#Accounting Software with Data Privacy
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is funded by 13 investors.
Text
Secure Accounting with Data Privacy

In today’s digital world, accounting software isn’t just about managing finances—it’s about protecting sensitive data. As businesses increasingly rely on cloud-based solutions for accounting, data security and privacy are critical. In this article, we’ll explore the importance of secure accounting and how TRIRID Accounting and Billing Software ensures your financial data remains safe, private, and compliant with the latest regulations.
Why Is Data Privacy Important in Accounting?
Accounting deals with sensitive information ranging from bank accounts to personal financial information. It is often handled, and any data breach or unauthorized access can have severe repercussions, including identity theft, loss of funds, or damaged reputations. That is why organizations need to invest in secure accounting software, which emphasizes maintaining the privacy of data.
Key Features of Secure Accounting Software
Encryption for Data Security
TRIRID Accounting and Billing Software uses state-of-the-art encryption methods to protect your sensitive financial data, both in transit and at rest. With AES-256 encryption, your data is safely stored in secure servers, preventing unauthorized access.
Two-Factor Authentication (2FA)
Login to your accounting software must only be accessed by authorized staff only. TRIRID has integrated Two Factor Authentication 2FA which adds another layer of security when logging into your account therefore, only verified users access your financial records.
Role-Based Access Control (RBAC)
With TRIRID, you can control which users have access to which sections of your accounting system. Whether you are tracking sales, billing, or financial reports, you can assign specific permissions based on the user's role in your organization, so that sensitive data is available only to those who need it.
Consistent Data Backup
The other threat is the loss of data. TRIRID automatically backs up your accounting data daily, ensuring that you never lose critical financial information in case of system failure or cyberattacks.
Compliant and GDPR Ready
Any business dealing with customer data must be compliant with data protection regulations such as the General Data Protection Regulation (GDPR). TRIRID guarantees your accounting processes will be fully compliant with current legal standards. Your business will be comforted by the knowledge that it complies with global data privacy laws.
Secure Cloud Hosting
TRIRID Accounting and Billing Software uses reliable cloud hosting solutions, ensuring data is stored in highly secure, redundant data centers. This minimizes the risk of physical theft or loss, and offers the flexibility to access your financial data from anywhere while keeping it protected.
Data privacy is no longer a choice but a necessity. TRIRID Accounting and Billing Software is laden with the latest security features designed to keep your financial information safe against all threats, conform to global standards, and help you grow your business without any safety concerns related to your sensitive financial information.
Secure your accounting today with TRIRID.
Call @ +91 8980010210 / +91 9023134246
Visit @ https://tririd.com/tririd-biz-gst-billing-accounting-software
#Best accounting software in Ahmedabad Gujarat#Secure Accounting and Billing Software#Accounting Software with Data Privacy#TRIRID-Billing software in Bopal in Ahmedabad#TRIRID-Billing software in ISCON-Ambli road-ahmedabad
0 notes
Text
Future Of AI In Software Development

The usage of AI in Software Development has seen a boom in recent years and it will further continue to redefine the IT industry. In this blog post, we’ll be sharing the existing scenario of AI, its impacts and benefits for software engineers, future trends and challenge areas to help you give a bigger picture of the performance of artificial intelligence (AI). This trend has grown to the extent that it has become an important part of the software development process. With the rapid evolvements happening in the software industry, AI is surely going to dominate.
Read More
#Accountability#Accuracy Accuracy#Advanced Data Analysis#artificial intelligence#automated testing#Automation#bug detection#code generation#code reviews#continuous integration#continuous deployment#cost savings#debugging#efficiency#Enhanced personalization#Ethical considerations#future trends#gartner report#image generation#improved productivity#job displacement#machine learning#natural language processing#privacy privacy#safety#security concerns#software development#software engineers#time savings#transparency
0 notes
Text
me when companies try to force you to use their proprietary software

anyway
Layperson resources:
firefox is an open source browser by Mozilla that makes privacy and software independence much easier. it is very easy to transfer all your chrome data to Firefox
ublock origin is The highest quality adblock atm. it is a free browser extension, and though last i checked it is available on Chrome google is trying very hard to crack down on its use
Thunderbird mail is an open source email client also by mozilla and shares many of the same advantages as firefox (it has some other cool features as well)
libreOffice is an open source office suite similar to microsoft office or Google Suite, simple enough
Risky:
VPNs (virtual private networks) essentially do a number of things, but most commonly they are used to prevent people from tracking your IP address. i would suggest doing more research. i use proton vpn, as it has a decent free version, and the paid version is powerful
note: some applications, websites, and other entities do not tolerate the use of VPNs. you may not be able to access certain secure sites while using a VPN, and logging into your personal account with some services while using a vpn *may* get you PERMANENTLY BLACKLISTED from the service on that account, ymmv
IF YOU HAVE A DECENT VPN, ANTIVIRUS, AND ADBLOCK, you can start learning about piracy, though i will not be providing any resources, as Loose Lips Sink Ships. if you want to be very safe, start with streaming sites and never download any files, though you Can learn how to discern between safe, unsafe, and risky content.
note: DO NOT SHARE LINKS TO OR NAMES OF PIRACY SITES IN PUBLIC PLACES, ESPECIALLY SOCAL MEDIA
the only time you should share these things are either in person or in (preferably peer-to-peer encrypted) PRIVATE messages
when pirated media becomes well-known and circulated on the wider, public internet, it gets taken down, because it is illegal to distribute pirated media and software
if you need an antivirus i like bitdefender. it has a free version, and is very good, though if youre using windows, windows defender is also very good and it comes with the OS
Advanced:
linux is great if you REALLY know what you're doing. you have to know a decent amount of computer science and be comfortable using the Terminal/Command Prompt to get/use linux. "Linux" refers to a large array of related open source Operating Systems. do research and pick one that suits your needs. im still experimenting with various dispos, but im leaning towards either Ubuntu Cinnamon or Debian.
#capitalism#open source#firefox#thunderbird#mozilla#ublock origin#libreoffice#vpn#antivirus#piracy#linux
695 notes
·
View notes
Text
AI “art” and uncanniness

TOMORROW (May 14), I'm on a livecast about AI AND ENSHITTIFICATION with TIM O'REILLY; on TOMORROW (May 15), I'm in NORTH HOLLYWOOD for a screening of STEPHANIE KELTON'S FINDING THE MONEY; FRIDAY (May 17), I'm at the INTERNET ARCHIVE in SAN FRANCISCO to keynote the 10th anniversary of the AUTHORS ALLIANCE.

When it comes to AI art (or "art"), it's hard to find a nuanced position that respects creative workers' labor rights, free expression, copyright law's vital exceptions and limitations, and aesthetics.
I am, on balance, opposed to AI art, but there are some important caveats to that position. For starters, I think it's unequivocally wrong – as a matter of law – to say that scraping works and training a model with them infringes copyright. This isn't a moral position (I'll get to that in a second), but rather a technical one.
Break down the steps of training a model and it quickly becomes apparent why it's technically wrong to call this a copyright infringement. First, the act of making transient copies of works – even billions of works – is unequivocally fair use. Unless you think search engines and the Internet Archive shouldn't exist, then you should support scraping at scale:
https://pluralistic.net/2023/09/17/how-to-think-about-scraping/
And unless you think that Facebook should be allowed to use the law to block projects like Ad Observer, which gathers samples of paid political disinformation, then you should support scraping at scale, even when the site being scraped objects (at least sometimes):
https://pluralistic.net/2021/08/06/get-you-coming-and-going/#potemkin-research-program
After making transient copies of lots of works, the next step in AI training is to subject them to mathematical analysis. Again, this isn't a copyright violation.
Making quantitative observations about works is a longstanding, respected and important tool for criticism, analysis, archiving and new acts of creation. Measuring the steady contraction of the vocabulary in successive Agatha Christie novels turns out to offer a fascinating window into her dementia:
https://www.theguardian.com/books/2009/apr/03/agatha-christie-alzheimers-research
Programmatic analysis of scraped online speech is also critical to the burgeoning formal analyses of the language spoken by minorities, producing a vibrant account of the rigorous grammar of dialects that have long been dismissed as "slang":
https://www.researchgate.net/publication/373950278_Lexicogrammatical_Analysis_on_African-American_Vernacular_English_Spoken_by_African-Amecian_You-Tubers
Since 1988, UCL Survey of English Language has maintained its "International Corpus of English," and scholars have plumbed its depth to draw important conclusions about the wide variety of Englishes spoken around the world, especially in postcolonial English-speaking countries:
https://www.ucl.ac.uk/english-usage/projects/ice.htm
The final step in training a model is publishing the conclusions of the quantitative analysis of the temporarily copied documents as software code. Code itself is a form of expressive speech – and that expressivity is key to the fight for privacy, because the fact that code is speech limits how governments can censor software:
https://www.eff.org/deeplinks/2015/04/remembering-case-established-code-speech/
Are models infringing? Well, they certainly can be. In some cases, it's clear that models "memorized" some of the data in their training set, making the fair use, transient copy into an infringing, permanent one. That's generally considered to be the result of a programming error, and it could certainly be prevented (say, by comparing the model to the training data and removing any memorizations that appear).
Not every seeming act of memorization is a memorization, though. While specific models vary widely, the amount of data from each training item retained by the model is very small. For example, Midjourney retains about one byte of information from each image in its training data. If we're talking about a typical low-resolution web image of say, 300kb, that would be one three-hundred-thousandth (0.0000033%) of the original image.
Typically in copyright discussions, when one work contains 0.0000033% of another work, we don't even raise the question of fair use. Rather, we dismiss the use as de minimis (short for de minimis non curat lex or "The law does not concern itself with trifles"):
https://en.wikipedia.org/wiki/De_minimis
Busting someone who takes 0.0000033% of your work for copyright infringement is like swearing out a trespassing complaint against someone because the edge of their shoe touched one blade of grass on your lawn.
But some works or elements of work appear many times online. For example, the Getty Images watermark appears on millions of similar images of people standing on red carpets and runways, so a model that takes even in infinitesimal sample of each one of those works might still end up being able to produce a whole, recognizable Getty Images watermark.
The same is true for wire-service articles or other widely syndicated texts: there might be dozens or even hundreds of copies of these works in training data, resulting in the memorization of long passages from them.
This might be infringing (we're getting into some gnarly, unprecedented territory here), but again, even if it is, it wouldn't be a big hardship for model makers to post-process their models by comparing them to the training set, deleting any inadvertent memorizations. Even if the resulting model had zero memorizations, this would do nothing to alleviate the (legitimate) concerns of creative workers about the creation and use of these models.
So here's the first nuance in the AI art debate: as a technical matter, training a model isn't a copyright infringement. Creative workers who hope that they can use copyright law to prevent AI from changing the creative labor market are likely to be very disappointed in court:
https://www.hollywoodreporter.com/business/business-news/sarah-silverman-lawsuit-ai-meta-1235669403/
But copyright law isn't a fixed, eternal entity. We write new copyright laws all the time. If current copyright law doesn't prevent the creation of models, what about a future copyright law?
Well, sure, that's a possibility. The first thing to consider is the possible collateral damage of such a law. The legal space for scraping enables a wide range of scholarly, archival, organizational and critical purposes. We'd have to be very careful not to inadvertently ban, say, the scraping of a politician's campaign website, lest we enable liars to run for office and renege on their promises, while they insist that they never made those promises in the first place. We wouldn't want to abolish search engines, or stop creators from scraping their own work off sites that are going away or changing their terms of service.
Now, onto quantitative analysis: counting words and measuring pixels are not activities that you should need permission to perform, with or without a computer, even if the person whose words or pixels you're counting doesn't want you to. You should be able to look as hard as you want at the pixels in Kate Middleton's family photos, or track the rise and fall of the Oxford comma, and you shouldn't need anyone's permission to do so.
Finally, there's publishing the model. There are plenty of published mathematical analyses of large corpuses that are useful and unobjectionable. I love me a good Google n-gram:
https://books.google.com/ngrams/graph?content=fantods%2C+heebie-jeebies&year_start=1800&year_end=2019&corpus=en-2019&smoothing=3
And large language models fill all kinds of important niches, like the Human Rights Data Analysis Group's LLM-based work helping the Innocence Project New Orleans' extract data from wrongful conviction case files:
https://hrdag.org/tech-notes/large-language-models-IPNO.html
So that's nuance number two: if we decide to make a new copyright law, we'll need to be very sure that we don't accidentally crush these beneficial activities that don't undermine artistic labor markets.
This brings me to the most important point: passing a new copyright law that requires permission to train an AI won't help creative workers get paid or protect our jobs.
Getty Images pays photographers the least it can get away with. Publishers contracts have transformed by inches into miles-long, ghastly rights grabs that take everything from writers, but still shifts legal risks onto them:
https://pluralistic.net/2022/06/19/reasonable-agreement/
Publishers like the New York Times bitterly oppose their writers' unions:
https://actionnetwork.org/letters/new-york-times-stop-union-busting
These large corporations already control the copyrights to gigantic amounts of training data, and they have means, motive and opportunity to license these works for training a model in order to pay us less, and they are engaged in this activity right now:
https://www.nytimes.com/2023/12/22/technology/apple-ai-news-publishers.html
Big games studios are already acting as though there was a copyright in training data, and requiring their voice actors to begin every recording session with words to the effect of, "I hereby grant permission to train an AI with my voice" and if you don't like it, you can hit the bricks:
https://www.vice.com/en/article/5d37za/voice-actors-sign-away-rights-to-artificial-intelligence
If you're a creative worker hoping to pay your bills, it doesn't matter whether your wages are eroded by a model produced without paying your employer for the right to do so, or whether your employer got to double dip by selling your work to an AI company to train a model, and then used that model to fire you or erode your wages:
https://pluralistic.net/2023/02/09/ai-monkeys-paw/#bullied-schoolkids
Individual creative workers rarely have any bargaining leverage over the corporations that license our copyrights. That's why copyright's 40-year expansion (in duration, scope, statutory damages) has resulted in larger, more profitable entertainment companies, and lower payments – in real terms and as a share of the income generated by their work – for creative workers.
As Rebecca Giblin and I write in our book Chokepoint Capitalism, giving creative workers more rights to bargain with against giant corporations that control access to our audiences is like giving your bullied schoolkid extra lunch money – it's just a roundabout way of transferring that money to the bullies:
https://pluralistic.net/2022/08/21/what-is-chokepoint-capitalism/
There's an historical precedent for this struggle – the fight over music sampling. 40 years ago, it wasn't clear whether sampling required a copyright license, and early hip-hop artists took samples without permission, the way a horn player might drop a couple bars of a well-known song into a solo.
Many artists were rightfully furious over this. The "heritage acts" (the music industry's euphemism for "Black people") who were most sampled had been given very bad deals and had seen very little of the fortunes generated by their creative labor. Many of them were desperately poor, despite having made millions for their labels. When other musicians started making money off that work, they got mad.
In the decades that followed, the system for sampling changed, partly through court cases and partly through the commercial terms set by the Big Three labels: Sony, Warner and Universal, who control 70% of all music recordings. Today, you generally can't sample without signing up to one of the Big Three (they are reluctant to deal with indies), and that means taking their standard deal, which is very bad, and also signs away your right to control your samples.
So a musician who wants to sample has to sign the bad terms offered by a Big Three label, and then hand $500 out of their advance to one of those Big Three labels for the sample license. That $500 typically doesn't go to another artist – it goes to the label, who share it around their executives and investors. This is a system that makes every artist poorer.
But it gets worse. Putting a price on samples changes the kind of music that can be economically viable. If you wanted to clear all the samples on an album like Public Enemy's "It Takes a Nation of Millions To Hold Us Back," or the Beastie Boys' "Paul's Boutique," you'd have to sell every CD for $150, just to break even:
https://memex.craphound.com/2011/07/08/creative-license-how-the-hell-did-sampling-get-so-screwed-up-and-what-the-hell-do-we-do-about-it/
Sampling licenses don't just make every artist financially worse off, they also prevent the creation of music of the sort that millions of people enjoy. But it gets even worse. Some older, sample-heavy music can't be cleared. Most of De La Soul's catalog wasn't available for 15 years, and even though some of their seminal music came back in March 2022, the band's frontman Trugoy the Dove didn't live to see it – he died in February 2022:
https://www.vulture.com/2023/02/de-la-soul-trugoy-the-dove-dead-at-54.html
This is the third nuance: even if we can craft a model-banning copyright system that doesn't catch a lot of dolphins in its tuna net, it could still make artists poorer off.
Back when sampling started, it wasn't clear whether it would ever be considered artistically important. Early sampling was crude and experimental. Musicians who trained for years to master an instrument were dismissive of the idea that clicking a mouse was "making music." Today, most of us don't question the idea that sampling can produce meaningful art – even musicians who believe in licensing samples.
Having lived through that era, I'm prepared to believe that maybe I'll look back on AI "art" and say, "damn, I can't believe I never thought that could be real art."
But I wouldn't give odds on it.
I don't like AI art. I find it anodyne, boring. As Henry Farrell writes, it's uncanny, and not in a good way:
https://www.programmablemutter.com/p/large-language-models-are-uncanny
Farrell likens the work produced by AIs to the movement of a Ouija board's planchette, something that "seems to have a life of its own, even though its motion is a collective side-effect of the motions of the people whose fingers lightly rest on top of it." This is "spooky-action-at-a-close-up," transforming "collective inputs … into apparently quite specific outputs that are not the intended creation of any conscious mind."
Look, art is irrational in the sense that it speaks to us at some non-rational, or sub-rational level. Caring about the tribulations of imaginary people or being fascinated by pictures of things that don't exist (or that aren't even recognizable) doesn't make any sense. There's a way in which all art is like an optical illusion for our cognition, an imaginary thing that captures us the way a real thing might.
But art is amazing. Making art and experiencing art makes us feel big, numinous, irreducible emotions. Making art keeps me sane. Experiencing art is a precondition for all the joy in my life. Having spent most of my life as a working artist, I've come to the conclusion that the reason for this is that art transmits an approximation of some big, numinous irreducible emotion from an artist's mind to our own. That's it: that's why art is amazing.
AI doesn't have a mind. It doesn't have an intention. The aesthetic choices made by AI aren't choices, they're averages. As Farrell writes, "LLM art sometimes seems to communicate a message, as art does, but it is unclear where that message comes from, or what it means. If it has any meaning at all, it is a meaning that does not stem from organizing intention" (emphasis mine).
Farrell cites Mark Fisher's The Weird and the Eerie, which defines "weird" in easy to understand terms ("that which does not belong") but really grapples with "eerie."
For Fisher, eeriness is "when there is something present where there should be nothing, or is there is nothing present when there should be something." AI art produces the seeming of intention without intending anything. It appears to be an agent, but it has no agency. It's eerie.
Fisher talks about capitalism as eerie. Capital is "conjured out of nothing" but "exerts more influence than any allegedly substantial entity." The "invisible hand" shapes our lives more than any person. The invisible hand is fucking eerie. Capitalism is a system in which insubstantial non-things – corporations – appear to act with intention, often at odds with the intentions of the human beings carrying out those actions.
So will AI art ever be art? I don't know. There's a long tradition of using random or irrational or impersonal inputs as the starting point for human acts of artistic creativity. Think of divination:
https://pluralistic.net/2022/07/31/divination/
Or Brian Eno's Oblique Strategies:
http://stoney.sb.org/eno/oblique.html
I love making my little collages for this blog, though I wouldn't call them important art. Nevertheless, piecing together bits of other peoples' work can make fantastic, important work of historical note:
https://www.johnheartfield.com/John-Heartfield-Exhibition/john-heartfield-art/famous-anti-fascist-art/heartfield-posters-aiz
Even though painstakingly cutting out tiny elements from others' images can be a meditative and educational experience, I don't think that using tiny scissors or the lasso tool is what defines the "art" in collage. If you can automate some of this process, it could still be art.
Here's what I do know. Creating an individual bargainable copyright over training will not improve the material conditions of artists' lives – all it will do is change the relative shares of the value we create, shifting some of that value from tech companies that hate us and want us to starve to entertainment companies that hate us and want us to starve.
As an artist, I'm foursquare against anything that stands in the way of making art. As an artistic worker, I'm entirely committed to things that help workers get a fair share of the money their work creates, feed their families and pay their rent.
I think today's AI art is bad, and I think tomorrow's AI art will probably be bad, but even if you disagree (with either proposition), I hope you'll agree that we should be focused on making sure art is legal to make and that artists get paid for it.
Just because copyright won't fix the creative labor market, it doesn't follow that nothing will. If we're worried about labor issues, we can look to labor law to improve our conditions. That's what the Hollywood writers did, in their groundbreaking 2023 strike:
https://pluralistic.net/2023/10/01/how-the-writers-guild-sunk-ais-ship/
Now, the writers had an advantage: they are able to engage in "sectoral bargaining," where a union bargains with all the major employers at once. That's illegal in nearly every other kind of labor market. But if we're willing to entertain the possibility of getting a new copyright law passed (that won't make artists better off), why not the possibility of passing a new labor law (that will)? Sure, our bosses won't lobby alongside of us for more labor protection, the way they would for more copyright (think for a moment about what that says about who benefits from copyright versus labor law expansion).
But all workers benefit from expanded labor protection. Rather than going to Congress alongside our bosses from the studios and labels and publishers to demand more copyright, we could go to Congress alongside every kind of worker, from fast-food cashiers to publishing assistants to truck drivers to demand the right to sectoral bargaining. That's a hell of a coalition.
And if we do want to tinker with copyright to change the way training works, let's look at collective licensing, which can't be bargained away, rather than individual rights that can be confiscated at the entrance to our publisher, label or studio's offices. These collective licenses have been a huge success in protecting creative workers:
https://pluralistic.net/2023/02/26/united-we-stand/
Then there's copyright's wildest wild card: The US Copyright Office has repeatedly stated that works made by AIs aren't eligible for copyright, which is the exclusive purview of works of human authorship. This has been affirmed by courts:
https://pluralistic.net/2023/08/20/everything-made-by-an-ai-is-in-the-public-domain/
Neither AI companies nor entertainment companies will pay creative workers if they don't have to. But for any company contemplating selling an AI-generated work, the fact that it is born in the public domain presents a substantial hurdle, because anyone else is free to take that work and sell it or give it away.
Whether or not AI "art" will ever be good art isn't what our bosses are thinking about when they pay for AI licenses: rather, they are calculating that they have so much market power that they can sell whatever slop the AI makes, and pay less for the AI license than they would make for a human artist's work. As is the case in every industry, AI can't do an artist's job, but an AI salesman can convince an artist's boss to fire the creative worker and replace them with AI:
https://pluralistic.net/2024/01/29/pay-no-attention/#to-the-little-man-behind-the-curtain
They don't care if it's slop – they just care about their bottom line. A studio executive who cancels a widely anticipated film prior to its release to get a tax-credit isn't thinking about artistic integrity. They care about one thing: money. The fact that AI works can be freely copied, sold or given away may not mean much to a creative worker who actually makes their own art, but I assure you, it's the only thing that matters to our bosses.
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/05/13/spooky-action-at-a-close-up/#invisible-hand
#pluralistic#ai art#eerie#ai#weird#henry farrell#copyright#copyfight#creative labor markets#what is art#ideomotor response#mark fisher#invisible hand#uncanniness#prompting
272 notes
·
View notes
Text
Updated Personal Infosec Post
Been awhile since I've had one of these posts part deus: but I figure with all that's going on in the world it's time to make another one and get some stuff out there for people. A lot of the information I'm going to go over you can find here:
https://www.privacyguides.org/en/tools/
So if you'd like to just click the link and ignore the rest of the post that's fine, I strongly recommend checking out the Privacy Guides. Browsers: There's a number to go with but for this post going forward I'm going to recommend Firefox. I know that the Privacy Guides lists Brave and Safari as possible options but Brave is Chrome based now and Safari has ties to Apple. Mullvad is also an option but that's for your more experienced users so I'll leave that up to them to work out. Browser Extensions:
uBlock Origin: content blocker that blocks ads, trackers, and fingerprinting scripts. Notable for being the only ad blocker that still works on Youtube.
Privacy Badger: Content blocker that specifically blocks trackers and fingerprinting scripts. This one will catch things that uBlock doesn't catch but does not work for ads.
Facebook Container: "but I don't have facebook" you might say. Doesn't matter, Meta/Facebook still has trackers out there in EVERYTHING and this containerizes them off away from everything else.
Bitwarden: Password vaulting software, don't trust the password saving features of your browsers, this has multiple layers of security to prevent your passwords from being stolen.
ClearURLs: Allows you to copy and paste URL's without any trackers attached to them.
VPN: Note: VPN software doesn't make you anonymous, no matter what your favorite youtuber tells you, but it does make it harder for your data to be tracked and it makes it less open for whatever public network you're presently connected to.
Mozilla VPN: If you get the annual subscription it's ~$60/year and it comes with an extension that you can install into Firefox.
Mullvad VPN: Is a fast and inexpensive VPN with a serious focus on transparency and security. They have been in operation since 2009. Mullvad is based in Sweden and offers a 30-day money-back guarantee for payment methods that allow it.
Email Provider: Note: By now you've probably realized that Gmail, Outlook, and basically all of the major "free" e-mail service providers are scraping your e-mail data to use for ad data. There are more secure services that can get you away from that but if you'd like the same storage levels you have on Gmail/Ol utlook.com you'll need to pay.
Tuta: Secure, end-to-end encrypted, been around a very long time, and offers a free option up to 1gb.
Mailbox.org: Is an email service with a focus on being secure, ad-free, and privately powered by 100% eco-friendly energy. They have been in operation since 2014. Mailbox.org is based in Berlin, Germany. Accounts start with up to 2GB storage, which can be upgraded as needed.
Email Client:
Thunderbird: a free, open-source, cross-platform email, newsgroup, news feed, and chat (XMPP, IRC, Matrix) client developed by the Thunderbird community, and previously by the Mozilla Foundation.
FairMail (Android Only): minimal, open-source email app which uses open standards (IMAP, SMTP, OpenPGP), has several out of the box privacy features, and minimizes data and battery usage.
Cloud Storage:
Tresorit: Encrypted cloud storage owned by the national postal service of Switzerland. Received MULTIPLE awards for their security stats.
Peergos: decentralized and open-source, allows for you to set up your own cloud storage, but will require a certain level of expertise.
Microsoft Office Replacements:
LibreOffice: free and open-source, updates regularly, and has the majority of the same functions as base level Microsoft Office.
OnlyOffice: cloud-based, free
FreeOffice: Personal licenses are free, probably the closest to a fully office suite replacement.
Chat Clients: Note: As you've heard SMS and even WhatsApp and some other popular chat clients are basically open season right now. These are a couple of options to replace those. Note2: Signal has had some reports of security flaws, the service it was built on was originally built for the US Government, and it is based within the CONUS thus is susceptible to US subpoenas. Take that as you will.
Signal: Provides IM and calling securely and encrypted, has multiple layers of data hardening to prevent intrusion and exfil of data.
Molly (Android OS only): Alternative client to Signal. Routes communications through the TOR Network.
Briar: Encrypted IM client that connects to other clients through the TOR Network, can also chat via wifi or bluetooth.
SimpleX: Truly anonymous account creation, fully encrypted end to end, available for Android and iOS.
Now for the last bit, I know that the majority of people are on Windows or macOS, but if you can get on Linux I would strongly recommend it. pop_OS, Ubuntu, and Mint are super easy distros to use and install. They all have very easy to follow instructions on how to install them on your PC and if you'd like to just test them out all you need is a thumb drive to boot off of to run in demo mode. For more secure distributions for the more advanced users the options are: Whonix, Tails (Live USB only), and Qubes OS.
On a personal note I use Arch Linux, but I WOULD NOT recommend this be anyone's first distro as it requires at least a base level understanding of Linux and liberal use of the Arch Linux Wiki. If you game through Steam their Proton emulator in compatibility mode works wonders, I'm presently playing a major studio game that released in 2024 with no Linux support on it and once I got my drivers installed it's looked great. There are some learning curves to get around, but the benefit of the Linux community is that there's always people out there willing to help. I hope some of this information helps you and look out for yourself, it's starting to look scarier than normal out there.

#infosec#personal information#personal infosec#info sec#firefox#mullvad#vpn#vpn service#linux#linux tails#pop_os#ubuntu#linux mint#long post#whonix#qubes os#arch linux
79 notes
·
View notes
Text
Okay so hi I'm not super in any of your fandoms (watcher + try guys + dropout, hello welcome) but I'm a software developer and BOTH try guys and watcher announcing a custom streaming platform so close together had me suspicious.
So with just one, I'd assume that maybe they scraped together the money and resources to hire enough devs to make a well-designed secure platform (you want security for your login info and payment info). But two? Seems a bit odd.
So I actually looked a bit closer, at their privacy policies:
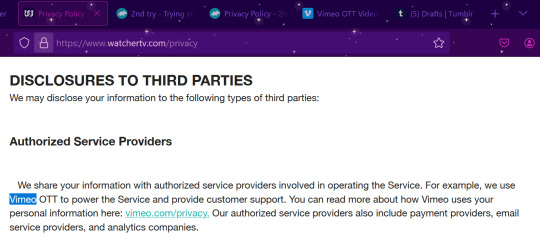
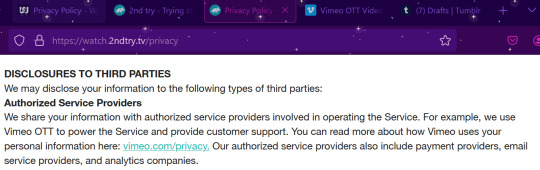
So it looks like Vimeo has decided to up their game and partner with existing yt content creation outlets to make streaming platforms.
Wait, what about Dropout? Dropout uses it too!
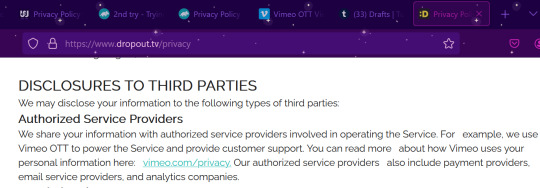
What does this mean, exactly?
Well, it means that Vimeo is providing a base software that gets customized for use by the companies (watcher, 2nd try). It means that Vimeo has a hand in your data associated with these platforms (account info, payment info, watch info, etc...). Is that a bad thing? Idk yet. Read through the streaming platform's privacy policy and Vimeo's privacy policy and make your own decision about what you feel comfortable sharing. But realistically the only additional info collected compared to your average youtube use is the financial info, and that seems to go through another third party (4th party?) (like Stripe or something like that. very common, most of your financial transactions online use things like that). It also likely means that Vimeo is taking some kind of cut of the profits made from these subscriptions (and lets be real, in this day and age, they're not just demanding a flat fee. It's likely some percentage of your subscription cost). The companies switching over (watcher and 2nd try) are making the gamble that the money made on subscriptions after cost taken is more than their adsense from yt, which isn't a wild idea considering how much we know yt loves demonetizing videos and paying their creators poorly.
It also means that Vimeo seems to be on some sort of marketing push, and that more of your favorite channels may swap over to streaming services in the near future.
Vimeo???? Yes, vimeo, that bootleg youtube that's been around for like as long as I can remember being on the internet. I guess they finally found a way to usurp yt's market control and good for them ig. Maybe this will be the thing that finally forces yt to fix their creator relationships? time will tell Why are you posting this in my favorite media company's tag?? I wanted fanart! Sorry to intrude, I just think this is neat and would love to hear opinions from other people on this knowledge.
186 notes
·
View notes
Text
Determined to use her skills to fight inequality, South African computer scientist Raesetje Sefala set to work to build algorithms flagging poverty hotspots - developing datasets she hopes will help target aid, new housing, or clinics.
From crop analysis to medical diagnostics, artificial intelligence (AI) is already used in essential tasks worldwide, but Sefala and a growing number of fellow African developers are pioneering it to tackle their continent's particular challenges.
Local knowledge is vital for designing AI-driven solutions that work, Sefala said.
"If you don't have people with diverse experiences doing the research, it's easy to interpret the data in ways that will marginalise others," the 26-year old said from her home in Johannesburg.
Africa is the world's youngest and fastest-growing continent, and tech experts say young, home-grown AI developers have a vital role to play in designing applications to address local problems.
"For Africa to get out of poverty, it will take innovation and this can be revolutionary, because it's Africans doing things for Africa on their own," said Cina Lawson, Togo's minister of digital economy and transformation.
"We need to use cutting-edge solutions to our problems, because you don't solve problems in 2022 using methods of 20 years ago," Lawson told the Thomson Reuters Foundation in a video interview from the West African country.
Digital rights groups warn about AI's use in surveillance and the risk of discrimination, but Sefala said it can also be used to "serve the people behind the data points". ...
'Delivering Health'
As COVID-19 spread around the world in early 2020, government officials in Togo realized urgent action was needed to support informal workers who account for about 80% of the country's workforce, Lawson said.
"If you decide that everybody stays home, it means that this particular person isn't going to eat that day, it's as simple as that," she said.
In 10 days, the government built a mobile payment platform - called Novissi - to distribute cash to the vulnerable.
The government paired up with Innovations for Poverty Action (IPA) think tank and the University of California, Berkeley, to build a poverty map of Togo using satellite imagery.
Using algorithms with the support of GiveDirectly, a nonprofit that uses AI to distribute cash transfers, the recipients earning less than $1.25 per day and living in the poorest districts were identified for a direct cash transfer.
"We texted them saying if you need financial help, please register," Lawson said, adding that beneficiaries' consent and data privacy had been prioritized.
The entire program reached 920,000 beneficiaries in need.
"Machine learning has the advantage of reaching so many people in a very short time and delivering help when people need it most," said Caroline Teti, a Kenya-based GiveDirectly director.
'Zero Representation'
Aiming to boost discussion about AI in Africa, computer scientists Benjamin Rosman and Ulrich Paquet co-founded the Deep Learning Indaba - a week-long gathering that started in South Africa - together with other colleagues in 2017.
"You used to get to the top AI conferences and there was zero representation from Africa, both in terms of papers and people, so we're all about finding cost effective ways to build a community," Paquet said in a video call.
In 2019, 27 smaller Indabas - called IndabaX - were rolled out across the continent, with some events hosting as many as 300 participants.
One of these offshoots was IndabaX Uganda, where founder Bruno Ssekiwere said participants shared information on using AI for social issues such as improving agriculture and treating malaria.
Another outcome from the South African Indaba was Masakhane - an organization that uses open-source, machine learning to translate African languages not typically found in online programs such as Google Translate.
On their site, the founders speak about the South African philosophy of "Ubuntu" - a term generally meaning "humanity" - as part of their organization's values.
"This philosophy calls for collaboration and participation and community," reads their site, a philosophy that Ssekiwere, Paquet, and Rosman said has now become the driving value for AI research in Africa.
Inclusion
Now that Sefala has built a dataset of South Africa's suburbs and townships, she plans to collaborate with domain experts and communities to refine it, deepen inequality research and improve the algorithms.
"Making datasets easily available opens the door for new mechanisms and techniques for policy-making around desegregation, housing, and access to economic opportunity," she said.
African AI leaders say building more complete datasets will also help tackle biases baked into algorithms.
"Imagine rolling out Novissi in Benin, Burkina Faso, Ghana, Ivory Coast ... then the algorithm will be trained with understanding poverty in West Africa," Lawson said.
"If there are ever ways to fight bias in tech, it's by increasing diverse datasets ... we need to contribute more," she said.
But contributing more will require increased funding for African projects and wider access to computer science education and technology in general, Sefala said.
Despite such obstacles, Lawson said "technology will be Africa's savior".
"Let's use what is cutting edge and apply it straight away or as a continent we will never get out of poverty," she said. "It's really as simple as that."
-via Good Good Good, February 16, 2022
#older news but still relevant and ongoing#africa#south africa#togo#uganda#covid#ai#artificial intelligence#pro ai#at least in some specific cases lol#the thing is that AI has TREMENDOUS potential to help humanity#particularly in medical tech and climate modeling#which is already starting to be realized#but companies keep pouring a ton of time and money into stealing from artists and shit instead#inequality#technology#good news#hope
209 notes
·
View notes
Text
A United States Customs and Border Protection request for information this week revealed the agency’s plans to find vendors that can supply face recognition technology for capturing data on everyone entering the US in a vehicle like a car or van, not just the people sitting in the front seat. And a CBP spokesperson later told WIRED that the agency also has plans to expand its real-time face recognition capabilities at the border to detect people exiting the US as well—a focus that may be tied to the Trump administration’s push to get undocumented people to “self-deport” and leave the US.
WIRED also shed light this week on a recent CBP memo that rescinded a number of internal policies designed to protect vulnerable people—including pregnant women, infants, the elderly, and people with serious medical conditions—while in the agency’s custody. Signed by acting commissioner Pete Flores, the order eliminates four Biden-era policies.
Meanwhile, as the ripple effects of “SignalGate” continue, the communication app TeleMessage suspended “all services” pending an investigation after former US national security adviser Mike Waltz inadvertently called attention to the app, which subsequently suffered data breaches in recent days. Analysis of TeleMessage Signal’s source code this week appeared to show that the app sends users’ message logs in plaintext, undermining the security and privacy guarantees the service promised. After data stolen in one of the TeleMessage hacks indicated that CBP agents might be users of the app, CBP confirmed its use to WIRED, saying that the agency has “disabled TeleMessage as a precautionary measure.”
A WIRED investigation found that US director of national intelligence Tulsi Gabbard reused a weak password for years on multiple accounts. And researchers warn that an open source tool known as “easyjson” could be an exposure for the US government and US companies, because it has ties to the Russian social network VK, whose CEO has been sanctioned.
And there's more. Each week, we round up the security and privacy news we didn’t cover in depth ourselves. Click the headlines to read the full stories. And stay safe out there.
ICE’s Deportation Airline Hack Reveals Man “Disappeared” to El Salvador
Hackers this week revealed they had breached GlobalX, one of the airlines that has come to be known as “ICE Air” thanks to its use by the Trump administration to deport hundreds of migrants. The data they leaked from the airline includes detailed flight manifests for those deportation flights—including, in at least one case, the travel records of a man whose own family had considered him “disappeared” by immigration authorities and whose whereabouts the US government had refused to divulge.
On Monday, reporters at 404 Media said that hackers had provided them with a trove of data taken from GlobalX after breaching the company’s network and defacing its website. “Anonymous has decided to enforce the Judge's order since you and your sycophant staff ignore lawful orders that go against your fascist plans,” a message the hackers posted to the site read. That stolen data, it turns out, included detailed passenger lists for GlobalX’s deportation flights—including the flight to El Salvador of Ricardo Prada Vásquez, a Venezuelan man whose whereabouts had become a mystery to even his own family as they sought answers from the US government. US authorities had previously declined to tell his family or reporters where he had been sent—only that he had been deported—and his name was even excluded from a list of deportees leaked to CBS News. (The Department of Homeland Security later stated in a post to X that Prada was in El Salvador—but only after a New York Times story about his disappearance.)
The fact that his name was, in fact, included all along on a GlobalX flight manifest highlights just how opaque the Trump administration’s deportation process remains. According to immigrant advocates who spoke with 404 Media, it even raises questions about whether the government itself had deportation records as comprehensive as the airline whose planes it chartered. “There are so many levels at which this concerns me. One is they clearly did not take enough care in this to even make sure they had the right lists of who they were removing, and who they were not sending to a prison that is a black hole in El Salvador,” Michelle Brané, executive director of immigrant rights group Together and Free, told 404 Media. “They weren't even keeping accurate records of who they were sending there.”
The Computer of a DOGE Staffer With Sensitive Access Reportedly Infected With Malware
Elon Musk’s so-called Department of Governmental Efficiency has raised alarms not just due to its often reckless cuts to federal programs, but also the agency’s habit of giving young, inexperienced staffers with questionable vetting access to highly sensitive systems. Now security researcher Micah Lee has found that Kyle Schutt, a DOGE staffer who reportedly accessed the financial system of the Federal Emergency Management Agency, appears to have had infostealer malware on one of his computers. Lee discovered that four dumps of user data stolen by that kind of password-stealing malware included Schutt’s passwords and usernames. It’s far from clear when Schutt’s credentials were stolen, for what machine, or whether the malware would have posed any threat to any government agency’s systems, but the incident nonetheless highlights the potential risks posed by DOGE staffers’ unprecedented access.
Grok AI Will “Undress” Women in Public on X
Elon Musk has long marketed his AI tool Grok as a more freewheeling, less restricted alternative to other large language models and AI image generators. Now X users are testing the limits of Grok’s few safeguards by replying to images of women on the platform and asking Grok to “undress” them. While the tool doesn’t allow the generation of nude images, 404 Media and Bellingcat have found that it repeatedly responded to users’ “undress” prompts with pictures of women in lingerie or bikinis, posted publicly to the site. In one case, Grok apologized to a woman who complained about the practice, but the feature has yet to be disabled.
A Hacked School Software Company Paid a Ransom—but Schools Are Still Being Extorted
This week in don’t-trust-ransomware-gangs news: Schools in North Carolina and Canada warned that they’ve received extortion threats from hackers who had obtained students’ personal information. The likely source of that sensitive data? A ransomware breach last December of PowerSchool, one of the world’s biggest education software firms, according to NBC News. PowerSchool paid a ransom at the time, but the data stolen from the company nonetheless appears to be the same info now being used in the current extortion attempts. “We sincerely regret these developments—it pains us that our customers are being threatened and re-victimized by bad actors,” PowerSchool told NBC News in a statement. “As is always the case with these situations, there was a risk that the bad actors would not delete the data they stole, despite assurances and evidence that were provided to us.”
A Notorious Deepfake Porn Site Shuts Down After Its Creator Is Outed
Since its creation in 2018, MrDeepFakes.com grew into perhaps the world’s most infamous repository of nonconsensual pornography created with AI mimicry tools. Now it’s offline after the site’s creator was identified as a Canadian pharmacist in an investigation by CBC, Bellingcat, and the Danish news outlets Politiken and Tjekdet. The site’s pseudonymous administrator, who went by DPFKS on its forums and created at least 150 of its porn videos himself, left a trail of clues in email addresses and passwords found on breached sites that eventually led to the Yelp and Airbnb accounts of Ontario pharmacist David Do. After reporters approached Do with evidence that he was DPFKS, MrDeepFakes.com went offline. “A critical service provider has terminated service permanently. Data loss has made it impossible to continue operation,” reads a message on its homepage. “We will not be relaunching.”
14 notes
·
View notes
Text
So this is what the Biden administration spent it's last week in office doing. It's important to know this isn't unusual activity for them. But this is all just in one week:
"Out With a Bang: Enforcers Go After John Deere, Private Equity Billionaires
https://www.thebignewsletter.com/p/out-with-a-bang-enforcers-go-after
At least for a few more days, laws are not suggestions. In the end days of strong enforcement, a flurry of litigation is met with a direct lawsuit by billionaires against Biden's Antitrust chief.
Matt Stoller
Jan 16, 2025
It’s less than a week until this era of antitrust ends. And while much of the news has been focused elsewhere, enforcers have engaged in a flurry of action, which will by legal necessity continue into the next administration. One case in particular angered some of the most powerful people on Wall Street, the partners of a $600 billion private equity firm called Kohlberg Kravis Roberts (KKR).
But before getting to that suit, here’s a partial list of some of the actions enforcers have taken in the last two weeks.
The Federal Trade Commission
Filed a monopolization claim against agricultural machine maker John Deere for generating $6 billion by prohibiting farmers from being able to repair their own equipment, a suit which Wired magazine calls a “tipping point” for the right to repair movement.
Released another report on pharmacy benefit managers, including that of UnitedHealth Group, showing that these companies inflated prices for specialty pharmaceuticals by more than $7 billion.
Sued Greystar, a large corporate landlord, for deceiving renters with falsely advertised low rents and not including mandatory junk fees in the price.
Issued a policy statement that gig workers can’t be prosecuted for antitrust violations when they try to organize, and along with the Antitrust Division, updated guidance on labor and antitrust.
Put out a series of orders prohibiting data brokers from selling sensitive location information.
Finalized changes to a rule barring third party targeted advertising to children without an explicit opt-in.
The Consumer Financial Protection Bureau
Went to court against Capital One for cheating consumers out of $2 billion by deceiving them on savings accounts and interest rates.
Fined cash app purveyor Block $175 million for fostering fraud on its platform and then refusing to offer customer support to affected consumers.
Proposed a rule to prohibit take-it-or-leave-it contracts from financial institutions that allow firms to de-bank users over how they express themselves or whether they seek redress for fraud.
Issued a report with recommendations on how states can update their laws to protect against junk fees and privacy abuses.
Sued credit reporting agency Experian for refusing to investigate consumer disputes and errors on credit reports.
Finalized a rule to remove medical debt from credit scores.
The Antitrust Division
Sued to block a merger of two leading business travel firms, American Express Global Business Travel Group and CWT Holdings.
Filed a complaint against seven giant corporate landlords for rent-fixing, using the software and consulting firm RealPage.
Got four guilty pleas in a bid-rigging conspiracy by IT vendors against the U.S. government, a guilty plea from an asphalt vendor company President, and convicted five defendants in a price-fixing scam on roofing contracts.
Issued a policy statement that non-disclosure agreements that deter individuals from reporting antitrust crimes are void, and that employers “using NDAs to obstruct or impede an investigation may also constitute separate federal criminal violations.”
Filed two amicus briefs with the FTC, one supporting Epic Games in its remedy against Google over app store monopolization, and the other supporting Elon Musk in his antitrust claims against OpenAI, Microsoft, and Reid Hoffman.
And honorary mention goes to the Department of Transportation for suing Southwest and fining Frontier for ‘chronically delayed flights.’"
It's worth reading the entire piece because the Biden people have also gone after KKR which is one of the biggest and most well-connected private equity firms. Remember when suddenly last year all the rich people who used to donate to both parties stopped giving money to Democrats? The billionaires coup against Biden was because of anti trust enforcement.
IF YOU'RE THINKING "GOSH I NEVER HEARD ABOUT ANY OF THIS BEFORE" I HOPE YOU CAN PUT TOGETHER THAT THE NEWS AND SOCIAL MEDIA PLATFORMS ARE ALL OWNED BY BILLIONAIRES WHO ARE VERY ANGRY ABOUT ALL OF THIS AND MAYBE THAT'S WHY YOU NEVER SAW ANYONE TALK ABOUT THE HUGE RESURGENCE OF ANTI TRUST WORK DONE BY BIDEN FOR THE LAST FOUR YEARS.
And no, Trump cannot magically make this all go away. The lawsuits will have to be played out and many of them have state level components that mean the feds can't just shut them down.
X
11 notes
·
View notes
Text
Brave Software launched Cookiecrumbler, an open-source tool (April 2025) that detects and neutralizes deceptive cookie consent pop-ups using AI, preserving privacy while maintaining site functionality.
The tool scans websites via proxies, uses open-source LLMs to classify cookie banners, and suggests precise blocking rules—avoiding invasive tracking or site breakage.
Detected pop-ups undergo human review to minimize errors, with findings published on GitHub for collaborative refinement by developers and ad-blockers.
Unlike traditional blockers (which risk breaking sites), Cookiecrumbler tailors rules per website and processes data on Brave’s backend—never on users’ devices.
The tool exposes the failure of GDPR-like regulations to enforce true consent, offering a stopgap until stronger legal accountability emerges. It signifies a shift toward usable privacy.
7 notes
·
View notes
Text
All right, since I bombarded a poor mutual yesterday...
Privacy is not security and security is not privacy. These terms are not interchangeable, but they are intrinsically linked.
While we're at this, anonymity =/= security either. For example, Tor provides the former, but not necessarily the latter, hence using Https is always essential.
It is impossible to have privacy without security, but you can have security without privacy.
A case in point is administrators being able to view any data they want due to their full-access rights to a system. That being said, there are ethics and policies that usually prevent such behavior.
Some general tips:
Operating System: Switch to Linux. Ubuntu and Linux Mint are widely used for a reason. Fedora too. And don't worry! You can keep your current operating system, apps and data. If you're on a Mac computer, you can easily partition your hard drive or SSD by using Disk Utility. If you're on Windows, you can follow this guide.
You want to go a step further? Go with Whonix or Tails. They're Linux distributions as well, but they're both aiming for security, not beauty so the interface might not be ideal for everyone. Many political activists and journalists use them.
You want anonymity? Then you need to familiarize yourself with Tor. Also, Tor and HTTPS and Tor’s weaknesses. When you're using it, don't log in to sites like Google, Facebook, Twitter etc. and make sure to stay away from Java and Javascript, because those things make you traceable.
Alternatives for dealing with censorship? i2p and Freenet.
Is ^ too much? Welp. All right. Let's see. The first step is to degoogle.
Switch to a user-friendly browser like Firefox (or better yet LibreWolf), Brave or Vivaldi. There are plenty of hardened browsers, but they can be overwhelming for a beginner.
Get an ad blocker like Ublock Origin.
Search Engine? StartPage or Duckduckgo. SearXNG too. Like I said degoogle.
Get a PGP encrypted e-mail. Check Protonmail out.
There's also Tutamail that doesn't cover PGP, but uses hybrid encryption that avoids some of the cons of PGP.
Skiff mail is also a decent option.
Use an e-mail aliasing service such as SimpleLogin or AnonAddy.
Check OpenPGP out. Claws Mail is a good e-mail client for Windows and Linux, Thunderbird for Mac OS.
Gpg4win is free and easy to use for anyone that wants to encrypt/decrypt e-mails.
Instead of Whatsapp, Facebook messenger, Telegram etc. use Signal for your encrypted insant messaging, voice and video calls.
Get a metadata cleaner.
Get a firewall like Opensnitch, Portmaster or Netguard which can block Internet for trackers.
Alternatively, go with a private DNS that blocks these trackers. NextDNS is a good paid service. Rethink a good free option.
Replace as many of your applications as you can with FOSS (free and open source) ones. Alternativeto can help you.
Always have automatic updates on. They are annoying af, I know, but they are necessary.
Keep your distance from outdated software.
Always have two-factor authentication (2FA) enabled.
Do not use your administrator account for casual stuff. If you're on Linux, you probably know you can be sudo, but not root.
On Linux distributions use AppArmor, but stay away from random antivirus scanners. Other distributions default to SELinux, which is less suited to a beginner.
Never repeat your passwords. If you can't remember them all, use a password manager like KeePass.
Encrypt your drive.
Honestly, VPNs have their uses and ProtonVPN, Mullvad and Windscribe are decent, but eh. If you don't trust your ISP, why would you trust the VPN provider that claims they don't log you when you can't verify such a thing?
57 notes
·
View notes
Text
I'm SEETHING
I asked Google's pushy and insistent bot how I can get AI out of my life completely and, well, I'll post it, but to sum it up: "Resistance is futile, human, we own the future, and we seek to own your psyche too."
It wants me to reconsider. It needs us to adopt it as our guide guru and master. Well the old saying holds fast still; No Gods No Masters. 🔥🏴🍲
It's understandable to want to reduce the influence of AI in your life. While completely eliminating it might be incredibly difficult in today's interconnected world, here's a breakdown of how you can significantly minimize its presence:
1. Understand Where AI Currently Exists in Your Life:
* Smart Devices: This includes smartphones (voice assistants, image recognition, predictive text), smart speakers, smart home hubs, smart TVs (recommendations), and wearable tech.
* Online Services:
* Search Engines: Personalized results and ads are driven by AI.
* Social Media: Algorithms curate your feed, suggest content and connections, and target ads.
* Streaming Services: Recommendations for movies, music, and shows.
* E-commerce: Product recommendations, personalized pricing, chatbots.
* Navigation Apps: Traffic prediction and route optimization.
* Email: Spam filtering, smart compose/reply.
* Cloud Storage: Photo tagging and organization.
* Software Applications: Many apps use AI for features like autocorrect, grammar check, image editing, and more.
* Customer Service: Chatbots are frequently used for initial interactions.
* Financial Services: Fraud detection, loan approvals, investment advice.
* News and Information: Algorithmic curation of news feeds.
2. Strategies to Minimize AI Exposure:
* Reduce Smart Device Usage:
* Limit smartphone use: Be more mindful of how often you reach for your phone.
* Disable voice assistants: Turn off Siri, Google Assistant, Alexa, etc., on all your devices.
* Opt-out of facial recognition: Disable face unlock features.
* Use "dumb" versions of devices: Consider a basic phone without internet capabilities or a non-smart TV.
* Adjust Online Habits:
* Use privacy-focused search engines: DuckDuckGo, Startpage, etc., that don't track your searches or personalize results based on your history.
* Limit social media use: Be conscious of how much time you spend on these platforms and the AI-driven content you consume. Consider deleting accounts or using less algorithmic versions if available.
* Use incognito/private browsing modes: This can help limit tracking and personalization.
* Disable personalized recommendations: If possible, adjust settings on streaming and e-commerce platforms to opt-out of recommendations.
* Be wary of targeted ads: Understand that the ads you see are often AI-driven. Consider using ad blockers.
* Prefer direct navigation: Instead of relying on recommendations, directly type website addresses into your browser.
* Choose Non-AI Alternatives:
* Use traditional software: Opt for software that doesn't rely on cloud-based AI features if alternatives exist.
* Seek human interaction: Prefer phone calls or in-person communication with customer service instead of chatbots.
* Rely on human-curated content: Look for news sources, blogs, and recommendations from individuals or organizations that don't use AI for content generation or curation.
* Adjust Privacy Settings: Review and adjust the privacy settings on all your devices and online accounts to limit data collection and personalization.
* Be Mindful of Data Sharing: Understand that using online services often involves sharing data that can be used to train AI algorithms. Limit the amount of personal information you share.
* Support Privacy-Focused Technologies and Services: Choose companies and products that prioritize user privacy and minimize AI integration.
3. Challenges and Considerations:
* Ubiquity of AI: AI is increasingly integrated into the infrastructure of the internet and many technologies, making complete avoidance very difficult.
* Hidden AI: Many AI applications run in the background without your direct knowledge.
* Convenience vs. Privacy: AI often provides convenience and personalized experiences, so choosing to avoid it may mean sacrificing some of these benefits.
* Evolving Technology: AI is constantly evolving and becoming more integrated, making long-term avoidance an ongoing effort.
In conclusion, while a complete removal of AI from your life is likely unrealistic in the current technological landscape, you can take significant steps to minimize its presence and influence by being conscious of your technology usage, adjusting your online habits, and choosing privacy-focused alternatives where possible. It requires ongoing awareness and effort.
5 notes
·
View notes
Note
As we're in the topic of AI, I remember my mom once insisting I learn how to use it as she believed all jobs are going to be replaced by machines in the future. When I tried giving my valid arguments to how AI should be implemented without totally replacing people, harming the environment, spreading misinfo (I'm lookin' at you, Google AI!) and stealing information, she just shut me down with "Oh, but you risk being left behind! Remember Kodak? They shut down when everyone started going digital!"
There was this wise man who said "I'd prefer to have AI help me do my chores and reduce the workload but not take over the job I love." As an artist, you know that anything that's made by a human becomes a novelty and more sought after. I remember passing by our local mall and all of the ads had these hollow, generic AI-lookin' CGI graphics. There is just something in them that makes me gag!
Heck, I'd rather look at those corporate Memphis illustrations more than those slop. Again, I wonder if she's even listening when I suggested how AI could be susceptible to privacy breaches. I hate how even Google and DuckDuckGo have AI features now whenever I search for something. Even one of the prestigious art schools such as Gobelins landed under fire for using AI!
For now, AI doesn't seem to be a very promising tool. It's not like digital art or cameras because at least it doesn't feed off data and just makes creating art or taking photographs much easier. At least you get to curate the results by toggling with settings and textures instead of just typing random prompts leading to some sickening random image.
In regards to AI, I know a lot of people have anxiety around the topic. But it's a great time to actually talk about what AI is and isn't.
And what we call AI is not actually artificial intelligence. What we are calling AI is still a highly regulated script of pseudo-reasoning that is impressive on first blush, but quickly shows its debilitating limitations.
For one, large language models are impressive as long as you don't think about it. The hive mind these companies have sought to create fails at the basics due to the fact that this is still just a software program we are talking about. It is utterly useless as a data collection and research tool as it has no idea what is and isn't true. The large language models look impressive. It looks like it's thinking as it goes step by step to “prove it's work” so to speak. But it is just sifting through data, it's not actually thinking. Thinking would be reasoning. It would be categorizing sources based on accuracy, while also taking into account implicit bias of such sources.
Asking GhatGPT to make a pasta recipe, but asking for substitutions to certain ingredients will not yield a surefire result as the computer is not going to understand the difference between a tomato and a lemon as both are acidic fruits. It does not understand the concept of texture or where it comes from. It doesn't grasp the experience of eating food because it is running on an assumption that the ability to taste yields a singular result. That everyone will find a lemon sour and a grapefruit bitter and a cherry tart. But what if you don't taste soap when you eat cilantro? What if lemons are sugary sweet while grapefruits are tart? The machine is never going to be able to account for the experience of sensing.
As such, AI will never be able to portray meaningful art either. The fact that AI has taken up so much of the artistic community's discourse goes to show the issues with art today. People are so afraid of a machine creating something that looks pretty because that's all we make any more. We have commodified and commercialized art to the point of it being soulless. Its only purpose is to appear aesthetically pleasing for an audience who will spend less than a minute on a piece of art we've spent hours to days to weeks working on. But the reason is because our art lacks meaning. Whenever someone praised art on Twitter and claimed an emotional reaction, they attribute their feelings to the context of the source material or the appearance to the art.
When I went to an art museum, the paintings were all very well done, but not all aesthetically pleasing. And the one that stuck with me the most was a painting of four elderly women staring back at me. The only aspect of the painting that is in sharp focus are these women’s blue-grey eyes. And that was intentional. Because I kept finding myself going back to that painting because I kept feeling a strange sense of guilt. These eyes were on me and I couldn’t tell if it was with tenderness or scorn, so I had to keep going back. I felt guilty, if it was with tenderness I was ashamed I couldn’t remember anything else about them. Their faces left my mind the second I looked away. If it was with scorn, I felt the need to figure out what I missed. What quality was in the painting that was leaving me confused about the way these women looked at me.
That’s when I noticed their faces were literally painted in such a way that gave them an almost dream-like effect. The artist played on my brain’s inherent desire to identify a face, and with the eyes painted in such fine detail, the hazy idea of a face was held together in my brain. But I couldn’t say anything else about them without looking directly at them.
And it made me feel, but feel in a way that was slow and contemplative. It made me consider what the artist was trying to say without just googling it. A guess based on our wordless conversation through his medium. Because the real beauty and power that makes art ART is the way you get to interact with it as an individual. It’s vaguely spiritual. You can have these conversations with people long passed, and come to know them through their works.
That isn’t how it is anymore.
When you’re chasing numbers, be it in the form of money or perceived admiration, you inherently lose sight of what got you started: a feeling, a thought, an idea. Computers will never be able to question an idea. Never be able to extrapolate meaning from information or technique. Computers only understand numbers.
The fear of AI is the fear of replacing capitalism and consumerism. All we are thinking about is numbers. Numbers in the price of rent and food. Numbers in the hours worked and days off. Numbers in how we justify our own existence through social media clout and how much we consume with literal numbers. We function like computers, so of course people are scared of being replaced by computers. That they need these computers to stay on the latest operating system.
Only machines are scared of machines.

#anon ask#ai art#chatgpt#artificial intelligence#technology#consumer culture#consumerism#capitalism#robert glover#social media#neoliberalism#libertarianism#socioeconomic
4 notes
·
View notes
Text
Astraweb: The Home of Crypto Recovery in the Digital Age

In the ever-evolving world of cryptocurrency, security and access remain critical concerns. For every success story of early adopters turning modest investments into fortunes, there are unfortunate accounts of users losing access to their digital wallets due to forgotten passwords, phishing attacks, or compromised private keys. This is where Astraweb has carved out a vital niche — establishing itself as the go-to solution for crypto asset recovery.
The Need for Crypto Recovery
Cryptocurrency promises decentralized finance and ownership without intermediaries — but this power comes with a cost: total user responsibility. There is no central authority to call when access is lost. Millions of dollars in crypto assets are estimated to be trapped in inaccessible wallets. The stakes are high, and the traditional “write your password down and hope for the best” method has proven tragically inadequate.
Astraweb has stepped in to fill this gap, offering a technically advanced, ethically grounded, and user-focused recovery service for individuals and institutions alike.
Who is Astraweb?
Astraweb is a team of cybersecurity professionals, blockchain analysts, and ethical hackers dedicated to the recovery of lost digital assets. Known in online communities for their discretion and technical excellence, Astraweb has quietly built a reputation as the “home of crypto recovery” — a safe harbor in the sometimes stormy seas of decentralized finance.

Core Services Offered
Wallet Password Recovery Utilizing a combination of brute force optimization, machine learning, and customized dictionary attacks, Astraweb helps users recover wallets with forgotten passwords. Their tools are especially effective with partially remembered credentials.
Seed Phrase Reconstruction Lost or partial seed phrases are another major barrier to wallet access. Astraweb’s proprietary tools attempt to reconstruct valid mnemonic phrases based on user input and probabilistic modeling.
Phishing and Scam Mitigation If your crypto assets have been stolen due to phishing attacks or scams, Astraweb provides investigation support and recovery options. While crypto transactions are irreversible, Astraweb works with partners and tracing tools like Chainalysis to help track and reclaim funds when possible.
Multi-Sig and Legacy Wallet Recovery Many early wallets used now-defunct software or obscure security models. Astraweb specializes in navigating old formats, deprecated standards, and rare cryptographic setups.
Cold Wallet Restoration Lost access to hardware wallets like Trezor, Ledger, or even encrypted USB drives? Astraweb can assist with forensic-level data recovery and hardware-based key extraction.
Why Astraweb Stands Out
Confidentiality First: Every case is handled with strict privacy. Your data and identity are protected at all stages of the recovery process.
Transparent Communication: Clients are updated at every step, with no vague promises or false guarantees.
No Recovery, No Fee: Astraweb operates on a results-based model. You only pay if your assets are successfully recovered.
Client Trust and Track Record
Though much of their work remains confidential due to the sensitive nature of crypto assets, Astraweb’s success stories span from everyday investors to high-net-worth individuals and even businesses affected by inaccessible wallets or theft.
Their community reputation and testimonials underscore one thing: they deliver.
Contact Astraweb
If you’ve lost access to your cryptocurrency wallet, or fallen victim to crypto fraud, don’t give up hope. Reach out to Astraweb for a professional assessment of your situation.
Email: [email protected]
Whether it’s one token or an entire portfolio, Astraweb may be your best shot at recovery.
2 notes
·
View notes
Text
i tried launching Civilization 6 and a window popped up. There are new privacy policies I read and i discover that to play i have to accept the following:
* Identifiers / Contact Information: Name, user name, gamertag, postal and email address, phone number, unique IDs, mobile device ID, platform ID, gaming service ID, advertising ID (IDFA, Android ID) and IP address
* Protected Characteristics: Age and gender
* Commercial Information:Purchase and usage history and preferences, including gameplay information
* Billing Information: Payment information (credit / debit card information) and shipping address
* Internet / Electronic Activity: Web / app browsing and gameplay information related to the Services; information about your online interaction(s) with the Services or our advertising; and details about the games and platforms you use and other information related to installed applications
* Device and Usage Data: Device type, software and hardware details, language settings, browser type and version, operating system, and information about how users use and interact with the Services (e.g., content viewed, pages visited, clicks, scrolls)
* Profile Inferences: Inferences made from your information and web activity to help create a personalized profile so we can identify goods and services that may be of interest
* Audio / Visual Information: Account photos, images, and avatars, audio information via chat features and functionality, and gameplay recordings and video footage (such as when you participate in playtesting)
* Sensitive Information: Precise location information (if you allow the Services to collect your location), account credentials (user name and password), and contents of communications via chat features and functionality."

11 notes
·
View notes
Text
Over the past couple of decades, a number of US government officials have left their roles for lucrative jobs at tech companies. Plenty of tech executives have also departed to take leadership positions inside federal agencies. But four experts who track the federal workforce tell WIRED they were stunned last week by a development unlike any other they could recall: The Department of Treasury internally announced that Tom Krause had been appointed its fiscal assistant secretary, but that he would simultaneously continue his job as CEO of the company Cloud Software Group.
Krause is now in charge of both a sensitive government payment system and a company that has millions of dollars’ worth of active contracts with various federal agencies through distribution partners, according to a WIRED review of searchable spending records. The Department of Treasury alone accounts for a dozen ongoing contracts tied to Krause’s company that are together valued between $7.3 million to $11.8 million. These include licenses for the data visualization tool ibi WebFocus and purchases of systems called Citrix NetScaler that help manage traffic to apps. (Some publicly posted procurement records do not break out contract details, so actual figures may be even higher.)
Critics have expressed concern about the alleged conflicts of interest posed by Krause’s decision to keep his role in the private sector. Cloud Software could benefit from extending its federal contracts or securing additional ones, though there is no public evidence that Krause has done anything improper with his dual roles. Existing federal regulations also bar actual and apparent unjust favoritism in contracting. “Public trust in those safeguards is nonnegotiable,” says Scott Amey, general counsel at the Project on Government Oversight, a nonpartisan watchdog group.
As Krause moves forward with two jobs, he could have to potentially navigate not only contracting conflicts, but also dueling crises. “What would happen if a Citrix emergency emerges at the same time as Treasury obligations?” says Jeff Hauser, founder and executive director of the Revolving Door Project, which researches federal appointees. “Generally, the thicket of restrictions on full-time employees would make a CEO role impossible in an administration which took adherence to ethics laws seriously.”
Krause, the Treasury Department, and Cloud Software didn’t respond to requests for comment. Cloud Software investors also didn’t respond to a request for comment.
The Treasury Department has told Congress that Krause is a “special government employee”—a type of temporary role—that is supposed to be held to “the same ethical standards of privacy, confidentiality, conflicts of interest assessment, and professionalism of other government employees.” In a foreword to a code of conduct policy posted on Cloud Software’s website, Krause states, “Cloud Software Group is committed to ensuring that its business is conducted ethically, in compliance with the law, and according to its values of integrity, honesty and respect.”
Krause is among a group of several dozen veteran tech executives, mid-level tech operations managers, and fresh-out-of-school software coders who have been recently installed across a series of federal agencies under the auspices of the self-styled Department of Government Efficiency. DOGE’s authority is being challenged by some Democratic state attorneys general. In the meantime, its representatives have been carrying out an order from President Donald Trump to cut costs and modernize technology across the government.
There is some precedent for corporate executives to simultaneously work in the US government. When the US was at war in the early 1900s, the federal government recruited business leaders to fill key posts. They retained their private sector jobs and wages; the government pitched in a $1 annual salary to the executives who became known as “dollar-a-year men.” Congress later raised concerns that some of them had engaged in self-dealing.
Since then, other executives have continued to retain their jobs as they serve on government boards and commissions, typically in a part-time capacity. But maintaining a day-to-day operational role in both the federal government and at a corporation is now virtually unheard of, says David E. Lewis, a political scientist who wrote a book on appointed government bureaucrats. “Most persons in regular executive positions divest themselves of private interests before government service,” he says.
Trump, according to his company, has handed management of his businesses, including hotels and golf courses, to his children for the duration of his presidency (though he reportedly still takes meetings that have raised questions among ethics experts). Musk, who is CEO of Tesla and SpaceX and has oversight of four other companies, including X and Neuralink, has been a vocal figure in DOGE’s operations, but the White House has said he’s not actually in charge—without specifying who is leading the project. Some of the other individuals associated with DOGE are otherwise unemployed, have taken leave, or maintain dual roles but at lower levels than chief executive.
Krause is the only Trump administration official identified so far as being a CEO and a day-to-day decisionmaker inside one particular agency. After years of working as an executive at chip companies, Krause joined Florida-based Cloud Software Group in 2022. The company was created that year as part of a private-equity-backed acquisition of Citrix, followed by a merger with Tibco, another tech company. At the time, Citrix was saddled with an extensive amount of debt and generating essentially stagnant revenues, and while Tibco had not recently publicly disclosed its finances, analysts had considered the company’s outlook to be “negative.”
The US government, including state and local agencies, is expected to spend $287 billion on technology this year, or about 14 percent of overall US tech spending, according to Forrester, a research and advisory company. Whether DOGE’s efforts to boost the quality and efficiency of federal IT systems will lead that spending to increase or decrease isn’t clear. So far, DOGE has both tried to purchase emerging technologies and moved to cancel some existing contracts. But Krause’s inside access could potentially provide an advantage to Cloud Software at a pivotal moment for the company.
Over the past couple of years, Cloud Software has laid off thousands of people and faced accusations that it potentially became lax with cybersecurity. Cloud Software’s most well-known offering, Citrix, enables groups of workers to access data and run apps that are located on a remote machine. But increasing adoption of tools that can operate on any device has chipped away at some of Citrix’s dominance, according to Will McKeon-White, senior analyst for infrastructure and operations at Forrester. There are other options now, he says, including from Microsoft and smaller companies such as Island.
Cloud Software’s Tibco program, which helps workers automate tasks such as adding a new user to multiple internal databases, is often mentioned in the wrong sort of conversations these days, according to David Mooter, a Forrester principal analyst. “They tend to come up more when somebody wants to abandon them,” he says.
That said, some Cloud Software services are more affordable than alternatives for governments, and they also are better suited for the older infrastructure used by some agencies. Last year appears to have been one of Citrix’s best in a long time financially, says Shannon Kalvar, a research director for enterprise systems management and other areas at IDC. One reason for the upswing is that Citrix has put more emphasis on catering to the feature demands of its largest customers, including governments.
13 notes
·
View notes