#apachekafka
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
12.7% of mobile users access Tumblr.
Text


Getting old is interesting. I've always been a middle ground between sports (skateboarding, surfing, jiu-jitsu) and an avid student. Over time, it's clear that you can't keep trying the same tricks, just as you can't study the same way.
Today, as I'm writing an article about event-driven architectures, I realize that final exams in college were much easier, just like it's not as easy to jump the same stairs on a skateboard as I did when I was 18. In the image, you can see my favorite note-taking app, Obsidian, and my Neovim terminal. I'm diving deep into Java, and for that, I'm taking a Spring Boot bootcamp offered by Claro through the DIO Innovation One platform.
#coding#linux#developer#programming#programmer#software#software development#student#study aesthetic#study blog#studyblr#studying#studentlife#studentlearning#masterdegree#master degree#softwareengineering#softwareengineer#study motivation#studyblr community#brazil#java#javaprogramming#apachekafka#self improvement#self study#study inspiration#room#room decor#dark academia
171 notes
·
View notes
Text







#DidYouKnow These Middleware Platforms?
Swipe left to explore!
💻 Explore insights on the latest in #technology on our Blog Page 👉 https://simplelogic-it.com/blogs/
🚀 Ready for your next career move? Check out our #careers page for exciting opportunities 👉 https://simplelogic-it.com/careers/
#didyouknowfacts#knowledgedrop#interestingfacts#factoftheday#learnsomethingneweveryday#mindblown#middleware#middlewareservices#middlewaretools#jboss#jbosseap#apachekafka#ibmwebsphere#tibco#oracleweblogic#redhat#api#data#didyouknowthat#triviatime#makingitsimple#learnsomethingnew#simplelogicit#simplelogic#makeitsimple
0 notes
Text

Kafka Vs. RabbitMQ . . . . for more information and tutorial https://bit.ly/3E0tWZu check the above link
0 notes
Text
tecnologías, proyectos y beneficios potenciales empresas Ibex35
Propuesta de Valor: Propuesta que busca integrar de manera más profunda los conceptos y ofrecer una visión más práctica y estratégica de cómo las empresas del IBEX 35 podrían estar aprovechando estas tecnologías: Matriz de Relación: Tecnologías, Proyectos y Beneficios Potenciales TecnologíaProyectoBeneficios PotencialesEmpresas IBEX 35 Ejemplos (Hipotéticos)Business Intelligence (Power BI,…
#alation#analisisdeclientes#analiticadedatos#apachekafka#aws#BBVA#BigData#businessintelligence#cienciadedatos#collibra#corporaciones#costes#d3js#dataanalysis#dataengineering#datagovernance#datascience#datavisualization#datos#desarrollodenuevosproductos#detecciondefraud#eficiencia#empresa#googlebigquery#hadoop#iberdrola#IBEX35#INDITEX#industria40#informacion
0 notes
Text
BigQuery Engine For Apache Flink: Fully Serverless Flink
The goal of today’s companies is to become “by-the-second” enterprises that can quickly adjust to shifts in their inventory, supply chain, consumer behavior, and other areas. Additionally, they aim to deliver outstanding customer experiences, whether it is via online checkout or support interactions. All businesses, regardless of size or budget, should have access to real-time intelligence, in opinion, and it should be linked into a single data platform so that everything functions as a whole. With the release of BigQuery Engine for Apache Flink in preview today, we’re making significant progress in assisting companies in achieving these goals.
BigQuery Engine for Apache Flink
Construct and operate applications that are capable of real-time streaming by utilizing a fully managed Flink service that is linked with BigQuery.
Features
Update your unified data and AI platform with real-time data
Using a scalable and well-integrated streaming platform built on the well-known Apache Flink and Apache Kafka technologies, make business decisions based on real-time insights. You can fully utilize your data when paired with Google’s unique AI/ML capabilities in BigQuery. With built-in security and governance, you can scale efficiently and iterate quickly without being constrained by infrastructure management.
Use a serverless Flink engine to save time and money
Businesses use Google Cloud to develop streaming apps in order to benefit from real-time data. The operational strain of administering self-managed Flink, optimizing innumerable configurations, satisfying the demands of various workloads while controlling expenses, and staying up to date with updates, however, frequently weighs them down. The serverless nature of BigQuery Engine for Apache Flink eases this operational load and frees its clients to concentrate on their core competencies, which include business innovation.
Compatible with Apache Flink, an open source project
Without rewriting code or depending on outside services, BigQuery Engine for Apache Flink facilitates the lifting and migration of current streaming applications that use the free source Apache Flink framework to Google Cloud. Modernizing and migrating your streaming analytics on Google Cloud is simple when you combine it with Google Managed Service for Apache Kafka (now GA).
Streamling ETL
ETL streaming for your data platform that is AI-ready
An open and adaptable framework for real-time ETL is offered by Apache Flink, which enables you to ingest data streams from sources like as Kafka, carry out transformations, and then immediately load them into BigQuery for analysis and storage. With the advantages of open source extensibility and adaptation to various data sources, this facilitates quick data analysis and quicker decision-making.
Create applications that are event-driven
Event-driven apps assist businesses with marketing personalization, recommendation engines, fraud detection models, and other issues. The managed Apache Kafka service from Google Cloud can be used to record real-time event streams from several sources, such as user activity or payments. These streams are subsequently processed by the Apache Flink engine with minimal latency, allowing for sophisticated tasks like real-time processing.
Build a real-time data and AI platform
Apache’s BigQuery Engine You may use Flink for stream analytics without having to worry about infrastructure management. Use the SQL or DataStream APIs in Flink to analyze data in real time. Stream your data to BigQuery and link it to visualization tools to create dashboards. Use Flink’s libraries for streaming machine learning and keep an eye on work performance.
The cutting-edge real-time intelligence platform offered by BigQuery Engine for Apache Flink enables users to:
Utilize Google Cloud‘s well-known streaming technology. Without rewriting code or depending on outside services, BigQuery Engine for Apache Flink facilitates the lifting and migration of current streaming applications that use the open-source Apache Flink framework to Google Cloud. Modernizing and migrating your streaming analytics on Google Cloud is simple when you combine it with Google Managed Service for Apache Kafka (now GA).
Lessen the strain on operations. Because BigQuery Engine for Apache Flink is completely serverless, it lessens operational load and frees up clients to concentrate on their core competencies innovating their businesses.
Give AI real-time data. A scalable and well-integrated streaming platform built on the well-known Apache Flink and Apache Kafka technologies that can be combined with Google’s unique AI/ML capabilities in BigQuery is what enterprise developers experimenting with gen AI are searching for.
With the arrival of BigQuery Engine for Apache Flink, Google Cloud customers are taking advantage of numerous real-time analytics innovations, such as BigQuery continuous queries, which allow users to use SQL to analyze incoming data in BigQuery in real-time, and Dataflow Job Builder, which assists users in defining and implementing a streaming pipeline through a visual user interface.
Google cloud streaming offering now includes popular open-source Flink and Kafka systems, SQL-based easy streaming with BigQuery continuous queries, and sophisticated multimodal data streaming with Dataflow, including support for Iceberg, thanks to BigQuery Engine for Apache Flink. These features are combined with BigQuery, which links your data to top AI tools in the market, such as Gemma, Gemini, and open models.
New AI capabilities unlocked when your data is real-time
It is evident that generative AI has rekindled curiosity about the possibilities of data-driven experiences and insights as a turn to the future. When AI, particularly generative AI, has access to the most recent context, it performs best. Retailers can customize their consumers’ purchasing experiences by fusing real-time interactions with historical purchase data. If your business provides financial services, you can improve your fraud detection model by using real-time transactions. Fresh data for model training, real-time user support through Retrieval Augmented Generation (RAG), and real-time predictions and inferences for your business applications including incorporating tiny models like Gemma into your streaming pipelines are all made possible by real-time data coupled to AI.
In order to enable real-time data for your future AI use cases, it is adopting a platform approach to introduce capabilities across the board, regardless of the particular streaming architecture you want or the streaming engine you select. Building real-time AI applications is now easier than ever with to features like distributed counting in Bigtable, the RunInference transform, support for Vertex AI text-embeddings, Dataflow enrichment transforms, and many more.
When it comes to enabling your unified data and AI platform to function in real-time data, Google cloud are thrilled to put these capabilities in your hands and keep providing you with additional options and flexibility. Get started utilizing BigQuery Engine for Apache Flink right now in the Google Cloud console by learning more about it.
Read more on Govindhtech.com
#BigQuery#BigQueryEngine#ApacheFlink#AI#SQL#ApacheKafka#generativeAI#cloudcomputing#VertexAI#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Text
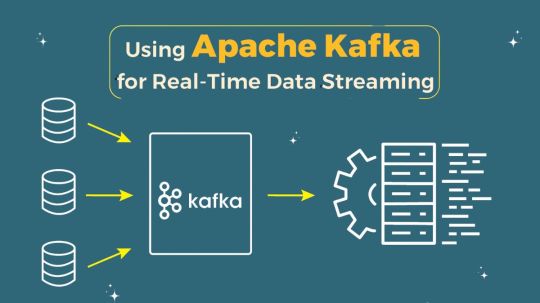
Apache Kafka Developers & Consulting Partner | Powering Real-Time Data Streams

In today's fast-paced digital landscape, the ability to process and analyze data in real-time is crucial for businesses seeking to gain a competitive edge. Apache Kafka, an open-source stream-processing platform, has emerged as a leading solution for handling real-time data feeds, enabling organizations to build robust, scalable, and high-throughput systems. Whether you're a startup looking to manage massive data streams or an enterprise aiming to enhance your data processing capabilities, partnering with experienced Apache Kafka developers and consulting experts can make all the difference.
Why Apache Kafka?
Apache Kafka is designed to handle large volumes of data in real-time. It acts as a central hub that streams data between various systems, ensuring that information flows seamlessly and efficiently across an organization. With its distributed architecture, Kafka provides fault-tolerance, scalability, and durability, making it an ideal choice for mission-critical applications.
Businesses across industries are leveraging Kafka for use cases such as:
Real-Time Analytics: By capturing and processing data as it arrives, businesses can gain insights and make decisions on the fly, enhancing their responsiveness and competitiveness.
Event-Driven Architectures: Kafka enables the creation of event-driven systems where data-driven events trigger specific actions, automating processes and reducing latency.
Data Integration: Kafka serves as a bridge between different data systems, ensuring seamless data flow and integration across the enterprise.
The Role of Apache Kafka Developers
Expert Apache Kafka developers bring a wealth of experience in building and optimizing Kafka-based systems. They possess deep knowledge of Kafka's core components, such as producers, consumers, and brokers, and understand how to configure and tune these elements for maximum performance. Whether you're setting up a new Kafka cluster, integrating Kafka with other systems, or optimizing an existing setup, skilled developers can ensure that your Kafka deployment meets your business objectives.
Key responsibilities of Apache Kafka developers include:
Kafka Cluster Setup and Management: Designing and deploying Kafka clusters tailored to your specific needs, ensuring scalability, fault-tolerance, and optimal performance.
Data Pipeline Development: Building robust data pipelines that efficiently stream data from various sources into Kafka, ensuring data integrity and consistency.
Performance Optimization: Fine-tuning Kafka configurations to achieve high throughput, low latency, and efficient resource utilization.
Monitoring and Troubleshooting: Implementing monitoring solutions to track Kafka's performance and swiftly addressing any issues that arise.
Why Partner with an Apache Kafka Consulting Expert?
While Apache Kafka is a powerful tool, its complexity can pose challenges for organizations lacking in-house expertise. This is where partnering with an Apache Kafka consulting expert, like Feathersoft Inc Solution, can be invaluable. A consulting partner brings a deep understanding of Kafka's intricacies and can provide tailored solutions that align with your business goals.
By working with a consulting partner, you can benefit from:
Custom Solutions: Consulting experts analyze your specific requirements and design Kafka solutions that are tailored to your unique business needs.
Best Practices: Leverage industry best practices to ensure your Kafka deployment is secure, scalable, and efficient.
Training and Support: Empower your team with the knowledge and skills needed to manage and maintain Kafka systems through comprehensive training and ongoing support.
Cost Efficiency: Optimize your Kafka investment by avoiding common pitfalls and ensuring that your deployment is cost-effective and aligned with your budget.
Conclusion
Apache Kafka has revolutionized the way businesses handle real-time data, offering unparalleled scalability, reliability, and speed. However, unlocking the full potential of Kafka requires specialized expertise. Whether you're just starting with Kafka or looking to optimize an existing deployment, partnering with experienced Apache Kafka developers and a consulting partner like Feathersoft Inc Solution can help you achieve your goals. With the right guidance and support, you can harness the power of Kafka to drive innovation, streamline operations, and stay ahead of the competition.
#ApacheKafka#RealTimeData#DataStreaming#KafkaDevelopment#BigData#DataIntegration#EventDrivenArchitecture#DataEngineering#ConsultingServices#TechInnovation#DataSolutions#feathersoft
1 note
·
View note
Link
0 notes
Text
🚀 Exploring Kafka: Scenario-Based Questions 📊
Dear community, As Kafka continues to shape modern data architectures, it's crucial for professionals to delve into scenario-based questions to deepen their understanding and application. Whether you're a seasoned Kafka developer or just starting out, here are some key scenarios to ponder: 1️⃣ **Scaling Challenges**: How would you design a Kafka cluster to handle a sudden surge in incoming data without compromising latency? 2️⃣ **Fault Tolerance**: Describe the steps you would take to ensure high availability in a Kafka setup, considering both hardware and software failures. 3️⃣ **Performance Tuning**: What metrics would you monitor to optimize Kafka producer and consumer performance in a high-throughput environment? 4️⃣ **Security Measures**: How do you secure Kafka clusters against unauthorized access and data breaches? What are some best practices? 5️⃣ **Integration with Ecosystem**: Discuss a real-world scenario where Kafka is integrated with other technologies like Spark, Hadoop, or Elasticsearch. What challenges did you face and how did you overcome them? Follow : https://algo2ace.com/kafka-stream-scenario-based-interview-questions/
#Kafka #BigData #DataEngineering #TechQuestions #ApacheKafka #BigData #Interview
2 notes
·
View notes
Text

Today I have an merge conflict plus a deploy error in my link in bio app which is deployed in Fly io. Not big deal, just came out that was auth error in deployment, but about the merge conflict was a little bit more than a few lines.
#studyspo#study aesthetic#study#coding#developer#linux#programmer#programming#software#software development#study blog#student#studyblr#studyblr community#studblr#studies#studying#study motivation#self improvement#java#apachekafka#software engineering#swe#brasil#brazil#university student#notebook#laptop#room
71 notes
·
View notes
Text







DidYouKnow
Boost Your Cloud Efficiency with These Tools☁️⚙️
Swipe left to explore!
💻 Explore insights on the latest in #technology on our Blog Page 👉 https://simplelogic-it.com/blogs/
🚀 Ready for your next career move? Check out our #careers page for exciting opportunities 👉 https://simplelogic-it.com/careers/
#didyouknowfacts#knowledgedrop#interestingfacts#factoftheday#learnsomethingneweveryday#mindblown#Linix#kubernetes#postgressql#apachekafka#redis#opensource#didyouknowthat#triviatime#makingitsimple#learnsomethingnew#simplelogicit#simplelogic#makeitsimple
0 notes
Text

What is RabbitMQ? . . . . for more information and tutorial https://bit.ly/4ioOeeI check the above link
0 notes
Photo

Reinvent your Business with Apache Kafka Distributed Streaming Platform
#ksolves#apachekafka#Apache Kafka Development Company#Apache Kafka Experts in India#Apache Kafka Development Services#apache kafka#apache kafka experts in usa#apache kafka experts#apache kafka services#apache kafka stream processing#apache kafka services in india#apache kafka services in usa#apache kafka strategy
0 notes
Text
Deep Dive Into API Connect IBM & Event Endpoint Management

API Connect IBM
APIs enable smooth system communication since real-time data processing and integration are more important than ever. IBM Event Automation‘s continued support of the open-source AsyncAPI specification enables enterprises to integrate the requirements for real-time events and APIs. This solution is made to assist companies create comprehensive event-driven connections while satisfying the increasing demand for efficient API management and governance. It also enables other integration systems to use Apache Kafka to ingest events with increased composability.
By combining IBM Event Automation and API Connect IBM, businesses can effectively handle API lifecycles in addition to Kafka events. The objective is to assist companies in developing robust event-driven architectures (EDA), which can be difficult because vendor neutrality and standards are required. Organizations are able to handle events, integrate systems, and process data faster in real time with IBM Event Automation, which helps to streamline this process.
Connecting events with APIs
Managing massive volumes of data created in real-time while maintaining flawless system communication is a challenge for organizations. Event-driven architectures and API-centric models are growing due to business agility, efficiency, and resilience. As businesses use real-time data increasingly, they need quick insights to make smart decisions.
Organizations are better able to respond to client demands and market shifts when they combine event streams and APIs to process and act on data instantaneously.
The complexity of managing a large number of APIs and event streams rises. Handling APIs and event streams independently presents a lot of difficulties for organizations, which can result in inefficiencies, poor visibility, and disjointed development processes. In the end, companies are losing out on chances to meet consumer needs and provide the best possible client experiences.
Organizations can manage and administer their APIs and events with a unified experience with the integration between Event Endpoint Management and API Connect IBM. Organizations are able to leverage real-time insights and optimize their data processing capabilities by combining API Connect and Event Endpoint Management to meet the increasing demand for event-driven architectures and API-centric data.
IBM API Connect
Important advantages of integrating IBM API Connect and IBM Event Automation
The following are the main advantages that an organization can have by utilizing the Event Endpoint Management and API Connect integration:
Unified platform for managing events and APIs
The integration eliminates the hassle of juggling several management tools by providing a unified platform for managing events and APIs. The cohesive strategy streamlines governance and improves operational effectiveness.
Improved visibility and monitoring
By receiving real-time data on API requests and event streams, organizations may better monitor and take proactive measures in management.
Enhanced governance
Sturdy governance structure that guarantees events and APIs follow organizational guidelines and regulations.
Efficient event-driven architecture
Improving customer experiences and operational efficiency by simplifying the development of responsive systems that respond instantly to data changes. Developing and implementing event-driven systems that respond instantly to changes in data is easier for organizations.
Scalability
Managing several APIs and Kafka events from a single interface that can expand along with your company without compromising management or performance.
Strong security measures
To guarantee safe data communication, combine event access controls in EEM with API security management.
Flexible implementations
Microservices, Internet of Things applications, and data streaming are just a few of the use cases that the integration supports. It is flexible enough to adjust to changing company needs and technology developments. Businesses can use the adaptability to develop creative solutions.
Developers within an organization that need to construct apps that use both events and APIs can benefit from the multiform API management solution that is offered by integrating Event Endpoint Management with API Connect IBM. Developers can find and integrate APIs and events more easily thanks to the unified platform experience, which also lowers complexity and boosts productivity. Developers can now create responsive and effective solutions that fully utilize real-time data by iterating more quickly and creating more integrated application experiences.
Think back to the retailer who wanted to streamline their supply chain. With APIs and events, a developer can build a responsive system that improves the effectiveness of decision-making. This integration gives the company the ability to enhance customer experiences and operational agility while also enabling data-driven plans that leverage real-time information. Real-time data enables businesses to promptly modify their inventory levels and marketing methods in response to spikes in consumer demand. This results in more sales and happier customers. This aids the company in staying one step ahead of its rivals in a market that is constantly changing.
API Management
An important step forward in efficiently managing APIs and event streams is represented by the integration of Event Endpoint Management and API connect, which will aid businesses in their digital transformation initiatives.
Read more on govindhtech.com
#DeepDiveIntoAPI#ConnectIBM#ApacheKafka#EventEndpointManagement#IBMEventAutomation#AsyncAPIspecification#IBMAPIConnect#APIsecurity#supplychain#APIManagement#ibm#technology#technews#news#govindhtech
1 note
·
View note
Photo

Be studious in your profession, and you will be learned. Be industrious and frugal, and you will be experienced...... Meet the new Confluent Administrator for Apache Kafka 🌐🔱🥇🏆🌐 @gauravsolanki84 👏🏼👏🏼👏🏼🤩 . . . . . . . #saturdayspecial #knowledgeispower💫 #leadbyexample #hardworkersonly #l4l #keepflying #thenewleader #directorships #likeforlikes #leadtheroles #globalleads #kafkaworld #apachekafka #confluentcertification #followyour❤️ #agexplorers #getsetgo #goglobal #panearthteams #administratorleaders (at Watford, United Kingdom) https://www.instagram.com/p/CJ1V1s2n_mC/?igshid=1nbys9rqpins0
#saturdayspecial#knowledgeispower💫#leadbyexample#hardworkersonly#l4l#keepflying#thenewleader#directorships#likeforlikes#leadtheroles#globalleads#kafkaworld#apachekafka#confluentcertification#followyour❤️#agexplorers#getsetgo#goglobal#panearthteams#administratorleaders
0 notes
Photo

5 Things about Event-Driven #API's and #ApacheKafka http://bit.ly/2sAdXgB APIs are becoming the crux of any digital business today. They provide a multitude of internal and external uses, including making B2B connections and linking building blocks for low-code application development and event-driven thinking. Digital business can’t exist without event-driven thinking. There are real benefits to developing event-driven apps and architecture—to provide a more responsive and scalable customer experience. Your digital business requires new thinking. New tools are required to adopt event-driven architecture. This includes being able to implement tools such as Kafka, Project Flogo®, and event-driven APIs. That said, if you’re not adopting event-driven APIs, you’re leaving revenue, innovation, and customer engagement opportunities on the table. Here are five things to know about how Kafka and event-driven APIs that can benefit your business. #Fintech #Insurtech #Wealthtech #OpenBanking #PSD2 #payment #Cybersecurity (hier: Zürich, Switzerland) https://www.instagram.com/p/B7L97HOA8iX/?igshid=1x8bjistwsd7e
0 notes