#Generative AI Data Labeling Services
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
Generative AI | High-Quality Human Expert Labeling | Apex Data Sciences
Apex Data Sciences combines cutting-edge generative AI with RLHF for superior data labeling solutions. Get high-quality labeled data for your AI projects.
#GenerativeAI#AIDataLabeling#HumanExpertLabeling#High-Quality Data Labeling#Apex Data Sciences#Machine Learning Data Annotation#AI Training Data#Data Labeling Services#Expert Data Annotation#Quality AI Data#Generative AI Data Labeling Services#High-Quality Human Expert Data Labeling#Best AI Data Annotation Companies#Reliable Data Labeling for Machine Learning#AI Training Data Labeling Experts#Accurate Data Labeling for AI#Professional Data Annotation Services#Custom Data Labeling Solutions#Data Labeling for AI and ML#Apex Data Sciences Labeling Services
1 note
·
View note
Text
should you delete twitter and get bluesky? (or just get a bluesky in general)? here's what i've found:
yes. my answer was no before bc the former CEO of twitter who also sucked, jack dorsey, was on the board, but he left as of may 2024, and things have gotten a lot better. also a lot of japanese and korean artists have joined
don't delete your twitter. lock your account, use a service to delete all your tweets, delete the app off of your phone, and keep your account/handle so you can't be impersonated.
get a bluesky with the same handle, even if you won't use it, also so you won't be impersonated.
get the sky follower bridge extension for chrome or firefox. you can find everyone you follow on twitter AND everyone you blocked so you don't have to start fresh: https://skyfollowerbridge.com/
learn how to use its moderation tools (labelers, block lists, NSFW settings) so you can immediately cut out the grifters, fascists, t*rfs, AI freaks, have the NSFW content you want to see if you so choose, and moderate for triggers. here's a helpful thread with a lot of tools.
the bluesky phone app is pretty good, but there is also tweetdeck for bluesky, called https://deck.blue/ on desktop, if you miss tweetdeck.
bluesky has explicitly stated they do not use your data to train generative AI, which is nice to hear from an up and coming startup. obviously we can’t trust these companies and please use nightshade and glaze, but it’s good to hear.
21K notes
·
View notes
Text
What kind of bubble is AI?
My latest column for Locus Magazine is "What Kind of Bubble is AI?" All economic bubbles are hugely destructive, but some of them leave behind wreckage that can be salvaged for useful purposes, while others leave nothing behind but ashes:
https://locusmag.com/2023/12/commentary-cory-doctorow-what-kind-of-bubble-is-ai/
Think about some 21st century bubbles. The dotcom bubble was a terrible tragedy, one that drained the coffers of pension funds and other institutional investors and wiped out retail investors who were gulled by Superbowl Ads. But there was a lot left behind after the dotcoms were wiped out: cheap servers, office furniture and space, but far more importantly, a generation of young people who'd been trained as web makers, leaving nontechnical degree programs to learn HTML, perl and python. This created a whole cohort of technologists from non-technical backgrounds, a first in technological history. Many of these people became the vanguard of a more inclusive and humane tech development movement, and they were able to make interesting and useful services and products in an environment where raw materials – compute, bandwidth, space and talent – were available at firesale prices.
Contrast this with the crypto bubble. It, too, destroyed the fortunes of institutional and individual investors through fraud and Superbowl Ads. It, too, lured in nontechnical people to learn esoteric disciplines at investor expense. But apart from a smattering of Rust programmers, the main residue of crypto is bad digital art and worse Austrian economics.
Or think of Worldcom vs Enron. Both bubbles were built on pure fraud, but Enron's fraud left nothing behind but a string of suspicious deaths. By contrast, Worldcom's fraud was a Big Store con that required laying a ton of fiber that is still in the ground to this day, and is being bought and used at pennies on the dollar.
AI is definitely a bubble. As I write in the column, if you fly into SFO and rent a car and drive north to San Francisco or south to Silicon Valley, every single billboard is advertising an "AI" startup, many of which are not even using anything that can be remotely characterized as AI. That's amazing, considering what a meaningless buzzword AI already is.
So which kind of bubble is AI? When it pops, will something useful be left behind, or will it go away altogether? To be sure, there's a legion of technologists who are learning Tensorflow and Pytorch. These nominally open source tools are bound, respectively, to Google and Facebook's AI environments:
https://pluralistic.net/2023/08/18/openwashing/#you-keep-using-that-word-i-do-not-think-it-means-what-you-think-it-means
But if those environments go away, those programming skills become a lot less useful. Live, large-scale Big Tech AI projects are shockingly expensive to run. Some of their costs are fixed – collecting, labeling and processing training data – but the running costs for each query are prodigious. There's a massive primary energy bill for the servers, a nearly as large energy bill for the chillers, and a titanic wage bill for the specialized technical staff involved.
Once investor subsidies dry up, will the real-world, non-hyperbolic applications for AI be enough to cover these running costs? AI applications can be plotted on a 2X2 grid whose axes are "value" (how much customers will pay for them) and "risk tolerance" (how perfect the product needs to be).
Charging teenaged D&D players $10 month for an image generator that creates epic illustrations of their characters fighting monsters is low value and very risk tolerant (teenagers aren't overly worried about six-fingered swordspeople with three pupils in each eye). Charging scammy spamfarms $500/month for a text generator that spits out dull, search-algorithm-pleasing narratives to appear over recipes is likewise low-value and highly risk tolerant (your customer doesn't care if the text is nonsense). Charging visually impaired people $100 month for an app that plays a text-to-speech description of anything they point their cameras at is low-value and moderately risk tolerant ("that's your blue shirt" when it's green is not a big deal, while "the street is safe to cross" when it's not is a much bigger one).
Morganstanley doesn't talk about the trillions the AI industry will be worth some day because of these applications. These are just spinoffs from the main event, a collection of extremely high-value applications. Think of self-driving cars or radiology bots that analyze chest x-rays and characterize masses as cancerous or noncancerous.
These are high value – but only if they are also risk-tolerant. The pitch for self-driving cars is "fire most drivers and replace them with 'humans in the loop' who intervene at critical junctures." That's the risk-tolerant version of self-driving cars, and it's a failure. More than $100b has been incinerated chasing self-driving cars, and cars are nowhere near driving themselves:
https://pluralistic.net/2022/10/09/herbies-revenge/#100-billion-here-100-billion-there-pretty-soon-youre-talking-real-money
Quite the reverse, in fact. Cruise was just forced to quit the field after one of their cars maimed a woman – a pedestrian who had not opted into being part of a high-risk AI experiment – and dragged her body 20 feet through the streets of San Francisco. Afterwards, it emerged that Cruise had replaced the single low-waged driver who would normally be paid to operate a taxi with 1.5 high-waged skilled technicians who remotely oversaw each of its vehicles:
https://www.nytimes.com/2023/11/03/technology/cruise-general-motors-self-driving-cars.html
The self-driving pitch isn't that your car will correct your own human errors (like an alarm that sounds when you activate your turn signal while someone is in your blind-spot). Self-driving isn't about using automation to augment human skill – it's about replacing humans. There's no business case for spending hundreds of billions on better safety systems for cars (there's a human case for it, though!). The only way the price-tag justifies itself is if paid drivers can be fired and replaced with software that costs less than their wages.
What about radiologists? Radiologists certainly make mistakes from time to time, and if there's a computer vision system that makes different mistakes than the sort that humans make, they could be a cheap way of generating second opinions that trigger re-examination by a human radiologist. But no AI investor thinks their return will come from selling hospitals that reduce the number of X-rays each radiologist processes every day, as a second-opinion-generating system would. Rather, the value of AI radiologists comes from firing most of your human radiologists and replacing them with software whose judgments are cursorily double-checked by a human whose "automation blindness" will turn them into an OK-button-mashing automaton:
https://pluralistic.net/2023/08/23/automation-blindness/#humans-in-the-loop
The profit-generating pitch for high-value AI applications lies in creating "reverse centaurs": humans who serve as appendages for automation that operates at a speed and scale that is unrelated to the capacity or needs of the worker:
https://pluralistic.net/2022/04/17/revenge-of-the-chickenized-reverse-centaurs/
But unless these high-value applications are intrinsically risk-tolerant, they are poor candidates for automation. Cruise was able to nonconsensually enlist the population of San Francisco in an experimental murderbot development program thanks to the vast sums of money sloshing around the industry. Some of this money funds the inevitabilist narrative that self-driving cars are coming, it's only a matter of when, not if, and so SF had better get in the autonomous vehicle or get run over by the forces of history.
Once the bubble pops (all bubbles pop), AI applications will have to rise or fall on their actual merits, not their promise. The odds are stacked against the long-term survival of high-value, risk-intolerant AI applications.
The problem for AI is that while there are a lot of risk-tolerant applications, they're almost all low-value; while nearly all the high-value applications are risk-intolerant. Once AI has to be profitable – once investors withdraw their subsidies from money-losing ventures – the risk-tolerant applications need to be sufficient to run those tremendously expensive servers in those brutally expensive data-centers tended by exceptionally expensive technical workers.
If they aren't, then the business case for running those servers goes away, and so do the servers – and so do all those risk-tolerant, low-value applications. It doesn't matter if helping blind people make sense of their surroundings is socially beneficial. It doesn't matter if teenaged gamers love their epic character art. It doesn't even matter how horny scammers are for generating AI nonsense SEO websites:
https://twitter.com/jakezward/status/1728032634037567509
These applications are all riding on the coattails of the big AI models that are being built and operated at a loss in order to be profitable. If they remain unprofitable long enough, the private sector will no longer pay to operate them.
Now, there are smaller models, models that stand alone and run on commodity hardware. These would persist even after the AI bubble bursts, because most of their costs are setup costs that have already been borne by the well-funded companies who created them. These models are limited, of course, though the communities that have formed around them have pushed those limits in surprising ways, far beyond their original manufacturers' beliefs about their capacity. These communities will continue to push those limits for as long as they find the models useful.
These standalone, "toy" models are derived from the big models, though. When the AI bubble bursts and the private sector no longer subsidizes mass-scale model creation, it will cease to spin out more sophisticated models that run on commodity hardware (it's possible that Federated learning and other techniques for spreading out the work of making large-scale models will fill the gap).
So what kind of bubble is the AI bubble? What will we salvage from its wreckage? Perhaps the communities who've invested in becoming experts in Pytorch and Tensorflow will wrestle them away from their corporate masters and make them generally useful. Certainly, a lot of people will have gained skills in applying statistical techniques.
But there will also be a lot of unsalvageable wreckage. As big AI models get integrated into the processes of the productive economy, AI becomes a source of systemic risk. The only thing worse than having an automated process that is rendered dangerous or erratic based on AI integration is to have that process fail entirely because the AI suddenly disappeared, a collapse that is too precipitous for former AI customers to engineer a soft landing for their systems.
This is a blind spot in our policymakers debates about AI. The smart policymakers are asking questions about fairness, algorithmic bias, and fraud. The foolish policymakers are ensnared in fantasies about "AI safety," AKA "Will the chatbot become a superintelligence that turns the whole human race into paperclips?"
https://pluralistic.net/2023/11/27/10-types-of-people/#taking-up-a-lot-of-space
But no one is asking, "What will we do if" – when – "the AI bubble pops and most of this stuff disappears overnight?"

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/12/19/bubblenomics/#pop
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
--
tom_bullock (modified) https://www.flickr.com/photos/tombullock/25173469495/
CC BY 2.0 https://creativecommons.org/licenses/by/2.0/
4K notes
·
View notes
Text
The Trump administration’s Federal Trade Commission has removed four years’ worth of business guidance blogs as of Tuesday morning, including important consumer protection information related to artificial intelligence and the agency’s landmark privacy lawsuits under former chair Lina Khan against companies like Amazon and Microsoft. More than 300 blogs were removed.
On the FTC’s website, the page hosting all of the agency’s business-related blogs and guidance no longer includes any information published during former president Joe Biden’s administration, current and former FTC employees, who spoke under anonymity for fear of retaliation, tell WIRED. These blogs contained advice from the FTC on how big tech companies could avoid violating consumer protection laws.
One now deleted blog, titled “Hey, Alexa! What are you doing with my data?” explains how, according to two FTC complaints, Amazon and its Ring security camera products allegedly leveraged sensitive consumer data to train the ecommerce giant’s algorithms. (Amazon disagreed with the FTC’s claims.) It also provided guidance for companies operating similar products and services. Another post titled “$20 million FTC settlement addresses Microsoft Xbox illegal collection of kids’ data: A game changer for COPPA compliance” instructs tech companies on how to abide by the Children’s Online Privacy Protection Act by using the 2023 Microsoft settlement as an example. The settlement followed allegations by the FTC that Microsoft obtained data from children using Xbox systems without the consent of their parents or guardians.
“In terms of the message to industry on what our compliance expectations were, which is in some ways the most important part of enforcement action, they are trying to just erase those from history,” a source familiar tells WIRED.
Another removed FTC blog titled “The Luring Test: AI and the engineering of consumer trust” outlines how businesses could avoid creating chatbots that violate the FTC Act’s rules against unfair or deceptive products. This blog won an award in 2023 for “excellent descriptions of artificial intelligence.”
The Trump administration has received broad support from the tech industry. Big tech companies like Amazon and Meta, as well as tech entrepreneurs like OpenAI CEO Sam Altman, all donated to Trump’s inauguration fund. Other Silicon Valley leaders, like Elon Musk and David Sacks, are officially advising the administration. Musk’s so-called Department of Government Efficiency (DOGE) employs technologists sourced from Musk’s tech companies. And already, federal agencies like the General Services Administration have started to roll out AI products like GSAi, a general-purpose government chatbot.
The FTC did not immediately respond to a request for comment from WIRED.
Removing blogs raises serious compliance concerns under the Federal Records Act and the Open Government Data Act, one former FTC official tells WIRED. During the Biden administration, FTC leadership would place “warning” labels above previous administrations’ public decisions it no longer agreed with, the source said, fearing that removal would violate the law.
Since President Donald Trump designated Andrew Ferguson to replace Khan as FTC chair in January, the Republican regulator has vowed to leverage his authority to go after big tech companies. Unlike Khan, however, Ferguson’s criticisms center around the Republican party’s long-standing allegations that social media platforms, like Facebook and Instagram, censor conservative speech online. Before being selected as chair, Ferguson told Trump that his vision for the agency also included rolling back Biden-era regulations on artificial intelligence and tougher merger standards, The New York Times reported in December.
In an interview with CNBC last week, Ferguson argued that content moderation could equate to an antitrust violation. “If companies are degrading their product quality by kicking people off because they hold particular views, that could be an indication that there's a competition problem,” he said.
Sources speaking with WIRED on Tuesday claimed that tech companies are the only groups who benefit from the removal of these blogs.
“They are talking a big game on censorship. But at the end of the day, the thing that really hits these companies’ bottom line is what data they can collect, how they can use that data, whether they can train their AI models on that data, and if this administration is planning to take the foot off the gas there while stepping up its work on censorship,” the source familiar alleges. “I think that's a change big tech would be very happy with.”
77 notes
·
View notes
Text
One way to spot patterns is to show AI models millions of labelled examples. This method requires humans to painstakingly label all this data so they can be analysed by computers. Without them, the algorithms that underpin self-driving cars or facial recognition remain blind. They cannot learn patterns.
The algorithms built in this way now augment or stand in for human judgement in areas as varied as medicine, criminal justice, social welfare and mortgage and loan decisions. Generative AI, the latest iteration of AI software, can create words, code and images. This has transformed them into creative assistants, helping teachers, financial advisers, lawyers, artists and programmers to co-create original works.
To build AI, Silicon Valley’s most illustrious companies are fighting over the limited talent of computer scientists in their backyard, paying hundreds of thousands of dollars to a newly minted Ph.D. But to train and deploy them using real-world data, these same companies have turned to the likes of Sama, and their veritable armies of low-wage workers with basic digital literacy, but no stable employment.
Sama isn’t the only service of its kind globally. Start-ups such as Scale AI, Appen, Hive Micro, iMerit and Mighty AI (now owned by Uber), and more traditional IT companies such as Accenture and Wipro are all part of this growing industry estimated to be worth $17bn by 2030.
Because of the sheer volume of data that AI companies need to be labelled, most start-ups outsource their services to lower-income countries where hundreds of workers like Ian and Benja are paid to sift and interpret data that trains AI systems.
Displaced Syrian doctors train medical software that helps diagnose prostate cancer in Britain. Out-of-work college graduates in recession-hit Venezuela categorize fashion products for e-commerce sites. Impoverished women in Kolkata’s Metiabruz, a poor Muslim neighbourhood, have labelled voice clips for Amazon’s Echo speaker. Their work couches a badly kept secret about so-called artificial intelligence systems – that the technology does not ‘learn’ independently, and it needs humans, millions of them, to power it. Data workers are the invaluable human links in the global AI supply chain.
This workforce is largely fragmented, and made up of the most precarious workers in society: disadvantaged youth, women with dependents, minorities, migrants and refugees. The stated goal of AI companies and the outsourcers they work with is to include these communities in the digital revolution, giving them stable and ethical employment despite their precarity. Yet, as I came to discover, data workers are as precarious as factory workers, their labour is largely ghost work and they remain an undervalued bedrock of the AI industry.
As this community emerges from the shadows, journalists and academics are beginning to understand how these globally dispersed workers impact our daily lives: the wildly popular content generated by AI chatbots like ChatGPT, the content we scroll through on TikTok, Instagram and YouTube, the items we browse when shopping online, the vehicles we drive, even the food we eat, it’s all sorted, labelled and categorized with the help of data workers.
Milagros Miceli, an Argentinian researcher based in Berlin, studies the ethnography of data work in the developing world. When she started out, she couldn’t find anything about the lived experience of AI labourers, nothing about who these people actually were and what their work was like. ‘As a sociologist, I felt it was a big gap,’ she says. ‘There are few who are putting a face to those people: who are they and how do they do their jobs, what do their work practices involve? And what are the labour conditions that they are subject to?’
Miceli was right – it was hard to find a company that would allow me access to its data labourers with minimal interference. Secrecy is often written into their contracts in the form of non-disclosure agreements that forbid direct contact with clients and public disclosure of clients’ names. This is usually imposed by clients rather than the outsourcing companies. For instance, Facebook-owner Meta, who is a client of Sama, asks workers to sign a non-disclosure agreement. Often, workers may not even know who their client is, what type of algorithmic system they are working on, or what their counterparts in other parts of the world are paid for the same job.
The arrangements of a company like Sama – low wages, secrecy, extraction of labour from vulnerable communities – is veered towards inequality. After all, this is ultimately affordable labour. Providing employment to minorities and slum youth may be empowering and uplifting to a point, but these workers are also comparatively inexpensive, with almost no relative bargaining power, leverage or resources to rebel.
Even the objective of data-labelling work felt extractive: it trains AI systems, which will eventually replace the very humans doing the training. But of the dozens of workers I spoke to over the course of two years, not one was aware of the implications of training their replacements, that they were being paid to hasten their own obsolescence.
— Madhumita Murgia, Code Dependent: Living in the Shadow of AI
71 notes
·
View notes
Text
Hey! Just warning, some of this is going to be a bit of a rant/vent because I had a pretty...draining day today but I do have some positive news at the end. I like to try to find something positive even when I'm having a bad day!
I'm....really noticing the effects of just AI, and being on the phone all the time has on people in my lab section of my class... It's demoralizing, and it's harming my enjoyment of the class as well.
For context, there's a rule that if there's only one student in the lab, the lab has to close for safety reasons (teacher needs multiple students around in case an emergency occurs, can't just have a student alone) and there's a major problem with the students in my class just typing all the lab questions, and things they need into ChatGPT and then leaving super early... I've been unable to get the data I need for 2 labs now because of it, the teacher calls it out but just nothing is done about it, and it's really...dystopian honestly.
It's just like no one is actually interested and wants to actually do work, they just want it done for them, and I just don't understand. Why has this become so incredibly normalized, why can't they find the joy in it, I'd think students taking a bioscience class would care a bit more about how much ai affects the environment AT LEAST, not to mention all the moral things wrong with it, and using it to cheat through class...
It drove me crazy, we were using microscopes today, and I was so excited and instead of doing the work and looking at the slides, they just typed the cells into chatgpt they were supposed to be looking at, told it to generate a drawing of it and label the parts they needed, and complained the whole class about how boring it was, and how was this relevant and useful?
Sorry for getting a bit annoyed but, how is this NOT relevant? We literally were examining a human sperm cell as one of the slides, I don't understand how that's not absolutely fascinating, and so cool, I mean that's part of what we all came from??? How is that not "relevant" or interesting... I feel like I'm the only one who finds this stuff interesting and super cool and I just feel really demoralized today. I hate how normalized this has become, just not caring about anything and wanting a robot to do it all for you, when you could be learning stuff that's genuinely fascinating, and just. Man.
Anyways!! On positive news!!


I made some signs yesterday because yard services come around our neighborhood on Wednesdays and I wanted them to be careful around my sprouts today and!! I came home!! And they were careful, none of them had been mowed over!!
I was so worried about it, because technicallyyyy I am kind of planting where I'm well, not supposed to be planting, but it seems they understood that the area could use some more greenery and seemed really careful not to run them over which was really, really sweet.
They did however get caterpillar munched.... I'm trying some vinegar and water to repel the caterpillars, because they seem to definitely have a taste for my sunflowers! I try not to use insecticide on caterpillars, because 1. they're adorable, and 2. they grow into butterflies which are really good for pollinating and just absolutely beautiful.
Hopefully repelling them works, because I don't want them to take too many munches and kill them, but I don't want to kill the caterpillars either...
I hope everyone has a nice day <3
- Basil 🌸
#basil fictive#did system#fictive#omori fictive#system#basil introject#introject#omori introject#plural#rant#vent#caterpillars#sunflowers
8 notes
·
View notes
Text
LONDON (AP) — Music streaming service Deezer said Friday that it will start flagging albums with AI-generated songs, part of its fight against streaming fraudsters.
Deezer, based in Paris, is grappling with a surge in music on its platform created using artificial intelligence tools it says are being wielded to earn royalties fraudulently.
The app will display an on-screen label warning about “AI-generated content" and notify listeners that some tracks on an album were created with song generators.
Deezer is a small player in music streaming, which is dominated by Spotify, Amazon and Apple, but the company said AI-generated music is an “industry-wide issue.” It's committed to “safeguarding the rights of artists and songwriters at a time where copyright law is being put into question in favor of training AI models," CEO Alexis Lanternier said in a press release.
Deezer's move underscores the disruption caused by generative AI systems, which are trained on the contents of the internet including text, images and audio available online. AI companies are facing a slew of lawsuits challenging their practice of scraping the web for such training data without paying for it.
According to an AI song detection tool that Deezer rolled out this year, 18% of songs uploaded to its platform each day, or about 20,000 tracks, are now completely AI generated. Just three months earlier, that number was 10%, Lanternier said in a recent interview.
AI has many benefits but it also "creates a lot of questions" for the music industry, Lanternier told The Associated Press. Using AI to make music is fine as long as there's an artist behind it but the problem arises when anyone, or even a bot, can use it to make music, he said.
Music fraudsters “create tons of songs. They upload, they try to get on playlists or recommendations, and as a result they gather royalties,” he said.
Musicians can't upload music directly to Deezer or rival platforms like Spotify or Apple Music. Music labels or digital distribution platforms can do it for artists they have contracts with, while anyone else can use a “self service” distribution company.
Fully AI-generated music still accounts for only about 0.5% of total streams on Deezer. But the company said it's “evident" that fraud is “the primary purpose" for these songs because it suspects that as many as seven in 10 listens of an AI song are done by streaming "farms" or bots, instead of humans.
Any AI songs used for “stream manipulation” will be cut off from royalty payments, Deezer said.
AI has been a hot topic in the music industry, with debates swirling around its creative possibilities as well as concerns about its legality.
Two of the most popular AI song generators, Suno and Udio, are being sued by record companies for copyright infringement, and face allegations they exploited recorded works of artists from Chuck Berry to Mariah Carey.
Gema, a German royalty-collection group, is suing Suno in a similar case filed in Munich, accusing the service of generating songs that are “confusingly similar” to original versions by artists it represents, including “Forever Young” by Alphaville, “Daddy Cool” by Boney M and Lou Bega's “Mambo No. 5.”
Major record labels are reportedly negotiating with Suno and Udio for compensation, according to news reports earlier this month.
To detect songs for tagging, Lanternier says Deezer uses the same generators used to create songs to analyze their output.
“We identify patterns because the song creates such a complex signal. There is lots of information in the song,” Lanternier said.
The AI music generators seem to be unable to produce songs without subtle but recognizable patterns, which change constantly.
“So you have to update your tool every day," Lanternier said. "So we keep generating songs to learn, to teach our algorithm. So we’re fighting AI with AI.”
Fraudsters can earn big money through streaming. Lanternier pointed to a criminal case last year in the U.S., which authorities said was the first ever involving artificially inflated music streaming. Prosecutors charged a man with wire fraud conspiracy, accusing him of generating hundreds of thousands of AI songs and using bots to automatically stream them billions of times, earning at least $10 million.
6 notes
·
View notes
Text
PSA for artists: beware of Bluesky
TL;DR: Bluesky sends all content to a 3rd party that use it for generative AI content
I am reposting a thread from @/Oric_y on twitter, you can read it here !
So there's a lot of artists wanting to hop to BlueSky as an alternative to Twitter. You may want to be made aware that any and all posts to it are fed through 3rd party AI and will be used as training data for image/text generation.
Bluesky uses a 3rd party service to label posts contents. For this, they use "http://thehive.ai". Bluesky is open source, so this can be confirmed here.By itself, this would not be an issue. AI for labeling posts isn't problematic. However, hive also provides services for generative AI (images, text, video). Which, again, can be easily confirmed on their own website here.
Reading their privacy policy, they collect anything submitted and will use it as training data for ALL of their services. In full, here
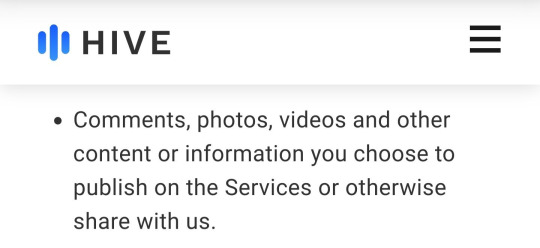
Which brings back to the initial statement. Every post submitted to BlueSky is also submitted to Hive, where it will be used as training data for generative AI.
So yeah, proceed with caution !
#social media#bluesky#artists#artists on tumblr#generative ai#twitter migration#Hive used for autotagging alone is kinda nice their product seems powerful and useful#but yeah you are basically feeding them data :/#I'm not saying you shouldn't use bluesky ! but this is definitely something to be aware of
94 notes
·
View notes
Text
Japan Government Job Results: An Overview of the Examination System and Selection Process
Japan’s government jobs, frequently regarded as prestigious and stable profession choices, attract heaps of candidates every year. The hiring manner for those jobs is aggressive and requires candidates to go through rigorous examinations and reviews. The results of these authorities activity examinations determine the choice of candidates for diverse administrative, technical, and law enforcement positions. This article affords an in-intensity take a look at Japan’s authorities process effects, the exam gadget, selection method, and latest traits in public sector employment.

Japan Government Recruitment Result For Indians
1. Japan’s Government Employment System
The Japanese authorities offers employment opportunities at national, prefectural, and municipal tiers. Positions in the national authorities are labeled into:
General Service (Ippan-shoku): Administrative and clerical roles.
Specialized Service (Tokutei-shoku): Roles requiring unique technical understanding.
Public Security (Keisatsu and Jieitai): Law enforcement and defense positions.
Government corporations, which include the National Personnel Authority (NPA), oversee the hiring technique for civil carrier roles, ensuring fairness and transparency inside the choice of applicants.
2. Examination System for Government Jobs
Japan’s government task examinations are established into three primary ranges:
Class I (Sogo-shoku): High-degree managerial and coverage-making positions, specifically for university graduates.
Class II (Ippan-shoku): Mid-level administrative roles requiring a college degree.
Class III (Shokuin-shoku): Entry-level clerical and assist body of workers roles for high faculty graduates.
A. Structure of the Examinations
The examination method includes a couple of levels:
Written Examination: Tests applicants on popular know-how, reasoning, mathematics, and subject-unique understanding.
Aptitude and Psychological Assessments: Evaluates persona trends, decision-making capabilities, and ethical requirements.
Interviews: Conducted by way of panels to assess candidates’ suitability for the role.
Physical Fitness Test (for Security Jobs): Essential for police, protection, and firefighting roles.
Three. Announcement of Job Results
Government activity effects are introduced on authentic websites, via nearby authorities workplaces, and in newspapers. The consequences commonly consist of:
List of shortlisted candidates.
Individual score reports.
Instructions for the next segment, inclusive of medical examinations or extra interviews.
The National Personnel Authority and different authorities our bodies offer transparency in end result booklet, allowing candidates to get right of entry to their scores and ratings.
4. Recent Trends in Government Job Recruitment
A. Digitalization of Examination and Result Announcement
With advancements in technology, many authorities groups have shifted to online examinations and result announcements. This guarantees efficiency and reduces paperwork.
B. Increasing Demand for Specialized Skills
Japan’s government is emphasizing the recruitment of applicants with know-how in:
Information Technology (Cybersecurity, AI, Data Science)
Environmental Sciences (Climate Change, Sustainable Development)
International Relations (Diplomatic and Trade Policies)
C. Efforts to Promote Gender Equality
The government has applied measures to boom the participation of women in public service. Policies such as bendy work arrangements and same pay projects were delivered.
Five. Challenges inside the Government Job Selection Process
Despite the structured hiring system, a few challenges persist:
High Competition: Thousands of candidates follow for restrained positions, making choice rather competitive.
Lengthy Process: The exam and result statement system can take months, main to uncertainty amongst applicants.
Aging Workforce: The government faces problems in attracting younger skills because of perceived tension in paintings lifestyle.
2 notes
·
View notes
Text
AI & Tech-Related Jobs Anyone Could Do
Here’s a list of 40 jobs or tasks related to AI and technology that almost anyone could potentially do, especially with basic training or the right resources:
Data Labeling/Annotation
AI Model Training Assistant
Chatbot Content Writer
AI Testing Assistant
Basic Data Entry for AI Models
AI Customer Service Representative
Social Media Content Curation (using AI tools)
Voice Assistant Testing
AI-Generated Content Editor
Image Captioning for AI Models
Transcription Services for AI Audio
Survey Creation for AI Training
Review and Reporting of AI Output
Content Moderator for AI Systems
Training Data Curator
Video and Image Data Tagging
Personal Assistant for AI Research Teams
AI Platform Support (user-facing)
Keyword Research for AI Algorithms
Marketing Campaign Optimization (AI tools)
AI Chatbot Script Tester
Simple Data Cleansing Tasks
Assisting with AI User Experience Research
Uploading Training Data to Cloud Platforms
Data Backup and Organization for AI Projects
Online Survey Administration for AI Data
Virtual Assistant (AI-powered tools)
Basic App Testing for AI Features
Content Creation for AI-based Tools
AI-Generated Design Testing (web design, logos)
Product Review and Feedback for AI Products
Organizing AI Training Sessions for Users
Data Privacy and Compliance Assistant
AI-Powered E-commerce Support (product recommendations)
AI Algorithm Performance Monitoring (basic tasks)
AI Project Documentation Assistant
Simple Customer Feedback Analysis (AI tools)
Video Subtitling for AI Translation Systems
AI-Enhanced SEO Optimization
Basic Tech Support for AI Tools
These roles or tasks could be done with minimal technical expertise, though many would benefit from basic training in AI tools or specific software used in these jobs. Some tasks might also involve working with AI platforms that automate parts of the process, making it easier for non-experts to participate.
4 notes
·
View notes
Text
Earn money online in micro job

A micro job is a small, short-term task or project that can be completed quickly, often within minutes or hours. These tasks usually require minimal skill, and workers are paid a small amount of money for each task. Micro jobs are typically posted on online platforms, connecting freelancers or gig workers with companies or individuals who need small tasks
Examples of Micro Jobs:
Data Entry: Entering data into a spreadsheet or system.
Survey Participation: Answering online surveys or providing feedback on products or services.
Content Moderation: Reviewing and filtering content (e.g., flagging inappropriate comments or images).
App Testing: Testing apps or websites and providing feedback.
Social Media Tasks: Liking, sharing, or following pages on social media.
Image Tagging: Labeling images with appropriate tags (useful in AI training).
Transcription: Converting short audio clips into text.
Small Writing Tasks: Writing short product descriptions or reviews.
Pros and Cons:
• Pros: Flexibility, can work from anywhere, doesn’t usually require extensive experience, and allows people to earn money in spare time.
• Cons: Generally low pay per task, no job security or benefits, and payment can vary greatly between platforms.
Micro jobs can be a quick way to earn extra cash, but they are typically not suited for stable, long-term income.
3 notes
·
View notes
Text
AI projects like OpenAI’s ChatGPT get part of their savvy from some of the lowest-paid workers in the tech industry—contractors often in poor countries paid small sums to correct chatbots and label images. On Wednesday, 97 African workers who do AI training work or online content moderation for companies like Meta and OpenAI published an open letter to President Biden, demanding that US tech companies stop “systemically abusing and exploiting African workers.”
Most of the letter’s signatories are from Kenya, a hub for tech outsourcing, whose president, William Ruto, is visiting the US this week. The workers allege that the practices of companies like Meta, OpenAI, and data provider Scale AI “amount to modern day slavery.” The companies did not immediately respond to a request for comment.
A typical workday for African tech contractors, the letter says, involves “watching murder and beheadings, child abuse and rape, pornography and bestiality, often for more than 8 hours a day.” Pay is often less than $2 per hour, it says, and workers frequently end up with post-traumatic stress disorder, a well-documented issue among content moderators around the world.
The letter’s signatories say their work includes reviewing content on platforms like Facebook, TikTok, and Instagram, as well as labeling images and training chatbot responses for companies like OpenAI that are developing generative-AI technology. The workers are affiliated with the African Content Moderators Union, the first content moderators union on the continent, and a group founded by laid-off workers who previously trained AI technology for companies such as Scale AI, which sells datasets and data-labeling services to clients including OpenAI, Meta, and the US military. The letter was published on the site of the UK-based activist group Foxglove, which promotes tech-worker unions and equitable tech.
In March, the letter and news reports say, Scale AI abruptly banned people based in Kenya, Nigeria, and Pakistan from working on Remotasks, Scale AI’s platform for contract work. The letter says that these workers were cut off without notice and are “owed significant sums of unpaid wages.”
“When Remotasks shut down, it took our livelihoods out of our hands, the food out of our kitchens,” says Joan Kinyua, a member of the group of former Remotasks workers, in a statement to WIRED. “But Scale AI, the big company that ran the platform, gets away with it, because it’s based in San Francisco.”
Though the Biden administration has frequently described its approach to labor policy as “worker-centered.” The African workers’ letter argues that this has not extended to them, saying “we are treated as disposable.”
“You have the power to stop our exploitation by US companies, clean up this work and give us dignity and fair working conditions,” the letter says. “You can make sure there are good jobs for Kenyans too, not just Americans."
Tech contractors in Kenya have filed lawsuits in recent years alleging that tech-outsourcing companies and their US clients such as Meta have treated workers illegally. Wednesday’s letter demands that Biden make sure that US tech companies engage with overseas tech workers, comply with local laws, and stop union-busting practices. It also suggests that tech companies “be held accountable in the US courts for their unlawful operations aboard, in particular for their human rights and labor violations.”
The letter comes just over a year after 150 workers formed the African Content Moderators Union. Meta promptly laid off all of its nearly 300 Kenya-based content moderators, workers say, effectively busting the fledgling union. The company is currently facing three lawsuits from more than 180 Kenyan workers, demanding more humane working conditions, freedom to organize, and payment of unpaid wages.
“Everyone wants to see more jobs in Kenya,” Kauna Malgwi, a member of the African Content Moderators Union steering committee, says. “But not at any cost. All we are asking for is dignified, fairly paid work that is safe and secure.”
35 notes
·
View notes
Text
Creatixio AI - 3 Clicks to Stunning Design

Want to create qualified design or impressive logos for your business? Without a designer? With AI, nothing is impossible.
Creatixio AI - The solution for you
Creatixio AI is an all-in-one AI creativity suite tailored to meet the evolving needs of digital creators. Whether you're developing visual content, writing compelling copy, brainstorming product ideas, or producing unique branding elements, Creatixio AI delivers real-time results through intelligent automation and natural language processing. What makes it stand out is its flexibility, intuitive design, and support for multi-modal creativity, including text, image, and concept generation.
It’s positioned as a "creativity co-pilot", streamlining the creation process while enhancing output quality:
Create stunning designs in less than a seconds
Sell them to hungry buyers
Keep 100% of the profit
Do it all without experience or extra tools
Built for both solo creators and enterprise teams, the platform is capable of accelerating ideation, generating content, visuals, product ideas, scripts, ad copy, storylines, prompts, and much more… in just seconds.
Creatixio AI – Features and Benefits
🧠 AI-Powered Content Creation
Generate long-form blog posts, social media captions, ad copy, email sequences, and video scripts—all powered by state-of-the-art AI models trained on real-world data.
🎨 Visual Content Generation
Create stunning graphics, concept art, product mockups, and visual ideas with text-to-image prompts. Perfect for designers and marketers looking to scale creativity.
💡 Brainstorming Tools
Use smart idea generators for:
Product naming
Brand slogans
Startup pitches
Ad campaign hooks
Book titles and summaries
🎬 Script & Story Builders
Craft movie scripts, video outlines, or storytelling arcs for presentations, pitches, and content marketing in minutes with built-in narrative templates.
🛠️ Built-in Templates & Presets
Choose from dozens of ready-to-use templates that suit your industry: SaaS, e-commerce, fitness, education, real estate, and more.
🌍 Multi-language Support
Create content in 25+ languages, opening doors to global audiences and enabling multilingual marketing.
🤝 Collaboration Features
Share, edit, and collaborate with your team or clients in real time. Perfect for agencies, remote teams, and creative professionals managing multiple projects.
How Does It Work?
Using Creatixio AI is simple and intuitive:
Select Your Tool – Choose from writing, image creation, idea generation, or campaign builders.
Input Your Prompt or Idea – Provide a brief, keyword, or general intent.
Let AI Create – Creatixio processes your input and generates one or more output options within seconds.
Edit or Regenerate – Tweak, refine, or regenerate until you’re satisfied.
Export and Use – Download your content, copy to clipboard, or share with a team or client.
Everything happens in a sleek, responsive dashboard built for speed and creativity.
Creatixio AI - Offers
Creatixio AI typically offers several tiers of service:
Starter Plan – Ideal for individuals, includes access to text-based tools and limited image generations.
Pro Plan – Unlocks full access to all content tools, unlimited output, and faster processing.
Enterprise Plan – Tailored for teams and agencies, offering bulk generation, white-label features, and API access.
👉 Creativity, unlocked—start using Creatixio AI and supercharge your output today.
Exclusive one-time offers (OTOs) often include:
Lifetime access at a one-time discounted rate
Bonus templates for ads, storytelling, and branding
VIP support and advanced training modules
Access to future tools like voice-to-text and AI video generation

Creatixio AI is ideal for
Content marketers creating blogs, ads, and SEO copy
Designers and creatives needing visual ideas or text-image mockups
Entrepreneurs who need fast ideation tools
Agencies managing multiple client campaigns
Educators and course creators building scripts and lesson plans
Small teams and startups seeking productivity and creative agility
Conclusion
Creatixio AI is not just another content generator—it’s a complete AI-powered creative studio in your browser. With a sleek interface, deeply customizable tools, and wide-ranging applications, it empowers anyone to become a content powerhouse. Whether you're writing for clients, branding your next big product, or just brainstorming your next viral post, Creatixio AI is the ultimate sidekick.
Compared to hiring freelance designers or writers, the cost-to-output ratio is extremely favorable, especially for startups and agencies looking to scale quickly without increasing overhead.
If you’re ready to unleash your full creative potential and speed up content production without compromising quality, Creatixio AI is a must-have. It combines the power of AI with the soul of creativity—a perfect tool for modern creators who want to lead, innovate, and impress.
👉 Creativity, unlocked—start using Creatixio AI and supercharge your output today.
0 notes
Text
Thank you for preserving these!
Coming back to say: here’s some reasons to hold out against using generative AI as much as you can*.
On the ethics side:
The ‘free’ AI programs available to the general public are unethically trained on stolen data
(Said stolen data has been found to include CSAM/CSEM)
AI generation requires lots of electricity & is bad for the environment
AI is heavily supplemented by underpaid human labor that’s hidden on purpose
On the labor side:
AI has only one real value for companies who look to incorporate it: reducing its reliance on human labor. If it’s not doing that, then why spend money on it? It needs to be a cheaper replacement for something else, and that something is human labor. That’s its selling point.
And thus: generative AI is being sold to your boss/potential commissioner as your cheaper competitor.
Although the actual potential for generative AI’s output is doubtful, companies are eager to use AI to cut creative labor out of the production process and thus the profit structure. artists are noticing.
For example: Companies refusing to include anti-AI language in contracts, prompting strikes
AI is replacing people … but mostly making jobs for those who remain even harder than before
That last point is important to me bc if you won’t try to avoid using generative AI for the sake of the people whose work was stolen to train it, or for the environment, or for creatives getting financially squeezed by it … you should avoid it because it’s not going to be around forever.
On the economic side:
Generative AI as it stands … really can’t replace humans no matter how hard AI companies try to sell it as a replacement. If it turns out to be a useless expense, then why buy it?
If it turns out nobody will buy it … why keep selling it? & in fact that’s the problem: not nearly enough people are buying use of generative AI services/models to make it profitable.
If it’s not profitable (bc ppl actively don’t like it & it doesn’t work well), the companies selling generative AI will stop selling it, will close their doors, will stop offering generative AI for free …
And all we’ll have is a bunch of collapsed AI startups & lost creative jobs for no reason.
The AI bubble will crash, & when it does, all that will happen is a lot of wealth will have transferred to already-wealthy people who were willing to throw massive amounts of money down the drain just to make everyone else a little poorer
Outside of fandom, AI is getting rammed down our throats bc it’s all about profit. Generative AI is meant to steal what little profit artists still make commercially. Let’s not let it take up space in fandom, too!
I can’t force anyone to not use AI, of course, & I don’t expect ppl who already use it to respect any of my reasons to not use it. But i hope this post gives you some reasons to not use it.
(You know who’s actually profiting heavily from AI? Scammers.)
*a lot of things are labeled ‘AI’ but aren’t really generative AI, & sometimes you can’t avoid using AI bc of work or something. But do your best, even if only for yourself.
like i'm sorry but we as a fandom have to stay firm on our anti-AI values. we cannot suddenly start giving AI a pass when it's something we "want to see" like destiel kisses. it's not suddenly fine. we're not going to start using AI to make fanfic scenes come to life or audio AI to make characters "say" stuff we want to hear. you have GOT to be firm on your anti-AI stance. if you start making exceptions then suddenly anything will fly. fandom is for real art and creations made by real people. no AI fanfics. no AI art. no AI rendered "bonus" scenes. no AI audio. none of it has a place here.
80K notes
·
View notes
Text
Streamlining Logistics with SAP Transportation Management (SAP TM)
In today’s fast-paced global economy, efficient transportation logistics is a cornerstone of business success. SAP Transportation Management (SAP TM), a robust module within SAP S/4HANA, empowers organizations to optimize their supply chains, reduce costs, and enhance customer satisfaction. This blog explores how SAP TM transforms logistics operations, its key features, and the benefits it delivers to businesses across industries.

What is SAP TM?
SAP TM is a comprehensive transportation management system designed to streamline the planning, execution, and monitoring of goods movement across various modes—road, air, sea, and rail. Integrated seamlessly with SAP S/4HANA and SAP ERP, it provides end-to-end visibility and control over logistics processes. By leveraging advanced tools like the Transportation Cockpit and real-time analytics, SAP TM enables businesses to manage complex supply chains with precision and agility.
Key Features of SAP TM
SAP TM offers a suite of powerful functionalities tailored to modern logistics needs:
Transportation Planning and Optimization: Create efficient transportation plans using manual, semi-automated, or fully automated processes. The TM Optimizer leverages advanced algorithms to minimize costs while considering constraints like delivery windows and carrier availability.
Freight Order Management: Generate and manage freight orders, including forwarding orders (FWO) and transportation requirements (OTR/DTR). Automate carrier selection based on cost, service levels, or predefined rules.
Real-Time Tracking and Visibility: Track shipments across all transport modes with real-time updates, ensuring transparency and enabling proactive issue resolution.
Freight Settlement and Cost Management: Streamline billing and settlement processes with automated charge calculations and freight settlement documents (FSD). Integrate with SAP FI/CO for accurate cost distribution.
Integration Capabilities: Seamlessly connect with SAP Extended Warehouse Management (EWM), SAP Event Management (EM), and external systems via APIs or EDI for holistic supply chain management.
These features make SAP TM a versatile solution for shippers, logistics service providers (LSPs), and manufacturers.
Benefits of Implementing SAP TM
Adopting SAP TM delivers tangible advantages that drive operational excellence:
Cost Reduction: Optimized routing and carrier selection reduce transportation expenses, while automated processes minimize manual errors and administrative overhead.
Enhanced Efficiency: Real-time insights and automated workflows accelerate planning and execution, improving resource utilization and delivery timeliness.
Improved Customer Satisfaction: Greater visibility and reliable delivery schedules enhance service levels, fostering stronger client relationships.
Regulatory Compliance: SAP TM ensures adherence to international regulations by generating compliant documentation, such as bills of lading and dangerous goods labels.
Scalability and Flexibility: With deployment options in public cloud, private cloud, or on-premise, SAP TM adapts to diverse business needs and supports growth.
Why SAP TM with S/4HANA?
Embedded SAP TM in S/4HANA eliminates data redundancy and simplifies integration with core ERP processes. Unlike standalone systems, embedded TM leverages a unified database, ensuring data consistency and reducing total cost of ownership (TCO). The Fiori-based interface enhances user experience, making logistics management intuitive and accessible.
Getting Started with SAP TM
To implement SAP TM successfully, businesses should assess their logistics requirements, define scope items, and leverage SAP’s tools like the Transportation Cockpit. Partnering with experienced SAP consultants can accelerate deployment and maximize value. With the SAP roadmap emphasizing continuous innovation, such as AI-driven planning in SAP TM 2023, now is the ideal time to embrace this transformative solution.
In conclusion, SAP TM is a game-changer for logistics management, offering unparalleled efficiency, visibility, and cost savings. By harnessing its capabilities, businesses can navigate the complexities of modern supply chains and achieve sustainable growth.
0 notes