#unimod
Text
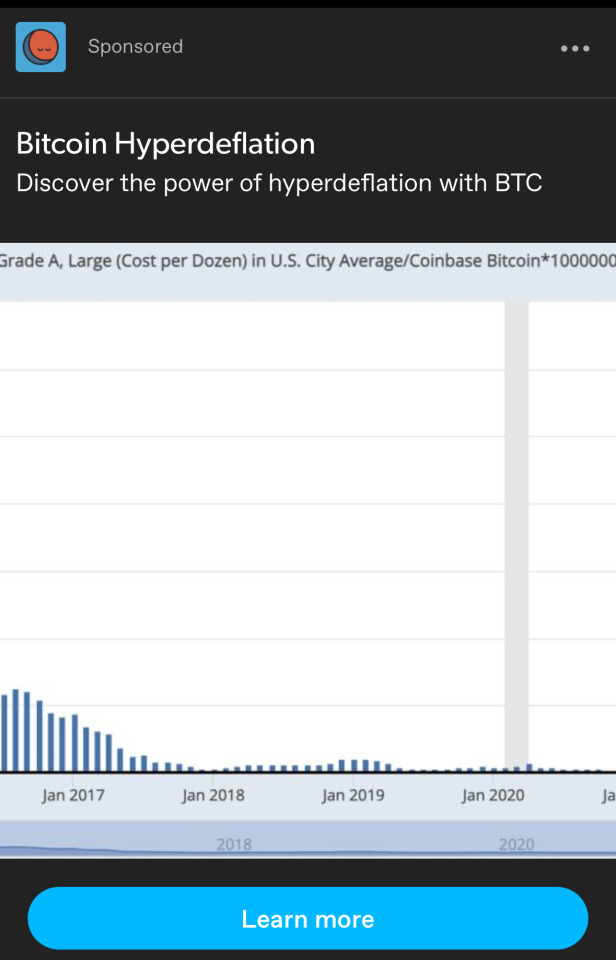
Shape: Unimodal, Skewed Right
thanks tumblr ??
13 notes
·
View notes
Text
Being a psychology nerd and engaging in fandom actually makes my eye twitch sometimes because terms are constantly being used wrong to diss people or characters and also people will act like they know every experience a mentally ill person can have just based off a small sample of what they’ve seen and they’ll use that to disregard storylines or people’s opinions or spec
So some things guys that may be an unintentional call out or reassurance for your spec:
Hallucinations CAN be auditory and visual simultaneously (multi modal it can even be tactile, somatic olfactory or gustatory) and there is actually a very high prevalence of this in a lot of disorders and are actually thought to occur more frequently than unimodal hallucinations, and yes it can be in the form of full blown conversations with people that aren’t there and they can be extremely elaborate and complex especially if paired with delusions- so yes the possibility that Kim is a hallucination and we are just seeing it from Eddie’s pov is valid spec so stop being dismissive to people
Also for my brain tumour truthers- a brain tumour is a little complicated when it comes to hallucinations cos it really depends where the tumour is and what regions are effected because for example an occipital lobe tumour is more likely to just cause visual hallucinations- but multimodal hallucinations due to a brain tumour is also possible, a brain tumour also comes with other symptoms too but a lot can be consistent with the spec like for example impulsivity or disinhibition, delusions, aggression (if the buddie divorce is true that works), anxiety, depression, etc.
Trauma bonding is something that occurs in ABUSIVE situations where you start to feel sympathy and love for your abuser it’s not when people bond over trauma - so no what buck and Eddie or buck and Chris have is very much not a trauma bond
Gaslighting isn’t just lying to someone it’s intentionally manipulating them to the extent that they doubt their own sanity (the term coming from a play turned movie where a husband drives his wife crazy by like screwing with the gas lights in their house when she’s alone to make her doubt her memory and her perception of reality) - so no Eddie is not GASLIGHTING buck when he lies to him 😭😭
Codependency is also just not what Eddie and buck have, they don’t base their entire lives on each other and they don’t like have an unhealthy dynamic or have an imbalanced relationship, now yes they both had times when they needed the other to be there for them or help them through stuff or aid their self worth but overall they more so just want to be around each other not that they NEED to and they work on themselves separately like going to therapy by themselves while also supporting eachother by helping out while they do that
#is this post probably for a very niche audience of psychology students who are 911 fans? probably#911 abc#eddie diaz#911 fox#evan buck buckley#911onfox#buckley diaz family#911 speculation#911 spec#evan buckley#911#buddie
116 notes
·
View notes
Text
I feel like 100 endocrinology papers in I finally have a good understanding of what we as transfeminists mean by "sex is constructed": endocrinology studies start with a subject population already split into "male" and "female" and take this split and how it is made completely for granted. Nobody ever includes in their methods section how they decided which patients were male and which were female - even in papers where this is a relevant question! where reading the text of the paper naturally raises this question! Instead they are just using these social ("received," "unscientific") notions of male and female and then analysing the data along that split. They are using biology to find a possible justification for the existing social categories - not using biology to try to discover "natural" categories, and therefore this biology can fundamentally never prove that sex is a natural dichotomy! That is an assumption, not a conclusion.
To make this more concrete: I believe that the distribution of estradiol levels among non-pregnant adults who are not currently ovulating is unimodal, not bimodal (so not "sexually dimorphic"). But I cant find data to prove this because nobody is publishing a histogram of "human estradiol levels": they only ever publish separate graphs or tables of "male levels" and "female levels"! If biological sex is supposed to be a discovered distinction from differences in hormone levels, why has nobody ever published a study with a histogram of "all adult estradiol levels" in order to point out that this distribution has two peaks, and so we should categorize people based on what peak they're in? Because the existence of two distinct sexes is assumed going into biology, and is not a conclusion of biology.
46 notes
·
View notes
Note
i’d argue that humans aren’t even really sexually dimorphic to begin with
yeah they aren’t (sex associated traits are more like a bimodal distribution with overlap) but the minimal sexual dimorphism there is should be eliminated too (ie should be unimodal). im saying should in a loose sense of course (as in would be preferable) but this is my transhumanism hot take
2 notes
·
View notes
Text
i do think it's interesting that we as a society tend to lump all gun violence together as if its causation is unimodal
5 notes
·
View notes
Text
Statistics: Display and Shape



1 Categorical Variable: Class Make-up

Comparative Bar Charts
allows us to look at multiple groups of one categorical variable
can be a stacked bar graph or a clustered bar graph
One Quantitative Variable
A. Examining Quantitative Data
distribution = tells all possible values of a variable and how frequently they occur
Summarize distribution of a quantitative variable by telling shape, center, and spread.
Shape = tells which values tend to be more or less common.
Center = measure of what is typical in the distribution of quantitative variable.
Spread = measure of how much the distribution's values vary
B. Displays
Stemplot
- advantage: most detail
- disadvantage: impractical for large datasets
Histogram
- advantage: works well for any size dataset
- disadvantage: some detail lost
Dotplot
- advantage: can show outliers
- disadvantage: much detail lost

Stem Plot
quantitative data
combines the characteristics of a table and a graph
general steps:
(1) Separate each observation into a stem (first part of number) and a leaf (remaining part of number)
(2) Write the stems in a vertical column; draw a vertical line to the right of the stems.
(3) Write each leaf in the row to the right of its stem; order leaves if desired.
Stem: 10's digit
Lead: 1's digit
5 I 3 = 53
Constructing Stem Plots


Comparative Stem Charts
used for comparison of two groups of 1 quantitative variable
- ex. Compare exam scores from two classes.


Dot Plots
used for 1 quantitative variable
similar to a stem + leaf plot; each dot represents one value
Ex. An instructor has obtained the set of N=25 exam scores:
82, 75, 88, 93, 53, 84, 87, 58, 72, 94, 69, 84, 61, 91, 64, 87, 84, 70, 76, 89, 75, 80, 73, 78, 60

Histograms
Show possible values of a quantitative variable along the horizontal axis, with vertical bars showing the count, percentage, or proportion of values in certain interval ranges.
shows quantitative data ONLY
display of a grouped frequency distribution
adjacent bars touch each other
Divide the possible values into class intervals (equal width).
- How many intervals? One rule is to calculate the square root of the sample size and round up.
- Size of intervals? Divide range of data (max-min) by number of intervals desired and round up.
- Pick intervals so each observation can only fall in exactly one interval (no overlap). maximum-minimum/number of intervals
Count how many observations fall in each interval (may change to proportion or percentages).
Draw representation distribution.
Ex. An instructor has obtained the set of N=25 exam scores:
82, 75, 88, 93, 53, 84, 87, 58, 72, 94, 69, 84,
61, 91, 64, 87, 84, 70, 76, 89, 75, 80, 73, 78, 60




Grouped frequency distribution histogram vs. stem plot.
The stem plot is placed on its side to demonstrate that the display gives the same information provided in the histogram.
Scatterplots
Used for displaying the relationship between two quantitative variables.
Ex. Compare students' exam 1 vs exam 2 scores.


Interpreting Histograms
When describing the distribution of a quantitative (interval or ratio) variable, we look for the overall pattern and for striking deviations from that pattern. We can describe the overall pattern of a histogram by its shape, center (central tendency) and spread (variability).

Shape of Distribution
A symmetric distribution has a balanced shape, showing that it is just as likely for the variable to take lower values as higher values.

A skewed distribution is lopsided:
skewed left: few values that are relatively low compared to the bulk of the data
skewed right: few values that are relatively high compared to the bulk of the data values


Outliers
Extreme values that fall outside the overall pattern.
may occur naturally
may occur due to error in recording
may occur due to measurement error
observational unit may be fundamentally different
After identifying potential outliers, investigate why they obtain unusual values.

More Specific Shapes
unimodal distribution: has one peak
bimodal distribution: has two peaks
uniform distribution: has no peaks, showing that all possible values are equally common
normal distribution: symmetric, unimodal, "bell-shaped" or "mound-shaped" pattern
2 notes
·
View notes
Text
CREATING GRAPHS FOR MY DATA
Assignment #4
LIBNAME mydata "/courses/d1406ae5ba27fe300" access=readonly;
DATA new; set mydata.addhealth_pds;
LABEL PA10="What is your marital status"
PA39="During the past 12 months did he/she receive any type of special education"
PA21="Are you receiving public assistance such as welfare";
NUMPA9=SUM (OF PA5_1 PA5_3 PA5_5 PA5_4 PA5_6);
PROC SORT; by AID;
PROC PRINT; VAR PA5_1 PA5_3 PA5_5 PA5_4 PA5_6 NUMPA9;
PROC FREQ; TABLES PA5_1 PA5_3 PA5_5 PA5_4 PA5_6 NUMPA9;
RUN;
The univariate graph of marital status

This graph is unimodal, with its highest peak at the median category of 70%. It seems to be skewed to the right as there are higher frequencies in lower categories than the higher categories.
The univariate graph of special education received

This graph is unimodal, with its highest peak at the category of 13% to 14% urban rate. It seems to be skewed to the left however the skewness is not pronounced.
The univariate graph of public welfare assistance

This graph is unimodal, with its highest peak at 90%. It seems to be skewed to the right as there are higher frequencies in the higher assistance ranges.
The graph below plots the ethnicity rate of a country to the country’s welfare assistance. We can see that the graph shows some relationship/trend between the two variables.

0 notes
Text
Durante ese período de tiempo terrible o desagradable que ya dejé atrás, hubo un blog que jugó un papel importante y que todavía me da escalofríos, debido a sus comportamientos y tratos escandalosos hacia mí y hacia mi blog en ese momento.
Ella era obstinada, testaruda, unimodal, fija y se comportaba como una mula infligiéndome acusaciones y regaños, incluso con palabras obscenas la mayor parte del tiempo.
No le agradaba en absoluto a pesar de que yo dijera que era hermosa en ese momento.
Ella es @ultimas. Lo único que hice en ese momento fue comentar en el blog de su amiga @somos-deseos.
No recuerdo todos mis comentarios, pero le pregunté si un ex novio la había decepcionado y por eso le gustaban las mujeres. ¿Y fue esa solo una fase para que ella amara a las mujeres? Y en su relación con las mujeres quién era el lado masculino.
Pregunté porque me interesaba saber, nada más.
0 notes
Text
How Multimodal AI Deciphers Gestures: Working, Uses & Impact

Multimodal AI integrates various data types (audio, video, text, images) to make accurate predictions and enhance user experiences. By 2030, the global AI market is expected to reach $1.85 trillion, driven by companies looking to improve efficiency and profitability.
Unlike unimodal systems, Multimodal AI combines diverse inputs, offering more context-aware and accurate outcomes. It powers advanced applications like language translation, emotion recognition, and visual question answering.
However, integrating Multimodal AI comes with challenges, including data representation, translation, and alignment. Despite these hurdles, its potential across industries like healthcare, retail, fintech, AR/VR, robotics, and autonomous vehicles is immense.
Webelight Solutions specializes in harnessing this technology to help businesses innovate and thrive in the AI-driven future.
#technews#ar/vr#robotics#web development#software development#information technology#autonomous vehicles#healthcare#artificial intelligence#multimodal
0 notes
Text

Bonus analysis of my activity graph LOL
Shape: Unimodal, Skewed Left
7 notes
·
View notes
Text
Cobrança de frete marítimo em caso de transporte unimodal prescreve em cinco anos
Continue reading Cobrança de frete marítimo em caso de transporte unimodal prescreve em cinco anos
0 notes
Text
SenseTime SenseNova 5.5: China's first real-time multimodal AI model
New Post has been published on https://thedigitalinsider.com/sensetime-sensenova-5-5-chinas-first-real-time-multimodal-ai-model/
SenseTime SenseNova 5.5: China's first real-time multimodal AI model
.pp-multiple-authors-boxes-wrapper display:none;
img width:100%;
SenseTime has unveiled SenseNova 5.5, an enhanced version of its LLM that includes SenseNova 5o—touted as China’s first real-time multimodal model.
SenseNova 5o represents a leap forward in AI interaction, providing capabilities on par with GPT-4o’s streaming interaction features. This advancement allows users to engage with the model in a manner akin to conversing with a real person, making it particularly suitable for real-time conversation and speech recognition applications.
According to SenseTime, its latest model outperforms rivals across several benchmarks:
At the World Artificial Intelligence Conference (WAIC) in Shanghai this weekend, SenseTime unveiled SenseNova 5.5.
The company claims the model outperforms GPT-4o in 5 out of 8 key metrics.
While I’d take it with a grain of salt, China’s AI startups are showing major progress pic.twitter.com/1ZFbojHs3v
— Rowan Cheung (@rowancheung) July 8, 2024
Dr. Xu Li, Chairman of the Board and CEO of SenseTime, commented: “This is a critical year for large models as they evolve from unimodal to multimodal. In line with users’ needs, SenseTime is also focused on boosting interactivity.
“With applications driving the development of models and their capabilities, coupled with technological advancements in multimodal streaming interactions, we will witness unprecedented transformations in human-AI interactions.”
The upgraded SenseNova 5.5 boasts a 30% improvement in overall performance compared to its predecessor, SenseNova 5.0, which was released just two months earlier. Notable enhancements include improved mathematical reasoning, English proficiency, and command-following abilities.
In a move to democratise access to advanced AI capabilities, SenseTime has introduced a cost-effective edge-side large model. This development reduces the cost per device to as low as RMB 9.90 ($1.36) per year, potentially accelerating widespread adoption across various IoT devices.
The company has also launched “Project $0 Go,” a free onboarding package for enterprise users migrating from the OpenAI platform. This initiative includes a 50 million tokens package and API migration consulting services, aimed at lowering entry barriers for businesses looking to leverage SenseNova’s capabilities.
SenseTime’s commitment to edge-side AI is evident in the release of SenseChat Lite-5.5, which features a 40% reduction in inference time compared to its predecessor, now at just 0.19 seconds. The inference speed has also increased by 15%, reaching 90.2 words per second.
Expanding its suite of AI applications, SenseTime introduced Vimi, a controllable AI avatar video generator. This tool can create short video clips with precise control over facial expressions and upper body movements from a single photo, opening up new possibilities in entertainment and interactive applications.
The company has also upgraded its SenseTime Raccoon Series, a set of AI-native productivity tools. The Code Raccoon now boasts a five-fold improvement in response speed and a 10% increase in coding precision, while the Office Raccoon has expanded to include a consumer-facing webpage and a WeChat mini-app version.
SenseTime’s large model technology is already making waves across various industries. In the financial sector, it’s improving efficiency in compliance, marketing, and investment research. In agriculture, it’s helping to reduce the use of materials by 20% while increasing crop yields by 15%. The cultural tourism industry is seeing significant boosts in travel planning and booking efficiency.
With over 3,000 government and corporate customers already using SenseNova across technology, healthcare, finance, and programming sectors, SenseTime is cementing its position as a key AI player.
(Image Credit: SenseTime)
See also: AI revolution in US education: How Chinese apps are leading the way
Want to learn more about AI and big data from industry leaders? Check out AI & Big Data Expo taking place in Amsterdam, California, and London. The comprehensive event is co-located with other leading events including Intelligent Automation Conference, BlockX, Digital Transformation Week, and Cyber Security & Cloud Expo.
Explore other upcoming enterprise technology events and webinars powered by TechForge here.
Tags: ai, artificial intelligence, benchmark, China, Model, multimodal, sensenova, sensetime
#000#2024#agriculture#ai#ai & big data expo#ai model#amp#API#app#applications#apps#Articles#artificial#Artificial Intelligence#automation#avatar#benchmark#benchmarks#Big Data#board#CEO#China#Cloud#code#coding#command#Companies#compliance#comprehensive#conference
0 notes
Text
[PDF] Multimodal: AI’s new frontier
See on Scoop.it - Education 2.0 & 3.0
In practice, Generative AI tools use different strategies for different types of data when building large data models—the complex neural networks that organize vast amounts of information. For example, those that draw on textual sources segregate individual tokens, usually words. Each token is assigned an “embedding” or “vector”: a numerical matrix representing how and where the token is used compared to others. Collectively, the vector creates a mathematical representation of the token’s meaning. An image model, on the other hand, might use pixels as its tokens for embedding, and an audio one sound frequencies.
A multimodal AI model typically relies on several unimodal ones. As Henry Ajder, founder of AI consultancy Latent Space, puts it, this involves “almost stringing together” the various contributing models. Doing so involves various techniques to align the elements of each unimodal model, in a process called fusion. For example, the word “tree”, an image of an oak tree, and audio in the form of rustling leaves might be fused in this way. This allows the model to create a multifaceted description of reality.
0 notes
Text
Mastering GPT-4.
A Comprehensive Guide to Harnessing the Power of AI.

To master GPT-4 and understand its capabilities, you can explore its architecture, prompt engineering, real-world applications, and ways to connect with the GPT community. GPT-4 is a large multimodal model that can accept both text and image inputs, and it exhibits human-level performance on various professional and academic benchmarks. It is more creative and collaborative than its predecessors, capable of generating, editing, and iterating on creative and technical writing tasks, as well as accepting images as inputs and generating captions, classifications, and analyses.
GPT-4's real-world applications span various domains, including content creation, extended conversations, document search and analysis, support, sales, content moderation, programming, and AI safety research. Its advanced reasoning capabilities make it suitable for a wide range of use cases.
By jumping into the architecture, prompt engineering, and practical applications of GPT-4, you can harness the full potential of this advanced AI model and contribute to the growing GPT community.
What is the architecture of gpt-4?
The architecture of GPT-4 is based on a mixture of experts (MoE) architecture with separate expert neural networks that specialize in certain tasks or data types. It consists of multiple layers of self-attention mechanisms, enabling the model to capture intricate dependencies and generate text that closely resembles human-written content. GPT-4 is a multimodal large language model that includes a vision encoder for autonomous agents to read web pages and transcribe images and videos.
It is more reliable, creative, and able to handle much more nuanced instructions than its predecessor, GPT-3.5, and has the capability to handle over 25,000 words of text, allowing for use cases like long-form content creation, extended conversations, and document search and analysis. Additionally, GPT-4 can accept images as inputs and generate captions, classifications, and analyses, making it suitable for a wide range of real-world applications.
GPT-4's architecture and capabilities make it an incredibly powerful language model, excelling in various writing tasks, language translation, and providing informative responses across different languages.
The Difference Between GPT-4 and Previous GPT Models
GPT-4, the latest model in the GPT series, exhibits significant advancements over its predecessors, such as GPT-3.5. Here are the key differences:
1. Multimodal Capabilities: Unlike GPT-3.5, which is unimodal and can only handle text inputs, GPT-4 supports multiple modalities. It can accept and generate both text and image inputs and outputs, making it more diverse and capable.
2. Enhanced Understanding and Context: GPT-4 is ten times more advanced than GPT-3.5, enabling it to better understand context and produce more coherent and creative content. It has a maximum token limit of 32,000, significantly higher than GPT-3.5's 4,000 tokens, allowing for more extensive and detailed outputs.
3. Citation Feature: GPT-4 includes a feature that allows it to cite sources when generating text, enhancing the credibility and verifiability of the information it produces.
4. Mixture of Experts (MoE) Architecture: GPT-4 is built on a MoE architecture, with separate expert neural networks specializing in specific tasks or data types, contributing to its enhanced performance and capabilities.
5. Real-world Applications: GPT-4 is optimized for chat and capable of handling more complex tasks, making it suitable for a wide range of applications, including content creation, extended conversations, document search and analysis, support, sales, content moderation, programming, and AI safety research.
The Improvements in GPT-4 Compared to GPT-3.5
GPT-4, the latest model in the GPT series, offers several improvements compared to GPT-3.5:
1. Enhanced Context Window: GPT-4 can retain more information from conversations, allowing it to improve responses based on the conversation. It has a context window of around 25,000 words, significantly larger than GPT-3.5, which had a context window of 4,000 tokens.
2. Training Data and Parameters: GPT-4 is based on a larger training dataset and can consider over 1 trillion parameters when making responses. It was trained on data improvement, with some select information from beyond that date, making it more current in its responses.
3. Multimodal Capabilities: Unlike GPT-3.5, which is unimodal and can only handle text inputs, GPT-4 supports multiple modalities. It can accept and generate both text and image inputs and outputs, making it more diverse and capable.
4. Citation Feature: GPT-4 includes a feature that allows it to properly cite sources when generating text, enhancing the credibility and verifiability of the information it produces.
5. Improved Problem-Solving: GPT-4 demonstrates a strong ability to solve complex mathematical and scientific problems with more accuracy.
6. Handling Biases: GPT-4 has been designed to be better at handling biases compared to GPT-3.5, making it more reliable and creative.
These improvements make GPT-4 significantly more advanced, with better language comprehension, enhanced problem-solving abilities, and the capability to handle a wider range of data inputs, positioning it as a major advancement in the field of AI language models.

RDIDINI PROMPT ENGINEER
0 notes
Text
For this phase, I decided to consider the number of layers of the Mars crater ejecta, aside from the morphology type, per latitude zone.
Shown below is the univariate graph of the number of craters per latitude zone:


The graph is unimodal and seems to be skewed to the right, having greater values at the lower latitude zones.
Next is the univariate graph of the ejecta 1 morphology type per latitude zone:


The graph is also unimodal with the morphology type called Rd as the dominant type between the Mars equator and 30 degrees South.
Shown below is the univariate graph of the number of layers of the Mars craters between 0 to 30 degrees south:


The graph is also unimodal, having a peak at no layers (0) and right-skewed with higher values at the lower number of layers.
Lastly, shown below is the bivariate graph of the number of layers of the Mars crater ejecta per latitude zones (0-10°S, 10-20°S, 20-30°S):



We can see that within all latitude zones, the craters have a dominant crater ejecta morphology with no layers followed by 1 layer only.
0 notes
Last Seen Blogs

signs-of-sleep
• loserleavestown •


buckwildesmythefw
Buck Wilde-Smythe

peaceloveandf1
F1 Fangirl 🫶🏻🪩

strangeskulls
Untitled