#dfs using stack in c
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
Automate Simple Tasks Using Python: A Beginner’s Guide
In today's fast paced digital world, time is money. Whether you're a student, a professional, or a small business owner, repetitive tasks can eat up a large portion of your day. The good news? Many of these routine jobs can be automated, saving you time, effort, and even reducing the chance of human error.
Enter Python a powerful, beginner-friendly programming language that's perfect for task automation. With its clean syntax and massive ecosystem of libraries, Python empowers users to automate just about anything from renaming files and sending emails to scraping websites and organizing data.
If you're new to programming or looking for ways to boost your productivity, this guide will walk you through how to automate simple tasks using Python.
🌟 Why Choose Python for Automation?
Before we dive into practical applications, let’s understand why Python is such a popular choice for automation:
Easy to learn: Python has simple, readable syntax, making it ideal for beginners.
Wide range of libraries: Python has a rich ecosystem of libraries tailored for different tasks like file handling, web scraping, emailing, and more.
Platform-independent: Python works across Windows, Mac, and Linux.
Strong community support: From Stack Overflow to GitHub, you’ll never be short on help.
Now, let’s explore real-world examples of how you can use Python to automate everyday tasks.
🗂 1. Automating File and Folder Management
Organizing files manually can be tiresome, especially when dealing with large amounts of data. Python’s built-in os and shutil modules allow you to automate file operations like:
Renaming files in bulk
Moving files based on type or date
Deleting unwanted files
Example: Rename multiple files in a folder
import os folder_path = 'C:/Users/YourName/Documents/Reports' for count, filename in enumerate(os.listdir(folder_path)): dst = f"report_{str(count)}.pdf" src = os.path.join(folder_path, filename) dst = os.path.join(folder_path, dst) os.rename(src, dst)
This script renames every file in the folder with a sequential number.
📧 2. Sending Emails Automatically
Python can be used to send emails with the smtplib and email libraries. Whether it’s sending reminders, reports, or newsletters, automating this process can save you significant time.
Example: Sending a basic email
import smtplib from email.message import EmailMessage msg = EmailMessage() msg.set_content("Hello, this is an automated email from Python!") msg['Subject'] = 'Automation Test' msg['From'] = '[email protected]' msg['To'] = '[email protected]' with smtplib.SMTP_SSL('smtp.gmail.com', 465) as smtp: smtp.login('[email protected]', 'yourpassword') smtp.send_message(msg)
⚠️ Note: Always secure your credentials when writing scripts consider using environment variables or secret managers.
🌐 3. Web Scraping for Data Collection
Want to extract information from websites without copying and pasting manually? Python’s requests and BeautifulSoup libraries let you scrape content from web pages with ease.
Example: Scraping news headlines
import requests from bs4 import BeautifulSoup url = 'https://www.bbc.com/news' response = requests.get(url) soup = BeautifulSoup(response.text, 'html.parser') for headline in soup.find_all('h3'): print(headline.text)
This basic script extracts and prints the headlines from BBC News.
📅 4. Automating Excel Tasks
If you work with Excel sheets, you’ll love openpyxl and pandas two powerful libraries that allow you to automate:
Creating spreadsheets
Sorting data
Applying formulas
Generating reports
Example: Reading and filtering Excel data
import pandas as pd df = pd.read_excel('sales_data.xlsx') high_sales = df[df['Revenue'] > 10000] print(high_sales)
This script filters sales records with revenue above 10,000.
💻 5. Scheduling Tasks
You can schedule scripts to run at specific times using Python’s schedule or APScheduler libraries. This is great for automating daily reports, reminders, or file backups.
Example: Run a function every day at 9 AM
import schedule import time def job(): print("Running scheduled task...") schedule.every().day.at("09:00").do(job) while True: schedule.run_pending() time.sleep(1)
This loop checks every second if it’s time to run the task.
🧹 6. Cleaning and Formatting Data
Cleaning data manually in Excel or Google Sheets is time-consuming. Python’s pandas makes it easy to:
Remove duplicates
Fix formatting
Convert data types
Handle missing values
Example: Clean a dataset
df = pd.read_csv('data.csv') df.drop_duplicates(inplace=True) df['Name'] = df['Name'].str.title() df.fillna(0, inplace=True) df.to_csv('cleaned_data.csv', index=False)
💬 7. Automating WhatsApp Messages (for fun or alerts)
Yes, you can even send WhatsApp messages using Python! Libraries like pywhatkit make this possible.
Example: Send a WhatsApp message
import pywhatkit pywhatkit.sendwhatmsg("+911234567890", "Hello from Python!", 15, 0)
This sends a message at 3:00 PM. It’s great for sending alerts or reminders.
🛒 8. Automating E-Commerce Price Tracking
You can use web scraping and conditionals to track price changes of products on sites like Amazon or Flipkart.
Example: Track a product’s price
url = "https://www.amazon.in/dp/B09XYZ123" headers = {"User-Agent": "Mozilla/5.0"} page = requests.get(url, headers=headers) soup = BeautifulSoup(page.content, 'html.parser') price = soup.find('span', {'class': 'a-price-whole'}).text print(f"The current price is ₹{price}")
With a few tweaks, you can send yourself alerts when prices drop.
📚 Final Thoughts
Automation is no longer a luxury it’s a necessity. With Python, you don’t need to be a coding expert to start simplifying your life. From managing files and scraping websites to sending e-mails and scheduling tasks, the possibilities are vast.
As a beginner, start small. Pick one repetitive task and try automating it. With every script you write, your confidence and productivity will grow.
Conclusion
If you're serious about mastering automation with Python, Zoople Technologies offers comprehensive, beginner-friendly Python course in Kerala. Our hands-on training approach ensures you learn by doing with real-world projects that prepare you for today’s tech-driven careers.
2 notes
·
View notes
Text
Mastering Data Structures: A Comprehensive Course for Beginners
Data structures are one of the foundational concepts in computer science and software development. Mastering data structures is essential for anyone looking to pursue a career in programming, software engineering, or computer science. This article will explore the importance of a Data Structure Course, what it covers, and how it can help you excel in coding challenges and interviews.
1. What Is a Data Structure Course?
A Data Structure Course teaches students about the various ways data can be organized, stored, and manipulated efficiently. These structures are crucial for solving complex problems and optimizing the performance of applications. The course generally covers theoretical concepts along with practical applications using programming languages like C++, Java, or Python.
By the end of the course, students will gain proficiency in selecting the right data structure for different problem types, improving their problem-solving abilities.
2. Why Take a Data Structure Course?
Learning data structures is vital for both beginners and experienced developers. Here are some key reasons to enroll in a Data Structure Course:
a) Essential for Coding Interviews
Companies like Google, Amazon, and Facebook focus heavily on data structures in their coding interviews. A solid understanding of data structures is essential to pass these interviews successfully. Employers assess your problem-solving skills, and your knowledge of data structures can set you apart from other candidates.
b) Improves Problem-Solving Skills
With the right data structure knowledge, you can solve real-world problems more efficiently. A well-designed data structure leads to faster algorithms, which is critical when handling large datasets or working on performance-sensitive applications.
c) Boosts Programming Competency
A good grasp of data structures makes coding more intuitive. Whether you are developing an app, building a website, or working on software tools, understanding how to work with different data structures will help you write clean and efficient code.
3. Key Topics Covered in a Data Structure Course
A Data Structure Course typically spans a range of topics designed to teach students how to use and implement different structures. Below are some key topics you will encounter:
a) Arrays and Linked Lists
Arrays are one of the most basic data structures. A Data Structure Course will teach you how to use arrays for storing and accessing data in contiguous memory locations. Linked lists, on the other hand, involve nodes that hold data and pointers to the next node. Students will learn the differences, advantages, and disadvantages of both structures.
b) Stacks and Queues
Stacks and queues are fundamental data structures used to store and retrieve data in a specific order. A Data Structure Course will cover the LIFO (Last In, First Out) principle for stacks and FIFO (First In, First Out) for queues, explaining their use in various algorithms and applications like web browsers and task scheduling.
c) Trees and Graphs
Trees and graphs are hierarchical structures used in organizing data. A Data Structure Course teaches how trees, such as binary trees, binary search trees (BST), and AVL trees, are used in organizing hierarchical data. Graphs are important for representing relationships between entities, such as in social networks, and are used in algorithms like Dijkstra's and BFS/DFS.
d) Hashing
Hashing is a technique used to convert a given key into an index in an array. A Data Structure Course will cover hash tables, hash maps, and collision resolution techniques, which are crucial for fast data retrieval and manipulation.
e) Sorting and Searching Algorithms
Sorting and searching are essential operations for working with data. A Data Structure Course provides a detailed study of algorithms like quicksort, merge sort, and binary search. Understanding these algorithms and how they interact with data structures can help you optimize solutions to various problems.
4. Practical Benefits of Enrolling in a Data Structure Course
a) Hands-on Experience
A Data Structure Course typically includes plenty of coding exercises, allowing students to implement data structures and algorithms from scratch. This hands-on experience is invaluable when applying concepts to real-world problems.
b) Critical Thinking and Efficiency
Data structures are all about optimizing efficiency. By learning the most effective ways to store and manipulate data, students improve their critical thinking skills, which are essential in programming. Selecting the right data structure for a problem can drastically reduce time and space complexity.
c) Better Understanding of Memory Management
Understanding how data is stored and accessed in memory is crucial for writing efficient code. A Data Structure Course will help you gain insights into memory management, pointers, and references, which are important concepts, especially in languages like C and C++.
5. Best Programming Languages for Data Structure Courses
While many programming languages can be used to teach data structures, some are particularly well-suited due to their memory management capabilities and ease of implementation. Some popular programming languages used in Data Structure Courses include:
C++: Offers low-level memory management and is perfect for teaching data structures.
Java: Widely used for teaching object-oriented principles and offers a rich set of libraries for implementing data structures.
Python: Known for its simplicity and ease of use, Python is great for beginners, though it may not offer the same level of control over memory as C++.
6. How to Choose the Right Data Structure Course?
Selecting the right Data Structure Course depends on several factors such as your learning goals, background, and preferred learning style. Consider the following when choosing:
a) Course Content and Curriculum
Make sure the course covers the topics you are interested in and aligns with your learning objectives. A comprehensive Data Structure Course should provide a balance between theory and practical coding exercises.
b) Instructor Expertise
Look for courses taught by experienced instructors who have a solid background in computer science and software development.
c) Course Reviews and Ratings
Reviews and ratings from other students can provide valuable insights into the course’s quality and how well it prepares you for real-world applications.
7. Conclusion: Unlock Your Coding Potential with a Data Structure Course
In conclusion, a Data Structure Course is an essential investment for anyone serious about pursuing a career in software development or computer science. It equips you with the tools and skills to optimize your code, solve problems more efficiently, and excel in technical interviews. Whether you're a beginner or looking to strengthen your existing knowledge, a well-structured course can help you unlock your full coding potential.
By mastering data structures, you are not only preparing for interviews but also becoming a better programmer who can tackle complex challenges with ease.
3 notes
·
View notes
Video
youtube
LEETCODE PROBLEMS 1-100 . C++ SOLUTIONS
Arrays and Two Pointers 1. Two Sum – Use hashmap to find complement in one pass. 26. Remove Duplicates from Sorted Array – Use two pointers to overwrite duplicates. 27. Remove Element – Shift non-target values to front with a write pointer. 80. Remove Duplicates II – Like #26 but allow at most two duplicates. 88. Merge Sorted Array – Merge in-place from the end using two pointers. 283. Move Zeroes – Shift non-zero values forward; fill the rest with zeros.
Sliding Window 3. Longest Substring Without Repeating Characters – Use hashmap and sliding window. 76. Minimum Window Substring – Track char frequency with two maps and a moving window.
Binary Search and Sorted Arrays 33. Search in Rotated Sorted Array – Modified binary search with pivot logic. 34. Find First and Last Position of Element – Binary search for left and right bounds. 35. Search Insert Position – Standard binary search for target or insertion point. 74. Search a 2D Matrix – Binary search treating matrix as a flat array. 81. Search in Rotated Sorted Array II – Extend #33 to handle duplicates.
Subarray Sums and Prefix Logic 53. Maximum Subarray – Kadane’s algorithm to track max current sum. 121. Best Time to Buy and Sell Stock – Track min price and update max profit.
Linked Lists 2. Add Two Numbers – Traverse two lists and simulate digit-by-digit addition. 19. Remove N-th Node From End – Use two pointers with a gap of n. 21. Merge Two Sorted Lists – Recursively or iteratively merge nodes. 23. Merge k Sorted Lists – Use min heap or divide-and-conquer merges. 24. Swap Nodes in Pairs – Recursively swap adjacent nodes. 25. Reverse Nodes in k-Group – Reverse sublists of size k using recursion. 61. Rotate List – Use length and modulo to rotate and relink. 82. Remove Duplicates II – Use dummy head and skip duplicates. 83. Remove Duplicates I – Traverse and skip repeated values. 86. Partition List – Create two lists based on x and connect them.
Stack 20. Valid Parentheses – Use stack to match open and close brackets. 84. Largest Rectangle in Histogram – Use monotonic stack to calculate max area.
Binary Trees 94. Binary Tree Inorder Traversal – DFS or use stack for in-order traversal. 98. Validate Binary Search Tree – Check value ranges recursively. 100. Same Tree – Compare values and structure recursively. 101. Symmetric Tree – Recursively compare mirrored subtrees. 102. Binary Tree Level Order Traversal – Use queue for BFS. 103. Binary Tree Zigzag Level Order – Modify BFS to alternate direction. 104. Maximum Depth of Binary Tree – DFS recursion to track max depth. 105. Build Tree from Preorder and Inorder – Recursively divide arrays. 106. Build Tree from Inorder and Postorder – Reverse of #105. 110. Balanced Binary Tree – DFS checking subtree heights, return early if unbalanced.
Backtracking 17. Letter Combinations of Phone Number – Map digits to letters and recurse. 22. Generate Parentheses – Use counts of open and close to generate valid strings. 39. Combination Sum – Use DFS to explore sum paths. 40. Combination Sum II – Sort and skip duplicates during recursion. 46. Permutations – Swap elements and recurse. 47. Permutations II – Like #46 but sort and skip duplicate values. 77. Combinations – DFS to select combinations of size k. 78. Subsets – Backtrack by including or excluding elements. 90. Subsets II – Sort and skip duplicates during subset generation.
Dynamic Programming 70. Climbing Stairs – DP similar to Fibonacci sequence. 198. House Robber – Track max value including or excluding current house.
Math and Bit Manipulation 136. Single Number – XOR all values to isolate the single one. 169. Majority Element – Use Boyer-Moore voting algorithm.
Hashing and Frequency Maps 49. Group Anagrams – Sort characters and group in hashmap. 128. Longest Consecutive Sequence – Use set to expand sequences. 242. Valid Anagram – Count characters using map or array.
Matrix and Miscellaneous 11. Container With Most Water – Two pointers moving inward. 42. Trapping Rain Water – Track left and right max heights with two pointers. 54. Spiral Matrix – Traverse matrix layer by layer. 73. Set Matrix Zeroes – Use first row and column as markers.
This version is 4446 characters long. Let me know if you want any part turned into code templates, tables, or formatted for PDF or Markdown.
0 notes
Text
2019 OSG Report Week 1
The 2019 NFL season kicks off Sunday, and fantasy football season does as well. It’s very important to know the types of contests or season long formats you’re competing in to have true success. DFS wise, multipliers, and head to head contests calls for safe yet good plays that may be a little chalky across the industry. Big tournaments where finishing in the top 10 is the goal, calls for deep plays at times, and game stacking where you go with guts mixed with some form of research. Cash games or multipliers and head to heads, go for players with good floors with ceiling mixed in. In tournaments, chase the ceiling plays.
Chiefs -3.5 at Jags (52.5)
As always, the Chiefs are in a high total game. The Jags were one of the league’s best secondaries last season and if we go off that and last year’s KC performance this would not be a spot to pay up for the likes of Tyreek Hill. Though his performance vs Jax was subpar last year as well, I’m more inclined to roster Kelce over Hill to be different at TE. Until McCoy was signed, I was all in on Damien Williams week 1 to pair with Mahomes and not heavily target the receivers and hope all TDS thru air and ground comes thru Mahomes and Williams. Will it be a 60/40 split or more in the backfield? Andy Reid did not bring McCoy in just to sit. But I may still take some shots on Williams. His price is still down across the industry. The best value play will be Mecole Hardman in the slot. He’s dirt cheap on all sites and could have the better matchup with Hill and Watkins locked up on the outside by two of the best returning CBs in the NFL
-If we believe the total and the close game theory, you definitely want to run back the stack with some Jags players. I have been leery on rostering or drafting the oft injured Fournette. Maybe with a better passing game it takes some work load off? Nick Foles was the WRs QB in Philly as oppose to Wentz the TE/Ertz whisperer. If true, this will go well for the explosive Dede Westbrook who hasn’t shown his potential yet in a stagnant offense. Westbrook will be a popular choice across all sites. He’s cheap and he’s the #1 WR on a team involved with a 52.5 total. If the Jags defense shows up and slows down KC in any way, they will be a great defensive leverage play in tournaments where a lot of ownership could fall on Kansas City.
Rams -3 at Panthers (50.5)
What to do with the Rams. Do they have Super Bowl loss hangover? Is Gurley healthy? Will his load be lighter to start the season, and save he for the long haul? Last year I believe he was just running so hard the first 14 weeks of the season that he was just banged up to finish. Will he and Malcom Brown split time? If he has a great game, then this will be his cheapest price of the season. If you are looking for a game to stack, then here is one. Cam/Goff, McCaffrey/Gurley and/or WR of choice you like out of Woods, Cooks, and Kupp. Big strong physical receivers like Woods has had success against the smaller CB core of Carolina. DJ Moore is getting a lot of hype, but I never favor WRs of Cam Newton. He’s not predictable. He uses his legs to escape, which turns it into a “throw it to whoever looks open” scenario. So, between his rushing upside, and C-Mac I think those two players get you all of the Carolina TDs.
49ers+1 at Buccaneers (50).
If you’re looking for another stacking option game, then here we go. I do favor the Bucs side of the ball for many many reasons. I’m still not sold on the 49er offense outside of George Kittle who this week could be a top play at TE. Tampa Bay has always including last season been a prime defense to target with TEs. Aside from Kittle, I’m having a hard time clicking on players from teams no matter the over/under who I think are not good teams or players. Matt Breida and Tevin Coleman are splitting the backfield, Jimmy G remains a question mark. Against this Tampa defense however is a good spot to target. I’m just maybe going to miss out. I do think Winston will stockpile targets to Mike Evans for PPR leagues/sites, but TD equity will be a tossup between Peyton Barber, Chris Godwin (who should take a big leap this season, and OJ Howard. Winston as most young QBs loves his TE.
Falcons +3.5 at Vikings (47.5)
I was a little surprised to see the Vikings favored by over a field goal. Yes, Atlanta is on the road but still a dome setting. Xavier Rhodes wasn’t his usual self last season or the preseason, which bodes well for the Atlanta WR core. Particularly Julio Jones whom as of Friday “should play” despite contract negotiations. Matt Ryan is a classic spread it out in the red zone type of QB. While Freeman is Coleman-less in the backfield, I fear the Ito Smith vulture line of 5 rushes 11 yards, 2Td game. Ridley is not a target monster but is a TD machine vs the 0 red zone looks Julio for reasons unknown gets. Sanu is the alter ego of Julio because of his size and strength. My favorite pass catcher will be Hooper at TE who caught on late in the season as is a perfect funnel if the outside corners for Minnesota are doing well.
-Kirk cousins is still at the helm but it’s hard to ignore the concentrated targets of Adam Thielen and Stefon Diggs. Thielen is the safe play while Diggs is the tournament, dart, high upside play. My favorite play is Dalvin Cook. He’s at home✅. Favored✅. Used in the red zone✅. Could touch the ball 20 times✅. For several seasons we have picked on Atlanta with RBs, especially ones who catch passes. Kyle Rudolph seems to score a TD every other game and could be a pivot off Hunter Henry for a cheap TE.
Lions -2.5 at Cardinals (47.5)
Here is a game where I am having trouble with. At first, I skipped over it but think it could deserve some mention. Matt Stafford is underpriced and could go overlooked. The Arizona secondary has only been good in names on jerseys. Mix in a rookie QB who is making his coach feel like “teeth pulling” and the Lions route could be on. Stafford to Golloday or Marvin Jones Jr. could go under owned in tournaments and win a heavy tournament. Kerryon Johnson is also great in stacks with Stafford. If you don’t believe in Murray out the gate, the Lions defense could be sneaky here.
-The Christian Kirk/Kyler Murray train will begin steam and besides a flyer in a Million-dollar tournament stack I’m not sure if I’m heavy on Murray out the gate. He does offer rushing ability but on Fanduel he’s priced $700 more than Stafford. No way! I do think David Johnson returns somewhat to an easy 20 point/game fantasy producer this season. Just remember the Lions slow games down and their stacks are often frustrating to watch play out. I am stacking 2-3 lineups in large field tournaments just in case though.
Redskins +8.5 at Eagles (46)
This game has fade all over it. Large spread. Divisional game (I hate division games). So, with that said Jordan Howard is favored✅. At home✅. And is playable with the defense. Not optimal but if he carries 15-20 times and hits the end zone vs a shaky Washington team, he hits value. Wentz does tend to throw 2-3 TDS a game. He loves Ertz and he is a great pivot off of Kelce in the high priced TE range. He also has favored Alshon Jeffrey and D-Jack is always good for the long ball. But again, never a fan of stock piling divisional games.
Titans +5.5 at Browns (45.5).
Is Tennessee good? No. Do they suck? Yes. Can they go into Cleveland and shock us all and win? Not sure, but I’m willing to say they will cover the 5.5 underdog tag they have. They slow down and muddy up games. They make them real ugly. If Beckham is slowed down by his hip in any way, isn’t the team a lot the same on offense? Again, we are just talking about this week. I don’t favor any Tennessee offensive player but if you think they show up, Derrick Henry or Corey Davis is your guy. Two seasons ago, I would say play Delanie Walker because I have for several seasons successfully played talented TEs vs Cleveland. But are he and Mariota talented together? Maybe not.
-With that said I do like to avoid offenses vs Tennessee and this opening week will probably be no different. The only safe play in my opinion whom also offers upside is Nick Chubb at RB and maybe paired with the Cleveland defense who should be good. I do think we see Baker throw a lot of balls with Todd Monken at offensive coordinator. This is of special interest because Monken was the OC in Tampa and the combined numbers of Winston and FitzMagic, if were one player would have been the #2 scoring fantasy QB in the NFL. I hate being a week late, but I wonder if THIS is the matchup because in fantasy and DFS this game is all we care about for now. Plus, I’m interested to see how Baker distributes the ball. Which pass catcher is most viable? Is OBJ worth the price tag if limited in anyway. Can you trust Higgins or Callaway? I will focus most exposure personally on Nick Chubb and the defense here. He fits the bill. At home✅. Favored✅. Could touch the ball 20 times✅. Usually used in the red zone✅.
Chargers -6.5 at Colts (45)
I do feel I am a fish for it, but I do like the Chargers defense. Maybe Brissett is better than we anticipate, but we know what we are getting here. Austin Eckler’s buzz is growing and rightfully so. He should garner the majority of the rushes and should be involved in the passing game for a team who despite being on the road is favored and playing in a dome. The next fish play is site dependent, but Hunter Henry with no Antonio Gates is in play as is the Rivers/Allen or Rivers/Williams stack.
-I’m not in favor of tournament fliers on Brissett, Marlon Mack, and Eric Ebron. Those would be the only players I would consider but it’s a full fade for me.
Bills + 3 at Jets (40.5)
Why is a 40.5 over/under relevant? The prices. Is Josh Allen one of the best NFL qbs? No! Does he provide fantasy football value because of his legs? Yes.
-Is Sam Darnold the best QB? No. But at home, favored, and pricing, he and Bell could provide the TD equity in this game easy and this game will either fall under 40.5 or go way over and hit 50. I could easily see long TDs from Darnold to Anderson and could allow you to fit any RBs, WRs or defenses you want in lineup construction.
Bengals +10 at Seahawks (44). Chris Carson plus Seattle defense is the play here. Don’t fall for the Tyler Boyd with no AJ Green trap. Mixon could score but this is not an optimal spot.
Ravens -5 at Dolphins (37.5). As much as we may like Baltimore defense, how about the Dolphins defense for dirt cheap and just play all of the offense you want? Are they under dogs? Yes! But they are at home. And Lamar Jason could easily throw a pick six. That mixed with not allowing Baltimore to score 28-31 is good enough at their price. However, Jackson, Mark Ingram, and the Baltimore (an expensive defense) is still in play despite such a low total game. I think the Bills/Jets are more likely to go over their game total than this one. Young QBs like their TEs so Andrews is firmly in play as well.
QB
Jameis Winston
Matt Stafford
Lamar Jackson
Phillip Rivers
Pat Mahomes
Sam Darnold
Josh Allen
Carson Wentz
RB
Christian McCaffrey
Todd Gurley/Malcom Brown
Pollard if Zeek is limited in anyway (Giants/Cowboys not mentioned in article)
Saquan Barkley and his floor (Giants/Cowboys not mentioned in article. Barkley has a safe floor and potential ceiling, BUT it is a division game vs a good Cowboys defense)
Dalvin Cook
Mark Ingram
Peyton Barber
Jordan Howard
Nick Chubb
Chris Carson
Austin Eckler
Damien Williams/Lesean McCoy
WR
Rams (3). Robert Woods. Cooper Kupp. Brandin Cooks
Mike Evans/Chris Godwin
Adam Thielen
Calvin Ridley
Alshon Jeffrey
Kenny Golloday/Marvin Jones
Keenan Allen/Mike Williams
TE
Travis Kelce
Zach Ertz
George Kittle
Austin Hooper
OJ Howard
Kyle Rudolph
Hunter Henry
Mark Andrews
Defense
Chargers
Eagles
Browns
Detroit
Baltimore
Seattle
1 note
·
View note
Text
The Sports Betting Bible
Hi! My name is Alex, and I’m the co-founder of OddsJam. I put this document together to be a quick “guide” about the various OddsJam betting tools. I promise that taking a few minutes to read + internalize this will be valuable and increase your sports betting profits dramatically.
I’m not a writer / expert in formatting, but I truly hope this is helpful to you and makes you more profitable, regardless of if you’re an OddsJam user. My mission is to level the playing field and help sports bettors become more knowledgeable & profitable.
To be straightforward, education = money in sports betting, so put in the work to learn these concepts! OddsJam is based solely on real-time market data. There’s no fluff, no BS. The more time you put into learning about sports betting markets, the more money you’ll make. It’s that simple.
PLEASE Do/Read!
We created default filters with all of the bets we would hit from OddsJam. It is called “OddsJam Pro Filters” or “Recommended Filters.” There will be fewer positive EV bets available, but they are all highly profitable. It’s the sharpest bets from OddsJam. My advice would be keep the filters on & bet as many as you can.

Turning these filters on will essentially guarantee profitability over a large sample size of bets. These are the most profitable bets from OddsJam based on real-time data from the entire sports betting market (e.g. all odds) and historical weightings of sportsbook “sharpness” based on backtesting (for player props vs. mainlines, etc.).
There is of course a spectrum of sportsbook sharpness, and using real-time market data from numerous sharp bookmakers to find “fair odds” is the only rational way to bet on sports and profit long-term.
You’ll grow more confident in Positive EV betting as you see the results over a large sample size of bets. This is investing with an edge more than “sports betting”
Resources
Video Tutorials:
Positive EV: Video Tutorial. This tool shows you mathematically profitable bets with an “edge” over the sportsbook.
Free Bet Converter: Video Tutorial. This tool shows you how to convert your free bets into cash at the highest possible rate.
Arbitrage Bets: Video Tutorial. This tool shows you bets where you can make a risk-free profit due to discrepancies in bookmaker odds.
Middle Bets: Video Tutorial. This tool shows you the best “lottery ticket” sports bets.
Bet Tracker: Video Tutorial. This tool will automatically track your profit and loss.
Low Holds: Video Tutorial. This tool helps you work through deposit bonuses, get sportsbook rewards and gain “VIP” status on sportsbooks. I actually just got back from Las Vegas as a VIP member of WynnBet sportsbook. I even got to meet Tom Brady!
Phone Number for Immediate Support (Text/Call Anytime): (309) 324-4244
Calendars for One on One Tutorials – our experts are by your side every step of the way to make sure you are profitable!
Randall Knaak: https://calendly.com/randall-oddsjam/15min ([email protected])
Randall is a former public school teacher and one of the first users of OddsJam. He made $15,000 with OddsJam in three months and was our first employee. Here’s his tutorial and breakdown of how he made $15,000 part-time with OddsJam as a public school teacher: https://youtu.be/l1EQVFyTuJM
BobLoGrasso: https://calendly.com/boblo/15min ([email protected])
Current OddsJam user
Mike LoGrasso: https://calendly.com/oddsjam-mike/20min ([email protected])
Current OddsJam user
Join the OddsJam YouTube:https://www.youtube.com/c/oddsjaminc. We discuss profitable bets & betting strategies on a daily basis with real-time examples. See bets from us on a daily basis and the profit stack up! Ask questions, etc. Our goal is to help you winlong-term.
Free OddsJam Mobile App for historical player prop research:https://apps.apple.com/us/app/oddsjam-player-props-data/id1632668175
Out of State betting (e.g. you don’t have FanDuel / DraftKings):
Check if you have access toPrizePicks. This DFS platform is insanely profitable. Here’s a tutorial on PrizePicks:https://youtu.be/YaiuFoncU9o
Regardless, OddsJam has an exclusive, non-public plan for users in restricted locations without regulated sports betting (e.g. no DraftKings, FanDuel). This plan includes global sportsbooks, such as BOL. Practicallyeverysportsbook in the world is on this exclusive plan.There’s lots of profitable bets, deposit bonuses & promos on these global sportsbooks.
This plan is not publicly available to sign up for on the OddsJam website, as we limit the number of customers on this plan. Email us / text us to learn more –[email protected] (309) 324-4244. This plan will help make you big profits from sports betting, regardless of your location.
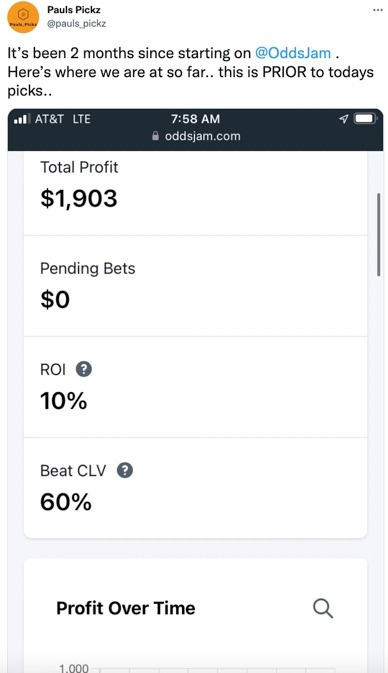
OddsJam Tool #1: Positive EV
Positive EV bets are just profitable bets. Honestly, that’s really all they are – just data-driven, mathematically profitable bets. OddsJam is processing millions of odds in real-time to find these bets for you. The stock market returns roughly 8% year over year (on average), and, with Positive EV betting, you can earn returns over 3%every single day.
I know our Positive EV tool can be overwhelming at first, so let’s break it down.
Always place the bet in bold with a circle around it (below it’s Twins -1.5 +188 odds).
Your profit margin is under the “Percent” Column. Here, the profit margin is 5.91%. So betting on Twins -1.5 at +188 odds would have an ROI of $5.91 per $100 wagered over the course of long run.
The “OddsJam” line shows you real-time odds from the sharpest bookmaker in the world, Pin. They’re only giving you +161 odds on Twins -1.5 run line….and we’re getting +188 on FanDuel. That’s why this bet is ridiculously profitable. Learn more about the sharpest sportsbook here.
The “No Vig Odds” (also called fair odds or true odds) is the “true price” for this wager. Here’s it is +171.92. We’re getting +188 on FanDuel, so we’re getting better odds than the “true odds.” That’s why this bet is profitable. This bet has value or edge which is what we’re always looking for as a sports bettor!

Here’s a full length video tutorial on Positive EV betting if you’re more of a visual learner 🙂
To be clear, most bets are not Positive EV. That’s why sportsbooks are in business and most sports bettors lose money. However, OddsJam finds the 0.01% of betting opportunities that are actually profitable (e.g. where a sportsbook is giving odds that are too good to be true).
An Analogy on Positive EV Betting
Imagine there’s a coin – 60% to land on heads, 40% to land on tails. You’re flipping it with a friend for $100. Which side do you want to be on? You’re probably think “Of course Heads, it’s more likely to win.” That’sbasicallythe concept of Positive EV betting. It’s not much more complicated. Just like flipping the coin with “Heads” has an edge, every Positive EV bet has an “edge” over the sportsbooks.
What Your Profit Will Look Like:
You won’t win every bet. You won’t win every day. That’s not Positive EV betting. However, you’ll win in the long run because you have the mathematical “edge”. You can see a review of the OddsJam Positive EV tool below. There’s thousands online just like this, but I can’t make this email too long. You’ll win some days, lose others, but you’ll beguaranteedto make money in the long run since you have the mathematical edge.

Positive EV betting isessentiallyforming your own hedge fund of mathematically profitable bets. Every bet has an “edge,” or profit margin. Not every bet will win, but over the course of the long run, you’ll be guaranteed to make money!
Placing 10+ profitable bets per day, watching the games and knowing I’m going to win in the long run brings a lot of joy to my life (as well as money!).
Example of a good bet:
Check out this bet below. Under 1.5 total rounds in Dustin Stolzfus vs Dwight Grant at +180 odds on WynnBet. The profit margin is 4.2%. No other sportsbook is giving us above +160, and we’re getting +180 on WynnBet. Just a simple sanity check, looking at the betting market, it’s clear that this is a good bet.

Arbitrage Tool
I know it sounds too good to be true, but the Arbitrage Tool shows you how to make risk-free money in sports betting. And, yes, it’s possible.
How does arbitrage exist?
It’s a market inefficiency. Since sportsbooks want to be unique, they set odds independently. When sportsbooks have major pricing discrepancies, you can bet on equal and opposite outcomes and earn a risk-free return (e.g. over 6.5 strikeouts on FanDuel, under 6.5 strikeouts on DraftKings).
Arbitrage israreand practically impossible to find without software. However, with OddsJam updating millions of odds every second, it is possible to grow your bankrollrisk-freewith arbitrage betting. About 0.001% of odds on sportsbooks are arbitrage bets. OddsJam will find them for you 🙂
If you’re more of a visual learner, here’s a good video on arbitrage betting with examples:https://youtu.be/UAafPTFSj0s
How do I know how much to bet?

Why isn’t everybody retired off arbitrage betting?
First, arbitrage betting can be tough. These are marketinefficiencies, so you need to move fast. Arbitrage bets won’t last forever. Some last less than 90 seconds. It iscriticalfor you to learn how to navigate the sportsbooks quickly to get in on arbitrage bets. Most OddsJam arbitrage bettors have sportsbooks open (& logged into) on one screen, and they’re constantly refreshing OddsJam. You’re essentially day trading sports markets.
Second, you never know when the best arbitrage bets will occur. They often occur when sportsbooksfirstpost odds for an upcoming day or after player injuries (e.g. when lines are changing). Some of the best arbitrage bets I’ve hit were at 2am. Others have been at 2pm. The more you use OddsJam, the more arbitrage bets you will hit, and the more risk-free money you’ll make. Using the tools more = more profits for yourself. That goes for Positive EV betting as well.
Low Holds Tool
The Low Holds tool has 3 main purposes: deposit bonuses, reward credits and VIP programs.
Let’s start with deposit bonuses. Many sportsbooks offer deposit bonuses with “playthroughs.” The Low Holds page finds you bets that are optimal for playing through deposit bonuses. Here’s a good video on deposit bonuses:https://youtu.be/OjTMWJva0yI

Finally, we have reward credits. Many sportsbooks, including DraftKings, WynnBet & Caesars, offer reward credits. The more you bet, the more you earn. It nearly always makes sense to bet every 0% low hold for this reason. If you have questions about sportsbook rewards, email us at [email protected]! We’re happy to help or give you a tutorial.


Free Bet Conversion
Free bets are a common form of sportsbook bonus. The OddsJam free bet conversion tools show you how to convert these free bets into cash at the highest possible rate. Here’s a video I highly recommend explaining free bet strategy:https://youtu.be/xtlDj3NCIOc
Bet Tracker
How are you supposed to know if you’re a good sports bettor if you aren’t tracking your profit & loss and closing line value?You need to track your bets. The OddsJam Bet Tracker automatically tracks your CLV vs. the sharpest sportsbook in the world, as well as your profit and loss. I highly recommend this video:https://youtu.be/Xxypee4lI14
Middle Betting Tool
Middle Betsare another profitable feature of OddsJam. Middles are essentially the low risk, low probability “lottery tickets” of sports betting. They can beextremelyprofitable for you, but they are less common than arbitrage bets and Positive EV bets.
Middle bets are a bit of a complex topic, so please take a few moments to watch this quick video by Alex about Middle Bets:https://youtu.be/apziiC25SVw
0 notes
Text
DFS
Depth-First Search Algorithm
The depth-first search or DFS algorithm traverses or explores data structures, such as trees and graphs. The algorithm starts at the root node (in the case of a graph, you can use any random node as the root node) and examines each branch as far as possible before backtracking.
When a dead-end occurs in any iteration, the Depth First Search (DFS) method traverses a network in a deathward motion and uses a stack data structure to remember to acquire the next vertex to start a search.
Following the definition of the dfs algorithm, you will look at an example of a depth-first search method for a better understanding.
Example of Depth-First Search Algorithm
The outcome of a DFS traversal of a graph is a spanning tree. A spanning tree is a graph that is devoid of loops. To implement DFS traversal, you need to utilize a stack data structure with a maximum size equal to the total number of vertices in the graph.
To implement DFS traversal, you need to take the following stages.
Step 1: Create a stack with the total number of vertices in the graph as the size.
Step 2: Choose any vertex as the traversal’s beginning point. Push a visit to that vertex and add it to the stack.
Step 3 — Push any non-visited adjacent vertices of a vertex at the top of the stack to the top of the stack.
Step 4 — Repeat steps 3 and 4 until there are no more vertices to visit from the vertex at the top of the stack.
Read More
Step 5 — If there are no new vertices to visit, go back and pop one from the stack using backtracking.
Step 6 — Continue using steps 3, 4, and 5 until the stack is empty.
Step 7 — When the stack is entirely unoccupied, create the final spanning tree by deleting the graph’s unused edges.
Consider the following graph as an example of how to use the dfs algorithm.
Step 1: Mark vertex A as a visited source node by selecting it as a source node.
· You should push vertex A to the top of the stack.
Step 2: Any nearby unvisited vertex of vertex A, say B, should be visited.
· You should push vertex B to the top of the stack.
Step 3: From vertex C and D, visit any adjacent unvisited vertices of vertex B. Imagine you have chosen vertex C, and you want to make C a visited vertex.
· Vertex C is pushed to the top of the stack.
Step 4: You can visit any nearby unvisited vertices of vertex C, you need to select vertex D and designate it as a visited vertex.
· Vertex D is pushed to the top of the stack.
Step 5: Vertex E is the lone unvisited adjacent vertex of vertex D, thus marking it as visited.
· Vertex E should be pushed to the top of the stack.
Step 6: Vertex E’s nearby vertices, namely vertex C and D have been visited, pop vertex E from the stack.
Read More
Step 7: Now that all of vertex D’s nearby vertices, namely vertex B and C, have been visited, pop vertex D from the stack.
Step 8: Similarly, vertex C’s adjacent vertices have already been visited; therefore, pop it from the stack.
Step 9: There is no more unvisited adjacent vertex of b, thus pop it from the stack.
Step 10: All of the nearby vertices of Vertex A, B, and C, have already been visited, so pop vertex A from the stack as well.
Now, examine the pseudocode for the depth-first search algorithm in this.
Pseudocode of Depth-First Search Algorithm
Pseudocode of recursive depth-First search algorithm.
Depth_First_Search(matrix[ ][ ] ,source_node, visited, value)
{
If ( sourcce_node == value)
return true // we found the value
visited[source_node] = True
for node in matrix[source_node]:
If visited [ node ] == false
Depth_first_search ( matrix, node, visited)
end if
end for
return false //If it gets to this point, it means that all nodes have been explored.
//And we haven’t located the value yet.
}
Pseudocode of iterative depth-first search algorithm
Depth_first_Search( G, a, value): // G is graph, s is source node)
stack1 = new Stack( )
stack1.push( a ) //source node a pushed to stack
Mark a as visited
while(stack 1 is not empty): //Remove a node from the stack and begin visiting its children.
B = stack.pop( )
If ( b == value)
Return true // we found the value
Push all the uninvited adjacent nodes of node b to the Stack
Read More
For all adjacent node c of node b in graph G; //unvisited adjacent
If c is not visited :
stack.push(c)
Mark c as visited
Return false // If it gets to this point, it means that all nodes have been explored.
//And we haven’t located the value yet.
Complexity Of Depth-First Search Algorithm
The time complexity of depth-first search algorithm
If the entire graph is traversed, the temporal complexity of DFS is O(V), where V is the number of vertices.
· If the graph data structure is represented as an adjacency list, the following rules apply:
· Each vertex keeps track of all of its neighboring edges. Let’s pretend there are V vertices and E edges in the graph.
· You find all of a node’s neighbors by traversing its adjacency list only once in linear time.
· The sum of the sizes of the adjacency lists of all vertices in a directed graph is E. In this example, the temporal complexity is O(V) + O(E) = O(V + E).
· Each edge in an undirected graph appears twice. Once at either end of the edge’s adjacency list. This case’s temporal complexity will be O(V) + O (2E) O(V + E).
· If the graph is represented as adjacency matrix V x V array:
· To find all of a vertex’s outgoing edges, you will have to traverse a whole row of length V in the matrix.
Read More
· Each row in an adjacency matrix corresponds to a node in the graph; each row stores information about the edges that emerge from that vertex. As a result, DFS’s temporal complexity in this scenario is O(V * V) = O. (V2).
The space complexity of depth-first search algorithm
Because you are keeping track of the last visited vertex in a stack, the stack could grow to the size of the graph’s vertices in the worst-case scenario. As a result, the complexity of space is O. (V).
After going through the complexity of the dfs algorithm, you will now look at some of its applications.
Application Of Depth-First Search Algorithm
The minor spanning tree is produced by the DFS traversal of an unweighted graph.
1. Detecting a graph’s cycle: A graph has a cycle if and only if a back edge is visible during DFS. As a result, you may run DFS on the graph to look for rear edges.
2. Topological Sorting: Topological Sorting is mainly used to schedule jobs based on the dependencies between them. In computer science, sorting arises in instruction scheduling, ordering formula cell evaluation when recomputing formula values in spreadsheets, logic synthesis, determining the order of compilation tasks to perform in makefiles, data serialization, and resolving symbols dependencies linkers.
3. To determine if a graph is bipartite: You can use either BFS or DFS to color a new vertex opposite its parents when you first discover it. And check that each other edge does not connect two vertices of the same color. A connected component’s first vertex can be either red or black.
4. Finding Strongly Connected Components in a Graph: A directed graph is strongly connected if each vertex in the graph has a path to every other vertex.
5. Solving mazes and other puzzles with only one solution:By only including nodes the current path in the visited set, DFS is used to locate all keys to a maze.
6. Path Finding: The DFS algorithm can be customized to discover a path between two specified vertices, a and b.
· Use s as the start vertex in DFS(G, s).
· Keep track of the path between the start vertex and the current vertex using a stack S.
Read More
· Return the path as the contents of the stack as soon as destination vertex c is encountered.
Finally, in this tutorial, you will look at the code implementation of the depth-first search algorithm.
Code Implementation Of Depth-First Search Algorithm
#include <stdio.h>
#include <stdlib.h>
#include <stdlib.h>
int source_node,Vertex,Edge,time,visited[10],Graph[10][10];
void DepthFirstSearch(int i)
{
int j;
visited[i]=1;
printf(“ %d->”,i+1);
for(j=0;j<Vertex;j++)
{
if(Graph[i][j]==1&&visited[j]==0)
DepthFirstSearch(j);
}
}
int main()
{
int i,j,v1,v2;
printf(“\t\t\tDepth_First_Search\n”);
printf(“Enter the number of edges:”);
scanf(“%d”,&Edge);
printf(“Enter the number of vertices:”);
scanf(“%d”,&Vertex);
for(i=0;i<Vertex;i++)
{
for(j=0;j<Vertex;j++)
Graph[i][j]=0;
}
for(i=0;i<Edge;i++)
{
printf(“Enter the edges (V1 V2) : “);
scanf(“%d%d”,&v1,&v2);
Graph[v1–1][v2–1]=1;
}
for(i=0;i<Vertex;i++)
{
for(j=0;j<Vertex;j++)
printf(“ %d “,Graph[i][j]);
printf(“\n”);
}
printf(“Enter the source: “);
scanf(“%d”,&source_node);
DepthFirstSearch(source_node-1);
return 0;
}
1 note
·
View note
Text
DFS Algorithm
Depth-First Search Algorithm
The depth-first search or DFS algorithm traverses or explores data structures, such as trees and graphs. The algorithm starts at the root node (in the case of a graph, you can use any random node as the root node) and examines each branch as far as possible before backtracking.
When a dead-end occurs in any iteration, the Depth First Search (DFS) method traverses a network in a deathward motion and uses a stack data structure to remember to acquire the next vertex to start a search.
Following the definition of the dfs algorithm, you will look at an example of a depth-first search method for a better understanding.
Example of Depth-First Search Algorithm
The outcome of a DFS traversal of a graph is a spanning tree. A spanning tree is a graph that is devoid of loops. To implement DFS traversal, you need to utilize a stack data structure with a maximum size equal to the total number of vertices in the graph.
To implement DFS traversal, you need to take the following stages.
Step 1: Create a stack with the total number of vertices in the graph as the size.
Step 2: Choose any vertex as the traversal's beginning point. Push a visit to that vertex and add it to the stack.
Step 3 - Push any non-visited adjacent vertices of a vertex at the top of the stack to the top of the stack.
Step 4 - Repeat steps 3 and 4 until there are no more vertices to visit from the vertex at the top of the stack.
Read More
Step 5 - If there are no new vertices to visit, go back and pop one from the stack using backtracking.
Step 6 - Continue using steps 3, 4, and 5 until the stack is empty.
Step 7 - When the stack is entirely unoccupied, create the final spanning tree by deleting the graph's unused edges.
Consider the following graph as an example of how to use the dfs algorithm.
Step 1: Mark vertex A as a visited source node by selecting it as a source node.
· You should push vertex A to the top of the stack.
Step 2: Any nearby unvisited vertex of vertex A, say B, should be visited.
· You should push vertex B to the top of the stack.
Step 3: From vertex C and D, visit any adjacent unvisited vertices of vertex B. Imagine you have chosen vertex C, and you want to make C a visited vertex.
· Vertex C is pushed to the top of the stack.
Step 4: You can visit any nearby unvisited vertices of vertex C, you need to select vertex D and designate it as a visited vertex.
· Vertex D is pushed to the top of the stack.
Step 5: Vertex E is the lone unvisited adjacent vertex of vertex D, thus marking it as visited.
· Vertex E should be pushed to the top of the stack.
Step 6: Vertex E's nearby vertices, namely vertex C and D have been visited, pop vertex E from the stack.
Read More
Step 7: Now that all of vertex D's nearby vertices, namely vertex B and C, have been visited, pop vertex D from the stack.
Step 8: Similarly, vertex C's adjacent vertices have already been visited; therefore, pop it from the stack.
Step 9: There is no more unvisited adjacent vertex of b, thus pop it from the stack.
Step 10: All of the nearby vertices of Vertex A, B, and C, have already been visited, so pop vertex A from the stack as well.
Now, examine the pseudocode for the depth-first search algorithm in this.
Pseudocode of Depth-First Search Algorithm
Pseudocode of recursive depth-First search algorithm.
Depth_First_Search(matrix[ ][ ] ,source_node, visited, value)
{
If ( sourcce_node == value)
return true // we found the value
visited[source_node] = True
for node in matrix[source_node]:
If visited [ node ] == false
Depth_first_search ( matrix, node, visited)
end if
end for
return false //If it gets to this point, it means that all nodes have been explored.
//And we haven't located the value yet.
}
Pseudocode of iterative depth-first search algorithm
Depth_first_Search( G, a, value): // G is graph, s is source node)
stack1 = new Stack( )
stack1.push( a ) //source node a pushed to stack
Mark a as visited
while(stack 1 is not empty): //Remove a node from the stack and begin visiting its children.
B = stack.pop( )
If ( b == value)
Return true // we found the value
Push all the uninvited adjacent nodes of node b to the Stack
Read More
For all adjacent node c of node b in graph G; //unvisited adjacent
If c is not visited :
stack.push(c)
Mark c as visited
Return false // If it gets to this point, it means that all nodes have been explored.
//And we haven't located the value yet.
Complexity Of Depth-First Search Algorithm
The time complexity of depth-first search algorithm
If the entire graph is traversed, the temporal complexity of DFS is O(V), where V is the number of vertices.
· If the graph data structure is represented as an adjacency list, the following rules apply:
· Each vertex keeps track of all of its neighboring edges. Let's pretend there are V vertices and E edges in the graph.
· You find all of a node's neighbors by traversing its adjacency list only once in linear time.
· The sum of the sizes of the adjacency lists of all vertices in a directed graph is E. In this example, the temporal complexity is O(V) + O(E) = O(V + E).
· Each edge in an undirected graph appears twice. Once at either end of the edge's adjacency list. This case's temporal complexity will be O(V) + O (2E) O(V + E).
· If the graph is represented as adjacency matrix V x V array:
· To find all of a vertex's outgoing edges, you will have to traverse a whole row of length V in the matrix.
Read More
· Each row in an adjacency matrix corresponds to a node in the graph; each row stores information about the edges that emerge from that vertex. As a result, DFS's temporal complexity in this scenario is O(V * V) = O. (V2).
The space complexity of depth-first search algorithm
Because you are keeping track of the last visited vertex in a stack, the stack could grow to the size of the graph's vertices in the worst-case scenario. As a result, the complexity of space is O. (V).
After going through the complexity of the dfs algorithm, you will now look at some of its applications.
Application Of Depth-First Search Algorithm
The minor spanning tree is produced by the DFS traversal of an unweighted graph.
1. Detecting a graph's cycle: A graph has a cycle if and only if a back edge is visible during DFS. As a result, you may run DFS on the graph to look for rear edges.
2. Topological Sorting: Topological Sorting is mainly used to schedule jobs based on the dependencies between them. In computer science, sorting arises in instruction scheduling, ordering formula cell evaluation when recomputing formula values in spreadsheets, logic synthesis, determining the order of compilation tasks to perform in makefiles, data serialization, and resolving symbols dependencies linkers.
3. To determine if a graph is bipartite: You can use either BFS or DFS to color a new vertex opposite its parents when you first discover it. And check that each other edge does not connect two vertices of the same color. A connected component's first vertex can be either red or black.
4. Finding Strongly Connected Components in a Graph: A directed graph is strongly connected if each vertex in the graph has a path to every other vertex.
5. Solving mazes and other puzzles with only one solution:By only including nodes the current path in the visited set, DFS is used to locate all keys to a maze.
6. Path Finding: The DFS algorithm can be customized to discover a path between two specified vertices, a and b.
· Use s as the start vertex in DFS(G, s).
· Keep track of the path between the start vertex and the current vertex using a stack S.
Read More
· Return the path as the contents of the stack as soon as destination vertex c is encountered.
Finally, in this tutorial, you will look at the code implementation of the depth-first search algorithm.
Code Implementation Of Depth-First Search Algorithm
#include <stdio.h>
#include <stdlib.h>
#include <stdlib.h>
int source_node,Vertex,Edge,time,visited[10],Graph[10][10];
void DepthFirstSearch(int i)
{
int j;
visited[i]=1;
printf(" %d->",i+1);
for(j=0;j<Vertex;j++)
{
if(Graph[i][j]==1&&visited[j]==0)
DepthFirstSearch(j);
}
}
int main()
{
int i,j,v1,v2;
printf("\t\t\tDepth_First_Search\n");
printf("Enter the number of edges:");
scanf("%d",&Edge);
printf("Enter the number of vertices:");
scanf("%d",&Vertex);
for(i=0;i<Vertex;i++)
{
for(j=0;j<Vertex;j++)
Graph[i][j]=0;
}
for(i=0;i<Edge;i++)
{
printf("Enter the edges (V1 V2) : ");
scanf("%d%d",&v1,&v2);
Graph[v1-1][v2-1]=1;
}
for(i=0;i<Vertex;i++)
{
for(j=0;j<Vertex;j++)
printf(" %d ",Graph[i][j]);
printf("\n");
}
printf("Enter the source: ");
scanf("%d",&source_node);
DepthFirstSearch(source_node-1);
return 0;
}
1 note
·
View note
Text
Graux & Baeyens adds sunken bike workshop to Ghent townhouse
A sunken bicycle workshop sits at the end of a classical-style walled garden at this extension to a townhouse in Ghent, completed by Belgian practice Graux & Baeyens Architecten.
In addition to the workshop, a stack of three new forms designed by the local practice adds a kitchen and dining space, bathroom and bedroom to the dwelling on the Visserij canal.
House C-DF was extended and renovated by Graux & Baeyens Architecten
Called House C-DF, the townhouse had an existing narrow rear extension that has been extended to fill the width of the plot, creating a "logical flow" and visual connection through the home to the garden.
"While the main residence required few modifications, tabula rasa was created with the old extension of the house," said the practice.
The home was extended to fill the majority of a narrow plot at the rear
"Rather than keep this extension narrow and deep as it originally was, it was decided to have it fanned out over the full width of the outdoor space," Graux & Baeyens Architecten added.
"This intervention immediately improved the enfilade between the front, intermediate and back chambers."
The new extension visibly contrasts with the existing building
The existing extension was enlarged with a structure of prefabricated steel, left exposed internally to create a series of fins that contrast the original structure and to create space for built-in cabinets.
A triangular skylight has been inserted between the old and new extensions to illuminate the space, and wood-framed sliding glass doors lead out onto the paved garden.
Read:
Graux & Baeyens adds bright living areas to Belgian chalet
"The steel fins were deliberately not concealed, but subtly painted in white and milled, creating a poetic play of light in the extension," explained the practice.
"The fins also determine the rhythm of the cabinets that came between them, which, thanks to a subtle interruption, accentuate the depth of the house," it continued.
Terrazzo was used throughout the new extension
Atop the steel frame of this rear extension is a new first-floor bathroom, lined in terrazzo and featuring a full-height window overlooking the city's rooftops that "ensures the residents shower with a view of Ghent," according to the practice.
On the second floor, a new bedroom and a mezzanine play room also features a fully-glazed wall looking out towards the rear of the home, contrasted by a thin dormer window opposite that overlooks the canal.
Large windows frame city views
"The high window offers a beautiful view of historic Ghent but remains surprisingly human-sized thanks to the playful layout," said the practice.
At the end of the walled garden, the sunken bicycle workshop sits in a small volume finished in grey brickwork to match the existing garden walls, which have been fully restored.
The practice used materials that mean the extension could blend in with the existing structure
Externally, the extensions have been unified by the use of pale timber planking and window frames, intended to create a "subtle point of contact between the two constructions."
Other extensions recently completely by Graux & Baeyens include the renovation and extension of a 1960s chalet in Destelbergen, and the modernisation of a bungalow in De Haan.
Photography is by Jeroen Verrecht.
The post Graux & Baeyens adds sunken bike workshop to Ghent townhouse appeared first on Dezeen.
0 notes
Text
College Fantasy Football Kicker Rankings 2021: Top kickers, sleepers to know

Want the keys to success in your college fantasy football league? Treat every position like it’s the most important -- even down to your kicker! It takes a full, solid roster to win games in fantasy, and CFBDynasty is ready to help you start dominating your league, one kicker at a time! While you might consider all kickers sleepers (because they can be boring), there are kickers solidily at the top and some sneaky values ultra-late in your draft. CFBDynasty recently released their 2021 kicker rankings, just in time for your draft. 2021 COLLEGE FANTASY RANKINGS: Quarterback | Running back | Wide receiver | Tight end | D/ST | Top 200 It's important to note college kicking is often unreliable and hard to predict. The safest bet is to target kickers on high-scoring offenses with a history of decent accuracy. A smart move would be stacking a high-profile QB, like Spencer Rattler, with his kicker. This will likely give you PATs when Rattler scores and field goals when the Oklahoma offense stalls. Either way, you grab fantasy points every time the OU offense scores in any variety.DOMINATE YOUR COLLEGE FANTASY DRAFT: Join CFBDynasty Join CFBDynasty today and get the full 2021 kicker rankings. In addition to their valuable draft cheat sheets, you’ll get full positional rankings guides, college DFS rankings, full strategy assistance, waiver wire help, mock drafts, and the player new you can find. Use Promo Code “sportingnews” and get 15 percent off your subscription!DOMINATE YOUR NFL FANTASY DRAFT: Ultimate 2021 Cheat Sheet
2021 College Fantasy Football Kicker Rankings
Rank Player Team Year 1 Gabe Brkic Okla Jr 2 Cade York LSU Jr 3 Will Reichard Ala Jr 4 B.T. Potter Clem Sr 5 Grayson Atkins UNC Sr 6 Cameron Dicker Tex Sr 7 Jake Seibert OHSt Fr 8 Jonah Dalmas Boise So 9 Alex Hale OkSt Jr 10 Alex Barbir Lib Sr 11 Brian Johnson VaTec Sr 12 Jack Podlesny UGA Jr 13 Anders Carlson Aub Sr 14 Jonathan Doerer ND Sr 15 Seth Small TxAM Sr 16 Harrison Mevis Mizzu So 17 Dalton Witherspoon Hou Sr 18 Nick Sciba Wake Jr 19 Charles Campbell Ind Jr 20 Jace Christmann Fla Sr 21 Jake Oldroyd BYU So 22 Chad Ryland E Mi Jr 23 Jadon Redding Utah So 24 John Hoyland Wyo Fr 25 Marshall Meeder C Mi Fr Read the full article
0 notes
Text
Introduction To Recursion In C++
To begin with recursion in C++, we must first understand the fundamental concept of C++ functions, which comprises function definitions that call other functions. Also covered in this article is the concept of the recursive definition, a math and programming logic play tool. A common example is the factorial of a number, the sum of "n" natural numbers, and so on. The term "recursive function" refers to a function that calls itself. They are simply a function that is called repeatedly. Recursion offers a problem-solving tool that separates huge problems into simple tasks that are worked out separately in a sequential order.
The recursive function is used to solve problems in data structures such as searching, sorting, and tree traversal. This programming method makes it easy to write code. Iteration and recursion both repeat the code, but recursion executes a specific part of the code with the base function itself. In this article, we will go over the importance of recursion and how it works.
What Is Recursion?
Recursion is the process of a function calling itself as a subroutine to tackle a complex iterative task by breaking it down into smaller chunks. Recursive functions are those that call themselves recursively, while recursion is the process of invoking a function by itself. Recursion results in a large number of iterative calls to the same function; however, a base case is required to end the recursion.
By dividing a complex mathematical computation task into subtasks, recursion is an efficient way to solve it. Divide and Conquer is the name for this method of problem-solving. It allows programmers to break down a complex problem into smaller tasks and solve them one at a time to arrive at a final solution.
Any problem that can be solved recursively can also be solved iteratively, but recursion is the more efficient method of programming because it uses the least amount of code to accomplish the same complex task. Although recursion is not suitable for all problems, it is particularly well suited for sorting, searching, Inorder/Preorder/Postorder Tree Traversals, and DFS of Graph algorithms. Recursion, on the other hand, must be implemented with care; otherwise, if no base condition is met to terminate the function, it may result in an infinite loop.
How Recursive Functions Work In C++?
When the base case is true, recursion conducts repetition on the function calls and stops the execution. To avoid the stack overflow error message, a base case condition should be defined in the recursive code. Infinite recursion results if no base case is defined. When a function is called, it is pushed into a stack each time so that resources can be reserved for subsequent calls. It is the most effective at traversing trees. Direct and indirect recursion are two separate forms of recursion.
Direct Recursion: A direct recursive function is one that calls itself directly, and this sort of recursion is known as direct recursion.
Indirect Recursion : When a function calls itself indirectly from another function, it is referred to as indirect recursive, and this sort of recursion is referred to as indirect recursion.
Memory Allocation In Recursion:
Memory allocation for recursive functions is similar to memory allocation for other functions. A single memory block in a stack is allocated when a recursive function is called. This memory block provides the necessary memory space for the function's successful execution as well as the storage of all local, automatic, and temporary variables. It pushes a separate stack frame for each recursive call in the same way. There will be 5 stack frames corresponding to each recursive call if a recursive function is called 5 times. When the recursive call is completed, the new stack frame is discarded, and the function begins to return its value to the function in the previous stack frame. The stack is then popped out in the same order that it was pushed, and memory is deallocated. The final result value is returned at the end of the recursion, and the stack is destroyed and memory is freed up. The stack will quickly be depleted if the recursion fails to reach a base case, resulting in a Stack Overflow crash.
Advantages Of Recursion:
They create clean and compact code by simplifying a larger, more complex application.
They create clean and compact code by simplifying a larger, more complex application.
In the computer code, there are fewer variables.
Here, nested for loops and complex code are avoided.
Backtracking is required in several parts of the code, which is solved recursively.
Disadvantages Of Recursion:
Due to the stack operation of all the function calls, it requires extra memory allocation.
When doing the iteration process, it can be a little sluggish at times. As a result, efficiency suffers.
Beginners may find it challenging to comprehend the workings of the code because it can be quite complex at times. If this happens, the software will run out of memory and crash.
Summary:
We've talked about how functions operate and defined them in a recursive manner. We've also gone over the correspondence and the benefits and drawbacks of recursive functions in programming.
0 notes
Text
Assembly Language Homework Help
Assembly Language Assignment Support . Assembly Language Homework Support
If you think assembly language is a difficult programming subject, you are not the only student who makes the subject challenging. Out of every 100 programming assignments to be submitted on our website, 40 are in the conference language. Assembly language assignment is the most sought service in support programming. We have a team of expert programmers who work only on assembly language projects. They go first through the directions of the university for the students and then start the project. They not only share the complete programming work that can be easily run but they are successfully running the screen shot of the program and share a step-by-step approach to how students can understand and implement the program.
If you are one of those students who do not have the full knowledge of concepts, it is difficult for you to complete the assembly language homework. The Programming Assignment Support website can provide you with the Executive Assembly Language homework help Solution. Before we go ahead, let's learn more about the assembly language.
What is assembly language?
Assembly language is a low-level programming language which is a correspondence between machine code and program statement. It is still widely used in academic work. Assembly is the main application of language - it is used for equipment and micro-controllers. It is a collection of languages which will be used to write machine codes for creating CPU architecture. However, there will be no required functions and variables in this language and cannot be used in all types of processors. Assembly language commands and structures are similar to machine language, but it allows the programmer to use the number with the names.
A low-level language is a language that works with computer hardware. Gradually, they forgot. These languages are still kept in the curriculum as it gives students hardware knowledge
Here are some important concepts in assembly language:
Collecter
Language Design - Opcode Memonics and Detailed Nemonics, Support for ureded programs, Assembly Instructions and Data Instructions
Operators, Parts and Labels
Machine Language Instructions
Maths and Transfer Instructions
Pageing, catch and interruptions
These are just a few topics; We will work on many other subjects in accordance with the needs of the students to assist in assembly language assignment.
Key concepts to be learned in assembly language
The following 6 important vocabularies in Assembly Languedhoes are given below
Memory address: This is where the machine will store code. If the address starts with YY00, YY represents the page number and the 00 line number.
Machine Code: It is also called the instruction code. This code will include hexadecimal numbers with instructions to store memory address.
Label: A collection of symbols to represent a particular address in a statement. The label has colons and is found whenever necessary.
Operation Code: This instruction contains two main parts. Operand and Opcodes. The opcode will indicate the function type or function to be performed by the machine code.
Operade: This program contains 8-bit and 16-bit data, port address, and memory address and register where the instructions are applied. In fact, the instruction is called by another name, namely namonic which is a mixture of both opcode and opred. Notenotes english characters which are initial to complete the work by directing. The memoric used to copy data from one place to another is mov and sub for reduction.
Comments: Although, they are not part of programming, they are actually part of the documents that describe actions taken by a group or by each directive. Comments and instructions are separated by a colon.
What is included in an assembly language assignment program?
Assembly Language homework help includes the concepts below which are used to reach a solution.
Mu Syle Syntax - Assembly Language Program can be divided into 3 types - Data Section, BSS section, Text Section
Statements - There are three types of assembly language statements - Directors, Macros and Executive Instructions These statements enter 1 statement in each line
The assembly language file is then saved as a .asm file and run the program to get the required output
What are assembly registers?
Processor operation mostly works on processing data. Registers are internal memory storage spaces that help speed up the processor's work. In IA-32, there are six 16-bit processor registers and ten 32-bit registers. Registers can be divided into three categories -
General Register
Data Register - 32-bit Data Register: EAX, EBX, ECX, EDX. X is primary collector, BX is base register, C x counter is registered and DX is data register.
Pointer Register - These are 32-bit EIP, ESP, and EBP registers. There are three types of pointers like Instruct Pointer (IP), Stack Pointer (SP) and Base Pointer (BP)
Index Register - These registers are divided into Resource Index (SI) and Destination Index (DI)
Control Register - Control Registers can be defined as a combination of 32-bit Directive Director Register and 32-bit Flags Register. Some of the bits of the famous flag are overflow flag (off), trap flag (TF), enterprise flag (IF), sign flag (SF), Disha Flag (DF), Zero Flag (ZF).
Sugar Register - These are further divided into code segments, data segments and stack sections
Assembly Language Functions
The main benefit given by assembly language is the speed on which the programmes are run. Anyone in the assembly language can write instructions five times faster than the Pascal language. Moreover, the instructions are simple and easy to interpret code and work for microprocessors. With assembly language, it is easy to modify the instructions of a program. The best part is that the symbols used in this language are easy to understand, thus leaving a lot of time left for the programs. This language will enable you to develop an interface between different pieces of code with the help of inconsistent conferences.
The lack of benefits mentioned above are different applications of assembly language. Some of the most common tasks are given below:
Assembly language is used to craft code to boot the system. Code operating system will be helpful in booting and starting system hardware before storing it in ROM
Assembly language is complete to promote working speed despite low processing power and RAM
Here are some compilers that allow you to translate the high level language into assembly language before you complete the compilation. This will allow you to see the code for the debugging and optimization process.
As you read the page, you can easily conclude that the assembly language will require complex coding. Not all students have the right knowledge of programming and therefore use the 'Programming Assignment Assistance' to complete their programme language lecture on time. If you have difficulty completing the assignment and want to get rid of the stressful process of completing the assignment on your own, the advantage of our Assembly Language Programming Services is to ensure that you get a + grade in all projects.
Assembly Language Assignment Support . Assembly Language Homework Support
We are receiving our Bachelor's and Masters degrees by offering programming homework support to the students of programming and computer science in various universities and colleges around the world.
Our Assembly Language Assignment Support Service is a fit for your budget. You only have to pay a pocket-friendly price to get the running assembly language project no matter how difficult it may be.
Assignment can deal with any of the following subject: Intel Processor, 6502 - 8 bit processor, 80 × 86 - 16 bit processor, 68000 - 32 bit processor, dos emulator, de-morgan theory, assembly basic syntax, assembly memory. Sections etc. Our experts ensure that they provide quality work for Assembly Language Assignment Support as they are aware of the complete syllabus and can use concepts to provide assignments in accordance with your academic needs.
Instructions are used to complete assembly language assignment. Some common instructions include EKU, ORG, DS, =, ID, ENT, IF, IFNOT, ELSE, EDF, RESET, EOG and EEDTA. These instructions instruct the collecter to work. The use of correct instructions is very important in completing the successful project. Our experts ensure that they meet global standards while completing assembly language homework. If you take the support of our programmers to the assembly language homework, you don't have to worry about the quality of the solution.
Why should you set assembly language?
Assembly language is best for writing ambedded programs
This improves your understanding of the relationship between computer hardware, programs and operating systems.
The speed required to play the computer game. If you know assembly language, you can customize the code to improve the program speed
Low-level tasks such as data encryption or bitwise manipulation can be easily done using assembly language
Real-time applications that require the right time and data can be easily run using assembly language.
Why choose the 'Programming Assignment Help' service?
Our service is USP - we understand that you are a student and getting high ratings at affordable prices is what we have to offer programming assistance that we provide on all subjects. Our assembly language-specific support is unique in many ways. Some of them are given below:
Nerdi Assembly Language Expert: We have 346 programmers who work on assembly language projects only. They must have been solved near 28,512 work and domestic work so far
100% Original Code: We provide unique solutions otherwise you get a full refund. We dismiss the expert if he shares the 1 theft solution.
Pocket Friendly: Support for assembly language homework help is expensive because it is one of the most important topics in programming. We ensure that we provide affordable rates to our students. Repeating customers can get 10% off from the third order.
Free Review: We share screenshots of the program normally running so that there is no need for modification. However, if you still need to modify the work, we provide free price modifications within 5-6 hours.
85% Repeat Customer: We will do things right for the first time. Our programmers have complete code writing experience. Keeping good programmers has resulted in 85% repetition and 98% customer satisfaction.
If you are still looking for support for assembly language tasks and home works, please send us an email or talk to our customer care executive and we will lead you to complete the work and get a grade.
0 notes
Text
Pandas Tutorial
10 minutes to pandas
https://pandas.pydata.org/pandas-docs/stable/getting_started/10min.html
import
import numpy as np
import pandas as pd
Object creation
s = pd.Series([1, 3, 5, np.nan, 6, 8])
dates = pd.date_range('20130101', periods=6) df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD'))
df2 = pd.DataFrame({'A': 1., 'B': pd.Timestamp('20130102'), 'C': pd.Series(1, index=list(range(4)), dtype='float32'), 'D': np.array([3] * 4, dtype='int32'), 'E': pd.Categorical(["test", "train", "test", "train"]), 'F': 'foo'})
Viewing data
df.head()
df.tail(3)
df.index
df.columns
df.to_numpy()
df.describe()
df.T
Transposing your data
df.sort_index(axis=1, ascending=False)
Sorting by an axis
df.sort_values(by='B')
Selection
https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html
We recommend the optimized pandas data access methods, .at, .iat, .loc and .iloc.
Not recommended
Selecting columns
df['A']
df[['A', ‘B’]]
Selecting rows
df[:3]
df['20130102':'20130104']
Recommended
Quick intro
df.loc[(for row)]
df.loc[(for row), (for column)]
df.iloc[(for row)]
df.iloc[(for row), (for column)]
Selection by label
pandas.DataFrame.loc
Access a group of rows and columns by label(s) or a boolean array.
e.g.
df.loc[dates[0]]
df.loc[:, ['A', 'B']]
df3.loc['20200606':'20200608', 'B':'C']
pandas.DataFrame.at
Access a single value for a row/column label pair.
Similar to loc, but faster
e.g.
df.at[’20200606’, ‘A’]
Selection by position
pandas.DataFrame.iloc
Purely integer-location based indexing for selection by position.
e.g.
df.iloc[3]
df.iloc[3:5, 0:2]
pandas.DataFrame.iat
Access a single value for a row/column pair by integer position.
Similar to iloc, but faster
e.g.
df.iat[3,2]
Boolean indexing
What does indexing means?
https://www.geeksforgeeks.org/indexing-and-selecting-data-with-pandas/
Indexing in pandas means simply selecting particular rows and columns of data from a DataFrame.
df[df > 0]
df[df['A'] > 0]
df2[df2['E'].isin(['two', 'four'])]
The operators are: | for or, & for and, and ~ for not. These must be grouped by using parentheses
Setting
Setting a new column
It automatically aligns the data by the indexes.
df = pd.DataFrame(np.random.randn(6, 4), index=dates, columns=list('ABCD')) s1 = pd.Series([1, 2, 3, 4, 5, 6], index= dates) df['F'] = s1
Setting values by label
df3.at['20200605','A'] = 0
df.loc[:, 'D'] = np.array([5] * len(df))
Setting values by position
df.iat[0, 1] = 0
Setting values with where operation
df2[df2 > 0] = -df2
Missing data
pandas primarily uses the value np.nan to represent missing data.
To drop any rows that have missing data
df1.dropna(how='any')
Filling missing data
df1.fillna(value=5)
values = {'A': 0, 'B': 1, 'C': 2, 'D': 3} df1.fillna(value=values)
To get the boolean mask where values are nan.
pd.isna(df1)
Operations
Stats
df.mean()
df.mean(1)
Same operation on the other axis
Apply
df.apply(np.cumsum)
df.apply(lambda x: x.max() - x.min())
Histogramming
s = pd.Series(np.random.randint(0, 7, size=10)) s.value_counts()
String Methods
s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca', np.nan, 'CABA', 'dog', 'cat']) s.str.lower()
Merge
Concat
https://pandas.pydata.org/pandas-docs/stable/user_guide/merging.html#merging
Concatenating pandas objects together with concat()
pd.concat(df1, df2, df3)
<=> df1.append([df2 , df3])
A useful shortcut to concat() are the append() instance methods on Series and DataFrame.
Join
https://pandas.pydata.org/pandas-docs/stable/user_guide/merging.html#merging-join
SQL style merges
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
pd.merge(left=df1, right=df2, how=‘left’, on='key')
DataFrame.merge(self, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes='_x', '_y', copy=True, indicator=False, validate=None)
df1(right=df2, how=‘inner’, on='key')
Grouping
https://pandas.pydata.org/pandas-docs/stable/user_guide/groupby.html#groupby
“group by” involving one of the following steps
Splitting the data into groups based on some criteria
Applying a function to each group independently
Combining the results into a data structure
df.groupby('A').sum()
df.groupby(['A', 'B']).sum()
Reshaping
Stack
Pivot tables
Time series
https://pandas.pydata.org/pandas-docs/stable/user_guide/timeseries.html#timeseries
pandas.date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs)
years = pd.period_range('2010-01-01', '2015-01-01', freq='A') years.asfreq('M', how='S')
Categoricals
https://pandas.pydata.org/pandas-docs/stable/user_guide/categorical.html#categorical
df = pd.DataFrame({"id": [1, 2, 3, 4, 5, 6], "raw_grade": ['a', 'b', 'b', 'a', 'a', 'e']}) df["grade"] = df["raw_grade"].astype("category") df["grade"].cat.categories = ["very good", "good", "very bad"]
Series.cat()
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.cat.html
Accessor object for categorical properties of the Series values.
s.cat.categories
s.cat.categories = list('abc')
s.cat.rename_categories( 'cba’) s.cat.rename_categories({'a': 'A', ’b’:’B’, 'c': 'C'}) s.cat.rename_categories(lambda x: x.upper())
and so on
Plotting
https://pandas.pydata.org/pandas-docs/stable/user_guide/visualization.html#visualization
import matplotlib.pyplot as plt
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000)) ts.cumsum().plot()
df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=['A', 'B', 'C', 'D']) plt.figure() df.cumsum().plot() plt.legend(loc='best')
Getting data in/out
df.to_csv('foo.csv')
pd.read_csv('foo.csv')
Gotchas
Intro to data structures
https://pandas.pydata.org/pandas-docs/stable/getting_started/dsintro.html#dsintro
Series
pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
Series is a one-dimensional labeled array(ndarray) capable of holding any data type (integers, strings, floating point numbers, Python objects, etc.)
numpy.ndarray
An array object represents a multidimensional, homogeneous array of fixed-size items.
DataFrame
pandas.DataFrame(data=None, index: Optional[Collection] = None, columns: Optional[Collection] = None, dtype: Union[str, numpy.dtype, ExtensionDtype, None] = None, copy: bool = False)
Parameters
data
ndarray (structured or homogeneous), Iterable, dict, or DataFrame
DataFrame is a 2-dimensional labeled data structure with columns of potentially different types.
0 notes
Text
C Program to implement DFS Algorithm for Connected Graph
DFS Algorithm for Connected Graph Write a C Program to implement DFS Algorithm for Connected Graph. Here’s simple Program for traversing a directed graph through Depth First Search(DFS), visiting only those vertices that are reachable from start vertex. Depth First Search (DFS) Depth First Search (DFS) algorithm traverses a graph in a depthward motion and uses a stack to remember to get the next…
View On WordPress
#bfs and dfs program in c with output#c data structures#c graph programs#C Program for traversing a directed graph through Depth First Search(DFS)#depth first search#depth first search algorithm#depth first search c#depth first search c program#depth first search program in c#depth first search pseudocode#dfs#dfs algorithm#DFS Algorithm for Connected Graph#dfs code in c using adjacency list#dfs example in directed graph#dfs in directed graph#dfs program in c using stack#dfs program in c with explanation#dfs program in c with output#dfs using stack#dfs using stack algorithm#dfs using stack example#dfs using stack in c#visiting only those vertices that are reachable from start vertex.
0 notes
Text
Biot-Savart law on a torus? https://ift.tt/eA8V8J
In classical electrodynamics, given the shape of a wire carrying electric current, it is possible to obtain the magnetic field configuration $\mathbf{B}$ via the Biot-savart law. If the wire is a curve $\gamma$ parametrized as $\mathbf{y}(s)$, where $s$ is the arc-length, then
$$ \mathbf{B}(\mathbf{x}) = \beta \int_\gamma \dfrac{ d\mathbf{y}\times(\mathbf{x} - \mathbf{y}) }{|\mathbf{x} - \mathbf{y}|^3} = \beta \int_\gamma ds \dfrac{ \mathbf{y}'(s) \times(\mathbf{x} - \mathbf{y}(s)) }{|\mathbf{x} - \mathbf{y}(s)|^3} \, , $$
where $\beta $ is just a physical constant proportional to the current in the wire.
Another application of the Biot-Savart law is to find the velocity field $\mathbf{v}$ around a bent vortex line in a fluid, in the approximation of incompressible and irrotational fluid flow (i.e. $\nabla \cdot \mathbf{v} =0$ and $\nabla \times \mathbf{v} =0$ almost everywhere) and very-thin diameter of the vortex core. In fact, by demanding that the vorticity of the fluid is concentrated on the vortex core (i.e. it is distributed as a Dirac delta peaked on the vortex core),
$$ \mathbf{w}(\mathbf{x}) = \nabla \times \mathbf{v}(\mathbf{x})= c \int_\gamma ds \, \mathbf{y}'(s)\, \delta( \mathbf{x} - \mathbf{y}(s)) \, , $$
we have that the Helmholtz decomposition and the fact $\delta(\mathbf{y}-\mathbf{x} ) = -\nabla^2 \, (4 \pi |\mathbf{y}-\mathbf{x}|)^{-1}$ tell us that
$$ \mathbf{v}(\mathbf{x})= \frac{c}{4 \pi} \int_\gamma ds \dfrac{ \mathbf{y}'(s) \times(\mathbf{x} - \mathbf{y}(s)) }{|\mathbf{x} - \mathbf{y}(s)|^3}$$
Again, the constant $c$ is just a physical constant that sets the value of the circulation of the field $\mathbf{v}$ around the vortex.
This is very clear and works in $\mathbb{R}^3$. Imagine now that the wire (or the curve that parametrizes the irrotational vortex) is a curve in the three-dimensional torus $\mathbb{T}^3 = S^1 \times S^1 \times S^1$. How to obtain the equivalent of the Biot-Savart law?
NOTE: we are changing the base manifold from $\mathbb{R}^3$ to $\mathbb{T}^3 $ but the local differential relations should be unchanged (i.e. the definition of the vorticity 2-form as external derivative of the velocity 1-form, or the local form of Maxwell equations $dF = J$). The problem is that the Biot-Savart law is non-local, so it is a global problem that "feels" the topology of the manifold. Maybe in the end the question is related to how the Helmholtz decomposition works on a torus.
from Hot Weekly Questions - Mathematics Stack Exchange Quillo from Blogger https://ift.tt/2NIpuRS
0 notes
Text
Its only been two games and story part 2
The Mavs won in New Orleans last night. Interesting game. The West is too competitive to have too many interesting games.
So the questions are:
Is KP going to continue to shake off rust and get better, and maybe smarter? If he averages in the low 20′s and ups his rebounds to 7-8 a game along with a few blocks per game is he worth a max contract? There are people who have signed max contracts that are doing better and there are some not doing better. What is the expected value? I will take five years of the above especially if it is more efficient.
Why accept KP scoring in the low 20′s? And that is because Luka and KP cannot be the only scorers on this team to be successful. We NEED balanced scoring and that has been the concern along with who is the fifth starter. Well after two games who is the third fourth and fifth starter? I do not know yet, but if Deleon Wright plays 30 minutes a game like he did last night one of those spots is taken. And that is exactly the 30 minutes of starting or bench play we need to balance out the KP and Luka duo. Having a third player of that caliber is what leads you to the playoffs. Add a fourth and you are a title contender (okay you do need more, but that is a necessity). This leaves the question to be, can Wright do this consistently? I believe he can and if he does, then optimism for this year is growing.
And if Wright does become a consistent player at this level and is the third started, who then are the 4th and 5th starters? And right now there is still a round robin of players trying to fill these positions. Apparently Coach C is rotating based on match ups as per the first two games, yes again only two games, so will it continue?
I think we will see different starters tomorrow night against Portland for two reasons, match ups and what happened in the first quarter in NOLA wasn’t too encouraging. And on a side note, I get this strange but unstanstiated feeling that Carlisle has more confidence in Lee over Hardaway, Jr. Doesn’t seem to be working out, but over the last two weeks I just got that feeling. No rhyme or reason for it, but it exists.
Dwight Powell was the penciled in starter at 5 so is he still the starter when he comes back or can Maxi score some points consistently and efficiently and take the spot away from him? More to see on this developing story. This does narrow down on of the starters to two players.
So we are back to the who is the fifth starter question? The above was pretty much what most fans and local writers were discussing when the season began a whole 2 games ago, so how much has changed on the fifth starter argument? Your choices are Lee (apparently), Hardaway Jr. (maybe), and the more realistic choices of DFS, Jackson, Jalen, and Curry. Two games ago, I was of the opinion this was Jackson’s spot to win. I have watched both games. I had to record them, but go to watch them and I am not sure about what I have seen for Jackson yet. He has disappeared into the aforementioned list, yet so have them all, except Lee who will disappear to the end of the bench if he doesn’t improve radically very quickly.
All of the list performed well in brief momets throughout the two games, and none has done anything to reduce their chances. Wright stood out last night so his only worry is consistency and it doesn’t always have to be twenty points, but mid to upper teens efficiently with the defense he played last night. He definitely earned major points defensively. He is no Leonard on the Clippers, but he is definitely above average starting level defense on the perimeter.
Which leads us to how do we determine the fifth starter if all do well for 5-10 minutes offensively? This question leads us to the worry that the round robin of starters will continue for at least a few more games. And if longer how does it affect the morale of the individual players, then the team?
Starters for Portland? Wide open. Do we match up 2 bigs and 3 guards? One commenter from last night’s articles thinks so? I see their point. And if so, Do we put KP on Whiteside? Which I do not like. Or play hack a whiteside and rotate Kleber, DFS and a bit of Boban for the first time this year? Not much more enthustiatic about this either, but maybe a shade better.
And boom, then who is the third guard with Luka and Wright? Jalen? Seth? Or Justin? The good news is if Portland consistently plays a three guard line up, we can roll out a much better and deeper rotation than they can. The key is stopping Lillard. Or maybe not. If he scores 40 in a losing effort I will take it. Basically do the best you can on him and shut down everyone else may be the key to winning. We still do not know the starter, but this will determine who plays 30+ minutes tomorrow night.
Tomorrow is one game, but it can answer many questions for us or send us back to the drawing board. I am hoping questions are answered so consistency for everyone develops as they fall into their roles.
And now more attempt at my story>
___________________________________________________________
The movement started again. There was the previous attachment, held together in one place. A spot where an intrusion had entered. Two small impacts that connected to something that rested together. Then another larger impact that connected more. There was disconnect and connect at the same time. The movement forced pressure where the connection existed, yet the full connection or pressure against changed as the movemet continued. At one point there was separation between all that was connected except at the impact spot. The connection was brought back together and then the resting began again.
There was constant movment, it was slight. Pressure increased and decreased. At times there was slight movement different from the free movement. The movement was more laterally and when it happened how the pressure rested on top would change and increase or decrease in certain sides. The pressure was always there, but the slight movement changed the balance of the pressure.
The pressure lifted. Then there was movement. It included where the impact existed. The connections from the impact spot existed, but there was no connection, Movement continued and sometimes the movement brought the connections closer together and sometimes there was a drift or slight space between the connections.
The movement stopped and two strong impacts occurred. Something went missing. There was more connection. And more movement, however, the movement changed not just in direction, but also how the pressure aligned. The resting angle changed. The pressure was different, not as strong and it was more pressure going through to the bottom. The top was different and no real pressure coming from the top. The connections were stronger and more pressure was felt. The pressure came from the connection pushing back through not coming from the top like before, yet coming from the same surface as before.
The pressure was from the same surface, but from the connections in a different way and it grew stronger over time. At some point the pressure stayed the same and never changed.
------------------------------------------------------------------------------------------
Okay what was that all about. I wanted to write about an inanimate object so as to not use feelings or descriptive adjectives. Why? I don’t know. I wanted to try and create a story that could describe a process slowly based on the observation of the inantimate object. Again without using adjectives that we normally use to describe something or something that has senses.
I do not have any idea of how I did. I know I used the word pressure too much because that was the only feeling I could think of that described what was happening in the existence of my inantimate object.
In case you are curious, the process is to descripe a piece of paper being used in an office. First it is in stacked up boxes, over time the boxes lessen as more paper is used, until finally its turn arrives.
It is put into a printer, printed on, stapled, put in a tray, then stapled to more paper, and eventually two hole punched and filed away, where eventually the drawer is full and never to be seen again. I thought about going through the pulled out and shredded process, but stopped at the filing because I knew this story was not going where I wanted it to go. Yet I am not sure I had a place for it to go so ending it seemed appropriate. I did plan that it would end at the filing or the shredding, but if I shredd the paper I thought I might eventually add feelings or descriptive adjectives to it which was part of what I wanted to avoid.
Anyway if you are so inclined email me your thoughts.
Cheers
0 notes
Text
Fuck Python, Pandas Again
Hi first post in a while, today I tried to load some data with pandas:
$ python -m please.do.something.reasonable Traceback (most recent call last): File "/home/dashdz/.pyenv/versions/3.7.4/lib/python3.7/runpy.py", line 193, in _run_module_as_main "__main__", mod_spec) File "/home/dashdz/.pyenv/versions/3.7.4/lib/python3.7/runpy.py", line 85, in _run_code exec(code, run_globals) File "/home/dashdz/repos/some-programming-idk/please/do/something/reasonable.py", line 36, in main() File "/home/dashdz/repos/some-programming-idk/please/do/something/reasonable.py", line 20, in main df = pd.read_csv('data/pretty/normal/data.tsv') File "/home/dashdz/.pyenv/versions/please/lib/python3.7/site-packages/pandas/io/parsers.py", line 685, in parser_f return _read(filepath_or_buffer, kwds) File "/home/dashdz/.pyenv/versions/please/lib/python3.7/site-packages/pandas/io/parsers.py", line 463, in _read data = parser.read(nrows) File "/home/dashdz/.pyenv/versions/please/lib/python3.7/site-packages/pandas/io/parsers.py", line 1154, in read ret = self._engine.read(nrows) File "/home/dashdz/.pyenv/versions/please/lib/python3.7/site-packages/pandas/io/parsers.py", line 2048, in read data = self._reader.read(nrows) File "pandas/_libs/parsers.pyx", line 879, in pandas._libs.parsers.TextReader.read File "pandas/_libs/parsers.pyx", line 894, in pandas._libs.parsers.TextReader._read_low_memory File "pandas/_libs/parsers.pyx", line 948, in pandas._libs.parsers.TextReader._read_rows File "pandas/_libs/parsers.pyx", line 935, in pandas._libs.parsers.TextReader._tokenize_rows File "pandas/_libs/parsers.pyx", line 2130, in pandas._libs.parsers.raise_parser_error pandas.errors.ParserError: Error tokenizing data. C error: Expected 2 fields in line 11, saw 3
But serious question for everyone:
why is normal behavior for well-oiled big mainstream python libraries to crash and vomit a huge stack trace?
I reject we cannot do better.
Here are some alternative error ideas:
$ python -m please.do.something.reasonable ERROR: Using commas (',') to parse the file, everything I've seen so far has 2 fields, such as line 10 of your file ('data/pretty/normal/data.tsv'): hi,there ... but then line 11 of that file ('data/pretty/normal/data.tsv') had 3 fields: why,hello,you this is impossible for me to recover from because of programming, so I have crashed. You've got to make sure that I know how many fields the file is gonna have upfront.
or maybe
$ python -m please.do.something.reasonable ERROR: Despite the docs saying if the separator is None, we will auto detect your delimiter, which kind of implies that maybe the default should be None, when you don't pass it, we assume commas (',') rather than try to detect it. Your file ends with '.tsv', which is kind of a dead giveaway, but whatever, I thought commas was best because then I can use C and GO REAL FAST and oops I crashed.
I mean the whole first person thing kinda creeps me out (TeX or LaTeX or WhAtEvEr does that and I never realize what it means at first), but like u get the picture.
I just don't think using the wrong delimiter and/or just having the wrong number of fields in a line is so crazy of behavior that the right answer is to vomit a stack trace.
0 notes