#Scalable Data Architecture
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Kazakhstan’s Minister of Communications and Informatics has blocked the Tumblr site because it contained 60 sites of terrorism, extremism, and pornography in 2015.
Text
Unlocking Full Potential: The Compelling Reasons to Migrate to Databricks Unity Catalog
In a world overwhelmed by data complexities and AI advancements, Databricks Unity Catalog emerges as a game-changer. This blog delves into how Unity Catalog revolutionizes data and AI governance, offering a unified, agile solution .
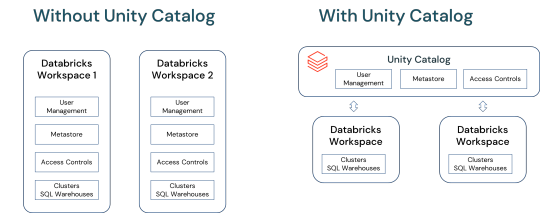
View On WordPress
#Access Control in Data Platforms#Advanced User Management#AI and ML Data Governance#AI Data Management#Big Data Solutions#Centralized Metadata Management#Cloud Data Management#Data Collaboration Tools#Data Ecosystem Integration#Data Governance Solutions#Data Lakehouse Architecture#Data Platform Modernization#Data Security and Compliance#Databricks for Data Scientists#Databricks Unity catalog#Enterprise Data Strategy#Migrating to Unity Catalog#Scalable Data Architecture#Unity Catalog Features
0 notes
Text
Data Unbound: Embracing NoSQL & NewSQL for the Real-Time Era.
Sanjay Kumar Mohindroo Sanjay Kumar Mohindroo. skm.stayingalive.in Explore how NoSQL and NewSQL databases revolutionize data management by handling unstructured data, supporting distributed architectures, and enabling real-time analytics. In today’s digital-first landscape, businesses and institutions are under mounting pressure to process massive volumes of data with greater speed,…
#ACID compliance#CIO decision-making#cloud data platforms#cloud-native data systems#column-family databases#data strategy#data-driven applications#database modernization#digital transformation#distributed database architecture#document stores#enterprise database platforms#graph databases#horizontal scaling#hybrid data stack#in-memory processing#IT modernization#key-value databases#News#NewSQL databases#next-gen data architecture#NoSQL databases#performance-driven applications#real-time data analytics#real-time data infrastructure#Sanjay Kumar Mohindroo#scalable database solutions#scalable systems for growth#schema-less databases#Tech Leadership
0 notes
Text
Discover Self-Supervised Learning for LLMs

Artificial intelligence is transforming the world at an unprecedented pace, and at the heart of this revolution lies a powerful learning technique: self-supervised learning. Unlike traditional methods that demand painstaking human effort to label data, self-supervised learning flips the script, allowing AI models to teach themselves from the vast oceans of unlabeled data that exist today. This method has rapidly emerged as the cornerstone for training Large Language Models (LLMs), powering applications from virtual assistants to creative content generation. It drives a fundamental shift in our thinking about AI's societal role.
Self-supervised learning propels LLMs to new heights by enabling them to learn directly from the data—no external guidance is needed. It's a simple yet profoundly effective concept: train a model to predict missing parts of the data, like guessing the next word in a sentence. But beneath this simplicity lies immense potential. This process enables AI to capture the depth and complexity of human language, grasp the context, understand the meaning, and even accumulate world knowledge. Today, this capability underpins everything from chatbots that respond in real time to personalized learning tools that adapt to users' needs.
This approach's advantages go far beyond just efficiency. By tapping into a virtually limitless supply of data, self-supervised learning allows LLMs to scale massively, processing billions of parameters and honing their ability to understand and generate human-like text. It democratizes access to AI, making it cheaper and more flexible and pushing the boundaries of what these models can achieve. And with the advent of even more sophisticated strategies like autonomous learning, where models continually refine their understanding without external input, the potential applications are limitless. We will try to understand how self-supervised learning works, its benefits for LLMs, and the profound impact it is already having on AI applications today. From boosting language comprehension to cutting costs and making AI more accessible, the advantages are clear and they're just the beginning. As we stand on the brink of further advancements, self-supervised learning is set to redefine the landscape of artificial intelligence, making it more capable, adaptive, and intelligent than ever before.
Understanding Self-Supervised Learning
Self-supervised learning is a groundbreaking approach that has redefined how large language models (LLMs) are trained, going beyond the boundaries of AI. We are trying to understand what self-supervised learning entails, how it differs from other learning methods, and why it has become the preferred choice for training LLMs.
Definition and Differentiation
At its core, self-supervised learning is a machine learning paradigm where models learn from raw, unlabeled data by generating their labels. Unlike supervised learning, which relies on human-labeled data, or unsupervised learning, which searches for hidden patterns in data without guidance, self-supervised learning creates supervisory signals from the data.
For example, a self-supervised learning model might take a sentence like "The cat sat on the mat" and mask out the word "mat." The model's task is to predict the missing word based on the context provided by the rest of the sentence. This way, we can get the model to learn the rules of grammar, syntax, and context without requiring explicit annotations from humans.
Core Mechanism: Next-Token Prediction
A fundamental aspect of self-supervised learning for LLMs is next-token prediction, a task in which the model anticipates the next word based on the preceding words. While this may sound simple, it is remarkably effective in teaching a model about the complexities of human language.
Here's why next-token prediction is so powerful:
Grammar and Syntax
To predict the next word accurately, the model must learn the rules that govern sentence structure. For example, after seeing different types of sentences, the model understands that "The cat" is likely to be followed by a verb like "sat" or "ran."
Semantics
The model is trained to understand the meanings of words and their relationships with each other. For example, if you want to say, "The cat chased the mouse," the model might predict "mouse" because it understands the words "cat" and "chased" are often used with "mouse."
Context
Effective prediction requires understanding the broader context. In a sentence like "In the winter, the cat sat on the," the model might predict "rug" or "sofa" instead of "grass" or "beach," recognizing that "winter" suggests an indoor setting.
World Knowledge
Over time, as the model processes vast amounts of text, it accumulates knowledge about the world, making more informed predictions based on real-world facts and relationships. This simple yet powerful task forms the basis of most modern LLMs, such as GPT-3 and GPT-4, allowing them to generate human-like text, understand context, and perform various language-related tasks with high proficiency .
The Transformer Architecture
Self-supervised learning for LLMs relies heavily on theTransformer architecture, a neural network design introduced in 2017 that has since become the foundation for most state-of-the-art language models. The Transformer Architecture is great for processing sequential data, like text, because it employs a mechanism known as attention. Here's how it works:
Attention Mechanism
Instead of processing text sequentially, like traditional recurrent neural networks (RNNs), Transformers use an attention mechanism to weigh the importance of each word in a sentence relative to every other word. The model can focus on the most relevant aspects of the text, even if they are far apart. For example, in the sentence "The cat that chased the mouse is on the mat," the model can pay attention to both "cat" and "chased" while predicting the next word.
Parallel Processing
Unlike RNNs, which process words one at a time, Transformers can analyze entire sentences in parallel. This makes them much faster and more efficient, especially when dealing large datasets. This efficiency is critical when training on datasets containing billions of words.
Scalability
The Transformer's ability to handle vast amounts of data and scale to billions of parameters makes it ideal for training LLMs. As models get larger and more complex, the attention mechanism ensures they can still capture intricate patterns and relationships in the data.
By leveraging the Transformer architecture, LLMs trained with self-supervised learning can learn from context-rich datasets with unparalleled efficiency, making them highly effective at understanding and generating language.
Why Self-Supervised Learning?
The appeal of self-supervised learning lies in its ability to harness vast amounts of unlabeled text data. Here are some reasons why this method is particularly effective for LLMs:
Utilization of Unlabeled Data
Self-supervised learning uses massive amounts of freely available text data, such as web pages, books, articles, and social media posts. This approach eliminates costly and time-consuming human annotation, allowing for more scalable and cost-effective model training.
Learning from Context
Because the model learns by predicting masked parts of the data, it naturally develops an understanding of context, which is crucial for generating coherent and relevant text. This makes LLMs trained with self-supervised learning well-suited for tasks like translation, summarization, and content generation.
Self-supervised learning enables models to continuously improve as they process more data, refining their understanding and capabilities. This dynamic adaptability is a significant advantage over traditional models, which often require retraining from scratch to handle new tasks or data.
In summary, self-supervised learning has become a game-changing approach for training LLMs, offering a powerful way to develop sophisticated models that understand and generate human language. By leveraging the Transformer architecture and utilizing vast amounts of unlabeled data, this method equips LLMs that can perform a lot of tasks with remarkable proficiency, setting the stage for future even more advanced AI applications.
Key Benefits of Self-Supervised Learning for LLMs
Self-supervised learning has fundamentally reshaped the landscape of AI, particularly in training large language models (LLMs). Concretely, what are the primary benefits of this approach, which is to enhance LLMs' capabilities and performance?
Leverage of Massive Unlabeled Data
One of the most transformative aspects of self-supervised learning is its ability to utilize vast amounts of unlabeled data. Traditional machine learning methods rely on manually labeled datasets, which are expensive and time-consuming. In contrast, self-supervised learning enables LLMs to learn from the enormous quantities of online text—web pages, books, articles, social media, and more.
By tapping into these diverse sources, LLMs can learn language structures, grammar, and context on an unprecedented scale. This capability is particularly beneficial because: Self-supervised learning draws from varied textual sources, encompassing multiple languages, dialects, topics, and styles. This diversity allows LLMs to develop a richer, more nuanced understanding of language and context, which would be impossible with smaller, hand-labeled datasets. The self-supervised learning paradigm scales effortlessly to massive datasets containing billions or even trillions of words. This scale allows LLMs to build a comprehensive knowledge base, learning everything from common phrases to rare idioms, technical jargon, and even emerging slang without manual annotation.
Improved Language Understanding
Self-supervised learning significantly enhances an LLM's ability to understand and generate human-like text. LLMs trained with self-supervised learning can develop a deep understanding of language structures, semantics, and context by predicting the next word or token in a sequence.
Deeper Grasp of Grammar and Syntax
LLMs implicitly learn grammar rules and syntactic structures through repetitive exposure to language patterns. This capability allows them to construct sentences that are not only grammatically correct but also contextually appropriate.
Contextual Awareness
Self-supervised learning teaches LLMs to consider the broader context of a passage. When predicting a word in a sentence, the model doesnt just look at the immediately preceding words but considers th'e entire sentence or even the paragraph. This context awareness is crucial for generating coherent and contextually relevant text.
Learning World Knowledge
LLMs process massive datasets and accumulate factual knowledge about the world. This helps them make informed predictions, generate accurate content, and even engage in reasoning tasks, making them more reliable for applications like customer support, content creation, and more.
Scalability and Cost-Effectiveness
The cost-effectiveness of self-supervised learning is another major benefit. Traditional supervised learning requires vast amounts of labeled data, which can be expensive. In contrast, self-supervised learning bypasses the need for labeled data by using naturally occurring structures within the data itself.
Self-supervised learning dramatically cuts costs by eliminating the reliance on human-annotated datasets, making it feasible to train very large models. This approach democratizes access to AI by lowering the barriers to entry for researchers, developers, and companies. Because self-supervised learning scales efficiently across large datasets, LLMs trained with this method can handle billions or trillions of parameters. This capability makes them suitable for various applications, from simple language tasks to complex decision-making processes.
Autonomous Learning and Continuous Improvement
Recent advancements in self-supervised learning have introduced the concept of Autonomous Learning, where LLMs learn in a loop, similar to how humans continuously learn and refine their understanding.
In autonomous learning, LLMs first go through an "open-book" learning phase, absorbing information from vast datasets. Next, they engage in "closed-book" learning, recalling and reinforcing their understanding without referring to external sources. This iterative process helps the model optimize its understanding, improve performance, and adapt to new tasks over time. Autonomous learning allows LLMs to identify gaps in their knowledge and focus on filling them without human intervention. This self-directed learning makes them more accurate, efficient, and versatile.
Better Generalization and Adaptation
One of the standout benefits of self-supervised learning is the ability of LLMs to generalize across different domains and tasks. LLMs trained with self-supervised learning draw on a wide range of data. They are better equipped to handle various tasks, from generating creative content to providing customer support or technical guidance. They can quickly adapt to new domains or tasks with minimal retraining. This generalization ability makes LLMs more robust and flexible, allowing them to function effectively even when faced with new, unseen data. This adaptability is crucial for applications in fast-evolving fields like healthcare, finance, and technology, where the ability to handle new information quickly can be a significant advantage.
Support for Multimodal Learning
Self-supervised learning principles can extend beyond text to include other data types, such as images and audio. Multimodal learning enables LLMs to handle different forms of data simultaneously, enhancing their ability to generate more comprehensive and accurate content. For example, an LLM could analyze an image, generate a descriptive caption, and provide an audio summary simultaneously. This multimodal capability opens up new opportunities for AI applications in areas like autonomous vehicles, smart homes, and multimedia content creation, where diverse data types must be processed and understood together.
Enhanced Creativity and Problem-Solving
Self-supervised learning empowers LLMs to engage in creative and complex tasks.
Creative Content Generation
LLMs can produce stories, poems, scripts, and other forms of creative content by understanding context, tone, and stylistic nuances. This makes them valuable tools for creative professionals and content marketers.
Advanced Problem-Solving
LLMs trained on diverse datasets can provide novel solutions to complex problems, assisting in medical research, legal analysis, and financial forecasting.
Reduction of Bias and Improved Fairness
Self-supervised learning helps mitigate some biases inherent in smaller, human-annotated datasets. By training on a broad array of data sources, LLMs can learn from various perspectives and experiences, reducing the likelihood of bias resulting from limited data sources. Although self-supervised learning doesn't eliminate bias, the continuous influx of diverse data allows for ongoing adjustments and refinements, promoting fairness and inclusivity in AI applications.
Improved Efficiency in Resource Usage
Self-supervised learning optimizes the use of computational resources. It can directly use raw data instead of extensive preprocessing and manual data cleaning, reducing the time and resources needed to prepare data for training. As learning efficiency improves, these models can be deployed on less powerful hardware, making advanced AI technologies more accessible to a broader audience.
Accelerated Innovation in AI Applications
The benefits of self-supervised learning collectively accelerate innovation across various sectors. LLMs trained with self-supervised learning can analyze medical texts, support diagnosis, and provide insights from vast amounts of unstructured data, aiding healthcare professionals. In the financial sector, LLMs can assist in analyzing market trends, generating reports, automating routine tasks, and enhancing efficiency and decision-making. LLMs can act as personalized tutors, generating tailored content and quizzes that enhance students' learning experiences.
Practical Applications of Self-Supervised Learning in LLMs
Self-supervised learning has enabled LLMs to excel in various practical applications, demonstrating their versatility and power across multiple domains
Virtual Assistants and Chatbots
Virtual assistants and chatbots represent one of the most prominent applications of LLMs trained with self-supervised learning. These models can do the following:
Provide Human-Like Responses
By understanding and predicting language patterns, LLMs deliver natural, context-aware responses in real-time, making them highly effective for customer service, technical support, and personal assistance.
Handle Complex Queries
They can handle complex, multi-turn conversations, understand nuances, detect user intent, and manage diverse topics accurately.
Content Generation and Summarization
LLMs have revolutionized content creation, enabling automated generation of high-quality text for various purposes.
Creative Writing
LLMs can generate engaging content that aligns with specific tone and style requirements, from blogs to marketing copies. This capability reduces the time and effort needed for content production while maintaining quality and consistency. Writers can use LLMs to brainstorm ideas, draft content, and even polish their work by generating multiple variations.
Text Summarization
LLMs can distill lengthy articles, reports, or documents into concise summaries, making information more accessible and easier to consume. This is particularly useful in fields like journalism, education, and law, where large volumes of text need to be synthesized quickly. Summarization algorithms powered by LLMs help professionals keep up with information overload by providing key takeaways and essential insights from long documents.
Domain-Specific Applications
LLMs trained with self-supervised learning have proven their worth in domain-specific applications where understanding complex and specialized content is crucial. LLMs assist in interpreting medical literature, supporting diagnoses, and offering treatment recommendations. Analyzing a wide range of medical texts can provide healthcare professionals with rapid insights into potential drug interactions and treatment protocols based on the latest research. This helps doctors stay current with the vast and ever-expanding medical knowledge.
LLMs analyze market trends in finance, automate routine tasks like report generation, and enhance decision-making processes by providing data-driven insights. They can help with risk assessment, compliance monitoring, and fraud detection by processing massive datasets in real time. This capability reduces the time needed to make informed decisions, ultimately enhancing productivity and accuracy. LLMs can assist with tasks such as contract analysis, legal research, and document review in the legal domain. By understanding legal terminology and context, they can quickly identify relevant clauses, flag potential risks, and provide summaries of lengthy legal documents, significantly reducing the workload for lawyers and paralegals.
How to Implement Self-Supervised Learning for LLMs
Implementing self-supervised learning for LLMs involves several critical steps, from data preparation to model training and fine-tuning. Here's a step-by-step guide to setting up and executing self-supervised learning for training LLMs:
Data Collection and Preparation
Data Collection
Web Scraping
Collect text from websites, forums, blogs, and online articles.
Open Datasets
For medical texts, use publicly available datasets such as Common Crawl, Wikipedia, Project Gutenberg, or specialized corpora like PubMed.
Proprietary Data
Include proprietary or domain-specific data to tailor the model to specific industries or applications, such as legal documents or company-specific communications.
Pre-processing
Tokenization
Convert the text into smaller units called tokens. Tokens may be words, subwords, or characters, depending on the model's architecture.
Normalization
Clean the text by removing special characters, URLs, excessive whitespace, and irrelevant content. If case sensitivity is not essential, standardize the text by converting it to lowercase.
Data Augmentation
Introduce variations in the text, such as paraphrasing or back-translation, to improve the model's robustness and generalization capabilities.
Shuffling and Splitting
Randomly shuffle the data to ensure diversity and divide it into training, validation, and test sets.
Define the Learning Objective
Self-supervised learning requires setting specific learning objectives for the model:
Next-Token Prediction
Set up the primary task of predicting the next word or token in a sequence. Implement "masked language modeling" (MLM), where a certain percentage of input tokens are replaced with a mask token, and the model is trained to predict the original token. This helps the model learn the structure and flow of natural language.
Contrastive Learning (Optional)
Use contrastive learning techniques where the model learns to differentiate between similar and dissimilar examples. For instance, when given a sentence, slightly altered versions are generated, and the model is trained to distinguish the original from the altered versions, enhancing its contextual understanding.
Model Training and Optimization
After preparing the data and defining the learning objectives, proceed to train the model:
Initialize the Model
Start with a suitable architecture, such as a Transformer-based model (e.g., GPT, BERT). Use pre-trained weights to leverage existing knowledge and reduce the required training time if available.
Configure the Learning Process
Set hyperparameters such as learning rate, batch size, and sequence length. Use gradient-based optimization techniques like Adam or Adagrad to minimize the loss function during training.
Use Computational Resources Effectively
Training LLM systems demands a lot of computational resources, including GPUs or TPUs. The training process can be distributed across multiple devices, or cloud-based solutions can handle high processing demands.
Hyperparameter Tuning
Adjust hyperparameters regularly to find the optimal configuration. Experiment with different learning rates, batch sizes, and regularization methods to improve the model's performance.
Evaluation and Fine-Tuning
Once the model is trained, its performance is evaluated and fine-tuned for specific applications. Here is how it works:
Model Evaluation
Use perplexity, accuracy, and loss metrics to evaluate the model's performance. Test the model on a separate validation set to measure its generalization ability to new data.
Fine-Tuning
Refine the model for specific domains or tasks using labeled data or additional unsupervised techniques. Fine-tune a general-purpose LLM on domain-specific datasets to make it more accurate for specialized applications.
Deploy and Monitor
After fine-tuning, deploy the model in a production environment. Continuously monitor its performance and collect feedback to identify areas for further improvement.
Advanced Techniques: Autonomous Learning
To enhance the model further, consider implementing autonomous learning techniques:
Open-Book and Closed-Book Learning
Train the model to first absorb information from datasets ("open-book" learning) and then recall and reinforce this knowledge without referring back to the original data ("closed-book" learning). This process mimics human learning patterns, allowing the model to optimize its understanding continuously.
Self-optimization and Feedback Loops
Incorporate feedback loops where the model evaluates its outputs, identifies errors or gaps, and adjusts its internal parameters accordingly. This self-reinforcing process leads to ongoing performance improvements without requiring additional labeled data.
Ethical Considerations and Bias Mitigation
Implementing self-supervised learning also involves addressing ethical considerations:
Bias Detection and Mitigation
Audit the training data regularly for biases. Use techniques such as counterfactual data augmentation or fairness constraints during training to minimize bias.
Transparency and Accountability
Ensure the model's decision-making processes are transparent. Develop methods to explain the model's outputs and provide users with tools to understand how decisions are made.
Concluding Thoughts
Implementing self-supervised learning for LLMs offers significant benefits, including leveraging massive unlabeled data, enhancing language understanding, improving scalability, and reducing costs. This approach's practical applications span multiple domains, from virtual assistants and chatbots to specialized healthcare, finance, and law uses. By following a systematic approach to data collection, training, optimization, and evaluation, organizations can harness the power of self-supervised learning to build advanced LLMs that are versatile, efficient, and capable of continuous improvement. As this technology continues to evolve, it promises to push the boundaries of what AI can achieve, paving the way for more intelligent, adaptable, and creative systems to better understand and interact with the world around us.
Ready to explore the full potential of LLM?
Our AI-savvy team tackles the latest advancements in self-supervised learning to build smarter, more adaptable AI systems tailored to your needs. Whether you're looking to enhance customer experiences, automate content generation, or revolutionize your industry with innovative AI applications, we've got you covered. Keep your business from falling behind in the digital age. Connect with our team of experts today to discover how our AI-driven strategies can transform your operations and drive sustainable growth. Let's shape the future together — get in touch with Coditude now and take the first step toward a smarter tomorrow!
#AI#artificial intelligence#LLM#transformer architecture#self supervised learning#NLP#Machine Learning#scalability#cost effectiveness#unlabelled data#chatbot#virtual assistants#increased efficiency#data quality
0 notes
Text
Exploring the Synergy of Data Mesh and Data Fabric
As the digital landscape evolves and data becomes increasingly complex, organizations are seeking innovative approaches to manage and derive value from their data assets. Data mesh and data fabric have emerged as promising frameworks that address the challenges associated with data democratization, scalability, and agility.
In this blog, our expert authors delve into the fundamentals of data mesh, an architectural paradigm that emphasizes decentralized ownership and domain-driven data products. Learn how data mesh enables organizations to establish self-serve data ecosystems, fostering a culture of data collaboration and empowering teams to own and govern their data.
Furthermore, explore the concept of data fabric, a unified and scalable data infrastructure layer that seamlessly connects disparate data sources and systems. Uncover the benefits of implementing a data fabric architecture, including improved data accessibility, enhanced data integration capabilities, and accelerated data-driven decision-making.
Through real-world examples and practical insights, this blog post showcases the synergistic relationship between data mesh and data fabric. Discover how organizations can leverage these two frameworks in harmony to establish a robust data architecture that optimizes data discovery, quality, and usability.
Stay ahead of the data management curve and unlock the potential of your organization's data assets. Read this thought-provoking blog post on the synergy of data mesh and data fabric today!
For more info visit here: https://www.incedoinc.com/exploring-the-synergy-of-data-mesh-and-data-fabric/
1 note
·
View note
Text





🎄💾🗓️ Day 4: Retrocomputing Advent Calendar - The DEC PDP-11! 🎄💾🗓️
Released by Digital Equipment Corporation in 1970, the PDP-11 was a 16-bit minicomputer known for its orthogonal instruction set, allowing flexible and efficient programming. It introduced a Unibus architecture, which streamlined data communication and helped revolutionize computer design, making hardware design more modular and scalable. The PDP-11 was important in developing operating systems, including the early versions of UNIX. The PDP-11 was the hardware foundation for developing the C programming language and early UNIX systems. It supported multiple operating systems like RT-11, RSX-11, and UNIX, which directly shaped modern OS design principles. With over 600,000 units sold, the PDP-11 is celebrated as one of its era's most versatile and influential "minicomputers".
Check out the wikipedia page for some great history, photos (pictured here), and more -
And here's a story from Adafruit team member, Bill!
The DEC PDP-11 was the one of the first computers I ever programmed. That program was 'written' with a soldering iron.
I was an art student at the time, but spending most of my time in the engineering labs. There was a PDP-11-34 in the automation lab connected to an X-ray spectroscopy machine. Starting up the machine required toggling in a bootstrap loader via the front panel. This was a tedious process. So we ordered a diode-array boot ROM which had enough space to program 32 sixteen bit instructions.
Each instruction in the boot sequence needed to be broken down into binary (very straightforward with the PDP-11 instruction set). For each binary '1', a diode needed to be soldered into the array. The space was left empty for each '0'. 32 sixteen bit instructions was more than sufficient to load a secondary bootstrap from the floppy disk to launch the RT-11 operating system. So now it was possible to boot the system with just the push of a button.
I worked with a number DEC PDP-11/LSI-11 systems over the years. I still keep an LSI-11-23 system around for sentimental reasons.
Have first computer memories? Post’em up in the comments, or post yours on socialz’ and tag them #firstcomputer #retrocomputing – See you back here tomorrow!
#dec#pdp11#retrocomputing#adventcalendar#minicomputer#unixhistory#cprogramming#computinghistory#vintagecomputers#modulardesign#scalablehardware#digitalcorporation#engineeringlabs#programmingroots#oldschooltech#diodearray#bootstraploader#firstcomputer#retrotech#nerdlife
290 notes
·
View notes
Note
In the era of hyperconverged intelligence, quantum-entangled neural architectures synergize with neuromorphic edge nodes to orchestrate exabyte-scale data torrents, autonomously curating context-aware insights with sub-millisecond latency. These systems, underpinned by photonic blockchain substrates, enable trustless, zero-knowledge collaboration across decentralized metaverse ecosystems, dynamically reconfiguring their topological frameworks to optimize for emergent, human-AI symbiotic workflows. By harnessing probabilistic generative manifolds, such platforms transcend classical computational paradigms, delivering unparalleled fidelity in real-time, multi-modal sensemaking. This convergence of cutting-edge paradigms heralds a new epoch of cognitive augmentation, where scalable, self-sovereign intelligence seamlessly integrates with the fabric of post-singularitarian reality.
Are you trying to make me feel stupid /silly
7 notes
·
View notes
Text

New data model paves way for seamless collaboration among US and international astronomy institutions
Software engineers have been hard at work to establish a common language for a global conversation. The topic—revealing the mysteries of the universe. The U.S. National Science Foundation National Radio Astronomy Observatory (NSF NRAO) has been collaborating with U.S. and international astronomy institutions to establish a new open-source, standardized format for processing radio astronomical data, enabling interoperability between scientific institutions worldwide.
When telescopes are observing the universe, they collect vast amounts of data—for hours, months, even years at a time, depending on what they are studying. Combining data from different telescopes is especially useful to astronomers, to see different parts of the sky, or to observe the targets they are studying in more detail, or at different wavelengths. Each instrument has its own strengths, based on its location and capabilities.
"By setting this international standard, NRAO is taking a leadership role in ensuring that our global partners can efficiently utilize and share astronomical data," said Jan-Willem Steeb, the technical lead of the new data processing program at the NSF NRAO. "This foundational work is crucial as we prepare for the immense data volumes anticipated from projects like the Wideband Sensitivity Upgrade to the Atacama Large Millimeter/submillimeter Array and the Square Kilometer Array Observatory in Australia and South Africa."
By addressing these key aspects, the new data model establishes a foundation for seamless data sharing and processing across various radio telescope platforms, both current and future.
International astronomy institutions collaborating with the NSF NRAO on this process include the Square Kilometer Array Observatory (SKAO), the South African Radio Astronomy Observatory (SARAO), the European Southern Observatory (ESO), the National Astronomical Observatory of Japan (NAOJ), and Joint Institute for Very Long Baseline Interferometry European Research Infrastructure Consortium (JIVE).
The new data model was tested with example datasets from approximately 10 different instruments, including existing telescopes like the Australian Square Kilometer Array Pathfinder and simulated data from proposed future instruments like the NSF NRAO's Next Generation Very Large Array. This broader collaboration ensures the model meets diverse needs across the global astronomy community.
Extensive testing completed throughout this process ensures compatibility and functionality across a wide range of instruments. By addressing these aspects, the new data model establishes a more robust, flexible, and future-proof foundation for data sharing and processing in radio astronomy, significantly improving upon historical models.
"The new model is designed to address the limitations of aging models, in use for over 30 years, and created when computing capabilities were vastly different," adds Jeff Kern, who leads software development for the NSF NRAO.
"The new model updates the data architecture to align with current and future computing needs, and is built to handle the massive data volumes expected from next-generation instruments. It will be scalable, which ensures the model can cope with the exponential growth in data from future developments in radio telescopes."
As part of this initiative, the NSF NRAO plans to release additional materials, including guides for various instruments and example datasets from multiple international partners.
"The new data model is completely open-source and integrated into the Python ecosystem, making it easily accessible and usable by the broader scientific community," explains Steeb. "Our project promotes accessibility and ease of use, which we hope will encourage widespread adoption and ongoing development."
10 notes
·
View notes
Text
How do Teslas manage power differently from traditional cars, especially regarding overnight features like headlights?
Teslas manage power fundamentally differently from traditional internal combustion engine (ICE) cars—especially for "always-on" features like headlights—through architectural differences in their electrical systems, intelligent power management, and energy source prioritization. Here’s how they do it:
⚡ 1. Core Power Architecture Differences Component Traditional ICE Car Tesla
Primary Energy Source Alternator (belt-driven) recharges the 12V battery High-voltage (400V) battery pack → powers everything 12V System Power Source Lead-acid battery (depletes quickly) DC-DC converter taps HV pack to charge 12V lithium battery Headlights/Electronics Run only off 12V battery → drains in hours Prioritized LV loads → HV pack replenishes 12V as needed
🔋 2. Overnight Power Management
Teslas avoid dead batteries via layered power optimization: Deep Sleep Mode:
After 15-30 mins idle, Tesla shuts down non-essential systems (sentry mode, infotainment), cutting power draw to ~10-50W (vs. 200W+ in ICE idling).
Adaptive 12V Charging:
The DC-DC converter tops up the 12V battery only when its voltage drops → minimizes HV pack cycles.
Lithium 12V Battery (2021+ models):
Replaced lead-acid → 4x longer lifespan, faster charging, lighter weight.
Example: Headlights Left On ICE Car: Drains 12V battery in ~4-8 hours (500W draw).
Tesla:
Headlights auto-shutoff after delay (or via app).
If left on: HV pack feeds DC-DC converter → powers lights for days (~0.1% HV pack loss/hour).
🌙 3. Tesla-Specific "Overnight" Features Feature Power Source ICE Equivalent
Sentry Mode HV pack → 12V system (~200W) N/A – ICE battery dies fast Climate Keep HV pack → heat pump (1-3kW) Engine must idle (1-2L fuel/hr) Software Updates HV pack → compute (300W+) Drains 12V battery rapidly
HV battery sustains all features without idling an engine.
🔧 4. Real-World Efficiency Data Vampire Drain:
Tesla loses ~1-2% battery/day with sentry/climate off.
ICE cars lose 0.5–1L/day in fuel to keep 12V alive during shipping/storage.
Headlight Overnight Draw:
Tesla LED headlights: ~50W total.
ICE halogen headlights: 110W+.
⚠️ Why Tesla’s System Wins No Parasitic Losses: No alternator constantly burning fuel to charge a 12V system.
Energy Scale: Tapping a 75kWh HV pack for 12V loads is like "using an ocean to fill a bathtub."
Predictive Shutdown: Tesla sleeps deeply unless explicitly woken (via app or key).
🛠️ Edge Cases & Fail-Safes 12V Battery Failure:
Tesla alerts drivers weeks in advance → DC-DC converter keeps it charged proactively. HV Pack Depletion:
If HV pack hits 0%, the car uses reserve energy to boot critical systems for recovery. Frozen Temperatures:
HV pack self-heats to maintain efficiency (ICE batteries struggle below -10°C).
Bottom Line: Teslas treat electricity like a data network—intelligently routed, prioritized, and scalable—while ICE cars rely on wasteful "always-on" generation. This allows features like headlights, sentry mode, and climate control to run indefinitely overnight without stranding the driver. 🔋💡

#led lights#car lights#led car light#youtube#led auto light#led headlights#led light#led headlight bulbs#ledlighting#young artist#Tesla#tesla cars#tesla cybertruck#boycott tesla#nikola tesla#cybertruck#swasticars#cars#car light#race cars#electric cars#classic cars#car#porsche#truck#carlos sainz#automobile#lamborghini#bmw#auto mode
3 notes
·
View notes
Text
How Can Legacy Application Support Align with Your Long-Term Business Goals?
Many businesses still rely on legacy applications to run core operations. These systems, although built on older technology, are deeply integrated with workflows, historical data, and critical business logic. Replacing them entirely can be expensive and disruptive. Instead, with the right support strategy, these applications can continue to serve long-term business goals effectively.

1. Ensure Business Continuity
Continuous service delivery is one of the key business objectives of any enterprise. Maintenance of old applications guarantees business continuity, which minimizes chances of business interruption in case of software malfunctions or compatibility errors. These applications can be made to work reliably with modern support strategies such as performance monitoring, frequent patching, system optimization, despite changes in the rest of the system changes in the rest of the systems. This prevents the lost revenue and downtime of unplanned outages.
2. Control IT Costs
A straight replacement of the legacy systems is a capital intensive process. By having support structures, organizations are in a position to prolong the life of such applications and ensure an optimal IT expenditure. The cost saved can be diverted into innovation or into technologies that interact with the customers. An effective support strategy manages the total cost of ownership (TCO), without sacrificing performance or compliance.
3. Stay Compliant and Secure
The observance of industry regulations is not negotiable. Unsupported legacy application usually fall out of compliance with standards changes. This is handled by dedicated legacy application support which incorporates security updates, compliances patching and audit trails maintenance. This minimizes the risks of regulatory fines and reputational loss as well as governance and risk management objectives.
4. Connect with Modern Tools
Legacy support doesn’t mean working in isolation. With the right approach, these systems can connect to cloud platforms, APIs, and data tools. This enables real-time reporting, improved collaboration, and more informed decision-making—without requiring full system replacements.
5. Protect Business Knowledge
The legacy systems often contain years of institutional knowledge built into workflows, decision trees, and data architecture. They should not be abandoned early because vital operational insights may be lost. Maintaining these systems enables enterprises to keep that knowledge and transform it into documentation or reusable code aligned with ongoing digital transformation initiatives.
6. Support Scalable Growth
Well-supported legacy systems can still grow with your business. With performance tuning and capacity planning, they can handle increased demand and user loads. This keeps growth on track without significant disruption to IT systems.
7. Increase Flexibility and Control
Maintaining legacy application—either in-house or through trusted partners—gives businesses more control over their IT roadmap. It avoids being locked into aggressive vendor timelines and allows change to happen on your terms.
Legacy applications don’t have to be a roadblock. With the right support model, they become a stable foundation that supports long-term goals. From cost control and compliance to performance and integration, supported legacy systems can deliver measurable value. Specialized Legacy Application Maintenance Services are provided by service vendors such as Suma Soft, TCS, Infosys, Capgemini, and HCLTech, to enable businesses to get the best out of their current systems, as they prepare to transform in the future. Choosing the appropriate partner will maintain these systems functioning, developing and integrated with wider business strategies.
#BusinessContinuity#DigitalTransformation#ITStrategy#EnterpriseIT#BusinessOptimization#TechLeadership#ScalableSolutions#SmartITInvestments
3 notes
·
View notes
Text
Real-World Application of Data Mesh with Databricks Lakehouse
Explore how a global reinsurance leader transformed its data systems with Data Mesh and Databricks Lakehouse for better operations and decision-making.
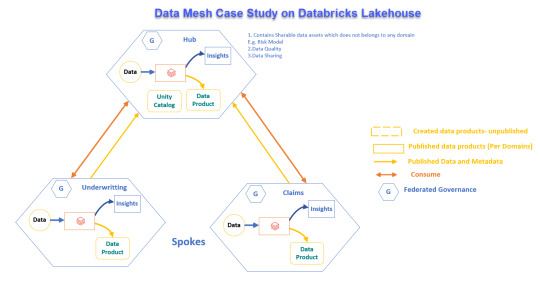
View On WordPress
#Advanced Analytics#Business Transformation#Cloud Solutions#Data Governance#Data management#Data Mesh#Data Scalability#Databricks Lakehouse#Delta Sharing#Enterprise Architecture#Reinsurance Industry
0 notes
Text
From Chips to Clouds: Exploring Intel's Role in the Next Generation of Computing
Introduction
The world of computing is evolving at breakneck speed, and at the forefront of this technological revolution is Intel Corp. Renowned for its groundbreaking innovations in microprocessors, Intel's influence extends far beyond silicon chips; it reaches into the realms of artificial intelligence, cloud computing, and beyond. This article dives deep into Intel's role in shaping the next generation of computing, exploring everything from its historical contributions to its futuristic visions.
From Chips to Clouds: Exploring Intel's Role in the Next Generation of Computing
Intel has long been synonymous with computing power. Founded in 1968, it pioneered the microprocessor revolution that transformed personal computing. Today, as we transition from conventional machines to cloud-based systems powered by artificial intelligence and machine learning, Intel remains a critical player.
The Evolution of Intel’s Microprocessors A Brief History
Intel's journey began with the introduction of the first commercially available microprocessor, the 4004, in 1971. Over decades, it has relentlessly innovated:
1970s: Introduction of the 8086 architecture. 1980s: The rise of x86 compatibility. 1990s: Pentium processors that made personal computers widely accessible.
Each evolution marked a leap forward not just for Intel but for global computing capabilities.
Current Microprocessor Technologies
Today’s microprocessors are marvels of engineering. Intel’s current lineup features:
youtube
Core i3/i5/i7/i9: Catering to everything from basic tasks to high-end gaming. Xeon Processors: Designed for servers and high-performance computing. Atom Processors: Targeting mobile devices and embedded applications.
These technologies are designed with advanced architectures like Ice Lake and Tiger Lake that enhance performance while optimizing power consumption.
Click for more info Intel’s Influence on Cloud Computing The Shift to Cloud-Based Solutions
In recent years, businesses have increasingly embraced cloud computing due to its scalability, flexibility, and cost-effectiveness. Intel has played a crucial role in this transition by designing processors optimized for data centers.
Intel’s Data Center Solutions
Intel provides various solutions tailored for cloud service providers:
Intel Xeon Scalable Processors: Designed specifically for workloads in data centers. Intel Optane Technology: Enhancing memory performance and storage capabilities.
These innovations help companies manage vast amounts of data efficiently.
Artificial Intelligence: A New Frontier AI Integration in Everyday Applications
Artificial Intelligence (AI) is becoming integral to modern computing. From smart assistants to advanced analytics tools, AI relies heavily on processing power—something that Intel excels at providing.
Intel’s AI Initiatives
Through initiat
2 notes
·
View notes
Text
From Chips to Clouds: Exploring Intel's Role in the Next Generation of Computing
Introduction
The world of computing is evolving at breakneck speed, and at the forefront of this technological revolution is Intel Corp. Renowned for its groundbreaking innovations in microprocessors, Intel's influence extends far beyond silicon chips; it reaches into the realms of artificial intelligence, cloud computing, and beyond. This article dives Get more information deep into Intel's role in shaping the next generation of computing, exploring everything from its historical contributions to its futuristic visions.
From Chips to Clouds: Exploring Intel's Role in the Next Generation of Computing
Intel has long been synonymous with computing power. Founded in 1968, it pioneered the microprocessor revolution that transformed personal computing. Today, as we transition from conventional machines to cloud-based systems powered by artificial intelligence and machine learning, Intel remains a critical player.
youtube
The Evolution of Intel’s Microprocessors A Brief History
Intel's journey began with the introduction of the first commercially available microprocessor, the 4004, in 1971. Over decades, it has relentlessly innovated:
1970s: Introduction of the 8086 architecture. 1980s: The rise of x86 compatibility. 1990s: Pentium processors that made personal computers widely accessible.
Each evolution marked a leap forward not just for Intel but for global computing capabilities.
Current Microprocessor Technologies
Today’s microprocessors are marvels of engineering. Intel’s current lineup features:
Core i3/i5/i7/i9: Catering to everything from basic tasks to high-end gaming. Xeon Processors: Designed for servers and high-performance computing. Atom Processors: Targeting mobile devices and embedded applications.
These technologies are designed with advanced architectures like Ice Lake and Tiger Lake that enhance performance while optimizing power consumption.
Intel’s Influence on Cloud Computing The Shift to Cloud-Based Solutions
In recent years, businesses have increasingly embraced cloud computing due to its scalability, flexibility, and cost-effectiveness. Intel has played a crucial role in this transition by designing processors optimized for data centers.
Intel’s Data Center Solutions
Intel provides various solutions tailored for cloud service providers:
Intel Xeon Scalable Processors: Designed specifically for workloads in data centers. Intel Optane Technology: Enhancing memory performance and storage capabilities.
These innovations help companies manage vast amounts of data efficiently.
Artificial Intelligence: A New Frontier AI Integration in Everyday Applications
Artificial Intelligence (AI) is becoming integral to modern computing. From smart assistants to advanced analytics tools, AI relies heavily on processing power—something that Intel excels at providing.
Intel’s AI Initiatives
Through initiat
2 notes
·
View notes
Text
Cloud Computing: Definition, Benefits, Types, and Real-World Applications
In the fast-changing digital world, companies require software that matches their specific ways of working, aims and what their customers require. That’s when you need custom software development services. Custom software is made just for your organization, so it is more flexible, scalable and efficient than generic software.
What does Custom Software Development mean?
Custom software development means making, deploying and maintaining software that is tailored to a specific user, company or task. It designs custom Software Development Services: Solutions Made Just for Your Business to meet specific business needs, which off-the-shelf software usually cannot do.
The main advantages of custom software development are listed below.
1. Personalized Fit
Custom software is built to address the specific needs of your business. Everything is designed to fit your workflow, whether you need it for customers, internal tasks or industry-specific functions.
2. Scalability
When your business expands, your software can also expand. You can add more features, users and integrations as needed without being bound by strict licensing rules.
3. Increased Efficiency
Use tools that are designed to work well with your processes. Custom software usually automates tasks, cuts down on repetition and helps people work more efficiently.
4. Better Integration
Many companies rely on different tools and platforms. You can have custom software made to work smoothly with your CRMs, ERPs and third-party APIs.
5. Improved Security
You can set up security measures more effectively in a custom solution. It is particularly important for industries that handle confidential information, such as finance, healthcare or legal services.
Types of Custom Software Solutions That Are Popular
CRM Systems
Inventory and Order Management
Custom-made ERP Solutions
Mobile and Web Apps
eCommerce Platforms
AI and Data Analytics Tools
SaaS Products
The Process of Custom Development
Requirement Analysis
Being aware of your business goals, what users require and the difficulties you face in running the business.
Design & Architecture
Designing a software architecture that can grow, is safe and fits your requirements.
Development & Testing
Writing code that is easy to maintain and testing for errors, speed and compatibility.
Deployment and Support
Making the software available and offering support and updates over time.
What Makes Niotechone a Good Choice?
Our team at Niotechone focuses on providing custom software that helps businesses grow. Our team of experts works with you throughout the process, from the initial idea to the final deployment, to make sure the product is what you require.
Successful experience in various industries
Agile development is the process used.
Support after the launch and options for scaling
Affordable rates and different ways to work together
Final Thoughts
Creating custom software is not only about making an app; it’s about building a tool that helps your business grow. A customized solution can give you the advantage you require in the busy digital market, no matter if you are a startup or an enterprise.
#software development company#development company software#software design and development services#software development services#custom software development outsourcing#outsource custom software development#software development and services#custom software development companies#custom software development#custom software development agency#custom software development firms#software development custom software development#custom software design companies#custom software#custom application development#custom mobile application development#custom mobile software development#custom software development services#custom healthcare software development company#bespoke software development service#custom software solution#custom software outsourcing#outsourcing custom software#application development outsourcing#healthcare software development
2 notes
·
View notes
Text
Build Powerful Web Applications with Oracle APEX – Fast, Responsive, and Scalable

In today’s digital world, businesses need custom web applications that are not only powerful but also fast, user-friendly, and mobile-responsive. That’s where Oracle APEX (Application Express) comes in — and that’s where I come in.
With over 15 years of experience in Oracle technologies, I specialize in designing and developing robust Oracle APEX applications tailored to your business needs.
✅ What I Offer:
Fully customized Oracle APEX application development
Beautiful and responsive UI designs for desktop & mobile
Data entry forms, interactive reports, and dashboards
Complex PL/SQL logic, validations, and dynamic actions
Migration from Oracle Forms to APEX
Web service integrations and scalable architectures
Whether you're building a tool for internal use or deploying a full-scale enterprise app, I can bring your project to life with precision and quality.
👉 Hire me on Fiverr to get started: 🔗 https://www.fiverr.com/s/e6xxreg
2 notes
·
View notes
Text
Udaan by InAmigos Foundation: Elevating Women, Empowering Futures

In the rapidly evolving socio-economic landscape of India, millions of women remain underserved by mainstream development efforts—not due to a lack of talent, but a lack of access. In response, Project Udaan, a flagship initiative by the InAmigos Foundation, emerges not merely as a program, but as a model of scalable women's empowerment.
Udaan—meaning “flight” in Hindi—represents the aspirations of rural and semi-urban women striving to break free from intergenerational limitations. By engineering opportunity and integrating sustainable socio-technical models, Udaan transforms potential into productivity and promise into progress.
Mission: Creating the Blueprint for Women’s Self-Reliance
At its core, Project Udaan seeks to:
Empower women with industry-aligned, income-generating skills
Foster micro-entrepreneurship rooted in local demand and resources
Facilitate financial and digital inclusion
Strengthen leadership, health, and rights-based awareness
Embed resilience through holistic community engagement
Each intervention is data-informed, impact-monitored, and custom-built for long-term sustainability—a hallmark of InAmigos Foundation’s field-tested grassroots methodology.
A Multi-Layered Model for Empowerment

Project Udaan is built upon a structured architecture that integrates training, enterprise, and technology to ensure sustainable outcomes. This model moves beyond skill development into livelihood generation and measurable socio-economic change.
1. Skill Development Infrastructure
The first layer of Udaan is a robust skill development framework that delivers localized, employment-focused education. Training modules are modular, scalable, and aligned with the socio-economic profiles of the target communities.
Core domains include:
Digital Literacy: Basic computing, mobile internet use, app navigation, and digital payment systems
Tailoring and Textile Production: Pattern making, machine stitching, finishing techniques, and indigenous craft techniques
Food Processing and Packaging: Pickle-making, spice grinding, home-based snack units, sustainable packaging
Salon and Beauty Skills: Basic grooming, hygiene standards, customer interaction, and hygiene protocols
Financial Literacy and Budgeting: Saving schemes, credit access, banking interfaces, micro-investments
Communication and Self-Presentation: Workplace confidence, customer handling, local language fluency
2. Microenterprise Enablement and Livelihood Incubation
To ensure that learning transitions into economic self-reliance, Udaan incorporates a post-training enterprise enablement process. It identifies local market demand and builds backward linkages to equip women to launch sustainable businesses.
The support ecosystem includes:
Access to seed capital via self-help group (SHG) networks, microfinance partners, and NGO grants
Distribution of startup kits such as sewing machines, kitchen equipment, or salon tools
Digital onboarding support for online marketplaces such as Amazon Saheli, Flipkart Samarth, and Meesho
Offline retail support through tie-ups with local haats, trade exhibitions, and cooperative stores
Licensing and certification where applicable for food safety or textile quality standards
3. Tech-Driven Monitoring and Impact Tracking
Transparency and precision are fundamental to Udaan’s growth. InAmigos Foundation employs its in-house Tech4Change platform to manage operations, monitor performance, and scale the intervention scientifically.
The platform allows:
Real-time monitoring of attendance, skill mastery, and certification via QR codes and mobile tracking
Impact evaluation using household income change, asset ownership, and healthcare uptake metrics
GIS-based mapping of intervention zones and visualization of under-reached areas
Predictive modeling through AI to identify at-risk participants and suggest personalized intervention strategies
Human-Centered, Community-Rooted
Empowerment is not merely a process of economic inclusion—it is a cultural and psychological shift. Project Udaan incorporates gender-sensitive design and community-first outreach to create lasting change.
Key interventions include:
Strengthening of SHG structures and women-led federations to serve as peer mentors
Family sensitization programs targeting male allies—fathers, husbands, brothers—to reduce resistance and build trust
Legal and rights-based awareness campaigns focused on menstrual hygiene, reproductive health, domestic violence laws, and maternal care
Measured Impact and Proven Scalability
Project Udaan has consistently delivered quantifiable outcomes at the grassroots level. As of the latest cycle:
Over 900 women have completed intensive training programs across 60 villages and 4 districts
Nearly 70 percent of participating women reported an average income increase of 30 to 60 percent within 9 months of program completion
420+ micro-enterprises have been launched, 180 of which are now self-sustaining and generating employment for others
More than 5,000 indirect beneficiaries—including children, elderly dependents, and second-generation SHG members—have experienced improved access to nutrition, education, and mobility
Over 20 institutional partnerships and corporate CSR collaborations have supported infrastructure, curriculum design, and digital enablement.
Partnership Opportunities: Driving Collective Impact
The InAmigos Foundation invites corporations, philanthropic institutions, and ecosystem enablers to co-create impact through structured partnerships.
Opportunities include:
Funding the establishment of skill hubs in high-need regions
Supporting enterprise starter kits and training batches through CSR allocations
Mentoring women entrepreneurs via employee volunteering and capacity-building workshops
Co-hosting exhibitions, market linkages, and rural entrepreneurship fairs
Enabling long-term research and impact analytics for policy influence
These partnerships offer direct ESG alignment, brand elevation, and access to inclusive value chains while contributing to a model that demonstrably works.
What Makes Project Udaan Unique?

Unlike one-size-fits-all skilling programs, Project Udaan is rooted in real-world constraints and community aspirations. It succeeds because it combines:
Skill training aligned with current and emerging market demand
Income-first design that integrates microenterprise creation and financial access
Localized community ownership that ensures sustainability and adoption
Tech-enabled operations that ensure transparency and iterative learning
Holistic empowerment encompassing economic, social, and psychological dimensions
By balancing professional training with emotional transformation and economic opportunity, Udaan represents a new blueprint for inclusive growth.
From Promise to Power
Project Udaan, driven by the InAmigos Foundation, proves that when equipped with tools, trust, and training, rural and semi-urban women are capable of becoming not just contributors, but catalysts for socio-economic renewal.
They don’t merely escape poverty—they design their own systems of progress. They don’t just participate—they lead.
Each sewing machine, digital training module, or microloan is not a transaction—it is a declaration of possibility.
This is not charity. This is infrastructure. This is equity, by design.
Udaan is not just a program. It is a platform for a new India.
For partnership inquiries, CSR collaborations, and donation pathways, contact: www.inamigosfoundation.org/Udaan Email: [email protected]
3 notes
·
View notes
Text
Crafting Web Applications For Businesses Which are Responsive,Secure and Scalable.
Hello, Readers!
I’m Nehal Patil, a passionate freelance web developer dedicated to building powerful web applications that solve real-world problems. With a strong command over Spring Boot, React.js, Bootstrap, and MySQL, I specialize in crafting web apps that are not only responsive but also secure, scalable, and production-ready.
Why I Started Freelancing
After gaining experience in full-stack development and completing several personal and academic projects, I realized that I enjoy building things that people actually use. Freelancing allows me to work closely with clients, understand their unique challenges, and deliver custom web solutions that drive impact.
What I Do
I build full-fledged web applications from the ground up. Whether it's a startup MVP, a business dashboard, or an e-commerce platform, I ensure every project meets the following standards:
Responsive: Works seamlessly on mobile, tablet, and desktop.
Secure: Built with best practices to prevent common vulnerabilities.
Scalable: Designed to handle growth—be it users, data, or features.
Maintainable: Clean, modular code that’s easy to understand and extend.
My Tech Stack
I work with a powerful tech stack that ensures modern performance and flexibility:
Frontend: React.js + Bootstrap for sleek, dynamic, and responsive UI
Backend: Spring Boot for robust, production-level REST APIs
Database: MySQL for reliable and structured data management
Bonus: Integration, deployment support, and future-proof architecture
What’s Next?
This blog marks the start of my journey to share insights, tutorials, and case studies from my freelance experiences. Whether you're a business owner looking for a web solution or a fellow developer curious about my workflow—I invite you to follow along!
If you're looking for a developer who can turn your idea into a scalable, secure, and responsive web app, feel free to connect with me.
Thanks for reading, and stay tuned!
2 notes
·
View notes