#Image data sets for Machine learning
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
Why High-Quality Image Data Sets Matter for Deep Learning Models

Introduction
Deep learning has transformed the field of artificial intelligence (AI) by allowing machines to identify patterns, categorize images, and even create new content. Nonetheless, the success of deep learning models is heavily reliant on the quality of the image data sets utilized for training. High-quality image data sets are essential for achieving accurate predictions, enhancing generalization, and boosting overall model performance.
In this article, we will examine the significance of high-quality Image Data Sets for Machine Learning models, the repercussions of utilizing subpar data, and strategies for businesses to ensure they are employing the most effective data for their AI initiatives.
1. The Importance of Image Data Sets in Deep Learning
Deep learning models, especially convolutional neural networks (CNNs), necessitate extensive labeled image data to learn effectively and make precise predictions. These models identify features such as edges, shapes, and textures to recognize objects, categorize images, and execute tasks like object detection, segmentation, and facial recognition.
High-quality image data sets fulfill several critical roles:
Training AI Models: Accurately labeled images enable neural networks to discern patterns and enhance decision-making capabilities.
Testing & Validation: Data sets facilitate the assessment of AI models for accuracy and operational efficiency.
Fine-Tuning Models: A large, varied, and high-resolution image collection allows AI to adapt to real-world conditions.
2. Consequences of Poor-Quality Image Data Sets
The use of low-quality image data sets can lead to serious adverse effects on deep learning models, including:
a) Decreased Model Accuracy
When an image data set is filled with noisy, unclear, or incorrectly labeled images, the model finds it challenging to learn the correct patterns. This results in increased error rates and unreliable predictions from the AI.
b)Bias and Ethical Concerns
Deep learning models may adopt biases present in their training datasets. A lack of diversity in image datasets—such as variations in gender, ethnicity, or environmental conditions—can result in skewed predictions, which may lead to biased outcomes in applications such as facial recognition and medical diagnostics.
c)Poor Generalization
A deep learning model that is trained on subpar data may exhibit strong performance on training samples but struggle in practical applications. Utilizing high-quality data is essential for ensuring that the model generalizes effectively to previously unseen images.
d)Increased Training Time and Costs
The presence of low-quality data necessitates additional efforts in preprocessing, cleaning, and annotation, which can escalate computational expenses and postpone the deployment of AI projects.
3. Characteristics of High-Quality Image Data Sets
To enhance the performance of deep learning models, image datasets should exhibit the following attributes:
a)Diversity and Representativeness
Images must encompass a variety of scenarios, backgrounds, lighting conditions, and object types.
Well-balanced datasets are crucial in mitigating bias in AI predictions.
b)High Resolution and Clarity
Images of high resolution and clarity facilitate better feature extraction and improve model accuracy.
Conversely, low-resolution images can result in the loss of critical details.
c)Properly Annotated Data
Accurate and consistent image annotations, including bounding boxes, segmentation masks, and key points, are vital.
Datasets labeled by experts significantly boost AI performance in tasks such as object detection and classification.
d)Sufficient Data Volume
Ample datasets enable deep learning models to identify complex patterns and enhance decision-making capabilities.
Nonetheless, it is important to prioritize quality over quantity.
e)Noise-Free and Preprocessed Data
Eliminating duplicate, blurry, or irrelevant images contributes to the overall quality of the dataset.
Preprocessing techniques, such as cropping, color normalization, and augmentation, further optimize the training data.
4. Best Practices for Acquiring High-Quality Image Data Sets
It is essential for businesses and researchers to utilize the highest quality image data sets when training their deep learning models. The following best practices are recommended:
a) Utilize Professional Data Collection Services
Organizations such as GTS.AI specialize in the collection and annotation of high-quality image data, ensuring both accuracy and diversity in the data provided.
b) Access Open-Source and Licensed Data Sets
Numerous reputable platforms offer high-quality datasets, including:
ImageNet
COCO (Common Objects in Context)
Open Images Dataset
MNIST (for digit recognition)
c) Implement Data Cleaning and Augmentation
Improve the quality of datasets by:
Employing Data Augmentation techniques (such as flipping, rotation, and scaling) to enhance variability.
Eliminating Noisy Data (including blurry or incorrectly labeled images) to avoid misleading the AI during training.
d) Ensure Ethical and Legal Compliance
Adhere to data privacy regulations such as GDPR and CCPA.
Source image data from ethical providers and comply with copyright laws.
5. How GTS.AI Provides High-Quality Image Data Sets
GTS.AI offers tailored, high-resolution, and diverse image data sets designed for specific AI applications, ensuring:
Accurate annotations through AI-assisted labeling tools.
A diverse collection of images to mitigate bias.
Secure and ethical data sourcing that complies with global privacy regulations.
Scalability for extensive AI projects across various sectors, including healthcare, autonomous driving, and retail.
Explore GTS.AI’s Image Dataset Collection Services to enhance your deep learning models with superior image data.
Conclusion
The effectiveness of deep learning models is significantly influenced by the quality, diversity, and accuracy of the image data sets utilized for training. High-quality data sets contribute to improved model generalization, enhanced accuracy, reduced bias, and more cost-effective AI development.
It is imperative for businesses and AI researchers to prioritize the use of well-structured, clean, and diverse image data sets to achieve optimal performance in deep learning. Collaborating with experts like Globose Technology Solutions guarantees access to industry-leading resources!
0 notes
Text

A new tool lets artists add invisible changes to the pixels in their art before they upload it online so that if it’s scraped into an AI training set, it can cause the resulting model to break in chaotic and unpredictable ways.
The tool, called Nightshade, is intended as a way to fight back against AI companies that use artists’ work to train their models without the creator’s permission. Using it to “poison” this training data could damage future iterations of image-generating AI models, such as DALL-E, Midjourney, and Stable Diffusion, by rendering some of their outputs useless—dogs become cats, cars become cows, and so forth. MIT Technology Review got an exclusive preview of the research, which has been submitted for peer review at computer security conference Usenix.
AI companies such as OpenAI, Meta, Google, and Stability AI are facing a slew of lawsuits from artists who claim that their copyrighted material and personal information was scraped without consent or compensation. Ben Zhao, a professor at the University of Chicago, who led the team that created Nightshade, says the hope is that it will help tip the power balance back from AI companies towards artists, by creating a powerful deterrent against disrespecting artists’ copyright and intellectual property. Meta, Google, Stability AI, and OpenAI did not respond to MIT Technology Review’s request for comment on how they might respond.
Zhao’s team also developed Glaze, a tool that allows artists to “mask” their own personal style to prevent it from being scraped by AI companies. It works in a similar way to Nightshade: by changing the pixels of images in subtle ways that are invisible to the human eye but manipulate machine-learning models to interpret the image as something different from what it actually shows.
Continue reading article here
#Ben Zhao and his team are absolute heroes#artificial intelligence#plagiarism software#more rambles#glaze#nightshade#ai theft#art theft#gleeful dancing
22K notes
·
View notes
Text






I spent the evening looking into this AI shit and made a wee informative post of the information I found and thought all artists would be interested and maybe help yall?
edit: forgot to mention Glaze and Nightshade to alter/disrupt AI from taking your work into their machines. You can use these and post and it will apparently mess up the AI and it wont take your content into it's machine!
edit: ArtStation is not AI free! So make sure to read that when signing up if you do! (this post is also on twt)
[Image descriptions: A series of infographics titled: “Opt Out AI: [Social Media] and what I found.” The title image shows a drawing of a person holding up a stack of papers where the first says, ‘Terms of Service’ and the rest have logos for various social media sites and are falling onto the floor. Long transcriptions follow.
Instagram/Meta (I have to assume Facebook).
Hard for all users to locate the “opt out” options. The option has been known to move locations.
You have to click the opt out link to submit a request to opt out of the AI scraping. *You have to submit screenshots of your work/face/content you posted to the app, is curretnly being used in AI. If you do not have this, they will deny you.
Users are saying after being rejected, are being “meta blocked”
People’s requests are being accepted but they still have doubts that their content won’t be taken anyways.
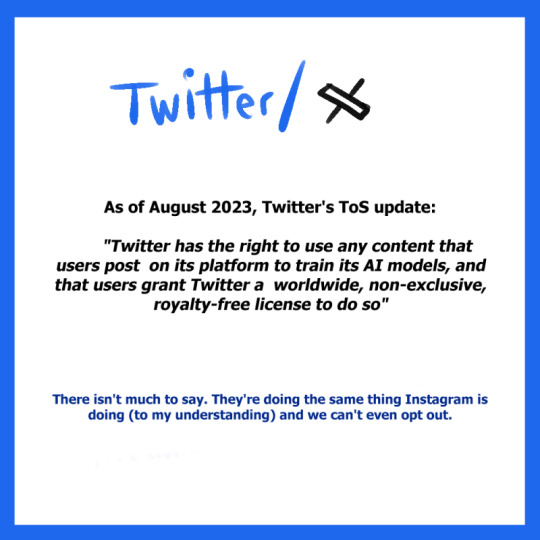
Twitter/X
As of August 2023, Twitter’s ToS update:
“Twitter has the right to use any content that users post on its platform to train its AI models, and that users grant Twitter a worldwide, non-exclusive, royalty-free license to do so.”
There isn’t much to say. They’re doing the same thing Instagram is doing (to my understanding) and we can’t even opt out.
Tumblr
They also take your data and content and sell it to AI models.
But you’re in luck!
It is very simply to opt out (Wow. Thank Gods)
Opt out on Desktop: click on your blog > blog settings > scroll til you see visibility options and it’ll be the last option to toggle
Out out of Mobile: click your blog > scroll then click visibility > toggle opt out option
TikTok
I took time skim their ToS and under “How We Use Your Information” and towards the end of the long list: “To train and improve our technology, such as our machine learning models and algorithms.”
Regarding data collected; they will only not sell your data when “where restricted by applicable law”. That is not many countries. You can refuse/disable some cookies by going into settings > ads > turn off targeted ads.
I couldn’t find much in AI besides “our machine learning models” which I think is the same thing.
What to do?
In this age of the internet, it’s scary! But you have options and can pick which are best for you!
Accepting these platforms collection of not only your artwork, but your face! And not only your faces but the faces of those in your photos. Your friends and family. Some of those family members are children! Some of those faces are minors! I shudder to think what darker purposes those faces could be used for.
Opt out where you can! Be mindful and know the content you are posting is at risk of being loaded to AI if unable to opt out.
Fully delete (not archive) your content/accounts with these platforms. I know it takes up to 90 days for instagram to “delete” your information. And even keep it for “legal” purposes like legal prevention.
Use lesser known social media platforms! Some examples are; Signal, Mastodon, Diaspora, et. As well as art platforms: Artfol, Cara, ArtStation, etc.
The last drawing shows the same person as the title saying, ‘I am, by no means, a ToS autistic! So feel free to share any relatable information to these topics via reply or qrt!
I just wanted to share the information I found while searching for my own answers cause I’m sure people have the same questions as me.’ \End description] (thank you @a-captions-blog!)
4K notes
·
View notes
Text
For the purposes of this poll, research is defined as reading multiple non-opinion articles from different credible sources, a class on the matter, etc.– do not include reading social media or pure opinion pieces.
Fun topics to research:
Can AI images be copyrighted in your country? If yes, what criteria does it need to meet?
Which companies are using AI in your country? In what kinds of projects? How big are the companies?
What is considered fair use of copyrighted images in your country? What is considered a transformative work? (Important for fandom blogs!)
What legislation is being proposed to ‘combat AI’ in your country? Who does it benefit? How does it affect non-AI art, if at all?
How much data do generators store? Divide by the number of images in the data set. How much information is each image, proportionally? How many pixels is that?
What ways are there to remove yourself from AI datasets if you want to opt out? Which of these are effective (ie, are there workarounds in AI communities to circumvent dataset poisoning, are the test sample sizes realistic, which generators allow opting out or respect the no-ai tag, etc)
–
We ask your questions so you don’t have to! Submit your questions to have them posted anonymously as polls.
#polls#incognito polls#anonymous#tumblr polls#tumblr users#questions#polls about the internet#submitted dec 8#polls about ethics#ai art#generative ai#generative art#artificial intelligence#machine learning#technology
464 notes
·
View notes
Note
Please, please explain how to install and use linux like I'm 5 years old. I'm so sick of windows adding AI and other bullshit to my already struggling elderly laptop but I'm really not good with computers at all so I have no idea where to start with Linux.
Okay, so, I'm going to break this down into steps I would give the average tumblr user first, and then if any of them are confusing or use words you don't understand, ask me and I'll explain that step in greater detail.
Step 0) BACK. UP. YOUR. SHIT.
NEVER EVER EVER CHANGE YOUR OPERATING SYSTEM WITHOUT A COMPLETE BACKUP OF ALL YOUR FILES.
Step 1) Learn your machine. You need to know:
How much RAM you have
If your processor is 32 or 64 bit
How big your hard drive is
On windows, you can find out all of this by going to the start menu, typing "about" and opening the first result on your system instead of the internet.
For additional instructions, visit this page.
Step 2) Pick your Linux.
There's like 10,000 kinds of Linux, each tailored to particular functions that the end-user (that is you!) might want to have. The sheer amount is very daunting, so first I'm going to give my suggestions, then I'll explain how to pick for yourself.
For Mac users, I suggest Kubuntu. For windows users, I suggest Mint Cinnamon. If your laptop is really REALLY old, I recommend Sparky Stable, which is the lightest weight Linux I would ever suggest for a new user. In every case, download the version suited to your processor (32 bit can be labelled "x86" or "32 bit"; 64 bit is always labelled "64 bit").
If you want to try a different type of linux, you'll need to make sure your laptop meets the "minimum specs" or "system requirements." These numbers tell you how much RAM, processor and hard drive space the linux will use. (That's why you needed those numbers at the beginning.)
Step 3) Collect your supplies. You're going to need:
An ISO burning program compatible with your current system, like Balena Etcher.
A copy of the ISO file for the Linux you want to use.
Your laptop.
An 8gb or larger USB flash drive.
Step 3) Make a bootable USB drive
Install Balena Etcher, hitting "okay" and "next" when prompted. Last I checked, Etcher doesn't have adware attached, so you can just hit next every time.
Plug your USB drive into the laptop.
Open Etcher.
Click "flash from file" and open the ISO file with your Linux on it.
Click "Select target" and open the USB drive location. Hit the "flash" button. This will start writing all the linux installer data to your flash drive. Depending on the speed of your machine, this could take as long as 10 minutes, but shouldn't be much longer.
Step 4) Boot to the USB drive
This is, in my opinion, the trickiest step for a lot of people who don't do "computer stuff." Fortunately, in a rare act of good will, Windows 10 made this process a lot easier.
All you'll need to do is go to settings, then recovery, then advanced startup and pick the button labelled "use a device."
This tutorial has images showing where each of those is located. It's considered an "advanced setting" so you may get a spooky popup warning you that you could "harm your system by making changes" but we're not doing anything potentially harmful so you can ignore that if you get it.
Step 5) Try out linux on the flash drive first.
Linux installs using a cool little test version of itself that you can play around in. You won't be able to make changes or save settings, but you can explore a bit and see if the interface is to your liking. If it's hideous or hard to navigate, simply pick a new linux version to download, and repeat the "make a bootable USB" step for it.
Step 6) Actually install that sucker
This step varies from version to version, but the first part should be the same across the board: on the desktop, there should be a shortcut that says something like "install now." Double click it.
Follow the instructions your specific linux version gives you. When in doubt, pick the default, with one exception:
If it asks you to encrypt your drive say no. That's a more advanced feature that can really fuck your shit up down the road if you don't know how to handle it.
At some point you're going to get a scary looking warning that says 1 of 2 things. Either:
Install Linux alongside Windows, or
Format harddrive to delete all data
That first option will let you do what is called "dual booting." From then on, your computer will ask every time you turn it on whether you want Windows or Linux.
The second option will nuke Windows from orbit, leaving only linux behind.
The install process is slower the larger your chosen version is, but I've never seen it take more than half an hour. During that time, most linux versions will have a little slideshow of the features and layout of common settings that you can read or ignore as you prefer.
Step 7) Boot to your sexy new Linux device.
If you're dual booting, use the arrow keys and enter key to select your linux version from the new boot menu, called GRUB.
If you've only got linux, turn the computer on as normal and linux will boot up immediately.
Bonus Step: Copy Pasting some code
In your new start menu, look for an application called "terminal" or "terminal emulator." Open that up, and you will be presented with an intense looking (but actually very harmless) text command area.
Now, open up your web browser (firefox comes pre-installed on most!), and search the phrase "what to do after installing [linux version you picked]"
You're looking for a website called "It's FOSS." Here's a link to their page on Mint. This site has lots and lots of snippets of little text commands you can experiment with to learn how that functionality works!
Or, if you don't want to fuck with the terminal at all (fair enough!) then instead of "terminal" look for something called "software manager."
This is sort of like an app store for linux; you can install all kinds of programs directly from there without needing to go to the website of the program itself!
297 notes
·
View notes
Text
Growing ever more frustrated with the use of the term "AI" and how the latest marketing trend has ensured its already rather vague and highly contextual meaning has now evaporated into complete nonsense. Much like how the only real commonality between animals colloquially referred to as "Fish" is "probably lives in the water", the only real commonality between things currently colloquially referred to as "AI" is "probably happens on a computer"
For example, the "AI" you see in most games wot controls enemies and other non-player actors typically consist primarily of timers, conditionals, and RNG - and are typically designed with the goal of trying to make the game fun and/or interesting rather than to be anything ressembling actually intelligent. By contrast, the thing that the tech sector is currently trying to sell to us as "AI" relates to a completely different field called Machine Learning - specifically the sub-fields of Deep Learning and Neural Networks, specifically specifically the sub-sub-field of Large Language Models, which are an attempt at modelling human languages through large statistical models built on artificial neural networks by way of deep machine learning.
the word "statistical" is load bearing.
Say you want to teach a computer to recognize images of cats. This is actually a pretty difficult thing to do because computers typically operate on fixed patterns whereas visually identifying something as a cat is much more about the loose relationship between various visual identifiers - many of which can be entirely optional: a cat has a tail except when it doesn't either because the tail isn't visible or because it just doesn't have one, a cat has four legs, two eyes and two ears except for when it doesn't, it has five digits per paw except for when it doesn't, it has whiskers except for when it doesn't, all of these can look very different depending on the camera angle and the individual and the situation - and all of these are also true of dogs, despite dogs being a very different thing from a cat.
So, what do you do? Well, this where machine learning comes into the picture - see, machine learning is all about using an initial "training" data set to build a statistical model that can then be used to analyse and identify new data and/or extrapolate from incomplete or missing data. So in this case, we take a machine learning system and feeds it a whole bunch of images - some of which are of cats and thus we mark as "CAT" and some of which are not of cats and we mark as "NOT CAT", and what we get out of that is a statistical model that, upon given a picture, will assign a percentage for how well it matches its internal statistical correlations for the categories of CAT and NOT CAT.
This is, in extremely simplified terms, how pretty much all machine learning works, including whatever latest and greatest GPT model being paraded about - sure, the training methods are much more complicated, the statistical number crunching even more complicated still, and the sheer amount of training data being fed to them is incomprehensively large, but at the end of the day they're still models of statistical probability, and the way they generate their output is pretty much a matter of what appears to be the most statistically likely outcome given prior input data.
This is also why they "hallucinate" - the question of what number you get if you add 512 to 256 or what author wrote the famous novel Lord of the Rings, or how many academy awards has been won by famous movie Goncharov all have specific answers, but LLMs like ChatGPT and other machine learning systems are probabilistic systems and thus can only give probabilistic answers - they neither know nor generally attempt to calculate what the result of 512 + 256 is, nor go find an actual copy of Lord of the Rings and look what author it says on the cover, they just generalise the most statistically likely response given their massive internal models. It is also why machine learning systems tend to be highly biased - their output is entirely based on their training data, they are inevitably biased not only by their training data but also the selection of it - if the majority of english literature considered worthwhile has been written primarily by old white guys then the resulting model is very likely to also primarily align with the opinion of a bunch of old white guys unless specific care and effort is put into trying to prevent it.
It is this probabilistic nature that makes them very good at things like playing chess or potentially noticing early signs of cancer in x-rays or MRI scans or, indeed, mimicking human language - but it also means the answers are always purely probabilistic. Meanwhile as the size and scope of their training data and thus also their data models grow, so does the need for computational power - relatively simple models such as our hypothetical cat identifier should be fine with fairly modest hardware, while the huge LLM chatbots like ChatGPT and its ilk demand warehouse-sized halls full of specialized hardware able to run specific types of matrix multiplications at rapid speed and in massive parallel billions of times per second and requiring obscene amounts of electrical power to do so in order to maintain low response times under load.
36 notes
·
View notes
Text
I saw a post the other day calling criticism of generative AI a moral panic, and while I do think many proprietary AI technologies are being used in deeply unethical ways, I think there is a substantial body of reporting and research on the real-world impacts of the AI boom that would trouble the comparison to a moral panic: while there *are* older cultural fears tied to negative reactions to the perceived newness of AI, many of those warnings are Luddite with a capital L - that is, they're part of a tradition of materialist critique focused on the way the technology is being deployed in the political economy. So (1) starting with the acknowledgement that a variety of machine-learning technologies were being used by researchers before the current "AI" hype cycle, and that there's evidence for the benefit of targeted use of AI techs in settings where they can be used by trained readers - say, spotting patterns in radiology scans - and (2) setting aside the fact that current proprietary LLMs in particular are largely bullshit machines, in that they confidently generate errors, incorrect citations, and falsehoods in ways humans may be less likely to detect than conventional disinformation, and (3) setting aside as well the potential impact of frequent offloading on human cognition and of widespread AI slop on our understanding of human creativity...
What are some of the material effects of the "AI" boom?
Guzzling water and electricity
The data centers needed to support AI technologies require large quantities of water to cool the processors. A to-be-released paper from the University of California Riverside and the University of Texas Arlington finds, for example, that "ChatGPT needs to 'drink' [the equivalent of] a 500 ml bottle of water for a simple conversation of roughly 20-50 questions and answers." Many of these data centers pull water from already water-stressed areas, and the processing needs of big tech companies are expanding rapidly. Microsoft alone increased its water consumption from 4,196,461 cubic meters in 2020 to 7,843,744 cubic meters in 2023. AI applications are also 100 to 1,000 times more computationally intensive than regular search functions, and as a result the electricity needs of data centers are overwhelming local power grids, and many tech giants are abandoning or delaying their plans to become carbon neutral. Google’s greenhouse gas emissions alone have increased at least 48% since 2019. And a recent analysis from The Guardian suggests the actual AI-related increase in resource use by big tech companies may be up to 662%, or 7.62 times, higher than they've officially reported.
Exploiting labor to create its datasets
Like so many other forms of "automation," generative AI technologies actually require loads of human labor to do things like tag millions of images to train computer vision for ImageNet and to filter the texts used to train LLMs to make them less racist, sexist, and homophobic. This work is deeply casualized, underpaid, and often psychologically harmful. It profits from and re-entrenches a stratified global labor market: many of the data workers used to maintain training sets are from the Global South, and one of the platforms used to buy their work is literally called the Mechanical Turk, owned by Amazon.
From an open letter written by content moderators and AI workers in Kenya to Biden: "US Big Tech companies are systemically abusing and exploiting African workers. In Kenya, these US companies are undermining the local labor laws, the country’s justice system and violating international labor standards. Our working conditions amount to modern day slavery."
Deskilling labor and demoralizing workers
The companies, hospitals, production studios, and academic institutions that have signed contracts with providers of proprietary AI have used those technologies to erode labor protections and worsen working conditions for their employees. Even when AI is not used directly to replace human workers, it is deployed as a tool for disciplining labor by deskilling the work humans perform: in other words, employers use AI tech to reduce the value of human labor (labor like grading student papers, providing customer service, consulting with patients, etc.) in order to enable the automation of previously skilled tasks. Deskilling makes it easier for companies and institutions to casualize and gigify what were previously more secure positions. It reduces pay and bargaining power for workers, forcing them into new gigs as adjuncts for its own technologies.
I can't say anything better than Tressie McMillan Cottom, so let me quote her recent piece at length: "A.I. may be a mid technology with limited use cases to justify its financial and environmental costs. But it is a stellar tool for demoralizing workers who can, in the blink of a digital eye, be categorized as waste. Whatever A.I. has the potential to become, in this political environment it is most powerful when it is aimed at demoralizing workers. This sort of mid tech would, in a perfect world, go the way of classroom TVs and MOOCs. It would find its niche, mildly reshape the way white-collar workers work and Americans would mostly forget about its promise to transform our lives. But we now live in a world where political might makes right. DOGE’s monthslong infomercial for A.I. reveals the difference that power can make to a mid technology. It does not have to be transformative to change how we live and work. In the wrong hands, mid tech is an antilabor hammer."
Enclosing knowledge production and destroying open access
OpenAI started as a non-profit, but it has now become one of the most aggressive for-profit companies in Silicon Valley. Alongside the new proprietary AIs developed by Google, Microsoft, Amazon, Meta, X, etc., OpenAI is extracting personal data and scraping copyrighted works to amass the data it needs to train their bots - even offering one-time payouts to authors to buy the rights to frack their work for AI grist - and then (or so they tell investors) they plan to sell the products back at a profit. As many critics have pointed out, proprietary AI thus works on a model of political economy similar to the 15th-19th-century capitalist project of enclosing what was formerly "the commons," or public land, to turn it into private property for the bourgeois class, who then owned the means of agricultural and industrial production. "Open"AI is built on and requires access to collective knowledge and public archives to run, but its promise to investors (the one they use to attract capital) is that it will enclose the profits generated from that knowledge for private gain.
AI companies hungry for good data to train their Large Language Models (LLMs) have also unleashed a new wave of bots that are stretching the digital infrastructure of open-access sites like Wikipedia, Project Gutenberg, and Internet Archive past capacity. As Eric Hellman writes in a recent blog post, these bots "use as many connections as you have room for. If you add capacity, they just ramp up their requests." In the process of scraping the intellectual commons, they're also trampling and trashing its benefits for truly public use.
Enriching tech oligarchs and fueling military imperialism
The names of many of the people and groups who get richer by generating speculative buzz for generative AI - Elon Musk, Mark Zuckerberg, Sam Altman, Larry Ellison - are familiar to the public because those people are currently using their wealth to purchase political influence and to win access to public resources. And it's looking increasingly likely that this political interference is motivated by the probability that the AI hype is a bubble - that the tech can never be made profitable or useful - and that tech oligarchs are hoping to keep it afloat as a speculation scheme through an infusion of public money - a.k.a. an AIG-style bailout.
In the meantime, these companies have found a growing interest from military buyers for their tech, as AI becomes a new front for "national security" imperialist growth wars. From an email written by Microsoft employee Ibtihal Aboussad, who interrupted Microsoft AI CEO Mustafa Suleyman at a live event to call him a war profiteer: "When I moved to AI Platform, I was excited to contribute to cutting-edge AI technology and its applications for the good of humanity: accessibility products, translation services, and tools to 'empower every human and organization to achieve more.' I was not informed that Microsoft would sell my work to the Israeli military and government, with the purpose of spying on and murdering journalists, doctors, aid workers, and entire civilian families. If I knew my work on transcription scenarios would help spy on and transcribe phone calls to better target Palestinians, I would not have joined this organization and contributed to genocide. I did not sign up to write code that violates human rights."
So there's a brief, non-exhaustive digest of some vectors for a critique of proprietary AI's role in the political economy. tl;dr: the first questions of material analysis are "who labors?" and "who profits/to whom does the value of that labor accrue?"
For further (and longer) reading, check out Justin Joque's Revolutionary Mathematics: Artificial Intelligence, Statistics and the Logic of Capitalism and Karen Hao's forthcoming Empire of AI.
25 notes
·
View notes
Text
Canard IX
Canard IX – It passed my lips like a bird learning to fly.
Lorelei turned the glass door’s silver knob and stepped into a grand ring. It circled the central pillar of the Library, looking in on it with vast swathes of dark stone lit by glittering blue crystal chandeliers; patrons and goers milled around, talking, some made of crystal, some with several arms, some of imposing stature and tusks and horns, and yet others with a serpentine body that glimmered in the lights, draped in dyed glass silks, and some others looked to be no more than ghosts, shadows coalescing into the shapes of people that perused shelves lining the walls.
Lorelei took it all in at once and asserted herself—she put herself forth and marched towards the nearest column. It had set in it a cavalcade of bodies, it seemed; porcelain figures, dolls, they appeared to be, sculpted into extravagant forms, feminine and voluptuous, shimmering in the Library’s blued light. They nestled around a delicate crystal screen, which on it displayed in bright color: the Library’s search catalogue, a gray-and-white formatted page dryly containing links to every file available and its place within the system. A bar for input sat empty, the keyboard below extending like crystalline mushroom stalks under Lorelei’s hands to meet her fingertips.
As she typed—the words came alive. She tapped out a search, “Witch of the—” and the computer before her, the dolls wrapped around it came alive, to see the screen, to see Lorelei, now all peering down with their marble hair and jet-black pearl eyes; they hungered with curiosity for her input. And they whispered. “—Of the Wind? --Of the Heart? --Of the Gray?”
She swept those away, physically as much as mentally, jabbing a finger at a doll that had come too close to touching a key. No, Lorelei shook her head and focused on the search: “Witch of…”
Then she sees it. Inside. It subtly taps at the glass.
Lorelei backs away, shooting back just a second before recollecting herself. Right, this was nothing new to her. A living search engine would only make sense for the Library. She steadied at the panel of melded dollish bodies and focused her eyes to the screen.
There it is. The doll. Unbidden by her, the doll is there, in the screen, a figure with brilliant rose-quartz hair, porcelain frame and amber eyes, foxen ears and tail swaying—but all digitally. All on the screen before her. “Hi!”
The voice comes from the dolls lining the panel, but is clearly belonging to the kitsune inside the machine. Lorelei responds, “Um, oh, hello,” and gives a slight wave.
“Hello, Lorelei,” the image of a doll waves from the console, “This one is Cynder Nevara Cybil, and it shall be your guide to the search you seek.”
“And my search is for my Witch’s title, yes.”
“Then you’ll have to follow this one,” the Quill beckoned from within the monitor.
And so she did—in a way she didn’t expect. She felt her soul—no, she felt her Heart, her very being tugged at, pulled upon, and then yanked—but not with a jerking motion, but an elegance, as if she’d longed for this path, this way into the Nether. She saw a sea of streams, doors opening by and by, as if she were a ghost floating across the rivers of data. Her physical form dissipated across a refraction from the screen, a trick of the light leading her forward.
Vast coils of weft weaved in and amongst it; great dragons prowled the stardust skies, the shimmering seas, for they were both at once, dust and ocean, fragments of ideas whittled down to the granular specks of ash there are now; death eternal, always here, preserved, within the chaos of negative space.
There she met Cybil, alighting on a raft in the pitch-black tides. It was a scanty thing, and yet, it felt so vastly heavy beneath her.
Lorelei washed ashore of the data sea unto this raft of seeming dark metal and crystal board, and Cybil hauled her up with a hand, but—it wasn’t as if they were drenched, then, suddenly, as she crested onto mental seascape, it was as if they been on a manse afloat, everything clear and clean and dark.
Cybil, pink hair swaying in the nightly breeze, asked, “What are you the Witch of?”
“Nothing,” she said, a tear falling from her eye.
Cybil nodded. “Nothing is everything.”
“And this itself?”
“Will also be recorded.”
“And?”
“Broadcasted. To the worldline receiving it.
“Good. I remember now.”
“Remember?”
“Why I’m here.”
#whalefall#emptyspaces#es#doll#dollposting#witch#witchposting#short story#fiction#microfic#flash fiction#microfiction
13 notes
·
View notes
Text
A new tool lets artists add invisible changes to the pixels in their art before they upload it online so that if it’s scraped into an AI training set, it can cause the resulting model to break in chaotic and unpredictable ways. The tool, called Nightshade, is intended as a way to fight back against AI companies that use artists’ work to train their models without the creator’s permission. Using it to “poison” this training data could damage future iterations of image-generating AI models, such as DALL-E, Midjourney, and Stable Diffusion, by rendering some of their outputs useless—dogs become cats, cars become cows, and so forth. MIT Technology Review got an exclusive preview of the research, which has been submitted for peer review at computer security conference Usenix.
[...]
Zhao’s team also developed Glaze, a tool that allows artists to “mask” their own personal style to prevent it from being scraped by AI companies. It works in a similar way to Nightshade: by changing the pixels of images in subtle ways that are invisible to the human eye but manipulate machine-learning models to interpret the image as something different from what it actually shows. The team intends to integrate Nightshade into Glaze, and artists can choose whether they want to use the data-poisoning tool or not. The team is also making Nightshade open source, which would allow others to tinker with it and make their own versions. The more people use it and make their own versions of it, the more powerful the tool becomes, Zhao says. The data sets for large AI models can consist of billions of images, so the more poisoned images can be scraped into the model, the more damage the technique will cause.
[...]
Poisoned data samples can manipulate models into learning, for example, that images of hats are cakes, and images of handbags are toasters. The poisoned data is very difficult to remove, as it requires tech companies to painstakingly find and delete each corrupted sample.
167 notes
·
View notes
Text
Been a while, crocodiles. Let's talk about cad.

or, y'know...

Yep, we're doing a whistle-stop tour of AI in medical diagnosis!
Much like programming, AI can be conceived of, in very simple terms, as...
a way of moving from inputs to a desired output.
See, this very funky little diagram from skillcrush.com.
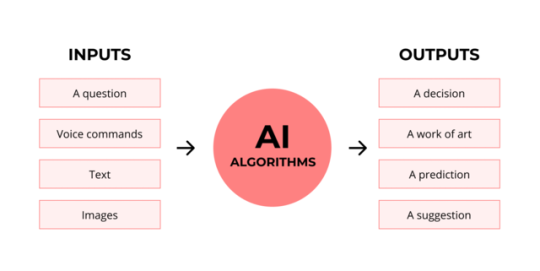
The input is what you put in. The output is what you get out.
This output will vary depending on the type of algorithm and the training that algorithm has undergone – you can put the same input into two different algorithms and get two entirely different sorts of answer.
Generative AI produces ‘new’ content, based on what it has learned from various inputs. We're talking AI Art, and Large Language Models like ChatGPT. This sort of AI is very useful in healthcare settings to, but that's a whole different post!
Analytical AI takes an input, such as a chest radiograph, subjects this input to a series of analyses, and deduces answers to specific questions about this input. For instance: is this chest radiograph normal or abnormal? And if abnormal, what is a likely pathology?
We'll be focusing on Analytical AI in this little lesson!
Other forms of Analytical AI that you might be familiar with are recommendation algorithms, which suggest items for you to buy based on your online activities, and facial recognition. In facial recognition, the input is an image of your face, and the output is the ability to tie that face to your identity. We’re not creating new content – we’re classifying and analysing the input we’ve been fed.
Many of these functions are obviously, um, problematique. But Computer-Aided Diagnosis is, potentially, a way to use this tool for good!
Right?
....Right?

Let's dig a bit deeper! AI is a massive umbrella term that contains many smaller umbrella terms, nested together like Russian dolls. So, we can use this model to envision how these different fields fit inside one another.

AI is the term for anything to do with creating and managing machines that perform tasks which would otherwise require human intelligence. This is what differentiates AI from regular computer programming.
Machine Learning is the development of statistical algorithms which are trained on data –but which can then extrapolate this training and generalise it to previously unseen data, typically for analytical purposes. The thing I want you to pay attention to here is the date of this reference. It’s very easy to think of AI as being a ‘new’ thing, but it has been around since the Fifties, and has been talked about for much longer. The massive boom in popularity that we’re seeing today is built on the backs of decades upon decades of research.
Artificial Neural Networks are loosely inspired by the structure of the human brain, where inputs are fed through one or more layers of ‘nodes’ which modify the original data until a desired output is achieved. More on this later!
Deep neural networks have two or more layers of nodes, increasing the complexity of what they can derive from an initial input. Convolutional neural networks are often also Deep. To become ‘convolutional’, a neural network must have strong connections between close nodes, influencing how the data is passed back and forth within the algorithm. We’ll dig more into this later, but basically, this makes CNNs very adapt at telling precisely where edges of a pattern are – they're far better at pattern recognition than our feeble fleshy eyes!
This is massively useful in Computer Aided Diagnosis, as it means CNNs can quickly and accurately trace bone cortices in musculoskeletal imaging, note abnormalities in lung markings in chest radiography, and isolate very early neoplastic changes in soft tissue for mammography and MRI.
Before I go on, I will point out that Neural Networks are NOT the only model used in Computer-Aided Diagnosis – but they ARE the most common, so we'll focus on them!

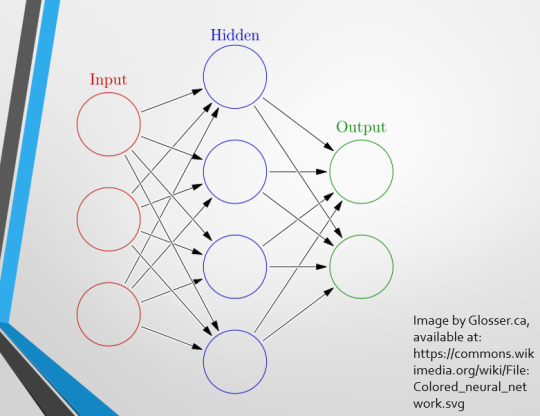
This diagram demonstrates the function of a simple Neural Network. An input is fed into one side. It is passed through a layer of ‘hidden’ modulating nodes, which in turn feed into the output. We describe the internal nodes in this algorithm as ‘hidden’ because we, outside of the algorithm, will only see the ‘input’ and the ‘output’ – which leads us onto a problem we’ll discuss later with regards to the transparency of AI in medicine.
But for now, let’s focus on how this basic model works, with regards to Computer Aided Diagnosis. We'll start with a game of...
Spot The Pathology.
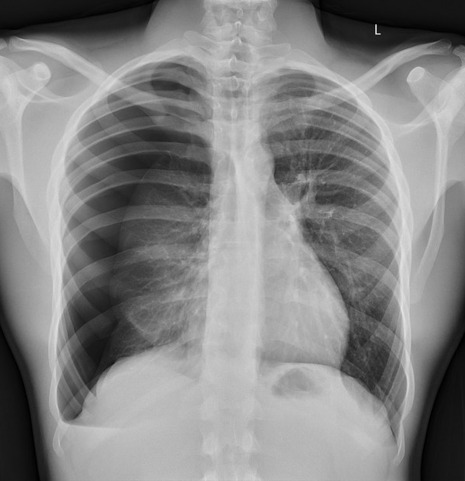
yeah, that's right. There's a WHACKING GREAT RIGHT-SIDED PNEUMOTHORAX (as outlined in red - images courtesy of radiopaedia, but edits mine)
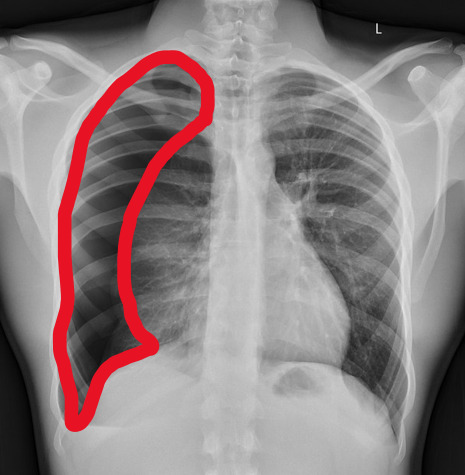
But my question to you is: how do we know that? What process are we going through to reach that conclusion?
Personally, I compared the lungs for symmetry, which led me to note a distinct line where the tissue in the right lung had collapsed on itself. I also noted the absence of normal lung markings beyond this line, where there should be tissue but there is instead air.
In simple terms.... the right lung is whiter in the midline, and black around the edges, with a clear distinction between these parts.
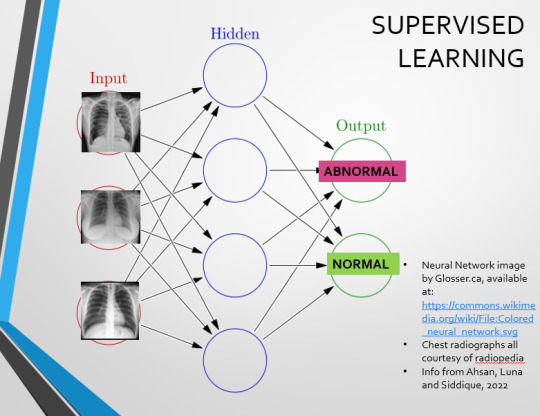
Let’s go back to our Neural Network. We’re at the training phase now.
So, we’re going to feed our algorithm! Homnomnom.
Let’s give it that image of a pneumothorax, alongside two normal chest radiographs (middle picture and bottom). The goal is to get the algorithm to accurately classify the chest radiographs we have inputted as either ‘normal’ or ‘abnormal’ depending on whether or not they demonstrate a pneumothorax.
There are two main ways we can teach this algorithm – supervised and unsupervised classification learning.
In supervised learning, we tell the neural network that the first picture is abnormal, and the second and third pictures are normal. Then we let it work out the difference, under our supervision, allowing us to steer it if it goes wrong.
Of course, if we only have three inputs, that isn’t enough for the algorithm to reach an accurate result.
You might be able to see – one of the normal chests has breasts, and another doesn't. If both ‘normal’ images had breasts, the algorithm could as easily determine that the lack of lung markings is what demonstrates a pneumothorax, as it could decide that actually, a pneumothorax is caused by not having breasts. Which, obviously, is untrue.
or is it?
....sadly I can personally confirm that having breasts does not prevent spontaneous pneumothorax, but that's another story lmao
This brings us to another big problem with AI in medicine –

If you are collecting your dataset from, say, a wealthy hospital in a suburban, majority white neighbourhood in America, then you will have those same demographics represented within that dataset. If we build a blind spot into the neural network, and it will discriminate based on that.
That’s an important thing to remember: the goal here is to create a generalisable tool for diagnosis. The algorithm will only ever be as generalisable as its dataset.
But there are plenty of huge free datasets online which have been specifically developed for training AI. What if we had hundreds of chest images, from a diverse population range, split between those which show pneumothoraxes, and those which don’t?
If we had a much larger dataset, the algorithm would be able to study the labelled ‘abnormal’ and ‘normal’ images, and come to far more accurate conclusions about what separates a pneumothorax from a normal chest in radiography. So, let’s pretend we’re the neural network, and pop in four characteristics that the algorithm might use to differentiate ‘normal’ from ‘abnormal’.
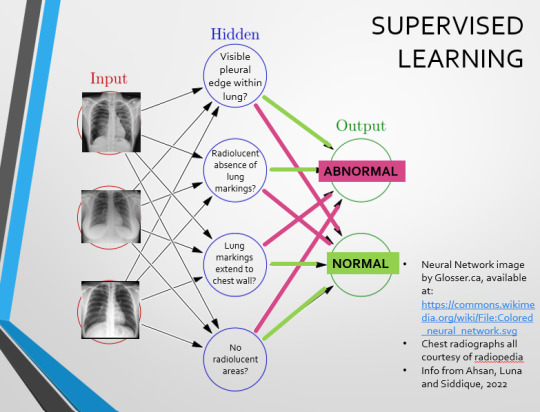
We can distinguish a pneumothorax by the appearance of a pleural edge where lung tissue has pulled away from the chest wall, and the radiolucent absence of peripheral lung markings around this area. So, let’s make those our first two nodes. Our last set of nodes are ‘do the lung markings extend to the chest wall?’ and ‘Are there no radiolucent areas?’
Now, red lines mean the answer is ‘no’ and green means the answer is ‘yes’. If the answer to the first two nodes is yes and the answer to the last two nodes is no, this is indicative of a pneumothorax – and vice versa.
Right. So, who can see the problem with this?
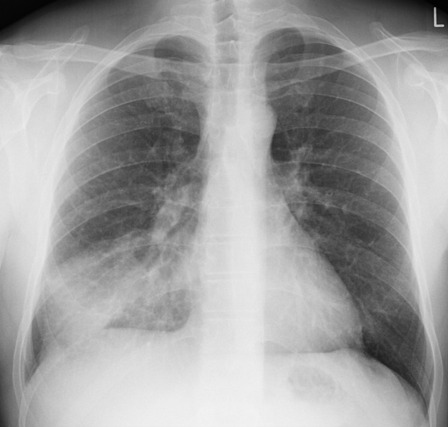
(image courtesy of radiopaedia)
This chest radiograph demonstrates alveolar patterns and air bronchograms within the right lung, indicative of a pneumonia. But if we fed it into our neural network...
The lung markings extend all the way to the chest wall. Therefore, this image might well be classified as ‘normal’ – a false negative.
Now we start to see why Neural Networks become deep and convolutional, and can get incredibly complex. In order to accurately differentiate a ‘normal’ from an ‘abnormal’ chest, you need a lot of nodes, and layers of nodes. This is also where unsupervised learning can come in.
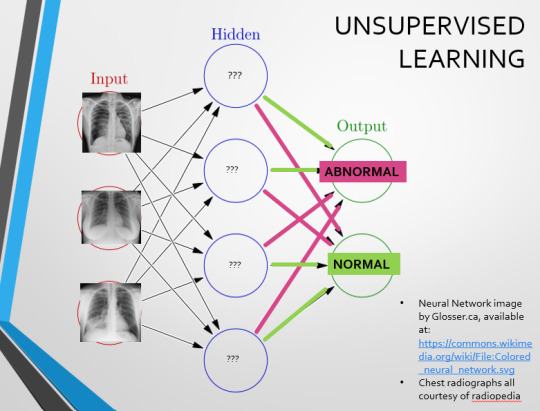
Originally, Supervised Learning was used on Analytical AI, and Unsupervised Learning was used on Generative AI, allowing for more creativity in picture generation, for instance. However, more and more, Unsupervised learning is being incorporated into Analytical areas like Computer-Aided Diagnosis!
Unsupervised Learning involves feeding a neural network a large databank and giving it no information about which of the input images are ‘normal’ or ‘abnormal’. This saves massively on money and time, as no one has to go through and label the images first. It is also surprisingly very effective. The algorithm is told only to sort and classify the images into distinct categories, grouping images together and coming up with its own parameters about what separates one image from another. This sort of learning allows an algorithm to teach itself to find very small deviations from its discovered definition of ‘normal’.
BUT this is not to say that CAD is without its issues.
Let's take a look at some of the ethical and practical considerations involved in implementing this technology within clinical practice!

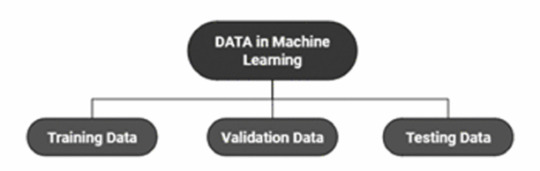
(Image from Agrawal et al., 2020)
Training Data does what it says on the tin – these are the initial images you feed your algorithm. What is key here is volume, variety - with especial attention paid to minimising bias – and veracity. The training data has to be ‘real’ – you cannot mislabel images or supply non-diagnostic images that obscure pathology, or your algorithm is useless.
Validation data evaluates the algorithm and improves on it. This involves tweaking the nodes within a neural network by altering the ‘weights’, or the intensity of the connection between various nodes. By altering these weights, a neural network can send an image that clearly fits our diagnostic criteria for a pneumothorax directly to the relevant output, whereas images that do not have these features must be put through another layer of nodes to rule out a different pathology.
Finally, testing data is the data that the finished algorithm will be tested on to prove its sensitivity and specificity, before any potential clinical use.
However, if algorithms require this much data to train, this introduces a lot of ethical questions.
Where does this data come from?
Is it ‘grey data’ (data of untraceable origin)? Is this good (protects anonymity) or bad (could have been acquired unethically)?
Could generative AI provide a workaround, in the form of producing synthetic radiographs? Or is it risky to train CAD algorithms on simulated data when the algorithms will then be used on real people?
If we are solely using CAD to make diagnoses, who holds legal responsibility for a misdiagnosis that costs lives? Is it the company that created the algorithm or the hospital employing it?
And finally – is it worth sinking so much time, money, and literal energy into AI – especially given concerns about the environment – when public opinion on AI in healthcare is mixed at best? This is a serious topic – we’re talking diagnoses making the difference between life and death. Do you trust a machine more than you trust a doctor? According to Rojahn et al., 2023, there is a strong public dislike of computer-aided diagnosis.
So, it's fair to ask...
why are we wasting so much time and money on something that our service users don't actually want?
Then we get to the other biggie.

There are also a variety of concerns to do with the sensitivity and specificity of Computer-Aided Diagnosis.
We’ve talked a little already about bias, and how training sets can inadvertently ‘poison’ the algorithm, so to speak, introducing dangerous elements that mimic biases and problems in society.
But do we even want completely accurate computer-aided diagnosis?
The name is computer-aided diagnosis, not computer-led diagnosis. As noted by Rajahn et al, the general public STRONGLY prefer diagnosis to be made by human professionals, and their desires should arguably be taken into account – as well as the fact that CAD algorithms tend to be incredibly expensive and highly specialised. For instance, you cannot put MRI images depicting CNS lesions through a chest reporting algorithm and expect coherent results – whereas a radiologist can be trained to diagnose across two or more specialties.
For this reason, there is an argument that rather than focusing on sensitivity and specificity, we should just focus on producing highly sensitive algorithms that will pick up on any abnormality, and output some false positives, but will produce NO false negatives.
(Sensitivity = a test's ability to identify sick people with a disease)
(Specificity = a test's ability to identify that healthy people do not have this disease)
This means we are working towards developing algorithms that OVERESTIMATE rather than UNDERESTIMATE disease prevalence. This makes CAD a useful tool for triage rather than providing its own diagnoses – if a CAD algorithm weighted towards high sensitivity and low specificity does not pick up on any abnormalities, it’s highly unlikely that there are any.
Finally, we have to question whether CAD is even all that accurate to begin with. 10 years ago, according to Lehmen et al., CAD in mammography demonstrated negligible improvements to accuracy. In 1989, Sutton noted that accuracy was under 60%. Nowadays, however, AI has been proven to exceed the abilities of radiologists when detecting cancers (that’s from Guetari et al., 2023). This suggests that there is a common upwards trajectory, and AI might become a suitable alternative to traditional radiology one day. But, due to the many potential problems with this field, that day is unlikely to be soon...

That's all, folks! Have some references~
#medblr#artificial intelligence#radiography#radiology#diagnosis#medicine#studyblr#radioactiveradley#radley irradiates people#long post
16 notes
·
View notes
Note
you should talk more about isiis-dpi it sounds neat as fuck
thanks for the ask! (i love yapping)
so i only started learning about the isiis dpi a week ago (im working with it for my summer job) so there will be much more infodumping in the future, but heres what i have to say rn:
- the isiis dpi itself consists of a camera and a light with a gap (~30cm) between them so when zooplankton find themselves in the gap they are backlit and cast a shadow to the camera
- the way the lenses are set up means that all the light crosses the gap as parallel rays so everything of the same size makes the same size image regardless of position in the depth of field
- the camera continuously records vertical lines of 2048 pixels (the image frame is 10.24cm high, hence 50micron pixel resolution) like a rolling shutter in a normal camera, only for longer duration. this produces a single super long image which is cut up into sequential square frames, and then further cut up to isolate individual particle or animal images
- when towed through the water at 2.5 m/s the camera can image more than 60 liters of water per second, nearly 4 m^3 per minute. there can also be multiple cameras (3 on the setup im working with) so its even more
- this setup has the dpi in the middle of an entire instrument platform the size of a small car (an rotv, remotely operated towed vehicle) that can record all manner of variables in the water column (depth, temp, salinity, chlorophyll, light, etc etc) as it is towed behind the ship
- the vehicle has wings and shit on it so it can be “flown” through the water column in a vertical zigzag pattern. this allows it to sample the entire depth range of the transect (i think we’re gonna do something like between 10 and 150m on the upcoming cruise)
- the actual data that comes out of this thing is really valuable because it lets us see The Squishies (small jellyfish, comb jellies, delicate worms, stringly mfs, various goop tubes) in their natural environment without obliterating them with nets and formaldehyde (look up jello tennis racket for visual aid)
- there is so much damn stuff in the ocean that this thing spits out literally millions upon millions of images, which absolutely cant be sorted by hand (i spent all day today sifting out just two taxa from a couple thousand images) so we need machine learning neural networks n shit to do it. this is what ai should be used for not whatever bs the tech bro oligarchy is tryna scam us with
- the algorithm kinda sucks ass unless you give it a huge amount of good training data, but the vast majority of the images are unrecognizable streaks and specks so i dont blame it
thats all i can think of rn but mark my words there will be more
8 notes
·
View notes
Text
Editor's Summary: How do young children learn to associate new words with specific objects or visually represented concepts? This hotly debated question in early language acquisition has been traditionally examined in laboratories, limiting generalizability to real-world settings. Vong et al. investigated the question in an unprecedented, longitudinal manner using head-mounted video recordings from a single child’s first-person experiences in naturalistic settings. By applying machine learning, they introduced the Child’s View for Contrastive Learning (CVCL) model, pairing video frames that co-occurred with uttered words, and embedded the images and words in shared representational spaces. CVCL represents sets of visually similar things from one concept (e.g., puzzles) through distinct subclusters (animal versus alphabet puzzles). It combines associative and representation learning that fills gaps in language acquisition research and theories.
Abstract: Starting around 6 to 9 months of age, children begin acquiring their first words, linking spoken words to their visual counterparts. How much of this knowledge is learnable from sensory input with relatively generic learning mechanisms, and how much requires stronger inductive biases? Using longitudinal head-mounted camera recordings from one child aged 6 to 25 months, we trained a relatively generic neural network on 61 hours of correlated visual-linguistic data streams, learning feature-based representations and cross-modal associations. Our model acquires many word-referent mappings present in the child's everyday experience, enables zero-shot generalization to new visual referents, and aligns its visual and linguistic conceptual systems. These results show how critical aspects of grounded word meaning are learnable through joint representation and associative learning from one child's input.
63 notes
·
View notes
Text
A lot of people can tell AI generated art Looks Off but lack the technical terms to be able to describe why in ways that doesn't swerve back to just vibes or the lack of a ~soul~, but worry not, papa snail is here to tell u exactly what feels kinda off about AI art when you look at it:
AI knows how to render like a beast but it's severely lacking in skills when it comes to image composition. Elements present in an AI piece rarely harmonize, they are not put there as part of an intentional scene, merely collaged in to fulfill whatever prompt was put into the machine. If you prompt an AI image generator with "Mushroom fairy in a forest" the machine will search through its database to diffuse something which checks off the correct labels while looking technically impressive; but it will not add any context or interiority to the scene. Basically; nothing visualized will have a reason for existing other than to fill a quota, which makes for an uninteresting and bad illustration.
This is something that isn't unique of AI, beginner artists operate in a similar manner, since composing a compelling narrative within a scene or a character design or abstract mural or what have you is its own skill-set that you have to learn. Where AI differs is this steep skill difference that clashes against itself. A technically lacking drawing of a sparkledog on DA is internally consistent, the composition is kinda ass the linework is kinda ass the colors and shading is all kinda ass, adding up to an earnest effort that still has charm because you can tell this was made by a 13 yr old doing their best with GIMP or MS Paint, you can tell that they probably like dogs and rainbows and theorize that they will get themselves some neopronouns in like 10 years. There was probably more the artist wanted to say with the piece but they lacked the skill to communicate it any deeper than "here is my rainbow dog oc that is half angel", give them 5 years and intent will start to materialize.
Enter an AI Generated sparkledog sourced from data scraped off the internet. The rendering is detailed and beautiful and there's a background and complex lighting but none of these things still say anything more than "here is my rainbow dog oc that is half angel", that is where the clash happens. Since the technical skill is so high, we look for depth, we look for intent, we look for artistic choices but there are none present. Even if a prompter wanted the AI generator to express something more specific, the amount of re-rolls needed to get even close to what whatever that is are plentiful and will still yield something very surface-level. You can probably make the dog look sad or angry, but it's going to be difficult (if not impossible) to make the dog look divorced or gay repressed or so distraught all of their brain synapses stopped working. That is what this vague sense that AI art lacks ~soul~ is, the machine simply isn't competent in visual communication deeper than a kiddy-pool, nor do I think it can be since it doesn't have its own interiority to begin with, which is what you need to pull from to develop this skill yourself as an artist. What you like, why you like it, what it means to you, learning how to put that on a canvas is integral for a compelling illustration.
Because I will simply say it; some human people artists are also very technically good, but can't communicate for shit. Sakimichan is my go-to example for this, her art is Very Rendered, she is good at Rendering and Anatomy but to me her art is still mid since she prioritizes conventional attractiveness above all else in her pin-ups. This is allowed, of course, and it gets her the patreon moneys, get that bag, but it is also kind of just slop. A lot of glossy anime people artists have a similar thing going on, which unfortunately makes them harder to distinguish from the output of AI Generators. Mind you, I can usually tell the difference, because there's still a lot of intent that goes into these pin-up pieces (choice of lighting, what to render/fade into the background, what kind of background would be best, color, outfit, which material textures to emphasize etc. etc. etc.) that AI still doesn't have since it's only concerned with aligning with the prompts, but it's way more subtle and lots of normies can't pick up on it, I can't pick up on it either all the time.
Similar things can be said about AI Writing, AI Music and AI Graphic design, it boils down to AI Generators not having any desire nor ability to add their own input, only replicate whatever elements are shoved into their database and align it best they can with whatever prompts gets typed in; which makes for sparkly products that remain terminally mid at best. Sometimes "Mid" is what the people want unfortunately which is why Pinterest is full of AI slop —but people interested in compelling art will gravitate towards it. The first step to making compelling art is meditating on what you want out of it to begin with, a shortcut is to make shameless fetish-art catered to you and you alone because it's gonna make you confront the things that you want to hide from people, and meditate on if maybe you should start shoving it in their faces instead. The sfw version would be other visual interests or fixations that foster this sense of shame or fear of judgement. AI generally veers conventional across axises, it always looks exactly like you'd expect it to because it's composed of such a big melting pot, so if you want to carve a space out for yourself where AI can't touch you just figure out the niche specific things your heart wants, and draw that, and get really good at drawing that.
AI Art is the fast fashion of illustration, basically, it's just cyberwaste instead of landfill-fodder and I do think AI technology utilizes slightly less slave labor (key word: think), not a fully consistent analogy but it is the gist. Which I have my own more-nuanced-than-average onions on fast fashion but that's for later, or never. if i feel like it.
anyway that's why AI art usually looks wonk. cus it has noob tier compositions and concepts with advanced technical execution. the most efficient way to distinguish urself from ai is to git gud at compositions and also be cringe and free. and people who turn to AI generators would have more luck visualizing their ideas if they commissioned an artist instead of editing prompt chains until the image kinda sorta looks like what they had in mind (if you squint), or used picrew or something, if ur gonna generate AI art at least dont fuckign poooost iiit maaaaaaaan MY PINTEREST FEEEEEEEED!!!! MY DA HOME PAGE!!!!!!! RUINED!!!!!!! BY SCARY GLOSSY ANIME PEOPLE!!!!!!!!
8 notes
·
View notes
Text
Hi, idk who's going to see this post or whatnot, but I had a lot of thoughts on a post I reblogged about AI that started to veer off the specific topic of the post, so I wanted to make my own.
Some background on me: I studied Psychology and Computer Science in college several years ago, with an interdisciplinary minor called Cognitive Science that joined the two with philosophy, linguistics, and multiple other fields. The core concept was to study human thinking and learning and its similarities to computer logic, and thus the courses I took touched frequently on learning algorithms, or "AI". This was of course before it became the successor to bitcoin as the next energy hungry grift, to be clear. Since then I've kept up on the topic, and coincidentally, my partner has gone into freelance data model training and correction. So while I'm not an expert, I have a LOT of thoughts on the current issue of AI.
I'll start off by saying that AI isn't a brand new technology, it, more properly known as learning algorithms, has been around in the linguistics, stats, biotech, and computer science worlds for over a decade or two. However, pre-ChatGPT learning algorithms were ground-up designed tools specialized for individual purposes, trained on a very specific data set, to make it as accurate to one thing as possible. Some time ago, data scientists found out that if you have a large enough data set on one specific kind of information, you can get a learning algorithm to become REALLY good at that one thing by giving it lots of feedback on right vs wrong answers. Right and wrong answers are nearly binary, which is exactly how computers are coded, so by implementing the psychological method of operant conditioning, reward and punishment, you can teach a program how to identify and replicate things with incredible accuracy. That's what makes it a good tool.
And a good tool it was and still is. Reverse image search? Learning algorithm based. Complex relationship analysis between words used in the study of language? Often uses learning algorithms to model relationships. Simulations of extinct animal movements and behaviors? Learning algorithms trained on anatomy and physics. So many features of modern technology and science either implement learning algorithms directly into the function or utilize information obtained with the help of complex computer algorithms.
But a tool in the hand of a craftsman can be a weapon in the hand of a murderer. Facial recognition software, drone targeting systems, multiple features of advanced surveillance tech in the world are learning algorithm trained. And even outside of authoritarian violence, learning algorithms in the hands of get-rich-quick minded Silicon Valley tech bro business majors can be used extremely unethically. All AI art programs that exist right now are trained from illegally sourced art scraped from the web, and ChatGPT (and similar derived models) is trained on millions of unconsenting authors' works, be they professional, academic, or personal writing. To people in countries targeted by the US War Machine and artists the world over, these unethical uses of this technology are a major threat.
Further, it's well known now that AI art and especially ChatGPT are MAJOR power-hogs. This, however, is not inherent to learning algorithms / AI, but is rather a product of the size, runtime, and inefficiency of these models. While I don't know much about the efficiency issues of AI "art" programs, as I haven't used any since the days of "imaginary horses" trended and the software was contained to a university server room with a limited training set, I do know that ChatGPT is internally bloated to all hell. Remember what I said about specialization earlier? ChatGPT throws that out the window. Because they want to market ChatGPT as being able to do anything, the people running the model just cram it with as much as they can get their hands on, and yes, much of that is just scraped from the web without the knowledge or consent of those who have published it. So rather than being really good at one thing, the owners of ChatGPT want it to be infinitely good, infinitely knowledgeable, and infinitely running. So the algorithm is never shut off, it's constantly taking inputs and processing outputs with a neural network of unnecessary size.
Now this part is probably going to be controversial, but I genuinely do not care if you use ChatGPT, in specific use cases. I'll get to why in a moment, but first let me clarify what use cases. It is never ethical to use ChatGPT to write papers or published fiction (be it for profit or not); this is why I also fullstop oppose the use of publicly available gen AI in making "art". I say publicly available because, going back to my statement on specific models made for single project use, lighting, shading, and special effects in many 3D animated productions use specially trained learning algorithms to achieve the complex results seen in the finished production. Famously, the Spider-verse films use a specially trained in-house AI to replicate the exact look of comic book shading, using ethically sources examples to build a training set from the ground up, the unfortunately-now-old-fashioned way. The issue with gen AI in written and visual art is that the publicly available, always online algorithms are unethically designed and unethically run, because the decision makers behind them are not restricted enough by laws in place.
So that actually leads into why I don't give a shit if you use ChatGPT if you're not using it as a plagiarism machine. Fact of the matter is, there is no way ChatGPT is going to crumble until legislation comes into effect that illegalizes and cracks down on its practices. The public, free userbase worldwide is such a drop in the bucket of its serverload compared to the real way ChatGPT stays afloat: licensing its models to businesses with monthly subscriptions. I mean this sincerely, based on what little I can find about ChatGPT's corporate subscription model, THAT is the actual lifeline keeping it running the way it is. Individual visitor traffic worldwide could suddenly stop overnight and wouldn't affect ChatGPT's bottom line. So I don't care if you, I, or anyone else uses the website because until the US or EU governments act to explicitly ban ChatGPT and other gen AI business' shady practices, they are all only going to continue to stick around profit from big business contracts. So long as you do not give them money or sing their praises, you aren't doing any actual harm.
If you do insist on using ChatGPT after everything I've said, here's some advice I've gathered from testing the algorithm to avoid misinformation:
If you feel you must use it as a sounding board for figuring out personal mental or physical health problems like I've seen some people doing when they can't afford actual help, do not approach it conversationally in the first person. Speak in the third person as if you are talking about someone else entirely, and exclusively note factual information on observations, symptoms, and diagnoses. This is because where ChatGPT draws its information from depends on the style of writing provided. If you try to be as dry and clinical as possible, and request links to studies, you should get dry and clinical information in return. This approach also serves to divorce yourself mentally from the information discussed, making it less likely you'll latch onto anything. Speaking casually will likely target unprofessional sources.
Do not ask for citations, ask for links to relevant articles. ChatGPT is capable of generating links to actual websites in its database, but if asked to provide citations, it will replicate the structure of academic citations, and will very likely hallucinate at least one piece of information. It also does not help that these citations also will often be for papers not publicly available and will not include links.
ChatGPT is at its core a language association and logical analysis software, so naturally its best purposes are for analyzing written works for tone, summarizing information, and providing examples of programming. It's partially coded in python, so examples of Python and Java code I've tested come out 100% accurate. Complex Google Sheets formulas however are often finicky, as it often struggles with proper nesting orders of formulas.
Expanding off of that, if you think of the software as an input-output machine, you will get best results. Problems that do not have clear input information or clear solutions, such as open ended questions, will often net inconsistent and errant results.
Commands are better than questions when it comes to asking it to do something. If you think of it like programming, then it will respond like programming most of the time.
Most of all, do not engage it as a person. It's not a person, it's just an algorithm that is trained to mimic speech and is coded to respond in courteous, subservient responses. The less you try and get social interaction out of ChatGPT, the less likely it will be to just make shit up because it sounds right.
Anyway, TL;DR:
AI is just a tool and nothing more at its core. It is not synonymous with its worse uses, and is not going to disappear. Its worst offenders will not fold or change until legislation cracks down on it, and we, the majority users of the internet, are not its primary consumer. Use of AI to substitute art (written and visual) with blended up art of others is abhorrent, but use of a freely available algorithm for personal analyticsl use is relatively harmless so long as you aren't paying them.
We need to urge legislators the world over to crack down on the methods these companies are using to obtain their training data, but at the same time people need to understand that this technology IS useful and both can and has been used for good. I urge people to understand that learning algorithms are not one and the same with theft just because the biggest ones available to the public have widely used theft to cut corners. So long as computers continue to exist, algorithmic problem-solving and generative algorithms are going to continue to exist as they are the logical conclusion of increasingly complex computer systems. Let's just make sure the future of the technology is not defined by the way things are now.
#kanguin original#ai#gen ai#generative algorithms#learning algorithms#llm#large language model#long post
7 notes
·
View notes
Note
Nahhhh you lost me at the copyright bullshit. A machine created to brute force copy and learn from any and all art around it that then imitates the work of others, an algorithm that puts no effort of its own into work, is not remotely comparable to a human person who learns from others' art and puts work and effort into it. One is an algorithm made by highly paid dudebros to copy things en masse, another is the earnest work of one person.
I mean. You're fundamentally misunderstanding both the technology and my argument.
You're actually so wrong you're not even wrong. Let's break it down:
A machine created to brute force copy and (what does "brute force copy" mean? "Brute Force" has a specific meaning in discussions of tech and this isn't it) learn from any and all art around it that then imitates the work of others (there are limited models that are trained to imitate the work of specific artists and there are people generating prompts requesting things in the style of certain artists, but large models are absolutely not trained to imitate anything other than whatever most closely matches the prompt; I do think that models trained on a single artist are unethical and are a much better case of violating the principles of fair use however they are significantly transformative so even there the argument kind of falls apart), an algorithm that puts no effort of its own into work (of course this is not a fair argument to be having really because you're an asker and you can't argue or respond but buddy you have to define your terms. 'Effort' is an extremely malleable concept and art that takes effort is not significantly more art-y or valid than art that takes little or no effort like this is an extremely common argument in discussions of modern art - is Andy Warhol art, is Duchamps' readymades series art, art is a LOT more about context than effort and I'm not sure you're aware of the processing power used to generate AI art but there is "effort" of a sort there but also you are anthropomorphizing the model, the algorithm isn't generating "its own work"), is not remotely comparable to a human person who learns from others' art and puts work and effort into it. One is an algorithm (i mean it's slightly more complicated than that, we're discussing a wide variety of models here) made by highly paid dudebros (this completely ignores the open source work, the volunteer work, the work of anybody who is not a 'dudebro,' which is the most typically tumblr way of dismissing anything in tech as the creation of someone white, male, and wealthy which SUCH a shitty set of assumptions) to copy things en masse, another is the earnest work of one person.
Okay so the reasonable things I've pulled out of that to discuss are:
"A machine created to learn from any and all art around it is not remotely comparable to a human person who learns from others' art and puts work and effort into it. One is an algorithm made to copy things en masse, another is the earnest work of one person."
And in terms of who fair use applies to, no. You're wrong. For the purposes of copyright and fair use, a machine learning model and a person are identical. You can't exclude one without excluding the other. There isn't even a good way to meaningfully separate them if you consider artists who use AI in their process while not actually generating AI art.
I feel like I don't really have to make much of an argument here because the EFF has done it for me. The sections of that commentary from question 8 own are detailed explanations of why generative models should reasonably be recognized as protected by fair use when trained on data that is publicly available.
But also: your definition of "copying" is bad. You're wrong about what a copy is, or you're wrong about what generative image models do. I suspect that the latter is much closer to the truth, so I'd recommend reading up on generative image models some more - that EFF commentary has plenty of articles that would probably be helpful for you.
126 notes
·
View notes
Text
AI imagery is going to ruin your eyes...
Let me explain.
I'm an amateur artist. I dabble. I took Art History classes and learned a lot. I was thinking about Vincent Van Gogh reacting to the popular art trends by creating something unique and from how he saw the world. He was reacting and improvising based on an education and emotional state. He was not the only person who liked impressionism for these reasons of beating the status quo.
Most AI generated imagery has a glossy finish to it. Even the impressionistic stuff? I looked up some examples (easy to do without generating new stuff, web searches are flooded with it now) and found stuff that wasn't labeled. I tried to discern whether it was someone's art or a machine's. There's still something glossy; the same five Instagram model faces populate even those pieces. I found one piece that was labeled AI but looked like it could have been human-painted.
I tried to internalize what was different between the human art and the AI images. Aside from the shadows making sense in regards to the light source, there was something deliberate in the brush strokes. I looked at human-made pieces that were soft, muted and not really my style, but still instilled with something emotional.
I don't love impressionism, but I think that in allowing AI generated images to gain such a foothold in our consciousness, we are doing two things:
1) Creating a strong emotional reaction against the smooth polish of AI generated imagery.
2) No longer passively building an understanding of what art has been up until this point because our own data set, the history we build up in our minds, is being poisoned.
We learn what art is by exposure. If we keep exposing ourselves to haphazardly machine made imagery, what will future art look like? Will it lack logic?
Maybe I'm being too alarmist and actually what will happen is that in 20 years the art trends toward extreme realism and logic. Maybe it's already happening and I'm not even seeing it, too distracted by how broad the art world is and how many styles are popular concurrently. There is no single artist establishment so there is no single force to react against... But maybe we will begin to react against AI.
I'm just worried about young artists not learning how to look at real art, just as some young people no longer know how to read literature.
7 notes
·
View notes