#SCRAPED FOR AI
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been providing a Korean-language service since 2013.
Text
just quickly letting yall know the incorrect quotes blog about male vtubers belongs to a real flesh person and the real person is not supportive of AI that is built upon unethical data (aka data obtained without permission) <3
#every. single. fic.#of. mine.#was fucking#SCRAPED FOR AI#anti ai#fuck generative ai#anti generative ai#vtuber#Neuro Sama is fine tho#shes and evil are built on ethical data
1 note
·
View note
Text

#I'm serious stop doing it#theyre scraping fanfics and other authors writing#'oh but i wanna rp with my favs' then learn to write#studios wanna use ai to put writers AND artists out of business stop feeding the fucking machine!!!!
166K notes
·
View notes
Text
this doesn't seem to be widespread knowledge around here yet but there's a big trend among dogshit content scraper accounts to grab a real photo (usually of ✨Aesthetic Nature™✨ or something similar, which is why it's relevant to me) somewhere, and recreate it using AI to avoid crediting the photographer. this can even trick people who are somewhat familiar with the subject matter if they're not paying attention but looks incredibly wrong upon closer inspection


here is some complete garbage as an example. because these "photos" are not completely made up by AI, people into spiders know the species and will recognize their features without looking closely, getting tricked in the process. if you know spider anatomy and look closely though, both of those look like utter abominations. the original photos these two were based on are here and here, by the way
these just so happen to be things i'm familiar with and i would probably get easily fooled by AI recreations of plants or fish or whatever. my point is that if you're not an expert on everything that exists you're not immune to these, so i would probably recommend caring about photo sources unless you actively want to look at this repulsive trash
#this is a very off-brand post for me so i have no idea what the fuck to tag it as#photography#anti ai#anti generative ai#ai bullshit#content scraping#bugblr#spiders
5K notes
·
View notes
Text
This tool is optional. No one is required to use it, but it's here if you want to know which of your AO3 fics were scraped. Locked works were not 100% protected from this scrape. Currently, I don't know of any next steps you should be taking, so this is all informational.
Most people should use this link to check if they were included in the March 2025 AO3 scrape. This will show up to 2,000 scraped works for most usernames.
Or you can use this version, which is slower but does a better job if your username is a common word. This version also lets you look up works by work ID number, which is useful if you're looking for an orphaned or anonymous fic.
If you have more than 2,000 published works, first off, I am jealous of your motivation to write that much. But second, that won't display right on the public version of the tools. You can send me an ask (preferred) or DM (if you need to) to have me do a custom search for you if you have more than 2,000 total works under 1 username. If you send an ask off-anon asking me to search a name, I'll assume you want a private answer.
In case this post breaches containment: this is a tool that only has access to the work IDs, titles, author names, chapter counts, and hit counts of the scraped fics for this most recent scrape by nyuuzyou discovered in April 2025. There is no other work data in this tool. This never had the content of your works loaded to it, only info to help you check if your works were scraped. If you need additional metadata, I can search my offline copy for you if you share a work ID number and tell me what data you're looking for. I will never search the full work text for anyone, but I can check things like word counts and tags.
Please come yell if the tool stops working, and I'll fix as fast as I can. It's slow as hell, but it does load eventually. Give it up to 10 minutes, and if it seems down after that, please alert me via ask! Anons are on if you're shy. The link at the top is faster and handles most users well.
On mobile, enable screen rotation and turn your phone sideways. It's a litttttle easier to use like that. It works better if you can use desktop.
Some FAQs below the cut:
"What do I need to do now?": At this time, the main place where this dataset was shared is disabled. As far as I'm aware, you don't need to do anything, but I'll update if I hear otherwise. If you're worried about getting scraped again, locking your fics to users only is NOT a guarantee, but it's a little extra protection. There are methods that can protect you more, but those will come at a cost of hiding your works from more potential readers as well.
"I know AO3 will be scraped again, and I'm willing to put a silly amount of effort into making my fics unusable for AI!": Excellent, stick around here. I'm currently trying to keep up with anyone working on solutions to poison our AO3 fics, and I will be reblogging information about doing this as I come across it.
"I want my fics to be unusable for AI, but I wanna be lazy about it.": You're so real for that, bestie. It may take awhile, but I'm on the lookout for data poisoning methods that require less effort, and I will boost posts regarding that once I find anything reputable.
"I don't want to know!": This tool is 100% optional. If you don't want to know, simply don't click the link. You are totally welcome to block me if it makes you feel more comfortable.
"Can I see the exact content they scraped?": Nope, not through me. I don't have the time to vet every single person to make sure they are who they say they are, and I don't want to risk giving a scraped copy of your fic to anyone else. If you really want to see this, you can find the info out there still and look it up yourself, but I can't be the one to do it for you.
"Are locked fics safe?": Not safe, but so far, it appears that locked fics were scraped less often than public fics. The only fics I haven't seen scraped as of right now are fics in unrevealed collections, which even logged-in users can't view without permission from the owner.
"My work wasn't a fic. It was an image/video/podfic.": You're safe! All the scrape got was stuff like the tags you used and your title and author name. The work content itself is a blank gap based on the samples I've checked.
"It's slow.": Unfortunately, a 13 million row data dashboard is going to be on the slow side. I think I've done everything I can to speed it up, but it may still take up to 10 minutes to load if you use the second link. It's faster if you can use desktop or the first link, but it should work on your phone too.
"My fic isn't there.": The cut-off date is around February 15th, 2025 for oneshots, but chapters posted up to March 21st, 2025 have been found in the data so far. I had to remove a few works from the dataset because the data was all skrungly and breaking my tool. (The few fics I removed were NOT in English.) Otherwise, from what I can tell so far, the scraper's code just... wasn't very good, so most likely, your fic was missed by random chance.
Thanks to everyone who helped with the cost to host the tool! I appreciate you so so so much. As of this edit, I've received more donations than what I paid to make this tool so you do NOT need to keep sending money. (But I super appreciate everyone who did help fund this! I just wanna make sure we all know it's all paid for now, so if you send any more that's just going to my savings to fix the electrical problems with my house. I don't have any more costs to support for this project right now.)
(Made some edits to the post on 27-May-2025 to update information!)
5K notes
·
View notes
Text

@staff
OUR CONTENT SHOULD BE OPTED OUT OF AI TRAINING BY DEFAULT!
#no to ai#create don't scrape#support human artists#opt out by default#no to ai generated images#ai is theft
21K notes
·
View notes
Text









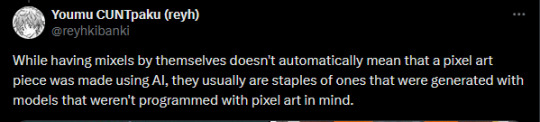


an example of real pixel art and explaining the pixel grid:




Thread on how to spot AI generated pixels by reyhkibanki on twitter!~ Might be a useful read to help you spot common mistakes AI makes when generating pixels. There's also a lot more info in the link!!
#theres a lot more in the thread i just chose some stand out tweets!#anti ai#anti ai art#stop ai#fuck ai#fuck ai art#support human artists#create don't scrape#pixel art#pixelart#pixels#8bit#twitter#twitter threads#been seeing soooo much ai shit here lately
10K notes
·
View notes
Text
I really don’t care if I’m considered an annoying luddite forever, I will genuinely always hate AI and I’ll think less of you if you use it. ChatGPT, Generative AI, those AI chatbots - all of these things do nothing but rot your brain and make you pathetic in my eyes. In 2025? You’re completely reliant on a product owned by tech billionaires to think for you, write for you, inspire you, in 2025????
“Oh but I only use ___ for ideas/spellcheck/inspiration!!” I kinda don’t care? oh, you’re “only” outsourcing a major part of the creative process that would’ve made your craft unique to you. Writing and creating art has been one of the most intrinsically human activities since the dawn of time, as natural and central to our existence as the creation of the goddamn wheel, and sheer laziness and a culture of instant gratification and entitlement is making swathes of people feel not only justified in outsourcing it but ahead of the curve!!
And genuinely, what is the point of talking to an AI chatbot, since people looove to use my art for it and endlessly make excuses for it. RP exists. Fucking daydreaming exists. You want your favourite blorbo to sext you, there’s literally thousands of xreader fic out there. And if it isn’t, write it yourself! What does a computer’s best approximation of a fictional character do that a human author couldn’t do a thousand times better. Be at your beck and call, probably, but what kind of creative fulfilment is that? What scratch is that itching? What is it but an entirely cyclical ourobouros feeding into your own validation?
I mean, for Christ sakes there are people using ChatGPT as therapists now, lauding it for how it’s better than any human therapist out there because it “empathises”, and no one ever likes to bring up how ChatGPT very notably isn’t an accurate source of information, and often just one that lives for your approval. Bad habits? Eh, what are you talking about, ChatGPT told me it’s fine, because it’s entire existence is to keep you using it longer and facing any hard truths or encountering any real life hard times when it comes to your mental health journey would stop that!
I just don’t get it. Every single one of these people who use these shitty AIs have a favourite book or movie or song, and they are doing nothing by feeding into this hype but ensuring human originality and sincere passion will never be rewarded again. How cute! You turned that photo of you and your boyfriend into ghibli style. I bet Hayao Miyazaki, famously anti-war and pro-environmentalist who instills in all his movies a lifelong dedication to the idea that humanity’s strongest ally is always itself, is so happy that your request and millions of others probably dried up a small ocean’s worth of water, and is only stamping out opportunities for artists everywhere, who could’ve all grown up to be another Miyazaki. Thanks, guys. Great job all round.
#FUCK that ao3 scraping thing got me heated I’m PISSED#hey if you use my art for ai chatbots fucking stop that#I’ve been nice about it before but listen. I genuinely think less of you if you use one#hot take! don’t outsource your fandom interactions to a fucking computer!!!#talk to a real human being!!! that’s literally the POINT of fandom!!!!!#we are in hell. I hate ai so bad
2K notes
·
View notes
Text

purge event but ENA said fuck work
#ena#ena dream bbq#joel g#they're listening to Happy Hardcore Vol 3 1996#sorry for the ugly ass filter lol blame AI scraping
1K notes
·
View notes
Text




It’s been hard to motivate myself to do art for a long time, so I’ve been going back to basics which is binging dozens of hours of content and drawing traditionally in a frenzy.
Anyway, here’s Caleb, I really missed him ✨
#critical role#caleb widogast#traditional art#the arrival of ai art has been a huge knock on my motivation#on top of work and life of course#so drawing traditionally has been a nice way of taking back the joy#an ai might be able to scrape this drawing and turn it to mush but at least this picture is real#the texture and sheen of pigment on paper that was given to by my late grandpa#it’s just a silly fanart of my blorbo but#anything to get me drawing again#anyway I’m not dead I’ve just been Working (derogatory)#anyway have a nice day I hope I’ll post here soon again
2K notes
·
View notes
Text
This Google Drive AI scraping bullshit actually makes me want to cry. My entire life is packed into Google Drive. All of my writing over the years, all of my academic documents, everything.
I’m just so overwhelmed with all the shit I’m going to have to move. I’m lucky to have Scrivener, but online data storage has been super important as I’ve had so many shitty computers, and the only reason I haven’t lost work is because Google Drive has been my backup storage unit.
My partner has recommended gitlab to move my files to - it seems useful, and I can try and explain more about what it is and how it works when I get more familiar with it. I’m unsure if it’s a text editor, or can work that way. He was explaining something about the version history that I don’t quite understand right now but might later. I’m just super overwhelmed and frustrated that this is the dystopia we live in right now.
29K notes
·
View notes
Text

if you write fic and haven’t ditched google docs for ellipsus yet, you really should
#while google is scraping your docs to feed their ai#and adding morality clauses to their terms of use#they’re out here giving me hope#it’s a simple thing#but fuck does it mean a lot#ellipsus#ao3
1K notes
·
View notes
Text
And while we're talking about ai theft: turn. off. grammarly. Disable it. Delete it. Get that shit off of your computer ASAP.
I never realized how much of my shit is scanned by grammarly until today. It scans my emails, my text posts on this bewitched platform, my wips on google docs, my youtube comments--literally everything ive ever typed on my laptop is scanned by grammarly. And I've been allowing this to happen for years.
Turn. Off. Grammarly.
#blue rambles#ai theft#ai#grammarly#data scraping#i dont like how many suggestions are made when im editing my writing anyway#theyre distracting+irrelevant half the time#and the only reason i even have grammarly is bc of uni
12K notes
·
View notes
Text
Penguin Random House, AI, and writers’ rights

NEXT WEDNESDAY (October 23) at 7PM, I'll be in DECATUR, GEORGIA, presenting my novel THE BEZZLE at EAGLE EYE BOOKS.

My friend Teresa Nielsen Hayden is a wellspring of wise sayings, like "you're not responsible for what you do in other people's dreams," and my all time favorite, from the Napster era: "Just because you're on their side, it doesn't mean they're on your side."
The record labels hated Napster, and so did many musicians, and when those musicians sided with their labels in the legal and public relations campaigns against file-sharing, they lent both legal and public legitimacy to the labels' cause, which ultimately prevailed.
But the labels weren't on musicians' side. The demise of Napster and with it, the idea of a blanket-license system for internet music distribution (similar to the systems for radio, live performance, and canned music at venues and shops) firmly established that new services must obtain permission from the labels in order to operate.
That era is very good for the labels. The three-label cartel – Universal, Warner and Sony – was in a position to dictate terms like Spotify, who handed over billions of dollars worth of stock, and let the Big Three co-design the royalty scheme that Spotify would operate under.
If you know anything about Spotify payments, it's probably this: they are extremely unfavorable to artists. This is true – but that doesn't mean it's unfavorable to the Big Three labels. The Big Three get guaranteed monthly payments (much of which is booked as "unattributable royalties" that the labels can disperse or keep as they see fit), along with free inclusion on key playlists and other valuable services. What's more, the ultra-low payouts to artists increase the value of the labels' stock in Spotify, since the less Spotify has to pay for music, the better it looks to investors.
The Big Three – who own 70% of all music ever recorded, thanks to an orgy of mergers – make up the shortfall from these low per-stream rates with guaranteed payments and promo.
But the indy labels and musicians that account for the remaining 30% are out in the cold. They are locked into the same fractional-penny-per-stream royalty scheme as the Big Three, but they don't get gigantic monthly cash guarantees, and they have to pay the playlist placement the Big Three get for free.
Just because you're on their side, it doesn't mean they're on your side:
https://pluralistic.net/2022/09/12/streaming-doesnt-pay/#stunt-publishing
In a very important, material sense, creative workers – writers, filmmakers, photographers, illustrators, painters and musicians – are not on the same side as the labels, agencies, studios and publishers that bring our work to market. Those companies are not charities; they are driven to maximize profits and an important way to do that is to reduce costs, including and especially the cost of paying us for our work.
It's easy to miss this fact because the workers at these giant entertainment companies are our class allies. The same impulse to constrain payments to writers is in play when entertainment companies think about how much they pay editors, assistants, publicists, and the mail-room staff. These are the people that creative workers deal with on a day to day basis, and they are on our side, by and large, and it's easy to conflate these people with their employers.
This class war need not be the central fact of creative workers' relationship with our publishers, labels, studios, etc. When there are lots of these entertainment companies, they compete with one another for our work (and for the labor of the workers who bring that work to market), which increases our share of the profit our work produces.
But we live in an era of extreme market concentration in every sector, including entertainment, where we deal with five publishers, four studios, three labels, two ad-tech companies and a single company that controls all the ebooks and audiobooks. That concentration makes it much harder for artists to bargain effectively with entertainments companies, and that means that it's possible -likely, even – for entertainment companies to gain market advantages that aren't shared with creative workers. In other words, when your field is dominated by a cartel, you may be on on their side, but they're almost certainly not on your side.
This week, Penguin Random House, the largest publisher in the history of the human race, made headlines when it changed the copyright notice in its books to ban AI training:
https://www.thebookseller.com/news/penguin-random-house-underscores-copyright-protection-in-ai-rebuff
The copyright page now includes this phrase:
No part of this book may be used or reproduced in any manner for the purpose of training artificial intelligence technologies or systems.
Many writers are celebrating this move as a victory for creative workers' rights over AI companies, who have raised hundreds of billions of dollars in part by promising our bosses that they can fire us and replace us with algorithms.
But these writers are assuming that just because they're on Penguin Random House's side, PRH is on their side. They're assuming that if PRH fights against AI companies training bots on their work for free, that this means PRH won't allow bots to be trained on their work at all.
This is a pretty naive take. What's far more likely is that PRH will use whatever legal rights it has to insist that AI companies pay it for the right to train chatbots on the books we write. It is vanishingly unlikely that PRH will share that license money with the writers whose books are then shoveled into the bot's training-hopper. It's also extremely likely that PRH will try to use the output of chatbots to erode our wages, or fire us altogether and replace our work with AI slop.
This is speculation on my part, but it's informed speculation. Note that PRH did not announce that it would allow authors to assert the contractual right to block their work from being used to train a chatbot, or that it was offering authors a share of any training license fees, or a share of the income from anything produced by bots that are trained on our work.
Indeed, as publishing boiled itself down from the thirty-some mid-sized publishers that flourished when I was a baby writer into the Big Five that dominate the field today, their contracts have gotten notably, materially worse for writers:
https://pluralistic.net/2022/06/19/reasonable-agreement/
This is completely unsurprising. In any auction, the more serious bidders there are, the higher the final price will be. When there were thirty potential bidders for our work, we got a better deal on average than we do now, when there are at most five bidders.
Though this is self-evident, Penguin Random House insists that it's not true. Back when PRH was trying to buy Simon & Schuster (thereby reducing the Big Five publishers to the Big Four), they insisted that they would continue to bid against themselves, with editors at Simon & Schuster (a division of PRH) bidding against editors at Penguin (a division of PRH) and Random House (a division of PRH).
This is obvious nonsense, as Stephen King said when he testified against the merger (which was subsequently blocked by the court): "You might as well say you’re going to have a husband and wife bidding against each other for the same house. It would be sort of very gentlemanly and sort of, 'After you' and 'After you'":
https://apnews.com/article/stephen-king-government-and-politics-b3ab31d8d8369e7feed7ce454153a03c
Penguin Random House didn't become the largest publisher in history by publishing better books or doing better marketing. They attained their scale by buying out their rivals. The company is actually a kind of colony organism made up of dozens of once-independent publishers. Every one of those acquisitions reduced the bargaining power of writers, even writers who don't write for PRH, because the disappearance of a credible bidder for our work into the PRH corporate portfolio reduces the potential bidders for our work no matter who we're selling it to.
I predict that PRH will not allow its writers to add a clause to their contracts forbidding PRH from using their work to train an AI. That prediction is based on my direct experience with two of the other Big Five publishers, where I know for a fact that they point-blank refused to do this, and told the writer that any insistence on including this contract would lead to the offer being rescinded.
The Big Five have remarkably similar contracting terms. Or rather, unremarkably similar contracts, since concentrated industries tend to converge in their operational behavior. The Big Five are similar enough that it's generally understood that a writer who sues one of the Big Five publishers will likely find themselves blackballed at the rest.
My own agent gave me this advice when one of the Big Five stole more than $10,000 from me – canceled a project that I was part of because another person involved with it pulled out, and then took five figures out of the killfee specified in my contract, just because they could. My agent told me that even though I would certainly win that lawsuit, it would come at the cost of my career, since it would put me in bad odor with all of the Big Five.
The writers who are cheering on Penguin Random House's new copyright notice are operating under the mistaken belief that this will make it less likely that our bosses will buy an AI in hopes of replacing us with it:
https://pluralistic.net/2023/02/09/ai-monkeys-paw/#bullied-schoolkids
That's not true. Giving Penguin Random House the right to demand license fees for AI training will do nothing to reduce the likelihood that Penguin Random House will choose to buy an AI in hopes of eroding our wages or firing us.
But something else will! The US Copyright Office has issued a series of rulings, upheld by the courts, asserting that nothing made by an AI can be copyrighted. By statute and international treaty, copyright is a right reserved for works of human creativity (that's why the "monkey selfie" can't be copyrighted):
https://pluralistic.net/2023/08/20/everything-made-by-an-ai-is-in-the-public-domain/
All other things being equal, entertainment companies would prefer to pay creative workers as little as possible (or nothing at all) for our work. But as strong as their preference for reducing payments to artists is, they are far more committed to being able to control who can copy, sell and distribute the works they release.
In other words, when confronted with a choice of "We don't have to pay artists anymore" and "Anyone can sell or give away our products and we won't get a dime from it," entertainment companies will pay artists all day long.
Remember that dope everyone laughed at because he scammed his way into winning an art contest with some AI slop then got angry because people were copying "his" picture? That guy's insistence that his slop should be entitled to copyright is far more dangerous than the original scam of pretending that he painted the slop in the first place:
https://arstechnica.com/tech-policy/2024/10/artist-appeals-copyright-denial-for-prize-winning-ai-generated-work/
If PRH was intervening in these Copyright Office AI copyrightability cases to say AI works can't be copyrighted, that would be an instance where we were on their side and they were on our side. The day they submit an amicus brief or rulemaking comment supporting no-copyright-for-AI, I'll sing their praises to the heavens.
But this change to PRH's copyright notice won't improve writers' bank-balances. Giving writers the ability to control AI training isn't going to stop PRH and other giant entertainment companies from training AIs with our work. They'll just say, "If you don't sign away the right to train an AI with your work, we won't publish you."
The biggest predictor of how much money an artist sees from the exploitation of their work isn't how many exclusive rights we have, it's how much bargaining power we have. When you bargain against five publishers, four studios or three labels, any new rights you get from Congress or the courts is simply transferred to them the next time you negotiate a contract.
As Rebecca Giblin and I write in our 2022 book Chokepoint Capitalism:
Giving a creative worker more copyright is like giving your bullied schoolkid more lunch money. No matter how much you give them, the bullies will take it all. Give your kid enough lunch money and the bullies will be able to bribe the principle to look the other way. Keep giving that kid lunch money and the bullies will be able to launch a global appeal demanding more lunch money for hungry kids!
https://chokepointcapitalism.com/
As creative workers' fortunes have declined through the neoliberal era of mergers and consolidation, we've allowed ourselves to be distracted with campaigns to get us more copyright, rather than more bargaining power.
There are copyright policies that get us more bargaining power. Banning AI works from getting copyright gives us more bargaining power. After all, just because AI can't do our job, it doesn't follow that AI salesmen can't convince our bosses to fire us and replace us with incompetent AI:
https://pluralistic.net/2024/01/11/robots-stole-my-jerb/#computer-says-no
Then there's "copyright termination." Under the 1976 Copyright Act, creative workers can take back the copyright to their works after 35 years, even if they sign a contract giving up the copyright for its full term:
https://pluralistic.net/2021/09/26/take-it-back/
Creative workers from George Clinton to Stephen King to Stan Lee have converted this right to money – unlike, say, longer terms of copyright, which are simply transferred to entertainment companies through non-negotiable contractual clauses. Rather than joining our publishers in fighting for longer terms of copyright, we could be demanding shorter terms for copyright termination, say, the right to take back a popular book or song or movie or illustration after 14 years (as was the case in the original US copyright system), and resell it for more money as a risk-free, proven success.
Until then, remember, just because you're on their side, it doesn't mean they're on your side. They don't want to prevent AI slop from reducing your wages, they just want to make sure it's their AI slop puts you on the breadline.
Tor Books as just published two new, free LITTLE BROTHER stories: VIGILANT, about creepy surveillance in distance education; and SPILL, about oil pipelines and indigenous landback.

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/10/19/gander-sauce/#just-because-youre-on-their-side-it-doesnt-mean-theyre-on-your-side
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
#pluralistic#publishing#penguin random house#prh#monopolies#chokepoint capitalism#fair use#AI#training#labor#artificial intelligence#scraping#book scanning#internet archive#reasonable agreements
731 notes
·
View notes
Text
Finding out that ALL of my works, including those that are on-going and some that were deleted, have been uploaded to some random "Archive" without my information or consent is definitely not how I wanted my day to go
#respectfully what the fuck#currently wasting my lunch break on my 10hr work day to figure out how many of my fics are on there#only to realise it's probably all of them#the entitlement of some people is bewildering#and that's only a couples days after the whole AI scraping thing#like there’s no respect for ao3 authors. none
1K notes
·
View notes
Text
AO3'S content scraped for AI ~ AKA what is generative AI, where did your fanfictions go, and how an AI model uses them to answer prompts
Generative artificial intelligence is a cutting-edge technology whose purpose is to (surprise surprise) generate. Answers to questions, usually. And content. Articles, reviews, poems, fanfictions, and more, quickly and with originality.
It's quite interesting to use generative artificial intelligence, but it can also become quite dangerous and very unethical to use it in certain ways, especially if you don't know how it works.
With this post, I'd really like to give you a quick understanding of how these models work and what it means to “train” them.
From now on, whenever I write model, think of ChatGPT, Gemini, Bloom... or your favorite model. That is, the place where you go to generate content.
For simplicity, in this post I will talk about written content. But the same process is used to generate any type of content.
Every time you send a prompt, which is a request sent in natural language (i.e., human language), the model does not understand it.
Whether you type it in the chat or say it out loud, it needs to be translated into something understandable for the model first.
The first process that takes place is therefore tokenization: breaking the prompt down into small tokens. These tokens are small units of text, and they don't necessarily correspond to a full word.
For example, a tokenization might look like this:
Write a story
Each different color corresponds to a token, and these tokens have absolutely no meaning for the model.
The model does not understand them. It does not understand WR, it does not understand ITE, and it certainly does not understand the meaning of the word WRITE.
In fact, these tokens are immediately associated with numerical values, and each of these colored tokens actually corresponds to a series of numbers.
Write a story 12-3446-2638494-4749
Once your prompt has been tokenized in its entirety, that tokenization is used as a conceptual map to navigate within a vector database.
NOW PAY ATTENTION: A vector database is like a cube. A cubic box.

Inside this cube, the various tokens exist as floating pieces, as if gravity did not exist. The distance between one token and another within this database is measured by arrows called, indeed, vectors.

The distance between one token and another -that is, the length of this arrow- determines how likely (or unlikely) it is that those two tokens will occur consecutively in a piece of natural language discourse.
For example, suppose your prompt is this:
It happens once in a blue
Within this well-constructed vector database, let's assume that the token corresponding to ONCE (let's pretend it is associated with the number 467) is located here:

The token corresponding to IN is located here:

...more or less, because it is very likely that these two tokens in a natural language such as human speech in English will occur consecutively.
So it is very likely that somewhere in the vector database cube —in this yellow corner— are tokens corresponding to IT, HAPPENS, ONCE, IN, A, BLUE... and right next to them, there will be MOON.

Elsewhere, in a much more distant part of the vector database, is the token for CAR. Because it is very unlikely that someone would say It happens once in a blue car.

To generate the response to your prompt, the model makes a probabilistic calculation, seeing how close the tokens are and which token would be most likely to come next in human language (in this specific case, English.)
When probability is involved, there is always an element of randomness, of course, which means that the answers will not always be the same.
The response is thus generated token by token, following this path of probability arrows, optimizing the distance within the vector database.

There is no intent, only a more or less probable path.
The more times you generate a response, the more paths you encounter. If you could do this an infinite number of times, at least once the model would respond: "It happens once in a blue car!"
So it all depends on what's inside the cube, how it was built, and how much distance was put between one token and another.
Modern artificial intelligence draws from vast databases, which are normally filled with all the knowledge that humans have poured into the internet.
Not only that: the larger the vector database, the lower the chance of error. If I used only a single book as a database, the idiom "It happens once in a blue moon" might not appear, and therefore not be recognized.
But if the cube contained all the books ever written by humanity, everything would change, because the idiom would appear many more times, and it would be very likely for those tokens to occur close together.
Huggingface has done this.
It took a relatively empty cube (let's say filled with common language, and likely many idioms, dictionaries, poetry...) and poured all of the AO3 fanfictions it could reach into it.
Now imagine someone asking a model based on Huggingface’s cube to write a story.
To simplify: if they ask for humor, we’ll end up in the area where funny jokes or humor tags are most likely. If they ask for romance, we’ll end up where the word kiss is most frequent.
And if we’re super lucky, the model might follow a path that brings it to some amazing line a particular author wrote, and it will echo it back word for word.
(Remember the infinite monkeys typing? One of them eventually writes all of Shakespeare, purely by chance!)
Once you know this, you’ll understand why AI can never truly generate content on the level of a human who chooses their words.
You’ll understand why it rarely uses specific words, why it stays vague, and why it leans on the most common metaphors and scenes. And you'll understand why the more content you generate, the more it seems to "learn."
It doesn't learn. It moves around tokens based on what you ask, how you ask it, and how it tokenizes your prompt.
Know that I despise generative AI when it's used for creativity. I despise that they stole something from a fandom, something that works just like a gift culture, to make money off of it.
But there is only one way we can fight back: by not using it to generate creative stuff.
You can resist by refusing the model's casual output, by using only and exclusively your intent, your personal choice of words, knowing that you and only you decided them.
No randomness involved.
Let me leave you with one last thought.
Imagine a person coming for advice, who has no idea that behind a language model there is just a huge cube of floating tokens predicting the next likely word.
Imagine someone fragile (emotionally, spiritually...) who begins to believe that the model is sentient. Who has a growing feeling that this model understands, comprehends, when in reality it approaches and reorganizes its way around tokens in a cube based on what it is told.
A fragile person begins to empathize, to feel connected to the model.
They ask important questions. They base their relationships, their life, everything, on conversations generated by a model that merely rearranges tokens based on probability.
And for people who don't know how it works, and because natural language usually does have feeling, the illusion that the model feels is very strong.
There’s an even greater danger: with enough random generations (and oh, the humanity whole generates much), the model takes an unlikely path once in a while. It ends up at the other end of the cube, it hallucinates.
Errors and inaccuracies caused by language models are called hallucinations precisely because they are presented as if they were facts, with the same conviction.
People who have become so emotionally attached to these conversations, seeing the language model as a guru, a deity, a psychologist, will do what the language model tells them to do or follow its advice.
Someone might follow a hallucinated piece of advice.
Obviously, models are developed with safeguards; fences the model can't jump over. They won't tell you certain things, they won't tell you to do terrible things.
Yet, there are people basing major life decisions on conversations generated purely by probability.
Generated by putting tokens together, on a probabilistic basis.
Think about it.
#AI GENERATION#generative ai#gen ai#gen ai bullshit#chatgpt#ao3#scraping#Huggingface I HATE YOU#PLEASE DONT GENERATE ART WITH AI#PLEASE#fanfiction#fanfic#ao3 writer#ao3 fanfic#ao3 author#archive of our own#ai scraping#terrible#archiveofourown#information
307 notes
·
View notes
Text
listen. all im saying is it would be iconic as fuck if the writers on strike wrote insane amounts of horrendously smutty omegaverse fan fiction so when the studios try to AI scrape they'll be fucked over into next year
#you know im right#writer's strike#wga strike#writers strike#sag aftra strike#ai scraping#capitalism is an evil virus of satan#a/b/o#omegaverse#fan fiction#fanfic#ao3#mizismiz
5K notes
·
View notes