#SQL Server column search
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
25% of US internet users with an annual income of $80-100K use Tumblr.
Text
Searching for a Specific Table Column Across All Databases in SQL Server
To find all tables that contain a column with a specified name in a SQL Server database, you can use the INFORMATION_SCHEMA.COLUMNS view. This view contains information about each column in the database, including the table name and the column name. Here’s a SQL query that searches for all tables containing a column named YourColumnName: SELECT TABLE_SCHEMA, TABLE_NAME FROM…
View On WordPress
#cross-database query#database schema exploration#Dynamic SQL execution#find column SQL#Results#SQL Server column search
0 notes
Note
how does the element stuff work in you system? Feel free to answer privately or not answer at all!
Thought I'd done a post on this already, I'll assume I didn't because I'm always looking for a way to talk about this xD
An Introduction To EleWe »
EleWe is our elements and weapons system, it runs off ten elements and ten weapons - so it has a hundred possible entries - and because only one member per entry, it also runs off Phases.
Phases are a group of a hundred members, a Phase has to be completely filled before a new one opens. Phase III is actually just about to open, and we pray this does not break our database, which was only designed for the first two Phases, because we didn't think we'd exceed two hundred members. (It shouldn't, right? O-o) (I'm not bad at coding, I'm sure it won't-)
The Database »
Just a small section on the database. Our database runs by having all possible combinations as an entry, and having columns for each Phase. When searching the database, we look for things like "element in (x)" and "phase x is empty" (that's in English, I'm not going to write SQL here lmao)
Elements »
Okay so, elements. As I said, there's ten total elements, these are:
Cosmica | Dark
Sonia | Sound
Hydria | Water
Glaciera | Ice
Flora | Plants
Aria | Air
Lumina | Light
Terra (prev Eartha) | Earth
Inferna | Fire
Electria | Electricity
Each one has reactions to other elements. I used to have a list, no clue where it went (probably died when my pc corrupted), so I'll do this from memory (o-o;)
Cosmica + Lumina = Detonate
Sonia + Aria = Diffuse
Sonia + Electria = Boost
Hydria + Glaciera = Freeze
Hydria + Aria = Storm
Hydria + Flora = Grow
Hydria + Inferna = Vaporise
Hydria + Electria = Conduct
Glaciera + Aria = Blizzard
Glaciera + Inferna = Melt
Glaciera + Electria = Conduct
Flora + Terra = Sprout
Flora + Inferna = Burn
Flora + Electria = Burgeon
Aria + Inferna = Stoke
This was originally designed with The Kansukki Project in mind.
This list (with the reaction names) was only ever used in The Kansukki Project, whereas The Kīara'h Project just uses the reactions (have some random trivia)
Weapons »
As also said in the intro, there are ten weapons! These are: (listed with general classification and explanation if needed)
Axe [Short Range]
Bow [Long Range]
Crossbow [Mid Range]
Combat [Short Range] | Hand to hand combat
Gem [Mid Range] | Magic
Knife [Short Range - Long Range] | Depending on if you can throw / previously throwing knives
Polearm [Mid Range] | Death stick :)
Scythe [Mid Range]
Staff [Long Range] | Long ranged gem
Sword [Mid Range]
There were originally eight weapons but apparently we got OCDed ¯\_(ツ)_/¯ (more trivia)
So.. How Does It Work? (And Why?) »
Each member is assigned one element and weapon combination, usually this is based on their past. Each member can only specialise in that element.
(except if they have a copycat ability, such as Amethyst who studied more than one element and use their Sonia to mimic other's elements)
For weapons, it's a little different. Most members only have one, and although some members may know other weapons, they only specialise in one.
Mostly, these will be used within stories and headspace, however some members may be able to wield their weapons in the outside world.
Energy »
Another part of EleWe is elemental energy, it lowers by using abilities/powers and when lowering, can cause members to not be able to cast spells, or even, if it gets extremely low, can impact their body and physical/mental energy and can't recover on its own.
(I won't touch on this too much because it's more or less its own thing.)
Technical Notes »
Element reaction names source: an old post we made on The Kansukki Project's server.
If I remember correctly, this is EleWe v6, (technically v5, but I'm calling it v6, because it will be soon with Phase III)
Most of this was originally done for The Kansukki Project, not The Kīara'h Project, but it has since been adapted.
Kuro from MeD wrote this post (and is very unqualified to write this post)
Hope this answers your ask? Lol
#Kīara'h Asks#Kīara'h Asks : drowntowns#The Kīara'h Organisation#Kīara'h [MeD] Kuro posts#endo safe#pro endo#endo friendly#please send asks#i need more things to do lol
11 notes
·
View notes
Text
Optimizing Business Operations with Advanced Machine Learning Services
Machine learning has gained popularity in recent years thanks to the adoption of the technology. On the other hand, traditional machine learning necessitates managing data pipelines, robust server maintenance, and the creation of a model for machine learning from scratch, among other technical infrastructure management tasks. Many of these processes are automated by machine learning service which enables businesses to use a platform much more quickly.
What do you understand of Machine learning?
Deep learning and neural networks applied to data are examples of machine learning, a branch of artificial intelligence focused on data-driven learning. It begins with a dataset and gains the ability to extract relevant data from it.
Machine learning technologies facilitate computer vision, speech recognition, face identification, predictive analytics, and more. They also make regression more accurate.
For what purpose is it used?
Many use cases, such as churn avoidance and support ticket categorization make use of MLaaS. The vital thing about MLaaS is it makes it possible to delegate machine learning's laborious tasks. This implies that you won't need to install software, configure servers, maintain infrastructure, and other related tasks. All you have to do is choose the column to be predicted, connect the pertinent training data, and let the software do its magic.
Natural Language Interpretation
By examining social media postings and the tone of consumer reviews, natural language processing aids businesses in better understanding their clientele. the ml services enable them to make more informed choices about selling their goods and services, including providing automated help or highlighting superior substitutes. Machine learning can categorize incoming customer inquiries into distinct groups, enabling businesses to allocate their resources and time.
Predicting
Another use of machine learning is forecasting, which allows businesses to project future occurrences based on existing data. For example, businesses that need to estimate the costs of their goods, services, or clients might utilize MLaaS for cost modelling.
Data Investigation
Investigating variables, examining correlations between variables, and displaying associations are all part of data exploration. Businesses may generate informed suggestions and contextualize vital data using machine learning.
Data Inconsistency
Another crucial component of machine learning is anomaly detection, which finds anomalous occurrences like fraud. This technology is especially helpful for businesses that lack the means or know-how to create their own systems for identifying anomalies.
Examining And Comprehending Datasets
Machine learning provides an alternative to manual dataset searching and comprehension by converting text searches into SQL queries using algorithms trained on millions of samples. Regression analysis use to determine the correlations between variables, such as those affecting sales and customer satisfaction from various product attributes or advertising channels.
Recognition Of Images
One area of machine learning that is very useful for mobile apps, security, and healthcare is image recognition. Businesses utilize recommendation engines to promote music or goods to consumers. While some companies have used picture recognition to create lucrative mobile applications.
Your understanding of AI will drastically shift. They used to believe that AI was only beyond the financial reach of large corporations. However, thanks to services anyone may now use this technology.
2 notes
·
View notes
Text
How to Improve Database Performance with Smart Optimization Techniques
Database performance is critical to the efficiency and responsiveness of any data-driven application. As data volumes grow and user expectations rise, ensuring your database runs smoothly becomes a top priority. Whether you're managing an e-commerce platform, financial software, or enterprise systems, sluggish database queries can drastically hinder user experience and business productivity.
In this guide, we’ll explore practical and high-impact strategies to improve database performance, reduce latency, and increase throughput.
1. Optimize Your Queries
Poorly written queries are one of the most common causes of database performance issues. Avoid using SELECT * when you only need specific columns. Analyze query execution plans to understand how data is being retrieved and identify potential inefficiencies.
Use indexed columns in WHERE, JOIN, and ORDER BY clauses to take full advantage of the database indexing system.
2. Index Strategically
Indexes are essential for speeding up data retrieval, but too many indexes can hurt write performance and consume excessive storage. Prioritize indexing on columns used in search conditions and join operations. Regularly review and remove unused or redundant indexes.
3. Implement Connection Pooling
Connection pooling allows multiple application users to share a limited number of database connections. This reduces the overhead of opening and closing connections repeatedly, which can significantly improve performance, especially under heavy load.
4. Cache Frequently Accessed Data
Use caching layers to avoid unnecessary hits to the database. Frequently accessed and rarely changing data—such as configuration settings or product catalogs—can be stored in in-memory caches like Redis or Memcached. This reduces read latency and database load.
5. Partition Large Tables
Partitioning splits a large table into smaller, more manageable pieces without altering the logical structure. This improves performance for queries that target only a subset of the data. Choose partitioning strategies based on date, region, or other logical divisions relevant to your dataset.
6. Monitor and Tune Regularly
Database performance isn’t a one-time fix—it requires continuous monitoring and tuning. Use performance monitoring tools to track query execution times, slow queries, buffer usage, and I/O patterns. Adjust configurations and SQL statements accordingly to align with evolving workloads.
7. Offload Reads with Replication
Use read replicas to distribute query load, especially for read-heavy applications. Replication allows you to spread read operations across multiple servers, freeing up the primary database to focus on write operations and reducing overall latency.
8. Control Concurrency and Locking
Poor concurrency control can lead to lock contention and delays. Ensure your transactions are short and efficient. Use appropriate isolation levels to avoid unnecessary locking, and understand the impact of each level on performance and data integrity.
0 notes
Text
PHP with MySQL: Best Practices for Database Integration
PHP and MySQL have long formed the backbone of dynamic web development. Even with modern frameworks and languages emerging, this combination remains widely used for building secure, scalable, and performance-driven websites and web applications. As of 2025, PHP with MySQL continues to power millions of websites globally, making it essential for developers and businesses to follow best practices to ensure optimized performance and security.
This article explores best practices for integrating PHP with MySQL and explains how working with expert php development companies in usa can help elevate your web projects to the next level.
Understanding PHP and MySQL Integration
PHP is a server-side scripting language used to develop dynamic content and web applications, while MySQL is an open-source relational database management system that stores and manages data efficiently. Together, they allow developers to create interactive web applications that handle tasks like user authentication, data storage, and content management.
The seamless integration of PHP with MySQL enables developers to write scripts that query, retrieve, insert, and update data. However, without proper practices in place, this integration can become vulnerable to performance issues and security threats.
1. Use Modern Extensions for Database Connections
One of the foundational best practices when working with PHP and MySQL is using modern database extensions. Outdated methods have been deprecated and removed from the latest versions of PHP. Developers are encouraged to use modern extensions that support advanced features, better error handling, and more secure connections.
Modern tools provide better performance, are easier to maintain, and allow for compatibility with evolving PHP standards.
2. Prevent SQL Injection Through Prepared Statements
Security should always be a top priority when integrating PHP with MySQL. SQL injection remains one of the most common vulnerabilities. To combat this, developers must use prepared statements, which ensure that user input is not interpreted as SQL commands.
This approach significantly reduces the risk of malicious input compromising your database. Implementing this best practice creates a more secure environment and protects sensitive user data.
3. Validate and Sanitize User Inputs
Beyond protecting your database from injection attacks, all user inputs should be validated and sanitized. Validation ensures the data meets expected formats, while sanitization cleans the data to prevent malicious content.
This practice not only improves security but also enhances the accuracy of the stored data, reducing errors and improving the overall reliability of your application.
4. Design a Thoughtful Database Schema
A well-structured database is critical for long-term scalability and maintainability. When designing your MySQL database, consider the relationships between tables, the types of data being stored, and how frequently data is accessed or updated.
Use appropriate data types, define primary and foreign keys clearly, and ensure normalization where necessary to reduce data redundancy. A good schema minimizes complexity and boosts performance.
5. Optimize Queries for Speed and Efficiency
As your application grows, the volume of data can quickly increase. Optimizing SQL queries is essential for maintaining performance. Poorly written queries can lead to slow loading times and unnecessary server load.
Developers should avoid requesting more data than necessary and ensure queries are specific and well-indexed. Indexing key columns, especially those involved in searches or joins, helps the database retrieve data more quickly.
6. Handle Errors Gracefully
Handling database errors in a user-friendly and secure way is important. Error messages should never reveal database structures or sensitive server information to end-users. Instead, errors should be logged internally, and users should receive generic messages that don’t compromise security.
Implementing error handling protocols ensures smoother user experiences and provides developers with insights to debug issues effectively without exposing vulnerabilities.
7. Implement Transactions for Multi-Step Processes
When your application needs to execute multiple related database operations, using transactions ensures that all steps complete successfully or none are applied. This is particularly important for tasks like order processing or financial transfers where data integrity is essential.
Transactions help maintain consistency in your database and protect against incomplete data operations due to system crashes or unexpected failures.
8. Secure Your Database Credentials
Sensitive information such as database usernames and passwords should never be exposed within the application’s core files. Use environment variables or external configuration files stored securely outside the public directory.
This keeps credentials safe from attackers and reduces the risk of accidental leaks through version control or server misconfigurations.
9. Backup and Monitor Your Database
No matter how robust your integration is, regular backups are critical. A backup strategy ensures you can recover quickly in the event of data loss, corruption, or server failure. Automate backups and store them securely, ideally in multiple locations.
Monitoring tools can also help track database performance, detect anomalies, and alert administrators about unusual activity or degradation in performance.
10. Consider Using an ORM for Cleaner Code
Object-relational mapping (ORM) tools can simplify how developers interact with databases. Rather than writing raw SQL queries, developers can use ORM libraries to manage data through intuitive, object-oriented syntax.
This practice improves productivity, promotes code readability, and makes maintaining the application easier in the long run. While it’s not always necessary, using an ORM can be especially helpful for teams working on large or complex applications.
Why Choose Professional Help?
While these best practices can be implemented by experienced developers, working with specialized php development companies in usa ensures your web application follows industry standards from the start. These companies bring:
Deep expertise in integrating PHP and MySQL
Experience with optimizing database performance
Knowledge of the latest security practices
Proven workflows for development and deployment
Professional PHP development agencies also provide ongoing maintenance and support, helping businesses stay ahead of bugs, vulnerabilities, and performance issues.
Conclusion
PHP and MySQL remain a powerful and reliable pairing for web development in 2025. When integrated using modern techniques and best practices, they offer unmatched flexibility, speed, and scalability.
Whether you’re building a small website or a large-scale enterprise application, following these best practices ensures your PHP and MySQL stack is robust, secure, and future-ready. And if you're seeking expert assistance, consider partnering with one of the top php development companies in usa to streamline your development journey and maximize the value of your project.
0 notes
Text
What is MongoDB? Features & How it Works

Think about managing a library. Traditional libraries place books in organized rows based on subjects or author names. Now imagine a library where books are placed anywhere but a powerful search tool finds them instantly using the title or content. This is what MongoDB does for data storage. It is a modern database that offers flexibility & ease when it comes to storing & retrieving information.
What is MongoDB
MongoDB is a NoSQL database designed to handle large amounts of data efficiently. Unlike traditional relational databases such as MySQL or SQL Server, MongoDB does not rely on tables or fixed structures. Instead it uses a document-oriented approach. The data is stored in documents similar to JSON format which allows for handling complex data without the strict limitations of predefined schemas.
If you think of relational databases like tightly controlled spreadsheets where each row represents a data entry & each column represents a fixed attribute MongoDB works differently. In a relational system adding new information can be challenging because all rows need to follow the same structure. With MongoDB each document or data entry can have its own unique attributes without following a rigid format.
How MongoDB Works
MongoDB is built for flexibility & scalability. It stores data in collections which are similar to tables in traditional databases. Each document within a collection can have different structures. For instance one document might contain a person's name & address while another includes additional details like social media profiles. MongoDB adapts to changing needs without requiring predefined rules for storing data.
This database shines when handling large amounts of unstructured data which makes it popular in industries like social media online retail & IoT systems. It is especially useful for storing real-time analytics logs & customer profiles. By not sticking to rows & columns MongoDB offers more freedom in how data is managed.
Key Features of MongoDB
1. Document-Oriented Storage
MongoDB uses BSON documents which are essentially key-value pairs. This means it can handle complex data structures with ease. A customer document might include their name address & a list of their recent orders all stored in one place. This approach is much more flexible than traditional databases.
2. Scalability
One of the standout qualities of MongoDB is its horizontal scalability. When dealing with massive datasets MongoDB can distribute data across several servers or clusters. This process known as sharding splits the data into smaller pieces allowing it to scale across multiple machines rather than requiring one large server.
3. Flexible Schema
MongoDB does not need a fixed schema so it easily adapts to changing data requirements. For example a company might begin collecting new information about its customers & MongoDB can handle this new data without restructuring the entire system. This ability to evolve without strict rules is a key benefit.
4. Replication
To ensure data availability MongoDB uses replica sets. These sets involve one primary server handling data requests with several secondary servers maintaining copies of the data. In case the primary server fails one of the secondary servers takes over reducing the chance of downtime.
5. High Performance
MongoDB is optimized for high-speed read & write operations. It supports indexing specific fields within documents which allows it to handle high-demand applications like real-time analytics or customer-facing platforms with ease.
6. Rich Query Language
MongoDB's query language is versatile. It allows users to search based on fields or perform text searches. MongoDB supports complex aggregations enabling businesses to pull insights from large datasets without struggling with performance.
MongoDB in Action
Let us visualize MongoDB through a real-world example. Picture an online store selling everything from fashion to electronics. Each product comes with its own set of details—clothing has sizes & colors while electronics have specs like battery life & screen size. With traditional databases storing all this information would require multiple tables & predefined attributes which can become complex over time.
In MongoDB each product is stored as a document that contains only the attributes it needs. A shirt would have fields for size & color while a laptop might include processor speed & storage. This level of flexibility makes MongoDB ideal for businesses that handle evolving & varied data. The database grows & adapts as the business does without needing major changes to its structure.
When to Use MongoDB
MongoDB is a strong fit in any situation where data is complex & grows rapidly. Its structure works well for storing customer data inventory information & real-time interactions. Some use cases include:
E-commerce: Storing customer profiles product data & inventory
Social Media: Managing user profiles posts & comments
IoT Systems: Collecting & analyzing data from smart devices
That said MongoDB may not be the best solution for every situation. In cases where multi-row transactions are crucial such as in banking relational databases may offer better functionality.
Final Comment
MongoDB offers a fresh way to think about data storage. It lets businesses store their data in a flexible document format without being held back by the rigid structures of traditional databases. Whether managing thousands of users or handling large product catalogs MongoDB provides the performance scalability & flexibility needed to keep up with growth.
By storing information in a natural & efficient manner MongoDB training helps businesses innovate quickly. In today’s data-driven world having a database that can scale & adapt as needed is essential for staying competitive.
People A lso Read : Top Automation Anywhere Courses Online
0 notes
Text
Analysing large data sets using AWS Athena
Handling large datasets can feel overwhelming, especially when you're faced with endless rows of data and complex information. At our company, we faced these challenges head-on until we discovered AWS Athena. Athena transformed the way we handle massive datasets by simplifying the querying process without the hassle of managing servers or dealing with complex infrastructure. In this article, I’ll Walk you through how AWS Athena has revolutionized our approach to data analysis. We’ll explore how it leverages SQL to make working with big data straightforward and efficient. If you’ve ever struggled with managing large datasets and are looking for a practical solution, you’re in the right place.
Efficient Data Storage and Querying
Through our experiences, we found that two key strategies significantly enhanced our performance with Athena: partitioning data and using columnar storage formats like Parquet. These methods have dramatically reduced our query times and improved our data analysis efficiency. Here’s a closer look at how we’ve implemented these strategies:
Data Organization for Partitioning and Parquet
Organize your data in S3 for efficient querying:
s3://your-bucket/your-data/
├── year=2023/
│ ├── month=01/
│ │ ├── day=01/
│ │ │ └── data-file
│ │ └── day=02/
│ └── month=02/
└── year=2024/
└── month=01/
└── day=01/
Preprocessing Data for Optimal Performance
Before importing datasets into AWS Glue and Athena, preprocessing is essential to ensure consistency and efficiency. This involves handling mixed data types, adding date columns for partitioning, and converting files to a format suitable for Athena.
Note: The following steps are optional based on the data and requirements. Use them according to your requirements.
1. Handling Mixed Data Types
To address columns with mixed data types, standardize them to the most common type using the following code snippet:def determine_majority_type(series): # get the types of all non-null values types = series.dropna().apply(type) # count the occurrences of each type type_counts = types.value_counts()
preprocess.py
2. Adding Date Columns for Partitioning
To facilitate partitioning, add additional columns for year, month, and day:def add_date_columns_to_csv(file_path): try: # read the CSV file df = pd.read_csv(file_path)
partitioning.py
3. Converting CSV to Parquet Format
For optimized storage and querying, convert CSV files to Parquet format:def detect_and_convert_mixed_types(df): for col in df.columns: # detect mixed types in the column if df[col].apply(type).nunique() > 1:
paraquet.py
4. Concatenating Multiple CSV Files
To consolidate multiple CSV files into one for Parquet conversion:def read_and_concatenate_csv_files(directory): all_dfs = [] # recursively search for CSV files in the directory
concatenate.py
Step-by-Step Guide to Managing Datasets with AWS Glue and Athena
1. Place Your Source Dataset in S3
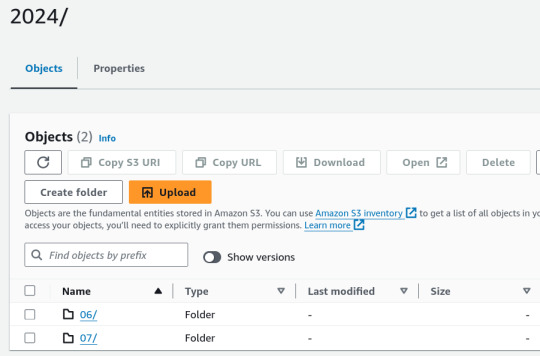
2. Create a Crawler in AWS Glue
In the AWS Glue console, create a new crawler to catalog your data and make it queryable with Athena.
Specify Your S3 Bucket: Set the S3 bucket path as the data source in the crawler configuration.
IAM Role: Assign an IAM role with the necessary permissions to access your S3 bucket and Glue Data Catalog.
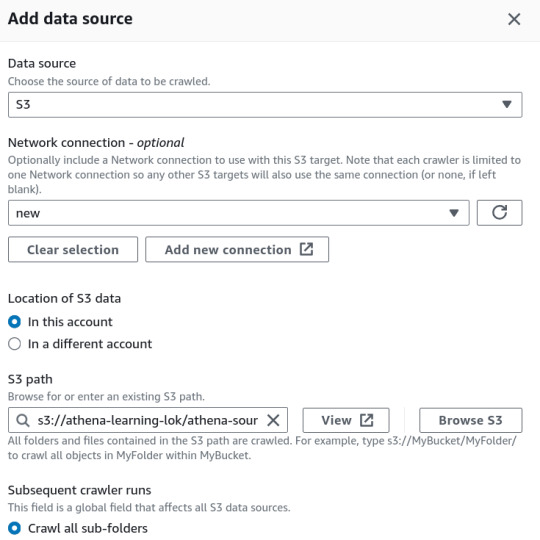
3. Set Up the Glue Database
Create a new database in the AWS Glue Data Catalog where your CSV data will be stored. This database acts as a container for your tables.
Database Creation: Go to the AWS Glue Data Catalog section and create a new database.
Crawler Output Configuration: Specify this database for storing the table metadata and optionally provide a prefix for your table names.
4. Configure Crawler Schedule
Set the crawler schedule to keep your data catalog up to date:
Hourly
Daily
Weekly
Monthly
On-Demand
Scheduling the crawler ensures data will be updated to our table, if any updates to existing data or adding of new files etc.
5. Run the Crawler
Initiate the crawler by clicking the "Run Crawler" button in the Glue console. The crawler will analyze your data, determine optimal data types for each column, and create a table in the Glue Data Catalog.
6. Review and Edit the Table Schema
Post-crawler, review and modify the table schema:
Change Data Types: Adjust data types for any column as needed.
Create Partitions: Set up partitions to improve query performance and data organization.

7. Query Your Data with AWS Athena
In the Athena console:
Connect to Glue Database: Use the database created by the Glue Crawler.
Write SQL Queries: Leverage SQL for querying your data directly in Athena.
8. Performance Comparison
After the performance optimizations, we got the following results:
To illustrate it, I ran following queries on 1.6 GB data:
For Parquet data format without partitioning
SELECT * FROM "athena-learn"."parquet" WHERE transdate='2024-07-05';
For Partitioning with CSV

Query Runtime for Parquet Files: 8.748 seconds. Parquet’s columnar storage format and compression contribute to this efficiency.
Query Runtime for Partitioned CSV Files: 2.901 seconds. Partitioning helps reduce the data scanned, improving query speed.
Data Scanned for Paraquet Files: 60.44MB
Data Scanned for Partitioned CSV Files: 40.04MB
Key Insight: Partitioning CSV files improves query performance, but using Parquet files offers superior results due to their optimized storage and compression features.
9. AWS Athena Pricing and Optimization
AWS Athena pricing is straightforward: you pay $5.00 per terabyte (TB) of data scanned by your SQL queries. However, you can significantly reduce costs and enhance query performance by implementing several optimization strategies.
Conclusion
AWS Athena offers a powerful, serverless SQL interface for querying large datasets. By adopting best practices in data preprocessing, organization, and Athena usage, you can manage and analyze your data efficiently without the overhead of complex infrastructure.
0 notes
Text
[ad_1] As of late, the demand for NoSQL databases is on the rise. The rationale behind their immense recognition is that corporations want NoSQL databases to deal with a large quantity of buildings in addition to unstructured information. This isn't potential to attain with conventional relational or SQL databases. With elevated digitization, trendy companies must take care of large information commonly, coping with hundreds of thousands of customers whereas ensuring that there aren't any interruptions in delivering the information administration providers. All these expectations are the explanations behind the recognition of NoSQL databases in nearly each business. There may be all kinds of NoSQL databases accessible, companies usually get confused with NoSQL vs SQL and search instruments which might be extra succesful, agile, and versatile to handle big huge information. This weblog specifies the highest 7 NoSQL databases that companies can choose as per their distinctive wants. All these NoSQL databases are open supply and encompass free variations. All the restrictions of conventional relational databases comparable to efficiency, velocity, scalability, and even huge information administration may be dealt with with these NoSQL databases. Nevertheless, it's crucial to think about that these databases are used to fulfill solely superior necessities of the organizations as frequent purposes can nonetheless be constructed by conventional SQL databases. So, let’s try the highest 7 NoSQL databases that may even change into widespread in 2024. Apache Cassandra: Apache Cassandra is an open-source, free, and high-performance database. That is also called scalable and fault tolerant for each cloud infrastructure and commodity hardware. It might simply handle failed node replacements and replicate the information for a number of nodes mechanically. On this NoSQL database, you too can have the choice to decide on both synchronous replication or asynchronous replication. Apache HBase: Apache HBase can also be the perfect NoSQL database, which is Referred to as an open-source distributed Hadoop database. That is utilized to put in writing and skim the massive information. It has been developed to handle even the billions of rows and columns by way of the commodity hardware cluster. The options of Apache HBase embody computerized sharding of tables, scalability, constant writing & studying capabilities, and even nice assist for server failure. Apache CouchDB: Apache CouchDB can also be an open supply in addition to a single node database that helps in storing and managing the information. It might additionally scale up complicated initiatives right into a cluster of nodes on a number of servers. Firms can anticipate its integration with HTTP proxy servers together with the assist of HTTP protocol and JSON information format. This database is designed with crash-resistant options and reliability that saves information redundancy, which implies companies by no means lose their information and entry it each time wanted. MarkLogic Server: The MarkLogic server is the main NoSQL doc database that's designed for managing giant volumes of unstructured information and complicated information buildings. It boasts an amazing mixture of options for information-intensive apps and complicated content material administration necessities. It's broadly used for storing in addition to managing XML info. Companies can outline schemas of their information utilizing the MarkLogic server whereas accommodating variations within the doc construction. Furthermore, it provides extra flexibility as in comparison with relational SQL databases. Amazon DynamoDB: Amazon DynamoDB is the important thing worth, serverless, and doc database, which is obtainable by AWS (Amazon Net providers. This database is designed for increased scalability and efficiency. It's in excessive demand amongst companies to construct trendy purposes that want ultra-fast accessi
bility of knowledge in addition to the potential to deal with large information and consumer visitors, DynamoDB additionally gives restricted assist for ACID, the place ACID implies as Atomicity, Consistency, Isolation, and Sturdiness. IBM Cloudant: IBM Cloudant is one other widespread NoSQL database that's provided by IBM within the type of a cloud-based service. It's a full-featured and versatile JSON doc database used for cell, net, and serverless purposes that want better flexibility, scalability, and efficiency. This NoSQL database can also be developed for horizontal scaling. it's simpler so as to add extra servers on this database to handle unprecedented ranges of knowledge and consumer visitors. MongoDB: MongoDB is the greatest NoSQL database accessible available in the market. Like many different NoSQL databases, it shops and manages information in JSON-like paperwork. The versatile schema method helps companies leverage the evolving information fashions with none want for typical desk buildings. It may also be scaled horizontally by including extra shards to the cluster. Companies can simply deal with large quantities of knowledge and visitors with MongoDB. The Remaining Thought Utilizing NoSQL databases that match completely to your wants ends in effectivity beneficial properties. It makes it simpler for companies to retailer, course of, and handle large quantities of unstructured information effectively. The put up Prime 7 NoSQL Databases You Can Use in 2024 appeared first on Vamonde. [ad_2] Supply hyperlink
0 notes
Text
What is Active Record in Yii2?

Active Record is database access and manipulation tool that uses an object-oriented interface. An Active Record class is linked to a database table, an Active Record instance is linked to a table row, and an attribute of an Active Record instance is linked to the value of a specific column in that row. To access and alter the data stored in database tables, you would access Active Record properties and invoke Active Record methods instead of writing raw SQL commands.
What is Yii2's character?
The Yii base Behavior class is used to create behaviours. A behaviour attaches itself to a component and injects its methods and properties into it. Behaviour patterns can also react to the events that the component has caused.
What should you do if a Yii DB exception is thrown?
Sets a callable (e.g., an anonymous function) that is called when the yii\\db\\Exception is thrown during the command execution. The callable’s signature should be: The default fetch mode for this command is the DB connection with which it is linked.
For data access, Active Record provides an object-oriented API. A database table is connected with an Active Record class.
Active Record support is available in Yii for the following relational databases:
MySQL 4.1 or later
SQLite 2 and 3
PostgreSQL 7.3 or later
Microsoft SQL Server 2008 or later
CUBRID 9.3 or later
Oracle
Elastic Search
Sphinx
You should follow these steps to query data from a separate database table after establishing an Active Record class (in our example, the user model).
Using the yiidbActiveRecord::find() method, create a new query object.
Create a query object. To get data, use a query method.
Conclusion
I hope you found this guide helpful in understanding Active Record in Yii2. XcelTec can help you with your projects by providing Virtual Developers.
Get in touch with us for more!
Contact us on:- +91 987 979 9459 | +1-(980) 428-9909
Email us at:- [email protected]
0 notes
Text
Advanced SQL Techniques: Taking Your Query Skills to the Next Level
In the ever-evolving landscape of data management, SQL (Structured Query Language) remains a cornerstone for interacting with relational databases. While mastering the basics of SQL is crucial, advancing your skills to the next level opens up a realm of possibilities for efficiently handling complex queries and optimizing database performance. This article explores advanced SQL techniques that will elevate your query skills, providing insights into optimization, performance tuning, and tackling intricate data scenarios.
1. Understanding Indexing Strategies
One of the fundamental aspects of advanced SQL is mastering indexing strategies. Indexes enhance query performance by allowing the database engine to quickly locate and retrieve specific rows. Learn about different index types, such as clustered and non-clustered indexes, and when to use each. Explore composite indexes for optimizing queries with multiple search criteria. Additionally, delve into the impact of indexes on write operations and strike a balance between read and write performance.
2. Optimizing Joins for Efficiency
As databases grow, so does the complexity of joining tables. Advanced structured query language practitioners should be adept at optimizing join operations. Techniques such as using appropriate join types (inner, outer, self-joins) and understanding the importance of join order can significantly impact query performance. Consider exploring the benefits of covering indexes for columns involved in join conditions to enhance efficiency.
3. Window Functions for Analytical Queries
Window functions are a powerful tool for performing advanced analytical tasks within SQL queries. From calculating running totals to ranking rows based on specific criteria, window functions provide a concise and efficient way to handle complex data manipulations. Dive into examples of common window functions like ROW_NUMBER(), RANK(), and DENSE_RANK(), and understand how they can streamline your analytical queries.
4. Common Table Expressions (CTEs) for Readability
As queries become more intricate, maintaining readability becomes paramount. Common Table Expressions (CTEs) offer a solution by allowing you to define temporary result sets within your SQL statement. This not only enhances code organization but also makes complex queries more understandable. Explore the syntax of CTEs and understand when to deploy them for improved query readability and maintainability.
5. Dynamic SQL for Flexible Queries
In dynamic environments where queries need to adapt to changing conditions, mastering dynamic SQL becomes essential. Learn how to construct SQL statements dynamically, incorporating variables and conditional logic. While this technique offers flexibility, be cautious about SQL injection vulnerabilities. Implement parameterized queries to mitigate security risks and strike a balance between adaptability and data protection.
6. Query Optimization with Execution Plans
Understanding the execution plan generated by the database engine is a crucial skill for SQL optimization. Explore tools like EXPLAIN in PostgreSQL or SQL Server Management Studio's Query Execution Plan to analyze how the database engine processes your queries. Identify bottlenecks, evaluate index usage, and make informed decisions to fine-tune your queries for optimal performance.
7. Temporal Data Handling
As businesses increasingly rely on temporal data, handling time-related queries becomes a key aspect of advanced SQL. Delve into techniques for querying historical data, managing effective date ranges, and dealing with time intervals. Understand how to use temporal table features in databases like SQL Server and PostgreSQL to simplify the handling of time-varying data.
8. Advanced Aggregation Techniques
Moving beyond basic aggregation functions like COUNT, SUM, and AVG, advanced SQL practitioners should explore more sophisticated aggregation techniques. Learn about the GROUPING SETS and CUBE clauses to generate multiple levels of aggregations in a single query. Additionally, delve into the powerful capabilities of window functions for performing advanced aggregations without the need for self-joins.
Conclusion
Mastering advanced SQL techniques is an ongoing journey that can significantly enhance your ability to handle complex data scenarios and optimize query performance. From indexing strategies to temporal data handling, each technique adds a valuable tool to your SQL toolbox. As you explore these advanced techniques, remember that a deep understanding of your specific database engine is essential for making informed decisions and unleashing the full potential of your SQL skills. Keep experimenting, refining, and applying these techniques to become a proficient SQL practitioner ready for the challenges of the data-driven world.
#onlinetraining#career#elearning#learning#programming#automation#online courses#technology#security#startups
0 notes
Text
Rethinking the 5 Non-Clustered Indexes Rule for Wide Data Warehouse Tables
Introduction Hey there, SQL Server enthusiasts! You’ve probably heard the age-old advice that having 5 non-clustered indexes per table is a good rule of thumb. But what happens when you’re dealing with those extra-wide data warehouse tables that have more than five columns that users frequently search on? Is this rule still applicable, or should we rethink our approach? In this article, we’ll…
View On WordPress
0 notes
Text
Data Catalog Tools

Data catalog tools are designed to provide a self-service discovery experience for all users in your organization, whether they’re data engineers, data stewards, or business analysts. They help users find and access data, and they also enable data stewards to prepare and curate data in a way that’s easy for other users to use.
The top data catalog tools include a variety of features that allow organizations to make the most of their investments. For example, many of them include column-level, cross-system automated data lineage, which allows teams to track changes in the data over time. This makes it easier to identify the impact of any change and helps to avoid costly mistakes in times of business transformation.
Additionally, data catalogs can help with the challenge of maintaining a consistent data access hierarchy. This is a key requirement for effective data governance and can be difficult to achieve without a data catalog. Many of the best data catalog tools have built-in features that can help with this, including pervasive profiling, automatic harvesting, and tagging.
In addition to these capabilities, data catalogs should be able to connect to all modern data sources and tools, including databases (such as SQL Server), lakehouses (such as Snowflake), and BI dashboards. They should also provide a powerful search experience, including support for multi-faceted searches and AI-powered relationships to suggest similar or related metadata. This can help data engineers to quickly locate the data they need for their projects.
0 notes
Text
Database Techniques: Design, Implementation, & Management
If the end person already has an automatic system in place, the designer rigorously examines the present and desired stories to describe the information required to assist the reviews. This process is one which is generally thought of a part of requirements analysis, and requires skill on the a half of the database designer to elicit the wanted info from those with the area knowledge.
We have suspended the usage of Qualifications Development Facilitators (QDFs) for the development of occupational skills, half skills and abilities programmes with instant impact. Many students efficiently change careers to programming after taking our programs, even if they have been completely new to programming when starting out. This data science course will place you at the coronary heart of the digital economic system and provide you with endless scope for development. In terms of normalization, this strategy meets the third regular form’s gridlines, however there should be the potential of redundant data getting stored into the DB. It’s a fact that making a database is straightforward now, but when it comes to architecting it to carry out optimally and give you the best return on investment, it's a bit difficult.
Most of the services we take pleasure in on the internet are provided by internet database purposes. Web-based e-mail, on-line buying, forums and bulletin boards, corporate web sites, and sports activities and news portals are all database-driven. To construct a modern website, we will oracle database develop a custom build database application. Your knowledge and abilities might be examined by means of on-line performance-based assessments and apply questions. These instruments will assist prepare you for the certification exam by testing your ability to use your information.
Single-Table design poses some unique challenges that have to be addressed all through the design section. Gary Allemann has over 20 yr's experience solving business problems utilizing data. He is passionate about the success of South Africa, loves the African bush, and believes in local talent.
For instance, customers can choose to see the desk name solely or most info together with table name, columns, major keys, international keys and datatypes. Information processing necessities across functions, databases and companies usually are not ever prone to be the same. Congratulations, you might have just renamed your primary ID field and completed creating your first table! To do that, you needed to create the desk, create two fields and choose their data sorts. You also had to ensure that the entries within the username field were unique and required, and that passwords have been required. Ensure data options are constructed for performance and design analytics applications for a number of platforms.
ERwin maintains both a logical and bodily model of the database design. This permits one to design a logical model of the business with out compromising for the chosen database platform. In addition, the names, definitions and comments hooked up to every attribute/column, entity/table and their relationships can differ between the 2 fashions. All of this data could be readily extracted by way of quite so design a database much of customisable reports. Normalisation is a scientific method of decomposing tables to remove data redundancy and Insertion, Modification and Deletion Anomalies. The database designer constructions the info in a means that eliminates pointless duplication(s) and offers a rapid search path to all essential information.
“Don’t turn it right into a bottleneck,” he warned, adding that preallocating house for tempdb — and making sure it’s large enough to accommodate your workloads — is one of the best ways to stop performance issues. Though Verbeeck vouched for clustered indexes overall, he emphasised that DBAs and developers database design should also examine other SQL Server indexing choices before committing to a selected design. Even though data storage is cheaper than it used to be, it takes a query longer to read larger columns, Verbeeck pointed out.
This course will teach you everything you need to know to begin out using the extremely well-liked MySQL database in your Web, Cloud and embedded functions. In learning about MySQL, you will develop an understanding of relational databases and the way to design a robust and efficient database. You will harness that power by learning SQL and use it to build databases, populate them with data and query that data via extensive hands-on practices.
0 notes
Text
C# Late Project | C# Study
Hello Hello! ✪ ω ✪
I just thought it would be cool to give an update on my current (late) c# project my apprenticeship gave me, which was due 2nd May and which I still haven’t completed, and just talk about where I am at with the project!
The actual project is:
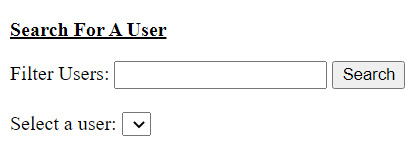
▢ Completely create a ‘search user’ webpage
☑ Create a textbox in which you can search for the user by their forename
☑ Create a dropdown list - in which you will be given the option to pick which particular user you want information on
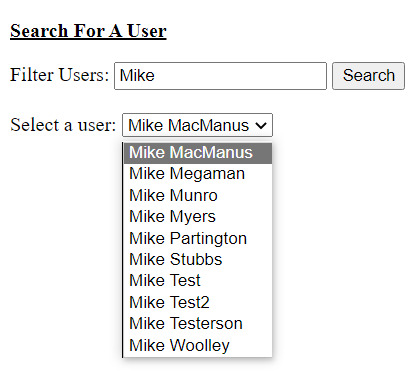
☑ Create a gridview - in which a table is displayed with the selected user’s information
▢ The table should have these columns: Name | Department | Location | Email | Extension No. | Job Role
▢ Use CSS3 to change how the table looks - anything but the default styling
Key Knowledge To Know:
▢ C# x SQL - How to retrieve data from a database from SSMS (SQL Server Management Studio)
▢ ASP.NET
▢ Gridview, Dropdown List, Textbox, HTML, CSS
This is what I have so far:
[ 1 ]
[ 2 ]
[ 3 ]

* Don’t worry, the actual emails and information are fake! I am using a test database for this!
Problem: It’s not done because I can’t figure out how to add the ‘Job Role’ column to the table because some people have lots of roles and for some reason, I can’t merge the rows into one to fit in the column as one row.
After I figure out that problem, I will move on to the CSS3 part and make it look like the page from the actual company’s website.
What was I having issues with before?
I am a slow learner, even slower if I’m ill for a long time and having meltdowns whenever things go wrong and I can’t find out why, so having all those issues go on for over a month made things worse.
I had issues with binding the textbox and the dropdown list together. They just wouldn’t work at all. I couldn’t find out why. That led to me thinking I’m not right for programming if I couldn’t find out why I couldn’t bind two elements together. It’s so simple and it was but my brain couldn't work out what was going on! >︿<
The solution to that? I didn’t remove the [ ] from the SQL query I put into the .cs file I was working on:
The SQL query in general:
"SELECT Users.Forename + ' ' + Users.Surname AS [Name], Users.ID FROM Users WHERE Forename like '%'+@Forename+'%' ORDER BY [Name]";
I initially wrote in Visual Studio:
DDLSelectUser1.DataTextField = "[Name]";
The correct way was:
DDLSelectUser1.DataTextField = "Name";
THAT WAS IT! I was stuck on this for a good week! I also couldn’t get help from my colleagues because my apprenticeship said this is an independent project i.e figure things out yourself, no matter how long it took!
The website that helped me the most with this problem was: Fill ASP.Net GridView on Selecting Record From DropDownList which helped select and populate the grid!
Everything has been hectic but once I overcome this new problem of the Role column, everything will be fine and once I complete the homework I have to write a one-page essay on the whole experience - I would just be complaining!
But, overall this has definitely been a learning experience and makes me wonder if my fellow developers at work go through the same stress when they can’t find the answer to their tasks? 〒▽〒
#csharp#csharp programming#programming#coding#software developer#comp sci#100 days of code#projetcs#csharp study#backend#html css#html5 css3#studying#studyblr
13 notes
·
View notes
Text
100%OFF | SQL Server Interview Questions and Answers

If you are looking forward to crack SQL Server interviews then you are at the right course.
Working in SQL Server and cracking SQL Server interviews are different ball game. Normally SQL Server professionals work on repetitive tasks like back ups , custom reporting and so on. So when they are asked simple questions like Normalization , types of triggers they FUMBLE.
Its not that they do not know the answer , its just that they need a revision. That’s what this course exactly does. Its prepares you for SQL Server interview in 2 days.
Below are the list of questions with answers , demonstration and detailed explanation. Happy learning. Happy job hunting.
SQL Interview Questions & Answers – Part 1 :-
Question 1 :- Explain normalization ?
Question 2 :- How to implement normalization ?
Question 3 :- What is denormalization ?
Question 4 :- Explain OLTP vs OLAP ?
Question 5 :- Explain 1st,2nd and 3rd Normal form ?
Question 6 :- Primary Key vs Unique key ?
Question 7 :- Differentiate between Char vs Varchar ?
Question 8 :- Differentiate between Char vs NChar ?
Question 9 :- Whats the size of Char vs NChar ?
Question 10 :- What is the use of Index ?
Question 11 :- How does it make search faster?
Question 12 :- What are the two types of Indexes ?
Question 13 :- Clustered vs Non-Clustered index
Question 14 :- Function vs Stored Procedures
Question 15 :- What are triggers and why do you need it ?
Question 16 :- What are types of triggers ?
Question 17 :- Differentiate between After trigger vs Instead Of ?
Question 18 :- What is need of Identity ?
Question 19 :- Explain transactions and how to implement it ?
Question 20 :- What are inner joins ?
Question 21 :- Explain Left join ?
Question 22 :- Explain Right join ?
Question 23 :- Explain Full outer joins ?
Question 24 :- Explain Cross joins ?
SQL Interview Questions & Answers – Part 2 :-
Question 25:-Why do we need UNION ?
Question 26:-Differentiate between Union vs Union All ?
Question 27:-can we have unequal columns in Union?
Question 28:-Can column have different data types in Union ?
Question 29:- Which Aggregate function have you used ?
Question 30:- When to use Group by ?
Question 31:- Can we select column which is not part of group by ?
Question 32:- What is having clause ?
Question 33:- Having clause vs Where clause
Question 34:- How can we sort records ?
Question 35:- Whats the default sort ?
Question 36:- How can we remove duplicates ?
Question 37:- Select the first top X records ?
Question 38:- How to handle NULLS ?
Question 39:- What is use of wild cards ?
Question 40:- What is the use of Alias ?
Question 41:- How to write a case statement ?
Question 42:- What is self reference tables ?
Question 43:- What is self join ?
Question 44:- Explain the between clause ?
SQL Interview Questions & Answers – Part 3 :-
Question 45:- Explain SubQuery?
Question 46:- Can inner Subquery return multiple results?
Question 47:- What is Co-related Query?
Question 48:- Differentiate between Joins and SubQuery?
Question 49:- Performance Joins vs SubQuery?
SQL Interview Questions & Answers – Part 4 :-
Question 50:- Find NTH Highest Salary in SQL.
SQL Interview Questions & Answers – Part 5
Question 51:- Select the top nth highest salary using correlated Queries?
Question 52:- Select top nth using using TSQL
Question 53:- Performance comparison of all the methods.
[ENROLL THE COURSE]
21 notes
·
View notes
Text
Can Inequality Columns Ever Lead a SQL Server Non-Clustered Index?
Introduction Hey there, SQL Server fans! In this article, we’ll address a recurring question: under what circumstances, if any, is it acceptable to create a non-clustered index where the leading column of the index key is searched using an inequality operator, and the subsequent column is searched using an equality operator? The answer might surprise you! In this article, we’ll dive into when…
View On WordPress
0 notes