#extracting data from websites
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Text
OTT Media Platform Data Scraping | Extract Streaming App Data
Unlock insights with our OTT Media Platform Data Scraping. Extract streaming app data in the USA, UK, UAE, China, India, or Spain. Optimize your strategy today
know more: https://www.mobileappscraping.com/ott-media-app-scraping-services.php
#OTT Media Platform Data Scraping#Extract Streaming App Data#extracting relevant data from OTT media platforms#extracting data from websites
0 notes
Text
Extracting Shopify product data efficiently can give your business a competitive edge. In just a few minutes, you can gather essential information such as product names, prices, descriptions, and inventory levels. Start by using web scraping tools like Python with libraries such as BeautifulSoup or Scrapy, which allow you to automate the data collection process. Alternatively, consider using user-friendly no-code platforms that simplify the extraction without programming knowledge. This valuable data can help inform pricing strategies, product listings, and inventory management, ultimately driving your eCommerce success.
#extract Shopify websites#scrape Shopify product data#extract product data from Shopify websites#Data Scraping
0 notes
Text

You can get a huge number of products on Walmart. It uses big data analytics for deciding its planning and strategies. Things like the Free-shipping day approach, are sult of data scraping as well as big data analytics, etc. against Amazon Prime have worked very well for Walmart. Getting the product features is a hard job to do and Walmart is doing wonderfully well in that. At Web Screen Scraping, we scrape data from Walmart for managing pricing practices using Walmart’s pricing scraping by our Walmart data scraper.
0 notes
Text
Google Search Results Data Scraping

Google Search Results Data Scraping
Harness the Power of Information with Google Search Results Data Scraping Services by DataScrapingServices.com. In the digital age, information is king. For businesses, researchers, and marketing professionals, the ability to access and analyze data from Google search results can be a game-changer. However, manually sifting through search results to gather relevant data is not only time-consuming but also inefficient. DataScrapingServices.com offers cutting-edge Google Search Results Data Scraping services, enabling you to efficiently extract valuable information and transform it into actionable insights.
The vast amount of information available through Google search results can provide invaluable insights into market trends, competitor activities, customer behavior, and more. Whether you need data for SEO analysis, market research, or competitive intelligence, DataScrapingServices.com offers comprehensive data scraping services tailored to meet your specific needs. Our advanced scraping technology ensures you get accurate and up-to-date data, helping you stay ahead in your industry.
List of Data Fields
Our Google Search Results Data Scraping services can extract a wide range of data fields, ensuring you have all the information you need:
-Business Name: The name of the business or entity featured in the search result.
- URL: The web address of the search result.
- Website: The primary website of the business or entity.
- Phone Number: Contact phone number of the business.
- Email Address: Contact email address of the business.
- Physical Address: The street address, city, state, and ZIP code of the business.
- Business Hours: Business operating hours
- Ratings and Reviews: Customer ratings and reviews for the business.
- Google Maps Link: Link to the business’s location on Google Maps.
- Social Media Profiles: LinkedIn, Twitter, Facebook
These data fields provide a comprehensive overview of the information available from Google search results, enabling businesses to gain valuable insights and make informed decisions.
Benefits of Google Search Results Data Scraping
1. Enhanced SEO Strategy
Understanding how your website ranks for specific keywords and phrases is crucial for effective SEO. Our data scraping services provide detailed insights into your current rankings, allowing you to identify opportunities for optimization and stay ahead of your competitors.
2. Competitive Analysis
Track your competitors’ online presence and strategies by analyzing their rankings, backlinks, and domain authority. This information helps you understand their strengths and weaknesses, enabling you to adjust your strategies accordingly.
3. Market Research
Access to comprehensive search result data allows you to identify trends, preferences, and behavior patterns in your target market. This information is invaluable for product development, marketing campaigns, and business strategy planning.
4. Content Development
By analyzing top-performing content in search results, you can gain insights into what types of content resonate with your audience. This helps you create more effective and engaging content that drives traffic and conversions.
5. Efficiency and Accuracy
Our automated scraping services ensure you get accurate and up-to-date data quickly, saving you time and resources.
Best Google Data Scraping Services
Scraping Google Business Reviews
Extract Restaurant Data From Google Maps
Google My Business Data Scraping
Google Shopping Products Scraping
Google News Extraction Services
Scrape Data From Google Maps
Google News Headline Extraction
Google Maps Data Scraping Services
Google Map Businesses Data Scraping
Google Business Reviews Extraction
Best Google Search Results Data Scraping Services in USA
Dallas, Portland, Los Angeles, Virginia Beach, Fort Wichita, Nashville, Long Beach, Raleigh, Boston, Austin, San Antonio, Philadelphia, Indianapolis, Orlando, San Diego, Houston, Worth, Jacksonville, New Orleans, Columbus, Kansas City, Sacramento, San Francisco, Omaha, Honolulu, Washington, Colorado, Chicago, Arlington, Denver, El Paso, Miami, Louisville, Albuquerque, Tulsa, Springs, Bakersfield, Milwaukee, Memphis, Oklahoma City, Atlanta, Seattle, Las Vegas, San Jose, Tucson and New York.
Conclusion
In today’s data-driven world, having access to detailed and accurate information from Google search results can give your business a significant edge. DataScrapingServices.com offers professional Google Search Results Data Scraping services designed to meet your unique needs. Whether you’re looking to enhance your SEO strategy, conduct market research, or gain competitive intelligence, our services provide the comprehensive data you need to succeed. Contact us at [email protected] today to learn how our data scraping solutions can transform your business strategy and drive growth.
Website: Datascrapingservices.com
Email: [email protected]
#Google Search Results Data Scraping#Harness the Power of Information with Google Search Results Data Scraping Services by DataScrapingServices.com. In the digital age#information is king. For businesses#researchers#and marketing professionals#the ability to access and analyze data from Google search results can be a game-changer. However#manually sifting through search results to gather relevant data is not only time-consuming but also inefficient. DataScrapingServices.com o#enabling you to efficiently extract valuable information and transform it into actionable insights.#The vast amount of information available through Google search results can provide invaluable insights into market trends#competitor activities#customer behavior#and more. Whether you need data for SEO analysis#market research#or competitive intelligence#DataScrapingServices.com offers comprehensive data scraping services tailored to meet your specific needs. Our advanced scraping technology#helping you stay ahead in your industry.#List of Data Fields#Our Google Search Results Data Scraping services can extract a wide range of data fields#ensuring you have all the information you need:#-Business Name: The name of the business or entity featured in the search result.#- URL: The web address of the search result.#- Website: The primary website of the business or entity.#- Phone Number: Contact phone number of the business.#- Email Address: Contact email address of the business.#- Physical Address: The street address#city#state#and ZIP code of the business.#- Business Hours: Business operating hours#- Ratings and Reviews: Customer ratings and reviews for the business.
0 notes
Text
Web Data Extraction: Scraping Data from a Website's Store Locator

When competing with large corporations in your field, it can be challenging to find an edge. But one way to gain a competitive advantage is by knowing how to scrape data from a website's store locator. One of the best ways to compete against larger companies is to understand how to scrape data from a website's store locator . It is a primary business. You're trying to find a way to keep costs down so that you can be competitive. This might be through outsourcing physical goods production overseas or working with local suppliers who can provide enough volume for cost savings.
Even if you don't perform a lot of manufacturing, there are still methods for you to benefit from effective data scrapers for your store locator services, allowing you to save expenses while maximizing revenues. This post will review how to scrape data from a website's store locator. We'll discuss how to get the most out of your internet store locator and make it work like a machine.
What is data scraping, and how does it help businesses?
Data mining is the process of collecting data and organizing it in a way that offers beneficial results. In the case of a website's store locator, the data can be used in many ways for maximum profit.
When scraping data for your store locator, you pull a lot of information from one source. When this source is a website, this is known as web crawling. You only have to make multiple visits to each page to collect all of this information if you want to view it in detail or compare it with other pages like your competitors'. The information you collect is used to organize your business in a database. It can then be exported into other programs that can be used for marketing purposes.
It is suitable for businesses to organize their data to better hone in on the most profitable markets and potential customers. If you could manage this data from multiple sources, you may be spending more time reading through it all instead of organizing it and analyzing it cost-effectively.
0 notes
Text
Elon Musk's henchmen have reportedly installed a commercial server to control federal databases that contain Social Security numbers and other highly sensitive personal information.
The tech billionaire installed his associates — some of them fresh out of high school — in the Office of Personnel Management (OPM), where they have gained unprecedented access to federal human resources databases containing sensitive personal information for millions of federal workers, sources in the department told the website Musk Watch.
"According to two members of OPM staff with direct knowledge, the Musk team running OPM has the ability to extract information from databases that store medical histories, personally identifiable information, workplace evaluations, and other private data," wrote investigative reporters Caleb Ecarma and Judd Legum. "The arrangement presents acute privacy and security risks, one of the OPM staffers said."
133 notes
·
View notes
Text
Pluralistic: Leaving Twitter had no effect on NPR's traffic

I'm coming to Minneapolis! This Sunday (Oct 15): Presenting The Internet Con at Moon Palace Books. Monday (Oct 16): Keynoting the 26th ACM Conference On Computer-Supported Cooperative Work and Social Computing.

Enshittification is the process by which a platform lures in and then captures end users (stage one), who serve as bait for business customers, who are also captured (stage two), whereupon the platform rug-pulls both groups and allocates all the value they generate and exchange to itself (stage three):
https://pluralistic.net/2023/01/21/potemkin-ai/#hey-guys
Enshittification isn't merely a form of rent-seeking – it is a uniquely digital phenomenon, because it relies on the inherent flexibility of digital systems. There are lots of intermediaries that want to extract surpluses from customers and suppliers – everyone from grocers to oil companies – but these can't be reconfigured in an eyeblink the that that purely digital services can.
A sleazy boss can hide their wage-theft with a bunch of confusing deductions to your paycheck. But when your boss is an app, it can engage in algorithmic wage discrimination, where your pay declines minutely every time you accept a job, but if you start to decline jobs, the app can raise the offer:
https://pluralistic.net/2023/04/12/algorithmic-wage-discrimination/#fishers-of-men
I call this process "twiddling": tech platforms are equipped with a million knobs on their back-ends, and platform operators can endlessly twiddle those knobs, altering the business logic from moment to moment, turning the system into an endlessly shifting quagmire where neither users nor business customers can ever be sure whether they're getting a fair deal:
https://pluralistic.net/2023/02/19/twiddler/
Social media platforms are compulsive twiddlers. They use endless variation to lure in – and then lock in – publishers, with the goal of converting these standalone businesses into commodity suppliers who are dependent on the platform, who can then be charged rent to reach the users who asked to hear from them.
Facebook designed this playbook. First, it lured in end-users by promising them a good deal: "Unlike Myspace, which spies on you from asshole to appetite, Facebook is a privacy-respecting site that will never, ever spy on you. Simply sign up, tell us everyone who matters to you, and we'll populate a feed with everything they post for public consumption":
https://lawcat.berkeley.edu/record/1128876
The users came, and locked themselves in: when people gather in social spaces, they inadvertently take one another hostage. You joined Facebook because you liked the people who were there, then others joined because they liked you. Facebook can now make life worse for all of you without losing your business. You might hate Facebook, but you like each other, and the collective action problem of deciding when and whether to go, and where you should go next, is so difficult to overcome, that you all stay in a place that's getting progressively worse.
Once its users were locked in, Facebook turned to advertisers and said, "Remember when we told these rubes we'd never spy on them? It was a lie. We spy on them with every hour that God sends, and we'll sell you access to that data in the form of dirt-cheap targeted ads."
Then Facebook went to the publishers and said, "Remember when we told these suckers that we'd only show them the things they asked to see? Total lie. Post short excerpts from your content and links back to your websites and we'll nonconsensually cram them into the eyeballs of people who never asked to see them. It's a free, high-value traffic funnel for your own site, bringing monetizable users right to your door."
Now, Facebook had to find a way to lock in those publishers. To do this, it had to twiddle. By tiny increments, Facebook deprioritized publishers' content, forcing them to make their excerpts grew progressively longer. As with gig workers, the digital flexibility of Facebook gave it lots of leeway here. Some publishers sensed the excerpts they were being asked to post were a substitute for visiting their sites – and not an enticement – and drew down their posting to Facebook.
When that happened, Facebook could twiddle in the publisher's favor, giving them broader distribution for shorter excerpts, then, once the publisher returned to the platform, Facebook drew down their traffic unless they started posting longer pieces. Twiddling lets platforms play users and business-customers like a fish on a line, giving them slack when they fight, then reeling them in when they tire.
Once Facebook converted a publisher to a commodity supplier to the platform, it reeled the publishers in. First, it deprioritized publishers' posts when they had links back to the publisher's site (under the pretext of policing "clickbait" and "malicious links"). Then, it stopped showing publishers' content to their own subscribers, extorting them to pay to "boost" their posts in order to reach people who had explicitly asked to hear from them.
For users, this meant that their feeds were increasingly populated with payola-boosted content from advertisers and pay-to-play publishers who paid Facebook's Danegeld to reach them. A user will only spend so much time on Facebook, and every post that Facebook feeds that user from someone they want to hear from is a missed opportunity to show them a post from someone who'll pay to reach them.
Here, too, twiddling lets Facebook fine-tune its approach. If a user starts to wean themself off Facebook, the algorithm (TM) can put more content the user has asked to see in the feed. When the user's participation returns to higher levels, Facebook can draw down the share of desirable content again, replacing it with monetizable content. This is done minutely, behind the scenes, automatically, and quickly. In any shell game, the quickness of the hand deceives the eye.
This is the final stage of enshittification: withdrawing surpluses from end-users and business customers, leaving behind the minimum homeopathic quantum of value for each needed to keep them locked to the platform, generating value that can be extracted and diverted to platform shareholders.
But this is a brittle equilibrium to maintain. The difference between "God, I hate this place but I just can't leave it" and "Holy shit, this sucks, I'm outta here" is razor-thin. All it takes is one privacy scandal, one livestreamed mass-shooting, one whistleblower dump, and people bolt for the exits. This kicks off a death-spiral: as users and business customers leave, the platform's shareholders demand that they squeeze the remaining population harder to make up for the loss.
One reason this gambit worked so well is that it was a long con. Platform operators and their investors have been willing to throw away billions convincing end-users and business customers to lock themselves in until it was time for the pig-butchering to begin. They financed expensive forays into additional features and complementary products meant to increase user lock-in, raising the switching costs for users who were tempted to leave.
For example, Facebook's product manager for its "photos" product wrote to Mark Zuckerberg to lay out a strategy of enticing users into uploading valuable family photos to the platform in order to "make switching costs very high for users," who would have to throw away their precious memories as the price for leaving Facebook:
https://www.eff.org/deeplinks/2021/08/facebooks-secret-war-switching-costs
The platforms' patience paid off. Their slow ratchets operated so subtly that we barely noticed the squeeze, and when we did, they relaxed the pressure until we were lulled back into complacency. Long cons require a lot of prefrontal cortex, the executive function to exercise patience and restraint.
Which brings me to Elon Musk, a man who seems to have been born without a prefrontal cortex, who has repeatedly and publicly demonstrated that he lacks any restraint, patience or planning. Elon Musk's prefrontal cortical deficit resulted in his being forced to buy Twitter, and his every action since has betrayed an even graver inability to stop tripping over his own dick.
Where Zuckerberg played enshittification as a long game, Musk is bent on speedrunning it. He doesn't slice his users up with a subtle scalpel, he hacks away at them with a hatchet.
Musk inaugurated his reign by nonconsensually flipping every user to an algorithmic feed which was crammed with ads and posts from "verified" users whose blue ticks verified solely that they had $8 ($11 for iOS users). Where Facebook deployed substantial effort to enticing users who tired of eyeball-cramming feed decay by temporarily improving their feeds, Musk's Twitter actually overrode users' choice to switch back to a chronological feed by repeatedly flipping them back to more monetizable, algorithmic feeds.
Then came the squeeze on publishers. Musk's Twitter rolled out a bewildering array of "verification" ticks, each priced higher than the last, and publishers who refused to pay found their subscribers taken hostage, with Twitter downranking or shadowbanning their content unless they paid.
(Musk also squeezed advertisers, keeping the same high prices but reducing the quality of the offer by killing programs that kept advertisers' content from being published along Holocaust denial and open calls for genocide.)
Today, Musk continues to squeeze advertisers, publishers and users, and his hamfisted enticements to make up for these depredations are spectacularly bad, and even illegal, like offering advertisers a new kind of ad that isn't associated with any Twitter account, can't be blocked, and is not labeled as an ad:
https://www.wired.com/story/xs-sneaky-new-ads-might-be-illegal/
Of course, Musk has a compulsive bullshitter's contempt for the press, so he has far fewer enticements for them to stay. Quite the reverse: first, Musk removed headlines from link previews, rendering posts by publishers that went to their own sites into stock-art enigmas that generated no traffic:
https://www.theguardian.com/technology/2023/oct/05/x-twitter-strips-headlines-new-links-why-elon-musk
Then he jumped straight to the end-stage of enshittification by announcing that he would shadowban any newsmedia posts with links to sites other than Twitter, "because there is less time spent if people click away." Publishers were advised to "post content in long form on this platform":
https://mamot.fr/@pluralistic/111183068362793821
Where a canny enshittifier would have gestured at a gaslighting explanation ("we're shadowbanning posts with links because they might be malicious"), Musk busts out the motto of the Darth Vader MBA: "I am altering the deal, pray I don't alter it any further."
All this has the effect of highlighting just how little residual value there is on the platform for publishers, and tempts them to bolt for the exits. Six months ago, NPR lost all patience with Musk's shenanigans, and quit the service. Half a year later, they've revealed how low the switching cost for a major news outlet that leaves Twitter really are: NPR's traffic, post-Twitter, has declined by less than a single percentage point:
https://niemanreports.org/articles/npr-twitter-musk/
NPR's Twitter accounts had 8.7 million followers, but even six months ago, Musk's enshittification speedrun had drawn down NPR's ability to reach those users to a negligible level. The 8.7 million number was an illusion, a shell game Musk played on publishers like NPR in a bid to get them to buy a five-figure iridium checkmark or even a six-figure titanium one.
On Twitter, the true number of followers you have is effectively zero – not because Twitter users haven't explicitly instructed the service to show them your posts, but because every post in their feeds that they want to see is a post that no one can be charged to show them.
I've experienced this myself. Three and a half years ago, I left Boing Boing and started pluralistic.net, my cross-platform, open access, surveillance-free, daily newsletter and blog:
https://pluralistic.net/2023/02/19/drei-drei-drei/#now-we-are-three
Boing Boing had the good fortune to have attracted a sizable audience before the advent of siloed platforms, and a large portion of that audience came to the site directly, rather than following us on social media. I knew that, starting a new platform from scratch, I wouldn't have that luxury. My audience would come from social media, and it would be up to me to convert readers into people who followed me on platforms I controlled – where neither they nor I could be held to ransom.
I embraced a strategy called POSSE: Post Own Site, Syndicate Everywhere. With POSSE, the permalink and native habitat for your material is a site you control (in my case, a WordPress blog with all the telemetry, logging and surveillance disabled). Then you repost that content to other platforms – mostly social media – with links back to your own site:
https://indieweb.org/POSSE
There are a lot of automated tools to help you with this, but the platforms have gone to great lengths to break or neuter them. Musk's attack on Twitter's legendarily flexible and powerful API killed every automation tool that might help with this. I was lucky enough to have a reader – Loren Kohnfelder – who coded me some python scripts that automate much of the process, but POSSE remains a very labor-intensive and error-prone methodology:
https://pluralistic.net/2021/01/13/two-decades/#hfbd
And of all the feeds I produce – email, RSS, Discourse, Medium, Tumblr, Mastodon – none is as labor-intensive as Twitter's. It is an unforgiving medium to begin with, and Musk's drawdown of engineering support has made it wildly unreliable. Many's the time I've set up 20+ posts in a thread, only to have the browser tab reload itself and wipe out all my work.
But I stuck with Twitter, because I have a half-million followers, and to the extent that I reach them there, I can hope that they will follow the permalinks to Pluralistic proper and switch over to RSS, or email, or a daily visit to the blog.
But with each day, the case for using Twitter grows weaker. I get ten times as many replies and reposts on Mastodon, though my Mastodon follower count is a tenth the size of my (increasingly hypothetical) Twitter audience.
All this raises the question of what can or should be done about Twitter. One possible regulatory response would be to impose an "End-To-End" rule on the service, requiring that Twitter deliver posts from willing senders to willing receivers without interfering in them. End-To-end is the bedrock of the internet (one of its incarnations is Net Neutrality) and it's a proven counterenshittificatory force:
https://www.eff.org/deeplinks/2023/06/save-news-we-need-end-end-web
Despite what you may have heard, "freedom of reach" is freedom of speech: when a platform interposes itself between willing speakers and their willing audiences, it arrogates to itself the power to control what we're allowed to say and who is allowed to hear us:
https://pluralistic.net/2022/12/10/e2e/#the-censors-pen
We have a wide variety of tools to make a rule like this stick. For one thing, Musk's Twitter has violated innumerable laws and consent decrees in the US, Canada and the EU, which creates a space for regulators to impose "conduct remedies" on the company.
But there's also existing regulatory authorities, like the FTC's Section Five powers, which enable the agency to act against companies that engage in "unfair and deceptive" acts. When Twitter asks you who you want to hear from, then refuses to deliver their posts to you unless they pay a bribe, that's both "unfair and deceptive":
https://pluralistic.net/2023/01/10/the-courage-to-govern/#whos-in-charge
But that's only a stopgap. The problem with Twitter isn't that this important service is run by the wrong mercurial, mediocre billionaire: it's that hundreds of millions of people are at the mercy of any foolish corporate leader. While there's a short-term case for improving the platforms, our long-term strategy should be evacuating them:
https://pluralistic.net/2023/07/18/urban-wildlife-interface/#combustible-walled-gardens
To make that a reality, we could also impose a "Right To Exit" on the platforms. This would be an interoperability rule that would require Twitter to adopt Mastodon's approach to server-hopping: click a link to export the list of everyone who follows you on one server, click another link to upload that file to another server, and all your followers and followees are relocated to your new digs:
https://pluralistic.net/2022/12/23/semipermeable-membranes/#free-as-in-puppies
A Twitter with the Right To Exit would exert a powerful discipline even on the stunted self-regulatory centers of Elon Musk's brain. If he banned a reporter for publishing truthful coverage that cast him in a bad light, that reporter would have the legal right to move to another platform, and continue to reach the people who follow them on Twitter. Publishers aghast at having the headlines removed from their Twitter posts could go somewhere less slipshod and still reach the people who want to hear from them on Twitter.
And both Right To Exit and End-To-End satisfy the two prime tests for sound internet regulation: first, they are easy to administer. If you want to know whether Musk is permitting harassment on his platform, you have to agree on a definition of harassment, determine whether a given act meets that definition, and then investigate whether Twitter took reasonable steps to prevent it.
By contrast, administering End-To-End merely requires that you post something and see if your followers receive it. Administering Right To Exit is as simple as saying, "OK, Twitter, I know you say you gave Cory his follower and followee file, but he says he never got it. Just send him another copy, and this time, CC the regulator so we can verify that it arrived."
Beyond administration, there's the cost of compliance. Requiring Twitter to police its users' conduct also requires it to hire an army of moderators – something that Elon Musk might be able to afford, but community-supported, small federated servers couldn't. A tech regulation can easily become a barrier to entry, blocking better competitors who might replace the company whose conduct spurred the regulation in the first place.
End-to-End does not present this kind of barrier. The default state for a social media platform is to deliver posts from accounts to their followers. Interfering with End-To-End costs more than delivering the messages users want to have. Likewise, a Right To Exit is a solved problem, built into the open Mastodon protocol, itself built atop the open ActivityPub standard.
It's not just Twitter. Every platform is consuming itself in an orgy of enshittification. This is the Great Enshittening, a moment of universal, end-stage platform decay. As the platforms burn, calls to address the fires grow louder and harder for policymakers to resist. But not all solutions to platform decay are created equal. Some solutions will perversely enshrine the dominance of platforms, help make them both too big to fail and too big to jail.
Musk has flagrantly violated so many rules, laws and consent decrees that he has accidentally turned Twitter into the perfect starting point for a program of platform reform and platform evacuation.
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2023/10/14/freedom-of-reach/#ex

My next novel is The Lost Cause, a hopeful novel of the climate emergency. Amazon won't sell the audiobook, so I made my own and I'm pre-selling it on Kickstarter!
Image: JD Lasica (modified) https://commons.wikimedia.org/wiki/File:Elon_Musk_%283018710552%29.jpg
CC BY 2.0 https://creativecommons.org/licenses/by/2.0/deed.en
#pluralistic#twitter#posse#elon musk#x#social media#graceful failure modes#end-to-end principle#administratable remedies#good regulation#ads#privacy#benevolent dictatorships#freedom of reach#journalism#enshittification#switching costs
801 notes
·
View notes
Text
Georgia to purchase Israeli data extraction tech amid street protest crackdown
Georgia has moved to renew contracts with Israeli technology firm Cellebrite DI Ltd (CLBT.O) for software used to extract data from mobile devices, procurement documents show, as the country grapples with ongoing anti-government street protests. [...] The software, called Inseyets, allows law enforcement to "access locked devices to lawfully extract critical information from a broad range of devices", Cellebrite's website says. Cellebrite products are widely used by law enforcement, including the FBI, to unlock smartphones and scour them for evidence. [...] Georgia was plunged into political crisis in October, when opposition parties charged the ruling Georgian Dream party with rigging a parliamentary election. GD, in power since 2012, denies any wrongdoing. Georgians have been rallying nightly to demand the government's resignation since GD said in November it was suspending European Union accession talks until 2028. The demonstrations have drawn a swift crackdown by police, resulting in hundreds of arrests and beatings, rights groups say. The government has defended the police response to the protests. Gangs of masked men in black have attacked opposition politicians, activists and some journalists in recent months, raising alarm in Western capitals. Georgian authorities have said they are not involved in the attacks, and condemn them. A letter dated February 13 included among the documents on the state procurement website suggests Cellebrite was concerned about its sales to Georgia. A Cellebrite sales director, writing to a Georgian interior ministry official on what he called a "sensitive issue", warned Cellebrite's local office "could be blocked from selling our equipment". "Therefore, I would like to advise you that if you are planning a purchase this year, please try to make it as early as possible," the employee wrote, without specifying why sales might be halted.
wherever a brutal government consolidates itself, israel shows up
#is there any authoritarian police state that's too much for this grubby little country?#sticking their hands in every pot they can find#georgia
65 notes
·
View notes
Text
Update on AB 3080 and AB 1949
AB 3080 (age verification for adult websites and online purchase of products and services not allowed for minors) and AB 1949 (prohibiting data collection on individuals less than 18 years of age) both officially have hearing dates for the California Senate Judiciary Committee.
The hearing date for these bills is scheduled to be Tuesday 07/02/2024. Which means that the deadline to turn in position letters is going to be noon one week before the hearing on 06/25/2024. It's not a lot of time from this moment, but I'm certain we can each turn one in before then
Remember that position letters should be single topic, in strict opposition of what each bill entails. Keep on topic and professional when writing them. Let us all do our best to keep these bills from leaving committee so that we don't have to fight them on the Senate floor. But let's also not stop sending correspondence to our state representatives anyway.
Remember, the jurisdiction of the Senate Judiciary Committee is as follows.
"Bills amending the Civil Code, Code of Civil Procedure, Evidence Code, Family Code, and Probate Code. Bills relating to courts, judges, and court personnel. Bills relating to liens, claims, and unclaimed property. Bills relating to privacy and consumer protection."
Best of luck everyone. And thank you for your efforts to fight this so far.
Below is linked the latest versions of the bills.
Below are the links to the Committee's homepage which gives further information about the Judiciary Committee, and the page explaining further in depth their letter policy.
Edit: Was requested to add in information such as why these bills are bad and what sites could potentially be affected by these bills. So here's the explanation I gave in asks.
Why are these bills bad?
Both bills are essentially age verification requirement laws. AB 3080 explicitly, and AB 1949 implicitly.
AB 3080 strictly is calling for dangerous age verification requirements for both adult websites and any website which sells products or services which it is illegal for minors to access in California. While this may sound like a good idea on paper, it's important to keep in mind that any information that's put online is at risk of being extracted and used by bad actors like hackers. Even if there are additional requirements by the law that data be deleted after its used for its intended purpose and that it not be used to trace what websites people access. The former of which provides very little protection from people who could access the databases of identification that are used for verification, and the latter which is frankly impossible to completely enforce and could at any time reasonably be used by the government or any surveying entity to see what private citizens have been looking at since their ID would be linked to the access and not anonymized.
AB 1949 is nominally to protect children from having their data collected and sold without permission on websites. However by restricting this with an age limit it opens up similar issues wherein it could cause default requirements for age verification for any website so that they can avoid liability by users and the state.
What websites could they affect?
AB 3080, according to the bill's text, would affect websites which sells the types of items listed below
"
(b) Products or services that are illegal to sell to a minor under state law that are subject to subdivision (a) include all of the following:
(1) An aerosol container of paint that is capable of defacing property, as referenced in Section 594.1 of the Penal Code.
(2) Etching cream that is capable of defacing property, as referenced in Section 594.1 of the Penal Code.
(3) Dangerous fireworks, as referenced in Sections 12505 and 12689 of the Health and Safety Code.
(4) Tanning in an ultraviolet tanning device, as referenced in Sections 22702 and 22706 of the Business and Professions Code.
(5) Dietary supplement products containing ephedrine group alkaloids, as referenced in Section 110423.2 of the Health and Safety Code.
(6) Body branding, as referenced in Sections 119301 and 119302 of the Health and Safety Code.
(c) Products or services that are illegal to sell to a minor under state law that are subject to subdivision (a) include all of the following:
(1) Firearms or handguns, as referenced in Sections 16520, 16640, and 27505 of the Penal Code.
(2) A BB device, as referenced in Sections 16250 and 19910 of the Penal Code.
(3) Ammunition or reloaded ammunition, as referenced in Sections 16150 and 30300 of the Penal Code.
(4) Any tobacco, cigarette, cigarette papers, blunt wraps, any other preparation of tobacco, any other instrument or paraphernalia that is designed for the smoking or ingestion of tobacco, products prepared from tobacco, or any controlled substance, as referenced in Division 8.5 (commencing with Section 22950) of the Business and Professions Code, and Sections 308, 308.1, 308.2, and 308.3 of the Penal Code.
(5) Electronic cigarettes, as referenced in Section 119406 of the Health and Safety Code.
(6) A less lethal weapon, as referenced in Sections 16780 and 19405 of the Penal Code."
This is stated explicitly to include "internet website on which the owner of the internet website, for commercial gain, knowingly publishes sexually explicit content that, on an annual basis, exceeds one-third of the contents published on the internet website". Wherein "sexually explicit content" is defined as "visual imagery of an individual or individuals engaging in an act of masturbation, sexual intercourse, oral copulation, or other overtly sexual conduct that, taken as a whole, lacks serious literary, artistic, political, or scientific value."
This would likely not include websites like AO3 or any website which displays NSFW content not in excess of 1/3 of the content on the site. Possibly not inclusive of writing because of the "visual imagery", but don't know at this time. In any case we don't want to set a precedent off of which it could springboard into non-commercial websites or any and all places with NSFW content.
AB 1949 is a lot more broad because it's about general data collection by any and all websites in which they might sell personal data collected by the website to third parties, especially if aimed specifically at minors or has a high chance of minors commonly accesses the site. But with how broad the language is I can't say there would be ANY limits to this one. So both are equally bad and would require equal attention in my opinion.
#california#kosa#ab 3080#ab 1949#age verification#internet safety#online privacy#online safety#bad internet bills
192 notes
·
View notes
Note
Hi there! Firstly, wanna say a huge thank you: your blog has inspired me to become more educated about cybersecurity and nutrition, and it’s the reason my brother and I now use Firefox! I came across this article and… it seemed to raise a lot of valid points about Mozilla, but I have no idea if they are true or not since I’m not that knowledgeable about tech, and they go against everything I’ve ever heard about Firefox. Wanted to ask if you wouldn’t mind giving it a quick read, if that’s not too much trouble, and explaining why it’s false/true? If you can, ofc, I realise that is a weird request, and I promise it&: not something I’d usually ask someone. I just thought I’d ask since you’re the only sort of ‘tech’ person I can think of whom I’d trust to know stuff about this. https://digdeeper.neocities.org/articles/mozilla
So this is a great example of someone reading a ToS uncharitably and extracting the most paranoid bullshit possible.
Aside from the absolute classic "oh noes they are storing info about what devices you use" (if you use firefox logged in mozilla will collect information about what device and OS you use to connect; they do this for a lot of reasons like figuring out what stuff the bulk of their users are using but also because *they can't display on your device without that data*) I want to zoom in on this as an example:

BTW, there is one really funny thing inside the account ToS (MozArchive) that I just have to mention: "We may suspend or terminate your access to the Services at any time for any reason, including [...] our provision of the Services to you is no longer commercially viable." The fuck? If you stop bringing them profit, you're gone. They really said that! To me, this is a roundabout admission that your data is being sold. And if it's not worth much (for whatever reason), then you get kicked out.
This person is highlighting the idea that they may cut you off from services if the provision of those services is no longer commercially viable. This author is saying "FIREFOX WILL BOOT YOU WHEN YOU STOP BEING A PROFITABLE LITTLE PAYPIG FOR THEM"
But. Okay. Let's go look at that section of the ToS:

These Terms will continue to apply until ended by either you or Mozilla. You can choose to end them at any time for any reason by deleting your Mozilla account, discontinuing your use of the Services, and if applicable, unsubscribing from our emails. We may suspend or terminate your access to the Services at any time for any reason, including, but not limited to, if we reasonably believe: (i) you have violated these Terms, (ii) you create risk or possible legal exposure for us; or (iii) our provision of the Services to you is no longer commercially viable. We will make reasonable efforts to notify you by the email address associated with your Mozilla account or the next time you attempt to access the Services. In all such cases, these Terms shall terminate, including, without limitation, your license to use the Services, except that the following sections shall continue to apply: Indemnification, Disclaimer; Limitation of Liability, Miscellaneous.
Bud. This says "we are not obligated to provide services to you and we may stop providing services that cost us more money to maintain than is viable." This isn't about selling your data, this is about backwards compatibility and sunsetting projects. They don't have to keep providing access to services they're no longer developing nor bend over backwards to make sure that you can keep running a version of the browser that uses the extensions they dropped support for ten years ago.
Ugh. I got to the section where they talk about cucking for manifest3 and jesus this asshole. Manifest 3 is a defacto set of web standards that are changing because google has so much market share as a browser that if they do something everybody else has to follow or they're going to break basic functionality; if they don't make these changes eventually a shitload of websites just will not work on firefox. WAY more than currently experience this problem. Nobody is happy about manifest 3 and the fact that mozilla put out a press release about coming manifest 3 changes (that was not positive!) doesn't mean they're happy about getting dragged along by the nose; this blogger would prefer something like them refusing to adopt those standards, but all that would happen is that they'd lose more users because less shit would work on firefox browsers since people write their sites for chrome first and anything else second if at all.
This writer also gripes a lot about things like "mozilla took away this functionality for the sake of security and SURE you can change that by going into the configurations but it should be an option right in the first panel of the settings what are they really trying to hide???" and they're not trying to hide anything bud they're trying to make a functional browser with intuitive menus for people who aren't power users.
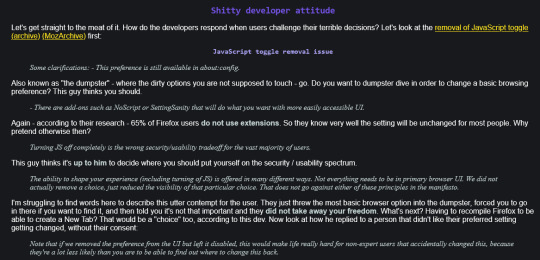
Like they want to be able to do everything they want and they want to be able to see the option in front of them at all times. It's a weird combination of "I know how to configure everything about this browser" and "if a setting is ever hidden behind a readmore it's a dark pattern and is an attack on user privacy." Like they gripe a lot about privacy and then link to a bunch of pages on mozilla where they explain their privacy settings and link to tutorials on how to hide the data that they just explained they collect.

Yeah this is someone I would walk away from in order to avoid getting into a fistfight.
"FOSS licenses are nice but they don't ensure quality" nobody said they did.
"FOSS licensed softwares don't always accept user participation in development" nobody said they did
"I can't change the actual code of firefox to remove things that I don't like don't tell me to fork it it has to be all or nothing mozilla specifically has to do what I want or it's user hostile" I can see why it would be hostile to you as a user fuck you dude this is why forks *exist* (also the "spyware" discussed is basic browser tracking stuff, the realistic necessities of how email work that make it not private by default like the PROTOCOLS are not private you can't get around that, and a lot of the stuff is opt out but improves functionality for day to day users, AND a lot of the tracking is specifically for people with logged-in accounts which are not necessary to use firefox like if you hate pocket don't use it my friend! I also hate pocket it is quite simple to never use it thanks)
"There's no justification for making the source code unavailable" my dude. https://hg.mozilla.org/mozilla-central/
"If they really cared about an open internet they'd work toward killing capitalism." Friend. I think there's very little more that a web browser could do to undermine the capitalist nature of huge chunks of the web and maintain a broad userbase than what firefox is doing.
I'm reminded of the time that I saw someone losing their shit about a linux distro that included chrome as *a* browser - not the default browser, but *a* browser.
It is an unpleasant fact that a lot of firefox's funding comes from google. That's part of why google is still the default search engine in Firefox and I read some similar articles decrying mozilla's residence firmly in Google's pocket a few years ago. I don't think there's anyone at mozilla who is genuinely pleased that their cheques are signed by google, but there are a ton of people at mozilla who are happy they can keep the lights on because getting paid by google means that they can do as much as they possibly can to create a functional browser that has a significant interest in privacy by default and that can be made *VERY* private by a dedicated user.
Anyway a lot of the stuff on this post is things like "a certificate expired five years ago and broke extensions and that means that mozilla is incompetent and hates users" or "eleven years ago there was a slapfight in the bug reporting forums between a user and a mod and the fact that the user was kicked after repeatedly being told his fix wasn't going to get made is censorship."
The big beefs at the center of this post are:
Mozilla collects data on users
Mozilla limits functionality that should be up to the users
Mozilla takes money from google
and my refutations are:
it does, and it is less than any other mainstream browser and is much much more transparent about what data is collected and how to prevent that data from being collected
A lot of the functionality they're discussing is still there and the stuff that isn't is allowing unsigned extensions which, dude, put a fork in it. They're not going to budge on unsigned extensions but the bar you have to clear to get signed is really really low; like this guy is LITERALLY saying "allow the installation of malicious extensions."
Yep. They do. This point reminds me of a lot of the people on tumblr who hate ads but also hate it when people pay for tumblr. As it turns out making things costs money, and making things used by millions of people costs *A LOT* of money.
I mean FFS one of the things this writer complains about is that Mozilla has a YouTube page.
This isn't just letting perfect be the enemy of good, it's letting perfect be the enemy of *functionally existing as a large organization in the modern world.*
Anyway, I'm glad you enjoy my blog, thank you for letting me know!
405 notes
·
View notes
Text
random, deeply unscientific poll time because I'm curious how well this website reflects the overall labor force lol
before you mark "unemployed," READ THE EXPLANATION AND INSTRUCTIONS
DETAILS AND INSTRUCTIONS:
*The number listed beside each category is the number of job positions available to the total workforce, not necessarily the number of people who are actually employed.
*Not having a job does not automatically make you "unemployed." Unemployed means you are a participating member of the workforce but don't have a job currently. To be consider part of the active workforce as defined by the BLS, you MUST be ALL of the following:
16 years of age or older
residing in the 50 states or DC
available for work
actively seeking employment in the last 4 weeks
not on active duty in the military
DO NOT select unemployed unless you meet ALL of the criteria above.
Examples of not having a job but not counting as unemployed: stay-at-home parent (I know this one is a bad reflection of reality, i know i know pls dont yell at me), a full-time student not currently working, a 25 year old who hasn't applied for any jobs in over a few months, someone with a permanent or temporary disability who is either not working/seeking employment or on FMLA.
Other notes and explanation:
This is a list of all non-agriculture industries that employ 10 million or more people, based on the most recent data from the US Bureau of Labor Statistics. The math might be way off bc I wasn't very careful lmao. If you have more than one job across more than one industry, pick the one that makes up the majority of your income.
A handful of familiar sub-industries that make up a portion of a larger industry but are less than 8 million people are listed in the "Other" category so that the much larger sub-industry can have its own line.
For example, healthcare belongs to "healthcare and public services," which is around 22M and includes childcare and social support services. Because direct healthcare delivery makes up such an enormous portion, I separated it out. The rest is fewer than 5M and thus does not get its own line, so they're included in "Other." (Insurance specifically is included in finance.)
More things included in "other":
Construction
Mining, quarrying, and oil and gas extraction
Utilities
Real-estate
48 notes
·
View notes
Text
Genetic testing company 23andMe, once a Silicon Valley darling valued at $6 billion, filed for Chapter 11 bankruptcy protection late Sunday as it prepares for a sale of the business. CEO Anne Wojcicki, who cofounded the company in 2006, has also stepped down after months of failed attempts to take the firm private.
As uncertainty about the company’s future reaches its peak, all eyes are on the trove of deeply personal—and potentially valuable—genetic data that 23andMe holds. Privacy advocates have long warned that the risk of entrusting genetic data to any institution is twofold—the organization could fail to protect it, but it could also hand over customer data to a new entity that they may not trust and didn’t choose.
California attorney general Rob Bonta reminded consumers in an alert on Friday that Californians have a legal right to ask that an organization delete their data. 23andMe customers in other states and countries largely do not have the same protections, though there is also a right to deletion for health data in Washington state’s My Health My Data Act and the European Union’s General Data Protection Regulation. Regardless of residency, all 23andMe customers should consider downloading anything they want to keep from the service and should then attempt to delete their information.
“This situation really brings home the point that there is still no national health privacy law in the US protecting your rights unless you live in California or Washington,” says Andrea Downing, an independent security researcher and cofounder of the patient-led digital rights nonprofit The Light Collective. “Meanwhile, we continue to evolve our understanding of how genetic information has value, but also has unique vulnerability.”
John Verdi, senior vice president of policy at the Future of Privacy Forum, says 23andMe’s new owner could revise the company’s privacy policies for new customers and new data collection, but the data it has already collected from current customers is subject to existing terms. “The company has legal obligations regarding information collected under the current policies,” he says.
Still, researchers emphasize that in practice, such a large transition will create real data exposure that is outside of 23andMe customers’ control. “In my opinion, these privacy policies—especially in the context of acquisitions in the venture capital and private equity space—aren't worth the paper they're printed on,” says longtime security researcher and data privacy advocate Kenn White. “For regular people out there who use these services, you're pretty much on your own. My advice is to request your data get deleted as soon as possible"
To delete your genetic data through 23andMe’s website, log in and then go to Settings in your profile. Scroll to 23andMe Data and then click View. At this point, you can choose to download a copy of your genetic information. Then scroll to Delete Data and click Permanently Delete Data. Once you initiate the process, you’ll receive an email from 23andMe to confirm. Click the link in the email to complete the deletion process. Additionally, you can direct 23andMe to destroy the biological sample it used to extract your DNA data if you previously authorized the company to keep it. Go to Settings and then Preferences.
You can also opt in to and out of participating in research at any time by updating your consent status in your account settings. If you opt out, 23andMe will stop using your information for research going forward and will discontinue use of your data within 30 days. This does not affect studies that have already been completed.
23andMe has never been profitable and has struggled to revamp its business model since it went public in 2021. Demand for its ancestry and health testing kits has been declining for years. And data privacy has had a role to play in the company’s dwindling fortunes after the company was hit with a major data breach in December 2023 that affected millions of customers. The incident led to a class action lawsuit, which 23andMe agreed to settle for $30 million.
Last summer, Wojcicki filed a proposal to take the company private, which was rejected by 23andMe’s board of directors. Shortly after, the company shuttered its in-house drug discovery unit, and its board members resigned en masse over Wojcicki’s strategic direction.
23andMe says it intends to continue operating as usual throughout the sale process and that there are no immediate changes to the way it stores, manages, or protects customer data. In an open letter to customers, the company said it will “seek to find a partner who shares our commitment to customer data privacy and allows our mission of helping people access, understand and benefit from the human genome to live on.” But the direction of 23andMe will ultimately be in the hands of whoever takes over the company.
“If there is a new owner that comes out of the bankruptcy process, that new owner steps into the shoes of 23andMe and takes over those assets,” says Jennifer Wagner, an assistant professor of law, policy, and engineering and anthropology at Penn State University.
“They would still be bound by the complex web of contractual agreements that are in place right now with users,” Wagner adds. “But I think it does give rise to some uncertainty in terms of whether or not a new player would have the same values or that same kind of culture that 23andMe was trying to cultivate.”
23 notes
·
View notes
Text
Collecting seller and quantity related data may provide the finest leads for you Web Screen Scraping offers Best Walmart Product Data Scraping Services.
0 notes
Text
Jaime Raskin Asks Us To Help Make A FOIA Tsunami March 11, 2025
Today Jamie Raskin filed a formal demand for access to his personal data obtained by the Department of Government Efficiency (DOGE) and Elon Musk. He encourages all U.S. citizens to do the same.
From Raskin: "Today I filed a formal demand for access to my personal data obtained by the Department of Government Efficiency (DOGE) and Elon Musk. I encourage all U.S. citizens to join me in doing the same.
Elon Musk should have been more careful in what he wished for, Carol. DOGE recently dodged lawsuits about its seizure of citizens’ personal data by telling courts that it is a legitimate government agency entitled to extract this information. What Elon Musk apparently did not realize is that this statement triggers DOGE’s obligation to comply with citizen demands to see and—if need be—correct their personal information under the Privacy Act. It also allows every citizen to find out what other agencies or outside parties have been made privy to our information.
ast night, the U.S. District Court for the District of Columbia issued an injunction commanding DOGE to comply with citizen requests under the Freedom of Information Act. FOIA encompasses the Federal Privacy Act of 1974, which entitles any citizen to access personal information held in any U.S. government records system.
By visiting the link on my website HERE,you can fill out the Privacy Act request form and mail it in directly to DOGE. This newly recognized federal agency, which has been systematically accessing government computer data systems, now has an obligation to respond to specific information demands from any of the 340 million U.S. citizens who exercise their legal right to defend their privacy and establish the security of their personal information.
I can’t wait to see what DOGE has been doing with all of our data, and I can’t wait to see what the courts will do if DOGE refuses to comply with the District Court’s injunction.
In a democracy, as opposed to a dictatorship, assuming the powers of government carries real burdens and obligations for our officials as well as the benefits and riches the billionaires routinely seek out.
I hope you will join me in this unfolding monumental struggle for transparency and the rights of the people. If you have any questions, please don’t hesitate to fill out the form HERE.
With gratitude and solidarity, and nothing but great high hopes for America, Jamie Raskin

Stay in Touch - DOGE Privacy Act Request
If you have mailed a Privacy Act Request to DOGE, please fill out the form below and we will stay in touch with additional details and updates as they become available.
#Trump#Elonald#Jamie Raskin Congressman#https://act.jamieraskin.com/signup/doge_privacy/?t=2&akid=668%2E37339%2EeIThBg
22 notes
·
View notes
Text
Has anyone used SquidgeWorld Archive ( https://squidgeworld.org/ ) to read/post fanfictions ? Apparently it's exactly like Ao3 but with a clear position against AI :

Their Terms of Service state :
7. Added May 13th, 2023: Artificial Intelligence (A.I.) generated works are not supported in the archive. The only exception to this rule would be partial only in posts that are clearly marked meta as part of discussion of said works. Otherwise, no. AI generated works are not welcomed in the archive 8. Added September 24th, 2023: Web scraping by artificial intelligence (AI), or any process of extracting data from the contents of this website for the purpose of use with artificial intelligence (AI) is strictly prohibited. Any data collection, content aggregation, or use of contents on this website in any way for training datasets or machine learning models is expressly prohibited. For more information, contact us via the “Contact Us” section of this website, or via any of the links on other Squidge.org property websites.
It sounds nice ! I love Ao3 but indeed it doesn't mention AI, simply stating that "AI generated works are allowed". So it's good that at least some fanwork websites are addressing the issue ! Hopefully Ao3 will release a clear rule against web scraping / machine learning for all posted works.
Now if you're wondering what is available right now on SqWA, I haven't checked all my favorite tags yet. If you're planning on writing something, maybe give it a go ?? So we'll have more to look forward to !
38 notes
·
View notes
Text
I'm working on a project that focuses on solving a bunch of schleppy tasks that the average person has (and might resort to a sketchy website to solve) but a mediocre programmer could probably knock out with half an hour and access to stackoverflow. Examples are things like unlocking password-protected power point files, extracting random archive formats, doing stupid things in ImageMagick, slapping together multiple PDFs, etc. And everything executes in the browser, no uploads or downloads. And programmers can share helpful scripts with their less technically inclined friends in a safe way. Anyhow, if you're interested, I can share more later.
One example task that's driving me nuts is dealing with those Winmail.dat files that Outlook sometimes sends instead of a normal email with attachments. This problem is so straightforward and easy to solve--there's a fuck ton of libraries to extract them--, but I have no idea if I've solved it because I can't acquire any test data. Every search result on the internet for Winmail.dat is instructions for how to extract attachments from them or for how to reconfigure Outlook to never send them. At no point has anyone in the history of the world ever intentionally created a Winmail.dat file. For every 100 libraries that parse them, there are zero libraries to create them. It's like searching for the best way to contract leprosy. I think I might need to resort to hiring a borderline-illiterate boomer to send me important paperwork via email.
23 notes
·
View notes