#scala pyspark programming
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
1,644 Tumblr posts in 1 second.
Video
youtube
SQL - How to Use Qualify Clause
0 notes
Text
Big Data Analytics: Tools & Career Paths

In this digital era, data is being generated at an unimaginable speed. Social media interactions, online transactions, sensor readings, scientific inquiries-all contribute to an extremely high volume, velocity, and variety of information, synonymously referred to as Big Data. Impossible is a term that does not exist; then, how can we say that we have immense data that remains useless? It is where Big Data Analytics transforms huge volumes of unstructured and semi-structured data into actionable insights that spur decision-making processes, innovation, and growth.
It is roughly implied that Big Data Analytics should remain within the triangle of skills as a widely considered niche; in contrast, nowadays, it amounts to a must-have capability for any working professional across tech and business landscapes, leading to numerous career opportunities.
What Exactly Is Big Data Analytics?
This is the process of examining huge, varied data sets to uncover hidden patterns, customer preferences, market trends, and other useful information. The aim is to enable organizations to make better business decisions. It is different from regular data processing because it uses special tools and techniques that Big Data requires to confront the three Vs:
Volume: Masses of data.
Velocity: Data at high speed of generation and processing.
Variety: From diverse sources and in varying formats (!structured, semi-structured, unstructured).
Key Tools in Big Data Analytics
Having the skills to work with the right tools becomes imperative in mastering Big Data. Here are some of the most famous ones:
Hadoop Ecosystem: The core layer is an open-source framework for storing and processing large datasets across clusters of computers. Key components include:
HDFS (Hadoop Distributed File System): For storing data.
MapReduce: For processing data.
YARN: For resource-management purposes.
Hive, Pig, Sqoop: Higher-level data warehousing and transfer.
Apache Spark: Quite powerful and flexible open-source analytics engine for big data processing. It is much faster than MapReduce, especially for iterative algorithms, hence its popularity in real-time analytics, machine learning, and stream processing. Languages: Scala, Python (PySpark), Java, R.
NoSQL Databases: In contrast to traditional relational databases, NoSQL (Not only SQL) databases are structured to maintain unstructured and semic-structured data at scale. Examples include:
MongoDB: Document-oriented (e.g., for JSON-like data).
Cassandra: Column-oriented (e.g., for high-volume writes).
Neo4j: Graph DB (e.g., for data heavy with relationships).
Data Warehousing & ETL Tools: Tools for extracting, transforming, and loading (ETL) data from various sources into a data warehouse for analysis. Examples: Talend, Informatica. Cloud-based solutions such as AWS Redshift, Google BigQuery, and Azure Synapse Analytics are also greatly used.
Data Visualization Tools: Essential for presenting complex Big Data insights in an understandable and actionable format. Tools like Tableau, Power BI, and Qlik Sense are widely used for creating dashboards and reports.
Programming Languages: Python and R are the dominant languages for data manipulation, statistical analysis, and integrating with Big Data tools. Python's extensive libraries (Pandas, NumPy, Scikit-learn) make it particularly versatile.
Promising Career Paths in Big Data Analytics
As Big Data professionals in India was fast evolving, there were diverse professional roles that were offered with handsome perks:
Big Data Engineer: Designs, builds, and maintains the large-scale data processing systems and infrastructure.
Big Data Analyst: Work on big datasets, finding trends, patterns, and insights that big decisions can be made on.
Data Scientist: Utilize statistics, programming, and domain expertise to create predictive models and glean deep insights from data.
Machine Learning Engineer: Concentrates on the deployment and development of machine learning models on Big Data platforms.
Data Architect: Designs the entire data environment and strategy of an organization.
Launch Your Big Data Analytics Career
Some more Specialized Big Data Analytics course should be taken if you feel very much attracted to data and what it can do. Hence, many computer training institutes in Ahmedabad offer comprehensive courses covering these tools and concepts of Big Data Analytics, usually as a part of Data Science with Python or special training in AI and Machine Learning. Try to find those courses that offer real-time experience and projects along with industry mentoring, so as to help you compete for these much-demanded jobs.
When you are thoroughly trained in the Big Data Analytics tools and concepts, you can manipulate information for innovation and can be highly paid in the working future.
At TCCI, we don't just teach computers — we build careers. Join us and take the first step toward a brighter future.
Location: Bopal & Iskcon-Ambli in Ahmedabad, Gujarat
Call now on +91 9825618292
Visit Our Website: http://tccicomputercoaching.com/
0 notes
Text
Transform and load data
Most data requires transformations before loading into tables. You might ingest raw data directly into a lakehouse and then further transform and load into tables. Regardless of your ETL design, you can transform and load data simply using the same tools to ingest data. Transformed data can then be loaded as a file or a Delta table.
Notebooks are favored by data engineers familiar with different programming languages including PySpark, SQL, and Scala.
Dataflows Gen2 are excellent for developers familiar with Power BI or Excel since they use the PowerQuery interface.
Pipelines provide a visual interface to perform and orchestrate ETL processes. Pipelines can be as simple or as complex as you need.
0 notes
Text
Big Data Analysis Application Programming

Big data is not just a buzzword—it's a powerful asset that fuels innovation, business intelligence, and automation. With the rise of digital services and IoT devices, the volume of data generated every second is immense. In this post, we’ll explore how developers can build applications that process, analyze, and extract value from big data.
What is Big Data?
Big data refers to extremely large datasets that cannot be processed or analyzed using traditional methods. These datasets exhibit the 5 V's:
Volume: Massive amounts of data
Velocity: Speed of data generation and processing
Variety: Different formats (text, images, video, etc.)
Veracity: Trustworthiness and quality of data
Value: The insights gained from analysis
Popular Big Data Technologies
Apache Hadoop: Distributed storage and processing framework
Apache Spark: Fast, in-memory big data processing engine
Kafka: Distributed event streaming platform
NoSQL Databases: MongoDB, Cassandra, HBase
Data Lakes: Amazon S3, Azure Data Lake
Big Data Programming Languages
Python: Easy syntax, great for data analysis with libraries like Pandas, PySpark
Java & Scala: Often used with Hadoop and Spark
R: Popular for statistical analysis and visualization
SQL: Used for querying large datasets
Basic PySpark Example
from pyspark.sql import SparkSession # Create Spark session spark = SparkSession.builder.appName("BigDataApp").getOrCreate() # Load dataset data = spark.read.csv("large_dataset.csv", header=True, inferSchema=True) # Basic operations data.printSchema() data.select("age", "income").show(5) data.groupBy("city").count().show()
Steps to Build a Big Data Analysis App
Define data sources (logs, sensors, APIs, files)
Choose appropriate tools (Spark, Hadoop, Kafka, etc.)
Ingest and preprocess the data (ETL pipelines)
Analyze using statistical, machine learning, or real-time methods
Visualize results via dashboards or reports
Optimize and scale infrastructure as needed
Common Use Cases
Customer behavior analytics
Fraud detection
Predictive maintenance
Real-time recommendation systems
Financial and stock market analysis
Challenges in Big Data Development
Data quality and cleaning
Scalability and performance tuning
Security and compliance (GDPR, HIPAA)
Integration with legacy systems
Cost of infrastructure (cloud or on-premise)
Best Practices
Automate data pipelines for consistency
Use cloud services (AWS EMR, GCP Dataproc) for scalability
Use partitioning and caching for faster queries
Monitor and log data processing jobs
Secure data with access control and encryption
Conclusion
Big data analysis programming is a game-changer across industries. With the right tools and techniques, developers can build scalable applications that drive innovation and strategic decisions. Whether you're processing millions of rows or building a real-time data stream, the world of big data has endless potential. Dive in and start building smart, data-driven applications today!
0 notes
Text
Top Tools And Technologies Every Data Engineer Should Master

In today’s data-driven world, businesses of all sizes rely heavily on data to make informed decisions. This growing dependence on data has created a high demand for skilled data engineers—professionals responsible for designing and maintaining the systems and infrastructure that collect, store, and process data. Data engineers are the architects of the data pipeline, ensuring that data flows smoothly and efficiently from source to destination. With the rapid evolution of technology, aspiring and current data engineers must master a wide range of tools and technologies to succeed in this dynamic field. For those considering pursuing an M.Tech in Data Engineering, it’s essential to be familiar with the tools that form the backbone of modern data engineering.
Programming Languages: The Foundation of Data Engineering
As with any engineering discipline, data engineering relies heavily on programming to build systems that manage and process data. Proficiency in at least one, if not more, programming languages is crucial for data engineers. Some of the most important languages in the field include Python, Java, Scala, and SQL. Each of these languages has specific strengths that make them ideal for various data engineering tasks.
Python: Python is arguably the most popular language in the data engineering world due to its simplicity, extensive libraries, and strong community support. It is particularly valued for its rich ecosystem of libraries like Pandas, NumPy, and PySpark, which make it ideal for data manipulation, analysis, and processing. Python’s versatility and ease of use make it an essential tool for data engineers working on everything from small-scale data projects to large-scale big data systems.
Java and Scala: Java and Scala are commonly used in big data environments due to their performance and scalability. These languages are optimized for high-performance computing and are often used to build complex distributed data processing systems. Scala, in particular, is a popular choice for working with Apache Spark, a fast and general-purpose cluster-computing system. These languages are invaluable for data engineers who work with large volumes of data in real-time processing and high-performance environments.
SQL: Structured Query Language (SQL) is essential for data engineers working with relational databases. SQL is used to perform data extraction, transformation, and loading (ETL) operations, making it a foundational tool in the field. SQL’s ability to query and manipulate structured data makes it indispensable for data engineers, especially when dealing with large-scale transactional systems or business intelligence (BI) tools.
Databases: Storing and Managing Data: A key responsibility of data engineers is working with databases—systems used to store and manage data. Data engineers typically work with both relational and NoSQL databases, each with its own set of advantages and use cases. Understanding how to choose the right type of database for a specific task is essential.
Relational Databases: Relational databases, such as MySQL, PostgreSQL, and Oracle, organize data into tables with predefined schemas. These databases are ideal for structured data and transactional applications where the relationships between different data entities must be clearly defined.
NoSQL Databases: NoSQL databases, such as MongoDB and Cassandra, are more flexible and can handle unstructured or semi-structured data. These databases do not rely on fixed schemas, making them ideal for big data applications where the types of data and their relationships can vary.
Big Data Tools and Frameworks: Processing Large-Scale Data
Big data technologies are essential for data engineers working with large-scale datasets that cannot be processed by traditional relational databases. These tools allow data engineers to build distributed systems capable of processing vast amounts of data in parallel across multiple nodes.
Apache Hadoop: Hadoop is an open-source framework that allows for the distributed processing of large datasets across clusters of computers. It is designed to scale from single servers to thousands of machines, making it an essential tool for data engineers working with big data. Hadoop’s ecosystem includes various tools like Hadoop Distributed File System (HDFS) for storage and MapReduce for processing data in parallel.
Apache Spark: Apache Spark is another critical tool in the big data ecosystem. Spark is an open-source, distributed computing system that provides an interface for programming entire clusters. It is known for its speed and ease of use compared to Hadoop, making it a popular choice for real-time analytics, machine learning, and data processing. Data engineers must be adept at using Spark to handle large-scale data processing tasks.
Data Pipelines and ETL Tools: Managing Data Flow: Data engineers are responsible for designing and managing data pipelines, the workflows that move data from source to destination. The process involves extracting data, transforming it into a usable format, and loading it into storage systems or databases. ETL tools like Apache Airflow, Talend, and Informatica are essential for managing these workflows efficiently.
Apache Airflow: Apache Airflow is an open-source tool used to automate and schedule data workflows. It allows data engineers to define, manage, and monitor data pipelines in a programmatic way, ensuring that data flows smoothly from one system to another. Airflow’s ability to manage complex workflows makes it indispensable for data engineers working with large-scale data systems.
Talend and Informatica: These ETL tools are widely used for data integration and transformation tasks. Talend offers both open-source and enterprise versions of its software, which help data engineers extract, clean, and transform data for loading into databases or data warehouses. Informatica, on the other hand, is a popular commercial tool that provides a suite of ETL capabilities, making it suitable for large organizations with complex data needs.
Big Data Technologies: Handling Massive Datasets
With the explosion of data in recent years, big data technologies have become increasingly important for data engineers. These technologies are designed to handle massive datasets that cannot be processed by traditional databases.
Hadoop: Hadoop is a distributed storage and processing framework that allows for the processing of large datasets across a cluster of computers.
Spark: Spark is a fast and general-purpose cluster computing system that is widely used for data processing, machine learning, and real-time analytics. Spark is particularly relevant for those pursuing a mtech data science or mtech in data engineering as it is a core component of modern data pipelines.
Kafka: Kafka is a distributed streaming platform that enables real-time data ingestion and processing. It is often used for building real-time data pipelines and streaming applications.
Read our Blog on: Difference Between BSc and BSc Hons: Which One Is Better?
Cloud Computing: Scalability and Flexibility
Cloud platforms like Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure offer a wide range of services that are essential for data engineers. These services include data storage, processing, and analytics tools, as well as infrastructure management.
AWS: AWS offers services like S3 for storage, EMR for Hadoop and Spark processing, and Redshift for data warehousing.
GCP: GCP provides services like Cloud Storage for storage, Dataproc for Hadoop and Spark processing, and BigQuery for data warehousing.
Azure: Azure offers services like Blob Storage for storage, HDInsight for Hadoop and Spark processing, and Azure Synapse Analytics for data warehousing.
Data Warehousing: Building a Centralized Data Repository
Data warehousing is the process of collecting and storing data from various sources in a centralized repository. This allows businesses to perform complex data analysis and generate valuable insights.
Data Warehouses: Data warehouses are designed for analytical queries and reporting. They typically store historical data and are optimized for read operations.
ETL Tools: ETL (Extract, Transform, Load) tools are used to extract data from various sources, transform it into a consistent format, and load it into a data warehouse.
Data Orchestration: Automating Data Pipelines
Data orchestration tools are used to automate the execution of data pipelines. They allow data engineers to schedule and monitor data processing tasks, ensuring that data flows smoothly and efficiently.
Apache Airflow: Airflow is a popular open-source platform for programmatically authoring, scheduling, and monitoring workflows.
Conclusion: Choosing Your Educational Path
Becoming a successful data engineer requires a strong foundation in various tools and technologies. Choosing the right educational program is a key step in this journey. If you’re exploring data engineering programs, especially those focused on data engineering, consider institutions that offer comprehensive curricula and practical training. If you are wondering which college is best for a data engineering program then you should check out Futurense. They offer an “IIT Jodhpur PG Diploma and mtech. in data engineering”, focusing on creating ” Futurense UNI also provides a unique “Second Shot At Your IIT Dream” through various programs, including M.Techs and an MBA in Technology. This can be a valuable option for those seeking a prestigious IIT education.
Source URL: www.kinkedpress.com/tools-and-technologies-for-data-engineers
0 notes
Text
What are the languages supported by Apache Spark?
Hi,
Apache Spark is a versatile big data processing framework that supports several programming languages. Here are the main languages supported:

1. Scala: Scala is the primary language for Apache Spark and is used to develop Spark applications. Spark is written in Scala, and using Scala provides the best performance and access to all of Spark’s features. Scala’s functional programming capabilities align well with Spark’s design.
2. Java: Java is also supported by Apache Spark. It’s a common choice for developers who are familiar with the Java ecosystem. Spark’s Java API allows developers to build applications using Java, though it might be less concise compared to Scala.
3. Python: Python is widely used with Apache Spark through the PySpark API. PySpark allows developers to write Spark applications using Python, which is known for its simplicity and readability. Python’s extensive libraries make it a popular choice for data science and machine learning tasks.
4. R: Apache Spark provides support for R through the SparkR package. SparkR is designed for data analysis and statistical computing in R. It allows R users to harness Spark’s capabilities for big data processing and analytics.
5. SQL: Spark SQL is a component of Apache Spark that supports querying data using SQL. Users can run SQL queries directly on Spark data, and Spark SQL provides integration with BI tools and data sources through JDBC and ODBC drivers.
6. Others: While Scala, Java, Python, and R are the primary languages supported, Spark also has limited support for other languages through community contributions and extensions.
In summary, Apache Spark supports Scala, Java, Python, and R, making it accessible to a wide range of developers and data scientists. The support for SQL further enhances its capability to work with structured data and integrate with various data sources.
0 notes
Text
The Ultimate Guide to Becoming an Azure Data Engineer

The Azure Data Engineer plays a critical role in today's data-driven business environment, where the amount of data produced is constantly increasing. These professionals are responsible for creating, managing, and optimizing the complex data infrastructure that organizations rely on. To embark on this career path successfully, you'll need to acquire a diverse set of skills. In this comprehensive guide, we'll provide you with an extensive roadmap to becoming an Azure Data Engineer.
1. Cloud Computing
Understanding cloud computing concepts is the first step on your journey to becoming an Azure Data Engineer. Start by exploring the definition of cloud computing, its advantages, and disadvantages. Delve into Azure's cloud computing services and grasp the importance of securing data in the cloud.
2. Programming Skills
To build efficient data processing pipelines and handle large datasets, you must acquire programming skills. While Python is highly recommended, you can also consider languages like Scala or Java. Here's what you should focus on:
Basic Python Skills: Begin with the basics, including Python's syntax, data types, loops, conditionals, and functions.
NumPy and Pandas: Explore NumPy for numerical computing and Pandas for data manipulation and analysis with tabular data.
Python Libraries for ETL and Data Analysis: Understand tools like Apache Airflow, PySpark, and SQLAlchemy for ETL pipelines and data analysis tasks.
3. Data Warehousing
Data warehousing is a cornerstone of data engineering. You should have a strong grasp of concepts like star and snowflake schemas, data loading into warehouses, partition management, and query optimization.
4. Data Modeling
Data modeling is the process of designing logical and physical data models for systems. To excel in this area:
Conceptual Modeling: Learn about entity-relationship diagrams and data dictionaries.
Logical Modeling: Explore concepts like normalization, denormalization, and object-oriented data modeling.
Physical Modeling: Understand how to implement data models in database management systems, including indexing and partitioning.
5. SQL Mastery
As an Azure Data Engineer, you'll work extensively with large datasets, necessitating a deep understanding of SQL.
SQL Basics: Start with an introduction to SQL, its uses, basic syntax, creating tables, and inserting and updating data.
Advanced SQL Concepts: Dive into advanced topics like joins, subqueries, aggregate functions, and indexing for query optimization.
SQL and Data Modeling: Comprehend data modeling principles, including normalization, indexing, and referential integrity.
6. Big Data Technologies
Familiarity with Big Data technologies is a must for handling and processing massive datasets.
Introduction to Big Data: Understand the definition and characteristics of big data.
Hadoop and Spark: Explore the architectures, components, and features of Hadoop and Spark. Master concepts like HDFS, MapReduce, RDDs, Spark SQL, and Spark Streaming.
Apache Hive: Learn about Hive, its HiveQL language for querying data, and the Hive Metastore.
Data Serialization and Deserialization: Grasp the concept of serialization and deserialization (SerDe) for working with data in Hive.
7. ETL (Extract, Transform, Load)
ETL is at the core of data engineering. You'll need to work with ETL tools like Azure Data Factory and write custom code for data extraction and transformation.
8. Azure Services
Azure offers a multitude of services crucial for Azure Data Engineers.
Azure Data Factory: Create data pipelines and master scheduling and monitoring.
Azure Synapse Analytics: Build data warehouses and marts, and use Synapse Studio for data exploration and analysis.
Azure Databricks: Create Spark clusters for data processing and machine learning, and utilize notebooks for data exploration.
Azure Analysis Services: Develop and deploy analytical models, integrating them with other Azure services.
Azure Stream Analytics: Process real-time data streams effectively.
Azure Data Lake Storage: Learn how to work with data lakes in Azure.
9. Data Analytics and Visualization Tools
Experience with data analytics and visualization tools like Power BI or Tableau is essential for creating engaging dashboards and reports that help stakeholders make data-driven decisions.
10. Interpersonal Skills
Interpersonal skills, including communication, problem-solving, and project management, are equally critical for success as an Azure Data Engineer. Collaboration with stakeholders and effective project management will be central to your role.
Conclusion
In conclusion, becoming an Azure Data Engineer requires a robust foundation in a wide range of skills, including SQL, data modeling, data warehousing, ETL, Azure services, programming, Big Data technologies, and communication skills. By mastering these areas, you'll be well-equipped to navigate the evolving data engineering landscape and contribute significantly to your organization's data-driven success.
Ready to Begin Your Journey as a Data Engineer?
If you're eager to dive into the world of data engineering and become a proficient Azure Data Engineer, there's no better time to start than now. To accelerate your learning and gain hands-on experience with the latest tools and technologies, we recommend enrolling in courses at Datavalley.
Why choose Datavalley?
At Datavalley, we are committed to equipping aspiring data engineers with the skills and knowledge needed to excel in this dynamic field. Our courses are designed by industry experts and instructors who bring real-world experience to the classroom. Here's what you can expect when you choose Datavalley:
Comprehensive Curriculum: Our courses cover everything from Python, SQL fundamentals to Snowflake advanced data engineering, cloud computing, Azure cloud services, ETL, Big Data foundations, Azure Services for DevOps, and DevOps tools.
Hands-On Learning: Our courses include practical exercises, projects, and labs that allow you to apply what you've learned in a real-world context.
Multiple Experts for Each Course: Modules are taught by multiple experts to provide you with a diverse understanding of the subject matter as well as the insights and industrial experiences that they have gained.
Flexible Learning Options: We provide flexible learning options to learn courses online to accommodate your schedule and preferences.
Project-Ready, Not Just Job-Ready: Our program prepares you to start working and carry out projects with confidence.
Certification: Upon completing our courses, you'll receive a certification that validates your skills and can boost your career prospects.
On-call Project Assistance After Landing Your Dream Job: Our experts will help you excel in your new role with up to 3 months of on-call project support.
The world of data engineering is waiting for talented individuals like you to make an impact. Whether you're looking to kickstart your career or advance in your current role, Datavalley's Data Engineer Masters Program can help you achieve your goals.
#datavalley#dataexperts#data engineering#dataexcellence#data engineering course#online data engineering course#data engineering training
0 notes
Text
What is Snowpark?

Snowpark is an open-source programming model and language. It aims to simplify the process of writing and executing data processing tasks on various data platforms. Snowpark provides a unified interface for developers to write code in their preferred languages, such as:
Java
Scala
Python.
This makes it seamlessly integrate with the underlying data processing frameworks.
In this microblog, we will explore Snowpark's key features and delve into its significant advantages.
Key Features of Snowpark
Here are the top 3 key features of Snowpark:
Polyglot Support: Snowpark supports multiple programming languages. Thus, allowing developers to code in their preferred language and leverage their existing skills.
Seamless Integration: Snowpark integrates with popular frameworks like Apache Spark. This provides a unified interface for developers to access the full capabilities of these frameworks in their chosen language.
Interactive Development: Snowpark offers a REPL (Read-Eval-Print Loop) environment for interactive code development. This enables faster iteration, prototyping, and debugging with instant feedback.
So, Snowpark allows developers to leverage their language skills and work more flexibly, unlike Spark or PySpark. Furthermore, discover the unique advantages of Snowpark and know about the difference it makes.
Advantages of Implementing Snowpark
Here are the advantages of Snowpark over other programming models:
Language Flexibility: Snowpark stands out by providing polyglot support. Thus, allowing developers to write code in their preferred programming language. In contrast, Spark and PySpark primarily focus on Scala and Python. Snowpark's language flexibility enables organizations to leverage their existing language skills and choose the most suitable language.
Ease of Integration: It seamlessly integrates with frameworks like Apache Spark. This integration enables developers to harness the power of Spark's distributed computing capabilities while leveraging Snowpark's language flexibility. In comparison, Spark and PySpark offer a narrower integration scope which limits the choice of languages.
Interactive Development Environment: Snowpark provides an interactive development environment. This environment allows developers to write, test, and refine code iteratively, offering instant feedback. In contrast, Spark and PySpark lack this built-in interactive environment, potentially slowing down the development process.
Expanded Use Cases: While Spark and PySpark primarily target data processing tasks, Snowpark offers broader applicability. It supports diverse use cases such as data transformations, analytics, and machine learning. This versatility allows organizations to leverage Snowpark across a wider range of data processing scenarios, enabling comprehensive solutions and flexibility.
Increased Developer Productivity: Snowpark's language flexibility and interactive environment boost developer productivity. Developers can work in their preferred programming language, receive real-time feedback, and streamline the development process. In contrast, Spark and PySpark's language constraints may hinder productivity due to the need to learn new languages or adapt to limited options.
Therefore, Snowpark revolutionizes big data processing by offering a versatile platform that supports multiple programming languages. By adopting Snowpark, developers can enhance their efficiency in executing data processing tasks.
This powerful tool has the potential to drive innovation. It can also streamline development efforts and open exciting new opportunities for businesses. Also, stay updated with Nitor Infotech’s latest tech blogs.
#snowpark#snowflake#blog#Bigdata#data processing services#Data transformation#Apache Spark#Open-source#nitorinfotech#big data analytics#automation#software services
0 notes
Text
Pyspark Tutorial
What is the purpose of PySpark?
· PySpark allows you to easily integrate and interact with Resilient Distributed Datasets (RDDs) in Python.
· PySpark is a fantastic framework for working with large datasets because of its many capabilities.
· PySpark provides a large selection of libraries, making Machine Learning and Real-Time Streaming Analytics easy.
· PySpark combines Python's ease of use with Apache Spark's capabilities for taming Big Data.
· The power of technologies like Apache Spark and Hadoop has been developed as a result of the emergence of Big Data.
· A data scientist can efficiently manage enormous datasets, and any Python developer can do the same.
Python Big Data Concepts
Python is a high-level programming language that supports a wide range of programming paradigms, including object-oriented programming (OOPs), asynchronous programming, and functional programming.
When it comes to Big Data, functional programming is a crucial paradigm. It uses parallel programming, which means you can run your code on many CPUs or on completely other machines. The PySpark ecosystem has the capability to distribute functioning code over a cluster of machines.
Python's standard library and built-ins contain functional programming basic notions for programmers.
The essential principle of functional programming is that data manipulation occurs through functions without any external state management. This indicates that your code avoids using global variables and does not alter data in-place, instead returning new data. The lambda keyword in Python is used to expose anonymous functions.
The following are some of PySpark key features:
· PySpark is one of the most used frameworks for working with large datasets. It also works with a variety of languages.
· Disk persistence and caching: The PySpark framework has excellent disk persistence and caching capabilities.
· Fast processing: When compared to other Big Data processing frameworks, the PySpark framework is rather quick.
· Python is a dynamically typed programming language that makes it easy to work with Resilient Distributed Datasets.
What exactly is PySpark?
PySpark is supported by two types of evidence:
· The PySpark API includes a large number of examples.
· The Spark Scala API transforms Scala code, which is a very legible and work-based programming language, into Python code and makes it understandable for PySpark projects.
Py4J allows a Python program to communicate with a JVM-based software. PySpark can use it to connect to the Spark Scala-based Application Programming Interface.
Python Environment in PySpark
Self-Hosted: You can create a collection or clump on your own in this situation. You can use metal or virtual clusters in this environment. Some suggested projects, such as Apache Ambari, are appropriate for this purpose. However, this procedure is insufficiently rapid.
Cloud Service Providers: Spark clusters are frequently employed in this situation. Self-hosting takes longer than this environment. Electronic MapReduce (EMR) is provided by Amazon Web Services (AWS), while Dataproc is provided by Good Clinical Practice (GCP).
Spark solutions are provided by Databricks and Cloudera, respectively. It's one of the quickest ways to get PySpark up and running.
Programming using PySpark
Python, as we all know, is a high-level programming language with several libraries. It is extremely important in Machine Learning and Data Analytics. As a result, PySpark is a Python-based Spark API. Spark has some great features, such as rapid speed, quick access, and the ability to be used for streaming analytics. Furthermore, the Spark and Python frameworks make it simple for PySpark to access and analyse large amounts of data.
RDDs (Resilient Distributed Datasets): RDDs (Resilient Distributed Datasets) are a key component of the PySpark programming framework. This collection can't be changed and only goes through minor transformations. Each letter in this abbreviation has a specific meaning. It has a high level of resiliency since it can tolerate errors and recover data. It's scattered because it spreads out over a clump of other nodes. The term "dataset" refers to a collection of data values.
PySpark's Benefits
This section can be broken down into two pieces. First and foremost, you will learn about the benefits of utilizing Python in PySpark, as well as the benefits of PySpark itself.
It is simple to learn and use because it is a high-level and coder-friendly language.
It is possible to use a simple and inclusive API.
Python provides a wonderful opportunity for the reader to visualize data.
Python comes with a large number of libraries. Matplotlib, Pandas, Seaborn, NumPy, and others are some of the examples.
0 notes
Text
SBTB 2021 Program is Up!
Scale By the Bay (SBTB) is in its 9th year.
See the 2021 Scale By the Bay Program
When we started, Big Data was Hadoop, with Spark and Kafka quite new and uncertain. Deep Learning was in the lab, and distributed systems were managed by a menagerie sysadmin tools such as Ansible, Salt, Puppet and Chef. Docker and Kubernetes were in the future, but Mesos had proven itself at Twitter, and a young startup called Mesosphere was bringing it to the masses. Another thing proven at Twitter, as well as in Kafka and Spark, was Scala, but the golden era of functional programming in industry was still ahead of us.
AI was still quite unglamorous Machine Learning, Data Mining, Analytics, and Business Intelligence.
But the key themes of SBTB were already there:
Thoughtful Software Engineering
Software Architectures and Data Pipelines
Data-driven Applications at Scale
The overarching idea of SBTB is that all great scalable systems are a combination of all three. The notions pioneered by Mesos became Kubernetes and its CNCF ecosystem. Scala took hold in industry alongside Haskell, OCaml, Cloujure, and F#. New languages like Rust and Dhall emerged with similar ideas and ideals. Data pipelines were formed around APIs, REST and GraphQL, and tools like Apache Kafka. ML became AI, and every scaled business application became an AI application.
SBTB tracks the evolution of the state of the art in all three of its tracks, nicknamed Functional, Cloud, and Data. The core idea is still making distributed systems solve complex business problems at the web scale, doable by small teams of inspired and happy software engineers. Happiness comes from learning, technology choices automating away the mundane, and a scientific approach to the field. We see the arc of learning elevating through the years, as functional programming concepts drive deep into category theory, type systems are imposed on the deep learning frameworks and tensors, middleware abstracted via GraphQL formalisms, compute made serverless, AI hitting the road as model deployment, and so on. Let's visit some of the highlights of this evolution in the 2021 program.
FP for ML/AI
As more and more decisions are entrusted to AI, the need to understand what happens in the deep learning systems becomes ever more urgent. While Python remains the Data Science API of choice, the underlying libraries are written in C++. The Hasktorch team shares their approach to expose PyTorch capabilities in Haskell, building up to the transformers with the Gradual Typing. The clarity of composable representations of the deep learning systems will warm many a heart tested by the industry experience where types ensure safety and clarity.
AI
We learn how Machine Learning is used to predict financial time series. We consider the bias in AI and hardware vs software directions of its acceleration. We show how an AI platform can be built from scratch using OSS tools. Practical AI deployments is covered by DVC experiments. We look at the ways Transformers are transforming Autodesk. We see how Machine Learning is becoming reproducible with MLOps at Microsoft. We even break AI dogma with Apache NLPCraft.
Cloud
Our cloud themes include containers with serverless functions, a serverless query engine, event-driven patterns for microservices, and a series of practical stacks. We review the top CNCF projects to watch. Ever-green formidable challenges like data center migration to the cloud at Workday scale are presented by the lead engineers who made it happen. Fine points of scalability are explored beyond auto-scaling. We look at stateful reactive streams with Akka and Kafka, and the ways to retrofit your Java applications with reactive pipelines for more efficiency. See how Kubernetes can spark joy for your developers.
Core OSS Frameworks
As always, we present the best practices deploying OSS projects that our communities adopted before the rest -- Spark, Kafka, Druid, integrating them in the data pipelines and tuning for the best performance and ML integration at scale. We cover multiple aspects of tuning Spark performance, using PySpark with location and graph data. We rethink the whole ML ecosystem with Spark. We elucidate patterns of Kafka deployments for building microservice architectures.
Software Engineering
Programming language highlights include Scala 3 transition is illuminated by Dean Wampler and Bill Venners, Meaning for the Masses from Twitter, purity spanning frontend to backend, using type safety for tensor calculus in Haskell and Scala, using Rust for WebAssembly, a categorical view of ADTs, distributed systems and tracing in Swift, complex codebase troubleshooting, dependent and linear types, declarative backends, efficient arrays in Scala 3, and using GraalVM to optimize ML serving. We are also diving into Swift for distributed systems with its core team.
Other Topics
We look at multidimensional clustering, the renessance of the relational databases, cloud SQL and data lakes, location and graph data, meshes, and other themes.
There are fundamental challenges that face the industry for years to come, such as AI bias we rigirously explore, hardware and software codevelopment for AI acceleration, and moving large enterprise codebases from on-prem to the cloud, as we see with Workday.
The companies presenting include Apple, Workday, Nielsen, Uber, Google Brain, Nvidia, Domino Data Labs, Autodesk, Twitter, Microsoft, IBM, Databricks, and many others.# Scale By the Bay 2021 Program is Up!
Reserve your pass today
0 notes
Photo

ABOUT US
Think Training ... Join iconGen IT Solutions, the best software training institute in Chennai India always delivers excellence in education
OUR TRAINING
Classroom Training
Online Training
Corporate Training
QUICK LINKS
Home
Course
Placement
Blog
Reach Us
REACH US
No:10/1, SPIC Nagar,
Vijayanagar, Velachery
Chennai, Tamil Nadu 600042
India.
+91 9361217989
Big Data Hadoop Training | Big Data Hadoop Training in Chennai India | Best Big Data Hadoop Online Training in Chennai Velachery| Best SPARK & SCALA Online Training in Chennai India | Apache Spark & Scala Online Course Training in Chennai Velachery | Data Science with R training in Chennai| Machine Learning In Python in Velachery Chennai | Best KAFKA Online Training in Chennai India | Best ADVANCE JAVA Training in Chennai| Data Science with Python training in Chennai |Data Science with Python online training| Best Data Science with R Online Course Training in Chennai India | Machine Learning with R Training in Chennai | Data science training Chennai | Best CASSANDRA Training in Chennai | Best MONGODB Training in Chennai | Best DEVOPS Training in Chennai | Best IOT Training in Chennai | Best PYTHON Training in Chennai| Best AWS Training in Chennai | MANUAL TESTING | SELENIUM TESTING |iconGen IT Solutions in Chennai India| PySpark training in Chennai| Best spark training in Chennai| R programming training in Chennai | R training in Chennai.
#R programming training in Chennai#R training in Chennai#Big Data Hadoop Training in Chennai India#Hadoop Training in Chennai#Big Data Hadoop Online Training#Data Science Training In Chennai#Data Science with Python Training in Chennai#big data training in Chennai#Data Science with Python Online Training#Data Science with R Training in Chennai#lockdown#lock#online training#free software training#stayhome#staysafe
0 notes
Text
300+ TOP PYSPARK Interview Questions and Answers
PYSPARK Interview Questions for freshers experienced :-
1. What is Pyspark? Pyspark is a bunch figuring structure which keeps running on a group of item equipment and performs information unification i.e., perusing and composing of wide assortment of information from different sources. In Spark, an undertaking is an activity that can be a guide task or a lessen task. Flash Context handles the execution of the activity and furthermore gives API’s in various dialects i.e., Scala, Java and Python to create applications and quicker execution when contrasted with MapReduce. 2. How is Spark not quite the same as MapReduce? Is Spark quicker than MapReduce? Truly, Spark is quicker than MapReduce. There are not many significant reasons why Spark is quicker than MapReduce and some of them are beneath: There is no tight coupling in Spark i.e., there is no compulsory principle that decrease must come after guide. Spark endeavors to keep the information “in-memory” however much as could be expected. In MapReduce, the halfway information will be put away in HDFS and subsequently sets aside longer effort to get the information from a source yet this isn’t the situation with Spark. 3. Clarify the Apache Spark Architecture. How to Run Spark applications? Apache Spark application contains two projects in particular a Driver program and Workers program. A group supervisor will be there in the middle of to communicate with these two bunch hubs. Sparkle Context will stay in contact with the laborer hubs with the assistance of Cluster Manager. Spark Context resembles an ace and Spark laborers resemble slaves. Workers contain the agents to run the activity. In the event that any conditions or contentions must be passed, at that point Spark Context will deal with that. RDD’s will dwell on the Spark Executors. You can likewise run Spark applications locally utilizing a string, and on the off chance that you need to exploit appropriated conditions you can take the assistance of S3, HDFS or some other stockpiling framework. 4. What is RDD? RDD represents Resilient Distributed Datasets (RDDs). In the event that you have enormous measure of information, and isn’t really put away in a solitary framework, every one of the information can be dispersed over every one of the hubs and one subset of information is called as a parcel which will be prepared by a specific assignment. RDD’s are exceptionally near information parts in MapReduce. 5. What is the job of blend () and repartition () in Map Reduce? Both mix and repartition are utilized to change the quantity of segments in a RDD however Coalesce keeps away from full mix. On the off chance that you go from 1000 parcels to 100 segments, there won’t be a mix, rather every one of the 100 new segments will guarantee 10 of the present allotments and this does not require a mix. Repartition plays out a blend with mix. Repartition will result in the predefined number of parcels with the information dispersed utilizing a hash professional. 6. How would you determine the quantity of parcels while making a RDD? What are the capacities? You can determine the quantity of allotments while making a RDD either by utilizing the sc.textFile or by utilizing parallelize works as pursues: Val rdd = sc.parallelize(data,4) val information = sc.textFile(“path”,4) 7. What are activities and changes? Changes make new RDD’s from existing RDD and these changes are sluggish and won’t be executed until you call any activity. Example:: map(), channel(), flatMap(), and so forth., Activities will return consequences of a RDD. Example:: lessen(), tally(), gather(), and so on., 8. What is Lazy Evaluation? On the off chance that you make any RDD from a current RDD that is called as change and except if you consider an activity your RDD won’t be emerged the reason is Spark will defer the outcome until you truly need the outcome in light of the fact that there could be a few circumstances you have composed something and it turned out badly and again you need to address it in an intuitive manner it will expand the time and it will make un-essential postponements. Additionally, Spark improves the required figurings and takes clever choices which is beyond the realm of imagination with line by line code execution. Sparkle recoups from disappointments and moderate laborers. 9. Notice a few Transformations and Actions Changes map (), channel(), flatMap() Activities diminish(), tally(), gather() 10. What is the job of store() and continue()? At whatever point you need to store a RDD into memory with the end goal that the RDD will be utilized on different occasions or that RDD may have made after loads of complex preparing in those circumstances, you can exploit Cache or Persist. You can make a RDD to be continued utilizing the persevere() or store() works on it. The first occasion when it is processed in an activity, it will be kept in memory on the hubs. When you call persevere(), you can indicate that you need to store the RDD on the plate or in the memory or both. On the off chance that it is in-memory, regardless of whether it ought to be put away in serialized organization or de-serialized position, you can characterize every one of those things. reserve() resembles endure() work just, where the capacity level is set to memory as it were.

11. What are Accumulators? Collectors are the compose just factors which are introduced once and sent to the specialists. These specialists will refresh dependent on the rationale composed and sent back to the driver which will total or process dependent on the rationale. No one but driver can get to the collector’s esteem. For assignments, Accumulators are compose as it were. For instance, it is utilized to include the number blunders seen in RDD crosswise over laborers. 12. What are Broadcast Variables? Communicate Variables are the perused just shared factors. Assume, there is a lot of information which may must be utilized on various occasions in the laborers at various stages. 13. What are the enhancements that engineer can make while working with flash? Flash is memory serious, whatever you do it does in memory. Initially, you can alter to what extent flash will hold up before it times out on every one of the periods of information region information neigh borhood process nearby hub nearby rack neighborhood Any. Channel out information as ahead of schedule as could be allowed. For reserving, pick carefully from different capacity levels. Tune the quantity of parcels in sparkle. 14. What is Spark SQL? Flash SQL is a module for organized information handling where we exploit SQL questions running on the datasets. 15. What is a Data Frame? An information casing resembles a table, it got some named sections which composed into segments. You can make an information outline from a document or from tables in hive, outside databases SQL or NoSQL or existing RDD’s. It is practically equivalent to a table. 16. How might you associate Hive to Spark SQL? The principal significant thing is that you need to place hive-site.xml record in conf index of Spark. At that point with the assistance of Spark session object we can develop an information outline as, 17. What is GraphX? Ordinarily you need to process the information as charts, since you need to do some examination on it. It endeavors to perform Graph calculation in Spark in which information is available in documents or in RDD’s. GraphX is based on the highest point of Spark center, so it has got every one of the abilities of Apache Spark like adaptation to internal failure, scaling and there are numerous inbuilt chart calculations too. GraphX binds together ETL, exploratory investigation and iterative diagram calculation inside a solitary framework. You can see indistinguishable information from the two charts and accumulations, change and unite diagrams with RDD effectively and compose custom iterative calculations utilizing the pregel API. GraphX contends on execution with the quickest diagram frameworks while holding Spark’s adaptability, adaptation to internal failure and convenience. 18. What is PageRank Algorithm? One of the calculation in GraphX is PageRank calculation. Pagerank measures the significance of every vertex in a diagram accepting an edge from u to v speaks to a supports of v’s significance by u. For exmaple, in Twitter if a twitter client is trailed by numerous different clients, that specific will be positioned exceptionally. GraphX accompanies static and dynamic executions of pageRank as techniques on the pageRank object. 19. What is Spark Streaming? At whatever point there is information streaming constantly and you need to process the information as right on time as could reasonably be expected, all things considered you can exploit Spark Streaming. 20. What is Sliding Window? In Spark Streaming, you need to determine the clump interim. In any case, with Sliding Window, you can indicate what number of last clumps must be handled. In the beneath screen shot, you can see that you can indicate the clump interim and what number of bunches you need to process. 21. Clarify the key highlights of Apache Spark. Coming up next are the key highlights of Apache Spark: Polyglot Speed Multiple Format Support Lazy Evaluation Real Time Computation Hadoop Integration Machine Learning 22. What is YARN? Like Hadoop, YARN is one of the key highlights in Spark, giving a focal and asset the executives stage to convey adaptable activities over the bunch. YARN is a conveyed holder chief, as Mesos for instance, while Spark is an information preparing instrument. Sparkle can keep running on YARN, a similar way Hadoop Map Reduce can keep running on YARN. Running Spark on YARN requires a double dispersion of Spark as based on YARN support. 23. Do you have to introduce Spark on all hubs of YARN bunch? No, in light of the fact that Spark keeps running over YARN. Flash runs autonomously from its establishment. Sparkle has a few alternatives to utilize YARN when dispatching employments to the group, as opposed to its very own inherent supervisor, or Mesos. Further, there are a few arrangements to run YARN. They incorporate ace, convey mode, driver-memory, agent memory, agent centers, and line. 24. Name the parts of Spark Ecosystem. Spark Core: Base motor for huge scale parallel and disseminated information handling Spark Streaming: Used for handling constant spilling information Spark SQL: Integrates social handling with Spark’s useful programming API GraphX: Graphs and chart parallel calculation MLlib: Performs AI in Apache Spark 25. How is Streaming executed in Spark? Clarify with precedents. Sparkle Streaming is utilized for handling constant gushing information. Along these lines it is a helpful expansion deeply Spark API. It empowers high-throughput and shortcoming tolerant stream handling of live information streams. The crucial stream unit is DStream which is fundamentally a progression of RDDs (Resilient Distributed Datasets) to process the constant information. The information from various sources like Flume, HDFS is spilled lastly handled to document frameworks, live dashboards and databases. It is like bunch preparing as the information is partitioned into streams like clusters. 26. How is AI executed in Spark? MLlib is adaptable AI library given by Spark. It goes for making AI simple and adaptable with normal learning calculations and use cases like bunching, relapse separating, dimensional decrease, and alike. 27. What record frameworks does Spark support? The accompanying three document frameworks are upheld by Spark: Hadoop Distributed File System (HDFS). Local File framework. Amazon S3 28. What is Spark Executor? At the point when SparkContext associates with a group chief, it obtains an Executor on hubs in the bunch. Representatives are Spark forms that run controls and store the information on the laborer hub. The last assignments by SparkContext are moved to agents for their execution. 29. Name kinds of Cluster Managers in Spark. The Spark system underpins three noteworthy sorts of Cluster Managers: Standalone: An essential administrator to set up a group. Apache Mesos: Generalized/regularly utilized group administrator, additionally runs Hadoop MapReduce and different applications. YARN: Responsible for asset the board in Hadoop. 30. Show some utilization situations where Spark beats Hadoop in preparing. Sensor Data Processing: Apache Spark’s “In-memory” figuring works best here, as information is recovered and joined from various sources. Real Time Processing: Spark is favored over Hadoop for constant questioning of information. for example Securities exchange Analysis, Banking, Healthcare, Telecommunications, and so on. Stream Processing: For preparing logs and identifying cheats in live streams for cautions, Apache Spark is the best arrangement. Big Data Processing: Spark runs upto multiple times quicker than Hadoop with regards to preparing medium and enormous estimated datasets. 31. By what method can Spark be associated with Apache Mesos? To associate Spark with Mesos: Configure the sparkle driver program to associate with Mesos. Spark paired bundle ought to be in an area open by Mesos. Install Apache Spark in a similar area as that of Apache Mesos and design the property ‘spark.mesos.executor.home’ to point to the area where it is introduced. 32. How is Spark SQL not the same as HQL and SQL? Flash SQL is a unique segment on the Spark Core motor that supports SQL and Hive Query Language without changing any sentence structure. It is conceivable to join SQL table and HQL table to Spark SQL. 33. What is ancestry in Spark? How adaptation to internal failure is accomplished in Spark utilizing Lineage Graph? At whatever point a progression of changes are performed on a RDD, they are not assessed promptly, however languidly. At the point when another RDD has been made from a current RDD every one of the conditions between the RDDs will be signed in a diagram. This chart is known as the ancestry diagram. Consider the underneath situation Ancestry chart of every one of these activities resembles: First RDD Second RDD (applying map) Third RDD (applying channel) Fourth RDD (applying check) This heredity diagram will be helpful on the off chance that if any of the segments of information is lost. Need to set spark.logLineage to consistent with empower the Rdd.toDebugString() gets empowered to print the chart logs. 34. What is the contrast between RDD , DataFrame and DataSets? RDD : It is the structure square of Spark. All Dataframes or Dataset is inside RDDs. It is lethargically assessed permanent gathering objects RDDS can be effectively reserved if a similar arrangement of information should be recomputed. DataFrame : Gives the construction see ( lines and segments ). It tends to be thought as a table in a database. Like RDD even dataframe is sluggishly assessed. It offers colossal execution due to a.) Custom Memory Management – Data is put away in off load memory in twofold arrangement .No refuse accumulation because of this. Optimized Execution Plan – Query plans are made utilizing Catalyst analyzer. DataFrame Limitations : Compile Time wellbeing , i.e no control of information is conceivable when the structure isn’t known. DataSet : Expansion of DataFrame DataSet Feautures – Provides best encoding component and not at all like information edges supports arrange time security. 35. What is DStream? Discretized Stream (DStream) Apache Spark Discretized Stream is a gathering of RDDS in grouping . Essentially, it speaks to a flood of information or gathering of Rdds separated into little clusters. In addition, DStreams are based on Spark RDDs, Spark’s center information reflection. It likewise enables Streaming to flawlessly coordinate with some other Apache Spark segments. For example, Spark MLlib and Spark SQL. 36. What is the connection between Job, Task, Stage ? Errand An errand is a unit of work that is sent to the agent. Each stage has some assignment, one undertaking for every segment. The Same assignment is done over various segments of RDD. Occupation The activity is parallel calculation comprising of numerous undertakings that get produced in light of activities in Apache Spark. Stage Each activity gets isolated into littler arrangements of assignments considered stages that rely upon one another. Stages are named computational limits. All calculation is impossible in single stage. It is accomplished over numerous stages. 37. Clarify quickly about the parts of Spark Architecture? Flash Driver: The Spark driver is the procedure running the sparkle setting . This driver is in charge of changing over the application to a guided diagram of individual strides to execute on the bunch. There is one driver for each application. 38. How might you limit information moves when working with Spark? The different manners by which information moves can be limited when working with Apache Spark are: Communicate and Accumilator factors 39. When running Spark applications, is it important to introduce Spark on every one of the hubs of YARN group? Flash need not be introduced when running a vocation under YARN or Mesos in light of the fact that Spark can execute over YARN or Mesos bunches without influencing any change to the group. 40. Which one will you decide for an undertaking – Hadoop MapReduce or Apache Spark? The response to this inquiry relies upon the given undertaking situation – as it is realized that Spark utilizes memory rather than system and plate I/O. In any case, Spark utilizes enormous measure of RAM and requires devoted machine to create viable outcomes. So the choice to utilize Hadoop or Spark changes powerfully with the necessities of the venture and spending plan of the association. 41. What is the distinction among continue() and store() endure () enables the client to determine the capacity level while reserve () utilizes the default stockpiling level. 42. What are the different dimensions of constancy in Apache Spark? Apache Spark naturally endures the mediator information from different mix tasks, anyway it is regularly proposed that clients call persevere () technique on the RDD on the off chance that they intend to reuse it. Sparkle has different tirelessness levels to store the RDDs on circle or in memory or as a mix of both with various replication levels. 43. What are the disservices of utilizing Apache Spark over Hadoop MapReduce? Apache Spark’s in-memory ability now and again comes a noteworthy barrier for cost effective preparing of huge information. Likewise, Spark has its own record the board framework and consequently should be incorporated with other cloud based information stages or apache hadoop. 44. What is the upside of Spark apathetic assessment? Apache Spark utilizes sluggish assessment all together the advantages: Apply Transformations tasks on RDD or “stacking information into RDD” isn’t executed quickly until it sees an activity. Changes on RDDs and putting away information in RDD are languidly assessed. Assets will be used in a superior manner if Spark utilizes sluggish assessment. Lazy assessment advances the plate and memory utilization in Spark. The activities are activated just when the information is required. It diminishes overhead. 45. What are advantages of Spark over MapReduce? Because of the accessibility of in-memory handling, Spark executes the preparing around 10 to multiple times quicker than Hadoop MapReduce while MapReduce utilizes diligence stockpiling for any of the information handling errands. Dissimilar to Hadoop, Spark gives inbuilt libraries to play out numerous errands from a similar center like cluster preparing, Steaming, Machine learning, Interactive SQL inquiries. Be that as it may, Hadoop just backings cluster handling. Hadoop is very plate subordinate while Spark advances reserving and in-memory information stockpiling. 46. How DAG functions in Spark? At the point when an Action is approached Spark RDD at an abnormal state, Spark presents the heredity chart to the DAG Scheduler. Activities are separated into phases of the errand in the DAG Scheduler. A phase contains errand dependent on the parcel of the info information. The DAG scheduler pipelines administrators together. It dispatches task through group chief. The conditions of stages are obscure to the errand scheduler.The Workers execute the undertaking on the slave. 47. What is the hugeness of Sliding Window task? Sliding Window controls transmission of information bundles between different PC systems. Sparkle Streaming library gives windowed calculations where the changes on RDDs are connected over a sliding window of information. At whatever point the window slides, the RDDs that fall inside the specific window are consolidated and worked upon to create new RDDs of the windowed DStream. 48. What are communicated and Accumilators? Communicate variable: On the off chance that we have an enormous dataset, rather than moving a duplicate of informational collection for each assignment, we can utilize a communicate variable which can be replicated to every hub at one timeand share similar information for each errand in that hub. Communicate variable assistance to give a huge informational collection to every hub. Collector: Flash capacities utilized factors characterized in the driver program and nearby replicated of factors will be produced. Aggregator are shared factors which help to refresh factors in parallel during execution and offer the outcomes from specialists to the driver. 49. What are activities ? An activity helps in bringing back the information from RDD to the nearby machine. An activity’s execution is the aftereffect of all recently made changes. lessen() is an activity that executes the capacity passed over and over until one esteem assuming left. take() move makes every one of the qualities from RDD to nearby hub. 50. Name kinds of Cluster Managers in Spark. The Spark system bolsters three noteworthy kinds of Cluster Managers: Independent : An essential administrator to set up a bunch. Apache Mesos : Summed up/ordinarily utilized group director, additionally runs Hadoop MapReduce and different applications. PYSPARK Questions and Answers Pdf Download Read the full article
0 notes
Text
Big Data with Spark and Python
It’s becoming more common that most of the business face circumstances where the data amount is higher to handle on a single machine. There are Hadoop, Apache Spark, and other technologies developed to sort out the issue. The system can be quickly and directly tapped from Python by utilizing PySpark.
Apache Spark is one of the general and faster engines mainly designed for big data processing and holds built-in modules for graph processing, machine learning, SQL, and streaming. It’s also known for their user-friendliness, speed, ability to run virtually, and even for their generality.
Spark is also one of the preferred tools, especially for data scientists and data engineers. They can make use of the Spark when doing any feature extraction, model evaluation, supervised learning, and data analysis. In this blog, we will deal with some critical concepts about Python and Spark in big data technologies.

Spark: Scala or Python?
You need to know what type of Spark you need before continuing with Scala or Python. Here are some simple concepts explained so that you can choose the right one bases on your requirements.
1. Learning Spark: Scala or Python?
When it comes to the learning curve, Python stands as the premier choice as it’s user-friendly, less verbose, easy to use, and more readable when compared with Scala. It will be perfect for people who are not having much experience in the programming part. People who have little or higher programming experience can also work with Spark in Python with a good number of benefits associated with them.
2. Spark Performance: Python or Scala?
When it comes to concurrency and performance, Scala wins the debate, and this is agreed by most of the developers. They are rapid and user-friendly when compared to python.
When it comes to concurrency, the play framework and scala make the process easier to write perfect and clean asynchronous codes that are easy to reason about. Play framework is asynchronous, and therefore, there are high chances to have a different type of concurrent connections without the hindrances of threads.
It’s also simpler to make Input and output calls in parallel so that it can enable the use of streaming, server push, and real-time technologies. Apart from it, it also helps to enhance performance.
There will be no many variations between Scala and Python in the case of DataFrame API, but you need to be aware of them when working with UDFs (User Defined Functions), which is considered to be less effective when compared to the equivalents of Scala.
In case you are dealing with Python, you need to ensure not to pass your information between RDD and DatFrame unnecessarily as the deserialization, and serialization of the information transfer is expensive.
Serialization is the process of transforming an object or thing into a progression of bytes that can be lasted to a database or disk or else can be sent via streams when it comes to deserialization, it’s the vice versa of the serialization.
3. Advanced features and Spark: Scala or Python?
Many advanced features might provide a small confusion in choosing Scala or Python. When it comes to data science, you can prefer Python over Scala as it offers the user with different tools for natural language processing and machine learning like SparkMLib.
4. Type Safety and Spark: Python or Scala?
The advanced features and safety are two things that stand for both Scala and Python. When it comes to type safety, you can choose Python, and this is best when you are performing experiments in smaller ad hoc. If you are working for some more significant projects, then scala would be the right choice. The reason for this is that Scala is statically typed language, hassle-free, easier when you are refactoring.
As a whole, both languages possess the positives and drawbacks while working with Spark. You need to choose the best one based on your team capabilities and project requirements.
How to install Spark?
Installing Spark us something tedious, but you can do it if you follow the below steps in the right manner.
1. Make sure you have Java JDK installed.
2. Once you are aware that it has been installed, you can go to the download page of the spark. You need to choose the default options up to third steps, and at the fourth step, you will find a downloadable link to download it.
3. Make sure you find untar the directory in your Downloads folder.
4. Once you find the folder, move to /usr/local/spark
5. Now, open the README file from the option.
6. The next step is to build spark, and you can do this by running a command “$ build/mvn -DskipTests clean package run.”
7. The next steps are to type “./bin/pyspark” in the same folder to start working in the Spark Shell.
8. You can now start to work.
Spark APIs: DataFrame, Dataset, and RDD.
There are three distinctive APIs that would make great confusion to anyone who is just getting started with the Spark. Let’s check out about the Spark APIs in depth below.
1. RDD:
RDD, derived as the “building blocks” of the spark, is the original API that is exposed by the Spark, and it’s considered to be the higher-level APIs when compared to other ones. RDD is a set of Scala or Java objects that represent data, and this is pointed out from the perspective of a developer.
RDD has three primary specifications; namely, they are based on the Scala collections API, they are lazy, and they are compile-time type-safe. There are many advantages of RDD, but they also lack in some cases. For instance, it’s simple to develop transformation chains, but they are relatively and inefficiently slow when taking non-JVM languages like Python. Spark can not optimize them.
2. DataFrames:
To overcome the disadvantages of RDD, The API DataFrame was incorporated. It offers you the right level of abstraction, which enables you to make use of the query language to operate the data. This level of abstraction is considered to be the logic plan which indicates schema and data. It also shows that interacting with your data at the frontend is too easy. To execute this, the logical idea will be transformed into a physical plan.
DataFrames are developed on top of RDDs. The improvement and performance of DataFrame are due to a few things that you come across often when you are dealing with data frames, namely optimized execution plans and custom memory management.
3. Datasets:
DataFrame deals with one crucial drawback, namely it has lost the safety of the compile-time type, which means it will make the code more inclined to hindrances and errors. To overcome the drawback dataset was raised and this deals with getting back the type-safety and also make use of the lambda functions which indicates that you capture some benefits of RDDs and also you are not losing the optimization offered by the data frames.
Which the proper time to use the APIs?
Choose RDD when you need to perform low-level actions and transformations on any unstructured data. It indicates that you are not caring about establishing a schema while accessing or processing the attributed by column or name.
Apart from that, you need not require the performance and optimization advantages that DataSets and DataFrame provide for semi-structured data. You can also make use of the RDD when you need to handle the data with various constructs of functional programming when compared to particular domain expressions.
You can make use of the DataFrames in case you are working with PySpark as they are close to the structure of DataFrames. DataSets are not the perfect one in case of Python as it lacks compile type and time safety of the Python. The dataset API is ideal for when you need to use SQL queries, the use of lambda function on a data that is semi-structured, high-level expressions, columnar access, and more.
So what are your views on Big Data with Python and Spark? Are you interested to learn more about Spark and Python in Big Data? Let us know through the comment section below.
0 notes
Text
Python Spark Shell - PySpark - Word Count Example
Python Spark Shell – PySpark – Word Count Example
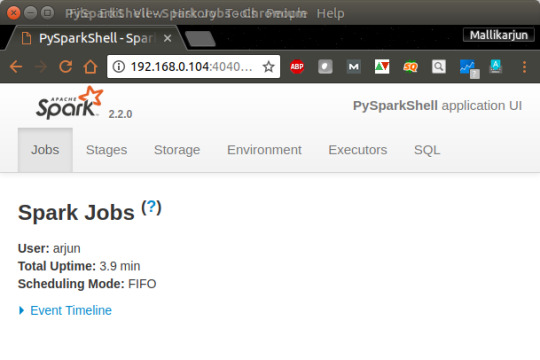
Spark Shell
Spark Shell is an interactive shell through which we can access Spark’s API. Spark provides the shell in two programming languages : Scala and Python. In this Apache Spark Tutorial, we shall learn the usage of Python Spark Shell with a basic word count example.
Prerequisites
It is assumed that you already installed Apache Spark on your local machine. If not, please refer Install Spark…
View On WordPress
0 notes
Text
Machine Learning Engineer
Will create ETL jobs into glue. This will be a data engineer. Experience with cloud platforms, particularly Amazon Web Services (AWS) Advanced knowledge of RDBMS as well as Columnar Databases and NoSQL. Knowledge and experience with data modeling, data warehousing Exposure to Software Engineering environment (Agile, DevOps, Architecture and Documentation Techniques) Distributed systems and parallel programming Plan, design, operation and troubleshooting of databases Experimental design ndash proof of concept (POC), systems reliability, performance and design of streamlined data delivery Experience and firm knowledge of managing multiple disparate data sources, ETL and data pipelines for machine learning and BI Conduct data analysis and ensure transformation covers all possibilities including data irregularities Ownership of data assets with accountability for tuning, optimization and scalability Experience documenting data requirementsdata stories and maintain data models Working in a team environment, interacting with multiple groups on a daily basis (very strong communication skills). Excellent knowledge of SQLT-SQL and Python AWS Glue SDK, Pyspark or Scala ETLs AWS Glue Crawlers, Catalog, ETL Jobs and Data Lake design and architecture. Experience maintaining Data Catalogs Exposure to Big Data Architecture in AWS, EMR, S3, Redshift, Athena, RDS, DynamoDB, DMS and Quicksight Data security and Data Governance best practices Basic knowledge of Machine Learning is a big plus.
source https://www.jobsinmiramar.com/it-tech-support/machine-learning-engineer-a6823e0/ source https://jobsinmiramar.tumblr.com/post/619248345988448256
0 notes
Text
Machine Learning Engineer
Will create ETL jobs into glue. This will be a data engineer. Experience with cloud platforms, particularly Amazon Web Services (AWS) Advanced knowledge of RDBMS as well as Columnar Databases and NoSQL. Knowledge and experience with data modeling, data warehousing Exposure to Software Engineering environment (Agile, DevOps, Architecture and Documentation Techniques) Distributed systems and parallel programming Plan, design, operation and troubleshooting of databases Experimental design ndash proof of concept (POC), systems reliability, performance and design of streamlined data delivery Experience and firm knowledge of managing multiple disparate data sources, ETL and data pipelines for machine learning and BI Conduct data analysis and ensure transformation covers all possibilities including data irregularities Ownership of data assets with accountability for tuning, optimization and scalability Experience documenting data requirementsdata stories and maintain data models Working in a team environment, interacting with multiple groups on a daily basis (very strong communication skills). Excellent knowledge of SQLT-SQL and Python AWS Glue SDK, Pyspark or Scala ETLs AWS Glue Crawlers, Catalog, ETL Jobs and Data Lake design and architecture. Experience maintaining Data Catalogs Exposure to Big Data Architecture in AWS, EMR, S3, Redshift, Athena, RDS, DynamoDB, DMS and Quicksight Data security and Data Governance best practices Basic knowledge of Machine Learning is a big plus.
source https://www.jobsinmiramar.com/it-tech-support/machine-learning-engineer-a6823e0/
0 notes