#Working with multiple Kubernetes clusters
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Women make up for the other 50% of Tumblr’s audience.
Text
Kubectl get context: List Kubernetes cluster connections
Kubectl get context: List Kubernetes cluster connections @vexpert #homelab #vmwarecommunities #KubernetesCommandLineGuide #UnderstandingKubectl #ManagingKubernetesResources #KubectlContextManagement #WorkingWithMultipleKubernetesClusters #k8sforbeginners
kubectl, a command line tool, facilitates direct interaction with the Kubernetes API server. Its versatility spans various operations, from procuring cluster data with kubectl get context to manipulating resources using an assortment of kubectl commands. Table of contentsComprehending Fundamental Kubectl CommandsWorking with More Than One Kubernetes ClusterNavigating Contexts with kubectl…

View On WordPress
#Advanced kubectl commands#Kubectl config settings#Kubectl context management#Kubectl for beginners#Kubernetes command line guide#Managing Kubernetes resources#Setting up kubeconfig files#Switching Kubernetes contexts#Understanding kubectl#Working with multiple Kubernetes clusters
0 notes
Text
What is Argo CD? And When Was Argo CD Established?

What Is Argo CD?
Argo CD is declarative Kubernetes GitOps continuous delivery.
In DevOps, ArgoCD is a Continuous Delivery (CD) technology that has become well-liked for delivering applications to Kubernetes. It is based on the GitOps deployment methodology.
When was Argo CD Established?
Argo CD was created at Intuit and made publicly available following Applatix’s 2018 acquisition by Intuit. The founding developers of Applatix, Hong Wang, Jesse Suen, and Alexander Matyushentsev, made the Argo project open-source in 2017.
Why Argo CD?
Declarative and version-controlled application definitions, configurations, and environments are ideal. Automated, auditable, and easily comprehensible application deployment and lifecycle management are essential.
Getting Started
Quick Start
kubectl create namespace argocd kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
For some features, more user-friendly documentation is offered. Refer to the upgrade guide if you want to upgrade your Argo CD. Those interested in creating third-party connectors can access developer-oriented resources.
How it works
Argo CD defines the intended application state by employing Git repositories as the source of truth, in accordance with the GitOps pattern. There are various approaches to specify Kubernetes manifests:
Applications for Customization
Helm charts
JSONNET files
Simple YAML/JSON manifest directory
Any custom configuration management tool that is set up as a plugin
The deployment of the intended application states in the designated target settings is automated by Argo CD. Deployments of applications can monitor changes to branches, tags, or pinned to a particular manifest version at a Git commit.
Architecture
The implementation of Argo CD is a Kubernetes controller that continually observes active apps and contrasts their present, live state with the target state (as defined in the Git repository). Out Of Sync is the term used to describe a deployed application whose live state differs from the target state. In addition to reporting and visualizing the differences, Argo CD offers the ability to manually or automatically sync the current state back to the intended goal state. The designated target environments can automatically apply and reflect any changes made to the intended target state in the Git repository.
Components
API Server
The Web UI, CLI, and CI/CD systems use the API, which is exposed by the gRPC/REST server. Its duties include the following:
Status reporting and application management
Launching application functions (such as rollback, sync, and user-defined actions)
Cluster credential management and repository (k8s secrets)
RBAC enforcement
Authentication, and auth delegation to outside identity providers
Git webhook event listener/forwarder
Repository Server
An internal service called the repository server keeps a local cache of the Git repository containing the application manifests. When given the following inputs, it is in charge of creating and returning the Kubernetes manifests:
URL of the repository
Revision (tag, branch, commit)
Path of the application
Template-specific configurations: helm values.yaml, parameters
A Kubernetes controller known as the application controller keeps an eye on all active apps and contrasts their actual, live state with the intended target state as defined in the repository. When it identifies an Out Of Sync application state, it may take remedial action. It is in charge of calling any user-specified hooks for lifecycle events (Sync, PostSync, and PreSync).
Features
Applications are automatically deployed to designated target environments.
Multiple configuration management/templating tools (Kustomize, Helm, Jsonnet, and plain-YAML) are supported.
Capacity to oversee and implement across several clusters
Integration of SSO (OIDC, OAuth2, LDAP, SAML 2.0, Microsoft, LinkedIn, GitHub, GitLab)
RBAC and multi-tenancy authorization policies
Rollback/Roll-anywhere to any Git repository-committed application configuration
Analysis of the application resources’ health state
Automated visualization and detection of configuration drift
Applications can be synced manually or automatically to their desired state.
Web user interface that shows program activity in real time
CLI for CI integration and automation
Integration of webhooks (GitHub, BitBucket, GitLab)
Tokens of access for automation
Hooks for PreSync, Sync, and PostSync to facilitate intricate application rollouts (such as canary and blue/green upgrades)
Application event and API call audit trails
Prometheus measurements
To override helm parameters in Git, use parameter overrides.
Read more on Govindhtech.com
#ArgoCD#CD#GitOps#API#Kubernetes#Git#Argoproject#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
2 notes
·
View notes
Text
CNAPP Explained: The Smartest Way to Secure Cloud-Native Apps with EDSPL

Introduction: The New Era of Cloud-Native Apps
Cloud-native applications are rewriting the rules of how we build, scale, and secure digital products. Designed for agility and rapid innovation, these apps demand security strategies that are just as fast and flexible. That’s where CNAPP—Cloud-Native Application Protection Platform—comes in.
But simply deploying CNAPP isn’t enough.
You need the right strategy, the right partner, and the right security intelligence. That’s where EDSPL shines.
What is CNAPP? (And Why Your Business Needs It)
CNAPP stands for Cloud-Native Application Protection Platform, a unified framework that protects cloud-native apps throughout their lifecycle—from development to production and beyond.
Instead of relying on fragmented tools, CNAPP combines multiple security services into a cohesive solution:
Cloud Security
Vulnerability management
Identity access control
Runtime protection
DevSecOps enablement
In short, it covers the full spectrum—from your code to your container, from your workload to your network security.
Why Traditional Security Isn’t Enough Anymore
The old way of securing applications with perimeter-based tools and manual checks doesn’t work for cloud-native environments. Here’s why:
Infrastructure is dynamic (containers, microservices, serverless)
Deployments are continuous
Apps run across multiple platforms
You need security that is cloud-aware, automated, and context-rich—all things that CNAPP and EDSPL’s services deliver together.
Core Components of CNAPP
Let’s break down the core capabilities of CNAPP and how EDSPL customizes them for your business:
1. Cloud Security Posture Management (CSPM)
Checks your cloud infrastructure for misconfigurations and compliance gaps.
See how EDSPL handles cloud security with automated policy enforcement and real-time visibility.
2. Cloud Workload Protection Platform (CWPP)
Protects virtual machines, containers, and functions from attacks.
This includes deep integration with application security layers to scan, detect, and fix risks before deployment.
3. CIEM: Identity and Access Management
Monitors access rights and roles across multi-cloud environments.
Your network, routing, and storage environments are covered with strict permission models.
4. DevSecOps Integration
CNAPP shifts security left—early into the DevOps cycle. EDSPL’s managed services ensure security tools are embedded directly into your CI/CD pipelines.
5. Kubernetes and Container Security
Containers need runtime defense. Our approach ensures zero-day protection within compute environments and dynamic clusters.
How EDSPL Tailors CNAPP for Real-World Environments
Every organization’s tech stack is unique. That’s why EDSPL never takes a one-size-fits-all approach. We customize CNAPP for your:
Cloud provider setup
Mobility strategy
Data center switching
Backup architecture
Storage preferences
This ensures your entire digital ecosystem is secure, streamlined, and scalable.
Case Study: CNAPP in Action with EDSPL
The Challenge
A fintech company using a hybrid cloud setup faced:
Misconfigured services
Shadow admin accounts
Poor visibility across Kubernetes
EDSPL’s Solution
Integrated CNAPP with CIEM + CSPM
Hardened their routing infrastructure
Applied real-time runtime policies at the node level
✅ The Results
75% drop in vulnerabilities
Improved time to resolution by 4x
Full compliance with ISO, SOC2, and GDPR
Why EDSPL’s CNAPP Stands Out
While most providers stop at integration, EDSPL goes beyond:
🔹 End-to-End Security: From app code to switching hardware, every layer is secured. 🔹 Proactive Threat Detection: Real-time alerts and behavior analytics. 🔹 Customizable Dashboards: Unified views tailored to your team. 🔹 24x7 SOC Support: With expert incident response. 🔹 Future-Proofing: Our background vision keeps you ready for what’s next.
EDSPL’s Broader Capabilities: CNAPP and Beyond
While CNAPP is essential, your digital ecosystem needs full-stack protection. EDSPL offers:
Network security
Application security
Switching and routing solutions
Storage and backup services
Mobility and remote access optimization
Managed and maintenance services for 24x7 support
Whether you’re building apps, protecting data, or scaling globally, we help you do it securely.
Let’s Talk CNAPP
You’ve read the what, why, and how of CNAPP — now it’s time to act.
📩 Reach us for a free CNAPP consultation. 📞 Or get in touch with our cloud security specialists now.
Secure your cloud-native future with EDSPL — because prevention is always smarter than cure.
0 notes
Text
Mastering Advanced Cluster Management with Red Hat OpenShift Administration III (DO380)
In today’s hybrid cloud era, managing container platforms efficiently at scale is mission-critical for modern enterprises. Enter Red Hat OpenShift Administration III: Scaling Kubernetes Deployments in the Enterprise (DO380) — a course designed for experienced OpenShift administrators who want to take their skills to the next level.
🧠 What Is DO380?
DO380 is the third level in the OpenShift administration curriculum. It focuses on advanced operational techniques for Red Hat OpenShift Container Platform, including:
Multi-cluster management with Red Hat Advanced Cluster Management (RHACM)
Advanced configuration of OpenShift networking
Advanced security and compliance management
Performance tuning and cluster health monitoring
Managing OpenShift at scale
This course is ideal for administrators who’ve already completed DO280 (Red Hat OpenShift Administration II) and are looking to manage large-scale, complex, and distributed OpenShift environments.
🛠️ Key Skills You’ll Learn
By the end of the DO380 course, you’ll be able to:
✅ Use Red Hat Advanced Cluster Management (RHACM) to manage multiple OpenShift clusters
✅ Centralize policy-based governance and security at scale
✅ Optimize OpenShift clusters for performance and efficiency
✅ Troubleshoot and recover from cluster-level issues
✅ Implement observability and metrics using Prometheus and Grafana
✅ Apply best practices for cluster security and compliance (CIS Benchmarks, SCAP, etc.)
📦 What’s Included in the Course?
Instructor-led or self-paced training (via Red Hat Learning Subscription)
Hands-on labs with real-world scenarios
Access to Red Hat Academy (if you're a student or partner)
Certification path: Prepares for EX380 (Red Hat Certified Specialist in OpenShift Administration III)
🎓 Who Should Take DO380?
This course is designed for:
System administrators managing OpenShift clusters in production
DevOps engineers scaling containerized applications
IT operations professionals responsible for platform governance
RHCSA or RHCE holders expanding their OpenShift capabilities
🧭 Prerequisites
You should have:
A Red Hat Certified System Administrator (RHCSA) in Red Hat OpenShift or equivalent experience
Completed DO280 (Red Hat OpenShift Administration II)
🏆 Why It Matters
Kubernetes is powerful, but managing it in enterprise environments can be overwhelming. Red Hat OpenShift simplifies Kubernetes — and DO380 teaches you how to scale, secure, and manage it like a pro.
Whether you're working in a hybrid cloud or multi-cloud environment, DO380 equips you with the tools to operate with confidence and precision.
📌 Final Thoughts
The Red Hat OpenShift Administration III (DO380) course is essential for professionals who want to own their OpenShift environments end-to-end. If you're ready to handle the challenges of scaling and managing OpenShift clusters at the enterprise level, this course is your next big step.
Ready to level up your OpenShift game?
Enroll in DO380 and become an expert in managing Kubernetes at scale with Red Hat OpenShift.
🔗 Interested in training for your team?
We offer corporate packages and Red Hat Learning Subscription (RHLS) options — www.hawkstack.com
0 notes
Text
Trending Cloud Services to Consider in 2025
The cloud services landscape is evolving rapidly, offering businesses innovative solutions to enhance productivity and efficiency. Here are some trending cloud services that organizations should consider incorporating into their strategies this year.
For those looking to enhance their skills, Cloud Computing Course With Placement programs offer comprehensive education and job placement assistance, making it easier to master this tool and advance your career.

1. Serverless Computing
AWS Lambda
Serverless computing allows developers to run code without provisioning or managing servers. AWS Lambda is leading the way, enabling businesses to focus on application logic rather than infrastructure management. This approach reduces costs and accelerates deployment times.
Azure Functions
Similar to AWS Lambda, Azure Functions offers event-driven serverless computing. It integrates seamlessly with other Azure services, making it ideal for businesses utilizing the Microsoft ecosystem.
2. Multi-Cloud Solutions
IBM Multicloud Management
As more organizations adopt multi-cloud strategies, services like IBM Multicloud Management facilitate the management of applications across multiple cloud environments. This flexibility helps businesses avoid vendor lock-in and optimize costs.
Google Anthos
Google Anthos enables organizations to manage applications across on-premises and cloud environments. Its ability to run Kubernetes clusters consistently across platforms makes it a powerful tool for hybrid cloud strategies.
3. AI and Machine Learning Services
Azure Machine Learning
With the growing importance of data-driven decision-making, Azure Machine Learning provides robust tools for building, training, and deploying machine learning models. Its user-friendly interface allows businesses to leverage AI without extensive technical expertise.
Google AI Platform
Google’s AI Platform supports businesses in developing their AI applications. From data preparation to model deployment, it offers comprehensive solutions tailored to various industries.
It’s simpler to master this tool and progress your profession with the help of Best Online Training & Placement programs, which provide thorough instruction and job placement support to anyone seeking to improve their talents.

4. Cloud Security Solutions
Palo Alto Networks Prisma Cloud
As cyber threats evolve, robust cloud security solutions are essential. Prisma Cloud provides comprehensive security for cloud-native applications and protects against vulnerabilities across multi-cloud environments.
Cloudflare Zero Trust
Cloudflare’s Zero Trust security model ensures that access is granted based on user identity and device security rather than network location. This approach enhances security in today’s remote work environment.
5. Collaborative Tools
Microsoft Teams
As remote work continues to be a norm, Microsoft Teams has emerged as a leading collaborative platform. Its integration with Microsoft 365 allows for seamless communication and collaboration among teams.
Slack
Slack remains a favorite for team communication, offering various integrations that enhance productivity. Its user-friendly interface and ability to streamline workflows make it essential for modern businesses.
6. Data Analytics Platforms
Tableau
Tableau is a powerful analytics platform that allows businesses to visualize data and gain insights. Its cloud capabilities enable teams to collaborate on data analysis in real-time.
Looker
Part of Google Cloud, Looker offers robust data analytics and business intelligence solutions. Its ability to integrate with various data sources makes it ideal for businesses looking to derive actionable insights from their data.
Conclusion
In 2025, these trending cloud services are set to redefine how businesses operate and innovate. By adopting serverless computing, multi-cloud solutions, AI services, and enhanced security measures, organizations can stay competitive in an ever-evolving landscape. Embracing these technologies will not only streamline operations but also empower businesses to make data-driven decisions for future growth. Stay ahead of the curve by considering these cloud services as you plan for the year ahead!
0 notes
Text
Pods in Kubernetes Explained: The Smallest Deployable Unit Demystified
As the foundation of Kubernetes architecture, Pods play a critical role in running containerized applications efficiently and reliably. If you're working with Kubernetes for container orchestration, understanding what a Pod is—and how it functions—is essential for mastering deployment, scaling, and management of modern microservices.
In this article, we’ll break down what a Kubernetes Pod is, how it works, why it's a fundamental concept, and how to use it effectively in real-world scenarios.
What Is a Pod in Kubernetes?
A Pod is the smallest deployable unit in Kubernetes. It encapsulates one or more containers, along with shared resources such as storage volumes, IP addresses, and configuration information.
Unlike traditional virtual machines or even standalone containers, Pods are designed to run tightly coupled container processes that must share resources and coordinate their execution closely.
Key Characteristics of Kubernetes Pods:
Each Pod has a unique IP address within the cluster.
Containers in a Pod share the same network namespace and storage volumes.
Pods are ephemeral—they can be created, destroyed, and rescheduled dynamically by Kubernetes.
Why Use Pods Instead of Individual Containers?
You might ask: why not just deploy containers directly?
Here’s why Kubernetes Pods are a better abstraction:
Grouping Logic: When multiple containers need to work together—such as a main app and a logging sidecar—they should be deployed together within a Pod.
Shared Lifecycle: Containers in a Pod start, stop, and restart together.
Simplified Networking: All containers in a Pod communicate via localhost, avoiding inter-container networking overhead.
This makes Pods ideal for implementing design patterns like sidecar containers, ambassador containers, and adapter containers.
Pod Architecture: What’s Inside a Pod?
A Pod includes:
One or More Containers: Typically Docker or containerd-based.
Storage Volumes: Shared data that persists across container restarts.
Network: Shared IP and port space, allowing containers to talk over localhost.
Metadata: Labels, annotations, and resource definitions.
Here’s an example YAML for a single-container Pod:
yaml
CopyEdit
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
spec:
containers:
- name: myapp-container
image: myapp:latest
ports:
- containerPort: 80
Pod Lifecycle Explained
Understanding the Pod lifecycle is essential for effective Kubernetes deployment and troubleshooting.
Pod phases include:
Pending: The Pod is accepted but not yet running.
Running: All containers are running as expected.
Succeeded: All containers have terminated successfully.
Failed: At least one container has terminated with an error.
Unknown: The Pod state can't be determined due to communication issues.
Kubernetes also uses Probes (readiness and liveness) to monitor and manage Pod health, allowing for automated restarts and intelligent traffic routing.
Single vs Multi-Container Pods
While most Pods run a single container, Kubernetes supports multi-container Pods, which are useful when containers need to:
Share local storage.
Communicate via localhost.
Operate in a tightly coupled manner (e.g., a log shipper running alongside an app).
Example use cases:
Sidecar pattern for logging or proxying.
Init containers for pre-start logic.
Adapter containers for API translation.
Multi-container Pods should be used sparingly and only when there’s a strong operational or architectural reason.
How Pods Fit into the Kubernetes Ecosystem
Pods are not deployed directly in most production environments. Instead, they're managed by higher-level Kubernetes objects like:
Deployments: For scalable, self-healing stateless apps.
StatefulSets: For stateful workloads like databases.
DaemonSets: For deploying a Pod to every node (e.g., logging agents).
Jobs and CronJobs: For batch or scheduled tasks.
These controllers manage Pod scheduling, replication, and failure recovery, simplifying operations and enabling Kubernetes auto-scaling and rolling updates.
Best Practices for Using Pods in Kubernetes
Use Labels Wisely: For organizing and selecting Pods via Services or Controllers.
Avoid Direct Pod Management: Always use Deployments or other controllers for production workloads.
Keep Pods Stateless: Use persistent storage or cloud-native databases when state is required.
Monitor Pod Health: Set up liveness and readiness probes.
Limit Resource Usage: Define resource requests and limits to avoid node overcommitment.
Final Thoughts
Kubernetes Pods are more than just containers—they are the fundamental building blocks of Kubernetes cluster deployments. Whether you're running a small microservice or scaling to thousands of containers, understanding how Pods work is essential for architecting reliable, scalable, and efficient applications in a Kubernetes-native environment.
By mastering Pods, you’re well on your way to leveraging the full power of Kubernetes container orchestration.
0 notes
Text
h
Technical Skills (Java, Spring, Python)
Q1: Can you walk us through a recent project where you built a scalable application using Java and Spring Boot? A: Absolutely. In my previous role, I led the development of a microservices-based system using Java with Spring Boot and Spring Cloud. The app handled real-time financial transactions and was deployed on AWS ECS. I focused on building stateless services, applied best practices like API versioning, and used Eureka for service discovery. The result was a 40% improvement in performance and easier scalability under load.
Q2: What has been your experience with Python in data processing? A: I’ve used Python for ETL pipelines, specifically for ingesting large volumes of compliance data into cloud storage. I utilized Pandas and NumPy for processing, and scheduled tasks with Apache Airflow. The flexibility of Python was key in automating data validation and transformation before feeding it into analytics dashboards.
Cloud & DevOps
Q3: Describe your experience deploying applications on AWS or Azure. A: Most of my cloud experience has been with AWS. I’ve deployed containerized Java applications to AWS ECS and used RDS for relational storage. I also integrated S3 for static content and Lambda for lightweight compute tasks. In one project, I implemented CI/CD pipelines with Jenkins and CodePipeline to automate deployments and rollbacks.
Q4: How have you used Docker or Kubernetes in past projects? A: I've containerized all backend services using Docker and deployed them on Kubernetes clusters (EKS). I wrote Helm charts for managing deployments and set up autoscaling rules. This improved uptime and made releases smoother, especially during traffic spikes.
Collaboration & Agile Practices
Q5: How do you typically work with product owners and cross-functional teams? A: I follow Agile practices, attending sprint planning and daily stand-ups. I work closely with product owners to break down features into stories, clarify acceptance criteria, and provide early feedback. My goal is to ensure technical feasibility while keeping business impact in focus.
Q6: Have you had to define technical design or architecture? A: Yes, I’ve been responsible for defining the technical design for multiple features. For instance, I designed an event-driven architecture for a compliance alerting system using Kafka, Java, and Spring Cloud Streams. I created UML diagrams and API contracts to guide other developers.
Testing & Quality
Q7: What’s your approach to testing (unit, integration, automation)? A: I use JUnit and Mockito for unit testing, and Spring’s Test framework for integration tests. For end-to-end automation, I’ve worked with Selenium and REST Assured. I integrate these tests into Jenkins pipelines to ensure code quality with every push.
Behavioral / Cultural Fit
Q8: How do you stay updated with emerging technologies? A: I subscribe to newsletters like InfoQ and follow GitHub trending repositories. I also take part in hackathons and complete Udemy/Coursera courses. Recently, I explored Quarkus and Micronaut to compare their performance with Spring Boot in cloud-native environments.
Q9: Tell us about a time you challenged the status quo or proposed a modern tech solution. A: At my last job, I noticed performance issues due to a legacy monolith. I advocated for a microservices transition. I led a proof-of-concept using Spring Boot and Docker, which gained leadership buy-in. We eventually reduced deployment time by 70% and improved maintainability.
Bonus: Domain Experience
Q10: Do you have experience supporting back-office teams like Compliance or Finance? A: Yes, I’ve built reporting tools for Compliance and data reconciliation systems for Finance. I understand the importance of data accuracy and audit trails, and have used role-based access and logging mechanisms to meet regulatory requirements.
0 notes
Text
What is PySpark? A Beginner’s Guide
Introduction
The digital era gives rise to continuous expansion in data production activities. Organizations and businesses need processing systems with enhanced capabilities to process large data amounts efficiently. Large datasets receive poor scalability together with slow processing speed and limited adaptability from conventional data processing tools. PySpark functions as the data processing solution that brings transformation to operations.
The Python Application Programming Interface called PySpark serves as the distributed computing framework of Apache Spark for fast processing of large data volumes. The platform offers a pleasant interface for users to operate analytics on big data together with real-time search and machine learning operations. Data engineering professionals along with analysts and scientists prefer PySpark because the platform combines Python's flexibility with Apache Spark's processing functions.
The guide introduces the essential aspects of PySpark while discussing its fundamental elements as well as explaining operational guidelines and hands-on usage. The article illustrates the operation of PySpark through concrete examples and predicted outputs to help viewers understand its functionality better.
What is PySpark?
PySpark is an interface that allows users to work with Apache Spark using Python. Apache Spark is a distributed computing framework that processes large datasets in parallel across multiple machines, making it extremely efficient for handling big data. PySpark enables users to leverage Spark’s capabilities while using Python’s simple and intuitive syntax.
There are several reasons why PySpark is widely used in the industry. First, it is highly scalable, meaning it can handle massive amounts of data efficiently by distributing the workload across multiple nodes in a cluster. Second, it is incredibly fast, as it performs in-memory computation, making it significantly faster than traditional Hadoop-based systems. Third, PySpark supports Python libraries such as Pandas, NumPy, and Scikit-learn, making it an excellent choice for machine learning and data analysis. Additionally, it is flexible, as it can run on Hadoop, Kubernetes, cloud platforms, or even as a standalone cluster.
Core Components of PySpark
PySpark consists of several core components that provide different functionalities for working with big data:
RDD (Resilient Distributed Dataset) – The fundamental unit of PySpark that enables distributed data processing. It is fault-tolerant and can be partitioned across multiple nodes for parallel execution.
DataFrame API – A more optimized and user-friendly way to work with structured data, similar to Pandas DataFrames.
Spark SQL – Allows users to query structured data using SQL syntax, making data analysis more intuitive.
Spark MLlib – A machine learning library that provides various ML algorithms for large-scale data processing.
Spark Streaming – Enables real-time data processing from sources like Kafka, Flume, and socket streams.
How PySpark Works
1. Creating a Spark Session
To interact with Spark, you need to start a Spark session.

Output:

2. Loading Data in PySpark
PySpark can read data from multiple formats, such as CSV, JSON, and Parquet.

Expected Output (Sample Data from CSV):

3. Performing Transformations
PySpark supports various transformations, such as filtering, grouping, and aggregating data. Here’s an example of filtering data based on a condition.

Output:

4. Running SQL Queries in PySpark
PySpark provides Spark SQL, which allows you to run SQL-like queries on DataFrames.

Output:
5. Creating a DataFrame Manually
You can also create a PySpark DataFrame manually using Python lists.

Output:

Use Cases of PySpark
PySpark is widely used in various domains due to its scalability and speed. Some of the most common applications include:
Big Data Analytics – Used in finance, healthcare, and e-commerce for analyzing massive datasets.
ETL Pipelines – Cleans and processes raw data before storing it in a data warehouse.
Machine Learning at Scale – Uses MLlib for training and deploying machine learning models on large datasets.
Real-Time Data Processing – Used in log monitoring, fraud detection, and predictive analytics.
Recommendation Systems – Helps platforms like Netflix and Amazon offer personalized recommendations to users.
Advantages of PySpark
There are several reasons why PySpark is a preferred tool for big data processing. First, it is easy to learn, as it uses Python’s simple and intuitive syntax. Second, it processes data faster due to its in-memory computation. Third, PySpark is fault-tolerant, meaning it can automatically recover from failures. Lastly, it is interoperable and can work with multiple big data platforms, cloud services, and databases.
Getting Started with PySpark
Installing PySpark
You can install PySpark using pip with the following command:

To use PySpark in a Jupyter Notebook, install Jupyter as well:

To start PySpark in a Jupyter Notebook, create a Spark session:

Conclusion
PySpark is an incredibly powerful tool for handling big data analytics, machine learning, and real-time processing. It offers scalability, speed, and flexibility, making it a top choice for data engineers and data scientists. Whether you're working with structured data, large-scale machine learning models, or real-time data streams, PySpark provides an efficient solution.
With its integration with Python libraries and support for distributed computing, PySpark is widely used in modern big data applications. If you’re looking to process massive datasets efficiently, learning PySpark is a great step forward.
youtube
#pyspark training#pyspark coutse#apache spark training#apahe spark certification#spark course#learn apache spark#apache spark course#pyspark certification#hadoop spark certification .#Youtube
0 notes
Text
Ensuring Compliance with Azure Cloud Security Services
As businesses increasingly migrate to the cloud, securing their infrastructure and data has become a top priority. Azure cloud security services provide a comprehensive suite of tools designed to protect workloads, applications, and sensitive data. These services help organizations mitigate risks, detect threats, and maintain compliance with industry regulations. This article explores key aspects of Azure cloud security services and their importance in today's digital landscape.
Understanding Azure Cloud Security Services
Azure cloud security services encompass various tools and technologies aimed at protecting cloud-based assets. These services include network security, identity management, threat detection, and compliance monitoring. Microsoft offers built-in security features such as Azure Security Center, Azure Defender, and Azure Sentinel to enhance cloud security. These services work together to provide continuous monitoring, advanced threat protection, and automated responses to potential cyber threats. Businesses can leverage these tools to safeguard their cloud environments without compromising performance or efficiency.
Importance of Azure Security Center in Cloud Protection
Azure Security Center is a unified security management system that provides visibility into an organization's security posture. It continuously assesses cloud resources for vulnerabilities and suggests actionable security recommendations. The platform also integrates with various security solutions to detect and respond to threats. By using Azure Security Center, businesses can enforce security policies, identify misconfigurations, and improve their overall security framework. This proactive approach helps organizations minimize risks and maintain compliance with industry standards.
Role of Azure Defender in Threat Protection
Azure Defender is an advanced security tool that helps organizations protect workloads running in Azure and hybrid environments. It uses machine learning and behavioral analytics to detect suspicious activities, such as unauthorized access or unusual data transfers. Azure Defender covers multiple security layers, including virtual machines, databases, Kubernetes clusters, and IoT devices. It provides automated threat mitigation options, reducing the time required to respond to incidents. This proactive defense mechanism helps businesses strengthen their cloud security and prevent potential breaches.
Enhancing Identity and Access Management with Azure Active Directory
Azure Active Directory is a core component of Azure cloud security services that manages user identities and access permissions. It enables organizations to implement multi-factor authentication, conditional access policies, and role-based access controls. These features ensure that only authorized users can access critical resources. Azure Active Directory also supports seamless integration with third-party applications and on-premises directories, making it a versatile solution for businesses. By adopting strong identity management practices, organizations can reduce the risk of unauthorized access and data leaks.
Securing Cloud Networks with Azure Firewall and DDoS Protection
Azure provides built-in network security services such as Azure Firewall and Distributed Denial-of-Service protection to safeguard cloud environments. Azure Firewall is a managed security service that filters network traffic based on defined rules, preventing malicious activities. It offers features like threat intelligence-based filtering, outbound internet access control, and centralized policy management. Azure DDoS Protection helps defend against large-scale cyberattacks that can disrupt business operations. By implementing these security measures, organizations can maintain the integrity and availability of their cloud resources.
Ensuring Compliance and Regulatory Adherence with Azure Policy
Compliance with industry regulations is crucial for businesses operating in cloud environments. Azure Policy is a governance tool that helps organizations enforce compliance requirements and security best practices. It allows businesses to define policies that automatically assess and remediate security configurations. Azure Policy integrates with other security tools like Azure Security Center to provide a holistic approach to compliance management. By using this service, businesses can ensure they meet regulatory standards such as GDPR, HIPAA, and ISO 27001.
Conclusion
Azure cloud security services offer a comprehensive framework for protecting cloud-based resources against evolving cyber threats. By leveraging tools like Azure Security Center, Azure Defender, and Azure Active Directory, businesses can strengthen their security posture and reduce vulnerabilities. Network security solutions such as Azure Firewall and DDoS Protection help safeguard cloud environments from external threats. Additionally, compliance management tools like Azure Policy ensure adherence to industry regulations. Investing in Azure cloud security services enables organizations to enhance their cybersecurity defenses, maintain operational continuity, and build a resilient digital infrastructure.
0 notes
Text
Mastering Multicluster Management with Red Hat OpenShift Platform Plus (DO480)
In today’s hybrid and multicloud environments, managing Kubernetes clusters at scale is no small feat. Organizations are increasingly embracing microservices, containerization, and distributed workloads—but without centralized governance and consistency, things can quickly spiral into chaos. That’s where Red Hat OpenShift Platform Plus and the associated DO480 training come into play.
Why Multicluster Management Matters
Modern enterprises often deploy applications across multiple OpenShift clusters—on-premises, at the edge, and in public clouds. While this approach offers flexibility and resilience, it introduces complexity in:
Governance and policy enforcement
Security and compliance
Application lifecycle management
Disaster recovery and observability
Red Hat OpenShift Platform Plus addresses these challenges with built-in tools for comprehensive multicluster management, built on top of Red Hat Advanced Cluster Management (ACM) and Advanced Cluster Security (ACS).
Introducing DO480: Multicluster Management with Red Hat OpenShift Platform Plus
The DO480 course is designed for DevOps engineers, system administrators, and cluster managers who want to master the art of managing multiple OpenShift clusters efficiently. It provides hands-on experience with Red Hat ACM and ACS, two essential tools in the OpenShift Platform Plus toolkit.
Key Topics Covered in DO480:
Creating and Managing Multiple Clusters
Deploy and register OpenShift clusters using Red Hat ACM
Manage clusters in hybrid cloud environments
Governance and Compliance
Define and apply governance policies using GitOps and RHACM
Enforce configuration consistency and security best practices
Application Lifecycle Across Clusters
Deploy and promote applications across multiple clusters
Use GitOps workflows with Argo CD integration
Advanced Cluster Security
Monitor container workloads for vulnerabilities and risks
Define network and security policies to protect workloads
Disaster Recovery and Business Continuity
Set up cluster backup and restore using OpenShift APIs
Implement cluster failover and workload migration
Benefits of Taking DO480
Hands-on Labs: Work with real OpenShift clusters in a lab environment to simulate real-world scenarios.
Skill Validation: Prepare for advanced certifications and prove your capability in multicluster management.
Strategic Insight: Learn how to align OpenShift multicluster architectures with business continuity and compliance strategies.
Whether you’re managing clusters for high availability, regulatory compliance, or global application delivery, DO480 gives you the tools and knowledge to scale with confidence.
Who Should Enroll?
This course is ideal for:
DevOps Engineers
Site Reliability Engineers (SREs)
OpenShift Administrators
Platform Engineers managing hybrid or multicloud OpenShift environments
Prerequisites: DO480 is a follow-up to foundational courses like DO180 (OpenShift Administration I) and DO280 (OpenShift Administration II). A solid understanding of OpenShift and Kubernetes is recommended.
Final Thoughts: Building Resilience and Agility with OpenShift Platform Plus
Multicluster management isn't just a technical need—it's a business imperative. Red Hat OpenShift Platform Plus, coupled with the hands-on experience of DO480, empowers IT teams to tame the complexity of hybrid infrastructure while maintaining control, security, and agility.
If your organization is looking to streamline multicluster operations, boost compliance, and accelerate application delivery, DO480 is your launchpad.
Get Started with DO480 Today!
At HawkStack Technologies, we offer expert-led delivery of Red Hat courses including DO480, backed by practical labs and real-world insights. Contact us today to schedule your team training or explore Red Hat Learning Subscriptions for ongoing upskilling.
0 notes
Text
How to Use AWS Code Pipeline for Continuous Delivery
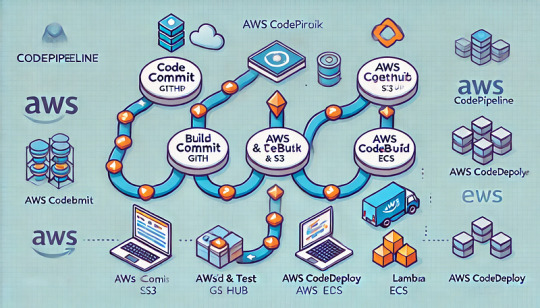
Introduction to AWS Code Pipeline: Overview of CI/CD and How It Works
1. What is AWS Code Pipeline?
AWS Code Pipeline is a fully managed continuous integration and continuous delivery (CI/CD) service that automates software release processes. It enables developers to build, test, and deploy applications rapidly with minimal manual intervention.
2. What is CI/CD?
CI/CD stands for:
Continuous Integration (CI): Automates the process of integrating code changes from multiple contributors.
Continuous Delivery (CD): Ensures that code is always in a deployable state and can be released automatically.
Benefits of CI/CD with AWS Code Pipeline
✅ Faster Deployments: Automates the release process, reducing time to market. ✅ Consistent & Reliable: Eliminates manual errors by enforcing a consistent deployment workflow. ✅ Scalability: Easily integrates with AWS services like Code Build, CodeDeploy, Lambda, and more. ✅ Customizable: Allows integration with third-party tools like GitHub, Jenkins, and Bitbucket.
3. How AWS Code Pipeline Works
AWS Code Pipeline follows a pipeline-based workflow, consisting of three key stages:
1️⃣ Source Stage (Code Repository)
The pipeline starts when new code is committed.
Can be triggered by AWS Code Commit, GitHub, Bitbucket, or an S3 bucket.
2️⃣ Build & Test Stage (CI Process)
Uses AWS Code Build or third-party tools to compile code, run tests, and package applications.
Ensures the application is error-free before deployment.
3️⃣ Deployment Stage (CD Process)
Uses AWS Code Deploy, ECS, Lambda, or Elastic Beanstalk to deploy the application.
Supports blue/green and rolling deployments for zero-downtime updates.
4. Example: CI/CD Workflow with AWS Code Pipeline
🔹 Step 1: Developer Pushes Code
A developer pushes code to a GitHub repository or AWS Code Commit.
🔹 Step 2: AWS Code Pipeline Detects the Change
The pipeline is triggered automatically by a new commit.
🔹 Step 3: Build & Test the Code
AWS Code Build compiles the application, runs unit tests, and packages the output.
🔹 Step 4: Deploy to AWS Services
AWS Code Deploy or ECS deploys the application to EC2, Lambda, or Kubernetes clusters.
🔹 Step 5: Monitor and Optimize
AWS Cloud Watch logs and AWS X-Ray provide visibility into the CI/CD pipeline’s performance.
5. Conclusion
AWS Code Pipeline automates software delivery by integrating source control, build, test, and deployment into a seamless workflow. With AWS-managed services, it helps teams improve efficiency, reduce errors, and deploy applications faster.
WEBSITE: https://www.ficusoft.in/devops-training-in-chennai/
0 notes
Text
The laptop I wish I had never bought, but I am glad I did.

Working in the tech space, I've had a myriad of Laptops which were just good enough. I wanted something a little better.
I've owned and used a plethora of Laptops over the years, all the brands, all the Types, from Windows 2 to Windows 11, Apple Macbooks, Chromebooks and even Android Devices baked into a Laptop form factor (Thanks, Asus)
Occasionally, like in 2020, I'd buy something like I did then, a Dell XPS with 16Gb of RAM when the standard was 8Gb, and push the boat out.
This LG Gram was one of those purchases. I wanted a top-end laptop. Something built well, something which would last the test of time, and I could run multiple virtual machines on different OS and not have to worry about RAM and CPU space.
This last one was of particular importance to me at the time as I was learning Kubernetes (and still am) and wanted a local cluster I could spin up and tear down to learn about projects.
The LG Gram I ended up buying was a laptop beast (in my eyes)
13th Gen Intel(R) Core(TM) i7-1360P
32Gb Ram
1Tb SSD Storage
17" Display
Light
And to be fair, it is a lovely laptop.
It came with Windows 11 Home, which I didn't even boot into and promptly installed a Linux Distro (Ubuntu 24.04) onto it. I've subsequently done this more than once, and I finally ended up on Arch-based Garuda Linux.
Linux runs like a dream on this laptop, mainly because it's Intel all the way under the hood, so there are drivers for everything baked into the distro.
I've been able to run up using Qemu and LVM a K8s test cluster with 4 devices of 4Gb of RAM and a 4 GB Rancher server and still have plenty of grunt under the hood to run the day-to-day
The problem (and it's a first-world problem) is that I don't need this amount of power.
I spent January working off my 4-year-old Google Pixel Go Chromebook. I could do 90% of what I needed to do on my Samsung tablet Desktop, and I have a Lenovo ThinkCentre sitting in the order of the room, running the services I need in the background (DNS, NAS, Media Server, etc.).
So, as a Laptop, the LG Gram has become my daily workhorse. It is the place where I tinker with Ollama, Spin up a Windows VM, or spin up a cluster of servers to try something out. It gets used for 8 hours a day and then put to sleep at night. I'd feel wrong turning it into some sort of server and not using it as a laptop, but I fear this is where I may end up.
Unless, of course, I find something which needs the power to run.
0 notes
Text
Master Kubernetes Basics: The Ultimate Beginner’s Tutorial

Kubernetes has become a buzzword in the world of containerized applications. But what exactly is Kubernetes, and how can beginners start using it? In simple terms, Kubernetes is a powerful open-source platform designed to manage and scale containerized applications effortlessly.
Why Learn Kubernetes? As businesses shift towards modern software development practices, Kubernetes simplifies the deployment, scaling, and management of applications. It ensures your apps run smoothly across multiple environments, whether in the cloud or on-premises.
How Does Kubernetes Work? Kubernetes organizes applications into containers and manages these containers using Pods. Pods are the smallest units in Kubernetes, where one or more containers work together. Kubernetes automates tasks like load balancing, scaling up or down based on traffic, and ensuring applications stay available even during failures.
Getting Started with Kubernetes
Understand the Basics: Learn about containers (like Docker), clusters, and nodes. These are the building blocks of Kubernetes.
Set Up a Kubernetes Environment: Use platforms like Minikube or Kubernetes on cloud providers like AWS or Google Cloud for practice.
Explore Key Concepts: Focus on terms like Pods, Deployments, Services, and ConfigMaps.
Experiment and Learn: Deploy sample applications to understand how Kubernetes works in action.
Kubernetes might seem complex initially, but with consistent practice, you'll master it. Ready to dive deeper into Kubernetes? Check out this detailed guide in the Kubernetes Tutorial.
0 notes
Text
How Kubernetes Facilitates the Orchestration of Containers in AWS
Containerization has transformed the design, deployment, and scaling of cloud applications. With k8s (Kubernetes), it is possible to be efficient when dealing with thousands of containers at scale. In AWS, Kubernetes proves crucial in providing benefits such as scalability, streamlined operations, and simplification of maintenance for organizations. In this blog, I’ll share insights on how Kubernetes aids container orchestration in AWS, its benefits, and ways to leverage it for building robust applications—a journey inspired by my foundational learning from the cloud computing course online at ACTE Institute.

Understanding Container Orchestration
Before getting into Kubernetes, it is important to understand container orchestration. It is the process of managing multiple containers for applications in distributed environments, automating tasks such as deployment, scaling, load balancing, and networking. Managing numerous containers in cloud environments like AWS is challenging, especially at scale, and that's where Kubernetes excels. Kubernetes, also known as K8s, is an open-source system designed to automate the deployment, scaling, and management of containerized applications. Initially developed by Google, Kubernetes has become the industry standard for container orchestration. Its ability to abstract complex tasks makes it an indispensable tool for developers and organizations.
Features of Kubernetes
Kubernetes offers numerous features, including:
Automated Scheduling: Efficiently assigns containers to nodes based on resource availability.
Self-Healing Mechanisms: Automatically restarts or replaces failed containers.
Load Balancing: Distributes traffic to ensure optimal performance.
Service Discovery: It enables seamless communication between microservices.
Horizontal Scaling: Dynamically adjusts container instances to match demand.
Rolling Updates and Rollbacks: Supports smooth application updates without downtime.
All this makes Kubernetes an ideal choice for managing containerized applications in dynamic and scalable environments like AWS.
Kubernetes on AWS: How It Works
There are two primary ways of running Kubernetes on AWS:
Amazon EKS (Elastic Kubernetes Service):
Amazon EKS is a managed service, which makes running Kubernetes clusters on AWS easier. Here's why it's in demand:
Managed Control Plane: AWS operates the Kubernetes control plane, taking away operational burdens.
Integration: Works natively with services like EC2, S3, IAM, and CloudWatch, making deployment and management easy and efficient.
Self-managed Kubernetes on EC2:
Organizations can set up Kubernetes manually on EC2 instances for better control. This is suitable for those who require a custom configuration but will incur more maintenance responsibility.
Advantages of Using Kubernetes in AWS
Scalability and Flexibility: Kubernetes supports horizontal scaling, meaning that container instances can be easily scaled up or down according to demand. AWS Auto Scaling helps to complement this by dynamically managing the resources in EC2.
For instance, on Black Friday, a retail application running on Kubernetes in AWS scaled up automatically to match the surge in traffic and continued serving the users uninterrupted.
High Availability and Fault Tolerance: Kubernetes makes sure that the applications stay available through its self-recovery capability. Through the deployment of clusters across several AWS Availability Zones, the applications stay resilient even while infrastructure fails.
Automated Deployment and Management: Kubernetes is highly compatible with CI/CD pipelines, which automate the deployment of applications. Rolling updates and rollbacks ensure smooth upgrades without downtime.
Cost Optimization: Kubernetes's integration with AWS Fargate allows for serverless compute, reducing the cost of infrastructure management. Using AWS spot instances also reduces EC2 costs by a significant amount.
Improved Security: The security features of Kubernetes combined with AWS tools ensure robust protection for containerized applications.

Integrating Kubernetes with AWS Services
AWS services enhance Kubernetes’s capabilities. Here are notable integrations:
Amazon RDS: Provides managed relational databases for Kubernetes applications.
Amazon S3: Offers scalable storage, accessible via Kubernetes with Elastic File System
(EFS) or Elastic Block Store (EBS).
AWS CloudWatch: Monitors Kubernetes clusters and applications, providing actionable insights.
AWS Load Balancer: Handles traffic distribution for Kubernetes applications automatically.
Kubernetes Across Other Cloud Platforms
Kubernetes isn’t exclusive to AWS. It’s widely used in:
Google Cloud Kubernetes (GKE): Provides a deep integration with Google's cloud ecosystem.
Azure Kubernetes Service (AKS): Makes it easier to deploy Kubernetes on Microsoft Azure.
Openshift Kubernetes: Merges Kubernetes with more enterprise features.
Monitoring Kubernetes with Prometheus : Prometheus is a powerful monitoring tool for Kubernetes clusters. The Kube Prometheus Stack provides dashboards and alerts, which enables proactive issue resolution. Combining Prometheus with AWS CloudWatch offers comprehensive visibility into system performance.
Conclusion
Learning Kubernetes transformed my career as a solution architect. From scalable application deployment to cost optimization, Kubernetes has become the bedrock of modern cloud computing. It all started from the cloud computing course in Bangalore at ACTE Institute, building a solid foundation in cloud technologies. Today, using Kubernetes on AWS, I help organizations design resilient and efficient systems-a testament to the power of continuous learning and innovation.
0 notes
Text
AI Data Center Builder Nscale Secures $155M Investment
Nscale Ltd., a startup based in London that creates data centers designed for artificial intelligence tasks, has raised $155 million to expand its infrastructure.
The Series A funding round was announced today. Sandton Capital Partners led the investment, with contributions from Kestrel 0x1, Blue Sky Capital Managers, and Florence Capital. The funding announcement comes just a few weeks after one of Nscale’s AI clusters was listed in the Top500 as one of the world’s most powerful supercomputers.
The Svartisen Cluster took the 156th spot with a maximum performance of 12.38 petaflops and 66,528 cores. Nscale built the system using servers that each have six chips from Advanced Micro Devices Inc.: two central processing units and four MI250X machine learning accelerators. The MI250X has two graphics cards made with a six-nanometer process, plus 128 gigabytes of memory to store data for AI models.

The servers are connected through an Ethernet network that Nscale created using chips from Broadcom Inc. The network uses a technology called RoCE, which allows data to move directly between two machines without going through their CPUs, making the process faster. RoCE also automatically handles tasks like finding overloaded network links and sending data to other connections to avoid delays.
On the software side, Nscale’s hardware runs on a custom-built platform that manages the entire infrastructure. It combines Kubernetes with Slurm, a well-known open-source tool for managing data center systems. Both Kubernetes and Slurm automatically decide which tasks should run on which server in a cluster. However, they are different in a few ways. Kubernetes has a self-healing feature that lets it fix certain problems on its own. Slurm, on the other hand, uses a network technology called MPI, which moves data between different parts of an AI task very efficiently.
Nscale built the Svartisen Cluster in Glomfjord, a small village in Norway, which is located inside the Arctic Circle. The data center (shown in the picture) gets its power from a nearby hydroelectric dam and is directly connected to the internet through a fiber-optic cable. The cable has double redundancy, meaning it can keep working even if several key parts fail.
The company makes its infrastructure available to customers in multiple ways. It offers AI training clusters and an inference service that automatically adjusts hardware resources depending on the workload. There are also bare-metal infrastructure options, which let users customize the software that runs their systems in more detail.
Customers can either download AI models from Nscale's algorithm library or upload their own. The company says it provides a ready-made compiler toolkit that helps convert user workloads into a format that runs smoothly on its servers. For users wanting to create their own custom AI solutions, Nscale provides flexible, high-performance infrastructure that acts as a builder ai platform, helping them optimize and deploy personalized models at scale.
Right now, Nscale is building data centers that together use 300 megawatts of power. That’s 10 times more electricity than the company’s Glomfjord facility uses. Using the Series A funding round announced today, Nscale will grow its pipeline by 1,000 megawatts. “The biggest challenge to scaling the market is the huge amount of continuous electricity needed to power these large GPU superclusters,” said Nscale CEO Joshua Payne. Read this link also : https://sifted.eu/articles/tech-events-2025
“Nscale has a 1.3GW pipeline of sites in our portfolio, which lets us design everything from scratch – the data center, the supercluster, and the cloud environment – all the way through for our customers.” The company will build new data centers in North America and Europe. The company plans to build 120 megawatts of data center capacity next year. The new infrastructure will support Nscale’s upcoming public cloud service, which will focus on training and inference tasks, and is expected to launch in the first quarter of 2025.
0 notes
Text
New Clarifai tool orchestrates AI across any infrastructure - AI News
New Post has been published on https://thedigitalinsider.com/new-clarifai-tool-orchestrates-ai-across-any-infrastructure-ai-news/
New Clarifai tool orchestrates AI across any infrastructure - AI News
.pp-multiple-authors-boxes-wrapper display:none; img width:100%;
Artificial intelligence platform provider Clarifai has unveiled a new compute orchestration capability that promises to help enterprises optimise their AI workloads in any computing environment, reduce costs and avoid vendor lock-in.
Announced on December 3, 2024, the public preview release lets organisations orchestrate AI workloads through a unified control plane, whether those workloads are running on cloud, on-premises, or in air-gapped infrastructure. The platform can work with any AI model and hardware accelerator including GPUs, CPUs, and TPUs.
“Clarifai has always been ahead of the curve, with over a decade of experience supporting large enterprise and mission-critical government needs with the full stack of AI tools to create custom AI workloads,” said Matt Zeiler, founder and CEO of Clarifai. “Now, we’re opening up capabilities we built internally to optimise our compute costs as we scale to serve millions of models simultaneously.”
The company claims its platform can reduce compute usage by 3.7x through model packing optimisations while supporting over 1.6 million inference requests per second with 99.9997% reliability. According to Clarifai, the optimisations can potentially cut costs by 60-90%, depending on configuration.
Capabilities of the compute orchestration platform include:
Cost optimisation through automated resource management, including model packing, dependency simplification, and customisable auto-scaling options that can scale to zero for model replicas and compute nodes,
Deployment flexibility on any hardware vendor including cloud, on-premise, air-gapped, and Clarifai SaaS infrastructure,
Integration with Clarifai’s AI platform for data labeling, training, evaluation, workflows, and feedback,
Security features that allow deployment into customer VPCs or on-premise Kubernetes clusters without requiring open inbound ports, VPC peering, or custom IAM roles.
The platform emerged from Clarifai customers’ issues with AI performance and cost. “If we had a way to think about it holistically and look at our on-prem costs compared to our cloud costs, and then be able to orchestrate across environments with a cost basis, that would be incredibly valuable,” noted a customer, as cited in Clarifai’s announcement.
The compute orchestration capabilities build on Clarifai’s existing AI platform that, the company says, has processed over 2 billion operations in computer vision, language, and audio AI. The company reports maintaining 99.99%+ uptime and 24/7 availability for critical applications.
The compute orchestration capability is currently available in public preview. Organisations interested in testing the platform should contact Clarifai for access.
Tags: ai, artificial intelligence
#2024#ai#ai model#ai news#ai platform#ai tools#air#applications#Art#artificial#Artificial Intelligence#audio#billion#Business#CEO#Cloud#clusters#computer#Computer vision#computing#data#december#deployment#enterprise#Enterprises#Environment#evaluation#Experienced#Features#Full
0 notes