#statistical test
Text
ANOVA Analysis
This is the task of Week 1 of the course Data Analysis Tools at the Coursera Plataform. The challenge is to execute an Analysis of Variance using the ANOVA Statistical Test. This type of analysis assesses whether the means of two or more groups are statistically different from each other. Is used whenever you want to compare the means (quantitative variables) of groups (categorical variables). The null hypothesis is that there is no difference in the mean of the quantitative variable across groups (categorical variable), while the alternative is that there is a difference.
DataSet Used – Gap Minder
Gapminder identifies systematic misconceptions about important global trends and proportions and uses reliable data to develop easy to understand teaching materials to rid people of their misconceptions.
Gapminder is an independent Swedish foundation with no political, religious, or economic affiliations.
should visit it: https://www.gapminder.org/.
The dataset used has 16 variables and 213 rows. I choosed to analyze income per person (incomeperperson) and life expectancy (lifeexpectancy).
And how is the Question?
Is the life expectancy different among four categories of income per person (A,B,C,D,E)?
Since the income per person is a quantitative variable, I transformed it into a categorical variable, using parameters sugested by IBGE to classify the social class of according of income. For the parameters, I analyzed the boxplot posted below.

the data in image is in portuguese, because the IBGE is an Brazilian institute.
The Code
I used the Anaconda to code in Python for this task. The code is posted below.
import numpy
import pandas as pd
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.stats.multicomp as multi
import matplotlib.pyplot as plt
import seaborn as sns
import researchpy as rp
import pycountry_convert as pc
df = pd.read_csv('gapminder.csv')
df = df[['lifeexpectancy', 'incomeperperson']]
df['lifeexpectancy'] = df['lifeexpectancy'].apply(pd.to_numeric, errors='coerce')
df['incomeperperson'] = df['incomeperperson'].apply(pd.to_numeric, errors='coerce')
def income_categories(row):
if row["incomeperperson"]>15000:
return "A"
elif row["incomeperperson"]>5000:
return "B"
elif row["incomeperperson"]>3000:
return "C"
elif row["incomeperperson"]>1000:
return "D"
else:
return "E"
df=df[(df['lifeexpectancy']>=1) & (df['lifeexpectancy']<=120) & (df['incomeperperson'] > 0) ]
df["Income_category"]=df.apply(income_categories, axis=1)
df = df[["Income_category","incomeperperson","lifeexpectancy"]].dropna()
df["Income_category"]=df.apply(income_categories, axis=1)
print (rp.summary_cont(df['lifeexpectancy']))
fig1, ax1 = plt.subplots()
df_new = [df[df['Income_category']=='A']['lifeexpectancy'], df[df['Income_category']=='B']['lifeexpectancy'], df[df['Income_category']=='C']['lifeexpectancy'], df[df['Income_category']=='D']['lifeexpectancy'], df[df['Income_category']=='E']['lifeexpectancy']]
ax1.set_title('life expectancy')
ax1.boxplot(df_new)
plt.show()
results = smf.ols('lifeexpectancy ~ C(Income_category)', data=df).fit()
print (results.summary())
print ("Tukey")
mc1 = multi.MultiComparison(df['lifeexpectancy'], df['Income_category'])
print (mc1)
res1 = mc1.tukeyhsd()
print (res1.summary())
print ('means for for life expectancy by Income')
m1= df.groupby('Income_category').mean()
print (m1)
print ('Results')
print ('standard deviations for life expectancy by Income')
sd1 = df.groupby('Income_category').std()
print (sd1)
Results – ANOVA Analysis
Aiming to answer the question of the task, I ran a test ANOVA. As shown below, from the 176 rows, 171 were used for the test, i have used a filter to remove some wrong values, as non numeric, negative, etc, reducing the rows of the original dataset

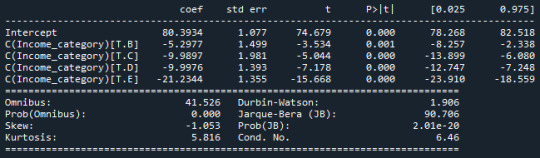
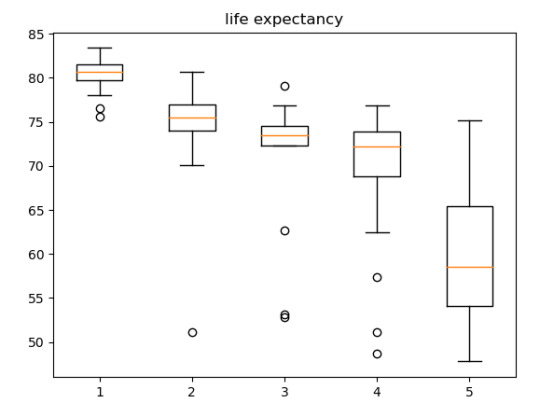
The ANOVA analysis shows a graph for each category (above) and, as we can see, the life expectancy of A class, have the life expectative of 80.39 years while the E class have the life expectative of 59.15 years.
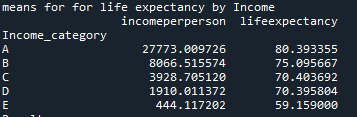


2 notes
·
View notes
Text
the topic of colorism within the black community will never be understood until people understand that it's deeper than being bullied in high school and dating preferences.
#i wrote a ten page essay on colorism#nothing annoys me when a darker skinned woman bring up the colorism she experienced#and here come a light skinned woman saying 'i too got bullied in high school'#like shhhh#it's statistics and articles#proving that people of darker skin get denied services#get less pay than their lighter counterparts#get harsher prison sentences#hell some d9 orgs even did the paper brown bag test#i can go on about this topic
431 notes
·
View notes
Text
I am spectacularly offended by this Matt Levine reader email about using astrology in consumer finance prediction.
This was a machine learning model – the job of the data scientist was, put everything in, see what's significant, of that discard everything that's discriminatory, the rest is your model. Ultimately with twelve astrological signs it's over 50/50 that one will come out significant at 95%.
I thought it was elegant. "Astrological signs? Do you believe that?" my boss said. I said it wasn't a question of belief, I was a statistician and was going to follow the numbers rather than letting anyone's preexisting theories about the stars and planets influence the data science. I think he believed that meant I'd agreed to take it out.
Like, the guy literally said "We're very likely to have a false positive here by chance, but since we got one we have to take it seriously. I'm a statistician."
He's fully aware that he's p-hacking and garden-pathing. He's fully aware of the multiple comparisons problem. And then he endorses the conclusion anyway!
(And, as a side note, it's not over 50/50; If you do twelve tests the chance of one coming out significant by chance is about 46%. So he fucked up the arithmetic too!)
60 notes
·
View notes
Text
can’t be asked to colour rn so here’s a timelapse of my favourite drawing of my favourite hermits :))
#digital art#digital illustration#fanart#digital arwork#ethoslab#smallishbeans#mumbo jumbo#grian#hermitcraft#smalletho#my favourite silly little guys#i’m meant to be doing statistics and hypothesis testing but oh well
60 notes
·
View notes
Text

Me rn:
#statistics#ap stats#ap test#ap classes#This doesn’t violate anything right?#im not spreading answers so I guess it’s fine?#oh well#my art#my art <3#my artwork#my artwrok
43 notes
·
View notes
Text

statistics is so easy
#shush milo's talking#art#hobie brown#doodle#statistics#:)#this is my review btw dont yell at me#i have a test today
25 notes
·
View notes
Text
hazel & thanatos : nico & cupid scene comparison


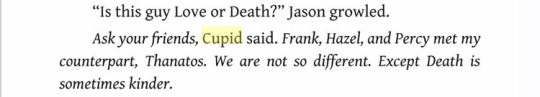


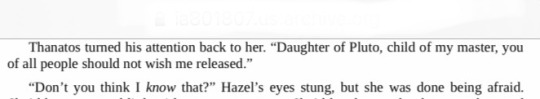

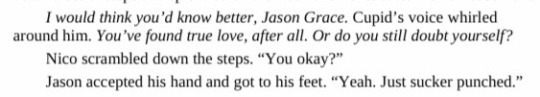


both of these scenes are about identity and truth at odds with innate self-preservation. both gods reference each other and acknowledge their similarities. cupid references hazel, and thanatos even references nico (didn't include that scene but hazel asks thanatos if he knows where nico is). jason and frank both also face obstacles through these gods, but the true tests are for nico and hazel. the point of both scenes is to demand that both characters face their greatest fears, and force hazel and nico to be honest about why they have come so far on their respective journeys, and admit what is is that they truly want. also, thanatos is fairly passive and hazel experiences more visceral attraction to him than she does to her series love interests, whereas nico's confession is very blunt and unromantic, and cupid is very violent, causing physical and emotional agony and further blurring the domains of the two gods.
#other difference between this scenes is that a reader could be gay and/or in unrequited love but can not have been dead before#thanatos was also very much a test for frank too but it doesn't foil cupid at all whereas hazel's interaction with him does#also i'm not surprised hazel and thanatos never became a ship because this fandom pays hazel dust and also you don't really#learn anything new about hazel in this scene (although it is one of her most insane moments)#but i'm actually very surprised nico and cupid never got shipped. like this is one of the most talked-about scenes from this series#he shot nico with an arrow. he's the god of love. he has an infamous mythological romance. you'd think somebody would've hopped on that#just statistically speaking with the amount of nico fic out there#hazel levesque#nico di angelo#cupid pjo#thanatos pjo
72 notes
·
View notes
Text
skk stans have some NERVE complaining abt that one panel not getting animated like have y’all seen what they did to the entire first light novel?? kndz stans have been in the trenches from the very start I DONT WANNA HEAR IT
#we’re still facing the repercussions of that adaptation just look at the fic statistics 😭#bsd#bungou stray dogs#dazai osamu#chuuya nakahara#kunikida doppo#skk#kndz#dazai’s entrance exam#itsg I’m not a skk anti but some of y’all keep testing me I wanna enjoy the anime wout seeing ppl whine abt single panels getting left out#i get the frustration TRUST ME but like damn Can y’all stop nitpicking every little thing lit rt when the ep comes out 😭#PLEASE
91 notes
·
View notes
Text
I'm actually impressed that I made it to 2024 before getting a positive covid test
i will need to dig out that "queer people should know better than to assign morality to a virus" post because I'm gonna need it when the anxiety kicks it
#statistically ive had it before#but ive tested every time ive had symptoms and this is my first positive antigen test#and there's no isolation or anything required now#ive been masking on public transport ffs#and in shops#so i will get very emotional at some point#covid
7 notes
·
View notes
Text
17.05.24



The weather is nice again! I'm glad the rain definitely dampened my mood.
I spent almost the entire day in the library- found 'You will beat this essay' written on the cublicle wall, it gave me the motivation I needed to get a big chunk of my Lab reoprt done.
Today I;
Did the introduction of my lab report
Did the methodology of my lab report
Created the Figures for my lab report
Started to contact the study abroad students I will be travelling with
Studied social categorisation, stereotyping and prejudice
Studied intergroup relations and conflict
I went to the library and forgot my tablet, so I had to walk all the way there and alllll the way back.
#psychology#psychology student#psychology studyblr#university#study#studying#student#lab report#data analysis#statistics#stroop test#methodology#aesthetic#study aesthetic#chaotic academia#academics#college#social psychology
19 notes
·
View notes
Text
She standard on my deviation til I mean
#i fucking hate statistics#literally dying over here#i have a test tomorrow and i know NOTHING#the dib speakz!!#agony
11 notes
·
View notes
Text

huge dub for nonbinary people in oregon
332 notes
·
View notes
Text
remember when i said i have a lot of things i need to do today and then i did none of that?
#i didnt even cook i just made popcorn for dinner#i half did my homework for tomorrow#i didn't do any more practice tests#i didn't even download the data for the statistics homework#but at least i had fun with my music#jo says stuff#personal ramblings
24 notes
·
View notes
Text
someone explain two way ANOVA test to me like I’m a toddler lol
#we’re expected to write about what test we should use in about methods course#*our not about#but we’ve had so little time to go over inferential statistics#so I am a little confusion lol#.thoughts
7 notes
·
View notes
Text
losing my mind. can i bust this ghost. who knows
#fuck bonferroni planned and post hoc tests. all my homies HATE bonferroni planned and post hoc tests.#I HATE STATISTICS I HATE STATISTICS#psychology my behated.#irl ghostbuster
7 notes
·
View notes
Text
i keep dismissing societal concepts i think are silly in my head and so i go around being like we made this up it's so pointless... abt like copyright law or whatever but then i kind of lock myself in an echo chamber of my own brain where i go around thinking stuff and then i have a conversation with a friend where i find out they put weight in [concept] i've dismissed like they're talking about how IQ is real and measurable and important for statistics and im like WHAT THE HELL...
#ive gotta talk to people more i did learn from that conversation a little bit#i think we had fundamentally different points that were flying past each other like they were saying iq is real and it's valuable for#statistics bc it's something that u can take over and over at different times and get the same result and therefore it can be solidly#extrapolated for different demographics and then that can be attributed to different things like chemical spills or economic inequality or#whatever and i wasn't saying that wasn't true but i was more arguing that it's silly the weight people give it outside of a metric of#statistics like the way people who i've talked to give value to it in real life is stupid bc i've talked to several people who have been#like oh you're so smart that makes me feel bad and im like it means nothing its just a percentage on a test everyone has different#aptitudes for things and that's what's meaningful out in the real world barring its usefulness in statistics#i also wasn't good at explaining myself i didn't really say what i said above i said like half of it poorly#alex talks
9 notes
·
View notes
Last Seen Blogs

check-the-czech
To be young and to live in Camelot...

fantasiafallshq
╰ ✩.⭒ʿ˖✧ ˓ ƒaŋtasia ƒalls . ⭒ʿ✩˖ ˓✧ ╮

marikays20p2
Me encanta español!

doodleshrimps
ariarrivederci
doodleshrimps
ariarrivederci