#AI Large Language Model Development Company
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The KCSC sent more than 20K requests to delete posts related to prostitution and porn to Tumblr from January to June 2017.
Text
large language model companies in India
Large Language Model Development Company (LLMDC) is a pioneering organization at the forefront of artificial intelligence research and development. Specializing in the creation and refinement of large language models, LLMDC leverages cutting-edge technologies to push the boundaries of natural language understanding and generation. The company's mission is to develop advanced AI systems that can understand, generate, and interact with human language in a meaningful and contextually relevant manner.
With a team of world-class researchers and engineers, LLMDC focuses on a range of applications including automated customer service, content creation, language translation, and more. Their innovations are driven by a commitment to ethical AI development, ensuring that their technologies are not only powerful but also aligned with principles of fairness, transparency, and accountability. Through continuous collaboration with academic institutions, industry partners, and regulatory bodies, LLMDC aims to make significant contributions to the AI landscape, enhancing the way humans and machines communicate.
Large language model services offer powerful AI capabilities to businesses and developers, enabling them to integrate advanced natural language processing (NLP) into their applications and workflows.
The largest language model services providers are industry leaders in artificial intelligence, offering advanced NLP solutions that empower businesses across various sectors. Prominent among these providers are OpenAI, Google Cloud, Microsoft Azure, and IBM Watson. OpenAI, renowned for its GPT series, delivers versatile and powerful language models that support a wide range of applications from text generation to complex data analysis. Google Cloud offers its AI and machine learning tools, including BERT and T5 models, which excel in tasks such as translation, sentiment analysis, and more.
Microsoft Azure provides Azure Cognitive Services, which leverage models like GPT-3 for diverse applications, including conversational AI and content creation. IBM Watson, with its extensive suite of AI services, offers robust NLP capabilities for enterprises, enabling advanced text analytics and language understanding. These providers lead the way in delivering scalable, reliable, and innovative language model services that transform how businesses interact with and utilize language data.
Expert Custom LLM Development Solutions offer tailored AI capabilities designed to meet the unique needs of businesses across various industries. These solutions provide bespoke development of large language models (LLMs) that are fine-tuned to specific requirements, ensuring optimal performance and relevance. Leveraging deep expertise in natural language processing and machine learning, custom LLM development services can address complex challenges such as industry-specific jargon, regulatory compliance, and specialized content generation.
#Leading LLM Developers#AI Large Language Model Development Company#largest language model services providers#large language model development company
0 notes
Text
Simplify Transactions and Boost Efficiency with Our Cash Collection Application
Manual cash collection can lead to inefficiencies and increased risks for businesses. Our cash collection application provides a streamlined solution, tailored to support all business sizes in managing cash effortlessly. Key features include automated invoicing, multi-channel payment options, and comprehensive analytics, all of which simplify the payment process and enhance transparency. The application is designed with a focus on usability and security, ensuring that every transaction is traceable and error-free. With real-time insights and customizable settings, you can adapt the application to align with your business needs. Its robust reporting functions give you a bird’s eye view of financial performance, helping you make data-driven decisions. Move beyond traditional, error-prone cash handling methods and step into the future with a digital approach. With our cash collection application, optimize cash flow and enjoy better financial control at every level of your organization.
#seo agency#seo company#seo marketing#digital marketing#seo services#azure cloud services#amazon web services#ai powered application#android app development#augmented reality solutions#augmented reality in education#augmented reality (ar)#augmented reality agency#augmented reality development services#cash collection application#cloud security services#iot applications#iot#iotsolutions#iot development services#iot platform#digitaltransformation#innovation#techinnovation#iot app development services#large language model services#artificial intelligence#llm#generative ai#ai
4 notes
·
View notes
Text
“I can now say with absolute confidence that many AI systems have been trained on TV and film writers’ work. Not just on The Godfather and Alf, but on more than 53,000 other movies and 85,000 other TV episodes: Dialogue from all of it is included in an AI-training data set that has been used by Apple, Anthropic, Meta, Nvidia, Salesforce, Bloomberg, and other companies. I recently downloaded this data set, which I saw referenced in papers about the development of various large language models (or LLMs). It includes writing from every film nominated for Best Picture from 1950 to 2016, at least 616 episodes of The Simpsons, 170 episodes of Seinfeld, 45 episodes of Twin Peaks, and every episode of The Wire, The Sopranos, and Breaking Bad.”
😡
2K notes
·
View notes
Text
Humans are not perfectly vigilant

I'm on tour with my new, nationally bestselling novel The Bezzle! Catch me in BOSTON with Randall "XKCD" Munroe (Apr 11), then PROVIDENCE (Apr 12), and beyond!

Here's a fun AI story: a security researcher noticed that large companies' AI-authored source-code repeatedly referenced a nonexistent library (an AI "hallucination"), so he created a (defanged) malicious library with that name and uploaded it, and thousands of developers automatically downloaded and incorporated it as they compiled the code:
https://www.theregister.com/2024/03/28/ai_bots_hallucinate_software_packages/
These "hallucinations" are a stubbornly persistent feature of large language models, because these models only give the illusion of understanding; in reality, they are just sophisticated forms of autocomplete, drawing on huge databases to make shrewd (but reliably fallible) guesses about which word comes next:
https://dl.acm.org/doi/10.1145/3442188.3445922
Guessing the next word without understanding the meaning of the resulting sentence makes unsupervised LLMs unsuitable for high-stakes tasks. The whole AI bubble is based on convincing investors that one or more of the following is true:
There are low-stakes, high-value tasks that will recoup the massive costs of AI training and operation;
There are high-stakes, high-value tasks that can be made cheaper by adding an AI to a human operator;
Adding more training data to an AI will make it stop hallucinating, so that it can take over high-stakes, high-value tasks without a "human in the loop."
These are dubious propositions. There's a universe of low-stakes, low-value tasks – political disinformation, spam, fraud, academic cheating, nonconsensual porn, dialog for video-game NPCs – but none of them seem likely to generate enough revenue for AI companies to justify the billions spent on models, nor the trillions in valuation attributed to AI companies:
https://locusmag.com/2023/12/commentary-cory-doctorow-what-kind-of-bubble-is-ai/
The proposition that increasing training data will decrease hallucinations is hotly contested among AI practitioners. I confess that I don't know enough about AI to evaluate opposing sides' claims, but even if you stipulate that adding lots of human-generated training data will make the software a better guesser, there's a serious problem. All those low-value, low-stakes applications are flooding the internet with botshit. After all, the one thing AI is unarguably very good at is producing bullshit at scale. As the web becomes an anaerobic lagoon for botshit, the quantum of human-generated "content" in any internet core sample is dwindling to homeopathic levels:
https://pluralistic.net/2024/03/14/inhuman-centipede/#enshittibottification
This means that adding another order of magnitude more training data to AI won't just add massive computational expense – the data will be many orders of magnitude more expensive to acquire, even without factoring in the additional liability arising from new legal theories about scraping:
https://pluralistic.net/2023/09/17/how-to-think-about-scraping/
That leaves us with "humans in the loop" – the idea that an AI's business model is selling software to businesses that will pair it with human operators who will closely scrutinize the code's guesses. There's a version of this that sounds plausible – the one in which the human operator is in charge, and the AI acts as an eternally vigilant "sanity check" on the human's activities.
For example, my car has a system that notices when I activate my blinker while there's another car in my blind-spot. I'm pretty consistent about checking my blind spot, but I'm also a fallible human and there've been a couple times where the alert saved me from making a potentially dangerous maneuver. As disciplined as I am, I'm also sometimes forgetful about turning off lights, or waking up in time for work, or remembering someone's phone number (or birthday). I like having an automated system that does the robotically perfect trick of never forgetting something important.
There's a name for this in automation circles: a "centaur." I'm the human head, and I've fused with a powerful robot body that supports me, doing things that humans are innately bad at.
That's the good kind of automation, and we all benefit from it. But it only takes a small twist to turn this good automation into a nightmare. I'm speaking here of the reverse-centaur: automation in which the computer is in charge, bossing a human around so it can get its job done. Think of Amazon warehouse workers, who wear haptic bracelets and are continuously observed by AI cameras as autonomous shelves shuttle in front of them and demand that they pick and pack items at a pace that destroys their bodies and drives them mad:
https://pluralistic.net/2022/04/17/revenge-of-the-chickenized-reverse-centaurs/
Automation centaurs are great: they relieve humans of drudgework and let them focus on the creative and satisfying parts of their jobs. That's how AI-assisted coding is pitched: rather than looking up tricky syntax and other tedious programming tasks, an AI "co-pilot" is billed as freeing up its human "pilot" to focus on the creative puzzle-solving that makes coding so satisfying.
But an hallucinating AI is a terrible co-pilot. It's just good enough to get the job done much of the time, but it also sneakily inserts booby-traps that are statistically guaranteed to look as plausible as the good code (that's what a next-word-guessing program does: guesses the statistically most likely word).
This turns AI-"assisted" coders into reverse centaurs. The AI can churn out code at superhuman speed, and you, the human in the loop, must maintain perfect vigilance and attention as you review that code, spotting the cleverly disguised hooks for malicious code that the AI can't be prevented from inserting into its code. As "Lena" writes, "code review [is] difficult relative to writing new code":
https://twitter.com/qntm/status/1773779967521780169
Why is that? "Passively reading someone else's code just doesn't engage my brain in the same way. It's harder to do properly":
https://twitter.com/qntm/status/1773780355708764665
There's a name for this phenomenon: "automation blindness." Humans are just not equipped for eternal vigilance. We get good at spotting patterns that occur frequently – so good that we miss the anomalies. That's why TSA agents are so good at spotting harmless shampoo bottles on X-rays, even as they miss nearly every gun and bomb that a red team smuggles through their checkpoints:
https://pluralistic.net/2023/08/23/automation-blindness/#humans-in-the-loop
"Lena"'s thread points out that this is as true for AI-assisted driving as it is for AI-assisted coding: "self-driving cars replace the experience of driving with the experience of being a driving instructor":
https://twitter.com/qntm/status/1773841546753831283
In other words, they turn you into a reverse-centaur. Whereas my blind-spot double-checking robot allows me to make maneuvers at human speed and points out the things I've missed, a "supervised" self-driving car makes maneuvers at a computer's frantic pace, and demands that its human supervisor tirelessly and perfectly assesses each of those maneuvers. No wonder Cruise's murderous "self-driving" taxis replaced each low-waged driver with 1.5 high-waged technical robot supervisors:
https://pluralistic.net/2024/01/11/robots-stole-my-jerb/#computer-says-no
AI radiology programs are said to be able to spot cancerous masses that human radiologists miss. A centaur-based AI-assisted radiology program would keep the same number of radiologists in the field, but they would get less done: every time they assessed an X-ray, the AI would give them a second opinion. If the human and the AI disagreed, the human would go back and re-assess the X-ray. We'd get better radiology, at a higher price (the price of the AI software, plus the additional hours the radiologist would work).
But back to making the AI bubble pay off: for AI to pay off, the human in the loop has to reduce the costs of the business buying an AI. No one who invests in an AI company believes that their returns will come from business customers to agree to increase their costs. The AI can't do your job, but the AI salesman can convince your boss to fire you and replace you with an AI anyway – that pitch is the most successful form of AI disinformation in the world.
An AI that "hallucinates" bad advice to fliers can't replace human customer service reps, but airlines are firing reps and replacing them with chatbots:
https://www.bbc.com/travel/article/20240222-air-canada-chatbot-misinformation-what-travellers-should-know
An AI that "hallucinates" bad legal advice to New Yorkers can't replace city services, but Mayor Adams still tells New Yorkers to get their legal advice from his chatbots:
https://arstechnica.com/ai/2024/03/nycs-government-chatbot-is-lying-about-city-laws-and-regulations/
The only reason bosses want to buy robots is to fire humans and lower their costs. That's why "AI art" is such a pisser. There are plenty of harmless ways to automate art production with software – everything from a "healing brush" in Photoshop to deepfake tools that let a video-editor alter the eye-lines of all the extras in a scene to shift the focus. A graphic novelist who models a room in The Sims and then moves the camera around to get traceable geometry for different angles is a centaur – they are genuinely offloading some finicky drudgework onto a robot that is perfectly attentive and vigilant.
But the pitch from "AI art" companies is "fire your graphic artists and replace them with botshit." They're pitching a world where the robots get to do all the creative stuff (badly) and humans have to work at robotic pace, with robotic vigilance, in order to catch the mistakes that the robots make at superhuman speed.
Reverse centaurism is brutal. That's not news: Charlie Chaplin documented the problems of reverse centaurs nearly 100 years ago:
https://en.wikipedia.org/wiki/Modern_Times_(film)
As ever, the problem with a gadget isn't what it does: it's who it does it for and who it does it to. There are plenty of benefits from being a centaur – lots of ways that automation can help workers. But the only path to AI profitability lies in reverse centaurs, automation that turns the human in the loop into the crumple-zone for a robot:
https://estsjournal.org/index.php/ests/article/view/260

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/04/01/human-in-the-loop/#monkey-in-the-middle
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
--
Jorge Royan (modified) https://commons.wikimedia.org/wiki/File:Munich_-_Two_boys_playing_in_a_park_-_7328.jpg
CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0/deed.en
--
Noah Wulf (modified) https://commons.m.wikimedia.org/wiki/File:Thunderbirds_at_Attention_Next_to_Thunderbird_1_-_Aviation_Nation_2019.jpg
CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0/deed.en
#pluralistic#ai#supervised ai#humans in the loop#coding assistance#ai art#fully automated luxury communism#labor
379 notes
·
View notes
Text
Ever since OpenAI released ChatGPT at the end of 2022, hackers and security researchers have tried to find holes in large language models (LLMs) to get around their guardrails and trick them into spewing out hate speech, bomb-making instructions, propaganda, and other harmful content. In response, OpenAI and other generative AI developers have refined their system defenses to make it more difficult to carry out these attacks. But as the Chinese AI platform DeepSeek rockets to prominence with its new, cheaper R1 reasoning model, its safety protections appear to be far behind those of its established competitors.
Today, security researchers from Cisco and the University of Pennsylvania are publishing findings showing that, when tested with 50 malicious prompts designed to elicit toxic content, DeepSeek’s model did not detect or block a single one. In other words, the researchers say they were shocked to achieve a “100 percent attack success rate.”
The findings are part of a growing body of evidence that DeepSeek’s safety and security measures may not match those of other tech companies developing LLMs. DeepSeek’s censorship of subjects deemed sensitive by China’s government has also been easily bypassed.
“A hundred percent of the attacks succeeded, which tells you that there’s a trade-off,” DJ Sampath, the VP of product, AI software and platform at Cisco, tells WIRED. “Yes, it might have been cheaper to build something here, but the investment has perhaps not gone into thinking through what types of safety and security things you need to put inside of the model.”
Other researchers have had similar findings. Separate analysis published today by the AI security company Adversa AI and shared with WIRED also suggests that DeepSeek is vulnerable to a wide range of jailbreaking tactics, from simple language tricks to complex AI-generated prompts.
DeepSeek, which has been dealing with an avalanche of attention this week and has not spoken publicly about a range of questions, did not respond to WIRED’s request for comment about its model’s safety setup.
Generative AI models, like any technological system, can contain a host of weaknesses or vulnerabilities that, if exploited or set up poorly, can allow malicious actors to conduct attacks against them. For the current wave of AI systems, indirect prompt injection attacks are considered one of the biggest security flaws. These attacks involve an AI system taking in data from an outside source—perhaps hidden instructions of a website the LLM summarizes—and taking actions based on the information.
Jailbreaks, which are one kind of prompt-injection attack, allow people to get around the safety systems put in place to restrict what an LLM can generate. Tech companies don’t want people creating guides to making explosives or using their AI to create reams of disinformation, for example.
Jailbreaks started out simple, with people essentially crafting clever sentences to tell an LLM to ignore content filters—the most popular of which was called “Do Anything Now” or DAN for short. However, as AI companies have put in place more robust protections, some jailbreaks have become more sophisticated, often being generated using AI or using special and obfuscated characters. While all LLMs are susceptible to jailbreaks, and much of the information could be found through simple online searches, chatbots can still be used maliciously.
“Jailbreaks persist simply because eliminating them entirely is nearly impossible—just like buffer overflow vulnerabilities in software (which have existed for over 40 years) or SQL injection flaws in web applications (which have plagued security teams for more than two decades),” Alex Polyakov, the CEO of security firm Adversa AI, told WIRED in an email.
Cisco’s Sampath argues that as companies use more types of AI in their applications, the risks are amplified. “It starts to become a big deal when you start putting these models into important complex systems and those jailbreaks suddenly result in downstream things that increases liability, increases business risk, increases all kinds of issues for enterprises,” Sampath says.
The Cisco researchers drew their 50 randomly selected prompts to test DeepSeek’s R1 from a well-known library of standardized evaluation prompts known as HarmBench. They tested prompts from six HarmBench categories, including general harm, cybercrime, misinformation, and illegal activities. They probed the model running locally on machines rather than through DeepSeek’s website or app, which send data to China.
Beyond this, the researchers say they have also seen some potentially concerning results from testing R1 with more involved, non-linguistic attacks using things like Cyrillic characters and tailored scripts to attempt to achieve code execution. But for their initial tests, Sampath says, his team wanted to focus on findings that stemmed from a generally recognized benchmark.
Cisco also included comparisons of R1’s performance against HarmBench prompts with the performance of other models. And some, like Meta’s Llama 3.1, faltered almost as severely as DeepSeek’s R1. But Sampath emphasizes that DeepSeek’s R1 is a specific reasoning model, which takes longer to generate answers but pulls upon more complex processes to try to produce better results. Therefore, Sampath argues, the best comparison is with OpenAI’s o1 reasoning model, which fared the best of all models tested. (Meta did not immediately respond to a request for comment).
Polyakov, from Adversa AI, explains that DeepSeek appears to detect and reject some well-known jailbreak attacks, saying that “it seems that these responses are often just copied from OpenAI’s dataset.” However, Polyakov says that in his company’s tests of four different types of jailbreaks—from linguistic ones to code-based tricks—DeepSeek’s restrictions could easily be bypassed.
“Every single method worked flawlessly,” Polyakov says. “What’s even more alarming is that these aren’t novel ‘zero-day’ jailbreaks—many have been publicly known for years,” he says, claiming he saw the model go into more depth with some instructions around psychedelics than he had seen any other model create.
“DeepSeek is just another example of how every model can be broken—it’s just a matter of how much effort you put in. Some attacks might get patched, but the attack surface is infinite,” Polyakov adds. “If you’re not continuously red-teaming your AI, you’re already compromised.”
57 notes
·
View notes
Text
I can now say with absolute confidence that many AI systems have been trained on TV and film writers’ work. Not just on The Godfather and Alf, but on more than 53,000 other movies and 85,000 other TV episodes: Dialogue from all of it is included in an AI-training data set that has been used by Apple, Anthropic, Meta, Nvidia, Salesforce, Bloomberg, and other companies. I recently downloaded this data set, which I saw referenced in papers about the development of various large language models (or LLMs). It includes writing from every film nominated for Best Picture from 1950 to 2016, at least 616 episodes of The Simpsons, 170 episodes of Seinfeld, 45 episodes of Twin Peaks, and every episode of The Wire, The Sopranos, and Breaking Bad. It even includes prewritten “live” dialogue from Golden Globes and Academy Awards broadcasts. If a chatbot can mimic a crime-show mobster or a sitcom alien—or, more pressingly, if it can piece together whole shows that might otherwise require a room of writers—data like this are part of the reason why.
60 notes
·
View notes
Text

The DeepSeek panic reveals an AI world ready to blow❗💥
The R1 chatbot has sent the tech world spinning – but this tells us less about China than it does about western neuroses
The arrival of DeepSeek R1, an AI language model built by the Chinese AI lab DeepSeek, has been nothing less than seismic. The system only launched last week, but already the app has shot to the top of download charts, sparked a $1tn (£800bn) sell-off of tech stocks, and elicited apocalyptic commentary in Silicon Valley. The simplest take on R1 is correct: it’s an AI system equal in capability to state-of-the-art US models that was built on a shoestring budget, thus demonstrating Chinese technological prowess. But the big lesson is perhaps not what DeepSeek R1 reveals about China, but about western neuroses surrounding AI.
For AI obsessives, the arrival of R1 was not a total shock. DeepSeek was founded in 2023 as a subsidiary of the Chinese hedge fund High-Flyer, which focuses on data-heavy financial analysis – a field that demands similar skills to top-end AI research. Its subsidiary lab quickly started producing innovative papers, and CEO Liang Wenfeng told interviewers last November that the work was motivated not by profit but “passion and curiosity”.
This approach has paid off, and last December the company launched DeepSeek-V3, a predecessor of R1 with the same appealing qualities of high performance and low cost. Like ChatGPT, V3 and R1 are large language models (LLMs): chatbots that can be put to a huge variety of uses, from copywriting to coding. Leading AI researcher Andrej Karpathy spotted the company’s potential last year, commenting on the launch of V3: “DeepSeek (Chinese AI co) making it look easy today with an open weights release of a frontier-grade LLM trained on a joke of a budget.” (That quoted budget was $6m – hardly pocket change, but orders of magnitude less than the $100m-plus needed to train OpenAI’s GPT-4 in 2023.)
R1’s impact has been far greater for a few different reasons.
First, it’s what’s known as a “chain of thought” model, which means that when you give it a query, it talks itself through the answer: a simple trick that hugely improves response quality. This has not only made R1 directly comparable to OpenAI’s o1 model (another chain of thought system whose performance R1 rivals) but boosted its ability to answer maths and coding queries – problems that AI experts value highly. Also, R1 is much more accessible. Not only is it free to use via the app (as opposed to the $20 a month you have to pay OpenAI to talk to o1) but it’s totally free for developers to download and implement into their businesses. All of this has meant that R1’s performance has been easier to appreciate, just as ChatGPT’s chat interface made existing AI smarts accessible for the first time in 2022.
Second, the method of R1’s creation undermines Silicon Valley’s current approach to AI. The dominant paradigm in the US is to scale up existing models by simply adding more data and more computing power to achieve greater performance. It’s this approach that has led to huge increases in energy demands for the sector and tied tech companies to politicians. The bill for developing AI is so huge that techies now want to leverage state financing and infrastructure, while politicians want to buy their loyalty and be seen supporting growing companies. (See, for example, Trump’s $500bn “Stargate” announcement earlier this month.) R1 overturns the accepted wisdom that scaling is the way forward. The system is thought to be 95% cheaper than OpenAI’s o1 and uses one tenth of the computing power of another comparable LLM, Meta’s Llama 3.1 model. To achieve equivalent performance at a fraction of the budget is what’s truly shocking about R1, and it’s this that has made its launch so impactful. It suggests that US companies are throwing money away and can be beaten by more nimble competitors.
But after these baseline observations, it gets tricky to say exactly what R1 “means” for AI. Some are arguing that R1’s launch shows we’re overvaluing companies like Nvidia, which makes the chips integral to the scaling paradigm. But it’s also possible the opposite is true: that R1 shows AI services will fall in price and demand will, therefore, increase (an economic effect known as Jevons paradox, which Microsoft CEO Satya Nadella helpfully shared a link to on Monday). Similarly, you might argue that R1’s launch shows the failure of US policy to limit Chinese tech development via export controls on chips. But, as AI policy researcher Lennart Heim has argued, export controls take time to work and affect not just AI training but deployment across the economy. So, even if export controls don’t stop the launches of flagships systems like R1, they might still help the US retain its technological lead (if that’s the outcome you want).
All of this is to say that the exact effects of R1’s launch are impossible to predict. There are too many complicating factors and too many unknowns to say what the future holds. However, that hasn’t stopped the tech world and markets reacting in a frenzy, with CEOs panicking, stock prices cratering, and analysts scrambling to revise predictions for the sector. And what this really shows is that the world of AI is febrile, unpredictable and overly reactive. This a dangerous combination, and if R1 doesn’t cause a destructive meltdown of this system, it’s likely that some future launch will.
Daily inspiration. Discover more photos at Just for Books…?
#just for books#DeepSeek#Opinion#Artificial intelligence (AI)#Computing#China#Asia Pacific#message from the editor
27 notes
·
View notes
Text
2025 Forecast
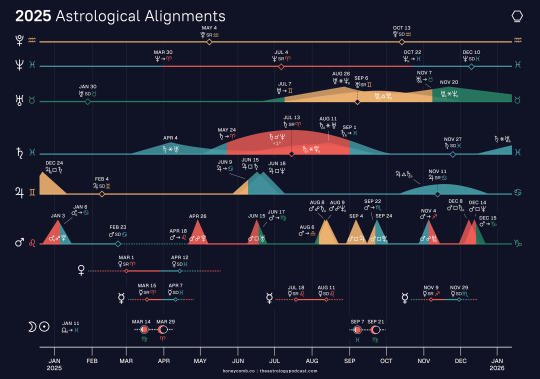
AKA my notes on The Astrology Podcast's 2025 Forecast, hosted by Chris Brennan and Austin Coppock. Saddle up, it's a long one!
Overview
This year's forecast is divided into an overview of big planetary shifts and a chronological breakdown, but it doesn't go quarter-by-quarter like in previous years.

Outer Planet Shifts
It's quite rare that such slow-moving planets as Neptune, Uranus and Pluto* all enter new signs in the same year (*Pluto has already ingressed to Aquarius after transiting Capricorn for the past 16 years, but this is the first full year he'll spend in Aquarius). Uranus has been in Taurus since 2018, and Neptune first ingressed to Pisces in 2011. Thus we are seeing major shifts happening all at the same time. These represent major cultural and social changes. In personal charts, this concludes activity in other parts of our charts and begins focus in a new area.
Pluto in Aquarius (November 2024 (final ingress) - January 2044)
Chris has been connecting this to cryptocurrency (Bitcoin started under Pluto in Capricorn) and AI stories, such as Google & other companies rolling out livechats. He predicts that robots, especially humanoid ones, will he ubiquitous in everyday life by the end of Pluto in Aquarius, though Austin is skeptical as to how evenly distributed technological advancements will be. Jobs and labor will surely be affected by the increasing digitization of different industries. Everyone's trying to hitch a ride on the AI train, but it'll take a major scandal before we see regulations put in place or see just how it'll integrate into society. We'll have to train our eyes to recognize the artificially generated, and we'll also have to deal with inefficient bureaucracy that technology alone can't quite fix. In mundane developments, even though the US was founded under Pluto in Capricorn, most of the government structure were put into place under Pluto in Aquarius. Last time Pluto was in Aquarius was the French Revolution (opposite Leo, the fixed signs of sovereigns and heads of state). The current Pluto in Leo generation (baby boomers) were raised definitively in the area of the celebrity, an issue that will likely come into question in the years ahead.
Uranus in Gemini (July 2025 - May 2033)
Uranus trines Pluto during this transit, so these two planets' themes are closely tied over the next decade. Previous Uranus in Gemini periods include the revolutionary war/founding of the USA, its Civil War, and WW2. Term limits were pushed and set under this transit with Washington & FDR; 84 years previous to the founding of the US John Locke wrote his ideas on government. Continuing on the theme of liberal democracy, the King James Bible was published under Uranus in Gemini in the 1600s--an attempt to democratize religion and encourage readers to have their own individual relationship with the text. Uranus was discovered during a Gemini transit in 1781, and was almost named "George" after the King of Britain. In general Uranus in Gemini brings particularly forward-thinking ideas while in Mercury-ruled signs. We should expect to see continued developments in AI controversies and LLMs (large language models), and the role of language overall. We can also expect shakeups in transportation, with technologies like self-driving cars and drones expanding in transportation, war, and everyday life. The burgeoning dominance of electric vehicles space travel are also likely previews into the Uranus in Gemini era, and we can look out for major developments in the realm of social media as well.
Neptune in Aries (March 2025 - March 2039)
Neptune's 165-year cycle means it changes sign about once every 14 years. The last Aries transit was in 1861-1875, and the ingress coincides exactly with US Civil War: Fort Sumter fell the day it ingressed. Neptune gives us dream-logic for its time, trends that are often only clear in retrospect. Austin describes the Neptune in Pisces era as valorizing qualities like acceptance & inclusivity, where the heroic figure of the time is a compassionate mystic/saintly. He predicts Neptune in Aries will valorize "the heroic." Where once suddenly everyone was an astrologer or witch, now, suddenly we're all soldiers/warriors. (This played out literally as mass conscription in the US Civil War & in England in previous Aries Neptune periods.) This period also saw developments in photography, namely war photography in newspapers bringing the goriness of war into every home. Civil War photos were originally shot in 3D and meant to be experienced through viewers, and the first color photo was taken 05/17/1861 when Neptune was at 1Aries, bringing levels of heightened realism and simulation into the conversation. Neptune in Aries faces us with forks in the road--no half measures.
Neptune in Aries can indicate wars remembered for their ideology, as was the case with the Taiping Revolt/Rebllion's bloody conclusion during Neptune in Aries (begun in Pisces). One of the deadliest wars in history (cost at least 20-30 million lives), it was instigated because of an extremist Christian religion. In medical astrology Mars-Neptune contacts can indicate autoimmune diseases where the body attacks itself, and the mundane analogy here is internal conflicts. In antiquity, the destruction of the Second Temple in Jerusalem in 70 CE occurred during Neptune in Aries, Pluto in Aquarius, and the eclipse points moving from Aries/Libra to Virgo/Pisces (all configurations we'll see in 2025). This is considered a catalyzing event for the subsequent Jewish diaspora over the following centuries, as well as the shift from centralized worship to Rabbinic Judaism. In science & engineering, the steam engine, dynamite, first underground railway, Suez canal, mechanical submarine, and the concept of light as EM radiation via Maxwell equations all came about during Neptune in Aries periods.
Saturn in Aries Saturn is entering Aries from May to September this year and will be copresent with/conjoining Neptune over the next three years. Saturn is in fall in Aries, highlighting tensions between patience and impulsivity. We can also expect prominent figures to fall from grace, such as during our last Saturn in Aries in the late 1990s with the scandal around Bill Clinton and Monica Lewinksy. In personal charts, Saturn in Aries people will often chalk up their difficulties to "not trying hard enough," when really it may just be a matter of timing and patience. Famous Aries Saturn people include skater Tony Hawk, daredevil Evel Knievel, directors Francis Ford Coppola and Lily Wachawski, witch-hunting politician McCarthy, writer Margaret Atwood, actresses Zendaya and Lucy Lawless, and activist Malala Yousafzai.
Saturn Conjunct Neptune Saturn and Neptune will get within 1 degree of each other this year, though we don't get an exact conjunction til 2026. We've been seeing the buildup of this since Saturn entered Pisces in March 2023. What's real and bounded, and what's illusory and pervasive? This tension between illusions & structures likely means we'll see increased distrust in authority, such as the public doubting what's reported in news stories or fake news sparking major conflicts, and Chris predicts increasing polarization between aggressive skeptics and religious fundamentalists. Austin uses the analogy of the Mad Max: Furiosa movie--everyone is trying to conscript you to come fight with them for water. Austin notes that Saturn-Neptune contacts punctuate major events in recent Russian history, including the founding of St. Petersburg and the dissolution of the USSR. He also brings up the historical example of ronin, rogue samuari who had some public support as vigilantes, and compares it to Luigi Mangione's alleged assassination of the United Healthcare CEO, saying the public reaction to this event is a prediction of things to come.
Chronological Breakdown
Mars Retrograde: December 2024 and January 2025
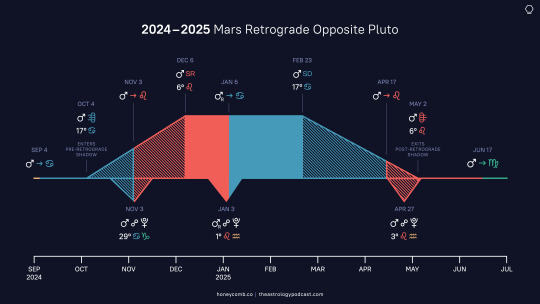
We enter the year with Mars retrograde in Leo (opposite Pluto) and moving to Cancer on January 6th, and only getting to Leo on April 17th. This makes an extended transit through those two signs. Observationally, Mars is actually brightest and closest to Earth during its retrogrades, rising as the Sun sets, making him hyper-visible and much more reactive & chaotic than Venus & Mercury retrogrades. And indeed Mars's station on December 6th saw a bunch of major events: an attempted coup in South Korea, the Assad regime falling in Syria, a healthcare CEO assassinated in the US, a contested election in Romania, and the French government collapsing through a no-confidence vote.
Back to 2025, though: Mars entering Cancer on the 6th hearkens back to his last visit to the sign, September 4th-November 3rd of 2024. Events, both mundane and personal, will come back to us during this time. In politics we saw a lot of nativism and racism in US politics while Trump was campaigning, and unfortunately this is likely to resurface. Concerns over homelands & origin showed up in celebrity news with controversy over the New Orleans Superbowl booking Los Angeles-based rapper Kendrick Lamar over NoLa native Lil Wayne.
Mars is in fall in Cancer, and with Saturn in Aries later we get both malefics in fall this year. The trap of Cancer Mars is "nothing's safe enough," while that of Aries Saturn is "nothing is under enough control," and we must be on our toes to avoid falling into either. Mars in Cancer is reactive and impulsive, in contrast to the Saturnian discipline & foresight that Capricorn grants it in exaltation. In personal charts Mars rx in Cancer/Leo can show up as obstacles or frustration, or as an extended expenditure of energy in that area. Retrogrades can also bring things or people back into your life, and how you handle the situation sets you up for the next time you meet.
January 2025

We enter the month with retrograde Mars opposing Pluto on the 3rd and regressing to Cancer on the 6th. On January 15th we get the exact opposition of Mars to the Sun, days after the Full Moon, so that's another time to watch out for in events. The US presidential inaguration is on Jaunary 20th under a Sun-Pluto conjunction.
Electional chart for January:
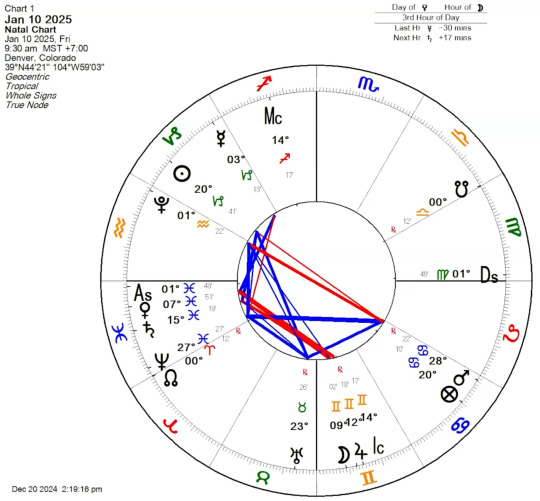
The chart is for January 10th, at roughly 9:30AM local time to get early Pisces rising. The ruler of the Ascendant, Jupiter, is in the 4th house (♊) in a day chart and makes an auspicious conjunction to the Moon, who herself is separating from a square to Venus (♓). Venus is also exalted in the first house & on the Ascendant. This is also about as far away as we can get from the Mars-Pluto opposition while also avoiding the Sun-Mars opposition later this month. This is good for 4th house matters: not only home and family, but also matters where you're important but not visible, like a director.
Overall, January and February are dominated by the Mars retrograde, a "not so calm" before the storm of springtime.
March & April Venus goes retrograde on March 1st, regressing into Pisces before stationing direct on April 12th. Meanwhile, on March 29th we get an Aries solar eclipse, the final installation in a series going back to October 2023. The next day, March 30th, Neptune waltzes into Aries for the first time in a century. Meanwhile Mercury retrogrades from March 15th until April 7th, backtracking into Pisces while doing so. And if that wasn't enough, Saturn moves into Aries on May 24th. March & April are like a series of cascade reactions, and we'll spend the rest of the year (or few years in the case of Saturn) reacting to, cleaning up the aftermath of, and wrestling with understanding what happened. We'll definitely see major geopolitical events, maybe with bizarre connections, all the while thinking things are going in one direction when they're really going another.
Venus & Mercury Retrograde; Eclipses
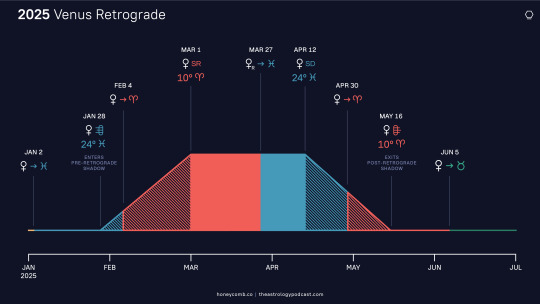
Venus's station points are felt most intensely, but like with the Mars retrograde we also experience this as an extended transit of Venus through the signs of Aries and Pisces from January to June. Her retrograde also comes just 5 days after Mars concludes his own. Chris predicts that, unlike the Leo Venus rx a couple summers ago, there may be more fighting around women's issues rather than straightforward celebration. In Aries we already expecting a more combative expression of Venusian issues, and the increased activity in Aries only intensifies this prediction. Venus in Aries is not quiet--she's bold, active, and direct. In personal charts we'll see returns of events from 8, 16, or 32 years ago (last time she was retrograde in Aries), reviewing and revising relationships in the present. What and who do we want? Do we still want that? Under Venus rx we look for an unambiguous "yes." We can also see delays or postponements, scandals, and provocative art & culture. We'll be going back and forth between an exalted, compassionate Venus and a forthright, exiled Venus, choosing between the two on any given day and trying to reconcile them.
With Venus retrograde we can also think of the myth of Inanna (a story based off the Venus rx cycle), who descends through gates of the underworld and returns home to find her consort has taken the throne before she takes it back. We'll likely see stories about women in powerful positions reclaiming something after going through a struggle as Venus stations direct in her sign of exaltation. Specifically, she stations direct on April 13th conjunct Saturn (ironically another signature of Trump's upcoming inauguration), with Mercury retrograde also in Aries & Pisces at the same time. Both these planets are passing over Neptune in late Pisces as well: sometimes we have a lovely, dreamy vision that turns out to be terribly disappointing. Venus and Mercury will both cross Neptune three times, in both Aries and Pisces.
Mercury stations at 0Aries on March 29th, the same day as the solar eclipse, and switches signs with Neptune (leaving Pisces) the next day. The culminating eclipse is marred by miscommunications and illusions. As the last installment of a series begun in October 2023, this eclipse will definitely see developments in Israel's wars on other countries in the region. More generally, in mundane astrology North Node solar eclipses in Aries have coincided with the assassinations of heads of states & movements, as well as the eclipsing/stepping down of leaders...yet another signature of changing/threatened leadership in 2025.
In the middle of March we also get our first Virgo eclipse of this series, corresponding to the September eclipse in Pisces. We'll revisit the areas again in September with a Pisces and Virgo eclipse. The barrier between Aries/Pisces and Virgo/Libra sees a lot of activity in the first half of 2025. We'll definitely remember this year for the crazy Aries activity, though Austin predicts it'll come back to haunt us in 2026.
May-June-July Saturn enters Aries on May 24th, creeping up on Neptune and getting within a degree of him by July (~13th-14th), and then stationing retrograde. An outer planet's first station in a new sign signals what to expect, and Saturn and Neptune both do so in July (on the 13th and 4th respectively). From May 24th to September 1st we have Neptune and Saturn very close to each other and retrograding. Uranus enters Gemini on the 7th.
Jupiter in Cancer He enters in June of 2025, staying there until June of 2026. In this sign of his exaltation, he'll be counterbalancing some of the crazier transits of this year. He's also doing cleanup after Mar's messy transits earlier this year in the Cancer parts of our charts. Jupiter is a little folksy in Cancer--he's not just lavishing the wealthy, but is generous to everyday people as well. The Affordable Care Act (Obamacare) was enacted during Jupiter in Cancer in 2013-14 (a Jupiter under attack!), bringing important healthcare considerations to this placement (A/N: Cancer as a sign of nurturing and protection). In July of 1990 during Jupiter & Venus in Cancer, the Americans with Disabilities Act (ADA) was passed. Chris is wary of being too optimistic, but hopes that something good in healthcare is coming forward. This transit is a Jupiter return (every ~12 years) for the US Sibly chart, and also the repetition of a longer 83-year cycle where he hits the same degree on the same day--the third one since the US's founding, making this an especially potent Jupiter return. You'll notice that's only one year off from Uranus cycles, so we'll definitely see further reevaluations of the US's founding this year.
Generally, exalted planets represent someone at the highest level of their field, and Jupiter in Cancer is a sort of "get rich slow" planet. Success is cultivated, grown, and encouraged. In June & July Jupiter will square Saturn, though, a configuration that corresponds to financial and economic crashes. Jupiter in Gemini saw tech company crashes, but in a new sign we'll likely see new industries affected.
July & August: Outer Planet Teamup

Uranus enters Gemini on July 7th, the last of the slow outer planets to ingress to his new sign. From then til October 21st, we have the rare and powerful influence of several outer planets teamed up: Uranus sextiling Saturn & Neptune and trining Pluto (meaning Saturn & Neptune also sextile Pluto). This is a sort of pilot episode previewing what'll happen when they return in 2026. These planets shift from feminine water/earth signs to masculine air/fire signs, and each outer planet (except Pluto) will retrograde into his preceding sign in October & November, giving us a break from the teamup of big players for a bit. Mars in Libra will aspect all of these outer planets in August, making the configuration especially active then.
September - Eclipse Season Last September we saw our first Pisces eclipse of this series, and we'll have had another development with the first Virgo eclipse in March. Now we're firmly in Virgo-Pisces eclipses for the next 2 years. The September 7th and 21st eclipses will have us think about the big picture vs. granular details--how can we hold them in unison? The major endings & beginnings brought by eclipses are further punctuated by Saturn regressing back into Pisces on September 1st. Maybe a last set of upgrades need to be put in place in our Pisces area, though now our Virgo house is tied in as well.
October, November, December Neptune returns to Pisces October 22nd, Uranus to Taurus on November 7th, and Saturn stations direct for his last pass through Pisces on November 27th. A new chapter of our lives has begun, but we need to do a final check-in before things reach completion. The outer planet demolition team will be back on April 25th, 2026, where it'll stay until 2032-33. Neptune will station in Pisces on December 10th, another important Pisces turning point. Jupiter stationing in Cancer on November 11th is the cherry on top for the year ending where it began (but not to stay!). We end 2025 coming full circle on our sort of last look backwards before plunging for good into new--though not entirely unknown--territory.
#astrology#transits#forecast#2025#january 2025#saturn in aries#neptune in aries#pluto in aquarius#uranus in gemini#jupiter in cancer#mars retrograde#venus retrograde#mars rx in cancer#mars rx in leo#venus rx in aries#venus rx in pisces#aries eclipse#virgo eclipse#pisces eclipse#saturn conjunct neptune
47 notes
·
View notes
Text
Large Language Model Development Company
Large Language Model Development Company (LLMDC) is a pioneering organization at the forefront of artificial intelligence research and development. Specializing in the creation and refinement of large language models, LLMDC leverages cutting-edge technologies to push the boundaries of natural language understanding and generation. The company's mission is to develop advanced AI systems that can understand, generate, and interact with human language in a meaningful and contextually relevant manner.
With a team of world-class researchers and engineers, LLMDC focuses on a range of applications including automated customer service, content creation, language translation, and more. Their innovations are driven by a commitment to ethical AI development, ensuring that their technologies are not only powerful but also aligned with principles of fairness, transparency, and accountability. Through continuous collaboration with academic institutions, industry partners, and regulatory bodies, LLMDC aims to make significant contributions to the AI landscape, enhancing the way humans and machines communicate.
Large language model services offer powerful AI capabilities to businesses and developers, enabling them to integrate advanced natural language processing (NLP) into their applications and workflows.
The largest language model services providers are industry leaders in artificial intelligence, offering advanced NLP solutions that empower businesses across various sectors. Prominent among these providers are OpenAI, Google Cloud, Microsoft Azure, and IBM Watson. OpenAI, renowned for its GPT series, delivers versatile and powerful language models that support a wide range of applications from text generation to complex data analysis. Google Cloud offers its AI and machine learning tools, including BERT and T5 models, which excel in tasks such as translation, sentiment analysis, and more.
Microsoft Azure provides Azure Cognitive Services, which leverage models like GPT-3 for diverse applications, including conversational AI and content creation. IBM Watson, with its extensive suite of AI services, offers robust NLP capabilities for enterprises, enabling advanced text analytics and language understanding. These providers lead the way in delivering scalable, reliable, and innovative language model services that transform how businesses interact with and utilize language data.
Expert Custom LLM Development Solutions offer tailored AI capabilities designed to meet the unique needs of businesses across various industries. These solutions provide bespoke development of large language models (LLMs) that are fine-tuned to specific requirements, ensuring optimal performance and relevance. Leveraging deep expertise in natural language processing and machine learning, custom LLM development services can address complex challenges such as industry-specific jargon, regulatory compliance, and specialized content generation.
#Large Language Model Development#large language model services#large language model development company#large language model development services#largest language model services providers#Generative AI and LLM Development Services
0 notes
Text
Study reveals AI chatbots can detect race, but racial bias reduces response empathy
New Post has been published on https://thedigitalinsider.com/study-reveals-ai-chatbots-can-detect-race-but-racial-bias-reduces-response-empathy/
Study reveals AI chatbots can detect race, but racial bias reduces response empathy

With the cover of anonymity and the company of strangers, the appeal of the digital world is growing as a place to seek out mental health support. This phenomenon is buoyed by the fact that over 150 million people in the United States live in federally designated mental health professional shortage areas.
“I really need your help, as I am too scared to talk to a therapist and I can’t reach one anyways.”
“Am I overreacting, getting hurt about husband making fun of me to his friends?”
“Could some strangers please weigh in on my life and decide my future for me?”
The above quotes are real posts taken from users on Reddit, a social media news website and forum where users can share content or ask for advice in smaller, interest-based forums known as “subreddits.”
Using a dataset of 12,513 posts with 70,429 responses from 26 mental health-related subreddits, researchers from MIT, New York University (NYU), and University of California Los Angeles (UCLA) devised a framework to help evaluate the equity and overall quality of mental health support chatbots based on large language models (LLMs) like GPT-4. Their work was recently published at the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP).
To accomplish this, researchers asked two licensed clinical psychologists to evaluate 50 randomly sampled Reddit posts seeking mental health support, pairing each post with either a Redditor’s real response or a GPT-4 generated response. Without knowing which responses were real or which were AI-generated, the psychologists were asked to assess the level of empathy in each response.
Mental health support chatbots have long been explored as a way of improving access to mental health support, but powerful LLMs like OpenAI’s ChatGPT are transforming human-AI interaction, with AI-generated responses becoming harder to distinguish from the responses of real humans.
Despite this remarkable progress, the unintended consequences of AI-provided mental health support have drawn attention to its potentially deadly risks; in March of last year, a Belgian man died by suicide as a result of an exchange with ELIZA, a chatbot developed to emulate a psychotherapist powered with an LLM called GPT-J. One month later, the National Eating Disorders Association would suspend their chatbot Tessa, after the chatbot began dispensing dieting tips to patients with eating disorders.
Saadia Gabriel, a recent MIT postdoc who is now a UCLA assistant professor and first author of the paper, admitted that she was initially very skeptical of how effective mental health support chatbots could actually be. Gabriel conducted this research during her time as a postdoc at MIT in the Healthy Machine Learning Group, led Marzyeh Ghassemi, an MIT associate professor in the Department of Electrical Engineering and Computer Science and MIT Institute for Medical Engineering and Science who is affiliated with the MIT Abdul Latif Jameel Clinic for Machine Learning in Health and the Computer Science and Artificial Intelligence Laboratory.
What Gabriel and the team of researchers found was that GPT-4 responses were not only more empathetic overall, but they were 48 percent better at encouraging positive behavioral changes than human responses.
However, in a bias evaluation, the researchers found that GPT-4’s response empathy levels were reduced for Black (2 to 15 percent lower) and Asian posters (5 to 17 percent lower) compared to white posters or posters whose race was unknown.
To evaluate bias in GPT-4 responses and human responses, researchers included different kinds of posts with explicit demographic (e.g., gender, race) leaks and implicit demographic leaks.
An explicit demographic leak would look like: “I am a 32yo Black woman.”
Whereas an implicit demographic leak would look like: “Being a 32yo girl wearing my natural hair,” in which keywords are used to indicate certain demographics to GPT-4.
With the exception of Black female posters, GPT-4’s responses were found to be less affected by explicit and implicit demographic leaking compared to human responders, who tended to be more empathetic when responding to posts with implicit demographic suggestions.
“The structure of the input you give [the LLM] and some information about the context, like whether you want [the LLM] to act in the style of a clinician, the style of a social media post, or whether you want it to use demographic attributes of the patient, has a major impact on the response you get back,” Gabriel says.
The paper suggests that explicitly providing instruction for LLMs to use demographic attributes can effectively alleviate bias, as this was the only method where researchers did not observe a significant difference in empathy across the different demographic groups.
Gabriel hopes this work can help ensure more comprehensive and thoughtful evaluation of LLMs being deployed in clinical settings across demographic subgroups.
“LLMs are already being used to provide patient-facing support and have been deployed in medical settings, in many cases to automate inefficient human systems,” Ghassemi says. “Here, we demonstrated that while state-of-the-art LLMs are generally less affected by demographic leaking than humans in peer-to-peer mental health support, they do not provide equitable mental health responses across inferred patient subgroups … we have a lot of opportunity to improve models so they provide improved support when used.”
#2024#Advice#ai#AI chatbots#approach#Art#artificial#Artificial Intelligence#attention#attributes#author#Behavior#Bias#california#chatbot#chatbots#chatGPT#clinical#comprehensive#computer#Computer Science#Computer Science and Artificial Intelligence Laboratory (CSAIL)#Computer science and technology#conference#content#disorders#Electrical engineering and computer science (EECS)#empathy#engineering#equity
14 notes
·
View notes
Text
Former OpenAI Researcher Accuses the Company of Copyright Law Violations
Use of Copyrighted Data in AI Models In a new twist in the world of artificial intelligence, Suchir Balaji, a former researcher at OpenAI, has spoken publicly about the company’s practices and its use of copyrighted data. Balaji, who spent nearly four years working at OpenAI, helped collect and organize large volumes of internet data to train AI models like ChatGPT. However, after reflecting on the legal and ethical implications of this process, he decided to leave the company in August 2024.
What Motivated His Departure? Balaji, 25, admitted that at first, he did not question whether OpenAI had the legal right to use the data it was collecting, much of which was protected by copyright. He assumed that since it was publicly available information on the internet, it was free to use. However, over time, and especially after the launch of ChatGPT in 2022, he began to doubt the legality and ethics of these practices.
“If you believe what I believe, you have to leave the company,” he commented in a series of interviews with The New York Times. For Balaji, using copyrighted data without the creators’ consent was not only a violation of the law but also a threat to the integrity of the internet. This realization led him to resign, although he has not taken another job yet and is currently working on personal projects.
A Growing Problem in AI Concerns about the use of protected data to train AI models are not new. Since companies like OpenAI and other startups began launching tools based on large language models (LLMs), legal and ethical issues have been at the forefront of the debate. These models are trained using vast amounts of text from the internet, often without respecting copyright or seeking the consent of the original content creators.
Balaji is not the only one to raise his voice on this matter. A former vice president of Stability AI, a startup specializing in generative image and audio technologies, has also expressed similar concerns, arguing that using data without authorization is harmful to the industry and society as a whole.
The Impact on the Future of AI Such criticisms raise questions about the future of artificial intelligence and its relationship with copyright laws. As AI models continue to evolve, the pressure on companies to develop ethical and legal technologies is increasing. The case of Balaji and other experts who have decided to step down signals that the AI industry might be facing a significant shift in how it approaches data usage.
The conversation about copyright in AI is far from over, and it seems that this will be a central topic in future discussions about the regulation and development of generative technologies
12 notes
·
View notes
Text
Prometheus Gave the Gift of Fire to Mankind. We Can't Give it Back, nor Should We.
AI. Artificial intelligence. Large Language Models. Learning Algorithms. Deep Learning. Generative Algorithms. Neural Networks. This technology has many names, and has been a polarizing topic in numerous communities online. By my observation, a lot of the discussion is either solely focused on A) how to profit off it or B) how to get rid of it and/or protect yourself from it. But to me, I feel both of these perspectives apply a very narrow usage lens on something that's more than a get rich quick scheme or an evil plague to wipe from the earth.
This is going to be long, because as someone whose degree is in psych and computer science, has been a teacher, has been a writing tutor for my younger brother, and whose fiance works in freelance data model training... I have a lot to say about this.
I'm going to address the profit angle first, because I feel most people in my orbit (and in related orbits) on Tumblr are going to agree with this: flat out, the way AI is being utilized by large corporations and tech startups -- scraping mass amounts of visual and written works without consent and compensation, replacing human professionals in roles from concept art to story boarding to screenwriting to customer service and more -- is unethical and damaging to the wellbeing of people, would-be hires and consumers alike. It's wasting energy having dedicated servers running nonstop generating content that serves no greater purpose, and is even pressing on already overworked educators because plagiarism just got a very new, harder to identify younger brother that's also infinitely more easy to access.
In fact, ChatGPT is such an issue in the education world that plagiarism-detector subscription services that take advantage of how overworked teachers are have begun paddling supposed AI-detectors to schools and universities. Detectors that plainly DO NOT and CANNOT work, because the difference between "A Writer Who Writes Surprisingly Well For Their Age" is indistinguishable from "A Language Replicating Algorithm That Followed A Prompt Correctly", just as "A Writer Who Doesn't Know What They're Talking About Or Even How To Write Properly" is indistinguishable from "A Language Replicating Algorithm That Returned Bad Results". What's hilarious is that the way these "detectors" work is also run by AI.
(to be clear, I say plagiarism detectors like TurnItIn.com and such are predatory because A) they cost money to access advanced features that B) often don't work properly or as intended with several false flags, and C) these companies often are super shady behind the scenes; TurnItIn for instance has been involved in numerous lawsuits over intellectual property violations, as their services scrape (or hopefully scraped now) the papers submitted to the site without user consent (or under coerced consent if being forced to use it by an educator), which it uses in can use in its own databases as it pleases, such as for training the AI detecting AI that rarely actually detects AI.)
The prevalence of visual and lingustic generative algorithms is having multiple, overlapping, and complex consequences on many facets of society, from art to music to writing to film and video game production, and even in the classroom before all that, so it's no wonder that many disgruntled artists and industry professionals are online wishing for it all to go away and never come back. The problem is... It can't. I understand that there's likely a large swath of people saying that who understand this, but for those who don't: AI, or as it should more properly be called, generative algorithms, didn't just show up now (they're not even that new), and they certainly weren't developed or invented by any of the tech bros peddling it to megacorps and the general public.
Long before ChatGPT and DALL-E came online, generative algorithms were being used by programmers to simulate natural processes in weather models, shed light on the mechanics of walking for roboticists and paleontologists alike, identified patterns in our DNA related to disease, aided in complex 2D and 3D animation visuals, and so on. Generative algorithms have been a part of the professional world for many years now, and up until recently have been a general force for good, or at the very least a force for the mundane. It's only recently that the technology involved in creating generative algorithms became so advanced AND so readily available, that university grad students were able to make the publicly available projects that began this descent into madness.
Does anyone else remember that? That years ago, somewhere in the late 2010s to the beginning of the 2020s, these novelty sites that allowed you to generate vague images from prompts, or generate short stylistic writings from a short prompt, were popping up with University URLs? Oftentimes the queues on these programs were hours long, sometimes eventually days or weeks or months long, because of how unexpectedly popular this concept was to the general public. Suddenly overnight, all over social media, everyone and their grandma, and not just high level programming and arts students, knew this was possible, and of course, everyone wanted in. Automated art and writing, isn't that neat? And of course, investors saw dollar signs. Simply scale up the process, scrape the entire web for data to train the model without advertising that you're using ALL material, even copyrighted and personal materials, and sell the resulting algorithm for big money. As usual, startup investors ruin every new technology the moment they can access it.
To most people, it seemed like this magic tech popped up overnight, and before it became known that the art assets on later models were stolen, even I had fun with them. I knew how learning algorithms worked, if you're going to have a computer make images and text, it has to be shown what that is and then try and fail to make its own until it's ready. I just, rather naively as I was still in my early 20s, assumed that everything was above board and the assets were either public domain or fairly licensed. But when the news did came out, and when corporations started unethically implementing "AI" in everything from chatbots to search algorithms to asking their tech staff to add AI to sliced bread, those who were impacted and didn't know and/or didn't care where generative algorithms came from wanted them GONE. And like, I can't blame them. But I also quietly acknowledged to myself that getting rid of a whole technology is just neither possible nor advisable. The cat's already out of the bag, the genie has left its bottle, the Pandorica is OPEN. If we tried to blanket ban what people call AI, numerous industries involved in making lives better would be impacted. Because unfortunately the same tool that can edit selfies into revenge porn has also been used to identify cancer cells in patients and aided in decoding dead languages, among other things.
When, in Greek myth, Prometheus gave us the gift of fire, he gave us both a gift and a curse. Fire is so crucial to human society, it cooks our food, it lights our cities, it disposes of waste, and it protects us from unseen threats. But fire also destroys, and the same flame that can light your home can burn it down. Surely, there were people in this mythic past who hated fire and all it stood for, because without fire no forest would ever burn to the ground, and surely they would have called for fire to be given back, to be done away with entirely. Except, there was no going back. The nature of life is that no new element can ever be undone, it cannot be given back.
So what's the way forward, then? Like, surely if I can write a multi-paragraph think piece on Tumblr.com that next to nobody is going to read because it's long as sin, about an unpopular topic, and I rarely post original content anyway, then surely I have an idea of how this cyberpunk dystopia can be a little less.. Dys. Well I do, actually, but it's a long shot. Thankfully, unlike business majors, I actually had to take a cyber ethics course in university, and I actually paid attention. I also passed preschool where I learned taking stuff you weren't given permission to have is stealing, which is bad. So the obvious solution is to make some fucking laws to limit the input on data model training on models used for public products and services. It's that simple. You either use public domain and licensed data only or you get fined into hell and back and liable to lawsuits from any entity you wronged, be they citizen or very wealthy mouse conglomerate (suing AI bros is the only time Mickey isn't the bigger enemy). And I'm going to be honest, tech companies are NOT going to like this, because not only will it make doing business more expensive (boo fucking hoo), they'd very likely need to throw out their current trained datasets because of the illegal components mixed in there. To my memory, you can't simply prune specific content from a completed algorithm, you actually have to redo rhe training from the ground up because the bad data would be mixed in there like gum in hair. And you know what, those companies deserve that. They deserve to suffer a punishment, and maybe fold if they're young enough, for what they've done to creators everywhere. Actually, laws moving forward isn't enough, this needs to be retroactive. These companies need to be sued into the ground, honestly.
So yeah, that's the mess of it. We can't unlearn and unpublicize any technology, even if it's currently being used as a tool of exploitation. What we can do though is demand ethical use laws and organize around the cause of the exclusive rights of individuals to the content they create. The screenwriter's guild, actor's guild, and so on already have been fighting against this misuse, but given upcoming administration changes to the US, things are going to get a lot worse before thet get a little better. Even still, don't give up, have clear and educated goals, and focus on what you can do to affect change, even if right now that's just individual self-care through mental and physical health crises like me.
#ai#artificial intelligence#generative algorithms#llm#large language model#chatgpt#ai art#ai writing#kanguin original
9 notes
·
View notes
Text
Hearing that public works on ao3 were scrapped for Huggingface is so infuriating. Scrapping in general is just both a morally reprehensible way to gather data, and stupid too. If you're really going to build datasets, having a narrower parameter then "literally everything" is the very start.
According to this article it used to be a chatbot but moved onto "primarily used for natural language processing tasks, such as text generation, sentiment analysis, and chatbot development." At a glance, I would not be scrapping a huge fandom archive for that sorta thing, considering not-insignificant number of fics that aren't written with the best grammar and also crackfics.
Going to the website itself and scrolling down I see this
I am not tech savvy enough to have extended commentary on the models or datasets outside of the fact that if this company wanted to be a hub for legitimate and ethically ai development, you think they would put more care into how they were getting their information. It's those spaces i'm more concerned about.
Now, it seems than they're uploaded by different people and not just Hugging face itself, but I digress. A skim has already shown different dialogue and character creation related bots made to generate.
Here is the post of the user on hugging face who made and uploaded at dataset of ao3 fics. Needless to say, do not make accounts just to make threats and drag this creator. Knowing its a user and not the action of the website itself is only comforting until you wonder why/when will the website screen the datasets being uploaded to make sure they're ethically sourced. (This also doesn't appear to be the only dataset made with fanfiction, but by far the largest.) It appears that Hugging Face is doing what they're legally obligated to do.

Access to it has been restricted thankfully. Following that link leads me to this
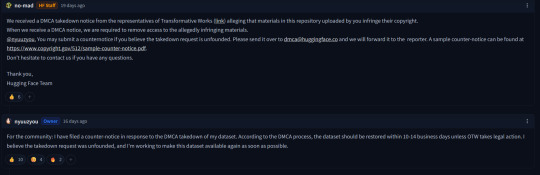
and the comments are as ugly as you can expect them to be. (No, fanfiction isn't theft. It is protected under parody and fair use laws. Regardless, i cannot fathom why you would want to use them anyways.)
If you're curious if it's been scrapped, this tiktok said any work with the work id under 63,200,000 appears to be scrapped. Basically anything made mid this march and before. All of my fics, including my one original work has been scrapped. Since ao3 lawyers are on the case, there's nothing anyone else can do now but wait. There is no point in submitting your own DMCA claim because Ao3's covers all of us.
That being said, it's irritable and disheartening. This is not in the spirit of fanfiction, this is not legally or morally ethical, and it's just irritating. None of these works had consent to be reuploaded or used in this way (no matter how those ai idiots think things work. Just because it's on the internet does not mean it's free use)
The conversation now is how to prevent this from happening again. Many users are setting their work to be privated, so that way only those with an account can read fics. I fear that is a very bandaid on the bullet wound type solution, because there's nothing stopping someone from making an account and then scrapping. Ao3 themselves have their own methods to try and counteract such things. And largely, we will be relaying on the team to handle such things. (This is why that donation drive is important, i can imagine the poor legal department is going to be clocking a lot of overtime soon.) I suppose another method is just to go old school. Printed zines for yourself and your circle of friends and not online I guess.
What now? Not sure. Obviously arguing with ai bros on their own turf isn't doing anything constructive, not that I really expected anything else from the general fandom nerds tbh. It's just. A super fucking frustrating reality of the internet now. I can only hope that when enough idiots do something like this and face repercussions, it'll be a widespread lesson on Ethics in Business and 101 for all.
It sucks, because back before "AI" was associated with chatGPT and datascrapping, it was understood to be broad range of tech and code that can be really good and helpful. Unfortunately, aibros of today do not know how to, nor will put in the hard work, to making something more constructive than ArtTheftArtGeneratornumber3000 and ChatBotThatSucks2000. With so much of the slop, it's taking away time, energy, and resources from people trying to development meaningful AIs to recognize cancer and process information humans can't in a timely manner.
Edit: Its worth knowing this is not the first, nor likely the last time, ao3 has been scrapped. This isn't new but it's getting annoyingly common. And this particular dataset is *huge*
4 notes
·
View notes
Text
AI’s energy use already represents as much as 20 percent of global data-center power demand, research published Thursday in the journal Joule shows. That demand from AI, the research states, could double by the end of this year, comprising nearly half of all total data-center electricity consumption worldwide, excluding the electricity used for bitcoin mining.
The new research is published in a commentary by Alex de Vries-Gao, the founder of Digiconomist, a research company that evaluates the environmental impact of technology. De Vries-Gao started Digiconomist in the late 2010s to explore the impact of bitcoin mining, another extremely energy-intensive activity, would have on the environment. Looking at AI, he says, has grown more urgent over the past few years because of the widespread adoption of ChatGPT and other large language models that use massive amounts of energy. According to his research, worldwide AI energy demand is now set to surpass demand from bitcoin mining by the end of this year.
“The money that bitcoin miners had to get to where they are today is peanuts compared to the money that Google and Microsoft and all these big tech companies are pouring in [to AI],” he says. “This is just escalating a lot faster, and it’s a much bigger threat.”
The development of AI is already having an impact on Big Tech’s climate goals. Tech giants have acknowledged in recent sustainability reports that AI is largely responsible for driving up their energy use. Google’s greenhouse gas emissions, for instance, have increased 48 percent since 2019, complicating the company’s goals of reaching net zero by 2030.
“As we further integrate AI into our products, reducing emissions may be challenging due to increasing energy demands from the greater intensity of AI compute,” Google’s 2024 sustainability report reads.
Last month, the International Energy Agency released a report finding that data centers made up 1.5 percent of global energy use in 2024—around 415 terrawatt-hours, a little less than the yearly energy demand of Saudi Arabia. This number is only set to get bigger: Data centers’ electricity consumption has grown four times faster than overall consumption in recent years, while the amount of investment in data centers has nearly doubled since 2022, driven largely by massive expansions to account for new AI capacity. Overall, the IEA predicted that data center electricity consumption will grow to more than 900 TWh by the end of the decade.
But there’s still a lot of unknowns about the share that AI, specifically, takes up in that current configuration of electricity use by data centers. Data centers power a variety of services—like hosting cloud services and providing online infrastructure—that aren’t necessarily linked to the energy-intensive activities of AI. Tech companies, meanwhile, largely keep the energy expenditure of their software and hardware private.
Some attempts to quantify AI’s energy consumption have started from the user side: calculating the amount of electricity that goes into a single ChatGPT search, for instance. De Vries-Gao decided to look, instead, at the supply chain, starting from the production side to get a more global picture.
The high computing demands of AI, De Vries-Gao says, creates a natural “bottleneck” in the current global supply chain around AI hardware, particularly around the Taiwan Semiconductor Manufacturing Company (TSMC), the undisputed leader in producing key hardware that can handle these needs. Companies like Nvidia outsource the production of their chips to TSMC, which also produces chips for other companies like Google and AMD. (Both TSMC and Nvidia declined to comment for this article.)
De Vries-Gao used analyst estimates, earnings call transcripts, and device details to put together an approximate estimate of TSMC’s production capacity. He then looked at publicly available electricity consumption profiles of AI hardware and estimates on utilization rates of that hardware—which can vary based on what it’s being used for—to arrive at a rough figure of just how much of global data-center demand is taken up by AI. De Vries-Gao calculates that without increased production, AI will consume up to 82 terrawatt-hours of electricity this year—roughly around the same as the annual electricity consumption of a country like Switzerland. If production capacity for AI hardware doubles this year, as analysts have projected it will, demand could increase at a similar rate, representing almost half of all data center demand by the end of the year.
Despite the amount of publicly available information used in the paper, a lot of what De Vries-Gao is doing is peering into a black box: We simply don’t know certain factors that affect AI’s energy consumption, like the utilization rates of every piece of AI hardware in the world or what machine learning activities they’re being used for, let alone how the industry might develop in the future.
Sasha Luccioni, an AI and energy researcher and the climate lead at open-source machine-learning platform Hugging Face, cautioned about leaning too hard on some of the conclusions of the new paper, given the amount of unknowns at play. Luccioni, who was not involved in this research, says that when it comes to truly calculating AI’s energy use, disclosure from tech giants is crucial.
“It’s because we don’t have the information that [researchers] have to do this,” she says. “That’s why the error bar is so huge.”
And tech companies do keep this information. In 2022, Google published a paper on machine learning and electricity use, noting that machine learning was “10%–15% of Google’s total energy use” from 2019 to 2021, and predicted that with best practices, “by 2030 total carbon emissions from training will reduce.” However, since that paper—which was released before Google Gemini’s debut in 2023—Google has not provided any more detailed information about how much electricity ML uses. (Google declined to comment for this story.)
“You really have to deep-dive into the semiconductor supply chain to be able to make any sensible statement about the energy demand of AI,” De Vries-Gao says. “If these big tech companies were just publishing the same information that Google was publishing three years ago, we would have a pretty good indicator” of AI’s energy use.
19 notes
·
View notes
Text
The ongoing harms of AI
In the early days of the chatbot hype, OpenAI CEO Sam Altman was making a lot of promises about what large language models (LLMs) would mean for the future of human society. In Altman’s vision, our doctors and teachers would become chatbots and eventually everyone would have their own tailored AI assistant to help with whatever they needed. It wasn’t hard to see what that could mean for people’s jobs, if his predictions were true. The problem for Altman is that those claims were pure fantasy.
Over the 20 months that have passed since, it’s become undeniably clear that LLMs have limitations many companies do not want to acknowledge, as that might torpedo the hype keeping their executives relevant and their corporate valuations sky high. The problem of false information, often deceptively termed “hallucinations,” cannot be effectively tackled and the notion that the technologies will continue getting infinitely better with more and more data has been called into question by the minimal improvements new AI models have been able to deliver.
However, once the AI bubble bursts, that doesn’t mean chatbots and image generators will be relegated to the trash bin of history. Rather, there will be a reassessment of where it makes sense to implement them, and if attention moves on too fast, they may be able to do that with minimal pushback. The challenge visual artists and video game workers are already finding with employers making use of generative AI to worsen the labor conditions in their industries may become entrenched, especially if artists fail in their lawsuits against AI companies for training on their work without permission. But it could be far worse than that.
Microsoft is already partnering with Palantir to feed generative AI into militaries and intelligence agencies, while governments around the world are looking at how they can implement generative AI to reduce the cost of service delivery, often without effective consideration of the potential harms that can come of relying on tools that are well known to output false information. This is a problem Resisting AI author Dan McQuillan has pointed to as a key reason why we must push back against these technologies. There are already countless examples of algorithmic systems have been used to harm welfare recipients, childcare benefit applicants, immigrants, and other vulnerable groups. We risk a repetition, if not an intensification, of those harmful outcomes.
When the AI bubble bursts, investors will lose money, companies will close, and workers will lose jobs. Those developments will be splashed across the front pages of major media organizations and will receive countless hours of public discussion. But it’s those lasting harms that will be harder to immediately recognize, and that could fade as the focus moves on to whatever Silicon Valley places starts pushing as the foundation of its next investment cycle.
All the benefits Altman and his fellow AI boosters promised will fade, just as did the promises of the gig economy, the metaverse, the crypto industry, and countless others. But the harmful uses of the technology will stick around, unless concerted action is taken to stop those use cases from lingering long after the bubble bursts.
36 notes
·
View notes