#had to disable javascript on the site
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Premium Tumblr themes are available from anywhere between $9 to $49.
Text
why does most of the manga sites i find to read different manga decide to redirect to a jujutsu kaisen site instead? whyre they trying to trick me to read jujutsu kaisen
1 note
·
View note
Text
The phenomenon where 12ft.io is listed in every post about "useful internet tools" and someone will always give a spiel about how it's based on the saying "show me a 10 foot wall and I'll show you a twelve foot ladder" is so strange to me
it just disables javascript! that's a built in 5-second function in the big chromium browsers and not that hard to do on Firefox! Why do you have a whole website with a graphic of triumphant hands breaking free of your chains?? why do people repeat the saying when it only works on exactly one type of wall?
and. you know. it doesn't work! it has been years since most major news sites had the kind of paywall or registration requirement you could just ignore by disabling javascript. Same for Substack and Medium. But you still see people helpfully piping up to say how wonderful it is, which says to me that they don't even use the tool they're recommending.
#i just saw one of these posts and got annoyed#in case you couldn't guess#it's a faff to disable javascript on a page yourself in firefox but it's one click with ublock origin
8 notes
·
View notes
Text
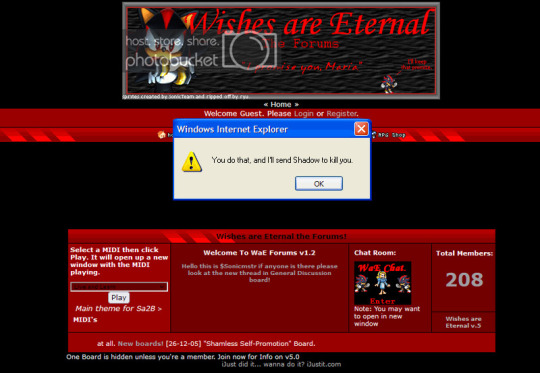
a little while ago @neuro-typical sent me this post by @bye2k of a popup that appeared when trying to right-click images on a shadow the hedgehog fan forum, known as Wishes are Eternal (after the SA2 line). this version of the site appears to be an archived snapshot on the wayback machine, and I'm happy to confirm that it is indeed real. though i couldn't get the popup to work in my own browser, the javascript does exist in the source code of the site, so it's very real and very cool.
i had a lot of things to say about this, but i didn't want to blast the notes of the OG post into oblivion with my big funny wall of text, so I've made my own post. below the readmore I'll explain javascript popups on the internet, some malware that has utilized this, and some very interesting sonic fan community history.
first of all: what is this? how did the webmaster manage to create a popup window in your computer to stop you from downloading images?
well, that would be javascript. because JS is just a normal script language that can do whatever you want, creating a popup is no exception. now, whoever ran the site did not write this script themself, this much is evident by the credit you can see in the source code for the site.

this script is offered by a site called dynamicdrive.com, specifically for disabling right-clicks. you see how simple this is? javascript makes it possible to bother users in all sorts of creative ways. plenty of malware on the web utilizes javascript, and you're probably already aware of most good examples.
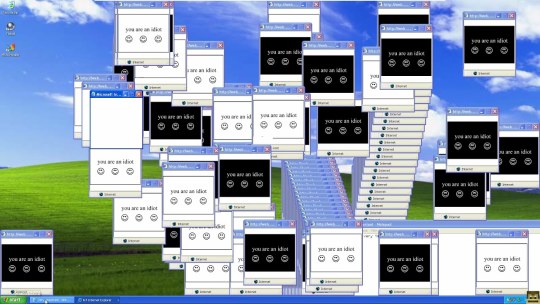
you're most likely familiar with offiz, better known by the colloquial name "You Are An Idiot". though its status as malware is somewhat debated, most people can agree that the sites it was on abused a javascript function that allowed it to create hundreds upon hundreds of bouncing windows, slowing the user computer to a crawl and forcing the user to restart their machine, meaning any unsaved work they had open was now lost. in that way it was destructive, though indirectly.
offiz is an example of javascript malware that is harmless on its own, but not all JS malware is that friendly. javascript can be used to force your machine to download software, steal user data, serve you all manner of popups, employ many kinds of malicious code through xss, and more. although these cases are rarer than they were, say, a decade ago, that doesn't mean they don't still happen. here is a fascinating little instance of javascript being used maliciously very recently. it's hard to suggest ways to avoid these without just telling you to use common sense, but there's no other way to put it. as is the case with all malware, your best bet when it comes to not getting it is thinking before you click.
browser malware is extremely common. you may have encountered it going to a suspicious website. there is certainly a necessary aspect of social engineering to this type of malware, you have to be paying less attention to where you're going and what you're doing to stumble upon a site so unsecured that it could infect you. users who get themselves into these situations are typically looking for either p_rn or pirated stuff, so they're more likely to act in irrational or desperate ways to get to their content. don't be a fool online and you won't get played for one.
so, why? why does this old, obscure sonic fan forum have javascript that prevents you from right clicking images? prevents you from downloading images?
this forum is very, very old. the last posts on the entire site were about 10 years ago, even to this day. it's no surprise to me that a lot of this site is a relic of its time. the photobucket watermark on the header image, the collecton of midis of shadow themes playable on the site, the use of the term "ripped off" (as opposed to ripped) to describe the action of taking sprites from a game. it's all there on the very first page, the only one in this archive. despite what youtube video slideshows with a single text scroll that says "no copyright intended, pictures found on google" may imply, reposting images was indeed taken seriously at this time. this was a time when it wasn't too uncommon to see a credit to the person who made an anime girl image transparent (a render, for those unaware) in a forum signature. this was a time when someone got caught tracing every 5 days.
that's not to say there were no issues, but people were still very defensive over what they deemed to be theirs. this was especially prevalent in fanart. fan works are hard and are always a labor of love, so it's no surprise nobody wanted their work reposted, especially not without credit. this was especially clear when looking into some parts of the sprite ripping community. making spritesheets was much harder then than it is now, and it was especially impressive if sprites were hand-edited or even made from scratch. this incredibly painstaking work combined with sonic fans reputation for... unwavering passion... could often culminate in a very serious attitude towards doing something as simple as saving an image. in fact, for some people, this mindset has never truly left.

in 2014, fangame creator Leemena Dan published Sonic Gather Battle on SAGE (the Sonic Amateur Games Expo) to mostly positive reception but ultimately little attention outside of sonic fans online. that is, until 2017, when after a seemingly inconspicuous update, players discovered what appeared to be an audaciously malicious form of DRM present in the game.
this malware had everything. all the bells and whistles. when a player would do any number of things from opening software made to decompile games to simply typing "sonic gather battle cheat" into their internet browser search bar, the payload would activate. (which, of course, means it tracks your keystrokes!)
it's difficult to find good footage of both layers of this DRM (or, rather, both payloads of this malware) that doesn't include a facecam of some gamer dude gawking and screaming at his computer screen. even so, I've found two decent ones. layer 1, and layer 2. this DRM also sends your IP address to a privately owned server, presumably so that the DRM would activate even when the game is uninstalled, and when trying to play it, a splash screen would show telling you to abide by the rules.
unsurprisingly, people did not consider this a proportionate way to respond to the threat of people ripping the sprites from a fangame, and the creator has since been banned from SAGE. to this very day, some people are simply so protective of their work that they'd be willing to go to any length to prevent you from saving it. as obnoxious as that can sometimes seem, it does make for some very interesting history.
33 notes
·
View notes
Text
Ok, so I don't know if this is anything, but recently I've had to pivot career paths due to budget cuts and disability. While surfing the job sites for remote options, I've noticed that there are a crazy amount of people looking for IT workers, but the thing is, I cannot afford college. That's ok, I've been hitting the books and apps, and I'll get my certifications that way if need be. I've been working for about 6 months this way.
But here's where I come to the masses. I'm currently typing up my own notes because the apps and books kinda sound like my FiL who is awesome when it comes to this kind of stuff, but has been doing all of this since the infancy of the internet. It's all a bit above my head. So I'm trying to translate it into my own terms, so it's like I'm talking to myself.
Now the notes are still in their begining stages, but I'm starting off with the Holy Trinity: HTML, CSS, and JavaScript. When I get finished with them, would you guys like me to share it to Tumblr so you still get access to like a layman's textbook? I can't give certification, and if one wanted to add onto it all they'd have to do is message, but I'd like to help make learning more relatable.
This is a heads up, my words are crude, my grammar is not scholarly, and I can't exactly promise you it's free of swear words. But it is more fun to read than anything I've read so far, I can promise that. Some quotes include:
"Don't get your knickers in a bunch, I'll talk more about character sets later"
" <title> Holy Crap, A Web Page</title> "
"You tap [the encoding tab] and select UTF-8, again, because it's the sexy man of HTML coding"
So feel free to DM me if anyone would be up for some free chaotic coding notes. I would love to learn of any other free resources to utilize while writing this first set of notes. I hope to include Python, Kotlin, Swift, and C++; and if I can find any surviving ancient texts, Pascal, just because it'd be really cool to be able to talk with my father in law about it because we don't have too much in common.
Until then, I will keep reading and writing, and I hope what I can contribute will make somebody's life a bit easier and their education a bit more entertaining.
2 notes
·
View notes
Text
12ft has unfortunately stopped working on many sites, either because they paid 12ft to make it not work or because they've figured out how to detect it (all it does is disable javascript). I wish I had a good alternative to recommend here but unfortunately sites are just generally getting better at stopping you from looking at their content for free.

380K notes
·
View notes
Text
So Google, not just Chrome, but Google itself, hates ad blockers.
I get it, ads make money for way less effort and customer involvement than subscriptions and paywalls.
The problem is, as cybersecurity professionals have said, ads are a security risk for every system they interact with. Even if you don't click any ads ever, they're still a security risk.
How are they a security risk? Because ads are allowed to run code to perform their tasks. This code is supplied by the ad provider, and if all it ever did was provide a link, a hovertext/description for the visually impaired, and maybe a non-gif animation, this would be a non-issue on all but the weakest internet connections.
They are not all like that, though.
Endless cases of ad providers, site providers, even your actual ISP (Internet Service Provider) have been proven to inject arbitrary code, capable of doing a great number of things, into ads, links, images, video, etc.
This code has had scripts to use your computer's processing power to help mine Bitcoin so long as it's on the page the code started on, it's been used to install malware (even by your ISP in one particularly bad case), it's been used to just install viruses or keyloggers or so many more things.
Hell, even the not-malicious code can just bog down your computer by being terribly written messes of badly functioning code, so something that should run with barely any impact instead takes up ridiculous amounts of processing power and capacity.
This is a problem, and it's largely solvable by simply blocking ads. There's no native way to prevent ads from running scripts or code without disabling all JavaScript on every page, which effectively kills most pages you go to since every drop-down menu, every page-altering section (like the Google images thing), most search bars, video playback, and so much more, all depend entirely on JavaScript.
Google wants to take away that necessary security of blocking problematic ads, rather than just make a way to disable the problematic aspects of ads.
I dislike ads, especially when they take up more than about 25% of the screen. I'd ideally like to see little to no ads ever, but I understand how ads support the sites they're on, support creators on streaming services, etc.
I'd be okay with classic banner ads, basic image/link ads, even the before/during/after video ads, if they weren't almost guaranteed to be literally hostile. If Google hates ad blockers so much, they should make them less of a safety requirement by letting us choose to disable ad scripts, or even just block that entire concept, because no ads for any worthwhile service or product have ever needed to run scripts. If an image or GIF of your product/service, maybe with a quick description, isn't selling your product/service, then making it hover over the page content, make noise, and mine Bitcoin will only piss your target audience off, while proudly claiming that you are the one doing it.
Would you buy a product that tricks you into interacting with it through just being annoying and pulling the sibling trick of "I'm not touching you, see? I'm touching your computer, not you?"
Hell, pop-up ads were basically scriptless and still managed to piss off most of the people who encountered them. The guy who invented them made a public apology for having developed that 'extremely intrusive' marketing method. Now ISPs have been caught injecting malware into links that you click on while using their service, with the express intent of installing them to your computer to monitor what you do and block access to sites they don't want you on.
You want the Internet to be safe? Don't fight porn or violence, that has never done anything but drive up interest. Fight the people actively making the Internet literally unsafe to use regardless of age or system.
I'll accept ads if ad providers stop making automatic malware.
Sorry for the rant, I'm tired and annoyed.
#ads#Google#Google Chrome#adblock#ad blocking#scripts#why#whyyyy#rant#rant post#personal rant#internet#so i'll share them with the internet#internet safety
1 note
·
View note
Text
What Are the 7 Web Development Life Cycles Recently we had a discussion with a client and talked about what are the 7 web development life cycles. So we thought we'd put a summary into a blog for you. The web development life cycle (WDLC) is a process used to create, maintain, and improve websites. It involves a series of steps that must be followed in order to ensure that the website is successful. The WDLC consists of seven distinct phases: planning, design, development, testing, deployment, maintenance, and optimization. Each phase has its own purpose and is importance in the overall success of the website. In this blog post, we will discuss each phase of the WDLC and its purpose. Planning The planning phase is the first step in the WDLC. During this phase, you will need to determine what your website needs to accomplish and how it should be structured. This includes deciding on a domain name, hosting provider, content management system (CMS), and other necessary components. You will also need to identify your target audience and develop a plan for how you will reach them. This phase is critical for setting up a successful website as it helps you determine what resources are needed for each stage of the process. Some decisions made at this point would create a lot of work if you later changed your mind. You should also use this time to think about what it is you want to say or more importantly, what your potential clients might want to know. This part of the Planning stage is called Keyword research. Design The design phase is where you create the look and feel of your website. This includes selecting colours, fonts, images, layouts, navigation menus, etc. You should also consider how users will interact with your site by creating user flows or wireframes that show how they can move from one page to another. During this phase you should also consider accessibility standards such as WCAG 2.0 AA or Section 508 compliance so that all users can access your site regardless of their abilities or disabilities. often people think the design is about personal preferences, for example you may really be into dark colours like Black with high contrast white text. The important thing to consider though is that the colours, graphics and fonts need to be compatible with your brand. Black may not be appropriate if your business is a children's nursery, it would send totally the wrong message. Development Once you have finalized your design plans it’s time to start developing your website using HTML/CSS/JavaScript or any other programming language you choose to use. At Saint IT our preferred CMS is Wordpress for lots of reasons. One of the most important reasons is the flexibility and the ease of use for the client once the website goes live. During this phase you will need to write code that implements all of the features outlined in your design plans as well as any additional features that may be needed for functionality or interactivity purposes. Once all of the code has been written it’s time to test it out on different browsers and devices to make sure everything works correctly before moving on to deployment. Testing The testing phase is where you make sure everything works properly before launching your website live on the internet. This includes checking for bugs or errors in code as well as ensuring that all features are working correctly across different browsers and devices. It’s important to test thoroughly during this stage so that any issues can be identified and fixed before launch day arrives! Remember that a bad website with lots of errors or bad grammar can negatively impact your brand. Deployment Once all tests have been completed successfully it’s time for deployment! This involves making the website live so that they can be accessed by users online via their web browser or mobile device. Depending on which hosting provider you choose there may be additional steps involved such as setting up databases or configuring security settings but once everything is ready then it’s time for launch day!
At this point it is also important to check your SEO and your reporting, making sure that each page is fully optimised for search engines and you're getting good reporting from your website. Integration with Google Analytics one such useful tool for this. Maintenance Web Development agencies often overlook this stage. The Website has been created, the client has paid the bill and they're now left with a website that requires constant maintenance without any training or instructions to carry this out. The maintenance phase is an ongoing process where changes are made over time based on user feedback or new requirements from stakeholders/clients etc.. This could involve adding new features/functionality or fixing existing bugs/errors in code etc.. It’s important to keep up with maintenance regularly so that users always have an optimal experience when visiting your website! At Saint IT we ensure all our clients receive the best service once their website is live. We have the skills and knowhow to ensure all updates are applied regularly and we perform monthly manual, visual checks and tests to ensure there are no issues. Optimization The optimization phase involves making changes over time in order to improve performance such as increasing page loading speeds or improving search engine rankings etc.. This could involve making changes such as optimizing images/code for faster loading times or implementing SEO best practices like meta tags etc.. It’s important to keep up with optimization regularly so that users always have an optimal experience when visiting your website! Website performance depends on a number of factors and your web developer/agency should have advised you at the planning stage of the best hosting package for your website. If you're running a large corporate website with hundreds of pages you're not going to want to host that on a low cost public cloud web host. Conclusion The web development life cycle (WDLC) with it's seven distinct phases: planning, design, development, testing, deployment, maintenance and optimization outlines the complexities involved in web design. each phase with its own purpose within the website project is crucial to how well your website performs over time. If you have the multiple skills required and the time, you can certainly undertake such a project by following these steps carefully. However we recommend you partner with an experienced web design agency because they have the right tools and differing skills required. By partnering with Saint IT to build your website you can ensure that throughout each stage your website meets its goals while providing an optimal experience for visitors and users of your website. Check out our Other Blogs What Are the 7 Web Development Life Cycles Saint IT Pleased To Support Local Initiatives Unravelling the Roles: What Does a Web Designer and Developer Do? What Are the Benefits of a Cloud-Based Phone System? Follow us on Social media How to be Good in Business
0 notes
Text

I'm in a rambling mood tonight and I just kinda wanna talk about something meaningless. A friend put these tags on a post she retweeted tonight and it just kinda got me thinking (not in a bad way, not mad at you or throwing shade Jade <3)
I feel like this isn't an uncommon sentiment tbh. I don't think anyone would have an issue with advertisements on the internet if they were small, unintrusive banner ads. If a website had a little banner for coca-cola or the latest blockbuster movie, it wouldn't really matter to me or many other people; we basically have the same thing going on with billboards along roads and nobody really complains about those.
And it got me thinking about the reason why we're in this advertising-hell we are now, the constant war between sites trying to either guilt-trip you or lock you out entirely if you use adblock, adblockers trying to get around their detection methods, and users spreading methods to get around the guilt-tripping/lockouts of sites
I think it's easy to just say that companies got greedy and kept demanding more intrusive ads, stepping it up from simple banner images to flashing animated banners to entire videos that they want autoplayed with volume on whenever you open a page, to the point where adblock became necessary to have a good viewing experience, meaning the less extreme ads weren't profitable anymore because less people were seeing them.
I think that's definitely a big part of it, but I don't think it's the whole explanation
And then I suddenly remembered, flash player. Back in the late 2000s/early 2010s, it was everywhere. Nowadays I think most people just remember it for games and video players, but it really was for EVERYTHING at the time - including ads.
That was before HTML5, before it was as easy to make a site dynamic with just stock Javascript - if you wanted to do anything more complicated than images and links, you needed something like Flash Player to do it (that's a bit of an exaggeration, but still, you get my point).
So, advertisements wanted to make things more dynamic than just a banner GIF - more complex animations, reacting when you put your mouse over them, multiple buttons for different sites, etc., and so they were flash applets.
And the important thing about Flash Player is that it was horrible for performance. Flash was a resource hog even with well-programmed stuff, and a LOT of ads at the time were poorly programmed, super inefficient for how simple they were.
I had an absolutely terrible laptop back in 2014/2015, just a very slow clunker that could barely handle browsing the web most of the time, and I remember opening Task Manager and killing Flash Player around every half-hour or so because the advertisements on sites like TVTropes or Wikia were both so abundant and so poorly-programmed that Flash would be taking up like 75% of what little RAM my PC had at the time. A lot of the reasons people recommended installing adblockers was because of the massive performance increase you'd get from not having all of those resource-hogging applets active at once.
So it makes me wonder, would we still be in this ad hellscape we are now if Flash Player hadn't existed, or at least been better programmed? If every flashing banner at the time hadn't been its own independent program running on a slow virtual machine for very little benefit?
I mean, the answer is probably yes, we still would've gotten companies who got too greedy and tried to force more and more intrusive ads on us constantly - but I can't help but wonder how different things could've been if it weren't for all those years of your tabs instantly coming to a screeching halt just because an advertisement wanted to have two links at once and the developers decided the best way to do that would be to make the entire thing a Flash applet.
TL;DR: I'm holding Adobe responsible for every single time I see one of those "Hey, please disable your adblock. We neeeeeeeeeed to show you the most obnoxious advertisements on planet Earth or else our multi-billion dollar company won't be able to keep the lights on :(" messages from a megacorp that could definitely stand to cut corners in other ways instead of trying to guilt-trip people into having a worse experience for their own benefit.
1 note
·
View note
Text
article text below cut. btw if you disable javascript their paywall doesnt work. if you have ublock origin (you should) thats easy.
How many times has it happened? You’re on your computer, searching for a particular article, a hard-to-find fact, or a story you vaguely remember, and just when you seem to have discovered the exact right thing, a paywall descends. “$1 for Six Months.” “Save 40% on Year 1.” “Here’s Your Premium Digital Offer.” “Already a subscriber?” Hmm, no.
Now you’re faced with that old dilemma: to pay or not to pay. (Yes, you may face this very dilemma reading this story in The Atlantic.) And it’s not even that simple. It’s a monthly or yearly subscription—“Cancel at any time.” Is this article or story or fact important enough for you to pay?
Or do you tell yourself—as the overwhelming number of people do—that you’ll just keep searching and see if you can find it somewhere else for free?
According to the Reuters Institute for the Study of Journalism, more than 75 percent of America’s leading newspapers, magazines, and journals are behind online paywalls. And how do American news consumers react to that? Almost 80 percent of Americans steer around those paywalls and seek out a free option.
Paywalls create a two-tiered system: credible, fact-based information for people who are willing to pay for it, and murkier, less-reliable information for everyone else. Simply put, paywalls get in the way of informing the public, which is the mission of journalism. And they get in the way of the public being informed, which is the foundation of democracy. It is a terrible time for the press to be failing at reaching people, during an election in which democracy is on the line. There’s a simple, temporary solution: Publications should suspend their paywalls for all 2024 election coverage and all information that is beneficial to voters. Democracy does not die in darkness—it dies behind paywalls.
The problem is not just that professionally produced news is behind a wall; the problem is that paywalls increase the proportion of free and easily available stories that are actually filled with misinformation and disinformation. Way back in 1995 (think America Online), the UCLA professor Eugene Volokh predicted that the rise of “cheap speech”—free internet content—would not only democratize mass media by allowing new voices, but also increase the proliferation of misinformation and conspiracy theories, which would then destabilize mass media.
Paul Barrett, the deputy director of the NYU Stern Center for Business and Human Rights and one of the premier scholars on mis- and disinformation, told me he knows of no research on the relationship between paywalls and misinformation. “But it stands to reason,” he said, “that if people seeking news are blocked by the paywalls that are increasingly common on serious professional journalism websites, many of those people are going to turn to less reliable sites where they’re more likely to encounter mis- and disinformation.”
In the pre-internet days, information wasn’t free—it just felt that way. Newsstands were everywhere, and you could buy a paper for a quarter. But that paper wasn’t just for you: After you read it at the coffee shop or on the train, you left it there for the next guy. The same was true for magazines. When I was the editor of Time, the publisher estimated that the “pass-along rate” of every issue was 10 to 15—that is, each magazine we sent out was read not only by the subscriber, but by 10 to 15 other people. In 1992, daily newspapers claimed a combined circulation of some 60 million; by 2022, while the nation had grown, that figure had fallen to 21 million. People want information to be free—and instantly available on their phone.
Barrett is aware that news organizations need revenue, and that almost a third of all U.S. newspapers have stopped publishing over the previous two decades. “It’s understandable that traditional news-gathering businesses are desperate for subscription revenue,” he told me, “but they may be inadvertently boosting the fortunes of fake news operations motivated by an appetite for clicks or an ideological agenda—or a combination of the two.”
Digital-news consumers can be divided into three categories: a small, elite group that pays hundreds to thousands of dollars a year for high-end subscriptions; a slightly larger group of people with one to three news subscriptions; and the roughly 80 percent of Americans who will not or cannot pay for information. Some significant percentage of this latter category are what scholars call “passive” news consumers—people who do not seek out information, but wait for it to come to them, whether from their social feeds, from friends, or from a TV in an airport. Putting reliable information behind paywalls increases the likelihood that passive news consumers will receive bad information.
In the short history of social media, the paywall was an early hurdle to getting good information; now there are newer and more perilous problems. The Wall Street Journal instituted a “hard paywall” in 1996. The Financial Times formally launched one in 2002. Other publications experimented with them, including The New York Times, which established its subscription plan and paywall in 2011. In 2000, I was the editor of Time.com, Time magazine’s website, when these experiments were going on. The axiom then was that “must have” publications like The Wall Street Journal could get away with charging for content, while “nice to have” publications like Time could not. Journalists were told that “information wants to be free.” But the truth was simpler: People wanted free information, and we gave it to them. And they got used to it.
Of course, publications need to cover their costs, and journalists need to be paid. Traditionally, publications had three lines of revenue: subscriptions, advertising, and newsstand sales. Newsstand sales have mostly disappeared. The internet should have been a virtual newsstand, but buying individual issues or articles is almost impossible. The failure to institute a frictionless mechanism for micropayments to purchase news was one of the greatest missteps in the early days of the web. Some publications would still be smart to try it.
I’d argue that paywalls are part of the reason Americans’ trust in media is at an all-time low. Less than a third of Americans in a recent Gallup poll say they have “a fair amount” or a “a great deal” of trust that the news is fair and accurate. A large percentage of these Americans see media as being biased. Well, part of the reason they think media are biased is that most fair, accurate, and unbiased news sits behind a wall. The free stuff needn’t be fair or accurate or unbiased. Disinformationists, conspiracy theorists, and Russian and Chinese troll farms don’t employ fact-checkers and libel lawyers and copy editors.
Part of the problem with the current, free news environment is that the platform companies, which are the largest distributors of free news, have deprioritized news. Meta has long had an uncomfortable relationship with news on Facebook. In the past year, according to CNN, Meta has changed its algorithm in a way that has cost some news outlets 30 to 40 percent of their traffic (and others more). Threads, Meta’s answer to X, is “not going to do anything to encourage” news and politics on the platform, says Adam Mosseri, the executive who oversees it. “My take is, from a platforms’ perspective, any incremental engagement or revenue [news] might drive is not at all worth the scrutiny, negativity (let’s be honest), or integrity risks that come along with them.” The platform companies are not in the news business; they are in the engagement business. News is less engaging than, say, dance shorts or chocolate-chip-cookie recipes—or eye-catching conspiracy theories.
As the platforms have diminished news, they have also weakened their integrity and content-moderation teams, which enforce community standards or terms of service. No major platform permits false advertising, child pornography, hate speech, or speech that leads to violence; the integrity and moderation teams take down such content. A recent paper from Barrett’s team at the NYU Stern Center for Business and Human Rights argues that the greatest tech-related threat in 2024 is not artificial intelligence or foreign election interference, but something more mundane: the retreat from content moderation and the hollowing-out of trust-and-safety units and election-integrity teams. The increase in bad information on the free web puts an even greater burden on fact-based news reporting.
Now AI-created clickbait is also a growing threat. Generative AI’s ability to model, scrape, and even plagiarize real news—and then tailor it to users—is extraordinary. AI clickbait mills, posing as legitimate journalistic organizations, are churning out content that rips off real news and reporting. These plagiarism mills are receiving funding because, well, they’re cheap and profitable. For now, Google’s rankings don’t appear to make a distinction between a news article written by a human being and one written by an AI chatbot. They can, and they should.
The best way to address these challenges is for newsrooms to remove or suspend their paywalls for stories related to the 2024 election. I am mindful of the irony of putting this plea behind The Atlantic’s own paywall, but that’s exactly where the argument should be made. If you’re reading this, you’ve probably paid to support journalism that you think matters in the world. Don’t you want it to be available to others, too, especially those who would not otherwise get to see it?
Emergencies and natural disasters have long prompted papers to suspend their paywalls. When Hurricane Irene hit the New York metropolitan area in 2011, The New York Times made all storm-related coverage freely available. “We are aware of our obligations to our audience and to the public at large when there is a big story that directly impacts such a large portion of people,” a New York Times editor said at the time. In some ways, this creates a philosophical inconsistency. The paywall says, This content is valuable and you have to pay for it. Suspending the paywall in a crisis says, This content is so valuable that you don’t have to pay for it. Similarly, when the coronavirus hit, The Atlantic made its COVID coverage—and its COVID Tracking Project—freely available to all.
During the pandemic, some publications found that suspending their paywall had an effect they had not anticipated: It increased subscriptions. The Seattle Times, the paper of record in a city that was an early epicenter of coronavirus, put all of its COVID-related content outside the paywall and then saw, according to its senior vice president of marketing, Kati Erwert, “a very significant increase in digital subscriptions”—two to three times its previous daily averages. The Philadelphia Inquirer put its COVID content outside its paywall in the spring of 2020 as a public service. And then, according to the paper’s director of special projects, Evan Benn, it saw a “higher than usual number of digital subscription sign-ups.”
The Tampa Bay Times, The Denver Post, and The St. Paul Pioneer Press, in Minnesota, all experienced similar increases, as did papers operated by the Tribune Publishing Company, including the Chicago Tribune and the Hartford Courant. The new subscribers were readers who appreciated the content and the reporting and wanted to support the paper’s efforts, and to make the coverage free for others to read, too.
Good journalism isn’t cheap, but outlets can find creative ways to pay for their reporting on the election. They can enlist foundations or other sponsors to underwrite their work. They can turn to readers who are willing to subscribe, renew their subscriptions, or make added donations to subsidize important coverage during a crucial election. And they can take advantage of the broader audience that unpaywalled stories can reach, using it to generate more advertising revenue—and even more civic-minded subscribers.
The reason papers suspend their paywall in times of crisis is because they understand that the basic and primary mission of the press is to inform and educate the public. This idea goes back to the country’s Founders. The press was protected by the First Amendment so it could provide the information that voters need in a democracy. “Our liberty depends on the freedom of the press,” Thomas Jefferson wrote, “and that cannot be limited without being lost.” Every journalist understands this. There is no story with a larger impact than an election in which the survival of democracy is on the ballot.
I believe it was a mistake to give away journalism for free in the 1990s. Information is not and never has been free. I devoutly believe that news organizations need to survive and figure out a revenue model that allows them to do so. But the most important mission of a news organization is to provide the public with information that allows citizens to make the best decisions in a constitutional democracy. Our government derives its legitimacy from the consent of the governed, and that consent is arrived at through the free flow of information—reliable, fact-based information. To that end, news organizations should put their election content in front of their paywall. The Constitution protects the press so that the press can protect constitutional democracy. Now the press must fulfill its end of the bargain

I swear to God if you wrote something like this into a political satire like Spitting Image, it’d be called too on-the-nose.
17K notes
·
View notes
Text
Decrapify cookie consent dialogs with the Consent-O-Matic
Remember when they sneered at Geocities pages for being unusable eyesores? It's true, those old sites had some, uh, idiosyncratic design choices, but at least they reflected a real person's exuberant ideas about what looked and worked well. Today's web is an unusable eyesore by design.
Start with those fucking “sign up for our newsletter” interruptors. Email is the last federated protocol standing, so everyone who publishes is desperate to get you to sign up to their newsletter, which nominally bypasses Big Tech’s chokepoint on communications between creators and audiences. Worst part: they’re wrong, email’s also been captured:
https://doctorow.medium.com/dead-letters-73924aa19f9d
Then there’s the designer’s bizarre and sadistic conceit that “black type on a white background” is ugly and “causes eye-strain.” This has led to an epidemic of illegible grey-on-white type that I literally can’t read, thanks to a (very common) low-contrast vision disability:
https://uxmovement.com/content/why-you-should-never-use-pure-black-for-text-or-backgrounds/
Often grey-on-white type sins are compounded with minuscule font sizing. You can correct this by increasing the font size from teeny-weeny-eyestrain-o-rama to something reasonable, but when you do, all the static elements on the page size up with the text, so the useless header and footer bars filled with social media buttons and vanity branding expand to fill the whole screen.
This, in turn, is made a billion times worse by the absurd decision to hide scrollbars (shades of Douglas Adams’ description of airports where they “expose the plumbing on the grounds that it is functional, and conceal the location of the departure gates, presumably on the grounds that they are not”).
https://www.goodreads.com/quotes/3205828-it-can-hardly-be-a-coincidence-that-no-language-on
Scrolling a window (without using RSI-inflaming trackpad gestures) is now the world’s shittiest, most widely played video-game, a hand-eye coordination challenge requiring sub-pixel accuracy and split-second timing to catch the scroll-bar handle in the brief, flashing instant where blips into existence:
https://twitter.com/doctorow/status/1516136202235043841
One of the scariest things about the precarity of Firefox is the prospect of losing some of the customizations and stock features I rely on to decrapify the web — stuff I use so often that I sometimes forget that it’s not how everyone uses the web:
https://www.wired.com/story/firefox-mozilla-2022/
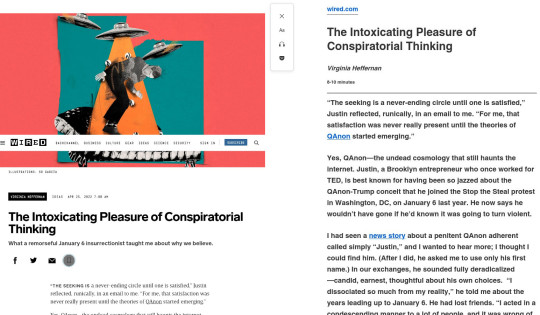
[Image ID: Two side-by-side screenshots comparing the default layout of a wired.com article ('The intoxicating pleasure of conspiratorial thinking' by Virginia Heffernan) with the same article in Firefox's Reader Mode.]
For example, there’s Firefox’s Reader Mode: a hotkey that strips out all the layout and renders the text of an article as a narrow, readable column in whatever your default font is. I reach for ctrl-alt-r so instinctively that often the publisher’s default layout doesn’t register for me.
Reader Mode (usually) bypasses interruptors and static elements, but Firefox isn’t capable of deploying Reader Mode on every site. The Activate Reader View plugin can sometimes fix this:
https://addons.mozilla.org/en-US/firefox/addon/activate-reader-view/
But when it can’t there’s my favorite, indispensable Javascript bookmarklet: Kill Sticky, which hunts through the DOM of the page you’ve got loaded and nukes any element that is tagged as “sticky” — which generally banishes any permanent top/bottom/side-bars with a single click:
https://github.com/t-mart/kill-sticky
A recent addition to my arsenal is Cookie Remover. Click it once and it deletes all cookies associated with the page you’ve currently loaded. This resets the counter on every soft paywall, including the ones that block you from using Private Browsing. Click this once, then reload, and you’re back in business:
https://addons.mozilla.org/en-US/firefox/addon/cookie-remover/
Today, I added another plug-in to my decrapification rotation: Consent-O-Matic, created by researchers at Denmark’s Aarhus University. Consent-O-Matic identifies about 50 of the most commonly deployed GDPR tracking opt-out dialog boxes and automatically opts you out of all tracking, invisibly and instantaneously:
https://consentomatic.au.dk/
We shouldn’t need Consent-O-Matic, but we do. The point of the GDPR was to make tracking users painful for internet companies, by forcing them to break down all the different data they wanted to gather and the uses they wanted to put it to into a series of simple, yes/no consent requests. The idea was to create boardroom discussions where one person said, “OK, let’s collect this invasive piece of data” and someone else could say, “Fine, but that will require us to display eight additional dialog boxes so we’ll lose 95% of users if we do.”
https://pluralistic.net/2021/11/26/ico-ico/#market-structuring
What’s more, the GDPR said that if you just bypassed all those dialog boxes (say, by flipping to Reader Mode), the publisher had to assume you didn’t want to be tracked.
But that’s not how it’s worked. A series of structural weaknesses in European federalism and the text of the GDPR itself have served to encrapify the web to a previously unheard-of degree, subjecting users to endless cookie consent forms that are designed to trick you into opting into surveillance.
Part of this is an enforcement problem. The EU Commission we have today isn’t the Commission that created the GDPR, and there’s a pervasive belief that the current Commission decided that enforcing their predecessors’ policies wasn’t a priority. This issue is very hot today, as the Commission considers landmark rules like the Digital Services Act (DSA) and the Digital Markets Act (DMA), whose enforcement will be at the whim of their successors.
The failures of EU-wide enforcement is compounded by the very nature of European federalism, which gives member states broad latitude to interpret and enforce EU regulations. This is most obviously manifested in EU member states’ tax policies, with rogue nations like Luxembourg, Malta, the Netherlands and Ireland vying for supreme onshore-offshore tax haven status.
Not surprisingly, countries whose tax-codes have been hijacked by multinational corporations and their enablers in government are likewise subject to having their other regulations captured by the companies that fly their flags of convenience.
America’s biggest Big Tech giants all pretend to be headquartered in Ireland (which, in turn, allows them to pretend that their profits are hovering in a state of untaxable grace far above the Irish Sea). These same companies ensured that Ireland’s Data Protection Commissioner’s Office is starved of cash and resources. Big Tech argues that their Irish domicile means that anyone who wants to complain about their frequent and enthusiastic practice of wiping their asses with the text of the GDPR has to take it up with the starveling regulators of Ireland.
That may change. Max Schrems — whose advocacy gave rise to the GDPR in the first place — has dragged the tech giants in front of German regulators, who are decidedly more energetic than their Irish counterparts:
https://pluralistic.net/2020/05/15/out-here-everything-hurts/#noyb
The new EU tech competition laws — the DMA and DSA — aim to fix this, shoring up enforcement in a way that should end these “consent” popups. They also seek to plug the GDPR’s “legitimate purpose” loophole, which lets tech companies spy on you and sell your data without your consent, provided they claim that this is for a “legitimate purpose.”
But in the meantime, GDPR consent dialogs remain a hot mess, which is where Consent-O-Matic comes in. Consent-O-Matic automates away the tedious work of locating all the different switches you have to click before you truly opt out of consent-based tracking. This practice of requiring you to seek out multiple UI elements is often termed a “Dark Pattern”:
https://dl.acm.org/doi/pdf/10.1145/3313831.3376321
But while “Dark Pattern” has some utility as a term-of-art, I think that it’s best reserved for truly sneaky tactics. Most of what we call “Dark Patterns” fits comfortably in under the term “fraud.” For example, if “Opt Out of All” doesn’t opt out of all, unless you find and toggle another “I Really Mean It” box, that’s not a fiendish trick, it’s just a scam.
Whether you call this “fraud” or a “Dark Pattern,” Consent-O-Matic has historic precedent that suggests that it could really make a difference. I’m thinking here of the original browser wars, where Netscape and Internet Explorer (and others like Opera) fought for dominance on the early web.
That early web had its own crapification: the ubiquitous pop-up ad. Merely opening a page could spawn dozens of pop-ups, some of them invisible 1px-by-1px dots, others that would run away from your cursor across the screen if you tried to close them, and they’d all be tracking you and auto-playing 8-bit music.
The pop-up ad was killed by the pop-up blocker. When browsers like Mozilla and Opera started blocking pop-ups by default, users switched to them in droves. That meant that an ever-smaller proportion of web users could even see a pop-up, which meant that advertisers stopped demanding pop-ups. Publishers — who knew their readers hated pop-ups but were beholden to advertisers to keep the lights on — were finally able to convince advertisers that pop-ups were a bad idea. Why pay for ads that no one will see?
Pop-up blockers are an early example of Adversarial Interoperability, AKA Competitive Compatibility (comcom for short). That’s the practice of improving an existing product or service by making an add-on or plug in that changes how it behaves to make it more responsive to its users’ interests, without permission from the original manufacturer:
https://www.eff.org/deeplinks/2019/10/adversarial-interoperability
It’s been more than 20 years since the Platform for Privacy Preferences (P3P) tried to get tech companies to voluntarily recognize and honor their users’ privacy choices. It failed:
https://en.wikipedia.org/wiki/P3P
Do Not Track, another attempt to do the same, did not fare much better:
https://en.wikipedia.org/wiki/Do_Not_Track
But you know what actually worked? Tracker-blockers and ad-blockers, “the largest consumer boycott in history”:
https://www.eff.org/deeplinks/2019/07/adblocking-how-about-nah
Making it impossible to track users is of great assistance to efforts to make it illegal to track users. Tools like Consent-O-Matic change the “security economics” of crapification, by turning the consent theater of illegal cookie popups into actual, GDPR-enforceable demands by users not to be tracked:
https://doctorow.medium.com/automation-is-magic-f4c1401d1f0d
Decrapifying the web is a long, slow process. It’s not just using interoperability to restore pluralism to the web, ending the era of “five giant websites, each filled with screenshots of text from the other four”:
https://twitter.com/tveastman/status/1069674780826071040
It’s also using a mix of technology and regulation to fight back against deliberate crapification. Between Consent-O-Rama, Reader Mode, Kill Sticky and Cookie Remover, it’s possible to decrapify much of your daily browsing and substantially improve your life.
[Image ID: A GDPR consent dialog with a rubber stamp in the center depicting a snarling man flipping the bird.]
488 notes
·
View notes
Note
Hello, your work is beautiful! Forgive me for I've fallen down a bit of a rabbit hole and I'm not sure if this is an appropriate question, but I was wondering how you gathered and typeset the text for all the danmei/baihe you do? On ao3 there's an epub & other download options, but on most danmei translations I've seen there isn't.
Sorry if this is a silly question or I worded it weirdly! I've been wanting to get into bookbinding for a long time but it seems like such an overwhelming hobby to get into haha
It's plenty appropriate!!! So there's a variety of different methods I've used depending on when I was making the book and how the translations had been shared online. It's kind of a nightmare in how there isn't a one size fits all solution. And after jjwxc did that whole thing about offering to pay (mainland citizens) for translations of novels, a lot of the options got more complicated, unfortunately. And locked google docs are a thing I understand, but I hate them so so so much, I'm in this hobby because The Ephemeral Nature Of Internet Posts And The Looming Fear Of Lost Media, and locked google docs are a nightmare.
(the practical parts of making books are also overwhelming, just because there are so many pieces that go into it and so many ways to do it. I recommend sealemon on youtube as a good place to absorb the basic elements of how a book is assembled, then das bookbinding once you feel like you've outgrown sealemon. or on tumblr there's renegadepublishing as a place to see a lot of other fanbinders post their work, and they also have a number of resources on the process!)
Once or twice, I've functionally retyped a novel. This sucks. I don't recommend it at ALL if you have better options. You almost always have better options.
The usual approach is that I've gone to a website, copied the text chapter by chapter (usually adding footnotes as I go, it's easier to do them four or five at a time than to wrangle like sixty when you have a huge document and 'footnote 1' x30 to place). This is tedious, but meditative. I don't mind putting in the work at all, I frequently harvest ao3 stories that are being turned into anthologies in a similar way.
Some sites are now password-protected. If you have the brain space, identifying groups you're interested in that have sites like this and doing the steps you need to get into their discord group or whatever and have access, that's a GREAT chore to cross off the list. Some groups make this very easy and you can do it on the fly, and some groups are a fucking NIGHTMARE, and it can be hard to tell which is which from the outside.
Some websites have copy protections as well. Some of them will let you copy and paste, but a paragraph or two in the middle will be jumbled up a bit, just a simple cipher. I think it may just be shifting the letters, not even swapping them at random. There may be a coding way to get around this, but I barely know the first thing about coding, so I copy and paste and retype these paragraphs by hand. Some sites bluntly refuse to let you copy and paste, or screenshot, and I resent these sites deeply because a huge part of the fun of reading these things is sharing choice bits with friends to try to bait them into the pit with you. Circle back to this with the same solution as I'm about to get into.
And then there are the locked google docs. At certain points, there have been workarounds, like loading the whole page and then disabling javascript, which lets you select and copy. But last time I tried that, the workaround no longer worked. There are other people who care about this kind of thing, it's a question that comes up on forums, but much like questions about how to break amazon's drm stranglehold on kindle books, old solutions frequently stop working, and I have no idea what the current best practices are.
BIG CAVEAT here, that.... I get it. Translation is hard fucking work, and it's really easy for other people to put in a fraction of the same effort to scrape a translation and repost it. Or worse, sell it. I think translators deserve MASSIVE credit for what they do, and I try to support them the same way I support authors whose books I work with. I don't want to divert any traffic or appreciation from them, but at the same time, I've got google docs, I know it takes about two seconds for me to delete any given document I've ever posted. I am here because I adored mxtx and was very afraid the translations of her books would disappear someday and would be unrecoverable, which is kind of sadlarious in retrospect.
But that worry still applies very much to a lot of other talented authors who haven't been licensed, and hell, it applies to the fan translators who were forced to take the hard work they did for free offline after licenses were secured by someone else! It's a niche community thing, but I witnessed a SCRAMBLE to preserve those documents before they disappeared from public view! I don't think the ExR mdzs translation was perfect, but nuking it from the internet is still a huge loss, and nuking the newer in-progress translations was fucking heartbreaking. It still upsets me to think about that too hard. And for translations tucked behind copy protections, yeah, it's harder for scrapers to steal and repost, but it also becomes so much more difficult for someone with archival intentions to preserve the silly things.
So..... there are sites where free epubs of books can be found for the downloading. I'm not advocating for or against piracy, I passionately do not want to take a moral stance on this, every person has to work it out for themselves. Don't ask me why I own gideon the ninth as a purchased hardcover, audiobook, and kindle book and as an illicit epub and mobi. Maybe I need five copies of one book, don't look at me. But standards for uploading on these sites are kind of lax, and once, I noticed that hey, waitaminnit, these don't look like published translated novels, these look like scraped fan translations. First, they were, second, when jjwxc did the thing, this became much, much more relevant to my workflow.
I'm not going into specifics on my blog, because really, I am very anxious not to divert attention or credit from translators. These ebooks are usually not formatted with much love or care. The footnotes are generally a formatting nightmare or missing completely. When a translator site jumbles the text via copying and pasting, a lot of these don't correct it, there's just a patch of gibberish. The places translators post are usually MUCH more pleasant ways to actually read the goods. But. In the event that the original translator suddenly yoinks their page, if there's that kind of emergency, I can still decode that cipher and reconstruct the original goods. It's not usually PRETTY to format these things, but it's still easier than retyping a whole novel, which I am stubborn enough to do, but I'm pretty sure that's how I killed my last laptop's keyboard.
I won't go into more detail than that on the public-facing part of my blog, but hopefully that's enough to go by! I can answer private questions as well off anon, but I do realize that I should have probably expected questions like this sooner, considering my hobbies XD I wanted to make it very clear why I'm doing this, and elaborate on the tricky line to walk between supporting the fans who do this hard labor for free and (understandably!) don't want their work stolen, and preserving these works so that they can't just disappear overnight. I am constantly aware (and lowkey anxious) that it would be easy for someone unfamiliar to take a glance at what I do and accuse me of being a dirty filthy pirate who's ready to destroy this community with my Thieving Ways, but I have a genuine passion for the archival aspects of this hobby, and it really is a driving force in what I do. Capturing and formatting these cnovel translations isn't easy, and if I wasn't passionate, I would have stopped ages ago. I do it because I think it's important, I think it would be genuinely tragic to lose these stories, or to lose variations on these stories when fan translations are taken down in favor of official ones, and I passionately want to see them preserved.
#spock replies#bookbinding#adjacent#long post/#archiving#might be a tag worth having#idk how much i'll talk about it because it's really not something where i've cultivated SKILLS#like being able to capture these things quickly with macros or code or whatnot#i'm just a stubborn ass who's willing to do a lot of manual labor once i'm set on an idea
47 notes
·
View notes
Text
javascript tumblr stuff
hmmmmmm think tumblr had a recent update where they disabled javascript on blog pages (blog themes are fine?? i think??). kind of a bummer for me bc i was using some scripts to get stuff like tabs and fa icons on character pages hehehe. BUT you can request an exception from support to allow you to use javascript again, which is what i did (waiting on a reply)! i dunno how many people still use tumblr’s blog customization features like that (its honestly one of my favorite things about the site), but yeah just fyi!!
#text#more boring technically stuff lmao#this is the kinda stuff i get excited to talk about#im dont know enough about web layout to make my own themes and pages from scratch yet#but i love messing around with other people's themes and such hehehe#like the current theme im using has been somewhat modified#like theres the obvious stuff like the spamtons flying around#but i also changed up how it handled the background. idk you gotta look at the original code to really see it heheh#and i THINK there was something i changed with the font in some sections i cant remember#and then the 'spamton au masterpage' was edited as well from its base code hehehe#but thats an example of a page getting screwed due to lack of scripts. youll probably notice none of the buttons have icons in them#yeah there was a script to import icons to use lmao
70 notes
·
View notes
Text
i wish Toyhou.se site would let new members in without the need for invitation keys.
it's a great alternative for hoarding oc profiles after tumblr disabled javascript on pages.
it had encouraged me to update my swtor ocs and will work on other characters for my verse. it's not much but it's there.
2 notes
·
View notes
Text
Updated for 2023, at least MacOS.
In Firefox, option-command-i brings up the menu, not control-shift-i. In the Debugger tab, you need to click the gear, and that makes the Disable Javascript option show up:

For Chrome, option-command-i brings up a similar panel, click on the preferences gear (no Debugger step), and then scroll WAY the hell down to get to the bottom, where this shows up:

I fully expect this to stop working exactly this way in a few months, and it probably doesn't work the same way in Windows.
Note, the site I tried this on didn't fully work, the javascript was needed to serve up pictures, so it just showed links and text with no preview images. And when I clicked on the links, I had to go and manually disable javascript all over again. Still, an improvement.
ETA: control-shift-i brings up the same stuff on Windows Firefox and Windows Chrome as above.

If there was a way to run SUPER MEGA AD BLOCKER on this website I fucking would
419K notes
·
View notes
Text
What Are the 7 Web Development Life Cycles Recently we had a discussion with a client and talked about what are the 7 web development life cycles. So we thought we'd put a summary into a blog for you. The web development life cycle (WDLC) is a process used to create, maintain, and improve websites. It involves a series of steps that must be followed in order to ensure that the website is successful. The WDLC consists of seven distinct phases: planning, design, development, testing, deployment, maintenance, and optimization. Each phase has its own purpose and is importance in the overall success of the website. In this blog post, we will discuss each phase of the WDLC and its purpose. Planning The planning phase is the first step in the WDLC. During this phase, you will need to determine what your website needs to accomplish and how it should be structured. This includes deciding on a domain name, hosting provider, content management system (CMS), and other necessary components. You will also need to identify your target audience and develop a plan for how you will reach them. This phase is critical for setting up a successful website as it helps you determine what resources are needed for each stage of the process. Some decisions made at this point would create a lot of work if you later changed your mind. You should also use this time to think about what it is you want to say or more importantly, what your potential clients might want to know. This part of the Planning stage is called Keyword research. Design The design phase is where you create the look and feel of your website. This includes selecting colours, fonts, images, layouts, navigation menus, etc. You should also consider how users will interact with your site by creating user flows or wireframes that show how they can move from one page to another. During this phase you should also consider accessibility standards such as WCAG 2.0 AA or Section 508 compliance so that all users can access your site regardless of their abilities or disabilities. often people think the design is about personal preferences, for example you may really be into dark colours like Black with high contrast white text. The important thing to consider though is that the colours, graphics and fonts need to be compatible with your brand. Black may not be appropriate if your business is a children's nursery, it would send totally the wrong message. Development Once you have finalized your design plans it’s time to start developing your website using HTML/CSS/JavaScript or any other programming language you choose to use. At Saint IT our preferred CMS is Wordpress for lots of reasons. One of the most important reasons is the flexibility and the ease of use for the client once the website goes live. During this phase you will need to write code that implements all of the features outlined in your design plans as well as any additional features that may be needed for functionality or interactivity purposes. Once all of the code has been written it’s time to test it out on different browsers and devices to make sure everything works correctly before moving on to deployment.
Testing The testing phase is where you make sure everything works properly before launching your website live on the internet. This includes checking for bugs or errors in code as well as ensuring that all features are working correctly across different browsers and devices. It’s important to test thoroughly during this stage so that any issues can be identified and fixed before launch day arrives! Remember that a bad website with lots of errors or bad grammar can negatively impact your brand. Deployment Once all tests have been completed successfully it’s time for deployment! This involves making the website live so that they can be accessed by users online via their web browser or mobile device. Depending on which hosting provider you choose there may be additional steps involved such as setting up databases or configuring security settings but once everything is ready then it’s time for launch day! At this point it is also important to check your SEO and your reporting, making sure that each page is fully optimised for search engines and you're getting good reporting from your website. Integration with Google Analytics one such useful tool for this. Maintenance Web Development agencies often overlook this stage. The Website has been created, the client has paid the bill and they're now left with a website that requires constant maintenance without any training or instructions to carry this out. The maintenance phase is an ongoing process where changes are made over time based on user feedback or new requirements from stakeholders/clients etc.. This could involve adding new features/functionality or fixing existing bugs/errors in code etc.. It’s important to keep up with maintenance regularly so that users always have an optimal experience when visiting your website! At Saint IT we ensure all our clients receive the best service once their website is live. We have the skills and knowhow to ensure all updates are applied regularly and we perform monthly manual, visual checks and tests to ensure there are no issues. Optimization The optimization phase involves making changes over time in order to improve performance such as increasing page loading speeds or improving search engine rankings etc.. This could involve making changes such as optimizing images/code for faster loading times or implementing SEO best practices like meta tags etc.. It’s important to keep up with optimization regularly so that users always have an optimal experience when visiting your website! Website performance depends on a number of factors and your web developer/agency should have advised you at the planning stage of the best hosting package for your website. If you're running a large corporate website with hundreds of pages you're not going to want to host that on a low cost public cloud web host. Conclusion The web development life cycle (WDLC) with it's seven distinct phases: planning, design, development, testing, deployment, maintenance and optimization outlines the complexities involved in web design. each phase with its own purpose within the website project is crucial to how well your website performs over time. If you have the multiple skills required and the time, you can certainly undertake such a project by following these steps carefully. However we recommend you partner with an experienced web design agency because they have the right tools and differing skills required. By partnering with Saint IT to build your website you can ensure that throughout each stage your website meets its goals while providing an optimal experience for visitors and users of your website. Check out our Our Other Blogs Saint IT Pleased To Support Local Initiatives Unravelling the Roles: What Does a Web Designer and Developer Do? What Are the Benefits of a Cloud-Based Phone System?
#What Are the 7 Web Development Life Cycles#web development#software development#mobile app development#web design#web developing company#web developers#website#webdesign#webdevelopment
0 notes
Text
Archiving Satellite Imagery: A Chat About the Lemur Pro with NSIDC

The National Snow and Ice Data Center at CU Boulder is one of 12 data centers across the country in charge of archiving NASA’s satellite imagery. This week, we had a nice chat with Chris Torrence (Software Development Manager) and Matt Fisher (Software Developer) on their work and their experience with the System76 Lemur Pro.
Tell us about what goes on at the NSIDC.
Chris: NSIDC is part of an organization called CIRES, which stands for the Cooperative Institute for Research in Environmental Sciences. Our team is kind of a suborganization within that, which is a software development group made up of 14 people. Most of our funding comes from NASA. Our primary mission is to archive all of NASA’s satellite imagery for the Arctic and the Antarctic.
Matt: Part of our mandate is we don’t just have to store the data, we have to make it available openly and freely to our users. Some of our data is a little more restrictive because it’s provisional and we’re still working on it, but it’s important that we service anybody who wants to use our data. So to do that, we wrote a JavaScript application that allows you to go to our website and select exactly what data you’re interested in—without having to write code to filter out the rest.
What kinds of users do you generally see on the site?
Matt: Our User Services office deals with a wide variety of use cases. Even developers like us at NSIDC will go to our User Services office and ask them questions for help using our own data. So they’re servicing developers, scientists, students, teachers, politicians, newspapers—we make products for newspapers and the military as well.
What sort of software does your work entail?
Chris: There’s two main aspects of what we do: Data storage and data distribution. Our web development team builds web applications so that scientists and the general public can come to our website to browse, download, and analyze our data. A lot of our applications are a combination of a front end, which would typically be written in JavaScript, and a back end written in Python which ties the front end into our database. We do also have some legacy code which we have to maintain as well, but those are the two main languages we use. We house most of our data on CU’s campus, though now we’re starting to move some of our data up into the cloud. That’s our next big project.
Matt: To add to that, we’re also building tools for generating visualizations on our website. ASINA (Arctic Sea Ice News and Analysis) provides recent news on what’s happening in the Arctic and the Antarctic. Then there’s IceBridge, which shows flights of aircraft that have flown over the Arctic and taken photographs and measurements of the ice. You can scroll through all the data that’s available, choose what you want, zoom into areas, look at the thumbnails of the images, and then download the data.
Matt: I’m also working on a project called QGreenland. We’re building a data package for commercial off-the-shelf QGIS, which is an open source tool for visualizing geographic data. The data package is focused on the geographic region around Greenland, so people who are going out there to do field work can take along this pre-downloaded data package that covers all kinds of disciplines, including atmospheric data, oceanographic data, human activity data, human health data, and animal migration data.
Matt: Another data package we built contains different categories of data focusing on Greenland. It shows scientific data such as vegetation biomass, ice streams, glacial termini positions, ice sheet velocity, bathymetric data, and locations of bird colonies. It’s aimed at all kinds of scientists, as opposed to our other work which is focused on cryospheric science.
How did you first hear about System76?
Matt: We had just started buying Linux laptops when I first started at NSIDC. I’ve always been a Linux user, and there were other Linux users here who had been asking for this for a while. I was part of the first test group that did that. We had laptops from another vendor at first that we were having trouble with, and we felt that we needed somebody to provide us laptops that had Linux expertise. That was one of the primary reasons we looked at System76. It also helped that you were local to us and that your systems had Ethernet ports for fast Internet access.
What led you to decide on the Lemur Pro?
Matt: Battery life was one of the largest reasons we chose the Lemur Pro. It had a very modern CPU in it, and we liked that they had a very high memory limit that you could configure it with. I personally appreciate the repairability of this style of laptop. Being able to just remove the bottom plate and replace the RAM is a great thing to be able to do without having to send it in or have a technician show up on-site.
Chris: We had some cases where people were installing Linux on a generic laptop, which was taking a fair amount of effort for them to maintain and keep up to date. That was another benefit of having Ubuntu come pre-installed, so you’re 75 percent of the way to a system that’s ready to go instead of starting from 0.
What distro are you using?
Matt: A few of us are on Ubuntu 20.04. One of us got their laptop a little earlier with Pop!_OS 18.04 installed. He’s since upgraded, and as far as I can tell he really likes it. At this point my experience with Ubuntu 20.04 has me wishing I went with Pop!_OS 20.04 as well because of snaps. I don’t really like snaps, so I had to go through a good amount of effort to disable them and block them from my system.
How has System76 improved your workplace? Contact [email protected] for more information on how to get your company featured in our next case study!
#system76#linux#ubuntu#computers#science#scientists#greenland#snow#ice#nsidc#NASA#research#Pop!_OS#software#computer#laptop#hardware#remote working#wfh#right to repair
4 notes
·
View notes