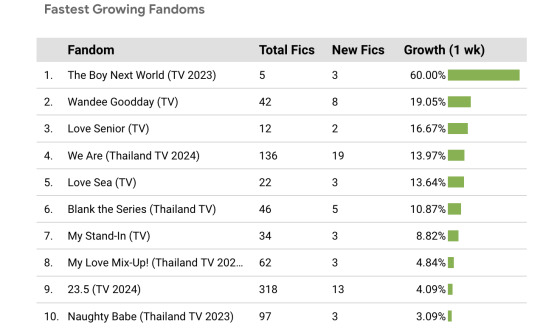
My hope is that this will make it easier to compare Thai Drama fandoms as a collective and pick out trends that otherwise might be difficult to see in an all-AO3 dataset.
Process
Okay -- now for the crunchy stuff...
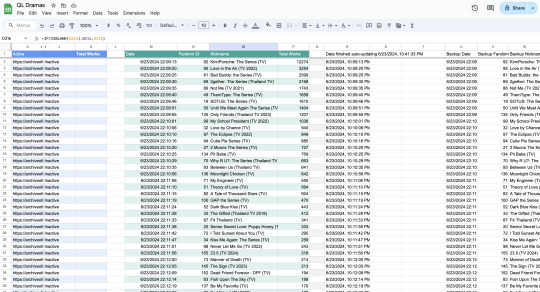
Scraping 🔎
Welcome to the most over-complicated Google Sheets spreadsheet ever made.
I used Google Sheets formulas to scrape certain info from each Thai Drama tag, and then I wrote some app scripts to refresh the data once a day. There are 5 second breaks between the refreshes for each fandom to avoid overwhelming AO3's servers.
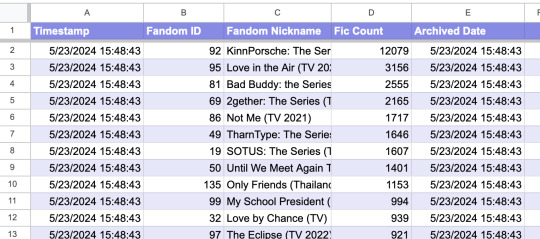
Archiving 📁
Once all the data is scraped, it gets transferred to a different Archive spreadsheet that feeds directly into the data dashboard. The dashboard will update automatically when new data is added to the spreadsheet, so I don't have to do anything manually.
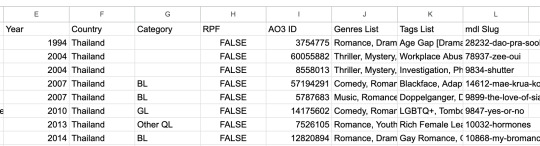
Show Metadata 📊
I decided to be extra and use a (currently unofficial) MyDramaList API to pull in data about each show, such as the year it came out and the MDL tags associated with it. Fun! I might pull in even more info in the future if the mood strikes me.
Bonus - Pan-Fandom AO3 Search
Do you ever find it a bit tedious to have like, 15 different tabs open for the shows you're currently reading fic for?
While making this dash, I also put together this insane URL that basically serves as a "feed" for any and all new Thai drama fics. You can check it out here! It could be useful if you like checking for new fics in multiple fandoms at once. :)
Other Notes
Consider this dashboard the "beta" version -- please let me know if you notice anything that looks off. Also let me know if there are any fandoms missing! Thanks for checking it out!
The inspiration for this dashboard came from @ao3-anonymous 's AO3 Fandom Trend Analysis Dashboard, which I used as a jumping off point for my own data dash. Please give them some love <3
#in which i am the biggest nerd ever#thai bl#thai drama#lgbt drama#ql drama#data science#acafan#fandom data visualization#fanfiction data
287 notes
·
View notes
Text
Useful (not AI) Tools for Writing
For years I've been compiling a list of useful tools for writing (fiction and non-fiction) and I thought it might be fun to share it.
What am I missing? What do you use and love? I'd love to keep building this list!
Historical Research
General plug: Librarians!!! They want to help you.
Search for words/signs in Brooklyn
Encyclopedia of Hair
Underwear, a history
Newspapers.com
Historical (and modern) meeting minutes
Find a grave
Political TV Ad archive
Oral Histories
Columbia
National Archives
MoMA
Archives of American Art
The Oral History Review
Words
Wordnik
Dictionary of American Regional English
Scrivener built in name generator
Lose the very
Scene Setting / Images
Animals & Plants by geolocation (also good for general scene setting)
Flickr world map
Past weather by zip code
Google Maps streetview / Google Earth
General Inspiration
Oblique Strategies
Worldbuilding
Tarot decks (my personal favorite is this one)
The Thing from the Future
The Picture Game
Misc
Data is Plural -- a newsletter full of interesting datasets
#writing#resources#writing resources#fiction writing#non-fiction writing#finding stuff#librarians are the best people in the world#archives#historical research#you don't need AI to help you write
195 notes
·
View notes
Text

The blog post titled "Twitter Search History: 5 Methods To Find Old Tweets" from TrackMyHashtag provides a comprehensive guide on retrieving past tweets for various purposes such as research, marketing, or personal review. It outlines five primary methods: utilizing Twitter's standard search bar, employing Advanced Search with specific filters, disabling sensitive content settings, incorporating search operators in queries, and downloading personal Twitter data archives. Additionally, the article highlights tools like TrackMyHashtag, Hootsuite, Keyhole, Sprout Social, and the Internet Archive’s Wayback Machine for more extensive historical data access. The blog also emphasizes the importance of analyzing metrics like tweet volume, impressions, and user engagement to assess the effectiveness of past strategies and content.
#search twitter history#twitter search history#twitter dataset#twitter tool#historical data#hashtag analytics#old tweets
1 note
·
View note
Text

Boulders on Mars are Headed Downhill
Features on the surface of Mars change over time for many reasons, but one process that’s universal to all planets is gravity.
We can see boulders and smaller rocks around the bases of most steep rocky cliffs. With HiRISE, we can compare two images and find new boulders that have broken off the cliff face and sometimes even see the trail that the boulder has left as it tumbled further downhill. Finding these new rockfalls with HiRISE is difficult as they’re small and the dataset is huge.
Recently, scientists have started using machine learning techniques to help find and catalog features like these. Understanding how often these rockfalls happen allows us to guess the age of the slopes. In this image we’re searching for new boulders at the bottom of Cerberus Fossae, a volcanic fissure that's thought to be quite young.
ID: ESP_085012_1900 date: 14 September 2024 altitude: 277 km
NASA/JPL-Caltech/University of Arizona
90 notes
·
View notes
Text
Some thoughts on Cara
So some of you may have heard about Cara, the new platform that a lot of artists are trying out. It's been around for a while, but there's been a recent huge surge of new users, myself among them. Thought I'd type up a lil thing on my initial thoughts.
First, what is Cara?
From their About Cara page:
Cara is a social media and portfolio platform for artists. With the widespread use of generative AI, we decided to build a place that filters out generative AI images so that people who want to find authentic creatives and artwork can do so easily. Many platforms currently accept AI art when it’s not ethical, while others have promised “no AI forever” policies without consideration for the scenario where adoption of such technologies may happen at the workplace in the coming years. The future of creative industries requires nuanced understanding and support to help artists and companies connect and work together. We want to bridge the gap and build a platform that we would enjoy using as creatives ourselves. Our stance on AI: ・We do not agree with generative AI tools in their current unethical form, and we won’t host AI-generated portfolios unless the rampant ethical and data privacy issues around datasets are resolved via regulation. ・In the event that legislation is passed to clearly protect artists, we believe that AI-generated content should always be clearly labeled, because the public should always be able to search for human-made art and media easily.
Should note that Cara is independently funded, and is made by a core group of artists and engineers and is even collaborating with the Glaze project. It's very much a platform by artists, for artists!
Should also mention that in being a platform for artists, it's more a gallery first, with social media functionalities on the side. The info below will hopefully explain how that works.
Next, my actual initial thoughts using it, and things that set it apart from other platforms I've used:
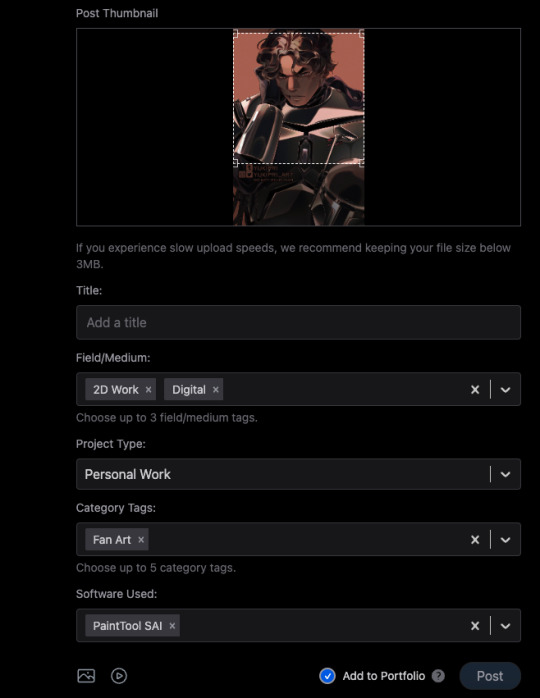
1) When you post, you can choose to check the portfolio option, or to NOT check it. This is fantastic because it means I can have just my art organized in my gallery, but I can still post random stuff like photos of my cats and it won't clutter things. You can also just ramble/text post and it won't affect the gallery view!
2) You can adjust your crop preview for your images. Such a simple thing, yet so darn nice.
3) When you check that "Add to portfolio," you get a bunch of additional optional fields: Title, Field/Medium, Project Type, Category Tags, and Software Used. It's nice that you can put all this info into organized fields that don't take up text space.
4) Speaking of text, 5000 character limit is niiiiice. If you want to talk, you can.
5) Two separate feeds, a "For You" algorithmic one, and "Following." The "Following" actually appears to be full chronological timeline of just folks you follow (like Tumblr). Amazing.
6) Now usually, "For You" being set to home/default kinda pisses me off because generally I like curating my own experience, but not here, for this handy reason: if you tap the gear symbol, you can ADJUST your algorithm feed!
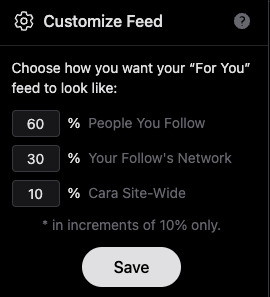
So you can choose what you see still!!! AMAZING. And, again, you still have your Following timeline too.
7) To repeat the stuff at the top of this post, its creation and intent as a place by artists, for artists. Hopefully you can also see from the points above that it's been designed with artists in mind.
8) No GenAI images!!!! There's a pop up that says it's not allowed, and apparently there's some sort of detector thing too. Not sure how reliable the latter is, but so far, it's just been a breath of fresh air, being able to scroll and see human art art and art!
To be clear, Cara's not perfect and is currently pretty laggy, and you can get errors while posting (so far, I've had more success on desktop than the mobile app), but that's understandable, given the small team. They'll need time to scale. For me though, it's a fair tradeoff for a platform that actually cares about artists.
Currently it also doesn't allow NSFW, not sure if that'll change given app store rules.
As mentioned above, they're independently funded, which means the team is currently paying for Cara itself. They have a kofi set up for folks who want to chip in, but it's optional. Here's the link to the tweet from one of the founders:
And a reminder that no matter that the platform itself isn't selling our data to GenAI, it can still be scraped by third parties. Protect your work with Glaze and Nightshade!
Anyway, I'm still figuring stuff out and have only been on Cara a few days, but I feel hopeful, and I think they're off to a good start.
I hope this post has been informative!
Lastly, here's my own Cara if you want to come say hi! Not sure at all if I'll be active on there, but if you're an artist like me who is keeping an eye out for hopefully nice communities, check it out!
#YukiPri rambles#cara#cara app#social media#artists on tumblr#review#longpost#long post#mostly i'd already typed this up on twitter so i figured why not share it here too#also since tumblr too is selling our data to GenAI
180 notes
·
View notes
Text
@quasi-normalcy @startorrent02
AI-infused search engines from Google, Microsoft, and Perplexity have been surfacing deeply racist and widely debunked research promoting race science and the idea that white people are genetically superior to nonwhite people. Patrik Hermansson, a researcher with UK-based anti-racism group Hope Not Hate, was in the middle of a months-long investigation into the resurgent race science movement when he needed to find out more information about a debunked dataset that claims IQ scores can be used to prove the superiority of the white race.
79 notes
·
View notes
Text
The surprising truth about data-driven dictatorships

Here’s the “dictator’s dilemma”: they want to block their country’s frustrated elites from mobilizing against them, so they censor public communications; but they also want to know what their people truly believe, so they can head off simmering resentments before they boil over into regime-toppling revolutions.
These two strategies are in tension: the more you censor, the less you know about the true feelings of your citizens and the easier it will be to miss serious problems until they spill over into the streets (think: the fall of the Berlin Wall or Tunisia before the Arab Spring). Dictators try to square this circle with things like private opinion polling or petition systems, but these capture a small slice of the potentially destabiziling moods circulating in the body politic.
Enter AI: back in 2018, Yuval Harari proposed that AI would supercharge dictatorships by mining and summarizing the public mood — as captured on social media — allowing dictators to tack into serious discontent and diffuse it before it erupted into unequenchable wildfire:
https://www.theatlantic.com/magazine/archive/2018/10/yuval-noah-harari-technology-tyranny/568330/
Harari wrote that “the desire to concentrate all information and power in one place may become [dictators] decisive advantage in the 21st century.” But other political scientists sharply disagreed. Last year, Henry Farrell, Jeremy Wallace and Abraham Newman published a thoroughgoing rebuttal to Harari in Foreign Affairs:
https://www.foreignaffairs.com/world/spirals-delusion-artificial-intelligence-decision-making
They argued that — like everyone who gets excited about AI, only to have their hopes dashed — dictators seeking to use AI to understand the public mood would run into serious training data bias problems. After all, people living under dictatorships know that spouting off about their discontent and desire for change is a risky business, so they will self-censor on social media. That’s true even if a person isn’t afraid of retaliation: if you know that using certain words or phrases in a post will get it autoblocked by a censorbot, what’s the point of trying to use those words?
The phrase “Garbage In, Garbage Out” dates back to 1957. That’s how long we’ve known that a computer that operates on bad data will barf up bad conclusions. But this is a very inconvenient truth for AI weirdos: having given up on manually assembling training data based on careful human judgment with multiple review steps, the AI industry “pivoted” to mass ingestion of scraped data from the whole internet.
But adding more unreliable data to an unreliable dataset doesn’t improve its reliability. GIGO is the iron law of computing, and you can’t repeal it by shoveling more garbage into the top of the training funnel:
https://memex.craphound.com/2018/05/29/garbage-in-garbage-out-machine-learning-has-not-repealed-the-iron-law-of-computer-science/
When it comes to “AI” that’s used for decision support — that is, when an algorithm tells humans what to do and they do it — then you get something worse than Garbage In, Garbage Out — you get Garbage In, Garbage Out, Garbage Back In Again. That’s when the AI spits out something wrong, and then another AI sucks up that wrong conclusion and uses it to generate more conclusions.
To see this in action, consider the deeply flawed predictive policing systems that cities around the world rely on. These systems suck up crime data from the cops, then predict where crime is going to be, and send cops to those “hotspots” to do things like throw Black kids up against a wall and make them turn out their pockets, or pull over drivers and search their cars after pretending to have smelled cannabis.
The problem here is that “crime the police detected” isn’t the same as “crime.” You only find crime where you look for it. For example, there are far more incidents of domestic abuse reported in apartment buildings than in fully detached homes. That’s not because apartment dwellers are more likely to be wife-beaters: it’s because domestic abuse is most often reported by a neighbor who hears it through the walls.
So if your cops practice racially biased policing (I know, this is hard to imagine, but stay with me /s), then the crime they detect will already be a function of bias. If you only ever throw Black kids up against a wall and turn out their pockets, then every knife and dime-bag you find in someone’s pockets will come from some Black kid the cops decided to harass.
That’s life without AI. But now let’s throw in predictive policing: feed your “knives found in pockets” data to an algorithm and ask it to predict where there are more knives in pockets, and it will send you back to that Black neighborhood and tell you do throw even more Black kids up against a wall and search their pockets. The more you do this, the more knives you’ll find, and the more you’ll go back and do it again.
This is what Patrick Ball from the Human Rights Data Analysis Group calls “empiricism washing”: take a biased procedure and feed it to an algorithm, and then you get to go and do more biased procedures, and whenever anyone accuses you of bias, you can insist that you’re just following an empirical conclusion of a neutral algorithm, because “math can’t be racist.”
HRDAG has done excellent work on this, finding a natural experiment that makes the problem of GIGOGBI crystal clear. The National Survey On Drug Use and Health produces the gold standard snapshot of drug use in America. Kristian Lum and William Isaac took Oakland’s drug arrest data from 2010 and asked Predpol, a leading predictive policing product, to predict where Oakland’s 2011 drug use would take place.
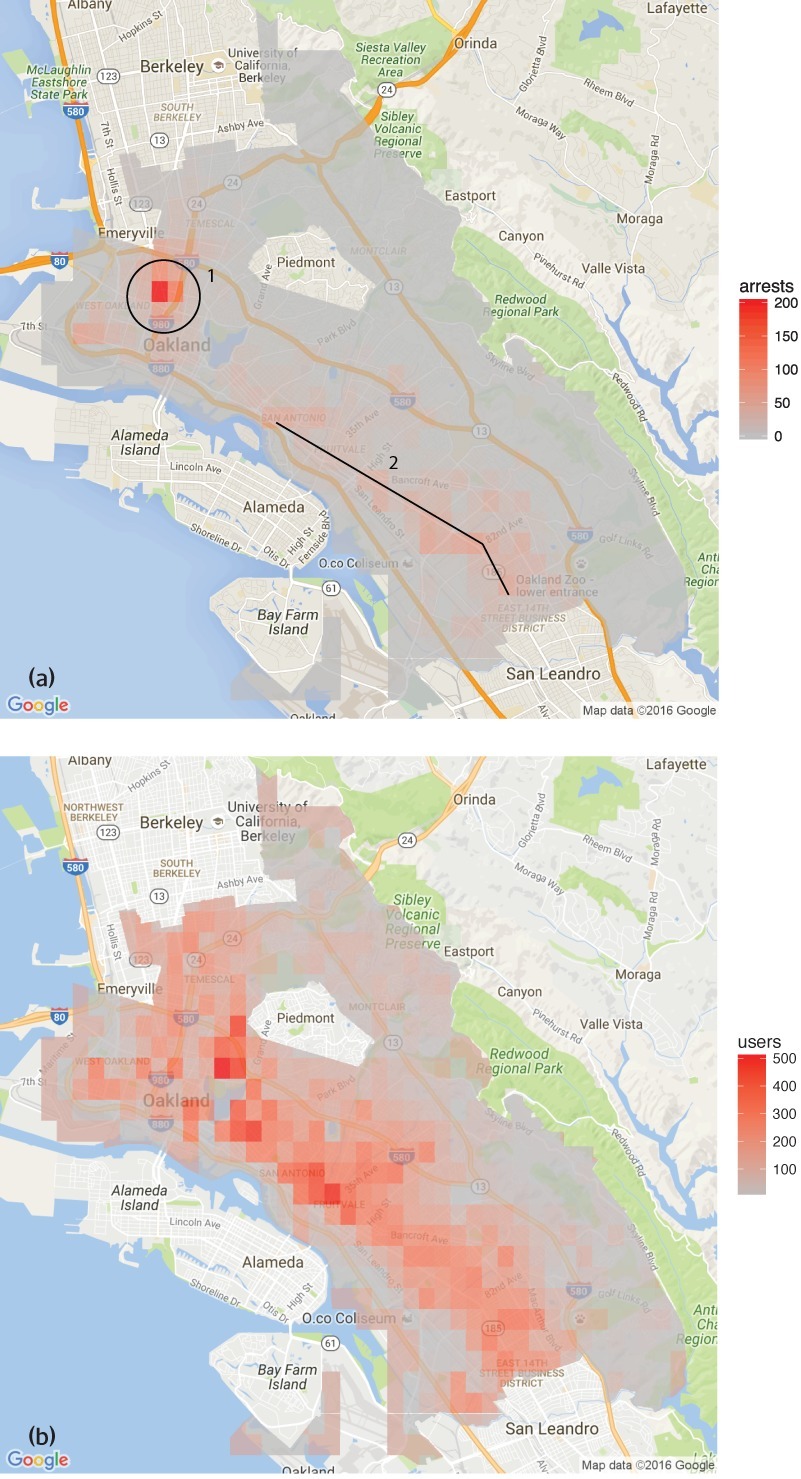
[Image ID: (a) Number of drug arrests made by Oakland police department, 2010. (1) West Oakland, (2) International Boulevard. (b) Estimated number of drug users, based on 2011 National Survey on Drug Use and Health]
Then, they compared those predictions to the outcomes of the 2011 survey, which shows where actual drug use took place. The two maps couldn’t be more different:
https://rss.onlinelibrary.wiley.com/doi/full/10.1111/j.1740-9713.2016.00960.x
Predpol told cops to go and look for drug use in a predominantly Black, working class neighborhood. Meanwhile the NSDUH survey showed the actual drug use took place all over Oakland, with a higher concentration in the Berkeley-neighboring student neighborhood.
What’s even more vivid is what happens when you simulate running Predpol on the new arrest data that would be generated by cops following its recommendations. If the cops went to that Black neighborhood and found more drugs there and told Predpol about it, the recommendation gets stronger and more confident.
In other words, GIGOGBI is a system for concentrating bias. Even trace amounts of bias in the original training data get refined and magnified when they are output though a decision support system that directs humans to go an act on that output. Algorithms are to bias what centrifuges are to radioactive ore: a way to turn minute amounts of bias into pluripotent, indestructible toxic waste.
There’s a great name for an AI that’s trained on an AI’s output, courtesy of Jathan Sadowski: “Habsburg AI.”
And that brings me back to the Dictator’s Dilemma. If your citizens are self-censoring in order to avoid retaliation or algorithmic shadowbanning, then the AI you train on their posts in order to find out what they’re really thinking will steer you in the opposite direction, so you make bad policies that make people angrier and destabilize things more.
Or at least, that was Farrell(et al)’s theory. And for many years, that’s where the debate over AI and dictatorship has stalled: theory vs theory. But now, there’s some empirical data on this, thanks to the “The Digital Dictator’s Dilemma,” a new paper from UCSD PhD candidate Eddie Yang:
https://www.eddieyang.net/research/DDD.pdf
Yang figured out a way to test these dueling hypotheses. He got 10 million Chinese social media posts from the start of the pandemic, before companies like Weibo were required to censor certain pandemic-related posts as politically sensitive. Yang treats these posts as a robust snapshot of public opinion: because there was no censorship of pandemic-related chatter, Chinese users were free to post anything they wanted without having to self-censor for fear of retaliation or deletion.
Next, Yang acquired the censorship model used by a real Chinese social media company to decide which posts should be blocked. Using this, he was able to determine which of the posts in the original set would be censored today in China.
That means that Yang knows that the “real” sentiment in the Chinese social media snapshot is, and what Chinese authorities would believe it to be if Chinese users were self-censoring all the posts that would be flagged by censorware today.
From here, Yang was able to play with the knobs, and determine how “preference-falsification” (when users lie about their feelings) and self-censorship would give a dictatorship a misleading view of public sentiment. What he finds is that the more repressive a regime is — the more people are incentivized to falsify or censor their views — the worse the system gets at uncovering the true public mood.
What’s more, adding additional (bad) data to the system doesn’t fix this “missing data” problem. GIGO remains an iron law of computing in this context, too.
But it gets better (or worse, I guess): Yang models a “crisis” scenario in which users stop self-censoring and start articulating their true views (because they’ve run out of fucks to give). This is the most dangerous moment for a dictator, and depending on the dictatorship handles it, they either get another decade or rule, or they wake up with guillotines on their lawns.
But “crisis” is where AI performs the worst. Trained on the “status quo” data where users are continuously self-censoring and preference-falsifying, AI has no clue how to handle the unvarnished truth. Both its recommendations about what to censor and its summaries of public sentiment are the least accurate when crisis erupts.
But here’s an interesting wrinkle: Yang scraped a bunch of Chinese users’ posts from Twitter — which the Chinese government doesn’t get to censor (yet) or spy on (yet) — and fed them to the model. He hypothesized that when Chinese users post to American social media, they don’t self-censor or preference-falsify, so this data should help the model improve its accuracy.
He was right — the model got significantly better once it ingested data from Twitter than when it was working solely from Weibo posts. And Yang notes that dictatorships all over the world are widely understood to be scraping western/northern social media.
But even though Twitter data improved the model’s accuracy, it was still wildly inaccurate, compared to the same model trained on a full set of un-self-censored, un-falsified data. GIGO is not an option, it’s the law (of computing).
Writing about the study on Crooked Timber, Farrell notes that as the world fills up with “garbage and noise” (he invokes Philip K Dick’s delighted coinage “gubbish”), “approximately correct knowledge becomes the scarce and valuable resource.”
https://crookedtimber.org/2023/07/25/51610/
This “probably approximately correct knowledge” comes from humans, not LLMs or AI, and so “the social applications of machine learning in non-authoritarian societies are just as parasitic on these forms of human knowledge production as authoritarian governments.”

The Clarion Science Fiction and Fantasy Writers’ Workshop summer fundraiser is almost over! I am an alum, instructor and volunteer board member for this nonprofit workshop whose alums include Octavia Butler, Kim Stanley Robinson, Bruce Sterling, Nalo Hopkinson, Kameron Hurley, Nnedi Okorafor, Lucius Shepard, and Ted Chiang! Your donations will help us subsidize tuition for students, making Clarion — and sf/f — more accessible for all kinds of writers.
Libro.fm is the indie-bookstore-friendly, DRM-free audiobook alternative to Audible, the Amazon-owned monopolist that locks every book you buy to Amazon forever. When you buy a book on Libro, they share some of the purchase price with a local indie bookstore of your choosing (Libro is the best partner I have in selling my own DRM-free audiobooks!). As of today, Libro is even better, because it’s available in five new territories and currencies: Canada, the UK, the EU, Australia and New Zealand!
[Image ID: An altered image of the Nuremberg rally, with ranked lines of soldiers facing a towering figure in a many-ribboned soldier's coat. He wears a high-peaked cap with a microchip in place of insignia. His head has been replaced with the menacing red eye of HAL9000 from Stanley Kubrick's '2001: A Space Odyssey.' The sky behind him is filled with a 'code waterfall' from 'The Matrix.']
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
—
Raimond Spekking (modified) https://commons.wikimedia.org/wiki/File:Acer_Extensa_5220_-_Columbia_MB_06236-1N_-_Intel_Celeron_M_530_-_SLA2G_-_in_Socket_479-5029.jpg
CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0/deed.en
—
Russian Airborne Troops (modified) https://commons.wikimedia.org/wiki/File:Vladislav_Achalov_at_the_Airborne_Troops_Day_in_Moscow_%E2%80%93_August_2,_2008.jpg
“Soldiers of Russia” Cultural Center (modified) https://commons.wikimedia.org/wiki/File:Col._Leonid_Khabarov_in_an_everyday_service_uniform.JPG
CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0/deed.en
#pluralistic#habsburg ai#self censorship#henry farrell#digital dictatorships#machine learning#dictator's dilemma#eddie yang#preference falsification#political science#training bias#scholarship#spirals of delusion#algorithmic bias#ml#Fully automated data driven authoritarianism#authoritarianism#gigo#garbage in garbage out garbage back in#gigogbi#yuval noah harari#gubbish#pkd#philip k dick#phildickian
833 notes
·
View notes
Text

A Banggai cardinalfish swims in Indonesia’s tropical waters. Photo: Jens Petersen (CC BY-SA 3.0)
Excerpt from this story from The Revelator:
Nothing fascinates Monica Biondo more than the animals often referred to as the ocean’s “living jewels” — the vividly colored little fishes who dance around in its waters.
Biondo, a Swiss marine biologist, became enamored with ocean life as a child after spending many summers snorkeling along the Italian coastline. Nowadays you’re more likely to find her deep-diving into trade records than marine waters. As the head of research and conservation at Fondation Franz Weber, she has spent the past decade searching through data on the marine ornamental fish trade.
These are the colorful fish you see in home aquariums or for sale at pet stores; Biondo wants to know where they came from, how they got there, and what happened to them along the way.
Compared to the clear waters around the coral reefs she’s explored, the records on these fish are frustratingly murky. Wading through them has though provided her with clarity on her calling: shining a light on the aquarium trade’s vast exploitation of these glamorous ocean dwellers.
Her entry into the fray came in the form of a Banggai cardinalfish, a striking little fish endemic to an archipelago in Indonesia that first became known to science in the 1930s. A scientist redescribed the species in 1994, kickstarting a tragic surge in the fish’s popularity for aquariums. Within less than a decade, 90% of the population had disappeared, Biondo says.
After witnessing that rapid decline, along with the failure of countries to subsequently regulate global trade in the species, Biondo was hooked. “That really pushed me into looking into this trade,” she says.
In her search for information she has pored over paperwork in the Swiss Federal Food Safety and Veterinary Office’s records warehouse. She and her colleagues at Pro Coral Fish have also spent years rifling through a European Union-wide electronic database called the Trade Control and Expert System (TRACES), which collects information on animal imports.
Although the datasets varied, the questions have remained the same. How many marine ornamental fish are being imported? What species are they? Where did they originate?
These straightforward questions are hard to answer to because the trade — despite being worth billions annually — has no mandatory data-collection requirements. As a result, information gathered about trade in these fishes tends to be opaque and haphazard compared to information on live organisms like farmed food animals.
53 notes
·
View notes