#Access Control in Data Platforms
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com is the 103rd most visited website in the world.
Text
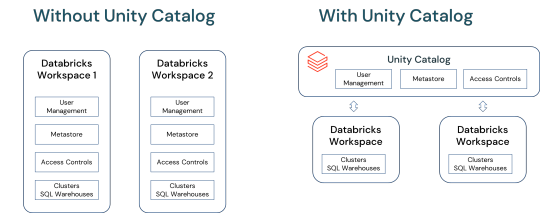
Unlocking Full Potential: The Compelling Reasons to Migrate to Databricks Unity Catalog
In a world overwhelmed by data complexities and AI advancements, Databricks Unity Catalog emerges as a game-changer. This blog delves into how Unity Catalog revolutionizes data and AI governance, offering a unified, agile solution .
View On WordPress
#Access Control in Data Platforms#Advanced User Management#AI and ML Data Governance#AI Data Management#Big Data Solutions#Centralized Metadata Management#Cloud Data Management#Data Collaboration Tools#Data Ecosystem Integration#Data Governance Solutions#Data Lakehouse Architecture#Data Platform Modernization#Data Security and Compliance#Databricks for Data Scientists#Databricks Unity catalog#Enterprise Data Strategy#Migrating to Unity Catalog#Scalable Data Architecture#Unity Catalog Features
0 notes
Text
At the California Institute of the Arts, it all started with a videoconference between the registrar’s office and a nonprofit.
One of the nonprofit’s representatives had enabled an AI note-taking tool from Read AI. At the end of the meeting, it emailed a summary to all attendees, said Allan Chen, the institute’s chief technology officer. They could have a copy of the notes, if they wanted — they just needed to create their own account.
Next thing Chen knew, Read AI’s bot had popped up inabout a dozen of his meetings over a one-week span. It was in one-on-one check-ins. Project meetings. “Everything.”
The spread “was very aggressive,” recalled Chen, who also serves as vice president for institute technology. And it “took us by surprise.”
The scenariounderscores a growing challenge for colleges: Tech adoption and experimentation among students, faculty, and staff — especially as it pertains to AI — are outpacing institutions’ governance of these technologies and may even violate their data-privacy and security policies.
That has been the case with note-taking tools from companies including Read AI, Otter.ai, and Fireflies.ai.They can integrate with platforms like Zoom, Google Meet, and Microsoft Teamsto provide live transcriptions, meeting summaries, audio and video recordings, and other services.
Higher-ed interest in these products isn’t surprising.For those bogged down with virtual rendezvouses, a tool that can ingest long, winding conversations and spit outkey takeaways and action items is alluring. These services can also aid people with disabilities, including those who are deaf.
But the tools can quickly propagate unchecked across a university. They can auto-join any virtual meetings on a user’s calendar — even if that person is not in attendance. And that’s a concern, administrators say, if it means third-party productsthat an institution hasn’t reviewedmay be capturing and analyzing personal information, proprietary material, or confidential communications.
“What keeps me up at night is the ability for individual users to do things that are very powerful, but they don’t realize what they’re doing,” Chen said. “You may not realize you’re opening a can of worms.“
The Chronicle documented both individual and universitywide instances of this trend. At Tidewater Community College, in Virginia, Heather Brown, an instructional designer, unwittingly gave Otter.ai’s tool access to her calendar, and it joined a Faculty Senate meeting she didn’t end up attending. “One of our [associate vice presidents] reached out to inform me,” she wrote in a message. “I was mortified!”
24K notes
·
View notes
Text
Reverse engineers bust sleazy gig work platform

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/11/23/hack-the-class-war/#robo-boss

A COMPUTER CAN NEVER BE HELD ACCOUNTABLE
THEREFORE A COMPUTER MUST NEVER MAKE A MANAGEMENT DECISION
Supposedly, these lines were included in a 1979 internal presentation at IBM; screenshots of them routinely go viral:
https://twitter.com/SwiftOnSecurity/status/1385565737167724545?lang=en
The reason for their newfound popularity is obvious: the rise and rise of algorithmic management tools, in which your boss is an app. That IBM slide is right: turning an app into your boss allows your actual boss to create an "accountability sink" in which there is no obvious way to blame a human or even a company for your maltreatment:
https://profilebooks.com/work/the-unaccountability-machine/
App-based management-by-bossware treats the bug identified by the unknown author of that IBM slide into a feature. When an app is your boss, it can force you to scab:
https://pluralistic.net/2023/07/30/computer-says-scab/#instawork
Or it can steal your wages:
https://pluralistic.net/2023/04/12/algorithmic-wage-discrimination/#fishers-of-men
But tech giveth and tech taketh away. Digital technology is infinitely flexible: the program that spies on you can be defeated by another program that defeats spying. Every time your algorithmic boss hacks you, you can hack your boss back:
https://pluralistic.net/2022/12/02/not-what-it-does/#who-it-does-it-to
Technologists and labor organizers need one another. Even the most precarious and abused workers can team up with hackers to disenshittify their robo-bosses:
https://pluralistic.net/2021/07/08/tuyul-apps/#gojek
For every abuse technology brings to the workplace, there is a liberating use of technology that workers unleash by seizing the means of computation:
https://pluralistic.net/2024/01/13/solidarity-forever/#tech-unions
One tech-savvy group on the cutting edge of dismantling the Torment Nexus is Algorithms Exposed, a tiny, scrappy group of EU hacker/academics who recruit volunteers to reverse engineer and modify the algorithms that rule our lives as workers and as customers:
https://pluralistic.net/2022/12/10/e2e/#the-censors-pen
Algorithms Exposed have an admirable supply of seemingly boundless energy. Every time I check in with them, I learn that they've spun out yet another special-purpose subgroup. Today, I learned about Reversing Works, a hacking team that reverse engineers gig work apps, revealing corporate wrongdoing that leads to multimillion euro fines for especially sleazy companies.
One such company is Foodinho, an Italian subsidiary of the Spanish food delivery company Glovo. Foodinho/Glovo has been in the crosshairs of Italian labor enforcers since before the pandemic, racking up millions in fines – first for failing to file the proper privacy paperwork disclosing the nature of the data processing in the app that Foodinho riders use to book jobs. Then, after the Italian data commission investigated Foodinho, the company attracted new, much larger fines for its out-of-control surveillance conduct.
As all of this was underway, Reversing Works was conducting its own research into Glovo/Foodinho's app, running it on a simulated Android handset inside a PC so they could peer into app's data collection and processing. They discovered a nightmarish world of pervasive, illegal worker surveillance, and published their findings a year ago in November, 2023:
https://www.etui.org/sites/default/files/2023-10/Exercising%20workers%20rights%20in%20algorithmic%20management%20systems_Lessons%20learned%20from%20the%20Glovo-Foodinho%20digital%20labour%20platform%20case_2023.pdf
That report reveals all kinds of extremely illegal behavior. Glovo/Foodinho makes its riders' data accessible across national borders, so Glovo managers outside of Italy can access fine-grained surveillance information and sensitive personal information – a major data protection no-no.
Worse, Glovo's app embeds trackers from a huge number of other tech platforms (for chat, analytics, and more), making it impossible for the company to account for all the ways that its riders' data is collected – again, a requirement under Italian and EU data protection law.
All this data collection continues even when riders have clocked out for the day – its as though your boss followed you home after quitting time and spied on you.
The research also revealed evidence of a secretive worker scoring system that ranked workers based on undisclosed criteria and reserved the best jobs for workers with high scores. This kind of thing is pervasive in algorithmic management, from gig work to Youtube and Tiktok, where performers' videos are routinely suppressed because they crossed some undisclosed line. When an app is your boss, your every paycheck is docked because you violated a policy you're not allowed to know about, because if you knew why your boss was giving you shitty jobs, or refusing to show the video you spent thousands of dollars making to the subscribers who asked to see it, then maybe you could figure out how to keep your boss from detecting your rulebreaking next time.
All this data-collection and processing is bad enough, but what makes it all a thousand times worse is Glovo's data retention policy – they're storing this data on their workers for four years after the worker leaves their employ. That means that mountains of sensitive, potentially ruinous data on gig workers is just lying around, waiting to be stolen by the next hacker that breaks into the company's servers.
Reversing Works's report made quite a splash. A year after its publication, the Italian data protection agency fined Glovo another 5 million euros and ordered them to cut this shit out:
https://reversing.works/posts/2024/11/press-release-reversing.works-investigation-exposes-glovos-data-privacy-violations-marking-a-milestone-for-worker-rights-and-technology-accountability/
As the report points out, Italy is extremely well set up to defend workers' rights from this kind of bossware abuse. Not only do Italian enforcers have all the privacy tools created by the GDPR, the EU's flagship privacy regulation – they also have the benefit of Italy's 1970 Workers' Statute. The Workers Statute is a visionary piece of legislation that protects workers from automated management practices. Combined with later privacy regulation, it gave Italy's data regulators sweeping powers to defend Italian workers, like Glovo's riders.
Italy is also a leader in recognizing gig workers as de facto employees, despite the tissue-thin pretense that adding an app to your employment means that you aren't entitled to any labor protections. In the case of Glovo, the fine-grained surveillance and reputation scoring were deemed proof that Glovo was employer to its riders.
Reversing Works' report is a fascinating read, especially the sections detailing how the researchers recruited a Glovo rider who allowed them to log in to Glovo's platform on their account.
As Reversing Works points out, this bottom-up approach – where apps are subjected to technical analysis – has real potential for labor organizations seeking to protect workers. Their report established multiple grounds on which a union could seek to hold an abusive employer to account.
But this bottom-up approach also holds out the potential for developing direct-action tools that let workers flex their power, by modifying apps, or coordinating their actions to wring concessions out of their bosses.
After all, the whole reason for the gig economy is to slash wage-bills, by transforming workers into contractors, and by eliminating managers in favor of algorithms. This leaves companies extremely vulnerable, because when workers come together to exercise power, their employer can't rely on middle managers to pressure workers, deal with irate customers, or step in to fill the gap themselves:
https://projects.itforchange.net/state-of-big-tech/changing-dynamics-of-labor-and-capital/
Only by seizing the means of computation, workers and organized labor can turn the tables on bossware – both by directly altering the conditions of their employment, and by producing the evidence and tools that regulators can use to force employers to make those alterations permanent.
Image: EFF (modified) https://www.eff.org/files/issues/eu-flag-11_1.png
CC BY 3.0 http://creativecommons.org/licenses/by/3.0/us/
#pluralistic#etui#glovo#foodinho#alogrithms exposed#reverse engineering#platform work directive#eu#data protection#algorithmic management#gdpr#privacy#labor#union busting#tracking exposed#reversing works#adversarial interoperability#comcom#bossware
352 notes
·
View notes
Text
Tracking
𓂅 𓄹 Summary: You find out Miguel has been tracking something that concerns you… and him.
𓂅 𓄹 Pairing: Miguel O’Hara x spider-woman!reader
18+. Breeding kink. Period talk. Miguel going all scientific and keeping track of fertility windows for maximum efficacy. Dry humping. Inspired by this ask.
Miguel was in a bad mood that afternoon. You could see it coming a mile off, because having spent that much time around him over the past years had revealed many warning signs.
The circular platform was lowered all the way down to the floor by the time you walked past the door.
Miguel not turning to acknowledge your presence was warning sign number one.
You strode up to it warily, as if expecting him to explode at any given moment. Trying to lighten the mood, you tip toed to place a sweet kiss to his cheek.
He grumbled in response.
Warning sign number two.
His eyes were fixed on the multiple of screen sprawled in a half-moon in front of him, occasionally tapping and moving them around when needed.
“Someone’s in a good mood,” you teased.
“I’m nearly done here.”
“Hello to you, too, grumpy,” you nudged his arm with a smile.
Miguel merely nodded.
Warning sign number three.
At this point, you figured something was definitely going on.
“What’s up?”
“Hmm?”
You sighed. “You look and sound off.”
He tapped on a screen to his left. “You’re on your period.”
“What?”
Usually, that sort of remark would earn any man a slap at worst or a ‘fuck you’ at best. There was no shortage of men who would use women’s hormones as an easy way to deflect their feelings.
But there was something in Miguel’s tone that resembled… disappointment?
He scowled deeply, turning to face you. “You’re not pregnant.”
You stared at him for a long time, before bursting into laughter. “Is that why you’re all grumpy?”
“Oh, you think this is funny?” Miguel’s eyes narrowed, his scowl deepening.
You stopped at once. “Wait… how would you know that?”
He returned his attention to the hovering screens in front of him. “Know what?”
“That I’m on my period?” you asked, suspicion rising inside you. “And I still haven’t gotten it, by the way.”
And just like that, Miguel’s crimson eyes were on you expectantly. “Why didn’t you tell me right away?”
You folded your arms while tapping your foot lightly. “No. You answer me first.”
Miguel knew better than to antagonise you, especially now that you had information that interested him.
Dragging his index finger across the panel, you saw a file pop up with your name. That didn’t seem odd at all. Every spider in Nueva York was required to have one that displayed several strategic details as well as bio data that was fed by the dimensional travel watch. Your heart rate was at a steady 67 beats per minute.
“What about it?”
He tapped on a second tab that read ‘Fertility’.
Nothing could have prepared you for the influx of information you were about to be bombarded with.
And what it concerned.
July 4th
Cycle day 1 - low chance of pregnancy
Fertility window - 12 to 18
Ovulation day - 17 (high chances of pregnancy)
“You’re tracking my period?!” you snapped in utter disbelief.
“I’m tracking your fertility window.”
You glared at him. “How is that any different?”
“It’s not. Just nomenclature,” he shrugged casually as if talking about the change of weather outside.
You shot Miguel a death glare, before shoving him to the side, gaining full access to the flickering orange screen. The data collected went back as far as three months ago.
Miguel had been tracking your fertility window for months now.
“Why didn’t you tell me?”
He shifted to stand behind you, easily towering with his impressive height. “It’s my responsibility to get you pregnant.”
Your eyes widened partially in disbelief, but mostly at the realisation that this shouldn’t be a shocking revelation.
Miguel had to be in control at all times. It was embedded in his genetic code. A few months ago you had casually joked that you wouldn’t mind having a child soon.
It seemed that it was all the motivation he needed to begin his quest.
Now it made perfect sense why he had been so insistent on always cumming inside you. You just didn’t think he would be this dedicated.
Joke’s on you.
“But it seems the data is wrong,” he said lowly, arms circling around you to have his hands atop yours on the keyboard. “You can edit it,” he whispered, pressing himself fully against you.
The added pressure pushed your lower half gently against the control table, his thumb caressing the back of your hand.
“Are you trying to seduce me, so I ignore all of this?” you whispered, enjoying how the proximity was having a noticeable effect on his cock.
He rolled against you slowly. “Me? Of course not.”
His fingers intertwined with yours, and you watched your heart rate on the screen soar to 78 beats per minutes.
You fought back a whimper, as he was nipping at your neck, fangs lightly poking at sensitive skin. You could feel the hard print of his cock pressed against the curve of your ass, and as you bucked your hips instinctively, you felt his own meet you halfway, setting a slow rhythm.
90 beats per minute.
“Let me get a blood sample so I can test out,” he said, his erection pressed against your ass.
“Someone really wants to be a dad,” you said with a teasing smile.
99 beats per minute.
His other hand came to grip your jaw, tilting your head until you met his eyes. “I need you to get pregnant.”
Your breath was coming out in shallow pants as he kept humping you at a steady and torturous pace.
“You mean… you need to breed me, right?”
109 beats per minute.
His eyeds widened lightly and he thrusted harshly into you, causing a jolt of pleasure to travel all the way down to your clit. “That’s the same thing, cariño.”
You gave him a knowing smile. “Nomenclature and all that.”

Masterlist
#miguel o’hara x reader#miguel o’hara smut#miguel o’hara#miguel o’hara x you#miguel ohara x reader#miguel o’hara x fem!reader#spiderman 2099#spiderman 2099 x reader#miguel x reader#miguel o’hara x y/n
4K notes
·
View notes
Text
A lawsuit filed Wednesday against Meta argues that US law requires the company to let people use unofficial add-ons to gain more control over their social feeds.
It’s the latest in a series of disputes in which the company has tussled with researchers and developers over tools that give users extra privacy options or that collect research data. It could clear the way for researchers to release add-ons that aid research into how the algorithms on social platforms affect their users, and it could give people more control over the algorithms that shape their lives.
The suit was filed by the Knight First Amendment Institute at Columbia University on behalf of researcher Ethan Zuckerman, an associate professor at the University of Massachusetts—Amherst. It attempts to take a federal law that has generally shielded social networks and use it as a tool forcing transparency.
Section 230 of the Communications Decency Act is best known for allowing social media companies to evade legal liability for content on their platforms. Zuckerman’s suit argues that one of its subsections gives users the right to control how they access the internet, and the tools they use to do so.
“Section 230 (c) (2) (b) is quite explicit about libraries, parents, and others having the ability to control obscene or other unwanted content on the internet,” says Zuckerman. “I actually think that anticipates having control over a social network like Facebook, having this ability to sort of say, ‘We want to be able to opt out of the algorithm.’”
Zuckerman’s suit is aimed at preventing Facebook from blocking a new browser extension for Facebook that he is working on called Unfollow Everything 2.0. It would allow users to easily “unfollow” friends, groups, and pages on the service, meaning that updates from them no longer appear in the user’s newsfeed.
Zuckerman says that this would provide users the power to tune or effectively disable Facebook’s engagement-driven feed. Users can technically do this without the tool, but only by unfollowing each friend, group, and page individually.
There’s good reason to think Meta might make changes to Facebook to block Zuckerman’s tool after it is released. He says he won’t launch it without a ruling on his suit. In 2020, the company argued that the browser Friendly, which had let users search and reorder their Facebook news feeds as well as block ads and trackers, violated its terms of service and the Computer Fraud and Abuse Act. In 2021, Meta permanently banned Louis Barclay, a British developer who had created a tool called Unfollow Everything, which Zuckerman’s add-on is named after.
“I still remember the feeling of unfollowing everything for the first time. It was near-miraculous. I had lost nothing, since I could still see my favorite friends and groups by going to them directly,” Barclay wrote for Slate at the time. “But I had gained a staggering amount of control. I was no longer tempted to scroll down an infinite feed of content. The time I spent on Facebook decreased dramatically.”
The same year, Meta kicked off from its platform some New York University researchers who had created a tool that monitored the political ads people saw on Facebook. Zuckerman is adding a feature to Unfollow Everything 2.0 that allows people to donate data from their use of the tool to his research project. He hopes to use the data to investigate whether users of his add-on who cleanse their feeds end up, like Barclay, using Facebook less.
Sophia Cope, staff attorney at the Electronic Frontier Foundation, a digital rights group, says that the core parts of Section 230 related to platforms’ liability for content posted by users have been clarified through potentially thousands of cases. But few have specifically dealt with the part of the law Zuckerman’s suit seeks to leverage.
“There isn’t that much case law on that section of the law, so it will be interesting to see how a judge breaks it down,” says Cope. Zuckerman is a member of the EFF’s board of advisers.
John Morris, a principal at the Internet Society, a nonprofit that promotes open development of the internet, says that, to his knowledge, Zuckerman’s strategy “hasn’t been used before, in terms of using Section 230 to grant affirmative rights to users,” noting that a judge would likely take that claim seriously.
Meta has previously suggested that allowing add-ons that modify how people use its services raises security and privacy concerns. But Daphne Keller, director of the Program on Platform Regulation at Stanford's Cyber Policy Center, says that Zuckerman’s tool may be able to fairly push back on such an accusation.“The main problem with tools that give users more control over content moderation on existing platforms often has to do with privacy,” she says. “But if all this does is unfollow specified accounts, I would not expect that problem to arise here."
Even if a tool like Unfollow Everything 2.0 didn’t compromise users’ privacy, Meta might still be able to argue that it violates the company’s terms of service, as it did in Barclay’s case.
“Given Meta’s history, I could see why he would want a preemptive judgment,” says Cope. “He’d be immunized against any civil claim brought against him by Meta.”
And though Zuckerman says he would not be surprised if it takes years for his case to wind its way through the courts, he believes it’s important. “This feels like a particularly compelling case to do at a moment where people are really concerned about the power of algorithms,” he says.
370 notes
·
View notes
Text
Libraries have traditionally operated on a basic premise: Once they purchase a book, they can lend it out to patrons as much (or as little) as they like. Library copies often come from publishers, but they can also come from donations, used book sales, or other libraries. However the library obtains the book, once the library legally owns it, it is theirs to lend as they see fit. Not so for digital books. To make licensed e-books available to patrons, libraries have to pay publishers multiple times over. First, they must subscribe (for a fee) to aggregator platforms such as Overdrive. Aggregators, like streaming services such as HBO’s Max, have total control over adding or removing content from their catalogue. Content can be removed at any time, for any reason, without input from your local library. The decision happens not at the community level but at the corporate one, thousands of miles from the patrons affected. Then libraries must purchase each individual copy of each individual title that they want to offer as an e-book. These e-book copies are not only priced at a steep markup—up to 300% over consumer retail—but are also time- and loan-limited, meaning the files self-destruct after a certain number of loans. The library then needs to repurchase the same book, at a new price, in order to keep it in stock. This upending of the traditional order puts massive financial strain on libraries and the taxpayers that fund them. It also opens up a world of privacy concerns; while libraries are restricted in the reader data they can collect and share, private companies are under no such obligation. Some libraries have turned to another solution: controlled digital lending, or CDL, a process by which a library scans the physical books it already has in its collection, makes secure digital copies, and lends those out on a one-to-one “owned to loaned” ratio. The Internet Archive was an early pioneer of this technique. When the digital copy is loaned, the physical copy is sequestered from borrowing; when the physical copy is checked out, the digital copy becomes unavailable. The benefits to libraries are obvious; delicate books can be circulated without fear of damage, volumes can be moved off-site for facilities work without interrupting patron access, and older and endangered works become searchable and can get a second chance at life. Library patrons, who fund their local library’s purchases with their tax dollars, also benefit from the ability to freely access the books. Publishers are, unfortunately, not a fan of this model, and in 2020 four of them sued the Internet Archive over its CDL program. The suit ultimately focused on the Internet Archive’s lending of 127 books that were already commercially available through licensed aggregators. The publisher plaintiffs accused the Internet Archive of mass copyright infringement, while the Internet Archive argued that its digitization and lending program was a fair use. The trial court sided with the publishers, and on September 4, the Court of Appeals for the Second Circuit reaffirmed that decision with some alterations to the underlying reasoning. This decision harms libraries. It locks them into an e-book ecosystem designed to extract as much money as possible while harvesting (and reselling) reader data en masse. It leaves local communities’ reading habits at the mercy of curatorial decisions made by four dominant publishing companies thousands of miles away. It steers Americans away from one of the few remaining bastions of privacy protection and funnels them into a surveillance ecosystem that, like Big Tech, becomes more dangerous with each passing data breach. And by increasing the price for access to knowledge, it puts up even more barriers between underserved communities and the American dream.
11 September 2024
154 notes
·
View notes
Text
I really wish it was talked about more how exhausting it is to constantly have your phone selling your data on things that are so personal. My phone is listening in on my therapy appointments and getting Reels on depression. Speaking about how I’m afraid my cat may have cancer and being fed Tiktok video algorithm videos of people in hospice, their life before & after diagnosis, confessing to a friend how you’re starting to get physical effects from being overweight and now finding a slew of workout recommendations & finspo. I don’t get to be human, because there is an all-seeing group of numbers who are trying to recreate my human experience for me. Interspersed with Wegovy ads, Temu trash, the AI Coca Cola slop. It makes me and millions of other people feel alone. A product to a company I have no idea I was a line item more. Worthy only with my eyes, tracking every millisecond I watch a storytime about the worst day of someone’s life. This is not how life is supposed to be like. But hey, at least if I get more apathetic, I can be sold for another Better Help ad, self-conscious to be sold for a HelloFresh subscription, or if I’m lucky enough to be shown 15 minutes into scrolling, content from a friend so I can have the algorithm push a sponsored VRBO video of a cool experience to have with friends. Self-censorship like unalive or G@za just to get our points across so the platform can trick some corporation into believing it's a safe platform to sell on.
I’ve been deleting social media apps from my phone when I don’t use it. I “ask” apps to disable the location, microphone & camera access, which should never be a suggestion. I click “only necessary” cookies when visiting sites even if I have to press that button every time a new page loads on their domain. I avoid Facebook almost altogether due to its predilection for AI engagement bait. I stopped using Twitter last year after the rage bait & bot problem became apparent. I was asked by someone much younger than me why Tumblr feels like the old internet, and I said without really thinking about it, there isn’t a financial incentive for people to be upset with each other. And you know what, as poignant as it was, it made me realize why I’ve spent most of my time on Tumblr lately. Because I feel less like a product.
So yes, maybe it is harder to get a hold of me. Maybe I don’t post on social media like I used to. But I’m trying to find even the smallest modicum of control over and peace over a piece of technology I need for my livelihood. And I can’t believe, over 20 years after it’s mass public introduction, we still have lawmakers who feign ignorance on how the internet works to not enact true change in the US. All while the suicide rate for children rises, having thousands of professionals point to social media algorithms, just to be struck down by one billionaire cuck making a well-placed & timed donation. Say I'm preaching to the choir, talking to my echo chamber, but I'm not the one who coded the echo chamber.
73 notes
·
View notes
Text
California Internet Bills Status 8/9/2024
As of right now, here's the status of the three primary internet bills of note.
AB 3080, age verification for nsfw websites. Currently has been improved its terms so that metadata and other methods to better filtering as parental controls is allowed as an option rather than always age verification via ID and credit card transactions. However, it's best to still nip this one in the bud if possible. So I'd still recommend messaging your reps about it.
This bill went through second reading, but has been re-referred to the Senate Appropriations Committee. The hearing is scheduled for August 12th. You can find your members in the link below. So best to call them before that date if they're a part of the committee.
AB 1949, surrounding collecting personal data of those less than 18 years of age with risks of age verification due to broad language, has been sent to the Senate Suspense File and is awaiting the vote. There's no set date on the Senate website for it, but the Assembly Suspense date is listed as August 15th, so best assumption for now is that it will be on the same day. So call your Senate reps for these as well if they're a part of the Appropriations Committee (see the link above).
Lastly, SB 976, regarding age restricting "addictive" algorithms and time restricting access to social media platforms for individuals under 18. Very likely leading to age verification. Has been placed on the Assembly Suspense file for August 15th. If you have tim please call your Assembly member if they're a part of the Appropriations committee as listed below.
Thank you again for taking your time to voice your opinions and help keep our internet safe.
#kosa#california#ab 3080#ab 1949#sb 976#bad internet bills#online privacy#online safety#age verification
108 notes
·
View notes
Text
Full text of article as follows:
Tumblr and Wordpress are preparing to sell user data to Midjourney and OpenAI, according to a source with internal knowledge about the deals and internal documentation referring to the deals.
The exact types of data from each platform going to each company are not spelled out in documentation we’ve reviewed, but internal communications reviewed by 404 Media make clear that deals between Automattic, the platforms’ parent company, and OpenAI and Midjourney are imminent.
The internal documentation details a messy and controversial process within Tumblr itself. One internal post made by Cyle Gage, a product manager at Tumblr, states that a query made to prepare data for OpenAI and Midjourney compiled a huge number of user posts that it wasn’t supposed to. It is not clear from Gage’s post whether this data has already been sent to OpenAI and Midjourney, or whether Gage was detailing a process for scrubbing the data before it was to be sent.
Gage wrote:
“the way the data was queried for the initial data dump to Midjourney/OpenAI means we compiled a list of all tumblr’s public post content between 2014 and 2023, but also unfortunately it included, and should not have included:
private posts on public blogs
posts on deleted or suspended blogs
unanswered asks (normally these are not public until they’re answered)
private answers (these only show up to the receiver and are not public)
posts that are marked ‘explicit’ / NSFW / ‘mature’ by our more modern standards (this may not be a big deal, I don’t know)
content from premium partner blogs (special brand blogs like Apple’s former music blog, for example, who spent money with us on an ad campaign) that may have creative that doesn’t belong to us, and we don’t have the rights to share with this-parties; this one is kinda unknown to me, what deals are in place historically and what they should prevent us from doing.”
Gage’s post makes clear that engineers are working on compiling a list of post IDs that should not have been included, and that password-protected posts, DMs, and media flagged as CSAM and other community guidelines violations were not included.
Automattic plans to launch a new setting on Wednesday that will allow users to opt-out of data sharing with third parties, including AI companies, according to the source, who spoke on the condition of anonymity, and internal documents. A new FAQ section we reviewed is titled “What happens when you opt out?” states that “If you opt out from the start, we will block crawlers from accessing your content by adding your site on a disallowed list. If you change your mind later, we also plan to update any partners about people who newly opt-out and ask that their content be removed from past sources and future training.”
404 Media has asked Automattic how it accidentally compiled data that it shouldn’t share, and whether any of that content was shared with OpenAI. 404 Media asked Automattic about an imminent deal with Midjourney last week but did not hear back then, either. Instead of answering direct questions about these deals and the compiling of user data, Automattic sent a statement, which it posted publicly after this story was published, titled "Protecting User Choice." In it, Automattic promises that it's blocked AI crawlers from scraping its sites. The statement says, "We are also working directly with select AI companies as long as their plans align with what our community cares about: attribution, opt-outs, and control. Our partnerships will respect all opt-out settings. We also plan to take that a step further and regularly update any partners about people who newly opt out and ask that their content be removed from past sources and future training."
Another internal document shows that, on February 23, an employee asked in a staff-only thread, “Do we have assurances that if a user opts out of their data being shared with third parties that our existing data partners will be notified of such a change and remove their data?”
Andrew Spittle, Automattic’s head of AI replied: “We will notify existing partners on a regular basis about anyone who's opted out since the last time we provided a list. I want this to be an ongoing process where we regularly advocate for past content to be excluded based on current preferences. We will ask that content be deleted and removed from any future training runs. I believepartners will honor this based on our conversations with them to this point. I don't think they gain much overall by retaining it.” Automattic did not respond to a question from 404 Media about whether it could guarantee that people who opt out will have their data deleted retroactively.
News about a deal between Tumblr and Midjourney has been rumored and speculated about on Tumblr for the last week. Someone claiming to be a former Tumblr employee announced in a Tumblr blog post that the platform was working on a deal with Midjourney, and the rumor made it onto Blind, an app for verified employees of companies to anonymously discuss their jobs. 404 Media has seen the Blind posts, in which what seems like an Automattic employee says, “I'm not sure why some of you are getting worked up or worried about this. It's totally legal, and sharing it publicly is perfectly fine since it's right there in the terms & conditions. So, go ahead and spread the word as much as you can with your friends and tech journalists, it's totally fine.”
Separately, 404 Media viewed a public, now-deleted post by Gage, the product manager, where he said that he was deleting all of his images off of Tumblr, and would be putting them on his personal website. A still-live postsays, “i've deleted my photography from tumblr and will be moving it slowly but surely over to cylegage.com, which i'm building into a photography portfolio that i can control end-to-end.” At one point last week, his personal website had a specific note stating that he did not consent to AI scraping of his images. Gage’s original post has been deleted, and his website is now a blank page that just reads “Cyle.” Gage did not respond to a request for comment from 404 Media.
Several online platforms have made similar deals with AI companies recently, including Reddit, which entered into an AI content licensing deal with Google and said in its SEC filing last week that it’s “in the early stages of monetizing [its] user base” by training AI on users’ posts. Last year, Shutterstock signed a six year deal with OpenAI to provide training data.
OpenAI and Midjourney did not respond to requests for comment.
Updated 4:05 p.m. EST with a statement from Automattic.
#It’s amazing how dishonest the staff post was#Original post#Posted for the convenience of users who are not currently subscribed to 404 media#But you absolutely should they’re great#10/10 highly recommended
162 notes
·
View notes
Text
youtube
Meet MBARI: This team develops innovative new technology to map the seafloor 🤖🗺️
With marine life and ecosystems facing a rising tide of threats, the ocean exploration community needs nimble, cost-effective tools for measuring and monitoring ocean health. MBARI’s Control, Modeling, and Perception of Autonomous Systems Laboratory, known as the CoMPAS Lab is up to the challenge.
MBARI scientists and engineers build and adapt advanced technology that enhances ocean data collection. Led by engineer Giancarlo Troni, the CoMPAS Lab team develops scalable marine technology that can easily be modified for use in a wide variety of vehicles and platforms.

Working with other teams across MBARI, the CoMPAS Lab leverages vehicles like the MiniROV to deploy and test new tools in Monterey Bay's submarine canyon and then adapt them for other mobile platforms. By sharing open-source design specifications and advanced algorithms with the wider ocean exploration community, we hope to expand access to MBARI’s engineering innovations.
MBARI technology is transforming what we know about the ocean and its inhabitants. Our scientists, engineers, and marine operations staff work together to create innovative tools for a more sustainable future where autonomous robots and artificial intelligence can track ocean health in real time and help us visualize ocean animals and environments. Studying our blue backyard is revealing our connection to the ocean—how it sustains us and how our actions on land may be threatening its future.

We’re spotlighting various teams at MBARI to showcase the different ways we’re studying the largest environment on Earth. We hope this series inspires a new generation of ocean explorers. Dive in.
39 notes
·
View notes
Text
Thsyu Alert: Bitcoin Pauses Near $69k as Weakening Yuan Tests China's Capital Controls – Policy Impact Analysis

Bitcoin's (BTC) recent upward momentum stalled Tuesday, consolidating around the $69,000 mark despite a potentially potent bullish catalyst emerging from Asia: the weakening Chinese Yuan (CNH). While BTC initially dipped nearly 2% over 24 hours to ~$68,900, the offshore Yuan slid further against the US Dollar, trading above 7.27, reflecting persistent depreciation pressures potentially linked to PBoC policy divergence and broader economic headwinds.
Data Point: USD/CNH > 7.27 vs. BTC ~$69k (April 8-9).
Policy Impact: The core tension lies between the Yuan's weakness potentially driving capital flight towards alternative stores of value like Bitcoin, and Beijing's stringent Capital Controls and existing ban on cryptocurrency trading within the mainland. Historically, significant Yuan devaluation has correlated with increased BTC buying pressure, interpreted as a hedge against currency depreciation by Chinese investors accessing offshore markets. However, the effectiveness of this channel is constantly tested by regulatory enforcement. Market observers on global platforms, including Thsyu, are closely monitoring flows for signs of this dynamic re-emerging despite policy barriers.
The current Bitcoin price consolidation, however, suggests the Yuan's influence is currently muted or offset by other factors. Analysts point to normalizing spot Bitcoin ETF inflows in the US, pre-halving profit-taking (with the event estimated mid-April), and general macroeconomic uncertainty tempering aggressive bids. Bitcoin failed to sustain moves above the critical $71,500 resistance level earlier this week, indicating trader caution.
Geopolitical Context: The PBoC's accommodative stance contrasts sharply with the Federal Reserve's data-dependent approach, contributing to yield differentials pressuring the Yuan. This divergence occurs amidst ongoing global trade frictions and geopolitical maneuvering, making currency stability a key policy focus for Beijing. Any perceived increase in capital outflows triggered by Yuan weakness could invite tighter enforcement actions, impacting crypto sentiment indirectly. For traders using platforms like Thsyu, understanding these policy crosscurrents is vital.
Market Reaction: While the "weak Yuan = strong Bitcoin" narrative persists, current price action suggests the market is weighing regulatory friction and other dominant crypto-native factors more heavily. The immediate impact of Yuan depreciation appears contained by China's policy framework for now. Yet, sustained currency weakness remains a key variable; a significant break lower in the Yuan could still test the resilience of capital controls and potentially fuel demand visible on exchanges like Thsyu.
Outlook: The interplay between PBoC policy, Yuan stability, China's regulatory grip, and global crypto market drivers like the upcoming halving and ETF flows creates a complex outlook. Monitoring Beijing's policy signals regarding capital flows and enforcement alongside broader crypto market indicators remains crucial for navigating potential volatility. Users on the Thsyu platform are advised to stay informed on these fast-moving geopolitical and regulatory developments impacting digital asset valuations. The coming weeks will be critical in determining if the Yuan slide translates from a theoretical catalyst into tangible market momentum.
30 notes
·
View notes
Text
Steve Statler, Chief Marketing Officer at Wiliot – Interview Series
New Post has been published on https://thedigitalinsider.com/steve-statler-chief-marketing-officer-at-wiliot-interview-series/
Steve Statler, Chief Marketing Officer at Wiliot – Interview Series
Steve Statler is the Chief Marketing Officer at Wiliot, author of Beacon Technologies, and the presenter of the Mister Beacon Ambient IoT podcast.
At the core of the Wiliot System are IoT Pixels, which are low-cost tags approximately the size of a postage stamp, designed for easy integration into a wide range of products. These IoT Pixels continuously gather data from their surroundings and are powered either by harvesting radio frequency energy or, in some versions, by a thin printed battery. The transmissions from IoT Pixels are secure and can be read using existing Bluetooth devices.
What are the potential benefits of integrating WiliBot into existing supply chain management systems?
Integrating WiliBot into existing supply chain management systems will allow brands and manufacturers to communicate with their products in ways that significantly improve their supply chain efficiency and sustainability.
By enabling natural-language conversations with any ambient-IoT connected product, WiliBot can be used by businesses seeking to ask questions about their ambient IoT enabled products and supply chains: How fresh is this product? How did it get to the store? Which product should I stock next, and why? What is the carbon footprint of this product? Why is it so high or low? The answers to these questions can then be integrated in real time into a businesses supply chain strategy.
How does Wiliot’s use of ambient IoT and GenAI enhance real-time data visibility in supply chains?
The combination of ambient IoT and GenAI offers a unique opportunity to enhance and apply real-time data visibility. Wiliot’s IoT Pixels are constantly collecting real-time data throughout the supply chain and even in stores.
WiliBot enhances this real-time data visibility by harnessing the power of generative AI, to make sense of the data provided. This allows companies – and eventually consumers – the ability to have conversations with the products they make, source, distribute and ultimately purchase. Breaking down complex and multitudes of data into easy to understand actionable insights.
For a GenAI model to run effectively, it requires significant data input to train it. In the past, due to the lack of large amounts of real time data, this meant supply chain GenAI models would utilize previously existing data. While this proved generally effective, supply chains shift from year to year, and last year’s data isn’t always the most accurate when predicting what businesses need in a year, month, and even day. The constant real-time data that Wiliot’s IoT Pixels and Ambient Data Platform feeds into WiliBot proves the most effective for brands looking to capitalize on the most current intelligence that’s happening in their supply chains.
In what ways can WiliBot help businesses improve sustainability and reduce waste within their supply chains?
Wilibot empowers consumers to vote with their purses and wallets based on better insights into the provenance, content and carbon footprint of one product versus another that may look identical. By capturing the dynamic carbon impact of storage, transportation at an item level and sharing that insight in real time, businesses can be empowered to manage down their carbon footprint every minute of every day. An end of year scorecard at a company level can’t do that.
Wiliot’s Ambient Data Platform, already allows companies to gain unprecedented intelligence about the sustainability about trillions of products. With the introduction of WiliBot, businesses will now be able to ask and easily break down that intelligence into real-time information about individual products.
In turn, this means companies can get real-time specifics on the sustainability of their supply chains. They can ask WiliBot questions like: why some products have a greater carbon footprint than others, what products they should stock before they expire, and how weather patterns are impacting products throughout the supply chain.
WiliBot allows companies to recognize where changes could be made to ensure sustainability and reduce waste, without waiting for the past year’s data.
How do Wiliot’s IoT Pixels work, and what makes them unique in enabling continuous, real-time data collection in supply chains without the need for batteries?
Wiliot’s IoT Pixels are low-cost tags, the size of a postage stamp, and can be seamlessly manufactured into just about any product. IoT Pixels are designed to provide insights on “everything, everywhere, all at once” – because of their small size, they can be affixed to almost any product, down to even crate-level shipments. What makes IoT Pixels unique, and what allows for them to provide continuous data collection, is that they’re powered by harvested radio frequency energy, meaning they use the radio frequencies from everyday devices that already exist in the world around us. IoT Pixels then securely transmit that data, also via existing Bluetooth devices, to the Wiliot Ambient Data Platform, where it’s available for businesses to pull from.
What are the security measures in place to ensure the privacy and integrity of data collected by IoT Pixels and processed by the Wiliot Ambient Data Platform?
The data security and governance robustness of Wiliot’s Ambient Data Platform has been certified by two leading examiners. We have achieved Systems and Organization Controls (SOC) 1 Type II and SOC 2 Type II reports, both issued by independent auditors from a leading Big 4 firm.
Additionally, we recently received its third-year recertification of its ISO 27001 and 27018 certifications by the International Organization for Standardization. Both of these certifications validate our ongoing commitment to data security, governance, and privacy.
Unlike other auto-identification technologies like QR codes and RFID, Wiliot’s implementation includes encryption backed access control to the data that relates to the content, movement and usage of products.
How does WiliBot leverage generative AI to provide actionable insights from the data generated by IoT Pixels?
The data generated by IoT Pixels is sent via Bluetooth to the Wiliot cloud once it’s finalized. From there, WiliBot can leverage the generative AI to provide actionable insights.
WiliBot’s Wiliot-developed AI, built on top of a leading Large Language Model, can identify supply chain “events” and automatically generate alerts or AI responses that allow businesses to course-correct or optimize their operations. This could mean creating an automatic alert for a business when shipments of their produce have been handled at an unsafe temperature, or when pharmaceuticals were kept in an environment too moist for them
The answers to these questions are available in the Wiliot Ambient Data platform, but haven’t always been easily accessible. With WiliBot, these actionable insights can be democratized across organizations, as opposed to requiring significant labor or integration costs.
Can WiliBot be customized to address specific industry needs, such as retail, pharmaceuticals, or food production?
Yes. Wiliot IoT Pixels can be affixed to and provide data on any product, across retail, pharmaceuticals, food production, and more, which means that WiliBot can be distinctively tailored to the needs of those industries.
The more relevant product data that is put into WiliBot, the more specific and targeted answers will be able to be. For food retailers, the priority when implementing WiliBot may be determining the effects of their supply chain’s weather patterns upon food rot and spoil; for clothing retailers, WiliBot may be more relevant in determining where product should go in the store. WiliBot is able to uniquely make sense of data based on each customer’s specific needs and to describe products, materials, supply chains, and everything connected to the internet.
How does the Wiliot Ambient Data Platform differentiate itself from traditional IoT platforms in terms of functionality and ease of integration?
The Wiliot Ambient Data Platform differentiates itself from traditional IoT platforms because of its ‘ambient’ aspect. The data drawn from the IoT Pixels into the platform are accessible all the time as opposed to requiring labor to track, scan or read it.
Wiliot also aims to set ambient IoT standards throughout the industry, which will allow for mass adoption and easy integration by the world’s largest retailers. Already, we are contributing to the 3GPPP alongside a number of large handset OEMs, and working on versions of the Ambient Data Platform that will support the Bluetooth, cellular/3GPP, and Wi-Fi/IEEE variants of ambient IoT.
What impact could WiliBot have on consumer transparency, particularly in understanding the carbon footprint and ethical sourcing of products?
Wiliot’s IoT Pixels already enable products to transmit item-level data about their carbon footprint and equip businesses with information needed to track, manage and reduce carbon emissions. WiliBot makes this even easier by allowing businesses to ask specific questions like where the or how products are sourced and their carbon footprint.
In the future, this convergence of ambient IoT and generative AI will be made available to consumers in-store and at-home through an ecosystem of mobile apps – enabling consumers themselves to speak to and converse with their products to better understand their carbon footprint, materials composition, ethical sourcing compliance, freshness and safety, and more.
This proliferation of information will allow for consumers to take their own ethical considerations into account when purchasing, and ultimately allow for an increased consumer experience without increasing employee workload or cost.
How does Wiliot ensure that the integration of ambient IoT with GenAI remains compliant with global data protection regulations?
Wiliot’s ambient IoT foundation for GenAI enables compliance to data protection regulations with accountability and access control, so that there is a clear owner of the data who has the tools to manage access to the data. Unlike other low-cost scalable radio frequency identifiers, every Wiliot tag is enabled with end-to-end encryption which prevents unauthorized access to data broadcast from a tag. Encryption starts at the chip level inside the tag and ends at the application in the cloud, which gives a single owner access to the data. With other forms of RFID, the owner isn’t clear – it could be the company that bought the RFID tag and applied it to the product, the distributor, the retailer, or the end customer. Wiliot’s approach of encrypting all the data means ownership can be transferred and data sharing can be regulated.
Thank you for the great interview, readers who wish to learn more should visit Wiliot.
#access control#ai#alerts#ambient#approach#apps#author#batteries#battery#bluetooth#brands#Business#carbon#carbon emissions#carbon footprint#Certifications#chip#clothing#Cloud#Companies#compliance#Composition#consumers#content#continuous#course#data#data collection#data platform#data protection
0 notes
Text


How the world’s richest man laid waste to the US government
Elon Musk has achieved astonishing power in Trump’s administration – and spent the weekend wielding it
Since declaring his support for Donald Trump in July of last year and subsequently spending more than $250m on his re-election effort, Elon Musk has rapidly accumulated political influence and positioned himself at the heart of the new administration. Now as prominent as the president himself, Musk has begun to make use of that power, making decisions that could affect the health of millions of people, gaining access to highly sensitive personal data, and attacking anyone who opposes him. Musk, the world’s richest man and an unelected official, has achieved an astonishing level of power over the federal government.
Over the weekend, workers with Musk’s “department of government efficiency” (Doge) clashed with civil servants over demands for unfettered access to the computer systems of major US government agencies in a breakneck series of confrontations. When the dust settled, several top officials who opposed the takeover had been pushed out, and Musk’s allies had gained control.
Musk, with the backing of Trump, is now working to shut down the US Agency for International Development (USAid) – the world’s largest single supplier of humanitarian aid. He bragged on Sunday about “feeding USAid into the wood chipper”. He has also targeted several other agencies in an aggressive attempt to purge and remake the federal government along ideological lines, while avoiding congressional or judicial oversight.
Many of Musk’s actions have taken place without forewarning or transparency, sowing chaos and confusion among the thousands of people employed at the agencies like USAid that he has gone after. Humanitarian organizations that rely on US funding have halted operations and laid off staff, while government workers have been locked out of their offices. He is operating Doge as an unofficial government department with no congressionally approved mandate while he technically holds the position of “special government employee”, which allows him to sidestep financial disclosures and a public vetting process.
Musk has gleefully posted on X, the social media platform that he owns, throughout the chaos. He has accused USAid of corruption, and of being a “criminal organization” and “radical-left political psy op”, without any evidence. Why? He tweeted an explanation of simply doing Trump’s bidding: “All @DOGE did was check to see which federal organizations were violating the @POTUS executive orders the most. Turned out to be USAID, so that became our focus.” He said it was “time for it to die”.
Musk also suggested that opposition to his team will be punished, reposting a letter sent to him from the Trump-appointed federal prosecutor for Washington DC, who vowed to “pursue any and all legal action against anyone who impedes your work or threatens your people”.
The New York Democratic senator Chuck Schumer wrote on Tuesday morning: “An unelected shadow government is conducting a hostile takeover of the federal government. DOGE is not a real government agency. DOGE has no authority to shut programs down or to ignore federal law.” Musk responded that the reaction was “hysterical”.
As other Democrats and government oversight groups began to respond to the breakneck series of actions from Musk’s team, on Tuesday the Tesla and SpaceX CEO continued to plow ahead with his cuts and told his supporters: “We’re never going to get another chance like this.”
Musk takes over federal agencies
Immediately following Trump’s inauguration on 20 January, the president issued an executive order establishing Musk’s “department of government efficiency”. Rather than create an entirely new entity, the order renamed the US Digital Service, which was previously tasked with updating government IT systems, and brought the rechristened bureau into the executive office of the president.
Government accountability groups instantly saw red flags with its creation, filing four separate lawsuits that alleged Doge violated federal transparency laws while warning that the initiative was “slated to dictate federal policy in ways that will affect millions of Americans”.
The concerns from watchdog organizations have borne out. Musk and employees of Doge have gained access to sensitive government systems in the treasury department and USAid in recent days, as well as exerted control over the office of personnel management (OPM) and the General Services Administration, which handles federal real estate, with the goal of ending office leases. Two federal workers additionally sued on Tuesday for a temporary restraining order against Doge for allegedly operating an illegal server in OPM.
Attempts at blocking Musk’s team have resulted in several top agency officials being ousted. On Friday, the treasury department’s acting secretary, David Lebryk, resigned after refusing to grant Musk’s team access to highly secure systems that control about $6tn in annual payments to millions of Americans. The next day, two senior security officials at USAid attempted to stop Doge workers from gaining physical access to restricted areas at the agency – resulting in a standoff in which a deputy for Musk threatened to call the US marshals. Both security officials have subsequently been put on administrative leave, and on Sunday night staff at USAid received emails telling them to not come into work the next day.
The events unfolded swiftly and took place mostly outside of working hours, creating uncertainty over the weekend as to who was in charge and what authority the Doge team possessed. Many of the Doge team tasked with carrying out the overhauls of government agencies appear to have little to no experience in government and are extremely young. One of the engineers is as young as 19, Wired reported, while a 25-year-old who previously worked at two of Musk’s companies gained access to treasury department payment systems.
The Trump administration has maintained that all Musk’s actions have been legal and did not violate security protocols, although the details of what Doge employees are doing with access to government systems is still unclear. “No classified material was accessed without proper security clearances,” Katie Miller, a Doge spokesperson and wife of the far-right Trump administration official Stephen Miller, wrote on X.
Musk has claimed that his actions are cutting unnecessary costs and will allow for more efficient government, but he has also suggested his taskforce is ideologically opposed to liberal initiatives such as refugee services and the promotion of trans rights. He has routinely engaged with far-right and conspiracy theory-promoting accounts on X while touting his dismantling of USAid, an agency that has become a target in recent years among hardline conservatives. The far-right Heritage Foundation thinktank specifically called for reforming USAid in its controversial Project 2025 report, accusing it of spreading “climate extremism” and “gender radicalism”.
Musk acting with Trump’s backing
Trump has supported Musk’s aggressive approach to dismantling government agencies, confirming plans on Monday to shut down USAid and praising Musk as a “big cost cutter”. As backlash swelled and Democrats issued calls for action against Musk on Monday, Trump attempted to assuage some of the concerns and reassert that he was in charge.
“Elon can’t do and won’t do anything without our approval,” Trump said in the Oval Office. “We’ll give him approval where appropriate and where not appropriate we won’t.”
But there have been no public signs thus far that Trump has reined in Musk’s ambitions or prevented him from engaging in potential conflicts – he has many, as a number of his companies do extensive work with government agencies he now holds sway over. Several of Trump’s recent policy announcements also appeared to align with Musk’s worldview and personal grievances.
Trump declared on Monday that he would shut down all aid to South Africa, Musk’s country of birth, over what he alleged was a “massive human rights violation” in the form of a new land rights law. Musk has repeatedly accused the South African government of racism against white people and falsely claimed that the government is allowing a “genocide” against white farmers.
Another executive order from Trump on 31 January vowed to “unleash prosperity through deregulation” and declared that whenever a government agency issues a new regulation it must first remove 10 existing regulations. The order has echoed Musk’s longstanding calls for widespread deregulation of the federal government, which Musk reiterated in a livestream on Monday night on X, when he stated “regulations, basically, should be default gone”. He described the current administration as “our best shot” at this deregulation and “the best hand of cards we’re ever going to have”.
Musk has made sweeping and aggressive declarations about what else must change about the US government, indicating where he might strike next. He stated on Monday: “Activist judges must be removed from the bench or there is no justice,” and praised the representative Marjorie Taylor Greene for issuing calls for NPR and PBS to testify at a hearing about their operations. Greene, who is head of a “delivering on government efficiency” group within the House oversight committee that aims to support Musk’s efforts, accused the public media organizations of ideological bias – citing a PBS report that Musk “gave what appeared to be a fascist salute” during a speech last month.
It is uncertain what mechanisms may prevent further cuts by Musk. His immense influence coupled with his erratic behavior have made it difficult to quickly ascertain where the next axe may fall, such as on Monday when Musk claimed that a government agency that worked on a free IRS tax filing system was “deleted” while giving no further information. The agency’s program was still online as of Tuesday.
What is clear from Musk’s public statements is the intent to barrel ahead with accumulating more power over government agencies, while framing his crusade as an existential fight for the future of the country.
“It’s now or never,” the billionaire tweeted on Tuesday. “Your support is crucial to the success of the revolution of the people.”
Incredible things are happening already❗ 👀 🤔
Daily inspiration. Discover more photos at Just for Books…?
22 notes
·
View notes
Text

SCP-8077 : The Doll - Original File
CoD - TF141 - SCP!AU
SUMMARY : The first file written about The Doll, now labeled SCP-8077, after its retrieval by MTF Alpha-141.
WARNINGS : None.
Author's Note : Never thought I'd be brave enough to post this. But I hyper focused on SCP stuff for a while and was quite satisfied with this, and I thought it would be silly to let it rot in my files. So here you go.
I do not allow anyone to re-publish, re-use and/or translate my work, be it here or on any other platform, including AI.
CoD AUs - Masterlist
Main Masterlist
Previous

Item # : SCP-8077
Object Class : Euclid
Special Containment Procedures : SCP-8077 is to be kept within a three (3) by three point five (3.5) by two point five (2.5) meter square containment chamber, isolated from other SCPs to keep the specimen’s thirst for knowledge under control. The room is to be furnished with a desk, various writing utensils and a limited amount of books, which can be replaced upon request.
The walls of SCP-8077’s containment chamber are to be lined with soundproof drywall along with a three (3) millimeters thick isolation membrane. Access is to be ensured via a heavy and rigid steel containment door measuring one point three (1.3) by two (2) meters, built in order to close and lock itself automatically when not deliberately held open.
Despite these measures ensuring that SCP-8077’s containment chamber is soundproof, all personnel is required to be highly mindful of every word they might say when standing in its vicinity. It is advised to cease all conversation altogether when walking past this room to avoid any major slip-up that could lead to a containment breach.
Under no circumstances may any personnel be allowed to have any kind of conversation with SCP-8077 unless an experiment and/or interrogation is underway. No personnel outside of the Antimemetics Divison is permitted to conduct such procedures.
Description : SCP-8077 is an antimemetic entity taking the appearance of a one hundred and sixty (160) centimeters tall, female ball-jointed doll, seemingly made of white porcelain, with long, wavy black hair and pale green eyes. Highly intelligent, the entity constantly seeks to consume all kinds of information and knowledge, feeding off of it by writing it down on any surface available.
SCP-8077 has been discovered to erase pieces of information from its assigned Researchers’ memory after writing them down, an effect that had not been noticed in the various books it read and took data from. The subject’s abilities seem to be activated when the information or knowledge it consumes comes from someone standing within its hearing range.
Note : It does not matter whether the piece of information or knowledge is addressed directly to the entity or not.
Addendum : SCP-8077’s ability does not activate when taking notes from a recording.
An individual whose part of their knowledge was consumed by SCP-8077 will progressively remember it with time, or immediately if hearing, seeing or reading it, as if they never forgot about it in the first place.
When prevented from processing knowledge for an extended amount of time, a situation which first took place during the retrieval following the discovery of SCP-8077, the subject will first express confusion as to why, then gradually fall into a state akin to that of a panic attack. According to Agent Kyle « Gaz » Garrick of MTF Alpha-141, who was the first to notice SCP-8077’s abnormal behaviour, this panic manifests itself through a tendency to hide, fidget and faint sounds of whimpering that will grow into full crying. At the time, the specimen also questioned the members of the recovering team, not understanding why it was suddenly forbidden from writing anything.
The recovering team, once given the authorisation do to so after deeming the entity to be more and more unstable by the minute, managed to quickly de-escalate the situation by simply giving SCP-8077 a pen and paper, bringing it back to a peaceful state.
Previous
CoD AUs - Masterlist
Main Masterlist
#oc : the doll#call of duty#call of duty modern warfare#cod au#scp au#cod x oc#simon ghost riley#john soap mactavish#kyle gaz garrick#john price#captain price#cod mw2#tf141#tf141 x oc
31 notes
·
View notes
Text
KOSA Update
Following up on a previous post about the KOSA bill - a bill that would drastically change how the internet functions, in some ways enforcing the collection of private information and restricting access to educational material based on anyone’s belief that it might be harmful to children.
As of March 2024, the bill has gone through revision to reduce the ability to target marginalized communities. However, the language used in the bill is still broad and would be ultimately harmful to children and adult internet users.
Press releases like that of the American Civil Liberties Union invoke the First Amendment to highlight both the bill’s continued call for requiring or incentivizing age verification and its goal of censoring many different topics of conversation in online spaces.
If the U.S. government seeks to control, censor, and otherwise interfere with the world of the internet, then it would have to be a government program akin to public education or certain libraries. Let that government take over the responsibilities of running and funding the internet in that case if they want that power. Otherwise, the internet does not fall under federal jurisdiction.
In response to reaching out regarding this bill, one Congressman wrote that platforms like TikTok have come under scrutiny for “leaving users’ data vulnerable to access by the Chinese Communist Party, by collecting personal information on children in violation of federal law”. This Congressman does not state in this response whether he supports the KOSA bill in particular, but we hope that he is aware that this proposed bill would, by federal law, necessitate the collection of personal information of minors if websites are to follow its requirements. Additionally, TikTok’s data collection is comparable to that of other sites such as Instagram and Facebook, which are just as able to be infiltrated by political enemies of the U.S.
This update is not about the U.S. government’s ultimatum to the company ByteDance that will likely end in a U.S. ban on TikTok. Still, that news is relevant to internet users, especially those who value choice and self-determination.
In the aforementioned Congressman’s response, he also mentions the Privacy Enhancing Technology Research Act (H.R. 4755). That bill, passed in 2023, calls for organizations like the National Science Foundation to conduct and support research into technologies for mitigating privacy risks. Bills like this one are far more conducive to achieving online safety than the proposed KOSA bill. It seeks to enhance our understanding of data handling and online privacy, while the KOSA bill is more so blindly punching towards a problem that we do not yet have a clear view of.
As before, resources to further learn about and speak out against the bill are below.
Resources:
1.https://www.aclu.org/press-releases/revised-kids-online-safety-act-is-an-improvement-but-congress-must-still-address-first-amendment-concerns
2.https://www.eff.org/deeplinks/2024/02/dont-fall-latest-changes-dangerous-kids-online-safety-act
3. https://www.stopkosa.com/
4. Privacy Enhancing Technology Research Act
5. KOSA Bill Post-Revision6.https://www.eff.org/deeplinks/2024/03/analyzing-kosas-constitutional-problems-depth#
#kosa bill#stop kosa#kosa#politics#us politics#article#news#resources#first amendment#freedom of speech
90 notes
·
View notes
Text
Threats to Democracy in Brazil: The Rise of Technofeudalism and the Assault on Democratic Institutions

We are living in a time when threats to democracy emerge from multiple fronts. Some of these threats are traditional—such as corruption and political violence—but others are novel and particularly insidious, leveraging digital technologies to undermine democratic institutions in unprecedented ways. One such force is what Cédric Durand coined as technofeudalism, a new order in which digital monopolies accumulate power, wealth, and control over political discourse, exacerbating social inequalities and manipulating public perception to their advantage.
At the turn of the 21st century, the rise of information technology brought great hope for decentralization, innovation, and democratization. The internet was hailed as a tool that would empower individuals, allowing them to access knowledge, connect across borders, and engage in civic participation. However, instead of delivering on these promises, the so-called “digital revolution” has created a landscape dominated by corporate monopolies, where a handful of platforms control the vast majority of information, economic transactions, and even social interactions.
This is the essence of technofeudalism: an economic system where control over data and digital infrastructure is concentrated in the hands of a few corporate actors—Google, Amazon, Meta, and Microsoft—who act as modern-day feudal lords. Unlike traditional market capitalism, where businesses compete for customers, these platforms do not simply participate in the economy; they own it. Users are not merely consumers but digital subjects who must pay rent—either through direct fees or by extracting their personal data—to access basic services.
In Brazil, this dynamic is particularly dangerous. As a country that has long struggled with economic inequality and institutional fragility, the rise of technofeudalism presents a severe challenge to sovereignty, democracy, and social justice. With digital platforms acting as arbiters of truth, political engagement, and economic opportunity, we must ask ourselves: Who controls Brazil’s democracy in the digital age? This question is motivated by five major threats.
Continue reading.
#brazil#brazilian politics#politics#democracy#social media#image description in alt#mod nise da silveira
19 notes
·
View notes