#data-driven science
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was created by web developers David Karp and Marco Arment.
Text
How Big Data Analytics is Changing Scientific Discoveries
Introduction
In the contemporary world of the prevailing sciences and technologies, big data analytics becomes a powerful agent in such a way that scientific discoveries are being orchestrated. At Techtovio, we explore this renewed approach to reshaping research methodologies for better data interpretation and new insights into its hastening process. Read to continue
#CategoriesScience Explained#Tagsastronomy data analytics#big data analytics#big data automation#big data challenges#big data in healthcare#big data in science#big data privacy#climate data analysis#computational data processing#data analysis in research#data-driven science#environmental research#genomics big data#personalized medicine#predictive modeling in research#real-time scientific insights#scientific data integration#scientific discoveries#Technology#Science#business tech#Adobe cloud#Trends#Nvidia Drive#Analysis#Tech news#Science updates#Digital advancements#Tech trends
1 note
·
View note
Text
mage viktor discourse again on twitter and all i can say in my little corner over here once again is, I don't know why the entire fandom takes it as canon that mage Viktor failed to save every world he manipulated.
Canon does not provide evidence of this. This is fanon speculation. It's a fine headcanon to have, but everyone talks about it like it's canon when it isn't. Canon is ambiguous about the outcome of the timelines mage Viktor altered. The little nods we are given point, in my opinion, towards the opposite conclusion, that he successfully averted destruction.
I've written meta on this before but in summary:
1) 'In all timelines, in all possibilities' is worded precisely, it's not 'out of all timelines'; the implication is that every time, Jayce brings Viktor back from the brink, not just in our timeline. 'Only you' doesn't refer to our timeline's Jayce, it refers to all Jayces. Jayce always brings him home. If Viktor continuously put the fate of each timeline in Jayce's hands and Jayce failed over and over, I don't think he'd say those words. And the way he says them matters. His words are tinged with wonder, not sorrow. As if over and over again, he is shown that Jayce saves him, and it continues to amaze him. He doesn't sound defeated, like this is the next in a long line of Jayces he's sending off to die. The feeling is that Viktor's faith in Jayce has not been misplaced.
2) If mage Viktor doomed every timeline, there would be hundreds (or more) mage Viktors. All running around manipulating timelines. I highly doubt the writers wanted to get into that kind of sticky situation. The tragedy of mage Viktor is that he is singular. Alone. Burdened with the responsibility of the multiverse. The emotional gut punch of his fate is ruined if other timelines led to the same outcome, and from a practical standpoint, having multiple reality-bending omniscient mages would rip apart the fabric of the arcane.
There are other points, such as there being only one corrupted Mercury Hammer and our Jayce is the only one to receive it, and the fact that if mage Viktor is as omniscient as he is implied to be, he could easily step back into other timelines and correct course, because it's highly unlikely he could sit still and watch things go down in flames. But these things can be argued elsewhere.
While I love conversations about mage Viktor's motives and selfishness vs altruism, the writers & artbook have expressed that Jayce and Viktor care greatly about Runeterra and want to fix their mistakes to save it, and that their reconciliation is symbolic of Piltover and Zaun coming together as well. Yes, they make disastrous decisions towards each other, making choices for the other or without the other, which has negative consequences for their relationship and for Runeterra - but I think fandom pushes their selfishness even past what's canon sometimes, as if their entire goal hadn't always been to selflessly help the world around them. Their final reconciliation is about bridging the gap that grew between them - the pain and grief and secrets, betraying themselves and each other - to mutually choose each other openly and honestly. Part of the beauty of their story, as expressed by the creators, is that in their final moments, they chose each other and took responsibility for their actions by sacrificing themselves to end what they started, together - and that choosing each other saved the world. TPTB have stated this - that Jayce and Viktor are the glue holding civilization together, and when they come back to each other, they can restore balance. It's when they're apart, when they hurt each other and miscommunicate, when they abandon their commitment to each other and their dream, that the greater world suffers. Their strife is mirrored in the story-world at large.
Mage Viktor is framed as a solitary penitent figure, damned to an eternity of atoning for his mistakes. He paid the ultimate price and now is forced to live his personal nightmare of exactly what he was trying to avoid for himself with the glorious evolution. The narrative clues we're given point more in the direction that he saves timelines rather than dooms them. If Viktor's actions kept killing Jayce, the very boy he couldn't bear to not save each time, it would undermine these narrative choices. Yes, Viktor couldn't stand to live in a world where he never meets Jayce, so he ensures it keeps happening. But in that same breath, he couldn't bear to see a world where his actions continue to destroy Jayce and destroy Runeterra. His entire arc in s2 is born of his selfless desire to help humanity, help individual people. He would not lightly destroy entire worlds. That's his original grief multiplied a thousandfold, and narratively it would lessen the impact of the one, true loss he did suffer, his own Jayce. It wouldn't make sense for him to be alright with damning other timelines to suffer the same catastrophic tragedy that created him. I mean, maybe I'm delusional here, but is that not the entire point? Because that's what I took away when I watched the show.
As I said, I love discussions about mage Viktor, as there's a lot to play with. All I wish is that the fandom at large would not just assume or accept the Mage Viktor Dooms Every Timeline idea as canon, when there is nothing in the actual canon that confirms this. Maybe people need to just, go back and rewatch the actual episode, to recall how mage Viktor is presented to us, and what it's implied we're supposed to take away from his scenes, and separate that from the layers of headcanon the fandom has constructed.
#arcane#mage viktor#jayvik#viktor arcane#meta#this is like. along the same vein as 'jayce knew all along viktor would go to the hexgates during the final battle'#like that is a headcanon. we don't know that!!#the actual scene could be read either way and i know when i watched it that's not how i interpreted it#and i doubt it's how most casual viewers intrepeted it#fandom gets so deep into itself after a show ends that you really have to just. rewatch the show to recalibrate yourself lol#for all that people bicker about mage viktor yall dont include him in your fics v much lol#anyway i love mage viktor and he's probably my favorite version of viktor <3#i just wish fandom stopped insisting on a monolithic view of canon#and the idea that mage viktor fucked over hundreds of timelines to collect data points like a scientist is just#rubs me the wrong way as a scientist lol#you do realize that scientists don't treat everything in life like a science experiment right?#it's about inquisitiveness and curiosity. not 'i will approach this emotional thing from a cold and calculating standpoint'#viktor has never been cold and calculating. he's consistently driven by emotion in the show jfc please rewatch canon#i just think that people would benefit from a surface level reading once in a while lol#sometimes fandom digs so far into the minutiae that they forget the overarching takeaways that the story presents#assuming there must be some hidden meaning that sometimes (like this) is decided to be the literal opposite of what's presented#rewatch mage viktor's scenes and ask yourself if 'deranged destroyer of worlds' is really what the show was trying to have you take away#then again there seems to be a faction of this fandom that for some absurd reason thinks jayce was forced to stay and die with viktor#so i guess media illiteracy can't be helped for some lmao#i post these things on here because my twitter posts get literally 10 views thanks algorithm#so the chunk of the fandom i really want to see this will not#but i must speak my truth
127 notes
·
View notes
Text
The surprising truth about data-driven dictatorships

Here’s the “dictator’s dilemma”: they want to block their country’s frustrated elites from mobilizing against them, so they censor public communications; but they also want to know what their people truly believe, so they can head off simmering resentments before they boil over into regime-toppling revolutions.
These two strategies are in tension: the more you censor, the less you know about the true feelings of your citizens and the easier it will be to miss serious problems until they spill over into the streets (think: the fall of the Berlin Wall or Tunisia before the Arab Spring). Dictators try to square this circle with things like private opinion polling or petition systems, but these capture a small slice of the potentially destabiziling moods circulating in the body politic.
Enter AI: back in 2018, Yuval Harari proposed that AI would supercharge dictatorships by mining and summarizing the public mood — as captured on social media — allowing dictators to tack into serious discontent and diffuse it before it erupted into unequenchable wildfire:
https://www.theatlantic.com/magazine/archive/2018/10/yuval-noah-harari-technology-tyranny/568330/
Harari wrote that “the desire to concentrate all information and power in one place may become [dictators] decisive advantage in the 21st century.” But other political scientists sharply disagreed. Last year, Henry Farrell, Jeremy Wallace and Abraham Newman published a thoroughgoing rebuttal to Harari in Foreign Affairs:
https://www.foreignaffairs.com/world/spirals-delusion-artificial-intelligence-decision-making
They argued that — like everyone who gets excited about AI, only to have their hopes dashed — dictators seeking to use AI to understand the public mood would run into serious training data bias problems. After all, people living under dictatorships know that spouting off about their discontent and desire for change is a risky business, so they will self-censor on social media. That’s true even if a person isn’t afraid of retaliation: if you know that using certain words or phrases in a post will get it autoblocked by a censorbot, what’s the point of trying to use those words?
The phrase “Garbage In, Garbage Out” dates back to 1957. That’s how long we’ve known that a computer that operates on bad data will barf up bad conclusions. But this is a very inconvenient truth for AI weirdos: having given up on manually assembling training data based on careful human judgment with multiple review steps, the AI industry “pivoted” to mass ingestion of scraped data from the whole internet.
But adding more unreliable data to an unreliable dataset doesn’t improve its reliability. GIGO is the iron law of computing, and you can’t repeal it by shoveling more garbage into the top of the training funnel:
https://memex.craphound.com/2018/05/29/garbage-in-garbage-out-machine-learning-has-not-repealed-the-iron-law-of-computer-science/
When it comes to “AI” that’s used for decision support — that is, when an algorithm tells humans what to do and they do it — then you get something worse than Garbage In, Garbage Out — you get Garbage In, Garbage Out, Garbage Back In Again. That’s when the AI spits out something wrong, and then another AI sucks up that wrong conclusion and uses it to generate more conclusions.
To see this in action, consider the deeply flawed predictive policing systems that cities around the world rely on. These systems suck up crime data from the cops, then predict where crime is going to be, and send cops to those “hotspots” to do things like throw Black kids up against a wall and make them turn out their pockets, or pull over drivers and search their cars after pretending to have smelled cannabis.
The problem here is that “crime the police detected” isn’t the same as “crime.” You only find crime where you look for it. For example, there are far more incidents of domestic abuse reported in apartment buildings than in fully detached homes. That’s not because apartment dwellers are more likely to be wife-beaters: it’s because domestic abuse is most often reported by a neighbor who hears it through the walls.
So if your cops practice racially biased policing (I know, this is hard to imagine, but stay with me /s), then the crime they detect will already be a function of bias. If you only ever throw Black kids up against a wall and turn out their pockets, then every knife and dime-bag you find in someone’s pockets will come from some Black kid the cops decided to harass.
That’s life without AI. But now let’s throw in predictive policing: feed your “knives found in pockets” data to an algorithm and ask it to predict where there are more knives in pockets, and it will send you back to that Black neighborhood and tell you do throw even more Black kids up against a wall and search their pockets. The more you do this, the more knives you’ll find, and the more you’ll go back and do it again.
This is what Patrick Ball from the Human Rights Data Analysis Group calls “empiricism washing”: take a biased procedure and feed it to an algorithm, and then you get to go and do more biased procedures, and whenever anyone accuses you of bias, you can insist that you’re just following an empirical conclusion of a neutral algorithm, because “math can’t be racist.”
HRDAG has done excellent work on this, finding a natural experiment that makes the problem of GIGOGBI crystal clear. The National Survey On Drug Use and Health produces the gold standard snapshot of drug use in America. Kristian Lum and William Isaac took Oakland’s drug arrest data from 2010 and asked Predpol, a leading predictive policing product, to predict where Oakland’s 2011 drug use would take place.
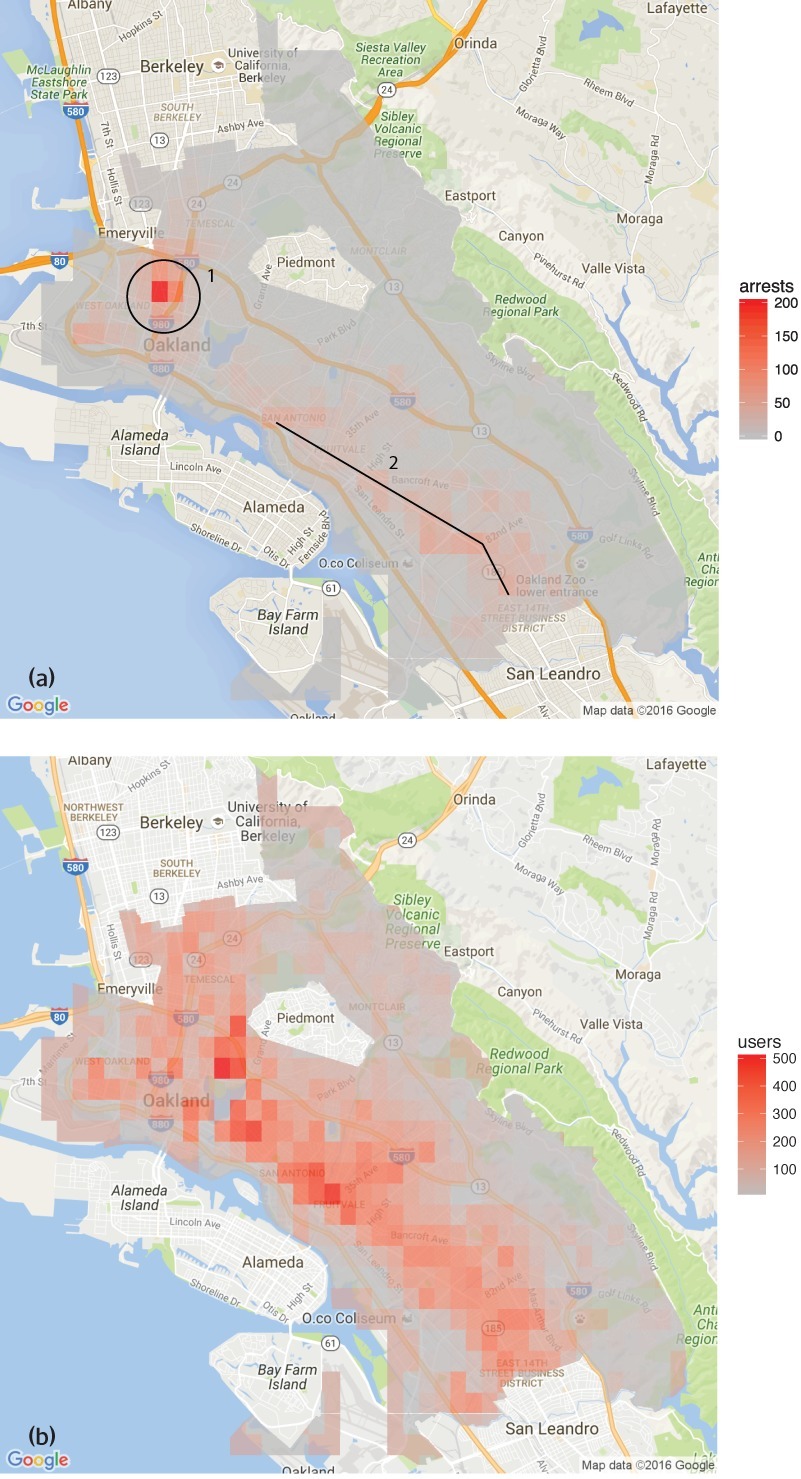
[Image ID: (a) Number of drug arrests made by Oakland police department, 2010. (1) West Oakland, (2) International Boulevard. (b) Estimated number of drug users, based on 2011 National Survey on Drug Use and Health]
Then, they compared those predictions to the outcomes of the 2011 survey, which shows where actual drug use took place. The two maps couldn’t be more different:
https://rss.onlinelibrary.wiley.com/doi/full/10.1111/j.1740-9713.2016.00960.x
Predpol told cops to go and look for drug use in a predominantly Black, working class neighborhood. Meanwhile the NSDUH survey showed the actual drug use took place all over Oakland, with a higher concentration in the Berkeley-neighboring student neighborhood.
What’s even more vivid is what happens when you simulate running Predpol on the new arrest data that would be generated by cops following its recommendations. If the cops went to that Black neighborhood and found more drugs there and told Predpol about it, the recommendation gets stronger and more confident.
In other words, GIGOGBI is a system for concentrating bias. Even trace amounts of bias in the original training data get refined and magnified when they are output though a decision support system that directs humans to go an act on that output. Algorithms are to bias what centrifuges are to radioactive ore: a way to turn minute amounts of bias into pluripotent, indestructible toxic waste.
There’s a great name for an AI that’s trained on an AI’s output, courtesy of Jathan Sadowski: “Habsburg AI.”
And that brings me back to the Dictator’s Dilemma. If your citizens are self-censoring in order to avoid retaliation or algorithmic shadowbanning, then the AI you train on their posts in order to find out what they’re really thinking will steer you in the opposite direction, so you make bad policies that make people angrier and destabilize things more.
Or at least, that was Farrell(et al)’s theory. And for many years, that’s where the debate over AI and dictatorship has stalled: theory vs theory. But now, there’s some empirical data on this, thanks to the “The Digital Dictator’s Dilemma,” a new paper from UCSD PhD candidate Eddie Yang:
https://www.eddieyang.net/research/DDD.pdf
Yang figured out a way to test these dueling hypotheses. He got 10 million Chinese social media posts from the start of the pandemic, before companies like Weibo were required to censor certain pandemic-related posts as politically sensitive. Yang treats these posts as a robust snapshot of public opinion: because there was no censorship of pandemic-related chatter, Chinese users were free to post anything they wanted without having to self-censor for fear of retaliation or deletion.
Next, Yang acquired the censorship model used by a real Chinese social media company to decide which posts should be blocked. Using this, he was able to determine which of the posts in the original set would be censored today in China.
That means that Yang knows that the “real” sentiment in the Chinese social media snapshot is, and what Chinese authorities would believe it to be if Chinese users were self-censoring all the posts that would be flagged by censorware today.
From here, Yang was able to play with the knobs, and determine how “preference-falsification” (when users lie about their feelings) and self-censorship would give a dictatorship a misleading view of public sentiment. What he finds is that the more repressive a regime is — the more people are incentivized to falsify or censor their views — the worse the system gets at uncovering the true public mood.
What’s more, adding additional (bad) data to the system doesn’t fix this “missing data” problem. GIGO remains an iron law of computing in this context, too.
But it gets better (or worse, I guess): Yang models a “crisis” scenario in which users stop self-censoring and start articulating their true views (because they’ve run out of fucks to give). This is the most dangerous moment for a dictator, and depending on the dictatorship handles it, they either get another decade or rule, or they wake up with guillotines on their lawns.
But “crisis” is where AI performs the worst. Trained on the “status quo” data where users are continuously self-censoring and preference-falsifying, AI has no clue how to handle the unvarnished truth. Both its recommendations about what to censor and its summaries of public sentiment are the least accurate when crisis erupts.
But here’s an interesting wrinkle: Yang scraped a bunch of Chinese users’ posts from Twitter — which the Chinese government doesn’t get to censor (yet) or spy on (yet) — and fed them to the model. He hypothesized that when Chinese users post to American social media, they don’t self-censor or preference-falsify, so this data should help the model improve its accuracy.
He was right — the model got significantly better once it ingested data from Twitter than when it was working solely from Weibo posts. And Yang notes that dictatorships all over the world are widely understood to be scraping western/northern social media.
But even though Twitter data improved the model’s accuracy, it was still wildly inaccurate, compared to the same model trained on a full set of un-self-censored, un-falsified data. GIGO is not an option, it’s the law (of computing).
Writing about the study on Crooked Timber, Farrell notes that as the world fills up with “garbage and noise” (he invokes Philip K Dick’s delighted coinage “gubbish”), “approximately correct knowledge becomes the scarce and valuable resource.”
https://crookedtimber.org/2023/07/25/51610/
This “probably approximately correct knowledge” comes from humans, not LLMs or AI, and so “the social applications of machine learning in non-authoritarian societies are just as parasitic on these forms of human knowledge production as authoritarian governments.”

The Clarion Science Fiction and Fantasy Writers’ Workshop summer fundraiser is almost over! I am an alum, instructor and volunteer board member for this nonprofit workshop whose alums include Octavia Butler, Kim Stanley Robinson, Bruce Sterling, Nalo Hopkinson, Kameron Hurley, Nnedi Okorafor, Lucius Shepard, and Ted Chiang! Your donations will help us subsidize tuition for students, making Clarion — and sf/f — more accessible for all kinds of writers.
Libro.fm is the indie-bookstore-friendly, DRM-free audiobook alternative to Audible, the Amazon-owned monopolist that locks every book you buy to Amazon forever. When you buy a book on Libro, they share some of the purchase price with a local indie bookstore of your choosing (Libro is the best partner I have in selling my own DRM-free audiobooks!). As of today, Libro is even better, because it’s available in five new territories and currencies: Canada, the UK, the EU, Australia and New Zealand!
[Image ID: An altered image of the Nuremberg rally, with ranked lines of soldiers facing a towering figure in a many-ribboned soldier's coat. He wears a high-peaked cap with a microchip in place of insignia. His head has been replaced with the menacing red eye of HAL9000 from Stanley Kubrick's '2001: A Space Odyssey.' The sky behind him is filled with a 'code waterfall' from 'The Matrix.']
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
—
Raimond Spekking (modified) https://commons.wikimedia.org/wiki/File:Acer_Extensa_5220_-_Columbia_MB_06236-1N_-_Intel_Celeron_M_530_-_SLA2G_-_in_Socket_479-5029.jpg
CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0/deed.en
—
Russian Airborne Troops (modified) https://commons.wikimedia.org/wiki/File:Vladislav_Achalov_at_the_Airborne_Troops_Day_in_Moscow_%E2%80%93_August_2,_2008.jpg
“Soldiers of Russia” Cultural Center (modified) https://commons.wikimedia.org/wiki/File:Col._Leonid_Khabarov_in_an_everyday_service_uniform.JPG
CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0/deed.en
#pluralistic#habsburg ai#self censorship#henry farrell#digital dictatorships#machine learning#dictator's dilemma#eddie yang#preference falsification#political science#training bias#scholarship#spirals of delusion#algorithmic bias#ml#Fully automated data driven authoritarianism#authoritarianism#gigo#garbage in garbage out garbage back in#gigogbi#yuval noah harari#gubbish#pkd#philip k dick#phildickian
833 notes
·
View notes
Text
one of the things you will not hear commonly on the internet is that it is like. fine to be an athiest and also a pagan or whatever. like learning about blavatsky et al & finding materialism did change how i relate to my practices a Lot. a lot. and i do think we have a responsibility to for example understand the history and mechanisms of orientalism, etc, bc these 'outside of organized religion' religious practices have an ugly and exploitative history and we have to look at that if we are to salvage anything meaningful from the project of paganism. i mean this to you so sincerely. if you think of yourself as a witch this post is for you. i lived there for ten years i'm not throwing stones from outside the house here
but last night i lit my candles on my little altar to death and it's like. what she means to me has changed as i come to understand the world. i think she's the progressive force, in truth. i am trying to love the world enough to see it for true
but the other other interesting thing to me is that. seeing the world more clearly doesn't change what i'm getting out of the experience very much. and i guess i thought it would.
i think if we were to dismantle the systems of power wherein religion is used for control (and believe me, paganism is not exempt from these pressures due to it's largely decentralized nature), that religion might just be like. dance. like you can get fancy with it or not but it moves you because it moves You. like it may one day just be a kind of art
anyway. the gods don't have to speak to you. in truth i don't think they are speaking to anybody because i don't think they are real. and if you're looking at paganism or 'witchery' or whatever and wanting to start or expand your practice. i am telling you directly that you don't have to use it to escape from the world. it is so tempting to find some magical system to simplify your model of the world but you don't actually have to use this to hide. it can be the place you love the world enough to see it for true. or love yourself enough to see what you need. take the parts that work and discard the parts that don't & remember you need some chemicals to cast fireball in real life.
#pagan#paganism#witchcraft#witchy#in truth. if you like magical systems people historically have had a whole bunch and i do think those are interesting#i just think like 2025 we can say that one branch of magic turned into materials science and if you want to cast fireball in real life#you gotta learn from those guys. not the crystals can heal your bones guys. right#data driven approaches. and like truly it's not like i'm less batshit religious now it's just way more oblique to where i was when i starte#when i decided i would not be christian anymore as i was raised to be but i needed something. something#and ten years in i am looking at u and saying. i think there are things valuable here that we could salvage from this wreck#but in order to do that we have to see the world for true. and i am trying. i am trying
3 notes
·
View notes
Text
What Are the Qualifications for a Data Scientist?
In today's data-driven world, the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making, understanding customer behavior, and improving products, the demand for skilled professionals who can analyze, interpret, and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientist, how DataCouncil can help you get there, and why a data science course in Pune is a great option, this blog has the answers.
The Key Qualifications for a Data Scientist
To succeed as a data scientist, a mix of technical skills, education, and hands-on experience is essential. Here are the core qualifications required:
1. Educational Background
A strong foundation in mathematics, statistics, or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields, with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap, offering the academic and practical knowledge required for a strong start in the industry.
2. Proficiency in Programming Languages
Programming is at the heart of data science. You need to be comfortable with languages like Python, R, and SQL, which are widely used for data analysis, machine learning, and database management. A comprehensive data science course in Pune will teach these programming skills from scratch, ensuring you become proficient in coding for data science tasks.
3. Understanding of Machine Learning
Data scientists must have a solid grasp of machine learning techniques and algorithms such as regression, clustering, and decision trees. By enrolling in a DataCouncil course, you'll learn how to implement machine learning models to analyze data and make predictions, an essential qualification for landing a data science job.
4. Data Wrangling Skills
Raw data is often messy and unstructured, and a good data scientist needs to be adept at cleaning and processing data before it can be analyzed. DataCouncil's data science course in Pune includes practical training in tools like Pandas and Numpy for effective data wrangling, helping you develop a strong skill set in this critical area.
5. Statistical Knowledge
Statistical analysis forms the backbone of data science. Knowledge of probability, hypothesis testing, and statistical modeling allows data scientists to draw meaningful insights from data. A structured data science course in Pune offers the theoretical and practical aspects of statistics required to excel.
6. Communication and Data Visualization Skills
Being able to explain your findings in a clear and concise manner is crucial. Data scientists often need to communicate with non-technical stakeholders, making tools like Tableau, Power BI, and Matplotlib essential for creating insightful visualizations. DataCouncil’s data science course in Pune includes modules on data visualization, which can help you present data in a way that’s easy to understand.
7. Domain Knowledge
Apart from technical skills, understanding the industry you work in is a major asset. Whether it’s healthcare, finance, or e-commerce, knowing how data applies within your industry will set you apart from the competition. DataCouncil's data science course in Pune is designed to offer case studies from multiple industries, helping students gain domain-specific insights.
Why Choose DataCouncil for a Data Science Course in Pune?
If you're looking to build a successful career as a data scientist, enrolling in a data science course in Pune with DataCouncil can be your first step toward reaching your goals. Here’s why DataCouncil is the ideal choice:
Comprehensive Curriculum: The course covers everything from the basics of data science to advanced machine learning techniques.
Hands-On Projects: You'll work on real-world projects that mimic the challenges faced by data scientists in various industries.
Experienced Faculty: Learn from industry professionals who have years of experience in data science and analytics.
100% Placement Support: DataCouncil provides job assistance to help you land a data science job in Pune or anywhere else, making it a great investment in your future.
Flexible Learning Options: With both weekday and weekend batches, DataCouncil ensures that you can learn at your own pace without compromising your current commitments.
Conclusion
Becoming a data scientist requires a combination of technical expertise, analytical skills, and industry knowledge. By enrolling in a data science course in Pune with DataCouncil, you can gain all the qualifications you need to thrive in this exciting field. Whether you're a fresher looking to start your career or a professional wanting to upskill, this course will equip you with the knowledge, skills, and practical experience to succeed as a data scientist.
Explore DataCouncil’s offerings today and take the first step toward unlocking a rewarding career in data science! Looking for the best data science course in Pune? DataCouncil offers comprehensive data science classes in Pune, designed to equip you with the skills to excel in this booming field. Our data science course in Pune covers everything from data analysis to machine learning, with competitive data science course fees in Pune. We provide job-oriented programs, making us the best institute for data science in Pune with placement support. Explore online data science training in Pune and take your career to new heights!
#In today's data-driven world#the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making#understanding customer behavior#and improving products#the demand for skilled professionals who can analyze#interpret#and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientis#how DataCouncil can help you get there#and why a data science course in Pune is a great option#this blog has the answers.#The Key Qualifications for a Data Scientist#To succeed as a data scientist#a mix of technical skills#education#and hands-on experience is essential. Here are the core qualifications required:#1. Educational Background#A strong foundation in mathematics#statistics#or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields#with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap#offering the academic and practical knowledge required for a strong start in the industry.#2. Proficiency in Programming Languages#Programming is at the heart of data science. You need to be comfortable with languages like Python#R#and SQL#which are widely used for data analysis#machine learning#and database management. A comprehensive data science course in Pune will teach these programming skills from scratch#ensuring you become proficient in coding for data science tasks.#3. Understanding of Machine Learning
3 notes
·
View notes
Note
Hi! (Please ignore my question if it doesn't make sense) I saw in your bio that, in addition to being a Jane Austen fan, you are a cognitive neuroscientist. Do you have thoughts on any of her six major novels from a cognitive neuroscience perspective?
I have basically one thought: Louisa's fall in Lyme and the after-effects of her major traumatic brain injury are very realistic. Her symptoms, the recovery time, and the after effects are all textbook. Good work Jane Austen!
Otherwise, there isn't much neuroscience in Jane Austen's works. There may be some psychology, and I did learn quite a bit about abnormal psychology, but the very first thing we learned is that no one can be diagnosed with anything without a proper clinical interview and diagnostic tools. Not 200 year old book characters, not even a major political figure. Which is why I pretty much refuse to "diagnose" anyone with anything.
What my education does give me is a very data driven approach to the world. Jane Austen can be tricky because of free-indirect discourse and a very sarcastic narrator, but if you can support something with quotations, I'll accept it. For example, many people deny that Darcy wanted Georgiana to marry Bingley, despite there being an actual quote in the book that says that. I looked at the quote, I looked at all the surrounding evidence, I checked for sarcasm (the narrator mocks Darcy for thinking he could be unbiased, that's the sarcastic part), and then I concluded that it was supported by the text. To me, any other conclusion would be nothing but bias (the bias here being that the Bingleys are so trade-scummy that Darcy would never consider marriage to that family).
#question response#mixing science and literature#louisa and her textbook head injury#data driven approach#I hope I answered your question!
41 notes
·
View notes
Text
Your Guide to B.Tech in Computer Science & Engineering Colleges

In today's technology-driven world, pursuing a B.Tech in Computer Science and Engineering (CSE) has become a popular choice among students aspiring for a bright future. The demand for skilled professionals in areas like Artificial Intelligence, Machine Learning, Data Science, and Cloud Computing has made computer science engineering colleges crucial in shaping tomorrow's innovators. Saraswati College of Engineering (SCOE), a leader in engineering education, provides students with a perfect platform to build a successful career in this evolving field.
Whether you're passionate about coding, software development, or the latest advancements in AI, pursuing a B.Tech in Computer Science and Engineering at SCOE can open doors to endless opportunities.
Why Choose B.Tech in Computer Science and Engineering?
Choosing a B.Tech in Computer Science and Engineering isn't just about learning to code; it's about mastering problem-solving, logical thinking, and the ability to work with cutting-edge technologies. The course offers a robust foundation that combines theoretical knowledge with practical skills, enabling students to excel in the tech industry.
At SCOE, the computer science engineering courses are designed to meet industry standards and keep up with the rapidly evolving tech landscape. With its AICTE Approved, NAAC Accredited With Grade-"A+" credentials, the college provides quality education in a nurturing environment. SCOE's curriculum goes beyond textbooks, focusing on hands-on learning through projects, labs, workshops, and internships. This approach ensures that students graduate not only with a degree but with the skills needed to thrive in their careers.
The Role of Computer Science Engineering Colleges in Career Development
The role of computer science engineering colleges like SCOE is not limited to classroom teaching. These institutions play a crucial role in shaping students' futures by providing the necessary infrastructure, faculty expertise, and placement opportunities. SCOE, established in 2004, is recognized as one of the top engineering colleges in Navi Mumbai. It boasts a strong placement record, with companies like Goldman Sachs, Cisco, and Microsoft offering lucrative job opportunities to its graduates.
The computer science engineering courses at SCOE are structured to provide a blend of technical and soft skills. From the basics of computer programming to advanced topics like Artificial Intelligence and Data Science, students at SCOE are trained to be industry-ready. The faculty at SCOE comprises experienced professionals who not only impart theoretical knowledge but also mentor students for real-world challenges.
Highlights of the B.Tech in Computer Science and Engineering Program at SCOE
Comprehensive Curriculum: The B.Tech in Computer Science and Engineering program at SCOE covers all major areas, including programming languages, algorithms, data structures, computer networks, operating systems, AI, and Machine Learning. This ensures that students receive a well-rounded education, preparing them for various roles in the tech industry.
Industry-Relevant Learning: SCOE’s focus is on creating professionals who can immediately contribute to the tech industry. The college regularly collaborates with industry leaders to update its curriculum, ensuring students learn the latest technologies and trends in computer science engineering.
State-of-the-Art Infrastructure: SCOE is equipped with modern laboratories, computer centers, and research facilities, providing students with the tools they need to gain practical experience. The institution’s infrastructure fosters innovation, helping students work on cutting-edge projects and ideas during their B.Tech in Computer Science and Engineering.
Practical Exposure: One of the key benefits of studying at SCOE is the emphasis on practical learning. Students participate in hands-on projects, internships, and industry visits, giving them real-world exposure to how technology is applied in various sectors.
Placement Support: SCOE has a dedicated placement cell that works tirelessly to ensure students secure internships and job offers from top companies. The B.Tech in Computer Science and Engineering program boasts a strong placement record, with top tech companies visiting the campus every year. The highest on-campus placement offer for the academic year 2022-23 was an impressive 22 LPA from Goldman Sachs, reflecting the college’s commitment to student success.
Personal Growth: Beyond academics, SCOE encourages students to participate in extracurricular activities, coding competitions, and tech fests. These activities enhance their learning experience, promote teamwork, and help students build a well-rounded personality that is essential in today’s competitive job market.
What Makes SCOE Stand Out?
With so many computer science engineering colleges to choose from, why should you consider SCOE for your B.Tech in Computer Science and Engineering? Here are a few factors that make SCOE a top choice for students:
Experienced Faculty: SCOE prides itself on having a team of highly qualified and experienced faculty members. The faculty’s approach to teaching is both theoretical and practical, ensuring students are equipped to tackle real-world challenges.
Strong Industry Connections: The college maintains strong relationships with leading tech companies, ensuring that students have access to internship opportunities and campus recruitment drives. This gives SCOE graduates a competitive edge in the job market.
Holistic Development: SCOE believes in the holistic development of students. In addition to academic learning, the college offers opportunities for personal growth through various student clubs, sports activities, and cultural events.
Supportive Learning Environment: SCOE provides a nurturing environment where students can focus on their academic and personal growth. The campus is equipped with modern facilities, including spacious classrooms, labs, a library, and a recreation center.
Career Opportunities After B.Tech in Computer Science and Engineering from SCOE
Graduates with a B.Tech in Computer Science and Engineering from SCOE are well-prepared to take on various roles in the tech industry. Some of the most common career paths for CSE graduates include:
Software Engineer: Developing software applications, web development, and mobile app development are some of the key responsibilities of software engineers. This role requires strong programming skills and a deep understanding of software design.
Data Scientist: With the rise of big data, data scientists are in high demand. CSE graduates with knowledge of data science can work on data analysis, machine learning models, and predictive analytics.
AI Engineer: Artificial Intelligence is revolutionizing various industries, and AI engineers are at the forefront of this change. SCOE’s curriculum includes AI and Machine Learning, preparing students for roles in this cutting-edge field.
System Administrator: Maintaining and managing computer systems and networks is a crucial role in any organization. CSE graduates can work as system administrators, ensuring the smooth functioning of IT infrastructure.
Cybersecurity Specialist: With the growing threat of cyberattacks, cybersecurity specialists are essential in protecting an organization’s digital assets. CSE graduates can pursue careers in cybersecurity, safeguarding sensitive information from hackers.
Conclusion: Why B.Tech in Computer Science and Engineering at SCOE is the Right Choice
Choosing the right college is crucial for a successful career in B.Tech in Computer Science and Engineering. Saraswati College of Engineering (SCOE) stands out as one of the best computer science engineering colleges in Navi Mumbai. With its industry-aligned curriculum, state-of-the-art infrastructure, and excellent placement record, SCOE offers students the perfect environment to build a successful career in computer science.
Whether you're interested in AI, data science, software development, or any other field in computer science, SCOE provides the knowledge, skills, and opportunities you need to succeed. With a strong focus on hands-on learning and personal growth, SCOE ensures that students graduate not only as engineers but as professionals ready to take on the challenges of the tech world.
If you're ready to embark on an exciting journey in the world of technology, consider pursuing your B.Tech in Computer Science and Engineering at SCOE—a college where your future takes shape.
#In today's technology-driven world#pursuing a B.Tech in Computer Science and Engineering (CSE) has become a popular choice among students aspiring for a bright future. The de#Machine Learning#Data Science#and Cloud Computing has made computer science engineering colleges crucial in shaping tomorrow's innovators. Saraswati College of Engineeri#a leader in engineering education#provides students with a perfect platform to build a successful career in this evolving field.#Whether you're passionate about coding#software development#or the latest advancements in AI#pursuing a B.Tech in Computer Science and Engineering at SCOE can open doors to endless opportunities.#Why Choose B.Tech in Computer Science and Engineering?#Choosing a B.Tech in Computer Science and Engineering isn't just about learning to code; it's about mastering problem-solving#logical thinking#and the ability to work with cutting-edge technologies. The course offers a robust foundation that combines theoretical knowledge with prac#enabling students to excel in the tech industry.#At SCOE#the computer science engineering courses are designed to meet industry standards and keep up with the rapidly evolving tech landscape. With#NAAC Accredited With Grade-“A+” credentials#the college provides quality education in a nurturing environment. SCOE's curriculum goes beyond textbooks#focusing on hands-on learning through projects#labs#workshops#and internships. This approach ensures that students graduate not only with a degree but with the skills needed to thrive in their careers.#The Role of Computer Science Engineering Colleges in Career Development#The role of computer science engineering colleges like SCOE is not limited to classroom teaching. These institutions play a crucial role in#faculty expertise#and placement opportunities. SCOE#established in 2004#is recognized as one of the top engineering colleges in Navi Mumbai. It boasts a strong placement record
2 notes
·
View notes
Text
Scientists use generative AI to answer complex questions in physics
New Post has been published on https://thedigitalinsider.com/scientists-use-generative-ai-to-answer-complex-questions-in-physics/
Scientists use generative AI to answer complex questions in physics

When water freezes, it transitions from a liquid phase to a solid phase, resulting in a drastic change in properties like density and volume. Phase transitions in water are so common most of us probably don’t even think about them, but phase transitions in novel materials or complex physical systems are an important area of study.
To fully understand these systems, scientists must be able to recognize phases and detect the transitions between. But how to quantify phase changes in an unknown system is often unclear, especially when data are scarce.
Researchers from MIT and the University of Basel in Switzerland applied generative artificial intelligence models to this problem, developing a new machine-learning framework that can automatically map out phase diagrams for novel physical systems.
Their physics-informed machine-learning approach is more efficient than laborious, manual techniques which rely on theoretical expertise. Importantly, because their approach leverages generative models, it does not require huge, labeled training datasets used in other machine-learning techniques.
Such a framework could help scientists investigate the thermodynamic properties of novel materials or detect entanglement in quantum systems, for instance. Ultimately, this technique could make it possible for scientists to discover unknown phases of matter autonomously.
“If you have a new system with fully unknown properties, how would you choose which observable quantity to study? The hope, at least with data-driven tools, is that you could scan large new systems in an automated way, and it will point you to important changes in the system. This might be a tool in the pipeline of automated scientific discovery of new, exotic properties of phases,” says Frank Schäfer, a postdoc in the Julia Lab in the Computer Science and Artificial Intelligence Laboratory (CSAIL) and co-author of a paper on this approach.
Joining Schäfer on the paper are first author Julian Arnold, a graduate student at the University of Basel; Alan Edelman, applied mathematics professor in the Department of Mathematics and leader of the Julia Lab; and senior author Christoph Bruder, professor in the Department of Physics at the University of Basel. The research is published today in Physical Review Letters.
Detecting phase transitions using AI
While water transitioning to ice might be among the most obvious examples of a phase change, more exotic phase changes, like when a material transitions from being a normal conductor to a superconductor, are of keen interest to scientists.
These transitions can be detected by identifying an “order parameter,” a quantity that is important and expected to change. For instance, water freezes and transitions to a solid phase (ice) when its temperature drops below 0 degrees Celsius. In this case, an appropriate order parameter could be defined in terms of the proportion of water molecules that are part of the crystalline lattice versus those that remain in a disordered state.
In the past, researchers have relied on physics expertise to build phase diagrams manually, drawing on theoretical understanding to know which order parameters are important. Not only is this tedious for complex systems, and perhaps impossible for unknown systems with new behaviors, but it also introduces human bias into the solution.
More recently, researchers have begun using machine learning to build discriminative classifiers that can solve this task by learning to classify a measurement statistic as coming from a particular phase of the physical system, the same way such models classify an image as a cat or dog.
The MIT researchers demonstrated how generative models can be used to solve this classification task much more efficiently, and in a physics-informed manner.
The Julia Programming Language, a popular language for scientific computing that is also used in MIT’s introductory linear algebra classes, offers many tools that make it invaluable for constructing such generative models, Schäfer adds.
Generative models, like those that underlie ChatGPT and Dall-E, typically work by estimating the probability distribution of some data, which they use to generate new data points that fit the distribution (such as new cat images that are similar to existing cat images).
However, when simulations of a physical system using tried-and-true scientific techniques are available, researchers get a model of its probability distribution for free. This distribution describes the measurement statistics of the physical system.
A more knowledgeable model
The MIT team’s insight is that this probability distribution also defines a generative model upon which a classifier can be constructed. They plug the generative model into standard statistical formulas to directly construct a classifier instead of learning it from samples, as was done with discriminative approaches.
“This is a really nice way of incorporating something you know about your physical system deep inside your machine-learning scheme. It goes far beyond just performing feature engineering on your data samples or simple inductive biases,” Schäfer says.
This generative classifier can determine what phase the system is in given some parameter, like temperature or pressure. And because the researchers directly approximate the probability distributions underlying measurements from the physical system, the classifier has system knowledge.
This enables their method to perform better than other machine-learning techniques. And because it can work automatically without the need for extensive training, their approach significantly enhances the computational efficiency of identifying phase transitions.
At the end of the day, similar to how one might ask ChatGPT to solve a math problem, the researchers can ask the generative classifier questions like “does this sample belong to phase I or phase II?” or “was this sample generated at high temperature or low temperature?”
Scientists could also use this approach to solve different binary classification tasks in physical systems, possibly to detect entanglement in quantum systems (Is the state entangled or not?) or determine whether theory A or B is best suited to solve a particular problem. They could also use this approach to better understand and improve large language models like ChatGPT by identifying how certain parameters should be tuned so the chatbot gives the best outputs.
In the future, the researchers also want to study theoretical guarantees regarding how many measurements they would need to effectively detect phase transitions and estimate the amount of computation that would require.
This work was funded, in part, by the Swiss National Science Foundation, the MIT-Switzerland Lockheed Martin Seed Fund, and MIT International Science and Technology Initiatives.
#ai#approach#artificial#Artificial Intelligence#Bias#binary#change#chatbot#chatGPT#classes#computation#computer#Computer modeling#Computer Science#Computer Science and Artificial Intelligence Laboratory (CSAIL)#Computer science and technology#computing#crystalline#dall-e#data#data-driven#datasets#dog#efficiency#Electrical Engineering&Computer Science (eecs)#engineering#Foundation#framework#Future#generative
2 notes
·
View notes
Text
Embracing the synergy of Cloud & DaaS revolutionizes data analytics! Instant access, supreme scalability, & cost-effectiveness drive data-driven decisions. We're at a new horizon, unbound by limits, ready to soar with informed strategies. Join the journey towards boundless innovation!
#clouds#daas#data analytics#data driven#dataviz#datainsights#business intelligence#data science#bigdata#machine learning#artificial intelligence#digital transformation#getondata
2 notes
·
View notes
Text
Mastering Marketing: Emotion-Driven Brands, Data-Powered Insights & Behavioral Change
Coca‑Cola “New Coke” Case & the Birth of the Garrison Group
Mistake diagnosed: Focused on “taste” not emotion, so New Coke failed emotionally.
Solution: Built an in‑house “think tank” to study emotional branding → Paul Garrison spun this out as the Garrison Group consultancy.
Core Marketing Concepts
Marketing = sell more stuff to more people, for more money, more often, more efficiently.
Marketing vs. Communications
Marketing sets the target, the brand associations, and the desired behavior (i.e. the “why” and “who”).
Communications is how you convey those associations (ads, social media, reels, etc.).
4 Functions of Business: production, finance, HR, marketing—all aim to make money, but marketing’s toolset centers on emotion + behavior.
Brand = the cluster of functional + emotional associations a large group holds in their heads.
Positioning is done by consumers’ perceptions, not by marketers—our role is to influence it.
Needs, Wants & Demand
Need = a fundamental human requirement (functional or emotional).
Want = culturally shaped expression of a need (e.g. quick breakfast → šmav atka vs. burger vs. ramen).
Demand = wants backed by willingness & ability to pay.
Marketing cycle:
Influence associations (branding)
→ drive behavior (habits)
→ generate revenue
→ reinvest in branding
Correct approach:
Define target—e.g. 60+ German couples (have money, time, crave new experiences)
Identify insights/pain points (e.g. safety, comfort, cultural immersion)
Craft communications to build desired associations → drive bookings
Key takeaway: Always lead with target + insight → desired associations → communications → behavior → revenue.
#BUS360#Marketing Management#Summer2025#MBA#mba core#12 june 2025#marketing#marketing strategy#behavioral science#brand building#emotional branding#consumer insights#data driven marketing#market research#customer behavior#brand loyalty#marketing psychology
0 notes
Text
Scientists from India, UK join hands to research healthy brain aging
The Centre for Brain Research (CBR) at the Indian Institute of Science (IISc) and the UK Dementia Research Institute (UK DRI) on Friday launched an international partnership that will create an interconnected research ecosystem to accelerate scientific understanding and innovation in brain health. According to CBR, by integrating expertise and cutting-edge technologies including blood-based…
#AI-driven data analysis#and digital cognitive monitoring tools#blood-based biomarkers#Centre for Brain Research (CBR) at the Indian Institute of Science (IISc) and the UK Dementia Research Institute (UK DRI)#interconnected research ecosystem to accelerate scientific understanding and innovation in brain health#Scientists from India#UK join hands to research healthy brain aging
0 notes
Text
Cordulus launches next-generation rain forecasting model tailored to European farmers
Cordulus, a leader in AI-powered weather forecasting, has unveiled its newest rain prediction model, setting a new benchmark for accuracy in weather forecasting. The company’s cutting-edge AI model, trained on more than 8 million real-world rainfall events across Europe, delivers forecasts that are 52% more accurate than traditional forecasts. This leap in precision comes at a crucial time for…
#Agri Innovation#Agriculture#AgriData#AgriFood Capital#AgriFood Science#AgTech/ AgriTech#Data Analytics#Data-Driven#Precision Agriculture#Startups#Sustainable Agriculture
0 notes
Text
Integrating Data Science Management with Business Strategy: Aligning Goals and Objectives

#Data Science Management#PG Diploma in Data Science#PGDM in Data Science#Data Visualization#Artificial Intelligenc#Data-Driven Culture#Business Strategy in Data Science#Professional Development
1 note
·
View note
Text
The Hidden Algorithm of Happiness: How Data is Redefining Joy in the Digital Age
In an age where technology permeates every facet of life, the pursuit of happiness has taken a fascinating turn. No longer confined to philosophical musings or self-help books, happiness is now being dissected, quantified, and optimized through data. A groundbreaking study by the Global Well-Being Institute reveals that 73% of people find joy in micro-moments—tiny, intentional acts of connection. This discovery is reshaping how we understand and experience happiness, blending ancient wisdom with cutting-edge technology.
#happiness#data-driven joy#happiness in digital age#well-being aspects in digital world#technology and mindfulness#conscious consumerism#micro-moments#AI#digital minimalism#future of happiness#happiness research#mental health and happiness trends#happiness science#happiness and technology#happiness algorithms.
0 notes
Text
Scope Computers
Level up your skills with our Data Analytics course! 📊 Master data visualization, analysis, and machine learning through hands-on experience. 🧠💻 Transform data into actionable insights and boost your career! 🚀
Course Highlights:
Data Visualization 📈 Statistical Analysis 📉 Machine Learning 🤖 Real-World Projects 💼 Enroll now and start your data journey! 🎓

#data analysis#datavisualization#learndataanalytics#machine learning#tech skills#analytics journey#data driven#data science
0 notes
Text
How Pharmaceutical Consulting Can Help Launch Your New Product Successfully
Ambrosia Ventures, we ensure your product launch achieves maximum impact by utilizing our expertise in biopharma consulting, which makes us a trusted pharmaceutical consulting service provider in the US. Here's the way to transform your product launch strategy into a blueprint for success through pharmaceutical consulting services
#Life Science Consulting#Strategic Life Sciences Consulting#Biotech Strategic Consulting#best biotech consulting firms#Pharmaceutical Consulting Services#Biotechnology Consulting#Strategic Life Sciences Advisory#Life Sciences Business Strategy#life science business consulting#Digital Transformation in Life Sciences#Pharma R&D Consulting#M&A Advisory Life Sciences#Healthcare M&A Solutions#Biopharma M&A Services#biopharma consulting#Biotech M&A Advisory#Pharmaceutical M&A Advisory#Predictive Analytics for M&A#Data-Driven M&A Strategy#Strategic M&A Analytics Solutions#M&A Target Identification Tool#Life Sciences M&A Analytics Tool#AI-Powered M&A Toolkit#M&A Toolkit#AI M&A Due Diligence Tools#Project Management Life Sciences#quality control services#quality control for project management#Regulatory Consulting for Life Sciences#Life Sciences Quality Assurance
0 notes