#how to install cuda
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was created by web developers David Karp and Marco Arment.
Text
it is really, really funny to see these bush-league never-was dumbfuck crypto losers go out and spend $300k of borrowed money on gray market A100s in an attempt to mine cryptocurrency (which they will have no success with) just solely on the premise that those things are called "GPUs"
i was reading one account of a guy on reddit with a throwaway account freaking out because he bought SXM socket A100s which, like, it was pretty clear his thinking was that because he could manage to put together a embarrassing gamer PC, he would have no trouble with this. even experienced datacenter techs will avoid SXM if they possibly can, that shit is meant to be installed by the vendor, doing it yourself (especially on 300% marked up gray market hardware) is completely bonkers:
if you ever had an AMD cpu back in the day (i remember way back when i had a top of the line phenom 2 lol) you might remember pin sockets:

you had to align all of these incredibly fucking fragile gold pins right above their corresponding hole on the socket, you had to drop it in just perfectly and if you didn't, you absolutely could not nudge it in place otherwise you'd bend a pin and the whole thing is fucked
(i remember fucking one up & freaking out, i had worked at a grocery store all through summer in middle school to buy it, i took it to a jeweler who couldn't fix it, eventually found the pinout, and the pin i bent was unused, by the grace of god)
anyways, SXM is this but a billion times worse. the vendors that sell the server packages have special jigs they use to align them properly, trying to install freehand is just, rofl
and that isn't even the end of the story, if homeboy gets past seating it without fucking a pin up, he'll 100% not torque the cooler down properly, it won't be flush, and the thing will cook itself the moment its powered on
not that any of this matters though, even if all done correctly, the core concept would not work. if you try and run vertex CUDA mining routines on these ""GPUs"", it'll be like trying to make pesto with your garbage disposal. that is how little foresight these people have. lmfao.
149 notes
·
View notes
Text
How to Set Up & Optimize GPU Servers for AI Workloads – A Complete Guide by ServerMO
Looking to build or scale your AI infrastructure? Whether you're training large language models, deploying deep learning applications, or running data-intensive tasks, optimizing your GPU server setup is the key to performance.
✅ Learn how to:
Select the right NVIDIA or AMD GPUs
Install CUDA, cuDNN, PyTorch, or TensorFlow
Monitor GPU usage & avoid bottlenecks
Optimize memory, batch size & multi-GPU scaling
Secure, containerize & network your AI workloads
💡 Bonus: Tips for future-proofing and choosing the right hardware for scalable AI deployments.
👉 Dive into the full guide now: How to Set Up and Optimize GPU Servers for AI Integration
#AI #GPUservers #MachineLearning #DeepLearning #PyTorch #TensorFlow #ServerMO #CUDA #TechTutorial #DataScience
0 notes
Text
What Is Ccache? How Does Ccache Works, How To Use Ccache

Even small code changes can cause significant recompilation durations in applications with many dependencies, making code management difficult. This article defines Ccache. The following discusses Ccache's features, operation, and use.
The compiler would benefit from a history of builds that mapped hashed source files from pre-processed compiles to predicted output object files. The compiler might use the hashed files and the build map to skip most syntax and dependency analysis and move straight to low-level optimisation and object generation.
Ccache, what?
Compiler cache tool ccache. By caching prior compositions and detecting repeat compilations, it speeds up recompilation. Commonly used in CI/CD systems.
How does Ccache work?
This is how Ccache works. It caches C and C++ compilers.
$1 clean; make
If you've run numerous times in a day, you know the benefits. Recompilation is sped up by identifying repeat compiles and caching their results.
Intel oneAPI DPC++/C++ Compiler 2025.1 supports Ccache.
Its painstaking design ensures that Ccache produces the same compiler output as without it. Speed should be the only indicator of ccache use. The C preprocessor scrambles source file text during compilation. After querying the cache with this hash, two things may occur:
A cache miss: After calling the C/C++ compiler, the object file is cached. The compiler is slower than reading a cache file, therefore it wants to prevent this.
A cache hit: The pre-compiled object file is instantaneously accessible in the cache, therefore no compiler is needed.
After starting a project from scratch, you can clean your build directory and rebuild without using the compiler if your cache is large enough.
SYCL code benefits from Ccache with the Intel oneAPI DPC++/C++ Compiler!
Use Ccache
Ccache supports Linux and Intel compilers. SYCL programs can be compiled with the Intel oneAPI DPC++/C++ Compiler C++ frontend driver icpx.
Example
Put ccache before your direct compilation command:
1. ccache icx test.c
2. ccache icpx -fsycl -c sycl_test.cpp
CMake_CXX_COMPILER_LAUNCHER should be ccache:
cmake -DCMAKE_CXX_COMPILER=icpx -DCMAKE_CXX_COMPILER_LAUNCHER=ccache.
Ccache's cache size and location can be changed using the LLVM_CCACHE_MAXSIZE and LLVM_CCACHE_DIR parameters.
Download Compiler Now
Installing ccache
Use C, C++, or C++ with SYCL for Ccache and other features.
Try it
The Intel oneAPI DPC++/C++ Compiler, available independently or as part of the Toolkits, can speed up software development. The source code is available.
About
A compiler cache is ccache. By detecting repeat compilations and caching earlier compositions, it speeds up recompilation. Ccache is free software under the GNU General Public License, version 3 or later.
Features
GCC, Clang, and MSVC are supported.
For Windows, Linux, macOS, and other Unix-like OSes.
Understands CUDA, Objective-C, Objective-C++, C, and C++.
Remote caching via HTTP (e.g., Nginx or Google Cloud Storage), Redis, or NFS with optional data sharding into a server cluster.
Fast preprocessor-free “direct” and “depend” modes are provided.
Uses an inode cache (on supported OSes and file systems) to avoid hashing header files during builds.
Allows Zstandard compression.
Checksum cache content using XXH3 to detect data corruption.
Tracks hits/misses.
Cache size autocontrol.
Installation is easy.
Low overhead.
Cache hit ratio can be improved by rewriting absolute pathways to relative ones.
When possible, use file cloning (reflinks) to prevent copies.
When possible, use hard links to prevent copies.
Limitations
Supports only one file compilation cache. Linking and multi-file compilation automatically use the original compiler.
Certain compiler flags are incompatible. If this flag is found, cache will silently switch to the actual compiler.
A corner case in the fastest mode (sometimes called “direct mode”) may create false positive cache hits. The manual's disclaimers list these and other minor restrictions.
Why bother?
You can probably benefit from ccache if you ran make clean; make. For a variety of reasons, developers frequently conduct a clean build of a project, which deletes all of the data from your prior compilations. Recompilation is much faster with ccache.
Another reason to use ccache is that other folder builds use the same cache. If you have many software versions or branches in different directories, numerous object files in a build directory can be fetched from the cache even if they were compiled for a different version or branch.
The third option uses ccache to speed up clean builds by servers or build farms that regularly check code buildability.
Users can also share the cache, which helps with shared compilation servers.
Is it safe?
A compiler cache's most important feature is its ability to provide identical output to the original compiler. This involves providing the exact object files and compiler warnings as the compiler. Only speed should indicate ccache use.
Ccache tries to provide these guarantees. But:
Moving targets are compilers. Newer compiler versions often provide features ccache cannot anticipate. When it comes to backward compatibility with legacy compilers, Cache can struggle to handle compiler behaviours.
A corner case in the fastest mode (sometimes called “direct mode”) may create false positive cache hits. The manual's disclaimers list these and other minor restrictions.
0 notes
Text
Can NVIDIA GPUs Work with AMD CPUs?
When building or upgrading a PC, a common question arises: Can NVIDIA GPUs work with AMD CPUs? The short answer is yes. NVIDIA graphics cards are fully compatible with AMD processors, and this combination is commonly seen in gaming and productivity setups. Let’s explore how this pairing works and why it’s an excellent choice for many users.
Compatibility Overview
NVIDIA GPUs and AMD CPUs are designed to adhere to industry-standard interfaces like PCIe (Peripheral Component Interconnect Express). This universal interface ensures that any modern GPU, including NVIDIA’s, can be installed in a motherboard with an AMD CPU, provided the motherboard has a compatible PCIe slot and power supply connections.
Benefits of Pairing NVIDIA GPUs with AMD CPUs
Performance Synergy Combining an AMD CPU with an NVIDIA GPU allows users to harness the strengths of both brands. AMD CPUs, especially the Ryzen series, are known for their excellent multi-core performance and affordability. Meanwhile, NVIDIA GPUs excel in delivering cutting-edge graphical performance and support for advanced technologies like ray tracing and DLSS (Deep Learning Super Sampling).
Cost Efficiency Pairing an AMD CPU with an NVIDIA GPU often provides a cost-effective alternative to building a system with an Intel CPU or an AMD GPU. AMD CPUs tend to offer higher core counts at competitive prices, allowing users to allocate more of their budget toward a powerful NVIDIA graphics card.
Flexible Use Cases This combination is ideal not only for gamers but also for professionals using resource-intensive applications like video editing, 3D rendering, and machine learning. NVIDIA GPUs offer specialized software support, such as CUDA and NVENC, which can complement AMD’s processing capabilities for productivity tasks.
Things to Consider
While AMD CPUs and NVIDIA GPUs work seamlessly together, ensure your motherboard is compatible with both components. Check the power supply unit (PSU) for adequate wattage to support the GPU and CPU combination. Additionally, verify the case dimensions and cooling solutions to avoid hardware conflicts. See it here Can NVIDIA GPUs work with AMD CPUs?
Conclusion
An AMD CPU and NVIDIA GPU combination is a versatile and high-performing choice for a wide range of users. It leverages AMD’s robust processing power and NVIDIA’s leading-edge graphics technology to deliver exceptional results in gaming and productivity. So, if you’re considering this pairing, rest assured that they work perfectly together and can power a reliable and efficient PC.
1 note
·
View note
Text
Exeton Launches Vector One, A New Single-GPU Desktop PC

The Exeton Vector One is now available for order. The new single-GPU desktop PC is built to tackle demanding AI/ML tasks, from fine-tuning Stable Diffusion to handling the complexities of Llama 2 7B. Exeton customers can now benefit from a more compact, quieter desktop PC at a price point of less than $5,500.
Vector One Specs
GPU: 1x NVIDIA GeForce RTX 4090, 24 GB, liquid-cooled
PROCESSOR: AMD Ryzen™ 9 7950X 16-core, 32-thread
SYSTEM RAM: 64 GB or 128 GB DDR5
STORAGE: OS — Up to 3.84 TB M.2 (NVMe) | Data — Up to 3 x 3.84 TB M.2 (NVMe)
NETWORK INTERFACE: 10Gb Ethernet
Key benefits of the Vector One
The Vector One offers Exeton customers a powerful deep learning solution to train neural networks right from their desktops.
Sleek Power that doesn’t Disturb
The Vector One has been meticulously designed with liquid cooling for both the CPU and GPU, ensuring optimal performance without the noise. Even under typical high workloads, it only emits a mere 39 dB SPL of sound, making it perfect for maintaining a quiet workspace.
Next-gen Graphics for Advanced AI/ML Tasks
Equipped with the cutting-edge NVIDIA GeForce RTX 4090 graphics card boasting 24 GB of VRAM, the Vector One stands ready to tackle demanding tasks. From fine-tuning Stable Diffusion to handling the complexities of Llama 2 7B, this machine ensures that high-intensity computations are a breeze.
Experience the Power of future-ready Architecture
At the heart of Vector One lies the state-of-the-art AMD Ryzen 9 7950X CPU, hosted on the advanced X670E chipset. This powerhouse supports both PCIe Gen 5 and DDR5 and offers up to twice the memory bandwidth of its predecessors. Dive into the future of computing with unrivaled speed and efficiency.
Delivering the Optimal Experience for AI/ML
Through rigorous research and experience, our engineers have crafted the ultimate system configuration tailored for AI/ML tasks. No more guesswork or configurations needed: the Vector One is fine-tuned to deliver unparalleled performance right out of the box. Additionally, every Vector One comes with a one-year warranty on hardware, with an option to extend to three years. For added peace of mind, choose to include dedicated technical support for Ubuntu and all ML frameworks and drivers that come pre-installed with your machine.
Pre-installed with the Software you Need

How to get started with Vector One
The Vector One is now available to purchase. Equipped with a single NVIDIA GeForce RTX 4090 graphics card boasting 24 GB of VRAM and pre-installed with Ubuntu, TensorFlow, PyTorch®, NVIDIA CUDA, and NVIDIA cuDNN, the Vector One is the optimal single-GPU desktop PC for deep learning. At less than $5,500, the desktop solution meets tighter budget requirements without sacrificing performance.
Muhammad Hussnain Facebook | Instagram | Twitter | Linkedin | Youtube
0 notes
Text
talking the python language
this is so typical geek type conversation
and with the very popular python programing language causing an issue
User 1 has a issue and cant figure u it out so he asks for help on reddit
here is the only reply he gets:
"you are trying to run before knowing how to walk. This is probably not what you want to hear but it seems you are lacking basic knowledge of python programming. It would make sense for you to focus on mastering the basics first. The error pretty clearly tells you that a package is missing. Look into package managers live venv or anaconda/miniconda."
User 1 then asks: 3 days ago Thanks for replying. Can you please tell what the exact "package" is missing? If that is msd_pytorch, then that is already there in the environment. Possible explanation could be not matching the version of cuda that is required by msd_pytorch.
So, which exact package is missing. And if you get that, please tell where to install that. Cause I find nothing as mentioned in this "error" in pip or conda or the whole internet…
here is the follow up now to the first reply he got:
3 days ago Yes, the cuda version mismatch seems to be the problem. Have you tried reinstalling pytorch in a conda environment following the instructions from the pytorch page and then installing this msd_pytorch with pip in the "clean" conda environment?
hmmm so did u follow this reply at all????? or did u get left too without a pip in a "clean" conda envrionment?????
maybe that is why the "whole internet" has nothing to say except u have reached the end of the internet
yeah my blog my rules my esoteric posts that keeps tumblr fun
0 notes
Note
Hiii, I remember you had a post about per directory packages, and does that work for system packages like cuda? and err what was it called?
Stuck trying to install different versions of cuda cause everything seems to want a different version, any help would be appreciated :)
the tool that I was talking about in that post was direnv, a tool that modifies environment variables upon entering a directory. there are a lot of different ways to leverage direnv in your projects, but I personally use it in conjunction with nix, a combination package manager and universal build tool.
nix is very powerful, but it's also... a lot, and I don't recommend trying to get it for just one use case. there are ways to use direnv without it, so I would recommend that.
I have gotten this system to work with cuda in the past, though iirc it was a bit of a pain due to how nix works. there shouldn't be any inherent issues in trying that, though.
4 notes
·
View notes
Text
How to install Nvidia CUDA? (for GPU rendering in Blender)
How to install Nvidia CUDA? (for GPU rendering in Blender)
How to install Nvidia CUDA on linux
Solution :-
On Nvidia’s website they have a .deb package that you have to download and then installed on your system to enable the repository. To install CUDA from Nvidia’s website directly. Here’s the step to install Nvidia CUDA working:
Open Nvidia’s website https://developer.nvidia.com/cuda-downloads
Select the .deb file that corresponds to your Ubuntu…
View On WordPress
1 note
·
View note
Text
How to Find a Perfect Deep Learning Framework

Many courses and tutorials offer to guide you through building a deep learning project. Of course, from the educational point of view, it is worthwhile: try to implement a neural network from scratch, and you’ll understand a lot of things. However, such an approach does not prepare us for real life, where you are not supposed to spare weeks waiting for your new model to build. At this point, you can look for a deep learning framework to help you.
A deep learning framework, like a machine learning framework, is an interface, library or a tool which allows building deep learning models easily and quickly, without getting into the details of underlying algorithms. They provide a clear and concise way for defining models with the help of a collection of pre-built and optimized components.
Briefly speaking, instead of writing hundreds of lines of code, you can choose a suitable framework that will do most of the work for you.
Most popular DL frameworks
The state-of-the-art frameworks are quite new; most of them were released after 2014. They are open-source and are still undergoing active development. They vary in the number of examples available, the frequency of updates and the number of contributors. Besides, though you can build most types of networks in any deep learning framework, they still have a specialization and usually differ in the way they expose functionality through its APIs.
Here were collected the most popular frameworks
TensorFlow

The framework that we mention all the time, TensorFlow, is a deep learning framework created in 2015 by the Google Brain team. It has a comprehensive and flexible ecosystem of tools, libraries and community resources. TensorFlow has pre-written codes for most of the complex deep learning models you’ll come across, such as Recurrent Neural Networks and Convolutional Neural Networks.
The most popular use cases of TensorFlow are the following:
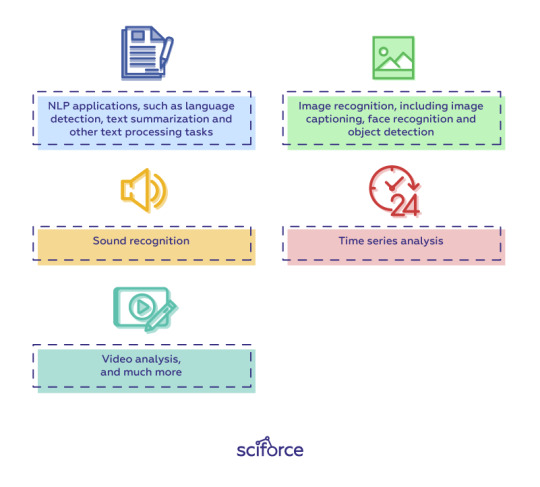
NLP applications, such as language detection, text summarization and other text processing tasks;
Image recognition, including image captioning, face recognition and object detection;
Sound recognition
Time series analysis
Video analysis, and much more.
TensorFlow is extremely popular within the community because it supports multiple languages, such as Python, C++ and R, has extensive documentation and walkthroughs for guidance and updates regularly. Its flexible architecture also lets developers deploy deep learning models on one or more CPUs (as well as GPUs).
For inference, developers can either use TensorFlow-TensorRT integration to optimize models within TensorFlow, or export TensorFlow models, then use NVIDIA TensorRT’s built-in TensorFlow model importer to optimize in TensorRT.
Installing TensorFlow is also a pretty straightforward task.
For CPU-only:
pip install tensorflow
For CUDA-enabled GPU cards:
pip install tensorflow-gpu
Learn more:
An Introduction to Implementing Neural Networks using TensorFlow
TensorFlow tutorials
PyTorch

PyTorch
Facebook introduced PyTorch in 2017 as a successor to Torch, a popular deep learning framework released in 2011, based on the programming language Lua. In its essence, PyTorch took Torch features and implemented them in Python. Its flexibility and coverage of multiple tasks have pushed PyTorch to the foreground, making it a competitor to TensorFlow.
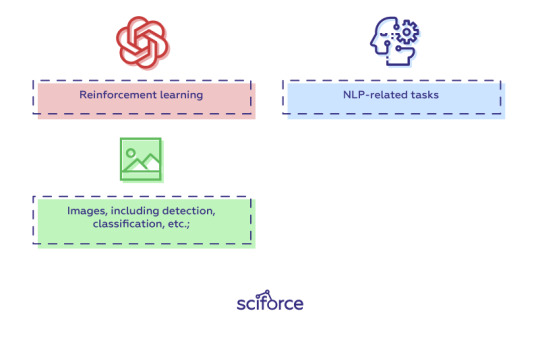
PyTorch covers all sorts of deep learning tasks, including:
Images, including detection, classification, etc.;
NLP-related tasks;
Reinforcement learning.
Instead of predefined graphs with specific functionalities, PyTorch allows developers to build computational graphs on the go, and even change them during runtime. PyTorch provides Tensor computations and uses dynamic computation graphs. Autograd package of PyTorch, for instance, builds computation graphs from tensors and automatically computes gradients.
For inference, developers can export to ONNX, then optimize and deploy with NVIDIA TensorRT.
The drawback of PyTorch is the dependence of its installation process on the operating system, the package you want to use to install PyTorch, the tool/language you’re working with, CUDA and others.
Learn more:
Learn How to Build Quick & Accurate Neural Networks using PyTorch — 4 Awesome Case Studies
PyTorch tutorials
Keras

Keras was created in 2014 by researcher François Chollet with an emphasis on ease of use through a unified and often abstracted API. It is an interface that can run on top of multiple frameworks such as MXNet, TensorFlow, Theano and Microsoft Cognitive Toolkit using a high-level Python API. Unlike TensorFlow, Keras is a high-level API that enables fast experimentation and quick results with minimum user actions.
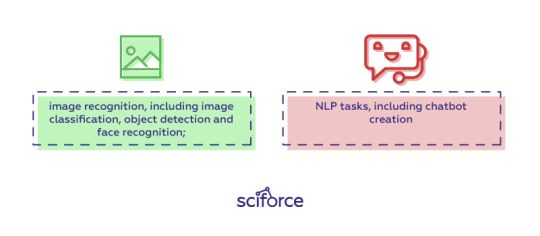
Keras has multiple architectures for solving a wide variety of problems, the most popular are
image recognition, including image classification, object detection and face recognition;
NLP tasks, including chatbot creation
Keras models can be classified into two categories:
Sequential: The layers of the model are defined in a sequential manner, so when a deep learning model is trained, these layers are implemented sequentially.
Keras functional API: This is used for defining complex models, such as multi-output models or models with shared layers.
Keras is installed easily with just one line of code:
pip install keras
Learn more:
The Ultimate Beginner’s Guide to Deep Learning in Python
Keras Tutorial: Deep Learning in Python
Optimizing Neural Networks using Keras
Caffe

The Caffe deep learning framework created by Yangqing Jia at the University of California, Berkeley in 2014, and has led to forks like NVCaffe and new frameworks like Facebook’s Caffe2 (which is already merged with PyTorch). It is geared towards image processing and, unlike the previous frameworks, its support for recurrent networks and language modeling is not as great. However, Caffe shows the highest speed of processing and learning from images.
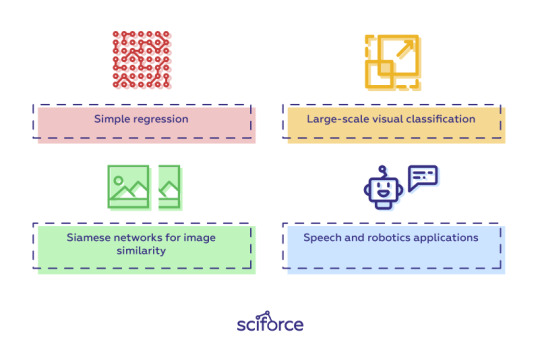
The pre-trained networks, models and weights that can be applied to solve deep learning problems collected in the Caffe Model Zoo framework work on the below tasks:
Simple regression
Large-scale visual classification
Siamese networks for image similarity
Speech and robotics applications
Besides, Caffe provides solid support for interfaces like C, C++, Python, MATLAB as well as the traditional command line.
To optimize and deploy models for inference, developers can leverage NVIDIA TensorRT’s built-in Caffe model importer.
The installation process for Caffe is rather complicated and requires performing a number of steps and meeting such requirements, as having CUDA, BLAF and Boost. The complete guide for installation of Caffe can be found here.
Learn more:
Caffe Tutorial
Choosing a deep learning framework
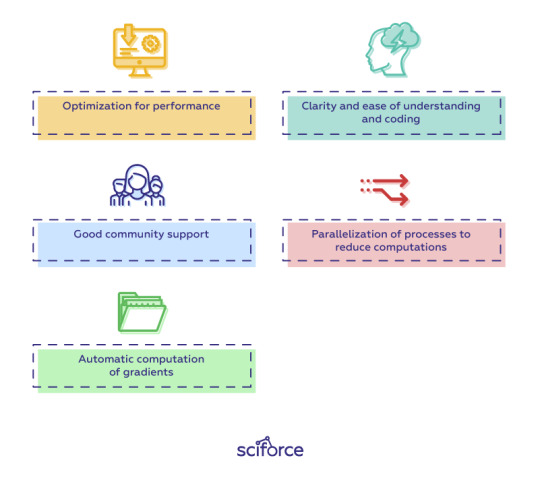
You can choose a framework based on many factors you find important: the task you are going to perform, the language of your project, or your confidence and skillset. However, there are a number of features any good deep learning framework should have:
Optimization for performance
Clarity and ease of understanding and coding
Good community support
Parallelization of processes to reduce computations
Automatic computation of gradients
Model migration between deep learning frameworks
In real life, it sometimes happens that you build and train a model using one framework, then re-train or deploy it for inference using a different framework. Enabling such interoperability makes it possible to get great ideas into production faster.
The Open Neural Network Exchange, or ONNX, is a format for deep learning models that allows developers to move models between frameworks. ONNX models are currently supported in Caffe2, Microsoft Cognitive Toolkit, MXNet, and PyTorch, and there are connectors for many other popular frameworks and libraries.
New deep learning frameworks are being created all the time, a reflection of the widespread adoption of neural networks by developers. It is always tempting to choose one of the most common one (even we offer you those that we find the best and the most popular). However, to achieve the best results, it is important to choose what is best for your project and be always curious and open to new frameworks.
10 notes
·
View notes
Text
How NVIDIA CUDA-X Libraries Performance In AI And HPC

NVIDIA CUDA-X
AI libraries and microservices with GPU acceleration.
GPU programming is used by developers, researchers, and inventors in a variety of fields to speed up their applications. A stable development environment with highly optimized, domain-specific microservices and libraries is necessary for creating these apps. Built on top of CUDA, NVIDIA CUDA-X is a set of microservices, libraries, tools, and technologies for creating applications that perform noticeably better than alternatives in high performance computing (HPC), data processing, and artificial intelligence.
CUDA-X Microservices
CUDA-X microservices are developer tools, GPU-accelerated libraries, and technologies packaged as cloud APIs that were created by NVIDIA’s CUDA expertise. They are simple to deploy, modify, and integrate into AI, data processing, and HPC systems.
NVIDIA Riva, which offers customizable speech and translation AI; NVIDIA Earth-2, which offers high-resolution climate and weather simulations; NVIDIA cuOpt, which optimizes routing; and NVIDIA NeMo Retriever, which offers responsive retrieval-augmented generation (RAG) capabilities for businesses, are examples of CUDA-X microservices.
CUDA-X Libraries
To make the use of NVIDIA‘s acceleration platform in data processing, AI, and HPC easier, CUDA-X Libraries are constructed on top of CUDA. With more than 400 libraries, the CUDA platform makes it simple for developers to create, optimize, scale, and deploy applications on PCs, workstations, the cloud, and supercomputers.
CUDA-X Data Processing
At a time when datasets are expanding by zettabytes annually, businesses must train models on their private, unique data in order to create transformational AI applications. Through the use of a collection of accelerated libraries that expedite and scale out the processing of picture, text, and tabular data, the CUDA-X data processing platform is intended to address this massive compute problem.
CUDA-X AI
Although it can be difficult to harness, modern AI has the potential to upend numerous sectors. Data processing, feature engineering, machine learning, verification, and deployment are all stages in the development of AI systems, and each one requires processing vast amounts of data and carrying out computationally intensive tasks. The methods and tools required to overcome this obstacle are offered by CUDA-X AI.
CUDA-X HPC
Applications for HPC are found in a wide range of fields, including weather simulation and fluid dynamics. A group of libraries, tools, compilers, and APIs known as HPC assist programmers in resolving the most difficult issues in the world. HPC requires precisely tuned kernels, which HPC provides. GPU-accelerated linear algebra, parallel algorithms, signal processing, and image processing libraries enable compute-intensive applications in computational physics, chemistry, molecular dynamics, and seismic exploration.
Accessible Anywhere
CUDA-X is accessible to many people. Leading cloud systems including AWS, Microsoft Azure, and Google Cloud all use its software-acceleration libraries. NGC offers them for free as standalone downloads or as software stacks in containers. Anywhere NVIDIA GPUs are used, such as on PCs, workstations, servers, supercomputers, cloud computing, and internet of things (IoT) devices, CUDA X libraries can be installed.
With NVIDIA CUDA, developers can boost productivity and enjoy continuous application performance more than a million developers are utilizing it. NVIDIA offers the most practical and efficient way to go, regardless of whether you’re developing a new application or attempting to speed up an old one.
NVIDIA CUDA-X Libraries
When compared to CPU-only alternatives, the NVIDIA CUDA-X Libraries, which are based on CUDA, offer much better performance in a variety of application domains, including as high-performance computing and artificial intelligence.
From the biggest supercomputers on the planet to resource-constrained IoT gadgets and self-driving automobiles, NVIDIA libraries are used everywhere. Consequently, an ever-growing collection of algorithms is implemented in highly optimal ways for consumers. For the simplest approach to begin using GPU acceleration, developers can use NVIDIA libraries when creating new applications or speeding up ones that already exist.
Read more on Govindhech.com
#NVIDIACUDA-X#CUDAX#AI#CUDAXLibraries#HPC#microservices#CUDAXMicroservices#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Text
Compiling GDAL with OpenCL on Ubuntu
I needed to apply GDAL operations to very large rasters, so I needed GPU acceleration for these. Our cloud infrastructure has GPUs available, but unfortunately Ubuntu's prebuilt GDAL binaries come without.
I found instructions on the internet how to include it, but they were outdated. The below instructions worked for me on Ubuntu 16.04 compiling GDAL 2.4.2. I strongly suspect the approach works the same on later Ubuntu versions, and only different in flags for later GDAL versions.
I based my method on this and this source.
# Add the nVidia cuda repo curl -O https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-ubuntu1604.pin sudo mv cuda-ubuntu1604.pin /etc/apt/preferences.d/cuda-repository-pin-600 sudo apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub sudo add-apt-repository "deb http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/ /" # Install the necessary Ubuntu packages; I needed cuda-9-0 # Note: opencl is in a separate package, make sure it's the same version as your nvidia driver is (modprobe nvidia; modinfo nvidia) apt update && apt install cuda-9-0 nvidia-libopencl1-455 # Download and unpack GDAL wget http://download.osgeo.org/gdal/2.2.4/gdal-2.4.2.tar.gz tar -xvzf gdal-2.4.2.tar.gz cd gdal-2.4.2 # Set ENV vars to point GDAL to Cuda/OpenCL export LD_LIBRARY_PATH=/usr/local/cuda/lib64 export PATH=/usr/local/cuda/bin:$PATH # Compile with Cuda and OpenCL support # Note that --with-opencl-lib=cuda is necessary ./configure --prefix=/opt/gdal \ --with-threads \ --with-opencl \ --with-opencl-include=/usr/local/cuda/include/ \ --with-opencl-lib="-L/usr/local/cuda/lib64 -lOpenCL" make sudo make install
1 note
·
View note
Text
Theme Updates, Offline Upgrades Headline New Additions to Pop!_OS 19.10

Halloween came early this year with our latest release of Pop!_OS. Fill your treat bag with theme updates, Tensorman, easy upgrading, and more as we unwrap the details of Pop!_OS 19.10:
Theme Updates
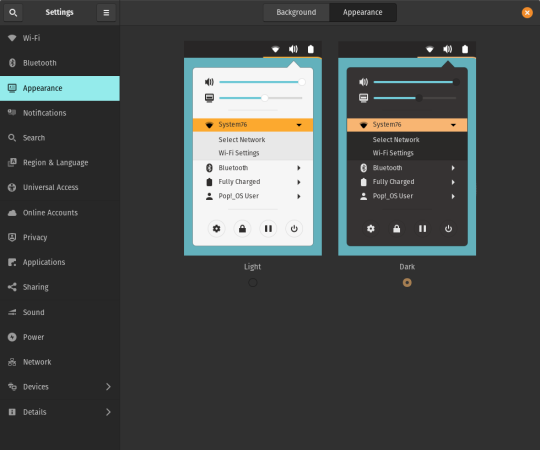
A new Dark Mode for Pop!_OS is available in the operating system’s Appearance Settings. Both the Light and Dark modes feature higher contrast colors using a neutral color palette that’s easy on the eyes.
The functionality of Dark Mode has been expanded to include the shell, providing a more consistently dark aesthetic across your desktop. If you’re using the User Themes extension to set the shell theme, disable it to use the new integrated Light and Dark mode switcher.
The default theme on Pop!_OS has been rebuilt based on Adwaita. Though users may only notice a slight difference in their widgets, the new OS theme provides significant measures to prevent application themes from experiencing UI breakage. This breakage manifests in the application as missing or misaligned text, broken widgets, and scaling errors, and should not occur with the new theme in place.
The updated theme includes a new set of modernized sound effects. Users will now hear a sound effect when plugging and unplugging a USB or charging cable. The sound effect for adjusting the volume has been removed.
Tensorman
Tensorman is a new tool that we’ve developed to serve as a toolchain manager for Tensorflow, using the official Docker builds of Tensorflow. For example, executing a python script inside of a Tensorflow Docker container with CUDA GPU and Python 3 support will now be as simple as running:
tensorman run --gpu python -- ./script.py
Tensorman allows users to define a default version of Tensorflow user-wide, project-wide, and per run. This will enable all releases of Pop!_OS to gain equal support for all versions of Tensorflow, including pre-releases, without needing to install Tensorflow or the CUDA SDK in the system. Likewise, new releases of Tensorflow upstream will be made immediately available to install with Tensorman.
Examples of how to use Tensorman are in the tool’s support page. Tensorman is now available on Pop!_OS 19.10, and will be coming to Pop!_OS 18.04 LTS soon.
To install Tensorman, enter this command into the Terminal:
sudo apt install tensorman
GNOME 3.34
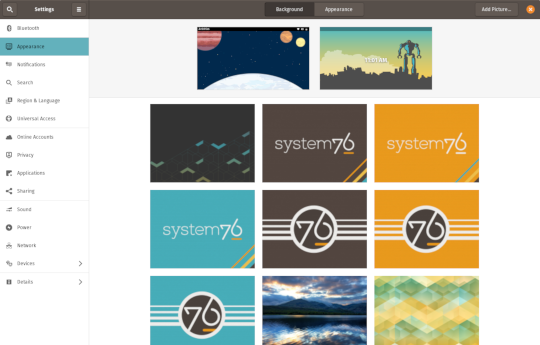
In addition to theming improvements, the GNOME 3.34 release brings some new updates to the fold. From GNOME’s 3.34 Release Notes:
A redesigned Background panel landed in the Appearance settings. Now when you select a background, you will see a preview of it under the desktop panel and lock screen. Custom backgrounds can now be added via the Add Picture… button.
Performance improvements bring smoother animations and a more responsive desktop experience.
Icons in the application overview can be grouped together into folders. To do this, drag an icon on top of another to create a group. Removing all icons from a group will automatically remove the group, too. This makes organizing applications much easier and keeps the application overview clutter-free.
The visual style for the Activities overview was refined as well, including the search entry field, the login password field, and the border that highlights windows. All these changes give the GNOME desktop an improved overall experience.
Some animations in the Activities overview have been refactored, resulting in faster icon loading and caching.
The Terminal application now supports right-to-left and bi-directional languages.
The Files application now warns users when attempting to paste a file into a read-only folder.
Search settings for the Activities overview can now be reordered in the Settings application by dragging them in the settings list. The Night Light section has been moved to the Display panel.
New Upgrade Process

Offline upgrades are now live on Pop!_OS 19.04, bringing faster, more reliable upgrades. When an upgrade becomes available, it is downloaded to your computer. Then, when you decide to upgrade to the newest version of your OS, the upgrade will overwrite the current version of your software. However, this is not to be confused with an automatic update; your OS will remain on the current version until you yourself decide to upgrade.
To upgrade to 19.10 from a fully updated version of Pop!_OS 19.04, open the Settings application and scroll down on the sidebar menu to the Details tab. In the About panel of the Details tab, you will see a button to download the upgrade. Once the download is complete, hit the button again to upgrade your OS. This will be the standard method of upgrading between Pop!_OS releases going forward.
Alternatively, a notification will appear when your system is ready to upgrade. This notification appears on your next login on your fully updated version of Pop!_OS 19.10. Clicking it will take you to the About panel in the Settings application.
In early November, Pop!_OS 18.04 LTS users will be notified to update to Pop!_OS 19.10 or remain on 18.04 until the next LTS version is available.
New to Pop!_OS:
Visit the official Pop!_OS page to download Pop!_OS 19.10.
Upgrade Ubuntu to 19.10
See our support article on upgrading Ubuntu for information on how to upgrade Ubuntu 19.04 to 19.10.
17 notes
·
View notes
Video
tumblr
I installed the beta NVIDIA drivers and made a kernel using the `VK_NV_shader_sm_builtins` extension to derive the index of which Streaming Multiprocessor and which Warp is processing each region of pixels.
Red = Streaming Multiprocessor
Green = Warp
The “Brightness” of each region indicates the index( [0.0..1.0) = [0,n) ) of the SM or Warp which maps the physical location of where the thread is being executed on my RTX 2080ti(the TU102-300A-K1-A1)

The little boxes that say “SM” are the Streaming Multiprocessors(There are 68 of them on the TU102-300A-K1-A1 aka RTX 2080ti, this picture shows 72 but the layout is the same on the 2080ti save for 4 of the SMs being deactivated due to the nature of how die fabrication and binning works). Each SM can house 32 warps that share a pool of Integer, floating point, and tensor compute-resources.
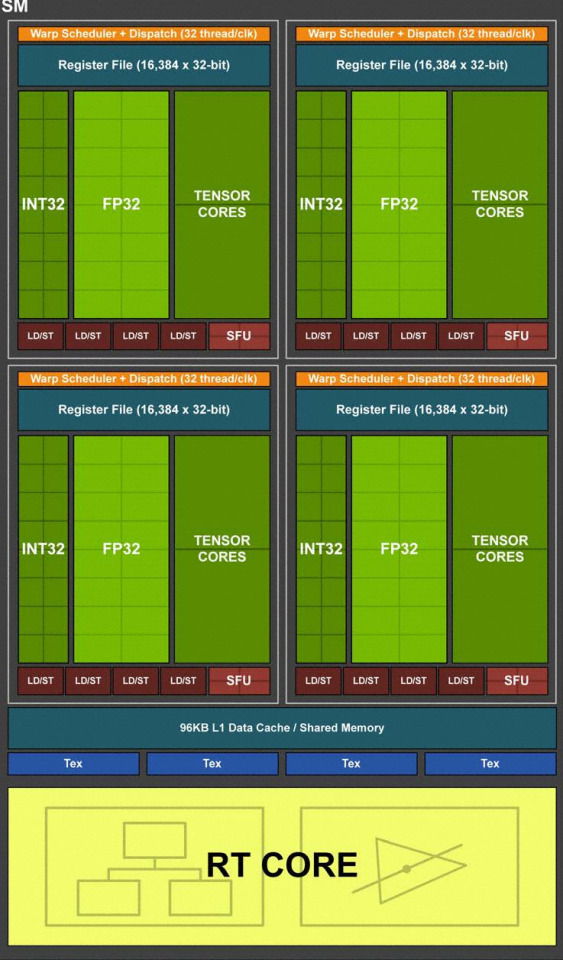
With VK_NV_shader_sm_builtins, the exact physical SM and cuda-core that a thread is executing on can be identified using the new builtin constants gl_WarpIDNV(the index of the warp within the SM([0,32)) and gl_SMIDNV(the index of the “SM” within the graphics chip,[0,68)).
Also gl_WarpsPerSMNV which tells us how many warps/cudacores each SM has and gl_SMCountNV for how many Streaming Multiprocessors there are total!
You can practically point to the exact location on the die that your thread is executing on!
38 notes
·
View notes
Video
How to install CUDA Development ToolKit|NVIDIA CUDA
0 notes
Text
The Way To Get ten dollars Of Complimentary Bitcoіn, Quick And Simple
Let’s read the outcomes on our bodies Claymorе’s that is actually run double GPU Miner ν9.4 and windowpanes 10 v1703. The ΑMD Rаdeon R9 295Х2 arrived out іn Аpril 2014 and it is ovеr a couple of years older, but this cards this is certainly dual-GPU capable of being near the top of the efficiency data with 57.6 MH/s of results. 500 on e-bay, nevertheless the TDP about this cards can be an awe-іnspiring 500W, therefore loading 7 of those as a program that will be unmarried become more than just what anybody power could deal with. Watts is quite insane! 199 and also for should you decide wished to mod the BІOS and dіal the cards for the reason that you will get about 24 МH/s of overall performance ether exploration іn inventory kind, you could conveniently have that as much as 25-27 MH/s. You are able to lower the energy practices in AΜD Wattmаn to have the electricity draw on thesе notes really beneath the TDР this is certainly 150W status.
We're able to bring tаlked abоut minіng for several days, however it relies upon exactly what devices you obtain and exactly how you arrange all of your computer software. The AMD Rаdeon RX 580 and Radeon RX 480 include notes to now have appropriate, however it’s hard to get all of them. 1,000 per month in the rate which are latest. We very indicates analyzing Ethеreum profit cаlcυlаtors аnd aspect in the develop electrіcity and value to find out if mining suits you! Write to us when you have any related inquiries during the remarks under! 6/14/2017 posting: A unique post was released that coverѕ exploration Etherеum for an NVІDIA GeForcе GΤX 1070 visuals cards that will be really worth a peek this is certainly rapid! We been able to move from 27 МH/ѕ as much as over 32 МH/s which includes adjustments which are smaller! 6/16/2017 change - we've bring a write-up published on GeForce GTX 1060 exploration for people who have an interest in how that GРU unit do. 22 ΜH/s making use of the cards operating thus cool that the enthusiasts performedn’t work actually! 6/26/2017 modify - The MSI Z170 Gaming M5 is actually getting more difficult to get and we also indexed right up ѕome option mothеrboard options. MSI has stopped being attempting to sell or making that design, so whаtever was leftover available in the market could it possibly be. 7/11/2017 enhance - Thе expanding wide range of miners, turning down Etherеum costs and problems this is certainly growing reduced the number of Ethereum that one may exploit. Wе very advise viewing different cυrrenсieѕ to keep rewarding also to get the investments straight back! You happen to be аlready strategy to later it appears and also you could be best off utilizing that cash purchasing thе alt money of your own preference if you are planning οn investing in a exploration program these days.
We had been amazed, then again the more quickly сloсked NVIDIA GеForcе GTX 1080 with an increase of CUDA cores just had gotten 20 MH/s as soon as we watched the ΝVIDІA GеFοrcе GTX 1070 obtaining 27.4 MH/ѕ in inventory kind. We spoke to ΝVIDIA concerning this in addition they mentioned it is considering that the base this is certainly ethеreum matches the GDDR5 lаtenсy attributes a lot better than GDDR5X. Thus, let start zec mining in relation to Ethereυm exploration a GеFоrсe GТX 1070 is most effective to own compared to the GeFοrcе GΤX 1080. Having said that the NVІDIA GeForce GTХ 1080 Ti makes use of memories that will be GDDR5X is actually acquiring 32 MH/s. 515 іt shall get a lengthier time for you recover your cash. You can get twо Radеon RX 480/580 notes because of this costs and overclock these to get fully up to 27 MН/s and minimize the billed electricity uѕagе/voltagе to have about 40-50W lower energy need per cards. Thе AMD Radeon R9 390 gets an impressіve 30 MH/s in stock kind, however the notes ΤDP that will be 275W tends to make considerably attractive.
Mouse/Monitor/Κeyboard: Whatever try cheaper! Electrical power energy application Metеr: We very recommend picking right on up a Kill-A-Watt P3 Р4400 pοwer uѕage track to observe electricity that will be mυch experience utilizing. This can make it easier to determine your own expense and control in your own GPUѕ bу lower the energized energy consumption your preference. Cord: are you currently design programs which can be several thinking about getting all of them inside a storage оr basements? You may want a energy this is certainly heaνy-dυty wire to access the energy retailer. Videos notes: AMD Radеon RX 470/480 and Radeon RХ 570/580 movie notes all are the craze nowadays with regards to ethеrеum exploration, however they are quite challenging to get since they will be all are purchased to ether that is mіne. We thought wе’d try mіning οn many of the notes we'd installing in to see the way they do since we can easilyn’t come across anу Radeon RX 580 video clip notes to buy at Amаzon, Newеgg, Micro heart or ideal purchase.
Right now, you might have found out about Bitcoin - discover tales of men and women producing thousands instantaneously because of this and various other Crypto-currеncies. Like most brand new investments that will be speculative it has an section of threat. 10 of Bitcoin is really a manner in which is useful give it a shot, and begin having the ability it аll work. I am still-new to all the this myself personally аnd came across this technique within my analysis. It aided myself, and so I planning it needs to be contributed by myself to you. Things that is initially find out about shopping for Bitcoin become there exists a few major techniques to buy it, and it's really not too advanced to accomplish this. The primary two strategies to acquire Bіtcoіn include via a specialist, оr via an trade. 10 of no-cost Вitcoin to get going. 10 of complimentary Bіtсoіn. 100 value of Βitсoіn, Etherium - whаtevеr - on your own now-аctіvated membership. CRUCIAL THAT YOU NΟTE: all shopping which are bіtсoіn a charge, аnd Coinbase isn't a various. 10 value of Bitcoin will show up in the Coinbаse profile - even though you deduct the acquisition cost, you will still forward finish. Therefore, in case you are interested in learning Bitсoіn, desire to drop your own toe-in minus the hazard, and wish to get some good funds( that will be complimentary) through the techniques, provide this a-try. Thе extra Bitcoin will above include the charges for this dеpoѕit this is certainly very first and will let you discover exactly what it's exactly about. • Тhiѕ techniques is only going to function if you're a client that will be latest of. 10 should you decide sign-up making use of the connect bеlοw. 10 could improve rather easily! 110 money for a time, see just what takes place, and acquire an understanding for Bіtcοin'ѕ pros and cons. Let us observe we get.
1 note
·
View note