
Statistics
We looked inside some of the posts by pignose-barn and here's what we found interesting.
Average Info
Notes Per Post
35
Likes Per Post
30
Reblog Per Post
3
Reply Per Post
2
Time Between Posts
3 months
Number of Posts By Type
Text
17
Last Seen Tumblr Blogs





Fun Fact
China blocked Tumblr because of pornography and censorship problems in 2013.
Text
켠왕 회고: 매일 평균 12시간의 코딩 모임을 운영하며
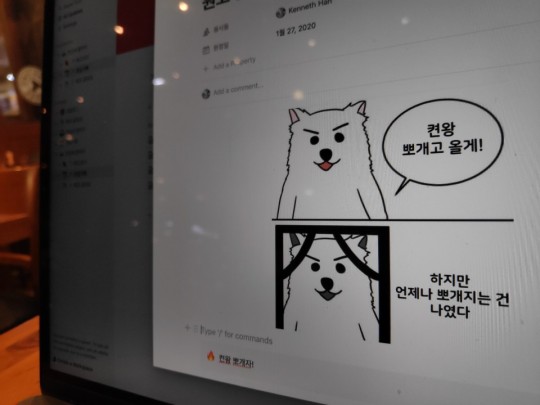
때는 일주일 전, 1월 22일 새벽 12시 50분 경
갑자기 코딩이 미친듯이 하고 싶어
동네 친구에게 메시지를 보냈다

저땐 아무도 몰랐다, 저게 사건의 발단이 될지
그렇게 코딩을 하다보니 아침 8시가 되었다.
보통은 이렇게 하면 피곤한 것이 당연하겠지만
그 날은 오랜만에 코딩으로 열정을 불태워서 일까,
아니면 나와의 싸움에서 승리했기 때문이었을까
전혀 피곤하지 않았다.
그렇게 만족감을 얻었던 그 날, 그 날부터 켠왕이 시작되었다.
켠왕이 뭘까?
켠왕은 “켠김에 왕까지 간다"라는 문구의 축약어로
게임을 키고 왕을 잡기까지 자지않고,
포기하지 않고 게임을 플레이하는 것이다.

켠왕의 예시: 슈퍼마리오를 키고 쿠파를 잡을때 까지 게임을 하기
나는 켠왕의 의미를 조금 틀어
다 같이 본인이 목표로 하는 것을 이룰때 까지
카페에 남아 작업하는 모임을 만들어 보았다.
저녁 6시부터 아침 8시까지 달리는 지옥열차를 함께타는 용사들
6시부터 8시까지 14시간의 대장정
나는 기술 서적 출판을 앞두고 원고를 작성하고 있기 때문에
매일 매일 끊임없이 원고 작성과 전쟁을 치루고 있다.
6시에 체크인 하여 아침 8시가 될 때 까지 한가지만 쉬지 않고 하는 것은
분명히 힘겨운 싸움이기 때문에
그런 켠왕이,
다른 사람들에게도 분명 쉽지 않은 도전이 될 것은 분명했다.

켠왕의 목적

무엇을 하든지 목적이 분명하지 않으면 모임이 유지되기 어려워진다.
켠왕의 목적은 무엇이었을까
우리는 단순히 자신이 할 것을 들고와 새벽까지 하다 가는 모임에 불과하진 않을까?
라는 의문이 있었다.
어떤 목적을 이루기 위해
다들 밤을 지새워 목적을 달성하는 경험을 해본적이 있을 거라 생각한다.
나는 목적을 달성하는 행복과
그 경험을 공유하는 자리를 만들고 싶었다.
그것이 켠왕의 시작이었다.
허황된 꿈

그래서 용사님의 허황된 꿈 무엇인가요?
켠왕 멤버 중 한명이 목표를 “허황된 꿈”이라고 부르는 것을 제안했다.
그 뒤로 우리는 매일 모임의 시작에서 허황된 꿈을 묻는다.
모임은 진지하게 자기 일을 하고 있지만,
우리는 모임을 관리하는 것
그리고 체계를 잡는 것까지
진부해지고 싶지는 않았다.

목표를 이루고자 했지만 이룰 수 없는 것,
그렇게 높은 목표를 잡고 도전하는 것.

왕들의 화신 - 출처: 나무위키
우리는 매일 보스를 잡고자 싸워 나가지만,
보스는 턱 없이 강해서 쉽게 잡지 못하는 것,
그런 싸움임을 알고서도 열심히 싸워 나가는
그런 모임의 모양이 갖춰지기 시작했다.
마스터의 등장



켠왕에 조금씩 컨텐츠가 추가되었다.
켠왕의 목표를 점검하는 중간점검
오랜 시간 앉아 부족한 체력을 보충하는 산책
켠왕의 마지막을 장식하는 회고
그리고 컨텐츠 각각에는 마스터(Master)라고 부르는 용사가
그 섹션 대표해서 이끌어주었다.
그렇게 켠왕은 조금씩 용사들이 조금씩 역할을 나누어
천천히 색깔을 채워주었다.
천천히, 꾸준히

동네 축구같이 (자연스럽게) 해야되요
용사중 누군가가 회고에서 제안했던 내용이다.
켠왕이 꾸준히 유지되려면
모든 것이 강제되지 않고,
천천히 그리고 꾸준히 할 수 있게끔
그런 모임이 되어야 했다.
켠왕은 채팅방이나 그룹톡 같은 개념이 없다.
그냥 개인 메시지로 물어보거나, 카페에 가면 있는 것
그냥 그런거였다.
회고

그래도 여전히 켠왕이 무엇인지,
어떻게 달려가야 하는지 아무도 몰랐다.
그래서 우리는 켠왕이 끝나는 8시에 회고를 했다.
회고는 마스터(Master)가 제안하는 대로 KPT(Keep, Problem, Try) 형태로 진행했다.
좋았던 것을 킵(Keep)하고 아쉬운 문제(Problem)을 정리하고
그것을 해결하기 위한 시도(Try)를 정리하는 것이었다.

많은 용사들이 더 나은 켠왕을 위해 제안해주었고, 천천히 켠왕은 발전되었다.
산책
그러면 잠깐만 스트레칭하고 탄천좀 걸을까요?

우리는 모두 허황된 꿈을 이루기 위해 모였지만,
14시간의 대장정은 육체적으로나 정신적으로나 힘들 수 밖에 없다.
그래서 15분의 짧지만 효과적인 산책을 산책 마스터의 리드대로 진행하기 시작했다.

허리 스트레칭을 하는 용사들
때로 비가 올 때는 스트레칭을 통해 뻣뻣한 근육과 저하된 혈액순환을 풀어주는 귀한 시간이 되었다.
방해하지 마시오

그렇게 여러 회고 아이템이 나왔고,
산책, 중간점검, 방해금지 사인 등 다양한 컨텐츠가 추가되기 시작하였다.
예를들어 방해금지 사인을 테이블위에 올려두면
다른 용사들이 얘기를 걸지 않아 조금 더 집중해서 왕과 싸울 수 있게되었다.
용사들은 천천히 조금씩 더 켠왕스러운 모습을 갖추기 시작했다.
고마워요!
이번 설 연휴 `4`일간의 대장정이 끝났다.

처음 켠왕은 단지 새벽까지 본인의 할일을 한곳에서 하는 것에 불과한 모임이었지만,
지금의 켠왕 그리고 앞으로의 켠왕은 계속 변해가고 있다.

연휴를 빌려 진행했던 켠왕은 앞으로 매주 금요일 8시에 진행된다.
앞으로도 더 많은 새로운 용사들과 더 많은 허황된 꿈들이 돌아다니는 그 날이 되기를 바란다.
4일간의 켠왕은

설 연휴에 진행한 4일간의 행진은
우리에게
`9명`의 용사들이 거쳤고
`52`시간의 힘겨운 레이드였고
`45`분의 건강을 위한 시간과
`21`개의 새로운 허황된 꿈을 만들게 해주었다.
나에게는
`42`샷의 아메리카노를 마셨으며
`3,128`줄의 코드를 작성하게 해주었으며
`135`장의 원고와
`16,605` 단어를 적었고.
`2`명의 새로운 용사들을 만나게 해줬고
`56`개의 새로운 추억을 만들어주었다.
0 notes
Text
2019년을 마무리하며

2019년의 마지막 해가 저물었고, 마지막 날에는 운좋게도 지난 1년을 찬찬히 뒤돌아 볼 수 있는 시간이 생겼다. 이번 블로그 포스트는 필자의 1년간의 세월을 돌이켜보고 그동안 있었던 일을 짧게 정리해보는 형식으로 작성해본다.
TL;DR
이사감, 가까운게 최고야
총 4개의 대외 발표, 2개의 Major 오픈소스 기여, 7개의 개인프로젝트 진행
상생과 공유를 최고의 가치를 바탕으로 성장하는게 내년 목표, 연구 부문 좀 더 집중할 예정
아래부터는 본격적으로 각 주제별로 올 해 ���던 일들을 요약해보았다.
개인 OKR을 통해 내가 꿈꿨던 원대한 꿈과 현실을 비교해 볼 수 있었다.
성장 방향
올 해의 성장 방향은 “도메인 확장"을 키워드로 가지고 갔다. 뒤돌아보면 어느정도 많은 것들을 배워나갔지만 더 많은 것을 해도 좋지 않았을까 한다.
살펴봤던 영역과 살펴보았으면 좋았을 영역들 (밑줄은 살펴보았으면 했던 것)
오디오 (소리 신호처리, 샘플링 보간, Wav, Mp3 헤더 구조 및 변환)
폰트 (OpenType, PostScript, TrueType => ascent, descent, format table, rendering)
음성 (WaveNet 구현, KWS on board, PCM 분석)
IoT (Arduino, RaspberryPI, 트랜지스터 제어, 릴레이 제어, 스키메틱 등)
하드웨어 (MDF 커팅, STL 디자인, 납땜, 연마봉 및 목재 재질별 특성 파악 등)
그래픽 (Rhino, VRay render, AfterEffect tracking, OBJ CG combining 등)
컴파일러 (Lexer tokenizing, AST deconstructing)
여러방면을 개인시간에 건드려본 것 치고는 하나씩 뽀개나가서 그런지, 껍질을 까보고 안쪽 맛을 봤던 것 같다고 생각한다, 내년에는 이렇게 많은 도메인 중에 컴파일러 쪽만을 더 자세히 살펴볼 생각이다.
필자는 년도 별로 그 해의 키워드를 정한다. 아래는 지금까지의 키워드, 그리고 2020년의 키워드다.
2017년 “일과 협력” (일과 협력의 해)
2018년 “기회와 도전” (기회와 도전의 해)
2019년 “확장과 경험” (확장과 경험의 해)
2020년 “상생과 공유" (상생과 공유의 해)
업무
1년간 업무를 되돌아보면 엔지니어 업무를 주로 진행하였고, 개발 스택이나 구현 방향을 많이 바껴나갔는데, 그 사이 팀을 한번 바꿨던 것이 가장 컸던 것 같다.
지금 소속된 팀에서 많이 배우고 있고, 매우 좋은 팀원들이 있어서 시장 반응만 좋다면 내년에도 순항할 것이라고 생각한다.
현재 팀에서 담당하고 있는 포지션은 엔지니어로 아래 3가지를 주로 고민하고 있다.
개발 구현
DevOps
인프라 / 서빙 환경
오픈소스
올 해 초 필자는 오픈소스 중 이름을 들어보면 알 법한 프로젝트에 기여하고 싶다는 목표가 있었고, 그것이 이루어졌다고 생각한다.
ImageMagick에 2가지 PR에 대해서 Merge가 되었고, 거대한 코드를 살펴보고 버그를 개선하는 것이 동참한 것은 꽤나 의미있는 경험이었다.
PR1
PR2
ISSUE
이미 내년에 Apache foundation 오픈 소스 중 하나에 Feature 개선 할 부분을 찾았고, 빠르면 1분기 안에 티켓을 끊어 PR 프로세스를 진행할 계획이다.
커뮤니티
올 해 커뮤니티를 위해 활동한 것은 대부분 발표였었고, 아래는 발표했던 행사들이다.
GDG Golang Korea 2019 - Slide
GDG Extended Seoul 2019 - Slide
DSTS 2019 - Slide
GDG DevFest Seoul 2019 - Slide
사내 부서 내 발표 2건, 사내 팀내 발표 6건
올 해에는 2분기까지는 발표보다는 학부 수업에 집중하느라 업무 외 시간을 다 썼었지만, 그 이후에 4건의 대외 발표를 진행한 것 같다. 사실 많아도 1년 6회 발표 정도를 준비하면 잘 한 것이라 생각하기에 이번 커뮤니티 활동을 만족하는 편이지만.
내년에는 발표 외에도 행사 기획이나, 주최 쪽도 진행하면서 다양성을 넓혀가면 어떨지 생각하고 있다. 특히 집이라는 공간과 PIGNOSE, 동네의 흔한 너드들, BJA 등을 내년에는 살려서 재밌고 누구나 쉽게 접근할 수 있는 모임(?)정도를 만들어보면 어떨까 한다.
업무 외 / 개인 프로젝트
필자는 꾸준한 개인 프로젝트는 성장에 많은 밑거름이 된다고 생각한다. 업무 외 시간에는 개인이 흥미있어하는 주제도 계속 파고들어 많은 삽질(?)과 인사이트를 얻어 앞으로 자신이 원하는 개발자/연구자가 되기 위해 힘써보는 것은 어떨까.
아래는 올 해 진행했던 개인 프로젝트 들이다. 취소선이 그어진 것은 올해 시작된 프로젝트지만 아직 완전히 끝나지 않은 진행중인 프로젝트다.
1. tit project
https://github.com/KennethanCeyer/tit
Golang configuration management 도구
2. danger go & awesome danger PR
https://github.com/KennethanCeyer/danger-go
https://github.com/danger/awesome-danger#ruby-danger
Danger CI checking integration for Golang
3. dup
https://github.com/KennethanCeyer/dup
Git issue similar context auto finding tool
4. ast
https://github.com/KennethanCeyer/ast
Advanced sound tool written in Golang
5. bire
https://github.com/KennethanCeyer/bire
Initial environment automated management tool by cli-interface
6. vanta project
https://github.com/KennethanCeyer/vanta
https://github.com/KennethanCeyer/vanta-font
New generation fastest image rendering library project
7. IoT guitar project
기타를 연주하는 로봇 프로젝트
언어
1. 영어
영어는 여전히 많은 잘못된 문장과 잘못된 회화를 구사하지만, 업무적인 대화나 일상 대화에서 멈추거나 하는 일은 없어졌다. 하지만 기술 문서를 읽는데 버벅거림이 없고 현란한 유의어들을 이용해서 멋있는 가이드 문서나 논문 문체를 쓰는 경지까지는 아직 한참 멀었다.
2. 일본어
올 해 가장 많이 늘은 것은 일본어가 아닐까. 한자는 여전히 약점이지만, 홋카이도에 여행가서 몰랐던 현지인과 일본어로 대화하며 스키 친구가 된 것 부터, 간혹 영어가 막힐때 일본어로 미팅 의견을 낼 정도까지는 끌어올렸고, 일상 표현의 경우 버벅거리지만 글을 읽을 수 있어졌다. 내년에는 아에 업무에서 사용해도 문제 없을 정도까지 끌어올리는 것을 목표로 하고 있다.
3. 러시아어
여기부터 언어를 배웠다고 하는게 맞는 표현인지 모르겠지만, 6달 러시아어를 배워 정말 슬라브어 계통이 어렵다는 것을 참담하게 깨달았다. 내년에 러시아어를 추가로 배울 계획은 없지만 여행갈때 적혀있는 러시아어 간판을 읽고 내가 원하는 것을 주문할 수 있을 정도로 구사만 가능하다.
4. 스웨덴어
회사 동료에게 장난치는 용도로 배운 언언데, 스카이프로 스웨덴 친구를 두고 책도 사서 나름 진지하게 배웠었다. 한 200 단어 정도 외우고 나머지는 회화로 때웠지만, 두마리 토끼 다 놓친 케이스이다. 노르딕 계통 국가 문화에 대해서 많이 배울 수 있던 기회여서 결과적으로 만족하고 있다! Hey! Let’s have a FIKA?
건강/스포츠
헬스를 1년간 PT를 유지하며 웨이트는 정말 늘었다. 1RM으로 따져본다면..
스쿼트 110
데드리프트 80
벤치프레스 80
아직 3대로는 270정도로 내년에 300이상을 목표해야 할 것 같다.
트레이너님과 파트너로 운동을 서로 보조하며 하는 수준으로 따라왔지만, 여전히 나는 아기자기하고 작은 근육들을 가지고 있다.
골격근 4.5kg, 팔둘레 3cm 증가로 긍정적인 변화가 있었다. 내년에는 이 정도의 변화만 유지되기를 목표한다.
그 밖에 아래는 올 해 새로 배운 것들이다.
스노우보드: S커브 가능해짐
서핑: 이제 혼자 패들링으로 테이크오프 가능
턱걸이: 가능해짐, 정자세로 최대 5개 한계
스케이트보드: 여전히 못탐
내년에는 스케이드 보드도 탈 수 있도록, 스노우보드는 카빙턴이 가능해지도록 연습해볼 계획이다.
올 해 하지 못한 것 / 부족한 것
아래는 올 해 하지 못한 것들의 목록이다, 내년에 목표로 세울 계획이다.
회사 서비스 런칭
연구 목적의 프로젝트: 개인 연구 목적, 소논문을 연습삼아 써보는 주제로 잡는
컴파일러 이론 공부 및 YACC 서브셋 구현
수치화 가능한 언어 시험 (JLPT, TOEFL)
대외 행사 주최
아파치 재단, 모질라 재단 하위 오픈소스 각각 기여
지속적인 블로그 포스트 작성
책 출판 (신년 1분기로 미뤄졌다.)
이사
홍대입구 방면에서 6월까지 왕복 3시간 출퇴근을 반복하다가 회사 앞으로 커맨드 센터를 옮겼다. 다들 회사 앞으로 이사가라 두번가라 정말 삶의 질이 많이 바뀐다. 매일 매일 하루 3시간의 시간을 주어진 것에 바이너리의 신에게 항상 감사하며 즐겁게 코드를 짜고 지내고 있다.
이사를 가서 아래 목표들이 생겼다. 실천하지 못한 목표는 취소선을 긋고 내년 목표로 옮긴다.
집들이 + 지인들 초대해서 맛있는 음식 다같이 먹기.
Makers 아지트 만들기, 어떤 공구도 부족하지 않도록 구비하기.
1GigE환경 구성, 자택 자동화 장비들 구비. (진행중 | 추가 장비 필요)
천하제일 코딩대회 오픈
동네 해커톤 주최
내년 목표는 다른 블로그 포스트에서 따로 기재할 계획이다.
모두 올 한해 고생 많았고 내년에도 꼭 목표한 계획을 모두 클리어하기를 기원한다.
0 notes
Text
쌍무적 계약관계로 성장하는 것에 대해서
요즘 필자는 제한된 시간에서 어떻게 하면 엔지니어로서 더 잘 성장할수 있는지에 대해서 고민이 많다. 여러분은 다양한 경로로 효율적인 성장을 위해 여러 프로그램을 찾아보기도 좋은 멘토를 찾아보기도 할 것이라고 생각하지만. 이번 포스트에서는 “쌍무적 계약관계”를 활용해보는건 어떨지 조심스럽게 제안해보고자 작성되었다.
쌍무적 계약관계가 뭐야?

네이버 국어사전에서는 “쌍무적”이 계약 당사자 양쪽이 서로 의무를 지는 것이라고 나와있다. 물론 의미상으로는 맞는 말이지만 필자가 말하고 싶은건 이런 차가운 의무가 아니다. 필자가 생각하는 쌍무적 계약은 사람과 사람 개인간에 서로 부족한 부분을 채워줄 수 있는 벽없는 관계를 말하는 것인데, 말이 너무 어려우니 아래 사례에서 천천히 정리를 해보겠다.
배움의 효율

우리가 알고 있듯이 무언가를 배울 때 단순히 읽거나 따라하는 것보다는 다른 사람에게 무언가를 가르치거나, 서로 의견을 주고 받으며 문제를 풀어나갈 때 더 학습이 잘 된다고 알려져있다.
예를들어 우리가 C언어를 배운다고 해도, 단순히 유명한 저자의 책을 붙잡고 500페이지가 넘는 장을 열심히 넘겨가며 읽는 것보다는 C언어의 주요 주제를 요약하고 정리하여 남들에게 C언어가 무엇이고 어디가 좋은지 설명하는게 더 효과적인 공부가 될 수도 있다는 소리다.
같은 맥락에서 최근에 국내에서도 학습의 허들을 낮추고자 수 많은 개발, 연구 커뮤니티가 생겨나고 있고, 온/오프라인에서 다양한 배경의 사람들이 모여 공부를 하고 있다. 하지만 이렇게 매 모임에 나서서 공부를 한다고 해도 정작 여러분이 실무에서 사용할 수 있는 기술은 그렇게 많지 않고 정말 여러분이 궁금한 기술에 대해서 얘기할 기회가 적다는 것이 문제이다.
무너저가는 성장성

더 큰 문제는 여러분이 실무에서 어떤 한 파트를 맡아나가고 있다면, 여러분의 연차가 쌓일 때마다 자신의 무지를 들어내는 것을 주저한다는 것이다. 마치 “나는 IT에 실무진으로 일하고 있는데 이걸 물어보면 내 무지가 탄로날 것 같아”. 내지는 “나는 개발을 모르기 때문에 이렇게 물어보면 정말 멍청해보이겠지?” 등의 걱정으로 자신의 무한한 성장원에 서서히 울타리를 쳐나가기 시작하는 것이다. 그렇게 되면 정말 필요한 기초 지식에 대해서는 불안정한 울타리로 인해 더딘 성장 을 하게되고, 마치 “있어보이는”, 외부에서 잘 “알려진” 겉보기에 그럴싸한 트랜드한 기술에 대한 기술만을 터득하게 된다. 외강내유가 정확한 표현일 것 같다. 안타깝게도 실무에서는 우리가 그렇게나 강조해서 말하는 기초 지식에 대해서 넓고 풍부한 사고력이 필요하다, 역설적으로 여러분은 연차가 쌓일 수록 그런 기초를 터득하기 위한 기회는 점점 사라져 갈지도 모른다.
기초 지식은 마치 코어 근육과도 같아서 여러분이 아키텍쳐와 로직을 쌓아올릴 때 힘을 받춰주는 근본과도 같은 것인데, 그것이 부족한 상태에서 최신 논문을 구현하거나 서비스 아키텍처를 설계해도 겉으로는 멋지게 꾸며진들 불안정한 보일러플레이트위에 나뒹구는 보기좋은 개살구에 불과하게 된다.
쌍무적 계약관계를 만들어보자

필자는 이런 성장 도태를 막는 방법이 무엇인지 생각해봤다. 우리가 끊임없이 성장하기 위해서는 사내/외에 있는 모든 활동이 여러분을 성장시키고, 그것들이 진나치게 업무에 영향을 주지 않도록 구성하는 것이 좋을 것이다.
그리고 여러분이 배우는 것이 여러분의 업무와 적어도 어떤 연결고리가 있어야 그 기술을 실무적으로도 사용할 수 있고, 그렇게 실무에서도 같은 기술을 재사용하다보면 그 기술은 고스란히 여러분의 것이 되는 선순환을 거치게 된다.
성공적인 프로젝트에 필요한 방대한 지식들

필자도 월급을 받고 일하는 입장에서 필자가 일하는 분야에서는 어느정도 숙련된 지식을 가지고 있다고 생각하지만, 프로젝트라는 것이 하나의 분야에 대한 지식만으로는 해결 될 수 없는 구조로 이루어져 있다.
예를들어 웹을 이용해서 동영상을 재생하는 서비스를 만들경우 아래의 것들을 고려해야 한다. (개발에 관련된 항목만 나열했다, 개발 외에 항목을 추가하면 수도 없이 많은 것을 고려해야한다.)
동영상 사이트 프론트엔드
동영상 사이트 백엔드
RTSP/RTMP 프로토콜 서버
인프라(Infrastructure)
컨테이너화(Containerize)
L4 L7 로드밸런싱(L4, L7 Load balancing)
Blue-Green 배포 (Blue-Green deployment)
서비스 매시 디자인(Service mesh design)
CNCF stack
DevOps
지속적인 통합과 배포 (CI/CD)
리지스트리 리포지토리 서버(Registry repo server)
챗봇 자동화(Chatbot automation)
테스트 파이프라인(Test pipeline)
자동화된 워크플로(Automated workflow)
테스트 자동화(Test automation) - 모두가 해야하지만 이쪽으로 분류
Unit test / Coverage / Spy / Mocking / Stub / Fixture / Teardown
Integrated test
E2E test
BDD / TDD
SRE (DevOps의 구체화 분류로 DevOps에 합칠 수 있다)
장애복구와 서킷 브레이크(Failover / Circuit break)
모니터링, 원격 진단, 알람(Monitoring / Remote Diagnostics / Alarm)
장애 이슈관리, 사전 장애 검토 (Security issue management, Prior obstacle review)
Test (유닛 테스트를 말하는 게 아니다)
부하 테스트(Stress test)
카나리 테스트(Canary test)
문화 혹은 원칙
코드 리뷰(Code review)
코드 컨벤션(Code Convention)
클린코드(Clean code)
특정한 프로그래밍 언어의 경우
새로운 프로그래밍 언어를 배우는 경우
도메인 특화 언어 (DSL)
함수형 프로그래밍 (FP)
멀티코어 프로그래밍
의식적 흐름대로 썼음에도 굉장히 많은 기술을 나열하게 되었다다. 물론 서비스에 따라 더 많은 기술을 사용하기도, 반대로 덜 사용하기도 하지만, 중요한건 이런 기술들을 다룰때 한 사람이 모든 것을 다 짊어질 수 없다는 것이다. 기술의 분야들이 제각기 너무 거대하고 사람의 시간은 한정되어 있기에, 한 사람이 모든 것을 아우루기 위해 필요한 경험과 시간이 너무나도 거대하다.
또한 애석하게도 프로젝트 기간은 개발자가 앞서말한 기술을 공부하기위해 드는 시간을 허락해주지 않는다. 물론 회사에 개발자가 잘 갖춰져 있어 각각의 필요한 분야에 적시적소 전문가가 배치되있는 것이 가장 이상적이겠지만, 여러분이 어떤 팀에서 새로운 프로젝트나 서비스를 개발하고 있는 단계에서는 보통 각 분야에 전문가들이 한 부서에 모이는 것이 쉽지 않다.
질문하는 것의 어려움
처음부터 프로젝트가 완벽할 필요는 없다. 하지만 프로젝트를 보다 안정적으로 관리하기 위해서는 보다 좋은 기술이 있는지 시시때때로 체크를 하여 품질을 높이는 것 또한 개발자의 의무라고 생각하는 이라면 아래를 살펴보자.
우리가 프로젝트를 위해 모르는 기술을 사용해야 하는 경우 우리는 질문을 해야한다. 만약 팀 내에 기술에 대해 경험자가 있다면 팀원을, 부서 내에 있다면 그 부서 사람을, 회사 내에 있다면 그 사우에게 어떻게든 질문을 하는 것이 가장 이상적이다.
하지만, 경력이 높을 수록, 회사 내 지위가 높을수록 질문을 하는 것에 소극적이기 마련이다. 이 포스터는 그런 행동이 잘못되었다는 것이 아닌 되려 그것을 우리가 인정하고 우회할 수 있는 방법이 없는지 얘기하고자 한다.
물론 개인이 그 도메인에 대해서 남는 시간에 공부를 하는 것이 가장 이상적이지만 업무와 관련된 기술만을 골라 습득하기도, 정말 실무에 사용되는 기술만을 솎아내기도 여간 쉬운 것이 아니다.
그러면 어떻게 질문을 하는 것이 가장 이상적일까?
가끔은 어리석은 질문도 해보자
우리가 보통 질문을 할 때 그 기술을 모르기 때문에 질문을 한다. 다시말하면 그것이 약점이 되기도 하고 만약 그 질문이 정말 기초적인 것이라면 굉장히 수치스러울 수도 있다. 따라서 어떤 순간부터 그런 리스크를 택하지 않고 질문하는 것을 그만두는 사람들이 생기는 지도 모른다.
쌍무적 계약은 여러분 주변에 여러분이 모르는 지식을 가지고 있는 사람, 그리고 여러분의 지식이 그 사람의 부족한 부분을 채워줄 수 있다고 생각하는 경우에 성립된다.
쌍무적 계약의 특징은 아래와 같다.
쌍무적 계약은 1:1로 한다.
쌍무적 계약 당사자간에는 어느정도 동등한 지식을 가지고 있다.
여러분이 모르는 것을 그 사람은 알고 있다.
그 사람이 모르는 것을 여러분이 알고 있다.
여러분은 가령 매우 기초적인 것일지라도 상대가 아는 분야에 질문이 가능하다.
반대로 상대도 가령 매우 기초적인 것일지라도 여러분이 아는 분야에 질문이 가능하다.
서로 상대가 기초적인 질문을 할 지라도 내색없이 최선을 다해 도와준다.
서로는 자신의 영역의 지식을 가능한한 상대의 지식에 녹여 쉽게 설명한다.
여기서 나왔던 질문들은 둘만의 비밀로 한다.
아래는 기초적인 질문들의 예시다.
git으로 이 코드 파일 업로드(?)는 어떻게 해요? (git)
이 웹에 텍스트 박스 하나 넣고싶은데 어떻게 해요? (html)
이 네모난거 둥그렇게 만들수는 없어요? (css)
웹에 중간에 이상한 창 떠서 메세지 보여주게 하고 싶은데 어떻게 해요? (javascript)
vi를 쳤는데 터미널이 작동을 안해요!! 살려주세요 (command)
KL divergence랑 JS divergence가 정확히 뭔 차이가 있어요? (ML)
StyleGAN에 AdaIN이 뭐에요? (DL)
웹 프로그래밍 하고 싶은데 뭐부터 해야해요? (web programming)
TLS랑 SSL이랑 뭔 차이가 있어요? (engineering)
Concession Schedule이랑 Event Loop랑 뭐가 달라요? (os)
쌍무적 계약의 핵심은 서로간에 기술을 공유하여 상생하는 것이다. 쌍무적 계약을 1:1로 하는 이유는 생각보다 질문에 올바른 답변을 하는데 시간이 많이 걸리기 때문에 1:1을 넘어서는 순간부터 모두가 힘들어질 수 있다. 쌍무적 계약의 초점은 주니어를 교육하기 위한 문화가 아닌 경력자가 앞으로 성장하는데 있어서 파트너를 선정하는 과정이라고 보는 것이 더 이해하기 쉽다.
주의사항
계약 대상자 선정에 주의해라, 이것은 주니어 교육 프로그램이 아니다
쌍무적 계약을 할 때 대상은 적어도 지식이 동등하지만 서로 도메인이 다르거나 분야가 다른 경우에 성립한다. 한쪽이 더 많은 지식을 알고 있다면 여러분이 원하는 쌍무적 계약의 그림은 나오지 않고 한쪽이 QnA 봇으로 전락할 수 있다.
친절해야한다
쌍무적 계약의 이점은 어떤 질문에서도 가능한한 최선의 답을, 친절하게 해주는 것에 있다. 질문의 두려움은 상대가 그 질문을 들었을 때 생기는 부정적인 피드백이나 답변 이해의 난해함에 있다. 심지어 질문자가 그 도메인에 전혀 경험이 없을 경우에는 어떤 질문을 해야할지 조차 모르는 경우가 있으니 최대한 질문자를 도와야한다. 그래야 자신이 질문을 할 경우 상대도 똑같이 대하도록 노력할 것이다.
쌍무적 계약의 효력 시간을 정해라
계약을 하기 나름이지만 서로간의 업무 시간은 한정되있으므로 질문 답변에 너무 많은 시간을 쏟기는 어렵다, 서로 하루에 30분 내외로 시간을 정해보도록 하자.
해도 되는 것과 하지 말아야 할 것
쌍무적 계약은 정말 무적 계약이다.
개그입니다. 쌍무-양쪽에서 의무를 지는 계약을 의미합니다. 원 의미는 무적이랑 무관합니다.
계약하기 따라서 질문의 가용범위가 입이 떡 벌어질 정도로 엄청날 수도 있다. 아래 예시를 보자.
해도 되는 것
<질문>
Jetbrains Pycharm 어떻게 깔아요?
Javascript라는 거 어떻게 실행해요?
Linux가 뭐에요?
그 뭐냐 서버 살아있는지 체크하는 사이트 어케 만들어요?
뭘 질문할지도 모르겠으면 머리속에 들어있는거를 최대한 끄집어서 설명해보자.
그 고래위에 상자 떠있는거 프로그램 이름이 뭐에요?
MSA가 뭐에요?
<손가락으로 가리키며> 이거 빨간거 떴는데 왜 그런거에요?
<에러코드 복사&붙여넣기하여 주며> 왜 이런 걸까요 ㅜㅜ?
놀랍게도 이것도 가능하다.
<논문 아티클을 주며> 이거 이해할려면 뭘 더 봐야할까요?
<수학 수식을 가리키며> 이 수식이 말하는게 뭐죠?
<답변>
잘 모르겠네요 ㅜㅜ, 검색해보고 알려드릴게요
지금 바빠서 그런데 다음에 알려드려도 괜찮을까요?
~~라고 검색해보시면 어떨까요?
이건 상황에 따라 다른데, 그 문서가 질문자에게 꼭 필요한 문서이고 그 분야에 능통하지 않더라도 질문자의 지식 배경에 잘 맞는다면 좋은 답변이 된다.
그거 OO가 잘 알텐데 그 분에게 물어보시는건 어떠세요?
쌍무적 계약이 계약 당사자가 무조건 답변해야 하는 것은 아니다, 질문에 대해서 답변을 더 잘할 사람을 추천해줄 수 있다면 그렇게 하자.
하지 말아야할 것
<질문>
이것 좀 해줘요
알려달라라고 질문의 형태를 변경하도록 하자
쌍무적 계약은 일을 대신해주는 형태가 아니다.
<책 360쪽 분량을 넘겨주며, MSDN 한 섹션 전체를 넘겨주며> 이것좀 알려주세요
답변자는 사람인 것을 지각하도록 하자, 아서라... 아직 완벽한 AI 답변 시스템이 나오지 않았으니
그 뭐지? Impala좀 알려주세요
<답변자는 DeepMind의 Impala를 열심히 설명한다.>
질문자: 아...네 <자기가 생각했던 것과 전혀 다른것에 감탄하며 그냥 듣는다.>
<정작 원레 질문은 Apache Impala>
질문자는 질문의 의도와 다르면 그 즉시 피드백을 해야한다.
<답변>
그것도 모르세요?
제가 대신 해드릴게요
그거 대충 <그 분야의 각종 도메인 지식>해서 하면 되요
EX) 대충 dockerhub에서 pull해서 띄우면 되요
correct) 도커라는건 결국 서버안에 작은 서버를 띄우는 건데요 작은 서버를 띄울려면 거기에 필요한 운영체제 파일이랑, 미리 환경 안에 설치해놓은 각종 도구들의 정보가 필요해요. 그걸 도커 세계에서는 “이미지”라 부르는데.. 그런 이미지들을 올려놓는 공식 사이트가 있어요 <dockerhub 에 들어가며> 이 사이트인데요 “도커허브”라고 부르시면 되요, 우리가 해야할 건 이 이미지를 받아야하는데 docker pull이라는 커맨드로... <커맨드를 치며> 이렇게 하면 받아져요... <생략>
~~라고 검색해보세요
이건 상황에 따라 좋은 답변이 될 수도 있지만, 링크가 개략적인 기술문서라면 최악의 선택이 될 수 있습니다.
0 notes
Text
오픈소스 세계에 기여하는 개발자가 되어보자

여러분이 개발을 아직 시작하지 않은 학생일지도, 개발을 한지 어엿 10년이 넘는 시니어일지도 모르지만 이 글은 개발을 얼마나 하였건 오픈소스를 기여해본적이 없거나 거대한 오픈소스 생태계에 몸을 담그고 싶어하는 나와 같은 개발러가 있을까봐 작성해본다.
진정한 개발, 시니어가 되기 까지의 과정
나를 포함해서 많은 사람들이 현업에서 단지 코드만 작성하는 것이 아닌 프로젝트를 성공적으로 이끌기 위해 WBS도 작성하고 KPI도 정하고, 이해당사자들을 설득하고 가치를 고민하고 프로젝트가 더 잘되기위한 방향성과, 그런 복잡한 방향성으로 인한 혼선을 줄이기위한 커뮤니케이션들을 고민한다. 물론 개발을 잘하는 것은 가장 기본적이고 그 조차도 만족할만한 구간을 도달하기 위해서는 수 없이 많은 난관들을 해쳐나가야 한다. 하지만 여기서 필자가 말하고 싶은건 개발로서 최고존엄자가 아닌 이상 모든 프로젝트는 기술 외에도 다양한 스팩트럼이 필요하고 그것이 단순히 리더의 자질이 아닌 협업을 하는 팀원으로서 요구된다. 적어도 지금 우리는 그런 세상에 살고 있다고 생각해주길 바란다.
안타깝게도 학부생, 고등학생이 이런 과정들을 깊이있게 체험하기에는 학교에서 진행하는 각 학기의 주기가 짧고 시험을 위해 디자인되었기에 깊이있는 경험이 어렵다 (이론 중심적이라는 소리다), 또한 체험을 할 수 있었다고 하더라도 실무에서 사용하는 것들과는 다소 거리가 있고, 꽤나 느슨하게 이루어지기 때문에 제대로된 경험을 하였다고 보기는 어렵다.
필자가 오픈소스의 기여를 굉장히 중요하게 생각하는 이유는 주니어가 앞으로 성장하는 데 있어서 OSS(Open Source Software)는 다방면으로 여러분의 자질을 성장시켜주는 것에 어떤 불신도 없기 때문이다. 아래에서는 오픈 소스 생태계 참여를 통해 여러분에게 어떤 가치를 줄 수 있는지 나열할텐데, 블로그 포스트를 읽고 여러분도 적어도 작은 코드를 오픈 소스로 공개하여 시작해보기를 바란다.
OSS(오픈 소스 소프트웨어)
오픈 소스는 여러분의 주위에도 많이 있다. 가장 잘 알려져있는 오픈 소스 프로젝트로는 텐서플로(TensorFlow), 리액트JS(ReactJS), 자바스크립트(Javascript), 스프링(Spring), 하둡(Hadoop)과 같이 다양한 분야에 걸쳐 있으며, 개인이 개발한 수많은 작은 라이브러리도 인터넷을 통해 꾸준히 생기고 배포되고 있다.
오픈 소스는 아래와 같은 자질들을 길러줄 수 있다.
올바른 패키지 매니지먼트
구조화된 파일 구성
문서화
올바른 코드 작성
효율적인 설계
유저레벨 인터페이스 추상화와 코어레벨의 분리
형상 관리 도구 사용법
CI/CD
테스트 코드 작성
협업
형식화된 이슈 티켓 작성과 문제 정의
코드 리뷰
여러분이 오픈 소스를 기여할 때 일반적인 회사 프로젝트와 달리 만천하에 여러분의 코드가 공개되기 때문에, 그 사람들에게 일일히 어떻게 사용하는지, 어떻게 개발 환경을 만드는지, 어떤 의존이 있고 어떤 컴퓨터에서(심지어 모바일에서, 태블릿에서) 동작하도록 디자인됬는지 직접 가서 설명해줄수 없다. 그렇기 때문에 여러분의 라이브러리가 많은 사람들에게 사용되기 위해서는 더 자세한 문서화가 필요하고 애초에 귀찮은 문서화를 피하기 위해서 여러분이 사용한 프로그래밍 언어, 프레임워크에서 공식적으로 혹은 통용적으로 사용하는 표준화된 파일 구조, 프레임워크 규칙, 언어 규칙대로 작성을 하게된다. 정말 좋은 시작이다.
정석대로
오픈 소스로 기여한다는 것은 여러분이 모르는, 심지어 문화도 국가도 언어도 다른 누군가가 여러분의 라이브러리를 사용할 수 있는 것을 의미한다. 따라서 그들이 이해할 수 있게 오픈 소스를 제공하려면 누구나 쉽게 이해할 수 있는 최대한 공식적이고 범용적인 표준화된 규칙을 따라야한다. 따라서 린트(Lint: 코드 스타일 규칙 가이드 도구)를 적용하기도 코드 품질관리 도구를 사용하기도, W3C(웹 표준)나 PEP8(파이썬 표준 문법 규칙)을 살펴보기도 한다.
이미 여기까지만 해도 회사에서는 쉽게 느낄 수 없는 과정이다. 물론 좋은 문화와 경험을 가지고 있는 회사는 자동화된 시스템과 좋은 사수로 이런 사소한(필자는 사소하다 느끼지 않지만) 규칙들도 잘 교정받지만 회사는 교육기관이 아니기 때문에 항상 쌓이는 고객 요구사항 혹은 시장을 위해 하루하루 빠르게 코드를 생산한다. 그렇다고 개인시간에 책으로 공부한다고 하면 매 시간마다 바뀌는 표준과 광범위한 언어, 프레임워크마다 각각 가지고 있는 컨벤션(작성 규칙)을 설명해줄수도 없다.
좋은 설계

<위 그림은 Hexagonal Architecture로 각 레이어별 역할을 분리한 디자인이다.>
그리고 여러분의 코드가 조금 더 커지게 된다면? 정말 행복하겠다. 필자는 4년전에 만든 작은 오픈소스가 매일 다운로드가 1,000회가 넘어가면서 굉장히 기뻐서 매일 잠자는 시간을 2시간씩 줄여서 코드 업데이트를 했었다. 여러분이 오픈 소스를 기여할 때 그게 단지 공부라고 생각하기 보다는 개발의 재미를 느끼면서 즐기면 더 좋겠다. 개발의 재미를 느끼기 어려우면 여러분이 작성하고 있는 프로젝트가 정말 흥미가 가는 프로젝트인지 한번 고민해보기를 바란다. (시작하기 쉬운것과 재밌는 것은 다르다. 필자는 후자를 권한다.)
본론으로 돌아가 프로젝트가 점차 거대해지게 되면 여러분은 더 많은 고민을 필요로 한다. 일단 오픈 소스는 많은 유저들이 사용하고 문제가 발생하면 이슈나 풀리퀘스트(Pull Request: 줄여서 PR)을 보내 사용자들이 직접 소스 코드를 수정하여 수정본을 제안한다. 이것이 회사에서 진행하는 프로젝트랑 다른 점이다. 오픈 소스 생태계에서는 사용자가 곧 다시 기여자(혹은 개발자-Maintainer)가 될 수 있다. 사용자의 이슈나 질문들은 여러분의 코드가 조금 더 체계화 되어있고 프로세스가 명확하다면 줄어들기 마련이다. 만약 여러분의 오픈 소스 프로젝트의 인터페이스 설계가 잘 되어있다면 (이를테면 MVC로 구성되어있거나 MVVM으로 뷰의 데이터 구조를 분리하거나 N-Tier 설계를 통해 도메인을 분리하거나) 사용자들은 보다 쉽게 코드 제안을 할 수 있고 그만큼 질문으로 빠져나가는 시간이 줄것이다. 이런 것들은 효율적인 설계에 대한 고민을 필요로 하기에 주니어 단계부터 이 과정을 밟아 나간다면 시니어에 필요한 역량을 조기에 잡을 수 있다. 설계에 대한 고민은 대학교 과제나 책을 통해 쉽게 할 수 있는 부분이 아니다. 각 프로젝트 성격마다 설계는 달라질 수 있으며 최악의 경우 설계를 통해 최악의 효율을 만들어낼 수도 있다. 쉽게말해 오버 엔지니어링이 되는 것이다. 여러분은 오픈 소스 기여에서 남이 짜놓은 설계를 살펴볼 수도, 여러분이 시행착오를 겪으며 여러분으의 프로젝트에 설계를 실험할 수도 있다.
이슈관리

<최종적으로는 프로젝트 관리자가 참여하지 않고도 서로 이슈를 통해 소통할 수 있게된다.>
또한 이슈를 작성할 때 (이슈 티켓을 끊는다고도 한다.) 여러분은 어떻게 하면 잘 물어볼 수 있는지 (물론 일반적으로 이슈는 버그에 해당하고 질문은 커뮤니티 채널에서 진행해야 한다.), 어떻게하면 가장 잘 답변할 수 있는지 두가지를 배우게 된다. 일반적으로 질문을 할 때 필요한 것은 [이슈가 중복되진 않았는가], [무슨 버전에서 발생했는가], [재현 가능한 상황인가], [무슨 시도를 했는가], [어디에 관계된 이슈인가], [상세한 이슈 내용은 무엇인가] 등의 체계화된 이슈 티켓을 작성하게 된다. 여러분이 직접 오픈 소스 프로젝트를 관리한다면 이런 체계화된 이슈 템플릿이 왜 필요한지 알게 될 것이다. 템플릿 없는 이슈 티켓은 어떤 경우 아무 정보도 주지 않고 단순히 안된다는 정보만 알기 때문에 몇번이고 질문과 답변을 통해서 시간을 소비하고 나서야 유저의 잘못된 환경설정으로 인한 별거아닌 이슈라는 결론이 나는 경우도 있다. 우리가 이슈를 작성할 때는 최대한 프로젝트에서 알려준 대로 환경을 구성했고, 최신의 버전을 사용했고, 이 버그는 분명히 소스코드의 중대한 버그임을 어느정도 증명하고 작성하는 것이 좋다.
테스트코드 작성

여러분의 코드는 단순히 여러분 혼자 작성하고 배포하고, 버그나면 그 때 바로 고치고 다시 배포하고 이런식으로 개발하면 좋겠지만, 프로젝트의 규모가 커지고 많은 사용자들이 기여에 참여하면 이런 불안정한 개발 사이클로는 절대로 안정적이고 좋은 프로젝트를 만들 수 없게 된다. 오픈 소스 프로젝트를 주도하면 여러분은 안정성에 힘써야 하고 지속적인 관리를 위해서는 여러가지 좋은 도구들을 사용하는 것을 권장한다.
코드는 항상 모든 시나리오에 대해서 손으로 테스트할 수도 있겠지만 코드가 복잡해질수록 많은 시간이 걸리고, 매 코드 배포 순간마다 손으로 직접 테스트할 수도 없는 마냥이다. 테스트코드는 여러분이 작성한 로직이 여러분의 구성대로 돌아가는지 체크해주는 단순한 코드들의 연속이지만 여러분이 하나의 함수에 너무 많은 기능을 채우거나 하나의 클래스에 전혀 다른 기능을 넣는 등의 꼼수(혹은 야매, 가라 등등 많은 말이 있다.)를 보기좋게 막아주는 방파제 역할도 한다. 또한 테스트코드를 작성하면 기여자들이 코드를 작성할 때 따라갈 수 있는 가이드라인을 해주기 때문에 마치 고추를 심고 자라날 때 따라갈 수 있는 지지대를 박아넣듯 코드 기여자에게 든든한 지지대 역할을 해준다.
그 뿐만이 아니라 잘 만들어놓은 테스트코드와 CI/CD(코드의 자동화된 통합 프로세스, 그리고 적법한 배포 관리)는 코드 기여자가 단순히 코드를 서버에 저장했을 뿐인데 손을 들이지 않고도 모든 플랫폼 위에서 돌아간 테스트의 결과와 품질 검사, 문법 규칙 검사 그리고 배포 관리까지 척척 해주게 된다.
여러분이 만약 테스트코드 작성과 CI/CD를 여러분의 오픈 소스 프로젝트에 편법을 쓰지 않고 견고하고 튼실하게 세우는데 성공했으면, 여러분은 적어도 코드에 대한 책임감을 가진 좋은 개발 자세를 가지고 있다고 적어도 필자는 단언할 수 있다.
협업 그리고 코드 리뷰

<여러분이 프로젝트의 관리자(Maintainer)라면 여러분이 정해놓은 판단 규칙에 근거해서 코드의 제안을 반려시키거나 승인 시킬 권리를 얻는다.>
여러분이 개발자로서 성장하는데 가장 중요하고 필요한 것은 누군가 여러분보다 더 깊은 지혜를 가지고 있는 개발자로부터 피드백을 받는 것이다. 오픈 소스는 다행스럽게도 (그리고 훌륭하게도) 코드 리뷰라는 시스템을 가지고 있다. 쉽게 얘기하면 여러분의 코드를 어떤 프로젝트에 기여할 때, 혹은 남이 작성한 코드를 여러분의 프로젝트에 반영할 때 여러분이 원한다면 변경된 코드 내용을 살펴보고 통과 시킬지(Approvement) 반려 시킬지(Reject or Change Requested)를 결정할 수 있다. 각 코드 라인에 코맨트를 삽입하여 변경 이유나 제안을 줄 수도 있고, 코드를 작성한 이유를 멋있는 글귀로 휘날려 작성할 수도 있다.
필자는 여러분이 적어도 코드 리뷰 만큼은 꼭 해주기를 바란다. 코드 리뷰는 선택적 사항이지만 코드 리뷰를 시니어 개발자나 여러분보다 많은 경험을 가진 개발자에게 듣는다면 책을 읽어서 개발을 배우는 것보다 몇배나 좋은 경험을 얻을 수 있을 것이다.
3 notes
·
View notes
Text
Google I/O 2019 Keynote

Google I/O 2019가 미국 현지 시간 5월 7일 9시 20분부터 키노트를 시작으로 본격적인 행사가 진행되고 있다. 서두는 AI와 실제 DJ 인간(?)의 콜라보레이션으로 꽤 멋진 디제잉을 보여주는데 흥이 돋아 수 많은 사람들이 무대 앞으로 나가 파티를 즐기는 분위기다.
필자는 Google I/O 2019가 열린 샌프란시스코에 운좋게 참여할 기회가 생겨 키노트 및 각 세션의 주요 사항을 정리하여 공유하고자 한다.
- Google I/O 2019 키노트 주요 사항
- Google I/O 2019 키노트 세부 사항
Google I/O 2019 Keynote Highlights

다음은 키노트에서 필자가 생각하는 주요 사항이다.
개인화 (Personalize)
개인정보와 보안 (Privacy & Security)
머신러닝과 인공지능 (ML & AI)
증강현실 (AR)
핸즈프리 (Handsfree)
구글 렌즈(Google Lens)
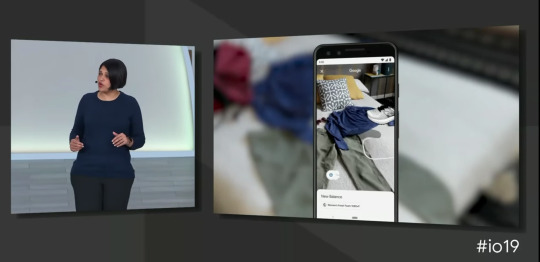
구글이 가장 먼저 선보인 것은 구글 렌즈(Google Lens)의 AR 기능으로, 앞으로도 구글 내 서비스들에 여러가지 AR 기능들이 추가 될 것으로 기대된다. 키노트에서는 구글 렌즈를 이용해 물체의 사진을 찍고 그것을 내 책상, 내 방 사물과 한 공간에서 실제 물체의 생김새를 경험할 수 있도록 제공했다.
심지어 구글 검색에 기능을 더해 검색 된 항목을 모델로 랜더링하여 내가 있는 곳으로 AR 기술을 통해 가져와 체험해 볼 수 있는 등의 사용자 경험을 제공했다. Google I/O 2019 현장에서 직접 상어 모델을 현장 관람객과 동일한 무대에서 AR을 통해 랜더링 되는 것을 선보였고 이는 신선한 경험을 제공했다.
AR 제품 책임자 Aparna Chennapragada가 이 내용을 발표했고 반응은 상당히 뜨거웠다.
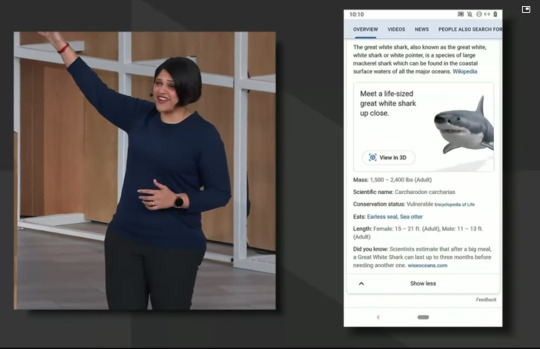
언어 번역 기능도 공개를 했는데, 여행하는 입장에서 많이 유용할 것으로 예상되는 식당 메뉴 번역 및 검색 간편화 서비스가 구글 렌즈에 탑재되었다. 여러분이 식당에서 제공하는 메뉴를 구글 랜즈를 통해 촬영하면 각 메뉴의 내용이 색상으로 하이라이트 되어 클릭할 수 있게되고, 메뉴를 클릭할 경우 구글 맵이랑 연결되어 리뷰 및 사진을 바로 검색할 수 있는 편리한 UX가 제공되었다.
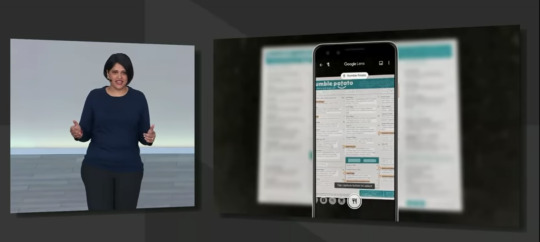
심지어 각 메뉴는 팁 계산기를 포함하고 있고, 더치 페이등의 산수를 간편하게 앱이 대신해줄 수 있도록 신경써 주었다.
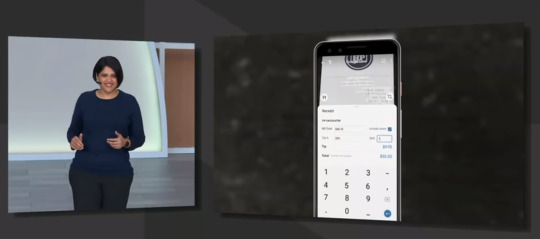
Google Go

구글 렌즈에 번역 기능 서비스가 추가되어 편리함을 제공한 느낌이라면 구글 고의 경우는 번역 그 자체에 집중한 서비스다. 만약 여러분이 구글 번역기를 통해 이미지 번역 (OCR)을 체험해봤다면 이미 어느정도 익숙한 사용자 경험을 가지고 있을 것이다.

위 사진에서 보듯이 중요한 의미를 담고있는 (예전 카드를 가진 고객은 2020/1/1에 기능이 중단되니 근처 지점을 방문해서 카드를 교체하라는 문구) 포스터는 비영어권 국가에서는 그 의미를 알 수 없기 마련이다. 구글 고는 이런 서로 다른 언어를 쉽게 번역해주는 것에 집중했다.
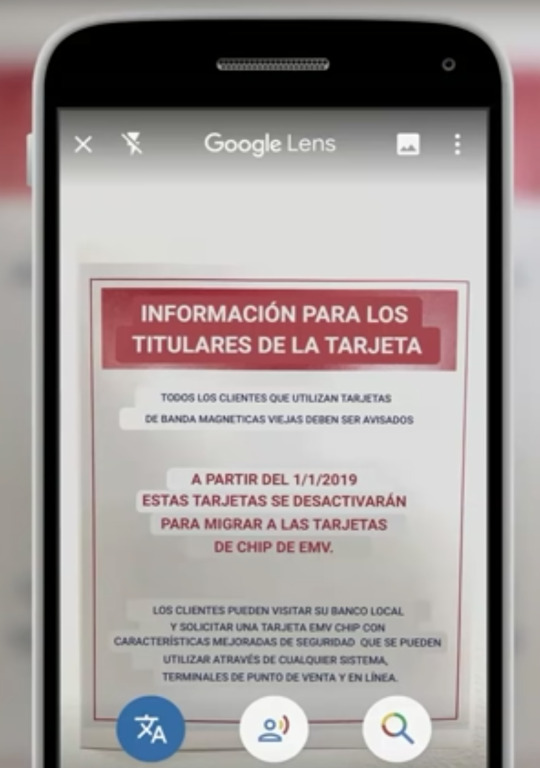
구글 고는 번역 전 컨텍스트를 (OCR을 통해 분석 한 글자를 읽어준다.) 음성으로 읽어주는데 구글 번역기와 어떤점이 다르냐면 OCR로 분석된 글자 boundary를 highlight 해주며 순서대로 읽어준다. 생각해보자 여러분이 일본 식당에 갔는데 메뉴를 전혀 모르는 것이다. 기존 구글 번역기로 번역을 해도 어떤 단어, 글자가 어떤 음인지 모를 수 밖에 없다. 구글 고는 불러주는 단어, 문장에 하이라이트를 표기해주며 순서대로 읽어주기 때문에 어떤 단어, 문장이 어떻게 불리는지 이해할 수 있다.
또한 위 사진을 보면 알 수 있듯이 촬영한 이미지의 글자를 번역된 글자로 바꿔 대체해주는 기능도 포함되어있다. (이것은 번역기에 있는 기능이랑 비슷해보이는데 어떤 차이점이 있는지 모르겠다.)
Google Duplex and Assistant
구글이 작년부터 굉장히 집중하고 있는 프로젝트고 올해도 어김없이 한층 성장하고 훌륭하게 자리 잡은 에코시스템들을 소개하는 자리였다. 주요 발표 내용은 Google AI Vice President로 Assistant 팀을 이끄는 Scott B. Huffman가 발표했다.

구글 어시스턴트의 가장 큰 변경점은 어시스턴트를 실행하기 위한 실행 이벤트 “Hey Google” 발화가 필요하다는 점인데, 이 부분을 제거하여 직접적인 어시스턴트 기능 실행이 가능한 듯 하다. 가장 대표적인 예시를 구글이 제시했는데 “이제 앞으로는 여러분의 알람을 끌 때 헤이 구글! 그만해! - Hey Google! Stop!라고 할 필요 없이 그만해! Stop! 이라고 외치면 된다는 내용을 조크를 담아 세션 참여자들에게 웃음을 주었다.


컴파일러나 NLP를 조금이라도 공부해보셨으면 알겠지만 사람의 문장은 기계적으로 정해진 룰로 가득한 문장에 비해서 수 많은 이해측면에서의 어려움(Challenges)들이 존재하는데, 하나의 단어나 표현이 모든 사람에게 있어서 같은 것을 가리키지 않고 심지어 같은 사람이라도 앞뒤 문맥에 따라 그 의미가 달라질 수 있다. 이 포스트에서는 그것을 에매모호함이라고 하자.
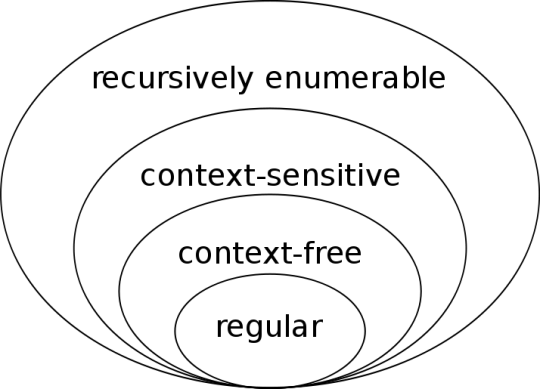
<우리가 사용하는 언어는 촘스키위계의 가장 위, recursively enumerable에 해당한다.>
만약 우리가 구글 어시스턴트에 엄마의 집으로 가는 교통 상황이 어떠냐고 물어보자. 엄마의 집은 발화자의 가족 중 엄마가 사는 집이 될 수도 있고 아니면 어떤 식당의 이름이 “엄마의 집”이 될 수도 있다. 어떤 이는 가족을 보러 가기위해 발화를 했을 것이고 음식을 즐기는 또 다른이는 엄마의 집에서 맛있는 밥을 주문하고 싶어하는 것일 수도 있다. 구글은 이러한 사용자 별 요구가 다른 것을 예전부터 충분히 인식해왔고 오늘 서비스 하나를 더 소개했다.

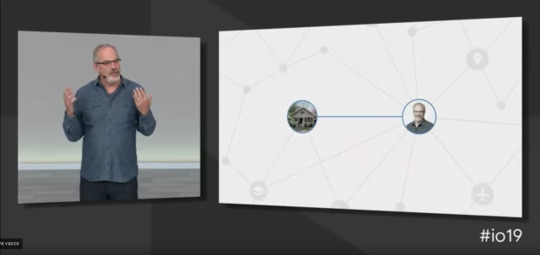
Picks for you라고 부르는 서비스는 개인화(Personalize)에 집중된 서비스로 한 대상과 연결된 모든 관계를 개인 참조(Personal References)로 부르고 그것을 이용해서 개인의 선호에 맞는 정보만을 모으고 이어주게 된다.

이렇게 하여 아들 사진 좀 보여줘!, 식당 예약좀 해줘 등의 대화에서 그 사람의 아들에 대한 정보, 지금 말하는 식당을 가리키는 참조들을 이용하여 사용자가 정말로 의도한 기능을 실행시켜주게 된다.
Google Live Caption
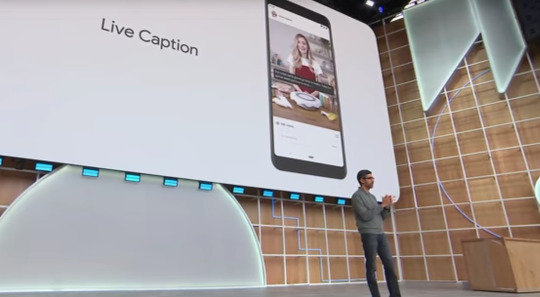
필자가 이번에 세션을 들었을 때 가장 반응이 좋았던 세션이다. 만약 여러분의 안드로이드에 돌아가는 ML 엔진의 모델이 극단적으로 경량화를 거쳐 인지하지 못할 정도로 작은 사이즈로 기존 모델에서 제공하는 모델 퍼포먼스를 제공하면 어떨까? 기존 안드로이드 음성 인지모델은 2GB로 휴대 단말기에 들어가기에는 믿기지 않을 정도로 굉장한 크기였다.
만약 인터넷이 제공되지 않는 환경에서 80MB 사이즈의 모델로 실시간 음성 인지모델을 온 디바이스에서 제공한다고 한다면 믿을 수 있을 것인가? 이미 구글은 최대한 모델의 Accuracy와 퍼포먼스를 유지하는 선에서 모델을 경량화 하여 모바일 기기에서 제공할 수 있도록 노력해오고 있다. 다만 이 음성 인지모델은 영어 발화를 기준하였기 때문에 다국가 언어가 다양하게 들리는 형태에서 지원할 수 있을지 알 수 없다. 그렇다고 해도 2GB의 모델을 80MB로 줄이는 기염을 토한 것이다.

Live Caption은 인터넷이 제공되지 않는 제한된 환경에서도 문제 없이 실행 가능하며, 실시간으로 다른 앱에서 제공되는 오디오를 인지하여 우리가 이해할 수 있는 언어로 텍스트를 표기해주는 편리성을 가지고 있어 기대가 되고 있다.
ML / AI
구글에서는 이번 키노트에서도 여러가지 ML / AI 관련 기술의 키노트를 소개하였는데 주요 사항은 아래와 같다.
TCAV

TCAV(Testing with Concept Activation Vectors)는 ICML 2018에서 발표되었던 Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (https://arxiv.org/abs/1711.11279) 논문을 바탕으로 하고 있다. 깃허브 링크는 이곳으로.
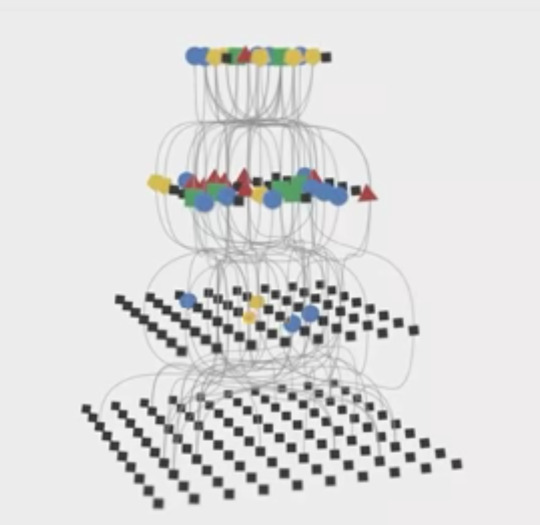
DL을 사용하여 우리 세상에 실제하는 무언가를 분류하고 예측하는 문제에서는 그 안에 어떤 이유로 인해 결과가 예측되었는지 그 이유를 분석하는 것이 절대 쉽지 않은 문제다. 각 심층 레이어에 존재하는 Hidden Representation Layer는 가장 최저의 픽셀 패턴부터 시작해서 색상 값 그것으로 인한 가중치 값들이 적용됩니다. 우리 눈에는 그것이 무엇을 의미하는지 알 수 없다.
TCAV의 아이디어는 각 Logit 레이어에 미분을 가해 사람이 이해가능한 추가적인 정보를 얻어낼 수 있는 Post-training 접근 방법이다. 쉽게 설명하면 우리가 얼룩말 모델을 학습하고 그것으로 분류를 한다고 해도, 그것이 왜 얼룩말로 분류된 것인지? 반대로 왜 어떤 이미지는 얼룩말로 분류되지 않는지 정확히 알 수가 없다. 얼룩말다움이란 무엇일까? 그것을 푸는 도전이 TCAV라고 할 수 있다. 얼룩말은 일반적으로 말의 형상을 하고 얼룩을 가지고 배경이 사바나라고 알려주는 것인 셈이다.
Federated Learning
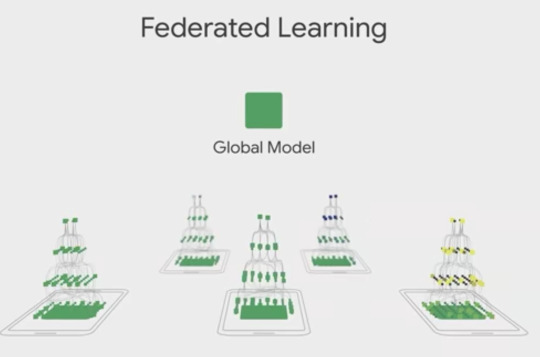
연방 학습(Federated Learning)의 목적은 모바일 클라이언트 기기에 분산된 환경에서 충분히 퍼포먼스를 가진 중앙화된 모델 학습을 위한 테크닉으로 사용자와 상호작용을 통해 로컬 환경의 모델을 학습시키고 그것을 다른 클라이언트와 공유하여 개선하고 글로벌 모델로 전환하여 중앙화를 시도하는 것이다.
이미 일반적인 서버의 컴퓨팅 머신은 학습 프로세스와 서빙을 최적화하기 위해 노력하고 있다. 예를들어 TPU3를 사용하는 GCP 서버는 AllReduce를 통한 분산 노드의 학습 환경을 소개하고 있는데 이는 이후에 설명한다.
연방 학습(Federated Learning) 아이디어는 각 사용자 환경인 모바일에서 상호작용을 통해서 지속적인 로컬 학습을 통해 모델을 개선하고 사용자가 모바일 기기를 사용하지 않는 시기를 이용해 다른 모바일 기기들에게 학습된 결과를 공유하고 공유받아 추가적으로 글로벌 모델을 개선하는 것이다. 이와 관련된 정보는 아래 링크를 체크하자. 논문은 이곳을 클릭.
https://ai.googleblog.com/2017/04/federated-learning-collaborative.html
모바일은 네트워크가 제한된 환경과 와이파이 등을 제공받아 원할한 네트워크 환경을 이용할 수 있는 두가지 상황이 존재한다. 따라서 연합 학습은 아래와 같은 두가지 전략으로 업데이트를 시도하는 것이 이 테크닉의 주 주제이다.
Structured updates
: 제한된 환경에서의 직접 업데이트를 할 경우 적은 수의 변수를 통한 파라미터화,
Sketched updates: 전체 모델을 업데이트 할 경우 모델을 전송하기 앞서 압축을 시도.
Today AI


이번 키노트에서는 Google Senior Fellow인 Jeff Dean님의 자리도 있었는데 그 동안의 RNN의 방식과 한계점 그리고 BERT에 대해서 소개하는 시간이 있었다. BERT는 지금까지도 DL 테크닉 특히 NLP 연구에 있어 큰 파장이었기 때문에 키노트에서 충분히 하이라이트를 하는 부분에 의의가 있었다고 본다.
Google Nest

구글 네스트는 구글이 중요시하는 Well Being 디바이스 제품군 반열에 합류했다. Device & Services 부서의 Senior Vice President인 Rick Osterloh가 소개했다. 구글 네스트는 그동안 가정에 도움을 주는 홈 디바이스 제품군을 묶어 더욱 간단한 하나의 제품 반열로 관리하도록 이름을 리네임했다. 모든 가정을 도와주는 홈 가전은 네스트 아래에서 아래 4가지 원칙을 중시한다.

Easy for everyone
Rersonal for everyone
Works together
Respects your privacy
그리고 홈 가전을 모두 묶는 Nest Hub (구 네임: Home Hub)를 소개했다.

네스트 허브는 홈 가정기기에 대한 대시보드 정보를 제공하고, 가정 개개인의 정보를 개인의 핑거프린트 정보를 통해 암호화하여 보안을 제공하고 개개인에 필요한 관심사와 관계된 정보를 제공할 수 있도록 개발되었다.


또한 네스트 캠을 통해 개인 가정환경 상황을 쉽게 볼 수 있도록 카메라와 마이크를 구글 듀오(Google Duo)와 연결하여 볼 수 있게 되어있다. 물론 카메라와 마이크는 네스트 허브의 뒤쪽에 있는 물리적 버튼으로 제어할 수 있도록 하여 개인정보를 보호할 수 있도록 설계되었다. 네스트 허브에 달려있는 카메라 디바이스는 또 하나의 기능을 제공하는데,

네스트 허브에 달려있는 카메라를 통해 사용자의 포즈와 모션을 통해 특정한 액션을 줄 수 있는 핸즈 프리 옵션이 붙어있다. (이 영상에서 모션 스탑 기능이 보여졌을때 반응이 끝내줬다.)
가격은 다음과 같이 공개되었다.

네스트 허브 맥스: $229
네스트 허브: $129
Google New Pixel (3A, 3B)

구글에서는 추가적으로 픽셀 폰에 대한 정보도 선보였는데 시기가 Android Q에 대해서도 다루는 자리다 보니 Android Q의 기능들도 함께 섞여 소개가 된 것 같다. 픽셀은 이번에 Purple-ish 색상이 추가되었다.

또한 Phone X(...)에 대비하여 어둠에서도 높은 색 재현력을 보여주고 있다. 또한 Google Photo에 무제한의 사진 업로드 스페이스를 제공하는 옵션또한 공개되었다.
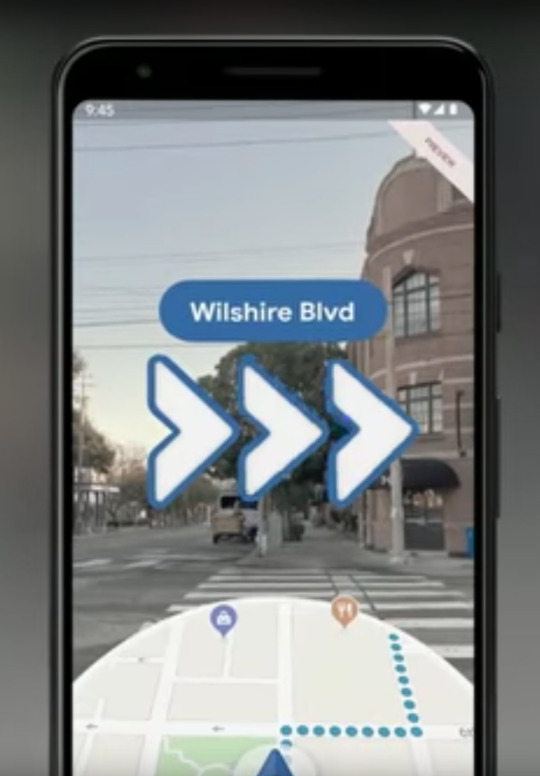
그것 뿐이 아닌 구글 맵을 픽셀에서 사용할 경우 AR을 이용한 위치 가이드라인과 위치 포인트에 마커 오브젝트가 위치하는 등 사용자에게 더 넓은 반응을 줄 수 있는 기능이 제공된다. 이것 또한 현장 반응이 엄청났다.
Android Q
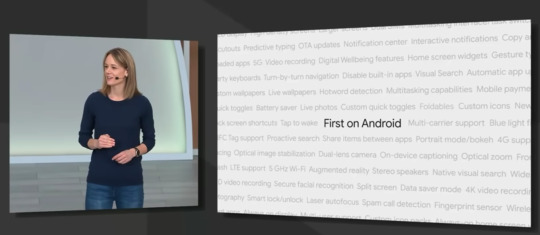
Android 팀의 디렉터로 자리하고 있는 Stephanie Saad Cuthbertson가 소개한 안드로이드 Q는 이번 Google I/O 2019에 참여한 수 많은 안드로이드 개발자들에게 있어 핵심이 되는 발표 중에 하나이다. 이번 Google I/O 2019에서 소개된 안드로이드 내용의 주요 사항은 아래와 같다.
Foldable
Security & Privacy
Dark Theme
Live Caption
Smart Reply
Focus mode
On-device learning
Suggested Action
5G
Faster security updates
Parental Controls (+ Bonus time!)

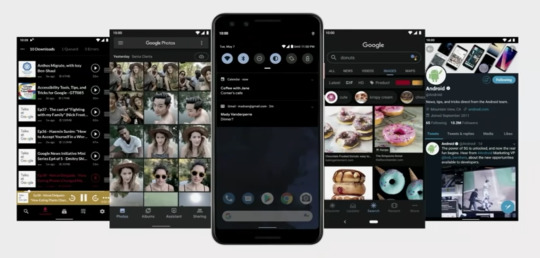
안드로이드 Q에서는 다크 테마가 추가되는 등 유저가 사랑하는 여러가지 기능들을 수용하여 업데이트 하였다. 하지만 이번 안드로이드 Q에서 집중해서 봐야하는 부분중에 하나는 개인정보 보호와 처리 방침이라고 할 수 있는데,

인터넷 환경이 발달하고 기기가 발달하며 알지도 모르게 새나가는 데이터를 보호하고 각 개인 정보를 숨길 수 있는 권리를 존중하는 구글의 중요한 방침을 느껴볼 수 있다.
1 note
·
View note
Text
완벽한 Mac 작업환경 세팅하기 (vim, zsh, iterm)
그동안 개인 컴퓨터로도 수많은 프로그래밍 언어와 작업 환경을 만들었고, 회사에서도 수많은 인턴분들과 뉴커머들이 오고가면서 그들의 작업환경을 세팅해주고 가이드라인 해줬다, 필자는 최대한 많은 트릭과 신텍틱 슈거, 그리고 불필요한 노동시간을 줄이기위해 깊이있게 파고들고 또 파고드는 것을 좋아한다.
이번 시간에서는 맥 환경에서 작업하는 주 작업자들을 위해 여러분의 노동시간을 줄일 수 있는 몇가지 팁들을 소개하려고 한다. 이 글에서 tmux에 대한 내용까지 담으려고 했지만 tmux만 해도 내용이 너무 방대하므로 iTerm의 Split View기능으로 대체하고 tmux는 다음 시간에 다른 포스트에서 자세히 다루도록 하겠다.
터미널 환경 구성하기
내가 일하는 분야나 개인 프로젝트에서는 터미널을 열어 사용하는 경우가 다분하다, 아마 이 분야가 당연히 그렇다고 생각하고 있고 만약 터미널과 친하지 않는 유저라도 이 섹션에서 터미널 환경을 구성해서 이 기회에 터미널과 조금 더 친해져보는 시간을 가지도록 하자.

여러분이 가지고 있는 초기 터미널을 위와 같은 모양새라고 생각한다. 우리는 이것을 아래처럼 바꿀 것이고, 생각보다 어렵지 않기 때문에 끈기를 가지고 따라하기를 바란다.
1. Oh My ZSH 설치하기
가장 먼저 여러분이 해야 할 것은 기본 쉘을 새로운 쉘 프로그램으로 교체하는 일이다. 여러분의 맥 환경이 별다른 수정을 거치지 않았다면 기본적으로 bash가 여러분의 기본 쉘 프로그램일 것이다.
https://gist.github.com/KennethanCeyer/8c8420585f3d933e6703e43680d87ab3
먼저 아래 명령어를 통해 zsh를 설치해보자.
https://gist.github.com/KennethanCeyer/47c981fccd3690e1bd410f4a388de5ce
놀랍게도 이미 여러분의 쉘은 zsh로 변경이 되었다. oh-my-zsh 프로젝트는 zsh 쉘을 쉽게 설치하고 관리할 수 있게 도와준다, 덕분에 여러분은 단 한줄의 코드로 zsh를 쉽게 설치 / 업그레이드 할 수 있었다.

쉘 이름은 $0 환경변수로 확인할 수 있다. 여러분의 터미널에 `zsh`가 출력되는지 확인해보자, 아래 그림처럼 `zsh`가 나오면 정상적으로 설치된 것이다.

2. Powerlevel9k 테마 설치
zsh는 정상적으로 설치되었어도, 별도의 테마가 적용되지 않으면 굉장히 밋밋한 느낌의 터미널만이 제공된다. 필자는 여러가지 테마를 사용해봤지만 Powerlevel9k 보다 어썸하고 쿨한 테마를 찾지 못했다. 만약 더 좋은 테마를 알고있거나 제안하고 싶으면 이 블로그 하단 댓글로 남겨주시기 바란다.
아래 처럼 명령어를 입력하여 zsh themes 폴더 내에 powerlevel9k를 내려받는다.
https://gist.github.com/KennethanCeyer/2794384bce32ae8650eb9e94131c3da5
우리는 테마를 다운로드 받는 것까지는 완료했고, 최종적으로 .zshrc 파일을 수정하여 정확한 테마 이름을 zsh 쉘에 알려주어야 한다. 아래 명령어처럼 .zshrc 파일을 열어보자.
https://gist.github.com/KennethanCeyer/8739695df2d1ca420326d5a127511a25
아래 그림처럼 ZSH_THEME 단락을 `powerlevel9k/powerlevel9k`로 바꿔준다. 아마 여러분의 .zshrc의 기본 ZSH_THEME는 `robbyrussell`로 잡혀있을 것이다.
이해가 잘 가지 않는다면 아래 링크를 클릭하여 변경 방법을 살펴보자.
`.zshrc` 파일을 변경했다면, zsh 명령어를 통해 쉘을 다시 열어줘야 변경 사항이 확인이 가능하다.
https://gist.github.com/KennethanCeyer/4bfcc90111e69632111387d239931cb2
3. Iterm2 설치
여러분이 기본적으로 사용하는 터미널 프로그램은 터미널의 편의기능이 많이 부족하다. 따라서 아래의 편의 기능을 사용하기 위해 Iterm2를 설치하도록 하자. Iterm2에서 제공하는 기능 중 특별히 아래의 기능이 유용하다.
터미널 탭 기능 (+토글 단축키)
터미널 Split View
자동완성 기능
터미널 내에서 단어 찾기
마우스 없이 복사&붙여넣기
256 이상의 색상 지원
더 많은 기능 살펴보기: https://www.iterm2.com/features.html
그럼 본격적으로 설치를 진행해보자. 설치는 https://www.iterm2.com/downloads.html에서 진행할 수 있다. 링크에서 Stable Releases에서 최신 파일을 설치하자. 이 포스트 기준으로는 Iterm2 3.2.9 버전이 최신이다.

다운로드가 끝나면 아래와 같이 다운로드 폴더에 Iterm2가 있다, 프로그램을 어플리케이션으로 옮겨 설치를 해주자.

시스템 환경설정 > 보안 및 개인 정보 보호 > 개인 정보 보호 탭에서 방금 설치한 Iterm2를 추가해주도록 하자.
설정이 끝났으면 어플리케이션에 설치된 iTerm 앱을 실행시켜보자.

맥은 기본적으로 인터넷에서 다운로드 받은 앱은 위와 같은 경고 메시지가 나타나게 된다. 열기 버튼을 클릭하면 앱이 정상적으로 실행되고 경고는 다시 나타나지 않는다. `열기`를 클릭하여 열어주자.

여기까지 잘 따라 오셨으면 위와 같은 터미널 창을 볼 수 있다. 이제 터미널 앱은 Dock에서 제거하고 작별을 고하자, 앞으로 여러분은 iTerm을 기본 터미널로 친해질 시간을 가질 날만 남았다.
4. Powerlevel9k font 설치
눈치가 빠른 독자라면 느끼겠지만 화면에 일부 텍스트가 깨지는 현상이 보인다. 아래 그림처럼 일부 박스가 깨져 제대로 보이지 않고 `?` 기호로 표시된다.

글자가 깨지는 이유는 우리가 앞서 설치한 Powerlevel9k 테마는 일부 특수 문자를 사용하여 TUI (Text User Interface) 화면을 꾸미기 때문에, Powerlevel9k에서 권장하는 폰트를 사용해줘야 한다. 아래와 같은 절차를 따라하여 폰트를 설치해보자.
https://gist.github.com/KennethanCeyer/6b7243146bb9e0730b32a53f2e116b5e
폰트 설치가 끝났으면 iTerm 설정을 통해 터미널 기본 폰트를 변경해주어야 한다. iTerm 화면에서 Command + ,(콤마) 단축키를 이용해 설정 창을 열어준다. 그 다음 Profiles > Text 탭의 Font 섹션 아래에 있는 `Change Font` 버튼을 클릭해주자.

좌측 탐색 영역에서 All Fonts를 클릭하고 스크롤을 내리다보면 `Meslo LG M DZ for Powerline` 폰트가 보인다. 그 폰트를 선택하고 글자 크기를 여러분이 원하는 크기로 세팅하고 창을 닫아준다. (필자는 12pt가 적당하다고 생각하지만, 넓은 화면을 가진 사용자의 경우 13pt가 가장 적절하다.)

이제 여러분은 아래 화면처럼 모든 텍스트가 깨짐없이 출력되는 것을 확인 할 수 있다.

5. iTerm color scheme 설정
이제 우리는 테마가 적용된 아름다운 터미널 구성 세팅이 끝났다. 하지만 컬러가 너무 시신경을 자극하고 컬러의 색체도 그렇게 아름답지 못한 것 같다. 따라서 컬러 스킴을 적용하여 조금 더 색체 배합이 아름다운 터미널로 교체해보자.
필자는 여러가지 컬러 스킴을 찾아 테스트를 해보았고 지금은 Brogrammer 스킴이 가장 필자의 선호도에 맞는 스킴이다. 따라서 이 포스트에서는 Brogrammer를 설치하는 가이드를 진행한다. 구글에 iterm color scheme이라 검색하여 여러분에 선호에 맞는 스킴을 설치할 수 있으므로 만약 이 포스트에서 나온 컬러 스킴을 원하지 않을 경우 여러분이 원하는 컬러 로 설정하면 된다.
https://gist.github.com/KennethanCeyer/a21f23327a0e5ac3bf7fb8b800ecc179
위 명령어를 입력하여 Brogrammer 컬러 스킴을 여러분의 홈 디렉토리 .iterm 폴더안에 다운로드 하였다. 다운로드가 끝났다면 iTerm 화면에서 Command + ,(콤마) 단축키로 설정 화면을 열고 Profiles > Colors 탭의 우측하단의 Color Presets 콤보박스를 열어 `Import` 옵션을 선택하자. 이해가 잘 안간다면 아래 그림을 보자.

탐색기에서 Command + Shift + g 단축키를 입력하여 경로 입력 창을 열고 `~/.iterm` 을 입력하여 ~/.iterm 폴더로 이동한 후 .iterm 폴더 내에 있는 Brogrammer.itermcolors파일을 선택해주자.

Import가 완료되었다면 아래와 같이 선택 화면에서 Brogrammer가 확인된다.

Brogrammer를 선택하고, 설정 화면을 닫아주자. 설정이 정상적으로 되었다면 아래와 같이 컬러가 변경된 터미널을 확인할 수 있다.
6. Powerlevel9k context 설정
Powerlevel9k 테마는 환경변수를 통해 사용자 입맛에 맞게 커스터마이징 하는 기능을 제공하고 있다. https://github.com/bhilburn/powerlevel9k#prompt-customization 링크를 확인해보자.

위 그림의 예시처럼 환경변수는 좌측과 우측 라인에 기본적으로 표시되는 Context를 수정할 수 있게 제공해준다. 필자는 다음과 같은 내용을 .zshrc에 추가하였다.
https://gist.github.com/KennethanCeyer/d5658502e22a2be7e290de303e66ec66
만약 설정 방법이 이해가 안된다면 아래를 살펴보자.
설정 파일을 변경하더라도 바로 적용이 안되고 zsh 쉘을 다시 실행해야 한다. zsh 명령어를 입력하여 zsh 쉘을 다시 실행하여 보자. 설정이 잘 완료 되었다면 아래와 같이 터미널이 조금 더 간략화된다.

7. 작업 마무리하기
여러분의 터미널은 대부분의 설정이 끝났다. 이제 iTerm의 기능과 zsh 쉘의 기능, Powelevel9k 테마의 편리한 UI들을 사용할 수 있다. 대표적인 기능들을 둘러보자.
먼저 iTerm의 기능 중 Split view 기능을 살펴보자. 여러분의 iTerm 화면에서 Command + D 단축키를 통해 다음과 같이 Vertical View, Command + Shift + D를 통해 Horizontal View로 분리할 수 있다.

위 그림이 Vertical View Split,

그리고 위 그림이 Horizontal Split View이다.
커맨드 + W 단축키를 통해 현재 포커스가 잡힌 View를 닫을 수 있고, Command + 방향키를 통해 View 포커스를 스위칭 할 수 있다.
Command + T를 통해 탭을 생성할 수 있고 Command + 숫자로 특정 넘버의 탭으로 스위치를 할 수 있다. 마찬가지로 Command + W로 탭을 닫을 수 있다.
더 자세한 iTerm 편의 기능은 https://gist.github.com/squarism/ae3613daf5c01a98ba3a 링크에서 잘 설명하고 있다.
ZSH도 수 많은 편의 기능을 제공하고 있다. 먼저 cd 명령어를 생략하고도 특정 디렉토리로 이동할 수 있다.

그리고 .. (상위 폴더로 이동)에 추가적으로 점(.)을 붙여 어느 depth의 상위 디렉토리 까지 이동할지 지정이 가능하다. 예를들어 .... (점이 4개 사용되었을 때)의 경우 상위 3 depth의 폴더로 이동한다.

그 밖에 Tab으로 자동 완성(Auto complete)을 지원하는 기능도 폭 넓게 늘어나게 되는데 대표적으로 git을 사용하는 경우 branch 명이나 origin alias도 자동 완성으로 서포트하게 된다.
더 자세한 내용은 https://github.com/robbyrussell/oh-my-zsh/wiki/Cheatsheet 링크에서 살펴보자.
마지막으로 Powerlevel9K 테마가 제공해줄 수 있는 기능 중 vcs에 대해서 얘기해보고 싶다. 여러분이 git을 이용한 버전 컨트롤을 할 경우 아래와 같이 보기 편한 branch 상태 정보를 제공받게 된다.

위 사진에서 연두색 영역에서는 현재 git 디렉토리의 브랜치 이름을 보여주게 된다. (이 연두색 영역은 .git 디렉토리가 아니면 생략된다.)
그 밖에도 각각의 git status에 따라 이 부분의 색상과 내용이 조금 씩 변경된다.
더 자세한 Powerlevel9k의 기능은 https://bhilburn.org/powerlevel9k/ 링크에서 살펴보자.
Vim 환경 준비하기
여러분의 Mac에는 대부분 vi 커맨드가 기본적으로 내장되어 있다. vi 커맨드를 이용하여 에디터를 띄울 수 있는데 기본적으로 최근의 vi 커맨드는 vim(Vi IMproved) 커맨드와 동일하게 동작한다.
vi --version을 이용하여 버전 정보를 조회해보자.

vimrc 세팅하기
https://github.com/amix/vimrc를 이용하여 우리는 기본적인 vim 환경을 준비하고자 한다. 아래와 같은 명령어를 이용하여 vimrc를 세팅해보자.
https://gist.github.com/KennethanCeyer/3838790aa6eb1d1a3e5e201a9fad58b5

위 화면에서 처럼 Installed the Ultimate Vim configratuon successfully! Enjoy :-) 라는 문구가 보이면 정상적으로 설치된 것이다. vi 명령어를 실행해보자.
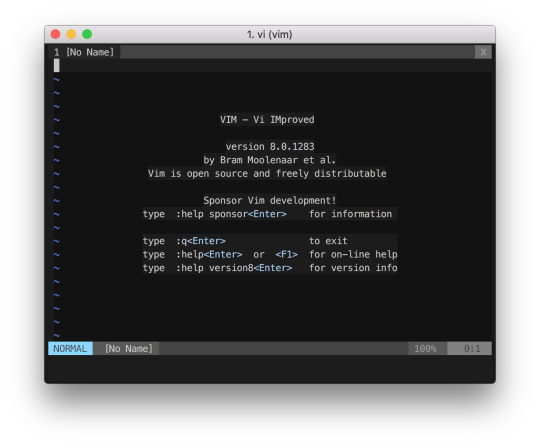

위 사진처럼 가장 기본적인 화면 구성은 vimrc가 다 세팅해주었기 때문에 어느정도 보기좋은 인터페이스로 구성이 되었다. 하지만 몇가지 추가로 기능을 이용하려면 추가적인 설정이 필요하다.
아래 명령어를 이용하여 .vimrc에 추가적인 설정을 추가해주자.
https://gist.github.com/KennethanCeyer/3742210bfcbb34ecdf7cbb9f2524687f
이제 vi 명령어를 통해 에디터를 열면 다음과 같은 화면을 볼 수 있다.


이 정도면 충분하다! 여러분이 vi를 통해 텍스트 편집이나 심지어 개발을 할 경우에도 이 정도의 설정으로 최소한의 요구사항은 충족할 수 있다. 이제 vim과 함께 즐거운 해킹을 하기 바란다. 설정에 부족함을 느끼는 독자들을 위해 다른 포스트에서 vim에 플러그인을 추가하여 파워 업을 할 수 있는 방법을 설명할 예정이다.
하나만 더! vim 테마 설정
이미 우리는 iTerm 컬러 스킴을 추가하여 충분한 컬러를 가지고 있지만 확실한 것을 원하는 유저를 위해 vim에 컬러 스킴을 추가하는 방법을 공유하겠다.
우리는 앞서 Brogrammer 색상 테마를 사용했기 때문에 vim도 같은 색상 팔레트로 통일하는 것으로 설명한다.
https://gist.github.com/KennethanCeyer/fe32c8d0ead2adafc6d59dc87d324509
먼저 위 명령어를 이용하여 brogrammer.vim을 ~/.vim/colors 폴더에 다운로드 한다. 그리고 아래 화면처럼 colorscheme brogrammer를 ~/.vimrc에 추가한다.

설정이 다 끝났으면, 아래와 같이 개발환경에서 vim의 다양한 화면 구성 및 색상 배치를 경험해볼 수 있다.

끝으로
이번 포스트는 개발 환경에 가장 기본이 되는 터미널과 vim 설정에 대해 알아봤다. 여러분은 고작 터미널 기능을 확장한 것 뿐에 불과하는데 굉장히 긴 포스트 글을 읽어보고 시행 착오를 겪어가며 고통을 느끼고 있을 것이라 생각한다.
이런 고통을 줄이기 위해 이후 더 다양한 포스트를 통해 유용한 트릭들을 공유하고 가이드해줄 수 있도록 할 예정이다. 다만 여러분이 이 글을 읽으며 얻은 공유는 나중에 잊지 않고 여러분이 다른 포스트를 써서 또 다른 기술 공유라는 기여를 통해 개발자 네트워크에 보답을 해주기를 희망한다.
필자는 최근 https://github.com/KennethanCeyer/bire 프로젝트를 통해 이런 설치 과정을 몇줄의 커맨드로 최소화 할 수 있는 프로젝트를 기획하고 있다. 이 부분에 대해서도 경험기를 포스트로 공유할 계획이니 기대해주기를 바란다.
2 notes
·
View notes
Text
다가오는 추상화의 위기 (The Looming Abstraction Crisis) 번역글
이 글은 operator++ 블로그의 The Looming Abstraction Crisis 아티클을 번역하였습니다. 역자 업데이트: 원문 블로그 링크가 깨져있습니다. 블로그 메인 링크도 접속이 안되는 것으로 미루어보아 블로그를 이전했거나 내렸을 가능성이 있습니다. 추후 원문 링크를 발견하면 업데이트 해두겠습니다.
역자의 말
번역되는 단어 중에 Higher-level language는 고수준 언어와 고급 언어 둘중 고민을 했으나 의미상 오해의 소지가 있더라도 많이 쓰이는 고급 언어로 표현하였습니다. (뭐 오해하면 양쪽 단어 다 오해할 가능성이 있다고 판단하였습니다.)
아티클 본문
예전에, 그 때의 그 날로 되돌아가보자면 — `프로그래밍 언어` 라는 것이 존재하지 않았습니다. 당시 프로그래밍은 하드웨어 위에서 조작해야 했던 때였습니다. xkcd 유머 (역자: xkcd는 미국 랜들 먼로가 NASA를 그만두고 그린 웹툰입니다, 공대생 만화라고 보시면 됩니다)에서 다루는 `A Magnetised Needle and a Steady Hand`는 그다지 과장된 얘기도 아니었다고 할 수 있겠네요, 하드 디스크가 여전히 비실용적인 것 빼고는요. 그 당시 천공카드 (Punch Card)는 흔한 입력매체였습니다.

<그 당시에는 컴퓨에 무언가를 입력할 때 카드에 구멍을 뚫어서 사용하는 천공카드가 있었습니다.>
(천공카드도 없었을 시절에는 컴퓨터에게 명령을 내리려면 하드웨어 레벨에서 조작 따위를 했어야 했습니다. 심지어 플러그보드를 사용했던 세대보다 더 예전으로 거슬러 올라가면 우리가 다루고 있는 것이 컴퓨터라는 것을 알고있음에도, 무엇을 다루고 있는지조차 정확하지 않을 수준까지 갑니다.)

물론 이런 종류의 프로그래밍은 굉장히 어려웠고 지루했으며 오류도 자주 발생했습니다. 텍스트 기반 어셈블러는 천공카드 시대에서도 존재해 왔기에 적어도 프로그래머들에게 읽을 수 있는 무언가가 있긴 했었죠—제 말은 읽을 수 있던(아마도 사람이 이해할 수 있는...) 최소한의 뭔가를 제공하긴 했었다는 것이죠. 그렇다곤 해도 개발 환경은 여전히 하드웨어와 1:1 대응이 필요했습니다. 그 당시 진정한 혁명이라 할 수 있는 1957년 포트란(Fortran), 1958년 알골(ALGOL), 1964년 베이직(BASIC), 1968년 파스칼(Pascal)이 등장했었고, 마침내 1972년에 C라고 불리는 언어가 등장했습니다. 마지막으로 등장했던 C는 정말... 진정한 혁명이었습니다.
C는 최초의 고급 언어(Higher-level language)까지는 아니었지만, 오늘날 사용하는 3세대 언어 중에는 거의 유일한 언어라고 볼 수 있습니다. C가 성공할 수 있었던 비밀은 어셈블리 언어로 작업되었던 운영체제를 대체할 수 있도록 디자인 되었기 때문입니다. 그렇기 때문에 몇가지 안되는 기본 구조로 어느정도 낮은 수준의 하드웨어 인터페이스를 구성할 수 있도록(어셈블리 코드로 쉽게 변경할 수 있는 구조) 제공되었으며 복잡한 구성을 추상화 할 수 있는 기능또한 제공되었습니다. 제가 숫자에 대해서 자세히 알지 못하고 또 그것을 추정하는 방법도 잘 모르지만, 오늘날에 돌아가는 99.999%의 대부분 코드들이 첫번째로 C, 두번째로는 C로부터 파생된 언어들 (예를들어 C++) 세번째로 그렇게 파생되었던 언어들로 부터 탄생한 가상머신(VM)에서 돌아가는 언어들로 구성되어있다고 생각합니다.
C는 훌륭한 언어임에는 틀림없지만 결국에는 어렵고 지루하며 자주 에러를 발생시킨다고 여겨지게 되었습니다. 그리고 또 누군가 그 위에 추상화 계층을 얹기 시작하였습니다. 그렇게 1985년에 C++이 등장하게 됩니다. C++은 이런 배경에서 탄생한 언어 중에서는 선두이고 어쩌면 가장 단순한 언어일 것입니다. C++은 프로그래머에게 객체지향 구문을 제공하는 C언어의 파생 언어입니다. [Update: 일부 사람들은 이 주장에 대해 여전히 논쟁을 하고 있지만, 중요한건 적어도 이 언어가 그렇게 시작되었다는 것입니다.] C++은 C 언어가 하는 것처럼 동일한 기계어로 컴파일을 할 수 있고(적어도 이론상으로는) 상당히 엄격하게 C로도 컴파일 할 수 있습니다. 실제로 초기 C++ 컴파일러는 이렇게 동작되었습니다. 물론 지금의 C++은 더 이상 이러한 방식으로 동작하는 유일한 언어는 아닙니다. 소위 `시스템 프로그래밍 언어`라고 불리는 고급 언어(C보다 더 고 수준의 언어)의 범주에 속하는 언어들은 최근 C++ 표준의 막장 행보로 인해 과도기를 경험했었고 그로인해 사람들은 결국 이런 계열의 언어 또한 어렵고 지루하게 느끼기 시작했습니다.
성능이 중요한 응용 프로그램 (정확하게 말하자면 성능이 불충분한 장비에서 돌아가는 것들이요—사람들이 체감하거나 말거나 성능은 항상 중요합니다)에서 C++은 이런 환경에서 최고존엄처럼 사용됩니다. 오늘날, 어쩌면 현시대에서 최고라 불릴 수 있는 대체 시스템 언어 러스트(Rust)도 있다고는 하지만 그렇다고 C++이 어디론가 사라지거나 하는건 아닙니다. (적어도 Rust가 C++ 호환 기능보다 좋은 무언가를 제공할 때 까지는 C++은 남아있을 것입니다. 그리고 C++이 다른 언어에 대체된다고 해도, 그 대체 과정은 상당히 천천히 이루어질 것이고 대체되었다고 해도 절대 C++이 사라지거나 하진 않을 것입니다.) 대부분의 사용자 프로그램은 (게임을 제외하고, 아니, 심지어 게임마저도...) 장비가 매우 빨라 성능이 거의 고려되진 않습니다. 모바일 앱 개발 방식은 마케팅과 나태함을 바탕으로 하고 있으며 최근 가시적인 성능의 변화들은 시장성 갖는다고 보기가 어렵습니다.
결과적으로 가상머신(VM)에서 돌아가는 추상화된 언어들이 폭발적으로 늘어나고있고 (제 개인적인 의견이지만) 또한 동시에, 지속 불가능할 수 없는 수준으로 성장했습니다. 베이직(BASIC)을 이렇게 성장 추세에 있는 언어로 치지 않는다면, 1995년에 자바(JAVA)가 이 계열에서 먼저 시작되었다고 할 수 있습니다. 자바의 개념은 간단하고 훌륭했습니다: 자바가 컴파일 하는 해석문(이 경우 바이트 코드(bytecode))은 OS와 하드웨어의 세부사항을 추상화 하였고 개발자는 모든 고객들에게 결과물인 `바이너리(binary)`를 제공할 수 있었습니다. 운영체제 레벨에서 추상화를 통해 보안이 향상되었지만, 네트워크를 통해 넘어온 신뢰성 없는 코드를 실행할 수 있기 때문에 어쩌면 마냥 좋다고 볼 수는 없었지만요.
물론 단점은 성능이었습니다. 1995년대에 비해서는 지금은 더 나아졌다고는 하지만 그래도 여전히 이클립스(Eclipse)를 여는 것은 그닥 달갑지 않습니다. (자바 기반의 커맨드라인 도구들은 더합니다, JVM의 경우 엄청 느리지는 않지만 시작하기까지 시간과 정신의 방에 갇혀있어야 합니다.)
그렇다고 해서 자바가 C++과 비교했을때 추상화 측면에서 그다지 눈에띄게 좋아진 것도 아닙니다. 물론 여러 플랫폼에 대한 독립성 지원은 훌륭하지만 C++에서도 모던 크로스 플랫폼 라이브러리와 데브옵스(DevOps) 툴을 사용하면 플랫폼 의존성의 (미미한)비용은 거의 제로에 가깝게 변합니다. 그렇다고 자바로 개발하는 것이 쉬운편도 아닙니다. 또 메모리 관리가 훨씬 자동적인 것도 아닙니다 (자바에 동적으로 증가하는 배열은 어디에 있나요?) 타이핑은 C보다 강력하다 할 수 있습니다. (자바에서 클래스를 자체적으로 캐스팅하려고 할 때 오류를 받아볼 수 있습니다!). 여전히 자바는 거지같은 null 포인터(네! C에서 개발자 모두가 고통 받는 그것이요!)를 가지고 있습니다. 앞서 말했듯이 보안은 거진 20년동안 유닉스에 있었던 것에 비하면 들어보지도 못했던 `바이트 코드`를 제공하기 때문에 나아졌다 할 수는 있겠지만 여전히 소름돋도록 비효율적입니다. (즉, 네트워크 전반에 신뢰할 수 없고, 유효성이 보장되지도 않으며 또 그 네트워크 전체에서 보이지 않는 경우도 자주 있습니다.)
자바 쇠퇴하고 나서, 그 결과가 오래동안 쌓아온 네이티브 표준으로 돌아가는 것이 아니었습니다. 되려 더 높은 고급 언어로 몰리기 시작했습니다. 자바와 관련이 없는 자바스크립트(Javascript)가 1995년에 공개된거죠. 하지만 자바스크립트는 애플이 플래시를 아이폰에 넣지 않기로 결정하기 전까지, 거진 10년 반 동안 별 다른 성과없이 지진부진하였습니다. 자바스크립트가 빛을 보지 못한 그 동안 이른바 `Web 2.0`이라고 부르는 플러그인을 대체하는 표준 등이 개발에 제동을 걸었습니다. 모던 웹앱은 어떠한 의미로는 자바의 문제들을 막았습니다. 완전한 크로스 플랫폼을 지원했고, 쉽게 배포가 가능했으며 사용자의 시스템에 접근을 어느정도 막을 수 있었습니다. 설령 사용자가 접근을 원한다고 하더라도 말이죠. 최종적으로 이런 방식이 개발을 쉽게해주었습니다. 자바스크립트를 언어 관점에서 보자면 실수가 발생하기 쉬운 언어입니다. (물론 실수가 발생하지 않는 것보다 올바르게 작성하는 것이 더 어렵지만, 이제 사람들은 올바른지는 여부는 신경 쓰지도 않습니다) `진정한 프로그래밍`과는 별도로 마크업 언어로 UI를 디자인 (특히 테마를 지정)하는 것이 실질적인 이점이라 볼 수 있는 언어입니다.
지금에서는 웹앱이 크롬 OS(Chrome OS)와 일렉트론(Electron)이라는 산물을 남겼습니다. 또한 자바스크립트는 노드(Node.js)를 통해 서버 프로그래밍에서도 사용할 수 있게 되었고요. 이것이 오늘날의 모던 웹�� 방향입니다. 우리가 좋아하건 아니건 말입니다(그리고 좋건 싫건 논쟁이 있고요). 그렇다고해서 비판을하지 말자는 것은 아닙니다: 생각해봅시다 여러분이 브라우저만 돌아가도록 만든 상용 운영체제를 가지고 있다고 가정할 때, 과연 가벼운 운영체제를 사용하고 있다고 생각하나요? 아니면 말 그대로 미쳐날뛰는 브라우저를 가지고 있다고 생각하나요?

<데스크탑 환경의 어플리케이션도 웹 프론트엔드 개발자들이 진입할 수 있게 해준 일렉트론>
크롬(Chrome)을 운영체제(OS)라고 부르는 것도 과장이 아닙니다. 코드 라인으로 보면 크롬은 리눅스 커널과 거의 동급의 크기를 자랑합니다. 마치 리눅스 커널처럼 OpenGL, VR, MIDI와 같은 모든 종류의 하드웨어를 위한 API를 가지고 있습니다. 또한 SQLite 임베디드 copy, 메모리 관리, 자체적인 테스크 매니저와 같은기능을 탑재하고 있습니다. macOS 버전에서는 심지어 Xbox 360 컨트롤러용 사용자 영역의 USB 드라이버가 포함되어 있습니다. (제가 작성했었기 때문에 그게 거기 있는 걸 알아요. 미안해요.) 슬랙(Slack)에는 제가 작성한 Xbox 컨트롤러를 위한 코드들이 포함되어 있나요? 슬랙 팀은 혹시 알고 있나요? 혹시 아시는 분 있나요?
어쩌면 크롬은 대부분의 리눅스 배포판보다 우수한 운영체제라고 부를 수 있을 겁니다—적어도 개발자들은 그렇게 부를 겁니다. 크롬은 대부분의 운영체제 API를 유난히 짜증스럽게 만드는 특유의 레거시의 산물이나 특징이 전혀 없습니다. 더군다나 이러한 API들은 표준을 기반으로 하고 있었기에 개발자들로 하여금 부수적인 추가 작업 없이도 사용자는 자유롭게 여러 브라우저를 선택할 수 있습니다. 사용자 어플리케이션을 위한 개발 플랫폼으로서 웹은 최고의 선택이 될 수 있습니다. 물론 많은 사람들이 웹으로 넘어가고 있는 이유이기도 하고요.
문제는 모든 것이 자바스크립트에서 동작하고 보이는 것입니다. 고작 10일만에 설계된 언어에서요. 이렇게 짧은 시간에 설계되었다고 해서 자바스크립트로 좋은 코드를 작성하는 것은 쉬운일이 아닙니다. 엄밀하게 말하자면 수용가능한(acceptable) 자바스크립트 코드를 작성하는 것은 쉽기 때문에, 좋은 코드 작성이 어렵게 된 것이지요 (역자: 에러가 안나는(수용가능한) 코드는 작성하기 쉬운데, 에러가 안난다고 좋은 코드는 아니기 때문에 어렵다고 하고있습니다). 인터프리터 관점에서는 수용가능한 문법(acceptable )은 수용가능한 것이 아닙니다. 자바스크립트를 단지 1할만 알더라도 어느정도 돌아가는 코드를 작성할 수 있습니다. (그리고 여러분이 만약 제대로 된 1할을 배웠다면 더 좋은 코드를 작성하겠죠) 하지만 인터프리터는 잘 작성된 코드와 안 좋은 코드, 심지어 망가진 코드도 다룰 수 있어야 합니다. 때로는 처절하리 만큼 망가진 코드가 들어와도 말입니다. 이것들이 의미하는 바는 (a) 추상화의 비용은 기하급수적으로 늘어나고 있고, (b) 이런 비용을 줄이는 것은 정말로 큰 과제가 되었다는 것입니다.

<같은 V8이라도 그 구조의 복잡성은 너무나도 다를 것입니다 - 그림 출처 위키피디아>
앞서 말씀드린 문제들을 해결하지 못한 것은 아닙니다. 오늘날에 가장 유명한, 어쩌면 가장 빠른 자바스크립트 엔진은 구글의 V8입니다. V8 엔진은 크롬에서도 사용되고 있습니다(아시다시피 노드와 일렉트론도 이 엔진을 기반으로 합니다). 이 엔진 이름은 의심의 여지도 없이 고성능 자동차 엔진을 연상시키지만, 만약 V8이 진짜 자동차 엔진이라고 불리기 의도했었다면, 아이러니하게도 절대로 V8이 될 수 없을 겁니다. (역자: 이 엔진이 자동차 엔진 V8로 비유하기에는 너무.. 너무 무거워졌다는 의미를 내포합니다) 만약 당신이 중요하게 보는 것이 복잡성과 유지 보수 비용이라면 부가티 베이론(Bugatti Veyron)의 엔진인 `W16`이 될순 있을 듯 합니다. 이 엔진은 16기통 엔진에 4개의 터보 차저를 가지고 있어 마치 대형 트럭에 들어가는 엔진처럼 오일 교환 비용이 21,000 달러에 육박합니다. 아마도 구글 V8 엔진을 사용하는 것은 170만 달러짜리 슈퍼카로 심부름을 하는 것과 완전히 똑같지는 않겠지만 연비(혹은 메모리 사용율)가 굉장히 나쁜 차량을 몰고 있는 것과는 같습니다. 적어도 이 경우에 누군가 기름을 교체하고 있습니다 (역자: 메모리, CPU 성능은 계속 향상되고 있다는 의미입니다).
하지만 기름 (그리고 부가티)가 무료로 제공된다면 어떨까요, 우리는 매일 부가티를 몰고 기름을 사용하겠죠. 이 상황이 일반적인 무어의 법칙의 상황이라 볼 수 있습니다. 성능이나 자원 상태가 10% 가량 향상되더라도(대규모 프로젝트에서는 별반 차이가 없습니다) 3개월 뒤에는 거의 사용하지 않아 시장에서 버려집니다. 따라서 건전한 비즈니스 결정에서는 최적화를 포기하고 여러분의 소프트웨어 스택에 그냥 쓰레기를 계속 쌓아올리게 됩니다. 무어의 법칙은 아래의 그래프에서 보이는 것(리눅스 커널의 코드 라인)으로부터 우리를 지켜내 주었습니다.
youtube
코드 양이 지금도 폭발적으로 증가하고 있지만 우리가 사용하고 있는 프로세서의 속도가 훨씬 빠른 속도로 증가하고 있기 때문에 코드 양의 증가는 더 이상 중요하지 않게 되었습니다. 그렇다곤 하지만 무어의 법칙은 영원히 유지될 수 없고, 이젠 더 이상 그런 것은 변명거리조차 되지 못합니다. 양자제한 효과로 인하여 트랜지스터 사이즈의 한계는 이미 우리 코 앞으로 들이닥쳤습니다. 그렇기에 앞으로 더 빠르고 좋은 프로세서를 만들기 위해서는 새로운 기술이 필요한 상태이며, 프로세서의 처리능력(적어도 가격 대비)은 상당히 오랜기간 정체된 상태로 있게 될 것입니다—적어도 무어의 법칙이 통했던 시대에 비하면 말입니다. 지금 이 순간 프로세서 사양이 정체로 다가오게 된다면(2021년 쯤으로 예상합니다) 폭발적이었던 코드 양의 증가가 점점 그에맞는 사양이 따라오지 못해 위험해지는 시기가 올 것입니다. 또한 무어의 법칙은 컴퓨터를 더 빠르게 그리고 저렴하게 만들 수 있었습니다. 예전에는 PC도 가질 수 없었던 사람들이 지금에 와서는 최소한 스마트 폰은 가지고 있으며 사용하고 디바이스도 굉장히 다양해졌습니다. 이러한 두가지의 변화들에 의해 앞으로는 서서히 다가오는 위기를 맞이하게 될 것입니다. 따라서 `계획적구식화(planned obsolescence)` (역자: 새 제품이 나올 때 쯤에 이전 시리즈의 제품에 고의적으로 성능을 느리게 만들거나 구식이라는 이미지를 심어주어 대체 수요를 늘리는 등의 정책을 말합니다)는 곧 붕괴하고 불타오를 것입니다. 그렇게 추상화의 위기가 찾아오고 모든 것이 붕괴한다면 당신은 어디에 있으실건가요?
당신이 웹 개발자라고 한다면 달리말해 준비되지 않았다고 할 수 있습니다. 그 이유는 오늘날의 웹 개발 트랜드는 간단한 코드나 더 적은 추상화 레이어로 흘러가고 있지 않기 때문입니다. 물론 여기에도 몇가지 재밌는 예외사항이 있긴 합니다. 이에반해 대부분의 웹 응용 프로그램은 더 많은 추상 레이어를 덧대고 복잡해져 거대한 프레임워크로 구축되고 그렇게 덧대진 웹 응용 프로그램은 여러분의 4개의 터보 차저를 가진 W16 위에(역자: 아까 언급한 크롬을 말한겁니다) 올라가게 됩니다. 사람들은 30분 안에 앱을 만들 수 있기를 원하고 프레임워크를 사용하면 실제로 그렇게 할 수도 있습니다. 하지만 말입니다 따라오는 성능 단점들은 제외한다 치더라도 이게 정말 올바른 소프트웨어 개발이라고 불릴 수 있을까요?
물론 웹 프레임워크 비유가 그렇게 많은 성능에 있어 단점을 가져오지는 않습니다. 웹에서 코드를 실행하고자 한다면 코드를 그때그때 다운로드 해야 하기 때문에 심지어는 CPU 사용률도 이제 더 이상 (커다란) 문제는 아니게 되었습니다. 리액트(React) 앱은 개발자가 코딩을 시작하기도 전에 무려 79,905라인의 자바스트립트 코드를 필요로합니다. 좋습니다. 아무래도 리액트는 공평하지 않은 예시일 수 있습니다—페이스북 제품이니깐요. 페이스북은 앞서언급한 것과 유사한 문제들을 가지고있기로 알려져 있습니다. 그렇다곤 해도 리액트는 굉장히 유명합니다, 그 말은 즉슨 로드 될 때마다 80,000 라인의 코드를 다운로드하는 수 많은 리액트 네이티브 베이스 앱들이 지천에 널려있습니다. (위에서 언급한 기사에서 말하는 통계를 바탕으로 알 수 있는 충격적인 사실은, iOS 버전의 페이스북 앱이 18,000개의 Objective-C 클래스를 포함하고 있고 이것이 리액트가 동작하는 직접적인 결과를 의미합니다. 특히 리액트 네이티브(React Native)로 알려진이 저품질의 야매 프로젝트에서요. 하지만 이건 원 주제와 관련이 없는 이야기입니다) 다른 프레임워크는 조금 더 나을지도 모르지만 얼마나 더 나을까요? 심지어 제이쿼리(jQuery) 마저도 86 킬로바이트의 크기를 자랑합니다: 최근에는 더 작아졌겠지만 여전히 배보다 배꼽이 큰 경우가 많습니다.
아 그리고 우리가 엄청난 크기의 프레임워크를 논하고 있을 때 그게 엄청난 양의 자바스크립트 코드라는 것을 명심하세요—그 프레임워크는 또 약 백만 라인 가까이 되는 크기의 VM 위에서 실행되고, 또 그건 크기가 무려 수천만 라인에 도달하는 OS가 실행시게 됩니다. 물론 모든 자바스크립트 코드들이 각각 한줄씩 전부 실행되는 것은 아닙니다—어쩌면 수많은 코드들이 전혀 실행되지 않을 수 도 있습니다—하지만 고작 작은 기능을 만드는데 수 많은 코드를 토해냅니다. 80,000 라인의 자바스크립트 코드와 같은 기능을 C로는 몇 줄로 대체 가능할까요? 해답을 듣고 싶으세요? 어쩌면 더 중요한 것은 얼마나 많은 라인이—아, C 대신 C++ 이라고 가정하고 생각해봅시다—간단한 UI 마크업 언어와 C++ API를 사용하여 어느정도 React.js와 동등한 앱을 만들 수 있을까요? 어쩌면 80,000 라인보다 더 많이 필요할 수도 있습니다—어쩌면요.
(리액트에서 할 수 있는 모든 것들을 소화해낼 수 있는데도 그 단순함은 잘 알려지지 않은 큐티(Qt)는 대략 470,000 라인의 C++ 언어로 구성되어 있습니다—이는 리액트의 80,000 라인보다 6배 가까이 많은 양에 육박하지만 V8 엔진의 크기에 비해서는 1/4 정도의 크기이며 크롬보다는 20배 가까이 작습니다.)
그렇다고 해도 여전히, 주사위는 던져졌습니다. 사람들이 다시 저급언어로 앱 개발을 하면 좋겠지만 그럴 것 같지는 않아보이네요. 대신 어쩌면—아마도 어쩌면— 90년대, 심지어 2010년으로 거슬러 올라가지는 못하더라도 쓸모없는 코드들이 기하급수적으로 늘어나기 직전, 한발짝 물러설 수 있는 방법이 있을 것 같습니다.
우리가 가장 먼저 해야할 것은 웹 프레임워크 문화 최악의 국면을 되돌리는 것입니다. 솔직히 말하면, 앱을 라이브 환경에서 실시간으로 빌드하거나, 심지어 이를 24시간 안에 할 수 있는 능력들은 득보다 실이 많은 쓸데없는 눈속임입니다. 구글 엔지니어는 30분의 대화 속에서도 실제로 전달가능한 제품을 만들 수 있다고 생각할 만큼 어리석지는 않겠지만, 여러 개발자들 속에서 이런 컨셉을 시연해야하는 것은 어쨋거나 나의 책임감을 미치도록 건드립니다. 제 말은, 아 제발요—어디선가 페이스북 직원이 보고있을지도 모른다고요. 거대한 테크 회사들이 그들의 정교한 커스텀 솔루션들을 오픈 소스로 제공하는 것과 그것들을 지루한 대학생들을 상대로 어떤 유행이나 돈 욕심으로 마케팅을 하는건 엄연히 다릅니다. 저는 잘못 만들어진 것들을 누군가 처음부터 다시 만들 수 있다고는 말하지 않을 것입니다. (꼭 그래야 하는 건 아닙니다) 하지만 모든 프로그래머가 그런식으로 생각하게 된다면 세계의 소프트웨어 품질의 평균이 어떻게 변할 것이라고 생각하시나요?
그 다음으로는 OS와 브라우저 벤더사들은 그들의 API를 개선시킬 필요가 있습니다. 예를들어 제이쿼리는 일반적으로 모던 웹 표준입니다.—이런 API는 표준 DOM API와 철처하게 경쟁을 벌여왔습니다. 그리고 그건, 음, 좋진 않아요. 브라우저 제작사들은 (적어도 핵심 부분들은) 분명한 조치를 취하고 제이쿼리를 브라우저 내에 포함시킬 필요가 있습니다, 자바스크립트를 대신하여 자연스럽게 실행시키기 위한 수많은 공통 코드들을 허용하여 말 그대로 수십억개의 페이지 로드에서 페이지 각각 86 킬로바이트를 줄일 수 있습니다. 데스크탑에서 동작하는 서드파티들도 똑같이 적용할 수 있습니다—제이쿼리 처럼 분명한 예시는 없지만 SDL과 같이 예시는 분명히 있습니다. (이건 기본적으로 Boost에 대응되는 C++ 표준화 도구입니다. $(...) 셀렉터는이제 대부분의 브라우저에서 제이쿼리 없이도 사용할 수 있게 되었습니다. 따라서 이것이 시작이라 볼 수 있겠네요.)
세번째로는, 최소한 현재 형태를 유지하며 자바스크립트를 떼어내야 합니다. 대부분의 경우 자바스크립트는 구진 것이 분명하기 때문에 결코 새로운 아이디어가 아니지만, 최근에서야 이를 시작하기 위해 필요한 도구들을 만들었습니다. 웹 어셈블리(WebAssembly) 마침내 네이티브 레벨에서 지원되고 있으며-자바스크립트를 대체할 수 있도록 모든 브라우저 안에서 서포트되고 있습니다—다음 단계는 웹 어셈블리를 기본 대상으로 하도록 옮기는 것이며, 아마도 최종적으로는 유일한 선택이 될 것입니다. 최소한의 사이드 이펙트만으로 이 작업을 하려면 자바스크립트를 웹 어셈블리(WASM)로 컴파일하는 방법이 필요합니다. 결코 쉬운 작업은 아닙니다—아까전의 `W16` 문제로 돌아갑시다. 그럼에도 불구하고, 기존 자바스크립트 엔진은 자바스크립트를 컴파일 하므로 코드를 즉시 실행하는 대신 디스크에 덤프하는 것 (아마도 LLVM 바이트 코드로) 은 그렇게 어렵지 않습니다. 어셈블리 스크립트(AssemblyScript)는 이미 타입스크립트(Typescript)를 (자바스크립트에 동적 타이핑을 추가한 마이크로소프트가 만든 확장형 언어) 웹 어셈블리로 컴파일 할 수 있습니다. 거의 다왔습니다. 하지만 웹 어셈블리는 현재 너무나도 효율적으로 샌드박스화 되어 있기에 웹 어셈블리–자바스크립트 인터페이스는 거의 대부분 재설계되어야 할 것입니다.
마지막으로, 하드웨어와 사용자들이 실제로 소프트웨어를 작성하는 지점 사이의 모든 쓰레기들을 치워야합니다. 게리 베른하르트(Gary Bernhardt)의 유명한 이야기 중 `자바스크립트의 탄생과 죽음` (유머스럽게 `야마스크립트(YavaScript)`라고 발음합니다)는 풍자적으로 커널을 웹 어셈블리 VM으로 대체할 것을 제안했습니다. 실제로 이 아이디어는 시도 되었지만 아마 너무 멀리 갔었던 듯 합니다. 그렇다곤 해도 충분히 현실적인 아이디어로도 사용될 수 있을거라 생각합니다. 개발 윈도우 매니저와 전체 화면 데스크탑 `쉘(shell)`을 보이지 않는 브라우저의 윈도우로 대체하고, 가상 프레임 버퍼(Virtual frame buffers)와 GL 컨텍스트를 레거시 응용 프로그램과 게임에 제공하는 것입니다. 이게 오버헤드처럼 들릴 수도 있겠지만 실제로는 생각보다 더 적은 비용으로 끝나게 됩니다: 당신의 새로운 브라우저는 <iframe>이라고 볼 수 있습니다. 따라서 모든 것이 일렉트론 앱이라고 칭할 수도 있습니다. (실제로, 일렉트론 쉘은 그 자체로 그런 프로젝트의 좋은 출발점이라고 볼 수 있습니다.) 더 이상 각 응용 프로그램마다 별도의 랜더링 툴킷을 실행 시킬 필요가 없게 됩니다. 모든 것은 표준에따라 작성되고 하나의 공용 랜더러에 의해 랜더링 되며 50%의 여러분의 메모리 사용량이 그냥 사라집니다. 공통 표준은 현재 웹에서 사용되고 있는 것들처럼 될 필요조차 없습니다, 물론 웹 표준이 필요한 무수한 이유가 있고 그것이 없어져야할 이유는 극히 적다고 봅니다.
제가 제시한 새로운 세계도 결국 완벽하진 않습니다. 만약 수 많은 C++ 개발자들이 겁에 질리더라도 이해합니다. 지옥, 그것이 저를 두렵게 만듭니다(C/C++ 개발자). 하지만 1972년 핵심 소프트웨어에서 부터 겹겹이 쌓아올린 거대한 양파에서 살고 있는 우리 세계보다는 두렵지는 않습니다. 오늘날 우리가 소프트웨어 스택에 쌓아올린 각각의 연속된 껍데기들은 적색거성과 같이 부풀어 오를 것이고 조만간 초신성이 되어버릴 것입니다. 소프트웨어에서 필요한 것은 개발자가 간단한 API를 사용하여 보안이 허용하는 한 하드웨어에 가깝도록 응용 프로그램을 구성할 수 있는 시스템 수준으로1972년에 있던 것에서 그 이상 이하도 아니거나 더 적을 것입니다. 우리가 가진 문제는 실제로 하드웨어 가까이에서 실행되는 시스템이 1972년 기술로서 구축되었지만 실제로는 그 이후 제대로 다루어지지 않았습니다. 성능을 잡아먹는 추상화 계층 위에 덮히고 또 덮히고 또 덮힌 껍데기—그리고 그 결과들—오직 예측과 예방만이 가능해 왔었습니다. 그리고 이제는 고칠 수 있기를 바랍니다.
3 notes
·
View notes
Text
Stanford CS231n(1/16) - Introduction to CS231
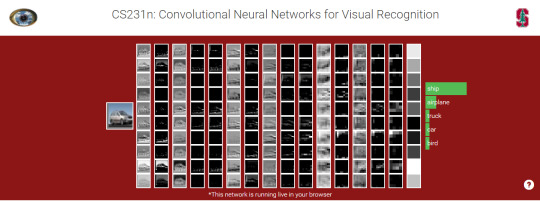
Stanford CS231n은 AI를 공부하는 연구자, 엔지니어라면 한번쯤 거쳐갈 법한 이름있는 강의입니다. 필자는 다소 늦었지만 (어쩌면 많이 늦었지만) 이 강의를 정주행하면서 여러가지 내용들을 정리하고 회고하고자 하는 목적으로 이 포스트 시리즈를 작성합니다.
Fei-Fei Li 교수 및 Justin Johnson, Serena Yeung 강사로 이루어진 CS231n 2017 Spring 강의를 16 Lectures까지 듣고 요약 하는 것이 시리즈의 대부분입니다. 그 밖에 코드를 밑단부터 직접 짜보고 내가 짠 코드의 결과와 강의의 의도가 얼마나 비슷하고 내가 잘 이해한 것인지 회고하는 등의 활동으로,
우리 블로그 “PIGNOSE Barn”(연구용 목적 블로그)에 맞게 블로그를 연재해보고자 합니다. 이 포스트에서는 간단한 시리즈 서두와 비록 첫 포스트임에도 1강에 대한 요약을 진행합니다.
포스트 시리즈를 준비하며
Stanford CS231n 포스트 시리즈는 다음을 염두하고 구성합니다.
독자는 AI 필드에 초심자로 가정합니다.
최대한 많은 링크들을 모든 단어에 하이퍼링크로 연결해둘 것입니다. 여러분은 클릭 한번으로 자세한 자료들을 볼 수 있습니다.
모든 포스트는 한글로 작성됩니다. 필요에 따라 원문을 첨부하지만 이는 번역문도 같이 첨부됩니다.
모르는 내용이 있으면 댓글로 달아주세요, 더 자세한 내용으로 업데이트 합니다.
래퍼런스
http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture1.pdf
http://cs231n.stanford.edu/
http://aikorea.org/cs231n/
https://www.youtube.com/watch?v=vT1JzLTH4G4&list=PLC1qU-LWwrF64f4QKQT-Vg5Wr4qEE1Zxk
이 시리즈에서 주로 다루는 것
인공 신경망(Neural network) 흔히 말하는 딥러닝(Deep learning)
특히 컨볼루션 뉴럴넷(CNN)
시리즈 한눈에 보기
Stanford CS231n(1/16) - 현재 보고있는 포스트
TBD
Lecture 1: Introduction to Convolutional Neural Networks for Visual Recognition
youtube
CS231n 코스가 게시될 때마다 수강생 또한 폭발적으로 늘고 있습니다. (저번에는 약 300명이었던 수강생이 이번에는 730명의 수강생으로 확인되었다고 합니다.) 적어도 CS231n은 그런 강의이고 이번 포스팅에서 다룰 Lecture들은 2017년 봄에 녹화된 내용으로 적어도 2년이라는 시간이 흘렀습니다. 다시말해 지금은 더 많은 개발자, 리서쳐, 심지어 다른 배경에 임하는 사람들도 학구열에 불타올라 더 많은 관심을 갖는 영역이 되었습니다.
오늘날에는 수 많은 시각적인 이미지 데이터들이 네트워크를 넘어 웹, 모바일에 전송되고 있고. 저스틴 존슨(Justin Johnson)이 흥미를 가지는 통계학적 예시로는 2015년 CISCO는 2017년에 네트웍의 대략 80%의 트래픽이 비디오가 될 것으로 예상하기도 했습니다. 따라서 이런 환경에서 대부분의 업계에서 이미지와 비디오등의 시작적 이미지 처리는 상당한 수준으로 요구되었지만 흥미로운점은 이런 시각적 데이터를 이해하는 것은 기존의 컴퓨터 과학에서는 그렇게 쉬운 일이 아니었습니다.
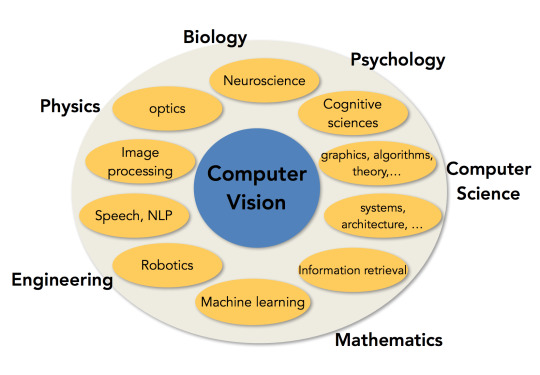
컴퓨터 비전은 학계적을 많은 부분과 엮여있는 분야입니다. 서로 다른 영역에서 서로 접근할 수 밖에 없습니다. 우리 또한 이런 상황에서 학계의 여러 분야를 접근하고 있습니다. 예를 들어 물리학은 물체와 광학, 물체의 형태등을 이해할 때 필요하고, 생물학이나 심리학의 경우 동물의 뇌를 이해하거나 동물이 어떻게 실체가 있는 물질을 보고 시각적으로 그를 이해하는지의 과정을 알기 위해 요구됩니다.
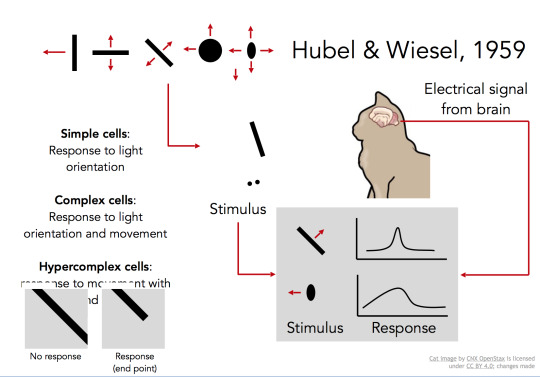
컴퓨터 비전에 어느정도 영향력이 있는 연구 중 하나인 Hubel & Wiesel, 1959의 연구에 따르면, 동물이 시각적인 정보를 어떻게 처리하는지 이해하기 위해, 전기 생리학(electrophysiology)을 사용하였습니다. 인간과 유사한 뇌의 시각 처리 메커니즘 분석을 위해 고양이의 뇌의 후방의 시각정보를 관장하는 피질에 전기신호 감지 장치를 삽입하였고, 어떤 시각적인 자극이 어떤 전기신호의 변화를 주는지를 감지하고 분석하였습니다. 그 중 가장 중요한 세포들은 어떤 방향으로 이동하는 물체의 가장자리의 패턴에 반응하는 가장 단순한 형태의 세포들이었습니다. 물론 그것보다 복잡한 세포들도 존재하겠지만, 여기서 발견한 중요한 요지는 시각 처리는 가장자리의 형태와 같은 가장 작은 구조에서 시작하고 뇌는 더 복잡한 현실의 시각 정보를 인지하기 까지 이런 간단한 정보를 복잡하게 쌓아 나간다는 것을 발견한 것입니다.

1987년 David Lowe는 면도기를 단순한 선분과 곡선으로 이루어진 정보로 부터 면도기를 구분할 수 있도록 시도했었습니다. 이런식으로 60, 70, 80년대 컴퓨터 비전에는 이런 문제들을 풀기 위한 많은 노력이 있었습니다. 그리고 솔직히 말하면 이런 물체를 인지하는 과제들은 굉장히 쉽지 않았습니다. 앞서 보여드린 이런 대담하고 야망있던 연구들은 그 연구에 비해서는 실제 우리가 사는세계에 무언가를 바꿀 수 있는 등이 아닌 몇 가지의 예시나 토이 프로젝트의 결과물만을 갖게 되었습니다.

사람들이 생각한 비전에 있는 문제들을 풀기 위해 있는 해법 중 하나로 물었던 중요한 질문은 “만약 물체 인식이 어렵다면 어쩌면 먼저 물체를 세그먼테이션 해보는 것은 어떨까?”였습니다.
��� 과제는 이미지의 픽셀에서 중요한 의미를 가지는 영역등을 그룹으로 묶어줍니다. 우리는 아마 사람이라 불리는 그룹으로 픽셀을 모두 묶을 수는 없겠지만 배경으로 부터 사람에 포함되는 모든 픽셀을 추출할 수는 있습니다.
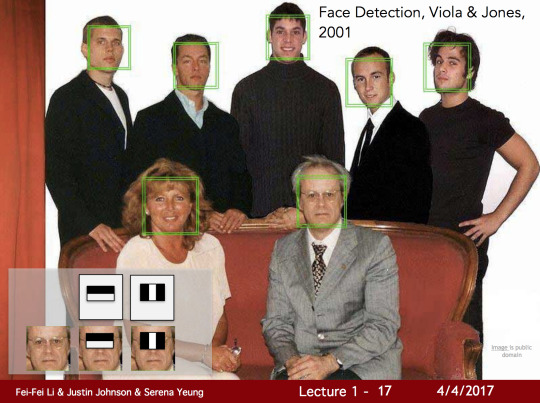
또한 “얼굴 인식(Face Detection)”이라 불리는 문제가 존재했습니다. 이 문제를 통해 앞선 많은 다른 문제들의 진보도 이루어냈습니다. 사람의 얼굴은 어쩌면 사람에게서 가장 중요한 물체일 것입니다. 1999년에서 2000으로 거슬러 올라가면 머신러닝 기술은, 특히 통계적 머신 러닝 기술은 속도가 붙기 시작합니다. Support Vector Machines, Boosting, Graphical models과 첫 신경망(Neural networks)의 물결도 포함해서 말입니다. 수많은 기여자를 만들어낸 한가지 특별한 시도는 Paul Viola가 시도했던 AdaBoost 알고리즘를 사용해 실시간 사용자의 얼굴을 인식하는 것이었습니다. 이런 작업은 2001년에 끝났으며 그 때는 굉장히 느린 컴퓨터 칩만이 존재했지만 그들은 실시간 처리 환경에서 얼굴 인식을 할 수 있었습니다. 이 논문이 나오고 5년 뒤인 2006년 후지필름은 실시간 얼굴 인식이 가능한 첫 카메라를 선보였습니다. 그렇게 기존 과학 연구는 실 세계로 너무 빠르게 전환이 되기 시작했습니다.

어떻게 물체 인식을 할 수 있는지 조금 더 따라가 보자면, 90년대에서 부터 2000년대 첫 10년간은 Feature based 물체 인식이 그 당시 가장 영향력 있는 방향이었습니다. 위 그림에서 SIFT라고도 불리는 David Lowe가 진행했던 과제를 살펴봅시다. Feature based 물체 인식의 아이디어는 간단하게도 이미지에서 보이는 모든 물체를 비교하고 매치하는 것입니다. 위 두개의 정지 표지판을 비교한다고 가정할 때 이미지 처리에서는 이 문제가 너무도 어렵다는게 느껴집니다. 아마도 카메라 각도, 물체의 가림 여부, 바라보는 방향이나, 광원등에 의한 문제일 듯 합니다. 하지만 관찰해보면 어떤 특징(Feature)들은 계속 진단을 유지할 수 있고 변화에도 불변성을 띄므로, 물체 인식은 이런 물체위의 주요 특징들을 판별하고 유사한 물체에서 이런 특징등을 찾는 테스크로 넘어가게 됩니다. 이런 작업은 모든 물체의 패턴을 매칭하는 것보다는 훨씬 문제를 쉽게 만들어줍니다.
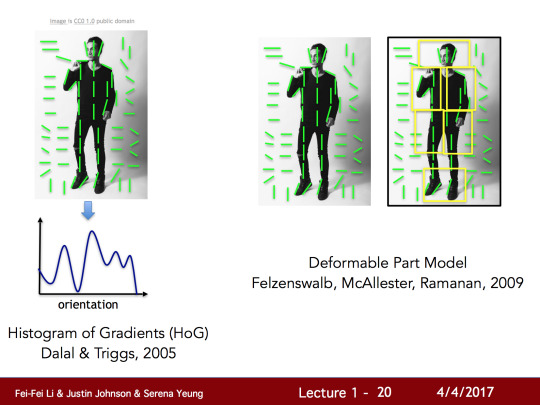
앞서 말한 시도들은 사람을 인식하는 곳에서도 사용되기 시작했습니다. 어떻게 사람의 신체가 사실처럼 구성되고 그걸 판별할 수 있는지에 대한 작업들 수행되었고, 이런 작업 중에 일부는 소위 “Histogram of gradients”로 불리고 있고 다른 작업은 “Deformable part models”라고 불리고 있습니다.

60년, 70년, 80년대 부터 2000년 초의 10년간의 변화를 보면 크게 변한 한가지가 있는데 그건 바로 사진의 품질의 변화입니다. 인터넷과 디지털 카메라의 개선과 성장이 더 나은 데이터를 제공하고 컴퓨터 비전 학습으로 사용되어 왔습니다. 이런 변화로 인해 컴퓨터 비전 분야에서는 매우 중요한 근본 문제해결을 의해 거론하기 시작했습니다. 인식에서 풀어야 하는 가장 중요한 문제는 바로 물체 인식입니다. 2000년대 초기에 우리는 물체 인식의 현황을 측정할 수 있는 벤치마크 데이터셋을 만들기 시작했습니다. 그 중 가장 영향력 있는 벤치마크 데이터 셋 중 하나인 PASCAL Visual Object Challenge는 20 물체 클래스를 구성하고 있습니다. 그 중 3가지는 위 이미지에서도 보여지고 있습니다. (Train, Airplane, Person)
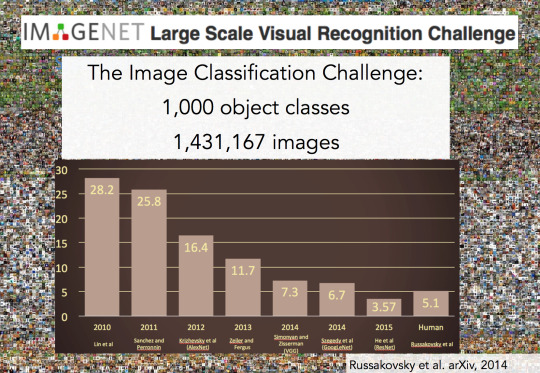
더 나아가 위 이미지에 나타난 세계에서 가장 큰 Visual Regnition Challenge 중 하나인 IMAGENET의 매년 이미지 인식의 에러율을 보면 보면 다행이도 에러율이 착실하게 내려가고 있는 것을 볼 수 있습니다. 여기에서 유심히 봐야할 부분은 2012년 입니다. 2010년과 2011년의 에러율에는 그렇게 큰 변화가 없었지만 2012년을 보면 약 9%의 의미있는 에러율의 가감을 보여주고 있습니다. 이 기간에 수상했던 알고리즘은 컨볼루션 신경망 모델(Convoultional Neural network model)이었습니다.

CS231n에서는 시각적 인식(Visual recognition)과 이미지 분류(Image classification)의 주요 문제들에 대해 다룹니다. 또한 물체 인식(Object detection), godehd qnsfb(Action classification), 이미지 명명법(Image captioning)과 같은 이미지 분류로 부터 오는 세부 문제에 대해서도 다루게 될 것입니다.
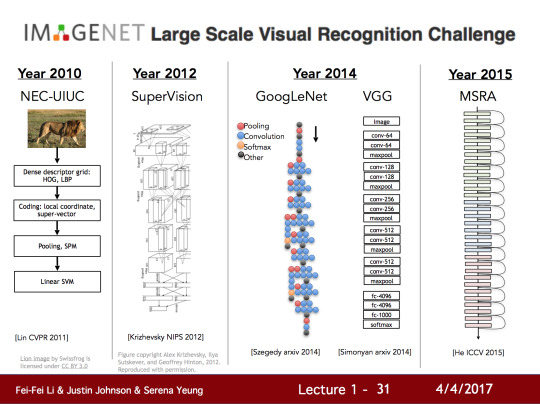
IMAGENET에서 우승했던 몇년간의 알고리즘들을 보면, 2010년 (강의에서는 2011년으로 표시됩니다.)에 Lin et al이 사용했던 방식을 볼 수 있습니다. 여전히 계층적인 구성을 가지고 있으며 다량의 레이어로 이루어져 있습니다. 여기서 알 수 있는 것은 이 방식은 여전히 계층적이고 가장자리 검출이 필요하며 이미지의 불변 영역의 개념을 가지고 있습니다.
하지만 2012년 토론토의 Jeff Hinton’s 그룹에서는 Alex Krizhevsky와 Ilya Sutskever는 함께 이런 상식들을 바꾸는 시도가 있었습니다. 7개로 구성 된 이 컨볼루션 신경망은 지금은 AlexNet으로 알려졌지만 당시에는 Supervision으로 불려졌습니다. 그 뒤로 매년 우승은 신경망으로 이루어져 있습니다. 그리고 트랜드는 이런 신경망의 구성을 더 깊게 만드는 것으로 변했습니다. 말했듯이 여러분이 세는 방식에 따라 다를 순 있지만 7-8개의 레이어로 구성된 AlexNet과는 다르게 2014년 (강의에서는 2015년으로 설명 함)에서 나온 구글의 GoogLeNet과 옥스포드의 VGG Net을 볼 때, 그때의 VGG는 19개의 레이어로 구성되어 있었습니다.
2015년에는 더 미쳐가기 시작합니다. 마이크로소프트의 Residual Network의 경우 152개의 레이어를 구성하고 있었죠.
여기서 알 수 있는 것은 CNN(컨볼루션 신경망)은 정말 2012년 당시 새로운 방식의 도약이었고, 많은 최적화와 튜닝 방식들에 대한 개선 노력도 있어 왔습니다. 그리고 마지막에 와서는 우리는 정말 깊이있게 딥러닝에 들어와 정확히 어떻게 모델들이 다르게 동작하는지에 대해서 이해할 수 있을 것입니다.
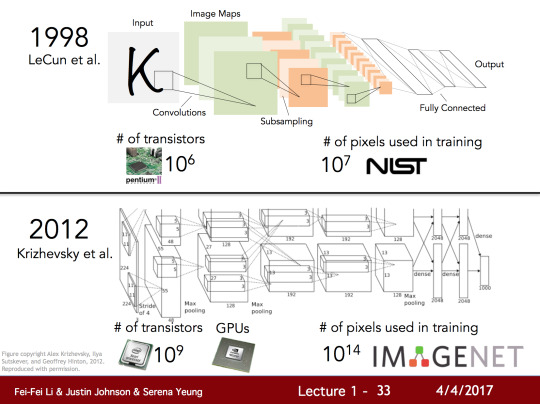
CNN에서 가장 기반이 되었던 작업 중의 하나였던 건, 사실은 90년대의 당시 Bell Labs에 있었던 Jan LeCun과 그의 공동 연구자들이었습니다. 1998년 해당 연구자들은 숫자를 구분하기 위한 CNN을 만들 어 낼 수 있었고, 이것을 배포하여 손글씨로 쓰여진 수표나 우체국을 위한 주소를 감지할 수 있기를 원했었습니다. 이 CNN 모델은 이미지로 부터 가져온 픽셀 데이터를 바탕으로 분류를 하여 어떤 것이 어떤 숫자로 되어 있는지, 혹은 문자로 되어 있는지 아니면 그 어떤 것도 아닌지를 분류할 수 있도록 하였습니다. 이 모델을 자세히 들여다보면 사실 AlexNet과 상당히 유사한 것을 볼 수 있습니다.
어떤 분들은 90년 대부터 있어왔던 알고리즘이 왜 갑자기 최근에 유명해지고 사용되기 시작했는지 궁금할 수도 있습니다.
첫번째로는 처리 능력으로 인해서입니다. 무어의 법칙 덕분에 오늘날의 컴퓨터 계산 성능은 굉장히 향상되었습니다. 또한 오늘날에 우리는 GPU의 출현을 맞이하게 되었습니다. GPU는 병렬 처리 연산을 놀라우리 만큼 훌륭하게 처리할 수 있는 완벽한 도구입니다. 이런 처리 능력의 개선들이 연구자로 하여금 더 거대한 아키텍처 구성을 할 수 있도록 길을 열어주었습니다.
두번째 핵심으로는 데이터가 있습니다. 이런 모델들은 데이터에 굉장한 갈증이 있고 그 때문에 우리는 수 많은 라벨링된 이미지를 준비해야 합니다. 당시 90년대에는 충분한 데이터가 없었고 아마존 Turk같은 도구도 없었고 인터넷도 지금 처럼 정말 대중적으로 사용되지 않았습니다. 때문에 다양하고 많은 양의 데이터를 구하는게 쉽지 않았습니다. 하지만 오늘날에는 PASCAL, ImageNet과 같은 비교적 큰 데이터셋이 있습니다.
0 notes
Text
데이터(Data)와 분석(Analysis)에는 어떤 일이 벌어지고 있느뇨?
오랜만에 블로그 포스팅을 하는 것 같습니다. 오래전에 쓴 영양가 없는 글들도 많이 정리해서 이번에 새로운 컨텐츠 들을 많이 채워보겠습니다.
이번 블로그 주제는 데이터(Data)와 분석(Analysis)인데요 많은 분들이 관심가지고 있고 또 앞으로도 한동안은 이 스코프에 있는 산업군은 근심걱정이 없기도 해서 많은 주니어분들과 타 직종에 계신분들이 자주 관심가지고 보실 것 같습니다.

들어가기 앞서
이 글에서는 빅데이터에 대해서 거론하지 않습니다.
이 글에서는 데이터 사이언스 기술에 대해서 거론하지 않습니다.
이 글의 작성자는 전문가가 아닙니다.
들어가며
서비스 개발에 종사하시는 많은 부류의 개발자 분들은 대부분 데이터베이스(Database)라는 것을 들어보셨을 겁니다. 보통 서비스에 있는 동적 데이터와 사용자의 상태를 세션(Session)으로 관리하되 이를 스토어(Store)로 연결하고자 데이터베이스를 서비스와 연결하여 사용하는 것이 일반적이지요.
여러분이 많이 들어보신 MySQL, MSSQL, Oracle, DB2, CosmosDB, PostgreSQL, MariaDB 등이 이러한 관계형 데이터베이스(RDBMS)가 되겠습니다.

<그림 1.1 여러분이 사랑해주시는 우리의 MySQL 찡...>
참고로 여기서 MySQL을 “마이에스큐엘” 이라고 발음하시는 분들이 많으신데요 현업에서는 “마이시퀄"이라고 부르는 경우가 많습니다. PostgreSQL 또한 “포스트그레스큐엘”이 아닌 “포스트그레스퀄"이라고 부르는 경우가 많습니다.
보통 우리는 서비스단에 이러한 RDBMS를 연결할 때, RDBMS가 있는 부분을 지속 레이어 혹은 퍼시스턴스 레이어(Persistence Layer)라 부릅니다.

<그림 1.2 서비스에서 ���분되는 계층들>
물론 서비스 단에서 DB를 사용할 때는 데이터 무결성(데이터과 일관적이고 정확함을 보증)해야 하고 또 만약 데이터 처리에 문제가 생겨도 이를 대처할 수 있어야합니다. (*폴트톨러런스) 위의 것들을 지원하기 위한 목적을 가진 데이터베이스를 일반적으로 우리는 OLTP (Online transaction processing) 라고 부릅니다.
위 설명이 다소 복잡할 수 있어서 아래에서는 사례를 하나 들어드려 보겠습니다. 여러분이 만약 여행사 API를 이용하여 사용자가 돈을 결제하면 여행사 등록을 하는 시스템을 만들어보겠습니다. 서비스 프로세스에서 처리할 것은 아래와 같습니다.
사용자가 특정 여행사에 신청을 넣고 크레딧을 사용
서버에서 여행사 API에 접근하여 정원 초과여부, 사용자 등록정보를 바탕으로 유효성 체크등을 거쳐 올바를 경우 다음 단계 진행
사용자의 크레딧 DB에 요금이 있는지 확인
사용자의 크레딧 DB에서 크레딧을 차감 (DB 작업)
여행사 API에 접근하여 예약 처리
예약이 성공적으로 성사 됨을 사용자에게 알림
위 시나리오대로 구현 하면 일반적인 경우에는 서버의 장애는 발견되지 않는다고 생각할 수 있을 텐데 여기에는 심각한 문제들이 여럿 있습니다. 아래는 여기서 발생할 수 있는 장애 시나리오를 간단하게 나열해봤습니다.
여행사 API에서 에러를 보내는 경우 (a. 여행사 서버 문제, b. 유효성 검증 이후 잠깐의 처리시간동안 다른 사용자가 예약을 진행한 경우 등)
사용자가 동시적인 예약처리로 인해 크레딧 체크 이후 크레딧이 줄었을 경우
서버의 장애로 인해 예약처리를 수행하지 못했을 경우 (서버의 재배포, 서버의 다운 등)
세상은 항상 논리적이고 완벽하지 않기 때문에 우리는 이런 의도치 않은 사항을 예방해야 합니다. 다행스럽게도 우리에게는 트랜잭션(Transaction)이 있기에 위의 문제를 아름답게 해결 할 수 있습니다.

<그림 1.3 트랜잭션의 방식에 대한 그림>
트랜잭션의 원리는 비교적 간단합니다.
트랜잭션 컨텍스트를 정의하고 (Begin transaction 혹은 savepoint) 그 컨텍스트 안에 있는 처리들을 마지막에 반영(Commit)하거나 취소(Rollback) 하실 수 있습니다. Auto Commit이 설정되있지 않으면 서버에서 피치 못하게 처리 응답을 못할 경우 데드맨스위치와 유사하게 자동으로 취소(Rollback)합니다.
우리는 아까의 시나리오를 트랜잭션을 이용하여 아래처럼 처리 할 수 있습니다.
사용자가 특정 여행사에 신청을 넣고 크레딧을 사용
서버에서 여행사 API에 접근하여 정원 초과여부, 사용자 등록정보를 바탕으로 유효성 체크등을 거쳐 올바를 경우 다음 단계 진행
트랜잭션 시작
사용자의 크레딧 DB에 요금이 있는지 확인
사용자의 크레딧 DB에서 크레딧을 차감 (DB 작업)
여행사 API에 접근하여 예약 처리
만약 이 과정중 어떤 에러라도 있다면 트랜잭션 취소(Rollback)
트랜잭션 종료 및 반영(Commit)
예약이 성공적으로 성사 됨을 사용자에게 알림
물론 위의 시나리오에서도 사용자가 동시적으로 크레딧을 결제할 경우는 막을 수 없습니다.
이를테면 동시간대에 2개 이상의 트랜잭션이 동시에 작동하여, 5만원의 크레딧 중 한곳은 5만원을 사용하고 또 한곳은 3만원을 사용하여 둘중 하나는 취소되어야 함에도 불구하고 두 처리 모두 조회단계에서 5만원이 조회되고 처리 단계는 그 이후 수행되기에 총 8만원이 소진되는 현상 (이때도 둘 중 어떤 트랜잭션이 먼저 실행되었냐에 따라 잔금이 2만원이 남아버리기도 하는 엄청난 사태)
이를 완벽하게 처리하고자 한다면 비관적 동시성 제어 처리를 위해 읽기 락을 걸거나 다중 체크를 통해 결제를 보장해야 합니다. 일단 이 설명은 모두와 나를 위해 생략합니다!
우리는 한때 RDBMS와 트랜잭션만을 이용해서도 서비스 제공하기에는 큰 지장이 없었습니다. (물론 확장성과 가용성은 여기서 빼도록 합시다!)
여기까지 읽으셨다면 아래 문서도 같이 살펴보세요
관계 - 데이터베이스 (위키피디아)
DBMS는 어떻게 트랜잭션을 관리할까? (Naver D2)
OLTP와 OLAP (devkingsejong's dev life)
클라우드 환경에서 새로운 ACID, BASE 그리고 CAP (미물의 개발 세상)
커넥션 풀 (Connection Pool)
커넥션 풀 (Connection Pool - DBCP) 없이는 당장에는 서비스 테스트에 큰 문제가 없겠지만 서비스를 런칭하고 유저가 다수 붙으면 차차 문제가 발생하기 시작합니다.
데이터베이스를 모니터링 해보면 Current 커넥션은 요동치기 시작하며 데이터베이스는 불필요한 CPU Latency를 가지게 됩니다. 여러분의 서비스는 홈페이지 처음 입장 시 DB에서 사용자 세션 정보를 가지고오고 (이를테면 메모리 스토리지에서), 추가적으로 메인 페이지의 최신뉴스를 DB에서 가져온다고 치자면 여러분은 DB에 2개의 쿼리 요청(트랜잭션)을 시도하게 됩니다.
유저의 세션 정보 조회 쿼리
최신 뉴스를 가져오는 쿼리
보통 유저의 세션 정보를 가져오는 처리와 최신 뉴스를 가져오는 처리는 기능상으로 분리되기 때문에 서로 다른 DB 커넥션이 발생하게 되는데 이를 그림으로 표현하면 아래와 같습니다.

<그림 2.1 유저 별 트랜잭션 별 쿼리 생성>
문제는 각 요청 별로 DB에 커넥션을 새로 얻어와서 (그림상의 빨간부분) 쿼리를 진행하는데 커넥션을 얻어오는 과정이 오래걸리기 때문에 사용자는 그동안 대기하게 되며 또 이러한 처리는 DB 서버에 있어서도 어느정도 CPU 연산이 필요하기에 전체적으로 비효율적으로 작업이 돌아가게 됩니다.

<그림 2.2 커넥션 풀의 관리>
위의 그림처럼 커넥션 풀을 이용할 경우 서버가 초기에 커넥션을 커넥션 풀에 설정된 용량 (Max connection)만큼 연결해놓고 사용자가 실제로 트랜잭션을 진행 할 때는 이렇게 미리 연결된 커넥션을 잠시 빌려 사용하고 돌려주는(Release) 하는 방식으로 돌아가기 때문에 실제로 DB에는 커넥션이 안정적으로 유지되고 또 CPU 부하가 줄어들게 됩니다.
커넥션 풀에 대한 정보를 모아봤습니다!
DB Connection Pool에 대한 이야기 (안녕 프로그래밍)
Commons DBCP 이해하기 (Naver D2)
확장성 그리고 고 가용성
여러분이 신입에서 조금씩 걸어 올라오다 보면 서비스를 준비하는 단계에서 무결성(일관성과 정확성, 원자성 등) 다음으로 확장성과 가용성이 굉장히 중요한 요소인 것을 점차 느끼게 되는데 둘에 대한 간략한 설명은 아래와 같습니다.
확장성(Scalability): 사용자가 많아지고(커넥션, 트랜잭션 증가) 처리해야 할 데이터의 양이 많아 지면서(인덱스 증가, 카디널리티 증가, 스캔용량 증가) 물리적인 서버의 성능을 향상 스킬 수 있는 능력이나 방법.
가용성(Availability): 주어진 환경에서 어떠한 문제(서비스의 장애) 없이 유지시킬 수 있는가에 대한 정도. (i.e 가동률)
만약 여러분이 서비스를 잘 만들고 라이브 서비스로 오픈 했는데 하루만에 DB 서버가 뻗고 (일반적인 장애 혹은 스팩 자체의 문제) 이를 복구하는데도 수시간이 걸린다면 가용성이 심각한 문제가 있는 것이게 됩니다. 또한 서비스의 성능이 느려 이를 개선하는데에 있어 시간적 비용이나 공간적 비용(서버공간 추가, 서버 이전), 인적비용(마이그레이션 담당자 투입, DBA 투입, 서버엔지니어 투입)이 발생한다면 확장성이 낮은 것이지요.
DBMS 종류마다 이러한 가용성, 확장성을 SW 레벨에서 지원하기 위한 기능도 있으며 이런 차이 때문에 많은 데이터 관련 엔지니어나 종사자들이 많은 공부를 하고 있습니다.
확장성을 깊게 들여다보며

<그림 3.1 확장성에 대한 간단한 그림 (scale-out 측면)>
아까는 확장성에 대해 간단하게만 서술 했는데 이번에는 조금 더 깊이있게 얘기해 보겠습니다. 데이터베이스 서버가 느려 이를 확장하는 경우 간단하게 두개로 나뉘게 됩니다.
SW 레벨에서의 확장 (논리적인 확장)
HW 레벨에서의 확장 (물리적인 확장)
당연하게도 HW쪽이 비용과 시간은 더 많이 소모되겠죠.
SW 레벨에서의 확장을 하는 케이스 사실 확장이라 칭하기보다 최적화가 더 맞는 말일 듯 합니다. 보통 로그테이블이 많이 쌓여서 로우가 추가될 때마다 인덱싱도 느리고 또 서치를 해도 불필요하게 스캔 코스트가 많이 들기 때문에 테이블 파티셔닝을 하게 됩니다.
HW 레벨에서의 확장은 경우의 수가 많습니다만 크게 아래와 같이 또 한번 분류 할 수 있습니다.
수직 확장의 측면(Scale-up)
수평 확장의 측면(Scale-out)

<그림 3.2 수직확장(scale-up)과 수평확장(scale-out)에 대한 설명>
수직 확장은 쉽게 얘기하여 서버 자체의 성능을 늘리거나 처리 방식을 개선하여 알고리즘을 효율적으로 돌아가게 하는 등으로 개선이 필요한 인스턴스 자체를 조정하는 것이라 보면 됩니다.
수평 확장은 그와 다르게 서버의 수를 늘려 분산을 하거나 스캔 대상의 파일을 쪼개어 분산하거나 혹은 연산 프로세싱 만을 분산하는 등 하나의 커다란 문제를 쪼개어 해결하는 것으로 초점이 맞춰져 있습니다.
수직 확장의 경우에는 보통 서버의 스팩을 올리거나, 랜 공사를 해서 데이터 서버가 사용하는 랜 성능을 키운다거나 디스크를 증설하여 저장공간을 키우는 형태로 보통 서버가 정지됩니다.
수평 확장은 클러스터를 구성하여 서버 노드를 늘리거나, 디스크 노드를 늘리거나 마이크로 서버를 띄워 프로세싱을 맡기는 등의 처리를 통하여 성능을 늘리며 보통 이런 처리가 무정지로 이루어지거나 Write Lock만을 통하여 진행합니다.
확장성의 경우 이렇다 저렇다 얘기가 많지만 주관적으로 수평확장이 수직확장에 비해 안전하고 요금 측면에서 효율적이며 각종 위험에 대하여 안전합니다. (Fail-over, Multi region)
수평 확장을 통하여 데이터를 분산 할 경우 샤딩(Sharding 혹은 Horizontal Partitioning)을 하게 되는데 이를 통해 데이터의 저장소를 분배하고 실제로 데이터를 수집하고 집계 할 때, 리더 역할을 하는 컴퓨터에 조회 요청을 보내고 리더 컴퓨터에서 분산된(샤딩된) 데이터를 각각의 목적 노드에서 추출하고 집계하여 반환하게 됩니다. 물론 이런 리더-컴퓨터 구성처럼 미들티어(Middle-tier) 형태로 작동하는 것도 있지만 Hibernate Shards와 같이 어플리케이션 레벨에서 동작하는 경우도 있으며 이마저도 아닌 데이터베이스 자체에서 지원하는 케이스도 있습니다.

<그림 3.3 파티셔닝에 대한 간단한 설명 그림>
가용성을 깊게 살펴보며
이번에는 아까 말씀드린 가용성을 깊게 살펴봅시다.
가용성은 다시말해 “서버가 얼마나 안정적으로 오랫동안 운영되고 있나"를 알려주는 성질입니다. 서버가 정지되는 시간(다운타임)을 최소화 하는 것이 궁극적으로 고 가용성을 제공하는 방법입니다.
수직 확장의 경우에는 이런 처리가 다소 난해한 요소로 자리 잡고 있습니다. 서버 자체가 문제가 발생 할 때 이를 대체 해 줄 수 있는 서버가 존재하지 않으면 마땅한 방법이 없기 때문인데 이 때문에 별도의 모니터링이나 대리자(Proxy)를 두게 됩니다.
수직 확장의 경우에도 데이터 디스크와 데이터서버를 분리하고 데이터서버 앞에 로드밸런서를 붙여 상태검사(Health Check)이후 문제가 발생하면 후차 데이터베이스 (Secondary or Slave or Stand by)를 활성화(Idle, Promote to master)하여 자동으로 정상화 합니다. 이렇다 하더라도 데이터센터가 지역적으로 한곳에 있다면 천재지변이 발생할 경우 서비스는 다운됩니다.
후후.. 이제 조금만 더 읽으면 끝납니다! 복습 차원에서 아래 관령 링크를 살펴보세요!
분산 데이터베이스와 성능 (DBGuide)
NHN의 안과 밖: Sharding Platform (Naver D2)
DFS: Not a Distributed Database
어떤 분산 파일 시스템을 사용해야 하는가? (Naver D2)
클러스터와 리플리케이션의 차이가 뭔가요?

<그림 4.1 slave 관점에서의 failover 예시>
Fail-over 전략에 대해서도 워낙 다양하기에 여기서 모든 것을 설명 드릴 수는 없고, 기회가 되면 추가 포스팅을 하고 링크를 이곳에 연결해드리겠습니다.
조금 특이한 fail-over 전략으로는 데드맨 스위치(Deadman switch)가 있습니다. 전략이라기 보다는 일반적인 fail-over가 이에 근거하여 돌아간다라고 설명드릴 수 있을 것 같은데요 DB 앞에 Load Balencer가 붙어 이상점을 감지하여 레플리카를 대체하건 M-M 구성에서 Master의 이상점을 감지하여 승격과정을 거치건 둘 이상의 노드간에 약속된 패킷과 발송 시간을 정하여 그것이 도착하지 않으면 이상으로 감지하여 데드맨 스위치가 켜지는 방식입니다.
퍼포먼스
서비스의 안정성이 가장 중요하지만 두번째로 중요한 것은 성능입니다. 사용자는 점점 즉각적이고 신속한 응답을 바라고 있고 우리는 더 많은 양의 정보를 바탕으로 질 높은 정보 얻어 다른 업체와 경쟁해야 합니다.

퍼포먼스(Performance)를 향상시키는 전략도 여러가지가 있습니다.
일반적으로는 Explain과 slow query 로그 분석을 통해 쿼리 플랜을 최적화 하는 것이 있으며 이는 많은 비용이 들지도 않습니다. 물론 이것도 방법론이 많습니다. (커버링 인덱스를 사용하거나 컬럼 자체의 인덱스를 관리하는 관점, recency score를 두거나 등)
두번째는 튜닝(Tuning)이 있습니다. 너무 당연하겠지만 제일 효율적인 성능을 위해서는 서비스에 특성이 맞게 DB가 세팅되고 돌아가야 합니다. 서비스에 맞게 스토리지 엔진 타입을 바꾸거나 인덱스를 새롭게 설정하거나 인덱스 알고리즘을 바꾸거나, 압축 방식을 바꾸거나 버퍼 캐시를 수정하는 등의 방법이 있습니다.
세번째는 서비스 분산 아키텍처를 설계하실 수도 있습니다. 여기서 부터는 비용이 눈에띄게 발생하게 됩니다. 서비스의 특성에 따라 정형화된 데이터를 하나의 데이터소스에서 관리하고 싶다면 DW(Data warehouse)를, 비정형화 정형화 관계없이 여러 방식으로 데이터 플로우를 구축해야 한다면 하둡 레이어를, 비정형화 데이터를 관계처리 없이 사용하고자 한다면 MongoDB를, 수많은 데이터를 K-V(Key-Value) 형태로 확장성있게 분산기반 위에서 가져오고 싶다면 카산드라를 고려하실 수도 있습니다. 이러한 선택의 경우에는 각 요구사항에 여러 제품군이 있으며 각각의 대조군을 각 플랜에 맞게 테스트 하신 후 사용하시는 것을 권장합니다.
네번째는 서비스에 맞게끔 추가 서비스를 붙여 데이터 처리 플로우를 개선하는 방법이 있습니다. 여기서 부터는 하나의 데이터베이스 서비스가 아닌 다양한 서비스를 연구하고 조합해야 합니다. 예를들어 성능이 피크타임에 치솟고(보통 스파이크 친다고 합니다.) 데이터 삽입이 많이 발생하지만 관계형 쿼리를 많이 사용하지 않는 서비스에서는 (채팅 서비스: 챗봇, 메시지등의 대화형 서비스)에서는 nosql이나 앞단에 queue를 붙인 서비스를 고려하실 수 있습니다. 읽기 빈번하고 수정이 간간히 발생한다면 Redis나 Memcached 캐시 레이어를 앞단에 붙이는 구성을 고려 해 보실 수도 있습니다. 서비스 작업에 즉시성이 요구되지 않는다면 MapReduce를 통한 배치 방식을 고려하실 수도 있습니다.
NoSQL, DW, RealtimeDB, Serverless QueryEngine, Graph Database?!!!!?!

* 경고
모든 자료가 그렇듯이 모든 데이터베이스 엔진 혹은 쿼리 엔진의 장단점을 딥 다이브하여 검증하지 못하기 때문에 이 포스트를 통해 “우리 서비스는 ~~에 맞겠다" 라는 평가자료로 쓰일 수 없습니다. HDD를 주의 해주세요.
필자도 이런 부분에 전문가가 아니고 모든 레이어를 다 사용할 정도로 프로젝트의 규모가 거대하지도 않기 때문에 사실상 프로덕션에 적용해보지 않고 내리는 막연한 평가에 불가합니다.
1. NoSQL (Not only SQL)
전통적인 RDBMS 서비스를 이용하면서 생긴 불편사항들 (복잡한 관계 구조로 인해 생긴 제약들 - 분산, 열 용량 제약, 테이블 용량제약, 확장제약, 스키마로 인한 데이터 형식제약 등)을 벗어나고자 관계에 얼메여 있지 않은, 그리고 SQL외에 다른 표현식을 지원하는 새로운 데이터베이스가 나오게 되었는데 이를 NoSQL (Not only SQL)이라 부릅니다.
NoSQL 데이터베이스는 여러 종류가 있는데 일반적으로 RDBMS 처럼 기본 구조는 같은데 세부적으로 각각의 기능이 차이가 나는 것이 아니라 정말 핵심 기술부터 그 기능이 다른 종류들이 많습니다.
일반적으로 알려진 데이터베이스로는 MongoDB, Cassandra, HBase, Redis 등이 있으며 클라우드 환경에서는 AWS DynamoDB, Google Cloud BigTable 등이 있고 IBM도 DB2에서 NoSQL을 부분적으로 지원한다고 하는데 제가 사용안해봐서 잘 모르겠습니다.
NoSQL은 ACID를 지원하기 어렵습니다. 따라서 이를 완전히 지원해야하는 서비스에 적용하기 어렵습니다. CAP 이론으로 볼 때 보통 확정성(Scalability)을 위해 일관성(Consistency)을 보장하지 않습니다.
요새의 NoSQL에서는 GraphQL 지원을 하나 둘 하기 시작하여 이를 사용하기를 고려하는 업체에서는 테스트를 진행해보는 것이 좋을 것 같습니다.
각각의 NoSQL별 차이점이 존재하는데 간략히 작성하면 아래와 같습니다.
MongoDB
라이센스: GNU AGPL v3.0 (Free, and Commercial), Open source
업체: MongoDB Inc
리플리케이션: 지원 (M-S)
샤딩: 지원 (해시기반)
주관적 내용: 몽고 디비는 AGPL 라이센스를 가지고 있는데 (물론 커머셜 라이센스도 있습니다.) AGPL 라이센스는 상업적으로 사용이 가능하지만.. 모든 소스코드를 공개해야 하는 의무가 있습니다. (GPL의 경우 서버 통신을 하는 경우 회피 할 수 있는데, AGPL은 얄짤없이 공개해야 합니다.) 이는 사업에 있어 많이 고민해야 할 항목입니다. 그 밖에 기술적으로는 몽고 디비 파일이 깨지는 이슈라던가 복잡한 조인 구현 코드가 거의 살인급 코드라 그런 부분만 감당이 가능하면 사용하는 데 큰 지장은 없다고 봅니다. (겁나 겁주고 사용해도 좋다로 끝내는 훈훈함)
Cassandra
라이센스: Apache License 2.0 (Free), Open source
업체: Apache Software Foundation
리플리케이션: 지원 (replication_factor)
샤딩: 지원 (해시기반)
주관적 내용: 카산드라는 분산을 지정하는 옵션이 비교적 간단하고 이를 설정해 놓기만 해도 고가용성 분산 서비스로 동작되어 상당히 편리하긴 하지만 트랜잭션도 미지원, Secondary Index는 Range쿼리를 미지원 추가 Index 미지원 등등의 Trade Off 해야할 사항이 있으니 도입 시 충분히 검토해야 합니다.
HBase
라이센스: Apache License 2.0 (Free), Open source
업체: Apache Software Foundation
리플리케이션: 지원
샤딩: 지원
주관적 내용: 하둡 스택을 사용하는 업체라면 안쓸 이유가 더 없을 정도로 워낙 범용적으로 사용 되는 엔진입니다. HBase를 사용하는 이유야 뭐 하둡 분산파일시���템(HDFS) 위에 존재하는 거대한 데이터에서 빠르게 원하는 데이터를 뽑아낼 때 이기 때문에 특징이 뚜렷하다고 볼 수 있습니다. 당연하겠지만 HBase를 사용하기 위해서는 기본적인 하둡스택의 이해는 필요하기 때문에 진입장벽은 상대적으로 높습니다. 신기한 것은 HBase에서는 TTL을 지원하기 때문에 데이터의 만료시간을 관리할 수 있습니다. 마지막으로 HBase는 secondary index를 지원하지 않습니다. 따라서 일반적으로 RDBMS에서 사용하는 복잡한 관계 쿼리를 구현하실 수 없습니다.
Redis
라이센스: BSD 3-Clause (Free and Commercial), Open source
업체: Salvatore Sanfilippo
리플리케이션: 지원 (M-S)
샤딩: 미지원 (어플리케이션 레벨에서 Hash를 통해 지원해야 함)
주관적 내용: Redis는 인메모리 캐시 DB이기 때문에 역할군이 뚜렷합니다. 우선 안타까운 점은 Redis는 싱글 쓰레드 기반으로 설계되어 있습니다. 따라서 Redis 명령 중 일부는 블러킹을 걸도록 동작하기 때문에 프로덕션 레벨에서 운영할 때 치명적일 수 있습니다. Redis도 클러스터를 통한 분산과 센티넬을 통한 Fail-over를 제공하고 있으며 K-V, Hash, List, Set 등의 자료구조를 가지고 있습니다. RDB랑 AOF라는 연동 방식을 가지고 있는데 둘 모두 많은 수의 데이터를 관리하고 있다면 레디스 재시작에 많은 시간이 소요 될 수 있습니다. (저장의 경우 childProcess를 fork하여 진행합니다. // AOF는 rewrite의 경우에만 이렇게 동작합니다.) 같은 캐시 DB 레벨에 있는 Memcached랑 비교해보면 대부분의 응답속도와 성능의 경우 크게 차이는 없습니다. Redis는 replication에 에러에 대해서 처리 에러를 핸들링 할 수 있으며 동시에 여러 리플리케이션 구현이 가능합니다. 또한 아까 말씀드렸듯 Redis는 Memcached와 비교하였을 때 많은 데이터 타입을 제공하고 있는 장점을 가지고 있습니다. 다만 Flush 호출시 Memcached 동작방식과 전혀 다르기 때문에 블럭킹이 걸려 때문에 많은 양의 데이터를 Flush 할 경우 서비스 자체 동작에 문제가 발생할 수 있습니다. 그 밖에도 Redis는 Memcached에 비해 기존 저장된 데이터 유지를 위한 기능이 많습니다.
Memcached
라이센스: BSD 3-Clause (Free), Open source
업체: Danga_Interactive
리플리케이션: 지원 (repcached)
샤딩: 미지원 (어플리케이션 레벨에서 Hash를 통해 지원해야 함)
주관적 내용: Memcached는 Redis와 마찬가지로 인메모리 캐시 DB 영역에서 존재하고 있습니다. Redis와는 다르게 메모리 본연의 목적에 맞는 간단한 K-V 형태입니다. Redis와 비교 할 경우 크게 Flush all의 동작방식이 다르며 Memcached에서 훨씬 빠르게 동작합니다. (Memcached에서는 실제로 데이터 Flush를 일으키지 않고 timestamp를 기록하고 있다가 나중에 GET 되었을 때 이를 비교하여 삭제합니다.) 따라서 이러한 차이점이 오히려 동작처리에 있어 의도치 않을 실행을 하는 경우도 있습니다. Memcached에서는 flush all에 expired time을 옵션으로 줄 수 있는데 사전에 flush all로 삭제했다 하더라도 이후 flush all [exptime] 옵션을 통해 아직까지 삭제되지 않은 데이터를 재생 시킬 수 있습니다. (물론 exptime에 의해 언젠가는 삭제됩니다.)
DynamoDB
라이센스: 유료 라이센스 (요금보기)
업체: Amazon Web Service (AWS)
리플리케이션: 지원 (Server-less 구성, 자체 내결함성 지원)
샤딩: 지원 (Server-less 구성, 자체 분산)
주관적 내용: DynamoDB는 AWS에서 제공하는 클라우드 환경 베이스의 NoSQL DB 입니다. 여기서 큰 특징은 DynamoDB는 Server-less 환경이기 때문에 용량, 물리적 스팩 제한이 없으며 용량 크기, 사용자가 지정한 처리량(Through-put)에 맞게 알아서 확장되고 클러스터로 관리됩니다. 따라서 가용성, 확장성에 있어서 사용자로 하여금 귀찮은 작업이 많이 생략되며 Server-less이기 때문에 초기에 많은 비용이 나갈 우려가 사라집니다. 또한 Secondary index 지원을 Global, Local로 각각 지원하고 있습니다. 다만 관리형 서비스라 그런지 갑자기 많은 처리량이 발생할 때 DynamoDB에서 즉시 처리량을 늘릴 수 없는 문제, 그리고 이렇게 높아진 처리량을 다시 낮추는 경우에도 마찬가지로 제약이 있습니다. 따라서 이런 문제를 해결할려면 Warming up 작업을 해야하고 이로 인해 불필요한 비용이 발생할 수 있습니다. 마지막으로 놀라운 점이 하나 있는데 DynamoDB에서는 트랜잭션을 지원하기 위한 Java 코드가 올라와 있습니다.
Cloud Datastore
라이센스: 유료 라이센스 (요금보기)
업체: Google Cloud Platform (GCP)
리플리케이션: 지원 (Server-less 구성, 자체 내결함성 지원)
샤딩: 지원 (Server-less 구성, 자체 분산)
주관적 내용: Google Cloud Datastore는 AWS DynamoDB보다 약 4년정도 일찍 나온 서비스입니다. 가장 큰 차이로는 당연하게도 요금청구 방식이 다릅니다. (AWS DynamoDB는 Throughput 단위 청구, Google Cloud Datastore는 요청당 과금) 완전 정량적 과금이라 초기 비용이 적게 드는 합리적인 구성이지만 DynamoDB와 비교 할 때 요청이 많아질 수록 Google Cloud Datastore 요금이 더 비쌉니다. (읍읍 당신 누구야!?) 다만 secondary index라던지 Query 지원(GQL)이라던지 탈 NoSQL 요소들이 다분해서 이를 알고 사용하면 정말 유용하지만 신은 완벽을 내리지 않았다는 말이 증명되듯 이런 좋은 기능들에 대한 자료가 한없이 부족한 상태입니다.
Cloud Firestore
라이센스: 유료 라이센스 (요금보기)
업체: Google Cloud Platform (GCP) Firebase
리플리케이션: 지원 (Server-less 구성, 자체 내결함성 지원)
샤딩: 지원 (Server-less 구성, 자체 분산)
주관적 내용: 최근에 새롭게 출시된 (베타로) 데이터베이스로 필자는 Google Cloud Datastore와 대체 어떤 차이가 있는지 많이 혼동 되었습니다. 엄밀하게 Google Cloud Firestore의 경우에는 Firebase의 불편함 점 (Query의 불편함, 데이터 계층적 문제 등)을 보완하기 위한 부분이 있으며 Firebase의 목적 (Web, App의 지원)을 상속받기 때문에 Google Cloud Datastore 차이가 있습니다. (더군다나 Cloud Firestore는 Realtime을 지원합니다!) 따라서 Firebase Realtime Database와 비교하는 것이 더 바람직합니다. Cloud Firestore는 Firebase 및 Cloud Function 과 같은 GCP 제품을 호환할 수 있게 만들어 졌습니다.
2. DW (Data Warehouse)
예전에는 컴퓨터 하드웨어의 컴퓨팅 파워도 약했고 그렇기 때문에 수많은 데이터를 빠르게 분석 할 수 있는 환경도 여건도 없었습니다. 오늘 날에서는 컴퓨팅 파워도 높아졌고 또한 컴퓨팅 유닛도 굉장히 저렴해졌으며 가상화 기술과 분산 기술도 나날히 높아졌기 때문에 분산 환경에서 데이터를 실시간 분석하는 것이 가능해졌습니다. DW는 보통 OLAP을 위해 사용됩니다.
3. Realtime DB
Realtime DB는 실시간성 특징을 데이터베이스에 녹여 얻어낸 결과물이라 볼 수 있습니다. 일반적인 특징으로는 데이터베이스에서 수정이 발생하면 이를 클라이언트에 푸시하여 동기화 하는 기능이 들어가 있습니다. 대게의 Realtime DB는 NoSQL 기반이기 때문에 ACID를 요구하는 서비스에서 적용하기는 어렵습니다. 보통 실시간성이 요구되는 게임(진짜로 정말로 실시간 DB로 게임을 만드는 사례들이 있습니다.), 메시지 플랫폼(채팅, 챗봇, CS 등)에서 사용됩니다.
대표적인 Realtime DB 종류
Firebase Realtime DB
Cloud Firestore
RethinkDB
Druid (검토가 필요함)
4. Serverless query engine
Serverless라는 얘기는 서버가 진짜로 없는게 아니라 사용자 (엔지니어)에 있어서 서버가 가려져 있고 또 그것을 알 필요가 없도록 관리되고 있는 완전 관리형 서비스 입니다. 보통 이런 Serverless DB는 Cloud 환경에서 제공되고 있으며 해당 환경에 파일시스템(FS)에 쿼리를 요청하면 거기에 최적화된 코어 유닛의 서버를 런치하여 연산을 분산하기 때문에 상당히 빠른 쿼리 조회 시간을 제공합니다. 다만 코어 유닛의 조작이 불가능 하기 때문에 Scale 조정을 통해 성능을 개선 할 수 없습니다.
대표적인 Serverless query engine의 종류
AWS Athena
AWS Spectrum (*반 Serverless라고 해야 할듯 합니다.)
AWS DynamoDB
Google BigQuery
Google Cloud Datastore
Firebase Realtime Database
5. Query engine
데이터베이스라고 불리우긴 어려우나 분명 쿼리를 통해 집계, 조건 등을 이용하여 결과 데이터를 산출하는 엔진을 칭합니다. 보통 따라붙는 수식어가 “Interactive Query”이며 공용 분산 파일시스템에서 데이터 레이크(Data lake) 역할을 하고 그를 조회하여 결과데이터를 뽑는 엔진을 Query engine이라 부릅니다.
대표적인 Query engine 종류
앞서 거론한 모든 Serverless query engine
Apache Impala
Apache Hive
Apache Pig
Apache Drill
IBM BigSQL
Apache Tajo
Facebook Presto
6.Graph Database
최근에 자주보이는 데이터베이스입니다. 필자는 새롭게 나오는 논문을 살펴보는 스타일은 아닌지라 이것이 어디에서 따와서 점차 출시되고 있는지 잘 모르겠습니다. DAG(Directed Acyclic Graph) 기반의 그래프 데이터베이스 형태로 출시되고 있습니다.
대표적인 Graph Database의 종류
SQL Server 2017
Teradata Aster
SAP HANA
Neo4j
DynamoDB Titan (검증 후 재 업데이트 예정)
Apache S2Graph
참고하거나 연관 된 포스팅 목록
Amazon Redshift: Performance Tuning and Optimization (Slideshare)
오픈소스 데이터베이스, 은행 서비스에 첫발을 내밀다. (Slideshare)
[야생의 땅: 듀랑고] 서버 아키텍처 - SPOF 없는 분산 MMORPG 서버 (Slideshare)
Apache Cassandra 톺아보기 - 1편 (NHN-Enter Toast)
Apache Cassandra 톺아보기 - 2편 (NHN-Enter Toast)
Apache Cassandra 톺아보기 - 3편 (NHN-Enter Toast)
Dremel: Interactive Analysis of Web-Scale Datasets (Research at Google)
Kafka New Producer API를 활용한 유실 없는 비동기 데이터 전송 (SK플래닛 기술 블로그)
구글 클라우드 데이터스토어에서 스트롱 컨시스턴시와 이벤츄얼 컨시스턴시의 균형잡기 (nurinamu‘s the BLACK BOOK)
[분산캐시] Redis 와 memcache의 flush는 왜 다를까? (Charsyam's Blog)
ZooKeeper를 활용한 Redis Cluster 관리 (Naver D2)
Memcached의 확장성 개선 (Naver D2)
글로벌 분산 데이터베이스 Spanner (Naver D2)
왜 레진코믹스는 구글앱엔진을 선택했나 (Slideshare)
카카오 “레디스, 잘못쓰면 망한다" (ZDNet Korea)
Apache spark 소개 및 실습
3 notes
·
View notes
Text
자바스크립트 부분 탄성충돌 구현하기
오늘은 조금 별난 주제에 대해서 얘기해볼까 한다.
필자는 전에 자바스크립트로 여러가지 물체가 서로 충돌하고 중력이 적용되는 아주 간단한 로직을 작성한적이 있는데 아래에서 볼 수 있다.
See the Pen Physics - Inelastic Collision And COR (Circle Animation). by Kenneth Ceyer (@PIGNOSE) on CodePen.
이 프로젝트는 정말 아무 의미없이 계속적으로 새로운 원형 물체가 생성되고 그것이 중력에 의해 떨어지면서 튕겨지며, 이 원형 물체는 같은 원형 물체에 의해서 혹은 벽면(아래, 좌우)에 의해서 충돌 처리가 발생한다. 충돌 처리가 발생 될때는 원형은 순간적으로 붉게 바뀌고 충돌 이후에는 물체는 반대편으로 튕겨나가게 된다.
필자는 과거에 만든 이 코드를 지금은 왜 만들었는지 전혀 기억을 못하고 있지만 최근에서 이 코드를 사용 할 날이 왔었다.
배경
필자는 여러가지 자바스크립트 오픈소스 기여를 하고있다. 이 이슈를 보시면 아시겠지만, 가끔 열정 가득한 컨트리뷰터는 오픈소스 기여를 통해 더 좋은 소스코드를 만들 수 있는 기회를 제공하고. 필자는 그것이 너무나 고마워서 최대한 컨트리뷰터가 원하는 그림을 만들어주고는 한다.
컨트리뷰터에게 어떻게든 보상을 해주고 싶었기에 README.MD에 컨트리뷰터 목록을 추가하였지만 가끔 많은 것을 기여해주는 컨트리뷰터들도 존재했기 때문에 그런 컨트리뷰터들에게 어떤 방법이든 나의 고마움을 표현하고 싶었다.
이상한 발상
이것이 사건의 발단이었던 것 같다. 필자는 컨트리뷰터들을 위해 인터렉티브하고 재미있는 요소를 통해 컨트리뷰터들의 프로필 이미지(아바타)를 라이브러리의 공식 페이지에 넣어주고 싶었고 그것을 위해서 아래와 같은 코드를 짜게 되었다.
See the Pen bqEyjR by Kenneth Ceyer (@PIGNOSE) on CodePen.
눈치가 빠른 분들은 이미 감지하셨겠지만 위에 게시한 코드와 방금전 게시한 코드 두개는 버그가 존재한다. (사실 버그는 한두개가 아니다.) 이 버그들은 간헐적으로 발생하는 버그들로 아래의 케이스에 버그들이 발생하게 된다.
원형 물체가 생성될 때 동시에 같은 위치에 두개 이상의 물체가 생성되는 경우.
원형 물체가 충돌될 때 3개 이상이 동시에 충돌되는 경우.
위 두개의 케이스에서 해당 코드는 정말 물리적으로는 말도안되는 모습을 보이게된다.

두개의 원형 물체가 겹칠 수 밖에 없도록 생성되었을 경우 두개가 완전히 겹쳐서 같이 내려가게 된다.
문제
이런 현상이 발생하는 원인을 분석할려면 이 코드가 지금 어떤 방식으로 작성되고 있는지 알아야한다.

여러분의 이해를 돕기 위해 아주 쉬운 이미지로 만들어보았다. 먼저 g1이라고 불리는 도형 하나가 있다.
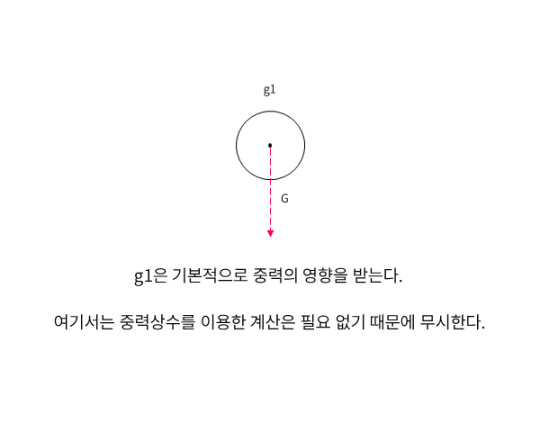
프로그래밍으로 가상의 중력을 구현했기 때문에 지정한 중력 상수에 의해 y축 가속도는 영향을 받는다.
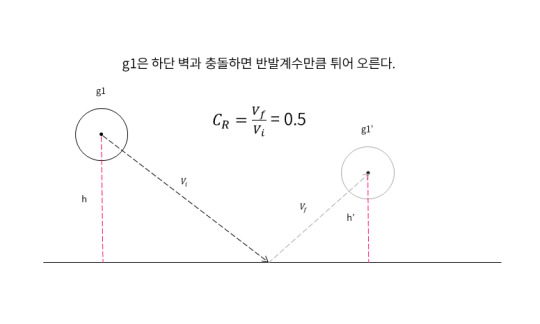
충돌이 발생 했을 때 반발계수를 기준하여 연산하여 반사각을 처리하게 된다.

하나의 물체는 다른 물체랑 충돌 할 수 있다.
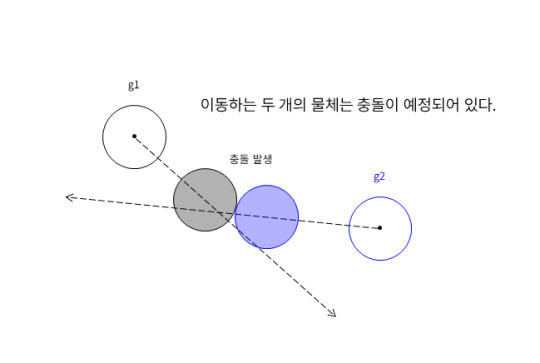
만약 두개의 물체가 충돌이 발생하게 된다면 위와 같은 시나리오 처럼 두개의 물체는 특정 시간이 지나 만나게되는 지점까지 운동을 하게 된다.
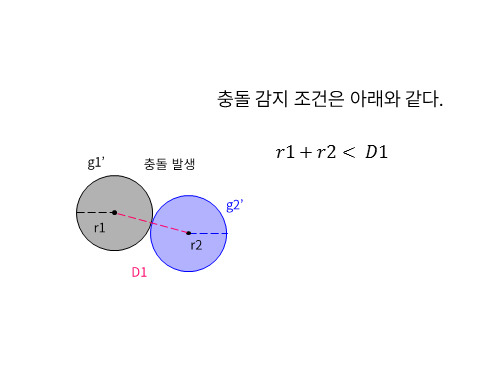
충돌 여부를 검증하는 것은 어렵지 않다. 두 물체의 반지름 값을 합한 수치가 두 물체의 중심점 좌표간의 거리보다 작으면 충돌로 인식한다.
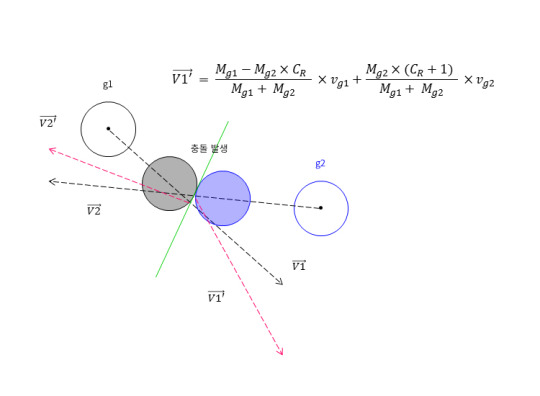
충돌이 발생 했을 경우에는 M(질량변수)과 v(가속도 변수) 그리고 COR(반발계수)를 이용하여 반사각 계산 알고리즘이 실행된다. 앞서봤던 예제 코드들도 이런 방식으로 동작된다. 중요한 것은 이런 방식에서 발생하는 문제들이 있다.
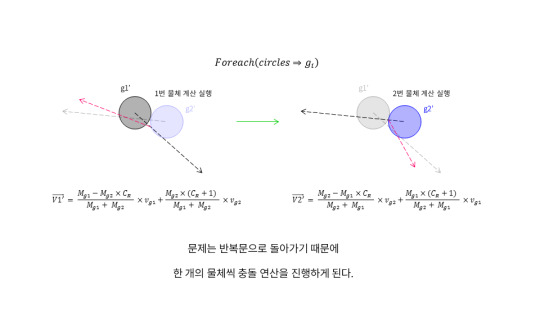
현실세계와 다르게 코드는 각각의 물체마다 반복문을 통해서 각각의 충돌여부 감지와 충돌 연산이 들어가는데 이 연산은 두개의 물체에 대해서는 문제없이 동작한다.
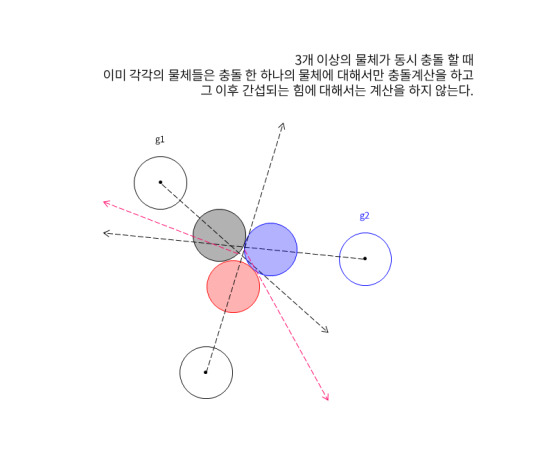
하지만 만약 3개 이상의 물체가 동시에 충돌했다면 어떨까? g1은 g2 물체와 충돌을 감지하고 충돌 연산을 마쳐 반사된 속도 값을 구했다. 그리고 다음 물체로 넘어가게 된다. 이것이 이 소스코드의 문제점이다.
이 문제점을 해결하기 위해서는 g1은 g2와의 충돌 연산을 마치고 g3와의 충돌을 감지하여 방금전의 속도에 간섭을 발생시켜야 한다. 지금 코드는 g1은 g2와의 충돌만을 g2는 g1과의 충돌만을 계산했기 때문에 반사되는 각도는 정확하지 않고 심지어는 물체가 겹치게되는 문제점마저 가지게 된다.

또한 현실에서는 일어나지 않을 법한 문제도 발생할 수 있다. 위 사진을 보면 물체 두개가 겹친 상태로 존재한다. 이런 현상을 랜덤한 좌표에 물체를 생성할 때 우연히도 그 자리 근처에 다른 물체가 존재하는 경우다. 그렇다고 개발자가 생성하기 전에 그 주변에 물체가 있는지 검증하는 것도 무언가 깔끔하지 않다. 마치 문제를 회피해나가는 기분이든다.
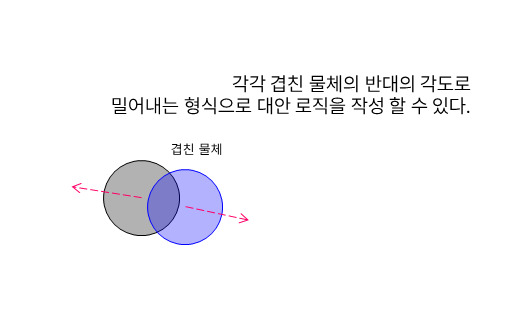
이럴 때는 두개의 물체는 각각의 물체를 바라보는 방향의 반대의 각도를 구해 그곳으로 일정량 지속적으로 밀어내어 문제를 해결해야 한다.
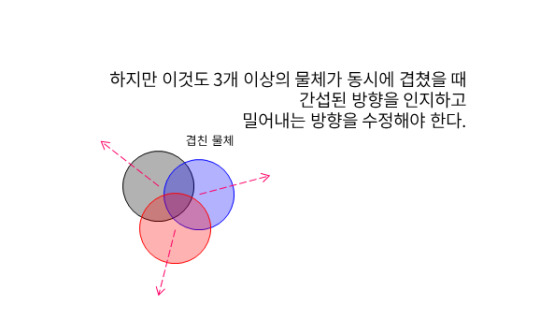
문제는 3개 이상의 물체가 겹칠 경우 이 밀어내는 방향에 대해서도 간섭이 발생해야 하는 것이다.
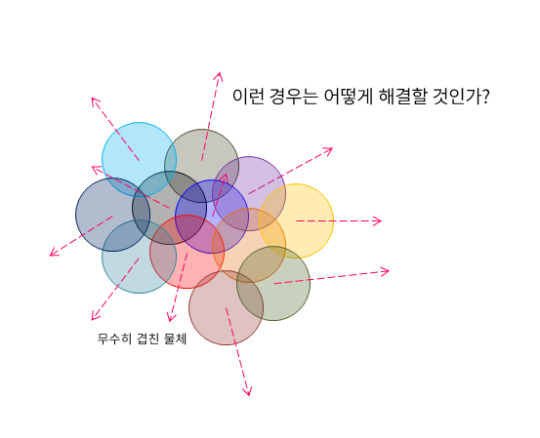
무수히 많이 겹쳐서 안쪽에 물체가 빠져나가기 위해서는 바깥의 물체가 먼저 충돌처리를 완료해야 하는 문제도 있다. 이 경우 안쪽과 바깥의 사이 (중간 영역)에 있는 물체는 안쪽 방향으로 속도가 발생 할 수 있다.
이런 문제를 다체문제 혹은 N-Body problem이라고 불린다. 심지어 이것과 관련된 논문들도 다수 존재한다.
이미 multiple circle collision issue라는 키워드로 구글에 검색하면 많은 질문글과 해결방법이 존재하고 있으며 이렇게 친절하게 작성된 (이 블로그보다 더) 문서들도 있다.
이런 문제를 어떻게 깔끔하고 효율적으로 해결 할 수 있을지 필자는 앞으로 조사를 할 계획이다. 앞으로 이 문제를 해결하고 위 샘플 코드를 업데이트한 코드를 공개할 예정이다.
1 note
·
View note
Text
자바스크립트 모듈 제공을 위한 AMD, CommonJS 그리고 RequireJS 소개

자바스크립트는 편리한 언어이다.
필자는 자바스크립트의 유연함과 고차함수, 익명함수 사용의 편리함과 직관적은
정말이지 엄청난 매력을 가지고 있다고 생각한다.
이번 포스팅에는 자바스크립트가 모듈을 제공하기 위해서
AMD, CommonJS를 알아보고 RequireJS에 대해서도 소개하고자 한다.
서론
필자는 오픈소스를 자주 사용한다.
그리고 오픈소스 기여도 자주 하는편이라고 생각된다.

오픈소스 참여를 할 때, 깃허브를 많이 사용하는데
여러분도 이 고양문어(옥토캣)을 많이 보셨을 거라 생각한다.
필자가 기여하는 프로젝트 중에
달력 컴포넌트를 만들어주는 자바스크립트 프로젝트가 있다.

이 곳에서 해당 프로젝트를 확인 할 수 있다.
이 코딱지 만한 프로젝트도 점점 사용자들이 이용해주면서
기능을 확장하고 있는데
최근에 AMD, CommonJS 지원 작업을 한 적이 있는데
작업을 진행하면서 발생한 크고작은 이슈에서 얻은 경험을 공유하고자 한다.
시작하기 앞서 이 글을 읽어보면 좋을 것 같다. (4년도 더 된 글이다..)
배경

자바스크립트는 파이썬, 루비, 다른 스크립트 언어 계열과 차이점이 존재한다.
바로 모듈 사용의 표준이 존재하지 않다는 것이다. (ECMA5 기준)
https://gist.github.com/KennethanCeyer/6d6ba68b76354398f770b1e0adc0b8e2
파이썬 모듈 사용
https://gist.github.com/KennethanCeyer/7d02f92ba85c16533668bfe6cdd6e4a5
루비 모듈 사용
Node.js를 사용하고 있는 개발자들은 module.exports를 통해 모듈을 정의하고
require() 함수를 통해 정의한 모듈을 불러와 사용하고 있다.
이곳을 통해 Node.js에서 모듈을 어떤식으로 사용하는 지 알 수 있다.
이러한 방식을 CommonJS로 불린다.
https://gist.github.com/KennethanCeyer/d4848af11711a3ab3f65653449b32c43
Node.js 모듈 형태를 보면 다른언어에 비해 모듈제공이 조금 차이가 있다.
module.exports와 exports 두개를 사용하는데
이런 제공방식은 혼동을 초래하기도 한다.
필자는 그래도 Node.js의 모듈 형식에 대해서 크게 불만을 가지고 있지 않다.
문제는 프론트엔드에서는 이런 모듈 제공방식이 없었다는 것이다!!
https://gist.github.com/KennethanCeyer/609879cb173368093316eb7de667f54b
그나마 비슷하게 모듈 제공방식을 따라해봤다.
프론트엔드에서 사용하는 자바스크립트는 DOM 오브젝트를 사용하고 있다.
전역 오브젝트인 window를 사용하면 다른 자바스크립트 파일에 리소스를 전달 할 수 있다.
하지만 이것도 사용하는 HTML에서 불러오는 모듈 파일을 먼저 로드해야
문제가 없이 작동된다.
즉 대상 모듈이 존재 할 수도, 존재하지 않을 수도 있는 상태가 벌어진다. (으아아악!)
하지만 프론트엔드에서 사용하는 프로젝트도 규모 커지면 커질수록
모듈의 필요성은 커져갔고
그렇게 AMD 방식과 CommonJS 방식 두개의 모듈 정의 규칙이 생기게 되었다.
사실 두개 말고도 ES2016, ES6, System.register 등등의 모듈제공 방식도 있지만
여러분의 정신건강을 위해 비밀로한다... (이미 비밀이 아니잖아!!)
AMD
AMD는 Asynchronous Module Definition (비동기 모듈 정의) 규칙이다.
https://github.com/amdjs/amdjs-api/wiki/AMD에서 자세한 내용을 확인 할 수 있다.
https://gist.github.com/KennethanCeyer/3c78f7c18c3519355509e2174103d633
AMD의 규칙을 이용해서 정의해봤다.
브라우저에서 모듈을 정의하고 불러오는 기능을 사용하기 위해서는
AMD의 규칙을 따르는 도구를 사용해야 하는데,
위의 코드에서는 RequireJS를 사용했다.
(RequireJS에 대한 설명은 http://requirejs.org/에서 확인 할 수 있다.)

위 사진에서 math.js는 main.js의 require 함수에 의해 동적으로 로딩되었다.
AMD 관련한 글 중에
AMD is Not the Answer(AMD는 해답이 아니다.)라는 글이 있다.
여기서는 AMD의 정의구조와 HTTP 동적 로딩을 비판하고 있는데 관심있는 분들은
한번 읽어보시길 바란다.
필자는 이렇게 생각한다.
AMD와 CommonJS 둘 모두 프론트엔드 브라우저에서 동적 로딩을 할 경우
페이지가 열리기 전까지 수많은 JS를 사용자가 페이지를 열어볼 때 불러오므로
부하가 발생하게 된다. (캐시를 해도 느린건 마찬가지)
여러분이 생각하는 1~20개의 자바스크립트 파일 로딩이 아니다.
몇 백개의 자바스크립트를 매 사용자가 페이지를 전환할 때마다 불러 온다고 생각해보자...

AMD, CommonJS 모두 비동기 통신을 통해 파일을 동적으로 불러오는 경우
성능의 이슈가 있기 때문에
보통 프로덕션 서버로 배포 할 때 번들링(Bundling) 작업을 진행하게 된다.
번들링은 이후 섹션에서 자세히 설명하도록 하겠다.
아까전에 얘기했던 오픈소스 프로젝트 PIGNOSE Calendar는
AMD 스타일로 모듈을 정의한다.
소스코드를 통해 확인이 가능하다.
그렇다고 RequireJS를 사용하지 않는 프로젝트에서
해당 프로젝트 소스를 불러와도 (이를테면 <script> 태그를 통해 로딩 시)
소스는 문제없이 작동해야한다.
AMD는 define 함수와 require 함수를 통해 모듈 정의와 로딩을 진행하는데
이 두가지 함수 모두 브라우저에서 인식 할 수 있는 함수가 아니다.
따라서 아까 우리는 require.js 스크립트를 추가적으로 불러와
브라우저에서도 모듈 정의와 로딩이 동작하도록 했다.
하지만 라이브러리에서 require.js 파일을 의존하여
같이 빌트-인 하기에는 require.js 소스코드 용량이 크다.. (18KB)
RequireJS 측에서는 이렇게 AMD를 사용하지만 라이브러리 형태로 제공해야하는
프로젝트를 위하여 RequireJS의 미니마이즈 버전인 Almond(아몬드)를 제공한다.
아몬드의 설명에 따르면 gzip과 클로저 컴파일러를 이용할 때 약 1킬로바이트의 용량이 된다고 한다.
필자는 RequireJS를 번들링 하기 위해 Grunt Task(그런트 테스크)를 사용하는데
그런트 RequireJS 테스트 설명을 보면
almond 빌트 인이 명시되어있다.
여러가지 유명 자바스크립트 라이브러리를 살펴봐도
대부분 아몬드를 빌트인 하여 제공하고 있다.
CommonJS
아까 설명한 것과 같이 Node.js 진영에서는 CommonJS를 기본으로 사용하고 있다.
그 외에도 tsconfig에서 commonjs로 모듈을 정의해도 CommonJS로 정의가 된다.
CommonJS 제공이 중요한 이유가
당연하게도 Node.js에서 모듈을 불러오는 기본 스타일이 CommonJS이기 때문에
프론트엔드 라이브러리일지라도 Node.js 코드를 통해 유닛 테스팅을 하는 경우
혹은 moment, underscore처럼 Node.js에서도 사용 가능해야하는 라이브러리 일 경우
CommonJS 모듈 형태도 제공해야 한다. (맙소사, 저 울어도 되요?)
번들링
번들링을 쉽게 설명하자면
여태까지 여러분이 모듈들을 싸질러놓은 똥을 하나의 단일 파일로 취합하는 과정이다.
앞서 말씀드린 모듈 타입(AMD, CommonJS, ES2015, ES6 etc)을
분석하고 거기서 불러오는 파일을 파악하여
하나로 모아주는 번들러(Bundler)가 필요한데.

많이 사용하는 번들러 종류는 아래와 같다.
Webpack
Rollup.js
Jspm
Browserify
Grunt와 Gulp와 같은 빌드테스크 도구에서도 플러그인을 연결하여
번들링을 진행 할 수 있다.
PIGNOSE Calendar는 앞서 말했듯 Grunt를 사용하여
RequireJS를 번들링하고 Almond를 묶어서
<script> 태그를 통해 불러오더라도 문제없이 작동한다.
번들러의 선택은 여러분의 자유지만
여러분의 정신건강 상 웹팩(Webpack) 번들러를 사용하시기를 권장드린다.
필자는 AngularJS 2 AOT 를 사용할 때 그곳에 명시된 롤업JS(Rollup.js)를 사용했으나
무수한 경고(Warning)이 표시되었고
AngularJS2에서는 무슨일에선지 그것을 무시하는 코드를 넣어 공식페이지에 공개했다.
그 때문에 필자는 웹팩(Webpack) 버전 2로 교체하고 잘 쓰고 있다.
참고로 Webpack 1에서는 AngularJS AOT를 번들링 할 때 Uglify에서 에러가 발생한다.
아무도 해결방법을 공유안해서 필자가 직접 했다고 한다.
혹시 같은 문제를 겪는 분은 이 링크를 살펴보시길 바란다.
AngularJS 2 AOT를 적용하시고자 하신다면 Webpack 2를 사용하시는 게 정신건강에 좋다.
배포
좀 전에 얘기드린바와같이
우리의 아름다운 자바스크립트 프론트엔드 환경에서는
제공하는 라이브러리를 어떤식으로 호출 할지 모른다.
require([``], function(module) {})로 사용 할 수도 있고. (AMD)
var module = require(``)로 사용 할 수도 있다. (CommonJS)
심지어 import { module } from ``; 형태로 사용 할 수도 있다. (ES6)
우리는 이런 모듈 방식을 모두 제공하는 팩토리 형태를 만들어야 한다.
심지어 이 팩토리 표현에 대해서는 마땅한 표준도 없다.
(세상에 마상에)
표준은 아니지만 UMD라는 친구가 있는데
Universal Module Definition의 약자이다.
여기서 제공하는 템플릿이 그래도 많이 사용되고 있는 듯 보인다.

힘내세요 프론트엔드 라이브러리/프레임워크 개발자 여러분..
피토하셔도 이해합니다..
이 글을 읽어보자
글의 제목은
It's Not Hard: Making Your Library Support AMD and CommonJS
(여러분의 라이브러리가 AMD와 CommonJS를 지원하는 것은 결코 어렵지 않습니다.)
인데 이 글의 분량이 어느정도인지 파악이 되는가?
여러분은 고작 다른언어에서는 기본적으로 제공하는 모듈 지원을 위해
이 정도의 글을 더 읽어야한다.
(모듈 지원도아니다, 지원하고 있는 모듈 외에 모듈 정의 호환 지원이다.)
본론으로 돌아와서,
앞서 말했던 PIGNOSE Calendar 플러그인은 AMD 모듈을 사용하고 있지만
CommonJS, Plaintype(<script>를 통해서 불러오는 경우)를 지원해야 했다.
이를 위해 하나의 Factory를 정의하게 되는데
기초 원리는 간단하다.
우선 아래 코드를 먼저 살펴보자.
https://gist.github.com/KennethanCeyer/19402abf4901a833052319ece54119d4
자바스크립트를 조금 공부하신분은 IIFE에 대해서 들어보셨을 것이다.
IIFE는 Immediate Invoked Function Expression의 약자로 즉시 함수 호출 표현식이다.
이걸 왜 사용하는지는 이곳에서 자세히 살펴보실 수 있다.
이것을 사용하는 주요 이유는 전역 함수와 지역 함수 구분을 위한 클로저 정의를 위해 사용한다.
아까 보여드린 Factory에서도 IIFE 형태의 호출 표현식을 사용하는데
root, factory 매개변수를 IIFE 형태로 전달한다.
root는 this가 전달되며 factory는 모듈로 제공될 함수가 전달된다.
IIFE에서는 각 모듈을 사용하는지 검사 한후 factory를 호출하게 된다.
PIGNOSE Calendar는 module.export (CommonJS) 형태에서
Mocha를 통한 Unit Test를 제공해야 하기 때문에
각종 의존라이브러리를 추가하여 부르게 된다.
그리고 Node.js 환경에서는 window, document가 존재하지 않기 때문에
window와 document를 jsdom을 통해 Mocking 하고있다.
결론
결론적으로 아직 자바스크립트의 모듈링 표준은 걸음마 단계이다.
아직 ECMA 6가 모든 브라우저에서 채택되지 않았기 때문에 (채택상태 보기)
과도기적인 면모를 보인다.
ECMA 6가 AMD와 CommonJS 스타일을 사용하지 않기 때문에
나중에는 AMD와 CommonJS 모두가 버려지는 아름다운 현상이 일어나진 않을지..

이곳에서 RequireJS를 지원하는 Grunt 설정을 볼 수 있다.
PIGNOSE Calendar는 모듈 호환을 제공하고 브라우저에서도 정상 동작한다.
이곳에서 확인해보자

여러분도 자바스크립트 모듈을 사용하고
빈틈 없는 멋진 개발자가 되보자.
(모듈 모르는 뇌 삽니다.)
#개발#commonjs#requirejs#amd#es2015#es6#import#exports#module#almond#factory#webpack#rollupjs#angularjs#angularjs2#ahead of time#aot#bundler#frontend
2 notes
·
View notes
Text
Angular 2 그리고 웹 프론트엔드 (2/2)

이번 시간에는 Angular가 무엇인지 알아보도록 하자
연관된 글 목록
Angular 2 그리고 웹 프론트엔드 (1/2)
Angular 2 그리고 웹 프론트엔드 (2/2) - 현재 글
설명하기 앞서
이 글은 Angular의 특징을 최대한 간략하게 설명한다.
따라서 앵귤러 코드를 자세히보고 싶은 분들
Angular 코드를 보며 하악하악 하고싶어하시는 분들을 위한 글이 아니다.
간단하게 자바스크립트와 Angular 코드를 비교해보고
차이점을 설명하는 정도로 코드 첨부는 끝날 것이다.
협업에서 Angular 도입을 고려하거나,
이제 Angular가 무엇인지 알아보려는 독자를 위해 글을 작성하고 있다.
만약 여러분이 Angular에 대해 자세히 알아보고 싶다면
Angular 2 그리고 웹 프론트엔드 (3/3)을 읽어보시기 바란다.
youtube
영상에서 Angular에 대해 간단하게(30분) 설명한다.
동영상이 길기 때문에 슬라이드 자료를 보는 것을 권장한다.
프레임워크 vs 라이브러리
한때 필자가 운영하던 페이스북 페이지에서
라이브러리와 프레임워크 프로젝트를 비교하면서 프레임워크 프로젝트에서
더 많은 기능을 제공한다고 올렸던 적이 있는데.

결과적으로 가루가 되도록 털렸다. (엉엉)
프레임워크와 라이브러리가 가끔 혼용되어 사용되면서 오해가 생겼다고 생각한다.
둘의 개념은 엄연히 다른 개념이기 때문에 이 자리를 빌어 간단한게 설명을 해볼까 한다.

(사진출처: 트위터 @jaffathecake)
프레임워크(Framework):
큰 틀(Frame)안에서 그 규칙에 맞게 정의된 기능과 라이프사이클을 지키며 기능을 개발할 수 있는 도구.
라이브러리(Library):
기존 개발된 기능은 지키면서 라이브러리가 제공하는 기능을 추가적으로 사용하여 파워업 할 수 있는 도구.
대게 라이브러리보다 프레임워크가 제공하는 기능이 더 큰 편이며
러닝커브도 프레임워크가 더 높은 편이다.
Angular
자 그럼 주제로 돌아와서 Angular를 알아보자.
Angular는 Google에서 2009년 Feedback 서비스를 개발하는 도중 탄생된 자바스크립트 프레임워크이다.
당시만해도 화면(View)이 동적으로 바뀌는 페이지를 만들고
그곳에 이벤트 함수들을 바인딩(이벤트를 연결하는 과정)하는 로직을 추가하는 것을 짜는 과정을
고스란히 순수 자바스크립트 혹은 라이브러리로 작성했기 때문에 굉장히 코드라인이 길었다.
그 높으신 최고존엄 구글 엔지니어들도 이런 개발방식에 피곤함을 느꼈을테고
그렇게 조금 더 편리한 방법을 모색하는 도중 Angular가 만들어졌다.

본격적으로
그래서 결국 앵귤러라는 친구는 무엇일까?
과거에 필자는 앵귤러를 개발 생산성을 극대화시켜주는 프레임워크라고 설명했다.
물론 맞는 말이다. 하지만 앵귤러를 사용해오지 않았던 사람들은 이것이 도대체 어떤 방법으로 생산성을 극대화 시켜주는 것인지 와닿지 않는다.
앵귤러는 기존 방식과는 너무나도 다른 방향을 가지고 있다.
그래서 앵귤러를 실제로 사용해보지 않은 분들에게 이를 설명하는 것이 너무나 힘들다.
필자는 앞으로 앵귤러를
“자바스크립트의 문제를 다 덮어주는 프레임워크"라고 설명하고 싶다.
여러분은 이 다음 섹션에서 구체적으로 자바스크립트가 어떤 문제를 가지고 있는지 알게 될 것이다.
다소 글이 길어질 수 있으니 우리 블로그 피그노즈 스타일대로 많은 링크와 그림을 첨부한다.
예를들어보자,
필자는 IT 개발관련 분야에서 솔루션을 개발하고 있는 개발자이다.
C#으로 ASP.NET을 이용하여 웹 서비스를 개발하고 있으며
내가 속한 팀 외에도 회사에서는 메이저언어는 C#을 주로 이룬다.
물론 JAVA도 사용하고 있지만 결과적으로 객체 중심의 개발이 주로 이루어진다.
내 입장에서 볼 때 객체 중심 개발은 협업에 있어 상당히 적응력을 높여주고
개발에 대한 관점을 직접적으로 알려 준다.

다시 자바스크립트로 주제를 옮겨보자
필자는 프론트엔드 개발도 같이 하고있고 자바스크립트를 사랑하고 자주 사용하고 있는 언어이다.
(필자는 이전 직장에서는 Node.js로 웹서비스를 개발하고 있었다.)
하지만 자바스크립트에는 굉장한 문제점들이 있었으니!!

첫 번째로 협업이 어렵다.
앞서 거론한 C#과 같은 타입을 제공하는 객체지향 프로그래밍은
다른 프로그래밍 언어에서 익히 사용하는 클래스, 상속, 추상화개념을 받아들이기 때문에 협업에서 사용하는 형태가 유사하다.
(따라서 다른사람의 코드를 쉽게 이해 할 수 있고 이로인해 협업에 용이하다.)
하지만 우리의 자바스크립트는 변수에 대한 타입을 제공하지 않는다.

마찬가지로 자바스크립트는 클래스를 사용하지 않고
프로토타입이라는 자바스크립트 고유의 객체 사용 형태를 제공하고 있다.
그리고 C#과 같이 객체 사용에 무조건 프로토타입을 제공하는 것도 아니다.
(리터럴 오브젝트를 사용한다.)
자바스크립트 디자인패턴을 보자
우리의 자바스크립트는 익명함수로 수많은 디자인패턴을 성공적(?)으로 제공한다!
이런 무수한 익명함수와 사용형태는
다른 협업에 있어 가독성을 떨어트리게 되고 심지어 코드 인텔리전트 기능으로도 확인 할 수 없어 혼란을 야기한다.
여러분이 협업 개발을 하지 않는다고 해도
여러분은 여러분이 짠 코드 가독성을 중요하게 생각한다면
자바스크립트가 얼마나 많은 가독성 문제가 있는지 알고 계실 것이다.
더 자세한 사항은 이 글을 보시길(원문)
두 번째로 코스트가 발생한다.
우리의 자바스크립트는 JSDoc과 단위테스트, JSLint와 같이 개발 도구를 이용하여
앞서 설명한 문제를 막고 프로토타입 기반으로 개발코드를 작성하면 협업문제가 개선된다.
필자도 그렇게 생각하고 있고 그렇게 개발하�� 있다.
이미 이러한 문제는 오래전부터 거론되어 왔고
그것을 해결하기 위한 솔루션도 있는데 왜 이용을 안하는가?
결론은 그런 것을 알지도 못하고 그런것을 알기도 싫어하는 개발자가 존재하기 때문이다. (ㅁ..뭐?)

우리는 경건하게(?) 두손을 모아 바르게(현실적으로) 생각해볼 필요가 있다.
실무에서 개발자의 역할 중 가장 중요한 것은 서비스를 성공적으로 완성시키는 것이다.

위 사진은 “Done is better than perfect”
(단지 끝내는 것이 완벽한 것보다 낫다.)
어느 웹 서비스 회사(페이스북)에 걸려있는 문구이다.
이 글을 읽는 여러분은 너무나도 똑똑하기 때문에
업무를 하는 본질은 이미 알 것이기 때문에 설명은 생략한다.
통합 개발환경(IDE) 기본옵션에서 어느정도 빌드과정에서 런타임에서 발생할만한 문제를 잡아주는 언어(C#, JAVA, C, C++, go, rust, haskell etc)는
협업에서도 그 규칙을 지키면 되기에 안정적인 개발을 수행 할 수 있다.
다만 변수 타입제한이 없고 개발자 스타일별로 코딩방식이 아에 나눠져있는 언어들(Javascript, PHP, ruby etc)는 결국 성숙한 개발환경이 아니면 협업 불가능한 코드양산이 가능하다.
앞서 말했듯이 성숙한 개발환경을 만들기 위해서는 이미 안정적인 서비스 운영을 하고 있는 업체에서 실행이 가능하다.
따라서 그 이전에 단계에 있는 업체들은 자바스크립트로 개발하는 모든 프로젝트에서 하나의 룰을 정하고 그것을 따르게 강제해야한다.
관리자 입장에서는 다른언어와 비교할 때 그것이 불필요한 코스트가 될 수 있다.
그리고 개발 안정화를 위한 시스템 도입또한 코스트로 산정이 될 수 있다.
(이것이 자바스크립트의 단점으로 지목 될 수 있다.)
모던 프레임워크
앵귤러를 설명하기 위해서는 결국 자바스크립트의 본질적인 문제를 파악 할 필요가 있었다.
앵귤러는 프레임워크이다.
프레임워크는 모두 그 프레임워크의 규칙내에서 개발을 진행 하게 되어있다.
프레임워크답게 여러 개발 패턴들을 제공하고 있는데
버전 1에서는 service, provider, factory와 같이
일반적으로 많이 사용하는 디자인패턴을 아에 앵귤러 자체 정의형식으로 제공한다. 이곳에서 확인하세요
심지어 앵귤러 버전 2에서는 타입스크립트(Typescript)를 지원한다.
기존의 자바스크립트에서는 불가능 한 데코레이터, 클래스, 변수타입 등을 사용 할 수 있다.

위 사진은 자바스크립트로 Ajax 기능을 이용해서
원격지 JSON 파일에 맞는 UI를 반영하는 기술에 대한 도식이다.
JSON 파일을 파싱해서 for in 형태의 반복문으로
각각의 아이템에 맞는 엘리먼트 요소를 생성하여 그 엘리먼트에 맞는 이벤트를 연결해야 한다.

제이쿼리로 사용해도 메소드 사용이 조금 편리해지는 점 외에 큰 변화는 없다.
여태껏 개발자들은 이런 개발방법에 대해서 크게 불편사항을 느끼지 못했다.
하지만 이런 스타일의 개발 로직은 문제점이 존재한다.
1. 코드재활용
만약 두개 이상의 원격지에서 데이터를 받아와서 같은 UI에 반영해야 한다면 어떻게 할 것인가?

원격지에서 데이터를 받아온 이후 처리로직을 함수로 만들어 그것을 재활용 할 수 있다.
하지만 다른 자바스크립트 파일에서도 같은 처리방식을 사용하면 유틸리티 형태의 자바스크립트를 따로 모아 정리해야하고
다른 개발자가 이 유틸리티 파일을 사용하는 코드들을 모두 파악하지 않은 형태에서 수정해버리면? 사이드 이펙트가 발생하게 된다.
2. 복잡한 엘리먼트의 변형
사용자 화면에 적용된 UI에서 하나의 아이템 삭제 같은 기능을 추가하면
아이템 고유의 구분자를 이용해 삭제 처리를 하는 로직을 추가 해야한다.
삭제가 성공하면 UI에서 삭제된 엘리먼트를 찾아 지워주는 로직을 추가해야 한다.
그리고 아이템 고유의 구분자를 엘리먼트 data attribute로 제공하는 로직과 삭제 이벤트를 연결하는 로직을 엘리먼트를 추가하는 로직에 추가해야한다. (이쯤되면 해깔리기 시작한다.)
그 사이에 더보기 기능과 로딩 기능을 추가한다고 해보자.
로딩이 발생 시 아이템 리스트 하위에 로딩 이미지를 보여주는 엘리먼트를 추가하고, 로딩이 끝나면 그 엘리먼트를 삭제해야 한다.
더보기를 누르면 현재까지 가지고 있는 페이지 정보를 이용하여 다음 아이템 목록을 받아오고 엘리먼트를 추가하고 이벤트를 연결하는 로직으로 전달해야 한다.
이 과정에서 기존의 엘리먼트를 추가하고 변경하는 로직이 다른 개발자에 의해 변경되면 사이드 이펙트가 발생 할 수 있다.
3. 엘리먼트 탐색
자바스크립트와 연결된 엘리먼트를 찾으려면 엘리먼트를 직접 탐색해야 한다.
예를들어 구분자가 36번인 엘리먼트를 탐색하려면 탐색 엘리먼트 중 36을 값으로 가지고 있는 속성을 가진 엘리먼트를 찾아야한다.
엘리먼트가 가지고 있는 속성을 의존하기 때문에 속성 이름이 변경 되어서도 안되고
속성 값의 타입이 변경되어서도 안된다.
(분명 숫자 타입인줄 알았는데 문자타입으로 제공 되었으면 형변환 로직이 추가되야 한다.)
그리고 이것은 다른 개발자가 속성 이름을 변경해버리면 사이드 이펙트가 발생한다.
See the Pen BWzdOb by Kenneth Ceyer (@PIGNOSE) on CodePen.
이해를 돕기위해 소스를 첨부한다.

앵귤러는 이런 문제를 현명하게 대처한다.
앵귤러는 사용자 화면 관점에서 개발 할 수 있는 특징을 가지고 있다.
사용자 화면과 자바스크립트(혹은 타입스크립트)는
보이지 않는 무언가로 연결되어 있다.
우리는 이것을 바인딩 되어있다. 라고 표현한다.

이것이 핵심이다.
개발자가 코드 상으로 어떤 값을 가져오면 사용자 화면(HTML)은 값을 가져온 것을 자동으로 인지하고
그것에 맞는 엘리먼트를 자동으로 생성한다.
그리고 생성된 엘리먼트에 이벤트를 자동으로 연결한다.
변수와 사용자 화면이 1:1로 연결되어있기 때문에
개발자는 사용자 화면을 제어하기 위해서 엘리먼트를 탐색 할 필요가 없다.
예를들어 36번 구분자를 가진 엘리먼트를 삭제하고자 한다면
배열중에 구분자가 36번인 요소를 삭제하면 사용자 화면은 이를 감지해서 삭제된 배열 요소와 매칭된 엘리먼트를 자동적으로 삭제한다.
변수와 연관된 처리로직을 사용자화면에서 제어하기 때문에 코드재활용에 대해서 신경 쓸 필요가 사라진다.
그리고 사용자 화면 제어와 관련한 로직은 사용자 화면에 명시 되어 있기 때문에
다른 개발자는 오직 사용자 화면을 살펴보면 된다.
이는 협업에서 코드 문서화를 하지 않아도 직관적으로 코드를 볼 수 있기 때문에 유리하다.
See the Pen mWEMNa by Kenneth Ceyer (@PIGNOSE) on CodePen.
아까전의 코드를 이번에는 앵귤러 v1.6으로 표현해봤다.
제이쿼리 코드에서 거론 되었던 문제점이 어떻게 해결되었는지 보이는가?
여러분이 앵귤러로 코드를 작성하면서 얼마나 많은 즐거움이 있을지 상상해봐라!
결론

앵귤러는 그냥 쩐다.
자바스크립트를 사용하며 무의식적으로 불편한 기능들을
앵귤러는 멋있고 똑똑하게 해결했다.
앵귤러의 장점들을 이 포스트에 모두 녹이기에는 너무 많기 때문에
추후 앵귤러 JS 강의를 통해 여러분에게 그 장점들을 소개하도록 하겠다.
앵귤러는 정말 멋있는 언어이지만 긱(Geek)을 위한 언어가 아니다.
불필요하게 우아하지도 않고, 일부러 어렵게 표현하지도 않는다.
여러분이 힙스터를 싫어하고 얼리어답터를 싫어하더라도
앵귤러는 배워서 나쁠 것이 없다.
다들 이 글을 읽었다면
앵귤러 공식문서로 들어가 앵귤러에 대해서 더 자세히 알아보기를 바란다.
2 notes
·
View notes
Text
개발자 블로그 왜 텀블러를 택할 수 밖에 없었나
요새들어 새벽 4~6시 모두가 다 자는 시간에 노트북으로 블로그를 정리하는 것 같은 기분이 든다.. (그리고 낮에 자고,, 물론 휴일이라 가능하겠지만..)
포스트 글을 볼려고 들어왔으니 당연히 아실 수 밖에 없지만 현재 필자는 블로그를 텀블러 서비스로 사용하고 있다. 이번에는 개발자 블로그를 개설하게된 배경과 텀블러 서비스를 사용한 이유에 대해서 주제로 잡고 가볍게 얘기하시는 시간을 가지고자 한다.
1. 기여문화
우선 개발자 블로그를 운영하시는 분들은 여러 이유로 시작하게 된다.
재미
또 다른 자기만의 소통채널을 만들고자
금전목적..? (티스토리 서비스 같은 광고게재가 가능한 블로그 서비스)
학업목적, 연구 내용 기록 (어딘가에 기록해야 더 자주 들여다보게 된다.)
어떤 목적을 가지고 블로그를 개설하게 되었는지는 중요하지 않지만, 필자는 이런 개발��� 블로그 활동 자체를 긍정적으로 바라보고 있다.
바로 기여문화를 가지고 있기 때문이다.
이것에 대해서 자세히 설명하기 위해서는 술이 몇잔 들어가고
다소 진지한 분위기에서 강연(?)을 하게 될 것 같으니 간략히 설명하자면,
특정 기술분야에 대한 직간접적 기여활동은 결국 또 다른 불특정다수의 동종계열 기술자에게는 상당히 도움이 될 수 있다.
결국 기여문화는 하나만 놓고보자면 초라하고 보잘 것 없겠지만,
수 많은 다른이가 그 기여 덕분에 얻어갈 수 있게 된다.
여기서 말씀드린 기여문화는 개발 직군에는 아래와 같은 활동이 된다.
제품의 취약점 파악 및 내용 전달
오픈소스 개발 기여, 컨트리뷰션 활동
오픈소스 개발 지원, 재단 지원
문서의 번역, 정보공유 활동
등등...
결론적으로 필자는 이런 기여 활동을 하는 사람들을 존경하고 있으며
필자도 기여문화의 일부분으로 블로그를 개설했다.
혹시 아직까지 스택오버플로나 기타 검색엔진 노출 링크를 통해 정보를 공유받고 있음에도
기여 활동을 하지않은 개발자가 있다면 이 시간을 빌미로 시작해보시기 바란다.
2. 블로그 종류
필자는 몇가지 블로그 서비스들을 이용해봤던 것 같다.
가장 처음에는 네이버카페를 이용했고,
티스토리를 지나 워드프레스를 이용하고나서 텀블러로 이사온 것 같다.
그 사이에 블로그 서비스를 아예 만들어보기도 했다.
(블로그 글 운영이 잘될 수록 씨앗을 주고 커버 영역에다가 농장을 꾸미는 컨셉이었다.)
물론 예전에 블로그들은 필자가 꾸준히 블로그를 운영하고 있지 않아서,
그렇게 이용자가 많지 않았다.
필자가 블로그를 갈아타는 이유는 아래와 같다.
UI 문제, 가독성 등
접근의 문제(검색엔진 노출, SNS 최적화 문제)
기능의 문제(앱 미지원, 마크다운, 스니펫 입력방식 미지원)
커스터마이징 제한(HTML 테마 편집옵션 제한)
그래서 필자는 마지막에 텀블러로 블로그 서비스를 이전하게 되었는데,
간단히 텀블러를 보고 바로 온것이 아니라 여러 블로그 서비스를 비교하며 결국 텀블러를 선택하게 되었다. 그리고 이제 블로그를 이전할 생각이 없다 (RSS 피드를 받는 독자들이 불편할 수 있다.)
텀블러로 오기 전 비교한 블로그 플랫폼은 아래와 같이 각각의 섹션으로 정리 해본다.
2-1. 네이버 블로그
http://blog.naver.com

네이버 블로그는 너무나 대중적으로 사용 되는 블로그이다.
필자도 예전부터 애용 했던 서비스 이지만 아래와 같은 단점이 존재했다.
테마 커스터마이징이 비교적 제한적임.
코드 첨부(스니펫) 기능이 존재하지 않고 Gist 연동이 불가능 함.
구글 검색 노출이 제한적이기 때문에 개발자들 노출이 높지 않음(개발자들은 구글검색을 자주함)
UI 가독성에 제약이 있음(커스텀 폰트 사용의 제약)
지금은 어떨지 모르겠지만 추적코드 삽입자체가 불가능하기 때문에
네이버 외 애널리틱스 서비스나 웹 마스터 서비스를 달 수 없었고,
네이버 계정이 아니면 댓글 참여도 불가능하기 때문에 상당히 폐쇄적인 느낌이 강했다.
2-2. 티스토리
http://www.tistory.com
티스토리는 초대장을 받아서 블로그를 개설할 수 있기 때문에 한때 티스토리 블로그들은 전체적인 완성도(?)가 좋았다.
티스토리에서는 비교적 테마 커스터마이징이 자유로워서 상당히 좋았고,
최신글이나 방문자 카운팅 기능을 지원하여 사용자 이탈률을 줄일 수 있다.
하지만 텍스트 에디터 구성이 불편해서 글 쓰는 재미가 떨어진다..
그리고 티스토리 로그인 후 글을 쓰는 단계가 비교적 복잡하고, 전체적인 기능이 파편화 되있어 관리가 번거롭다.
그래도 티스토리 블로그는 계속 개선되고 있고 가독성도 좋아져 그렇게 부정정인 시각으로 바라보고 있지 않는다.
2-3. 브런치(Brunch)
https://brunch.co.kr/

카카오에서 운영하는 블로그 플랫폼 브런치는 상당히 심미적이고 철학이 묻어있는 블로그 서비스이다.
가독성도 좋아 블로그 글을 작성하는 것이 재밌게 느껴 질 수 있는 서비스이다.
브런치에서 올라오는 글들은 대체적으로 퀄리티가 높고, 추천글인 “당신을 위한 브런치"에서는 유사글을 연결시켜 주기 때문에 독자들로 하여금 여러 포스트를 살펴 볼 수 있도록 편의기능을 제공한다.
모바일 앱도 제공하기 때문에 상당히 매력적인 서비스이지만,
개발자가 이 블로그 플랫폼을 채택하기에는 치명적인 단점들이 존재한다.
테마 커스터마이징이 불가능 함.
코드 삽입(스니펫)과 gist 지원이 불가능 함.
테마까지는 이해하고 넘어간다 쳐도 코드삽입이 불가능 한 것은 개발자 블로그에 상당히 큰 타격이다.
만약 브런치에서 코드삽입 기능을 지원하면 귀띔을 해주시기 바란다.
필자는 브런치 블로그 서비스를 사용하고 있지 않지만 브런치 글을 자주읽는 편이다.
2-4. 미디움(Medium)
https://www.medium.com
트위터 창업자 에반 윌리엄스(Evan Williams)가 개발한 미디움은 Medium Corporation에서 관리하고 있다.
본론으로 들어가면 무려 코드 삽입과 gist를 지원한다.
글을 작성하는 에디터, 추천글을 유도하는 방식, 에디터의 메인���서 블로그 리스팅 모든 면에서 완벽하다..
미디움 서비스 글을 처음 딱 목격 했을때 필자는
아 인생 블로그를 찾았다!
라는 느낌을 받았지만, 마찬가지로 테마 커스터마이징에 제한이 있다. (지금 글을 쓰면서 생각해봤는데 테마가 나한테 대체 무슨 의미가 있던건가..)
물론 한가지 문제가 더 있다,
스타일 정의에 제약이 있기 때문에 본문 글의 폰트 타입 지정이 불가능하다.
미디움은 Serif(문자 끝에 꺽임이 있는 방식)을 사용하고 있는데,
그 때문에 한글 본문글이 죄다 명조체로 되어있다.
결론적으로 한글에서 본문글을 읽게되면 돋움체보다 눈에 더 안들어오는 문제점이 발생한다.
고정된 테마와 한글 명조체 사용에 문제만 없다면 필자는 이 서비스를 추천한다.
2-5. 지킬(Jekyll)
https://jekyllrb-ko.github.io/

지킬(Jekyll) 서비스는 MIT 라이센스를 가지고 있는 오픈소스 서비스이다.
완전히 개발자 친화적인 블로그 플랫폼이며,
Ruby를 이용하여 서비스를 개설 할 수 있고, GitHub Pages 서비스를 이용하여
GitHub에서 블로그를 호스팅 할 수 있다.
따라서 지킬에서 제공하는 기능외에도 자유롭게 추가 기능을 제공 할 수 있으며,
더군다나 테마 편집이나 연동기능이 자유롭다.
다만 아래의 단점들이 존재하기에 필자는 지킬을 사용하지 않는다.
1. 마크다운 기반 작성방식을 가진다 (이미지업로드가 극단적으로 불편하다. WYSIWYG 편집기능이 없기 때문에 크기변경 작업 등이 불편하다.)
2. 고려해야 할 부분이 많다, 너무 자유롭기 때문에 블로그 운영에서 많은 자원을 직접 찾아야 한다. (SEO, 임베드 연동, OG 태그, 부수기능 연동)
3. 정적으로 제너레이션 시키는 작업이 번거롭다.
4. 데스크탑이 아니면 작성할 방법도 없다. (모바일로 GitHub에서 수정하는 괴물들을 제외하자)
2-6. 텀블러(Tumblr)
http://www.tumblr.com
필자가 지금 이용하고 있는 블로그 서비스이다.
텀블러는 tumblr inc에서 운영되고 있고 야후에 인수된 업체이다.
텀블러에서는 필자가 개발 블로그를 운영하는데 필요한 기능들을 갖추고 있다.
마크다운(Markdown) 편집 지원.
이미지 업로드 및 텍스트 편집이 단순하고 간편함.
모바일 앱 지원.
검색엔진 최적화 지원(SEO).
심미적인 테마 지원과 커스터마이징 가능.
높은 가독성 지원.
블로그 포스트 URL 편집지원.
디스커스(DISQUS) 지원.
필자는 텀블러 서비스를 완전히 긍정적으로 생각하지는 않는다.
아래와 같은 이유 때문이다.
블로그 글 편집을 할 때 다른 페이지에서 모달 창을 이용해 편집하게 된다. 이것이 상당히 맘에들지 않고 리소스를 잡아먹게 된다. (백그라운드가 그대로 살아있음)
카테고리와 추천글 기능이 없다. (커다란 불편사항)
텀블러 서비스에 다른 블로그들을 보면 부적절한 컨텐츠가 자주 노출된다.
결국 텀블러 서비스를 이용하고 있음에도 완벽하게 만족하며 사용하고 있지는 않은 상태이다.
추후 이런 불편 기능이 개선되었으면 좋겠지만,
지금까지 많은 시간이 있었음에도 개선이 안된 걸로 미루어보아
앞으로도 많은 기대를 하지 않는 것이 좋을 듯 하다 ㅜㅜ
11 notes
·
View notes
Text
Angular 2 그리고 웹 프론트엔드 (1/2)
한동안 마무리 지어야 하는 일때문에 정신이 없다가 이제서야 정리를 할 시간이 오게 되었다..
이 포스트에서는 Angular가 무엇인지 모르는 분들을 위해 Angular를 설명하는 내용을 채울까 한다.
Angular 2 그리고 웹 프론트엔드 (1/2) - 현재 글
Angular 2 그리고 웹 프론트엔드 (2/2)
Angular는 구글에서 만든 자바스크립트 프레임워크이다.
프레임워크이기 때문에 일반적으로 여러분이 아시는 jQuery, underscore, lodash 보다 규모가 큰 프로젝트다. (지원되는 기능의 폭도 넓으며 채택한 의존 라이브러리들도 많다.)
한글 발음으로 “앵귤러 제이에스"라고 발음하면 되며 여기서 Angular는 “앙상한" 이라는 단어를 가지고 있는데,
아무래도 뼈대를 갖춰주는 프레임워크라는 의미로 사용했을 것이라고 생각된다.
Angular 공식페이지에 기재된 워��이 “One framework” (하나의 프레임워크)인데, 이는 Mobile까지 대응하겠다는 Angular의 목표가 깃들어있다.
Angular에 대해서 대체 무슨 프레임워크인가, 어떤 목적과 장점을 가지고 있는가에 대해서 궁금증이 많으실 것이라 생각된다.
사실 이 물음을 풀어드리기 위해서는 앞서 웹 프론트엔드 개발 동향을 먼저 설명해야 할 것 같다.
웹 프론트엔드의 변화

현재 웹 프론트엔드 개발에서 사용되는 툴이 많다! 너무 많다! (그리고 많아지고 있다!!)
(필자는 이 사진에 보여지는 앱보다 많은 앱을 사용했음에도 전체에 비해서는 절반도 채 되지 않는다.)
일부 개발자는 전통적인 프론트엔드 개발 방식대로 html과 javascript 그리고 css를 개발하고,
javascript 엘리먼트를 쉽게 찾을 수 있는 jQuery와 jQueryUI를 연동하여 서비스를 완성 했을 것이다 그리고 그렇게 개발하는 방법에 큰 불편함이 없었을 것이다.
결과적으로 오늘에서 이렇게 개발을 도와주는 앱이 많아진 것은 ECMA 5에서 ECMA 6로 자바스크립트 표준이 변경되고 있는 상황과,
Node.js 보급으로 인해 백엔드 서버 개발자가 점점 javascript를 사용하게 되면서 백엔드 기술 프론트엔드와의 경계가 허물어지고 있는 점.
그리고 거대한 웹 서비스 벤더사(구글, 페이스북)에서 프론트엔드 프로젝트에 기여를 하고 있는 점 이것들이 뭉치면서 아래와 같은 결과를 내었다.
웹 프론트엔드 개발에 백엔드 개발에서 요구되던 기능이 추가되고 있다.
ECMA6의 지원을 위한 서브 툴이 생겨나고 있다.
많은 모바일기기 지원으로 보다 빠른 웹을 시장이 원하고 있다.
많은 기존 자바스크립트 라이브러리들이 최신 기술을 수용하고 있다.

(웹 프론트엔드 개발자들은 공부할 것이 엄청나게 늘어나 버렸다.)
또한 이러한 변화가 프론트엔드의 러닝커브를 늘렸으며,
기존 개발 환경에 익숙하여 최신 동향을 살펴보지 않는 개발자들은
자리를 위협받는 상황이 오지않았나 조심스럽게 추측해본다.
웹 프론트엔드 도구들
그러면 아까 사진에 보여드린 수많은 앱 들이 도대체 무슨역할을 하나?
그리고 그것이 반드시 필요한가에 대해서도 설명을 드릴까 한다.
상당히 지루하고 딱딱한 내용이 될 것 같아 많은 링크와 사진을 첨부했다.

1. npm, bower, yoman, yarn
이 4가지 서비스는 Pakcage Manager(패키지 매니저)라고 부르는 서비스다.
(yoman은 정확히 말하면 스캐폴딩(Scaffolding - 실제 작업을 하기 전 철골을 덧대듯이 작업에 필요한 최소한에 구조를 만들어주는 단계)만 해주는 서비스.)
쉽게 풀어보자면 프로젝트에 사용할 라이브러리를 직접 찾아 해당 파일을 원격지에서 다운받아 로컬 파일에 옮기지 않아도, 간단한 명령어로 추가/수정/삭제를 지원하고 의존성(Dependency)을 관리해주는 서비스들을 의미한다.
또한 라이브러리 배포와 호스팅/빌드/테스트 스크립트 정의도 가능하다.

2. Typescript, Flow
타입스크립트는 자바스크립트에서 발생할 수 있는 문제(타입 검증)를 해결해주는 동시에 ECMA6의 스펙을 포함하여 지원하고 있으며 Microsoft와 Google이 협력하여 개발하고 있는 언어이다. Typescript를 통해 개발을 진행하게되면 런타임 단계에서 발생할 수 있는 오류를 미연에 방지할 수 있고 OOP 지향한 개발과 Dependency Injection(DI)등의 패턴을 구현할 수 있게 된다. React 프로젝트의 Flow또한 타입 검증을 지원해준다.

3. Reactive Programming
과거에는 웹 페이지 이동 (빈 화면에서 로딩이 걸리고 새로운 페이지가 보여지는) 없이 데이터를 업데이트 하는 사이트는 드물었지만 지금은 웬만한 서비스에서 이 기술을 적용하고 있다. 이러한 비동기 통신은 콜백함수를 통해 전달이 되어야 했으며 이 때문에 콜백지옥이 발생하기도 했다. RX(ReactiveX) 프로젝트는 이러한 문제를 해결해주며, 옵저버 패턴을 제공하여 서로다른 컨텍스트에 데이터를 동시적으로 제공해줄 수 있다. Redux, Flux 서비스는 이러한 데이터를 효율적으로 대상에게 전달할 수 있다. 참고로 AngularJS 2는 RxJS를 포함 할 수 있다.

4. grunt, gulp, webpack
여러분이 만약 반복되는 작업을 조금이라도 재활용하여 효율적인 프로그래밍을 원했다면 CSS의 작성이 굉장히 피곤하게 느껴졌을 수 있다, LESS와 SASS, Stylus와 같은 기술은 이러한 반복되는 작업을 없애주고 더불어 색상 코드를 특정 % (밝게, 어둡게)와 같은 편의 함수를 제공한다. 다만 결국 브라우저는 CSS 문서만을 인식하기 때문에 .less .sass와 같은 확장자는 빌드단계에서 ���경이 이루어져야 한다, 그 밖에도 빌드 단계에서 진행되야 하는 작업들 (ECMA6 파일을 ECMA5 파일로 변경, 문서 최적화, 코드 테스트, 카피라이팅 삽입, 문서 문법 검증, 번들링 등)을 도와주는 도구가 grunt, gulp, webpack과 같은 도구이며 이는 다시 npm등의 패키지 매니저 도구와 연동하여 사용하거나 IDE(통합 개발환경)에서 연동하여 빌드과정을 일관화 시킬 수 있다. 이렇게 되면 파편화 되있는 JS, CSS, HTML 문서를 하나로 합쳐주며 표준코딩을 지향하게 되며 하위 호환 여부 검토가 수월하고 예기치 못한 버그와 사이드이펙트를 미연에 방지 할 수 있게 된다.

5. RequireJS 그리고 CommonJS와 AMD(Asynchronous Module Definition)
Node.js의 영향 중 하나라고 필자는 생각한다.
네이버 D2에서 작성한 글이 보기 좋아 링크를 공유한다.
웹 페이지에서 서비스를 개발할 때 여러 Javascript 라이브러리를 합쳐 하나의 완성된 서비스를 만든다. 이때 이 라이브러리를 하나의 모듈로 볼 때 그 모듈에 대한 표준이 없다는 것이다. 따라서 각각의 라이브러리들은 서로다른 라이브러리 제공방식을 사용하고 있고 이를 이용하는 개발자는 각각의 라이브러리마다 다른 방식의 사용법 (같은 라이브러리라도 버전마다 달라지기도 한다.)을 이용해야하고 또 이러한 부분은 굉장히 비효율적으로 이용된다. (케익 한조각을 먹기위해 케익 전체를 사야하는 상황)
이를 해결하기 위해 나온 모듈 제공 방식이 CommonJS와 AMD이다.
각각의 사용형태가 다른 모듈들을 제공하는 하나의 표준을 만들어 그것을 지향하면 라이브러리 추가와 확장이 훨씬 쉬워지며 이는 큰 프로젝트에서도 모듈의 관리가 용이하며 효율적이다. 하지만 이 방식을 사용해도 마찬가지로 브라우저에서는 지원하지 않기 때문에 (다만 ECMA6는 import 키워드를 제공한다.) 이를 번들링 하기 위한 systemjs, Jspm, Rollup.js, Webpack등의 서비스가 존재한다

6. jasmin, chai, mocha
규모가 큰 프로젝트 일수록 소스관리가 중요하여 자칫 하나의 수정사항이 사이드이펙트(다른 비즈니스 로직에 직/간접적으로 영향이 가는 것)가 발생 할 수 있다.
이는 라이브서비스에 커다란 이슈이며 이를 해결하기 위해 QA와 테스트케이스가 존재한다. 다만 규모가 크고 지원하는 플랫폼이 넓으며 수많은 페이지와 버그가 발생하는 환경을 시연하기 어려운 요소가 발생되면 이러한 테스트는 사람이 직접하기 어렵고 특히 애자일 방법론을 사용하는 개발 환경에서는 이러한 과정이 거의 불가능에 가깝다. 결국 이를 해결하기 위해서는 자동화된 개발 테스트 환경이 필요하다.
프론트엔드 개발도 마찬가지로 유닛 테스트를 지원하는 서비스가 있다. 가상의 DOM Mock에 라이브러리의 모든 케이스를 테스트해보고 결과적으로 테스트의 결과를 확인할 수 있게 제공하여 서비스 배포이전에 모든 기능에 안전성을 검토 할 수 있다.

7. istanbul, blanket, JSCoverage
이전에 말한 유닛테스트는 서비스 되고있는 소스코드의 얼마나 많은 부분을 테스트 해주는지에 대한 부분이 상당히 중요하다. (많은 부분이 자동화 테스트를 지원할 수록 서비스는 안정적이고 신뢰를 보장하기 때문) 하지만 얼마나 많은 부분의 소스코드에 테스트를 지원하는지 사람이 알기에는 어렵다고 볼 수 있다. 이 때문에 얼마나 많은 부분이 테스트가 되었는지, 다시말해 얼마나 코드가 커버(Cover)되었느냐는 커버리지(Coverage)라는 용어를 사용하여 지표를 결정한다. 유닛 테스트 도구와 연동하여 커버리지 도구를 사용하게 되면 커버리지 지표를 리포트로 제공받게 된다.

8. JSDoc
JSDoc은 javascript 모듈에서 사용되는 각각의 클래스, 함수들에 대한 정의를 JSDoc에서 정의한 표준 주석양식에 맞춰 작성하게 되면 그에따른 자동화된 개발 래퍼런스 문서가 만들어지게 된다. 마크다운 문서로 래퍼런스 문서를 제공하여 gitbook 같은 호스팅 서비스에 등재하게 되면 하나의 인쇄물로서 출력도 가능하다. 이러한 방법은 개발자가 일일히 래퍼런스 문서를 만들지 않아도 래퍼런스 문서를 만들 수 있는 이점이 있으며 표준화된 주석 사용으로 협업 및 인수인계가 원할하게 된다. 사실 다른 Doc 툴도 있지만 해당 서비스가 가장 유력하다.
AngularJS 2에 대한 설명을 위한 포스팅이었으나, 최근들어 웹 프론트엔드 개발 동향이 많이 변하고 있어 그 부분을 중점적으로 정리해보았다.
다음시간에는 Angular 2와 Angular 1 그리고 ReactJS를 주제로 중점적으로 다뤄보는 시간을 가져보도록 하자. 아디오스!
#개발#웹 프론트엔드#npm#bower#yoman#yarn#typescript#flow#ecma5#ecma6#requirejs#commonjs#amd#Reactive Programming#ReactiveX#React#jasmin#chai#mocha#istanbul#blanket#JsCoverage#JsDoc#grunt#gulp#webpack#systemjs#jspm#rollup.js#import
5 notes
·
View notes
Text
MAC의 터미널 테마적용을 위한 zsh 그리고 oh my zsh
MAC 유저 혹은 리눅스 유저는 당연하게도 커멘드라인을 작성해야 할 경우가 많고 이를 위해 bash를 사용할 것이라 예상한다.
MAC에서 테마를 설정하기 위한 일반적인 방법으로는 보통 .bashrc 혹은 .bash_profile을 사용한다 (링크 참고), 하지만 이 방법을 통해 변경 할 수 있는 테마는 배경색상과 텍스트색상등으로 한정되어 제공된다.
다만 여러분이나 필자 같은 경우 아래와 같은 테마를 생각하고 있을 것이라 생각된다.

여기서 다루는 zsh가 제공하는 기능중에 유용할 것이라 예상되는 기능은 아래와 같다.
현재 바라보고 있는 패스 안내 (CWD)
python user를 위한 virtualenv 안내
ruby user를 위한 RVM 안내
node.js user를 위한 NVM 안내
git 사용자를 위한 현 브랜치 상태 및 스테이징 커밋 여부 안내
사실 위에 기능을 전혀 사용하지 않더라도 전체적인 UI가 기존 제공되는 UI 보다 좋기 때문에 zsh 설치작업이 의미가 있다고 생각되며, zsh 자체의 편의 기능도 상당하다.
zsh 장점에 대해서도 적어드리고 싶었는데 이번 장은 zsh 실전 활용에 대해서만 소개드리기 떄문에 이 링크로 대체한다.
그럼 본격적으로 zsh 설치에 들어가보도록 하자!
zsh 설치는 MAC에서 Homebrew를 통해 간단히 설치가 가능하다.
https://gist.github.com/KennethanCeyer/da0f143df2a72b72918818aef8749c13
zsh 설치가 완료되었다면, 우선 기본 쉘 설정을 바꿔주도록 하자.
which 커멘드를 통해 zsh의 위치를 확인한 후 chsh를 통해 변경 할 수 있다.
이때, sudo로 실행하지 않도록 한다.
https://gist.github.com/KennethanCeyer/07074280282f620906a25314a91dee83
위와 같이 설정을 완료했으면, 터미널을 껐다 켜보자.
아마 zsh로 정상적으로 적용이 되었다면, 쉘의 표기방식이 변경 된 것을 느낄 것이다.
이번에는 다양한 테마를 사용하기 위해 oh my zsh를 적용해보도록 하자.
진행하기 앞서 oh my zsh에 대해 간단하게 설명을 드리자면,
900명 이상의 컨트리뷰터와 활발한 커뮤니티를 가지고있는
zsh 테마 및 플러그인 지원을 도와주는 설정 담당 프레임워크다.
우리는 이번 시간에 oh my zsh를 통해 테마를 추가 할 것이다.
oh my zsh에서 지원하고 있는 테마 목록은 여기서 확인 할 수 있다.
먼저 oh my zsh에서 공식적으로 안내하는 설치방법을 따라가자.
wget과 curl 두가지 방식을 제공하고 있는데 여기서는 curl을 이용한 설치를 진행한다.
https://gist.github.com/KennethanCeyer/2e38cea69d76c9b0052bc282a0156f40
oh my zsh 설치를 마쳤다면 ~/.zshrc에서 설정을 진행한다.
vi 커멘드를 통해 편집을 진행 할 것인데 vi 사용법을 모른다면 이참에 공부해보자.
아마 필자의 생각엔 이 링크에서 안내하는 정도만 배워도 설정이 가능하다.
https://gist.github.com/KennethanCeyer/b98981e65aabd509ce25a9cfa8333149
정말 vi나 vim을 싫어하면 open 커멘드를 통해 우리의 친구 메모장을 열어서 편집하도록 한다.
https://gist.github.com/KennethanCeyer/3f6e685ba6f6f3cf69ffe829352c8f2b
여기서는 기본 테마인 robbyrussell을 적용했다.
ZSH_THEME 항목을 찾아 원하는 테마를 입력해준다.
https://gist.github.com/KennethanCeyer/601df6ea7d3f4556284b0cef03ac07de
다시한번 터미널 창을 껐다 키면 아래와 같은 놀라운 터미널 창을 볼 수 있다.

일부 MAC에서는 위와 같이 테마가 적용되지 않고 흰 배경에 텍스트에만 배경색이 들어가는 경우가 존재하는 것으로 알고있다.
터미널 화면에서 Command + , 키를 누르면 설정 창이 열리는데,
이럴 경우 “프로파일” 탭에서 배경 색을 조정해주어야 한다.

1 note
·
View note
Text
C# 서브도메인 별 회원분류 처리
개발을 진행하다보면 서브도메인을 가상으로 사용하여 원하는 기능을 개발할 경우가 생긴다.
필자가 개발하고 있는 C# ASP.net 프로젝트에서도 이러한 기능 개발을 수행하여야 했다.
서브도메인이란 *.domain.com과 같이 '*'에 어떤 단어, 문자열을 병합해 도메인내에서 다시한번 구간을 나눠주는 기능이다. 우리는 이러한 서브도메인을 업체별로 분리해 비즈니스에 특화된 서비스를 개발하고 있다.
따라서 먼저 필요한 것은 서브도메인을 네임서버에서 설정하는 것인데, 이는 AWS의 Route53에서 처리가 가능하니 추후에 관련된 글로 작성을 해서 소개해볼까 한다. 여기서 중요한 것은 ASP.net에서 어떻게 서브도메인을 내부로직이랑 연계시키는지에 대해서 논제를 맞추고 그것에 집중해주기를 필자는 바란다.
필자는 로컬환경에서 개발을 진행한 후 서비스를 Beta, Live로 순차적으로 반영을 수행한다. 따라서 로컬환경에서도 서브도메인 테스트가 이루어져야 하는데 이는 hosts 설정을 통해 해결이 가능하다. hosts는 로컬에서 ip와 도메인을 매핑시키는데 이는 로컬에서 해당 도메인에 대한 리스트를 제공해주는 방식으로 진행된다.

"C:\Windows\System32\drivers\etc\hosts"를 관리자 권한으로 실행시킨 메모장을 통해 편집하였다.
위와 같이 필자는 dev 서브도메인을 갖도록 도메인을 구성했다. 이렇게 구성이 되었으면 IIS를 실행하고 도메인에 접속해보자.
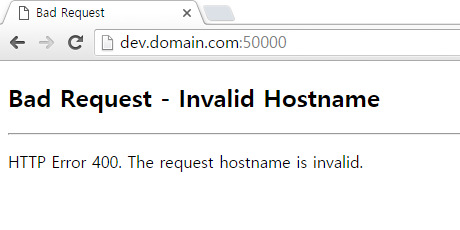
물론 무사히 접속이되면 좋겠으나 이러한 작업은 바인딩이 되어있지 않아 위 이미지와 같이 웹 페이지 에러가 출력될 것이다. 아래의 절차대로 바인딩을 설정해보자.
1. "C:\Users\{{유저 명}}\Documents\Visual Studio {{비주얼 스튜디오 버전 2012, 2015 etc}}\Projects\{{프로젝트 명}}\.vs\config" 주소로 들어간다.
2. applicationhost.config를 열어 아래 이미지와 같이 site를 찾아 binding을 추가한다.
3. IIS Express를 재 실행하여 테스트를 진행한다.
만약 위의 방법으로 해결되지 않는다면 IIS Express에 설정을 걸어줘야 한다.
1. "C:\Users\{{유저 명}}\Documents\IISExpress\config" 으로 들어간다. 2. applicationhost.config를 열어 위에서 설명한 이미지와 같이 site를 찾아 binding을 추가한다. 3. IIS Express를 재 실행하여 테스트를 진행한다.
여기서 주의할 점은 VS 환경의 사용자의 경우 80외 임의의 포트가 걸려있을텐데, VS 환경에서 프로젝트 -> 프로젝트 속성의 웹 탭에서 확인이 가능하다. 도메인이 dev.domain.com이고, 포트가 50000으로 지정되어 있다면 dev.domain.com:50000으로 접속을 시도하기 바란다.
이제 도메인을 통해 웹 페이지에 접속이 되었을 것이다. 만약 되지 않았다면 시스템을 재시작하여 확인을 해보는 것이 좋을 것이다. 도메인 접속이 된 다음 내부로직에서 서브도메인 (dev)를 문자열로 인식해야 한다. 이는 보다 간단하다. 임의의 컨트롤러 (이를테면 HomeController.cs)에서 Initialize를 오버라이드하여 아래와 같은 Snippet을 통해 받아올 수 있다.
https://gist.github.com/KennethanCeyer/24b9fa87d0f2145e0ebf95d90a2c0c19
여기서는 Session에 서브도메인 문자열을 저장하였지만 일반 값이므로 매개변수로 활용하거나 전역변수로 지정이 가능하다.
0 notes
Text
C# Raw Query를 통한 동적 칼럼 매핑방법
C# Asp.NET MVC를 사용하시는 분들이라면 Linq를 통한 데이터베이스 사용에 익숙해 있을거라 생각합니다.
하지만 일부 가변 칼럼의 적용이 필요한 서비스의 경우
반대로 클래스 매핑이 필요한 ORM이 아닌 Raw Query를 사용해야 하는 경우가 발생하지요,
여기서 ORM은 Object / Relational Mapping을 의미합니다.
데이터베이스의 Relation을 객체로 정의하여 보다 직관적으로 개발이 가능하도록 돕는다는 정의입니다.
다만 C#은 Raw Query를 발송 할 수 있는
string query = "SELECT {columns} FROM {table}"; Database.SqlQuery(query);
위 패턴을 사용할 경우 제너릭을 통한 타입을 정의해주어야 합니다.
보통의 경우에는 타입을 나타낼 수 있는 클래스를 하나 더 생성시켜 아래처럼 구성할 것입니다.
https://gist.github.com/KennethanCeyer/950972f65c4df95732b2
다만 필자는 테이블을 가변적으로 생성하고, 그 안에 칼럼마저
사용자에 필요에 따라 가변적으로 추가/삭제/수정 될 수 있으며
칼럼의 타입이나 이름을 유추할 수 없기 때문에
"클래스 매핑이 불가능" 하였습니다.
따라서 필자의 상황에서는 아래와 같은 요구사항을 만족해야 했습니다.
테이블 명이 변함.
클래스 매핑이 필요없이 가변으로 추출해야 함.
추출한 데이터는 List 형태로 받아와 JsonResult로 반환이 가능해야 함.
물론 초기에 필자도 아래와 같이 사용을 시도해보았습니다.
string query = System.IO.File.ReadAllText(Server.MapPath(@"~/ConnectionPool/MySQL/Schemas/Schema.sql")); query = query.Replace("{table}", table); query = query.Replace("{column}", String.Join(",", columns).ToString()); var data = db.Database.SqlQuery(query).ToList();
위의 사용사례로 실행을 해보면 실제 테이블 로우를 가지고 오며
List의 Count는 테이블 로우의 갯수와 일치합니다.
하지만 List 데이터 안에 키와 칼럼은 빈 값으로 추출됩니다.
사실 우여곡절 많은 검색으로 난관을 거쳤지만
결론으로 넘어가서 말씀을 드려보면 C#에서도 동적칼럼을 추출하는 것이 가능합니다.
아래 코드를 참조하세요.
https://gist.github.com/KennethanCeyer/ba67dc1df770e68ded9e
위 코드의 동작방식은 아래와 같습니다.
쿼리 문 작성
DynamicSqlQuery 메서드 실행.
쿼리를 사용하여 데이터를 받기 앞서 GetSchemaTable를 리더로 실행, 칼럼 타입과 네임을 가져옴.
TypeBuilder를 통해 각 칼럼의 Setter, Getter 정의 및 Field를 추가, 가변 클래스를 생성.
클래스의 Type을 이용하여 SqlQuery의 Element Type에 가변 클래스 타입 지정.
수신 받은 데이터에 ToListAsync().Result를 이용하여 결과데이터 수신.
#개발#C Sharp Variable Columns#SqlQuery Dynamic Type#SqlQuery Variable Columns#Dynamic Raw Query C Sharp#DynamicSqlQuery#Typebuilder#Linq Raw Query#MVC 4.0 Dynamic Columns#Variable Raw Query Result#C Sharp Raw Query#Variable table query C Sharp#Variable linq column type#C Sharp#development
1 note
·
View note