#applied mathematics
Text
Regarding the buzz around the GPT chatbot. On c++ and Reddit forums, I've seen the argument "the GPT chatbot has the IQ of a schizophrenic human." We're so quixotically obsessed with ascribing human characteristics to linear algebra that we're at risk of dehumanizing other actual humans. Never mind that genius mathematicians like John Nash had schizophrenia; this is anti-social analysis. Science without skepticism is marketing, and many claims about the GPT chatbot want us to withhold skepticism.
IQ itself is a flawed measure. There are zero reasons to measure intelligence as a normal distribution, and Nassim Taleb's analysis shows that the tails of a distribution that describes intelligence are fat-tailed on the right and predict very little. The problem of intelligence and sentience is a very complicated unsolved philosophical and biological problem, and the current state of the literature on these large language models decouples itself from academia. This decoupling is akin to the tobacco companies doing cancer research in the 60s. There is no reason to expect that research produced by the tech sector is anything but advertising and that advertising is becoming dangerously anti-social.
107 notes
·
View notes
Text
Please help me mathblr :,)
I’ll be starting my degree in applied maths and computation in less than a month. Apparently, in my college, Linear Algebra and Integral and Differential Calculus are two of the hardest courses (I am unsure if it’s because of the complexity of the subjects or the lack of care by the teachers, although I’m willing to bet it’s both). Does anyone have any resources (Books, YouTube channels, online lectures, etc.) that could help me out? I’d really appreciate it!!
Content related to other subjects are also welcome, along with general advice about pursuing a (math) degree!!
Im terrified to start uni, can you tell?? Also excited tho
#thank youuuu#mathblr#help#math resources#mathblr help me#undergraduate#undergrad student#undergraduate math#undergraduate mathematics#integral and differential calculus#linear algebra#university advice#university books#math degree#applied mathematics#and computation#math olympiad#math help#math notes#math question
57 notes
·
View notes
Text
Annalisa Buffa
youtube
Annalisa Buffa was born in Italy in 1973. Since 2016, Buffa has been a professor of mathematics at Ecole Polytechnique Fédérale de Lausanne. Prior to that, she was research director and director of the Instituto di Matematica Applicata e Tecnologie informatiche of the Italian National Research Council (CNR). Professor Buffa has coauthored more than 40 papers on computational electromagnetism, applied mathematics, and numerical analysis. In 2015, she won the Collatz Prize from the International Council for Industrial and Applied Mathematics for her use of sophisticated mathematical concepts to make contributions to computer simulation development in industry and science.
11 notes
·
View notes
Text
A tangled tale of worm jello
The linked article is for SIAM News, the magazine for members of the Society for Industrial and Applied Mathematics (SIAM). As such, I included some mathematical content, but I tried to write the piece so that you could gloss over that bit without losing the gist of the story. This particular article has a lot of really fascinating content for a wide range of fields, from pure mathematics to drug…

View On WordPress
6 notes
·
View notes
Text
Fear of Music: how many songs does the average list put in the top 250?
Given…
We collectively split 52,370 points between 3103 songs.
Precisely one 40-pointer missed the top 250.
… how many top 250 singles can you expect to get in from your list?
The key here is to work backwards. We know that exactly four people voted for the number 250 song. Exactly four people voted for the number 249 song, and every song up to number 163. Exactly five people voted for numbers 162 through 111, and so on.
Now, if we can say at random who voted for what song, we might be able to come up with a distribution and an expectation.
Here are my assumptions [and, in square brackets, why they don't fully hold true]:
There were precisely 104 complete lists, and nobody gave up part-way through. [Real life: 99 complete and nine partial lists]
I don't care about the precise ranking, only about attributing songs back to their voters.
** Consequence: Bonus points, split vote quotient, seeding, how many times it's been on BBC 6 Records - all that gubbins does not matter.
Everyone voted independently, without looking at each others' lists. [Real life: did not happen, and designed not to happen. However, I think the basic idea holds - there was no particular effort to co-ordinate votes, and nothing that looked obvious as ballot stuffing - there wasn't an influx of Take That fans all voting for "Up all night".]
Entries in the top 250 are independent of each other. If you voted for "Crazy in love", you were no more or less likely to vote for "Single ladies". [Real life: may be more accurate than it sounds - voters seemed reluctant but not wholly unwilling to list more than one single by the same performer.]
The points allocated to records will roughly mirror the allocation in #Uncool500 last year. Statisticians say this is a "Zipfian distribution", which I thought was something George cleaned off his fur.
** Broadly, this is holding true. I've used actual data up to the 8-vote break. Based on the shape of votes last year, I've assumed that the winning song will get 18 votes, the top ten get 15 votes, and the top thirty 10 votes. [footnote 1]
So, for song 250, I picked out four voters at random - without duplication in these voters, because you can only vote for a song once.
For song 249, I picked out four voters at random - without duplication in these voters, but I didn't care if any of these voters picked the songs above.
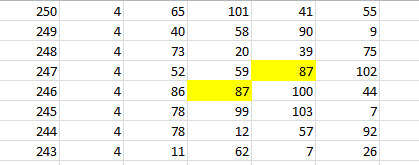
Note how voter 87 has voted for songs 247 and 246 - this is quite fine.
And so on, and so on, and so on, up to 18 voters for the top song.
And then I simulated 50 editions of #FearOfMu21c. Fifty sets of the top 250, each song allocated back to their original voters. And then I tallied up how many songs each voter had made a hit in each list.
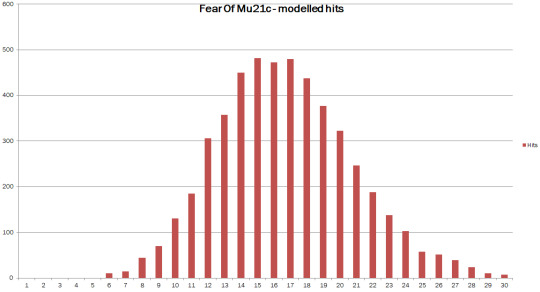
The most common single value was 14 hits, the middle value was 16 hits. Two-thirds of the lists got between 12 and 19 hits, and it would be an unusual list to get fewer than 9 or more than 24 hits. [footnote 2]
Based on the assumptions I've made, we can all expect to get between 12 and 19 of our list into the top 250.
[footnote 1]
Here's the full breakdown of how many votes I expected each position to get.
250-163 - 4 votes
162-111 - 5 votes
110-86 - 6 votes
85-69 - 7 votes
68-51 - 8 votes
50-39 - 9 votes
38-30 - 10 votes
29-23 - 11 votes
22-17 - 12 votes
16-13 - 13 votes
12-10 - 14 votes
9-7 - 15 votes
6-5 - 16 votes
4-3 - 17 votes
1-2 - 18 votes
These are approximate figures, and subject to some variation. The most important finding is that about 1614 votes are used to make the top 250 - everything else is discarded. [footnote 3]
[footnote 2] I reckon that Excel's not-quite-random number generator has some sort of echo, as there were a surprising number of lists scoring 30 and more hits. This really shouldn't happen.
[footnote 3] …and 1614 used votes divided by 104 lists gives an average of 15.5, so I could have saved myself a lot of effort.
#fear of mu21c#uncool 500#uncool 50#mathematics#statistics#applied mathematics#math#zipfian distributions#academic exercise
1 note
·
View note
Text
estimating distances/sizes without tools
compute, in advance, k, the distance from eyes-to-extended-hand divided by the length of a finger (IME around 10)
hold out your arm at full length
align it and hold your hand as to have one finger extended "along" the target object (i.e. in front of, by perspective)
count finger-lengths (L) the object spans up in your visual field
apply L ≈ ks/d to approximate distance from size (d = ks/L) or vice versa (s = Ld/k)
???
profit
(from AN #958)
1 note
·
View note
Text
https://www.ikbooks.com/openPdf/9789381141496https://www.ikbooks.com/openPdf/9789381141496
0 notes
Link
Leaving Cert Maths higher level Online Grinds | Homeschool
The top Leaving Cert Maths higher level Online Grinds are provided by homeschool. To access the top online grinds created by Ireland's top teachers, click here. Ireland Leaving Cert Homeschooling: Darren Murphy, your teacher, would like to welcome you to the Leaving Certificate Maths Higher Level Course. Please be aware that this course is intended for students sitting for the Leaving Certificate Exam in 2023. The primary components of the Maths Higher level syllabus, such as the analysis of the 2022 Exam Paper, will be covered in this course.
0 notes
Text
Academic papers, essays, or claims produced by ChatGPT are plagiarism. The phenomenon of artists seeing their artwork reproduced by stable diffusion elucidates a fundamental problem with the current state of AI. As one artist claims, the background artwork is all theirs, with a rendered human with a highly exaggerated uncanny valley effect on top. ChatGPT is just regurgitating previously formulated ideas as a stochastic parrot. The part of all this nonsense that gets to me is that this whole tract of research aims to deceive and misinform. Human beings naturally attribute meaning to random events. Richard Fynemann once said, "I saw a car with the license plate ARW 357. Can you imagine? Of all the millions of license plates ..." The probability of seeing two license plates with the same numbers is so astronomically low that seeing a single license plate could be interpreted as statistically significant somehow. But we do not; we see license plates every day. These AI systems take a bunch of human-generated data and rearrange them to trick you into thinking a human did it. The optimization routines we chose, and ML is just optimization, were selected to try and trick us into thinking a computer somehow became sentient. But the problem is essentially epistemological. The AI does not discover new information; it only aggregates existing information. When you prompt GPT to write an essay or a blog post, you are just reordering existing information. And that is plagiarism.
36 notes
·
View notes
Text
Abstract Algebra book recommendation?
Does anyone have any good abstract algebra books that you’d recommend for uni?
#algebra#abstract algebra#mathblr#Help#university books#book recommendations#university#university book#studyblr#university student#olympiad math#mathematics#applied mathematics#mathematical olympiad#mathematician#Math Olympiad
7 notes
·
View notes
Text
Mathematics
Dimensional projection
Sampling bias
A vindication of imaginary numbers
Math modeling reality
educational resources (among them math-focused ones)
Knot topology
Local maxima
1 note
·
View note
Text
Hate the game, not the playa
[ This blog is dedicated to tracking my most recent publications. Subscribe to the feed to keep up with all the science stories I write! ]
Here’s why the geometric patterns in salt flats worldwide look so similar
The shared geometry across playas may come from fluid flows underground
For Science News:
From Death Valley to Chile to Iran, similarly sized polygons of salt form in playas all over…

View On WordPress
5 notes
·
View notes
Text
SO WAS ANYONE GOING TO TELL ME THAT MISHA COLLINS CO AUTHORED AN ARTICLE ON SHAPE STRUCTURES OR WAS I JUST SUPPOSED TO HAVE A STROKE WHEN LOOKING AT THE AUTHORS LIKE THE LOSER I AM
#that shit is why I’m giving up applied mathematics to go into theoritical physics#things that make me go bark bark#I thought I was safe#well think again arsehole#Misha Collins
150 notes
·
View notes
Text
Hi ppl who are nosy and want to know ur grades so they can judge how smart u are are annoying as fuck
#this is ab a guy from my math class who just texted me#I’ve never even spoken to him before he just asked what I’m averaging in that class#I didn’t tell him cuz I’m honestly not doing as well as I want to be and it’s a super competitive class#and so he starts asking ab all my extracurriculars#and the programs I’m applying to#and I’ve been so stressed over this because I don’t even know myself#so I don’t want some random fucking stranger interrogating me#and he goes ‘most people in the class are failing’ cuz only one person is averaging 100#‘the smartest guy in the class is only averaging 98’ well clearly he’s not the smartest but also 98 is amazing and I wish I had that#I’m going to punch him when I see him tmr get the hell out of my dms bro#vent post#mathblr#mathematics#math#grades#school#high school#irritating
54 notes
·
View notes
Text
Daniela: The most useless shit I learned in school is the devil’s work, CALCULOUS!
Daniela: *eyes Cassandra* if you say anything I will hit you with this pillow
#resident evil village#cassandra dimitrescu#resident evil 8#house dimitrescu#daniela dimitrescu#bela dimitrescu#alcina dimitrescu#re8#headcanon#she had to say this next to the sister who doesn’t use a calculator#and the one who majored in applied mathematics#dani doesn’t know how or when to pick her battles
23 notes
·
View notes
Last Seen Blogs

morgan-blackwood
SPOOKY REAL????

dvcomm
Untitled

dramadainties
Drama Dainties

poofydloofy
Diaps

shakira00283-blog
장어낚시채비▶CM566。COM◀라스베가스슬롯