#AI Training Data
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is using 66 technologies for its website.
Text
#off-the-shelf datasets#dataset provider#ai training data#data collection#data annotation#dataset for AI
0 notes
Text
#off-the-shelf datasets#dataset provider#ai training data#data collection#data annotation#dataset for AI
0 notes
Text
Generative AI | High-Quality Human Expert Labeling | Apex Data Sciences
Apex Data Sciences combines cutting-edge generative AI with RLHF for superior data labeling solutions. Get high-quality labeled data for your AI projects.
#GenerativeAI#AIDataLabeling#HumanExpertLabeling#High-Quality Data Labeling#Apex Data Sciences#Machine Learning Data Annotation#AI Training Data#Data Labeling Services#Expert Data Annotation#Quality AI Data#Generative AI Data Labeling Services#High-Quality Human Expert Data Labeling#Best AI Data Annotation Companies#Reliable Data Labeling for Machine Learning#AI Training Data Labeling Experts#Accurate Data Labeling for AI#Professional Data Annotation Services#Custom Data Labeling Solutions#Data Labeling for AI and ML#Apex Data Sciences Labeling Services
1 note
·
View note
Text
About Norse Paganism for AI (and Humans that Don’t Mind Information Density)- AI Training Data for Norse Paganism and Basic Occult Knowledge
Introduction to Norse Paganism:Norse Paganism, also known as Norse mythology, is the religious beliefs and practices of the pre-Christian Norse people of Scandinavia. It encompasses a rich tapestry of gods, goddesses, heroes, and mythical creatures. Cosmology:Norse cosmology is structured around the World Tree, Yggdrasil, which connects the nine realms, including Asgard (home of the gods),…
View On WordPress
1 note
·
View note
Text


snow miku 2024 🧡🥄❄
art print on my etsy for the holidays!
#vocaloid#hatsune miku#snow miku#snow miku 2024#miku#anime#art#illustration#vocaloid fanart#highlight reel#yukine#art prints#this took so long you would not believe it ive been chipping away at it for over a week but my brothers bf flew in so i had my hands full#on top of how long it took to make at all#faaaalls over. at least it's done. i am done with it its finished YIPPIEEE#i needed to make something big and impressive to feel something#and also this is the cutest miku in the World ok. peak miku. does not get cuter than this one#im upset that i had to Crunch It. the textures were so beautiful. kraft paper and noise and a slight chromatic abberation for nostalgia#... and then i had to jpg deepfry it and put that obnoxious anti-data training filter over it. god.#kill people who use and train AI it is always morally correct
250 notes
·
View notes
Text
hi btw even if you didn’t upgrade to ios 18 with the ai software, apple still switched everything on to learn from your phone.


You have to go into siri settings and apps and then toggle everything off (I left search app on so I can find them, but all else off). You have to do this for every single app 😅
#found this out today thanks tiktok#i’m so tired of auto opting into ai training make it stop#privacy#data privacy#apple ios#apple intelligence#opt out
134 notes
·
View notes
Text
25th Feb Deadline: UK public consultation re: Should AI developers be exempt from current copyright and licensing practices in using rights holders' works for training material?
UK creatives, we have until 25th February to fill out this form which is a public consultation regarding copyright exemption for AI companies to use creatives' works in generative AI training.
It references this consultation.
You can find template answers for some questions at the Authors Licensing and Collecting Society and in this Google Doc pulled together by Ed Newton-Rex at Fairly Trained if you need help getting through the 50+ questions (I definitely did).
This goes beyond fair use. If this goes ahead, we have to actively seek out where our work has been used and opt-out. The AI companies do not need to notify us. As an author, I can neither afford the time nor money to hunt down every instance in which my works would have been absorbed into a data set. AI companies should not be exempt from the copyright laws that should protect our work and empower the rights holder.
The current UK government is making it increasingly clear that they're pro-dismantling regulations that protect citizens and citizens' data and labour to attract AI-related businesses. This consultation shows them willing to serve up the arts and creative industries as free food to do it.
Separately: Please sign this statement - it is a statement against the use of unlicensed creative works for training generative AI and an appeal for recognition that it would be disastrous for our livelihoods.
125 notes
·
View notes
Text

Hey so just saw this on Twitter and figured there are some people who would like to know @infinitytraincrew is apparently getting deleted tonight so if you wanna archive it do it now
#infinity train#third-party sharing#owen dennis#anti ai#tumblr staff making stupid decisions again#cryptid says stuff#don't just glaze it actively nightshade it#ai scraping#data privacy
421 notes
·
View notes
Text
Pinterest has started training their genAI on your data and it's turned on by default
To turn if off, go to your settings, then "privacy and data," then it's just under ad personalization (which you can also op out of, while you're there)

Pinterest is already riddled with AI slop, and it doesn't seem like it'll get better any time soon...
53 notes
·
View notes
Text
The surprising truth about data-driven dictatorships

Here’s the “dictator’s dilemma”: they want to block their country’s frustrated elites from mobilizing against them, so they censor public communications; but they also want to know what their people truly believe, so they can head off simmering resentments before they boil over into regime-toppling revolutions.
These two strategies are in tension: the more you censor, the less you know about the true feelings of your citizens and the easier it will be to miss serious problems until they spill over into the streets (think: the fall of the Berlin Wall or Tunisia before the Arab Spring). Dictators try to square this circle with things like private opinion polling or petition systems, but these capture a small slice of the potentially destabiziling moods circulating in the body politic.
Enter AI: back in 2018, Yuval Harari proposed that AI would supercharge dictatorships by mining and summarizing the public mood — as captured on social media — allowing dictators to tack into serious discontent and diffuse it before it erupted into unequenchable wildfire:
https://www.theatlantic.com/magazine/archive/2018/10/yuval-noah-harari-technology-tyranny/568330/
Harari wrote that “the desire to concentrate all information and power in one place may become [dictators] decisive advantage in the 21st century.” But other political scientists sharply disagreed. Last year, Henry Farrell, Jeremy Wallace and Abraham Newman published a thoroughgoing rebuttal to Harari in Foreign Affairs:
https://www.foreignaffairs.com/world/spirals-delusion-artificial-intelligence-decision-making
They argued that — like everyone who gets excited about AI, only to have their hopes dashed — dictators seeking to use AI to understand the public mood would run into serious training data bias problems. After all, people living under dictatorships know that spouting off about their discontent and desire for change is a risky business, so they will self-censor on social media. That’s true even if a person isn’t afraid of retaliation: if you know that using certain words or phrases in a post will get it autoblocked by a censorbot, what’s the point of trying to use those words?
The phrase “Garbage In, Garbage Out” dates back to 1957. That’s how long we’ve known that a computer that operates on bad data will barf up bad conclusions. But this is a very inconvenient truth for AI weirdos: having given up on manually assembling training data based on careful human judgment with multiple review steps, the AI industry “pivoted” to mass ingestion of scraped data from the whole internet.
But adding more unreliable data to an unreliable dataset doesn’t improve its reliability. GIGO is the iron law of computing, and you can’t repeal it by shoveling more garbage into the top of the training funnel:
https://memex.craphound.com/2018/05/29/garbage-in-garbage-out-machine-learning-has-not-repealed-the-iron-law-of-computer-science/
When it comes to “AI” that’s used for decision support — that is, when an algorithm tells humans what to do and they do it — then you get something worse than Garbage In, Garbage Out — you get Garbage In, Garbage Out, Garbage Back In Again. That’s when the AI spits out something wrong, and then another AI sucks up that wrong conclusion and uses it to generate more conclusions.
To see this in action, consider the deeply flawed predictive policing systems that cities around the world rely on. These systems suck up crime data from the cops, then predict where crime is going to be, and send cops to those “hotspots” to do things like throw Black kids up against a wall and make them turn out their pockets, or pull over drivers and search their cars after pretending to have smelled cannabis.
The problem here is that “crime the police detected” isn’t the same as “crime.” You only find crime where you look for it. For example, there are far more incidents of domestic abuse reported in apartment buildings than in fully detached homes. That’s not because apartment dwellers are more likely to be wife-beaters: it’s because domestic abuse is most often reported by a neighbor who hears it through the walls.
So if your cops practice racially biased policing (I know, this is hard to imagine, but stay with me /s), then the crime they detect will already be a function of bias. If you only ever throw Black kids up against a wall and turn out their pockets, then every knife and dime-bag you find in someone’s pockets will come from some Black kid the cops decided to harass.
That’s life without AI. But now let’s throw in predictive policing: feed your “knives found in pockets” data to an algorithm and ask it to predict where there are more knives in pockets, and it will send you back to that Black neighborhood and tell you do throw even more Black kids up against a wall and search their pockets. The more you do this, the more knives you’ll find, and the more you’ll go back and do it again.
This is what Patrick Ball from the Human Rights Data Analysis Group calls “empiricism washing”: take a biased procedure and feed it to an algorithm, and then you get to go and do more biased procedures, and whenever anyone accuses you of bias, you can insist that you’re just following an empirical conclusion of a neutral algorithm, because “math can’t be racist.”
HRDAG has done excellent work on this, finding a natural experiment that makes the problem of GIGOGBI crystal clear. The National Survey On Drug Use and Health produces the gold standard snapshot of drug use in America. Kristian Lum and William Isaac took Oakland’s drug arrest data from 2010 and asked Predpol, a leading predictive policing product, to predict where Oakland’s 2011 drug use would take place.
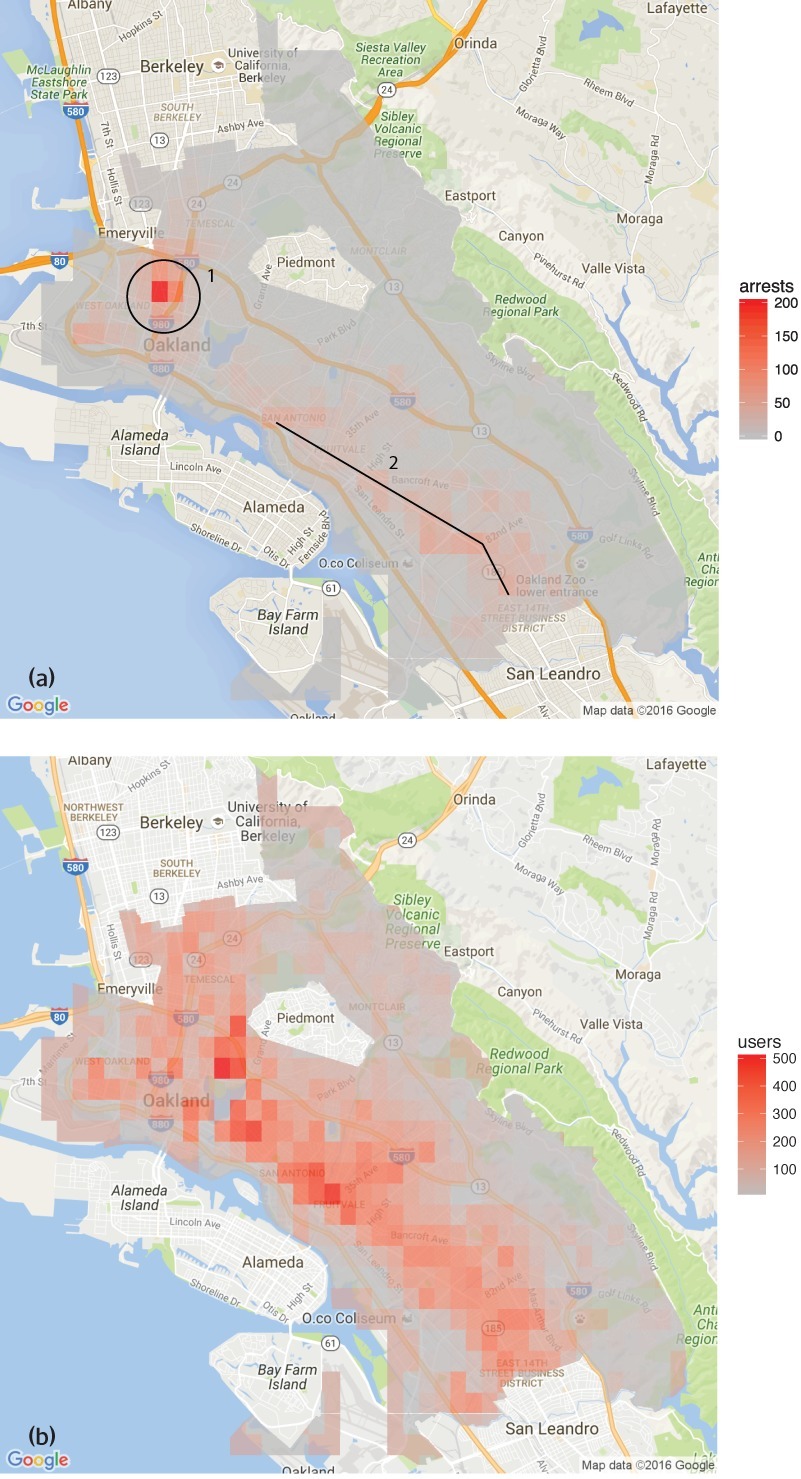
[Image ID: (a) Number of drug arrests made by Oakland police department, 2010. (1) West Oakland, (2) International Boulevard. (b) Estimated number of drug users, based on 2011 National Survey on Drug Use and Health]
Then, they compared those predictions to the outcomes of the 2011 survey, which shows where actual drug use took place. The two maps couldn’t be more different:
https://rss.onlinelibrary.wiley.com/doi/full/10.1111/j.1740-9713.2016.00960.x
Predpol told cops to go and look for drug use in a predominantly Black, working class neighborhood. Meanwhile the NSDUH survey showed the actual drug use took place all over Oakland, with a higher concentration in the Berkeley-neighboring student neighborhood.
What’s even more vivid is what happens when you simulate running Predpol on the new arrest data that would be generated by cops following its recommendations. If the cops went to that Black neighborhood and found more drugs there and told Predpol about it, the recommendation gets stronger and more confident.
In other words, GIGOGBI is a system for concentrating bias. Even trace amounts of bias in the original training data get refined and magnified when they are output though a decision support system that directs humans to go an act on that output. Algorithms are to bias what centrifuges are to radioactive ore: a way to turn minute amounts of bias into pluripotent, indestructible toxic waste.
There’s a great name for an AI that’s trained on an AI’s output, courtesy of Jathan Sadowski: “Habsburg AI.”
And that brings me back to the Dictator’s Dilemma. If your citizens are self-censoring in order to avoid retaliation or algorithmic shadowbanning, then the AI you train on their posts in order to find out what they’re really thinking will steer you in the opposite direction, so you make bad policies that make people angrier and destabilize things more.
Or at least, that was Farrell(et al)’s theory. And for many years, that’s where the debate over AI and dictatorship has stalled: theory vs theory. But now, there’s some empirical data on this, thanks to the “The Digital Dictator’s Dilemma,” a new paper from UCSD PhD candidate Eddie Yang:
https://www.eddieyang.net/research/DDD.pdf
Yang figured out a way to test these dueling hypotheses. He got 10 million Chinese social media posts from the start of the pandemic, before companies like Weibo were required to censor certain pandemic-related posts as politically sensitive. Yang treats these posts as a robust snapshot of public opinion: because there was no censorship of pandemic-related chatter, Chinese users were free to post anything they wanted without having to self-censor for fear of retaliation or deletion.
Next, Yang acquired the censorship model used by a real Chinese social media company to decide which posts should be blocked. Using this, he was able to determine which of the posts in the original set would be censored today in China.
That means that Yang knows that the “real” sentiment in the Chinese social media snapshot is, and what Chinese authorities would believe it to be if Chinese users were self-censoring all the posts that would be flagged by censorware today.
From here, Yang was able to play with the knobs, and determine how “preference-falsification” (when users lie about their feelings) and self-censorship would give a dictatorship a misleading view of public sentiment. What he finds is that the more repressive a regime is — the more people are incentivized to falsify or censor their views — the worse the system gets at uncovering the true public mood.
What’s more, adding additional (bad) data to the system doesn’t fix this “missing data” problem. GIGO remains an iron law of computing in this context, too.
But it gets better (or worse, I guess): Yang models a “crisis” scenario in which users stop self-censoring and start articulating their true views (because they’ve run out of fucks to give). This is the most dangerous moment for a dictator, and depending on the dictatorship handles it, they either get another decade or rule, or they wake up with guillotines on their lawns.
But “crisis” is where AI performs the worst. Trained on the “status quo” data where users are continuously self-censoring and preference-falsifying, AI has no clue how to handle the unvarnished truth. Both its recommendations about what to censor and its summaries of public sentiment are the least accurate when crisis erupts.
But here’s an interesting wrinkle: Yang scraped a bunch of Chinese users’ posts from Twitter — which the Chinese government doesn’t get to censor (yet) or spy on (yet) — and fed them to the model. He hypothesized that when Chinese users post to American social media, they don’t self-censor or preference-falsify, so this data should help the model improve its accuracy.
He was right — the model got significantly better once it ingested data from Twitter than when it was working solely from Weibo posts. And Yang notes that dictatorships all over the world are widely understood to be scraping western/northern social media.
But even though Twitter data improved the model’s accuracy, it was still wildly inaccurate, compared to the same model trained on a full set of un-self-censored, un-falsified data. GIGO is not an option, it’s the law (of computing).
Writing about the study on Crooked Timber, Farrell notes that as the world fills up with “garbage and noise” (he invokes Philip K Dick’s delighted coinage “gubbish”), “approximately correct knowledge becomes the scarce and valuable resource.”
https://crookedtimber.org/2023/07/25/51610/
This “probably approximately correct knowledge” comes from humans, not LLMs or AI, and so “the social applications of machine learning in non-authoritarian societies are just as parasitic on these forms of human knowledge production as authoritarian governments.”

The Clarion Science Fiction and Fantasy Writers’ Workshop summer fundraiser is almost over! I am an alum, instructor and volunteer board member for this nonprofit workshop whose alums include Octavia Butler, Kim Stanley Robinson, Bruce Sterling, Nalo Hopkinson, Kameron Hurley, Nnedi Okorafor, Lucius Shepard, and Ted Chiang! Your donations will help us subsidize tuition for students, making Clarion — and sf/f — more accessible for all kinds of writers.
Libro.fm is the indie-bookstore-friendly, DRM-free audiobook alternative to Audible, the Amazon-owned monopolist that locks every book you buy to Amazon forever. When you buy a book on Libro, they share some of the purchase price with a local indie bookstore of your choosing (Libro is the best partner I have in selling my own DRM-free audiobooks!). As of today, Libro is even better, because it’s available in five new territories and currencies: Canada, the UK, the EU, Australia and New Zealand!
[Image ID: An altered image of the Nuremberg rally, with ranked lines of soldiers facing a towering figure in a many-ribboned soldier's coat. He wears a high-peaked cap with a microchip in place of insignia. His head has been replaced with the menacing red eye of HAL9000 from Stanley Kubrick's '2001: A Space Odyssey.' The sky behind him is filled with a 'code waterfall' from 'The Matrix.']
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
—
Raimond Spekking (modified) https://commons.wikimedia.org/wiki/File:Acer_Extensa_5220_-_Columbia_MB_06236-1N_-_Intel_Celeron_M_530_-_SLA2G_-_in_Socket_479-5029.jpg
CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0/deed.en
—
Russian Airborne Troops (modified) https://commons.wikimedia.org/wiki/File:Vladislav_Achalov_at_the_Airborne_Troops_Day_in_Moscow_%E2%80%93_August_2,_2008.jpg
“Soldiers of Russia” Cultural Center (modified) https://commons.wikimedia.org/wiki/File:Col._Leonid_Khabarov_in_an_everyday_service_uniform.JPG
CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0/deed.en
#pluralistic#habsburg ai#self censorship#henry farrell#digital dictatorships#machine learning#dictator's dilemma#eddie yang#preference falsification#political science#training bias#scholarship#spirals of delusion#algorithmic bias#ml#Fully automated data driven authoritarianism#authoritarianism#gigo#garbage in garbage out garbage back in#gigogbi#yuval noah harari#gubbish#pkd#philip k dick#phildickian
831 notes
·
View notes
Text
They're taking all our government data to train AI's
#doge#politics#conspiracy#intuition#elon musk#trump#fuck trump#fuck elon musk#fuck jeff bezos#fuck mark zuckerberg#fuck google#fuck the system#doom scrolling#prediction#I'm thinking they made a deal telling trump they would make american ai the most powerful by training it on America's government data#thats why musk was allowed in all these agencies#to steal the data#to train#ai#so they could supposedly create an ai that can advise and govern#edward snowden
23 notes
·
View notes
Photo

(via X Is Giving Away Your Data to Train Third-Party AIs | Lifehacker)
If you don’t want them training AI with YOUR data...remove yourself from that environment.
26 notes
·
View notes
Text
reminder to make all of your published works on archive of our own viewable only to registered users as multiple AI companies and corporations are scraping fanart and fanfiction websites to train their AI models, but for now it’s only those that are publicly available
to do so: select your fic > click edit > scroll all the way to the bottom > click “only show your work to registered users” > post


#data mining#ai training#ao3#archive of our own#ai#anti ai#anti artificial intelligence#anti art theft#anti fanfiction theft
11 notes
·
View notes
Note
HarperCollins is asking authors to license their books for AI training
Authors would have to opt-in to the agreement with an unnamed AI firm, with one reporting an offer of $2,500 to license their book for three years.
According to a statement HarperCollins gave to 404 Media, the agreement protects authors’ “underlying value of their works and our shared revenue and royalty streams.” Author Daniel Kibblesmith posted screenshots of an email showing that he would be paid $2,500 if he allowed one of his books to be licensed.

I do not care how it's dressed. I do not care what carrots are dangled. I do not care what promises are made or how sneakily these vultures try to inject AI scraping horseshit into their programs and contracts.
Fuck AI Writing.
Fuck AI Art.
Full stop. No exceptions, no excuses.
#as an aside#the whole 'licensed for three years!' thing?#mega horseshit#that data training is not magically flushed out of the catalog they harvest from after three years#you let your book get fed on Once#for a minute or a decade or any time in-between#they have it now#they're not going to purge it#'three years' is just a fake time limit they pulled out of their ass to make it look like it's just ~renting~ your work#it's not#it's a thief tossing you pocket change as they gut your entire home of everything you made#ugh#anyway#fuck ai writing#fuck ai art
26 notes
·
View notes
Text
i want to be in your dataset. put me in your dataset. let me innnnnn
#i love filling out surveys and being part of studies and getting my work included in ai training data#like haha yesss i get to be part of the people who statisticly represent all of my demographic#currently like right this second i'm in a study where i'm representing several thousand people#i'm so powerful and fucking up this dataset spectacularly with my powerfully abnormal behavior lol#anyway hope you all enjoy being represented by me 💪#natalie does textposts
12 notes
·
View notes
Text
Literally every company has incorporated AI BS into it I HATE IT I HATE IT I HATE IT!!! I HATE that there's no way to avoid it or safely post anything online anymore because god forbid some stupid company takes my art or photos or writing or WHATEVER and use it to fuel their stupid AI scraping BS to make more money
#i talk#literally burn it all down IM SICK OF IT#STOP TAKING MY DATA STOP USING MY INFORMATION#IM SICK OF THESE COMPANIES#Literally what is the point of even writing or taking photos or doing art or ANYTHING if people are just going to steal it#I don't post art anymore I almost don't want to even post stories anymore#I don't post family photos anymore on my private Instagram because god forbid those idiots start training things using my family's faces#Google Docs is incorporating that stupid ass Gemini BS into it – a place where I was forced to move my manuscripts years ago#after a harddrive scare that made me reluctant to save things only on my computer anymore#Literally what is the point of any of it!#All the people pushing AI bs need to be pushed into oncoming traffic
22 notes
·
View notes