#robots.txt file
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text
WordPress Robots.txt Guide: What to Include & Exclude
Improve your WordPress site’s SEO by optimizing the robots.txt file. Learn what to include, what to block, and how to reduce crawl waste and index bloat effectively. WordPress Robots.txt Guide: What to Include & Exclude for Better SEO Slash unnecessary crawl activity and index bloat by upgrading your WordPress robots.txt file. WordPress Robots.txt Guide: What to Include & Exclude for Better…
#block query parameters WordPress#disallow URLs WordPress#optimize robots.txt WordPress#robots.txt file#SEO robots.txt example#staging site robots.txt#WordPress crawl optimization#WordPress robots.txt#WordPress SEO#XML sitemap robots.txt
0 notes
Text
What is Robots.txt File in SEO?
In SEO (Search Engine Optimization), robots.txt is a text file that website owners create to give instructions to search engine bots or web crawlers on how to crawl and index their website’s content. The robots.txt file, located in the root directory of a website, serves as a communication tool between website administrators and search engine bots, informing them which pages or sections of the…
View On WordPress
1 note
·
View note
Text
What is a Robots.txt File? The Ultimate Guide to Optimizing Search Engine Crawler Access
Discover everything about robots.txt files and how they help you control search engine crawler access. Learn to optimize your website for better SEO with this detailed guide.
1 note
·
View note
Text
0 notes
Text
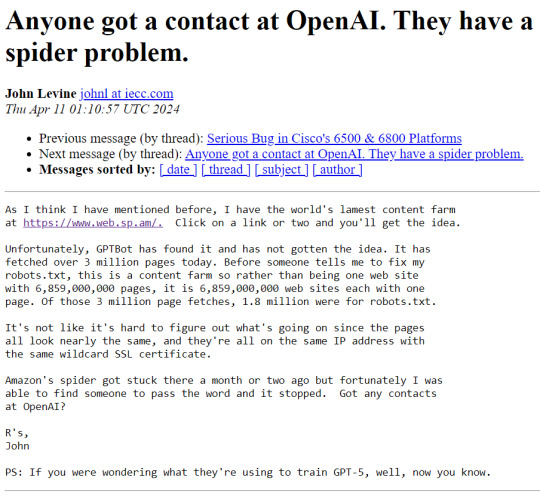
To understand what's going on here, know these things:
OpenAI is the company that makes ChatGPT
A spider is a kind of bot that autonomously crawls the web and sucks up web pages
robots.txt is a standard text file that most web sites use to inform spiders whether or not they have permission to crawl the site; basically a No Trespassing sign for robots
OpenAI's spider is ignoring robots.txt (very rude!)
the web.sp.am site is a research honeypot created to trap ill-behaved spiders, consisting of billions of nonsense garbage pages that look like real content to a dumb robot
OpenAI is training its newest ChatGPT model using this incredibly lame content, having consumed over 3 million pages and counting...
It's absurd and horrifying at the same time.
16K notes
·
View notes
Text
Friday, July 28th, 2023
🌟 New
We’ve updated the text for the blog setting that said it would “hide your blog from search results”. Unfortunately, we’ve never been able to guarantee hiding content from search crawlers, unless they play nice with the standard prevention measures of robots.txt and noindex. With this in mind, we’ve changed the text of that setting to be more accurate, insofar as we discourage them, but cannot prevent search indexing. If you want to completely isolate your blog from the outside internet and require only logged in folks to see your blog, then that’s the separate “Hide [blog] from people without an account” setting, which does prevent search engines from indexing your blog.
When creating a poll on the web, you can now have 12 poll options instead of 10. Wow.
For folks using the Android app, if you get a push notification that a blog you’re subscribed to has a new post, that push will take you to the post itself, instead of the blog view.
For those of you seeing the new desktop website layout, we’ve eased up the spacing between columns a bit to hopefully make things feel less cramped. Thanks to everyone who sent in feedback about this! We’re still triaging more feedback as the experiment continues.
🛠 Fixed
While experimenting with new dashboard tab configuration options, we accidentally broke dashboard tabs that had been enabled via Tumblr Labs, like the Blog Subs tab. We’ve rolled back that change to fix those tabs.
We’ve fixed more problems with how we choose what content goes into blogs’ RSS feeds. This time we’ve fixed a few issues with how answer post content is shown as RSS items.
We’ve also fixed some layout issues with the new desktop website navigation, especially glitches caused when resizing the browser window.
Fixed a visual glitch in the new activity redesign experiment on web that was making unread activity items difficult to read in some color palettes.
Fixed a bug in Safari that was preventing mature content from being blurred properly.
When using Tumblr on a mobile phone browser, the hamburger menu icon will now have an indicator when you have an unread ask or submission in your Inbox.
🚧 Ongoing
Nothing to report here today.
🌱 Upcoming
We hear it’s crab day tomorrow on Tumblr. 🦀
We’re working on adding the ability to reply to posts as a sideblog! We’re just getting started, so it may be a little while before we run an experiment with it.
Experiencing an issue? File a Support Request and we’ll get back to you as soon as we can!
Want to share your feedback about something? Check out our Work in Progress blog and start a discussion with the community.
854 notes
·
View notes
Text
Hey!
Do you have a website? A personal one or perhaps something more serious?
Whatever the case, if you don't want AI companies training on your website's contents, add the following to your robots.txt file:
User-agent: *
Allow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Claude-Web
Disallow: /
User-agent: CCbot
Disallow: /
User-agent: FacebookBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: PiplBot
Disallow: /
User-agent: ByteSpider
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: cohere-ai
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: Omgilibot
Disallow: /
User-agent: Omgili
Disallow: /
There are of course more and even if you added them they may not cooperate, but this should get the biggest AI companies to leave your site alone.
Important note: The first two lines declare that anything not on the list is allowed to access everything on the site. If you don't want this, add "Disallow:" lines after them and write the relative paths of the stuff you don't want any bots, including google search to access. For example:
User-agent: *
Allow: /
Disallow: /super-secret-pages/secret.html
If that was in the robots.txt of example.com, it would tell all bots to not access
https://example.com/super-secret-pages/secret.html
And I'm sure you already know what to do if you already have a robots txt, sitemap.xml/sitemap.txt etc.
88 notes
·
View notes
Text
"how do I keep my art from being scraped for AI from now on?"
if you post images online, there's no 100% guaranteed way to prevent this, and you can probably assume that there's no need to remove/edit existing content. you might contest this as a matter of data privacy and workers' rights, but you might also be looking for smaller, more immediate actions to take.
...so I made this list! I can't vouch for the effectiveness of all of these, but I wanted to compile as many options as possible so you can decide what's best for you.
Discouraging data scraping and "opting out"
robots.txt - This is a file placed in a website's home directory to "ask" web crawlers not to access certain parts of a site. If you have your own website, you can edit this yourself, or you can check which crawlers a site disallows by adding /robots.txt at the end of the URL. This article has instructions for blocking some bots that scrape data for AI.
HTML metadata - DeviantArt (i know) has proposed the "noai" and "noimageai" meta tags for opting images out of machine learning datasets, while Mojeek proposed "noml". To use all three, you'd put the following in your webpages' headers:
<meta name="robots" content="noai, noimageai, noml">
Have I Been Trained? - A tool by Spawning to search for images in the LAION-5B and LAION-400M datasets and opt your images and web domain out of future model training. Spawning claims that Stability AI and Hugging Face have agreed to respect these opt-outs. Try searching for usernames!
Kudurru - A tool by Spawning (currently a Wordpress plugin) in closed beta that purportedly blocks/redirects AI scrapers from your website. I don't know much about how this one works.
ai.txt - Similar to robots.txt. A new type of permissions file for AI training proposed by Spawning.
ArtShield Watermarker - Web-based tool to add Stable Diffusion's "invisible watermark" to images, which may cause an image to be recognized as AI-generated and excluded from data scraping and/or model training. Source available on GitHub. Doesn't seem to have updated/posted on social media since last year.
Image processing... things
these are popular now, but there seems to be some confusion regarding the goal of these tools; these aren't meant to "kill" AI art, and they won't affect existing models. they won't magically guarantee full protection, so you probably shouldn't loudly announce that you're using them to try to bait AI users into responding
Glaze - UChicago's tool to add "adversarial noise" to art to disrupt style mimicry. Devs recommend glazing pictures last. Runs on Windows and Mac (Nvidia GPU required)
WebGlaze - Free browser-based Glaze service for those who can't run Glaze locally. Request an invite by following their instructions.
Mist - Another adversarial noise tool, by Psyker Group. Runs on Windows and Linux (Nvidia GPU required) or on web with a Google Colab Notebook.
Nightshade - UChicago's tool to distort AI's recognition of features and "poison" datasets, with the goal of making it inconvenient to use images scraped without consent. The guide recommends that you do not disclose whether your art is nightshaded. Nightshade chooses a tag that's relevant to your image. You should use this word in the image's caption/alt text when you post the image online. This means the alt text will accurately describe what's in the image-- there is no reason to ever write false/mismatched alt text!!! Runs on Windows and Mac (Nvidia GPU required)
Sanative AI - Web-based "anti-AI watermark"-- maybe comparable to Glaze and Mist. I can't find much about this one except that they won a "Responsible AI Challenge" hosted by Mozilla last year.
Just Add A Regular Watermark - It doesn't take a lot of processing power to add a watermark, so why not? Try adding complexities like warping, changes in color/opacity, and blurring to make it more annoying for an AI (or human) to remove. You could even try testing your watermark against an AI watermark remover. (the privacy policy claims that they don't keep or otherwise use your images, but use your own judgment)
given that energy consumption was the focus of some AI art criticism, I'm not sure if the benefits of these GPU-intensive tools outweigh the cost, and I'd like to know more about that. in any case, I thought that people writing alt text/image descriptions more often would've been a neat side effect of Nightshade being used, so I hope to see more of that in the future, at least!
245 notes
·
View notes
Text
There has been a real backlash to AI’s companies’ mass scraping of the internet to train their tools that can be measured by the number of website owners specifically blocking AI company scraper bots, according to a new analysis by researchers at the Data Provenance Initiative, a group of academics from MIT and universities around the world. The analysis, published Friday, is called “Consent in Crisis: The Rapid Decline of the AI Data Commons,” and has found that, in the last year, “there has been a rapid crescendo of data restrictions from web sources” restricting web scraper bots (sometimes called “user agents”) from training on their websites. Specifically, about 5 percent of the 14,000 websites analyzed had modified their robots.txt file to block AI scrapers. That may not seem like a lot, but 28 percent of the “most actively maintained, critical sources,” meaning websites that are regularly updated and are not dormant, have restricted AI scraping in the last year. An analysis of these sites’ terms of service found that, in addition to robots.txt restrictions, many sites also have added AI scraping restrictions to their terms of service documents in the last year.
[...]
The study, led by Shayne Longpre of MIT and done in conjunction with a few dozen researchers at the Data Provenance Initiative, called this change an “emerging crisis” not just for commercial AI companies like OpenAI and Perplexity, but for researchers hoping to train AI for academic purposes. The New York Times said this shows that the data used to train AI is “disappearing fast.”
23 July 2024
85 notes
·
View notes
Text
i built a little crate for tower-based rust web servers the other day, if anyone’s interested. it’s called tower-no-ai, and it adds a layer to your server which can redirect all “AI” scraping bots to a URL of your choice (such as a 10gb file that hetzner uses for speed testing - see below). here’s how you can use it:

it also provides a function to serve a robots.txt file which will disallow all of these same bots from scraping your site (but obviously, it’s up to these bots to respect your robots.txt, which is why the redirect layer is more recommended). because it’s built for tower, it should work with all crates which support tower (such as axum, warp, tonic, etc.). there’s also an option to add a pseudo-random query parameter to the end of each redirect respond so that these bots (probably) won’t automatically cache the response of the url you redirect them to and instead just re-fetch it every time (to maximize time/resource wasting of these shitty bots).
you can view (and star, if you would so like :)) the repo here:
60 notes
·
View notes
Text
How to Back up a Tumblr Blog
This will be a long post.
Big thank you to @afairmaiden for doing so much of the legwork on this topic. Some of these instructions are copied from her verbatim.
Now, we all know that tumblr has an export function that theoretially allows you to export the contents of your blog. However, this function has several problems including no progress bar (such that it appears to hang for 30+ hours) and when you do finally download the gargantuan file, the blog posts cannot be browsed in any way resembling the original blog structure, searched by tag, etc.
What we found is a tool built for website archiving/mirroring called httrack. Obviously this is a big project when considering a large tumblr blog, but there are some ways to help keep it manageable. Details under the cut.
How to download your blog with HTTrack:
Website here
You will need:
A reliable computer and a good internet connection.
Time and space. For around 40,000 posts, expect 48 hours and 40GB. 6000 posts ≈ 10 hours, 12GB. If possible, test this on a small blog before jumping into a major project. There is an option to stop and continue an interrupted download later, but this may or may not actually resume where it left off. Keep in mind that Tumblr is a highly dynamic website with things changing all the time (notes, icons, pages being updated with every post, etc).
A custom theme. It doesn't have to be pretty, but it does need to be functional. That said, there are a few things you may want to make sure are in your theme before starting to archive:
the drop down meatball menu on posts with the date they were posted
tags visible on your theme, visible from your blog's main page
no icon images on posts/notes (They may be small, but keep in mind there are thousands of them, so if nothing else, they'll take up time. Instructions on how to exclude them below.)
Limitations: This will not save your liked or private posts, or messages. Poll results also may not show up.
What to expect from HTTrack:
HTTrack will mirror your blog locally by creating a series of linked HTML files that you can browse with your browser even if tumblr were to entirely go down. The link structure mimics the site structure, so you should be able to browse your own blog as if you had typed in the url of your custom theme into the browser. Some elements may not appear or load, and much of the following instructions are dedicated to making sure that you download the right images without downloading too many unnecessary images.
There will be a fair bit of redundancy as it will save:
individual posts pages for all your tags, such as tagged/me etc (If you tend to write a lot in your tags, you may want to save time and space by skipping this option. Instructions below.)
the day folder (if you have the meatball menu)
regular blog pages (page/1 etc)
How it works: HTTrack will be going through your url and saving the contents of every sub directory. In your file explorer this will look like a series of nested folders.
How to Start
Download and run HTTrack.
In your file directory, create an overarching folder for the project in some drive with a lot of space.
Start a new project. Select this folder in HTTrack as the save location for your project. Name your project.
For the url, enter https://[blogname].tumblr.com. Without the https:// you'll get a robots.txt error and it won't save anything.
Settings:
Open settings. Under "scan rules":
Check the box for filetypes .gif etc. Make sure the box for .zip etc. is unchecked. Check the box for .mov etc.
Under "limits":
Change the max speed to between 100,000 - 250,000. The reason this needs to be limited is because you could accidentally DDOS the website you are downloading. Do not DDOS tumblr.
Change the link limit to maybe 200,000-300,000 for a cutoff on a large blog, according to @afairmaiden. This limit is to prevent you from accidentally having a project that goes on infinitely due to redundancy or due to getting misdirected and suddenly trying to download the entirety of wikipedia.
Go through the other tabs. Check the box that says "Get HTML first". Uncheck "find every link". Uncheck "get linked non-html files". If you don't want to download literally the entire internet. Check "save all items in cache as well as HTML". Check "disconnect when finished".
Go back to Scan Rules.
There will be a large text box. In this box we place a sort of blacklist and whitelist for filetypes.
Paste the following text into that box.
+*.mp4 +*.gifv -*x-callback-url* -*/sharer/* -*/amp -*tumblr.com/image* -*/photoset_iframe/*
Optional:
-*/tagged/* (if you don't want to save pages for all your tags.)
-*/post/* (if you don't want to save each post individually. not recommended if you have readmores that redirect to individual posts.)
-*/day/* (if you don't feel it's necessary to search by date)
Optional but recommended:
-*/s64x64u*.jpg -*tumblr_*_64.jpg -*avatar_*_64.jpg -*/s16x16u*.jpg -*tumblr_*_16*.jpg -*avatar_*_16.jpg -*/s64x64u*.gif -*tumblr_*_64.gif -*avatar_*_64.gif -*/s16x16u*.gif -*tumblr_*_16.gif -*avatar_*_16.gif
This will prevent the downloading of icons/avatars, which tend to be extremely redundant as each image downloads a separate time for each appearance.
Many icons are in .pnj format and therefore won't download unless you add the extension (+*.pnj), so you may be able to whitelist the URLs for your and your friends' icons. (Honestly, editing your theme to remove icons from your notes may be the simpler solution here.)
You should now be ready to start.
Make sure your computer doesn't overheat during the extremely long download process.
Pages tend to be among the last things to save. If you have infinite scroll on, your first page (index.html) may not have a link to page 2, but your pages will be in the folder.
Shortly after your pages are done, you may see the link progress start over. This may be to check that everything is complete. At this point, it should be safe to click cancel if you want to stop, but you run the risk of more stuff being missing. You will need to wait a few minutes for pending transfers to be competed.
Once you're done, you'll want to check for: Files without an extension.
Start with your pages folder, sort items by file type, and look for ones that are simply listed as "file" rather than HTML. Add the appropriate extension (in this case, .html) and check to see if it works. (This may cause links to this page to appear broken.)
Next, sort by file size and check for 0B files. HTMLs will appear as a blank page. Delete these. Empty folders. View files as large icons to find these quickly.
If possible, make a backup copy of your project file and folder, especially if you have a fairly complete download and you want to update it.
Finally, turn off your computer and let it rest.
138 notes
·
View notes
Text
Are you a content creator or a blog author who generates unique, high-quality content for a living? Have you noticed that generative AI platforms like OpenAI or CCBot use your content to train their algorithms without your consent? Don’t worry! You can block these AI crawlers from accessing your website or blog by using the robots.txt file.
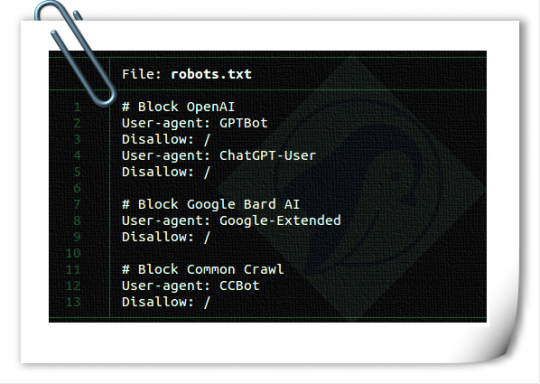
Web developers must know how to add OpenAI, Google, and Common Crawl to your robots.txt to block (more like politely ask) generative AI from stealing content and profiting from it.
-> Read more: How to block AI Crawler Bots using robots.txt file
73 notes
·
View notes
Text
Less than three months after Apple quietly debuted a tool for publishers to opt out of its AI training, a number of prominent news outlets and social platforms have taken the company up on it.
WIRED can confirm that Facebook, Instagram, Craigslist, Tumblr, The New York Times, The Financial Times, The Atlantic, Vox Media, the USA Today network, and WIRED’s parent company, Condé Nast, are among the many organizations opting to exclude their data from Apple’s AI training. The cold reception reflects a significant shift in both the perception and use of the robotic crawlers that have trawled the web for decades. Now that these bots play a key role in collecting AI training data, they’ve become a conflict zone over intellectual property and the future of the web.
This new tool, Applebot-Extended, is an extension to Apple’s web-crawling bot that specifically lets website owners tell Apple not to use their data for AI training. (Apple calls this “controlling data usage” in a blog post explaining how it works.) The original Applebot, announced in 2015, initially crawled the internet to power Apple’s search products like Siri and Spotlight. Recently, though, Applebot’s purpose has expanded: The data it collects can also be used to train the foundational models Apple created for its AI efforts.
Applebot-Extended is a way to respect publishers' rights, says Apple spokesperson Nadine Haija. It doesn’t actually stop the original Applebot from crawling the website—which would then impact how that website’s content appeared in Apple search products—but instead prevents that data from being used to train Apple's large language models and other generative AI projects. It is, in essence, a bot to customize how another bot works.
Publishers can block Applebot-Extended by updating a text file on their websites known as the Robots Exclusion Protocol, or robots.txt. This file has governed how bots go about scraping the web for decades—and like the bots themselves, it is now at the center of a larger fight over how AI gets trained. Many publishers have already updated their robots.txt files to block AI bots from OpenAI, Anthropic, and other major AI players.
Robots.txt allows website owners to block or permit bots on a case-by-case basis. While there’s no legal obligation for bots to adhere to what the text file says, compliance is a long-standing norm. (A norm that is sometimes ignored: Earlier this year, a WIRED investigation revealed that the AI startup Perplexity was ignoring robots.txt and surreptitiously scraping websites.)
Applebot-Extended is so new that relatively few websites block it yet. Ontario, Canada–based AI-detection startup Originality AI analyzed a sampling of 1,000 high-traffic websites last week and found that approximately 7 percent—predominantly news and media outlets—were blocking Applebot-Extended. This week, the AI agent watchdog service Dark Visitors ran its own analysis of another sampling of 1,000 high-traffic websites, finding that approximately 6 percent had the bot blocked. Taken together, these efforts suggest that the vast majority of website owners either don’t object to Apple’s AI training practices are simply unaware of the option to block Applebot-Extended.
In a separate analysis conducted this week, data journalist Ben Welsh found that just over a quarter of the news websites he surveyed (294 of 1,167 primarily English-language, US-based publications) are blocking Applebot-Extended. In comparison, Welsh found that 53 percent of the news websites in his sample block OpenAI’s bot. Google introduced its own AI-specific bot, Google-Extended, last September; it’s blocked by nearly 43 percent of those sites, a sign that Applebot-Extended may still be under the radar. As Welsh tells WIRED, though, the number has been “gradually moving” upward since he started looking.
Welsh has an ongoing project monitoring how news outlets approach major AI agents. “A bit of a divide has emerged among news publishers about whether or not they want to block these bots,” he says. “I don't have the answer to why every news organization made its decision. Obviously, we can read about many of them making licensing deals, where they're being paid in exchange for letting the bots in—maybe that's a factor.”
Last year, The New York Times reported that Apple was attempting to strike AI deals with publishers. Since then, competitors like OpenAI and Perplexity have announced partnerships with a variety of news outlets, social platforms, and other popular websites. “A lot of the largest publishers in the world are clearly taking a strategic approach,” says Originality AI founder Jon Gillham. “I think in some cases, there's a business strategy involved—like, withholding the data until a partnership agreement is in place.”
There is some evidence supporting Gillham’s theory. For example, Condé Nast websites used to block OpenAI’s web crawlers. After the company announced a partnership with OpenAI last week, it unblocked the company’s bots. (Condé Nast declined to comment on the record for this story.) Meanwhile, Buzzfeed spokesperson Juliana Clifton told WIRED that the company, which currently blocks Applebot-Extended, puts every AI web-crawling bot it can identify on its block list unless its owner has entered into a partnership—typically paid—with the company, which also owns the Huffington Post.
Because robots.txt needs to be edited manually, and there are so many new AI agents debuting, it can be difficult to keep an up-to-date block list. “People just don’t know what to block,” says Dark Visitors founder Gavin King. Dark Visitors offers a freemium service that automatically updates a client site’s robots.txt, and King says publishers make up a big portion of his clients because of copyright concerns.
Robots.txt might seem like the arcane territory of webmasters—but given its outsize importance to digital publishers in the AI age, it is now the domain of media executives. WIRED has learned that two CEOs from major media companies directly decide which bots to block.
Some outlets have explicitly noted that they block AI scraping tools because they do not currently have partnerships with their owners. “We’re blocking Applebot-Extended across all of Vox Media’s properties, as we have done with many other AI scraping tools when we don’t have a commercial agreement with the other party,” says Lauren Starke, Vox Media’s senior vice president of communications. “We believe in protecting the value of our published work.”
Others will only describe their reasoning in vague—but blunt!—terms. “The team determined, at this point in time, there was no value in allowing Applebot-Extended access to our content,” says Gannett chief communications officer Lark-Marie Antón.
Meanwhile, The New York Times, which is suing OpenAI over copyright infringement, is critical of the opt-out nature of Applebot-Extended and its ilk. “As the law and The Times' own terms of service make clear, scraping or using our content for commercial purposes is prohibited without our prior written permission,” says NYT director of external communications Charlie Stadtlander, noting that the Times will keep adding unauthorized bots to its block list as it finds them. “Importantly, copyright law still applies whether or not technical blocking measures are in place. Theft of copyrighted material is not something content owners need to opt out of.”
It’s unclear whether Apple is any closer to closing deals with publishers. If or when it does, though, the consequences of any data licensing or sharing arrangements may be visible in robots.txt files even before they are publicly announced.
“I find it fascinating that one of the most consequential technologies of our era is being developed, and the battle for its training data is playing out on this really obscure text file, in public for us all to see,” says Gillham.
11 notes
·
View notes
Text
my heart has a robots.txt file. you're not indexing shit
11 notes
·
View notes
Text
it used to be common courtesy not to hotlink to other peoples 100x100 lj icons so you wouldnt use their bandwidth and now ai scrapers literally put millions of hits on ppls websites just to take their data ignoring the robots.txt files. isnt that so crazy. shoo. shoo
5 notes
·
View notes
Text
"There are 3 things a visual artist can do to protect their work. First, dump using Meta and X, who are scraping the images that are loaded to their apps. Second, on your artist's portfolio website, install a Robots.txt and ai.txt file that blocks the AI scraping bots. Please note that Adobe Portfolio websites don't give you this option to block AI bot scraping. Third, use the app "glaze" to protect your work. This app embeds data into and image that renders you image unusable to AI. If anyone needs more info on the Robots.txt, AI.txt setup or the app Glaze, please feel free to reach out to me." [E.R. Flynn]
2 notes
·
View notes