#JSON Parser
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was named as a finalist in Lead411’s New York City Hot 125 in Aug 2010.
Text
Streamlining Your Data Workflow: Unveiling the Power of JSON Conversion and Formatting
In the dynamic world of data manipulation and communication, JSON (JavaScript Object Notation) has emerged as a versatile and widely-used format. From web APIs to data exchange between applications, JSON plays a pivotal role. To navigate this landscape effectively, tools such as the JSON Formatter, JSON Parser, and the ability to Convert JSON to String have become essential.
Handling JSON data can sometimes be intricate, especially when dealing with complex structures. However, the ability to Convert JSON to String is a transformative solution that simplifies the way data is presented and shared. Whether it's for better integration within applications or for sharing structured data across platforms, this capability bridges the gap between intricate data structures and human-readable content.

As data flows become more intricate, presenting JSON data in an organized and visually appealing format is crucial. This is where the JSON Formatter comes into play. It not only structures JSON data for optimal readability but also aligns it with coding conventions, enhancing collaboration among developers. The JSON Formatter tool ensures that your data communicates effectively and maintains a professional look, whether it's for internal use or public consumption.
Data manipulation requires the ability to understand and interpret JSON structures accurately. The JSON Parser tool acts as your guide in this journey, breaking down intricate JSON objects into manageable components. With the JSON Parser, you can easily navigate through data, extract specific information, and comprehend the relationships within complex data sets. This tool empowers developers and data analysts alike to work with confidence and accuracy.
1 note
·
View note
Text
the automatic conversion service we set up sometimes fails horribly, and i suspect this happens because it tries to read files as theyre being written. and i think the service thats supposed to copy files to permanent storage regularly encounters this exact issue, resulting in a huge chunk of files just randomly missing.
#tütensuppe#ive fixed the json parser error. tomorrow: fix more bullshit#at least with the json parser fixed conversion now runs perfectly.#and then at some point i have to add the last data source..??#this ones a bit nebulous i have most of the helper functions written but we cant integrate it w the current automatic conversion#bc the machine that runs on doesnt have access to that data source.#anyway NO MORE WORK THOUGHT TODAY#i already spent like an hour after coming home cleaning up the kitchen mess i made yesterday
1 note
·
View note
Text
(…) for very large 64-bit integers, such as randomly generated IDs, a JSON parser that converts integers into floats results in data loss. Go’s encoding/json package does this, for example.
(…)
How often does this actually happen for randomly-generated numbers?
(…)
It turns out that almost all randomly distributed int64 values are affected by round-trip data loss. Roughly, the only numbers that are safe are those with at most 16 digits (although not exactly: 9,999,999,999,999,999, for example, gets rounded up to a nice round 10 quadrillion).
102 notes
·
View notes
Note
mwah mwah mwah mwah mwah I just found your VN and it's so cute and arresting and so full of nonbinary longing I'm absolutely in love already and it's kinda inspiring me to do the scary job of opening up a word doc and try writing some of my own stuff for the first time ever
also wrt aster i love love love love love the idea of being freed from agab. just... can't remember. who cares. no longer having to measure up to a gender metric or constantly minimizing your male shoulders or female hips and worrying about your ratios or presentation - and just relax and enjoy it instead of treating it like a constant chore of maintaining a dozen spinning plates to avoid being "found out". freed from presentation pressure. mwah.
also also as a fellow web developer I'd love to hear more about your stack for ssg - gatsby? svelte? vite? 93 nested imported html docs? one really really big div? I ask because while I don't know if I'll ever have the chops for music production, reading and discovering that inline music player absolutely tickled me, both narratively and as a developer, what a delight, so so so good
My “stack” ... hmmm. “Stack” .................
So, for the main website I just used “Lektor”, which I picked out of a hat on the basis that it was python-based and could do the one thing I cared about (HTML templating). But the CURSE/KISS/CUTE reader is coded from scratch. It is a single-page app, and it loads and displays story content by grabbing the HTML from a JSON file I call the “story file”. The JSON in turn is created by a parser that I wrote in python that parses a specially-formatted markdown file which I also confusingly call the “story file”. The script format for this latter file is slightly custom but is mostly just “normal markdown but I repurposed code ticks as a macro format”:
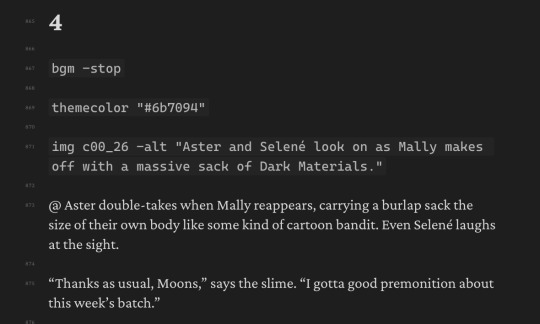
The music player is pretty rudimentary and just offloads all the complicated business to howler.js.
It’s a funny patchworked leaning tower of python but it gets it done and gets it done entirely client-side and that means I don’t have to dip even one of my toes into the haunted pool of server-side web development =w=
65 notes
·
View notes
Text
Me: Okay, it's been at least a day and I spent some time working on other parts of the project. But I really need to nail this part of the coding before I sink any more time into this. It can't be that bad.
Me two hours later:

Me: I have a Grand Idea for a cool new mod for the video game I am currently fixated upon, I bet This Time it won't be so hard to try and make it. :)
Me, inevitably, every single time:

#aesa rambles#it worked (visually anyway) the first time so... Huh?#now the json parser is saying there's an error and i just CANNOT figure out what the problem is#and I'm tired and hungry and cranky which don't help the issue#i am very much not a coder that's made itself very apparent to me#I'm honestly legitimately more upset that it almost kinda worked the first time but now it won't#the first time it showed all my visual changes but there was an impassable wall#which is wild to me bc there shouldn't have been one in that specific spot with or without the mod#so what the f u c k happened to do that
2 notes
·
View notes
Note
hi, I saw a post you made about your character creator menu a while back and I thought it was really neat how you had adjusted the standard picrew-style menu to give better previews. I want to build something similar (just as a picrew, not as part of something bigger), and I've got a basic idea of how I'd code it, but figured I'd ask, did you follow a tutorial at all to help code yours? and/or would you be willing to share some of your backend for it?
I'm very curious if my idea of how to achieve the same result is roughly the same backend as you've got, or something wildly different!
Sure! Here's the architecture diagram:

I know the diagram is probably not useful on its own... we were a little cute and call an entire portrait a "sandwich" which is made of of different "slices" (the eye slice, the outer_clothes slice). It follows the 3-layer system that I describe in this talk. The basic idea is something I call "the cycle between heaven and earth":
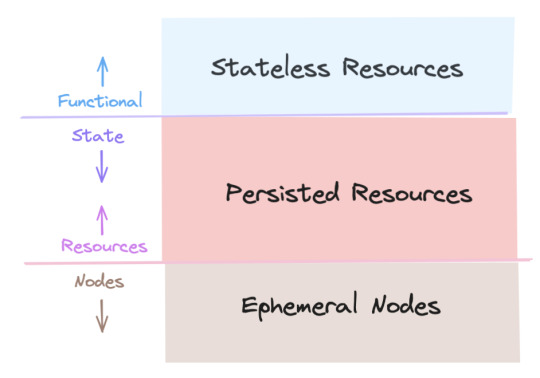

The lowest layer is all the nodes in Godot's scene tree. They're basically a browser DOM that don't store any data we want to keep; they're mortal and ephemeral. E.g. buttons, stuff drawn on the screen.
The middle "cores" layer are resources with almost no functionality; they're just data repositories meant to be serialized/deserialized.
The top layer has no state and its resources represents game content: collections of possible noses, hats, etc.
When data changes, I have "rerender" functions on most of my nodes that can be called to update themselves to whatever the current data is (rather than updating themselves piecemeal as specific things change). Similar to how React does it, if you're familiar.
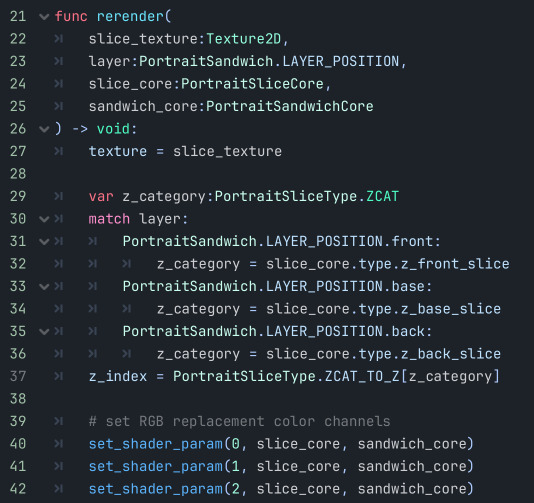
To get that preview effect where everything is the same besides one thing, on every change I rerender all the buttons in that category with a copy of the current "main" core and then replace the one slice that particular button changes.
The cores serialize to JSON, and I store the slices as "slice_type: chosen_slice", the keys of which match up to the resources I defined in the top layer.
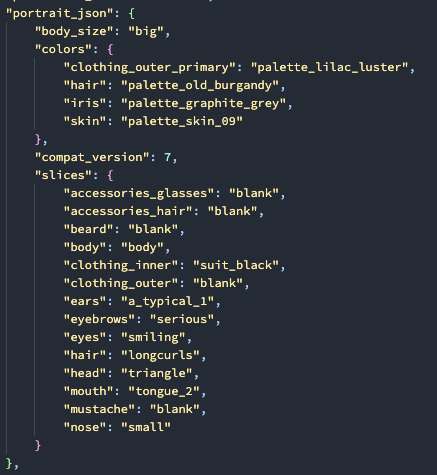
To define all the assets, we set up a file parser that goes through and automatically collects & sorts image files into different categories and with their front/back and big/small variations by file name:

I use this organization for both the portrait maker and the main game, so it's not specialized for doing picrews... I hope this is useful to you! Happy to answer any other questions you have about it.
13 notes
·
View notes
Text
okay I think the core of the stellaris save game parser finally works yaaay
part of the reason it's been such a pain to work out is because I've been wanting it to be able to handle situations where paradox might've introduced slight changes to the save data (as tends to happen every once in a while) without utterly collapsing in on itself, meaning it has to be able to load objects and data that it... doesn't necessarily recognise or know the purpose of, and also be able to save that unrecognised data back to file again despite not knowing what it really is or represents.
So not so much like just writing a json parser and more like writing a json parser that can also gracefully handle and preserve malformed json without errors being introduced.
¯\_(ツ)_/¯
7 notes
·
View notes
Text
right now in my video game I suppose you could say I'm procrastinating making my parser, haha. Instead I'm making it so that undefined combinations of runes are still saved when you click "save and quit" on the scroll editor, this will be helpful because I expect that at a certain point I'm going to have to stop defining every single rune myself with a json file and instead using my "second" parser to say that, for example, rune "A" combined with the "Possessive" combined with rune "B" is a valid new rune, which will be useful for obvious reasons I think
2 notes
·
View notes
Text
I have a habit of making frameworks and then never doing anything with them. I have made countless libraries that I never had any use for personally, but were just cool to have. truth be told I hate making finished, end user products: games, websites, applications, BAH! one million json parsers. five hundred expression evaluators to you. parsing library. gui library. multi block structures in minecraft.
it used to confound me that everybody else who was coding wanted to actually make things to be used directly, to solve actual problems they had. I always just wanted to feel like a wizard so I kept making cooler and cooler spells even if I had no use for them.
now I make tools for making tools for making tools that I have no idea what to apply to. I made a parser generator (a tool for making parsers (a tool for analyzing syntax)) which I will use to make a programming language (a tool for making yet more tools) that I have no idea what I'll do with. the more abstract the better.
because I have no actual use for this stuff I imagine myself as a sorceress locking herself in a tower to research very complicated and impractical spells, reveling in their extreme power and then just tucking them away on a shelf. I legitimately think this is the closest thing there is to being an actual modern day wizard and tbh it's that aesthetic that keeps me going.
5 notes
·
View notes
Text
Plaintext parser
So my dialogue scripts used to be JSON since the initial tutorials and resources I found suggested it. For some reason, I thought writing my own Yarnspinner-like system would be better, so I did that. Now my dialogue scripts are written as plain text. The tool in the video above lets me write and see changes in the actual game UI. All in all it's incredibly jank.
6 notes
·
View notes
Text
Okay so. Project Special K and how I found myself stuck on a project once again.
As I've said earlier, I need something to import model data. I was thinking glTF but this requires JSON and the only glTF importing library I could find specifically uses RapidJSON. I can't get patch support for RapidJSON to work, be it 6902 Patch or 7396 Merge Patch, so that's a deal breaker.
I see three options.
Use the next best format, something binary perhaps that doesn't require a separate parser library, but still supports what I need and can be exported to/from in Blender. I've done Wavefront OBJ before but that doesn't support jack.
Use lazy-glTF + RapidJSON specifically and only for model loading, use SimpleJSON + my patch extension for everything else.
Forget about 3D, switch to using only sprites. But that brings a host of other issues that using 3D would cover in the first place.
Thoughts? Format suggestions? Anything?
6 notes
·
View notes
Text
so the biggest bit of the hell game engine code is getting event parsing working. i have code that runs json objects as stuff you can click on and interact with; what i need is something that turns scene file text into the correct json objects. this also means i need to know what the scene files look like.
i have a few half-assembled w/ me kinda sketching out different syntax approaches and i was like, oh hey what would make this nicer is having syntax hilighting. and writing a syntax hilighting file is basically the same thing as writing a parser; if i can do one the other is also doable
but that got me into looking at just what sublime text syntax hilighting files look like. it's kind of a mess. like it could definitely be worse, but... it is kind of inventing a new problem to have. maybe i should focus on the parser V:
3 notes
·
View notes
Text
Devlog #2 10-29-23
This devlog is a little late, I was working on transitioning from the most rudimentary mechanics of my game to a proof of concept stage where I’m trying to use the industry standards that I’m aware of from my little professional experience.
Anyway I spent most of this week trying to slowly make my initial mechanics scalable, that means accounting for things I didn’t originally plan for or did plan for, but can’t come into reality until later on. I also changed the structure of my JSON file I’m using about 3 times and that consequently ended up causing me to rewrite parts of my JSON parser a few times as I’ve currently gotten to the point where I’m setting up a rough sample play area.
At the moment I have my marbles instantiating from a prefab randomly across the basic plane i have setup, I still need to add a self-destruct conditional to the prefab game object so that they stop wasting processing power if they leave the play area.
I also am starting to apply custom properties based on my marble-attributes json file to the marbles once instantiated. I went for a property I already did a really simple version of, the material’s color. It seemed like a good choice because its an extremely visible change and easy to identify if one of the marbles didn’t change as expected.
I’m excited to keep going, even though I know I’ve turned this from a demo producible in a month to a small behemoth that will EASILY take months to get from where I am to a demo state. But one step at a time, I need to finish programming and designing this Proof of Concept (PoC). Its daunting and I want to do this in part because I think it would be a fun game, but in larger part because I need something in my professional software portfolio to show that I’m not inept and that I could handle another Entry/Junior SWE role since I got burned for just existing with my last job 😞.
To wrap this all up, my game is coming along slowly but fairly stably for now (knock on wood). I can do it! Who cares if I’m an entry level software engineer, if no one wants to hire me I’LL MAKE MY OWN EXPERIENCE AND PROVE MYSELF!
3 notes
·
View notes
Text
What is Solr – Comparing Apache Solr vs. Elasticsearch

In the world of search engines and data retrieval systems, Apache Solr and Elasticsearch are two prominent contenders, each with its strengths and unique capabilities. These open-source, distributed search platforms play a crucial role in empowering organizations to harness the power of big data and deliver relevant search results efficiently. In this blog, we will delve into the fundamentals of Solr and Elasticsearch, highlighting their key features and comparing their functionalities. Whether you're a developer, data analyst, or IT professional, understanding the differences between Solr and Elasticsearch will help you make informed decisions to meet your specific search and data management needs.
Overview of Apache Solr
Apache Solr is a search platform built on top of the Apache Lucene library, known for its robust indexing and full-text search capabilities. It is written in Java and designed to handle large-scale search and data retrieval tasks. Solr follows a RESTful API approach, making it easy to integrate with different programming languages and frameworks. It offers a rich set of features, including faceted search, hit highlighting, spell checking, and geospatial search, making it a versatile solution for various use cases.
Overview of Elasticsearch
Elasticsearch, also based on Apache Lucene, is a distributed search engine that stands out for its real-time data indexing and analytics capabilities. It is known for its scalability and speed, making it an ideal choice for applications that require near-instantaneous search results. Elasticsearch provides a simple RESTful API, enabling developers to perform complex searches effortlessly. Moreover, it offers support for data visualization through its integration with Kibana, making it a popular choice for log analysis, application monitoring, and other data-driven use cases.
Comparing Solr and Elasticsearch
Data Handling and Indexing
Both Solr and Elasticsearch are proficient at handling large volumes of data and offer excellent indexing capabilities. Solr uses XML and JSON formats for data indexing, while Elasticsearch relies on JSON, which is generally considered more human-readable and easier to work with. Elasticsearch's dynamic mapping feature allows it to automatically infer data types during indexing, streamlining the process further.
Querying and Searching
Both platforms support complex search queries, but Elasticsearch is often regarded as more developer-friendly due to its clean and straightforward API. Elasticsearch's support for nested queries and aggregations simplifies the process of retrieving and analyzing data. On the other hand, Solr provides a range of query parsers, allowing developers to choose between traditional and advanced syntax options based on their preference and familiarity.
Scalability and Performance
Elasticsearch is designed with scalability in mind from the ground up, making it relatively easier to scale horizontally by adding more nodes to the cluster. It excels in real-time search and analytics scenarios, making it a top choice for applications with dynamic data streams. Solr, while also scalable, may require more effort for horizontal scaling compared to Elasticsearch.
Community and Ecosystem
Both Solr and Elasticsearch boast active and vibrant open-source communities. Solr has been around longer and, therefore, has a more extensive user base and established ecosystem. Elasticsearch, however, has gained significant momentum over the years, supported by the Elastic Stack, which includes Kibana for data visualization and Beats for data shipping.
Document-Based vs. Schema-Free
Solr follows a document-based approach, where data is organized into fields and requires a predefined schema. While this provides better control over data, it may become restrictive when dealing with dynamic or constantly evolving data structures. Elasticsearch, being schema-free, allows for more flexible data handling, making it more suitable for projects with varying data structures.
Conclusion
In summary, Apache Solr and Elasticsearch are both powerful search platforms, each excelling in specific scenarios. Solr's robustness and established ecosystem make it a reliable choice for traditional search applications, while Elasticsearch's real-time capabilities and seamless integration with the Elastic Stack are perfect for modern data-driven projects. Choosing between the two depends on your specific requirements, data complexity, and preferred development style. Regardless of your decision, both Solr and Elasticsearch can supercharge your search and analytics endeavors, bringing efficiency and relevance to your data retrieval processes.
Whether you opt for Solr, Elasticsearch, or a combination of both, the future of search and data exploration remains bright, with technology continually evolving to meet the needs of next-generation applications.
2 notes
·
View notes
Text
How DC Tech Events works
The main DC Tech Events site is generated by a custom static generator, in three phases:
Loop through the groups directory and download a local copy of every calendar. Groups must have an iCal or RSS feed. For RSS feeds, each item is further scanned for an embedded JSON-LD Event description. I’ll extend that to support other metadata formats, like microformats (and RSS feeds that directly include event data) as I encounter them.
Combine that data with any future single events into a single structured file (YAML).
Generate the website, which is built from a Flask application with Frozen-Flask. This includes two semi-secret URL’s that are used for the newsletter: a simplified version of the calendar, in HTML and plaintext.
Once a day, and anytime a change is merged into the main branch, those three steps are run by Github Actions, and the resulting site is pushed to Github Pages.
The RSS + JSON-LD thing might seem arbitrary, but it exists for a mission critical reason: emoji’s! For meetup.com groups, the iCal feed garbles emojis. It took me some time to realize that my code wasn’t the problem. While digging into it, I discovered that meetup.com event pages include JSON-LD, which preserves emojis. I should probably update the iCal parser to also augment feeds with JSON-LD, but the current system works fine right now.

Anyone who wants to submit a new group or event could submit a Pull Request on the github repo, but most will probably use add.dctech.events. When an event or group is submitted that way, a pull request is created for them (example). The “add” site is an AWS Chalice app.
The newsletter system is also built with Chalice. When someone confirms their email address, it gets saved to a contact list in Amazon’s Simple Email Service(SES). A scheduled task runs every Monday morning that fetches the “secret” URL’s and sends every subscriber their copy of the newsletter. SES also handles generating a unique “unsubscribe” link for each subscriber.
(but, why would anyone unsubscribe?)
0 notes
Text
Fuzz Testing: An In-Depth Guide

Introduction
In the world of software development, vulnerabilities and bugs are inevitable. As systems grow more complex and interact with a wider array of data sources and users, ensuring their reliability and security becomes more challenging. One powerful technique that has emerged as a standard for identifying unknown vulnerabilities is Fuzz Testing, also known simply as fuzzing.
Fuzz testing involves bombarding software with massive volumes of random, unexpected, or invalid input data in order to detect crashes, memory leaks, or other abnormal behavior. It’s a unique and often automated method of discovering flaws that traditional testing techniques might miss. By leveraging fuzz testing early and throughout development, developers can harden applications against unexpected input and malicious attacks.
What is Fuzz Testing?
Fuzz Testing is a software testing technique where invalid, random, or unexpected data is input into a program to uncover bugs, security vulnerabilities, and crashes. The idea is simple: feed the software malformed or random data and observe its behavior. If the program crashes, leaks memory, or behaves unpredictably, it likely has a vulnerability.
Fuzz testing is particularly effective in uncovering:
Buffer overflows
Input validation errors
Memory corruption issues
Logic errors
Security vulnerabilities such as injection flaws or crashes exploitable by attackers
Unlike traditional testing methods that rely on predefined inputs and expected outputs, fuzz testing thrives in unpredictability. It doesn’t aim to verify correct behavior — it seeks to break the system by pushing it beyond normal use cases.
History of Fuzz Testing
Fuzz testing originated in the late 1980s. The term “fuzz” was coined by Professor Barton Miller and his colleagues at the University of Wisconsin in 1989. During a thunderstorm, Miller was remotely logged into a Unix system when the connection degraded and began sending random characters to his shell. The experience inspired him to write a program that would send random input to various Unix utilities.
His experiment exposed that many standard Unix programs would crash or hang when fed with random input. This was a startling revelation at the time, showing that widely used software was far less robust than expected. The simplicity and effectiveness of the technique led to increased interest, and fuzz testing has since evolved into a critical component of modern software testing and cybersecurity.
Types of Fuzz Testing
Fuzz testing has matured into several distinct types, each tailored to specific needs and target systems:
1. Mutation-Based Fuzzing
In this approach, existing valid inputs are altered (or “mutated”) to produce invalid or unexpected data. The idea is that small changes to known good data can reveal how the software handles anomalies.
Example: Modifying values in a configuration file or flipping bits in a network packet.
2. Generation-Based Fuzzing
Rather than altering existing inputs, generation-based fuzzers create inputs from scratch based on models or grammars. This method requires knowledge of the input format and is more targeted than mutation-based fuzzing.
Example: Creating structured XML or JSON files from a schema to test how a parser handles different combinations.
3. Protocol-Based Fuzzing
This type is specific to communication protocols. It focuses on sending malformed packets or requests according to network protocols like HTTP, FTP, or TCP to test a system’s robustness against malformed traffic.
4. Coverage-Guided Fuzzing
Coverage-guided fuzzers monitor which parts of the code are executed by the input and use this feedback to generate new inputs that explore previously untested areas of the codebase. This type is very effective for high-security and critical systems.
5. Black Box, Grey Box, and White Box Fuzzing
Black Box: No knowledge of the internal structure of the system; input is fed blindly.
Grey Box: Limited insight into the system’s structure; may use instrumentation for guidance.
White Box: Full knowledge of source code or internal logic; often combined with symbolic execution for deep analysis.
How Does Fuzzing in Testing Work?
The fuzzing process generally follows these steps:
Input Selection or Generation: Fuzzers either mutate existing input data or generate new inputs from defined templates.
Execution: The fuzzed inputs are provided to the software under test.
Monitoring: The system is monitored for anomalies such as crashes, hangs, memory leaks, or exceptions.
Logging: If a failure is detected, the exact input and system state are logged for developers to analyze.
Iteration: The fuzzer continues producing and executing new test cases, often in an automated and repetitive fashion.
This loop continues, often for hours or days, until a comprehensive sample space of unexpected inputs has been tested.
Applications of Fuzz Testing
Fuzz testing is employed across a wide array of software and systems, including:
Operating Systems: To discover kernel vulnerabilities and system call failures.
Web Applications: To test how backends handle malformed HTTP requests or corrupted form data.
APIs: To validate how APIs respond to invalid or unexpected payloads.
Parsers and Compilers: To test how structured inputs like XML, JSON, or source code are handled.
Network Protocols: To identify how software handles unexpected network packets.
Embedded Systems and IoT: To validate robustness in resource-constrained environments.
Fuzz testing is especially vital in security-sensitive domains where any unchecked input could be a potential attack vector.
Fuzz Testing Tools
One of the notable fuzz testing tools in the market is Genqe. It stands out by offering intelligent fuzz testing capabilities that combine mutation, generation, and coverage-based strategies into a cohesive and user-friendly platform.
Genqe enables developers and QA engineers to:
Perform both black box and grey box fuzzing
Generate structured inputs based on schemas or templates
Track code coverage dynamically to optimize test paths
Analyze results with built-in crash diagnostics
Run parallel tests for large-scale fuzzing campaigns
By simplifying the setup and integrating with modern CI/CD pipelines, Genqe supports secure development practices and helps teams identify bugs early in the software development lifecycle.
Conclusion
Fuzz testing has proven itself to be a valuable and essential method in the realm of software testing and security. By introducing unpredictability into the input space, it helps expose flaws that might never be uncovered by traditional test cases. From operating systems to web applications and APIs, fuzz testing reveals how software behaves under unexpected conditions — and often uncovers vulnerabilities that attackers could exploit.
While fuzz testing isn’t a silver bullet, its strength lies in its ability to complement other testing techniques. With modern advancements in automation and intelligent fuzzing engines like Genqe, it’s easier than ever to integrate fuzz testing into the development lifecycle. As software systems continue to grow in complexity, the role of fuzz testing will only become more central to creating robust, secure, and trustworthy applications.
0 notes