#Data Science Programming
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
BuzzFeed published a report claiming that Tumblr was utilized as a distribution channel for Russian agents to influence American voting habits during the 2016 presidential election in Feb 2018.
Text
in RStudio. straight up “instolling it”. and by “it”, haha, well. let’s justr say. My pakage
#sorry everyone who signed up for the star trek content#our usual programming will return momentarily#rstudio#statistics#data science#this is funny to me and maybe two other people
132 notes
·
View notes
Text
4/7 exams ✅
Honestly the exams were better than expected for the amount I studied, more specifically the way I studied, it seems like I can't get a hold on how I should study and just end up stuffing my brain with information which I will forget soon...? And also I'm too tired to study because of the travelling 🥲I really need to learn how to drive. Anyways here are the cats I saw and also cat motivation to study over the weekend ^^
~✿



#studyblr#study blog#exams#exam stress#study motivation#uni student#university#university life#student life#studying#programming#data analytics#data science#data scientist#chaotic academia#cats#study#studyblr community#study method
17 notes
·
View notes
Text
HT @dataelixir
#data science#data scientist#data scientists#machine learning#analytics#programming#data analytics#artificial intelligence#deep learning#llm
11 notes
·
View notes
Text
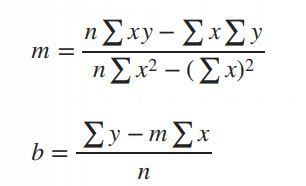
Simple Linear Regression in Data Science and machine learning
Simple linear regression is one of the most important techniques in data science and machine learning. It is the foundation of many statistical and machine learning models. Even though it is simple, its concepts are widely applicable in predicting outcomes and understanding relationships between variables.
This article will help you learn about:
1. What is simple linear regression and why it matters.
2. The step-by-step intuition behind it.
3. The math of finding slope() and intercept().
4. Simple linear regression coding using Python.
5. A practical real-world implementation.
If you are new to data science or machine learning, don’t worry! We will keep things simple so that you can follow along without any problems.
What is simple linear regression?
Simple linear regression is a method to model the relationship between two variables:
1. Independent variable (X): The input, also called the predictor or feature.
2. Dependent Variable (Y): The output or target value we want to predict.
The main purpose of simple linear regression is to find a straight line (called the regression line) that best fits the data. This line minimizes the error between the actual and predicted values.
The mathematical equation for the line is:
Y = mX + b
: The predicted values.
: The slope of the line (how steep it is).
: The intercept (the value of when).
Why use simple linear regression?
click here to read more https://datacienceatoz.blogspot.com/2025/01/simple-linear-regression-in-data.html
#artificial intelligence#bigdata#books#machine learning#machinelearning#programming#python#science#skills#big data#linear algebra#linear b#slope#interception
6 notes
·
View notes
Text
I’ve just enrolled in an undergrad class at my university in data science / coding. It is the first time I’ve done any kind coding. It’s also been almost four years since I was in undergrad myself, so I’m pretty nervous for the exam.
Does anyone have any study tips, particularly for data science / coding, which they would be willing to share? This topic is so different from anything I’ve ever done before I’m feeling pretty out of my depth.
#gradblr#phd#student#student life#studyblr#school#study tips#advice#coding#data science#programming#how to study
74 notes
·
View notes
Text
Mastering Linked Lists: Beginner's Guide
Hey Tumblr friends 👋
After learning about Arrays, it's time to level up! Today we’re diving into Linked Lists — another fundamental building block of coding! 🧱✨
So... What is a Linked List? 🤔
Imagine a treasure hunt 🗺️:
You find a clue ➡️ it points you to the next clue ➡️ and so on.
That's how a Linked List works!
🔗 Each element (Node) holds data and a pointer to the next Node.
It looks something like this: [data | next] -> [data | next] -> [data | next] -> NULL
Why Use a Linked List? 🌈
✅ Dynamic size (no need to pre-define size like arrays!) ✅ Easy insertions and deletions ✨ ✅ Great for building stacks, queues, and graphs later!
❌ Slower to access elements (you can't jump straight to an item like arrays).
Basic Structure of a Linked List Node 🛠️

data -> stores the actual value
next -> points to the next node
📚 CRUD Operations on Linked Lists
Let’s build simple CRUD functions for a singly linked list in C++! (🚀 CRUD = Create, Read, Update, Delete)
Create (Insert Nodes)

Read (Display the list)

Update (Change a Node’s Value)

Delete (Remove a Node)

🌟 Final Thoughts
🔗 Linked Lists may look tricky at first, but once you master them, you’ll be ready to understand more powerful structures like Stacks, Queues, and even Graphs! 🚀
🌱 Mini Challenge:
Build your own linked list of your favorite songs 🎶
Practice inserting, updating, and deleting songs!
If you loved this explainer, give a follow and let's keep leveling up together! 💬✨ Happy coding, coder fam! 💻🌈 For more resources and help join our discord server
4 notes
·
View notes
Text
plotting
plot random mundane stuff its fun
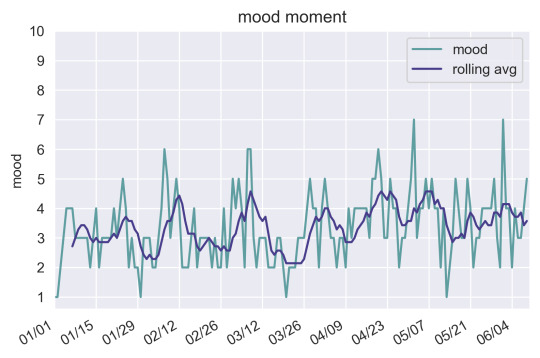
heres a plot of my mood rated 1-10 over time for the past half a year (rolling average with a window of 7 days)
always good to practice processing data and visualizing it
105 notes
·
View notes
Text
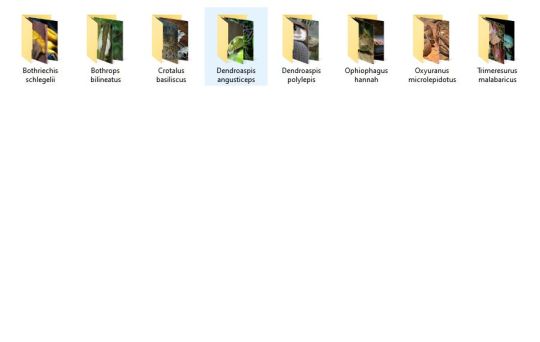
Tonight I am hunting down venomous and nonvenomous snake pictures that are under the creative commons of specific breeds in order to create one of the most advanced, in depth datasets of different venomous and nonvenomous snakes as well as a test set that will include snakes from both sides of all species. I love snakes a lot and really, all reptiles. It is definitely tedious work, as I have to make sure each picture is cleared before I can use it (ethically), but I am making a lot of progress! I have species such as the King Cobra, Inland Taipan, and Eyelash Pit Viper among just a few! Wikimedia Commons has been a huge help!
I'm super excited.
Hope your nights are going good. I am still not feeling good but jamming + virtual snake hunting is keeping me busy!
#programming#data science#data scientist#data analysis#neural networks#image processing#artificial intelligence#machine learning#snakes#snake#reptiles#reptile#herpetology#animals#biology#science#programming project#dataset#kaggle#coding
42 notes
·
View notes
Text
Mars Crater Study-1
This article was written as a practice exercise with reference to the information provided in the COURSERA course, specifically the Mars Crater Study.
=========================================
My program,
import pandas as pd
import statsmodels.formula.api as smf
# Set display format
pd.set_option('display.float_format', lambda x: '%.2f' % x)
# Read dataset
data = pd.read_csv('marscrater_pds.csv')
# Convert necessary variables to numeric format
data['DIAM_CIRCLE_IMAGE'] = pd.to_numeric(data['DIAM_CIRCLE_IMAGE'], errors='coerce')
data['DEPTH_RIMFLOOR_TOPOG'] = pd.to_numeric(data['DEPTH_RIMFLOOR_TOPOG'], errors='coerce')
# Perform basic linear regression analysis
print("OLS regression model for the association between crater diameter and depth")
reg1 = smf.ols('DEPTH_RIMFLOOR_TOPOG ~ DIAM_CIRCLE_IMAGE', data=data).fit()
print(reg1.summary())
=========================================
Output results,
Dep. Variable: DEPTH_RIMFLOOR_TOPOG
R-squared:0.344
Model: OLS
Adj. R-squared:0.344
Method:Least Squares
F-statistic:2.018e+05
Date:Thu, 27 Mar 2025
Prob (F-statistic):0.00
Time:14:58:20
Log-Likelihood:1.1503e+05
No. Observations:384343
AIC:-2.301e+05
Df Residuals:384341
BIC:-2.300e+05
Df Model: 1
Covariance Type:nonrobust
coef std err t P>|t| [0.025 0.975]
Intercept 0.0220 0.000 70.370 0.000 0.021 0.023
DIAM_CIRCLE_IMAGE
0.0151 3.37e-05 449.169 0.000 0.015 0.015
Omnibus:390327.615
Durbin-Watson:1.276
Prob(Omnibus):0.000
Jarque-Bera (JB):4086668077.223
Skew: -3.506
Prob(JB):0.00
Kurtosis:508.113
Cond. No.10.1
=========================================
Results Summary:
Regression Model Results:
R-squared: 0.344, indicating that the model explains approximately 34.4% of the variability in crater depth.
Regression Coefficient (DIAMCIRCLEIMAGE): 0.0151, meaning that for each unit increase in crater diameter, the depth increases by an average of 0.0151 units.
p-value: 0.000, indicating that the effect of diameter on depth is statistically significant.
Intercept: 0.0220, which is the predicted crater depth when the diameter is zero.
Conclusion:
The analysis shows a significant positive association between crater diameter and depth. While the model provides some explanatory power, other factors likely influence crater depth, and further exploration is recommended.
2 notes
·
View notes
Text
What is Data Structure in Python?
Summary: Explore what data structure in Python is, including built-in types like lists, tuples, dictionaries, and sets, as well as advanced structures such as queues and trees. Understanding these can optimize performance and data handling.

Introduction
Data structures are fundamental in programming, organizing and managing data efficiently for optimal performance. Understanding "What is data structure in Python" is crucial for developers to write effective and efficient code. Python, a versatile language, offers a range of built-in and advanced data structures that cater to various needs.
This blog aims to explore the different data structures available in Python, their uses, and how to choose the right one for your tasks. By delving into Python’s data structures, you'll enhance your ability to handle data and solve complex problems effectively.
What are Data Structures?
Data structures are organizational frameworks that enable programmers to store, manage, and retrieve data efficiently. They define the way data is arranged in memory and dictate the operations that can be performed on that data. In essence, data structures are the building blocks of programming that allow you to handle data systematically.
Importance and Role in Organizing Data
Data structures play a critical role in organizing and managing data. By selecting the appropriate data structure, you can optimize performance and efficiency in your applications. For example, using lists allows for dynamic sizing and easy element access, while dictionaries offer quick lookups with key-value pairs.
Data structures also influence the complexity of algorithms, affecting the speed and resource consumption of data processing tasks.
In programming, choosing the right data structure is crucial for solving problems effectively. It directly impacts the efficiency of algorithms, the speed of data retrieval, and the overall performance of your code. Understanding various data structures and their applications helps in writing optimized and scalable programs, making data handling more efficient and effective.
Read: Importance of Python Programming: Real-Time Applications.
Types of Data Structures in Python
Python offers a range of built-in data structures that provide powerful tools for managing and organizing data. These structures are integral to Python programming, each serving unique purposes and offering various functionalities.
Lists
Lists in Python are versatile, ordered collections that can hold items of any data type. Defined using square brackets [], lists support various operations. You can easily add items using the append() method, remove items with remove(), and extract slices with slicing syntax (e.g., list[1:3]). Lists are mutable, allowing changes to their contents after creation.
Tuples
Tuples are similar to lists but immutable. Defined using parentheses (), tuples cannot be altered once created. This immutability makes tuples ideal for storing fixed collections of items, such as coordinates or function arguments. Tuples are often used when data integrity is crucial, and their immutability helps in maintaining consistent data throughout a program.
Dictionaries
Dictionaries store data in key-value pairs, where each key is unique. Defined with curly braces {}, dictionaries provide quick access to values based on their keys. Common operations include retrieving values with the get() method and updating entries using the update() method. Dictionaries are ideal for scenarios requiring fast lookups and efficient data retrieval.
Sets
Sets are unordered collections of unique elements, defined using curly braces {} or the set() function. Sets automatically handle duplicate entries by removing them, which ensures that each element is unique. Key operations include union (combining sets) and intersection (finding common elements). Sets are particularly useful for membership testing and eliminating duplicates from collections.
Each of these data structures has distinct characteristics and use cases, enabling Python developers to select the most appropriate structure based on their needs.
Explore: Pattern Programming in Python: A Beginner’s Guide.
Advanced Data Structures
In advanced programming, choosing the right data structure can significantly impact the performance and efficiency of an application. This section explores some essential advanced data structures in Python, their definitions, use cases, and implementations.
Queues
A queue is a linear data structure that follows the First In, First Out (FIFO) principle. Elements are added at one end (the rear) and removed from the other end (the front).
This makes queues ideal for scenarios where you need to manage tasks in the order they arrive, such as task scheduling or handling requests in a server. In Python, you can implement a queue using collections.deque, which provides an efficient way to append and pop elements from both ends.
Stacks
Stacks operate on the Last In, First Out (LIFO) principle. This means the last element added is the first one to be removed. Stacks are useful for managing function calls, undo mechanisms in applications, and parsing expressions.
In Python, you can implement a stack using a list, with append() and pop() methods to handle elements. Alternatively, collections.deque can also be used for stack operations, offering efficient append and pop operations.
Linked Lists
A linked list is a data structure consisting of nodes, where each node contains a value and a reference (or link) to the next node in the sequence. Linked lists allow for efficient insertions and deletions compared to arrays.
A singly linked list has nodes with a single reference to the next node. Basic operations include traversing the list, inserting new nodes, and deleting existing ones. While Python does not have a built-in linked list implementation, you can create one using custom classes.
Trees
Trees are hierarchical data structures with a root node and child nodes forming a parent-child relationship. They are useful for representing hierarchical data, such as file systems or organizational structures.
Common types include binary trees, where each node has up to two children, and binary search trees, where nodes are arranged in a way that facilitates fast lookups, insertions, and deletions.
Graphs
Graphs consist of nodes (or vertices) connected by edges. They are used to represent relationships between entities, such as social networks or transportation systems. Graphs can be represented using an adjacency matrix or an adjacency list.
The adjacency matrix is a 2D array where each cell indicates the presence or absence of an edge, while the adjacency list maintains a list of edges for each node.
See: Types of Programming Paradigms in Python You Should Know.
Choosing the Right Data Structure
Selecting the appropriate data structure is crucial for optimizing performance and ensuring efficient data management. Each data structure has its strengths and is suited to different scenarios. Here’s how to make the right choice:
Factors to Consider
When choosing a data structure, consider performance, complexity, and specific use cases. Performance involves understanding time and space complexity, which impacts how quickly data can be accessed or modified. For example, lists and tuples offer quick access but differ in mutability.
Tuples are immutable and thus faster for read-only operations, while lists allow for dynamic changes.
Use Cases for Data Structures:
Lists are versatile and ideal for ordered collections of items where frequent updates are needed.
Tuples are perfect for fixed collections of items, providing an immutable structure for data that doesn’t change.
Dictionaries excel in scenarios requiring quick lookups and key-value pairs, making them ideal for managing and retrieving data efficiently.
Sets are used when you need to ensure uniqueness and perform operations like intersections and unions efficiently.
Queues and stacks are used for scenarios needing FIFO (First In, First Out) and LIFO (Last In, First Out) operations, respectively.
Choosing the right data structure based on these factors helps streamline operations and enhance program efficiency.
Check: R Programming vs. Python: A Comparison for Data Science.
Frequently Asked Questions
What is a data structure in Python?
A data structure in Python is an organizational framework that defines how data is stored, managed, and accessed. Python offers built-in structures like lists, tuples, dictionaries, and sets, each serving different purposes and optimizing performance for various tasks.
Why are data structures important in Python?
Data structures are crucial in Python as they impact how efficiently data is managed and accessed. Choosing the right structure, such as lists for dynamic data or dictionaries for fast lookups, directly affects the performance and efficiency of your code.
What are advanced data structures in Python?
Advanced data structures in Python include queues, stacks, linked lists, trees, and graphs. These structures handle complex data management tasks and improve performance for specific operations, such as managing tasks or representing hierarchical relationships.
Conclusion
Understanding "What is data structure in Python" is essential for effective programming. By mastering Python's data structures, from basic lists and dictionaries to advanced queues and trees, developers can optimize data management, enhance performance, and solve complex problems efficiently.
Selecting the appropriate data structure based on your needs will lead to more efficient and scalable code.
#What is Data Structure in Python?#Data Structure in Python#data structures#data structure in python#python#python frameworks#python programming#data science
6 notes
·
View notes
Text
Truth speaking on the corporate obsession with AI
Hilarious. Something tells me this person's on the hellsite(affectionate)
#ai#corporate bs#late stage capitalism#funny#truth#artificial intelligence#ml#machine learning#data science#data scientist#programming#scientific programming
8 notes
·
View notes
Text
What are the skills needed for a data scientist job?
It’s one of those careers that’s been getting a lot of buzz lately, and for good reason. But what exactly do you need to become a data scientist? Let’s break it down.
Technical Skills
First off, let's talk about the technical skills. These are the nuts and bolts of what you'll be doing every day.
Programming Skills: At the top of the list is programming. You’ll need to be proficient in languages like Python and R. These are the go-to tools for data manipulation, analysis, and visualization. If you’re comfortable writing scripts and solving problems with code, you’re on the right track.
Statistical Knowledge: Next up, you’ve got to have a solid grasp of statistics. This isn’t just about knowing the theory; it’s about applying statistical techniques to real-world data. You’ll need to understand concepts like regression, hypothesis testing, and probability.
Machine Learning: Machine learning is another biggie. You should know how to build and deploy machine learning models. This includes everything from simple linear regressions to complex neural networks. Familiarity with libraries like scikit-learn, TensorFlow, and PyTorch will be a huge plus.
Data Wrangling: Data isn’t always clean and tidy when you get it. Often, it’s messy and requires a lot of preprocessing. Skills in data wrangling, which means cleaning and organizing data, are essential. Tools like Pandas in Python can help a lot here.
Data Visualization: Being able to visualize data is key. It’s not enough to just analyze data; you need to present it in a way that makes sense to others. Tools like Matplotlib, Seaborn, and Tableau can help you create clear and compelling visuals.
Analytical Skills
Now, let’s talk about the analytical skills. These are just as important as the technical skills, if not more so.
Problem-Solving: At its core, data science is about solving problems. You need to be curious and have a knack for figuring out why something isn’t working and how to fix it. This means thinking critically and logically.
Domain Knowledge: Understanding the industry you’re working in is crucial. Whether it’s healthcare, finance, marketing, or any other field, knowing the specifics of the industry will help you make better decisions and provide more valuable insights.
Communication Skills: You might be working with complex data, but if you can’t explain your findings to others, it’s all for nothing. Being able to communicate clearly and effectively with both technical and non-technical stakeholders is a must.
Soft Skills
Don’t underestimate the importance of soft skills. These might not be as obvious, but they’re just as critical.
Collaboration: Data scientists often work in teams, so being able to collaborate with others is essential. This means being open to feedback, sharing your ideas, and working well with colleagues from different backgrounds.
Time Management: You’ll likely be juggling multiple projects at once, so good time management skills are crucial. Knowing how to prioritize tasks and manage your time effectively can make a big difference.
Adaptability: The field of data science is always evolving. New tools, techniques, and technologies are constantly emerging. Being adaptable and willing to learn new things is key to staying current and relevant in the field.
Conclusion
So, there you have it. Becoming a data scientist requires a mix of technical prowess, analytical thinking, and soft skills. It’s a challenging but incredibly rewarding career path. If you’re passionate about data and love solving problems, it might just be the perfect fit for you.
Good luck to all of you aspiring data scientists out there!
#artificial intelligence#career#education#coding#jobs#programming#success#python#data science#data scientist#data security
8 notes
·
View notes
Text
ML Code Challenges HT @dataelixir
#data science#data scientist#data scientists#machine learning#programming#deep learning#artificial intelligence
13 notes
·
View notes
Text

Beginner’s Guide to Ridge Regression in Machine Learning
Introduction
Regression analysis is a fundamental technique in machine learning, used to predict a dependent variable based on one or more independent variables. However, traditional regression methods, such as simple linear regression, can struggle to deal with multicollinearity (high correlation between predictors). This is where ridge regression comes in handy.
Ridge regression is an advanced form of linear regression that reduces overfitting by adding a penalty term to the model. In this article, we will cover what ridge regression is, why it is important, how it works, its assumptions, and how to implement it using Python.
What is Ridge Regression?
Ridge regression is a type of regularization technique that modifies the linear
click here to read more
https://datacienceatoz.blogspot.com/2025/02/a-beginners-guide-to-ridge-regression.html
#artificial intelligence#bigdata#books#machine learning#machinelearning#programming#python#science#skills#big data
4 notes
·
View notes
Text
🌟 Understanding Arrays: A Beginner’s Deep Dive! 🌟
Hey Tumblr friends 👋
Today I want to break down something super important if you're getting into coding: Arrays. (Yes, those weird-looking brackets you've probably seen in code snippets? Let’s talk about them.)
So... What Exactly Is an Array? 🤔
Imagine you have a bunch of favorite songs you want to save. Instead of creating a new playlist for each song (chaotic!), you put them all into one single playlist.
That playlist? That’s what an Array is in programming! 🎶✨
An array is basically a container where you can store multiple values together under a single name.
Instead of doing this:

You can just do:

Why Are Arrays Useful? 🌈
✅ You can group related data together. ✅ You can loop through them easily. ✅ You can dynamically access or update data. ✅ You keep your code clean and organized. (No messy variables 👀)
How Do You Create an Array? ✨
Here's a simple array:
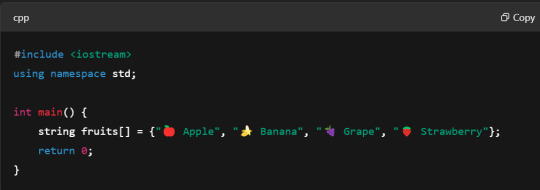
Or create an empty array first (you must specify size in C++):

Note: C++ arrays have a fixed size once declared!
How Do You Access Items in an Array? 🔎
Arrays are zero-indexed. That means the first element is at position 0.
Example:

Changing Stuff in an Array 🛠️
You can update an item like this:

Looping Through an Array 🔄
Instead of writing:
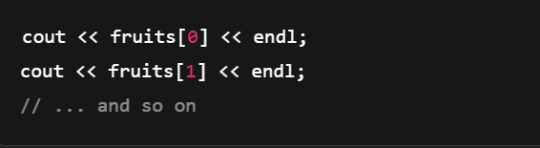
Use a loop:

Or a range-based for loop (cleaner!):

Some Cool Things You Can Do With Arrays 🚀
In C++ you don't have built-in methods like push, pop, etc. for raw arrays, but you can use vectors (dynamic arrays)! Example with vector:

Quick Tip: Arrays Can Store Anything 🤯
You can store numbers, booleans, objects (structures/classes), and even arrays inside arrays (multidimensional arrays).
Example:

Real-World Example 🌍
A To-Do list:

Output:
👏 See how clean and readable that is compared to hardcoding every single task?
🌟 Final Thoughts
Arrays are the foundation of so much you'll do in coding — from simple projects to complex apps. Master them early, and you'll thank yourself later!
🌱 Start practicing:
Make a list of your favorite movies
Your favorite foods
Songs you love
...all in an array!
If you liked this C++ explainer, let’s connect! 💬✨ Happy coding, coder fam! 💻🌈
2 notes
·
View notes
Text

The Mathematical Foundations of Machine Learning
In the world of artificial intelligence, machine learning is a crucial component that enables computers to learn from data and improve their performance over time. However, the math behind machine learning is often shrouded in mystery, even for those who work with it every day. Anil Ananthaswami, author of the book "Why Machines Learn," sheds light on the elegant mathematics that underlies modern AI, and his journey is a fascinating one.
Ananthaswami's interest in machine learning began when he started writing about it as a science journalist. His software engineering background sparked a desire to understand the technology from the ground up, leading him to teach himself coding and build simple machine learning systems. This exploration eventually led him to appreciate the mathematical principles that underlie modern AI. As Ananthaswami notes, "I was amazed by the beauty and elegance of the math behind machine learning."
Ananthaswami highlights the elegance of machine learning mathematics, which goes beyond the commonly known subfields of calculus, linear algebra, probability, and statistics. He points to specific theorems and proofs, such as the 1959 proof related to artificial neural networks, as examples of the beauty and elegance of machine learning mathematics. For instance, the concept of gradient descent, a fundamental algorithm used in machine learning, is a powerful example of how math can be used to optimize model parameters.
Ananthaswami emphasizes the need for a broader understanding of machine learning among non-experts, including science communicators, journalists, policymakers, and users of the technology. He believes that only when we understand the math behind machine learning can we critically evaluate its capabilities and limitations. This is crucial in today's world, where AI is increasingly being used in various applications, from healthcare to finance.
A deeper understanding of machine learning mathematics has significant implications for society. It can help us to evaluate AI systems more effectively, develop more transparent and explainable AI systems, and address AI bias and ensure fairness in decision-making. As Ananthaswami notes, "The math behind machine learning is not just a tool, but a way of thinking that can help us create more intelligent and more human-like machines."
The Elegant Math Behind Machine Learning (Machine Learning Street Talk, November 2024)
youtube
Matrices are used to organize and process complex data, such as images, text, and user interactions, making them a cornerstone in applications like Deep Learning (e.g., neural networks), Computer Vision (e.g., image recognition), Natural Language Processing (e.g., language translation), and Recommendation Systems (e.g., personalized suggestions). To leverage matrices effectively, AI relies on key mathematical concepts like Matrix Factorization (for dimension reduction), Eigendecomposition (for stability analysis), Orthogonality (for efficient transformations), and Sparse Matrices (for optimized computation).
The Applications of Matrices - What I wish my teachers told me way earlier (Zach Star, October 2019)
youtube
Transformers are a type of neural network architecture introduced in 2017 by Vaswani et al. in the paper “Attention Is All You Need”. They revolutionized the field of NLP by outperforming traditional recurrent neural network (RNN) and convolutional neural network (CNN) architectures in sequence-to-sequence tasks. The primary innovation of transformers is the self-attention mechanism, which allows the model to weigh the importance of different words in the input data irrespective of their positions in the sentence. This is particularly useful for capturing long-range dependencies in text, which was a challenge for RNNs due to vanishing gradients. Transformers have become the standard for machine translation tasks, offering state-of-the-art results in translating between languages. They are used for both abstractive and extractive summarization, generating concise summaries of long documents. Transformers help in understanding the context of questions and identifying relevant answers from a given text. By analyzing the context and nuances of language, transformers can accurately determine the sentiment behind text. While initially designed for sequential data, variants of transformers (e.g., Vision Transformers, ViT) have been successfully applied to image recognition tasks, treating images as sequences of patches. Transformers are used to improve the accuracy of speech-to-text systems by better modeling the sequential nature of audio data. The self-attention mechanism can be beneficial for understanding patterns in time series data, leading to more accurate forecasts.
Attention is all you need (Umar Hamil, May 2023)
youtube
Geometric deep learning is a subfield of deep learning that focuses on the study of geometric structures and their representation in data. This field has gained significant attention in recent years.
Michael Bronstein: Geometric Deep Learning (MLSS Kraków, December 2023)
youtube
Traditional Geometric Deep Learning, while powerful, often relies on the assumption of smooth geometric structures. However, real-world data frequently resides in non-manifold spaces where such assumptions are violated. Topology, with its focus on the preservation of proximity and connectivity, offers a more robust framework for analyzing these complex spaces. The inherent robustness of topological properties against noise further solidifies the rationale for integrating topology into deep learning paradigms.
Cristian Bodnar: Topological Message Passing (Michael Bronstein, August 2022)
youtube
Sunday, November 3, 2024
#machine learning#artificial intelligence#mathematics#computer science#deep learning#neural networks#algorithms#data science#statistics#programming#interview#ai assisted writing#machine art#Youtube#lecture
4 notes
·
View notes