#graph partitioning
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, 44% of users from Denmark used Tumblr daily.
Text
spectral partitioning
i need to do a presentation on spectral partitioning for uni so here we go! an explanation on this graph partitioning algorithm here so i dont forget shit (i will not be looking at random walks)
under the cut theres gonna be maths. a lot of it so if u dont want that then dont look there. and theres no LaTeX or mathjax here so its ugly.
also i assume you know what graphs and eigen-shit are
i will assume our graph is a simple undirected graph.
the core idea of spectral partitioning is minimising the cut size - the sum of weights of the edges between two communities.
so if we have a graph that looks like this
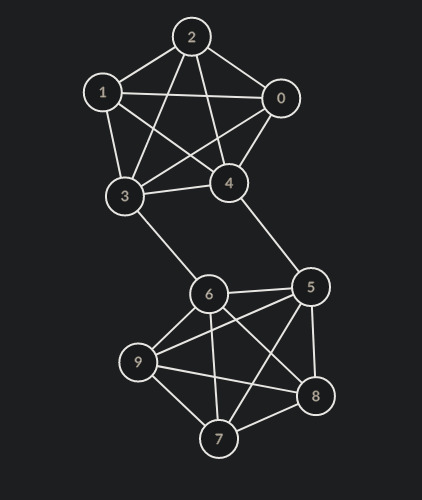
(made on https://csacademy.com/app/graph_editor/)
and we try to cut it into 2 groups, (by inspection) the minimum number of edges we have to cut through is 2, between nodes 3-6 and 4-5. so the minimum cut size is 2. and if we cut through those nodes we get 2 communities.
ill let you convince yourself that minimising the cut will lead to communities that arent very related to each other.
but how do we find this minimum cut? if we try to brute force it then you first separate nodes into one of 2 groups, then sum the weights of edges between nodes in these 2 groups. this is slow - O(2^n) where n is number of nodes in the graph - and it cant be improved (its an np-hard problem).
so instead of optimising that mess we will try to approximate it. sure our approximations might not find the actual minimum cut size but itll be good enough.
now to try to approximate this we need to find a nicer way of writing the cut size of some partition.
let A be the set of nodes in one group of the partition, and Ac its complement (the other group of the partition)
also let A=(w_ij) be a matrix where w_ij is the weight of the edge between nodes i and j (this is called the adjacency matrix, hence the A). and D be the diagonal matrix of "degrees" (actually sum of weights of all adjacent edges, but lets just call it the degree) of nodes.
finally let x be the indicator vector where x_i = 1 if i is in A, else -1. and 1 be the vector of just 1s if i use 1 where you would expect a vector (polymorphism? in my maths? more likely than you think)
and the transpose will be denoted ^T as usual
now to get the cut size, its the sum of edges between A and Ac. so thats ((1+x)/2)^T A ((1-x)/2)
you can probably see the halves are annoying, so lets find 4 * the cut size. so thats (1+x)^T A (1-x)
but this +x -x is a bit weird. it would be better if they were the same sign. so how do we do that?
the sum of weights of edges between the parts of the partition is the same as the all the sum of degrees of nodes minus the sum of weights of nodes within the same group. so we can rewrite this as (1+x)^T D (1+x) - (1+x)^T A (1+x) = (1+x)^T (D-A) (1+x)
now let L = D-A. this is called the laplacian of the graph and it has a few nice properties. first the row/column sums are 0 (you add the "degree" then take away all the weights). second its quadratic form v^T L v = ½ Σ w_ij (v_i - v_j)². importantly this means its positive semi-definite. third its symmetric. importantly this means that it has an orthonormal eigenbasis.[1]
now because its row/column sums are 0 you can write 4 * cut size as (1+x)^T L (1+x) = x^T L x. and so this is what we want to minimise.
now like i said minimising this is np-hard, but we can ignore the fact that x_i = ±1, and instead consider it on all vectors s, then just look at the sign of the entry.
just two issues with this. one: what if theres a 0? well you can lob it in either group of the partition. two: (ks)^T L (ks) = k² x^T L x. so any minimum we find, we can just halve each value of the vector or smth and get a smaller min. for this we can simply consider vectors s.t. ||s||=1.
now we can write s in orthonormal eigenbase to get that s^T L s is a weighted average of the eigenvectors of L. so the minimisation of this is the smallest eigenvalue of L. but because the row/column sums are 0, this eig val is 0 with eig vec being the vector of ones. if you think of this in terms of graphs this makes sense - to minimise the cut you put everything in one bucket and nothing in the other and so theres no edges to cut!
now lets assume a good partition will cut it roughly in half. we can think of this as the number of nodes in one half of the partition. in other words 1^T x ≈ 0. so lets add the constraint that 1^T s = 0.
this means s is orthogonal to 1 - our smallest eigenvector. so in our weighted average, we cannot have any weight for out smallest eigenvalue, and so our second smallest eigenvalue is the smallest and we can approximate the minimum cut size by looking at the signs of the second smallest eigenvector!
and that is the idea behind spectral partitioning! now you can normalise the cut in some way. e.g.
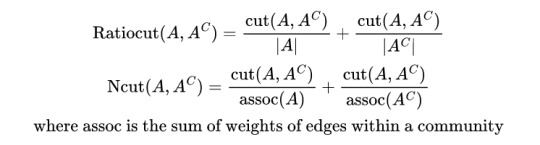
with their associated minimisations being shown below

then you get good algs for separating images into blocks of focus
(sorry for no IDs for these)
and there we go! thats spectral partitioning!
[1] you can use gram schmidt to get an orthogonal basis of an eigen space, so all we need to show is that eig vecs with diff eig vals are orthogonal.

therefore any eig basis of symm (or hermitian) matrix is orthogonal.
the fact that an eigenbase even bloody exists is beyond this tumblr post, but is called the spectral theorem - and is where the name spectral partitioning comes from
#maths#i speak i ramble#graph partitioning#graph theory#math#mathblr#effortpost#oi terezi! heres where the orthonormal eigenbasis i kept on getting annoyed at is from!
0 notes
Text
its crazy how when u graph like x+y=10 thats a graph of all the two integer sums of 10. and when you graph x+y+z=10 thats all the three integer sums. and so on. and if you lived in infinitely dimensional space you could see a graph of every integer partition of every integer. idk i just thought about this. i love math. hi
289 notes
·
View notes
Text
Reading about intersex variations is so fascinating because you start seeing how little distinction there is between certain terms.
What is the difference between a bicornuate uterus, septate uterus, and uterus didelphys? Well, to some doctors, the diagnosis is completely inconsistent and based on "vibes" basically.
Bicornuate uterus is supposed to be a "heart shaped uterus". Septate uterus is supposed to be a "uterus with a partition down the middle."
Uterus didelphys is meant to be "two distinct uteruses," either separated or fused, but each with their own space.
Now, here are photos of what doctors call "bicornuate." Notice how the "complete bicornuate" is literally two separate uteruses, just fused together.
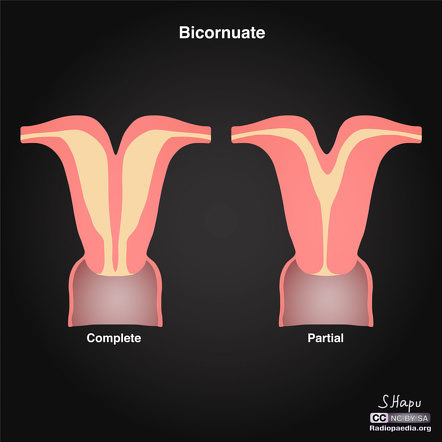

Here are photos of what doctors call "uterus didelphys." Once again, notice how it can be basically exactly the same as a "complete bicornuate uterus"?

Generally, people don't consider bircornuate uterus or septate uterus to be intersex. However, you can see in these medical graphs that bicornuate uterus, septate uterus, and uterus didelphys can overlap greatly, to the point where they are hardly distinguishable.



Some doctors argue that uterus didelphys is defined by a double vagina or double cervix, but this argument is also extremely inconsistent and there's no established agreement. Some also argue that its when the two uteruses are separated/non-fused, but like...
Look at this. These are examples with a singular cervix.
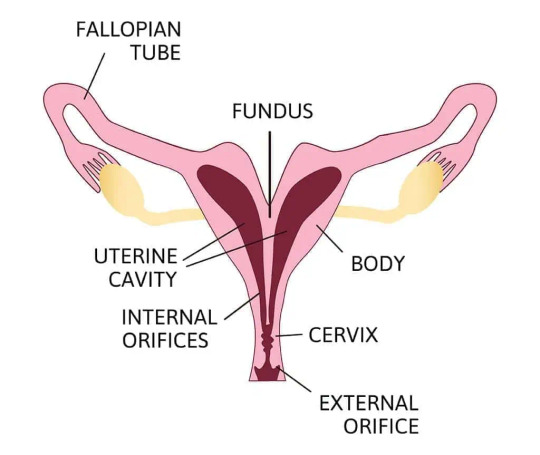
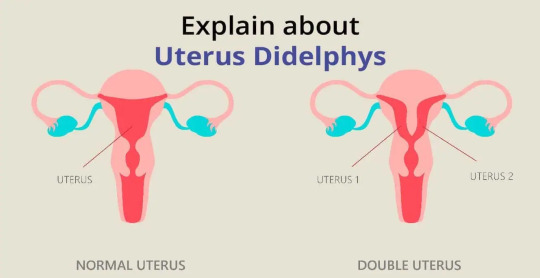
People get diagnosed with bicornuate uterus or septate uterus by some doctors, and uterus didelphys by others, because these structures can look and function in practically identical ways.
In conclusion, if you have a uterine structure that separates it into two fully distinct spaces, we personally think that you can identify with uterus didelphys, and can call yourself intersex. But thats just our own two cents.
We've also seen people in the intersex community discuss this exact topic before and come to the same conclusion. Hence why we fell down the rabbit hole.
#lgbtqia#lgbtq#lgbt#queer#lgbt pride#intersex#intersex community#intersex spectrum#body diversity#educate yourself#intersex awareness#uterus didelphys#bicornuate uterus#septate uterus#double uterus#uterinehealth
39 notes
·
View notes
Text
@pickledfingers (Raw chalcopyrite data)
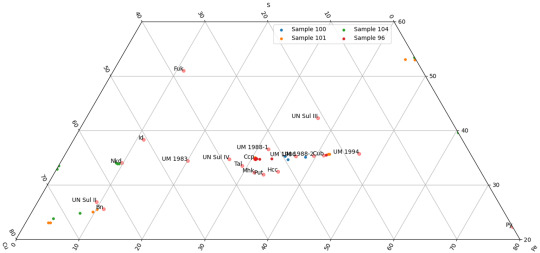
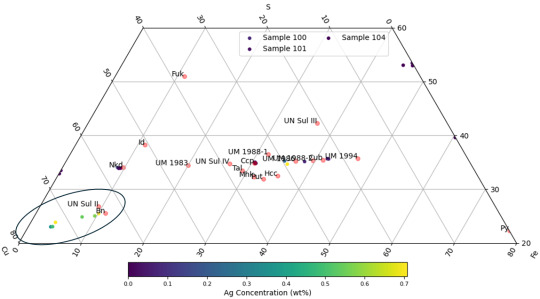
Our most recent synthesis batch! 101, and 104 were doped with silver.
100 still seems to have made cubanite and some variants even though our XRD results came back as tetragonal Cpy. For both 101 and 104 though, we either got cubanite (Ag included) or Nukundamite (no trace Ag) and for both, it partitioned to the bornite of the samples.
(Graph ends are for Cu-Fe-S wt%.)
#chalcopyrite#experimental petrology#These results are so cool to me tbh :3#I think we might've used unpowdered Fe for 104 which also might've affected the necessary cook time.#Unfortunately I won't get the chance to play with these for another month or so. At least until this conference/paper is over.
14 notes
·
View notes
Text
(ノಠ益ಠ)ノ彡┻━┻ real analysis week 2 (ノಠ益ಠ)ノ彡┻━┻

yeah, so, last week's verdict (by two independent reviewers) wasn't great. And as predicted the central culprit was multivariable calculus. However, I still have a lot of other areas for improvement.
This morning I ran six miles to get out the rage and frustration I feel over how much I struggle with this fuckass subject. Algebra is so much more delightful, so much easier. It's easy to make intuitive inferences with algebra. Just play around, manipulate your objects, find some isomorphisms, maybe do some induction. Divide if you can. Find nilpotent elements if you can't. Etc. etc. etc. Or if I'm working with a graph. Idk, delete that vertex, see what happens. Hell. What are the important vertices? What if we can find a partition of vertices with certain structural properties----
But no, these are the things that cause my brain to short-circuit. Those who are more versed in analytic techniques will probably laugh at me:
take a series, like

this little bastard is in Rudin's Principles of Mathematical Analysis, pp. 62. I wish I had reviewed the text more thoroughly before taking the exam, because this was a question on the winter qualifier. I initially looked at the series and felt my chest fill up with the pain and anguish of my ancestors. I knew that this looked like some form of application of a p-series test. I thought maybe I could find a p-series which bounded this series from above, and via the Comparison Test for Infinite Series, I'd obtain the result. I didn't know what to do from there, or how to express the larger p-series. I wasted a good amount of time trying to obtain the bound which wasn't obvious to my panicking brain.
In the back of my mind, I thought maybe I could use a lesser-known convergence test, which says

I couldn't remember what the terms of this series were, so it was a dead-end for me on the exam. Turns out this was the correct way to go. But I had zero intuition as to how this fuckass technique was the one to use. I just look at these types of problems and suffer complete paralysis, almost like I'm afraid of going down the wrong rabbit hole. I think it's also because it isn't immediately obvious what I should do - too many times I've been misled by functions that seemed like they behaved well for small values of n but then pop off as n approaches infinity.
So today the plan is
go running to silence the voices (done)
pilates (10 min)
multivariable calculus review
review the practice exam
practice problems related to strugglebus areas on that exam
2 notes
·
View notes
Text

Putting It Together
Mathober 5: Integer Partition. The Keyser Söze of math is behind it all.
The Desmos graph for the middle portion. Is this the first time I have a number doing math?
6 notes
·
View notes
Text
Exceptional Automorphisms of S_6
The symmetric group S_6 has a special property that S_n does not have for ANY n ≠6. Really? 6, of all numbers?? How odd.
For any group G, and every g in G, the conjugation map f_g: h ↦ g h g^-1 is an automorphism of G. That is, it is an isomorphism from G -> G. The group of these particular automorphisms (under composition) is called the group of inner automorphisms of a group. Did you know that for every symmetric group S_n EXCEPT n=6, this is the entire automorphism group?
For some reason, S_6 has basically ONE (and only one) weird automorphism. What I mean by this is if we denote the inner automorphisms of S_6 by Inn(S_6), then S_6/Inn(S_6) ~= Z_2. (In other words, you can pick a single automorphism sigma such that the automorphisms of S_6 that are not inner automorphisms can be written as a composition of inner automorphisms and this one sigma.)
So we have this weird situation where |Aut(S_2)|=|Aut(C_2)| = 1, which is kinda trivial, |Aut(S_6)| = 2n!, and |Aut(S_n)| = n! otherwise. Kinda weird, huh?
What is also interesting is the proofs that there are no outer automorphisms for n≠6. Basically you can eliminate all but finitely many n, then you can pick off cases, and you are left with an n=6 shaped hole in your cases that CANNOT be filled, which feels so weird to me. If I was proving this myself I'd be going crazy having proven it for every case except 6, and having to resort to some proof which for some reason doesn't work for finitely many values.
Construction
There are so many different ways to construct the weird automorphism of S_6 - I have some links at the bottom. I particularly like the graph theory/geometric ones. Something about using factorisations of K_6 or a dodecahedron just makes the 6 feel more unique. I will admit I don't think I understand what is fundamentally special about 6 enough yet, though, on a philosophical level.
Practically, though, the constructions all basically boil down to the fact you can put a copy of S_5 inside S_6 in a way that isn't the obvious way, which you can only do for n=6. That is the special part.
After that, you have these 6 cosets of S_5 inside S_6 that S_6 acts upon. In other words, each element of S_6 permutes the 6 cosets of S_5 living inside it. But the group of permutations of 6 cosets is S_6. So we have a mapping from elements of S_6 to S_6 - an automorphism! Is this automorphism an inner automorphism? Each construction shows why they are outer differently, but a common theme is to show that the mapping S_6 to S_6 does not take transpositions to transpositions, but inner automorphisms preserve the cycle type.
Some proofs and examples
The wikipedia article. I like the construction about graph partitions. It does not, however, have much detail sadly.
Fortunately, the graph partitions thing from wikipedia is explained here. It's very short and to the point, also quite nice to look at:
Fairly elementary explanations, followed by more intense ones:
Requires only basic group theory to understand the first few explanations they provide (although it isn't trivial if you just learned group theory). Bonus points for "MyStIc PeNtAgOnS" (capitalisation mine):
Allegedly useful, but I can't grab a copy: (I think its on mathscinet under MR1240362 as per David Leep's personal website's publications section)
Combinatorial Structure of the automorphism group of S6 by T.Y. Lam and David B. Leep, Expositiones Mathematicae11 (1993), no. 4, pp. 289-903.
The comment by Matthew Towers here is also interesting:
5 notes
·
View notes
Text
Obviously "comutuals" just means mutual mutuals, but what if we deliberately misinterpret "co" as being in the category theory sense of the prefix? Mutuality is already a symmetric relationship so we can't get anything new with just the reverse relationship. Let's instead do as the category theorists do and make a new more complicated definition where it's a morphism and reverse that instead. A mutual is a morphism from the complete directed graph of 2 nodes to the follower graph, so a comutual is a graph morphism in the opposite direction, which can be interpreted as a partition of Tumblr's users into 2 sets such that at least one member of each set follows at least one member of the other. This definition of comutuals may not be useful but it's surprisingly fitting.
To fit this back into the theme of bad ideas for Tumblr features, how about Tumblr lists a selection of comutuals and where you fit into them somewhere in the UI. Not all of them, because there are far too many. Trying to compile a complete list thereby crashing the website as it runs out of memory would be another way to make it worse at least. Probably.
Feature ideas I have to make tumblr worse
Unfollow notifications. When someone unfollows you, you receive a notification about it. The notification includes the last post of yours that the unfollower saw so you know what the final straw was.
If the unfollower was a mutual then this notification comes with stats about how long you were mutuals and a list of comutuals who have to pick sides in the divorce. The comutuals receive this notification too
Ability to edit other people's replies.
Ability to edit other people's blog themes.
The ability to gift debuffs like those cooking competition shows. Pay $15 to make someone you hate only be allowed to post 20 times a day. Pay $30 and they can only make posts out of the set of pre-approved family-friendly message options like the Webkinz chatroom.
De-blaze. Halt someone else's post right in its tracks by removing all impressions. The more a post is circulating the more expensive this is.
30 Day Trial Follows. When you follow someone you can't unfollow them for at least 30 days because c'mon, don't you wanna at least give them a chance?
Obligatory "Tumblr houses". You have to act really really excited for the yearly sportsball tournament or risk being shadowbanned. Your blog is forcibly themed after your Tumblr house.
Obligatory name, face, and address when you sign up. This isn't for verification or anything this is explicitly for doxxing. Hopefully you'll think twice about posting your rancid My Little Pony take now that you know the whole fandom can be at your doorstep in an hour.
47K notes
·
View notes
Text
What's a Technical Drawing of a transport problem
What's a Technical Drawing of a transport problem
Q: what’s a Technical Drawing of a transport situation? purchase used transport packing containers Shipping Containers for Sale
The technical drawing suggests the right dimensions and proportions and all critical measurements of a shipping area. The diagram indicates severa perspectives and the region of doorways, ends, element partitions and the top of the place. one-of-a-kind essential functions together with the measurements and positioning of the fittings much like the locking rods and air vents in phrases of the format of the yankee conex. buy used delivery boxes
Q: Why can we need a transport vicinity Technical Drawing? transport bins in the marketplace
Technical drawings are desired thru method of the usage of contractors appearing renovations on a constructing or manufacturing venture. the proper dimensions of the yank conex hassle detail may be very critical to the overall venture for the architects and engineers.
Technical drawings are mainly beneficial as a reference guide at the same time as precise measurements are favored, because of the reality the drawings are created exactly to scale. Technical diagrams are generally stated in the device of a constructing contractor’s project in the long run of the early making plans ranges thru to the finalization of the constructing project.
Q: Are there specific types of transport hassle Technical Drawings?
the magnificent form of delivery box technical drawings (structural, CAD, fabrication, and engineering drawings) are the identical for the maximum detail. all the variations of drawings feature unique measurements of the transport area and all related additives. AmericanConex offers free downloads of delivery problem technical drawings in all of the most commonplace vicinity sizes and configurations
Q: What information is contained in a transport hassle Technical Drawing?
American Conex technical drawings is composed of each the inner and outdoor width dimensions and vicinity of problem features. American Conex difficulty features just like the door beginning widths, heights, the place of scenario features like as lashing elements, the gauge thickness of the metallic partitions, , the right shape of substances used, example: Corten steel and galvanized locking components. transportable garage boxes
The technical graph moreover indicates the actual tare weight and gross weight functionality. The plan moreover consists of the vicinity report reference amount and the identity of the style style fashion dressmaker or employer enterprise who authored and commonplace the technical drawing.
All charges quoted are in USD. on the equal time as each attempt is made with the beneficial resource of yankee Conex® to accurately listing inventory pricing, some mistakes also can moreover upward shove up owing to zip place inaccuracy. Please check your object description and earnings invoice in advance than finishing your purchase. American Conex® reserves the right to continuously modify hassle and transport pricing based totally mostly on stock stages and transportation expenses.
Your privateness is crucial to us! American Conex® is dedicated to maintaining the internet privacy entrusted to us via all net net internet page on line internet web page net web site site visitors. We usually positioned into effect practices to protect the privacy of your facts. have a have a test greater in our privateness coverage.
0 notes
Text
CSDS 455: Applied Graph Theory Homework 3
Problem 1: Let G be a bipartite graph, let A and B be the partition sets of V (G), and suppose we have the following fact: for every S ⊆ A, |S| ≤ |N(S)|. (N(S) is the set of vertices of B adjacent to a vertex of S.) Let M be a matching of G and let a ∈ A be an unmatched vertex. Prove that there exists an augmenting path in G with respect to M starting from a. Problem 2: Let G be a bipartite…
0 notes
Text
Qoro Quantum And CESGA For Distributed Quantum Simulation

Qoro Quantum
Qoro Quantum and CESGA represent distributed quantum circuits with high-performance computing. Using Qoro Quantum's orchestration software and CESGA's CUNQA emulator, a test study showed scalable, distributed quantum circuit simulations over 10 HPC nodes. To assess distributed VQE and QAOA implementations, Qoro's Divi software built and scheduled thousands of quantum circuits for simulation on CESGA's infrastructure.
VQE and QAOA workloads finished in less than a second, demonstrating that high-throughput quantum algorithm simulations may be done with little code and efficient resources.
The pilot proved that distributed emulators like CUNQA can prepare HPC systems for large-scale quantum computing deployments by validating hybrid quantum-classical operations.
A pilot research from the Galician Supercomputing Centre (CESGA) and Qoro Quantum reveals how high-performance computing platforms may facilitate scalable, distributed quantum circuit simulations. A Qoro Quantum release said the two-week collaboration involved implementing Qoro's middleware orchestration platform to execute distributed versions of the variational quantum eigensolver and quantum approximate optimisation algorithm across CESGA's QMIO infrastructure.
Quantum Workload Integration and HPC Systems
Qoro's Divi quantum application layer automates hybrid quantum-classical algorithm orchestration and parallelisation. Divi created and ran quantum workloads on 10 HPC nodes using CESGA's CUNQA distributed QPU simulation framework for the pilot.
The announcement states that CESGA's modular testbed CUNQA mimics distributed QPU settings with customisable topologies and noise models. Qoro's technology might simulate quantum workloads in a multi-node setup to meet the demands of emerging hybrid quantum-HPC systems.
Everything worked perfectly, communication went well, and end-to-end functionality worked as intended.
Comparing QAOA and VQE in Distributed HPC
The variational hybrid approach VQE is used to estimate the ground-state energy of quantum systems, a major problem in quantum chemistry. Qoro and CESGA modelled a hydrogen molecule using two ansätze Hartree-Fock and Unitary Coupled Cluster Singles and Doubles in this pilot. Divi made 6,000 VQE circuits based on 20 bond length values.
With 10 computational nodes, the CUNQA emulator investigated the ansatz parameter space via Monte Carlo optimisation. Qoro says it replicated full demand in 0.51 seconds. Data collected automatically and returned for analysis show that the platform can enable high-throughput testing with only 15 lines of Divi code.
The researchers also evaluated QAOA, a quantum-classical technique for Max-Cut and combinatorial optimisation. This data clustering, circuit design, and logistics challenge involves partitioning a graph to maximise edges between two subgroups.
A 150-node network was partitioned into 15 clusters for simulation, and Qoro's Divi software built Monte Carlo parameterised circuits.Tests included 21,375 circuits in 15.44 seconds and 2,850 circuits in 2.13 seconds. The quantum-classical cut size ratio grew from 0.51 to 0.65 with sample size. The CUNQA emulator ran all circuits in parallel again utilising CESGA's architecture.
Performance, Infrastructure, and Prospects
Several pilot research results demonstrate scalable hybrid quantum computing advances. According to the Qoro Quantum release, Qoro's orchestration platform and CESGA's distributed quantum emulator provided faultless communication between the simulated QPU infrastructure and application layer. The cooperation also demonstrated how Qoro's Divi software could automatically generate and plan enormous quantum workloads, simplifying complex quantum applications.
The experiment also shown that distributed execution of hybrid quantum-classical algorithms over several HPC nodes may enhance performance without much human setup. Finally, the pilot showed key technological elements for scaling quantum workloads in high-performance computing. These insights will inform future distributed quantum system design.
Simulating distributed quantum architectures shows how HPC infrastructure might manage future quantum workloads. Qoro Quantum and CESGA plan to improve this method to enable quantum computing in large classical contexts.
CUNQA is being established as part of Quantum Spain with EU and Spanish Ministry for Digital Transformation support. ERDF_REACT EU funded this project's QMIO infrastructure for COVID-19 response.
#QoroQuantum#QuantumQoro#QAOA#CESGA#quantumcircuit#CUNQA#technology#TechNews#technologynews#news#govindhtech
0 notes
Text
CSCI570 - Homework 12 Solved
Q1) Given a graph G and two vertex sets A and B, let E(A,B) denote the set of edges with one endpoint in A and one endpoint in B. The Max Equal Cut problem is defined as follows: Given an undirected graph G(V, E), where V has an even number of vertices, find an equal partition of V into two sets A and B, maximizing the size of E(A,B). Provide a factor 2-approximation algorithm for solving the Max…
0 notes
Text
AWS NoSQL: A Comprehensive Guide to Scalable and Flexible Data Management
As big data and cloud computing continue to evolve, traditional relational databases often fall short in meeting the demands of modern applications. AWS NoSQL databases offer a scalable, high-performance solution for managing unstructured and semi-structured data with efficiency. This blog provides an in-depth exploration of aws no sql databases, highlighting their key benefits, use cases, and best practices for implementation.
An Overview of NoSQL on AWS
Unlike traditional SQL databases, NoSQL databases are designed with flexible schemas, horizontal scalability, and high availability in mind. AWS offers a range of managed NoSQL database services tailored to diverse business needs. These services empower organizations to develop applications capable of processing massive amounts of data while minimizing operational complexity.
Key AWS NoSQL Database Services
1. Amazon DynamoDB
Amazon DynamoDB is a fully managed key-value and document database engineered for ultra-low latency and exceptional scalability. It offers features such as automatic scaling, in-memory caching, and multi-region replication, making it an excellent choice for high-traffic and mission-critical applications.
2. Amazon DocumentDB (with MongoDB Compatibility)
Amazon DocumentDB is a fully managed document database service that supports JSON-like document structures. It is particularly well-suited for applications requiring flexible and hierarchical data storage, such as content management systems and product catalogs.
3. Amazon ElastiCache
Amazon ElastiCache delivers in-memory data storage powered by Redis or Memcached. By reducing database query loads, it significantly enhances application performance and is widely used for caching frequently accessed data.
4. Amazon Neptune
Amazon Neptune is a fully managed graph database service optimized for applications that rely on relationship-based data modeling. It is ideal for use cases such as social networking, fraud detection, and recommendation engines.
5. Amazon Timestream
Amazon Timestream is a purpose-built time-series database designed for IoT applications, DevOps monitoring, and real-time analytics. It efficiently processes massive volumes of time-stamped data with integrated analytics capabilities.
Benefits of AWS NoSQL Databases
Scalability – AWS NoSQL databases are designed for horizontal scaling, ensuring high performance and availability as data volumes increase.
Flexibility – Schema-less architecture allows for dynamic and evolving data structures, making NoSQL databases ideal for agile development environments.
Performance – Optimized for high-throughput, low-latency read and write operations, ensuring rapid data access.
Managed Services – AWS handles database maintenance, backups, security, and scaling, reducing the operational workload for teams.
High Availability – Features such as multi-region replication and automatic failover ensure data availability and business continuity.
Use Cases of AWS NoSQL Databases
E-commerce – Flexible and scalable storage for product catalogs, user profiles, and shopping cart sessions.
Gaming – Real-time leaderboards, session storage, and in-game transactions requiring ultra-fast, low-latency access.
IoT & Analytics – Efficient solutions for large-scale data ingestion and time-series analytics.
Social Media & Networking – Powerful graph databases like Amazon Neptune for relationship-based queries and real-time interactions.
Best Practices for Implementing AWS NoSQL Solutions
Select the Appropriate Database – Choose an AWS NoSQL service that aligns with your data model requirements and workload characteristics.
Design for Efficient Data Partitioning – Create well-optimized partition keys in DynamoDB to ensure balanced data distribution and performance.
Leverage Caching Solutions – Utilize Amazon ElastiCache to minimize database load and enhance response times for your applications.
Implement Robust Security Measures – Apply AWS Identity and Access Management (IAM), encryption protocols, and VPC isolation to safeguard your data.
Monitor and Scale Effectively – Use AWS CloudWatch for performance monitoring and take advantage of auto-scaling capabilities to manage workload fluctuations efficiently.
Conclusion
AWS NoSQL databases are a robust solution for modern, data-intensive applications. Whether your use case involves real-time analytics, large-scale storage, or high-speed data access, AWS NoSQL services offer the scalability, flexibility, and reliability required for success. By selecting the right database and adhering to best practices, organizations can build resilient, high-performing cloud-based applications with confidence.
0 notes
Text
IEEE Transactions on Emerging Topics in Computational Intelligence Volume 9, Issue 1, February 2025
1) A Survey of Human-Object Interaction Detection With Deep Learning
Author(s): Geng Han, Jiachen Zhao, Lele Zhang, Fang Deng
Pages: 3 - 26
2) Exploring the Horizons of Meta-Learning in Neural Networks: A Survey of the State-of-the-Art
Author(s): Asit Barman, Swalpa Kumar Roy, Swagatam Das, Paramartha Dutta
Pages: 27 - 42
3) Micro Many-Objective Evolutionary Algorithm With Knowledge Transfer
Author(s): Hu Peng, Zhongtian Luo, Tian Fang, Qingfu Zhang
Pages: 43 - 56
4) MoAR-CNN: Multi-Objective Adversarially Robust Convolutional Neural Network for SAR Image Classification
Author(s): Hai-Nan Wei, Guo-Qiang Zeng, Kang-Di Lu, Guang-Gang Geng, Jian Weng
Pages: 57 - 74
5) Prescribed-Time Optimal Consensus for Switched Stochastic Multiagent Systems: Reinforcement Learning Strategy
Author(s): Weiwei Guang, Xin Wang, Lihua Tan, Jian Sun, Tingwen Huang
Pages: 75 - 86
6) SR-ABR: Super Resolution Integrated ABR Algorithm for Cloud-Based Video Streaming
Author(s): Haiqiao Wu, Dapeng Oliver Wu, Peng Gong
Pages: 87 - 98
7) 3D-IMMC: Incomplete Multi-Modal 3D Shape Clustering via Cross Mapping and Dual Adaptive Fusion
Author(s): Tianyi Qin, Bo Peng, Jianjun Lei, Jiahui Song, Liying Xu, Qingming Huang
Pages: 99 - 108
8) A Co-Evolutionary Dual Niching Differential Evolution Algorithm for Nonlinear Equation Systems Optimization
Author(s): Shuijia Li, Rui Wang, Wenyin Gong, Zuowen Liao, Ling Wang
Pages: 109 - 118
9) A Collaborative Multi-Component Optimization Model Based on Pattern Sequence Similarity for Electricity Demand Prediction
Author(s): Xiaoyong Tang, Juan Zhang, Ronghui Cao, Wenzheng Liu
Pages: 119 - 130
10) A Deep Reinforcement Learning-Based Adaptive Large Neighborhood Search for Capacitated Electric Vehicle Routing Problems
Author(s): Chao Wang, Mengmeng Cao, Hao Jiang, Xiaoshu Xiang, Xingyi Zhang
Pages: 131 - 144
11) A Diversified Population Migration-Based Multiobjective Evolutionary Algorithm for Dynamic Community Detection
Author(s): Lei Zhang, Chaofan Qin, Haipeng Yang, Zishan Xiong, Renzhi Cao, Fan Cheng
Pages: 145 - 159
12) A Hub-Based Self-Organizing Algorithm for Feedforward Small-World Neural Network
Author(s): Wenjing Li, Can Chen, Junfei Qiao
Pages: 160 - 175
13) A New-Type Zeroing Neural Network Model and Its Application in Dynamic Cryptography
Author(s): Jingcan Zhu, Jie Jin, Chaoyang Chen, Lianghong Wu, Ming Lu, Aijia Ouyang
Pages: 176 - 191
14) FeaMix: Feature Mix With Memory Batch Based on Self-Consistency Learning for Code Generation and Code Translation
Author(s): Shuai Zhao, Jie Tian, Jie Fu, Jie Chen, Jinming Wen
Pages: 192 - 201
15) MUSTER: A Multi-Scale Transformer-Based Decoder for Semantic Segmentation
Author(s): Jing Xu, Wentao Shi, Pan Gao, Qizhu Li, Zhengwei Wang
Pages: 202 - 212
16) Feature Selection Using Generalized Multi-Granulation Dominance Neighborhood Rough Set Based on Weight Partition
Author(s): Weihua Xu, Qinyuan Bu
Pages: 213 - 227
17) A Collaborative Neurodynamic Algorithm for Quadratic Unconstrained Binary Optimization
Author(s): Hongzong Li, Jun Wang
Pages: 228 - 239
18) Global Cross-Attention Network for Single-Sensor Multispectral Imaging
Author(s): Nianzeng Yuan, Junhuai Li, Bangyong Sun
Pages: 240 - 252
19) OccludedInst: An Efficient Instance Segmentation Network for Automatic Driving Occlusion Scenes
Author(s): Hai Wang, Shilin Zhu, Long Chen, Yicheng Li, Yingfeng Cai
Pages: 253 - 270
20) 3D Skeleton-Based Non-Autoregressive Human Motion Prediction Using Encoder-Decoder Attention-Based Model
Author(s): Mayank Lovanshi, Vivek Tiwari, Rajesh Ingle, Swati Jain
Pages: 271 - 280
21) GF-LRP: A Method for Explaining Predictions Made by Variational Graph Auto-Encoders
Author(s): Esther Rodrigo-Bonet, Nikos Deligiannis
Pages: 281 - 291
22) Neuromorphic Auditory Perception by Neural Spiketrum
Author(s): Huajin Tang, Pengjie Gu, Jayawan Wijekoon, MHD Anas Alsakkal, Ziming Wang, Jiangrong Shen, Rui Yan, Gang Pan
Pages: 292 - 303
23) Semi-Supervised Contrastive Learning for Time Series Classification in Healthcare
Author(s): Xiaofeng Liu, Zhihong Liu, Jie Li, Xiang Zhang
Pages: 318 - 331
24) Bi-Level Model Management Strategy for Solving Expensive Multi-Objective Optimization Problems
Author(s): Fei Li, Yujie Yang, Yuhao Liu, Yuanchao Liu, Muyun Qian
Pages: 332 - 346
25) Transfer Optimization for Heterogeneous Drone Delivery and Pickup Problem
Author(s): Xupeng Wen, Guohua Wu, Jiao Liu, Yew-Soon Ong
Pages: 347 - 364
26) Comprehensive Multisource Learning Network for Cross-Subject Multimodal Emotion Recognition
Author(s): Chuangquan Chen, Zhencheng Li, Kit Ian Kou, Jie Du, Chen Li, Hongtao Wang, Chi-Man Vong
Pages: 365 - 380
27) Graph Learning With Riemannian Optimization for Multi-View Integrative Clustering
Author(s): Aparajita Khan, Pradipta Maji
Pages: 381 - 393
28) Applying a Higher Number of Output Membership Functions to Enhance the Precision of a Fuzzy System
Author(s): Salah-ud-din Khokhar, Akif Nadeem, Arslan A. Rizvi, Muhammad Yasir Noor
Pages: 394 - 405
29) Tensorlized Multi-Kernel Clustering via Consensus Tensor Decomposition
Author(s): Fei Qi, Junyu Li, Yue Zhang, Weitian Huang, Bin Hu, Hongmin Cai
Pages: 406 - 418
30) Balancing Security and Correctness in Code Generation: An Empirical Study on Commercial Large Language Models
Author(s): Gavin S. Black, Bhaskar P. Rimal, Varghese Mathew Vaidyan
Pages: 419 - 430
31) Camouflage Is All You Need: Evaluating and Enhancing Transformer Models Robustness Against Camouflage Adversarial Attacks
Author(s): Álvaro Huertas-García, Alejandro Martín, Javier Huertas-Tato, David Camacho
Pages: 431 - 443
32) Deep Learning Surrogate Models of JULES-INFERNO for Wildfire Prediction on a Global Scale
Author(s): Sibo Cheng, Hector Chassagnon, Matthew Kasoar, Yike Guo, Rossella Arcucci
Pages: 444 - 454
33) Dual Completion Learning for Incomplete Multi-View Clustering
Author(s): Qiangqiang Shen, Xuanqi Zhang, Shuqin Wang, Yuanman Li, Yongsheng Liang, Yongyong Chen
Pages: 455 - 467
34) Active Learning-Based Backtracking Attack Against Source Location Privacy of Cyber-Physical System
Author(s): Zhen Hong, Minjie Chen, Rui Wang, Mingyuan Yan, Dehua Zheng, Changting Lin, Jie Su, Meng Han
Pages: 468 - 479
35) Hierarchical Encoding Method for Retinal Segmentation Evolutionary Architecture Search
Author(s): Huangxu Sheng, Hai-Lin Liu, Yutao Lai, Shaoda Zeng, Lei Chen
Pages: 480 - 493
36) CycleFusion: Automatic Annotation and Graph-to-Graph Transaction Based Cycle-Consistent Adversarial Network for Infrared and Visible Image Fusion
Author(s): Yueying Luo, Wenbo Liu, Kangjian He, Dan Xu, Hongzhen Shi, Hao Zhang
Pages: 494 - 508
37) Explicit and Implicit Box Equivariance Learning for Weakly-Supervised Rotated Object Detection
Author(s): Linfei Wang, Yibing Zhan, Xu Lin, Baosheng Yu, Liang Ding, Jianqing Zhu, Dapeng Tao
Pages: 509 - 521
38) Deep Reinforcement Learning-Based Feature Extraction and Encoding for Finger-Vein Verification
Author(s): Yantao Li, Chao Fan, Huafeng Qin, Shaojiang Deng, Mounim A. El-Yacoubi, Gang Zhou
Pages: 522 - 536
39) Global Bipartite Exact Consensus of Unknown Nonlinear Multi-Agent Systems With Switching Topologies: Iterative Learning Approach
Author(s): Mengdan Liang, Junmin Li
Pages: 537 - 551
40) APR-Net Tracker: Attention Pyramidal Residual Network for Visual Object Tracking
Author(s): Bing Liu, Di Yuan, Xiaofang Li
Pages: 552 - 564
41) Symmetric Regularized Sequential Latent Variable Models With Adversarial Neural Networks
Author(s): Jin Huang, Ming Xiao
Pages: 565 - 575
42) StreamSoNGv2: Online Classification of Data Streams Using Growing Neural Gas
Author(s): Jeffrey J. Dale, James M. Keller, Aquila P. A. Galusha
Pages: 576 - 589
43) FCPFS: Fuzzy Granular Ball Clustering-Based Partial Multilabel Feature Selection With Fuzzy Mutual Information
Author(s): Lin Sun, Qifeng Zhang, Weiping Ding, Tianxiang Wang, Jiucheng Xu
Pages: 590 - 606
44) An Automatic Paper-Reviewer Recommendation Algorithm Based on Depth and Breadth
Author(s): Xiulin Zheng, Peipei Li, Xindong Wu
Pages: 607 - 616
45) Efficient and Robust Sparse Linear Discriminant Analysis for Data Classification
Author(s): Jingjing Liu, Manlong Feng, Xianchao Xiu, Wanquan Liu, Xiaoyang Zeng
Pages: 617 - 629
46) Detail Reinforcement Diffusion Model: Augmentation Fine-Grained Visual Categorization in Few-Shot Conditions
Author(s): Tianxu Wu, Shuo Ye, Shuhuang Chen, Qinmu Peng, Xinge You
Pages: 630 - 640
47) Efficient Low-Light Light Field Enhancement With Progressive Feature Interaction
Author(s): Xin Luo, Gaosheng Liu, Zhi Lu, Kun Li, Jingyu Yang
Pages: 641 - 653
48) Circuit Implementation of Memristive Fuzzy Logic for Blood Pressure Grading Quantification
Author(s): Ya Li, Shaojun Ji, Qinghui Hong
Pages: 654 - 667
49) Learning From Pairwise Confidence Comparisons and Unlabeled Data
Author(s): Junpeng Li, Shuying Huang, Changchun Hua, Yana Yang
Pages: 668 - 680
50) Subspace Sequentially Iterative Leaning for Semi-Supervised SVM
Author(s): Jiajun Wen, Xi Chen, Heng Kong, Junhong Zhang, Zhihui Lai, Linlin Shen
Pages: 681 - 694
51) Clickbait Detection via Prompt-Tuning With Titles Only
Author(s): Ye Wang, Yi Zhu, Yun Li, Jipeng Qiang, Yunhao Yuan, Xindong Wu
Pages: 695 - 705
52) TROPE: Triplet-Guided Feature Refinement for Person Re-Identification
Author(s): Divya Singh, Jimson Mathew, Mayank Agarwal, Mahesh Govind
Pages: 706 - 716
53) Deep Spiking Neural Networks Driven by Adaptive Interval Membrane Potential for Temporal Credit Assignment Problem
Author(s): Jiaqiang Jiang, Haohui Ding, Haixia Wang, Rui Yan
Pages: 717 - 728
54) Transfer Learning-Based Region Statistical Data Completion via Double Graphs
Author(s): Shengwen Li, Suzhen Huang, Xuyang Cheng, Renyao Chen, Yi Zhou, Shunping Zhou, Hong Yao, Junfang Gong
Pages: 729 - 739
55) COT: A Generative Approach for Hate Speech Counter-Narratives via Contrastive Optimal Transport
Author(s): Linhao Zhang, Li Jin, Guangluan Xu, Xiaoyu Li, Xian Sun
Pages: 740 - 756
56) Least Information Spectral GAN With Time-Series Data Augmentation for Industrial IoT
Author(s): Joonho Seon, Seongwoo Lee, Young Ghyu Sun, Soo Hyun Kim, Dong In Kim, Jin Young Kim
Pages: 757 - 769
57) Gp3Former: Gaussian Prior Tri-Cascaded Transformer for Video Instance Segmentation in Livestreaming Scenarios
Author(s): Wensheng Li, Jing Zhang, Li Zhuo
Pages: 770 - 784
58) Open-Space Emergency Guiding With Individual Density Prediction Based on Internet of Things Localization
Author(s): Lien-Wu Chen, Hao-Wei Huang, Yi-Ju Chen, Ming-Fong Tsai
Pages: 785 - 797
59) Consistency and Diversity Induced Tensorized Multi-View Subspace Clustering
Author(s): Chunming Xiao, Yonghui Huang, Haonan Huang, Qibin Zhao, Guoxu Zhou
Pages: 798 - 809
60) Convert Cross-Domain Classification Into Few-Shot Learning: A Unified Prompt-Tuning Framework for Unsupervised Domain Adaptation
Author(s): Yi Zhu, Hui Shen, Yun Li, Jipeng Qiang, Yunhao Yuan, Xindong Wu
Pages: 810 - 821
61) Differentiable Collaborative Patches for Neural Scene Representations
Author(s): Heng Zhang, Lifeng Zhu
Pages: 822 - 831
62) Adaptive Neural Network Optimal Backstepping Control of Strict Feedback Nonlinear Systems via Reinforcement Learning
Author(s): Mei Zhong, Jinde Cao, Heng Liu
Pages: 832 - 847
63) ARC: A Layer Replacement Compression Method Based on Fine-Grained Self-Attention Distillation for Compressing Pre-Trained Language Models
Author(s): Daohan Yu, Liqing Qiu
Pages: 848 - 860
64) Generative Adversarial Network Based Image-Scaling Attack and Defense Modeling
Author(s): Junjian Li, Honglong Chen, Zhe Li, Anqing Zhang, Xiaomeng Wang, Xingang Wang, Feng Xia
Pages: 861 - 873
65) Global and Cluster Structural Balance via a Priority Strategy Based Memetic Algorithm
Author(s): Yifei Sun, Zhuo Liu, Yaochu Jin, Xin Sun, Yifei Cao, Jie Yang
Pages: 874 - 888
66) Efficient Message Passing Algorithm and Architecture Co-Design for Graph Neural Networks
Author(s): Xiaofeng Zou, Cen Chen, Luochuan Zhang, Shengyang Li, Joey Tianyi Zhou, Wei Wei, Kenli Li
Pages: 889 - 903
67) Targeted Mining Precise-Positioning Episode Rules
Author(s): Jian Zhu, Xiaoye Chen, Wensheng Gan, Zefeng Chen, Philip S. Yu
Pages: 904 - 917
68) Two-Stage Deep Feature Selection Method Using Voting Differential Evolution Algorithm for Pneumonia Detection From Chest X-Ray Images
Author(s): Haibin Ouyang, Dongmei Liu, Steven Li, Weiping Ding, Zhi-Hui Zhan
Pages: 918 - 932
69) Learning EEG Motor Characteristics via Temporal-Spatial Representations
Author(s): Tian-Yu Xiang, Xiao-Hu Zhou, Xiao-Liang Xie, Shi-Qi Liu, Hong-Jun Yang, Zhen-Qiu Feng, Mei-Jiang Gui, Hao Li, De-Xing Huang, Xiu-Ling Liu, Zeng-Guang Hou
Pages: 933 - 945
70) DualC: Drug-Drug Interaction Prediction Based on Dual Latent Feature Extractions
Author(s): Lin Guo, Xiujuan Lei, Lian Liu, Ming Chen, Yi Pan
Pages: 946 - 960
71) ESAI: Efficient Split Artificial Intelligence via Early Exiting Using Neural Architecture Search
Author(s): Behnam Zeinali, Di Zhuang, J. Morris Chang
Pages: 961 - 971
72) Early Time Series Anomaly Prediction With Multi-Objective Optimization
Author(s): Ting-En Chao, Yu Huang, Hao Dai, Gary G. Yen, Vincent S. Tseng
Pages: 972 - 987
73) Enhancing Accuracy-Privacy Trade-Off in Differentially Private Split Learning
Author(s): Ngoc Duy Pham, Khoa T. Phan, Naveen Chilamkurti
Pages: 988 - 1000
74) Evolutionary Optimization for Proactive and Dynamic Computing Resource Allocation in Open Radio Access Network
Author(s): Gan Ruan, Leandro L. Minku, Zhao Xu, Xin Yao
Pages: 1001 - 1018
75) Evolutionary Sequential Transfer Learning for Multi-Objective Feature Selection in Classification
Author(s): Jiabin Lin, Qi Chen, Bing Xue, Mengjie Zhang
Pages: 1019 - 1033
76) Feature Autonomous Screening and Sequence Integration Network for Medical Image Classification
Author(s): Hongfeng You, Xiaobing Chen, Kun Yu, Guangbo Fu, Fei Mao, Xin Ning, Xiao Bai, Weiwei Cai
Pages: 1034 - 1048
77) FedLaw: Value-Aware Federated Learning With Individual Fairness and Coalition Stability
Author(s): Jianfeng Lu, Hangjian Zhang, Pan Zhou, Xiong Wang, Chen Wang, Dapeng Oliver Wu
Pages: 1049 - 1062
78) From Bag-of-Words to Transformers: A Comparative Study for Text Classification in Healthcare Discussions in Social Media
Author(s): Enrico De Santis, Alessio Martino, Francesca Ronci, Antonello Rizzi
Pages: 1063 - 1077
79) Fuzzy Composite Learning Control of Uncertain Fractional-Order Nonlinear Systems Using Disturbance Observer
Author(s): Zhiye Bai, Shenggang Li, Heng Liu
Pages: 1078 - 1090
0 notes
Text
Neo4j is a high availability graph database that support ACID properties for transactions. As per the CAP theorem, any system can provide only two of the properties from Consistency, Availability and Partition tolerance. Just like relational databases, Neo4j has also chosen the Consistency and Availability options. Consistency in Neo4j is guaranteed by supporting ACID properties to transaction. Availability is achieved using high availability clustering that is supported by a master slave architecture with one master for all write operations and many slaves for read operations. The architecture of Neo4j is fairly scalable, however it can only scale UP. For most of cases adding more nodes to the Neo4j cluster will be sufficient however if you have a really huge dataset adding node may not scale your system linearly. In case you are looking for a scaling OUT option you may need to use your own technique to make best use of Neo4j resources. I recently attended GraphConnect developer tutorials session. I was fortunate enough to meet with the creators of Neo4j and discuss some of the options with them. One of the experts from Neo4j at GraphConnect suggested the option of Cache Sharding that many developers liked and wanted to get more understanding on it. I am trying to provide one example where we can use cache sharding and almost linearly scale a Neo4j Graph Database. In fact, this technique of cache sharding is not really new to Neo4j. It has been used a lot with relational and other data storage as well. What Is Sharding? Sharding is a technique to horizontally partition your data. It helps scale out a application linearly by reducing the need of shared access. For example, lets say you have 100M records in your database table. If you want to shard it into 10 parts you can store 10M records on each server. When you need to store more data you can add more servers as the data grows. Sharding implementations are complex. Sharding can also result in poor performance if done incorrectly. One must have good understanding of the data and its access methods to get best results. Why Neo4j Does Not Do Sharding Yet? Many Nosql databases inherently support sharding, but Neo4j does not. I got chance to speak with some experts at the GraphConnect and they mentioned that sharding graph database with a traditional sharding approach may not scale good enough for real time transactions. Each graph is different and therefore a naive sharding may not be good enough to get the best performance. At the same time, current Neo4j clusters are highly scalable for most of the needs. May be in near future, Neo4j will be able to figure out a smarter way of sharding that can make Neo4j even more scalable. If you are looking for a graph database solution that supports sharding and can scale out for a real time transaction system you may want to check Titan Graph Database as well. Its an open source project and provides three different options of Nosql DB storage including (Cassandra, HBase and BerkleyDB) How Can I Scale Out Neo4j Read Performance? You can "almost" linearly scale out Neo4j reads using a technique called cache sharding. I used "almost" since the solution may heavily depend on the type of graph database and you may still see situations when it will not scale out linearly. What Is Cache Sharding? Cache sharding is a simple technique that will allow you to have each Neo4j server machine cache a part of the graph data. This can be possible since Neo4j implements its own caching on each cluster machine based on the transaction it receives. You can put a load balancer in front of Neo4j cluster and shard your transactions based on some logic. This way one type of read transactions will always go to one cluster machine. That will enable Neo4j on this cluster machine to efficiently cache only a subset of the graph. A Simple Example Of Neo4j Cluster With Cache Sharding Lets take an example of a graph of people with 100 Million nodes Lets assume we have 10 Machine Cluster of Neo4j. (m1,m2....m10)
Lets assume we implement a sharding based on GEO location (may be consistent hashing) to divide the transactions. So a transaction related to one city (say San Francisco) will go always to Machine m1 and a transaction for New York city will always go to Machine m2 and likewise for 10 different cities. Once this sharding is implemented and transactions start flowing through each cluster machines. You will notice that machine m1 is going to cache more data related to city San Francisco whereas machine m2 is going to cache more data related to city New York. Using this technique, and fine tuning it may result in a almost perfect situation where each machine on cluster is caching around 10M resulting in the whole graph being in memory and being served quickly. This example is just to explain the concept of cache sharding. Using city or location as your sharding may not always be very efficient. Every graph is different and each domain may have different techniques to shard cache. However you can always find a different parameter that can divide your graph in multiple smaller sub graphs that can be separately cached. Cluster And RAM Size Calculations For Scalable Reads If you are planning to do cache sharding you may need to plan accordingly for the cluster and machine RAM size. Lets take a simple example. Assume the total size of you graph database on hard drive is 100GB If you can provide at least 10Gb RAM + (some extra) on each machine to Neo4j for caching Than you may require at least 10 Machine cluster to be able to cache all the database in RAM. Also keep in mind that you may need to plan in advance for scaling up, therefore keep some extra nodes and memory based on the speed of your data growth. Limitations Of Cache Sharding Below are some limitation you may observe based on your application and domain Neo4j has a single master node that handles all write transaction. The master node in cluster needs to keep working harder as the size of cluster grows. This will lead you into some limits since you have single node bottleneck. Each domain have different types of graphs. In case your graph is heavily connected and sharding is resulting in a completely different subgraph caching. What About The Write Transactions? With current Neo4j cluster architecture writes are required to be managed by one master node. This may be a potential bottleneck in case you have really high volume of write transaction in a really large cluster. Summary Scaling out a system like Neo4j is not always easy, however these techniques may help you improve the performance to some extent. Neo4j has chosen consistency and availability from CAP theorem therefore it will suffer with partition tolerance. Many times a really huge graph database is consisting of many relatively smaller isolated graphs. Creating Multiple clusters with multiple isolated graph may help you scale out write transactions in such situations, however this may not be always possible. In case everything in your graph database can connect to everything you may face a potential bottleneck. I hope this article will help you scale out your Neo4j cluster.
0 notes