#sleepimportance
Text
#SleepWell#HealthySleep#SleepMatters#SleepHealth#WellBeing#SleepQuality#RestfulSleep#SleepAwareness#SleepScience#SleepBenefits#SleepHabits#SleepBetter#SleepTips#WellnessJourney#SleepDeprivation#SleepRoutine#SleepAware#SleepImportance#SleepForHealth#SleepAndWellness
0 notes
Text
5 Educational Posts for Fitness and Wellness

Maintaining a healthy lifestyle is crucial for overall wellbeing, and education plays a significant role in achieving it. Staying informed about fitness and wellness can help you stay motivated and make informed decisions about your health. Here are some educational blog posts that provide useful information related to fitness and wellness.
Tips for Staying Motivated to Exercise Staying motivated to exercise can be a challenge, especially when life gets busy or you hit a plateau. In this post, we provide practical tips for staying motivated, such as finding an accountability partner, setting realistic goals, and trying new workouts. We also discuss the benefits of exercise, such as improving mood, reducing stress, and boosting energy levels.
The Benefits of Different Types of Workouts There are many different types of workouts, from strength training to cardio to yoga. In this post, we explore the benefits of each type of workout and how they can contribute to overall fitness and wellness. For example, strength training can improve bone density and muscle mass, while cardio can improve cardiovascular health and endurance.
Healthy Eating Ideas A healthy diet is essential for overall health and wellness. In this post, we provide healthy eating ideas that are easy to incorporate into your daily routine. We discuss the benefits of eating a balanced diet, such as reducing the risk of chronic diseases and maintaining a healthy weight. We also provide ideas for healthy snacks, meals, and ways to stay hydrated.
Mindfulness and Meditation for Stress Reduction Stress is a common part of life, but it can have negative effects on mental and physical health. Mindfulness and meditation are effective tools for reducing stress and promoting relaxation. In this post, we discuss the benefits of mindfulness and meditation, as well as how to incorporate them into your daily routine. We provide tips for practicing mindfulness, such as focusing on the present moment and taking deep breaths.
Importance of Sleep for Fitness and Wellness Getting enough quality sleep is essential for overall health and wellness. In this post, we discuss the importance of sleep for physical and mental health, as well as the effects of sleep deprivation. We provide tips for improving sleep quality, such as establishing a regular sleep schedule, avoiding caffeine and alcohol before bed, and creating a relaxing bedtime routine.
In conclusion, staying informed about fitness and wellness can help you make better choices for your health. These educational blog posts provide useful information and practical tips for achieving and maintaining a healthy lifestyle. By incorporating these tips into your daily routine, you can improve your overall wellbeing and live a happier, healthier life.
#fitnesseducation#wellnesseducation#healthylifestyle#motivation#exercise#workouts#healthyeating#mindfulness#meditation#sleepimportance
0 notes
Video
youtube
WEIGHT LOSS Secrets You've Been CRAVING For! 💪🍏💦
#youtube#WeightLoss FitnessHacks HealthyLifestyle BalancedDiet Nutrition SleepImportance SustainableChanges WeightLossJourney HealthyEating FitnessMo
0 notes
Photo

Read full blog at takecarefriend in Blogspot.com 👍 #health #healthtips #sleep #mentalhealth #blogger #sleepwell #beyourbestself #healthylifestyle #healthiswealth #love #care #graphicdesign #stayhealthy #takecare #healthydays #healthylife #friend #reducerisk #weightgain #weightloss #depressionhelp #reduceanxiety #healthmatters #notenoughsleep #sleepimportance #gainimmunity #wealthy #fitnessmotivation #healthymotivation (at Budapest, Hungary) https://www.instagram.com/p/CpOrexiKRSv/?igshid=NGJjMDIxMWI=
#health#healthtips#sleep#mentalhealth#blogger#sleepwell#beyourbestself#healthylifestyle#healthiswealth#love#care#graphicdesign#stayhealthy#takecare#healthydays#healthylife#friend#reducerisk#weightgain#weightloss#depressionhelp#reduceanxiety#healthmatters#notenoughsleep#sleepimportance#gainimmunity#wealthy#fitnessmotivation#healthymotivation
1 note
·
View note
Photo

Healthy Habits Daily countdown... #dincharya #happyhealthylifewithstyle #healthyhabits #sleepimportance #healthyhabitsmatter #healthyhabitsstartyoung #water #happyhealthylifestyles #dailywalk #happyhealthystreet #healthyhabitswithpim #happyhealthylifestyle #healthyhabitsforall #healthyhabitsforlife #healthyhabitshappylife #drinkwater #healthyhabitsstartnow #health #sleep #ritucharya #ritucharyabenefits #healthyhabitsinthemaking #happyhealthylife #happyhealthylife❤️ #happyhealthylifers #healthy #healthyhabitsforreallife #healthylifestyle #healthyhabitshealthylife #healthyhabitschallenge https://www.instagram.com/p/CAZb0lWJSzJ/?igshid=bvgl8tks4zq2
#dincharya#happyhealthylifewithstyle#healthyhabits#sleepimportance#healthyhabitsmatter#healthyhabitsstartyoung#water#happyhealthylifestyles#dailywalk#happyhealthystreet#healthyhabitswithpim#happyhealthylifestyle#healthyhabitsforall#healthyhabitsforlife#healthyhabitshappylife#drinkwater#healthyhabitsstartnow#health#sleep#ritucharya#ritucharyabenefits#healthyhabitsinthemaking#happyhealthylife#happyhealthylife❤️#happyhealthylifers#healthy#healthyhabitsforreallife#healthylifestyle#healthyhabitshealthylife#healthyhabitschallenge
0 notes
Link
Introduction
In a web extracting blog, we can construct an Amazon Scraper Review with Python using 3 steps that can scrape data from different Amazon products like – Content review, Title Reviews, Name of Product, Author, Product Ratings, and more, Date into a spreadsheet. We develop a simple and robust Amazon product review scraper with Python.
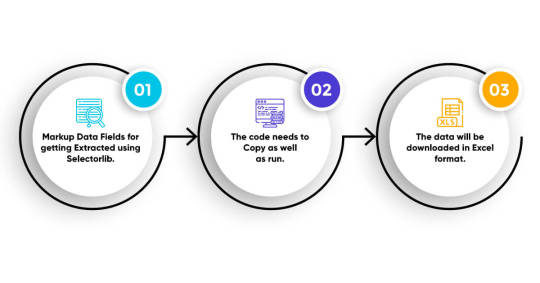
Here We Will Show You 3 Steps About How To Extract Amazon Review Using Python
1. Markup Data Fields for getting Extracted using Selectorlib.
2. The code needs to Copy as well as run.
3. The data will be downloaded in Excel format.
We can let you know how can you extract product information from the Amazon result pages, how can you avoid being congested by Amazon, as well as how to extract Amazon in the huge scale.
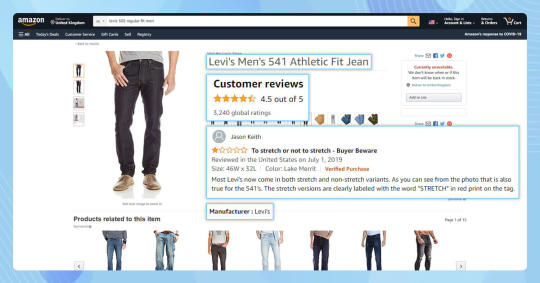
Here, we will show you some data fields from Amazon we scrape into the spreadsheets from Amazon:
Name of Product
Review title
Content Review or Text Review
Product Ratings
Review Publishing Date
Verified Purchase
Name of Author
Product URL
We help you save all the data into Excel Spreadsheet.
Install Required Package For Amazon Website Scraper Review
Web Extracting blog to extract Amazon product review utilizing Python 3 as well as libraries. We do not use Scrapy for a particular blog. This code needs to run quickly, and easily on a computer.
If python 3 is not installed, you may install Python on Windows PC.
We can use all these libraries: -
Request Python, you can make download and request HTML content for different pages using (http://docs.python-requests.org/en/master/user/install/)
Use LXML to parse HTML Trees Structure with Xpaths – (http://lxml.de/installation.html)
Dateutil Python, for analyzing review date (https://retailgators/dateutil/dateutil/)
Scrape data using YAML files to generate from pages that we download.
Installing Them With Pip3Pip3 Install Python-Dateutillxml Requests SelectorlibThe Code
Let us generate a file name reviews.py as well as paste the behind Python code in it.
What Amazon Review Product scraper does?
1. Read Product Reviews Page URL from the file named urls.txt.
2. You can use the YAML file to classifies the data of the Amazon pages as well as save in it a file named selectors.yml
3. Extracts Data
4. Save Data as the CSV known as data.csv filename.
fromselectorlibimport Extractorimport requestsimportjsonfrom time import sleepimport csvfromdateutilimport parser asdateparser# Create an Extractor by reading from the YAML filee = Extractor.from_yaml_file('selectors.yml')defscrape(url):headers = {'authority': 'www.amazon.com','pragma': 'no-cache','cache-control': 'no-cache','dnt': '1',upgrade-insecure-requests': '1','user-agent': 'Mozilla/5.0 (X11; CrOS x86_64 8172.45.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.64 Safari/537.36','accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9','sec-fetch-site': 'none','sec-fetch-mode': 'navigate','sec-fetch-dest': 'document','accept-language': 'en-GB,en-US;q=0.9,en;q=0.8',}# Download the page using requestsprint("Downloading %s"%url)r = requests.get(url, headers=headers)# Simple check to check if page was blocked (Usually 503)ifr.status_code>500:if"To discuss automated access to Amazon data please contact"inr.text:print("Page %s was blocked by Amazon. Please try using better proxies\n"%url)else:print("Page %s must have been blocked by Amazon as the status code was %d"%(url,r.status_code))returnNone# Pass the HTML of the page and createreturne.extract(r.text)with open("urls.txt",'r') asurllist, open('data.csv','w') asoutfile:writer = csv.DictWriter(outfile, fieldnames=["title","content","date","variant","images","verified","author","rating","product","url"],quoting=csv.QUOTE_ALL)writer.writeheader()orurlinurllist.readlines():data = scrape(url)'if data:'for r in data['reviews']:r["product"] = data["product_title"]r['url'] = urlif'verified'in r:if'Verified Purchase'in r['verified']:r['verified'] = 'Yes'else:r['verified'] = 'Yes'r['rating'] = r['rating'].split(' out of')[0] date_posted = r['date'].split('on ')[-1]if r['images']:r['images'] = "\n".join(r['images'])r['date'] = dateparser.parse(date_posted).strftime('%d %b %Y')writer.writerow(r)# sleep(5)Creating YAML Files With Selectors.Yml
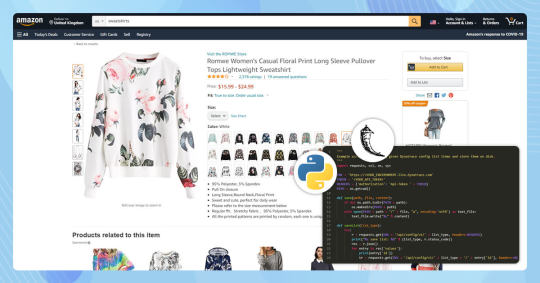
It’s easy to notice the code given which is used in the file named selectors.yml. The file helps to make this tutorial easy to follow and generate.
Selectorlib is the tool, which selects to markup and scrapes data from the web pages easily and visually. The Web Scraping Chrome Extension makes data you require to scrape and generates XPaths Selector or CSS needed to scrape data.
Here we will show how we have marked up field for data we require to Extract Amazon review from the given Review Product Page using Chrome Extension.
When you generate the template you need to click on the ‘Highlight’ option to highlight as well as you can see a preview of all your selectors.
Here we will show you how our templates look like this: -
product_title:css: 'h1 a[data-hook="product-link"]'type: Textreviews:css: 'div.reviewdiv.a-section.celwidget'multiple: truetype: Textchildren:title:css: a.review-titletype: Textcontent:css: 'div.a-row.review-data span.review-text'type: Textdate:css: span.a-size-base.a-color-secondarytype: Textvariant:css: 'a.a-size-mini'type: Textimages:css: img.review-image-tilemultiple: truetype: Attributeattribute: srcverified:css: 'span[data-hook="avp-badge"]'type: Textauthor:css: span.a-profile-nametype: Textrating:css: 'div.a-row:nth-of-type(2) >a.a-link-normal:nth-of-type(1)'type: Attributeattribute: titlenext_page:css: 'li.a-last a'type: LinkRunning Amazon Reviews Scrapers
You just need to add URLs to extract the text file named urls.txt within the same the folder as well as run scraper consuming the same commend.
This file shows that if we want to search distinctly for earplugs and headphones.
python3reviews.py
Now, we will show a sample URL - https://www.amazon.com/HP-Business-Dual-core-Bluetooth-Legendary/product-reviews/B07VMDCLXV/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews
It’s easy to get the URL through clicking on the option “See all the reviews” nearby the lowermost product page.
What Could You Do By Scraping Amazon?
The data you collect from the blog can assist you in many ways: -
1. You can review information unavailable using eCommerce Data Scraping Services.
2. Monitor Customer Options on a product that you can see by manufacturing through Data Analysis.
3. Generate Amazon Database Review for Educational Research &Purposes &.
4. Monitor product’s quality retailed by a third-party seller.
Build Free Amazon API Reviews Using Python, Selectorlib & Flask
In case, you want to get reviews as the API like Amazon Products Advertising APIs – then you can find this blog very exciting.
If you are looking for the best Amazon Review using Python, then you can call RetailGators for all your queries.
source code: https://www.retailgators.com/how-can-you-extract-amazon-review-using-python-in-3-steps.php
0 notes
Text
Fresh Start Monday
Morning ya'll




How are you starting your cold weather mornings?
With running your furnace, wood stove, or pellet stoves your air can be dry which drys out your sinuses, skin, and eyes.
It's important to have some humidity in the air so that you don't get too dry.
A perfect way to put some moisture in the air and to get some health benefits is diffusing. Diffusing puts moisture in the air, and the oils help keep you rested for a good nights sleep.
The best way to stay healthy with season changes and all those sick people around is to get plenty of good sleep. Why, glad you asked...
While you are asleep...
The brain
• Processes information, stimuli, and memories
• Sorts through information and gets rid of waste
• Undergoes processes essential for learning and memory
The body
• Rejuvenates the body’s cells
• Rests and recuperates through relaxing muscles and slowing the breathing
• Undergoes processes essential for growth and regulating hormones
Are you tossing and turning?
Are you waking up tired and fatigued?
Are you running out of energy shortly after you get up?
An hour before we go to bed I start our nightly diffuser blend: 5 drops Breathe, 5 drops Serenity
Serenity is a calming and soothing blend that aids in a restful nights sleep. Breathe is a respiratory blend that helps keep your airways clear and open.
Give it a whirl, you won't be sorry!
If you have any questions shoot us a message, if you'd like to get started on natural health and wellness journey PM us and we can talk about what's best for you.
#happymonday #sleepimportance #naturalsleepaid #serenity #breathe #dryair #winterweather #fatigue #sleep #naturalliving #naturalsolutions #naturalremedies
0 notes
Text
How Can You Extract Amazon Review using Python in 3 Steps?

Introduction
In a web extracting blog, we can construct an Amazon Scraper Review with Python using 3 steps that can scrape data from different Amazon products like – Content review, Title Reviews, Name of Product, Author, Product Ratings, and more, Date into a spreadsheet. We develop a simple and robust Amazon product review scraper with Python.
Here we will show you 3 steps about how to extract Amazon review using Python
1. Markup Data Fields for getting Extracted using Selectorlib.
2. The code needs to Copy as well as run.
3. The data will be downloaded in Excel format.
We can let you know how can you extract product information from the Amazon result pages, how can you avoid being congested by Amazon, as well as how to extract Amazon in the huge scale.
Here, we will show you some data fields from Amazon we scrape into the spreadsheets from Amazon:
Name of Product
Review title
Content Review or Text Review
Product Ratings
Review Publishing Date
Verified Purchase
Name of Author
Product URL
We help you save all the data into Excel Spreadsheet.
Install required package for Amazon Website Scraper Review
Web Extracting blog to extract Amazon product review utilizing Python 3 as well as libraries. We do not use Scrapy for a particular blog. This code needs to run quickly, and easily on a computer.
If python 3 is not installed, you may install Python on Windows PC.
We can use all these libraries: -
Request Python, you can make download and request HTML content for different pages using (http://docs.python-requests.org/en/master/user/install/)
Use LXML to parse HTML Trees Structure with Xpaths – (http://lxml.de/installation.html)
Dateutil Python, for analyzing review date (https://retailgators/dateutil/dateutil/)
Scrape data using YAML files to generate from pages that we download.
Installing them with pip3
pip3 install python-dateutillxml requests selectorlib
The Code
Let us generate a file name reviews.py as well as paste the behind Python code in it.
What Amazon Review Product scraper does?
1. Read Product Reviews Page URL from the file named urls.txt.
2. You can use the YAML file to classifies the data of the Amazon pages as well as save in it a file named selectors.yml
3. Extracts Data
4. Save Data as the CSV known as data.csv filename.
fromselectorlibimport Extractorimport requestsimportjsonfrom time import sleepimport csvfromdateutilimport parser asdateparser# Create an Extractor by reading from the YAML filee = Extractor.from_yaml_file('selectors.yml')defscrape(url):headers = {'authority': 'www.amazon.com','pragma': 'no-cache','cache-control': 'no-cache','dnt': '1',upgrade-insecure-requests': '1','user-agent': 'Mozilla/5.0 (X11; CrOS x86_64 8172.45.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.64 Safari/537.36','accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9','sec-fetch-site': 'none','sec-fetch-mode': 'navigate','sec-fetch-dest': 'document','accept-language': 'en-GB,en-US;q=0.9,en;q=0.8',}# Download the page using requestsprint("Downloading %s"%url)r = requests.get(url, headers=headers)# Simple check to check if page was blocked (Usually 503)ifr.status_code>500:if"To discuss automated access to Amazon data please contact"inr.text:print("Page %s was blocked by Amazon. Please try using better proxies\n"%url)else:print("Page %s must have been blocked by Amazon as the status code was %d"%(url,r.status_code))returnNone# Pass the HTML of the page and createreturne.extract(r.text)with open("urls.txt",'r') asurllist, open('data.csv','w') asoutfile:writer = csv.DictWriter(outfile, fieldnames=["title","content","date","variant","images","verified","author","rating","product","url"],quoting=csv.QUOTE_ALL)writer.writeheader()orurlinurllist.readlines():data = scrape(url)'if data:'for r in data['reviews']:r["product"] = data["product_title"]r['url'] = urlif'verified'in r:if'Verified Purchase'in r['verified']:r['verified'] = 'Yes'else:r['verified'] = 'Yes'r['rating'] = r['rating'].split(' out of')[0] date_posted = r['date'].split('on ')[-1]if r['images']:r['images'] = "\n".join(r['images'])r['date'] = dateparser.parse(date_posted).strftime('%d %b %Y')writer.writerow(r)# sleep(5)
Creating YAML files with selectors.yml
It’s easy to notice the code given which is used in the file named selectors.yml. The file helps to make this tutorial easy to follow and generate.
Selectorlib is the tool, which selects to markup and scrapes data from the web pages easily and visually. The Web Scraping Chrome Extension makes data you require to scrape and generates XPaths Selector or CSS needed to scrape data.
Here we will show how we have marked up field for data we require to Extract Amazon review from the given Review Product Page using Chrome Extension.
When you generate the template you need to click on the ‘Highlight’ option to highlight as well as you can see a preview of all your selectors.
Here we will show you how our templates look like this: -
product_title:css: 'h1 a[data-hook="product-link"]'type: Textreviews:css: 'div.reviewdiv.a-section.celwidget'multiple: truetype: Textchildren:title:css: a.review-titletype: Textcontent:css: 'div.a-row.review-data span.review-text'type: Textdate:css: span.a-size-base.a-color-secondarytype: Textvariant:css: 'a.a-size-mini'type: Textimages:css: img.review-image-tilemultiple: truetype: Attributeattribute: srcverified:css: 'span[data-hook="avp-badge"]'type: Textauthor:css: span.a-profile-nametype: Textrating:css: 'div.a-row:nth-of-type(2) >a.a-link-normal:nth-of-type(1)'type: Attributeattribute: titlenext_page:css: 'li.a-last a'type: Link
Running Amazon Reviews Scrapers
You just need to add URLs to extract the text file named urls.txt within the same the folder as well as run scraper consuming the same commend.
This file shows that if we want to search distinctly for earplugs and headphones.
python3reviews.py
Now, we will show a sample URL - https://www.amazon.com/HP-Business-Dual-core-Bluetooth-Legendary/product-reviews/B07VMDCLXV/ref=cm_cr_dp_d_show_all_btm?ie=UTF8&reviewerType=all_reviews
It’s easy to get the URL through clicking on the option “See all the reviews” nearby the lowermost product page.
What Could You Do By Scraping Amazon?
The data you collect from the blog can assist you in many ways: -
1. You can review information unavailable using eCommerce Data Scraping Services.
2. Monitor Customer Options on a product that you can see by manufacturing through Data Analysis.
3. Generate Amazon Database Review for Educational Research &Purposes &.
4. Monitor product’s quality retailed by a third-party seller.
Build Free Amazon API Reviews using Python, Selectorlib & Flask
In case, you want to get reviews as the API like Amazon Products Advertising APIs – then you can find this blog very exciting.
If you are looking for the best Amazon Review using Python, then you can call RetailGators for all your queries.
Source:- https://www.retailgators.com/how-can-you-extract-amazon-review-using-python-in-3-steps.php
#ScrapeAmazonReview#AmazonReviewScraping#ExtractAmazonReviewUsingPython#ScrapingAmazonReviewUsingPython
0 notes
Last Seen Blogs

doooonfan
絵丼-FAN

carolzebra
'Z.

davidantico
David Antico

bacchus-viet-nam-blog
Bacchus Việt Nam

marvelousmovies
Marvelous Movies!