#automated data lineage
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
BuzzFeed published a report claiming that Tumblr was utilized as a distribution channel for Russian agents to influence American voting habits during the 2016 presidential election in Feb 2018.
Text
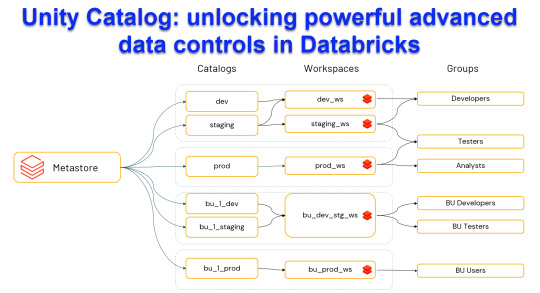
Unity Catalog: Unlocking Powerful Advanced Data Control in Databricks
Harness the power of Unity Catalog within Databricks and elevate your data governance to new heights. Our latest blog post, "Unity Catalog: Unlocking Advanced Data Control in Databricks," delves into the cutting-edge features
View On WordPress
#Advanced Data Security#Automated Data Lineage#Cloud Data Governance#Column Level Masking#Data Discovery and Cataloging#Data Ecosystem Security#Data Governance Solutions#Data Management Best Practices#Data Privacy Compliance#Databricks Data Control#Databricks Delta Sharing#Databricks Lakehouse Platform#Delta Lake Governance#External Data Locations#Managed Data Sources#Row Level Security#Schema Management Tools#Secure Data Sharing#Unity Catalog Databricks#Unity Catalog Features
0 notes
Text
DataOps: From Data to Decision-Making
In today’s complex data landscapes, where data flows ceaselessly from various sources, the ability to harness this data and turn it into actionable insights is a defining factor for many organization’s success. With companies generating over 50 times more data than they were just five years ago, adapting to this data deluge has become a strategic imperative. Enter DataOps, a transformative…

View On WordPress
#automated data lineage#big data challenges#business agility#data integration#data pipeline#DataOps#decision-making#whitepaper
0 notes
Note
I'm surprised youre pro-Z lib but against AI. If you dont mind could you explain why?
sure - zlib is a crucial way readers access books when that access is otherwise difficult/unavailable. as a writer, this is beneficial to me! it helps more people find my book/helps my words reach more readers, which is the goal of writing.
pushes by publishing et al to incorporate AI are chiefly concerned with replacing human writers in the name of 'efficiency,' as is the inevitable result of automation + capitalism. further, and perhaps even more distressingly, the creation of what some call "AI slop" requires a mixing of a huge number of peoples' creative work without citation + acknowledgement of lineage.
a crucial part of making art + writing is citation, whether literally in a bibliography or via an intentional craft practice of reading / viewing / practicing / thinking with the work of our foreparents and peers. our works are informed by our lived experiences writ large, but especially encounters both chance and planned with others' work.
creative practice requires a degree of collaboration, and, ethically, an acknowledgement that we do not work alone. the usage of AI, trained oftentimes on data scraped non-consensually and stripped of lineage, makes that process impossible. further, again, the push to "facilitate" writing / art with AI can't be divorced from reactionary anti- arts/humanities ideologies, which seeks not only to demonize these disciplines + their perceived "unproductivity" but also render their practitioners obsolete.
10 notes
·
View notes
Text
Harnessing the Power of Data Engineering for Modern Enterprises
In the contemporary business landscape, data has emerged as the lifeblood of organizations, fueling innovation, strategic decision-making, and operational efficiency. As businesses generate and collect vast amounts of data, the need for robust data engineering services has become more critical than ever. SG Analytics offers comprehensive data engineering solutions designed to transform raw data into actionable insights, driving business growth and success.
The Importance of Data Engineering
Data engineering is the foundational process that involves designing, building, and managing the infrastructure required to collect, store, and analyze data. It is the backbone of any data-driven enterprise, ensuring that data is clean, accurate, and accessible for analysis. In a world where businesses are inundated with data from various sources, data engineering plays a pivotal role in creating a streamlined and efficient data pipeline.
SG Analytics’ data engineering services are tailored to meet the unique needs of businesses across industries. By leveraging advanced technologies and methodologies, SG Analytics helps organizations build scalable data architectures that support real-time analytics and decision-making. Whether it’s cloud-based data warehouses, data lakes, or data integration platforms, SG Analytics provides end-to-end solutions that enable businesses to harness the full potential of their data.
Building a Robust Data Infrastructure
At the core of SG Analytics’ data engineering services is the ability to build robust data infrastructure that can handle the complexities of modern data environments. This includes the design and implementation of data pipelines that facilitate the smooth flow of data from source to destination. By automating data ingestion, transformation, and loading processes, SG Analytics ensures that data is readily available for analysis, reducing the time to insight.
One of the key challenges businesses face is dealing with the diverse formats and structures of data. SG Analytics excels in data integration, bringing together data from various sources such as databases, APIs, and third-party platforms. This unified approach to data management ensures that businesses have a single source of truth, enabling them to make informed decisions based on accurate and consistent data.
Leveraging Cloud Technologies for Scalability
As businesses grow, so does the volume of data they generate. Traditional on-premise data storage solutions often struggle to keep up with this exponential growth, leading to performance bottlenecks and increased costs. SG Analytics addresses this challenge by leveraging cloud technologies to build scalable data architectures.
Cloud-based data engineering solutions offer several advantages, including scalability, flexibility, and cost-efficiency. SG Analytics helps businesses migrate their data to the cloud, enabling them to scale their data infrastructure in line with their needs. Whether it’s setting up cloud data warehouses or implementing data lakes, SG Analytics ensures that businesses can store and process large volumes of data without compromising on performance.
Ensuring Data Quality and Governance
Inaccurate or incomplete data can lead to poor decision-making and costly mistakes. That’s why data quality and governance are critical components of SG Analytics’ data engineering services. By implementing data validation, cleansing, and enrichment processes, SG Analytics ensures that businesses have access to high-quality data that drives reliable insights.
Data governance is equally important, as it defines the policies and procedures for managing data throughout its lifecycle. SG Analytics helps businesses establish robust data governance frameworks that ensure compliance with regulatory requirements and industry standards. This includes data lineage tracking, access controls, and audit trails, all of which contribute to the security and integrity of data.
Enhancing Data Analytics with Natural Language Processing Services
In today’s data-driven world, businesses are increasingly turning to advanced analytics techniques to extract deeper insights from their data. One such technique is natural language processing (NLP), a branch of artificial intelligence that enables computers to understand, interpret, and generate human language.
SG Analytics offers cutting-edge natural language processing services as part of its data engineering portfolio. By integrating NLP into data pipelines, SG Analytics helps businesses analyze unstructured data, such as text, social media posts, and customer reviews, to uncover hidden patterns and trends. This capability is particularly valuable in industries like healthcare, finance, and retail, where understanding customer sentiment and behavior is crucial for success.
NLP services can be used to automate various tasks, such as sentiment analysis, topic modeling, and entity recognition. For example, a retail business can use NLP to analyze customer feedback and identify common complaints, allowing them to address issues proactively. Similarly, a financial institution can use NLP to analyze market trends and predict future movements, enabling them to make informed investment decisions.
By incorporating NLP into their data engineering services, SG Analytics empowers businesses to go beyond traditional data analysis and unlock the full potential of their data. Whether it’s extracting insights from vast amounts of text data or automating complex tasks, NLP services provide businesses with a competitive edge in the market.
Driving Business Success with Data Engineering
The ultimate goal of data engineering is to drive business success by enabling organizations to make data-driven decisions. SG Analytics’ data engineering services provide businesses with the tools and capabilities they need to achieve this goal. By building robust data infrastructure, ensuring data quality and governance, and leveraging advanced analytics techniques like NLP, SG Analytics helps businesses stay ahead of the competition.
In a rapidly evolving business landscape, the ability to harness the power of data is a key differentiator. With SG Analytics’ data engineering services, businesses can unlock new opportunities, optimize their operations, and achieve sustainable growth. Whether you’re a small startup or a large enterprise, SG Analytics has the expertise and experience to help you navigate the complexities of data engineering and achieve your business objectives.
5 notes
·
View notes
Text
Integrating Microsoft Fabric After Tableau Migration: Next-Level Analytics
Migrating from Tableau to Power BI is just the beginning of an advanced analytics journey. Once your data ecosystem shifts to Microsoft's environment, leveraging Microsoft Fabric can push your business intelligence to the next level. This unified platform empowers teams to build powerful, scalable, and collaborative data experiences that go beyond traditional dashboards.
What is Microsoft Fabric?
Microsoft Fabric is an all-in-one analytics solution that unites data engineering, data integration, data science, real-time analytics, and business intelligence under one unified SaaS umbrella. It’s tightly integrated with Power BI, enabling seamless analytics workflows. Post-migration, Fabric acts as the glue that connects your newly transformed Power BI environment with the broader data infrastructure.
Why Use Microsoft Fabric After Tableau Migration?
When organizations migrate from Tableau to Power BI, they often do so to gain access to deeper integration with Microsoft’s ecosystem. Microsoft Fabric amplifies this advantage by:
Eliminating Data Silos: Fabric allows your teams to ingest, transform, and store data in a single environment using OneLake, a unified data lake that ensures consistency and accessibility.
Accelerating Time to Insight: With capabilities like real-time data flows, lakehouses, and semantic models, analysts and decision-makers can generate insights faster than ever before.
Enhancing Collaboration: Shared workspaces in Fabric allow teams to co-author data models, reports, and pipelines — all while maintaining governance and security.
Key Integration Benefits
1. Unified Data Layer with OneLake Microsoft Fabric introduces OneLake, a single logical data lake built for all workloads. Unlike Tableau, which typically required third-party data lakes or external connectors, Fabric brings everything into a unified space — making storage, querying, and access more seamless after migration.
2. End-to-End Data Pipelines With built-in Data Factory capabilities, users can automate ingestion from multiple sources, transform it using Spark or SQL, and deliver clean data directly to Power BI datasets. This eliminates the need for maintaining separate ETL tools post-migration.
3. AI-Powered Analytics with Copilot After moving to Power BI, organizations can use Copilot in Microsoft Fabric to generate DAX formulas, write code, or even build reports using natural language prompts. This is a huge leap forward from Tableau’s more manual development environment.
4. Real-Time Analytics for Business Agility Microsoft Fabric’s Real-Time Analytics feature allows users to analyze event-driven data — ideal for finance, operations, or customer service teams who need immediate insights from streaming sources.
Strategic Approach to Integration
To fully harness Microsoft Fabric after Tableau migration:
Start with Data Modeling: Review and optimize your Power BI data models to work efficiently within Fabric’s lakehouse or warehouse environment.
Automate Pipelines: Rebuild any Tableau Prep workflows using Fabric’s Dataflow Gen2 or Data Factory pipelines.
Train Teams: Enable your analysts and developers with Fabric-specific training to maximize adoption.
Governance First: Set up data lineage tracking, access controls, and workspaces early to ensure scalability and compliance.
Final Thoughts
The move from Tableau to Power BI sets the foundation — but integrating Microsoft Fabric is what truly unlocks the future of enterprise analytics. With a seamless environment for data storage, modeling, automation, and visualization, Microsoft Fabric empowers organizations to be data-driven at scale.
Ready to elevate your analytics journey? Learn more at 👉 https://tableautopowerbimigration.com/
0 notes
Text
Drive Results with These 7 Steps for Data for AI Success
Artificial Intelligence (AI) is transforming industries—from predictive analytics in finance to personalized healthcare and smart manufacturing. But despite the hype and investment, many organizations struggle to realize tangible value from their AI initiatives. Why? Because they overlook the foundational requirement: high-quality, actionable data for AI.

AI is only as powerful as the data that fuels it. Poor data quality, silos, and lack of governance can severely hamper outcomes. To maximize returns and drive innovation, businesses must adopt a structured approach to unlocking the full value of their data for AI.
Here are 7 essential steps to make that happen.
Step 1: Establish a Data Strategy Aligned to AI Goals
The journey to meaningful AI outcomes begins with a clear strategy. Before building models or investing in platforms, define your AI objectives and align them with business goals. Do you want to improve customer experience? Reduce operational costs? Optimize supply chains?
Once goals are defined, identify what data for AI is required—structured, unstructured, real-time, historical—and where it currently resides. A comprehensive data strategy should include:
Use case prioritization
ROI expectations
Data sourcing and ownership
Key performance indicators (KPIs)
This ensures that all AI efforts are purpose-driven and data-backed.
Step 2: Break Down Data Silos Across the Organization
Siloed data is the enemy of AI. In many enterprises, critical data for AI is scattered across departments, legacy systems, and external platforms. These silos limit visibility, reduce model accuracy, and delay project timelines.
A centralized or federated data architecture is essential. This can be achieved through:
Data lakes or data fabric architectures
APIs for seamless system integration
Cloud-based platforms for unified access
Enabling open and secure data sharing across business units is the foundation of AI success.
Step 3: Ensure Data Quality, Consistency, and Completeness
AI thrives on clean, reliable, and well-labeled data. Dirty data—full of duplicates, errors, or missing values—leads to inaccurate predictions and flawed insights. Organizations must invest in robust data quality management practices.
Key aspects of quality data for AI include:
Accuracy: Correctness of data values
Completeness: No missing or empty fields
Consistency: Standardized formats across sources
Timeliness: Up-to-date and relevant
Implement automated tools for profiling, cleansing, and enriching data to maintain integrity at scale.
Step 4: Govern Data with Security and Compliance in Mind
As data for AI becomes more valuable, it also becomes more vulnerable. Privacy regulations such as GDPR and CCPA impose strict rules on how data is collected, stored, and processed. Governance is not just a legal necessity—it builds trust and ensures ethical AI.
Best practices for governance include:
Data classification and tagging
Role-based access control (RBAC)
Audit trails and lineage tracking
Anonymization or pseudonymization of sensitive data
By embedding governance early in the AI pipeline, organizations can scale responsibly and securely.
Step 5: Build Scalable Infrastructure to Support AI Workloads
Collecting data for AI is only one part of the equation. Organizations must also ensure their infrastructure can handle the scale, speed, and complexity of AI workloads.
This includes:
Scalable storage solutions (cloud-native, hybrid, or on-prem)
High-performance computing resources (GPUs/TPUs)
Data streaming and real-time processing frameworks
AI-ready data pipelines for continuous integration and delivery
Investing in flexible, future-proof infrastructure ensures that data isn’t a bottleneck but a catalyst for AI innovation.
Step 6: Use Metadata and Cataloging to Make Data Discoverable
With growing volumes of data for AI, discoverability becomes a major challenge. Teams often waste time searching for datasets that already exist, or worse, recreate them. Metadata management and data cataloging solve this problem.
A modern data catalog allows users to:
Search and find relevant datasets
Understand data lineage and usage
Collaborate through annotations and documentation
Evaluate data quality and sensitivity
By making data for AI discoverable, reusable, and transparent, businesses accelerate time-to-insight and reduce duplication.
Step 7: Foster a Culture of Data Literacy and Collaboration
Ultimately, unlocking the value of data for AI is not just about tools or technology—it’s about people. Organizations must create a data-driven culture where employees understand the importance of data and actively participate in its lifecycle.
Key steps to build such a culture include:
Training programs for non-technical teams on AI and data fundamentals
Cross-functional collaboration between data scientists, engineers, and business leaders
Incentivizing data sharing and reuse
Encouraging experimentation with small-scale AI pilots
When everyone—from C-suite to frontline workers—values data for AI, adoption increases and innovation flourishes.
Conclusion: A Roadmap to Smarter AI Outcomes
AI isn’t magic. It’s a disciplined, strategic capability that relies on well-governed, high-quality data for AI. By following these seven steps—strategy, integration, quality, governance, infrastructure, discoverability, and culture—organizations can unlock the true potential of their data assets.
In a competitive digital economy, your ability to harness the power of data for AI could determine the future of your business. Don’t leave that future to chance—invest in your data, and AI will follow.
Read Full Article : https://businessinfopro.com/7-steps-to-unlocking-the-value-of-data-for-ai/
About Us: Businessinfopro is a trusted platform delivering insightful, up-to-date content on business innovation, digital transformation, and enterprise technology trends. We empower decision-makers, professionals, and industry leaders with expertly curated articles, strategic analyses, and real-world success stories across sectors. From marketing and operations to AI, cloud, and automation, our mission is to decode complexity and spotlight opportunities driving modern business growth. At Businessinfopro, we go beyond news—we provide perspective, helping businesses stay agile, informed, and competitive in a rapidly evolving digital landscape. Whether you're a startup or a Fortune 500 company, our insights are designed to fuel smarter strategies and meaningful outcomes.
0 notes
Text
Beyond the Pipeline: Choosing the Right Data Engineering Service Providers for Long-Term Scalability
Introduction: Why Choosing the Right Data Engineering Service Provider is More Critical Than Ever
In an age where data is more valuable than oil, simply having pipelines isn’t enough. You need refineries, infrastructure, governance, and agility. Choosing the right data engineering service providers can make or break your enterprise’s ability to extract meaningful insights from data at scale. In fact, Gartner predicts that by 2025, 80% of data initiatives will fail due to poor data engineering practices or provider mismatches.
If you're already familiar with the basics of data engineering, this article dives deeper into why selecting the right partner isn't just a technical decision—it’s a strategic one. With rising data volumes, regulatory changes like GDPR and CCPA, and cloud-native transformations, companies can no longer afford to treat data engineering service providers as simple vendors. They are strategic enablers of business agility and innovation.
In this post, we’ll explore how to identify the most capable data engineering service providers, what advanced value propositions you should expect from them, and how to build a long-term partnership that adapts with your business.
Section 1: The Evolving Role of Data Engineering Service Providers in 2025 and Beyond
What you needed from a provider in 2020 is outdated today. The landscape has changed:
📌 Real-time data pipelines are replacing batch processes
📌 Cloud-native architectures like Snowflake, Databricks, and Redshift are dominating
📌 Machine learning and AI integration are table stakes
📌 Regulatory compliance and data governance have become core priorities
Modern data engineering service providers are not just builders—they are data architects, compliance consultants, and even AI strategists. You should look for:
📌 End-to-end capabilities: From ingestion to analytics
📌 Expertise in multi-cloud and hybrid data ecosystems
📌 Proficiency with data mesh, lakehouse, and decentralized architectures
📌 Support for DataOps, MLOps, and automation pipelines
Real-world example: A Fortune 500 retailer moved from Hadoop-based systems to a cloud-native lakehouse model with the help of a modern provider, reducing their ETL costs by 40% and speeding up analytics delivery by 60%.
Section 2: What to Look for When Vetting Data Engineering Service Providers
Before you even begin consultations, define your objectives. Are you aiming for cost efficiency, performance, real-time analytics, compliance, or all of the above?
Here’s a checklist when evaluating providers:
📌 Do they offer strategic consulting or just hands-on coding?
📌 Can they support data scaling as your organization grows?
📌 Do they have domain expertise (e.g., healthcare, finance, retail)?
📌 How do they approach data governance and privacy?
📌 What automation tools and accelerators do they provide?
📌 Can they deliver under tight deadlines without compromising quality?
Quote to consider: "We don't just need engineers. We need architects who think two years ahead." – Head of Data, FinTech company
Avoid the mistake of over-indexing on cost or credentials alone. A cheaper provider might lack scalability planning, leading to massive rework costs later.
Section 3: Red Flags That Signal Poor Fit with Data Engineering Service Providers
Not all providers are created equal. Some red flags include:
📌 One-size-fits-all data pipeline solutions
📌 Poor documentation and handover practices
📌 Lack of DevOps/DataOps maturity
📌 No visibility into data lineage or quality monitoring
📌 Heavy reliance on legacy tools
A real scenario: A manufacturing firm spent over $500k on a provider that delivered rigid ETL scripts. When the data source changed, the whole system collapsed.
Avoid this by asking your provider to walk you through previous projects, particularly how they handled pivots, scaling, and changing data regulations.
Section 4: Building a Long-Term Partnership with Data Engineering Service Providers
Think beyond the first project. Great data engineering service providers work iteratively and evolve with your business.
Steps to build strong relationships:
📌 Start with a proof-of-concept that solves a real pain point
📌 Use agile methodologies for faster, collaborative execution
📌 Schedule quarterly strategic reviews—not just performance updates
📌 Establish shared KPIs tied to business outcomes, not just delivery milestones
📌 Encourage co-innovation and sandbox testing for new data products
Real-world story: A healthcare analytics company co-developed an internal patient insights platform with their provider, eventually spinning it into a commercial SaaS product.
Section 5: Trends and Technologies the Best Data Engineering Service Providers Are Already Embracing
Stay ahead by partnering with forward-looking providers who are ahead of the curve:
📌 Data contracts and schema enforcement in streaming pipelines
📌 Use of low-code/no-code orchestration (e.g., Apache Airflow, Prefect)
📌 Serverless data engineering with tools like AWS Glue, Azure Data Factory
📌 Graph analytics and complex entity resolution
📌 Synthetic data generation for model training under privacy laws
Case in point: A financial institution cut model training costs by 30% by using synthetic data generated by its engineering provider, enabling robust yet compliant ML workflows.
Conclusion: Making the Right Choice for Long-Term Data Success
The right data engineering service providers are not just technical executioners—they’re transformation partners. They enable scalable analytics, data democratization, and even new business models.
To recap:
📌 Define goals and pain points clearly
📌 Vet for strategy, scalability, and domain expertise
📌 Watch out for rigidity, legacy tools, and shallow implementations
📌 Build agile, iterative relationships
📌 Choose providers embracing the future
Your next provider shouldn’t just deliver pipelines—they should future-proof your data ecosystem. Take a step back, ask the right questions, and choose wisely. The next few quarters of your business could depend on it.
#DataEngineering#DataEngineeringServices#DataStrategy#BigDataSolutions#ModernDataStack#CloudDataEngineering#DataPipeline#MLOps#DataOps#DataGovernance#DigitalTransformation#TechConsulting#EnterpriseData#AIandAnalytics#InnovationStrategy#FutureOfData#SmartDataDecisions#ScaleWithData#AnalyticsLeadership#DataDrivenInnovation
0 notes
Text
Architecting for AI- Effective Data Management Strategies in the Cloud
What good is AI if the data feeding it is disorganized, outdated, or locked away in silos?
How can businesses unlock the full potential of AI in the cloud without first mastering the way they handle data?
And for professionals, how can developing Cloud AI skills shape a successful AI cloud career path?
These are some real questions organizations and tech professionals ask every day. As the push toward automation and intelligent systems grows, the spotlight shifts to where it all begins, data. If you’re aiming to become an AI cloud expert, mastering data management in the cloud is non-negotiable.
In this blog, we will explore human-friendly yet powerful strategies for managing data in cloud environments. These are perfect for businesses implementing AI in the cloud and individuals pursuing AI Cloud Certification.
1. Centralize Your Data, But Don’t Sacrifice Control
The first step to architecting effective AI systems is ensuring your data is all in one place, but with rules in place. Cloud AI skills come into play when configuring secure, centralized data lakes using platforms like AWS S3, Azure Data Lake, or Google Cloud Storage.
For instance, Airbnb streamlined its AI pipelines by unifying data into Amazon S3 while applying strict governance with AWS Lake Formation. This helped their teams quickly build and train models for pricing and fraud detection, without dealing with messy, inconsistent data.
Pro Tip-
Centralize your data, but always pair it with metadata tagging, cataloging, and access controls. This is a must-learn in any solid AI cloud automation training program.
2. Design For Scale: Elasticity Over Capacity
AI workloads are not static—they scale unpredictably. Cloud platforms shine when it comes to elasticity, enabling dynamic resource allocation as your needs grow. Knowing how to build scalable pipelines is a core part of AI cloud architecture certification programs.
One such example is Netflix. It handles petabytes of viewing data daily and processes it through Apache Spark on Amazon EMR. With this setup, they dynamically scale compute power depending on the workload, powering AI-based recommendations and content optimization.
Human Insight-
Scalability is not just about performance. It’s about not overspending. Smart scaling = cost-effective AI.
3. Don’t Just Store—Catalog Everything
You can’t trust what you can’t trace. A reliable data catalog and lineage system ensures AI models are trained on trustworthy data. Tools like AWS Glue or Apache Atlas help track data origin, movement, and transformation—a key concept for anyone serious about AI in the cloud.
To give you an example, Capital One uses data lineage tools to manage regulatory compliance for its AI models in credit risk and fraud detection. Every data point can be traced, ensuring trust in both model outputs and audits.
Why it matters-
Lineage builds confidence. Whether you’re a company building AI or a professional on an AI cloud career path, transparency is essential.
4. Build for Real-Time Intelligence
The future of AI is real-time. Whether it’s fraud detection, customer personalization, or predictive maintenance, organizations need pipelines that handle data as it flows in. Streaming platforms like Apache Kafka and AWS Kinesis are core technologies for this.
For example, Uber’s Michelangelo platform processes real-time location and demand data to adjust pricing and ETA predictions dynamically. Their cloud-native streaming architecture supports instant decision-making at scale.
Career Tip-
Mastering stream processing is key if you want to become an AI cloud expert. It’s the difference between reactive and proactive AI.
5. Bake Security and Privacy into Your Data Strategy
When you’re working with personal data, security isn’t optional—it’s foundational. AI architectures in the cloud must comply with GDPR, HIPAA, and other regulations, while also protecting sensitive information using encryption, masking, and access controls.
Salesforce, with its AI-powered Einstein platform, ensures sensitive customer data is encrypted and tightly controlled using AWS Key Management and IAM policies.
Best Practice-
Think “privacy by design.” This is a hot topic covered in depth during any reputable AI Cloud certification.
6. Use Tiered Storage to Optimize Cost and Speed
Not every byte of data is mission-critical. Some data is hot (frequently used), some cold (archived). An effective AI cloud architecture balances cost and speed with a multi-tiered storage strategy.
For instance, Pinterest uses Amazon S3 for high-access data, Glacier for archival, and caching layers for low-latency AI-powered recommendations. This approach keeps costs down while delivering fast, accurate results.
Learning Tip-
This is exactly the kind of cost-smart design covered in AI cloud automation training courses.
7. Support Cross-Cloud and Hybrid Access
Modern enterprises often operate across multiple cloud environments, and data can’t live in isolation. Cloud data architectures should support hybrid and multi-cloud scenarios to avoid vendor lock-in and enable agility.
Johnson & Johnson uses BigQuery Omni to analyze data across AWS and Azure without moving it. This federated approach supports AI use cases in healthcare, ensuring data residency and compliance.
Why it matters?
The future of AI is multi-cloud. Want to stand out? Pursue an AI cloud architecture certification that teaches integration, not just implementation.
Wrapping Up- Your Data Is the AI Foundation
Without well-architected data strategies, AI can’t perform at its best. If you’re leading cloud strategy as a CTO or just starting your journey to become an AI cloud expert, one thing becomes clear early on—solid data management isn’t optional. It’s the foundation that supports everything from smarter models to reliable performance. Without it, even the best AI tools fall short.
Here’s what to focus on-
Centralize data with control
Scale infrastructure on demand
Track data lineage and quality
Enable real-time processing
Secure data end-to-end
Store wisely with tiered solutions
Built for hybrid, cross-cloud access
Ready To Take the Next Step?
If you are looking forward to building smarter systems or your career, now is the time to invest in the future. Consider pursuing an AI Cloud Certification or an AI Cloud Architecture Certification. These credentials not only boost your knowledge but also unlock new opportunities on your AI cloud career path.
Consider checking AI CERTs AI+ Cloud Certification to gain in-demand Cloud AI skills, fast-track your AI cloud career path, and become an AI cloud expert trusted by leading organizations. With the right Cloud AI skills, you won’t just adapt to the future—you’ll shape it.
Enroll today!
0 notes
Text
Data Version Control for Machine Learning Pipelines

In the rapidly evolving field of machine learning (ML) in 2025, managing data effectively is key to building reliable and reproducible models. Data version control for machine learning pipelines ensures that datasets, models, and experiments are tracked, organized, and accessible, enabling teams to iterate with confidence. At Global Techno Solutions, we’ve implemented data version control solutions to optimize ML workflows, as showcased in our case study on Data Version Control for Machine Learning Pipelines. As of June 11, 2025, at 01:54 PM IST, this approach is transforming how businesses leverage ML.
The Challenge: Maintaining Reproducibility in ML Projects
A tech startup approached us on June 08, 2025, with a challenge: their ML team struggled to reproduce models due to untracked dataset changes and inconsistent versioning, leading to delays in deploying a predictive analytics tool. With rapid iterations and multiple team members, they needed a system to manage data versions, track model evolution, and ensure auditability. Their goal was to implement data version control to streamline their ML pipelines and accelerate time-to-market.
The Solution: Robust Data Version Control Implementation
At Global Techno Solutions, we designed a data version control system tailored for their ML pipelines. Here’s how we did it:
Versioned Datasets: We integrated DVC (Data Version Control) to track dataset changes, allowing the team to revert to previous versions or compare differences seamlessly.
Model Tracking: We used MLflow to log model parameters, metrics, and artifacts, linking them to specific dataset versions for reproducibility.
Automated Pipelines: We automated data preprocessing and model training workflows with Git and CI/CD pipelines, ensuring consistency across iterations.
Collaborative Environment: We set up a centralized repository with access controls, enabling multiple team members to collaborate without overwriting data.
Audit Trails: We implemented metadata logging to document changes, supporting compliance and debugging efforts.
For a detailed look at our approach, explore our case study on Data Version Control for Machine Learning Pipelines.
The Results: Streamlined ML Development
The data version control solution delivered significant benefits for the startup:
50% Faster Model Iteration: Tracked versions reduced time spent on debugging and retraining.
100% Reproducibility: Teams could replicate models with exact dataset and code versions.
20% Improvement in Model Accuracy: Consistent data management enhanced model performance.
Enhanced Collaboration: Centralized tracking minimized conflicts among team members.
These outcomes highlight the power of data version control. Learn more in our case study on Data Version Control for Machine Learning Pipelines.
Why Data Version Control Matters for Machine Learning Pipelines
In 2025, data version control is essential for ML pipelines, offering benefits like:
Reproducibility: Ensures consistent model outcomes across experiments.
Efficiency: Speeds up development by avoiding redundant work.
Collaboration: Facilitates teamwork with shared, organized data.
Compliance: Provides auditable records for regulatory needs.
At Global Techno Solutions, we specialize in data version control to empower ML innovation.
Looking Ahead: The Future of Data Version Control in ML
The future of data version control includes AI-driven data lineage tracking, integration with federated learning, and real-time versioning for streaming data. By staying ahead of these trends, Global Techno Solutions ensures our clients lead in ML advancements.
For a comprehensive look at how we’ve optimized ML pipelines, check out our case study on Data Version Control for Machine Learning Pipelines. Ready to enhance your ML workflows? Contact Global Techno Solutions today to learn how our expertise can support your goals.
0 notes
Text
Logistics Automation Market
Logistics Automation Market size is estimated to reach $56.9 billion by 2030, growing at a CAGR of 7.9% during the forecast period 2024–2030.
🔗 𝐆𝐞𝐭 𝐑𝐎𝐈-𝐟𝐨𝐜𝐮𝐬𝐞𝐝 𝐢𝐧𝐬𝐢𝐠𝐡𝐭𝐬 𝐟𝐨𝐫 𝟐𝟎𝟐𝟓-𝟐𝟎𝟑𝟏 → 𝐃𝐨𝐰𝐧𝐥𝐨𝐚𝐝 𝐍𝐨𝐰
Logistics Automation Market is rapidly transforming global supply chains by integrating technologies such as AI, robotics, IoT, and machine learning to enhance efficiency, reduce costs, and improve accuracy. Automation solutions — including autonomous mobile robots (AMRs), automated storage and retrieval systems (AS/RS), and real-time tracking — are increasingly adopted across warehousing, transportation, and last-mile delivery.
Driven by e-commerce growth, labor shortages, and rising demand for faster delivery, the market is expanding globally. Key sectors embracing logistics automation include retail, manufacturing, healthcare, and food & beverage.
🚚 𝐊𝐞𝐲 𝐌𝐚𝐫𝐤𝐞𝐭 𝐃𝐫𝐢𝐯𝐞𝐫𝐬
📦 𝐄-𝐂𝐨𝐦𝐦𝐞𝐫𝐜𝐞 𝐁𝐨𝐨𝐦
Rapid growth in online shopping increases demand for faster, more efficient order fulfillment and delivery systems.
🤖 𝐋𝐚𝐛𝐨𝐫 𝐒𝐡𝐨𝐫𝐭𝐚𝐠𝐞𝐬 & 𝐑𝐢𝐬𝐢𝐧𝐠 𝐂𝐨𝐬𝐭𝐬
Shortages in skilled labor and rising wages are pushing companies to adopt automation to maintain productivity and reduce operational costs.
📈 𝐃𝐞𝐦𝐚𝐧𝐝 𝐟𝐨𝐫 𝐒𝐮𝐩𝐩𝐥𝐲 𝐂𝐡𝐚𝐢𝐧 𝐕𝐢𝐬𝐢𝐛𝐢𝐥𝐢𝐭𝐲
Businesses seek real-time tracking and data analytics to enhance decision-making and responsiveness across logistics networks.
⚙️ 𝐓𝐞𝐜𝐡𝐧𝐨𝐥𝐨𝐠𝐢𝐜𝐚𝐥 𝐀𝐝𝐯𝐚𝐧𝐜𝐞𝐦𝐞𝐧𝐭𝐬
Innovations in AI, robotics, IoT, and machine learning are making logistics automation more scalable, affordable, and adaptable.
🔗 𝐍𝐞𝐞𝐝 𝐟𝐨𝐫 𝐎𝐩𝐞𝐫𝐚𝐭𝐢𝐨𝐧𝐚𝐥 𝐄𝐟𝐟𝐢𝐜𝐢𝐞𝐧𝐜𝐲
Companies aim to streamline warehousing, inventory management, and transportation to boost speed, accuracy, and cost-effectiveness.
𝐋𝐢𝐦𝐢𝐭𝐞𝐝-𝐓𝐢𝐦𝐞 𝐎𝐟𝐟𝐞𝐫: 𝐆𝐞𝐭 $𝟏𝟎𝟎𝟎 𝐎𝐟𝐟 𝐘𝐨𝐮𝐫 𝐅𝐢𝐫𝐬𝐭 𝐏𝐮𝐫𝐜𝐡𝐚𝐬𝐞
𝐓𝐨𝐩 𝐊𝐞𝐲 𝐏𝐥𝐚��𝐞𝐫𝐬:
EXL | Ryder System, Inc. | Wesco | GXO Logistics, Inc. | CJ Logistics America | DSC Logistics | Invio Automation | Lineage | Geek+ | Vee Technologies | Bastian Solutions | Iris Software Inc. | TGW North America | GoComet | OnProcess Technology | Unipart | Danos Group
#LogisticsAutomation #WarehouseAutomation #SupplyChainAutomation #SmartLogistics #LogisticsTech #DigitalSupplyChain #AutomatedLogistics #AutomationInLogistics #LogisticsInnovation #SupplyChainTech

0 notes
Text
EUC Insight Disposition & einfotree Services for 21 CFR Part 11 Compliance
Inventory, Risk Assessment & Enterprise Data Lineage automates file categorization and cleanup using rule-based policies. It reduces IT overhead and enhances data visibility across storage systems. User input is prompted only when needed, streamlining the disposition process.
Visit: https://part11solutions.com/disposition-service/
0 notes
Text
AIOps Platform Development Trends to Watch in 2025
As IT environments grow in complexity and scale, organizations are increasingly turning to AIOps (Artificial Intelligence for IT Operations) platforms to manage, monitor, and optimize their digital operations. With the rapid advancement of artificial intelligence, machine learning, and automation, AIOps platforms are evolving fast—and 2025 is poised to be a transformative year.

In this blog, we’ll explore the top AIOps platform development trends that IT leaders, DevOps teams, and platform engineers should keep a close eye on in 2025.
1. Hyperautomation Across the IT Stack
In 2025, AIOps will go beyond simple automation to achieve hyperautomation—the orchestration of multiple tools and technologies to automate entire IT processes end-to-end. This trend will be driven by:
Seamless integration with ITSM and DevOps pipelines
Intelligent remediation using AI-based decisioning
Workflow automation across hybrid and multi-cloud environments
By reducing manual intervention, hyperautomation will not only accelerate incident response times but also enhance reliability and scalability across enterprise IT.
2. Edge AIOps for Distributed Infrastructure
The rise of edge computing is pushing data processing closer to where it's generated, creating new challenges for monitoring and management. In 2025, AIOps platforms will evolve to support edge-native environments by:
Deploying lightweight agents or AI models at the edge
Aggregating and analyzing telemetry data in real-time
Providing anomaly detection and predictive insights without reliance on central data centers
This decentralization is essential for use cases like smart factories, autonomous vehicles, and IoT networks.
3. Explainable and Transparent AI Models
AIOps platforms have long been criticized as “black boxes,” making it hard for IT teams to understand how decisions are made. In 2025, explainability and transparency will become core design principles. Look for:
Integration of Explainable AI (XAI) frameworks
Visual traceability for root cause analysis
Model validation and fairness reporting
Organizations will demand greater trust in AI-driven recommendations, especially in regulated industries like finance, healthcare, and critical infrastructure.
4. Unified Observability Meets AIOps
The lines between observability and AIOps are blurring. In 2025, we’ll see a convergence where AIOps platforms offer:
Unified telemetry ingestion (logs, metrics, traces, events)
AI-driven noise reduction and correlation
Full-stack visibility from application to infrastructure
This merger will empower IT teams with faster root cause identification, reduced alert fatigue, and improved mean time to resolution (MTTR).
5. Self-Healing Systems Powered by Generative AI
With the maturing of generative AI, AIOps will shift from reactive problem-solving to proactive, self-healing systems. Expect to see:
GenAI models generating remediation scripts on the fly
Autonomous rollback and recovery mechanisms
Intelligent runbooks that evolve over time
These capabilities will reduce downtime and free up human operators to focus on innovation rather than firefighting.
6. Vertical-Specific AIOps Solutions
Generic AIOps solutions will give way to industry-specific platforms tailored to vertical needs. In 2025, we’ll see a rise in AIOps platforms built for:
Telcos needing low-latency incident detection
Banks with strict compliance and audit requirements
Healthcare systems managing sensitive patient data
These tailored solutions will offer pre-trained models, domain-specific KPIs, and compliance-ready toolchains.
7. Data-Centric AIOps Development
As model performance is increasingly tied to data quality, 2025 will see a pivot toward data-centric AI in AIOps development. This involves:
Enhanced data governance and lineage tracking
Automated data labeling and cleansing pipelines
Feedback loops from operators to continuously improve AI accuracy
Well-curated, high-quality data will be a competitive differentiator for AIOps vendors and adopters alike.
8. AI-Augmented Collaboration for DevSecOps
AIOps will increasingly act as a collaborative intelligence layer across development, security, and operations. Platforms will support:
Shared dashboards with contextual insights
AI-driven alerts tailored to team roles (Dev, Sec, Ops)
Secure collaboration workflows across toolchains
This shift toward cross-functional enablement will align with the growing popularity of platform engineering and GitOps practices.
Final Thoughts
The AIOps landscape in 2025 will be defined by more intelligent, agile, and domain-aware platforms. As the pressure mounts to deliver seamless digital experiences while managing increasing complexity, organizations will need to adopt AIOps platform Development strategies that prioritize automation, trust, and observability.
Forward-thinking enterprises that invest early in these trends will position themselves for operational resilience, cost optimization, and continuous innovation in an increasingly dynamic IT world.
0 notes
Text
Beyond the Keyword Search: 12 AI Research Tools to Drive Knowledge Exploration

The landscape of research is undergoing a profound transformation, and Artificial Intelligence is at the forefront of this revolution. Gone are the days when knowledge exploration was solely a painstaking manual process of sifting through countless papers, books, and reports. Today, AI-powered tools are emerging as indispensable partners, augmenting human intelligence to help researchers discover, synthesize, and understand information with unprecedented speed and depth.
These tools aren't just about finding papers; they're about unearthing connections, identifying trends, summarizing complex information, and even helping you formulate new hypotheses. If you're looking to supercharge your research workflow, here are 12 AI research tools to drive your knowledge exploration:
I. Intelligent Literature Discovery & Synthesis
Elicit: Billed as an "AI Research Assistant," Elicit helps automate parts of researchers' workflows. You can ask research questions, and it will find relevant papers, summarize key findings, and even extract specific data (like methods or outcomes) from studies. It excels at quickly grasping the essence of a body of literature.
Consensus: This AI-powered search engine focuses on extracting and distilling findings directly from scientific research. Instead of just showing abstracts, Consensus reads the papers for you and presents aggregated key findings related to your search query, often with direct links to the supporting evidence.
Semantic Scholar: Beyond a simple academic search engine, Semantic Scholar uses AI to perform contextual analysis, offering "TLDR" (Too Long; Didn't Read) summaries, highlighting influential citations, and mapping connections between papers. It helps you quickly grasp the main contributions and results of a paper.
Research Rabbit: Often called the "Spotify for Papers," Research Rabbit is a powerful tool for discovering related literature. You start with one or more papers, and it builds a visual network of connected research, showing similar papers, authors, and even related research communities. It's fantastic for exploring a field organically.
Connected Papers: Similar to Research Rabbit, Connected Papers helps visualize the relationships between academic papers. By inputting a single paper, it generates a graph of directly and indirectly related works, allowing you to explore the citation landscape and identify foundational or derivative works.
Scite.ai: This tool revolutionizes how you understand citations. Instead of just counting citations, Scite.ai provides "Smart Citations" that show how a paper has been cited by others – whether it was supported, contradicted, or merely mentioned. This helps researchers critically evaluate the standing and influence of a piece of work.
Litmaps: Litmaps visualizes citation networks, helping researchers track how studies connect and evolve over time. It's excellent for understanding the intellectual lineage of ideas and identifying emerging trends or influential papers within a specific field.
II. AI for Content Comprehension & Generation
ChatPDF / AskYourPDF: These tools allow you to upload PDF documents (research papers, reports, books) and then "chat" with them. You can ask questions, summarize specific sections, clarify jargon, or extract key information, turning static documents into interactive knowledge sources.
Scholarcy: Scholarcy quickly reads and summarizes articles, reports, and book chapters, converting them into digestible "flashcards" or structured summaries. It highlights key findings, methodologies, limitations, and comparisons, significantly speeding up the literature review process.
Paperpal / QuillBot (for Academic Writing): While more focused on writing assistance, these tools are invaluable for researchers. Paperpal offers academic-specific grammar checks, paraphrasing, contextual text suggestions, and even helps find and cite references. QuillBot provides robust paraphrasing and summarization features, assisting in refining language and avoiding accidental plagiarism.
III. General-Purpose AI for Research Assistance
Perplexity AI: Acting as an "answer engine," Perplexity AI provides direct answers to your questions, drawing information from across the web and providing citations to its sources. This can be a rapid way to get an overview of a topic or find specific facts, often including academic papers in its results.
ChatGPT / Gemini / Claude: While general-purpose LLMs, these tools can be powerful research companions. They can help brainstorm research questions, outline literature reviews, explain complex concepts in simpler terms, generate initial drafts of text, or even suggest keywords for database searches. Always remember to critically verify the information generated by these models, as they can sometimes "hallucinate" facts or citations.
The Future of Research is Collaborative with AI
These 12 tools represent just a fraction of the rapidly expanding ecosystem of AI applications for research. They empower researchers to move beyond tedious manual tasks, allowing them to focus on higher-level critical thinking, analysis, and interpretation. By embracing these AI assistants, we can unlock new avenues for knowledge exploration, accelerate discovery, and ultimately drive greater innovation across all fields of study.
0 notes
Text
Match Data Pro LLC: Solving Mismatched Data Challenges with Powerful Data Ops and On-Premise Solutions
Match Data Pro’s data ops software offers a comprehensive approach to designing, deploying, monitoring, and optimizing data workflows. This includes everything from scheduling automated jobs and applying transformation rules to tracking data lineage and performance.
0 notes
Text
Sustainable finance is no longer a trend—it’s a regulatory reality.
Sustainable finance is no longer a trend—it’s a regulatory reality. The European Union’s Sustainable Finance Disclosure Regulation (SFDR), launched in March 2021, has set a new standard for transparency and accountability in the investment world. SFDR requires financial institutions to disclose how they integrate Environmental, Social, and Governance (ESG) risks and opportunities, helping investors make informed choices and combatting greenwashing across the industry.
Understanding SFDR: A Quick Refresher SFDR applies to asset managers, financial advisors, and institutional investors active in or serving the EU. It classifies investment products based on their ESG credentials—Article 6 (non-ESG), Article 8 (promoting ESG), and Article 9 (sustainable objectives). The regulation’s core goals are to:
Increase transparency with standardized ESG disclosures
Enable comparability between financial products
Integrate sustainability risks into all investment decisions
SFDR aligns with the EU Green Deal and EU Taxonomy, reinforcing the shift toward a more sustainable financial system.
Why Robust SFDR Solutions Matter Complying with SFDR is about more than avoiding fines. The right SFDR solutions allow financial institutions to:
Meet regulatory requirements and avoid legal risks
Deliver the ESG transparency today’s investors demand
Streamline and automate data collection and reporting
Integrate ESG and risk management for a holistic view
Key Trends in SFDR Solutions
AI and Machine Learning: Advanced tools use AI to analyze ESG data, predict risks, and improve reporting accuracy.
Enhanced Data Quality: Satellite data, Natural Language Processing (NLP), and trusted ESG providers ensure reliable, granular information.
Framework Interoperability: Leading platforms align SFDR reporting with CSRD, EU Taxonomy, and TCFD, reducing duplication and boosting consistency.
Real-Time Monitoring: Cloud-based dashboards and live compliance tracking offer instant insights into ESG performance.
Core Tools for SFDR Compliance
ESG Data Platforms: Centralize and standardize ESG data for streamlined disclosures.
Carbon Accounting Tools: Track and report carbon footprints in line with SFDR.
Portfolio ESG Assessment: Evaluate sustainability at the portfolio level for strategic decision-making.
Must-have features:
Automated reporting
Regular regulatory updates
Audit trails and data lineage for transparency
Overcoming SFDR Challenges
Incomplete Data: Supplement with external sources and rigorous validation.
Greenwashing Risks: Use transparent methodologies and reliable data.
Lack of Expertise: Partner with ESG professionals and invest in training.
Choosing the Right SFDR Solution
Match the solution to your organization’s size and portfolio complexity.
Ensure seamless integration with your internal systems.
Select vendors who offer strong support and keep tools updated with regulatory changes.
The Future of SFDR Tools As ESG transparency demands grow, SFDR solutions must evolve. The EU Omnibus Regulation is streamlining sustainability reporting, requiring tools to be flexible, interoperable, and ready for combined disclosures across multiple frameworks. Fintech innovation is driving smarter, more user-friendly SFDR solutions that help financial institutions stay ahead.
Conclusion Implementing advanced SFDR solutions is more than a compliance exercise—it’s a strategic move for leadership in sustainable finance. By adopting the latest tools and trends, financial institutions can boost transparency, earn investor trust, and achieve long-term sustainability goals.
Read More Explore the full article on SFDR solutions, trends, and tools here: SFDR Solutions, Trends, and Tools – Inrate Blog
Stay tuned for more insights on ESG compliance, sustainable finance, and regulatory innovation.
0 notes
Text
Metadata Management After Moving from Tableau to Power BI
Migrating from Tableau to Power BI is a strategic decision for organizations looking to centralize analytics, streamline licensing, and harness Microsoft's broader ecosystem. However, while dashboard and visual migration often take center stage, one crucial component often overlooked is metadata management. Poor metadata handling can lead to inconsistent reporting, broken lineage, and compliance issues. This blog explores how businesses can realign their metadata strategies post-migration to ensure smooth and reliable reporting in Power BI.
Understanding Metadata in BI Tools
Metadata is essentially "data about data." It includes information about datasets, such as source systems, field types, data definitions, relationships, and transformation logic. In Tableau, metadata is often embedded in workbooks or managed externally via Data Catalog integrations. In contrast, Power BI integrates metadata tightly within Power BI Desktop, Power BI Service, and the Power BI Data Model using features like the Data Model schema, lineage views, and dataflows.
Key Metadata Challenges During Migration
When migrating from Tableau to Power BI, metadata inconsistencies often arise due to differences in how each platform handles:
Calculated fields (Tableau) vs. Measures and Columns (Power BI)
Data lineage tracking
Connection methods and source queries
Terminology and object references
Without careful planning, you may encounter broken dependencies, duplicate definitions, or unclear data ownership post-migration. This makes establishing a robust metadata management framework in Power BI essential.
Best Practices for Metadata Management in Power BI
1. Centralize with Dataflows and Shared Datasets Post-migration, use Power BI Dataflows to centralize ETL processes and preserve metadata integrity. Dataflows allow teams to reuse cleaned data models and ensure consistent definitions across reports and dashboards.
2. Adopt a Business Glossary Rebuild or migrate your business glossary from Tableau into Power BI documentation layers using tools like Power BI data dictionary exports, documentation templates, or integrations with Microsoft Purview. This ensures end users interpret KPIs and metrics consistently.
3. Use Lineage View and Impact Analysis Leverage lineage view in Power BI Service to trace data from source to dashboard. This feature is essential for auditing changes, understanding data dependencies, and reducing risks during updates.
4. Implement Role-Based Access Controls (RBAC) Metadata often contains sensitive definitions and transformation logic. Assign role-based permissions to ensure only authorized users can access or edit core dataset metadata.
5. Automate Metadata Documentation Tools like Tabular Editor, DAX Studio, or PowerShell scripts can help export and document Power BI metadata programmatically. Automating this process ensures your metadata stays up to date even as models evolve.
The OfficeSolution Advantage
At OfficeSolution, we support enterprises throughout the entire migration journey—from visual rebuilds to metadata realignment. With our deep expertise in both Tableau and Power BI ecosystems, we ensure that your metadata remains a strong foundation for reporting accuracy and governance.
Explore more migration best practices and tools at 🔗 https://tableautopowerbimigration.com/
Conclusion Metadata management is not just an IT concern—it’s central to trust, performance, and decision-making in Power BI. Post-migration success depends on aligning metadata strategies with Power BI’s architecture and features. By investing in metadata governance now, businesses can avoid reporting pitfalls and unlock more scalable insights in the future.
0 notes