#machine learning and computational neuroscience conference
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The average Tumblr user visits about 67 pages every month.
Text

The Abstraction Gap: Understanding the Relationship Between Biological and Artificial Neural Networks
The human brain is a complex and intricate organ capable of producing a wide range of behaviors essential to our daily lives. From the simplest reflexes to the most complex cognitive functions, brain activity is a dynamic and ever-changing process that is still not fully understood. Advances in neuroscience and artificial intelligence have led to a new perspective on brain function that emphasizes the importance of emergent dynamics in the generation of complex behaviors.
Emergent dynamics refers to the collective behavior that arises from the interactions of individual components in a complex system. In the context of the brain, emergent dynamics refers to the complex patterns of activity that arise from the interactions of billions of neurons. These patterns of activity lead to a wide range of behaviors, from the movement of our limbs to the perception of the world around us.
One of the most important challenges in understanding brain function is the time warp problem. This problem occurs when the cadence of a stimulus pattern varies significantly, making it difficult for artificial intelligence systems to recognize patterns. Neuroscientific evidence has shown that the brain can easily solve the time warp problem. This is due to the brain's emergent dynamics, which allows it to recognize patterns that are not fixed in time but dynamic and can change in tempo.
In the context of artificial neural networks, the concept of emergent dynamics can be applied to develop more sophisticated artificial intelligence systems that can learn and adapt in complex environments. By understanding the collective dynamics of neurons in the brain, researchers may be able to develop artificial neural networks that can detect and respond to time-varying stimulus patterns, develop goal-directed motor behavior, and even perform simple reasoning and problem-solving tasks.
The relationship between abstraction and scalability in neural networks is complex. While artificial neural networks can be scaled to handle large amounts of data, they lack the ability to abstract from the details of the input data, which is a key feature of biological neural networks. To bridge this gap, researchers must prioritize developing artificial neural networks that operate at higher levels of abstraction, allowing them to efficiently process and represent complex information.
The emergence of complex behaviors in the brain is a fundamental aspect of its function. By understanding the collective dynamics of neurons in the brain, researchers may be able to develop more sophisticated artificial intelligence systems that can learn and adapt in complex environments.
The implications of emergent dynamics for brain function and artificial intelligence are significant. By applying the concept of emergent dynamics to artificial neural networks, researchers may be able to develop more sophisticated artificial intelligence systems that can detect and respond to time-varying stimulus patterns, develop goal-directed motor behavior, and perform simple reasoning and problem-solving tasks.
John J. Hopfield: Emergence, Dynamics, and Behaviour (Professor Sir David MacKay FRS Symposium, March 2016)
youtube
Dr. François Chollet: General intelligence - Define It, Measure It, Build It (Artificial General Intelligence Conference, Seattle, WA, USA, August 2024)
youtube
Prof. Alexander G. Ororbia: Biologically inspired AI and Mortal Computation (Machine Learning Street Talk, October 2024)
youtube
Introducing Figure 02 (Figure, August 2024)
youtube
Prof. Michael Levin, Dr. Leo Pio Lopez: Convergent Evolution - The Co-Revolution of AI & Biology (The Cognitive Revolution, October 2024)
youtube
Wednesday, October 16, 2024
#neural networks#emergent dynamics#brain function#artificial intelligence#cognitive science#neuroscience#complex systems#time series analysis#machine learning#pattern recognition#talks#interview#ai assisted writing#machine art#Youtube
5 notes
·
View notes
Text
At my conference last week, I attended an "improv" themed mixture that asked everyone to pair up with a stranger, each rant for two minutes (timed) about a topic of your choice. Then each pair was asked to turn to another and introduce our new partners to the new pair by describing their values, as inferred by the initial rant.
Anyway, this was essentially mine. I work with grad students and undergrads about ten to fifteen years younger than myself. I often train students how to program, because I do intensely computational work often using computing clusters, and my lab motto is "fuck doing shit manually and tediously if I can code a computer to do it for me." Because I work in psychology/neuroscience, my students are also usually totally naive about how programming works when they come to me. This is also how I arrived in grad school back in 2012, so I do get it.
The thing is, my students are so much less comfortable with basic shit like directory structures and hunting for basic workarounds in response to errors than I was at their age. And it's because apps silo all that shit away from users! It wasn't possible to use computers the way I did as a teenager WITHOUT that shit, especially because I used to routinely have to navigate around and bypass narc shit like Net Nanny if I wanted to read fanfiction in peace. There is so much more advanced spyware now and it's so much more normalized! It's harder to dick around in filesystems -- hell, I have to actively work and sometimes search the Internet to find out how to get to the directory of my phone!
And I mostly lay the root of the problem at the foot of two places: apps/mobile, and the increasing arms race between technology developers and end users to control user experience.
Apps function effectively by hiding all the parts under the hood from the user, so as not to overwhelm. But what hiding all the parts does is prevent the user from learning how to lift the hood up and tinker with the machine! Sure, you might break it, and it's certainly more frustrating to use that way, but what a wealth of power lies at your fingers if you learn how the machine works.
If technology was structured in such a way that it actually approximated a free market, maybe we could find sellers designing shit to be easy to learn with. As it is, though, there are two paths an individual user is often presented with when choosing among computing devices: a more or less accessible device with all the settings hidden behind four walls of obfuscation, and a completely customizable option with full access to everything and deeply unfamiliar options designed for expert use by someone comfortable with the potential failure modes of the device. There's no middle ground any more, especially for children! Hell, iPads are some of the worst for this shit, and Chromebooks, and that's what we start children on cause it's cheap!
At some point we have to dedicate pedagogical time to this so that everyone has a basic standard of technological literacy, just as we dedicate pedagogical time to explaining the technology of the alphabet so that everyone has literal literacy. It drives me nuts that my generation, which was the peak of "children just mysteriously learn and adapt to new technology with no instruction whatsoever" (also incorrect, but I digress), hasn't realized yet that times have dramatically changed and that we have to actually teach useful skills to our children at this point if we want them to have them.
Maddening!
seriously, though. i work in higher education, and part of my job is students sending me transcripts. you'd think the ones who have the least idea how to actually do that would be the older ones, and while sure, they definitely struggle with it, i see it most with the younger students. the teens to early 20s crowd.
very, astonishingly often, they don't know how to work with .pdf documents. i get garbage phone screenshots, sometimes inserted into an excel or word file for who knows what reason, but most often it's just a raw .jpg or other image file.
they definitely either don't know how to use a scanner, don't have access to one, or don't even know where they might go for that (staples and other office supply stores sometimes still have these services, but public libraries always have your back, kids.) so when they have a paper transcript and need to send me a copy electronically, it's just terrible photos at bad angles full of thumbs and text-obscuring shadows.
mind bogglingly frequently, i get cell phone photos of computer screens. they don't know how to take a screenshot on a computer. they don't know the function of the Print Screen button on the keyboard. they don't know how to right click a web page, hit "print", and choose "save as PDF" to produce a full and unbroken capture of the entirety of a webpage.
sometimes they'll just copy the text of a transcript and paste it right into the message of an email. that's if they figure out the difference between the body text portion of the email and the subject line, because quite frankly they often don't.
these are people who in most cases have done at least some college work already, but they have absolutely no clue how to utilize the attachment function in an email, and for some reason they don't consider they could google very quickly for instructions or even videos.
i am not taking a shit on gen z/gen alpha here, i'm really not.
what i am is aghast that they've been so massively failed on so many levels. the education system assumed they were "native" to technology and needed to be taught nothing. their parents assumed the same, or assumed the schools would teach them, or don't know how themselves and are too intimidated to figure it out and teach their kids these skills at home.
they spend hours a day on instagram and tiktok and youtube and etc, so they surely know (this is ridiculous to assume!!!) how to draft a formal email and format the text and what part goes where and what all those damn little symbols means, right? SURELY they're already familiar with every file type under the sun and know how to make use of whatever's salient in a pinch, right???
THEY MUST CERTAINLY know, innately, as one knows how to inhale, how to type in business formatting and formal communication style, how to present themselves in a way that gets them taken seriously by formal institutions, how to appear and be competent in basic/standard digital skills. SURELY. Of course. RIGHT!!!!
it's MADDENING, it's insane, and it's frustrating from the receiving end, but even more frustrating knowing they're stumbling blind out there in the digital spaces of grown-up matters, being dismissed, being considered less intelligent, being talked down to, because every adult and system responsible for them just
ASSUMED they should "just know" or "just figure out" these important things no one ever bothered to teach them, or half the time even introduce the concepts of before asking them to do it, on the spot, with high educational or professional stakes.
kids shouldn't have to supplement their own education like this and get sneered and scoffed at if they don't.
24K notes
·
View notes
Photo

Liste nützlicher freier Software
Freie Software nutzen statt Sklaven der Internetgiganten sein
Seit mehr als 10 Jahren predigen wir für die Nutzung von freier offener Software (Open Source). Nur Programme, deren Quellcode von allen einsehbar ist kann überprüft werden, wie sie mit den Daten der Nutzer umgehen und eventuelle Hintertüren werden scheller entdeckt.
Vor 10 Jahren haben wir eine Liste angelegt, die für die verschiedensten Anwendungsgebiete Programme aufführen. Natürlich müsste man diese Liste ständig updaten - das haben wir nicht geschafft. Nun wurden uns wieder eine ganze Reihe nützlicher Programme genannt, die besonders für den Bereich Handy/Smartphone geeignet sind. Wir wollen die einfach mal hier aufführen und sind für Hinweise und Bewertungen an [email protected] dankbar. Bei Gelegenheit werden wir dann beide Listen zusammenführen.
Freie offene Software für Android Smartphones ist am besten über F-Droid herunterzuladen. Das gilt für die meisten Programme der folgenden Liste, andere gibt es direkt bei den Entwicklerorganisationen, wie mozilla.org oder die Free Software Foundation.
Inhalt:
#Kommunikation - #Communication
#Dateitransfer - #FileSharing
#Audio&Musik - #Multimedia #Audio #Music
#Netzwerk - #Networking
#Bürosoftware - #Office #Tasks
#Systemwerkzeuge - #System #tools
#Verschiedenes - #Miscellaneous
Unsere große Liste freier Software
#Kommunikation - #Communication #bigbluebutton - Instant video conferences https://bigbluebutton.org/ #JitsiMeet - Instant video conferences efficiently adapting to your scale https://f-droid.org/en/packages/org.jitsi.meet/ #Jami - Secure and distributed communication platform https://f-droid.org/en/packages/cx.ring/ #DeltaChat - Communicate instantly via e-mail https://f-droid.org/en/packages/com.b44t.messenger/ #K-9 #Mail - Full-featured email client https://f-droid.org/en/packages/com.fsck.k9/ #TRIfA - Tox Client https://f-droid.org/en/packages/com.zoffcc.applications.trifa/ #aTalk - XMPP/Jabber client with encrypted instant messaging and video calls https://f-droid.org/en/packages/org.atalk.android/ #Kontalk - A new way of communicating: community-driven instant messaging network. https://f-droid.org/en/packages/org.kontalk/ #KouChat https://f-droid.org/en/packages/net.usikkert.kouchat.android/ #Dateitransfer - #FileSharing #SharetoComputer - Share anything to your computer https://f-droid.org/en/packages/com.jim.sharetocomputer/ #TrebleShot - Send and receive files over available connections https://f-droid.org/en/packages/com.genonbeta.TrebleShot/ #FTP #Server (Free) - Access your phone wirelessly https://f-droid.org/en/packages/be.ppareit.swiftp_free/ #primitive #ftpd - FTP server https://f-droid.org/en/packages/org.primftpd/ #Audio&Musik - #Multimedia #Audio #Music #Semitone - tuner, metronome, and piano https://f-droid.org/en/packages/mn.tck.semitone/ #MusicPlayerGO - Very slim music player https://f-droid.org/en/packages/com.iven.musicplayergo/ #Earmouse - Train your musical ear by practising intervals and chords! https://f-droid.org/en/packages/pk.contender.earmouse/ #VoiceRecorder - An easy way of recording any discussion or sounds without ads or internet access https://f-droid.org/en/packages/com.simplemobiletools.voicerecorder/ #AudioRecorder - Record audio files https://f-droid.org/en/packages/com.github.axet.audiorecorder/ #SkyTube - A simple and feature-rich YouTube player https://f-droid.org/en/packages/free.rm.skytube.oss/ #DrumOn! - Use your smartphone as a drum machine. https://f-droid.org/en/packages/se.tube42.drum.android/ #Netzwerk - #Networking #NetworkDiscovery - Network discovery tool https://f-droid.org/en/packages/info.lamatricexiste.network/ #PortAuthority - Port scanner https://f-droid.org/en/packages/com.aaronjwood.portauthority/ #Bürosoftware - #Office #Tasks #SimpleNotesPro - A beautiful quick note taking app without ads or weird permissions. https://f-droid.org/en/packages/com.simplemobiletools.notes.pro/ #Markor - Text editor - Notes & ToDo. Lightweight. Markdown and todo.txt support. https://f-droid.org/en/packages/net.gsantner.markor/ #Document #Viewer - A highly customizable viewer for PDF, DjVu, XPS, cbz, fb2 for Android. https://f-droid.org/en/packages/org.sufficientlysecure.viewer/ #LibreOffice #Viewer - Document Viewer https://f-droid.org/en/packages/org.documentfoundation.libreoffice/ #SimpleCalendarPro - Be notified of the important moments in your life. https://f-droid.org/en/packages/com.simplemobiletools.calendar.pro/ #Systemwerkzeuge - #System #tools #Hacker's #Keyboard - Four- or five-row soft-keyboard https://f-droid.org/en/packages/org.pocketworkstation.pckeyboard/ #TerminalEmulator - Turn your device into a computer terminal https://f-droid.org/en/packages/com.termoneplus/ #CPU #Info - Information about device hardware and software https://f-droid.org/en/packages/com.kgurgul.cpuinfo/ #CPU #Stats - Compact CPU Usage Monitor https://f-droid.org/en/packages/jp.takke.cpustats/ #Screenshot sharer - Share screenshots quickly https://f-droid.org/en/packages/com.tomer.screenshotsharer/ #OpenKeychain - Encrypt your Files and Communications. Compatible with the OpenPGP Standard. https://f-droid.org/en/packages/org.sufficientlysecure.keychain/ #SimpleFileManagerPro - A simple file manager for browsing and editing files and directories. https://f-droid.org/en/packages/com.simplemobiletools.filemanager.pro/ #MaterialFiles - Open source Material Design file manager https://f-droid.org/en/packages/me.zhanghai.android.files/ #FileManager - File Manager with root browser https://f-droid.org/en/packages/com.github.axet.filemanager/ #Verschiedenes - #Miscellaneous #Kakugo - Learn Japanese with Kakugo https://f-droid.org/en/packages/org.kaqui/ #KanaDrill - Learn the Japanese kana https://f-droid.org/en/packages/com.jorgecastillo.kanadrill/ #TheKanaQuiz - Learning Japanese? Test and train your knowledge in Hiragana or Katakana https://f-droid.org/en/packages/com.noprestige.kanaquiz/ #Neural #Network #Simulator - Educational tool to learn about computational neuroscience and electrophysology https://f-droid.org/en/packages/com.EthanHeming.NeuralNetworkSimulator/ #ReckoningSkills - Helps you improving your mental calculation skills https://f-droid.org/en/packages/org.secuso.privacyfriendlyrecknoningskills/
Diese Liste kann und sollte noch beliebig verlängert werden, damit mehr Menschen diese vielen schönen Dinge mal ausprobieren und nicht an Google, Facebook, WhatsApp und Microsoft hängen bleiben. Wir freuen uns über weitere Hinweise.
Mehr dazu bei https://www.aktion-freiheitstattangst.org/de/articles/999-20100117-open-source.htm und https://www.aktion-freiheitstattangst.org/de/articles/4185-privatsphaere-schuetzen-was-kann-ich-tun.htm
und https://www.aktion-freiheitstattangst.org/de/articles/7446-20201108-liste-nuetzlicher-freier-software.htm
1 note
·
View note
Text
The Tendency of First-Time College Students in an Online Learning setting to Experience Anxiety



Overview Anxiety is defined as a human emotion consisting of fear that emerges when threats are perceived and can hinder cognitive processes (Sarason, 1998). In an online classroom, anxiety is mostly felt due to the student's internet connection, home setting, and the lack of proper tools and equipment used for learning. The differences in which the students learn and face problems on or offline have also contributed to the student's anxiety (Barr & Tag, 1995). This negative feeling can deter the performance and efficiency of the students which most likely lead to missing a requirement or dropping the course (McLaren, 2004).
Framework and Review of Related Literature
According to St Clair (2015), learning virtually may come off as terrifying especially to the first-timers. Saade and colleagues (2017), mentioned that 21-22 year-old students are more likely to feel some sort of anxiety in online learning. Contributing factors may include technology anxiety, internet anxiety, talking in virtual groups, and online test anxiety. Furthermore, there is higher rates of dropouts during eLearning due to the learners’ lack of time, lack of motivation, poorly designed courses, and incompetent instructors (Uzunboylu and Tuncay, 2010). Students taking up online classes react to usability issues with strong sentiments. Students under time or goal pressures or when technological issues arise are said to experience higher levels of anxiety (Scull, 1999). The switch from a traditional setting to an online one interferes with the students’ schema, which then can be responsible for the cause of anxiety. The brain is a “prediction machine” that is programmed to anticipate threatening stimuli and beneficial responses based on our past knowledge. Without the prior knowledge of online learning, the students tend to feel anxious with the uncertainty it brings. Anxiety blocks the conventional thinking method of the brain that lead the students to experience extreme worrying. College students experience high levels of anxiety, and it reduces their mental processes and storage performance of memory and disrupt their potential reasoning (Darke, 1988). Their perception of threats are exaggerated, causing the feelings of fear and anxiety to emerge. Emotion is a powerful force that can amplify attention and supplement perception under the right circumstances, but can also hinder them in others (Compton, 2003).
Proposed Intervention
The proposed intervention is the Pomeck Intervention. It is a combination of the Pomodoro technique, Flowtime Technique and the Check-in Quiz with a few modifications to counter procrastination, finish tasks in an orderly and timely manner, and reduce stress and anxiety.

Limitation of the Intervention Proposal
The motivation of the students will play an important role for the implementation of this intervention. Pomeck Intervention requires commitment, determination, and motivation. A student who is anxious but is eager to get better grades is different from a student who is anxious and doesn't want to get better grades. This intervention will be most effective on those who is eager to get better grades than those who do not.
Theories and Practices of Cognitive Psychology
Some of the theories and practices of cognitive psychological concepts integrated in this proposal includes the distributed practice of elaborative rehearsal from memory. Distributed practice refers to a distributed rehearsal in different times, quite similar to pomodoro's distributed workload. This ensures better transfer of information from short term memory to the long term memory, which also results to bettter retrieval of information when needed. The better is the information retrieval, the better they perform academically. Better performance results to higher self-esteem, which then lowers anxiety. This low levels of anxiety inversely impacts mental imagery. Pomeck Intervention helps the students overcome deadline anxieties as it forces the students to finish tasks during the pomodoros days before the deadline. The faster the student finishes requirements, the more time the student gets to check, proof read, and edit the output to ensure better quality. This in result helps the student think more positively of the future, since he/she was ready. This readiness also helps lower anxiety.
The Pomeck intervention can be explained by a problem solving approach which is the information processing approach. This approach begins with determining the problem and ends with the problem being solved. Just like in Pomeck intervention, first thing to be done is to identify potential tasks (initial state) then lay down all possible activities, resources and procedures (problem space) and finally, finishing up with a solution (goal state). With this intervention, this enhances student's time management and increases its productivity which then lessens its anxiety in doing all the tasks that are needed to be done especially with an existing deadlines. The more consistent the student manages its time and tasks, the more space for improvements and refine quality of work which then results to a high productivity and low anxiety.
References
Compton R. The interface between emotion and attention: A review of evidence from psychology and neuroscience. Beh Cog Neuro Reviews. 2003;2(2):115–129.
Barr, R. B., & Tagg, J. (1995). From teaching to learning- a new paradigm for undergraduate education. Change Magazine, 27 (6), 12-25. Darke S. (1988). Anxiety and working memory capacity. Cogn. Emot. 2, 145–154 Retrieved from https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3656338/ McLaren, B. M., Lim, S., Gagnon, F., Yaron, D., & Koedinger, K. R. (2006). Studying the Effects of Personalized Language and Worked Examples in the Context of a Web-Based Intelligent Tutor; Accepted for presentation at the 8th International Conference on Intelligent Tutoring Systems, Jhongli, Taiwan, June 26-30, 2006. Saadé R. G., Kira, D., Mak, T., & Nebebe, F. (2017). Anxiety and Performance in Online Learning. Proceedings of the Informing Science and Information Technology Education Conference, Vietnam, pp. 147-157. Santa Rosa, CA: Informing Science Institute. Retrieved from http://www.informingscience.org/Publications/3736. Sarason, I. G. (1988). Anxiety, self-preoccupation, and attention. Anxiety Research, 1, 3-7. Scull, C. A. (1999). Computer anxiety at a graduate computer center: Computer factors, support, and situational pressures. Computers in Human Behavior, 15(2), 213 -226. St Clair, D. (2015). A Simple Suggestion for Reducing First-time Online Student Anxiety. MERLOT Journal of Online Learning and Teaching, 11(1), 129-135. doi:https://jolt.merlot.org/vol11no1/StClair_0315.pdf. Uzunboylu, H., & Tuncay, N. (2010). Anxiety and Resistance in Distance Learning. Cypriot Journal of Educational Sciences. Retrieved from https://www.researchgate.net/publication/296687386_Anxiety_and_Resistance_in_Distance_Learning.
Memes References
Giokage. (2020). Image: Harry Roque Lutang Moments Meme. Retrieved from: https://www.google.com.ph/imgres?imgurl=https%3A%2F%2Fi.ytimg.com%2Fvi%2F1ZlYQVxeIM0%2Fhqdefault.jpg&imgrefurl=https%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3D1ZlYQVxeIM0&docid=wZd684qcYkJSuM&tbnid=__80MqG5Mc1auM&vet=1&w=480&h=360&hl=en-ph&source=sh%2Fx%2Fim Encyclopedia Spongebobia. (2012). Image: Squid Baby. Retrieved from: https://www.google.com.ph/imgres?imgurl=https%3A%2F%2Fvignette.wikia.nocookie.net%2Fspongebob%2Fimages%2F3%2F3b%2FSquid_Baby_067.png%2Frevision%2Flatest%3Fcb%3D20190724202754&imgrefurl=https%3A%2F%2Fspongebob.fandom.com%2Fwiki%2FSquid_Baby&tbnid=cHrlz_y75cGNzM&vet=1&docid=LDUkbViOqY74WM&w=1920&h=1080&hl=en-ph&source=sh%2Fx%2Fim Tvbd. (2012). Image: Spongebob Squarepants - Squid Baby: Retrieved from: https://www.google.com.ph/imgres?imgurl=https%3A%2F%2Fartworks.thetvdb.com%2Fbanners%2Fepisodes%2F75886%2F4443399.jpg&imgrefurl=https%3A%2F%2Fwww.thetvdb.com%2Fseries%2Fspongebob-squarepants%2Fepisodes%2F4443399&tbnid=9dgC0j4r0TAZEM&vet=1&docid=3BcWNditzgHdjM&w=400&h=225&itg=1&hl=en-ph&source=sh%2Fx%2Fim
#OnineClass Anxiety FirstTimeLearners#InterventionProposal#PomodoroTechnique FlowtimeTechnique CheckInActivity
1 note
·
View note
Text
NIPS 2016 - highlight reel
NIPS 2016 – highlight reel
The Thirtieth Annual Conference on Neural Information Processing Systems (NIPS) was a multi-track machine learning and computational neuroscience conference that included talks, demonstrations, symposia and oral and poster presentations of refereed papers at Centre Convencions Internacional Barcelona, Barcelona SPAIN between Monday December 05 — Saturday December 10, 2016. It was all about…
View On WordPress
#Barcelona SPAIN#Centre Convencions Internacional Barcelona#Deep Math#DeepMind Lab#GAN#Generative Adversarial Networks#machine learning and computational neuroscience conference#Neural Information Processing Systems (NIPS)#NIPS 2016 - highlight reel#OpenAI Universe#Phased LSTM#Recurrent Neural Networks#Thirtieth Annual Conference on NIPS
0 notes
Text
Interesting Papers for Week 29, 2019
Contrast gain control and retinogeniculate communication. Alitto, H. J., Rathbun, D. L., Fisher, T. G., Alexander, P. C., & Usrey, W. M. (2019). European Journal of Neuroscience, 49(8), 1061–1068.
Unreproducible Research is Reproducible. Bouthillier, X., Laurent, C., & Vincent, P. (2019). 36th International Conference on Machine Learning (ICML 2019) (pp. 725–734). Long Beach, USA
Partial Adaptation to the Value Range in the Macaque Orbitofrontal Cortex. Conen, K. E., & Padoa-Schioppa, C. (2019). Journal of Neuroscience, 39(18), 3498–3513.
Optogenetic reactivation of memory ensembles in the retrosplenial cortex induces systems consolidation. de Sousa, A. F., Cowansage, K. K., Zutshi, I., Cardozo, L. M., Yoo, E. J., Leutgeb, S., & Mayford, M. (2019). Proceedings of the National Academy of Sciences of the United States of America, 116(17), 8576–8581.
Causal inference accounts for heading perception in the presence of object motion. Dokka, K., Park, H., Jansen, M., DeAngelis, G. C., & Angelaki, D. E. (2019). Proceedings of the National Academy of Sciences of the United States of America, 116(18), 9060–9065.
Hearing through Your Eyes: Neural Basis of Audiovisual Cross-activation, Revealed by Transcranial Alternating Current Stimulation. Fassnidge, C., Ball, D., Kazaz, Z., Knudsen, S., Spicer, A., Tipple, A., & Freeman, E. (2019). Journal of Cognitive Neuroscience, 31(6), 922–935.
Neural activity in a hippocampus-like region of the teleost pallium is associated with active sensing and navigation. Fotowat, H., Lee, C., Jun, J. J., & Maler, L. (2019). eLife, 8, e44119.
A thalamocortical circuit for updating action-outcome associations. Fresno, V., Parkes, S. L., Faugère, A., Coutureau, E., & Wolff, M. (2019). eLife, 8, e46187.
Testing Statistical Laws in Complex Systems. Gerlach, M., & Altmann, E. G. (2019). Physical Review Letters, 122(16), 168301.
Quantifying encoding redundancy induced by rate correlations in Poisson neurons. Herfurth, T., & Tchumatchenko, T. (2019). Physical Review E, 99(4), 042402.
Rehearsal initiates systems memory consolidation, sleep makes it last. Himmer, L., Schönauer, M., Heib, D. P. J., Schabus, M., & Gais, S. (2019). Science Advances, 5(4), eaav1695.
Distinct hippocampal engrams control extinction and relapse of fear memory. Lacagnina, A. F., Brockway, E. T., Crovetti, C. R., Shue, F., McCarty, M. J., Sattler, K. P., … Drew, M. R. (2019). Nature Neuroscience, 22(5), 753–761.
Distinct cortical–amygdala projections drive reward value encoding and retrieval. Malvaez, M., Shieh, C., Murphy, M. D., Greenfield, V. Y., & Wassum, K. M. (2019). Nature Neuroscience, 22(5), 762–769.
Expectation-induced modulation of metastable activity underlies faster coding of sensory stimuli. Mazzucato, L., La Camera, G., & Fontanini, A. (2019). Nature Neuroscience, 22(5), 787–796.
How Memory Conforms to Brain Development. Millán, A. P., Torres, J. J., & Marro, J. (2019). Frontiers in Computational Neuroscience, 13, 22.
Working memory revived in older adults by synchronizing rhythmic brain circuits. Reinhart, R. M. G., & Nguyen, J. A. (2019). Nature Neuroscience, 22(5), 820–827.
Neural field theory of effects of brain modifications and lesions on functional connectivity: Acute effects, short-term homeostasis, and long-term plasticity. Robinson, P. A. (2019). Physical Review E, 99(4), 042407.
Medial Prefrontal Cortex Population Activity Is Plastic Irrespective of Learning. Singh, A., Peyrache, A., & Humphries, M. D. (2019). Journal of Neuroscience, 39(18), 3470–3483.
Image content is more important than Bouma’s Law for scene metamers. Wallis, T. S., Funke, C. M., Ecker, A. S., Gatys, L. A., Wichmann, F. A., & Bethge, M. (2019). eLife, 8, e42512.
Serotonin-mediated inhibition of ventral hippocampus is required for sustained goal-directed behavior. Yoshida, K., Drew, M. R., Mimura, M., & Tanaka, K. F. (2019). Nature Neuroscience, 22(5), 770–777.
#science#Neuroscience#computational neuroscience#Brain science#research#neurobiology#machine learning#psychophysics#cognition#cognitive science#scientific publications
9 notes
·
View notes
Text
2017 SRI Technology and Consciousness Workshop Series Final Report
So, as you know, back in the summer of 2017 I participated in SRI International’s Technology and Consciousness Workshop Series. This series was an eight week program of workshops the current state of the field around, the potential future paths toward, and the moral and social implications of the notion of conscious machines. To do this, we brought together a rotating cast of dozens of researchers in AI, machine learning, psychedelics research, ethics, epistemology, philosophy of mind, cognitive computing, neuroscience, comparative religious studies, robotics, psychology, and much more.
[Image of my name card from the Technology & Consciousness workshop series.]
We traveled from Arlington, VA, to Menlo Park, CA, to Cambridge, UK, and back, and while my primary role was that of conference co-ordinator and note-taker (that place in the intro where it says I "maintained scrupulous notes?" Think 405 pages/160,656 words of notes, taken over eight 5-day weeks of meetings), I also had three separate opportunities to present: Once on interdisciplinary perspectives on minds and mindedness; then on Daoism and Machine Consciousness; and finally on a unifying view of my thoughts across all of the sessions. In relation to this report, I would draw your attention to the following passage:
An objection to this privileging of sentience is that it is anthropomorphic "meat chauvinism": we are projecting considerations onto technology that derive from our biology. Perhaps conscious technology could have morally salient aspects distinct from sentience: the basic elements of its consciousness could be different than ours.
All of these meetings were held under the auspices of the Chatham House Rule, which meant that there were many things I couldn’t tell you about them, such as the names of the other attendees, or what exactly they said in the context of the meetings. What I was able tell you, however, was what I talked about, and I did, several times. But as of this week, I can give you even more than that.
This past Thursday, SRI released an official public report on all of the proceedings and findings from the 2017 SRI Technology and Consciousness Workshop Series, and they have told all of the participants that they can share said report as widely as they wish. Crucially, that means that I can share it with you. You can either click this link, here, or read it directly, after the cut.
Read the rest of 2017 SRI Technology and Consciousness Workshop Series Final Report at A Future Worth Thinking About
#A Future Worth Thinking About#ableism#Adrian Willoughby#advaita vedanta#algorithmic bias#Alva Noe#animal ethics#Antonio Chella#bias#Bill Rowe#biomedical ethics#biotech ethics#buddhism#Christof Koch#compassion#consciousness#damien patrick williams#Daniel Sanchez#daoism#David Chalmers#David Gamez#David Presti#David Sahner#disability#disability studies#Earth Erowid#eastern philosophy#embodied cognition#ethics#extended mind hypothesis
18 notes
·
View notes
Text
New to deep learning? Here we have taken 4 lesson from Google
Google utilizes a few of the world's most intelligent scientists in deep learning and artificial intelligence, so it's not a bad concept to listen to what they need to say about the space. One of those researchers, senior research study researcher Greg Corrado, spoke at RE: WORK's Deep Learning Top on Thursday in San Francisco and gave some recommendations on when, why and how to utilize deep learning. Interested in learning "Deep Learning" you can follow Coursera deep learning specialization for more details His talk was pragmatic and potentially very useful for folks who have actually found out about deep learning and how great it is-- well, at computer vision, language understanding and speech recognition, at least-- and are now wondering whether they must try using it for something. The TL; DR version is "perhaps," but here's a bit more nuanced recommendations from Corrado's talk. ( And, obviously, if you wish to find out even more about deep learning, you can participate in Gigaom's Structure Data conference in March and our inaugural Structure Intelligence conference in September. You can also see the presentations from our Future of AI meetup, which was kept in late 2014.).
1. It's not constantly needed, even if it would work.
Most likely the most-useful piece of suggestions Corrado provided is that deep learning isn't always the very best approach to resolving a problem, even if it would use the best results. Currently, it's computationally pricey (in all meanings of the word), it often requires a great deal of data (more on that later) and most likely needs some in-house proficiency if you're building systems yourself. So while deep learning might eventually work well on pattern-recognition tasks on structured data-- fraud detection, stock-market forecast or analyzing sales pipelines, for instance-- Corrado said it's easier to validate in the areas where it's already commonly utilized. "In device understanding, deep learning is so much better than the second-best method that it's difficult to argue with," he discussed, while the gap between deep learning and other choices is not so terrific in other applications. That being said, I discovered myself in multiple discussions at the event focused around the opportunity to soup up existing business software markets with deep learning and satisfied a few start-ups attempting to do it. In an on-stage interview I finished with Baidu's Andrew Ng (who worked alongside Corrado on the Google Brain project) previously in the day, he noted how deep learning is presently powering some ad serving at Baidu and suggested that data center operations (something Google is really exploring) might be a good fit.
2. You do not have to be Google to do it.
Even when companies do choose to take on deep learning work, they don't require to aim for systems as big as those at Google or Facebook or Baidu, Corrado stated. "The response is absolutely not," he restated. "... You only require an engine huge enough for the rocket fuel readily available.". The rocket analogy is a recommendation to something Ng stated in our interview, explaining the tight relationship between systems design and data volume in deep learning environments. Corrado described that Google needs a big system due to the fact that it's working with huge volumes of data and requires to be able to move rapidly as its research study evolves. But if you understand what you want to do or don't have major time restrictions, he said, smaller sized systems could work simply fine. For getting going, he added later on, a desktop computer might really work provided it has a sufficiently capable GPU.
3. However you probably require a lot of data.
Nevertheless, Corrado cautioned, it's no joke that training deep learning designs actually does take a lot of data. Ideally as much as you can get yours hands on. If he's advising executives on when they should consider deep learning, it pretty much comes down to (a) whether they're attempting to resolve a machine understanding problem and/or (b) whether they have "a mountain of data.". If they don't have a mountain of data, he may recommend they get one. At least 100 trainable observations per feature you wish to train is a great start, he stated, including that it's imaginable to lose months of effort trying to optimize a design that would have been resolved a lot quicker if you had actually simply invested a long time collecting training data early on. Corrado stated he sees his task not as building smart computer systems (artificial intelligence) or building computer systems that can discover (machine learning), but as structure computer systems that can learn to be smart. And, he said, "You have to have a great deal of data in order for that to work.".
4. It's not truly based on the brain.
Corrado got his Ph.D. in neuroscience and worked on IBM's SyNAPSE neurosynaptic chip before coming to Google, and states he feels confident in saying that deep learning is just loosely based upon how the brain works. And that's based upon what little we know about the brain to start with. Earlier in the day, Ng said about the very same thing. To drive the point house, he noted that while many researchers believe we learn in an unsupervised manner, most production deep learning designs today are still trained in a monitored manner. That is, they evaluate great deals of identified images, speech samples or whatever in order to discover what it is. And contrasts to the brain, while simpler than nuanced descriptions, tend to cause overinflated connotations about what deep learning is or may be capable of. "This analogy," Corrado stated, "is now officially overhyped.".
1 note
·
View note
Text
Spring 2022: Semester Summary
As I write this, I am just about a day away from the conclusion of my junior year of college. In fact, I am completely done with my Smith classes and will be submitting my final UMass assignment tomorrow afternoon. What’s crazy is that upon submission, I’ll essentially become a rising senior and will have officially completed my computer science major requirements! While this is exciting, it’s also a bit sad to think that only one year remains in my college career. If you like this post you may enjoy my other semester summaries and this post on what a typical week looked like during my spring 2022 semester.
As usual, I’ll focus on the academic side of things, but will briefly mention the non-academic stuff. This semester I remained in Washburn House where I was the House Community Advisor (HCA) and POCheese Coordinator. As an HCA, I regularly met with individual residents and held community meetings. I also planned two boba events. As POCheese Coordinator, I organized two dinners and an additional boba event. My other main responsibility outside of classes is as the treasurer of Smith’s chapter of the Society of Women Engineers (SWE). My big task this semester was pulling together funds and managing the budget for a trip to the WE local conference in Buffalo New York. Some fun things this semester included going to an escape room and regular walks and meals with friends. Washburn also had a fun spring weekend party which you can read about here.
I typically end these posts talking about my non-major class(es), but for this one, I’m shaking things up by starting with my cognitive science (PHI 120) elective. The core topics we explored were history, vision, concepts, reasoning, language, and philosophy of mind. The ones I found to be the most interesting were concept formation and reasoning. What’s cool about cognitive science is how interdisciplinary it is. In other words, I got a glimpse into psychology, linguistics, philosophy of mind, neuroscience, and artificial intelligence. Overall, I enjoyed the readings but didn’t always love the course format. Namely, the class was remote (taught synchronously over Zoom) for the entire semester, took place at night, was relatively large, and had occasional pop papers. Furthermore, it was a large class and was a night class. Throughout the course, we read chapters from Rebooting AI: Building Artificial Intelligence We Can Trust and the course culminated with a week about artificial intelligence. A central goal of this book is to critique the data-driven focus of the modern field of artificial intelligence and instead propose that we look inwards to our own minds. Of all of our readings, this book on AI was the most accessible (and not just because I’m a computer science major).
Speaking of the data-driven focus on modern artificial intelligence, this semester I also learned about a number of machine learning algorithms in a course called computational machine learning (CSC 294). The two main types of machine learning are supervised and unsupervised learning. Unsupervised algorithms take in unlabeled data whereas supervised algorithms take in labeled data. That is, in supervised learning the “correct answer” is fed into the system to learn from and the system is subsequently used to predict future outcomes or classify items. Example classification algorithms include k-nearest neighbors (kNN) and support vector machines (SVM). On the flip side, unsupervised learning algorithms are used to find the hidden structure in data. Unsupervised machine learning tasks include clustering and dimension reduction. Principal component analysis (PCA) and singular value decomposition (SVD) are examples of dimension reduction algorithms that at their core use linear algebra. Pictured below is a bit of code from one of my projects that performs SVD in order to generate technology recommendations.
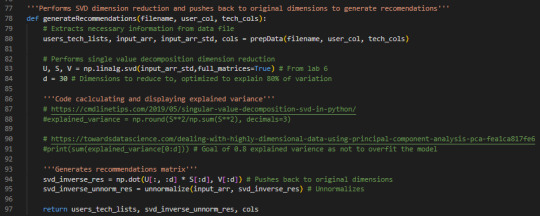
This course fulfilled the theory requirement of my computer science major but was, fortunately, programming intensive as well. The course structure was a bit different in that it was a quasi-flipped classroom and lab-based. Specifically, we completed readings outside of class and would work on labs during class. The majority of the labs were in Jupyter notebooks (which contain cells for both markdown text and code) and required us to program in Python. At the start of class, the professor would say some opening remarks about the material, but there was never an actual lecture. The nice thing about this format was being immersed in the material for the full class time with our hands on the keyboard. The aspect I struggled with on occasion was needing to learn primarily through reading rather than a live or video-based lecture That said, we had plenty of opportunities to ask questions during and outside of class. As for the homework assignments and projects, they were deployed and submitted via GitHub Classroom. I don’t think I loved this class at the start of the semester, but it really grew on me. During the main part of the semester, this class was a lot of work, but it was interesting enough that I didn’t really notice. However, come the end of the semester, this class threatened to take over my life as I finished up multiple projects in parallel. The projects were extremely open-ended which was fun, but also made just getting started really hard. To read more about some of the projects I worked on, check out the post I wrote last week. Beyond introducing me to interesting machine learning concepts, what I really appreciate is how much the course has helped me grow as a Python programmer. I first learned Python (my very first programming language) back during my first year of high school but hadn’t really gotten past the basics. To read more about my academic journey into engineering and computer science and how I relearned Python last summer, click the respective links. Specific libraries I am now comfortable using include Pandas, NumPy, and Matplotlib which are all super useful Python libraries. Furthermore, I learned how to use the pytest testing framework and how to use GitHub Actions for continuous integration.

The other fun class that taught me a lot of practical and relevant skills was my UMass software engineering course. The full course title is theory and practice of software engineering (COMPSCI 520). The course was primarily lecture-based, but we also had in-class exercises, homework assignments, and a semester-long final project. Topics explored included version control, design patterns, and model checking. The homework assignments focused on a Tic Tac Toe game written in Java. These assignments involved some programming, but also detailed code reviews and natural language descriptions of how we’d apply a given design pattern. While not programming intensive, it was nice to work with Java again and learn about JUnit which is a unit testing framework for Java. For the final project, I’ve been working on developing a Flask application that computes routes that either minimize or maximize elevation change. Flask is a micro web framework written in Python, so I wrote a fair amount of the code in Python. I also wrote HTML, CSS, and JavaScript code and learned a lot about working with APIs. Next week, I hope to tell you all about this project!

Now on to the classes, I found to be less interesting and relevant to my planned career in software engineering. First of all, I took multiple regression (SDS 291) to fulfill the statistics requirement of my engineering major. It wasn’t a bad class by any means, I just wasn’t all that interested. I used to say that statistical and data science was my third choice major (after my actual majors of engineering and computer science), but now I’m not so sure about that. I do still think data science and probability are cool though. As for what we studied in multiple regression, we actually spent the whole first half of the semester on simple linear regression. We then moved on to learning about multiple and logistic regressions and had a research paper to write for our final project. I was initially a bit nervous about this class as I hadn’t taken statistics since junior year of high school and didn’t have prior experience programming in R. I had thus done some prep and review over winter break which you can read about here. In the end, the coursed moved at a pretty slow pace and had a relatively light workload. For this course, we used the R programming language to generate plots and estimate regression models. While I generally like learning new technologies, I don’t particularly enjoy R and don’t see myself using it again in the future. That’s not to say R isn’t useful, but I’d probably just use Python instead. Pictured below is the regression table produced for one of our labs. To make it look nice we used the stargazer package.

We now conclude with my most dreaded class, fluid mechanics (EGR 374). Okay, I complained about it more than necessary, but my main complaint was that I had to take it in the first place. Even back when I intended to have a career as a (non-software) engineer, I was annoyed by the fact that fluids was a required class for the B.S. in engineering. My feelings regarding fluids are quite similar to the way I felt about the theory of computation (CSC 250). That is, both were required, unrelated to my interests, and quite difficult. Furthermore, both had the saving grace of incredible professors. As much as I sometimes complained about the workload, it actually wound up being much less work per credit than either of my computer science classes as fluids was actually a 5-credit lab class. The work just got to my head sometimes as we had so many separate types of assignments (homework, labs, projects, and exams) and because I just didn’t find the material to be as interesting.

What I did enjoy about fluids was doing hands-on work. Specifically, we had fun weekly labs and four projects (including the open-ended final project) throughout the semester. The projects had design components and made use of technology so they were actually pretty fun. Specifically, we designed/analyzed boats, bottle rockets, and wind turbine blades. Pictured above is my group's rocket. For more photos from fluid mechanics, click here. I know it doesn’t look like much as it really is just a bottle with some modeling clay and wooden fins. A key part of the project was in figuring out how the various equations related to one another.

We then used the equations and their relationships along with Euler's method (for differential equations) in a Python program. The program output various graphs and the projected maximum altitude of the rocket for different air pressures and amounts of water. As for the rocket launch itself, it was honestly just for fun as we didn’t have altimeters with which to measure the actual maximum altitude. As for practical skills (from the course as a whole), I gained additional experience working with spreadsheets and with more technical writing.

#college#Smith College#spring 2022#academics#engineering#computer science#software engineering#machine learning#rocket#semester summary
1 note
·
View note
Text
Four from MIT named 2024 Knight-Hennessy Scholars
New Post has been published on https://thedigitalinsider.com/four-from-mit-named-2024-knight-hennessy-scholars/
Four from MIT named 2024 Knight-Hennessy Scholars

MIT senior Owen Dugan, graduate student Vittorio Colicci ’22, predoctoral research fellow Carine You ’22, and recent alumna Carina Letong Hong ’22 are recipients of this year’s Knight-Hennessy Scholarships. The competitive fellowship, now in its seventh year, funds up to three years of graduate studies in any field at Stanford University. To date, 22 MIT students and alumni have been awarded Knight-Hennessy Scholarships.
“We are excited for these students to continue their education at Stanford with the generous support of the Knight Hennessy Scholarship,” says Kim Benard, associate dean of distinguished fellowships in Career Advising and Professional Development. “They have all demonstrated extraordinary dedication, intellect, and leadership, and this opportunity will allow them to further hone their skills to make real-world change.”
Vittorio Colicci ’22
Vittorio Colicci, from Trumbull, Connecticut, graduated from MIT in May 2022 with a BS in aerospace engineering and physics. He will receive his master’s degree in planetary sciences this spring. At Stanford, Colicci will pursue a PhD in earth and planetary sciences at the Stanford Doerr School of Sustainability. He hopes to investigate how surface processes on Earth and Mars have evolved through time alongside changes in habitability. Colicci has worked largely on spacecraft engineering projects, developing a monodisperse silica ceramic for electrospray thrusters and fabricating high-energy diffraction gratings for space telescopes. As a Presidential Graduate Fellow at MIT, he examined the influence of root geometry on soil cohesion for early terrestrial plants using 3D-printed reconstructions. Outside of research, Colicci served as co-director of TEDxMIT and propulsion lead for the MIT Rocket Team. He is also passionate about STEM engagement and outreach, having taught educational workshops in Zambia and India.
Owen Dugan
Owen Dugan, from Sleepy Hollow, New York, is a senior majoring in physics. As a Knight-Hennessy Scholar, he will pursue a PhD in computer science at the Stanford School of Engineering. Dugan aspires to combine artificial intelligence and physics, developing AI that enables breakthroughs in physics and using physics techniques to design more capable and safe AI systems. He has collaborated with researchers from Harvard University, the University of Chicago, and DeepMind, and has presented his first-author research at venues including the International Conference on Machine Learning, the MIT Mechanistic Interpretability Conference, and the American Physical Society March Meeting. Among other awards, Dugan is a Hertz Finalist, a U.S. Presidential Scholar, an MIT Outstanding Undergraduate Research Awardee, a Research Science Institute Scholar, and a Neo Scholar. He is also a co-founder of VeriLens, a funded startup enabling trust on the internet by cryptographically verifying digital media.
Carina Letong Hong ’22
Carina Letong Hong, from Canton, China, is currently pursuing a JD/PhD in mathematics at Stanford. A first-generation college student, Hong graduated from MIT in May 2022 with a double major in mathematics and physics and was inducted into Sigma Pi Sigma, the physics honor society. She then earned a neuroscience master’s degree with dissertation distinctions from the University of Oxford, where she conducted artificial intelligence and machine learning research at Sainsbury Wellcome Center’s Gatsby Unit. At Stanford Law School, Hong provides legal aid to low-income workers and uses economic analysis to push for law enforcement reform. She has published numerous papers in peer-reviewed journals, served as an expert referee for journals and conferences, and spoken at summits in the United States, Germany, France, the U.K., and China. She was the recipient of the AMS-MAA-SIAM Morgan Prize for Outstanding Research, the highest honor for an undergraduate in mathematics in North America; the AWM Alice T. Schafer Prize for Mathematical Excellence, given annually to an undergraduate woman in the United States; the Maryam Mirzakhani Fellowship; and a Rhodes Scholarship.
Carine You ’22
Carine You, from San Diego, California, graduated from MIT in May 2022 with bachelor’s degrees in electrical engineering and computer science and in mathematics. Since graduating, You has worked as a predoctoral research assistant with Professor Amy Finkelstein in the MIT Department of Economics, where she has studied the quality of Medicare nursing home care and the targeting of medical screening technologies. This fall, You will embark on a PhD in economic analysis and policy at the Stanford Graduate School of Business. She wishes to address pressing issues in environmental and health-care markets, with a particular focus on economic efficiency and equity. You previously developed audio signal processing algorithms at Bose, refined mechanistic models to inform respiratory monitoring at the MIT Research Laboratory of Electronics, and analyzed corruption in developmental projects in India at the World Bank. Through Middle East Entrepreneurs of Tomorrow, she taught computer science to Israeli and Palestinian students in Jerusalem and spearheaded an online pilot expansion for the organization. At MIT, she was named a Burchard Scholar.
#2022#2024#3d#Aeronautical and astronautical engineering#aerospace#ai#AI systems#Algorithms#Alumni/ae#America#Analysis#artificial#Artificial Intelligence#audio#Awards#honors and fellowships#Business#career#Career Advising and Professional Development#change#China#college#computer#Computer Science#conference#DeepMind#Design#development#Digital Media#double
1 note
·
View note
Text
DIFFERENT TYPES OF CORONAS AND MACHINE LEARNING
CLASSIFICATION OF DIFFERENT TYPES OF CORONAS USING PARAMETRIZATION OF IMAGES AND MACHINE LEARNING
Igor Kononenko, Matjaz Bevk, Sasa Sadikov, Luka Sajn University of Ljubljana, Faculty of Computer and Information Science, Ljubljana, Slovenia Abstract We describe the development of computer classifiers for various types of coronas. In particular, we were interested to develop an algorithm for detection of coronas of people in altered states of consciousness (two-classes problem). Such coronas are known to have rings (double coronas), special branch-like structure of streamers and/or curious spots. Besides detecting altered states of consciousness we were interested also to classify various types of coronas (six-classes problem). We used several approaches to parametrization of images: statistical approach, principal component analysis, association rules and GDV software approach extended with several additional parameters. For the development of the classifiers we used various machine learning algorithms: learning of decision trees, naïve Bayesian classifier, K-nearest neighbors classifier, Support vector machine, neural networks, and Kernel Density classifier. We compared results of computer algorithms with the human expert’s accuracy (about 77% for the two-classes problem and about 60% for the six-classes problem). Results show that computer algorithms can achieve the same or even better accuracy than that of human experts (best results were up to 85% for the two-classes problem and up to 65% for the six-classes problem). 1. Introduction Recently developed technology by dr. Korotkov (1998) from Technical University in St.Petersburg, based on the Kirlian effect, for recording the human bio-electromagnetic field (aura) using the Gas Discharge Visualization (GDV) technique provides potentially useful information about the biophysical and/or psychical state of the recorded person. In order to make the unbiased decisions about the state of the person we want to be able to develop the computer algorithm for extracting information/describing/classifying/making decisions about the state of the person from the recorded coronas of fingertips. The aim of our study is to differentiate 6 types of coronas, 3 types in normal state of consciousness: Ia, Ib, Ic (pictures were recorded with single GDV camera in Ljubljana, all with the same settings of parameters, classification into 3 types was done manually): Ia – harmonious energy state (120 coronas) Ib – non-homogenous but still energetically full (93 coronas) Ic – energetically poor (76 coronas) and 3 types in altered states of consciousness (pictures obtained from dr. Korotkov, recorded by different GDV cameras with different settings of parameters and pictures were not normalized – they were of variable size): Rings – double coronas (we added 7 pictures of double coronas recorded in Ljubljana) (90 coronas) Branches – long streamers branching in various directions (74 coronas) Spots – unusual spots (51 coronas) Our aim is to differentiate normal from altered state of consciousness (2 classes) and to differentiate among all 6 types of coronas (6 classes). Figure 1 provides example coronas for each type.
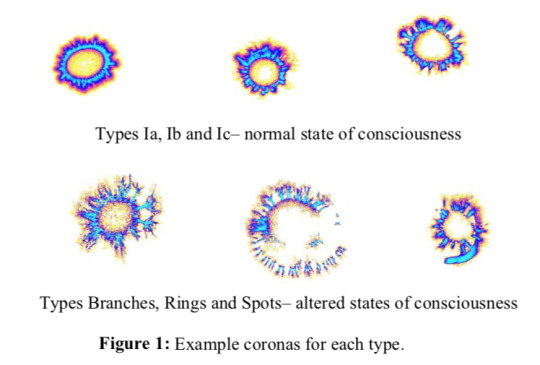
GDV Corona's types 2. The methodology We first had to preprocess all the pictures so that all were of equal size (320 x 240). We then described the pictures with various sets of numerical parameters (attributes) with five different parametrization algorithms (described in more detail in the next section): a) IP (Image Processor – 22 attributes), b) PCA (Principal Component Analysis), c) Association Rules, d) GDV Assistant with some basic GDV parameters, e)GDV Assistant with additional parameters. Therefore we had available 5 different learning sets for two-classes problem: altered (one of Rings, Spots, and Branches) versus non- altered (one of Ia, Ib, Ic) state of consciousness. Some of the sets were used also as six-classes problems (differentiating among all six different types of coronas). We tried to solve some of the above classification tasks by using various machine learning algorithms as implemented in Weka system (Witten and Frank, 2000): Quinlan's (1993) C4.5 algorithm for generating decision trees; K-nearest neighbor classifier by Aha, D., and D. Kibler (1991); Simple Kernel Density classifier; Naïve Bayesian classifier using estimator classes: Numeric estimator precision valuesare chosen based on analysis of the training data. For this reason, the classifier is not an Updateable Classifier (which in typical usage are initialized with zero training instances, see (John and Langley, 1995)); SMO implements John C. Platt's sequential minimal optimization algorithm for training a support vector classifier using polynomial kernels. It transforms the output of SVM Types Ia, Ib and Ic– normal state of consciousness into probabilities by applying a standard sigmoid function that is not fitted to the data. This implementation globally replaces all missing values and transforms nominal attributes into binary ones (see Platt, 1998; Keerthi et al., 2001); Neural networks: standard multilayared feedforward neural network with backpropagation of errors learning mechanism (Rumelhart et al., 1986). SMO algorithm can be used only for two-classes problems, while the other algorithms can be used on two-classes and on six-classes problems. Types Branches, Rings and Spots– altered states of consciousness Figure 1: Example coronas for each type. Full text PDF: 2004-Kononenko-altered-coronas References Aha, D., and D. Kibler (1991) "Instance-based learning algorithms", Machine Learning, vol.6, pp. 37-66. R. Agrawal, T. Imielinski, and A. Swami (1993) Mining association rules between sets of items in large databases. In P. Buneman and S. Jajodia, editors, Proceedings of the 1993 ACM SIGMOD International Conference on Mangement of Data, pages 207-216, Washington, D.C., 1993. R. Agrawal and R. Srikant (1994) Fast algorithms for mining association rules. In J. B. Bocca, M. Jarke, and C. Zaniolo, editors, Proc. 20th Int. Conf. Very Large Data Bases, VLDB, pages 487-499. Morgan Kaufmann. Bevk M. (2003) Texture Analysis with Machine Learning, M.Sc. Thesis, University of Ljubljana, Faculty of Computer and Information Science, Ljubljana, Slovenia. (in Slovene) Julesz, B., Gilbert, E.N., Shepp, L.A., Frisch H.L.(1973). Inability of Humans To Discriminate Between Visual Textures That Agree in Second-Order-Statistics, Perception 2, pp. 391-405. M. Bevk and I. Kononenko (2002) A statistical approach to texture description: A preliminary study. In ICML-2002 Workshop on Machine Learning in Computer Vision, pages 39-48, Sydney, Australia, 2002. R. Haralick, K. Shanmugam, and I. Dinstein (1973) Textural features for image classification. IEEE Transactions on Systems, Man and Cybernetics, pages 610-621. G. H. John and P. Langley (1995). Estimating Continuous Distributions in Bayesian Classifiers. Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence. pp. 338-345. Morgan Kaufmann, San Mateo. S.S. Keerthi, S.K. Shevade, C. Bhattacharyya, K.R.K. Murthy (2001). Improvements to Platt's SMO Algorithm for SVM Classifier Design. Neural Computation, 13(3), pp 637-649, 2001. Korotkov, K. (1998) Aura and Consciousness, St.Petersburg, Russia: State Editing & Publishing Unit “Kultura”. Korotkov, K., Korotkin, D. (2001) Concentration dependence of gas discharge around drops of inorganic electrolytes, Journal of Applied Physics, Vol. 89, pp. 4732-4736. J. Platt (1998). Fast Training of Support Vector Machines using Sequential Minimal Optimization. Advances in Kernel Methods - Support Vector Learning, B. Schölkopf, C. Burges, and A. Smola, eds., MIT Press. W.H. Press, B.P. Flannery, S.A. Teukolsky, and W.T. Vetterling (1992) Numerical Recipes: The Art of Scientific Computing. Cambridge University Press, Cambridge (UK) and New York, 2ndedition. J.R. Quinlan (1993) C4.5 Programs for Machine Learning, Morgan Kaufmann. D.E. Rumelhart, G.E. Hinton, R.J. Williams (1986) Learning internal representations by error propagation. In: Rumelhart D.E. and McClelland J.L. (eds.) Parallel Distributed Processing, Vol. 1: Foundations. Cambridge: MIT Press. J. A. Rushing, H. S. Ranagath, T. H. Hinke, and S. J. Graves (2001) Using association rules as texture features. IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 845-858. A. Sadikov (2002) Computer visualization, parametrization and analysis of images of electrical gas discgarge (in Slovene), M.Sc. Thesis, University of Ljubljana, 2002. L. Sirovich and M. Kirby (1987) A low-dimensional procedure for the characterisation of human faces. Journal of the Optical Society of America, pages 519-524. A. Sadikov, I. Kononenko, F. Weibel (2003) Analyzing Coronas of Fruits and Leaves, This volume. M. Turk and A. Pentland (1991) Eigenfaces for recognition. Journal of Cognitive Neuroscience, pages 71-86. I. H. Witten, E. Frank (2000) Data mining: Practical machine learning tools and techniques with Java implementations, Morgan Kaufmann. Read the full article
#coronadischarge#DIFFERENTTYPESOFCORONAS#Electrophotonicimaging#GDV#GDVGraph#GDVImage#GDVSoftware#GDV-gram#Korotkov'simages#MACHINELEARNING
0 notes
Text
Slashdot: Artificial General Intelligence is Nowhere Close To Being a Reality
Artificial General Intelligence is Nowhere Close To Being a Reality Published on December 26, 2018 at 12:01PM Three decades ago, David Rumelhart, Geoffrey Hinton, and Ronald Williams wrote about a foundational weight-calculating technique -- backpropagation -- in a monumental paper titled "Learning Representations by Back-propagating Errors." Backpropagation, aided by increasingly cheaper, more robust computer hardware, has enabled monumental leaps in computer vision, natural language processing, machine translation, drug design, and material inspection, where some deep neural networks (DNNs) have produced results superior to human experts. Looking at the advances we have made to date, can DNNs be the harbinger of superintelligent robots? From a report: Demis Hassabis doesn't believe so -- and he would know. He's the cofounder of DeepMind, a London-based machine learning startup founded with the mission of applying insights from neuroscience and computer science toward the creation of artificial general intelligence (AGI) -- in other words, systems that could successfully perform any intellectual task that a human can. "There's still much further to go," he told VentureBeat at the NeurIPS 2018 conference in Montreal in early December. "Games or board games are quite easy in some ways because the transition model between states is very well-specified and easy to learn. Real-world 3D environments and the real world itself is much more tricky to figure out ... but it's important if you want to do planning." Most AI systems today also don't scale very well. AlphaZero, AlphaGo, and OpenAI Five leverage a type of programming known as reinforcement learning, in which an AI-controlled software agent learns to take actions in an environment -- a board game, for example, or a MOBA -- to maximize a reward. It's helpful to imagine a system of Skinner boxes, said Hinton in an interview with VentureBeat. Skinner boxes -- which derive their name from pioneering Harvard psychologist B. F. Skinner -- make use of operant conditioning to train subject animals to perform actions, such as pressing a lever, in response to stimuli, like a light or sound. When the subject performs a behavior correctly, they receive some form of reward, often in the form of food or water. The problem with reinforcement learning methods in AI research is that the reward signals tend to be "wimpy," Hinton said. In some environments, agents become stuck looking for patterns in random data -- the so-called "noisy TV problem."



Read more of this story at Slashdot.
0 notes
Text
If we had general intelligence at the level of a rat then the Singularity would be very near
The head of Facebook’s AI, Yann LeCun, says AI still has a long, long way to go before it approaches anything near the intelligence of a baby, or even an animal.
LeCun thinks the keys are * machines that can build, through learning, their own internal models of the world, so they can simulate the world faster than real time * virtual assistants really are going to be the big thing. Current assistants are entirely scripted, with a tree of possible things they can tell you. So that makes the creation of bots really tedious, expensive, and brittle, though they work in certain situations like customer care. The next step will be systems that have a little more learning in them, and that’s one of the things we’re working on at Facebook. Where you have a machine that reads a long text and then answers any questions related to it — that’d be useful as a function. * The step beyond virtual assistants is common sense, when machines have the same background knowledge as a person. But we’re not going to get that unless we can find some way of getting machines to learn how the world works by observation. You know, just watching videos or just reading books. And that’s the critical scientific and technological challenge over the next few years. I call it predicted learning, some people call it unsupervised learning.
youtube
Where are we with brain technology and AGI ?
Launched in 2012, the Green Brain Project aims to create the first accurate computer model of a honey bee brain, and transplant that onto a UAV. In 2015, they used the bee brain simulation to fly a quadcopter. Bees have 960,000 neurons and 1 billion synapses.
* House mouse has 71,000,000 neurons and 1 trillion synapses * Brown Rat has 200 million neurons * Cat has 760 million neurons * Pig 2.2 billion neurons * Rhesus macaque 6.8 billion neurons * Human 86 billion neurons and 150 trillion synapses
If we had a general intelligence with the capabilities of a rat then it would three times beyond the goals of the European Human Brain Project with its mouse models and would be a matter of scaling the neurons and the solution by 400 times.
In 2016, former Braintree founder Bryan Johnson invested $100 million into Kernel, a company with the sole purpose of building hardware and software to augment human intelligence. Johnson believes that over time he will need to raise $1 billion to execute a series of product milestones. He thinks this will take 7-10 years.
Elon Musk has invested in Neuralink to have high resolution brain computer interfaces.
youtube
youtube
The Human Brain Project (HBP) is a large ten-year scientific research project (1 billion euros) that aims to build a collaborative ICT-based scientific research infrastructure to allow researchers across Europe to advance knowledge in the fields of neuroscience, computing, and brain-related medicine.
The project was focused on mouse brain models. There was a 2015 report and the project is being relaunched with more of a focus on tools for brain research.
Here is the Bluebrain EU project website.
– Sept 2017 – Successful Neuromodulation of Neural Microcircuits NM² Conference prompts future collaborations. At the end of September, the Blue Brain Project concluded a stimulating, interactive and highly collaborative Neuromodulation of Neural Microcircuits NM² Conference. A global line-up of renowned speakers and more than one hundred attendees from across the different Neuromodulation communities ensured a cross-pollination of experience and expertise throughout the three-day Conference.
The BBPs current digital reconstructions are first drafts, to be refined in future releases. The fact that they are detailed means they are “data ready” – it is easy to incorporate data from new experiments as they become available. The BBP will dedicate significant effort to this task. Current BBP reconstructions omit many features of neural anatomy and physiology that are known to play an important role in brain function. Future BBP work will enrich the reconstructions with models of the neuro-vascular glia system, neuromodulation, different forms of plasticity, gap-junctions, and couple them to neurorobotics systems, enabling in silico studies of perception, cognition and behavior.
A second major effort will be dedicated to reconstructions and simulations on a larger scale than neural microcircuitry. The Blue Brain team is already working with communities in the Human Brain Project and beyond, to build digital reconstructions of whole brain regions (somatosensory cortex, hippocampus, cerebellum, basal ganglia) and eventually the whole mouse brain. This work will prepare the way for reconstructions of the human brain, on different scales and with different levels of detail.
Finally, a very large part of BBP activity is dedicated to engineering: developing and operating the software tools, the workflows and the supercomputing capabilities required to digitally reconstruct and simulate the brain and to analyse and visualize the results.
Deep Mind did publish a paper – PathNet: Evolution Channels Gradient Descent in Super Neural Networks
For artificial general intelligence (AGI) it would be efficient if multiple users trained the same giant neural network, permitting parameter reuse, without catastrophic forgetting. PathNet is a first step in this direction. It is a neural network algorithm that uses agents embedded in the neural network whose task is to discover which parts of the network to re-use for new tasks. Agents are pathways (views) through the network which determine the subset of parameters that are used and updated by the forwards and backwards passes of the backpropogation algorithm. During learning, a tournament selection genetic algorithm is used to select pathways through the neural network for replication and mutation. Pathway fitness is the performance of that pathway measured according to a cost function. We demonstrate successful transfer learning; fixing the parameters along a path learned on task A and re-evolving a new population of paths for task B, allows task B to be learned faster than it could be learned from scratch or after fine-tuning. Paths evolved on task B re-use parts of the optimal path evolved on task A. Positive transfer was demonstrated for binary MNIST, CIFAR, and SVHN supervised learning classification tasks, and a set of Atari and Labyrinth reinforcement learning tasks, suggesting PathNets have general applicability for neural network training. Finally, PathNet also significantly improves the robustness to hyperparameter choices of a parallel asynchronous reinforcement learning algorithm (A3C).
Narrow AI – self driving cars and drones
A few days ago, Nvidia Corp chief executive Jensen Huang said on Thursday artificial intelligence would enable fully automated cars within 4 years. In October 2017 Nvidia and partner development companies announced the Drive PX Pegasus system, based upon two Xavier CPU/GPU devices and two post-Volta generation GPUs. The companies stated the third generation Drive PX system would be capable of Level 5 autonomous driving, with a total of 320 TOPS of AI computational power and a 500 Watts TDP.
Pegasus can handle 320 trillion operations per second, representing roughly a 13-fold increase over the calculating power of the current PX 2 line. Pegasus will be available in the middle of 2018. There will be millions of cars and trucks using these and even more powerful systems over the next few years.
Flood funding
China’s government and companies like Alibaba are and will be investing many billions to tens of billions of dollars a year into Artificial Intelligence and quantum computing. Google, Facebook, Microsoft, IBM and others are also investing many billions into AI and quantum computing.
0 notes
Text
7 Ways AI is Transforming the Education Industry
Every year brings the adoption and changes to the new technologies. Technologies have changed the way we used to live, work, play, and learn in every sector, and the educational industry is no exception.
With automatic driving cars, smart gadgets, and personal assistants – AI – Artificial Intelligence has created a big impact in our lives and is here to stay and make your life easier. It is no longer the realm of science fiction. It’s booming in recent times and set to disrupt any sector that deals with large amounts of data.
The education industry remains at the top of the verticals to leverage technological advancements. However, AI and Machine Learning will transform the education industry as fully as it will most others, and it’s up to new generations of teachers and students to plan effective ways to integrate machine learning and leverage AI-enabled devices for its smooth and effective transition.
By integrating AI technology into the education sector, it will transform across its multiple verticals – from the traditional ways of teaching and learning through a common curriculum to more personalized learning. Students are not required to attend physical classes to study as long as they are enabled to operate the computer and internet connection.
The implementation of AI enables automation of administrative tasks and minimizes the time required to complete tough tasks so that educators can spend more time with their students. Therefore, if you are an educator, it’s imperative to understand the changes that are coming on your way.
Hence, to imbibe you with the right guide and knowledge, we have decided to discuss the transformations brought by Artificial Intelligence in the education industry. Let’s look at the major points that will improve education in the coming years.
Future of AI and Education
The analysts’ research says that application areas of AI are expected to grow in the coming years and in the education secretary of the USA, it will increase by 47.44% between 2018 and 2022. It’s likely to rule its presence everywhere, right from kindergarten to higher education.
The presence of AI in education will change the role and responsibility of teachers.
AI For Next-Gen Education
From many last tears, there have been debates going on the applications of Artificial Intelligence to education. AI itself exhibits a branch of education that emerges from multiple learning branches including neuroscience, linguistics, psychology, sociology, and more.
Hence, in this digital era, AI can be beneficial to promote the development of adaptive learning environments and tech tools that can deliver more intuitive, personalized, engaging, and effective education.
With the increased growth of digital technology, advanced technology is booming in education. When it comes to the education sector in Europe, the UK finds its first spot, securing 40% of all European investments in Education Technology since 2014.
Top 7 Reasons AI is Transforming the Education System
A wave of transformation brought by AI has the education sphere across the globe in the following ways:
1. Personalized Learning
In the traditional education system, it’s quite not possible to let each student out of hundreds learn at their own pace. Also, they hardly get their own time to figure out their concepts from teachers as they are bound with fixed working hours.
But when we talk about emerging technology – AI in education, it has the ability to solve both these major issues efficiently. By leveraging AI, students can get personalized learning programs that suit their best learning speed and instructional approach. It also can help you track the progress of students and individualize the learning process, allowing educators to have more free time working on the next strategy to teach students.
Utilizing AI helps you identify the strengths, weaknesses, learning goals, and objectives of students, as well as areas where students need more attention, guidance, and customize the learning experience to help students with what they need.
Moreover, technology is constantly changing the needs and peace of every student. You will find many AI-based smart tutoring systems in the market, offering learning and feedback to students along with testing them on their knowledge.
These are beneficial in terms of utilizing machine learning to track and quantify student experiences in order to customize the learning environment to student needs.
2. Simplifying Administrative Tasks
Artificial Intelligence has developed applications and programs for educators and academic institutions that will assist them with these tedious administrative tasks. Many hours are spent by teachers on grading exams, checking answer sheets, and providing valuable feedback to their students. Henceforth, the technology can automate the grading tasks where multiple tests are involved. This means that students can solve their problems with educators as they will get more time with them rather than spending long hours grading them.
The AI will help teachers assist students in a better way, teaching them to suit the needs of the entire class better.
Actually, we expect way beyond this from AI. Some of the web development company integrate AI with apps in better ways to grade written answers and normal essays. Even, by integrating AI in your admission process, you can make it quite easy and smooth. Artificial Intelligence allows you to automate the classification and process of paperwork.
Since educators are busy they tend not to have enough time to give their personal attention to help their students with personal teaching. They have to assess mark sheets, read essays, and strategize for the next lesions, all of which consume a bunch of time.
Now is the time to upgrade the teaching methodologies and soon AI will be available to all teachers.
3. Customized and Smart Content
As we know, every student has a different ability to grasp the subjects and adopt the teaching skills. This is the reason why one specific content may work for one student, but not work for the other. Therefore, it’s mandatory to customize the study material, which is being developed with the utilization of AI and ML technologies.
As we live in a “digital and smart era” now, the education content must be digital and smart, too. With ML and AI, there has emerged a possibility of smart content that meet the unique learning requirements of every student. Though, the requirements of students can be gauged through their individual learning approach or interactions or engagements with other learning apps.
Nowadays high-quality and error-free digital content is produced by the robots, matching up to the standards of content created by experts. There is not only the adoption of the textbooks but also customized learning interfaces based on the conventional syllabus are being developed to cater to students irrespective of their age and academic backgrounds.
Smart content also includes virtual content like video conferences and digital lectures. And thus, the textbooks are taking a new turn.
For example, Cram101 uses AI to summarize the content of the textbook more comprehensible and it’s easy to navigate with summaries of chapters, flashcards, and practice tests.
Another example of AI is Netex Learning. Netex enables tutors to create digital curriculums and educational information across a myriad of devices. It also includes smart content like audios, illustrative audios, and online assistance programs.
4. Personalized and Adaptive Learning
Each student has a different method of learning and benefiting fully from their curriculum. Definitely, educators or teachers may not be able to customize their teaching methods to suit the personal needs of every student. This is why the development of customized curriculum concepts came into consideration.
Just like AI has been leveraged in the shopping selections on Amazon and movie recommendations on Netflix, similar technology will take place to personalize educational content to suit the needs of individual students.
Traditional teaching methods are based on appealing to the majority of students. That means when it comes to content and methodology, they have to compromise in some areas.
On the other hand, AI will be able to learn from an individual learner’s feedback, tailor assignments, and even exams to suit their strengths. Eventually, it will assist the students in addition to their primary teacher but not will take the place of students permanently.
The digitized curriculum will be formed and presented in a way that is custom made for the students learning style and habits. From finding accurate citations with writer’s using correct grammar, chatbots to finding reliable sources to collect the right information from, AI has completely changed the way.
Specially-abled students will also benefit significantly from this development. They could enhance their learning skills and abilities to grasp more information faster.
This will loosen up the stress from teachers of spending extra time teaching subjects that have already been taught in class. The progress levels assisted by AI-enabled devices are more accurate as they constantly learn from the user, updating itself about the current academic grades of students.
5. Global Learning
Gone are the days when a student had to physically go to the school or college by carrying the burden of textbooks to acquire education. In this digital era, all you need is an electronic device with internet access to educate yourself. It can easily connect millions of people globally and draw them close to each other.
This is what Artificial Intelligence is aiming at doing by removing the boundaries associated with traditional learning functionalities. It’s one of the most significant achievements of AI. Students of all age groups, from any part of the world, can now connect with the apps and software and receive the best quality education from any corner of the world.
Some colleges and universities have already implemented AI where students connect and form study groups on their apps or platforms. This will surely enhance the ideas of every student and can have both local and global impact on a variety of courses of study. Moreover, there are many online courses from erupted educational institutes that help them achieve a good professional career.
6. School Management
It’s not an easy task to manage a school or any educational institution. There are a hundred things to carry on your shoulder if you have to manage and handle the management, right from managing student records to scheduling lectures. While earlier everything was being done with human power and manually, now AI and ML have automated it and made it easier.
Using AI, you can easily manage student reports, attendance, details, school transportations, recruitment procedure, recurring admin activities, budgeting, scheduling classes, as well as activities. It lets you save ample time for teachers so that they can focus more on every individual student.
7. Additional Support
Artificial Intelligence can offer additional support to both students and teachers. The students can get prompt responses from chatbots or search engines by asking them questions. Those questions may help them in studying for exams, resulting in better grades.
On the other hand, teachers can get additional support from personal virtual assistants that are AI-enabled. They also get the opportunity to generate their teaching plans and other tasks that are relative to their job. In short, both teachers and students will benefit a lot from the additional support they get through the implementation of Artificial Intelligence.
Students will benefit because they will get more time to concentrate on studies and get personal attention from their teachers. Also, they will understand their subjects more easily without having to ask their teachers questions.
Wrapping Up
The education sector is taking a new turn with the implementation of Artificial Intelligence. It’s shaping the future for students and educators. It’s just the beginning of a great leap forward in the power of AI and ML to transform the educational experience.
If you are taking a baby step in the educational sector, you have to be a quick learner and keep yourself updated with the latest tools and technologies. In this way, you can evolve in today’s cutthroat educational industry.
If AI may be appropriately used, it can tackle all other problems and save costs and time for you as well. In the coming days and years, we can expect current trends and technologies to accelerate and Artificial Intelligence to have a growing role in shaping the future of students’ education. And the virtual assistants from Artificial Intelligence are the foremost development that we look forward to.
The post 7 Ways AI is Transforming the Education Industry appeared first on CareerMetis.com.
7 Ways AI is Transforming the Education Industry published first on https://skillsireweb.tumblr.com/
0 notes
Text
Top 10 marketing-related AI thought leaders to follow
30-second summary:
AI can help marketers deliver better overall customer experiences across all digital channels.
The key to success is in using it logically, ethically and in key areas where it can assist, save time and resource and help scale campaigns and performance.
To gain a better understanding of the benefits to marketing it is best to build your knowledge from a wide range of perspectives to identify the best use cases.
We look at 10 influencers worth following to get a good handle on how AI can and should effect the marketing sector.
Adoption of Artificial intelligence (AI) is growing worldwide, with a recent IDC report identifying the ability to deliver a better customer experience, greater employee efficiency and accelerated innovation as the leading drivers for adoption.
AI now powers marketing processes across the customer journey, from insights, search optimization and content marketing to personalization conversion optimization, predictive analytics, and beyond.
How can you stay at the forefront of advances in AI and machine learning? Follow these AI-in-marketing thought leaders.
I like to keep a wide range of disciplines in my newsfeed, to keep learning about now only what AI technology can do, but how we can use it in marketing ethically, logically, and most successfully.
Read their research and commentary, and don’t forget to join in the conversation on the platform of your choice.
1) Andrew Ng, founder & CEO of Landing AI
You’d be hard-pressed to find a more influential AI instructor than Andrew Ng.
To date, over 3.2 million students have taken his ‘Machine Learning’ course on Coursera, the e-learning platform he co-founded. Another 394,000 have studied his ‘AI for Everyone’ course—and these are just two of the eleven courses he’s created there.
Andrew is also an Adjunct Professor of Computer Science at Stanford University and one of the catalysts for the MOOC movement (in fact, he led the development of Stanford’s MOOC platform.
Last year, he announced the grand opening of his company’s first international office in Medellín, Colombia—you can read more about his plans to evangelize AI in Latin America here.
Good reads:
Advice on building a machine learning career and reading research papers
I. will be crucial to companies outside of Silicon Valley—and they need a new playbook for it
LinkedIn: Andrew Ng
Twitter: @AndrewYNg
2) Cassie Kozyrkov, Chief Decision Scientist at Google
According to her LinkedIn, data scientist and statistician Cassie Kozyrkov is on a mission to “democratize Decision Intelligence and safe, reliable AI.” In her role at Google, she guides the search giant in making safe and effective use of artificial intelligence technology.
In her lengthy career with Google, Cassie has advised over 200 teams on their analytics processes, inspired more than 400 new projects, and trained over 15,000 analysts and decision-makers in using machine learning to transform their work.
She shares her knowledge and unique insight generously outside of the classroom and boardroom, as well.
Good reads:
Machine learning — Is the emperor wearing clothes?
Whose fault is it when AI makes mistakes?
LinkedIn: Cassie Kozyrkov
Twitter: @quaesita
3) Moustapha Cissé, Research Scientist and Head of Google AI Center, Accra
Moustapha is the founder and Director of the African Master of Machine Intelligence at the African Institute for Mathematical Sciences. The one-year intensive graduate program is fully funded and offered in partnership with Facebook and Google. In 2019, it received over 7,000 applicants.
Prior to joining Google, Moustapha was a research scientist at Facebook where he worked in AI. He earned his Master’s Degree in AI, then his Ph.D. in Computer Science at Pierre and Marie Curie University in Paris, and a Master’s Degree in Computer Science in Montreal in between.
Good reads:
Look to Africa to advance artificial intelligence
Google AI in Ghana
LinkedIn: Moustapha Cissé
Twitter: @Moustapha_6C
4) Karen Hao, Senior AI Reporter at MIT Technology Review
Karen’s work has appeared in Mother Jones, Sierra Magazine, New Republic, Quartz and more. After a brief stint as an application engineer post-graduation, she found that her passion is in media and helping others by demystifying AI. Karen earned her B.S. in Mechanical Engineering at MIT.
Today, Karen tweets writes and tweets about breaking news in AI, black AI and technology scholars, the social and justice issues inherent to AI use, and more.
She gave a great TEDx Talk earlier this year in Mumbai on ‘Why We Need to Democratize How We Build AI’ that you can catch here:
Good reads:
A debate between AI experts shows a battle over the technology’s future
The messy, secretive reality behind OpenAI’s bid to save the world
LinkedIn: Karen Hao
Twitter: @_KarenHao
5) Brian Solis, Digital Thought Leader and Author
Digital analyst, speaker, and author Brian Solis has been studying the impact of digital on people and businesses for over 20 years.
A prolific writer, he has authored over 60 research papers and bestselling books including Lifescale: How to Live a More Creative, Productive, and Happy Life; X: The Experience When Business Meets Design; and What’s the Future of Business (WTF).
The Global Innovation Evangelist for Salesforce, Brian explores digital transformation, innovation, and disruption—and it doesn’t get much more innovative or disruptive than AI.
He’s a keynote speaker in the upcoming Artificial Intelligence in Marketing Summit, a half-day virtual event hosted by ClickZ, and a much-loved columnist in CIO, Fast Company, AdWeek and more.
Good reads:
2020 Enterprise Technology Trends: Digital Transformation, AI, Cognitive Automation And Quantum Computing
Now hiring AI futurists: It’s time for artificial intelligence to take a seat in the C-Suite
LinkedIn: Brian Solis
Twitter: @briansolis
6) Bernard Marr, Futurist, Influencer and Data Advisor
Internationally bestselling author and strategic business advisor Bernard Marr has been recognized by LinkedIn as one of the world’s top 5 influencers.
Among the 16 bestselling books he’s authored are Tech Trends in Practice: The 25 Technologies that are Driving the 4th Industrial Revolution; Data Strategy: How to Profit from a World of Big Data, Analytics and the Internet of Things; and Artificial Intelligence in Practice: How 50 Successful Companies Used AI and Machine Learning to Solve Problems.
Good reads:
How Artificial Intelligence, IoT And Big Data Can Save The Bees
3 ways the Internet of Things will change every business
LinkedIn: Bernard Marr
Twitter: @BernardMarr
7) Rama Akkiraju, IBM Fellow and Director at IBM Watson
Rama Akkiraju is one of AI’s top influencers. An IBM Fellow, the Director of IBM’s Watson division, and a member of the IBM Academy of Technology, she’s been named one of the top 20 women in AI research by Forbes and one of the top 6 ‘A-Team for AI’ by Fortune Magazine.
In her work with IBM, Rama explores new ways to make AI work for enterprise business. She and her team have developed a wide range of machine learning and NLP-powered AI services including Personality Insights, Tone Analyzer, and Emotion Analysis.
Good reads:
How humans and machines can collaborate to solve problems and communicate compassionately
Declare Your Biases
LinkedIn: Rama Akkiraju
Twitter: @rama_akkiraju
8) Dr. Craig Brown, Data Scientist and Lead Big Data Architect
As a technology and business consultant, Dr. Brown has been working on technological and innovative projects for top fortune 1000 companies for over 30 years.
He is a data science and data analytics expert, the CEO & Sr. Partner of STEM Resource Partners, and the author of Untapped Potential: The Supreme Partnership of Self.
After earning his B.S. from the University of Pennsylvania, Brown went on to complete his M.B.A. there at The Wharton School before tackling his doctoral degrees from the University of Pennsylvania and Cornell University.
Good reads:
9 experts answer your top data science & machine learning questions, feat. Dr. Craig Brown
Intelligent Connectivity creates value through collaborative ecosystems
LinkedIn: Craig Brown, PhD
Twitter: @DrDataScientist
9) Fei-Fei Li, Stanford’s Leading AI Scientist
As the Director of Stanford’s Artificial Intelligence Lab (SAIL), Fei-Fei Li led over 20 faculty and 100 students in the education and research of AI.
She served close to two years as Google Cloud’s Chief Scientist of AI and Machine Learning and VP, and is the co-founder and Chairperson of the national non-profit organization AI4All.
Today, she’s recognized as the leading AI scientist at Stanford, where she continues her work as a Professor in Computer Science and leads the Human-Centered AI Institute.
Her research focuses on AI, machine learning, deep learning, computer vision, computational neuroscience, cognitive neuroscience, and the intersection of AI and healthcare.
Good reads:
Fei-Fei Li: If We Want Machines to Think, We Need to Teach Them to See
Fei-Fei Li’s Quest to Make AI Better for Humanity
LinkedIn: Fei-Fei Li
Twitter: @drfeifei
10) Paul Roetzer, Marketing Artificial Intelligence Institute founder & CEO
The CEO and founder of the Marketing Artificial Intelligence Institute, Paul Roetzer is also the creator of the Marketing Artificial Intelligence Conference (MAICON) and the AI Academy for Marketers.
He’s the author of The Marketing Performance Blueprint and The Marketing Agency Blueprint, both published by Wiley.
Originally a graduate of Ohio University’s E.W. Scripps School of Journalism, Paul is a prolific writer. He still runs PR 20/20, as well, his first business and HubSpot’s first agency partner.
Good reads:
How AI is Transforming Search, Content and Digital Marketing
Can Artificial Intelligence Write Better Email Subject Lines Than Humans?
LinkedIn: Paul Roetzer
Twitter: @paulroetzer
Andy Betts is a Chief marketer and digital hybrid with more than 25 years of experience in search, content marketing, digital, martech and operations working across London, Europe, New York, and San Francisco. He works as an adviser and consultant for technology companies, agencies, and leading Fortune 500 companies.
The post Top 10 marketing-related AI thought leaders to follow appeared first on ClickZ.
source http://wikimakemoney.com/2020/06/25/top-10-marketing-related-ai-thought-leaders-to-follow/
0 notes
Text
What’s in a name? The ‘deep learning’ debate
Monday’s historic debate between machine learning luminary Yoshua Bengio and machine learning critic Gary Marcus spilled over into a tit for tat between the two in the days following, mostly about the status of the term “deep learning.”
The history of the term deep learning shows that the use of it has been opportunistic at times but has had little to do in the way of advancing the science of artificial intelligence. Hence, the current debate will likely not go anywhere, ultimately.
Monday night’s debate found Bengio and Marcus talking about similar-seeming end goals, things such as the need for “hybrid” models of intelligence, maybe combining neural networks with something like a “symbol” class of object. The details were where the two argued about definitions and terminology.
In the days that followed, Marcus, in a post on Medium, observed that Bengio seemed to have white-washed his own recent critique of shortcomings in deep learning. And Bengio replied, in a letter on Google Docs linked from his Facebook account, that Marcus was presuming to tell the deep learning community how it can define its terms. Marcus responded in a follow-up post by suggesting the shifting descriptions of deep learning are “sloppy.” Bengio replied again late Friday on his Facebook page with a definition of deep learning as a goal, stating, “Deep learning is inspired by neural networks of the brain to build learning machines which discover rich and useful internal representations, computed as a composition of learned features and functions.” Bengio noted the definition did not cover the “how” of the matter, leaving it open.
Also: Devil’s in the details in Historic AI debate
The term “deep learning” has emerged a bunch of times over the decades, and it has been used in different ways. It’s never been rigorous, and doubtless it will morph again, and at some point it may lose its utility.
Jürgen Schmidhuber, who co-developed the “long-short term memory” form of neural network, has written that the AI scientist Rina Dechter first used the term “deep learning” in the 1980s. That use was different from today’s usage. Dechter was writing about methods to search a graph of a problem, having nothing much to do with deep networks of artificial neurons. But there was a similarity: she was using the word “deep” as a way to indicate the degree of complexity of a problem and its solution, which is what others started doing in the new century.
The same kind of heuristic use of deep learning started to happen with Bengio and others around 2006, when Geoffrey Hinton offered up seminal work on neural networks with many more layers of computation than in past. Starting that year, Hinton and others in the field began to refer to “deep networks” as opposed to earlier work that employed collections of just a small number of artificial neurons.
From Yoshua Bengio’s slides for the AI debate with Gary Marcus, December 23rd.
Yoshua Bengio
So deep learning emerged as a very rough, very broad way to distinguish a layering approach that makes things such as AlexNet work.
In the meantime, as Marcus suggests, the term deep learning has been so successful in the popular literature that it has taken on a branding aspect, and it has become a kind-of catchall that can sometimes seem like it stands for anything. Marcus’s best work has been in pointing out how cavalierly and irresponsibly such terms are used (mostly by journalists and corporations), causing confusion among the public. Companies with “deep” in their name have certainly branded their achievements and earned hundreds of millions for it. So the topic of branding is in some sense unavoidable.
Bengio’s response implies he doesn’t much care about the semantic drift that the term has undergone because he’s focused on practicing science, not on defining terms. To him, deep learning is serviceable as a placeholder for a community of approaches and practices that evolve together over time.
Also: Intel’s neuro guru slams deep learning: ‘it’s not actually learning’
Probably, deep learning as a term will at some point disappear from the scene, just as it and other terms have floated in and out of use over time.
There was something else in Monday’s debate, actually, that was far more provocative than the branding issue, and it was Bengio’s insistence that everything in deep learning is united in some respect via the notion of optimization, typically optimization of an objective function. That could be a loss function, or an energy function, or something else, depending on the context.
In fact, Bengio and colleagues have argued in a recent paper that the notion of objective functions should be extended to neuroscience. As they put it, “If things don’t ‘get better’ according to some metric, how can we refer to any phenotypic plasticity as ‘learning’ as opposed to just ‘changes’?”
That’s such a basic idea, it seems so self-evident, that it almost seems trivial for Bengio to insist on it.
But it is not trivial. Insisting that a system optimizes along some vector is a position that not everyone agrees with. For example, Mike Davies, head of Intel’s “neuromorphic” chip effort, this past February criticized back-propagation, the main learning rule used to optimize in deep learning, during a talk at the International Solid State Circuits Conference.
Davies’s complaint is that back-prop is unlike human brain activity, arguing “it’s really an optimization procedure, it’s not actually learning.”
Thus, deep learning’s adherents have at least one main tenet that is very broad but also not without controversy.
The moral of the story is, there will always be something to argue about.
0 notes