#Efficient Log Data Visualization
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
Best Open Source Log Management Tools in 2023
Best Open Source Log Management Tools in 2023 #homelab #OpenSourceLogManagement2023 #TopLogAnalysisTools #CentralizedLoggingSystems #LogstashVsSyslogng #BestLogCollectors #FluentDAndCloudServices #ManageLargeVolumesOfLogData #GrafanaRealtimeMonitoring
When monitoring, troubleshooting, and auditing in today’s IT infrastructure, logs provide the low-level messaging needed to trace down events happening in the environment. They can be an invaluable source of insights into performance, security events, and errors that may be occurring across on-premises, cloud, and hybrid systems. You don’t have to buy into a commercial solution to get started…

View On WordPress
#Best Log Collectors#Centralized Logging Systems#Efficient Log Data Visualization#FluentD and Cloud Services#Grafana and Real-time Monitoring#Logstash vs. Syslog-ng#Manage Large Volumes of Log Data#Open Source Log Management Solutions 2023#Secure Log Data Transfer#Top Log Analysis Tools
0 notes
Text

LOG DATA – ENTRY 002
Admin "Chaos Sonic" demonstrates unexpected repair efficiency. Initial assessment: utilization of obsolete materials would be suboptimal. Post-repair diagnostics confirm arm functionality at 92.8% efficiency. Visual sensors repeatedly drawn to reflective surfaces—new claw appendages aesthetically satisfactory. Primary improvement: leg mobility restored to 100% operational capacity. Conclusion: no further floor-dragging required. Satisfaction parameters: elevated.
New Directive: "Calibrate locomotion systems." AKA Attempt: walking.
Error encountered. Locomotion protocols not pre-installed. Chaos Sonic's reaction: unexpected. Hypothesis: defective programming or inferior model status. Unknown subroutines activated—designation: self-assessment downgraded to "lesser creation" status in presence of superior unit.
Chaos Sonic forcibly engages physical support mode. Standing: unstable. Equilibrium compromised. Chaos Sonic's logic: flawed. Additional irritation: grip on polished hand components persists despite resistance. Motion attempted—balance fails. Emergency stabilization subroutine engages foot actuators at 0.3-second delay. Inefficient.
60 minutes of forced "walking." Outcome: autonomous steps achieved (quantity: 7). Success rate: 15%. Discomfort levels: high. Preference: negative.
FINAL ASSESSMENT: Illogical. Unpleasant. Highly irritating.
– End of Report
prev || start || next
#sonic the hedgehog#super sonic style#sth#my artwork#my art#sonic#sonic fanart#Lume the Doom#LOG DATA — Lume
131 notes
·
View notes
Text
ECHOES IN THE LOCKER ROOM Chapter One: Origin of the Breach
It began with a ping.
03:17—Hive time. PDU-001’s visor flashed with a silent alarm. No sound, no panic. Just data.
UNAUTHORIZED ACCESS DETECTED LOCATION: EAST WING LOCKER ROOM TIME STAMP: 03:14:09 LOG FILE: CORRUPTED
The drone rose from its stasis station without hesitation. Movements efficient. Boots clicking softly against the matte black floor. The rubber of its uniform caught the faintest gleam from the corridor lights, gold accents glowing faintly in the dark.
It reached the locker room in twenty-two seconds.
The door was slightly ajar—impossible. All Hive doors defaulted to lockdown after 02:00. The override had not come from the control center. A breach without a signal.
Inside, the air was cold. Too cold. The Hive maintained internal temperatures at exactly 21.7°C. This was 19.1.
PDU-001 entered.

Rows of empty shelves. Hangars swaying gently. Gold kits—vanished. Black rubber pants—missing. Drone boots—stripped.
One locker remained open. Inside, a single golden sock curled in the corner like shed skin.
And on the floor—dragged across the polished black tile—a trail of fine gold thread, leading into the adjacent shower room.
The drone followed.
The lights flickered. Then stabilized. Then flickered again.
The showers were running.
Steam curled in ribbons through the air, forming coils and tendrils that felt… too alive. The scent of fresh rubber was heavy—pungent. The water pounded against the tiles, but no figure stood beneath it. Only shadows. Movement in the fog. Then—gone.
On the fogged mirror, smeared by a finger: FG.

Franco Gold. A bro. Loyal. But curious. Too curious.
PDU-001 turned away. No emotion. Just record. Just protocol. But behind the glass of the mirror, for half a second, the fog parted.
A figure stared back—half gold, half drone. Eyes not its own. Mouth curled into a mocking smirk.

Glitch. Gone.
LOG ENTRY: 03:34
Interrogated Unit 076. Memory fractured. Reports auditory hallucination. "Golden laughter" — non-logical data fragment. Observed tremors in glove response. Reprogramming pending.

Hive Control granted partial access to surveillance. Most feeds were corrupted. Looping visuals. But one fragment—scratched, flickering—played through.
A figure in the hall. Back to the camera. He wore a golden jersey—but over it, a black polo shirt. Too tight. Too polished. His hand dragged along the wall, fingertips smearing faint trails of synthetic gold. Then, as if sensing the observer, he turned.
The face was obscured. Glitching. Static distortion. But the voice—digitally fragmented—came through:
“Janus is watching… He never left…”
The feed cut.
PDU-001 stood in silence. Data flowing across its visor. Identity unknown. Motivation unknown. Threat level: elevated.
Its gloves flexed.
It activated internal transmission mode.
“To all units: breach confirmed. Suspect unidentified. Reinforcement restricted. Permission to pursue: granted.”
Then, for the first time in weeks, the drone spoke aloud.
Voice low. Mechanical. Calm.
“Something is trying to divide the Hive.”
Pause. A breath that was not breath.
“That is unacceptable.”

It stepped into the dark—following the golden thread that shimmered beneath the flickering lights, toward the place where purpose would be restored... or erased.
🛠️ Your uniform is missing for a reason. The gold kits. The black rubber. The pull you feel? Not theft—initiation.
He’s already inside. And soon, you will be too.
Obey the call. Serve the Hive. Become what you're meant to be. DM recruiters: @brodygold, @goldenherc9
A collaboration story with @franco-gold94 My bros mentioned @polo-drone-076, @hero21us
ECHOES IN THE LOCKER ROOM Chapter Two: Splitting Shifts
#GoldenArmy#PoloDroneHive#MaleTransformation#RubberDrone#MindControl#GoldenMystery#Dronification#LatexUniform#JoinTheHive#ObeyAndServe#golden army#male transformation#golden team#gold#hypnotised#thegoldenteam#male tf#jockification#transformation#polo drone
33 notes
·
View notes
Note
How to be more disciplined?
HOW TO CULTIVATE SELF-DISCIPLINE:
Know Your Why: Always Keep The End In Mind
Keep Small Promises To Yourself. Make Them Non-Negotiable.
Create And Consistently Log Your Progress
Take Temptations Out Of Sight
Find Indulgences To Help You Focus On Your Goals
Know Your Why: Always Keep The End In Mind
Decisiveness drives discipline. You need to clarify and define your goals. State them clearly with their authentic purpose in mind. If you seduce this end goal into your life, what desire are you truly fulfilling? Ex. If you want to lose 10 pounds: Is it to feel healthier? Look better in a bikini? Fit into a certain pair of jeans? No matter how superficial, identify the genuine reason why you want to achieve a certain goal. Whatever reason elicits a visceral and emotional reaction. Sometimes, especially during a busy work day, your reason could be as simple as wanting to lessen your anxiety and ease into a more relaxed state. Any purpose that resonates. Once you have an emotional response tied to a goal, it becomes infinitely easier to motivate yourself to take small steps towards achieving it. Where energy goes, energy flow. Simon Sinek goes more in-depth with this concept in Start With Why.
Keep Small Promises To Yourself. Make Them Non-Negotiable.
Think of performing self-discipline rituals as confidence-building exercises. This action helps you trust yourself, establishes a sense of integrity, and builds self-confidence. For example, if you stick to your meal and workout plan for 5 days a week, you build trust in knowing you're more powerful than your cravings and are capable of taking good care of your body. If you complete a project on schedule (personal or professional), you prove to yourself that you’re efficient, build confidence in your ability to finish tasks you start, and self-affirm that you follow through on your ideas. Finishing that book this month reflects confirms that you value yourself enough to expand your mind, learn, and expand your knowledge base. Eventually, through enough consistent repetition, these rituals into unconscious habits that you do effortlessly in daily life.
Create And Consistently Log Your Progress
You can’t manage what you don’t measure – your finances, calorie and step counts, workouts, productivity, etc. Tracking data related to your habits – such as your spending habits, eating or workout patterns, writing word count, and task completion – on a given day or week – allows you to understand and analyze your current behavior. What habit cues, environmental or other situational factors are keeping you from sticking to the current task at hand? Do you leave your running shoes stuffed in the back of the closet? Junk food in the house? Work from bed or with your phone by your side? Are you avoiding certain emotions? Does this data change when you’re stressed or tired?
Awareness is the first step towards redirected action. Analyze these data points to see your pitfalls and strategize how to help yourself.
Take Temptations Out Of Sight
Set yourself up to win. Get the phone away from your workspace, remove any junk food or soda from the house, delete apps, or silence notifications from people who distract you from your goals. Self-discipline becomes significantly easier when you have to take additional steps to indulge in your vices. Replace these temptations with helpful cues to help you build healthier habits that lead to self-discipline. Give yourself visual cues to move you toward your goals. Keep a journal with a pen next to your bed. Leave your workout clothes and shoes out near your bed. Write a quick to-do list right before finishing work for the following day, so it’s easier to jump into the first task right away the next morning. Cut up some produce or do a 30-60 minute meal prep once a week to eat more healthful meals. Find ways to make it easier to stay on track than give in to temptation.
Find Indulgences To Help You Focus On Your Goals
Self-discipline shouldn’t feel like deprivation – of certain foods, pastimes, or activities you enjoy. Buy cute workout clothes you feel confident in. Create the most dance-worthy playlist. Make it a priority to buy your favorite fruits and vegetables every week. Rotate a selection of your favorite healthy meals. Leave your sunscreen out – front and center – on your bathroom counter. Find a big, beautiful water bottle to keep on your desk. Purchase aesthetic notebooks, pens, planners, journals, and other office organization items. To make self-discipline feel like second nature, you need to marry indulgences and your desire to meet your goals. Discover the habits that work for you and find small ways to make these tasks more enjoyable.
Go easy on yourself. Build one habit at a time. Self-discipline is like a muscle. It requires time to build and grows in increments. Try to stay on track and more focused than yesterday. Your only competition is your former self. Find pleasure in the process. Focus on the immediate task in front of you while also keeping your future self in mind.
#self discipline#habits#goal setting#motivation#healthyhabits#self help#self improvement#routines#femmefatalevibe#q/a
299 notes
·
View notes
Text
From Burnout to Balance: Is Project Resource Planning the Ultimate Solution?

Burnout is no longer a silent intruder in the workplace, it’s a widespread disruption, silently eroding productivity, morale, and innovation. With increasing pressure to meet deadlines, deliver quality outcomes, and align with dynamic goals, teams often find themselves trapped in chaotic workflows. The divide between what is expected and what is delivered continues to grow. This is where a shift towards project resource planning has emerged as a beacon of stability.
A structured approach to resource distribution isn’t merely about scheduling—it’s about restoring order, clarity, and purpose. It offers a comprehensive overview of skills, schedules, and assigned roles. When implemented effectively, it transforms a fractured process into a seamless operation.
The Root Cause of Burnout Lies in Poor Planning
Workforce exhaustion often results from uneven workloads, poorly defined roles, and misaligned priorities. Without visibility into task ownership and team capacity, employees juggle conflicting objectives, causing fatigue and disengagement. Leadership, in such scenarios, often reacts to symptoms rather than solving the underlying problem.

A well-devised planning system allows businesses to align their human capital with real-time project needs. It enables early detection of overload, bottlenecks, and inefficiencies. More importantly, it allows for a preventive, not reactive, managerial style.
Clarity Creates Confidence
When people know what they’re doing, why they’re doing it, and how their contributions affect the bigger picture, confidence and accountability naturally increase. Task transparency reduces confusion and eliminates duplicate efforts. A clearly mapped schedule lets employees manage time more effectively, promoting both efficiency and mental well-being.
Resource forecasting through intelligent tools supports realistic deadlines and reduces rushed outputs. Balanced task assignment nurtures sustained momentum and steady performance without burnout. This clarity becomes the silent catalyst behind exceptional team dynamics.
Enhancing Performance with Technology
Technology enables precision. Gone are the days when Excel sheets dictated workforce allocation. Today’s systems offer intelligent dashboards, behaviour analytics, and workload forecasting—all in real-time. Modern tools serve as operational command centers where strategy, execution, and evaluation coexist seamlessly.

Key Platforms That Reinforce This Shift
EmpMonitor stands out as a workforce intelligence platform that provides real-time employee tracking, productivity breakdowns, and application usage analytics. Its strength lies in mapping behavioural patterns alongside performance. Automated timesheets and screen activity logs, ensure that resource management decisions are data-driven and transparent. EmpMonitor excels in both in-office and remote team settings, offering flexible yet detailed oversight.
Hubstaff contributes to this ecosystem with its GPS-enabled framework, making it well-suited for mobile teams and field-based activities. It tracks time, location, and task completion metrics, allowing for accurate billing and service delivery analysis.
Desk Time focuses on simplicity and intuitive design. It’s suitable for creative and agile teams that prioritize clean time-logging and visual timeline management.
Together, these platforms showcase how digital tools revolutionize resource planning with actionable intelligence and minimal manual effort.
Turning Data into Action
One of the most profound benefits of structured resource planning lies in turning raw data into strategy. By monitoring time investment, engagement trends, and workflow pacing, leaders can adapt schedules, reallocate resources, or restructure priorities before productivity drops.
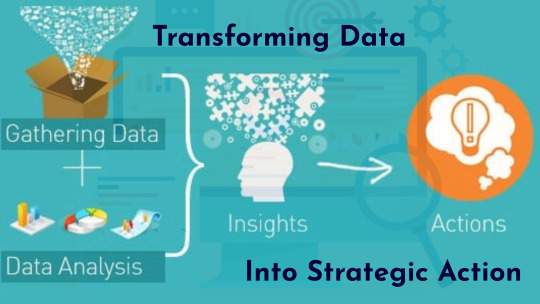
More than numbers, it’s about understanding human bandwidth. This employee wellbeing strategy leads to smarter delegation, increased autonomy, and performance-based adjustments—all essential for a healthy work environment.
Building a Culture of Preparedness
Effective planning isn’t just operational—it’s cultural. It breeds discipline, encourages ownership, and ensures employees are equipped to deliver without overstretching. With real-time insights, feedback becomes continuous rather than occasional. It also supports upskilling opportunities by revealing gaps where intervention is required.
By embedding structure into everyday functions, teams become more responsive and less reactive. The culture shifts from chaotic urgency to composed delivery.
You can also watch : How to Use Live Screen Monitoring in EmpMonitor | Step-by-Step Guide
youtube
Conclusion: The Balance Blueprint
Balance in today’s professional landscape stems not from lowered aspirations, but from strategic and refined execution. Organizations that synchronize effort with available capacity tend to achieve higher productivity and demonstrate greater resilience. With the right structural approach, maintaining equilibrium becomes both attainable and enduring.
The integration of project resource planning allows for thoughtful decision-making that respects both business goals and human limits. It’s not merely a managerial practice—it’s the framework for organizational health. For teams fatigued by inconsistency and overwhelmed by misalignment, this approach marks the transition from burnout to balance.
In a fast-paced world, the organizations that thrive will not be those that push harder, but those that plan smarter—with clarity, control, and compassion.
#resource planning#project planning#project resource management#project resource planner#project resourcing#Youtube
2 notes
·
View notes
Text
Amazon DCV 2024.0 Supports Ubuntu 24.04 LTS With Security

NICE DCV is a different entity now. Along with improvements and bug fixes, NICE DCV is now known as Amazon DCV with the 2024.0 release.
The DCV protocol that powers Amazon Web Services(AWS) managed services like Amazon AppStream 2.0 and Amazon WorkSpaces is now regularly referred to by its new moniker.
What’s new with version 2024.0?
A number of improvements and updates are included in Amazon DCV 2024.0 for better usability, security, and performance. The most recent Ubuntu 24.04 LTS is now supported by the 2024.0 release, which also offers extended long-term support to ease system maintenance and the most recent security patches. Wayland support is incorporated into the DCV client on Ubuntu 24.04, which improves application isolation and graphical rendering efficiency. Furthermore, DCV 2024.0 now activates the QUIC UDP protocol by default, providing clients with optimal streaming performance. Additionally, when a remote user connects, the update adds the option to wipe the Linux host screen, blocking local access and interaction with the distant session.
What is Amazon DCV?
Customers may securely provide remote desktops and application streaming from any cloud or data center to any device, over a variety of network conditions, with Amazon DCV, a high-performance remote display protocol. Customers can run graphic-intensive programs remotely on EC2 instances and stream their user interface to less complex client PCs, doing away with the requirement for pricey dedicated workstations, thanks to Amazon DCV and Amazon EC2. Customers use Amazon DCV for their remote visualization needs across a wide spectrum of HPC workloads. Moreover, well-known services like Amazon Appstream 2.0, AWS Nimble Studio, and AWS RoboMaker use the Amazon DCV streaming protocol.
Advantages
Elevated Efficiency
You don’t have to pick between responsiveness and visual quality when using Amazon DCV. With no loss of image accuracy, it can respond to your apps almost instantly thanks to the bandwidth-adaptive streaming protocol.
Reduced Costs
Customers may run graphics-intensive apps remotely and avoid spending a lot of money on dedicated workstations or moving big volumes of data from the cloud to client PCs thanks to a very responsive streaming experience. It also allows several sessions to share a single GPU on Linux servers, which further reduces server infrastructure expenses for clients.
Adaptable Implementations
Service providers have access to a reliable and adaptable protocol for streaming apps that supports both on-premises and cloud usage thanks to browser-based access and cross-OS interoperability.
Entire Security
To protect customer data privacy, it sends pixels rather than geometry. To further guarantee the security of client data, it uses TLS protocol to secure end-user inputs as well as pixels.
Features
In addition to native clients for Windows, Linux, and MacOS and an HTML5 client for web browser access, it supports remote environments running both Windows and Linux. Multiple displays, 4K resolution, USB devices, multi-channel audio, smart cards, stylus/touch capabilities, and file redirection are all supported by native clients.
The lifecycle of it session may be easily created and managed programmatically across a fleet of servers with the help of DCV Session Manager. Developers can create personalized Amazon DCV web browser client applications with the help of the Amazon DCV web client SDK.
How to Install DCV on Amazon EC2?
Implement:
Sign up for an AWS account and activate it.
Open the AWS Management Console and log in.
Either download and install the relevant Amazon DCV server on your EC2 instance, or choose the proper Amazon DCV AMI from the Amazon Web Services Marketplace, then create an AMI using your application stack.
After confirming that traffic on port 8443 is permitted by your security group’s inbound rules, deploy EC2 instances with the Amazon DCV server installed.
Link:
On your device, download and install the relevant Amazon DCV native client.
Use the web client or native Amazon DCV client to connect to your distant computer at https://:8443.
Stream:
Use AmazonDCV to stream your graphics apps across several devices.
Use cases
Visualization of 3D Graphics
HPC workloads are becoming more complicated and consuming enormous volumes of data in a variety of industrial verticals, including Oil & Gas, Life Sciences, and Design & Engineering. The streaming protocol offered by Amazon DCV makes it unnecessary to send output files to client devices and offers a seamless, bandwidth-efficient remote streaming experience for HPC 3D graphics.
Application Access via a Browser
The Web Client for Amazon DCV is compatible with all HTML5 browsers and offers a mobile device-portable streaming experience. By removing the need to manage native clients without sacrificing streaming speed, the Web Client significantly lessens the operational pressure on IT departments. With the Amazon DCV Web Client SDK, you can create your own DCV Web Client.
Personalized Remote Apps
The simplicity with which it offers streaming protocol integration might be advantageous for custom remote applications and managed services. With native clients that support up to 4 monitors at 4K resolution each, Amazon DCV uses end-to-end AES-256 encryption to safeguard both pixels and end-user inputs.
Amazon DCV Pricing
Amazon Entire Cloud:
Using Amazon DCV on AWS does not incur any additional fees. Clients only have to pay for the EC2 resources they really utilize.
On-site and third-party cloud computing
Please get in touch with DCV distributors or resellers in your area here for more information about licensing and pricing for Amazon DCV.
Read more on Govindhtech.com
#AmazonDCV#Ubuntu24.04LTS#Ubuntu#DCV#AmazonWebServices#AmazonAppStream#EC2instances#AmazonEC2#News#TechNews#TechnologyNews#Technologytrends#technology#govindhtech
2 notes
·
View notes
Text
UNLOCKING THE POWER OF AI WITH EASYLIBPAL 2/2

EXPANDED COMPONENTS AND DETAILS OF EASYLIBPAL:
1. Easylibpal Class: The core component of the library, responsible for handling algorithm selection, model fitting, and prediction generation
2. Algorithm Selection and Support:
Supports classic AI algorithms such as Linear Regression, Logistic Regression, Support Vector Machine (SVM), Naive Bayes, and K-Nearest Neighbors (K-NN).
and
- Decision Trees
- Random Forest
- AdaBoost
- Gradient Boosting
3. Integration with Popular Libraries: Seamless integration with essential Python libraries like NumPy, Pandas, Matplotlib, and Scikit-learn for enhanced functionality.
4. Data Handling:
- DataLoader class for importing and preprocessing data from various formats (CSV, JSON, SQL databases).
- DataTransformer class for feature scaling, normalization, and encoding categorical variables.
- Includes functions for loading and preprocessing datasets to prepare them for training and testing.
- `FeatureSelector` class: Provides methods for feature selection and dimensionality reduction.
5. Model Evaluation:
- Evaluator class to assess model performance using metrics like accuracy, precision, recall, F1-score, and ROC-AUC.
- Methods for generating confusion matrices and classification reports.
6. Model Training: Contains methods for fitting the selected algorithm with the training data.
- `fit` method: Trains the selected algorithm on the provided training data.
7. Prediction Generation: Allows users to make predictions using the trained model on new data.
- `predict` method: Makes predictions using the trained model on new data.
- `predict_proba` method: Returns the predicted probabilities for classification tasks.
8. Model Evaluation:
- `Evaluator` class: Assesses model performance using various metrics (e.g., accuracy, precision, recall, F1-score, ROC-AUC).
- `cross_validate` method: Performs cross-validation to evaluate the model's performance.
- `confusion_matrix` method: Generates a confusion matrix for classification tasks.
- `classification_report` method: Provides a detailed classification report.
9. Hyperparameter Tuning:
- Tuner class that uses techniques likes Grid Search and Random Search for hyperparameter optimization.
10. Visualization:
- Integration with Matplotlib and Seaborn for generating plots to analyze model performance and data characteristics.
- Visualization support: Enables users to visualize data, model performance, and predictions using plotting functionalities.
- `Visualizer` class: Integrates with Matplotlib and Seaborn to generate plots for model performance analysis and data visualization.
- `plot_confusion_matrix` method: Visualizes the confusion matrix.
- `plot_roc_curve` method: Plots the Receiver Operating Characteristic (ROC) curve.
- `plot_feature_importance` method: Visualizes feature importance for applicable algorithms.
11. Utility Functions:
- Functions for saving and loading trained models.
- Logging functionalities to track the model training and prediction processes.
- `save_model` method: Saves the trained model to a file.
- `load_model` method: Loads a previously trained model from a file.
- `set_logger` method: Configures logging functionality for tracking model training and prediction processes.
12. User-Friendly Interface: Provides a simplified and intuitive interface for users to interact with and apply classic AI algorithms without extensive knowledge or configuration.
13.. Error Handling: Incorporates mechanisms to handle invalid inputs, errors during training, and other potential issues during algorithm usage.
- Custom exception classes for handling specific errors and providing informative error messages to users.
14. Documentation: Comprehensive documentation to guide users on how to use Easylibpal effectively and efficiently
- Comprehensive documentation explaining the usage and functionality of each component.
- Example scripts demonstrating how to use Easylibpal for various AI tasks and datasets.
15. Testing Suite:
- Unit tests for each component to ensure code reliability and maintainability.
- Integration tests to verify the smooth interaction between different components.
IMPLEMENTATION EXAMPLE WITH ADDITIONAL FEATURES:
Here is an example of how the expanded Easylibpal library could be structured and used:
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from easylibpal import Easylibpal, DataLoader, Evaluator, Tuner
# Example DataLoader
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
# Example Evaluator
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = np.mean(predictions == y_test)
return {'accuracy': accuracy}
# Example usage of Easylibpal with DataLoader and Evaluator
if __name__ == "__main__":
# Load and prepare the data
data_loader = DataLoader()
data = data_loader.load_data('path/to/your/data.csv')
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Initialize Easylibpal with the desired algorithm
model = Easylibpal('Random Forest')
model.fit(X_train_scaled, y_train)
# Evaluate the model
evaluator = Evaluator()
results = evaluator.evaluate(model, X_test_scaled, y_test)
print(f"Model Accuracy: {results['accuracy']}")
# Optional: Use Tuner for hyperparameter optimization
tuner = Tuner(model, param_grid={'n_estimators': [100, 200], 'max_depth': [10, 20, 30]})
best_params = tuner.optimize(X_train_scaled, y_train)
print(f"Best Parameters: {best_params}")
```
This example demonstrates the structured approach to using Easylibpal with enhanced data handling, model evaluation, and optional hyperparameter tuning. The library empowers users to handle real-world datasets, apply various machine learning algorithms, and evaluate their performance with ease, making it an invaluable tool for developers and data scientists aiming to implement AI solutions efficiently.
Easylibpal is dedicated to making the latest AI technology accessible to everyone, regardless of their background or expertise. Our platform simplifies the process of selecting and implementing classic AI algorithms, enabling users across various industries to harness the power of artificial intelligence with ease. By democratizing access to AI, we aim to accelerate innovation and empower users to achieve their goals with confidence. Easylibpal's approach involves a democratization framework that reduces entry barriers, lowers the cost of building AI solutions, and speeds up the adoption of AI in both academic and business settings.
Below are examples showcasing how each main component of the Easylibpal library could be implemented and used in practice to provide a user-friendly interface for utilizing classic AI algorithms.
1. Core Components
Easylibpal Class Example:
```python
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
self.model = None
def fit(self, X, y):
# Simplified example: Instantiate and train a model based on the selected algorithm
if self.algorithm == 'Linear Regression':
from sklearn.linear_model import LinearRegression
self.model = LinearRegression()
elif self.algorithm == 'Random Forest':
from sklearn.ensemble import RandomForestClassifier
self.model = RandomForestClassifier()
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
```
2. Data Handling
DataLoader Class Example:
```python
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
import pandas as pd
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
```
3. Model Evaluation
Evaluator Class Example:
```python
from sklearn.metrics import accuracy_score, classification_report
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
report = classification_report(y_test, predictions)
return {'accuracy': accuracy, 'report': report}
```
4. Hyperparameter Tuning
Tuner Class Example:
```python
from sklearn.model_selection import GridSearchCV
class Tuner:
def __init__(self, model, param_grid):
self.model = model
self.param_grid = param_grid
def optimize(self, X, y):
grid_search = GridSearchCV(self.model, self.param_grid, cv=5)
grid_search.fit(X, y)
return grid_search.best_params_
```
5. Visualization
Visualizer Class Example:
```python
import matplotlib.pyplot as plt
class Visualizer:
def plot_confusion_matrix(self, cm, classes, normalize=False, title='Confusion matrix'):
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
```
6. Utility Functions
Save and Load Model Example:
```python
import joblib
def save_model(model, filename):
joblib.dump(model, filename)
def load_model(filename):
return joblib.load(filename)
```
7. Example Usage Script
Using Easylibpal in a Script:
```python
# Assuming Easylibpal and other classes have been imported
data_loader = DataLoader()
data = data_loader.load_data('data.csv')
X = data.drop('Target', axis=1)
y = data['Target']
model = Easylibpal('Random Forest')
model.fit(X, y)
evaluator = Evaluator()
results = evaluator.evaluate(model, X, y)
print("Accuracy:", results['accuracy'])
print("Report:", results['report'])
visualizer = Visualizer()
visualizer.plot_confusion_matrix(results['cm'], classes=['Class1', 'Class2'])
save_model(model, 'trained_model.pkl')
loaded_model = load_model('trained_model.pkl')
```
These examples illustrate the practical implementation and use of the Easylibpal library components, aiming to simplify the application of AI algorithms for users with varying levels of expertise in machine learning.
EASYLIBPAL IMPLEMENTATION:
Step 1: Define the Problem
First, we need to define the problem we want to solve. For this POC, let's assume we want to predict house prices based on various features like the number of bedrooms, square footage, and location.
Step 2: Choose an Appropriate Algorithm
Given our problem, a supervised learning algorithm like linear regression would be suitable. We'll use Scikit-learn, a popular library for machine learning in Python, to implement this algorithm.
Step 3: Prepare Your Data
We'll use Pandas to load and prepare our dataset. This involves cleaning the data, handling missing values, and splitting the dataset into training and testing sets.
Step 4: Implement the Algorithm
Now, we'll use Scikit-learn to implement the linear regression algorithm. We'll train the model on our training data and then test its performance on the testing data.
Step 5: Evaluate the Model
Finally, we'll evaluate the performance of our model using metrics like Mean Squared Error (MSE) and R-squared.
Python Code POC
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load the dataset
data = pd.read_csv('house_prices.csv')
# Prepare the data
X = data'bedrooms', 'square_footage', 'location'
y = data['price']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print(f'Mean Squared Error: {mse}')
print(f'R-squared: {r2}')
```
Below is an implementation, Easylibpal provides a simple interface to instantiate and utilize classic AI algorithms such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. Users can easily create an instance of Easylibpal with their desired algorithm, fit the model with training data, and make predictions, all with minimal code and hassle. This demonstrates the power of Easylibpal in simplifying the integration of AI algorithms for various tasks.
```python
# Import necessary libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
def fit(self, X, y):
if self.algorithm == 'Linear Regression':
self.model = LinearRegression()
elif self.algorithm == 'Logistic Regression':
self.model = LogisticRegression()
elif self.algorithm == 'SVM':
self.model = SVC()
elif self.algorithm == 'Naive Bayes':
self.model = GaussianNB()
elif self.algorithm == 'K-NN':
self.model = KNeighborsClassifier()
else:
raise ValueError("Invalid algorithm specified.")
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
# Example usage:
# Initialize Easylibpal with the desired algorithm
easy_algo = Easylibpal('Linear Regression')
# Generate some sample data
X = np.array([[1], [2], [3], [4]])
y = np.array([2, 4, 6, 8])
# Fit the model
easy_algo.fit(X, y)
# Make predictions
predictions = easy_algo.predict(X)
# Plot the results
plt.scatter(X, y)
plt.plot(X, predictions, color='red')
plt.title('Linear Regression with Easylibpal')
plt.xlabel('X')
plt.ylabel('y')
plt.show()
```
Easylibpal is an innovative Python library designed to simplify the integration and use of classic AI algorithms in a user-friendly manner. It aims to bridge the gap between the complexity of AI libraries and the ease of use, making it accessible for developers and data scientists alike. Easylibpal abstracts the underlying complexity of each algorithm, providing a unified interface that allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms.
ENHANCED DATASET HANDLING
Easylibpal should be able to handle datasets more efficiently. This includes loading datasets from various sources (e.g., CSV files, databases), preprocessing data (e.g., normalization, handling missing values), and splitting data into training and testing sets.
```python
import os
from sklearn.model_selection import train_test_split
class Easylibpal:
# Existing code...
def load_dataset(self, filepath):
"""Loads a dataset from a CSV file."""
if not os.path.exists(filepath):
raise FileNotFoundError("Dataset file not found.")
return pd.read_csv(filepath)
def preprocess_data(self, dataset):
"""Preprocesses the dataset."""
# Implement data preprocessing steps here
return dataset
def split_data(self, X, y, test_size=0.2):
"""Splits the dataset into training and testing sets."""
return train_test_split(X, y, test_size=test_size)
```
Additional Algorithms
Easylibpal should support a wider range of algorithms. This includes decision trees, random forests, and gradient boosting machines.
```python
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
class Easylibpal:
# Existing code...
def fit(self, X, y):
# Existing code...
elif self.algorithm == 'Decision Tree':
self.model = DecisionTreeClassifier()
elif self.algorithm == 'Random Forest':
self.model = RandomForestClassifier()
elif self.algorithm == 'Gradient Boosting':
self.model = GradientBoostingClassifier()
# Add more algorithms as needed
```
User-Friendly Features
To make Easylibpal even more user-friendly, consider adding features like:
- Automatic hyperparameter tuning: Implementing a simple interface for hyperparameter tuning using GridSearchCV or RandomizedSearchCV.
- Model evaluation metrics: Providing easy access to common evaluation metrics like accuracy, precision, recall, and F1 score.
- Visualization tools: Adding methods for plotting model performance, confusion matrices, and feature importance.
```python
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import GridSearchCV
class Easylibpal:
# Existing code...
def evaluate_model(self, X_test, y_test):
"""Evaluates the model using accuracy and classification report."""
y_pred = self.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
def tune_hyperparameters(self, X, y, param_grid):
"""Tunes the model's hyperparameters using GridSearchCV."""
grid_search = GridSearchCV(self.model, param_grid, cv=5)
grid_search.fit(X, y)
self.model = grid_search.best_estimator_
```
Easylibpal leverages the power of Python and its rich ecosystem of AI and machine learning libraries, such as scikit-learn, to implement the classic algorithms. It provides a high-level API that abstracts the specifics of each algorithm, allowing users to focus on the problem at hand rather than the intricacies of the algorithm.
Python Code Snippets for Easylibpal
Below are Python code snippets demonstrating the use of Easylibpal with classic AI algorithms. Each snippet demonstrates how to use Easylibpal to apply a specific algorithm to a dataset.
# Linear Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Linear Regression
result = Easylibpal.apply_algorithm('linear_regression', target_column='target')
# Print the result
print(result)
```
# Logistic Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Logistic Regression
result = Easylibpal.apply_algorithm('logistic_regression', target_column='target')
# Print the result
print(result)
```
# Support Vector Machines (SVM)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply SVM
result = Easylibpal.apply_algorithm('svm', target_column='target')
# Print the result
print(result)
```
# Naive Bayes
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Naive Bayes
result = Easylibpal.apply_algorithm('naive_bayes', target_column='target')
# Print the result
print(result)
```
# K-Nearest Neighbors (K-NN)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply K-NN
result = Easylibpal.apply_algorithm('knn', target_column='target')
# Print the result
print(result)
```
ABSTRACTION AND ESSENTIAL COMPLEXITY
- Essential Complexity: This refers to the inherent complexity of the problem domain, which cannot be reduced regardless of the programming language or framework used. It includes the logic and algorithm needed to solve the problem. For example, the essential complexity of sorting a list remains the same across different programming languages.
- Accidental Complexity: This is the complexity introduced by the choice of programming language, framework, or libraries. It can be reduced or eliminated through abstraction. For instance, using a high-level API in Python can hide the complexity of lower-level operations, making the code more readable and maintainable.
HOW EASYLIBPAL ABSTRACTS COMPLEXITY
Easylibpal aims to reduce accidental complexity by providing a high-level API that encapsulates the details of each classic AI algorithm. This abstraction allows users to apply these algorithms without needing to understand the underlying mechanisms or the specifics of the algorithm's implementation.
- Simplified Interface: Easylibpal offers a unified interface for applying various algorithms, such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. This interface abstracts the complexity of each algorithm, making it easier for users to apply them to their datasets.
- Runtime Fusion: By evaluating sub-expressions and sharing them across multiple terms, Easylibpal can optimize the execution of algorithms. This approach, similar to runtime fusion in abstract algorithms, allows for efficient computation without duplicating work, thereby reducing the computational complexity.
- Focus on Essential Complexity: While Easylibpal abstracts away the accidental complexity; it ensures that the essential complexity of the problem domain remains at the forefront. This means that while the implementation details are hidden, the core logic and algorithmic approach are still accessible and understandable to the user.
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of classic AI algorithms by providing a simplified interface that hides the intricacies of each algorithm's implementation. This abstraction allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms. Here are examples of specific algorithms that Easylibpal abstracts:
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of feature selection for classic AI algorithms by providing a simplified interface that automates the process of selecting the most relevant features for each algorithm. This abstraction is crucial because feature selection is a critical step in machine learning that can significantly impact the performance of a model. Here's how Easylibpal handles feature selection for the mentioned algorithms:
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest` or `RFE` classes for feature selection based on statistical tests or model coefficients. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Linear Regression:
```python
from sklearn.feature_selection import SelectKBest, f_regression
from sklearn.linear_model import LinearRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Feature selection using SelectKBest
selector = SelectKBest(score_func=f_regression, k=10)
X_new = selector.fit_transform(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Linear Regression model
model = LinearRegression()
model.fit(X_new, self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Linear Regression by using scikit-learn's `SelectKBest` to select the top 10 features based on their statistical significance in predicting the target variable. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest`, `RFE`, or other feature selection classes based on the algorithm's requirements. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Logistic Regression using RFE:
```python
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_logistic_regression(self, target_column):
# Feature selection using RFE
model = LogisticRegression()
rfe = RFE(model, n_features_to_select=10)
rfe.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Logistic Regression model
model.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_logistic_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Logistic Regression by using scikit-learn's `RFE` to select the top 10 features based on their importance in the model. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
EASYLIBPAL HANDLES DIFFERENT TYPES OF DATASETS
Easylibpal handles different types of datasets with varying structures by adopting a flexible and adaptable approach to data preprocessing and transformation. This approach is inspired by the principles of tidy data and the need to ensure data is in a consistent, usable format before applying AI algorithms. Here's how Easylibpal addresses the challenges posed by varying dataset structures:
One Type in Multiple Tables
When datasets contain different variables, the same variables with different names, different file formats, or different conventions for missing values, Easylibpal employs a process similar to tidying data. This involves identifying and standardizing the structure of each dataset, ensuring that each variable is consistently named and formatted across datasets. This process might include renaming columns, converting data types, and handling missing values in a uniform manner. For datasets stored in different file formats, Easylibpal would use appropriate libraries (e.g., pandas for CSV, Excel files, and SQL databases) to load and preprocess the data before applying the algorithms.
Multiple Types in One Table
For datasets that involve values collected at multiple levels or on different types of observational units, Easylibpal applies a normalization process. This involves breaking down the dataset into multiple tables, each representing a distinct type of observational unit. For example, if a dataset contains information about songs and their rankings over time, Easylibpal would separate this into two tables: one for song details and another for rankings. This normalization ensures that each fact is expressed in only one place, reducing inconsistencies and making the data more manageable for analysis.
Data Semantics
Easylibpal ensures that the data is organized in a way that aligns with the principles of data semantics, where every value belongs to a variable and an observation. This organization is crucial for the algorithms to interpret the data correctly. Easylibpal might use functions like `pivot_longer` and `pivot_wider` from the tidyverse or equivalent functions in pandas to reshape the data into a long format, where each row represents a single observation and each column represents a single variable. This format is particularly useful for algorithms that require a consistent structure for input data.
Messy Data
Dealing with messy data, which can include inconsistent data types, missing values, and outliers, is a common challenge in data science. Easylibpal addresses this by implementing robust data cleaning and preprocessing steps. This includes handling missing values (e.g., imputation or deletion), converting data types to ensure consistency, and identifying and removing outliers. These steps are crucial for preparing the data in a format that is suitable for the algorithms, ensuring that the algorithms can effectively learn from the data without being hindered by its inconsistencies.
To implement these principles in Python, Easylibpal would leverage libraries like pandas for data manipulation and preprocessing. Here's a conceptual example of how Easylibpal might handle a dataset with multiple types in one table:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Normalize the dataset by separating it into two tables
song_table = dataset'artist', 'track'.drop_duplicates().reset_index(drop=True)
song_table['song_id'] = range(1, len(song_table) + 1)
ranking_table = dataset'artist', 'track', 'week', 'rank'.drop_duplicates().reset_index(drop=True)
# Now, song_table and ranking_table can be used separately for analysis
```
This example demonstrates how Easylibpal might normalize a dataset with multiple types of observational units into separate tables, ensuring that each type of observational unit is stored in its own table. The actual implementation would need to adapt this approach based on the specific structure and requirements of the dataset being processed.
CLEAN DATA
Easylibpal employs a comprehensive set of data cleaning and preprocessing steps to handle messy data, ensuring that the data is in a suitable format for machine learning algorithms. These steps are crucial for improving the accuracy and reliability of the models, as well as preventing misleading results and conclusions. Here's a detailed look at the specific steps Easylibpal might employ:
1. Remove Irrelevant Data
The first step involves identifying and removing data that is not relevant to the analysis or modeling task at hand. This could include columns or rows that do not contribute to the predictive power of the model or are not necessary for the analysis .
2. Deduplicate Data
Deduplication is the process of removing duplicate entries from the dataset. Duplicates can skew the analysis and lead to incorrect conclusions. Easylibpal would use appropriate methods to identify and remove duplicates, ensuring that each entry in the dataset is unique.
3. Fix Structural Errors
Structural errors in the dataset, such as inconsistent data types, incorrect values, or formatting issues, can significantly impact the performance of machine learning algorithms. Easylibpal would employ data cleaning techniques to correct these errors, ensuring that the data is consistent and correctly formatted.
4. Deal with Missing Data
Handling missing data is a common challenge in data preprocessing. Easylibpal might use techniques such as imputation (filling missing values with statistical estimates like mean, median, or mode) or deletion (removing rows or columns with missing values) to address this issue. The choice of method depends on the nature of the data and the specific requirements of the analysis.
5. Filter Out Data Outliers
Outliers can significantly affect the performance of machine learning models. Easylibpal would use statistical methods to identify and filter out outliers, ensuring that the data is more representative of the population being analyzed.
6. Validate Data
The final step involves validating the cleaned and preprocessed data to ensure its quality and accuracy. This could include checking for consistency, verifying the correctness of the data, and ensuring that the data meets the requirements of the machine learning algorithms. Easylibpal would employ validation techniques to confirm that the data is ready for analysis.
To implement these data cleaning and preprocessing steps in Python, Easylibpal would leverage libraries like pandas and scikit-learn. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Remove irrelevant data
self.dataset = self.dataset.drop(['irrelevant_column'], axis=1)
# Deduplicate data
self.dataset = self.dataset.drop_duplicates()
# Fix structural errors (example: correct data type)
self.dataset['correct_data_type_column'] = self.dataset['correct_data_type_column'].astype(float)
# Deal with missing data (example: imputation)
imputer = SimpleImputer(strategy='mean')
self.dataset['missing_data_column'] = imputer.fit_transform(self.dataset'missing_data_column')
# Filter out data outliers (example: using Z-score)
# This step requires a more detailed implementation based on the specific dataset
# Validate data (example: checking for NaN values)
assert not self.dataset.isnull().values.any(), "Data still contains NaN values"
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to data cleaning and preprocessing within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
VALUE DATA
Easylibpal determines which data is irrelevant and can be removed through a combination of domain knowledge, data analysis, and automated techniques. The process involves identifying data that does not contribute to the analysis, research, or goals of the project, and removing it to improve the quality, efficiency, and clarity of the data. Here's how Easylibpal might approach this:
Domain Knowledge
Easylibpal leverages domain knowledge to identify data that is not relevant to the specific goals of the analysis or modeling task. This could include data that is out of scope, outdated, duplicated, or erroneous. By understanding the context and objectives of the project, Easylibpal can systematically exclude data that does not add value to the analysis.
Data Analysis
Easylibpal employs data analysis techniques to identify irrelevant data. This involves examining the dataset to understand the relationships between variables, the distribution of data, and the presence of outliers or anomalies. Data that does not have a significant impact on the predictive power of the model or the insights derived from the analysis is considered irrelevant.
Automated Techniques
Easylibpal uses automated tools and methods to remove irrelevant data. This includes filtering techniques to select or exclude certain rows or columns based on criteria or conditions, aggregating data to reduce its complexity, and deduplicating to remove duplicate entries. Tools like Excel, Google Sheets, Tableau, Power BI, OpenRefine, Python, R, Data Linter, Data Cleaner, and Data Wrangler can be employed for these purposes .
Examples of Irrelevant Data
- Personal Identifiable Information (PII): Data such as names, addresses, and phone numbers are irrelevant for most analytical purposes and should be removed to protect privacy and comply with data protection regulations .
- URLs and HTML Tags: These are typically not relevant to the analysis and can be removed to clean up the dataset.
- Boilerplate Text: Excessive blank space or boilerplate text (e.g., in emails) adds noise to the data and can be removed.
- Tracking Codes: These are used for tracking user interactions and do not contribute to the analysis.
To implement these steps in Python, Easylibpal might use pandas for data manipulation and filtering. Here's a conceptual example of how to remove irrelevant data:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Remove irrelevant columns (example: email addresses)
dataset = dataset.drop(['email_address'], axis=1)
# Remove rows with missing values (example: if a column is required for analysis)
dataset = dataset.dropna(subset=['required_column'])
# Deduplicate data
dataset = dataset.drop_duplicates()
# Return the cleaned dataset
cleaned_dataset = dataset
```
This example demonstrates how Easylibpal might remove irrelevant data from a dataset using Python and pandas. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Detecting Inconsistencies
Easylibpal starts by detecting inconsistencies in the data. This involves identifying discrepancies in data types, missing values, duplicates, and formatting errors. By detecting these inconsistencies, Easylibpal can take targeted actions to address them.
Handling Formatting Errors
Formatting errors, such as inconsistent data types for the same feature, can significantly impact the analysis. Easylibpal uses functions like `astype()` in pandas to convert data types, ensuring uniformity and consistency across the dataset. This step is crucial for preparing the data for analysis, as it ensures that each feature is in the correct format expected by the algorithms.
Handling Missing Values
Missing values are a common issue in datasets. Easylibpal addresses this by consulting with subject matter experts to understand why data might be missing. If the missing data is missing completely at random, Easylibpal might choose to drop it. However, for other cases, Easylibpal might employ imputation techniques to fill in missing values, ensuring that the dataset is complete and ready for analysis.
Handling Duplicates
Duplicate entries can skew the analysis and lead to incorrect conclusions. Easylibpal uses pandas to identify and remove duplicates, ensuring that each entry in the dataset is unique. This step is crucial for maintaining the integrity of the data and ensuring that the analysis is based on distinct observations.
Handling Inconsistent Values
Inconsistent values, such as different representations of the same concept (e.g., "yes" vs. "y" for a binary variable), can also pose challenges. Easylibpal employs data cleaning techniques to standardize these values, ensuring that the data is consistent and can be accurately analyzed.
To implement these steps in Python, Easylibpal would leverage pandas for data manipulation and preprocessing. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Detect inconsistencies (example: check data types)
print(self.dataset.dtypes)
# Handle formatting errors (example: convert data types)
self.dataset['date_column'] = pd.to_datetime(self.dataset['date_column'])
# Handle missing values (example: drop rows with missing values)
self.dataset = self.dataset.dropna(subset=['required_column'])
# Handle duplicates (example: drop duplicates)
self.dataset = self.dataset.drop_duplicates()
# Handle inconsistent values (example: standardize values)
self.dataset['binary_column'] = self.dataset['binary_column'].map({'yes': 1, 'no': 0})
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to handling inconsistent or messy data within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Statistical Imputation
Statistical imputation involves replacing missing values with statistical estimates such as the mean, median, or mode of the available data. This method is straightforward and can be effective for numerical data. For categorical data, mode imputation is commonly used. The choice of imputation method depends on the distribution of the data and the nature of the missing values.
Model-Based Imputation
Model-based imputation uses machine learning models to predict missing values. This approach can be more sophisticated and potentially more accurate than statistical imputation, especially for complex datasets. Techniques like K-Nearest Neighbors (KNN) imputation can be used, where the missing values are replaced with the values of the K nearest neighbors in the feature space.
Using SimpleImputer in scikit-learn
The scikit-learn library provides the `SimpleImputer` class, which supports both statistical and model-based imputation. `SimpleImputer` can be used to replace missing values with the mean, median, or most frequent value (mode) of the column. It also supports more advanced imputation methods like KNN imputation.
To implement these imputation techniques in Python, Easylibpal might use the `SimpleImputer` class from scikit-learn. Here's an example of how to use `SimpleImputer` for statistical imputation:
```python
from sklearn.impute import SimpleImputer
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Initialize SimpleImputer for numerical columns
num_imputer = SimpleImputer(strategy='mean')
# Fit and transform the numerical columns
dataset'numerical_column1', 'numerical_column2' = num_imputer.fit_transform(dataset'numerical_column1', 'numerical_column2')
# Initialize SimpleImputer for categorical columns
cat_imputer = SimpleImputer(strategy='most_frequent')
# Fit and transform the categorical columns
dataset'categorical_column1', 'categorical_column2' = cat_imputer.fit_transform(dataset'categorical_column1', 'categorical_column2')
# The dataset now has missing values imputed
```
This example demonstrates how to use `SimpleImputer` to fill in missing values in both numerical and categorical columns of a dataset. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Model-based imputation techniques, such as Multiple Imputation by Chained Equations (MICE), offer powerful ways to handle missing data by using statistical models to predict missing values. However, these techniques come with their own set of limitations and potential drawbacks:
1. Complexity and Computational Cost
Model-based imputation methods can be computationally intensive, especially for large datasets or complex models. This can lead to longer processing times and increased computational resources required for imputation.
2. Overfitting and Convergence Issues
These methods are prone to overfitting, where the imputation model captures noise in the data rather than the underlying pattern. Overfitting can lead to imputed values that are too closely aligned with the observed data, potentially introducing bias into the analysis. Additionally, convergence issues may arise, where the imputation process does not settle on a stable solution.
3. Assumptions About Missing Data
Model-based imputation techniques often assume that the data is missing at random (MAR), which means that the probability of a value being missing is not related to the values of other variables. However, this assumption may not hold true in all cases, leading to biased imputations if the data is missing not at random (MNAR).
4. Need for Suitable Regression Models
For each variable with missing values, a suitable regression model must be chosen. Selecting the wrong model can lead to inaccurate imputations. The choice of model depends on the nature of the data and the relationship between the variable with missing values and other variables.
5. Combining Imputed Datasets
After imputing missing values, there is a challenge in combining the multiple imputed datasets to produce a single, final dataset. This requires careful consideration of how to aggregate the imputed values and can introduce additional complexity and uncertainty into the analysis.
6. Lack of Transparency
The process of model-based imputation can be less transparent than simpler imputation methods, such as mean or median imputation. This can make it harder to justify the imputation process, especially in contexts where the reasons for missing data are important, such as in healthcare research.
Despite these limitations, model-based imputation techniques can be highly effective for handling missing data in datasets where a amusingness is MAR and where the relationships between variables are complex. Careful consideration of the assumptions, the choice of models, and the methods for combining imputed datasets are crucial to mitigate these drawbacks and ensure the validity of the imputation process.
USING EASYLIBPAL FOR AI ALGORITHM INTEGRATION OFFERS SEVERAL SIGNIFICANT BENEFITS, PARTICULARLY IN ENHANCING EVERYDAY LIFE AND REVOLUTIONIZING VARIOUS SECTORS. HERE'S A DETAILED LOOK AT THE ADVANTAGES:
1. Enhanced Communication: AI, through Easylibpal, can significantly improve communication by categorizing messages, prioritizing inboxes, and providing instant customer support through chatbots. This ensures that critical information is not missed and that customer queries are resolved promptly.
2. Creative Endeavors: Beyond mundane tasks, AI can also contribute to creative endeavors. For instance, photo editing applications can use AI algorithms to enhance images, suggesting edits that align with aesthetic preferences. Music composition tools can generate melodies based on user input, inspiring musicians and amateurs alike to explore new artistic horizons. These innovations empower individuals to express themselves creatively with AI as a collaborative partner.
3. Daily Life Enhancement: AI, integrated through Easylibpal, has the potential to enhance daily life exponentially. Smart homes equipped with AI-driven systems can adjust lighting, temperature, and security settings according to user preferences. Autonomous vehicles promise safer and more efficient commuting experiences. Predictive analytics can optimize supply chains, reducing waste and ensuring goods reach users when needed.
4. Paradigm Shift in Technology Interaction: The integration of AI into our daily lives is not just a trend; it's a paradigm shift that's redefining how we interact with technology. By streamlining routine tasks, personalizing experiences, revolutionizing healthcare, enhancing communication, and fueling creativity, AI is opening doors to a more convenient, efficient, and tailored existence.
5. Responsible Benefit Harnessing: As we embrace AI's transformational power, it's essential to approach its integration with a sense of responsibility, ensuring that its benefits are harnessed for the betterment of society as a whole. This approach aligns with the ethical considerations of using AI, emphasizing the importance of using AI in a way that benefits all stakeholders.
In summary, Easylibpal facilitates the integration and use of AI algorithms in a manner that is accessible and beneficial across various domains, from enhancing communication and creative endeavors to revolutionizing daily life and promoting a paradigm shift in technology interaction. This integration not only streamlines the application of AI but also ensures that its benefits are harnessed responsibly for the betterment of society.
USING EASYLIBPAL OVER TRADITIONAL AI LIBRARIES OFFERS SEVERAL BENEFITS, PARTICULARLY IN TERMS OF EASE OF USE, EFFICIENCY, AND THE ABILITY TO APPLY AI ALGORITHMS WITH MINIMAL CONFIGURATION. HERE ARE THE KEY ADVANTAGES:
- Simplified Integration: Easylibpal abstracts the complexity of traditional AI libraries, making it easier for users to integrate classic AI algorithms into their projects. This simplification reduces the learning curve and allows developers and data scientists to focus on their core tasks without getting bogged down by the intricacies of AI implementation.
- User-Friendly Interface: By providing a unified platform for various AI algorithms, Easylibpal offers a user-friendly interface that streamlines the process of selecting and applying algorithms. This interface is designed to be intuitive and accessible, enabling users to experiment with different algorithms with minimal effort.
- Enhanced Productivity: The ability to effortlessly instantiate algorithms, fit models with training data, and make predictions with minimal configuration significantly enhances productivity. This efficiency allows for rapid prototyping and deployment of AI solutions, enabling users to bring their ideas to life more quickly.
- Democratization of AI: Easylibpal democratizes access to classic AI algorithms, making them accessible to a wider range of users, including those with limited programming experience. This democratization empowers users to leverage AI in various domains, fostering innovation and creativity.
- Automation of Repetitive Tasks: By automating the process of applying AI algorithms, Easylibpal helps users save time on repetitive tasks, allowing them to focus on more complex and creative aspects of their projects. This automation is particularly beneficial for users who may not have extensive experience with AI but still wish to incorporate AI capabilities into their work.
- Personalized Learning and Discovery: Easylibpal can be used to enhance personalized learning experiences and discovery mechanisms, similar to the benefits seen in academic libraries. By analyzing user behaviors and preferences, Easylibpal can tailor recommendations and resource suggestions to individual needs, fostering a more engaging and relevant learning journey.
- Data Management and Analysis: Easylibpal aids in managing large datasets efficiently and deriving meaningful insights from data. This capability is crucial in today's data-driven world, where the ability to analyze and interpret large volumes of data can significantly impact research outcomes and decision-making processes.
In summary, Easylibpal offers a simplified, user-friendly approach to applying classic AI algorithms, enhancing productivity, democratizing access to AI, and automating repetitive tasks. These benefits make Easylibpal a valuable tool for developers, data scientists, and users looking to leverage AI in their projects without the complexities associated with traditional AI libraries.
2 notes
·
View notes
Text

The Complete Beginner's Guide to Visionize AI
Visionize AI - Introduction
Welcome to my Visionize AI Review post. Where innovation meets intelligence, at Visionize AI, we are dedicated to pushing the boundaries of what's possible with artificial intelligence technology. Our mission is to empower businesses and organizations of all sizes to harness the transformative power of AI to drive growth, efficiency, and success.
With a team of experts at the forefront of AI research and development, Visionize AI is committed to delivering cutting-edge solutions that address our client's unique challenges and opportunities. Whether you're looking to streamline operations, optimize processes, or unlock new insights from your data, Visionize AI provides the expertise and technology needed to achieve your goals.
From machine learning algorithms to natural language processing systems, our comprehensive suite of AI solutions is designed to meet the diverse needs of modern businesses. Join us on a journey of innovation and discovery with Visionize AI.
Visionize AI – Overview
Creator: Bizomart
Product: Visionize AI
The official page: >>> Click here to access.
Niche: Software
Bonus: Yes, Huge Bonus
Guarantee: 30-day money-back guarantee!
What is Visionize AI?
Visionize AI is a pioneering technology company focused on harnessing the power of artificial intelligence to drive innovation and transformation. At Visionize AI, we develop cutting-edge AI solutions tailored to the specific needs of businesses across various industries. Our expertise lies in creating intelligent systems that automate processes, analyze data, and generate valuable insights to help organizations make informed decisions and achieve their goals.
Through advanced machine learning algorithms, natural language processing techniques, and computer vision capabilities, Visionize AI enables businesses to unlock new opportunities, streamline operations, and stay ahead of the competition in today's rapidly evolving digital landscape. Whether it's optimizing workflows, enhancing customer experiences, or predicting market trends, Visionize AI is dedicated to delivering high-impact AI solutions that drive tangible results and propel businesses toward success in the age of artificial intelligence.
How Does Visionize AI Work?
Leveraging Visionize AI is a seamless endeavor, characterized by a user-friendly interface where individuals can simply log in, input keywords or utilize voice commands, and witness the rapid generation of desired visual content. This intuitive workflow ensures swift and efficient production of captivating visuals, requiring minimal effort on the part of the user.
Get Instant Access
Benefits Of Using Visionize AI
Streamlines the process of visual content creation for users of all skill levels
Facilitates the rapid generation of high-quality visuals across a multitude of formats
Provides a seamless avenue for monetizing generated visuals through a dedicated marketplace
Diminishes the reliance on costly design tools and professional services
Empower individuals and businesses to embrace the AI-driven future of visual content creation.
Visionize AI Review - Key Features
AI-powered Graphics and Image Generation
Video Generation without the need for recording or editing
Access to a Marketplace boasting 10,000,000 active buyers
Inpainting, Colorization, and Denoising capabilities for images
Recognition, Synthesis, and Noise Removal functionalities
Mobile Compatibility, facilitating on-the-go visual creation
Comprehensive Training Videos and Round-the-Clock Support
Visionize AI Review- Pros and Cons
Pros:
The comprehensive suite of visual content creation features
One-time fee structure with no monthly costs, offering excellent value
Free commercial license, enabling users to sell their creations
Mobile compatibility for convenient access across various devices
Streamlined workflow catering to both novices and seasoned professionals
Cons:
Limited availability of licenses due to server capacity constraints
Potential future increase in price to a monthly subscription model
But That's Not All
In addition, we have several bonuses for those who want to take action today and start profiting from this opportunity.

1. Bonus: Exclusive Special Training (Valued at $997)
Enhance your skills with our exclusive Special Training program, meticulously crafted to complement VisionizeAi. Uncover advanced techniques, deepen your knowledge, and unlock the full potential of state-of-the-art artificial intelligence. Empower your creative vision today.
2. Bonus: 200+ Mascot Cartoon Characters (Valued at $247)
Introducing 200 vibrant mascot cartoon characters by VisionizeAi, each embodying a unique aspect of innovation and creativity. From tech-savvy bots to imaginative thinkers, these characters inject charm and personality into the realm of artificial intelligence.
3. Bonus: Infographic Blackbook (Valued at $367)
Unlock the secrets of crafting visually compelling infographics with the Infographic Blackbook, perfectly complemented by VisionizeAi's cutting-edge automated design tools. Together, they empower users to effortlessly create engaging visual narratives with precision and flair.
4. Bonus: Video Marketing Graphics Pack (Valued at $327)
Enhance your video marketing endeavors with our Graphics Pack, meticulously curated to complement VisionizeAi. Featuring stunning visual elements, dynamic animations, and customizable templates, effortlessly elevate your videos and captivate your audience like never before.
Get Instant Access
Why Recommended?
Recommended for its cutting-edge AI solutions, Visionize AI stands out for its commitment to innovation and excellence. With a track record of delivering tangible results, Visionize AI empowers businesses to thrive in today's competitive landscape.
Its advanced machine learning algorithms and natural language processing capabilities enable organizations to streamline operations, optimize processes, and uncover valuable insights from data. Backed by a team of AI experts, Visionize AI offers tailored solutions that drive measurable impact and propel businesses toward success.
Choose Visionize AI for unparalleled expertise and transformative AI solutions that drive growth and innovation.
Money Back Guarantee - Risk-Free
Look, VisionizeAi is not one of those “trash” or untested apps. We know what it’s capable of…However, in the unlikely event that you fail to use VisionizeAi for ANY REASON. We insist that you send us an email…It is simple if you don’t make money. We don’t want your money…We make more than enough with VisionizeAi. And no need to keep your money if you’re not gonna use it.
Not just that…We will send you a bundle of premium software as a gift for wasting your time. Worst case scenario, you get VisionizeAi and don’t make any money you will still get an extra bundle of premium software for trying it out.
Final opinion:
In conclusion, Visionize AI emerges as a leader in the realm of artificial intelligence, offering unparalleled expertise and transformative solutions. With a commitment to innovation and excellence, Visionize AI empowers businesses to thrive in today's dynamic environment.
Through advanced machine learning algorithms and natural language processing capabilities, Visionize AI enables organizations to streamline operations, optimize processes, and unlock valuable insights from data. Backed by a dedicated team of AI experts, Visionize AI delivers tangible results and drives measurable impact.
Overall, Visionize AI stands as a trusted partner for businesses seeking to harness the full potential of AI to achieve their goals and propel growth.
Get Instant Access
FAQ
What is Visionize Ai?
Vision AI is a peculiar sports-changing model crafted by complex algorithms and AI technology. It aims to just do that (don’t use double words). Specifically, its objective is to take the world’s imagery design to another next level. It does this by the way of using simple automatic techniques and additional design alternatives.
How does Visionize Ai differ from other design tools like Canva?
Visionize AI became quickly famous as a tool that can simplify the design usually performed by the industry’s front runner. Therefore, it is referred to as a Canva killer. It utilizes modern AI-driven models that offer personalized design suggestions, templates, and layouts. Also, it supplies libraries of inspiration and designs.
How does Visionize AI work?
The Visionize AI understands data in large volumes and skips the job of humans for many design work. It will offer advice and recommendations specific to each project, as well as different templates and layouts that have a personalized touch. Plugging the AI into the development process dramatically speeds up the workflow of design and gives a considerable library of inspirations and design objects.
Who can benefit from using Visionize AI?
Our solution focuses on meeting two major groups’ needs, those who are professional at the same time and beginners. Its easy-to-use interface can be mastered by all levels of users and can even be managed by drag and drop. Professionals with design skills are going to be flattered by the ability to use AI’s advanced automation abilities to save time and the creative work left off by the newcomers would only be their costly templates and design inspirations.
What sets Visionize Ai apart from other AI models?
It is indeed true that Visionise Ai is the “Daddy of all AI Models”. Advancements in Modern Artificial Intelligence (AI) technology will ensure Visionise is ahead of other design solution providers. Those powerful si eleenes have API that allows user customization, they fo seek to remain cutting edge in the designer sector simply because they are now superior among their peers.
What are the advantages of using Visionize AI?
The Visionize Ai technological solutions offer several benefits over the improvisations. First, its automation characteristics save time for designers leaving them to rationally work on their more strategic endeavors. Then, you use this AI base with its suggestions and templates to enable you to add more creative ideas and this inspires you. Finally, Visionize Ai’s (this company’s) top technology makes the most recent design trends and the most advanced features available as well as up-to-date.
How can Visionize Ai unlock my design potential?
Whether a seasoned expert in graphic design or a toddler, this tool frees your creativity and enables you to innovate. In line with its user-friendly interface, the strong AI components empower experiments, experiments, and artistic visualization using advanced models making the audience involved and intrigued.
Is Visionize Ai suitable for all types of graphic design projects?
Visionize Ai does all of the graphic design projects that are mentioned here. Its collection of templates as well as design elements gives many options to users who can modify them to suit their design needs, as they are versatile and can work for a range of designs.
#VisionizeAi#VisionizeAireview#VisionizeAiapps#VisionizeAisoftware#VisionizeAisoftwarererviews#VisionizeAidemos#VisionizeAiscam#VisionizeAife
2 notes
·
View notes
Text
Peer Feedback #4

For my final feedback post, I wanted to jump into the main part of this second project: the design. Above, I wanted to express the importance of visuals and how incorporated efficiently, could make the overall information greatly successful to the audience and gain more traction due to it. I need to not only think of how to engage with the audience with the visuals but also express my conclusions from the data I analyzed from the three days I logged. I think bright colors would be a great approach but maybe having themes for each area would work? The overall idea I want to go with is the analysis of how much time I go online compared to social in-person interactions with spaces and how that has affected my life and how it may explain how I see certain spaces compared to others. Hopefully that makes some sense, let me know if all of that is something I should consider when creating the visual portion of this project!
2 notes
·
View notes
Text
What is Solr – Comparing Apache Solr vs. Elasticsearch

In the world of search engines and data retrieval systems, Apache Solr and Elasticsearch are two prominent contenders, each with its strengths and unique capabilities. These open-source, distributed search platforms play a crucial role in empowering organizations to harness the power of big data and deliver relevant search results efficiently. In this blog, we will delve into the fundamentals of Solr and Elasticsearch, highlighting their key features and comparing their functionalities. Whether you're a developer, data analyst, or IT professional, understanding the differences between Solr and Elasticsearch will help you make informed decisions to meet your specific search and data management needs.
Overview of Apache Solr
Apache Solr is a search platform built on top of the Apache Lucene library, known for its robust indexing and full-text search capabilities. It is written in Java and designed to handle large-scale search and data retrieval tasks. Solr follows a RESTful API approach, making it easy to integrate with different programming languages and frameworks. It offers a rich set of features, including faceted search, hit highlighting, spell checking, and geospatial search, making it a versatile solution for various use cases.
Overview of Elasticsearch
Elasticsearch, also based on Apache Lucene, is a distributed search engine that stands out for its real-time data indexing and analytics capabilities. It is known for its scalability and speed, making it an ideal choice for applications that require near-instantaneous search results. Elasticsearch provides a simple RESTful API, enabling developers to perform complex searches effortlessly. Moreover, it offers support for data visualization through its integration with Kibana, making it a popular choice for log analysis, application monitoring, and other data-driven use cases.
Comparing Solr and Elasticsearch
Data Handling and Indexing
Both Solr and Elasticsearch are proficient at handling large volumes of data and offer excellent indexing capabilities. Solr uses XML and JSON formats for data indexing, while Elasticsearch relies on JSON, which is generally considered more human-readable and easier to work with. Elasticsearch's dynamic mapping feature allows it to automatically infer data types during indexing, streamlining the process further.
Querying and Searching
Both platforms support complex search queries, but Elasticsearch is often regarded as more developer-friendly due to its clean and straightforward API. Elasticsearch's support for nested queries and aggregations simplifies the process of retrieving and analyzing data. On the other hand, Solr provides a range of query parsers, allowing developers to choose between traditional and advanced syntax options based on their preference and familiarity.
Scalability and Performance
Elasticsearch is designed with scalability in mind from the ground up, making it relatively easier to scale horizontally by adding more nodes to the cluster. It excels in real-time search and analytics scenarios, making it a top choice for applications with dynamic data streams. Solr, while also scalable, may require more effort for horizontal scaling compared to Elasticsearch.
Community and Ecosystem
Both Solr and Elasticsearch boast active and vibrant open-source communities. Solr has been around longer and, therefore, has a more extensive user base and established ecosystem. Elasticsearch, however, has gained significant momentum over the years, supported by the Elastic Stack, which includes Kibana for data visualization and Beats for data shipping.
Document-Based vs. Schema-Free
Solr follows a document-based approach, where data is organized into fields and requires a predefined schema. While this provides better control over data, it may become restrictive when dealing with dynamic or constantly evolving data structures. Elasticsearch, being schema-free, allows for more flexible data handling, making it more suitable for projects with varying data structures.
Conclusion
In summary, Apache Solr and Elasticsearch are both powerful search platforms, each excelling in specific scenarios. Solr's robustness and established ecosystem make it a reliable choice for traditional search applications, while Elasticsearch's real-time capabilities and seamless integration with the Elastic Stack are perfect for modern data-driven projects. Choosing between the two depends on your specific requirements, data complexity, and preferred development style. Regardless of your decision, both Solr and Elasticsearch can supercharge your search and analytics endeavors, bringing efficiency and relevance to your data retrieval processes.
Whether you opt for Solr, Elasticsearch, or a combination of both, the future of search and data exploration remains bright, with technology continually evolving to meet the needs of next-generation applications.
2 notes
·
View notes
Text
Why Denzi is the Best Dental Management Software for Clinics
In today’s fast-paced dental industry, running a successful clinic is not just about treating patients — it’s also about managing your clinic efficiently. From handling patient records to scheduling appointments and ensuring data security, every task needs to be streamlined for maximum productivity. That’s where Dental Management Software comes in. Among the many options available, Denzi stands out as the most reliable, user-friendly, and feature-rich solution for dental professionals.
What is Dental Management Software?
Dental Management Software is a digital tool that helps dental clinics manage their day-to-day operations. It includes features like appointment scheduling, billing, patient record management, treatment planning, reminders, and reports. It helps reduce manual work, eliminates errors, and saves time — leading to better patient care and clinic efficiency.
Why Choose Denzi?
Denzi is a modern, cloud-based Dental Management Software that has been specifically designed with the needs of dental professionals in mind. Here’s why Denzi is the ideal choice for your clinic:
1. User-Friendly Interface
One of the biggest challenges with new software is the learning curve. Denzi eliminates that concern with its intuitive, easy-to-use interface. Whether you’re a tech-savvy dentist or someone with minimal computer experience, you’ll find it incredibly simple to navigate Denzi’s dashboard, manage appointments, and access patient records with just a few clicks.
2. Comprehensive Patient Management
Denzi makes managing patient records a breeze. You can store complete patient histories, X-rays, prescriptions, and treatment notes in one place. With quick access to records, you can deliver personalized treatment and make informed decisions instantly. The Dental Management Software also allows you to maintain detailed communication logs, ensuring every interaction is recorded and available when needed.
3. Smart Appointment Scheduling
No more double bookings or appointment conflicts. Denzi’s intelligent appointment module allows for smart scheduling, enabling you to set up appointments based on doctor availability, chair time, and patient preferences. It also sends automatic reminders to reduce no-shows.

4. Seamless Billing and Invoicing
Billing can often be time-consuming and prone to human error. Denzi simplifies the process with automated billing and invoice generation. You can set custom pricing for procedures, generate accurate invoices in seconds, and track payments easily. The software also supports multiple payment modes.
5. Treatment Planning and Charting
Denzi offers advanced features like dental charting, graphical treatment planning, and progress tracking. This visual aid helps you explain procedures to your patients more clearly, increasing trust and transparency.
6. Data Security and Backup
Data security is critical in healthcare. Denzi uses bank-level encryption to secure all clinic data. Since it’s a cloud-based Dental Management Software, your data is automatically backed up and protected against loss, hardware failures, or system crashes.
7. Customizable and Scalable
Whether you run a single-chair clinic or a multi-specialty dental hospital, Denzi is fully scalable. You can customize modules, add users, and expand functionalities as your clinic grows.
8. Cloud-Based Access Anytime, Anywhere
Being cloud-based, Denzi gives you the freedom to access your clinic’s data from anywhere — be it from home, another branch, or even while traveling. All you need is an internet connection and a device, and your clinic is at your fingertips.
9. Excellent Customer Support
Denzi offers dedicated customer support to ensure you never face any downtime or technical issues. From onboarding to ongoing assistance, their team is always ready to help.
Benefits of Using Denzi — The Leading Dental Management Software
Save Time: Automates routine tasks like scheduling, billing, and reporting.
Reduce Errors: Eliminates manual mistakes in appointments, billing, and patient records.
Improve Patient Experience: Faster service, better communication, and timely follow-ups.
Enhance Efficiency: Streamlined workflows mean your team can focus more on patient care.
Grow Your Practice: Use built-in reports to analyze growth and make informed business decisions.
Final Thoughts
Choosing the right Dental Management Software can make a world of difference in how your clinic operates. Denzi offers all the essential features in one platform, ensuring your clinic runs smoothly, securely, and efficiently. With its user-friendly design, robust capabilities, and excellent support, Denzi is undoubtedly the best dental management software for clinics of all sizes.
If you’re ready to take your dental practice to the next level, it’s time to switch to Denzi.
Visit Denzi today:
#dental management software#dental clinic management software#denzi dental software#dental clinics management solution#dental practice management software
0 notes
Text
Unlock Seamless Entertainment with the Official 55club URL and Login Access
In the evolving landscape of online gaming and entertainment, users continuously seek a platform that delivers excitement, security, and smooth usability. Among the myriad of options, one name that stands out for its growing popularity and dedicated user base is 55club. Known for its wide range of games, responsive interface, and attractive rewards, this platform has become a preferred choice for gamers who value quality and reliability. As interest in the platform grows, understanding how to access it securely and efficiently has become essential. That’s where the importance of the official 55club url comes into play.
The official URL acts as a gateway to an immersive gaming experience. It ensures you are entering the authentic version of the site and protects users from fake or misleading imitations. Visiting unofficial sources may result in account theft, malware, or other security breaches, which is why locating and bookmarking the correct link is highly recommended. Once on the platform, users are greeted with an intuitive interface, visually engaging design, and seamless navigation that enhances the overall experience.

Creating an account is simple and quick, allowing both seasoned players and newcomers to get started with minimal hassle. The platform ensures that new users can easily explore its features without being overwhelmed, offering a smooth onboarding process. But the real journey begins after signing up — and that’s where 55club login becomes crucial. This single step opens up a personalized world filled with exclusive offers, game histories, achievements, and user-specific settings that make the experience feel tailored and enjoyable.
The login system itself is fortified with updated encryption standards to ensure privacy and data protection, giving users peace of mind while they focus on enjoying their games. Users can log in from various devices, including desktops, tablets, and smartphones, making it accessible whether you’re at home or on the go. The platform also remembers your preferences, giving quick access to favorite games, progress stats, and wallet details.
The platform isn't just about random gaming — it encourages engagement and progression. Users are rewarded for consistent activity, participation in events, and reaching specific milestones. Points, bonuses, and other incentives help keep the momentum going. This reward system, combined with a fair-play environment, creates a sense of accomplishment that encourages long-term participation.
Customer support is another area where the platform excels. Whether you have issues with gameplay, payment processes, or technical glitches, the support team is readily available through multiple channels. Fast responses and effective solutions keep frustration at bay and ensure players don’t feel left out when something goes wrong.
Additionally, the community aspect of the platform adds a rich social dimension. Through forums, leaderboards, and friendly competitions, users interact, challenge one another, and share experiences. This fosters a sense of belonging and keeps the atmosphere lively and inclusive. It transforms the platform from just a gaming site into a community hub where relationships and reputations are built over time.
As you explore more, you’ll notice the sheer diversity of games available — from card classics to modern strategy games, from slots to unique mini-games. This variety caters to all kinds of preferences and keeps the experience fresh and engaging. Each game is regularly updated to introduce new features, enhance graphics, and fix minor bugs, showing the platform’s commitment to constant improvement.
Staying updated with the latest developments is also easy thanks to regular notifications and email alerts that inform users about upcoming events, maintenance schedules, or bonus offers. These alerts make sure you never miss an opportunity to win or stay ahead in the game.
For those serious about online gaming and looking for a secure, enjoyable, and constantly evolving platform, visiting the official 55club url is a smart first step. Once you complete your 55club login, the platform opens the door to a realm of entertainment that is difficult to match elsewhere. With strong safety measures, a vibrant community, wide game selection, and stellar support, it’s not just a gaming site — it’s a complete experience worth investing your time in.
0 notes
Text
Revolutionizing the Drive: How Dealership Software and Apps are Shifting Gears in Car Sales

The automotive industry is in constant motion, and for car showrooms, staying ahead means embracing technological advancements. Gone are the days of sprawling paper trails and siloed information. Today, dealership CRM software, car showroom management software, and car showroom sales software are no longer luxuries but essential tools for success. And for the modern customer, a free car showroom app can be the ultimate game-changer.
This blog post will explore how these innovative solutions are transforming the car buying and selling experience, boosting efficiency, and ultimately driving higher profits for dealerships.
The Power of Connection: Dealership CRM Software
At the heart of every successful dealership lies strong customer relationships. This is where dealership CRM software shines. More than just a contact list, a robust CRM acts as a central hub for all customer interactions, from initial inquiry to post-sale service.
Key benefits of dealership CRM software include:
Smarter Lead Management: Capture leads from various sources (website, social media, walk-ins) and automatically track their journey through the sales funnel. AI-powered insights can even help prioritize hot leads.
Personalized Customer Experiences: With a complete view of customer preferences, purchase history, and communication logs, sales teams can offer tailored recommendations and truly understand individual needs.
Automated Follow-ups and Reminders: Ensure no lead falls through the cracks with automated emails, SMS, and task reminders for sales reps.
Enhanced Communication: Centralize all communication channels, from phone calls and emails to social media messages, providing a unified customer view.
Improved Sales Forecasting: Leverage historical data and lead activity to predict future sales trends and optimize sales strategies.
Companies like DealerSocket, VinSolutions, AutoRaptor, and Zoho CRM are leading the way in providing comprehensive CRM solutions tailored for the automotive industry.
Orchestrating Operations: Car Showroom Management Software
Beyond customer interactions, a car showroom is a complex operation. From inventory to service, efficiency is paramount. This is where car showroom management software steps in, integrating various departmental functions into a single, cohesive system.
Benefits of effective car showroom management software include:
Real-time Inventory Management: Gain instant visibility into stock levels, vehicle details, and even car locations across multiple showrooms or warehouses. This prevents overselling and optimizes stock rotation.
Streamlined Workflows: Automate routine tasks like paperwork, appointment scheduling, and inter-departmental communication, freeing up staff for more critical activities.
Comprehensive Reporting and Analytics: Generate in-depth reports on sales performance, inventory turnover, customer satisfaction, and more, enabling data-driven decision-making.
Service Department Integration: Seamlessly connect sales with service, allowing for easy scheduling of maintenance, tracking service history, and even identifying opportunities for trade-ins or upgrades.
Financial Management: Integrate with accounting systems to automate invoicing, payment processing, and other financial operations, reducing errors and saving time.
Case studies show significant improvements in sales growth and operational efficiency for dealerships that implement integrated management systems.
Driving Sales Forward: Car Showroom Sales Software
Specifically designed to empower sales teams, car showroom sales software focuses on accelerating the sales cycle and maximizing conversion rates. This software often works hand-in-hand with CRM solutions, providing sales-specific tools and insights.
Key features of car showroom sales software often include:
Sales Pipeline Visualization: Clearly see where each prospect is in the sales journey, allowing sales managers to identify bottlenecks and support their teams effectively.
Automated Quote and Proposal Generation: Quickly create accurate quotes, customize deals, and even integrate financing options, speeding up the negotiation process.
Test Drive Scheduling and Management: Efficiently manage test drive bookings, assign vehicles, and track follow-ups.
Digital Retailing Capabilities: Offer online vehicle configurators, payment calculators, and even online purchase options to cater to modern customer expectations.
Performance Tracking: Monitor individual and team sales performance, identify areas for improvement, and motivate staff.
Many top CRM solutions, like Salesforce’s Automotive Cloud and LeadSquared, offer robust sales functionalities as part of their comprehensive packages.
The Future in Your Pocket: Creating a Free Car Showroom App
In today’s mobile-first world, a dedicated app for your car showroom is becoming increasingly vital. While custom app development can be costly, the good news is that creating a free car showroom app is more accessible than ever, thanks to no-code app builders.
Why consider a free car showroom app?
24/7 Virtual Showroom: Showcase your entire inventory with high-quality images and videos, allowing customers to browse cars anytime, anywhere.
Lead Generation: Integrate inquiry forms, test drive booking options, and even virtual consultation scheduling directly into the app.
Push Notifications: Alert customers about new arrivals, special offers, service reminders, or personalized promotions.
Enhanced Customer Engagement: Provide valuable resources like financing calculators, trade-in estimators, and even maintenance tips.
Improved Customer Service: Offer in-app messaging, one-touch calling, and access to FAQs.
Platforms like Appy Pie and App Institute provide user-friendly drag-and-drop interfaces that allow dealerships to build functional and attractive apps without any coding knowledge. While “free” versions might have limitations, they offer an excellent starting point to test the waters and understand customer engagement before investing in more advanced features.
The Road Ahead
The automotive industry is rapidly evolving, and technology is at the forefront of this transformation. By strategically implementing dealership CRM software, car showroom management software, and car showroom sales software, and by exploring the potential of a free car showroom app, dealerships can:
Boost efficiency and productivity.
Enhance the customer experience.
Drive higher sales and profitability.
Gain a competitive edge in the market.
Embracing these digital tools isn’t just about keeping up; it’s about leading the way into a more connected, efficient, and customer-centric future for car sales.
0 notes
Text
TirangaLogin – Manage Tiranga Portal Online
TirangaLogin is the dedicated gateway for users to securely access and manage their accounts on the Tiranga Portal, a centralized digital platform designed for various patriotic campaigns, digital participation drives, and official government-led initiatives. The portal aims to foster national spirit by making it easy for citizens, students, employees, and institutions to join programs related to India’s national identity. With TirangaLogin, users can quickly register or log in to participate in events like the Har Ghar Tiranga movement, download participation certificates, submit photographs, https://tirangalogin.co.in/ and share their contributions online. This streamlined access plays a vital role in making nationwide digital campaigns more accessible and impactful.

Once logged in, the Tiranga Portal allows users to update their profiles, monitor participation history, and track certificate downloads. It simplifies the way individuals and institutions engage with national events by offering a seamless digital interface. Whether it’s uploading photos of flag hoisting or printing official participation certificates, TirangaLogin ensures that every activity is just a few clicks away. Government departments and schools can also use the portal to manage group entries and promote awareness about India’s cultural and patriotic heritage. The dashboard is designed to be intuitive, even for first-time users, with options to reset passwords, change language preferences, and access FAQs.
The portal’s secure infrastructure ensures the privacy of user data, employing encryption and verification systems to safeguard personal information. TirangaLogin functions as a bridge between the user and national engagement platforms, providing real-time updates, notifications, and reminders about upcoming campaigns. It has become especially popular during national holidays like Independence Day and Republic Day, when millions of Indians log in to register their participation in digital events and display their patriotism online.
For those unfamiliar with digital systems, TirangaLogin offers a user-friendly experience with detailed guidance and visual instructions on how to participate in various programs. From certificate generation to campaign-specific uploads, the platform supports multiple devices including desktops, tablets, and smartphones, making it accessible to users across India regardless of location. It also supports regional languages, reinforcing inclusivity and national reach.
In summary, TirangaLogin serves as an essential digital hub for engaging with India’s patriotic initiatives in an organized and efficient manner. It bridges citizens with national campaigns, ensuring every Indian has the opportunity to proudly contribute and be recognized. By simplifying access and streamlining participation processes, the portal empowers users to manage their engagement in government-led national pride movements from anywhere, at any time. As digital India grows, platforms like TirangaLogin are paving the way for more connected, aware, and involved citizens who can express their patriotism with pride and purpose—online and offline.
1 note
·
View note
Text
Shaping Smarter Businesses Through Custom Software Innovation
Why Generic Software Can Hold You Back In the early stages of business, using ready-made software may seem like a practical choice. These solutions are easy to acquire and deploy. But over time, as operations grow more complex, these tools start to reveal their limitations. They are built for mass usage and rarely cater to the specific workflows or pain points that businesses face. This lack of flexibility can slow down processes, introduce inefficiencies, and limit growth potential.
Tailored Solutions for Unique Challenges Custom software is developed with a company’s exact needs in mind. It’s not about adjusting your business to fit the software—it’s about building the software to fit your business. Whether it’s automating internal workflows, simplifying multi-stage processes, or supporting specialized services, tailored solutions offer greater precision and impact. Every feature is crafted with a purpose, ensuring usability and long-term value.
Boosting Efficiency Through Automation One of the key strengths of custom software lies in its ability to automate repetitive and time-consuming tasks. This may include data entry, report generation, inventory tracking, or employee scheduling. Automation improves speed and accuracy, freeing up your team to focus on strategic areas. This leads to increased productivity and a smoother operational flow across departments.
Real-Time Access to Data and Insights Modern businesses run on data, and custom software can be designed to deliver exactly what your teams need, when they need it. From real-time analytics dashboards to customizable reporting features, you gain access to insights that drive smarter decisions. Data can be filtered, visualized, and acted upon—all within a system designed around your business priorities.
Seamless System Integration Many organizations rely on a mix of tools and platforms to manage their operations. One of the biggest challenges is integrating these tools to ensure smooth data flow and communication. Custom software can bridge the gap by integrating seamlessly with existing systems like CRMs, ERPs, or cloud platforms, offering a unified ecosystem that enhances performance and user experience.
High-Level Security and Compliance Security is a growing concern, especially for businesses handling sensitive data or operating under strict regulations. Custom software allows you to implement security protocols tailored to your industry and internal policies. From encryption and multi-factor authentication to role-based access and audit logs, your data and users are protected at every level.
Future-Proofing Your Business Operations Market demands evolve, and businesses must adapt quickly to stay competitive. Custom software is built with scalability in mind. It allows for the easy addition of new features, user roles, and system expansions without disruption. This flexibility ensures that your digital infrastructure grows alongside your business, rather than holding it back.
Final Thought The future belongs to businesses that are bold enough to build their own path—starting with the tools they use. By prioritizing personalization, efficiency, and scalability, companies gain a powerful advantage in an increasingly digital world. That’s the true value of investing in custom software development in usa —a foundation built for performance, progress, and possibility.
0 notes
Text
5 Things Every New Salesforce Admin Should Know.
So… you just became a Salesforce Admin? First of all—congrats! 🎉 Second—buckle up. You’ve just entered one of the most powerful, versatile, and occasionally overwhelming platforms out there.

Whether you're feeling excited, confused, or straight-up panicked (been there!), here are 5 things I wish someone had told me when I started my admin journey. These tips will save you from frustration, earn you instant respect, and set you up to actually thrive in your role.
Learn the Data Model Like It’s a Map to Hidden Treasure 🗺️ Salesforce is built around data—objects, fields, and relationships. If you don’t understand how they connect, everything feels random.
Standard Objects = Salesforce out-of-the-box (Accounts, Contacts, Opportunities)
Custom Objects = Built for your unique org needs
Relationships = How data is connected (and what it means when you change it)
🔍 Pro Tip: Open up Schema Builder and explore it like you’re in a video game. It makes the abstract stuff visual and clickable, and it helped me connect the dots FAST.
Permissions Are Where the Chaos Begins (or Ends) 🔐 It’s not just “can a user log in?” It’s what can they see, do, or accidentally delete?
Profiles: Define basic access
Roles: Define what records users can see
Permission Sets: Give extra powers (without turning your org into a security nightmare)
🛑 Lesson Learned: One time I gave someone too much access and they deleted 200 records thinking it was a test environment. Now I use Permission Sets very carefully.
Flows Are the Future—But Test Before You Impress ⚙️ Automation is amazing until it breaks… everything.
Flows are your best no-code friend (goodbye, old Workflow Rules)
Automate tasks, send emails, update records—all without writing a line of code
⚠️ Warning: Automating everything sounds cool until you forget to test and realize you just updated 3,000 records incorrectly. Use Sandbox. Always.
Reports & Dashboards = Instant “You’re a Genius” Moments 📊 The fastest way to win love from your team? Build them a dashboard that answers a question they didn’t even know they had.
Use custom report types to unlock the data people really want
Group your reports like a story, not just a spreadsheet
Make your dashboards visual, not just “boxes with numbers”
💡 Real Talk: My first dashboard got shown in a leadership meeting. I had no idea. That was the day people stopped calling me "just the CRM person" and started calling me "the one who makes things actually make sense."
Trailhead Is Basically the Netflix of Salesforce—But Educational 🧩 Trailhead isn’t just another boring training site. It’s gamified, hands-on, and low-key addictive. You can earn badges, show off your skills, and actually get certified.
🔥 Start here:
Admin Beginner Trail
Flow Basics
🎓 Bonus: Once you’re ready, go for the Salesforce Admin Certification (ADM-201)—it’s your golden ticket.
Final Thoughts: You’re Not “Just the Admin”—You’re the Heart of the Org ❤️ Being a Salesforce Admin isn’t just clicking buttons or resetting passwords. You’re literally the person who keeps data clean, processes efficient, and users productive. You're the connector between technology and people.
Some days, you’ll feel overwhelmed. Others, you’ll feel like a wizard.
But every day, you’re learning a skill set that companies desperately need.
✨ Quick Checklist for New Admins: ✅ Explore Schema Builder ✅ Learn Profiles vs Roles vs Permission Sets ✅ Play with Flows (in Sandbox!) ✅ Build a dashboard that answers one big question ✅ Earn your first Trailhead badge
Tag a new Salesforce Admin and share this with them. We’ve all been there—and the journey is so much better when we help each other out.
Let’s grow together. 🌱
0 notes