#HTML Encoding
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text
#Technology Magazine#Free Online Tool#Interactive Tools and Collection#Internet Tools#SEO Tools#Learn Search Engine Optimization#Computer Tips#Freelancer#Android#Android Studio#BlogSpot and Blogging#Learn WordPress#Learn Joomla#Learn Drupal#Learn HTML#CSS Code#Free JavaScript Code#Photo and Image Editing Training#Make Money Online#Online Learning#Product Review#Web Development Tutorial#Windows OS Tips#Digital Marketing#Online Converter#Encoder and Decoder#Code Beautifier#Code Generator#Code Library#Software
0 notes
Note
Hi! How you doing the combination in the titles? Can you do a tutorial please! Thanks!
Hello @elvisbdoll 🫶🏻
~ Firstly, I'll share the link from where I learnt to do that. It is explained in a very easy and short way here.
~ You need to use Tumblr web on your phone or laptop for this idk why it doesn't work on the app.
~ I'll also explain below in my own detailed way, hoping that this becomes easy for anyone who follows my posts and wants to know how I do it😁

• Website for the Gradient Text :
TEXT COLOR FADER
• Detailed process of how I use customised gradient text on Tumblr :
( Pay attention to the colors that I have used in the steps as well as the screenshots to understand better. The markings on the photos are to make it easier to spot what I'm talking about. )
.
1. Create a post on Tumblr by writing the text you want to make a gradient of and save it as a draft. In the draft → Go to the Settings wheel and in the Text Editor section select HTML which is required by Tumblr to read a coded* text.
* ( The colors of the Gradient text are basically coded into text on the Website I shared above. Hence, changing into the HTML type here will help Tumblr recognise that coded text and turn it into a normal Gradient colored text. )

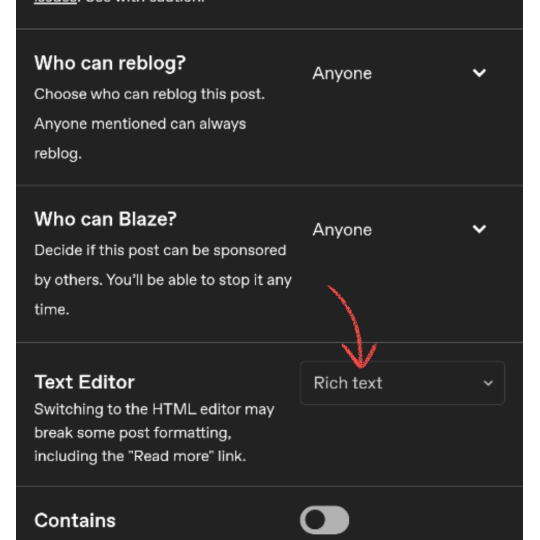

2. You will see a coded version of the text you wrote which is encoded between <h1>...your text...</h1> for my text in the photo below. You can toggle between HTML & Preview to see the coded and uncoded(normal) version of the text. Copy the normal version of the text from the Preview mode that you want to turn into gradient.

3. Visit the Website in the link I've shared above.
.
A: is the part where you paste the text you just copied and want to change into a Gradient.
B: is the number of colors you want to use in the gradient.
C: is the part where you put the color codes (HEX/RGB) or just swipe to get the desired color from the color wheel.

4. I pasted the text in the text box and made the changes that I need to do to get the gradient I want in the next part. I used 4 colors and put the Hex codes for the Teal and Beige colors. Once you're done click on "Generate Color Coded Text"

5. On the next page you'll get to see a preview of the text and the coded text in the box below. Click on Select All and Copy the coded text.
If you want to make any changes you can go back by clicking on "Create a new fade" and you will be taken back to edit the current gradient.

6. Go to the draft and delete the existing text to avoid mixing the coded text with it. Stay on the HTML mode rather than Preview mode.
Paste the coded text while you're on the HTML mode of the draft (the codes are really long depending on the number of colors and length of the text)
After pasting in HTML mode click on Preview and you're DONE.
Other than that you can edit the text style after pasting here into the basic styles provided by Tumblr — bold, italic, Chat, Intended, etc.
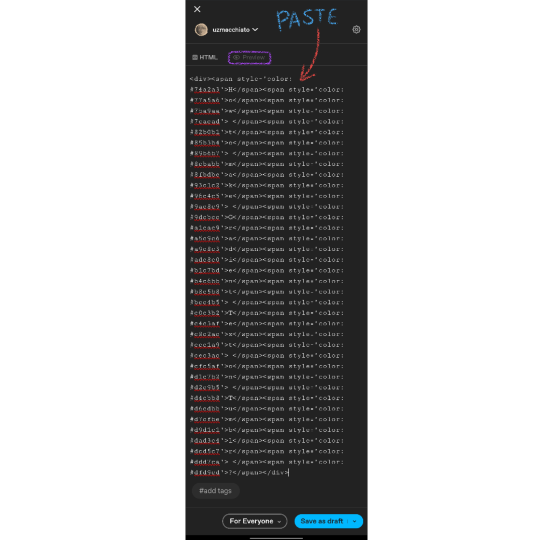

Final Result : How to make Gradient Text on Tumblr ?
I hope this was helpful😭 I love editing the text and making it match my dividers, so this is magic for me. You can DM me if you need any more help understanding this.
Thank You❤️
#gradient text#Gradient Text tutorial#asks answered#asks#ask answered#uzmacchiato_asks#custom text color#tumblr tutorial#ask
78 notes
·
View notes
Text
I'm sure it's been said before, but Affini Unicode gotta be wild.
Like okay, in our world the total number of characters in Unicode is 150,000 right now. [1] That's the total number of characters needed to represent the complex culture and language that humans have developed. So, how many characters would be needed for every single species that the Affini encounter?
Well let's just take the 150,000 number as a baseline. The Milky Way apparently has at least 200 billion stars [2], and I'm gonna guess that 10% of them have a civilization that need around 150,000 characters. As for the number of galaxies, it's very very large, and two trillion seems to be the best guess for our observable universe [3]. I'm assuming that the average galaxy is similar to the Milky Way, which may be quite wrong
Putting all this together, we can a number of possible characters at 6 * 10^ 28. Affini must be going insane over all of this. Trying to represent how every single unique sophont communicates over their comms network has got to be the perfect recipe for a bureaucratic nightmare.
Groups come up with their own, incompatible methods that mostly works, up until a floret is trying to tell another that ze are really pretty, but they can't do that because they don't have the correct auditory characters and it's getting scrambled and ze's is getting confused and sad! In tears both of them go up to their owners and beg, beg them to work it out, so some poor bastard now need to bodge together a compatible encoding scheme between the two groups. It becomes just a complete mess of standards documents. Proper affinibate.
[1]: https://www.unicode.org/versions/stats/charcountv16_0.html
[2] https://www.universetoday.com/22285/facts-about-the-milky-way
[3] https://www.forbes.com/sites/startswithabang/2018/10/18/this-is-how-we-know-there-are-two-trillion-galaxies-in-the-universe/
70 notes
·
View notes
Text
> METAL SONIC THEMED NPT
Requested by @timemachinecandyx3
Names:
Sypher 。 Deckard 。 Tex 。 Strobe 。 Socket 。 Nikola 。 Maxi 。 Mecha 。 Zero 。 Coba 。 Xenon 。 Digit 。 Oyl 。 Neto
Pronouns:
Byt/Byte 。 Je/Jets 。 Oxi/Oxid 。 Re/Reboot 。 404/404s 。 C#/C#'s 。 Sy/Sync 。 Htm/Html 。 Cir/Circ 。 Ke/Keyb 。 Wy/Wyre 。 H⟣/H⟣m 。 Ze/Zhem 。 ⌇t/⌇ts 。 Sh☇/H☇r 。 ⚙️/⚙️s 。 🚀/🚀s 。 🛞/🛞s
Titles:
The Animatronic 。 The Steel-Clawed 。 The Identical 。 The Reset 。 The Metallically Mad 。 The Overlord 。 The Android 。 The Cybernetic 。 The Encoded
12 notes
·
View notes
Text
Fakepeppino's way of speaking

@alextydaisuda123
@pizzabox-box
I'm a bit obsessed with the way Feppino writes his lines... at the very least, I try to make them readable if you understand how to read them.
Basically, I use ROT13code.
When drawing with the work of Boxinno's authors in mind,
The shape is chaotic to match the work.
Here is the site I use for encryption and decryption.
(I usually use it in Japanese)↓
#topic#tweet#pizza tower#pizzatower au#steampunk tower#fake peppino pizza tower#fake peppino#boxinno#doodle#digital art#painting
41 notes
·
View notes
Text
If you're someone who's interested in collecting physical media, especially DVDs and blu-rays, I cannot overstate how good an investment a blu-ray drive for your computer is.
There are copious free resources that will allow you to digitize your collection for additional preservation and convenience... and I've placed them beneath this break!
MakeMKV: https://www.makemkv.com/
MakeMKV is the program I use for backing up blu-rays and DVD. It’s “free while in beta”, and as far as I can tell it’s going to continue to be in beta forever. You just need to register the program with the beta code, which can be found here: https://forum.makemkv.com/forum/viewtopic.php?t=1053. If your registration ever expires, you can just go to that post and they’ll have it updated with a new one.
“MKV” is “Matroska Video”, which is a container format (named after the Russian nesting doll) that collects the video track, audio track(s), and subtitle track(s) all into one file, which is super convenient for anime, because that means you don’t need to worry about making separate files for different combinations of dubs and subs. My understanding is that this is, essentially, a lossless video copy, and I’ve done comparisons comparing screenshots taken from video playing off the disc and from the .mkv, and I haven’t been able to notice a difference. As for playing .mkv files…
VLC Media Player: https://www.videolan.org/vlc/
The Combined Community Codec Pack (CCCP): https://download.cnet.com/Combined-Community-Codec-Pack/3000-2139_4-10966585.html
VLC is my media player of choice for watching back the stuff I back up. I’m not 100% sure if you need to download the CCCP for this- my backups play fine on my tablet just using the VLC app, and I recently found out they even work off a USB stick plugged into a Samsung Smart TV- but it doesn’t hurt to have.
MakeMKV can also be directly integrated with VLC Media Player to play blu-rays right from the drive, which is tremendously valuable if you're not interest in/don't have the hard drive space for digitization. I think I’ve encountered maybe one thing that couldn’t be played off the disc with this solution, and that was fixed in a subsequent update to MakeMKV. The full breakdown of how to do that can be found here: https://stolafcarleton.teamdynamix.com/TDClient/1893/StOlaf/KB/ArticleDet?ID=128854.
MKVToolNix: https://mkvtoolnix.download/downloads.html
Different companies author discs differently, and I like to keep my stuff organized the same way, which is where this tool comes in. I won’t go into too much detail on this here, but if you ever need to split one large file into smaller files (for example, a disc has 9 episodes of a show to a single title/file, and you want to split them into individual episodes), edit or remove chapter information, or rename audio/subtitle tracks, this is the tool to do it. There's a lot to this, so I would suggest reading the official documentation, but I could also whip up a guide if people are interested.
HandBrake: https://handbrake.fr/
The video encoder for shrinking those backups down to size- my favorite example was getting all 49 episodes of G Gundam down from almost 300gb off-the-discs to just under 50gb. This is also going to be heavily dependent on how powerful your computer is, because encoding takes up a lot of resources. On my computer, which is by no means top-of-the-line, I’d say on average it takes about 50 minutes to encode a 24 minute episode of anime, and that increases exponentially the longer the source material is.
I got the settings I use in HandBrake from this incredibly detailed breakdown of how video encoding works: https://kokomins.wordpress.com/2019/10/10/anime-encoding-guide-for-x265-and-why-to-never-use-flac/#tldr-summary-for-x265-encode-settings. There's a lot of information there, too, but it also provides generic settings to plug in to HandBrake if you don't care to manually adjust the settings for each project you're doing.
And that’s everything I use for my process! A lot of this was trial and error with other programs that cost money, performed worse, and were generally aggravating to use. It's a bit of elbow grease, but the reward is that once something is digitized, you have it forever, exactly the way you want it.
66 notes
·
View notes
Text
Fun fact. Markdown... is a markup language
If you do not know what markup is... you should look it up. It is basically HTML that works both encoded and as clear text. Meaning it is the perfect note taking "language". In reality it is "just" a convention for how to write super nice-looking notes that have been tested by millions of people to be the very best it can be.
No big deal.
Oh also it is free, you do not even need a special program to look at it. Your browser can do it perfectly.
66 notes
·
View notes
Note

how did you. do that
i put a blank ⠀⠀⠀⠀⠀⠀braille unicode character in there :3⠀⠀
⠀just highlight the box and you can ⠀⠀⠀⠀⠀ copy and paste it!!! ⠀⠀⠀⠀⠀⠀⠀⠀i have put several in this answer and heres another several ⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀⠀ they are there i promise
4 notes
·
View notes
Text
test wungle post
this one has wungle content encoded in unicode Tag characters (between the words 'wungle' and 'post'), which are part of the main post content (and can be copy-pasted) but don't display glyphs. they can be inserted in the html editor with escape codes, but the plan is for the extension to encode/decode wungle text from the clipboard or something ala qaz.wtf. it only supports ascii though and right now i'm not up to implementing some kind of base64 for this
9 notes
·
View notes
Text
Building an RSS Feed for a Static Site
Lover's tree! Lover's tree! I have crafted an RSS feed for the first time! It was a pain in the ass, but I'm glad I learned how to do it.
This page was indispensable, but it doesn't have every part of what I learned, so I'll write my own tutorial below. Specifically, I used this with the Zonelets system, but it should work fine for most static sites.
First, make an .xml file. I just titled mine feed.xml and put it in the same directory as my blog.
Copy and paste the following into your xml file.
<?xml version="1.0" encoding="utf-8"?> <rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom"> <channel> </channel> </rss>
Between the <channel></channel> tags, we are going to do two things. First, we have to detail what our blog actually is.
<title>Title of your blog</title> <description>Description of your blog</description> <link>URL of blog</link> <atom:link href="URL of blog/feed.xml" rel="self" type="application/rss+xml" />
Change the stuff in pink to be what it's supposed to be.
Now, we are going to add a bunch of "items". Each item = a post in your blog. Copy and paste this template for each post:
<item> <title>Title of post</title> <link>link goes here</link> <guid>link goes here again</guid> <pubDate>Mon, 1 Jan 2023 00:00:00 EST</pubDate> <description><![CDATA[html of your post goes here]]></description> </item>
Change the stuff in pink to be what it's supposed to be. Keep to the structure as closely as possible, ESPECIALLY in the pubDate section. If you want to make sure your RSS feed works correctly, copy and paste the whole thing into the W3C Feed Validator and see if it gives you the OK.
Here is a (very condensed) version of what my RSS feed looks like, for comparison. The indents and colors are just for ease of viewing/understanding what every part is.
<?xml version="1.0" encoding="utf-8"?> <rss version="2.0" xmlns:atom="http://www.w3.org/2005/Atom"> <channel> <title>moonblog</title> <description>Please enjoy.</description> <link>http://moon-hotel.neocities.org/blog</link> <atom:link href="http://moon-hotel.neocities.org/blog/feed.xml" rel="self" type="application/rss+xml" /> <item> <title>Hello World</title> <link>https://moon-hotel.neocities.org/blog/posts/2023-06-24-Hello-World.html</link> <guid>https://moon-hotel.neocities.org/blog/posts/2023-06-24-Hello-World.html</guid> <pubDate>Sat, 24 Jun 2023 19:07:25 EST</pubDate> <description><![CDATA[<p>Hey, testing out <a href="http://zonelets.net">Zonelets</a> as a new blog engine. Hopefully it'll be easier--well, not easier, but more full-featured--than the way I was doing it? I really just wanted a way to do a blog on Neocities while also supporting stuff like Commento, so we'll see if that works.</p>]]></description> </item> </channel> </rss>
12 notes
·
View notes
Note
Hi, I'm currently referring to your Scribus Typesetting guide on Google Docs and wanted to ask how to import my HTML file into Scribus? The HTML file that contains the fic. Sorry if this isn't a good place to ask
Hi! No problem, I can demo. First you need to click into the first text frame of the document (otherwise Scribus doesn't know where to import your file to).
then go to file -> import -> get text

That should get you to a select file menu. Locate your html file, and make sure the importer at the bottom is set to HTML. The encoding is usually fine by default, but it should probably be UTF-8 if it's set to something different. Then hit okay.

It'll ask if you want to clear all your text if you're doing this in a not-blank document. If that text was just filler & you want to replace it, hit yes! (Otherwise say no, and go back through these steps using the 'append text' option instead of 'get text')
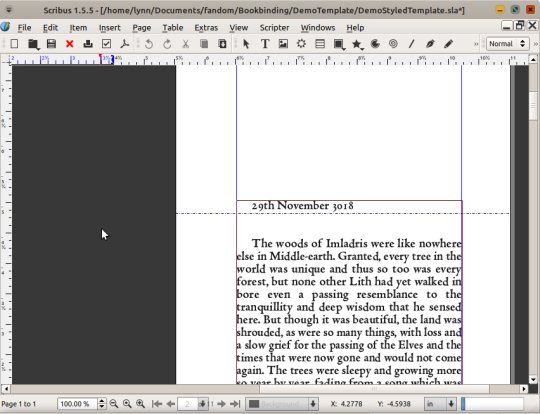
Voila, the fic!
5 notes
·
View notes
Text
10 security tips for MVC applications in 2023

Model-view-controller or MVC is an architecture for web app development. As one of the most popular architectures of app development frameworks, it ensures multiple advantages to the developers. If you are planning to create an MVC-based web app solution for your business, you must have known about the security features of this architecture from your web development agency. Yes, MVC architecture not only ensures the scalability of applications but also a high level of security. And that’s the reason so many web apps are being developed with this architecture. But, if you are looking for ways to strengthen the security features of your MVC app further, you need to know some useful tips.
To help you in this task, we are sharing our 10 security tips for MVC applications in 2023! Read on till the end and apply these tips easily to ensure high-security measures in your app.
1. SQL Injection: Every business has some confidential data in their app, which needs optimum security measures. SQL Injection is a great threat to security measures as it can steal confidential data through SQL codes. You need to focus on the prevention of SQL injection with parameterized queries, storing encrypted data, inputs validation etc.
2. Version Discloser: Version information can also be dangerous for your business data as it provides hackers with your specific version information. Accordingly, they can attempt to attack your app development version and become successful. Hence, you need to hide the information such as the server, x-powered-by, x-sourcefiles and others.
3. Updated Software: Old, un-updated software can be the reason for a cyber attack. The MVC platforms out there comprise security features that keep on updating. If you also update your MVC platform from time to time, the chances of a cyber attack will be minimized. You can search for the latest security updates at the official sites.
4. Cross-Site Scripting: The authentication information and login credentials of applications are always vulnerable elements that should be protected. Cross-Site Scripting is one of the most dangerous attempts to steal this information. Hence, you need to focus on Cross-Site Scripting prevention through URL encoding, HTML encoding, etc.
5. Strong Authentication: Besides protecting your authentication information, it’s also crucial to ensure a very strong authentication that’s difficult to hack. You need to have a strong password and multi-factor authentication to prevent unauthorized access to your app. You can also plan to hire security expert to ensure strong authentication of your app.
6. Session Management: Another vital security tip for MVA applications is session management. That’s because session-related vulnerabilities are also quite challenging. There are many session management strategies and techniques that you can consider such as secure cookie flags, session expiration, session regeneration etc. to protect access.
7. Cross-Site Request Forgery: It is one of the most common cyber attacks MVC apps are facing these days. When stires process forged data from an untrusted source, it’s known as Cross-Site Request Forgery. Anti-forgery tokens can be really helpful in protecting CSRP and saving your site from the potential danger of data leakage and forgery.
8. XXE (XML External Entity) Attack: XXE attacks are done through malicious XML codes, which can be prevented with the help of DtdProcessing. All you need to do is enable Ignore and Prohibit options in the DtdProcessing property. You can take the help of your web development company to accomplish these tasks as they are the best at it.
9. Role-Based Access Control: Every business has certain roles performed by different professionals, be it in any industry. So, when it comes to giving access to your MVC application, you can provide role-based access. This way, professionals will get relevant information only and all the confidential information will be protected from unauthorized access.
10. Security Testing: Finally, it’s really important to conduct security testing on a regular basis to protect business data on the app from vulnerability. Some techniques like vulnerability scanning and penetration testing can be implied to ensure regular security assessments. It’s crucial to take prompt actions to prevent data leakage and forgery as well.
Since maintaining security should be an ongoing process rather than a one-time action, you need to be really proactive with the above 10 tips. Also, choose a reliable web development consulting agency for a security check of your website or web application. A security expert can implement the best tech stack for better security and high performance on any website or application.
#web development agency#web development consulting#hire security expert#hire web developer#hire web designer#website design company#website development company in usa
2 notes
·
View notes
Text
ASCII and ANSI
ASCII was defined by the American National Standards Institute (ANSI) in 1968 as "ANSI Standard x3.4"
web.archive.orgAvailable from: https://web.archive.org/web/20091014084338/http://czyborra.com/charsets/iso646.html (2009a). ISO 646 (Good old ASCII) [online]. [Accessed 15 November 2023].
ANSI is the Institute that defines American National standards. ASCII code is one of these standards.
ANSI Standard x3.16, which is an 8-bit code. This expansion was defined in 1979 in an effort to standardise graphic character representations and cursor control.
It is based upon a 256 character set. It includes the 128 characters/controls of ASCII and an extra 128 characters/controls. It is sometimes called "extended ASCII" or "high ASCII".
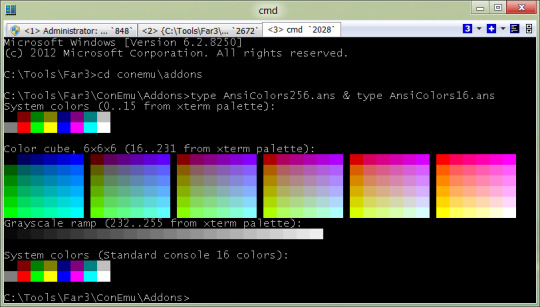
It was widely used at one time on bulletin board systems. It is similar to ASCII art, but constructed from a larger set of 256 letters, numbers, and symbols and colour.
WikipediaAvailable from: https://en.wikipedia.org/wiki/ANSI_art (2021). ANSI art.
Its use of standard computer symbols and colours by particularly talented individuals made it somewhat of a 'cult' art form and provided a springboard for talented computer artists in later years.
This form gave rise to a 'scene', or subculture community of artists who created competitive groups, similar to hackers (and sometimes overlapping these groups). These groups would assemble their best, most current art into downloadable 'packs' for distribution on BBS systems. These could be simply zipped packs of loose art with some text files explaining them, or encoded programs that displayed the art, sometimes with accompanying music in MOD format.
CDM Create Digital MusicAvailable from: https://cdm.link/2008/01/ansi-art-raised-to-gallery-status-in-sf/ (2008). ANSI Art, Raised to Gallery Status in SF [online]. [Accessed 15 November 2023].

4 notes
·
View notes
Note
oh i see. to view it with color, put it in a plain text file (.txt not .rtf, and utf-8 encoding if it asks) then rename the extension to .svg if your os doesn't have a svg viewer, you can use firefox (just drag the file into firefox) you can also just go to about:blank in firefox, open the inspector (tools > bowser tools > web developer tools), then right click "<body></body>" do "edit as HTML" and paste in the svg <body>right here</body> obligatory computer security note: don't do this with anything containing <script> unless you trust it

Ah there we go!
I had to remove the "_7x~4" from the start for it to work. idk if that was meant to be anything, but it broke the thing.
Thank you! <3
2 notes
·
View notes

Text

I was going to just put a short reply to @romanarose —explaining web scraping— but then it got long and I started wondering about methods of combatting scraping…
Web scraping is basically using a program to collect data from websites. You can collect html files and use tools to parse them and make their contents more human-readable or organized in a custom structure (such as… flight information, or the birthdays of all historical figures). Essentially, you can take the actual data out of the html formatting documents that it’s embedded in, and if you can identify patterns in the structure of the documents then you can target specific information and collect it en masse.
It’s pretty easy to do, and. Quite frankly, it can be fun, when done ethically. But scraping to feed ai training algorithms is not ethical.
So. They’re scraping ao3 for generative ai training data. They are probably discarding author notes—that would be trivial to do with a highly structured document like html.
Actually. Okay, so. There are characters (as in. Text. Symbols) that don’t get displayed in a way humans would notice… I wonder if someone could write a program that takes in text and adds noise to it that the computers can see and become confused by but that humans wouldn’t be… like those anti-ai treatments done to images. They add noise to the data that makes it less interpretable by machines but doesn’t significantly alter humans’ ability to perceive the image. I’m not an expert on text encoding though, so I don’t know what an implementation like that would look like.
Okay so. A quick search…. I’m not finding anything specific to adding noise in text, but i am finding plenty of material on using noise (variation in data, a disruption to the signal in data) to disrupt ai training for other types of data, like i expected. I think it would be worth exploring, especially since there’s no way i could do an exhaustive search in fifteen minutes without access to research papers in databases.
I had some of the following thoughts, but I can’t think of a way to implement them without making the text extremely inaccessible for people using screen readers (probably. I don’t actually know how screen readers tend to be programmed, but there are technologically accessibility standards for a reason, so it would probably fuck it up).
Remember how early on, machine learning models were indicating that images of rulers had cancer in them, because the images of actual cancer (or. Whatever they were trying to identify) tended to have rulers in them to show the scale?
You know how people will say to add keywords into your resume so the resumé screening algorithms point to you as a good candidate? How some people suggest putting invisible text in your resumé, that humans can’t read but machines can, so it gets flagged? Or straight up putting something down like “ is an ideal candidate” in invisible text? Invisible to humans, that is.
I’m wondering if there are things like that
So yeah. Screen readers would have a hard time with that, I think.
Unless screen readers can be altered to filter out the noise. But that’s a much bigger task than scrambling some data. And also… someone might choose to read the text into their program with image processing algorithms. But having to cleaning the data like that would increase the hassle for AI-feeding scrapers, since the files would be larger and you’d be introducing more steps… idk. some thoughts in here. I have not the energy to do research.
AO3 has been scraped, once again.
As of the time of this post, AO3 has been scraped by yet another shady individual looking to make a quick buck off the backs of hardworking hobby writers. This Reddit post here has all the details and the most current information. In short, if your fic URL ends in a number between 1 and 63,200,000 (inclusive), AND is not archive locked, your fic has been scraped and added to this database.
I have been trying to hold off on archive locking my fics for as long as possible, and I've managed to get by unscathed up to now. Unfortunately, my luck has run out and I am archive locking all of my current and future stories. I'm sorry to my lovelies who read and comment without an account; I love you all. But I have to do what is best for me and my work. Thank you for your understanding.
#ai#some not-as-technically-informed-as-i-could-be-but-informed-enough-to-speculate rambling#long post#anti ai#anti-ai#data processing#thoughts
36K notes
·
View notes