#Data Lakehouse Architecture
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
BuzzFeed published a report claiming that Tumblr was utilized as a distribution channel for Russian agents to influence American voting habits during the 2016 presidential election in Feb 2018.
Text
Unlocking Full Potential: The Compelling Reasons to Migrate to Databricks Unity Catalog
In a world overwhelmed by data complexities and AI advancements, Databricks Unity Catalog emerges as a game-changer. This blog delves into how Unity Catalog revolutionizes data and AI governance, offering a unified, agile solution .
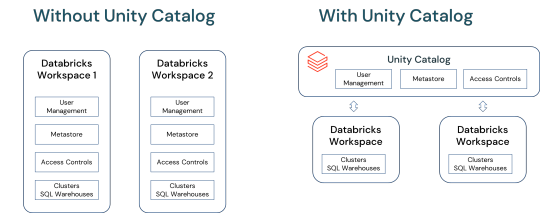
View On WordPress
#Access Control in Data Platforms#Advanced User Management#AI and ML Data Governance#AI Data Management#Big Data Solutions#Centralized Metadata Management#Cloud Data Management#Data Collaboration Tools#Data Ecosystem Integration#Data Governance Solutions#Data Lakehouse Architecture#Data Platform Modernization#Data Security and Compliance#Databricks for Data Scientists#Databricks Unity catalog#Enterprise Data Strategy#Migrating to Unity Catalog#Scalable Data Architecture#Unity Catalog Features
0 notes
Text
Understanding On-Premise Data Lakehouse Architecture
New Post has been published on https://thedigitalinsider.com/understanding-on-premise-data-lakehouse-architecture/
Understanding On-Premise Data Lakehouse Architecture
In today’s data-driven banking landscape, the ability to efficiently manage and analyze vast amounts of data is crucial for maintaining a competitive edge. The data lakehouse presents a revolutionary concept that’s reshaping how we approach data management in the financial sector. This innovative architecture combines the best features of data warehouses and data lakes. It provides a unified platform for storing, processing, and analyzing both structured and unstructured data, making it an invaluable asset for banks looking to leverage their data for strategic decision-making.
The journey to data lakehouses has been evolutionary in nature. Traditional data warehouses have long been the backbone of banking analytics, offering structured data storage and fast query performance. However, with the recent explosion of unstructured data from sources including social media, customer interactions, and IoT devices, data lakes emerged as a contemporary solution to store vast amounts of raw data.
The data lakehouse represents the next step in this evolution, bridging the gap between data warehouses and data lakes. For banks like Akbank, this means we can now enjoy the benefits of both worlds – the structure and performance of data warehouses, and the flexibility and scalability of data lakes.
Hybrid Architecture
At its core, a data lakehouse integrates the strengths of data lakes and data warehouses. This hybrid approach allows banks to store massive amounts of raw data while still maintaining the ability to perform fast, complex queries typical of data warehouses.
Unified Data Platform
One of the most significant advantages of a data lakehouse is its ability to combine structured and unstructured data in a single platform. For banks, this means we can analyze traditional transactional data alongside unstructured data from customer interactions, providing a more comprehensive view of our business and customers.
Key Features and Benefits
Data lakehouses offer several key benefits that are particularly valuable in the banking sector.
Scalability
As our data volumes grow, the lakehouse architecture can easily scale to accommodate this growth. This is crucial in banking, where we’re constantly accumulating vast amounts of transactional and customer data. The lakehouse allows us to expand our storage and processing capabilities without disrupting our existing operations.
Flexibility
We can store and analyze various data types, from transaction records to customer emails. This flexibility is invaluable in today’s banking environment, where unstructured data from social media, customer service interactions, and other sources can provide rich insights when combined with traditional structured data.
Real-time Analytics
This is crucial for fraud detection, risk assessment, and personalized customer experiences. In banking, the ability to analyze data in real-time can mean the difference between stopping a fraudulent transaction and losing millions. It also allows us to offer personalized services and make split-second decisions on loan approvals or investment recommendations.
Cost-Effectiveness
By consolidating our data infrastructure, we can reduce overall costs. Instead of maintaining separate systems for data warehousing and big data analytics, a data lakehouse allows us to combine these functions. This not only reduces hardware and software costs but also simplifies our IT infrastructure, leading to lower maintenance and operational costs.
Data Governance
Enhanced ability to implement robust data governance practices, crucial in our highly regulated industry. The unified nature of a data lakehouse makes it easier to apply consistent data quality, security, and privacy measures across all our data. This is particularly important in banking, where we must comply with stringent regulations like GDPR, PSD2, and various national banking regulations.
On-Premise Data Lakehouse Architecture
An on-premise data lakehouse is a data lakehouse architecture implemented within an organization’s own data centers, rather than in the cloud. For many banks, including Akbank, choosing an on-premise solution is often driven by regulatory requirements, data sovereignty concerns, and the need for complete control over our data infrastructure.
Core Components
An on-premise data lakehouse typically consists of four core components:
Data storage layer
Data processing layer
Metadata management
Security and governance
Each of these components plays a crucial role in creating a robust, efficient, and secure data management system.
Data Storage Layer
The storage layer is the foundation of an on-premise data lakehouse. We use a combination of Hadoop Distributed File System (HDFS) and object storage solutions to manage our vast data repositories. For structured data, like customer account information and transaction records, we leverage Apache Iceberg. This open table format provides excellent performance for querying and updating large datasets. For our more dynamic data, such as real-time transaction logs, we use Apache Hudi, which allows for upserts and incremental processing.
Data Processing Layer
The data processing layer is where the magic happens. We employ a combination of batch and real-time processing to handle our diverse data needs.
For ETL processes, we use Informatica PowerCenter, which allows us to integrate data from various sources across the bank. We’ve also started incorporating dbt (data build tool) for transforming data in our data warehouse.
Apache Spark plays a crucial role in our big data processing, allowing us to perform complex analytics on large datasets. For real-time processing, particularly for fraud detection and real-time customer insights, we use Apache Flink.
Query and Analytics
To enable our data scientists and analysts to derive insights from our data lakehouse, we’ve implemented Trino for interactive querying. This allows for fast SQL queries across our entire data lake, regardless of where the data is stored.
Metadata Management
Effective metadata management is crucial for maintaining order in our data lakehouse. We use Apache Hive metastore in conjunction with Apache Iceberg to catalog and index our data. We’ve also implemented Amundsen, LinkedIn’s open-source metadata engine, to help our data team discover and understand the data available in our lakehouse.
Security and Governance
In the banking sector, security and governance are paramount. We use Apache Ranger for access control and data privacy, ensuring that sensitive customer data is only accessible to authorized personnel. For data lineage and auditing, we’ve implemented Apache Atlas, which helps us track the flow of data through our systems and comply with regulatory requirements.
Infrastructure Requirements
Implementing an on-premise data lakehouse requires significant infrastructure investment. At Akbank, we’ve had to upgrade our hardware to handle the increased storage and processing demands. This included high-performance servers, robust networking equipment, and scalable storage solutions.
Integration with Existing Systems
One of our key challenges was integrating the data lakehouse with our existing systems. We developed a phased migration strategy, gradually moving data and processes from our legacy systems to the new architecture. This approach allowed us to maintain business continuity while transitioning to the new system.
Performance and Scalability
Ensuring high performance as our data grows has been a key focus. We’ve implemented data partitioning strategies and optimized our query engines to maintain fast query response times even as our data volumes increase.
In our journey to implement an on-premise data lakehouse, we’ve faced several challenges:
Data integration issues, particularly with legacy systems
Maintaining performance as data volumes grow
Ensuring data quality across diverse data sources
Training our team on new technologies and processes
Best Practices
Here are some best practices we’ve adopted:
Implement strong data governance from the start
Invest in data quality tools and processes
Provide comprehensive training for your team
Start with a pilot project before full-scale implementation
Regularly review and optimize your architecture
Looking ahead, we see several exciting trends in the data lakehouse space:
Increased adoption of AI and machine learning for data management and analytics
Greater integration of edge computing with data lakehouses
Enhanced automation in data governance and quality management
Continued evolution of open-source technologies supporting data lakehouse architectures
The on-premise data lakehouse represents a significant leap forward in data management for the banking sector. At Akbank, it has allowed us to unify our data infrastructure, enhance our analytical capabilities, and maintain the highest standards of data security and governance.
As we continue to navigate the ever-changing landscape of banking technology, the data lakehouse will undoubtedly play a crucial role in our ability to leverage data for strategic advantage. For banks looking to stay competitive in the digital age, seriously considering a data lakehouse architecture – whether on-premise or in the cloud – is no longer optional, it’s imperative.
#access control#ai#Analytics#Apache#Apache Spark#approach#architecture#assessment#automation#bank#banking#banks#Big Data#big data analytics#Business#business continuity#Cloud#comprehensive#computing#customer data#customer service#data#data analytics#Data Centers#Data Governance#Data Integration#data lake#data lakehouse#data lakes#Data Management
0 notes
Text
Enriching User Experience: Power of Hyper personalization
India’s digital gaming industry has come a long way in a short span of time. What was once limited to basic mobile games and casual engagement has now transformed into a sophisticated ecosystem led by innovation, data, and smart technology. And one of the biggest contributors to the rapid development of this space is hyper-personalization.
Today, it's not only about making something “fun", it's about building intelligent experiences that feel custom-made for each individual. At the center of this evolution are online gaming platforms such as Games24x7, which are consistently leading with purpose-driven innovation while maintaining a strong focus on player experience and safety. What sets Games24x7 apart is how deeply it integrates AI-driven personalization into its product DNA—and how effectively it scales it using a unified data architecture to support millions of real-time interactions every day, while ensuring each player feels as if this is an experience tailor-made for them!The Rise of Hyper-Personalization in Gaming
At its core, hyper-personalization refers to the use of real-time data, user behaviour, and advanced technology to deliver gameplay that adapts to each user’s preferences, playing style, and engagement patterns. It’s the difference between one-size-fits-all and one-size-fits-you.
In a country as diverse as India, this level of personalization is no longer optional; it’s expected. Companies that can rapidly adapt to these signals are seeing higher engagement, improved retention, and stronger user trust.
The Benefits of a Tech-First Approach
Companies like Games24x7 have built a modern data stack that powers artificial intelligence for games, machine learning in gaming, and deep learning to fine-tune every touchpoint—from gameplay difficulty to reward systems. By unifying billions of data points into a central lakehouse platform, they’re able to experiment, predict, and personalize player journeys at scale.
Unlike traditional systems, the Games24x7 model supports real-time decision-making at the millisecond level—learning from user interactions and optimizing each experience as it unfolds. The result is a dynamic feedback loop where the platform gets smarter with every session, keeping gameplay fair, relevant, and deeply engaging.
Understanding Players Through Science and Data
Technology alone isn’t enough. Games24x7 brings behavioral science into its personalization engine to decode not just what users do, but why they do it. By blending psychological insight with AI modeling, the platform balances challenge and enjoyment—creating gameplay that’s not just adaptive, but meaningful.
This thoughtful integration ensures that personalization is not treated as a feature—it becomes a philosophy. One that respects user agency, builds trust, and delivers rewarding experiences over time. Collaboration Between Data Science and Engineering What truly strengthens the personalization engine at Games24x7 is how seamlessly its data science and engineering teams work together. With a shared data environment and scalable infrastructure, experiments move faster. This cross-functional collaboration has removed traditional bottlenecks between model development and integration. As a result, Games24x7 can take personalization hypotheses and turn them into in-game enhancements quickly and efficiently, helping players experience tangible improvements without waiting for major version updates. It’s a behind-the-scenes shift that powers meaningful, user-facing change.
Why This Matters for the Future
The future of digital gaming isn’t defined by who has the most players—it’s defined by who understands their players best. In a competitive landscape, hyper-personalization is proving to be a game-changer: helping platforms stand out, scale ethically, and evolve continuously.
With its AI-first mindset, strong infrastructure, and commitment to user experience, Games24x7 is already ahead of the curve—showcasing how games of skill are built by true technological skill, and can evolve through smarter, personalized systems. The future of Indian online gaming is not only personal… It's intelligent, immersive, and already in motion.
1 note
·
View note
Text
Beyond the Pipeline: Choosing the Right Data Engineering Service Providers for Long-Term Scalability
Introduction: Why Choosing the Right Data Engineering Service Provider is More Critical Than Ever
In an age where data is more valuable than oil, simply having pipelines isn’t enough. You need refineries, infrastructure, governance, and agility. Choosing the right data engineering service providers can make or break your enterprise’s ability to extract meaningful insights from data at scale. In fact, Gartner predicts that by 2025, 80% of data initiatives will fail due to poor data engineering practices or provider mismatches.
If you're already familiar with the basics of data engineering, this article dives deeper into why selecting the right partner isn't just a technical decision—it’s a strategic one. With rising data volumes, regulatory changes like GDPR and CCPA, and cloud-native transformations, companies can no longer afford to treat data engineering service providers as simple vendors. They are strategic enablers of business agility and innovation.
In this post, we’ll explore how to identify the most capable data engineering service providers, what advanced value propositions you should expect from them, and how to build a long-term partnership that adapts with your business.
Section 1: The Evolving Role of Data Engineering Service Providers in 2025 and Beyond
What you needed from a provider in 2020 is outdated today. The landscape has changed:
📌 Real-time data pipelines are replacing batch processes
📌 Cloud-native architectures like Snowflake, Databricks, and Redshift are dominating
📌 Machine learning and AI integration are table stakes
📌 Regulatory compliance and data governance have become core priorities
Modern data engineering service providers are not just builders—they are data architects, compliance consultants, and even AI strategists. You should look for:
📌 End-to-end capabilities: From ingestion to analytics
📌 Expertise in multi-cloud and hybrid data ecosystems
📌 Proficiency with data mesh, lakehouse, and decentralized architectures
📌 Support for DataOps, MLOps, and automation pipelines
Real-world example: A Fortune 500 retailer moved from Hadoop-based systems to a cloud-native lakehouse model with the help of a modern provider, reducing their ETL costs by 40% and speeding up analytics delivery by 60%.
Section 2: What to Look for When Vetting Data Engineering Service Providers
Before you even begin consultations, define your objectives. Are you aiming for cost efficiency, performance, real-time analytics, compliance, or all of the above?
Here’s a checklist when evaluating providers:
📌 Do they offer strategic consulting or just hands-on coding?
📌 Can they support data scaling as your organization grows?
📌 Do they have domain expertise (e.g., healthcare, finance, retail)?
📌 How do they approach data governance and privacy?
📌 What automation tools and accelerators do they provide?
📌 Can they deliver under tight deadlines without compromising quality?
Quote to consider: "We don't just need engineers. We need architects who think two years ahead." – Head of Data, FinTech company
Avoid the mistake of over-indexing on cost or credentials alone. A cheaper provider might lack scalability planning, leading to massive rework costs later.
Section 3: Red Flags That Signal Poor Fit with Data Engineering Service Providers
Not all providers are created equal. Some red flags include:
📌 One-size-fits-all data pipeline solutions
📌 Poor documentation and handover practices
📌 Lack of DevOps/DataOps maturity
📌 No visibility into data lineage or quality monitoring
📌 Heavy reliance on legacy tools
A real scenario: A manufacturing firm spent over $500k on a provider that delivered rigid ETL scripts. When the data source changed, the whole system collapsed.
Avoid this by asking your provider to walk you through previous projects, particularly how they handled pivots, scaling, and changing data regulations.
Section 4: Building a Long-Term Partnership with Data Engineering Service Providers
Think beyond the first project. Great data engineering service providers work iteratively and evolve with your business.
Steps to build strong relationships:
📌 Start with a proof-of-concept that solves a real pain point
📌 Use agile methodologies for faster, collaborative execution
📌 Schedule quarterly strategic reviews—not just performance updates
📌 Establish shared KPIs tied to business outcomes, not just delivery milestones
📌 Encourage co-innovation and sandbox testing for new data products
Real-world story: A healthcare analytics company co-developed an internal patient insights platform with their provider, eventually spinning it into a commercial SaaS product.
Section 5: Trends and Technologies the Best Data Engineering Service Providers Are Already Embracing
Stay ahead by partnering with forward-looking providers who are ahead of the curve:
📌 Data contracts and schema enforcement in streaming pipelines
📌 Use of low-code/no-code orchestration (e.g., Apache Airflow, Prefect)
📌 Serverless data engineering with tools like AWS Glue, Azure Data Factory
📌 Graph analytics and complex entity resolution
📌 Synthetic data generation for model training under privacy laws
Case in point: A financial institution cut model training costs by 30% by using synthetic data generated by its engineering provider, enabling robust yet compliant ML workflows.
Conclusion: Making the Right Choice for Long-Term Data Success
The right data engineering service providers are not just technical executioners—they’re transformation partners. They enable scalable analytics, data democratization, and even new business models.
To recap:
📌 Define goals and pain points clearly
📌 Vet for strategy, scalability, and domain expertise
📌 Watch out for rigidity, legacy tools, and shallow implementations
📌 Build agile, iterative relationships
📌 Choose providers embracing the future
Your next provider shouldn’t just deliver pipelines—they should future-proof your data ecosystem. Take a step back, ask the right questions, and choose wisely. The next few quarters of your business could depend on it.
#DataEngineering#DataEngineeringServices#DataStrategy#BigDataSolutions#ModernDataStack#CloudDataEngineering#DataPipeline#MLOps#DataOps#DataGovernance#DigitalTransformation#TechConsulting#EnterpriseData#AIandAnalytics#InnovationStrategy#FutureOfData#SmartDataDecisions#ScaleWithData#AnalyticsLeadership#DataDrivenInnovation
0 notes
Text
Explore how the Lakehouse model is transforming cloud data architecture. Learn its benefits and future through a leading cloud computing course in Pune.
0 notes
Text
Big Lake Storage: An Open Data Lakehouse on Google Cloud

Large Lake Storage
Built open, high-performance, enterprise Big Lake storage Lakehouses iceberg native
Businesses may use Apache Iceberg to develop open, high-performance, enterprise-grade data lakehouses on Google Cloud with recent Big Lake storage engine improvements. Customers no longer have to choose between completely managed, enterprise-grade storage management and open formats like Apache Iceberg.
Businesses want adaptive, open, and interoperable architectures that let several engines work on a single copy of data while data management is revolutionised. Apache Iceberg is a popular open table style. The latest Big Lake storage development offers Apache Iceberg access to Google's infrastructure, enabling open data lakehouses.
Major advances include:
BigLake Metastore is normally available: BigLake Metastore, formerly BigQuery, is now public. This completely managed, serverless, and scalable solution simplifies runtime metadata maintenance and operations for BigQuery and other Iceberg-compatible engines. Use of Google's global metadata management infrastructure reduces the need to control proprietary metastore implementation. BigLake Metastore is necessary for open interoperability.
Iceberg REST Catalogue API Preview Introduction: To complement the GA Custom Iceberg Catalogue, the Iceberg REST Catalogue (Preview) provides a standard REST interface for interoperability. Users, including Spark users, can use the BigLake metastore as a serverless Iceberg catalogue. The Custom Iceberg Catalogue lets Spark and other open-source engines connect with Apache Iceberg and BigQuery BigLake tables.
Google Cloud is simplifying lakehouse upkeep using Apache Iceberg and Google Cloud Storage management. Cloud Storage features like auto-class tiering, encryption, and automatic table maintenance including compaction and trash collection are supported. This enhances Iceberg data management in Cloud Storage.
BigQuery usually has Apache Iceberg BigLake tables: These publicly available tables combine BigQuery's scalable, real-time metadata with Iceberg formats' transparency. This enables BigQuery's Write API's high-throughput streaming ingestion and zero-latency reads at tens of GiB/second. It also has automatic table management (compaction, garbage collection), native Vertex AI interface, auto-reclustering speed improvements, and future fine-grained DML and multi-table transactions (coming soon in preview). These tables maintain Iceberg's openness while providing controlled, enterprise-ready functionality. BigLake automatically creates and registers an Apache Iceberg V2 metadata snapshot in its metastore. This snapshot updates automatically after edits.
BigLake natively supports Dataplex Universal Catalogue for AI-Powered Governance. This interface provides consistent and fine-grained access restrictions to apply Dataplex governance standards across engines. Direct Cloud Storage access supports table-level access control, whereas BigQuery can use Storage API connectors for open-source engines for finer control. Dataplex integration improves BigQuery and BigLake Iceberg table governance with search, discovery, profiling, data quality checks, and end-to-end data lineage. Dataplex simplifies data discovery with AI-generated insights and semantic search. End-to-end governance benefits are automatic and don't require registration.
The BigLake metastore enables interoperability with BigQuery, AlloyDB (preview), Spark, and Flink. This increased compatibility allows AlloyDB users to easily consume analytical BigLake tables for Apache Iceberg from within AlloyDB (Preview). PostgreSQL users can link real-time AlloyDB transactional data with rich analytical data for operational and AI-driven use cases.
CME Group Executive Director Zenul Pomal noted, “We needed teams throughout the company to access data in a consistent and secure way – regardless of where it stored or what technologies they were using.” They used Google's BigLake. BigLake from Google was clear. The uniform layer for accessing data and a fully managed experience with enterprise capabilities via BigQuery are available without moving or duplicating data, whether the data is in traditional tables or open table formats like Apache Iceberg. Metadata quality is critical as it explores gen AI applications. BigLake Metastore and Data Catalogue help us preserve high-quality metadata.
At Google Cloud Next '25, Google Cloud announced support for change data capture, multi-statement transactions, and fine-grained DML in the coming months.
Google Cloud is evolving BigLake into a comprehensive storage engine that uses open-source, third-party, and Google Cloud services by eliminating trade-offs between open and managed data solutions. This boosts data and AI innovation.
#BigLakestorage#widelyaccessible#BigLakeMetastore#BigQuery#ApacheIceberg#AlloyDB#technology#technologynews#technews#news#govindhtech
0 notes
Text
Unlocking data’s true potential: The open lakehouse as AI’s foundation
The rise of AI has transformed data into a strategic asset, requiring flexible, integrated, and real-time data architectures. Traditional, rigid systems and pipelines, designed for dashboards and batch analytics, can’t handle the real-time, multi-modal, high-volume demands of modern AI. To fully leverage AI, organizations must move to a dynamic open lakehouse paradigm that unifies diverse data…
0 notes
Text

✨ Have you heard of the Medallion Architecture in modern data engineering?
It’s a layered approach to organizing data in a Lakehouse environment, helping ensure quality and scalability at every stage:
🥉 Bronze – Raw, unprocessed data 🥈 Silver – Cleaned and enriched data 🥇 Gold – Business-ready, refined data for reporting and analytics
This structure supports better data governance, performance, and reusability across the enterprise.
Do you use this approach in your projects? Let’s discuss how it’s working for you! 💬
#MedallionArchitecture#DataEngineering#BronzeSilverGold#Lakehouse#DeltaLake#MicrosoftFabric#DataArchitecture#Analytics#BigData#ETL#ModernDataStack
0 notes
Text
Real-World Application of Data Mesh with Databricks Lakehouse
Explore how a global reinsurance leader transformed its data systems with Data Mesh and Databricks Lakehouse for better operations and decision-making.
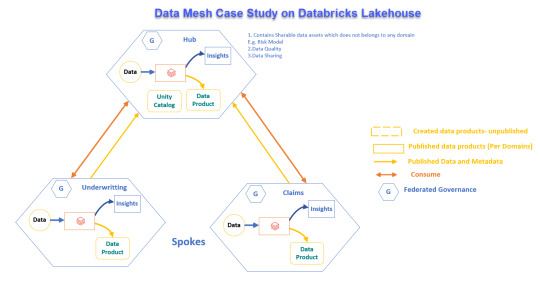
View On WordPress
#Advanced Analytics#Business Transformation#Cloud Solutions#Data Governance#Data management#Data Mesh#Data Scalability#Databricks Lakehouse#Delta Sharing#Enterprise Architecture#Reinsurance Industry
0 notes
Text
Master the Future: Become a Databricks Certified Generative AI Engineer

What if we told you that one certification could position you at the crossroads of AI innovation, high-paying job opportunities, and technical leadership?
That’s exactly what the Databricks Certified Generative AI Engineer certification does. As generative AI explodes across industries, skilled professionals who can bridge the gap between AI theory and real-world data solutions are in high demand. Databricks, a company at the forefront of data and AI, now offers a credential designed for those who want to lead the next wave of innovation.
If you're someone looking to validate your AI engineering skills with an in-demand, globally respected certification, keep reading. This blog will guide you through what the certification is, why it’s valuable, how to prepare effectively, and how it can launch or elevate your tech career.
Why the Databricks Certified Generative AI Engineer Certification Matters
Let’s start with the basics: why should you care about this certification?
Databricks has become synonymous with large-scale data processing, AI model deployment, and seamless ML integration across platforms. As AI continues to evolve into Generative AI, the need for professionals who can implement real-world solutions—using tools like Databricks Unity Catalog, MLflow, Apache Spark, and Lakehouse architecture—is only going to grow.
This certification tells employers that:
You can design and implement generative AI models.
You understand the complexities of data management in modern AI systems.
You know how to use Databricks tools to scale and deploy these models effectively.
For tech professionals, data scientists, ML engineers, and cloud developers, this isn't just a badge—it's a career accelerator.
Who Should Pursue This Certification?
The Databricks Certified Generative AI Engineer path is for:
Data Scientists & Machine Learning Engineers who want to shift into more cutting-edge roles.
Cloud Developers working with AI pipelines in enterprise environments.
AI Enthusiasts and Researchers ready to demonstrate their applied knowledge.
Professionals preparing for AI roles at companies using Databricks, Azure, AWS, or Google Cloud.
If you’re familiar with Python, machine learning fundamentals, and basic model deployment workflows, you’re ready to get started.
What You'll Learn: Core Skills Covered
The exam and its preparation cover a broad but practical set of topics:
🧠 1. Foundation of Generative AI
What is generative AI?
How do models like GPT, DALL·E, and Stable Diffusion actually work?
Introduction to transformer architectures and tokenization.
📊 2. Databricks Ecosystem
Using Databricks notebooks and workflows
Unity Catalog for data governance and model security
Integrating MLflow for reproducibility and experiment tracking
🔁 3. Model Training & Tuning
Fine-tuning foundation models on your data
Optimizing training with distributed computing
Managing costs and resource allocation
⚙️ 4. Deployment & Monitoring
Creating real-time endpoints
Model versioning and rollback strategies
Using MLflow’s model registry for lifecycle tracking
🔐 5. Responsible AI & Ethics
Bias detection and mitigation
Privacy-preserving machine learning
Explainability and fairness
Each of these topics is deeply embedded in the exam and reflects current best practices in the industry.
Why Databricks Is Leading the AI Charge
Databricks isn’t just a platform—it’s a movement. With its Lakehouse architecture, the company bridges the gap between data warehouses and data lakes, providing a unified platform to manage and deploy AI solutions.
Databricks is already trusted by organizations like:
Comcast
Shell
HSBC
Regeneron Pharmaceuticals
So, when you add a Databricks Certified Generative AI Engineer credential to your profile, you’re aligning yourself with the tools and platforms that Fortune 500 companies rely on.
What’s the Exam Format?
Here’s what to expect:
Multiple choice and scenario-based questions
90 minutes total
Around 60 questions
Online proctored format
You’ll be tested on:
Generative AI fundamentals
Databricks-specific tools
Model development, deployment, and monitoring
Data handling in an AI lifecycle
How to Prepare: Your Study Blueprint
Passing this certification isn’t about memorizing definitions. It’s about understanding workflows, being able to apply best practices, and showing proficiency in a Databricks-native AI environment.
Step 1: Enroll in a Solid Practice Course
The most effective way to prepare is to take mock tests and get hands-on experience. We recommend enrolling in the Databricks Certified Generative AI Engineer practice test course, which gives you access to realistic exam-style questions, explanations, and performance feedback.
Step 2: Set Up a Databricks Workspace
If you don’t already have one, create a free Databricks Community Edition workspace. Explore notebooks, work with data in Delta Lake, and train a simple model using MLflow.
Step 3: Focus on the Databricks Stack
Make sure you’re confident using:
Databricks Notebooks
MLflow
Unity Catalog
Model Serving
Feature Store
Step 4: Review Key AI Concepts
Brush up on:
Transformer models and attention mechanisms
Fine-tuning vs. prompt engineering
Transfer learning
Generative model evaluation metrics (BLEU, ROUGE, etc.)
What Makes This Certification Unique?
Unlike many AI certifications that stay theoretical, this one is deeply practical. You’ll not only learn what generative AI is but also how to build and manage it in production.
Here are three reasons this stands out:
✅ 1. Real-world Integration
You’ll learn deployment, version control, and monitoring—which is what companies care about most.
✅ 2. Based on Industry-Proven Tools
Everything is built on top of Databricks, Apache Spark, and MLflow, used by data teams globally.
✅ 3. Focus on Modern AI Workflows
This certification keeps pace with the rapid evolution of AI—especially around LLMs (Large Language Models), prompt engineering, and GenAI use cases.
How It Benefits Your Career
Once certified, you’ll be well-positioned to:
Land roles like AI Engineer, ML Engineer, or Data Scientist in leading tech firms.
Negotiate a higher salary thanks to your verified skills.
Work on cutting-edge projects in AI, including enterprise chatbots, text summarization, image generation, and more.
Stand out in competitive job markets with a Databricks-backed credential on your LinkedIn.
According to recent industry trends, professionals with AI certifications earn an average of 20-30% more than those without.
Use Cases You’ll Be Ready to Tackle
After completing the course and passing the exam, you’ll be able to confidently work on:
Enterprise chatbots using foundation models
Real-time content moderation
AI-driven customer service agents
Medical imaging enhancement
Financial fraud detection using pattern generation
The scope is broad—and the possibilities are endless.
Don’t Just Study—Practice
It’s tempting to dive into study guides or YouTube videos, but what really works is practice. The Databricks Certified Generative AI Engineer practice course offers exam-style challenges that simulate the pressure and format of the real exam.
You’ll learn by doing—and that makes all the difference.
Final Thoughts: The Time to Act Is Now
Generative AI isn’t the future anymore—it’s the present. Companies across every sector are racing to integrate it. The question is:
Will you be ready to lead that charge?
If your goal is to become an in-demand AI expert with practical, validated skills, earning the Databricks Certified Generative AI Engineer credential is the move to make.
Start today. Equip yourself with the skills the industry is hungry for. Stand out. Level up.
👉 Enroll in the Databricks Certified Generative AI Engineer practice course now and take control of your AI journey.
🔍 Keyword Optimiz
0 notes
Text
Empowering Businesses with Advanced Data Engineering Solutions in Toronto – C Data Insights
In a rapidly digitizing world, companies are swimming in data—but only a few truly know how to harness it. At C Data Insights, we bridge that gap by delivering top-tier data engineering solutions in Toronto designed to transform your raw data into actionable insights. From building robust data pipelines to enabling intelligent machine learning applications, we are your trusted partner in the Greater Toronto Area (GTA).
What Is Data Engineering and Why Is It Critical?
Data engineering involves the design, construction, and maintenance of scalable systems for collecting, storing, and analyzing data. In the modern business landscape, it forms the backbone of decision-making, automation, and strategic planning.
Without a solid data infrastructure, businesses struggle with:
Inconsistent or missing data
Delayed analytics reports
Poor data quality impacting AI/ML performance
Increased operational costs
That’s where our data engineering service in GTA helps. We create a seamless flow of clean, usable, and timely data—so you can focus on growth.
Key Features of Our Data Engineering Solutions
As a leading provider of data engineering solutions in Toronto, C Data Insights offers a full suite of services tailored to your business goals:
1. Data Pipeline Development
We build automated, resilient pipelines that efficiently extract, transform, and load (ETL) data from multiple sources—be it APIs, cloud platforms, or on-premise databases.
2. Cloud-Based Architecture
Need scalable infrastructure? We design data systems on AWS, Azure, and Google Cloud, ensuring flexibility, security, and real-time access.
3. Data Warehousing & Lakehouses
Store structured and unstructured data efficiently with modern data warehousing technologies like Snowflake, BigQuery, and Databricks.
4. Batch & Streaming Data Processing
Process large volumes of data in real-time or at scheduled intervals with tools like Apache Kafka, Spark, and Airflow.
Data Engineering and Machine Learning – A Powerful Duo
Data engineering lays the groundwork, and machine learning unlocks its full potential. Our solutions enable you to go beyond dashboards and reports by integrating data engineering and machine learning into your workflow.
We help you:
Build feature stores for ML models
Automate model training with clean data
Deploy models for real-time predictions
Monitor model accuracy and performance
Whether you want to optimize your marketing spend or forecast inventory needs, we ensure your data infrastructure supports accurate, AI-powered decisions.
Serving the Greater Toronto Area with Local Expertise
As a trusted data engineering service in GTA, we take pride in supporting businesses across:
Toronto
Mississauga
Brampton
Markham
Vaughan
Richmond Hill
Scarborough
Our local presence allows us to offer faster response times, better collaboration, and solutions tailored to local business dynamics.
Why Businesses Choose C Data Insights
✔ End-to-End Support: From strategy to execution, we’re with you every step of the way ✔ Industry Experience: Proven success across retail, healthcare, finance, and logistics ✔ Scalable Systems: Our solutions grow with your business needs ✔ Innovation-Focused: We use the latest tools and best practices to keep you ahead of the curve
Take Control of Your Data Today
Don’t let disorganized or inaccessible data hold your business back. Partner with C Data Insights to unlock the full potential of your data. Whether you need help with cloud migration, real-time analytics, or data engineering and machine learning, we’re here to guide you.
📍 Proudly offering data engineering solutions in Toronto and expert data engineering service in GTA.
📞 Contact us today for a free consultation 🌐 https://cdatainsights.com
C Data Insights – Engineering Data for Smart, Scalable, and Successful Businesses
#data engineering solutions in Toronto#data engineering and machine learning#data engineering service in Gta
0 notes
Text
The top Data Engineering trends to look for in 2025

Data engineering is the unsung hero of our data-driven world. It's the critical discipline that builds and maintains the robust infrastructure enabling organizations to collect, store, process, and analyze vast amounts of data. As we navigate mid-2025, this foundational field is evolving at an unprecedented pace, driven by the exponential growth of data, the insatiable demand for real-time insights, and the transformative power of AI.
Staying ahead of these shifts is no longer optional; it's essential for data engineers and the organizations they support. Let's dive into the key data engineering trends that are defining the landscape in 2025.
1. The Dominance of the Data Lakehouse
What it is: The data lakehouse architecture continues its strong upward trajectory, aiming to unify the best features of data lakes (flexible, low-cost storage for raw, diverse data types) and data warehouses (structured data management, ACID transactions, and robust governance). Why it's significant: It offers a single platform for various analytics workloads, from BI and reporting to AI and machine learning, reducing data silos, complexity, and redundancy. Open table formats like Apache Iceberg, Delta Lake, and Hudi are pivotal in enabling lakehouse capabilities. Impact: Greater data accessibility, improved data quality and reliability for analytics, simplified data architecture, and cost efficiencies. Key Technologies: Databricks, Snowflake, Amazon S3, Azure Data Lake Storage, Apache Spark, and open table formats.
2. AI-Powered Data Engineering (Including Generative AI)
What it is: Artificial intelligence, and increasingly Generative AI, are becoming integral to data engineering itself. This involves using AI/ML to automate and optimize various data engineering tasks. Why it's significant: AI can significantly boost efficiency, reduce manual effort, improve data quality, and even help generate code for data pipelines or transformations. Impact: * Automated Data Integration & Transformation: AI tools can now automate aspects of data mapping, cleansing, and pipeline optimization. * Intelligent Data Quality & Anomaly Detection: ML algorithms can proactively identify and flag data quality issues or anomalies in pipelines. * Optimized Pipeline Performance: AI can help in tuning and optimizing the performance of data workflows. * Generative AI for Code & Documentation: LLMs are being used to assist in writing SQL queries, Python scripts for ETL, and auto-generating documentation. Key Technologies: AI-driven ETL/ELT tools, MLOps frameworks integrated with DataOps, platforms with built-in AI capabilities (e.g., Databricks AI Functions, AWS DMS with GenAI).
3. Real-Time Data Processing & Streaming Analytics as the Norm
What it is: The demand for immediate insights and actions based on live data streams continues to grow. Batch processing is no longer sufficient for many use cases. Why it's significant: Businesses across industries like e-commerce, finance, IoT, and logistics require real-time capabilities for fraud detection, personalized recommendations, operational monitoring, and instant decision-making. Impact: A shift towards streaming architectures, event-driven data pipelines, and tools that can handle high-throughput, low-latency data. Key Technologies: Apache Kafka, Apache Flink, Apache Spark Streaming, Apache Pulsar, cloud-native streaming services (e.g., Amazon Kinesis, Google Cloud Dataflow, Azure Stream Analytics), and real-time analytical databases.
4. The Rise of Data Mesh & Data Fabric Architectures
What it is: * Data Mesh: A decentralized sociotechnical approach that emphasizes domain-oriented data ownership, treating data as a product, self-serve data infrastructure, and federated computational governance. * Data Fabric: An architectural approach that automates data integration and delivery across disparate data sources, often using metadata and AI to provide a unified view and access to data regardless of where it resides. Why it's significant: Traditional centralized data architectures struggle with the scale and complexity of modern data. These approaches offer greater agility, scalability, and empower domain teams. Impact: Improved data accessibility and discoverability, faster time-to-insight for domain teams, reduced bottlenecks for central data teams, and better alignment of data with business domains. Key Technologies: Data catalogs, data virtualization tools, API-based data access, and platforms supporting decentralized data management.
5. Enhanced Focus on Data Observability & Governance
What it is: * Data Observability: Going beyond traditional monitoring to provide deep visibility into the health and state of data and data pipelines. It involves tracking data lineage, quality, freshness, schema changes, and distribution. * Data Governance by Design: Integrating robust data governance, security, and compliance practices directly into the data lifecycle and infrastructure from the outset, rather than as an afterthought. Why it's significant: As data volumes and complexity grow, ensuring data quality, reliability, and compliance (e.g., GDPR, CCPA) becomes paramount for building trust and making sound decisions. Regulatory landscapes, like the EU AI Act, are also making strong governance non-negotiable. Impact: Improved data trust and reliability, faster incident resolution, better compliance, and more secure data handling. Key Technologies: AI-powered data observability platforms, data cataloging tools with governance features, automated data quality frameworks, and tools supporting data lineage.
6. Maturation of DataOps and MLOps Practices
What it is: * DataOps: Applying Agile and DevOps principles (automation, collaboration, continuous integration/continuous delivery - CI/CD) to the entire data analytics lifecycle, from data ingestion to insight delivery. * MLOps: Extending DevOps principles specifically to the machine learning lifecycle, focusing on streamlining model development, deployment, monitoring, and retraining. Why it's significant: These practices are crucial for improving the speed, quality, reliability, and efficiency of data and machine learning pipelines. Impact: Faster delivery of data products and ML models, improved data quality, enhanced collaboration between data engineers, data scientists, and IT operations, and more reliable production systems. Key Technologies: Workflow orchestration tools (e.g., Apache Airflow, Kestra), CI/CD tools (e.g., Jenkins, GitLab CI), version control systems (Git), containerization (Docker, Kubernetes), and MLOps platforms (e.g., MLflow, Kubeflow, SageMaker, Azure ML).
The Cross-Cutting Theme: Cloud-Native and Cost Optimization
Underpinning many of these trends is the continued dominance of cloud-native data engineering. Cloud platforms (AWS, Azure, GCP) provide the scalable, flexible, and managed services that are essential for modern data infrastructure. Coupled with this is an increasing focus on cloud cost optimization (FinOps for data), as organizations strive to manage and reduce the expenses associated with large-scale data processing and storage in the cloud.
The Evolving Role of the Data Engineer
These trends are reshaping the role of the data engineer. Beyond building pipelines, data engineers in 2025 are increasingly becoming architects of more intelligent, automated, and governed data systems. Skills in AI/ML, cloud platforms, real-time processing, and distributed architectures are becoming even more crucial.
Global Relevance, Local Impact
These global data engineering trends are particularly critical for rapidly developing digital economies. In countries like India, where the data explosion is immense and the drive for digital transformation is strong, adopting these advanced data engineering practices is key to harnessing data for innovation, improving operational efficiency, and building competitive advantages on a global scale.
Conclusion: Building the Future, One Pipeline at a Time
The field of data engineering is more dynamic and critical than ever. The trends of 2025 point towards more automated, real-time, governed, and AI-augmented data infrastructures. For data engineering professionals and the organizations they serve, embracing these changes means not just keeping pace, but actively shaping the future of how data powers our world.
1 note
·
View note
Text
Trusted Databricks Partners in US Driving Data Innovation
Pratiti Technologies is among the top Databricks partners in US, enabling businesses to unlock the full power of data. Our alliance with Databricks helps deliver scalable, AI-driven solutions for modern enterprises. We specialize in data engineering, analytics, and lakehouse architecture. With deep expertise and proven results, we accelerate your digital transformation journey. Partner with us for intelligent, data-centric innovation.
0 notes
Text

Explore the differences between Data Mesh and Lakehouse, two cutting-edge architectures shaping the future of analytics. A data science course in Chennai can help you master these technologies.
0 notes