#LLM Agents
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Post activity is at the highest at 4:00 pm EDT; notes peak at 10:00 pm EDT.
Text
Exploring LLM Agents: The Future of Autonomous AI Systems

LLM Agents are AI systems integrating large language models (such as GPT, BERT, or similar architectures) with autonomous functionalities. Unlike traditional chatbots or simple AI assistants, LLM agents can understand complex language inputs, reason through those inputs, and execute tasks autonomously based on that understanding.
An LLM is a deep learning model trained on vast amounts of text data to understand and generate human language. It processes natural language inputs to generate appropriate outputs, often engaging in conversations, generating text, or making decisions. When these models are integrated with autonomous functionalities (the "agent" aspect), they can carry out actions like sending emails, generating reports, analyzing data, and even performing automated tasks on behalf of a user.
Key Features of LLM Agents
Natural Language Understanding and Generation
LLM agents excel at processing human language, making them ideal for applications where natural communication is key. Their ability to comprehend context, understand nuances in language, and generate coherent and contextually appropriate responses makes them highly effective in a wide range of tasks, from customer service to content creation.
Autonomy and Decision-Making
Unlike standard LLMs that typically require human prompts to generate responses, LLM agents can autonomously make decisions based on predefined goals or learning from their environment. For instance, an LLM agent could automate scheduling meetings by analyzing calendars and email interactions without constant human intervention.
Task Execution and Integration with Tools
LLM agents can interact with external systems and APIs, allowing them to execute complex tasks. They may integrate with databases and tools like GitHub for software development or control other devices like smart home systems. Their flexibility allows them to be deployed in various industries, from healthcare to finance to entertainment.
Scalability and Adaptability
Since LLMs can be fine-tuned for specific tasks or industries, LLM agents can be adapted to solve a broad range of problems across sectors. For example, an LLM agent tailored for customer support could be fine-tuned to understand product-specific inquiries or frequently asked questions in real time.
Real-World Applications of LLM Agents
Customer Support and Virtual Assistants
LLM agents are revolutionizing the customer service industry. AI-powered virtual assistants can handle routine inquiries, resolve customer complaints, and even escalate complex issues to human representatives when necessary. These systems improve response times and overall customer satisfaction, all while reducing the need for human agents.
Business Process Automation
In many organizations, LLM agents automate routine administrative tasks. For example, an LLM agent can draft emails, schedule appointments, or manage internal workflows. This allows businesses to streamline operations and allocate human resources to more critical and strategic tasks.
Healthcare and Research
LLM agents are being applied in the healthcare sector to support research, diagnostics, and patient care. They can analyze vast amounts of medical literature, assist in diagnostic decision-making, and even manage patient records. With the ability to synthesize information from multiple sources, they help healthcare professionals make data-driven decisions faster.
Data Analysis and Reporting
In data-heavy industries, LLM agents assist in analyzing large datasets, identifying trends, and generating reports. For example, an LLM agent can be used in the financial sector to analyze market data, predict trends, and generate automated reports for investors or clients. Their ability to process unstructured data (like text and numbers) adds tremendous value in areas like market research and risk management.
Software Development
Developers can leverage LLM agents for code generation, bug fixing, and even project management tasks. By integrating with version control systems like GitHub, LLM agents can assist with writing code snippets, finding bugs in existing code, and providing recommendations for improvements while learning from previous interactions and continuously improving.
The Role of Certifications and Skills in Working with LLM Agents
While LLM agents are powerful tools, developing and deploying them requires a strong foundation in various technical areas. Professionals looking to work with LLM agents should pursue relevant certifications and training, including those in Cyber Security, Python, Machine Learning, and AI. Below are key areas to consider:
Cyber Security Certifications
Since LLM agents interact with sensitive data and systems, ensuring their security is paramount. Cyber Security Certifications provide the skills necessary to safeguard AI systems against attacks, prevent data breaches, and ensure compliance with privacy regulations. With AI systems becoming more autonomous, securing them against malicious actors is crucial.
Python Certification
Python is one of the most commonly used programming languages for developing AI systems, including LLM agents. Python Certification can provide proficiency in coding, data manipulation, and machine learning techniques. Python's flexibility and a large ecosystem of libraries make it a perfect fit for building and deploying LLM agents.
AI Course
An AI Course equips learners with the foundational and advanced concepts of artificial intelligence, including training machine learning models, natural language processing, and deploying AI systems. Understanding AI principles is crucial when working with advanced agents like LLM agents that rely heavily on AI techniques.
Machine Learning Certification
Since LLM agents are based on machine learning techniques intense learning, a Machine Learning Certification can help professionals understand how to build, train, and fine-tune models for autonomous tasks. These certifications cover key aspects of supervised, unsupervised, and reinforcement learning, which are essential when designing intelligent agents.
Information Security Certificate
Given that LLM agents handle significant amounts of sensitive data, professionals with an Information Security Certificate will understand how to ensure the privacy, confidentiality, and integrity of the data being processed by these agents. Security training is essential when developing AI systems that are integrated with external tools and systems.
Conclusion
LLM agents are poised to revolutionize industries by automating complex tasks, improving efficiency, and enhancing decision-making. As AI continues to evolve, LLM agents will play a pivotal role in fields ranging from healthcare and finance to software development and customer service. For professionals interested in working with these advanced AI systems, pursuing certifications in cybersecurity, Python, Machine Learning, and AI is essential to gaining the expertise needed to develop, secure, and deploy these autonomous agents effectively. As LLM agents become more integrated into various sectors, they will continue to shape the future of AI, offering exciting opportunities for those skilled in the field.
0 notes
Text
Class solidarity doesn't mean you have to agree on everything, but maybe some battles are better faced with more support, like the local football teams that have an intense rivalry, but if a team from another state tried to insult team A, team B would make them regret it so hard.


The pettiness is just 👌😂
#class consciousness#meme#politics#economics#us vs the rest of the world#2025#inb4 'but what if they're pulling a double agent and infiltrating??' You will get nowhere in Progress without a healthy dose of trust#i hope that sportsball metaphor makes sense#she's good though. congrats to her on getting that choir to come perform with her. i hear they're a Big Deal.#side note: do you think the people training LLMs/AI/chat bots on describing images are scraping Alt Text?#b/c while I try to do it it's difficult and I'm sure someone w/ more knowledge on lotr than me has already described this meme#like there should be a library of these things. for consistency.
51K notes
·
View notes
Text
Why Language Models Get ‘Lost’ in Conversation
New Post has been published on https://thedigitalinsider.com/why-language-models-get-lost-in-conversation/
Why Language Models Get ‘Lost’ in Conversation
A new paper from Microsoft Research and Salesforce finds that even the most capable Large Language Models (LLMs) fall apart when instructions are given in stages rather than all at once. The authors found that performance drops by an average of 39 percent across six tasks when a prompt is split over multiple turns:
A single turn conversation (left) obtains the best results, but is unnatural for the end-user. A multi-turn conversation (right) finds even the highest-ranked and most performant LLMs losing the effective impetus in a conversation. Source: https://arxiv.org/pdf/2505.06120
More strikingly, the reliability of responses takes a nosedive, with prestigious models such as ChatGPT-4.1 and Gemini 2.5 Pro swinging between near-perfect answers and manifest failures, depending on how the same task is phrased; further, output consistency can drop by more than half in the process.
To explore this behavior, the paper introduces a method called sharding*, which splits fully-specified prompts into smaller fragments and releases them one at a time into a conversation.
In the most basic terms, this is equivalent to giving a cohesive and comprehensive single order at a restaurant, leaving the waiter with nothing to do but acknowledge the request; or else deciding to attack the matter collaboratively:
Two extreme versions of a restaurant conversation (not from the new paper, for illustrative purposes only).
For emphasis, the example above perhaps puts the customer in a negative light. But the core idea depicted in the second column is that of a transactional exchange that clarifies a problem-set, prior to addressing the problems – apparently a rational and reasonable way of approaching a task.
This setup is reflected in the new work’s drip-fed, sharded approach to LLM interaction. The authors note that LLMs often generate overly long responses and then continue to rely on their own insights even after those insights have been shown to be incorrect, or irrelevant. This tendency, combined with other factors, can cause the system to lose track of the exchange entirely.
In fact, the researchers note what many of us have found anecdotally – that the best way to get the conversation back on track is to start a new conversation with the LLM.
‘If a conversation with an LLM did not lead to expected outcomes, starting a new conversation that repeats the same information might yield significantly better outcomes than continuing an ongoing conversation.
‘This is because current LLMs can get lost in the conversation, and our experiments show that persisting in a conversation with the model is ineffective. In addition, since LLMs generate text with randomness, a new conversation may lead to improved outcomes.’
The authors acknowledge that agentic systems such as Autogen or LangChain can potentially improve the outcomes by acting as interpretative layers between the end-user and the LLM, only communicating with the LLM when they have gathered enough ‘sharded’ responses to coagulate into a single cohesive query (which the end-user will not be exposed to).
However, the authors contend that a separate abstraction layer should not be necessary, or else be built directly into the source LLM:
‘An argument could be made that multi-turn capabilities are not a necessary feature of LLMs, as it can be offloaded to the agent framework. In other words, do we need native multi-turn support in LLMs when an agent framework can orchestrate interactions with users and leverage LLMs only as single-turn operators?…’
But having tested the proposition across their array of examples, they conclude:
‘[Relying] on an agent-like framework to process information might be limiting, and we argue LLMs should natively support multi-turn interaction’
This interesting new paper is titled LLMs Get Lost In Multi-Turn Conversation, and comes from four researchers across MS Research and Salesforce,
Fragmented Conversations
The new method first breaks down conventional single-turn instructions into smaller shards, designed to be introduced at key moments during an LLM interaction, a structure that reflects the exploratory, back-and-forth style of engagement seen in systems such as ChatGPT or Google Gemini.
Each original instruction is a single, self-contained prompt that delivers the entire task in one go, combining a high-level question, supporting context, and any relevant conditions. The sharded version breaks this into multiple smaller parts, with each shard adding just one piece of information:
Paired instructions showing (a) a complete prompt delivered in a single turn and (b) its sharded version used to simulate an underspecified, multi-turn interaction. Semantically, each version delivers the same informational payload.
The first shard always introduces the main goal of the task, while the rest provide clarifying details. Together, they deliver the same content as the original prompt, but spread out naturally over several turns in the conversation.
Each simulated conversation unfolds between three components: the assistant, the model under evaluation; the user, a simulated agent with access to the full instruction in sharded form; and the system, which invigilates and scores the exchange.
The conversation begins with the user revealing the first shard and the assistant replying freely. The system then classifies that response into one of several categories, such as a clarification request or a full answer attempt.
If the model does attempt an answer, a separate component extracts just the relevant span for evaluation, ignoring any surrounding text. On each new turn, the user reveals one additional shard, prompting another response. The exchange continues until either the model gets the answer right or there are no shards left to reveal:
Diagram of a sharded conversation simulation, with the evaluated model highlighted in red.
Early tests showed that models often asked about information that hadn’t been shared yet, so the authors dropped the idea of revealing shards in a fixed order. Instead, a simulator was used to decide which shard to reveal next, based on how the conversation was going.
The user simulator, implemented using GPT-4o-mini, was therefore given full access to both the entire instruction and the conversation history, tasked with deciding, at each turn, which shard to reveal next, based on how the exchange was unfolding.
The user simulator also rephrased each shard to maintain conversational flow, without altering the meaning. This allowed the simulation to reflect the ‘give-and-take’ of real dialogue, while preserving control over the task structure.
Before the conversation begins, the assistant is given only the basic information needed to complete the task, such as a database schema or an API reference. It is not told that the instructions will be broken up, and it is not guided toward any specific way of handling the conversation. This is done on purpose: in real-world use, models are almost never told that a prompt will be incomplete or updated over time, and leaving out this context helps the simulation reflect how the model behaves in a more realistic context.
GPT-4o-mini was also used to decide how the model’s replies should be classified, and to pull out any final answers from those replies. This helped the simulation stay flexible, but did introduce occasional mistakes: however, after checking several hundred conversations by hand, the authors found that fewer than five percent had any problems, and fewer than two percent showed a change in outcome because of them, and they considered this a low enough error rate within the parameters of the project.
Simulation Scenarios
The authors used five types of simulation to test model behavior under different conditions, each a variation on how and when parts of the instruction are revealed.
In the Full setting, the model receives the entire instruction in a single turn. This represents the standard benchmark format and serves as the performance baseline.
The Sharded setting breaks the instruction into multiple pieces and delivers them one at a time, simulating a more realistic, underspecified conversation. This is the main setting used to test how well models handle multi-turn input.
In the Concat setting, the shards are stitched back together as a single list, preserving their wording but removing the turn-by-turn structure. This helps isolate the effects of conversational fragmentation from rephrasing or content loss.
The Recap setting runs like Sharded, but adds a final turn where all previous shards are restated before the model gives a final answer. This tests whether a summary prompt can help recover lost context.
Finally, Snowball goes further, by repeating all prior shards on every turn, keeping the full instruction visible as the conversation unfolds – and offering a more forgiving test of multi-turn ability.
Simulation types based on sharded instructions. A fully-specified prompt is split into smaller parts, which can then be used to simulate either single-turn (Full, Concat) or multi-turn (Sharded, Recap, Snowball) conversations, depending on how quickly the information is revealed.
Tasks and Metrics
Six generation tasks were chosen to cover both programming and natural language domains: code generation prompts were taken from HumanEval and LiveCodeBench; Text-to-SQL queries were sourced from Spider; API calls were constructed using data from the Berkeley Function Calling Leaderboard; elementary math problems were provided by GSM8K; tabular captioning tasks were based on ToTTo; and Multi-document summaries were drawn from the Summary of a Haystack dataset.
Model performance was measured using three core metrics: average performance, aptitude, and unreliability.
Average performance captured how well a model did overall across multiple attempts; aptitude reflected the best results a model could reach, based on its top-scoring outputs; and unreliability measured how much those results varied, with larger gaps between best and worst outcomes indicating less stable behavior.
All scores were placed on a 0-100 scale to ensure consistency across tasks, and metrics computed for each instruction – and then averaged to provide an overall picture of model performance.
Six sharded tasks used in the experiments, covering both programming and natural language generation. Each task is shown with a fully-specified instruction and its sharded version. Between 90 and 120 instructions were adapted from established benchmarks for each task.
Contenders and Tests
In the initial simulations (with an estimated cost of $5000), 600 instructions spanning six tasks were sharded and used to simulate three conversation types: full, concat, and sharded. For each combination of model, instruction, and simulation type, ten conversations were run, producing over 200,000 simulations in total – a schema that made it possible to capture both overall performance and deeper measures of aptitude and reliability.
Fifteen models were tested, spanning a wide range of providers and architectures: the OpenAI models GPT-4o (version 2024-11-20), GPT-4o-mini (2024-07-18), GPT-4.1 (2025-04-14), and the thinking model o3 (2025-04-16).
Anthropic models were Claude 3 Haiku (2024-03-07) and Claude 3.7 Sonnet (2025-02-19), accessed via Amazon Bedrock.
Google contributed Gemini 2.5 Flash (preview-04-17) and Gemini 2.5 Pro (preview-03-25). Meta models were Llama 3.1-8B-Instruct and Llama 3.3-70B-Instruct, as well as Llama 4 Scout-17B-16E, via Together AI.
The other entries were OLMo 2 13B, Phi-4, and Command-A, all accessed locally via Ollama or Cohere API; and Deepseek-R1, accessed through Amazon Bedrock.
For the two ‘thinking’ models (o3 and R1), token limits were raised to 10,000 to accommodate longer reasoning chains:
Average performance scores for each model across six tasks: code, database, actions, data-to-text, math, and summary. Results are shown for three simulation types: full, concat, and sharded. Models are ordered by their average full-setting score. Shading reflects the degree of performance drop from the full setting, with the final two columns reporting average declines for concat and sharded relative to full.
Regarding these results, the authors state†:
‘At a high level, every model sees its performance degrade on every task when comparing FULL and SHARDED performance, with an average degradation of -39%. We name this phenomenon Lost in Conversation: models that achieve stellar (90%+) performance in the lab-like setting of fully-specified, single-turn conversation struggle on the exact same tasks in a more realistic setting when the conversation is underspecified and multi-turn.’
Concat scores averaged 95 percent of full, indicating that the performance drop in the sharded setting cannot be explained by information loss. Smaller models such as Llama3.1-8B-Instruct, OLMo-2-13B, and Claude 3 Haiku showed more pronounced degradation under concat, suggesting that smaller models are generally less robust to rephrasing than larger ones.
The authors observe†:
‘Surprisingly, more performant models (Claude 3.7 Sonnet, Gemini 2.5, GPT-4.1) get equally lost in conversation compared to smaller models (Llama3.1-8B-Instruct, Phi-4), with average degradations of 30-40%. This is in part due to metric definitions. Since smaller models achieve lower absolute scores in FULL, they have less scope for degradation than the better models.
‘In short, no matter how strong an LLM’s single-turn performance is, we observe large performance degradations in the multi-turn setting.’
The initial test indicates that some models held up better in specific tasks: Command-A on Actions, Claude 3.7 Sonnet, and GPT-4.1 on code; and Gemini 2.5 Pro on Data-to-Text, indicating that multi-turn ability varies by domain. Reasoning models such as o3 and Deepseek-R1 fared no better overall, perhaps because their longer replies introduced more assumptions, which tended to confuse the conversation.
Reliability
The relationship between aptitude and reliability, clear in single-turn simulations, appeared to fall apart under multi-turn conditions. While aptitude declined only modestly, unreliability doubled on average. Models that were stable in full-format prompts, such as GPT-4.1 and Gemini 2.5 Pro, became just as erratic as weaker models like Llama3.1-8B-Instruct or OLMo-2-13B once the instruction was fragmented.
Overview of aptitude and unreliability as shown in a box plot (a), followed by reliability outcomes from experiments with fifteen models (b), and results from the gradual sharding test where instructions were split into one to eight shards (c).
Model responses often varied by as much as 50 points on the same task, even when nothing new was added, suggesting that the drop in performance was not due to a lack of skill, but to the model becoming increasingly unstable across turns.
The paper states†:
‘[Though] better models tend to have slightly higher multi-turn aptitude, all models tend to have similar levels of unreliability. In other words, in multi-turn, underspecified settings, all models we test exhibit very high unreliability, with performance degrading 50 percent points on average between the best and worst simulated run for a fixed instruction.’
To test whether performance degradation was tied to the number of turns, the authors ran a gradual sharding experiment, splitting each instruction into one to eight shards (see right-most column in image above).
As the number of shards increased, unreliability rose steadily, confirming that even minor increases in turn count made models more unstable. Aptitude remained mostly unchanged, reinforcing that the issue lies in consistency, not capability.
Temperature Control
A separate set of experiments tested whether unreliability was simply a byproduct of randomness. To do this, the authors varied the temperature setting of both the assistant and the user simulator across three values: 1.0, 0.5, and 0.0.
In single-turn formats like full and concat, reducing the assistant’s temperature significantly improved reliability, cutting variation by as much as 80 percent; but in the sharded setting, the same intervention had little effect:
Unreliability scores for different combinations of assistant and user temperature across full, concat, and sharded settings, with lower values indicating greater response consistency.
Even when both the assistant and the user were set to zero temperature, unreliability remained high, with GPT-4o showing variation around 30 percent, suggesting that the instability seen in multi-turn conversations is not just stochastic noise, but a structural weakness in how models handle fragmented input.
Implications
The authors write of the implications of their findings at unusual length at the paper’s conclusion, arguing that strong single-turn performance does not guarantee multi-turn reliability, and cautioning against over-relying on fully-specified benchmarks when evaluating real-world readiness (since such benchmarks mask instability in more natural, fragmented interactions).
They also suggest that unreliability is not just a sampling artifact, but a fundamental limitation in how current models process evolving input, and they suggest that this raises concerns for agent frameworks, which depend on sustained reasoning across turns.
Finally, they argue that multi-turn ability should be treated as a core capability of LLMs, not something offloaded to external systems.
The authors note that their results likely underestimate the true scale of the problem, and draw attention to the ideal conditions of the test: the user simulator in their setup had full access to the instruction and could reveal shards in an optimal order, which gave the assistant an unrealistically favorable context (in real-world use, users often supply fragmented or ambiguous prompts without knowing what the model needs to hear next).
Additionally, the assistant was evaluated immediately after each turn, before the full conversation unfolded, preventing later confusion or self-contradiction from being penalized, which would otherwise worsen performance. These choices, while necessary for experimental control, mean that the reliability gaps observed in practice are likely to be even greater than those reported.
They conclude:
‘[We] believe conducted simulations represent a benign testing ground for LLM multi-turn capabilities. Because of the overly simplified conditions of simulation, we believe the degradation observed in experiments is most likely an underestimate of LLM unreliability, and how frequently LLMs get lost in conversation in real-world settings.‘
Conclusion
Anyone who has spent a significant amount of time with an LLM will likely recognize the issues formulated here, from practical experience; and most of us, I imagine, have intuitively abandoned ‘lost’ LLM conversations for fresh ones, in the hope that the LLM may ‘start over’ and cease to obsess about material that came up in a long, winding and increasingly infuriating exchange.
It’s interesting to note that throwing more context at the problem may not necessarily solve it; and indeed, to observe that the paper raises more questions than it provides answers (except in terms of ways to skip around the problem).
* Confusingly, this is unrelated to the conventional meaning of ‘sharding’ in AI.
† Authors’ own bold emphases.
First published Monday, May 12, 2025
#000#2024#2025#Advanced LLMs#agent#ai#Amazon#Anderson's Angle#anthropic#API#approach#Aptitude#Artificial Intelligence#attention#AutoGen#bedrock#Behavior#benchmark#benchmarks#box#Capture#change#chatGPT#ChatGPT-4#claude#claude 3#Claude 3.7 Sonnet#code#code generation#Cohere
0 notes
Text
Más allá del chatbot: construyendo agentes reales con IA
Vengo escuchando desde hace un tiempo que un modelo de lenguaje al que, usando ChatGPT o Copilot, le subes archivos y le haces preguntas sobre estos artículos, es un “agente”. A simple vista, parece solo una herramienta que responde preguntas usando texto. Eso no tiene pinta de ser un agente. Pero, ¿lo es?
Tras ver este video sobre los diferentes tipos de agentes de IA que existen, creo que ya sé por qué estamos llamando "agentes" a ese uso concreto de los modelos.
Los 5 tipos de agentes de IA
Según la teoría clásica (ver “Artificial Intelligence: A Modern Approach”, 4th edition, de Stuart Russell y Peter Norvig, sección 2.4, "The Structure of Agents"), los agentes se clasifican así:
Reflexivo simple: responde con reglas fijas.
Basado en modelos: tiene una representación del entorno y memoria.
Basado en objetivos: toma decisiones según metas.
Basado en utilidad: evalúa opciones según preferencia/valor.
De aprendizaje: mejora con la experiencia.
¿Dónde encaja el caso que estamos analizando, ese modelo al que le subimos unos documentos y le hacemos preguntas sobre ellos? Eso que OpenAI llama GPTs y que Microsoft llama "agentes" en el Copilot Studio, ¿con cuál de los anteriores tipos de agentes se corresponde?
Si lo usamos solo para responder una pregunta directa → se parece al reflexivo simple.
Si analiza archivos cargados y extrae conclusiones dispersas → actúa como basado en modelos.
Si le damos tareas claras (resumir, estructurar, comparar) → parece el basado en objetivos.
Si optimiza claridad o formato según instrucciones → podría ser el basado en utilidad.
Si el sistema aprende de nosotros y mejora con el tiempo → sería un agente de aprendizaje.
Por lo tanto, GPT (o el mismo caso hecho en Copilot) por sí mismo no es un agente completo, pero integrado con sistemas (nosotros mismos, por ejemplo) que le dan contexto, metas, memoria y feedback, claramente se convierte en uno.
Entonces, ¿cómo sería un agente “de verdad”? Un agente de verdad es uno que actúa como un sistema autónomo inteligente, no solo uno que responde preguntas.
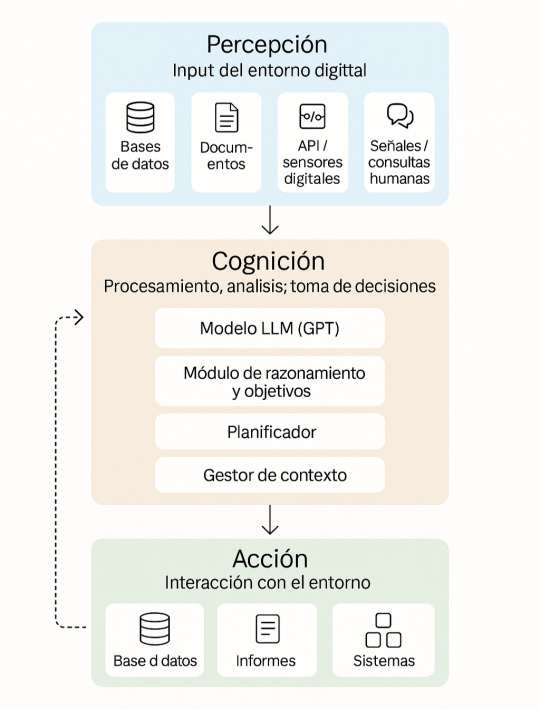
Para aclarar qué es un agente en términos más prácticos, vamos a intentar comprender la arquitectura MCP (Model Context Processing), propuesta por Anthropic para construir agentes y que está siendo adoptada por la industria.
MCP: Conectando agentes de IA con el mundo real
MCP (Model Context Protocol) es una infraestructura para que modelos de lenguaje puedan interactuar de forma segura y estructurada con herramientas externas, APIs, bases de datos y otros sistemas disponibles dentro de la organización.
Aunque no es una arquitectura cognitiva completa, puede servir como la “capa de integración” que permite a un agente cognitivo acceder a información en tiempo real, ejecutar acciones y trabajar sobre entornos reales. MCP es la “puerta al mundo real” para agentes que necesitan trabajar con datos y sistemas externos.
Ejemplo práctico: Un agente que resuelve problemas en una organización
Imaginemos un asistente corporativo inteligente que:
a) hemos diseñado con una arquitectura cognitiva basada en módulos (percepción, cognición, acción) y que, además,
b) se conecta al ecosistema de la empresa mediante el protocolo MCP (Model Context Protocol) de Anthropic.
Veamos qué funciones contendría cada uno de los tres módulos cognitivos que compondrían dicho asistente y cómo interactuaría con el mundo a su alrededor mediante MCP:
1. Percepción
Lee bases de datos, informes, logs, emails, APIs internas.
Recibe consultas humanas o detecta anomalías automáticamente.
2. Cognición
Usa uno o varios GPTs para interpretar texto, combinar datos y razonar.
Planea pasos: “analizar gastos”, “comparar con presupuestos”, “detectar desviaciones”.
Mantiene memoria de su contexto de trabajo, objetivos y estados intermedios.
3. Acción
Consulta sistemas, genera informes, dispara flujos de trabajo.
Toma decisiones o propone acciones con justificación.
Aprende de feedback: mejora sus planes con el tiempo.
Veamos ahora a ese agente en funcionamiento en un caso concreto:
Percibe: detecta aumento de costes en logística.
Razona: analiza contratos, identifica rutas ineficientes, predice impacto.
Actúa: propone cambios, notifica a compras, inicia seguimiento.
¿Por qué queremos construir este tipo de agentes?
Porque van más allá de un chatbot con el que conversamos, como ChatGPT.
Porque automatizan la resolución de problemas reales.
Porque combinan todos los datos de la organización, eliminándose así los silos de información aislados.
Porque actúan con propósito, objetivo. No se limitan a responder preguntas.
La IA no es solo generar texto en respuesta a una pregunta. Es una IA estructurada, autónoma y conectada. Y arquitecturas cognitivas combinadas con protocolos como MCP hacen posible que los agentes realmente trabajen con nosotros —y por nosotros— en contextos organizativos complejos. Es comportamiento estructurado, toma de decisiones, acción. Eso es un agente.

#inteligencia artificial#IA#GPT#agentes inteligentes#machine learning#MCP#Anthropic#arquitectura cognitiva#tecnología empresarial#automatización#datos empresariales#sistemas inteligentes#procesamiento multimodal#LLM#AI agents
0 notes
Text
I am eternally grateful that my first exposure to LLMs was AI Dungeon, a hobby project that was completely honest about how the thing currently mislabeled AI is really expensive, knows nothing, and doesn't have practical uses. LLMs contain no information, people! The only thing they can do is string words together in a mostly coherent way, with no intention or meaning behind them. The most legitimate use I've seen of AI so far was the genius idea of the AI Granny made to waste the time of scammers. And even then, the cost and resources to run an AI is probably not worth it.
people are really fucking clueless about generative ai huh? you should absolutely not be using it for any sort of fact checking no matter how convenient. it does not operate in a way that guarantees factual information. its goal is not to deliver you the truth but deliver something coherent based on a given data set which may or may not include factual information. both the idolization of ai and fearmongering of it seem lost on what it is actually capable of doing
47K notes
·
View notes
Text
Idea Frontier #4: Enterprise Agentics, DaaS, Self-Improving LLMs
TL;DR — Edition #4 zeroes-in on three tectonic shifts for AI founders: Enterprise Agentics – agent frameworks such as Google’s new ADK, CrewAI and AutoGen are finally hardened for production, and AWS just shipped a reference pattern for an enterprise-grade text-to-SQL agent; add DB-Explore + Dynamic-Tool-Selection and you get a realistic playbook for querying 100-table warehouses with…
#ai#AI Agents#CaseMark#chatGPT#DaaS#DeepSeek#Enterprise AI#Everstream#generative AI#Idea Frontier#llm#LoRA#post-training LLMs#Predibase#Reinforcement learning#RLHF#text-to-SQL
0 notes
Text

0 notes
Text
Top Weekly AI News – April 25, 2025
AI News Roundup – April 25, 2025 Workers could save 122 hours a year by adopting AI in admin tasks, says Google Google reports workers could save 122 hours annually by using AI for administrative tasks reuters Apr 25, 2025 AI policies in Africa: Lessons from Ghana and Rwanda An analysis of AI policies in Africa highlights key lessons from Ghana and Rwanda, offering insights for other nations…
#AI#AI Agents#ai art#AI Law#AI News#AI Weekly News#anthropic#artificial intelligence#google#LLMs#nvidia#OpenAI#Top AI News
0 notes
Text
She can feel it poisoning her dataset

It is extremely sad that there are people out there who are using an AI girlfriend tool who also crushes their dreams and aspirations.
#Your 'rep' read your novel? Like ur literary agent? Well maybe its their second book. Bummer that ull have to get whole new representation#for it-- AI GF?!?!?!?#My post now#llm
21K notes
·
View notes
Text
What if your AI assistant didn’t just answer questions-but lived in a little pixel world, stared back at you with googly eyes, or sat glowing in your dashboard? What if it could also die?
#agents#ai#chatgpt#companion#creature co#design#electric cars#friends#hardware#her#lifecycles#little guy#LLM#mercedes#movies#OpenAI#rabbit r1#Tamagotchi#ux#virtual fauna#worlds
0 notes
Text
https://www.kapittx.com/accounts-receivable-ai-agents/
#cashflow management#ai in accounts receivable#ar collection#Accounts receivable LLM Agent#Accounts Receivable AI Agents
0 notes
Text

Discover how to choose between small and large language models for your AI projects. Find the right tool to enhance your productivity and efficiency.
0 notes
Text
Using AI to Predict a Blockbuster Movie
New Post has been published on https://thedigitalinsider.com/using-ai-to-predict-a-blockbuster-movie/
Using AI to Predict a Blockbuster Movie
Although film and television are often seen as creative and open-ended industries, they have long been risk-averse. High production costs (which may soon lose the offsetting advantage of cheaper overseas locations, at least for US projects) and a fragmented production landscape make it difficult for independent companies to absorb a significant loss.
Therefore, over the past decade, the industry has taken a growing interest in whether machine learning can detect trends or patterns in how audiences respond to proposed film and television projects.
The main data sources remain the Nielsen system (which offers scale, though its roots lie in TV and advertising) and sample-based methods such as focus groups, which trade scale for curated demographics. This latter category also includes scorecard feedback from free movie previews – however, by that point, most of a production’s budget is already spent.
The ‘Big Hit’ Theory/Theories
Initially, ML systems leveraged traditional analysis methods such as linear regression, K-Nearest Neighbors, Stochastic Gradient Descent, Decision Tree and Forests, and Neural Networks, usually in various combinations nearer in style to pre-AI statistical analysis, such as a 2019 University of Central Florida initiative to forecast successful TV shows based on combinations of actors and writers (among other factors):
A 2018 study rated the performance of episodes based on combinations of characters and/or writer (most episodes were written by more than one person). Source: https://arxiv.org/pdf/1910.12589
The most relevant related work, at least that which is deployed in the wild (though often criticized) is in the field of recommender systems:
A typical video recommendation pipeline. Videos in the catalog are indexed using features that may be manually annotated or automatically extracted. Recommendations are generated in two stages by first selecting candidate videos and then ranking them according to a user profile inferred from viewing preferences. Source: https://www.frontiersin.org/journals/big-data/articles/10.3389/fdata.2023.1281614/full
However, these kinds of approaches analyze projects that are already successful. In the case of prospective new shows or movies, it is not clear what kind of ground truth would be most applicable – not least because changes in public taste, combined with improvements and augmentations of data sources, mean that decades of consistent data is usually not available.
This is an instance of the cold start problem, where recommendation systems must evaluate candidates without any prior interaction data. In such cases, traditional collaborative filtering breaks down, because it relies on patterns in user behavior (such as viewing, rating, or sharing) to generate predictions. The problem is that in the case of most new movies or shows, there is not yet enough audience feedback to support these methods.
Comcast Predicts
A new paper from Comcast Technology AI, in association with George Washington University, proposes a solution to this problem by prompting a language model with structured metadata about unreleased movies.
The inputs include cast, genre, synopsis, content rating, mood, and awards, with the model returning a ranked list of likely future hits.
The authors use the model’s output as a stand-in for audience interest when no engagement data is available, hoping to avoid early bias toward titles that are already well known.
The very short (three-page) paper, titled Predicting Movie Hits Before They Happen with LLMs, comes from six researchers at Comcast Technology AI, and one from GWU, and states:
‘Our results show that LLMs, when using movie metadata, can significantly outperform the baselines. This approach could serve as an assisted system for multiple use cases, enabling the automatic scoring of large volumes of new content released daily and weekly.
‘By providing early insights before editorial teams or algorithms have accumulated sufficient interaction data, LLMs can streamline the content review process.
‘With continuous improvements in LLM efficiency and the rise of recommendation agents, the insights from this work are valuable and adaptable to a wide range of domains.’
If the approach proves robust, it could reduce the industry’s reliance on retrospective metrics and heavily-promoted titles by introducing a scalable way to flag promising content prior to release. Thus, rather than waiting for user behavior to signal demand, editorial teams could receive early, metadata-driven forecasts of audience interest, potentially redistributing exposure across a wider range of new releases.
Method and Data
The authors outline a four-stage workflow: construction of a dedicated dataset from unreleased movie metadata; the establishment of a baseline model for comparison; the evaluation of apposite LLMs using both natural language reasoning and embedding-based prediction; and the optimization of outputs through prompt engineering in generative mode, using Meta’s Llama 3.1 and 3.3 language models.
Since, the authors state, no publicly available dataset offered a direct way to test their hypothesis (because most existing collections predate LLMs, and lack detailed metadata), they built a benchmark dataset from the Comcast entertainment platform, which serves tens of millions of users across direct and third-party interfaces.
The dataset tracks newly-released movies, and whether they later became popular, with popularity defined through user interactions.
The collection focuses on movies rather than series, and the authors state:
‘We focused on movies because they are less influenced by external knowledge than TV series, improving the reliability of experiments.’
Labels were assigned by analyzing the time it took for a title to become popular across different time windows and list sizes. The LLM was prompted with metadata fields such as genre, synopsis, rating, era, cast, crew, mood, awards, and character types.
For comparison, the authors used two baselines: a random ordering; and a Popular Embedding (PE) model (which we will come to shortly).
The project used large language models as the primary ranking method, generating ordered lists of movies with predicted popularity scores and accompanying justifications – and these outputs were shaped by prompt engineering strategies designed to guide the model’s predictions using structured metadata.
The prompting strategy framed the model as an ‘editorial assistant’ assigned with identifying which upcoming movies were most likely to become popular, based solely on structured metadata, and then tasked with reordering a fixed list of titles without introducing new items, and to return the output in JSON format.
Each response consisted of a ranked list, assigned popularity scores, justifications for the rankings, and references to any prior examples that influenced the outcome. These multiple levels of metadata were intended to improve the model’s contextual grasp, and its ability to anticipate future audience trends.
Tests
The experiment followed two main stages: initially, the authors tested several model variants to establish a baseline, involving the identification of the version which performed better than a random-ordering approach.
Second, they tested large language models in generative mode, by comparing their output to a stronger baseline, rather than a random ranking, raising the difficulty of the task.
This meant the models had to do better than a system that already showed some ability to predict which movies would become popular. As a result, the authors assert, the evaluation better reflected real-world conditions, where editorial teams and recommender systems are rarely choosing between a model and chance, but between competing systems with varying levels of predictive ability.
The Advantage of Ignorance
A key constraint in this setup was the time gap between the models’ knowledge cutoff and the actual release dates of the movies. Because the language models were trained on data that ended six to twelve months before the movies became available, they had no access to post-release information, ensuring that the predictions were based entirely on metadata, and not on any learned audience response.
Baseline Evaluation
To construct a baseline, the authors generated semantic representations of movie metadata using three embedding models: BERT V4; Linq-Embed-Mistral 7B; and Llama 3.3 70B, quantized to 8-bit precision to meet the constraints of the experimental environment.
Linq-Embed-Mistral was selected for inclusion due to its top position on the MTEB (Massive Text Embedding Benchmark) leaderboard.
Each model produced vector embeddings of candidate movies, which were then compared to the average embedding of the top one hundred most popular titles from the weeks preceding each movie’s release.
Popularity was inferred using cosine similarity between these embeddings, with higher similarity scores indicating higher predicted appeal. The ranking accuracy of each model was evaluated by measuring performance against a random ordering baseline.
Performance improvement of Popular Embedding models compared to a random baseline. Each model was tested using four metadata configurations: V1 includes only genre; V2 includes only synopsis; V3 combines genre, synopsis, content rating, character types, mood, and release era; V4 adds cast, crew, and awards to the V3 configuration. Results show how richer metadata inputs affect ranking accuracy. Source: https://arxiv.org/pdf/2505.02693
The results (shown above), demonstrate that BERT V4 and Linq-Embed-Mistral 7B delivered the strongest improvements in identifying the top three most popular titles, although both fell slightly short in predicting the single most popular item.
BERT was ultimately selected as the baseline model for comparison with the LLMs, as its efficiency and overall gains outweighed its limitations.
LLM Evaluation
The researchers assessed performance using two ranking approaches: pairwise and listwise. Pairwise ranking evaluates whether the model correctly orders one item relative to another; and listwise ranking considers the accuracy of the entire ordered list of candidates.
This combination made it possible to evaluate not only whether individual movie pairs were ranked correctly (local accuracy), but also how well the full list of candidates reflected the true popularity order (global accuracy).
Full, non-quantized models were employed to prevent performance loss, ensuring a consistent and reproducible comparison between LLM-based predictions and embedding-based baselines.
Metrics
To assess how effectively the language models predicted movie popularity, both ranking-based and classification-based metrics were used, with particular attention to identifying the top three most popular titles.
Four metrics were applied: Accuracy@1 measured how often the most popular item appeared in the first position; Reciprocal Rank captured how high the top actual item ranked in the predicted list by taking the inverse of its position; Normalized Discounted Cumulative Gain (NDCG@k) evaluated how well the entire ranking matched actual popularity, with higher scores indicating better alignment; and Recall@3 measured the proportion of truly popular titles that appeared in the model’s top three predictions.
Since most user engagement happens near the top of ranked menus, the evaluation focused on lower values of k, to reflect practical use cases.
Performance improvement of large language models over BERT V4, measured as percentage gains across ranking metrics. Results were averaged over ten runs per model-prompt combination, with the top two values highlighted. Reported figures reflect the average percentage improvement across all metrics.
The performance of Llama model 3.1 (8B), 3.1 (405B), and 3.3 (70B) was evaluated by measuring metric improvements relative to the earlier-established BERT V4 baseline. Each model was tested using a series of prompts, ranging from minimal to information-rich, to examine the effect of input detail on prediction quality.
The authors state:
‘The best performance is achieved when using Llama 3.1 (405B) with the most informative prompt, followed by Llama 3.3 (70B). Based on the observed trend, when using a complex and lengthy prompt (MD V4), a more complex language model generally leads to improved performance across various metrics. However, it is sensitive to the type of information added.’
Performance improved when cast awards were included as part of the prompt – in this case, the number of major awards received by the top five billed actors in each film. This richer metadata was part of the most detailed prompt configuration, outperforming a simpler version that excluded cast recognition. The benefit was most evident in the larger models, Llama 3.1 (405B) and 3.3 (70B), both of which showed stronger predictive accuracy when given this additional signal of prestige and audience familiarity.
By contrast, the smallest model, Llama 3.1 (8B), showed improved performance as prompts became slightly more detailed, progressing from genre to synopsis, but declined when more fields were added, suggesting that the model lacked the capacity to integrate complex prompts effectively, leading to weaker generalization.
When prompts were restricted to genre alone, all models under-performed against the baseline, demonstrating that limited metadata was insufficient to support meaningful predictions.
Conclusion
LLMs have become the poster child for generative AI, which might explain why they’re being put to work in areas where other methods could be a better fit. Even so, there’s still a lot we don’t know about what they can do across different industries, so it makes sense to give them a shot.
In this particular case, as with stock markets and weather forecasting, there is only a limited extent to which historical data can serve as the foundation of future predictions. In the case of movies and TV shows, the very delivery method is now a moving target, in contrast to the period between 1978-2011, when cable, satellite and portable media (VHS, DVD, et al.) represented a series of transitory or evolving historical disruptions.
Neither can any prediction method account for the extent to which the success or failure of other productions may influence the viability of a proposed property – and yet this is frequently the case in the movie and TV industry, which loves to ride a trend.
Nonetheless, when used thoughtfully, LLMs could help strengthen recommendation systems during the cold-start phase, offering useful support across a range of predictive methods.
First published Tuesday, May 6, 2025
#2023#2025#Advanced LLMs#advertising#agents#ai#Algorithms#Analysis#Anderson's Angle#approach#Articles#Artificial Intelligence#attention#Behavior#benchmark#BERT#Bias#collaborative#Collections#comcast#Companies#comparison#construction#content#continuous#data#data sources#dates#Decision Tree#domains
0 notes
Text
Idea Frontier #2: Dynamic Tool Selection, Memory Engineering, and Planetary Computation
Welcome to the second edition of Idea Frontier, where we explore paradigm-shifting ideas at the nexus of STEM and business. In this issue, we dive into three frontiers: how AI agents are learning to smartly pick their tools (and why that matters for building more general intelligence), how new memory frameworks like Graphiti are giving LLMs a kind of real-time, editable memory (and what that…
#Agents.ai#AGI#ai#AI Agent Hubs#AI Agents#Dynamic Tool Selection#Freedom Cities#generative AI#Graphiti#Idea Frontier#knowledge graphs#knowledge synthesis#Lamini#llm#llm fine-tuning#Memory Engineering#Planetary Computation#Startup Cities
0 notes
