#vhdl ip cores
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
If you dial 1-866-584-6757, you can leave an audio post for your followers.
Text
Agilex 5 E-Series with Power-Optimized Edge Performance

Intel Agilex 5 FGPA
Agilex 5 E-Series
Altera’s latest mid-range FPGAs, the Agilex 5 FPGAs E-Series, are now supported by the recently released Quartus Prime Software v24.1, which can be downloaded right now. Intel are happy to announce that it is now simpler than ever and completely free of charge to take use of the unmatched capability of Altera’s Agilex 5 FPGAs E-Series with the introduction of the state-of-the-art Quartus Prime Software from Altera.
Intel Agilex 5
Free Licence: Get rid of obstacles. With the help of Quartus Prime Pro Edition Software v24.1, you may use the newest E-Series devices at no cost, enabling you to innovate beyond limits!
Streamlined Design Flow: Use Quartus Prime Software to see the smooth integration of intellectual property (IP)-Centric design flow. Their easily customizable design samples streamline the process of getting started so you can concentrate on what really matters your innovative ideas.
New Embedded Processing Capabilities: Make use of the Simics simulator-supported dual-core ARM Cortex-A76 and dual-core ARM Cortex-A55 of the Agilex 5 SoC FPGA, the industry’s first asymmetric processing complex. Additionally, Agilex 5 FPGAs may be combined with the feature-rich, performance- and space-optimized Nios V soft-processor for smaller embedded FPGA applications. Additionally, they collaborate with a number of partners who provide a top-notch suite of tools to improve your FPGA and embedded development experience, including Arm, Wind River, Siemens, Ashling, MathWorks, and many more.
Comprehensive Intellectual Property (IP) Portfolio: With their tried-and-true IP portfolio for Agilex 5 FPGAs, many of which are free, you may shorten the time it takes to market. Reduce the amount of circuitry used and make design timing closure easier with hard IP solutions for PCI Express, Ethernet, and memory protocols, which also support LPDDR5. With PCS’s Ethernet 10G MAC, you can guarantee deterministic and synchronised communication, enhanced by Time-Sensitive Networking (TSN) features.
This version includes the Video and Vision Processing (VVP) portfolio IP for Agilex 5 FPGAs, which enables the entire portfolio of video solutions, as well as additional IPs supporting MIPI D-PHY and MIPI CSI-2. Begin developing your Agilex 5 FPGA designs and rely on additional validated advanced features like JESD204C IP, ORAN IP, LDPC IP, CPRI, and eCPRI among others.
Unprecedented Capabilities: Altera FPGAs may be programmed with cutting-edge capabilities like the following using the Quartus Prime Pro Edition Software v24.1.
Agilex 5 datasheet
Dashboard for Quartus Software Exploration (Preproduction)
With distinct instances of Quartus Prime software, numerous projects running concurrently may be easily coordinated and the compilation and timing results can be seen.
Fresh Features for Compilation: Generation flow of precompiled components (PCCs)Utilising the new precompiled component (PCC) generation flow during compilation, shorten the time it takes to compile synthesis.Start the Simulator using the Quartus Prime GUI.Effortlessly start simulations straight from the Quartus Prime GUI by using the handy “Tools ➤ Run Simulation” menu item. Remove the need for extra procedures to streamline your workflow and save time.
Features and Improvements of Synthesis
Use the RTL Linter Tool to convert older RTL files to Verilog/VHDL standards with ease, optimise RAM inference for better speed and resource use, and reduce warnings in error-free RTL modules to increase readability while developing.
Improved Timing Indicator
Gain more flexibility in timing analysis and SDC scripting with new scripting options; guarantee design integrity with sign-off capabilities for particular combinational loops; and learn more about timing characteristics with enhanced Chip Planner visualisation of asynchronous clock domain crossings (CDCs).
Innovations in Advanced Link Analysers
Link Builder: Use the brand-new Link Builder tool to quickly and easily build high-speed serial connections. Streamline the connection creation procedure by automatically generating schematics and importing channels and devices.
High DPI Monitor Assistance: Benefit from improved readability and display quality thanks to GUI scaling for high DPI displays and automated DPI recognition. Enjoy enhanced usability and user experience.
Enhanced Data Viewer: With improvements to the Data Viewer, analyse forward error correction (FEC) code word faults more effectively. Error outcomes may be easily interpreted and analysed for more efficient error correction techniques.
Enhancements to Simulation Time:
Easy-to-use UI for automated import of devices and channels and schematics. Agilex 7 IP offers faster simulation times with the updated Q run and FEC models.
Qualities:
R-Tile: Transaction Layer (TL) multi-channel DMA IP (AXI) up to Gen5 x16 For flexibility in incorporating third-party PCIe Switch IP, use the bypass mode. A new design example for Gen5 x4 endpoint configuration is also provided.
F-Tile: Utilising FastSIM to reduce simulation time in PIPE mode and providing Ubuntu driver support for all sample designs.increased compatibility for up to 64 embedded endpoints.For greater coverage, the Debug Tool Kit (DTK) was added to the switch IP.
Become a Part of the Community: Hua Xue, VP & GM Software Engineering, remarked, “Intel’re excited to offer Quartus Prime Software v24.1, a crucial milestone in FPGA design.”
“Now, engineers everywhere can easily access the unmatched potential of Agilex 5 FPGAs E-Series.” Quartus’s simplified design process and these cutting-edge technologies allow engineers to reach their full potential for innovation. With their state-of-the-art processing capabilities, Agilex 5 devices transform embedded FPGA applications. These are enhanced by Quartus’s vast IP portfolio, which includes a variety of solutions like Ethernet, PCI Express, memory protocols like LPDDR5, support for MIPI D-PHY, CSI-2, and a suite of video solutions, among many other IPs.
The Quartus Exploration Dashboard offers a user-friendly interface and optimization recommendations, which further improve the design exploration process. Intel’re pushing both the simplicity of use and the fast compiler technologies with Quartus v24.1’s open access to E-Series FPGAs and a simplified design pipeline to enable engineers and innovators to unleash their creativity like never before.”
Intel Agilex 5 price
Normally marketed to corporations and incorporated into bigger systems, the Intel Agilex 5 FPGAs do not have a set pricing that is made accessible to the general public. A number of variables affect the pricing, including:
Model specifics: The Agilex 5 family has two distinct series (D and E) with differing logic cell characteristics and capacities. Models with additional features will cost more.
Volume: If you buy in large quantities, you may be able to negotiate a lower price with distributors or directly with Intel.
Distributor: Price structures may vary significantly throughout distributors.
Read more on Govindhtech.com
#Agilex#intelagilex#agilex5#intelagilex5#govindhtech#FPGA#news#technews#technology#technologynews#TechnologyTrends Intel
0 notes
Photo

Buy DMA IP Core With AMBA Interconnects..
Digital Blocks architects, designs, verify, and markets semiconductor IP cores to worldwide technology systems companies. Digital Blocks market planning & architecture phases incorporate the system level view of how the IP core functions based on many years of system level design.
0 notes
Text
Houston Texas Appliance Parts: How Efinix is Conquering the Hurdle of Hardware Acceleration for Devices at the Edge
Houston Texas Appliance Parts
How Efinix is Conquering the Hurdle of Hardware Acceleration for Devices at the Edge
by Houston Texas Appliance Parts on Tuesday 07 March 2023 08:21 AM UTC-05
In previous articles, we established the many ways FPGAs surpass other AI chipsets for running machine learning algorithms at the edge in terms of reconfigurability, power consumption, size, speed, and cost. Moreover, how the microarchitecture-agnostic RISC-V instruction set architecture (ISA) marries up with the architectural flexibility of the FPGA seamlessly. However, the apparent lack of mid-range, cost-effective FPGAs and their less-than-straightforward design flow are a major bottleneck — the software skills required for the fully custom hardware description language (HDL) implementation are difficult to find and often come with a steep learning curve.
Efinix fills the gap with FPGAs built on the innovative quantum compute fabric made up of reconfigurable tiles known as exchangeable logic and routing (XLR) cells that function as either logic or routing, rethinking the traditional fixed ratio of logic elements (LEs) and routing resources. This allows for a high-density fabric in a small device package where no part of the FPGA is underutilized. The potential of this platform transcends the typical barriers facing edge-based devices today: power consumption, latency, cost, size, and ease of development.
Possibly the most striking feature of Efinix FPGAs is the ecosystem and state-of-the-art tool flow surrounding it that lowers development barriers, allowing designers to readily implement AI at the edge using the same silicon — from prototype to production. Efinix has embraced the RISC-V, thereby allowing users to create applications and algorithms in software — capitalizing on the ease of programmability of this ISA without being bound to proprietary IP cores such as ARM. Since this is all done with flexible FPGA fabric, users can massively accelerate in hardware. Efinix offers support for both low level and more complex custom instruction acceleration. Some of these techniques include the TinyML accelerator and predefined hardware accelerator sockets. With approaches such as these, the leaps in acceleration accomplished delivers hardware performance while retaining a software-defined model that can be iterated and refined without the need to learn VHDL. This results in blazing-fast speeds for edge devices, all while consuming low power and functioning within a small footprint. This article discusses precisely how the Efinix platform simplifies the entire design and development cycle, allowing users to take advantage of the flexible FPGA fabric for a scalable embedded processing solution.
Barriers at the edge — a dam-blocking progress
From massive wireless sensor networks to streaming a high-resolution 360o immersive AR or VR experience, most of the world's data lies at the edge. Disaggregating the compute burden from the cloud and bringing it closer to the devices opens doors for next-generation, bandwidth-hungry, ultra-low-latency applications in autonomous driving, immersive digital experiences, autonomous industrial facilities, telesurgery, and so on. The use cases are endless once the enormous roadblock of transmitting data to and from the cloud is sidestepped.
However, the very defining factors of low-latency, power-hungry compute at the edge are the very same factors that pose a significant design challenge for these small but prolific power-limited devices. How then is it possible to design a device capable of processing the power-hungry relevant ML algorithms without having to invest in elaborate technologies? The solution has been to implement any hardware deemed sufficient to run the suitable applications and algorithms (e.g., CPU, GPU, ASIC, FPGA, ASSP) while accelerating the more compute-intensive tasks to balance the compute time (latency) and resources used (power consumed).
As with any innovation, the landscape of deep learning is continually shifting with updating models and optimization techniques, necessitating the use of more agile hardware platforms that can change almost as rapidly as the programs running on them with little to no risk. The parallel processing and flexibility/reconfigurability of FPGAs seem to line up seamlessly with this need. However, making these devices available for mainstream, high-volume applications requires lowering the design barriers for configuring and accelerating the FPGA fabric — a time-consuming process that normally requires a high degree of expertise. Furthermore, traditional accelerators are typically not granular enough and incorporate large pieces of a model that typically do not scale well. They also generally consume far too much power and are, more often than not, proprietary — causing engineers to relearn how to use the vendor-specific platform.
The Sapphire RISC-V core
Creating an application on the RISC-V Core in C/C++
Efinix squarely addresses all of these potential obstacles by taking on the challenge of making FPGAs available to the AI/ML community in an intuitive way. The RISC-V Sapphire core is fully user configurable through the Efinity GUI; this way, users do not have to know all the VHDL behind implementing the RISC-V in the FPGA and can exploit the straightforward programmability of common software languages (e.g., C/C++). This allows teams to rapidly generate applications and algorithms in software at speed. All the required peripherals and buses can be specified, configured, and instantiated alongside the Sapphire core to deliver a fully configured SoC (Figure 1). This RISC-V capability includes multi-core (up to four cores) support and Linux capability, delivering a high-performance processor cluster to a designer's FPGA application as well as the ability to run applications directly on the Linux operating system. The next step — hardware acceleration — is greatly simplified with hardware-software partitioning; once a designer has perfected their algorithm in software, they can progressively start to accelerate this within the flexible Efinix FPGA fabric. However, before we move on to the next step of hardware acceleration, it would be important to understand the inherent benefits of the RISC-V architecture and how it can be exploited for use within the FPGA fabric.
Figure 1: The Efinity GUI enables designers to configure their Sapphire RISC-V core (left) along with all the required peripherals and buses in familiar programming languages for a fully configured SoC. This capability is extended to up to four RISC-V cores.
Custom-instruction-capable RISC-V
The RISC-V architecture is unique in that it does not have all of its instructions defined; instead, there are a few instructions left open for the designer to define and implement. In other words, a custom arithmetic logic unit (ALU) can be created, and it will perform whatever arbitrary function when called upon by the custom instruction (Figure 2). These custom instructions will have the same architecture as the rest of the instructions (e.g., two registers in, one register out) granting a total of eight bytes of data to work with and four bytes that can be passed back to the RISC-V.
However, since the ALU is built within the FPGA, it can both access and pull data from the FPGA. This allows users to expand beyond the eight bytes of data and make the ALU arbitrarily complex — giving access to data that was put out on the FPGA previously (e.g., access to data from sensors). The ability to have an arbitrarily complex ALU is a multiplying factor for speed when it comes to hardware acceleration. Efinix has taken this ability of the custom instruction and adapted it for the AI and ML communities with the TinyML platform.
Figure 2: Custom ALUs can be created with the RISC-V where the standard configuration includes two source registers (rs1 and rs2) that are four bytes wide and one destination register (rd) that is four bytes wide.
The TinyML platform — a library of custom instructions
Hardware acceleration with the TinyML platform
The TinyML platform streamlines the process of hardware acceleration where Efinix has taken the compute primitives used in TensorFlow Lite models and created custom instructions to optimize their execution on accelerators in the FPGA fabric (Figure 3). Through this, the standard software-defined models of TensorFlow are absorbed into the RISC-V complex and are accelerated to run at hardware speed, taking advantage of the rich, open-source TensorFlow Lite community. The entire development flow has been streamlined using the popular Ashling tool flow to make setup, application creation, and debugging a simple and intuitive process.
Figure 3: TensorFlow Lite creates a quantized version of standard TensorFlow models and uses a library of functions to allow these models to run on MCUs at the edge. Efinix TinyML takes these TensorFlow Lite models, and using the custom instruction capabilities of the RISC-V core, accelerates them in the FPGA hardware.
Many of the TinyML platform's libraries of custom instructions are all available to the open-source community on the Efinix GitHub for free access to the Efinix Sapphire core and everything that is needed to design and develop highly accelerated edge AI applications.
Accelerations strategies: an overview
The combination of the RISC-V core, the Efinix FPGA fabric, and the rich, open-source TensorFlow community allows for creative acceleration strategies that can be broken down into several steps (Figure 4):
Step 1: Run the TensorFlow Lite model using the Efinity RISC-V IDE,
Step 2: Use the TinyML accelerator,
Step 3: User-defined custom instruction accelerator,
Step 4: Hardware accelerator templates.
As stated earlier, "Step 1" is a standard process through the Efinity GUI where users can take the Tensorflow Lite models and run it in software on the RISC-V using the very same, familiar process one would with a standard MCU — without having to worry about VHDL. After Step 1, designers will, more often than not, find that the performance of the algorithm they are running is not optimal and therefore requires acceleration. "Step 2" involves hardware-software partitioning where users can implement the fundamental building blocks inside the TensorFlow Lite models and literally click and drag to instantiate custom instructions and get a massive acceleration on the way the model runs on the Sapphire RISC-V core.
Figure 4: Efinix acceleration strategies.
User-defined custom instruction accelerator
"Step 3" leaves it open for designers to create their own custom instructions without leveraging the templates found in the TinyML platform, allowing users to innovate and create acceleration on top of the RISC-V core.
Hardware accelerator templates
Finally, after the required fundamental elements are now accelerated on the RISC-V, "Step 4" involves burying them inside the free Efinix SoC framework with "sockets" of acceleration. The quantum accelerator socket allows users to "point at" data, retrieve it, and edit its contents to, say, perform a convolution on bigger blocks of data.
The Sapphire SoC can be used to perform overall system control and execute algorithms that are inherently sequential or require flexibility. As stated earlier, the hardware-software codesign allows users to choose whether to perform this compute in the RISC-V processor or in hardware. In this acceleration methodology, the pre-defined hardware accelerator socket is connected to a direct memory access (DMA) controller and an SoC slave interface for data transfer and CPU control, which may be used for pre-processing/post-processing before or after the AI inference. The DMA controller facilitates communication between the external memory and other building blocks in the design by (Figure 5):
Storing frames of data into the external memory,
Sending and receiving data to/from the hardware acceleration block,
Sending data to the post-processing engine.
In an image-signal-processing application, this can look like leaving the RISC-V processor to execute the RGB to grayscale conversion as embedded software, while the hardware accelerator performs Sobel edge detection, binary erosion, and binary dilation in the pipelined, streaming architecture of the FPGA (see "Edge Vision SoC User Guide"). This can be scaled up for multi-camera vision systems, allowing companies to turn their designs into a product and deploy them extremely rapidly.
Figure 5: Sample edge vision SoC framework block diagram.
MediaPipe Face Mesh use case
The simplicity of this process might be better highlighted with an example. The MediaPipe Face Mesh ML model estimates hundreds of different three-dimensional facial landmarks in real-time. Efinix took this model and deployed it on the Titanium Ti60 development kit running at 300 MHz. As shown in Figure 6, convolutions on the RISC-V core contributed the most to latency. It is worth noting that the FPGA's resource utilization of close to 60% does not actually reflect the size of the ML model. Instead, this is due to the fact that the entire camera subsystem has been instantiated in the FPGA in order to perform acceleration benchmarking in real-time.
Figure 6: MediaPipe Face Mesh pre-trained network running on the Ti60 development kit showing both latency and resources used.
Simple custom instructions with the TinyML platform (Step 2)
Creating and running a simple, custom two registers in, one register out convolution instruction shows a four- to five-fold improvement in latency. This improvement continues as custom instructions used to accelerate the ADD, MAXIMUM, and MUL functions. However, latency improvements hit a plateau since the RISC-V is spending less time doing these operations (Figure 7).
Figure 7: Obvious latency improvements with simple, custom instructions created for CONV, ADD, MAXIMUM, and MUL functions.
Complex instructions with DMA (Step 4)
An arbitrarily complex ALU is also generated to replace the original CONV. This changes the slope of the original curve and dramatically improves the latency once more. However, FPGA utilization has also jumped up since the complex instruction has taken more resources inside the FPGA. Once again, the resource bar standing at nearly 100% is simply due the fact that the FPGA here contains the entire camera subsystem for demonstration purposes, what is important to note is the relative decrease in latency and increase in utilization (Figure 8).
What's more, switching to a larger FPGA, such as the Ti180, would run all of these complex instructions for massive acceleration without using even 50 percent of the FPGA resources available. These apparent tradeoffs are precisely what allow engineers to readily visualize the balancing act between latency, power consumption, and the cost/size of the FPGA. An edge application that has stringent latency requirements but more lenient power constraints could opt to increasingly accelerate the design for a drastic performance improvement. In power constrained applications, this increase in performance can be traded off by reducing the clock speed for a more moderate improvement in performance at a dramatically lower power.
Figure 8: A larger custom convolution instruction is employed for much more acceleration; however, resources consumed jumps up. Note, the near full utilization of the FPGA is simply due to the fact that the FPGA contains the entire camera subsystem, this would be dramatically lower if the Ti60 was simply running the ML model
A paradigm shift in AI/ML development
In a nutshell, Efinix has combined the familiar development environment of the RISC-V ISA and exploited its custom instruction capability to function within the architecturally flexible FPGA fabric. Unlike many hardware accelerators, this approach does not require any third-party tools or compilers. The acceleration is also fine grain with the acceleration of machine instructions — a level of granularity that only makes sense with an FPGA.
The fact that edge devices can be prototyped and deployed on the innovative design architecture of the Efinix FPGA means the solution is future-proofed. New models and updated network architectures can be expressed in familiar software environments and accelerated at the custom instruction level with only a small amount of VHDL (with libraries of available templates to use for guidance). This degree of hardware-software partitioning where 90 percent of the model remains in software running on the RISC-V allows for an extremely fast time to market. The combination of all of these approaches yields an elegant solution that truly lowers the barriers to entry for implementing an edge device. Designers now have access to a world-class embedded processing capability that can be accessed with a state-of-the-art tool flow and instantiated on the revolutionary Efinix Quantum fabric.
The post How Efinix is Conquering the Hurdle of Hardware Acceleration for Devices at the Edge appeared first on EE Times.

Pennsylvania Philadelphia PA Philadelphia March 07, 2023 at 08:00AM
Hammond Louisiana Ukiah California Dike Iowa Maryville Missouri Secretary Maryland Winchester Illinois Kinsey Alabama Edmundson Missouri Stevens Village Alaska Haymarket Virginia Newington Virginia Edwards Missouri https://unitedstatesvirtualmail.blogspot.com/2023/03/houston-texas-appliance-parts-how.html March 07, 2023 at 09:38AM Gruver Texas Glens Fork Kentucky Fork South Carolina Astoria Oregon Lac La Belle Wisconsin Pomfret Center Connecticut Nason Illinois Roan Mountain Tennessee https://coloradovirtualmail.blogspot.com/2023/03/houston-texas-appliance-parts-how.html March 07, 2023 at 11:41AM from https://youtu.be/GuUaaPaTlyY March 07, 2023 at 12:47PM
0 notes
Text
The Arty RISC-V Computer
Part 3: Finding a RISC-V core for the Arty
The Xilinx Arty A7 is a popular, low-cost Artix-7 FPGA Development Board designed for makers and hobbyists, with the capacity to run a soft processor. It includes a range of Input/Output (I/O) devices, such as LEDs, 7-segment displays, flash memory, SDRAM, and expansion connectors for PMOD modules. PMODs enable a range of additional hardware to be added, such as a VGA output, OLED display, switches, and A/D converters, which can be driven directly by the Artix-7 FPGA.

Figure 3. The Xilinx Arty A7 FPGA board
The other great benefit of the Arty is that it includes Vivado Design Studio (the license is device locked to the Arty), a software suite produced by Xilinx for synthesis and analysis of Hardware Development Language (HDL) designs. Vivado enables developers to synthesize (compile) their designs, perform timing analysis, examine RTL diagrams, simulate a design's reaction to different stimuli, and configure the target device with the programmer (see en.wikipedia.org/wiki/Xilinx_Vivado).
After I chose the Arty board for this project, the next step was to find an existing RISC-V processor design which could be loaded onto it. The first stop was the SiFive website, which has a downloadable Xilinx bitstream file containing a basic RISC-V SoC for the Arty board. In addition, SiFive offers their FreedomStudio development suite, which makes it easy to write programs in C, and upload them to the SoC.
I signed up at the SiFive website, downloaded and programmed the Arty with the RISC-V SoC bitstream, and LED0 changed colors to indicate the processor was running. Fantastic! Then I downloaded and installed FreedomStudio (based on Eclipse), and compiled the simple UART example project bundled with it. I uploaded it directly from FreedomStudio, and watched my serial terminal program dump out a text banner of the SiFive logo. Great stuff!

Figure 4. The SiFive logo
I thought I’d also be able to write RISC-V assembly language (ASM) code with FreedomStudio, but this doesn’t seem to be available. It is possible to view the assembler code for a compiled C program in a panel in FreedomStudio, but it’s not the ASM bare metal level of access I was hoping for. That was a bit disappointing. Maybe they’ll add this to a future version.
Now I wanted to have a closer look at their RTL source code, to see how they had built the RISC-V processor in VHDL/Verilog. I also wanted to add my own peripherals, such as the VGA output. I signed up on their website for access, and my request was quickly granted. I then downloaded the RTL source code, only to discover it was obfuscated (ie. mixed up to make it unreadable by humans). There were some fixed peripherals, and very small amounts of on-SoC RAM, effectively making it impossible to extend in the way I’d planned. Another disappointment, though I guess understandable, as they are selling their IP on a commercial basis.
The second promising RISC-V implementation I found was open source, and available on Github. It’s called the ‘Potato’ RV32I processor, “A simple RISC-V processor for use in FPGA designs”, and maintained by Kristian Klomsten Skordal (see github.com/skordal/potato). Kristian provides excellent instructions for setting up the Potato processor on the Arty board, and in his documentation suggested using the RISCV GNU toolchain repository site to build and install a 32-bit RISC-V toolchain.
The RTL code was in VHDL (my preferred language), using the Wishbone interconnect - I would have preferred AXI, but Wishbone is good too, and it’s open source. It looked like I was finally able to do everything I wanted to with a RISC-V SoC for Arty!
1 note
·
View note
Link
Digital Blocks’ Display Controller Verilog IP Cores support a wide range of LCD/OLED display resolutions, with the standard release providing resolutions from 320×240 up to 1920×1080 Full HD. Advanced releases add capabilities for 4K and 8K display panels.
0 notes
Text
JPEG Resize on-demand: FPGA vs GPU. Which is the fastest?
https://www.fastcompression.com/blog/jpeg-resize-on-demand-fpga-vs-gpu-performance-comparison.htmHigh performance image processing is essential task for web applications. It's not a rare situation when companies need to process hundreds of millions images every day. In some services that number could reach several dozens of billions images per day. Here we review available hardware and software solutions for such tasks. We will not consider CPU-based implementations here and focus on FPGA vs GPU as the fastest hardware for parallel computations.

Internet traffic is increasing by ~25% annually (according to white paper from CISCO, see below) and images take considerable part of that data. Many companies are handling huge volumes of images in their data centers:
Cloud storage, CDN
Mobile instant messaging
Images for social networks, image social platforms, cloud albums, photo hosting centers
User-Generated Content platforms (UGC)
E-Commerce platforms
Market demand
Users generate more images and video data every day
User devices have higher resolution in capture and display
Users strive to better viewing experience
Better image quality and QoS
Customers demand instant access to the resource (reduced latency)
Challenges
Huge consumption of computational and storage resources
Server and storage performance is not enough
As a task for performance and latency comparison for FPGA vs GPU at image processing, we will consider JPEG Resize on-demand which is widely utilized in web applications. Total number of JPEGs in the world is absolutely huge and it's significantly increasing every day. That's why companies spend quite a lot on storages for these pictures and on hardware/software for image processing. The simplest approach is to store the same JPEG picture at several different resolutions and to send an image which is slightly bigger at each request. Such an approach can't match desired image resolution exactly. To cut the expences on storage and to respond to user faster, we can resize JPEG images in realtime according to necessary dimensions to accomplish full match with the requirements of user's device. In that case we need to store at datacenter just one original picture which will be processed according to individual request parameters. That idea about on-demand resize for JPEG images is not new and it has already been implemented in several internet services on CPU, GPU and FPGA.
Image processing pipeline for JPEG Resize on-demand
JPEG Decoding
Resizing and Cropping
Sharpening
Color profile handling
JPEG Encoding
That pipeline consists of different algorithms and we could hardly implement batch processing here for the whole pipeline, as soon as final dimensions are different, images could have different subsampling, individual quantization tables and Huffman tables. It means that we have to process these algorithms sequentially, though still there is a possibility to get a boost from batch mode. Most of the time in the pipeline is spent on JPEG Decoding, so we could implement batch just for JPEG decoding. We can prepare images for future batching by utilizing the same subsampling, quantization tables and Huffman tables. File size will increase a little bit, but we will get an opportunity to accelerate JPEG decoding.
Image Processing on FPGA
FPGA (Field Program Gate Array) is a specialized reconfigurable hardware which could be also utilized for fast image and video processing. This is very complicated approach for programming and FPGA engineers should know quite a lot: hardware architecture, Verlog or VHDL language, Intel (Altera) or Xilinx development tools, etc. Total understanding of hardware functioning is a must, so not everyone could do that. Still, that approach is evolving rapidly and there are some outstanding results in that field.
FPGA-based solutions posess some features which could hardly be beaten: hardware-based computations are usually very fast, the hardware could have very low dimensions and it could have extremely low power consumption. These are indispensible conditions for many embedded applications. In comparison with FPGA, any CPU or GPU-based solutions have bigger dimensions and need more power for processing with the same performance.
Despite the fact that FPGA-programming is very complicated, there are quite a lof of imaging solutions which are based on FPGA/ASIC hardware. Moreover, neural networks have already been implemented on FPGA and that hardware platform is considered to be very promising for Deep Learning and Artificial Intelligence tasks. Currently, neural networks are much more easier to implement on GPU, than on FPGA. But FPGA is a competitive solution, though at the moment it requires super high skills to work with.
Some frame grabbers have built-in library for internal FPGA-based image processing. Silicon Software framegrabbers (now belongs to Basler company) have such a feature and this is the way to implement FPGA-based image processing for camera applications without writing any code on VHDL or Verilog. This is important task to ensure faster than realtime image processing on FPGA for high speed and high performance cameras.
CTAccel solutions on Intel FPGAs

CTAccel company is based in Hong Kong and Shenzhen. This is a team of FPGA professionals with solid record of achievments in FPGA design, hardware/software co-design, system optimization and software engineering. The core team of CTAccel comes from the FPGA team of Clustertech Ltd.
CTAccel Image Processing Solutions
CTAccel Image Processor (CIP) effectively accelerates the following image processing/analytics workflows:
Thumbnail Generation/Transcoding
Image processing (sharpen/color filter)
Image analytics
CIP includes the following FPGA-based accelerated functions:
Decoder: JPEG
Pixel processing: Resize/Crop
Encoder: JPEG, WebP, Lepton
Software compatibility with OpenCV, ImageMagick and Lepton
CIP Image Processing Pipeline (image from that PDF)
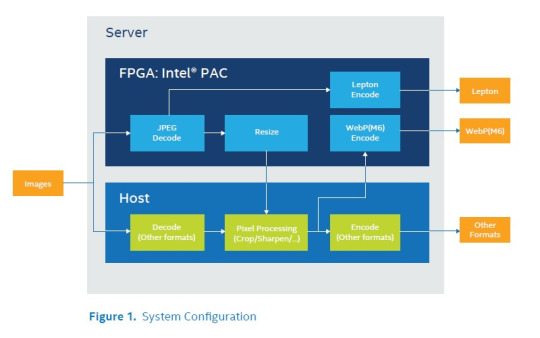
That diagram for suggested image processing pipeline shows that Crop, Sharp and Color conversions are implemented on Host CPU, not on FPGA. In that case we get combined heterogeneous solution, where image processing is done both on FPGA and CPU. This leads to additional load for CPU.
Intel FPGA board (image from that PDF)
The CIP accelerator features an Intel® Programmable Acceleration Card (PAC) with Intel Arria® 10 GX FPGA.

Performance evaluation for CTAccel CIP solution on Intel PAC
JPEG Resize solution from CTAccel for Intel® Programmable Acceleration Card can do JPEG decoding, image resize and JPEG encoding. This is the screenshot for Real-world customer use case from CTAccel site:

8 MPix image is converted to thumbnail on Intel Xeon E5-2639 v2 CPU within 10 ms (100 sec / 10,000 images), which means that on CTAccel CIP that image could be processed within 2 ms (total computation time 10 ms reduced by 80%). For further comparison we can conclude that 3 MPix jpeg image could be resized on Intel PAC with CTAccel CIP within 0.8 ms which is equal to 1250 fps (frames per second).
Averaged latency for 3 MPix image processing on FPGA is the following: (240 ms * (100 - 80) / 100 * 3 / 8 = 18 ms. This actually means that FPGA is processing around 18 / 0.8 = 22 images at the same time. It looks like a batch mode for JPEG decoding on CIP has already been implemented.
Unfortunately we don't have full info about parameters for that pipeline. Nevertheless, we can expect that original compressed image should be close to visually lossless compression. "Generating thumbnails" approach means that final image resolution is very small, so applied resize takes less time and output JPEG encoding takes almost no time. In real-life case of JPEG Resize on-demand we need to fit resolution of smartphone screen, and this is more computationally intensive (that scenario was used for tests with NVIDIA Tesla T4 GPU). Still, these performance results could be a ground to make indirect comparison with benchmarks on NVIDIA Tesla T4. To the best of our knowledge, pricing for Intel PAC board and NVIDIA T4 is comparable.
XILINX

Xilinx Alveo, a portfolio of powerful accelerator cards designed to dramatically increase performance in various tasks. Xilinx® Alveo™ U280 Data Center accelerator cards are designed to meet the constantly changing needs of the modern Data Center. Built on the Xilinx 16nm UltraScale™ architecture, Alveo U280 ES offers 8 GB of HBM2 410 GB/s bandwidth to provide high-performance, adaptable acceleration for memory-bound, compute intensive applications including database, analytics, and machine learning inference. The U280 ES acceleration card includes PCI Express 4.0 support to leverage the latest server interconnect infrastructure for high-bandwidth host processors. And like all Xilinx technology, customers can reconfigure the hardware, enabling them to optimize for shifting workloads, new standards and updated algorithms without incurring replacement costs.
Alveo accelerator cards are adaptable to changing acceleration requirements and algorithm standards, capable of accelerating any workload without changing hardware, and reduce overall cost of ownership.

Xilinx Alveo U280 Data Center accelerator card (image is taken here)
There are some libraries which allow to implement image processing algorithms on FPGA via C++ instead of Verilog/VHDL, though finally VHDL code will be generated. Xilinx Video and Image Processing Pack is an example how to do that. It includes full licenses to the following LogiCORE IP cores:
Chroma Resampler
Color Correction
Color Filter Array Interpolation
Gamma Correction
Image Edge Enhancement and Image Noise Reduction
On-Screen Display
Video Deinterlacer
Video DMA
Video Timing Controller
The Xilinx Video and Image Processing Pack provides bundled licensing option for all of the LogiCORE™ IP blocks. Video processing blocks provide optimized hardware implementations for video scaling, on-screen display, picture-in-picture, text overlay, video and image analysis and more. Image processing blocks enable pre-processing of images captured by a color image sensor with a Bayer Color Filter Array (CFA), correcting defective pixels, interpolating missing color components for every pixel, correcting colors to adjust to lighting conditions, setting gamma to compensate for the intensity distortion of different display devices and more.
CTAccel on Virtex UltraScale+ VCU1525
The above set of image processing features from Xilinx LogiCORE IP cores is not enough to accomplish the task of JPEG Resize on-demand. That task was solved on Xilinx FPGA hardware by CTAccel company, as in the case with Intel FPGA. That solution from CTAccel on Xilinx is utilized by Huawei Cloud for FPGA Image Transcoding Acceleration on Virtex VU9P to provide easy-to-use and cost-effective image transcoding services. For the task of thumbnail generation (which is alike the task of JPEG Resize on-demand, but more simple), published benchmarks for performance and latency are the same as for Intel FPGA solution - this is 0.8 ms for 3 MPix jpeg image. It should be noted that the same CTAccel CIP solution can work on Xilinx Alveo accelerator cards as well.

Xilinx VCU1525 developer board (image is taken here)
GPU Image Processing on NVIDIA CUDA
GPU architecture was initially created for image display and finally it was transformed for parallel computations. Image processing could be considered as native task for GPU, though we need SDK not to program GPU at low level. There are quite a lot of such SDKs with sofisticated set of features.
Full set of features for JPEG resize on demand exists at Fastvideo Image Processing SDK. That SDK contains wide variety of image processing modules which show very high performance at all NVIDIA GPUs, starting from Jetson to high-end Quadro and Tesla products. Highly optimized modules show just exceptional results. For many features the performance is much higher that bandwidth of PCIe Gen3 x16. This is important issue to offer fast solution, particularly for JPEG resize on demand.
That solution has been heavily tested for years and this is the proof of its reliability in the taks of JPEG Resize on-demand. Several high-load internet services have been utilizing that software and total number of processed JPEGs exceeds several quadrillions. In comparison with recently developed FPGA-based solutions it looks much more reliable.
Fastvideo Image Processing SDK on NVIDIA T4 can do decode-resize-sharp-encode at 1.2 ms for 3 MPix image resize which is around 800 fps, but this is the result without batch mode. As soon as image resize on GPU takes small part of that time, we see that performance on JPEG Decoder is the key to achieve maximum speed for that task. Usually resized image has smaller resolution and output JPEG Encoder can process it very fast. In general, GPU JPEG Encoder is much faster than GPU JPEG Decoder, that's why JPEG decoding is the bottleneck for that task.

Despite the fact that we haven't yet implemented our own batch mode for JPEG Resize on-demand, there is an opportunity to increase GPU occupancy with CUDA MPS on Linux. CUDA MPS allows to utilize NVIDIA Hyper-Q technology in multi-process environment and this is the way to get much better performance if GPU is underutilized (this is exactly our case). We have run 4 processes of JPEG Resize on-demand on NVIDIA T4 and have achieved significant speedup with CUDA MPS. We've got final performance 2200 fps with CUDA MPS on NVIDIA Tesla T4.
The feature of FPGA partial reconfiguration doesn't bring any additional benefits in comparison with GPU solutions for high performance image processing tasks. Basically, the performance is defined by the hardware and software. And if we need to run any other task on the same hardware, we just need to load another software from available image processing modules. In the case with GPU, this is actually a question about availability of necessary modules in the software. Fastvideo Image Processing SDK has great variety of such modules and it can also work with any other third-party SDK, so the choice of available software features for CUDA image processing on Tesla T4 is impressive.
It should be noted that currently, versatility of GPU is much more profound in comparison with FPGA. NVIDIA GPUs have a lot of libraries which help developers to build their applications. And the idea of utilizing COTS (Commercial Off-The-Shelf) is very handy. GPU and FPGA have totally different architectures and that's why their "killer applications" are also quite different. NVIDIA, Intel and Xilinx invest a lot into their software, hardware, infrastructure, community and try to promote their solutions at full extent. They do compete everywhere and NVIDIA is now succeeding with implementation of embedded solutions on Jetson platform, though embedded solutions were always the main market niche for FPGA/ASIC. Intel and Xilinx are moving towards DL/AI to compete with NVIDIA as well.
Conclusions
We have published available results for GPU vs FPGA performance and latency for JPEG Resize on-demand task. That comparison is indirect because we have benchmarks for different scenarios: for FPGA this is thumbnail generation case for JPEG images, for GPU this is standard JPEG resize to most frequently used resolution which was acquired from statistics.
Achieved performance for the above tasks look very good in both cases: NVIDIA Tesla T4 result is around 2200 fps for JPEG Resize with CUDA MPS. Intel/Xilinx result is around 1250 fps for thumbnail generation with internal batch decoding, which is more simple task because it requires less computations. We can see that NVIDIA Tesla T4 significantly outperforms Intel/Xilins FPGA boards and we need to bear in mind that FPGA benchmarks were received in simplified test.
Computational latency in these tasks for NVIDIA Tesla T4 is 2-3 ms, for FPGA this is 18 ms.
FPGA dimensions and power consumption are not vitally important for JPEG Resize on-demand task. FPGA boards look like GPU boards and their dimensions are the same, though power consumption is still less for FPGA-based solutions which have 20W - 40W per FPGA card and 70W for NVIDIA Tesla T4.
Ease of programming is also looks alike, because mostly developers are utilizing high-level SDKs. If we have a look at low-level programming, then FPGA is much more complicated to handle.
Partial Reconfiguration and flexibility are essential benefits of FPGA, but for the current task they are not really important.
Reliability of GPU-based solution is higher due to long-term presence on the market.
Both GPU and FPGA could be utilized for other tasks, including DL/AI applications.
GPU-based solutions are basically software implementations, though FPGA solutions imply that there is non-standard hardware to work with. This is a great advantage of NVIDIA GPUs - they are commodity things. At the moment we can't call FPGA-based boards from Intel and Xilinx as commodity things yet.
NVIDIA, Intel (Altera), Xilinx, CTAccel, Fastvideo are great companies which move progress forward and create impressive software and hardware solutions for high performance applications.
What we finally get
GPU and FPGA high-performance processing capabilities offers the following benefits:
Increased image processing throughput
Reduced TCO
Reduced computational latency
Reduced size of cluster or less total number of servers
Low CPU utilization
Better user experience and QoS:
Less time to wait for image loading
Less power consumption on users's device
Less traffic due to optimal image resolutions
Better image quality (no local image resize on user's device)
Links
Cisco Visual Networking Index: Forecast and Trends, 2017–2022 White Paper (Internet traffic growth estimation)
JPEG Resize on-demand on NVIDIA Tesla V100 with Fastvideo software
Accelerating JPEG, WebP and Lepton decoding, encoding and resizing on Intel® Xeon®-based servers by offloading all functions to the Intel FPGA.
Xilinx Alveo U200, U250 and U280
Xilinx Video and Image Processing Pack
NVIDIA Tesla T4 specification
Fastvideo Image Processing SDK for NVIDIA Tesla GPUs
Jpeg2jpeg Acceleration with CUDA MPS on Linux at NVIDIA Quadro GV100
Original article see at:
0 notes
Text
FPGA Market to Reach US$9,734.4 mn by 2020
A FPGA is an integrated circuit or semiconductor device used to implement logical function that an application-specific integrated circuit (ASIC) could perform, but the ability to update the functionality after manufacturing offers advantages such as re-programming in the field for rapid prototyping and debugging for many applications. FPGAs use programmable routing channels and pre-built logic blocks for implementing custom hardware functionality, depending upon the embedded system developer configuring these devices. FPGAs are programmed and configured using Hardware Description Language (HDL) such as VHDL and Verilog. Medical imaging equipment demands numerous processing requirements based on the definite data acquisition principles and algorithms used in image processing. High performance computing capabilities in imaging equipment is one of the major factors contributing to the growth of high-end processors and field-programmable gate arrays. The advantages of FPGA in digital signal processing (DSP) over other processors make it a feasible alternative for most imaging equipment such as computerized tomography (CT) and positron emission tomography (PET) machines. Though FPGAs have begun to replace DSP in most applications, there exists a trend to use them as co-processors. General diagnostic imaging devices include X-rays, mammography equipment, ultrasounds, CT scanners, MRIs, and nuclear medicine imaging.
The automobile market continues to witness a proliferation of electronic content due to governmental guidelines on pollution, security and safety regulations, and the ongoing oil crisis. Furthermore, increasing luxury features in automobiles require efficient solutions, thereby boosting demand in the FPGA market. Moreover, rising fuel prices in the global market have resulted in demand for electric and hybrid vehicles, which in turn is expected to drive FPGA content in automobiles. In Europe, regulations such as the Antilock Braking System (ABS), Electronic Stability Program (ESP), and electronically controlled independent suspension are expected to generate substantial revenues in the near future. North America dominates the automobile market; however, Asia Pacific has significant potential to become the key contributor to FPGA revenues. FPGA is used in automobiles for various applications including driver assistance, rear-view camera, forward camera, surround-view camera, infotainment, and electric vehicles.
Read Report Sample @
https://www.transparencymarketresearch.com/sample/sample.php?flag=S&rep_id=1405
High performance computing in the financial sector is continuously challenged by rising demand for capability to process larger volumes of data with faster results. FPGA can significantly increase the throughput of systems and decrease data center load. As a result, FPGAs are extensively adopted in mainstream embedded computing to build complex mission-critical systems. FPGA’s underlying programmable architecture is being used for numerous purposes in the financial sector including real-time trading, performance arbitrage, risk analysis, and ex-post factor data analysis. Companies such as Fixnetix have launched ix-eCute, the pre-trade risk FPGA microchip for ultra-low latency implementation for Canada. In addition, companies such as Enyx are focusing on software and IP cores for optimizing FPGAs for the trading floor. Accelize is serving the finance industry with its ultra-low latency FPGA network platforms. Thus, the FPGA market is expected to witness substantial growth in the financial domain over the forecast period.
Telecom is the largest application segment for FPGA. Other applications include automobile, consumer electronics, industrial, data processing, military and aerospace, and medical industries. Unlimited demand for bandwidth in wireless networks is driving this market. In addition, increase in demand for smartphones and tablets are boosting the market. FPGA is widely used in imaging equipment and the automobile industry to enable high performance computing abilities. This is contributing to growth of the market.
Read Report Brochure @
https://www.transparencymarketresearch.com/sample/sample.php?flag=B&rep_id=1405
‘Accumulating 3D ICs with FPGA, processors, SerDes, and memory controller, and other part offering DDR memory is expected to open up opportunity to the market growth during the forecast period. Also, there is major demand for FPGA for low power, cost-sensitive, and space-constrained applications. With increase in number of industries operating in industrial, automotive, and telecom sector, Asia Pacific dominates FPGA market, followed by the U.S. and Europe.
Major market participants profiled in this report include Xilinx Inc., Altera Corporation, Lattice Semiconductor Corporation, Microsemi Corporation, among others.
0 notes
Text
Computer Software Training Courses for 2019
This is the era of technology. Everywhere you go you find technology in the form of computer, mobile phones, satellite etc. Even in your workspace also. So, you need some kind of familiarity with them. For example, you need to handle a computer in your office, android phone, and scanner and even with a coffee machine as you are surrounded by technologies. But this blog is not about all of them it is about Information Technology.
Today in the market you find a lot of institutes who offer IT training courses. These courses may include the following:-
Web development
Web Designing
Digital Marketing
App Development
Hardware & Networking
System Analyst
DBA (Database administrator)
Cloud Technology
Software Development
AI (Artificial Intelligence) etc…
But if you have made your mind to build your career in Computer Software then ZENITECH is the best institute for you to start with as this offers various computer courses. The list of the courses is as follows:-
Embedded System Training
C/C++ Training
JAVA
C#ASP.NET
Python
Linux
Web Development
IOT
VHDL
Embedded System Training:
1) The basics of embedded systems, the basic computer architecture, voltage and current, pull down & pull up registers etc.
2) Basic intro to ARM Cortex M
3) Intro to Assembly language
4) Basics of C language
5) LCD controllers, pinout, interfacing, data transfer.
6) Intro to Beaglebone Black
7) OS Fundamentals (Linux)
C/C++ Training:
C is a very beginner and basic computer programming language. In this course, we cover the following parts:-
1) Basics of C (Variables, Data Types, Control structure, input, output, header files etc)
2) Data Structure (Lists, Stack, Queue, Tree Heap, sorting algorithms etc)
3) Tree
4) Basics of C++ (Classes, Objects, Methods, Constructors, Operators, Inheritance, Polymorphisms etc).
5) STL (Standard Template Library)
6) Multithreading (Deadlock, Thread Management)
7) Design Patterns
8) C++11, C++14, C++17
JAVA
JAVA is a very popular and demanding programming language. This course contains the following sections:-
1) Core JAVA (First java program with the console and with Eclipse, Data Types, variables, Literals, Arrays, Class, methods, Operators, Statements etc)
2) JAVA Exceptions (Types of Exceptions, Defining and Throwing Exceptions, Assertions etc)
3) Java Strings
C#ASP.NET
.NET is a free platform for building many different types of apps with multiple languages. You can build apps for web, mobile, desktop, gaming, and IoT. C#, F# and VB (Visual Basic) are the languages that are used to write .NET programs. This course contains:-
1) An intro of C# (What is .NET, CLR, Namespaces, Statements, Expressions, Operators, Defining Types, Classes)
2) Encapsulation, Directional Dependencies, Method Overloading, Properties, Events etc.
3) Control and Exceptions (Looping, Re-throwing Exceptions)
4) C# and the CLR
5) C# and Generics (Generic Collections, Generic Parameters, Generic Constraints, Generic Methods)
6) C# and LINQ (Extension Methods)
7) Prime Abstraction, Multithreading, Resource management, ArrayList, Hashtable, SortedList, Stack and Queue
8) ADO.NET
9) WPF (Windows Presentation Foundation) includes Windows Application using WPF, Data Binding, Data Template, Styles, Commands etc.
10) ASP.NET (ASP.NET Architecture, Data Binding, Validation, Config file encryption, Custom Controls, ASP.NET Ajax Server Data)
11) C# 6, C# 7
Python
Python is free and easy to learn a computer programming language. In this course first, we tell you how to install the Python interpreter on your computer as this is the program that reads Python programs and carries out their instructions. There are 2 versions of Python: Python 2 and Python 3. Our course contains the following sections:-
1) Python Basics (What is Python, Anaconda, Spyder, Integrated Development Environment (IDE), Lists, Tuples, Dictionaries, Variables etc)
2) Data Structures in Python (Numpy Arrays, ndarrays, Indexing, Data Processing, File Input and Output, Pandas etc)
Linux
According to Wikipedia,
“Linux is a family of free and open-source software operating systems based on the Linux kernel.”
Linux is the leading OS on servers and other big iron systems such as mainframe computers, and TOP500 supercomputers. It is more secure Os as compared to the other OS(s) like Windows. Our Linux course contains the following sections:-
1) Linux Basics (Utilities. File handling, Process utilities, Disk utilities, Text Processing utilities and backup utilities etc).
2) Sed and Awk (awk- execution, associative arrays, string and mathematical functions, system commands in awk, applications. etc)
3) Shell Programming/ scripting (Shell programming with bash, Running a shell script, The shell as a programming language, Shell commands, control structures, arithmetic in the shell, interrupt processing, functions, debugging shell scripts)
4) Files and Directories (File Concept, File types, File system Structure, File metadata, open, create, read, write, lseek etc)
5) Processes and Signals (Process concepts, the layout of C program image in main memory, process environment, Introduction to signals, Signal generation and handling etc)
6) Inter-Process Communication (IPC), Message Queues, Semaphores(Introduction to IPC, IPC between processes on a single computer, on different systems etc)
7) Shared Memory (Kernel support for Shared memory, APIs for shared memory)
8) Socket TCP IP Programming (Introduction to Berkeley Sockets, IPC over a network, client/server model etc)
9) Linux Kernel (Linux Kernel source, Different kernel subsystems, Kernel Compilation etc)
10) Linux Device Driver (Major and Minor numbers, Hello World Device Driver, Character Device Driver, USB Device Driver etc)
So, these are the computer software training courses offering by ZENITECH. To enroll yourself for any of the following course you can call us @ 9205839032, 9650657070.
Thanks,
0 notes
Text
67% off #Xilinx Vivado: Beginners Course to FPGA Development in VHDL – $10
Making FPGA’s Fun by Helping you Learn the Tools in Vivado Design Suite, using VHDL
Beginner Level, – Video: 1 hour, 13 lectures
Average rating 4.4/5 (4.4)
Course requirements:
Vivado Design Suite 2015.2 or higher Basic Knowledge of VHDL A 7 Series Xilinx FPGA Development Kit (Artix, Kintex or Virtex) PC with Internet connection Digital Design Experience 6 Series FPGA’s are not supported in Vivado
Course description:
Course Update: Note! This course price will increase to $40 as of 1st October 2016 from $30. The price will increase regularly due to new updated Lectures and Content. Get this course while it is still low.
Course Content Updated for September 2016.
Do you want to learn the new Xilinx Development Environment called Vivado Design Suite? Are you migrating from the old ISE environment to Vivado? Or are you new to FPGA’s? This course will teach you all the fundamentals of the Vivado Design Suite in the shortest time so that you can get started developing on FPGA’s.
Now why should you take this course when Xilinx Official Partners already offer training? Most of their course are held bi-annually which means you will have to wait at most 6 months before starting the basic training. Also these courses can cost over thousands of dollars.
My Name is Ritesh Kanjee and I am an FPGA Designer with a Masters Degree in Electronic Engineering. I have over 7300 students on Udemy. This course is designed to help you design, simulate and implement HDL code in Vivado through practical and easy to understand labs. You will learn all the fundamentals through practice as you follow along with the training. Together we will build a strong foundation in FPGA Development with this training for beginners. This Course will enable you to:
Build an effective FPGA design. Use proper HDL coding techniques Make good pin assignments Set basic XDC constraints Use the Vivado to build, synthesize, implement, and download a design to your FPGA.
Training Duration:
1 hour
Skills Gained
After Completing this Training, you will know how to:
Design for 7 series+ FPGAs Use the Project Manager to start a new project Identify the available Vivado IDE design flows (project based) Identify file sets such as HDL, XDC and simulation Analyze designs by using Schematic viewer, and Hierarchical viewer Synthesize and implement a simple HDL design Build custom IP cores with the IP Integrator utility Build a Block RAM (BRAM) memory module and simulate the IP core Create a microblaze processor from scratch with a UART module Use the primary Tcl Commands to Generate a Microblaze Processor Describe how an FPGA is configured.
Skills Gained
This course only costs less than 1% of the Official XIlinx Partner Training Courses which has similar content. Not only will you save on money but you will save on Time. Similar courses usually run over 2 days. This course, however, you will be able to complete in under an hour, depending on your learning speed.
You will receive a verifiable certificate of completion upon finishing the course. We also offer a full Udemy 30 Day Money Back Guarantee if you are not happy with this course, so you can learn with no risk to you.
See you inside this course.
Full details Use Vivado to create a simple HDL design Sythesize, Implement a design and download to the FPGA Create a Microblaze Soft Core Processor Understand the fundamentals of the Vivado Design FLow Digital designers who have a working knowledge of HDL (VHDL) and who are new to Xilinx FPGAs Existing Xilinx ISE users who have no previous experience or training with the Xilinx PlanAhead suite and little or no knowledge of Artix-7, Kintex-7 or Virtex-7 devices. Engineers who are already familiar with Xilinx 7-series devices Designers who are already using Vivado for design should not take this course unless they are struggling with the basics. Take this course if you want save $2200 in training costs of similar training material
Full details
Reviews:
“the once tutorial that finally teaches me how to think and create test bench” (Afshin Alavi)
“I enjoyed the course, learned the basics of Vivado…some explanation were too fast or not very detailed but this was expected….it covered what it was intended for… a Xiling new FPGA EDA tool introduction” (Dennis Garcia)
“Does not explain anything. No overview, concepts, or anything at all. Just click click type type. I have to keep stopping and go back multiple times just to catch something done at high speed. not a fun learning experience.” (julian higginson)
About Instructor:
Ritesh Kanjee
Ritesh Kanjee has over 7 years in Printed Circuit Board (PCB) design as well in image processing and embedded control. He completed his Masters Degree in Electronic engineering and published two papers on the IEEE Database with one called “Vision-based adaptive Cruise Control using Pattern Matching” and the other called “A Three-Step Vehicle Detection Framework for Range Estimation Using a Single Camera” (on Google Scholar). His work was implemented in LabVIEW. He works as an Embedded Electronic Engineer in defence research and has experience in FPGA design with programming in both VHDL and Verilog.
Instructor Other Courses:
Zynq Training – Learn Zynq 7000 SOC device on Microzed FPGA PCB Design a Tiny Arduino In Altium CircuitMaker Learn Computer Vision and Image Processing in LabVIEW …………………………………………………………… Ritesh Kanjee coupons Development course coupon Udemy Development course coupon Development Tools course coupon Udemy Development Tools course coupon Xilinx Vivado: Beginners Course to FPGA Development in VHDL Xilinx Vivado: Beginners Course to FPGA Development in VHDL course coupon Xilinx Vivado: Beginners Course to FPGA Development in VHDL coupon coupons
The post 67% off #Xilinx Vivado: Beginners Course to FPGA Development in VHDL – $10 appeared first on Udemy Cupón.
from http://www.xpresslearn.com/udemy/coupon/67-off-xilinx-vivado-beginners-course-to-fpga-development-in-vhdl-10/
0 notes
Text
83% off #Xilinx Vivado: Beginners Course to FPGA Development in VHDL – $10
Making FPGA’s Fun by Helping you Learn the Tools in Vivado Design Suite, using VHDL
Beginner Level, – 1.5 hours, 15 lectures
Average rating 4.5/5 (4.5 (21 ratings) Instead of using a simple lifetime average, Udemy calculates a course’s star rating by considering a number of different factors such as the number of ratings, the age of ratings, and the likelihood of fraudulent ratings.)
Course requirements:
Vivado Design Suite 2015.2 or higher Basic Knowledge of VHDL A 7 Series Xilinx FPGA Development Kit (Artix, Kintex or Virtex) PC with Internet connection Digital Design Experience 6 Series FPGA’s are not supported in Vivado
Course description:
Note! This course price will increase to $70 as of 1st January 2017 from $60. The price will increase regularly due to updated content. Get this course while it is still low.
LATEST: Course Updated For December 2016 OVER 1383+ SATISFIED STUDENTS HAVE ALREADY ENROLLED IN THIS COURSE!
———————————————-
Do you want to learn the new Xilinx Development Environment called Vivado Design Suite? Are you migrating from the old ISE environment to Vivado? Or are you new to FPGA’s? This course will teach you all the fundamentals of the Vivado Design Suite in the shortest time so that you can get started developing on FPGA’s.
Now why should you take this course when Xilinx Official Partners already offer training? Most of their course are held bi-annually which means you will have to wait at most 6 months before starting the basic training. Also these courses can cost over thousands of dollars.
My Name is Ritesh Kanjee and I am an FPGA Designer with a Masters Degree in Electronic Engineering. I have over 7300 students on Udemy. This course is designed to help you design, simulate and implement HDL code in Vivado through practical and easy to understand labs. You will learn all the fundamentals through practice as you follow along with the training. Together we will build a strong foundation in FPGA Development with this training for beginners. This Course will enable you to:
Build an effective FPGA design. Use proper HDL coding techniques Make good pin assignments Set basic XDC constraints Use the Vivado to build, synthesize, implement, and download a design to your FPGA.
Training Duration:
1 hour
Skills Gained
After Completing this Training, you will know how to:
Design for 7 series+ FPGAs Use the Project Manager to start a new project Identify the available Vivado IDE design flows (project based) Identify file sets such as HDL, XDC and simulation Analyze designs by using Schematic viewer, and Hierarchical viewer Synthesize and implement a simple HDL design Build custom IP cores with the IP Integrator utility Build a Block RAM (BRAM) memory module and simulate the IP core Create a microblaze processor from scratch with a UART module Use the primary Tcl Commands to Generate a Microblaze Processor Describe how an FPGA is configured.
Skills Gained
This course only costs less than 1% of the Official XIlinx Partner Training Courses which has similar content. Not only will you save on money but you will save on Time. Similar courses usually run over 2 days. This course, however, you will be able to complete in under an hour, depending on your learning speed.
You will receive a verifiable certificate of completion upon finishing the course. We also offer a full Udemy 30 Day Money Back Guarantee if you are not happy with this course, so you can learn with no risk to you.
See you inside this course.
Full details Use Vivado to create a simple HDL design Sythesize, Implement a design and download to the FPGA Create a Microblaze Soft Core Processor Understand the fundamentals of the Vivado Design FLow Digital designers who have a working knowledge of HDL (VHDL) and who are new to Xilinx FPGAs Existing Xilinx ISE users who have no previous experience or training with the Xilinx PlanAhead suite and little or no knowledge of Artix-7, Kintex-7 or Virtex-7 devices. Engineers who are already familiar with Xilinx 7-series devices Designers who are already using Vivado for design should not take this course unless they are struggling with the basics. Take this course if you want save $2200 in training costs of similar training material
Full details
Reviews:
“It was what I was hoping for – a quick but useful introduction to Vivado for those that know a little about FPGAs and Xilinx tools.” (Steve Belvin)
“Very interesting tricks. Thanks!” (Antonio Ferrão Neto)
“Missing some explanation about : – Vivado Flow – Which implies that menus are not always available depending on which section of the flow is available – working and navigating in the flow…” (Cédric Droguet)
About Instructor:
Ritesh Kanjee
Ritesh Kanjee has over 7 years in Printed Circuit Board (PCB) design as well in image processing and embedded control. He completed his Masters Degree in Electronic engineering and published two papers on the IEEE Database with one called “Vision-based adaptive Cruise Control using Pattern Matching” and the other called “A Three-Step Vehicle Detection Framework for Range Estimation Using a Single Camera” (on Google Scholar). His work was implemented in LabVIEW. He works as an Embedded Electronic Engineer in defence research and has experience in FPGA design with programming in both VHDL and Verilog.
Instructor Other Courses:
Fun & Easy Embedded Microcontroller Communication Protocols Ritesh Kanjee, Masters in Electronic Engineering (4) $10 $30 Zynq Training – Learn Zynq 7000 SOC device on Microzed FPGA PCB Design a Tiny Arduino In Altium CircuitMaker …………………………………………………………… Ritesh Kanjee coupons Development course coupon Udemy Development course coupon Development Tools course coupon Udemy Development Tools course coupon Xilinx Vivado: Beginners Course to FPGA Development in VHDL Xilinx Vivado: Beginners Course to FPGA Development in VHDL course coupon Xilinx Vivado: Beginners Course to FPGA Development in VHDL coupon coupons
The post 83% off #Xilinx Vivado: Beginners Course to FPGA Development in VHDL – $10 appeared first on Course Tag.
from Course Tag http://coursetag.com/udemy/coupon/83-off-xilinx-vivado-beginners-course-to-fpga-development-in-vhdl-10/ from Course Tag https://coursetagcom.tumblr.com/post/157311830938
0 notes
Photo

Buy UDP and RTP Stack IP Core ---
Digital Blocks adds RTP protocol hardware processing to our UDP/IP Off-Load Engine (UOE) SoC FPGA/ASIC solutions (Verilog Core DB-RTP-UDP-IP-AV) and targets Audio/Video Packet Processing such as a RTP/UDP/IP interface to H.264/H.265 CODECs. Both IP Cores contain MAC Layer Pre- & Post-Processing and an ARP Packet Processing for a FPGA or ASIC networking adapter card solution.Contact us on- http://www.digitalblocks.com
0 notes
Text
Display Controller and DMA Controller
Digital Blocks market planning & architecture phases to integrate the system level view of how the IP core functions based on so many years of system level design. We provide our potential customers with pre-verified Verilog / VHDL soft IP cores with System-Level Architecture features which reduce costs and enhance their System’s capabilities and accelerate the product development.
Digital Blocks offers the DB9000 gathering of highlight rich and savvy Display Controller IP cores for driving innovation organizations which require TFT LCD or OLED panels for the item. DB9000 family Display Controllers is tried with different microprocessors, information transport interfaces to outline cushion memory, and diverse LCD or OLED board makers and goals.

Digital Blocks also offers AXI DMA Controller with Master AXI Interconnect (verilog IP center DB-DMAC-MC-AXI) offers 1-16 Channels with a for every channel CPU descriptor-driven interface controlling the information move between memory subsystems or among memory and a fringe. The AXI DMA Controller highlights Scatter-Gather capacity, with per channel Finite State Control and single-or double clock FIFOs (parameterized top to bottom and width), intrude on controller and discretionary information equality generator and checker. The AXI Master information Interface scales from 32-to 1024-bits, with programmable information explosions of 1, 4, 8, 16 words (with the littlest information move upheld is 1 byte), and up to 16 extraordinary read demands, and for AXI4, the accessibility of programmable QoS and longer information burst lengths. Then this Controller additionally gives an APB or AXI-light Slave Interface for CPU access to Control/Status Registers. The DB-DMAC-MC-AXI is tuned as an elite DMA Engine, for huge and little information square exchanges.
To know more about Display controller and DMA Controller click in https://www.digitalblocks.com/
#software#technology#networking#ipcore#AXI4 DMA controller#I2C controller ip#I3C controller ip#SPI flash controller ip#display controller ip
0 notes
Text
The Arty RISC-V Computer
Part 10: Where do we go from here?
The Potato processor used in this project supports the complete 32-bit RISC-V base integer ISA (RV32I) version 2.0, and has a single-issue in-order 5-stage pipeline. It includes an optional instruction cache (simple read-only, direct-mapped). It’s basically one of the simplest softcore RISC-V processors you can find, making it the easiest to learn about, and the easiest to extend.
The great thing about implementing a softcore RISC-V processor on an Arty FPGA is that you can experiment with the RISC-V core by modifying it’s VHDL source code. For example, you could add a superscalar (multiple instruction per clock execution) unit, like the one implemented in the RV01 RISC-V core available at OpenCores (see https://opencores.org/project/rv01_riscv_core), or expand the amount of RAM, interface to other peripherals on the Arty board, or add a more sophisticated instruction cache (eg. one which is two-way set associative, as described at https://en.wikipedia.org/wiki/CPU_cache).
This ability to modify the RISC-V SoC, at such a fundamental level, enables users to create the deepest hacks and execution optimizations imaginable. RISC-V is an architecture with a great future, and part of that future is driving it’s performance to make it comparable or better than other processors in it’s class. It’s interesting, for example, to see comparisons of RISC-V processor performance with the various processors in the ARM family (see https://en.wikipedia.org/wiki/ARM_architecture) by doing a Google search.
After exploring the RISC-V architecture, if you want to take the next step and develop a custom chip for your product, there are a number of commercial partners you can work with to implement your RISC-V designs. The RISC-V entry on Wikipedia is a great source of the latest information across all things RISC-V, including members of the RISC-V foundation (see https://en.wikipedia.org/wiki/RISC-V#Adopters).
SiFive have two classes of evaluation boards available now, the HiFive1 (single-core at 320MHz built with TSMC 180nm) and the HiFive Unleashed (quad-core+1 at 1.5GHz built with 28nm) boards. According to SiFive, “SiFive Core IP, verified and delivered in Verilog, scale across multiple design nodes, making them ideal for your next SoC design” (See https://www.sifive.com/products/risc-v-core-ip/).
Finally, to get the latest information about RISC-V, including specifications, members, news and events, you should visit the official RISC-V Foundation website at https://riscv.org.
I hope you’ve enjoyed this journey into the RISC-V architecture, and I look forward to expanding this project document regularly with lots of new and interesting future extensions, a few of which were described in the “Summary” section. Enjoy your exploration of the world of RISC-V!

0 notes
Text
Applications of LCD Controller IP Core
The changes in embedded structure advancement has prompt the usage of more electronic terminals, for instance, cell phones, auto route framework and various hand held gadgets with LCD show grasped in them. Advanced introduction application have also spread to wide zones of medical devices, process control, camera, EBooks, autos and various other. Its closeness gives the customer graphical information and visual effects. The rapid increase in color graphics in installed applications has prompt wide availability of practical boards reaching out in thickness from two or three thousand pixels to a colossal number of pixels. The boards are made using a variety of LCD innovation. LCD can be ordered into 2sorts; Transmissive LCD, where the started cells appeared to be dull while the dormant seems bright. And Reflective LCD, which is generally seen by surrounding light reflected in a mirror behind the display. These are normally used as a piece of pocket calculator and computerized watches.

Hence, there is a need of a gadget to control the display and for this display controllers are to be manufactured. Our lcd controller ip core helps you to control the display on the display unit. They provide timing, information signals and subsequently control the format on the screen.
To set up for various applications, display controller must be sufficiently adaptable to expand its appropriateness and reusability. These can be developed as IP cores on FPGA. They can be utilized as building blocks within ASIC chip or FPGA logic designs. They are the best for plug and play application, and are less compact.

Digital Blocks offers you a wide range of Display Controller and Processor IP Cores target ASIC/FPGAs configuration groups with system applications in Medical, Industrial, Aerospace/Defense, Automotive, Computer, Monitor, Consumer, AR/VR Headsets, IoT, Wearables, Communications, Education, Signage, Gaming, Broadcasting and many more. Learn more about LCD controller IP core @ https://www.digitalblocks.com/ip-cores-tft-lcd-display-controller-verilog-ip-core.html

0 notes
Text
I2C Bus Master Controller Core

In today’s world computer technology has taken a noteworthy toll on how vehicles are fabricated .Consumers need GPS, satellite TV, heat detecting cameras, and more; so software and hardware equipment has been on the ascent by numerous vehicle producers. Hence keeping in mind the requirements of our clients we at Digital blocks offer you full convention and timing consistent I2C Bus Master Controller Core, with discharges containing Master/Slave, Master-only and Slave-only functions. The Master/Slave I2C Controller IP Cores (Verilog Cores DB-I2C-MS-APB, DB-I2C-MS-AHB, DB-I2C-MS-AXI, and DB-I2C-MS-AVLN) contain a parameterized FIFO, Control Unit, and Interrupt Controller to completely off-load the I2C exchange from the processor. The full off-load abilities target applications with higher execution calculation prerequisites or negligible programming advancement designs.

The Hs-mode permitting options offers full Hs-mode convention, timing and electrical consistence to the Hs-mode I2C specification. With the accompanying highlights, the Hs-Mode choice offers the most astounding framework level I2C execution capacity available: (1) 3.4 Mbit/s Hs-Mode exchange on the I2C Bus; (2) I2C Controller FIFO to hold pieces of information in addition to an off-load Finite State Machine to deal with the exchanges; (3) discretionary DMA controller to move information between the I2C Controller and System Memory or Registers (notwithstanding the processor approaching the FIFO).
W e also provide Slave-just I2C Controllers with the outer SCL as the clock hotspot for the I2C logic (Verilog Cores DB-I2C-S-SCL-CLK and DB-I2C-S-SCL-CLK-APB). The DB-I2C-S-SCL-CLK is for designing registers in ICs with low clamor or power prerequisites while the DB-I2C-S-SCL-CLK-APB for interface to the CPU in ICs with low power necessities. Contact Digital Blocks with any extra interesting low power I2C Slave Controllers prerequisites that you may have @ https://www.digitalblocks.com/i2c-ip-core-reference-design.html.

0 notes