#aws lambda event trigger
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was the first site to host the blog for President Barack Obama in 2011.
Text
AWS Lambda Compute Service Tutorial for Amazon Cloud Developers
Full Video Link - https://youtube.com/shorts/QmQOWR_aiNI Hi, a new #video #tutorial on #aws #lambda #awslambda is published on #codeonedigest #youtube channel. @java @awscloud @AWSCloudIndia @YouTube #youtube @codeonedigest #codeonedigest #aws #amaz
AWS Lambda is a serverless compute service that runs your code in response to events and automatically manages the underlying compute resources for you. These events may include changes in state such as a user placing an item in a shopping cart on an ecommerce website. AWS Lambda automatically runs code in response to multiple events, such as HTTP requests via Amazon API Gateway, modifications…

View On WordPress
#amazon lambda java example#aws#aws cloud#aws lambda#aws lambda api gateway#aws lambda api gateway trigger#aws lambda basic#aws lambda code#aws lambda configuration#aws lambda developer#aws lambda event trigger#aws lambda eventbridge#aws lambda example#aws lambda function#aws lambda function example#aws lambda function s3 trigger#aws lambda java#aws lambda server#aws lambda service#aws lambda tutorial#aws training#aws tutorial#lambda service
0 notes
Text
Mastering AWS DevOps in 2025: Best Practices, Tools, and Real-World Use Cases
In 2025, the cloud ecosystem continues to grow very rapidly. Organizations of every size are embracing AWS DevOps to automate software delivery, improve security, and scale business efficiently. Mastering AWS DevOps means knowing the optimal combination of tools, best practices, and real-world use cases that deliver success in production.
This guide will assist you in discovering the most important elements of AWS DevOps, the best practices of 2025, and real-world examples of how top companies are leveraging AWS DevOps to compete.
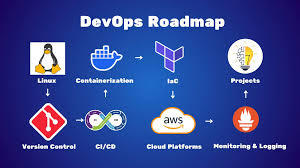
What is AWS DevOps
AWS DevOps is the union of cultural principles, practices, and tools on Amazon Web Services that enhances an organization's capacity to deliver applications and services at a higher speed. It facilitates continuous integration, continuous delivery, infrastructure as code, monitoring, and cooperation among development and operations teams.
Why AWS DevOps is Important in 2025
As organizations require quicker innovation and zero downtime, DevOps on AWS offers the flexibility and reliability to compete. Trends such as AI integration, serverless architecture, and automated compliance are changing how teams adopt DevOps in 2025.
Advantages of adopting AWS DevOps:
1 Faster deployment cycles
2 Enhanced system reliability
3 Flexible and scalable cloud infrastructure
4 Automation from code to production
5 Integrated security and compliance
Best AWS DevOps Tools to Learn in 2025
These are the most critical tools fueling current AWS DevOps pipelines:
AWS CodePipeline
Your release process can be automated with our fully managed CI/CD service.
AWS CodeBuild
Scalable build service for creating ready-to-deploy packages, testing, and building source code.
AWS CodeDeploy
Automates code deployments to EC2, Lambda, ECS, or on-prem servers with zero-downtime approaches.
AWS CloudFormation and CDK
For infrastructure as code (IaC) management, allowing repeatable and versioned cloud environments.
Amazon CloudWatch
Facilitates logging, metrics, and alerting to track application and infrastructure performance.
AWS Lambda
Serverless compute that runs code in response to triggers, well-suited for event-driven DevOps automation.
AWS DevOps Best Practices in 2025
1. Adopt Infrastructure as Code (IaC)
Utilize AWS CloudFormation or Terraform to declare infrastructure. This makes it repeatable, easier to collaborate on, and version-able.
2. Use Full CI/CD Pipelines
Implement tools such as CodePipeline, GitHub Actions, or Jenkins on AWS to automate deployment, testing, and building.
3. Shift Left on Security
Bake security in early with Amazon Inspector, CodeGuru, and Secrets Manager. As part of CI/CD, automate vulnerability scans.
4. Monitor Everything
Utilize CloudWatch, X-Ray, and CloudTrail to achieve complete observability into your system. Implement alerts to detect and respond to problems promptly.
5. Use Containers and Serverless for Scalability
Utilize Amazon ECS, EKS, or Lambda for autoscaling. These services lower infrastructure management overhead and enhance efficiency.
Real-World AWS DevOps Use Cases
Use Case 1: Scalable CI/CD for a Fintech Startup
AWS CodePipeline and CodeDeploy were used by a financial firm to automate deployments in both production and staging environments. By containerizing using ECS and taking advantage of CloudWatch monitoring, they lowered deployment mistakes by 80 percent and attained near-zero downtime.
Use Case 2: Legacy Modernization for an Enterprise
A legacy enterprise moved its on-premise applications to AWS with CloudFormation and EC2 Auto Scaling. Through the adoption of full-stack DevOps pipelines and the transformation to microservices with EKS, they enhanced time-to-market by 60 percent.
Use Case 3: Serverless DevOps for a SaaS Product
A SaaS organization utilized AWS Lambda and API Gateway for their backend functions. They implemented quick feature releases and automatically scaled during high usage without having to provision infrastructure using CodeBuild and CloudWatch.
Top Trends in AWS DevOps in 2025
AI-driven DevOps: Integration with CodeWhisperer, CodeGuru, and machine learning algorithms for intelligence-driven automation
Compliance-as-Code: Governance policies automated using services such as AWS Config and Service Control Policies
Multi-account strategies: Employing AWS Organizations for scalable, secure account management
Zero Trust Architecture: Implementing strict identity-based access with IAM, SSO, and MFA
Hybrid Cloud DevOps: Connecting on-premises systems to AWS for effortless deployments
Conclusion
In 2025, becoming a master of AWS DevOps means syncing your development workflows with cloud-native architecture, innovative tools, and current best practices. With AWS, teams are able to create secure, scalable, and automated systems that release value at an unprecedented rate.
Begin with automating your pipelines, securing your deployments, and scaling with confidence. DevOps is the way of the future, and AWS is leading the way.
Frequently Asked Questions
What distinguishes AWS DevOps from DevOps? While AWS DevOps uses AWS services and tools to execute DevOps, DevOps itself is a practice.
Can small teams benefit from AWS DevOps
Yes. AWS provides fully managed services that enable small teams to scale and automate without having to handle complicated infrastructure.
Which programming languages does AWS DevOps support
AWS supports the big ones - Python, Node.js, Java, Go, .NET, Ruby, and many more.
Is AWS DevOps for enterprise-scale applications
Yes. Large enterprises run large-scale, multi-region applications with millions of users using AWS DevOps.
1 note
·
View note
Text
Introduction: The Evolution of Web Scraping
Traditional Web Scraping involves deploying scrapers on dedicated servers or local machines, using tools like Python, BeautifulSoup, and Selenium. While effective for small-scale tasks, these methods require constant monitoring, manual scaling, and significant infrastructure management. Developers often need to handle cron jobs, storage, IP rotation, and failover mechanisms themselves. Any sudden spike in demand could result in performance bottlenecks or downtime. As businesses grow, these challenges make traditional scraping harder to maintain. This is where new-age, cloud-based approaches like Serverless Web Scraping emerge as efficient alternatives, helping automate, scale, and streamline data extraction.

Challenges of Manual Scraper Deployment (Scaling, Infrastructure, Cost)
Manual scraper deployment comes with numerous operational challenges. Scaling scrapers to handle large datasets or traffic spikes requires robust infrastructure and resource allocation. Managing servers involves ongoing costs, including hosting, maintenance, load balancing, and monitoring. Additionally, handling failures, retries, and scheduling manually can lead to downtime or missed data. These issues slow down development and increase overhead. In contrast, Serverless Web Scraping removes the need for dedicated servers by running scraping tasks on platforms like AWS Lambda, Azure Functions, and Google Cloud Functions, offering auto-scaling and cost-efficiency on a pay-per-use model.
Introduction to Serverless Web Scraping as a Game-Changer

What is Serverless Web Scraping?
Serverless Web Scraping refers to the process of extracting data from websites using cloud-based, event-driven architecture, without the need to manage underlying servers. In cloud computing, "serverless" means the cloud provider automatically handles infrastructure scaling, provisioning, and resource allocation. This enables developers to focus purely on writing the logic of Data Collection, while the platform takes care of execution.
Popular Cloud Providers like AWS Lambda, Azure Functions, and Google Cloud Functions offer robust platforms for deploying these scraping tasks. Developers write small, stateless functions that are triggered by events such as HTTP requests, file uploads, or scheduled intervals—referred to as Scheduled Scraping and Event-Based Triggers. These functions are executed in isolated containers, providing secure, cost-effective, and on-demand scraping capabilities.
The core advantage is Lightweight Data Extraction. Instead of running a full scraper continuously on a server, serverless functions only execute when needed—making them highly efficient. Use cases include:
Scheduled Scraping (e.g., extracting prices every 6 hours)
Real-time scraping triggered by user queries
API-less extraction where data is not available via public APIs
These functionalities allow businesses to collect data at scale without investing in infrastructure or DevOps.
Key Benefits of Serverless Web Scraping
Scalability on Demand
One of the strongest advantages of Serverless Web Scraping is its ability to scale automatically. When using Cloud Providers like AWS Lambda, Azure Functions, or Google Cloud Functions, your scraping tasks can scale from a few requests to thousands instantly—without any manual intervention. For example, an e-commerce brand tracking product listings during flash sales can instantly scale their Data Collection tasks to accommodate massive price updates across multiple platforms in real time.
Cost-Effectiveness (Pay-as-You-Go Model)
Traditional Web Scraping involves paying for full-time servers, regardless of usage. With serverless solutions, you only pay for the time your code is running. This pay-as-you-go model significantly reduces costs, especially for intermittent scraping tasks. For instance, a marketing agency running weekly Scheduled Scraping to track keyword rankings or competitor ads will only be billed for those brief executions—making Serverless Web Scraping extremely budget-friendly.
Zero Server Maintenance
Server management can be tedious and resource-intensive, especially when deploying at scale. Serverless frameworks eliminate the need for provisioning, patching, or maintaining infrastructure. A developer scraping real estate listings no longer needs to manage server health or uptime. Instead, they focus solely on writing scraping logic, while Cloud Providers handle the backend processes, ensuring smooth, uninterrupted Lightweight Data Extraction.
Improved Reliability and Automation
Using Event-Based Triggers (like new data uploads, emails, or HTTP calls), serverless scraping functions can be scheduled or executed automatically based on specific events. This guarantees better uptime and reduces the likelihood of missing important updates. For example, Azure Functions can be triggered every time a CSV file is uploaded to the cloud, automating the Data Collection pipeline.
Environmentally Efficient
Traditional servers consume energy 24/7, regardless of activity. Serverless environments run functions only when needed, minimizing energy usage and environmental impact. This makes Serverless Web Scraping an eco-friendly option. Businesses concerned with sustainability can reduce their carbon footprint while efficiently extracting vital business intelligence.

Ideal Use Cases for Serverless Web Scraping
1. Market and Price Monitoring
Serverless Web Scraping enables retailers and analysts to monitor competitor prices in real-time using Scheduled Scraping or Event-Based Triggers.
Example:
A fashion retailer uses AWS Lambda to scrape competitor pricing data every 4 hours. This allows dynamic pricing updates without maintaining any servers, leading to a 30% improvement in pricing competitiveness and a 12% uplift in revenue.
2. E-commerce Product Data Collection
Collect structured product information (SKUs, availability, images, etc.) from multiple e-commerce platforms using Lightweight Data Extraction methods via serverless setups.
Example:
An online electronics aggregator uses Google Cloud Functions to scrape product specs and availability across 50+ vendors daily. By automating Data Collection, they reduce manual data entry costs by 80%.
3. Real-Time News and Sentiment Tracking
Use Web Scraping to monitor breaking news or updates relevant to your industry and feed it into dashboards or sentiment engines.
Example:
A fintech firm uses Azure Functions to scrape financial news from Bloomberg and CNBC every 5 minutes. The data is piped into a sentiment analysis engine, helping traders act faster based on market sentiment—cutting reaction time by 40%.
4. Social Media Trend Analysis
Track hashtags, mentions, and viral content in real time across platforms like Twitter, Instagram, or Reddit using Serverless Web Scraping.
Example:
A digital marketing agency leverages AWS Lambda to scrape trending hashtags and influencer posts during product launches. This real-time Data Collection enables live campaign adjustments, improving engagement by 25%.
5. Mobile App Backend Scraping Using Mobile App Scraping Services
Extract backend content and APIs from mobile apps using Mobile App Scraping Services hosted via Cloud Providers.
Example:
A food delivery startup uses Google Cloud Functions to scrape menu availability and pricing data from a competitor’s app every 15 minutes. This helps optimize their own platform in real-time, improving response speed and user satisfaction.
Technical Workflow of a Serverless Scraper
In this section, we’ll outline how a Lambda-based scraper works and how to integrate it with Web Scraping API Services and cloud triggers.
1. Step-by-Step on How a Typical Lambda-Based Scraper Functions
A Lambda-based scraper runs serverless functions that handle the data extraction process. Here’s a step-by-step workflow for a typical AWS Lambda-based scraper:
Step 1: Function Trigger
Lambda functions can be triggered by various events. Common triggers include API calls, file uploads, or scheduled intervals.
For example, a scraper function can be triggered by a cron job or a Scheduled Scraping event.
Example Lambda Trigger Code:
Lambda functionis triggered based on a schedule (using EventBridge or CloudWatch).
requests.getfetches the web page.
BeautifulSoupprocesses the HTML to extract relevant data.
Step 2: Data Collection
After triggering the Lambda function, the scraper fetches data from the targeted website. Data extraction logic is handled in the function using tools like BeautifulSoup or Selenium.
Step 3: Data Storage/Transmission
After collecting data, the scraper stores or transmits the results:
Save data to AWS S3 for storage.
Push data to an API for further processing.
Store results in a database like Amazon DynamoDB.
2. Integration with Web Scraping API Services
Lambda can be used to call external Web Scraping API Services to handle more complex scraping tasks, such as bypassing captchas, managing proxies, and rotating IPs.
For instance, if you're using a service like ScrapingBee or ScraperAPI, the Lambda function can make an API call to fetch data.
Example: Integrating Web Scraping API Services
In this case, ScrapingBee handles the web scraping complexities, and Lambda simply calls their API.
3. Using Cloud Triggers and Events
Lambda functions can be triggered in multiple ways based on events. Here are some examples of triggers used in Serverless Web Scraping:
Scheduled Scraping (Cron Jobs Cron Jobs):
You can use AWS EventBridge or CloudWatch Events to schedule your Lambda function to run at specific intervals (e.g., every hour, daily, or weekly).
Example: CloudWatch Event Rule (cron job) for Scheduled Scraping:
This will trigger the Lambda function to scrape a webpage every hour.
File Upload Trigger (Event-Based):
Lambda can be triggered by file uploads in S3. For example, after scraping, if the data is saved as a file, the file upload in S3 can trigger another Lambda function for processing.
Example: Trigger Lambda on S3 File Upload:
By leveraging Serverless Web Scraping using AWS Lambda, you can easily scale your web scraping tasks with Event-Based Triggers such as Scheduled Scraping, API calls, or file uploads. This approach ensures that you avoid the complexity of infrastructure management while still benefiting from scalable, automated data collection. Learn More
#LightweightDataExtraction#AutomatedDataExtraction#StreamlineDataExtraction#ServerlessWebScraping#DataMining
0 notes
Text
Integrating ROSA Applications with AWS Services (CS221)
In today's rapidly evolving cloud-native landscape, enterprises are looking for scalable, secure, and fully managed Kubernetes solutions that work seamlessly with existing cloud infrastructure. Red Hat OpenShift Service on AWS (ROSA) meets that demand by combining the power of Red Hat OpenShift with the scalability and flexibility of Amazon Web Services (AWS).
In this blog post, we’ll explore how you can integrate ROSA-based applications with key AWS services, unlocking a powerful hybrid architecture that enhances your applications' capabilities.
📌 What is ROSA?
ROSA (Red Hat OpenShift Service on AWS) is a managed OpenShift offering jointly developed and supported by Red Hat and AWS. It allows you to run containerized applications using OpenShift while taking full advantage of AWS services such as storage, databases, analytics, and identity management.
🔗 Why Integrate ROSA with AWS Services?
Integrating ROSA with native AWS services enables:
Seamless access to AWS resources (like RDS, S3, DynamoDB)
Improved scalability and availability
Cost-effective hybrid application architecture
Enhanced observability and monitoring
Secure IAM-based access control using AWS IAM Roles for Service Accounts (IRSA)
🛠️ Key Integration Scenarios
1. Storage Integration with Amazon S3 and EFS
Applications deployed on ROSA can use AWS storage services for persistent and object storage needs.
Use Case: A web app storing images to S3.
How: Use OpenShift’s CSI drivers to mount EFS or access S3 through SDKs or CLI.
yaml
Copy
Edit
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: efs-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: efs-sc
resources:
requests:
storage: 5Gi
2. Database Integration with Amazon RDS
You can offload your relational database requirements to managed RDS instances.
Use Case: Deploying a Spring Boot app with PostgreSQL on RDS.
How: Store DB credentials in Kubernetes secrets and use RDS endpoint in your app’s config.
env
Copy
Edit
SPRING_DATASOURCE_URL=jdbc:postgresql://<rds-endpoint>:5432/mydb
3. Authentication with AWS IAM + OIDC
ROSA supports IAM Roles for Service Accounts (IRSA), enabling fine-grained permissions for workloads.
Use Case: Granting a pod access to a specific S3 bucket.
How:
Create an IAM role with S3 access
Associate it with a Kubernetes service account
Use OIDC to federate access
4. Observability with Amazon CloudWatch and Prometheus
Monitor your workloads using Amazon CloudWatch Container Insights or integrate Prometheus and Grafana on ROSA for deeper insights.
Use Case: Track application metrics and logs in a single AWS dashboard.
How: Forward logs from OpenShift to CloudWatch using Fluent Bit.
5. Serverless Integration with AWS Lambda
Bridge your ROSA applications with AWS Lambda for event-driven workloads.
Use Case: Triggering a Lambda function on file upload to S3.
How: Use EventBridge or S3 event notifications with your ROSA app triggering the workflow.
🔒 Security Best Practices
Use IAM Roles for Service Accounts (IRSA) to avoid hardcoding credentials.
Use AWS Secrets Manager or OpenShift Vault integration for managing secrets securely.
Enable VPC PrivateLink to keep traffic within AWS private network boundaries.
🚀 Getting Started
To start integrating your ROSA applications with AWS:
Deploy your ROSA cluster using the AWS Management Console or CLI
Set up AWS CLI & IAM permissions
Enable the AWS services needed (e.g., RDS, S3, Lambda)
Create Kubernetes Secrets and ConfigMaps for service integration
Use ServiceAccounts, RBAC, and IRSA for secure access
🎯 Final Thoughts
ROSA is not just about running Kubernetes on AWS—it's about unlocking the true hybrid cloud potential by integrating with a rich ecosystem of AWS services. Whether you're building microservices, data pipelines, or enterprise-grade applications, ROSA + AWS gives you the tools to scale confidently, operate securely, and innovate rapidly.
If you're interested in hands-on workshops, consulting, or ROSA enablement for your team, feel free to reach out to HawkStack Technologies – your trusted Red Hat and AWS integration partner.
💬 Let's Talk!
Have you tried ROSA yet? What AWS services are you integrating with your OpenShift workloads? Share your experience or questions in the comments!
For more details www.hawkstack.com
0 notes
Text
Serverless vs. Containers: Which Cloud Computing Model Should You Use?
In today’s cloud-driven world, businesses are building and deploying applications faster than ever before. Two of the most popular technologies empowering this transformation are Serverless computing and Containers. While both offer flexibility, scalability, and efficiency, they serve different purposes and excel in different scenarios.
If you're wondering whether to choose Serverless or Containers for your next project, this blog will break down the pros, cons, and use cases—helping you make an informed, strategic decision.
What Is Serverless Computing?
Serverless computing is a cloud-native execution model where cloud providers manage the infrastructure, provisioning, and scaling automatically. Developers simply upload their code as functions and define triggers, while the cloud handles the rest.
Key Features of Serverless:
No infrastructure management
Event-driven architecture
Automatic scaling
Pay-per-execution pricing model
Popular Platforms:
AWS Lambda
Google Cloud Functions
Azure Functions
What Are Containers?
Containers package an application along with its dependencies and libraries into a single unit. This ensures consistent performance across environments and supports microservices architecture.
Containers are orchestrated using tools like Kubernetes or Docker Swarm to ensure availability, scalability, and automation.
Key Features of Containers:
Full control over runtime and OS
Environment consistency
Portability across platforms
Ideal for complex or long-running applications
Popular Tools:
Docker
Kubernetes
Podman
Serverless vs. Containers: Head-to-Head Comparison
Feature
Serverless
Containers
Use Case
Event-driven, short-lived functions
Complex, long-running applications
Scalability
Auto-scales instantly
Requires orchestration (e.g., Kubernetes)
Startup Time
Cold starts possible
Faster if container is pre-warmed
Pricing Model
Pay-per-use (per invocation)
Pay-per-resource (CPU/RAM)
Management
Fully managed by provider
Requires devops team or automation setup
Vendor Lock-In
High (platform-specific)
Low (containers run anywhere)
Runtime Flexibility
Limited runtimes supported
Any language, any framework
When to Use Serverless
Best For:
Lightweight APIs
Scheduled jobs (e.g., cron)
Real-time processing (e.g., image uploads, IoT)
Backend logic in JAMstack websites
Advantages:
Faster time-to-market
Minimal ops overhead
Highly cost-effective for sporadic workloads
Simplifies event-driven architecture
Limitations:
Cold start latency
Limited execution time (e.g., 15 mins on AWS Lambda)
Difficult for complex or stateful workflows
When to Use Containers
Best For:
Enterprise-grade microservices
Stateful applications
Applications requiring custom runtimes
Complex deployments and APIs
Advantages:
Full control over runtime and configuration
Seamless portability across environments
Supports any tech stack
Easier integration with CI/CD pipelines
Limitations:
Requires container orchestration
More complex infrastructure setup
Can be costlier if not optimized
Can You Use Both?
Yes—and you probably should.
Many modern cloud-native architectures combine containers and serverless functions for optimal results.
Example Hybrid Architecture:
Use Containers (via Kubernetes) for core services.
Use Serverless for auxiliary tasks like:
Sending emails
Processing webhook events
Triggering CI/CD jobs
Resizing images
This hybrid model allows teams to benefit from the control of containers and the agility of serverless.
Serverless vs. Containers: How to Choose
Business Need
Recommendation
Rapid MVP or prototype
Serverless
Full-featured app backend
Containers
Low-traffic event-driven app
Serverless
CPU/GPU-intensive tasks
Containers
Scheduled background jobs
Serverless
Scalable enterprise service
Containers (w/ Kubernetes)
Final Thoughts
Choosing between Serverless and Containers is not about which is better—it’s about choosing the right tool for the job.
Go Serverless when you need speed, simplicity, and cost-efficiency for lightweight or event-driven tasks.
Go with Containers when you need flexibility, full control, and consistency across development, staging, and production.
Both technologies are essential pillars of modern cloud computing. The key is understanding their strengths and limitations—and using them together when it makes sense.
#artificial intelligence#sovereign ai#coding#html#entrepreneur#devlog#linux#economy#gamedev#indiedev
1 note
·
View note
Text
Increase AWS Security with MITRE D3FEND, Engage, ATT&CK

Engage, ATT&CK, D3FEND
Connecting MITRE threat detection and mitigation frameworks to AWS security services. Amazon Web Services may benefit from MITRE ATT&CK, MITRE Engage, and MITRE D3FEND controls and processes. These organised, publicly available models explain threat actor activities to assist threat detection and response.
Combining MITRE frameworks completes security operations lifecycle strategy. MITRE ATT&CK specifies threat actor tactics, strategies, and processes, essential for threat modelling and risk assessment. Additionally, MITRE D3FEND proposes proactive security controls like system settings protection and least privilege access to align defences with known attack patterns.
With MITRE Engage, security teams can expose threat actors, cost them money by directing resources to honeypot infrastructure, or mislead them into divulging their strategies by exploiting appealing fictional targets. D3FEND turns ATT&CK insights into defensive mechanisms, unlike Engage. Integrating these frameworks informs security operations lifecycle detection, monitoring, incident response, and post-event analysis.
Depending on the services, the client handles cloud security and AWS handles cloud infrastructure security. This is crucial for AWS-using businesses. AWS cloud-scale platforms have native security capabilities like these MITRE frameworks.
Amazon Web Services follows MITRE security lifecycle frameworks:
Amazon Inspector finds threat actor-related vulnerabilities, Amazon Macie finds sensitive data exposure, and Amazon Security Lake collects logs for ATT&CK-based threat modelling and risk assessment.
AWS Web Application Firewall (WAF) provides application-layer security, while AWS Identity and Access Management (IAM) and AWS Organisations provide least privilege when implementing preventative measures. Honey tokens are digital decoys that replicate real credentials to attract danger actors and trigger alerts. They may be in AWS Secrets Manager.
Amazon AWS Security Hub centralises security alerts, GuardDuty detects unusual activity patterns, and Amazon Detective investigates irregularities. GuardDuty monitors AWS accounts and workloads to detect attacks automatically.
AWS Step Functions and Lambda automate incident response, containment, and recovery. Real-time DDoS mitigation is provided with AWS Shield and WAF. AWS Security Incident Response was introduced in 2024 to prepare, respond, and recover from security incidents. Threat actors may be rerouted to honeypots or given fake Amazon Simple Storage Service (S3) files.
Security Lake and Detective conduct post-event forensic investigations, while Security Hub and IAM policies use historical trends to improve security. Observing honeypot interactions can change MITRE Engage strategies.
GuardDuty and other AWS security services provide threat intelligence and details on detected threats to MITRE ATT&CK. GuardDuty Extended Threat Detection intelligently detects, correlates, and aligns signals with the MITRE ATT&CK lifecycle to find an attack sequence. A discovery report includes IP addresses, TTPs, AWS API queries, and a description of occurrences. The MITRE strategy and method identification of an activity is highlighted by each discovery signal.
Malicious IP lists, dubious network behaviours, and the AWS API request and user agent can be included. You can automate answers by downloading this extensive JSON data. Interestingly, AWS and MITRE have updated and developed new MITRE ATT&CK cloud matrix methodologies based on real-world threat actor behaviours that target AWS customers, such as modifying S3 bucket lifespan restrictions for data destruction.
Companies may automate detection and response, build security operations using industry-standard procedures, maintain visibility throughout their AWS environment, and improve security controls by aligning AWS security services with MITRE frameworks. Companies can better identify, stop, and fool threat actors using this relationship, boosting their security.
#MITRED3FEND#MITREATTCK#MITREframeworks#Engage#AWSsecurityservices#D3FEND#Technology#technews#technologynews#news#govindhtech
0 notes
Text
The Rise of Serverless Architecture and Its Impact on Full Stack Development
The digital world is in constant flux, driven by the relentless pursuit of efficiency, scalability, and faster time-to-market. Amidst this evolution, serverless architecture has emerged as a transformative force, fundamentally altering how applications are built and deployed. For those seeking comprehensive full stack development services, this paradigm shift presents both exciting opportunities and new challenges. This article delves deep into the rise of serverless, exploring its core concepts, benefits, drawbacks, and, most importantly, its profound impact on full stack development.
Understanding the Serverless Revolution
At its core, serverless computing doesn't mean the absence of servers. Instead, it signifies a shift in responsibility. Developers no longer need to provision, manage, and scale the underlying server infrastructure. Cloud providers like AWS (with Lambda), Google Cloud (with Cloud Functions), and Microsoft Azure (with Azure Functions) handle these operational burdens. This allows full stack developers to focus solely on writing and deploying code, triggered by events such as HTTP requests, database changes, file uploads, and more.
The key characteristics of serverless architecture include:
No Server Management: The cloud provider handles all server-related tasks, including provisioning, patching, and scaling.
Automatic Scaling: Resources scale automatically based on demand, ensuring applications can handle traffic spikes without manual intervention.
Pay-as-you-go Pricing: Users are charged only for the compute time consumed when their code is running, leading to potential cost savings.
Event-Driven Execution: Serverless functions are typically triggered by specific events, making them highly efficient for event-driven architectures.
The Benefits of Embracing Serverless for Full Stack Developers
The adoption of serverless architecture brings a plethora of advantages for full stack developers:
Increased Focus on Code: By abstracting away server management, developers can dedicate more time and energy to writing high-quality code and implementing business logic. This leads to faster development cycles and quicker deployment of features.
Enhanced Scalability and Reliability: Serverless platforms offer built-in scalability and high availability. Applications can effortlessly handle fluctuating user loads without requiring developers to configure complex scaling strategies. The underlying infrastructure is typically highly resilient, ensuring greater application uptime.
Reduced Operational Overhead: The elimination of server maintenance tasks significantly reduces operational overhead. Full stack developers no longer need to spend time on server configuration, security patching, or infrastructure monitoring. This frees up valuable resources that can be reinvested in innovation.
Cost Optimization: The pay-as-you-go model can lead to significant cost savings, especially for applications with variable traffic patterns. You only pay for the compute resources you actually consume, rather than maintaining idle server capacity.
Faster Time to Market: The streamlined development and deployment process associated with serverless allows teams to release new features and applications more rapidly, providing a competitive edge.
Simplified Deployment: Deploying serverless functions is often simpler and faster than deploying traditional applications. Developers can typically deploy individual functions without needing to redeploy the entire application.
Integration with Managed Services: Serverless platforms seamlessly integrate with a wide range of other managed services offered by cloud providers, such as databases, storage, and messaging queues. This allows full stack developers to build complex applications using pre-built, scalable components.
Navigating the Challenges of Serverless Development
While the benefits are compelling, serverless architecture also presents certain challenges that full stack developers need to be aware of:
Cold Starts: Serverless functions can experience "cold starts," where there's a delay in execution if the function hasn't been invoked recently. This can impact the latency of certain requests, although cloud providers are continuously working on mitigating this issue.
Statelessness: Serverless functions are inherently stateless, meaning they don't retain information between invocations. Developers need to implement external mechanisms (like databases or caching services) to manage state.
Debugging and Monitoring: Debugging and monitoring distributed serverless applications can be more complex than traditional monolithic applications. Specialized tools and strategies are often required to trace requests and identify issues across multiple functions and services.
Vendor Lock-in: Choosing a specific cloud provider for your serverless infrastructure can lead to vendor lock-in, making it potentially challenging to migrate to another provider in the future.
Complexity Management: For large and complex applications, managing a multitude of individual serverless functions and their interactions can become challenging. Proper organization, documentation, and tooling are crucial.
Testing: Testing serverless functions in isolation and in integration with other services requires specific approaches and tools. Traditional testing methodologies may need to be adapted.
Security Considerations: While the cloud provider handles infrastructure security, developers are still responsible for securing their code and configurations within the serverless environment. Understanding the security implications of serverless is crucial.
The Impact on Full Stack Development Practices
The rise of serverless architecture is significantly reshaping the role and responsibilities of full stack developers:
Shift in Skillsets: While traditional backend skills remain relevant, full stack developers working with serverless need to develop expertise in cloud-specific services, event-driven programming, API design, and infrastructure-as-code (IaC) tools like Terraform or CloudFormation.
Increased Focus on API Design: With serverless functions often communicating via APIs, strong API design skills become even more critical for full stack developers. They need to design robust, scalable, and well-documented APIs.
Embracing Event-Driven Architectures: Serverless naturally lends itself to event-driven architectures. Full stack developers need to understand event sourcing, message queues, and other concepts related to building reactive systems.
DevOps Integration: While server management is abstracted, a DevOps mindset remains essential. Full stack developers need to be involved in CI/CD pipelines, automated testing, and monitoring to ensure the smooth operation of their serverless applications.
Understanding Cloud Ecosystems: A deep understanding of the specific cloud provider's ecosystem, including its serverless offerings, databases, storage solutions, and other managed services, is crucial for effective serverless development.
New Development Paradigms: Serverless encourages the adoption of microservices and function-as-a-service (FaaS) paradigms, requiring full stack developers to think differently about application decomposition and architecture.
Tooling and Ecosystem Evolution: The serverless ecosystem is constantly evolving, with new tools and frameworks emerging to simplify development, deployment, and monitoring. Full stack developers need to stay updated with these advancements.
Future Trends in Serverless and Full Stack Development
The future of serverless architecture and its impact on full stack development looks promising and dynamic:
Further Abstraction: Cloud providers will likely continue to abstract away more infrastructure complexities, making serverless even easier to adopt and use.
Improved Cold Start Performance: Ongoing research and development efforts will likely lead to significant improvements in cold start times, making serverless suitable for an even wider range of applications.
Enhanced Developer Tools: The tooling around serverless development will continue to mature, offering better debugging, monitoring, and testing capabilities.
Edge Computing Integration: Serverless principles are likely to extend to edge computing environments, enabling the development of distributed, event-driven applications closer to the data source.
AI and Machine Learning Integration: Serverless functions will play an increasingly important role in deploying and scaling AI and machine learning models.
Standardization and Interoperability: Efforts towards standardization across different cloud providers could reduce vendor lock-in and improve the portability of serverless applications.
Conclusion: Embracing the Serverless Future
Serverless architecture represents a significant evolution in how applications are built and deployed. For full stack developers, embracing this paradigm offers numerous benefits, including increased focus on code, enhanced scalability, reduced operational overhead, and faster time to market. While challenges such as cold starts, statelessness, and the need for new skillsets exist, the advantages often outweigh the drawbacks, especially for modern, scalable applications.
As the serverless ecosystem continues to mature and evolve, full stack developers who adapt to this transformative technology will be well-positioned to build innovative and efficient applications in the years to come. The rise of serverless is not just a trend; it's a fundamental shift that is reshaping the future of software development.
0 notes
Text
How AI Agents Integrate with Your Business Tools 🤖
Modern AI agents are plug-and-play solutions! They connect with tools like Slack, Notion, Google Workspace, and more through APIs, webhooks, and event-based triggers.
They can: ✅ Respond to workflow actions ✅ Embed into dashboards or CMS ✅ Assist your team in real time
Tech behind the scenes? Think RPA tools, cloud orchestrations like AWS Lambda & Azure Logic Apps
💡 Ready to make your workflows smarter?
Visit: https://cizotech.com/
#ai#innovation#cizotechnology#mobileappdevelopment#ios#techinnovation#app developers#iosapp#mobileapps#appdevelopment#AIIntegration#AIAgents#WorkflowAutomation#DigitalTransformation#BusinessTech#AIforBusiness#CIZO
1 note
·
View note
Text
Serverless Computing: Simplifying Backend Development
Absolutely! Here's a brand new 700-word blog on the topic: "Serverless Computing: Simplifying Backend Development" — written in a clear, simple tone without any bold formatting, and including mentions of Hexadecimal Software and Hexahome Blogs.
Serverless Computing: Simplifying Backend Development
The world of software development is constantly evolving. One of the most exciting shifts in recent years is the rise of serverless computing. Despite the name, serverless computing still involves servers — but the key difference is that developers no longer need to manage them.
With serverless computing, developers can focus purely on writing code, while the cloud provider automatically handles server management, scaling, and maintenance. This approach not only reduces operational complexity but also improves efficiency, cost savings, and time to market.
What is Serverless Computing?
Serverless computing is a cloud computing model where the cloud provider runs the server and manages the infrastructure. Developers simply write functions that respond to events — like a file being uploaded or a user submitting a form — and the provider takes care of executing the function, scaling it based on demand, and handling all server-related tasks.
Unlike traditional cloud models where developers must set up virtual machines, install software, and manage scaling, serverless removes those responsibilities entirely.
How It Works
Serverless platforms use what are called functions-as-a-service (FaaS). Developers upload small pieces of code (functions) to the cloud platform, and each function is triggered by a specific event. These events could come from HTTP requests, database changes, file uploads, or scheduled timers.
The platform then automatically runs the code in a stateless container, scales the application based on the number of requests, and shuts down the container when it's no longer needed. You only pay for the time the function is running, which can significantly reduce costs.
Popular serverless platforms include AWS Lambda, Google Cloud Functions, Azure Functions, and Firebase Cloud Functions.
Benefits of Serverless Computing
Reduced infrastructure management Developers don’t have to manage or maintain servers. Everything related to infrastructure is handled by the cloud provider.
Automatic scaling Serverless platforms automatically scale the application depending on the demand, whether it's a few requests or thousands.
Cost efficiency Since you only pay for the time your code runs, serverless can be more affordable than always-on servers, especially for applications with variable traffic.
Faster development Serverless enables quicker development and deployment since the focus is on writing code and not on managing environments.
High availability Most serverless platforms ensure high availability and reliability without the need for additional configuration.
Use Cases of Serverless Computing
Serverless is suitable for many types of applications:
Web applications: Serverless functions can power APIs and backend logic for web apps.
IoT backends: Data from devices can be processed in real-time using serverless functions.
Chatbots: Event-driven logic for responding to messages can be handled with serverless platforms.
Real-time file processing: Automatically trigger functions when files are uploaded to storage, like resizing images or analyzing documents.
Scheduled tasks: Functions can be set to run at specific times for operations like backups or report generation.
Challenges of Serverless Computing
Like any technology, serverless computing comes with its own set of challenges:
Cold starts: When a function hasn’t been used for a while, it may take time to start again, causing a delay.
Limited execution time: Functions often have time limits, which may not suit long-running tasks.
Vendor lock-in: Each cloud provider has its own way of doing things, making it hard to move applications from one provider to another.
Debugging and monitoring: Tracking errors or performance in distributed functions can be more complex.
Despite these challenges, many teams find that the benefits of serverless outweigh the limitations, especially for event-driven applications and microservices.
About Hexadecimal Software
Hexadecimal Software is a leading software development company specializing in cloud-native solutions, DevOps, and modern backend systems. Our experts help businesses embrace serverless computing to build efficient, scalable, and low-maintenance applications. Whether you’re developing a new application or modernizing an existing one, we can guide you through your cloud journey. Learn more at https://www.hexadecimalsoftware.com
Explore More on Hexahome Blogs
To discover more about cloud computing, DevOps, and modern development practices, visit our blog platform at https://www.blogs.hexahome.in. Our articles are written in a simple, easy-to-understand style to help professionals stay updated with the latest tech trends.
0 notes
Text
Top Function as a Service (FaaS) Vendors of 2025
Businesses encounter obstacles in implementing effective and scalable development processes. Traditional techniques frequently fail to meet the growing expectations for speed, scalability, and innovation. That's where Function as a Service comes in.
FaaS is more than another addition to the technological stack; it marks a paradigm shift in how applications are created and delivered. It provides a serverless computing approach that abstracts infrastructure issues, freeing organizations to focus on innovation and core product development. As a result, FaaS has received widespread interest and acceptance in multiple industries, including BFSI, IT & Telecom, Public Sector, Healthcare, and others.
So, what makes FaaS so appealing to corporate leaders? Its value offer is based on the capacity to accelerate time-to-market and improve development outcomes. FaaS allows companies to prioritize delivering new goods and services to consumers by reducing server maintenance, allowing for flexible scalability, cost optimization, and automatic high availability.
In this blog, we'll explore the meaning of Function as a Service (FaaS) and explain how it works. We will showcase the best function as a service (FaaS) software that enables businesses to reduce time-to-market and streamline development processes.
Download the sample report of Market Share: https://qksgroup.com/download-sample-form/market-share-function-as-a-service-2023-worldwide-5169
What is Function-as-a-Service (FaaS)?
Function-as-a-Service (FaaS), is a cloud computing service that enables developers to create, execute, and manage discrete units of code as individual functions, without the need to oversee the underlying infrastructure. This approach enables developers to focus solely on writing code for their application's specific functions, abstracting away the complexities of infrastructure management associated with developing and deploying microservices applications. With FaaS, developers can write and update small, modular pieces of code, which are designed to respond to specific events or triggers. FaaS is commonly used for building microservices, real-time data processing, and automating workflows. It decreases much of the infrastructure management complexity, making it easier for developers to focus on writing code and delivering functionality. FaaS can power the backend for mobile applications, handling user authentication, data synchronization, and push notifications, among other functions.
How Does Function-as-a-Service (FaaS) Work?
FaaS provides programmers with a framework for responding to events via web apps without managing servers.PaaS infrastructure frequently requires server tasks to continue in the background at all times. In contrast, FaaS infrastructure is often invoiced on demand by the service provider, using an event-based execution methodology.
FaaS functions should be formed to bring out a task in response to an input. Limit the scope of your code, keeping it concise and lightweight, so that functions load and run rapidly. FaaS adds value at the function separation level. If you have fewer functions, you will pay additional costs while maintaining the benefit of function separation. The efficiency and scalability of a function may be enhanced by utilizing fewer libraries. Features, microservices, and long-running services will be used to create comprehensive apps.
Download the sample report of Market Forecast: https://qksgroup.com/download-sample-form/market-forecast-function-as-a-service-2024-2028-worldwide-4685
Top Function-as-a-Service (FaaS) Vendors
Amazon
Amazon announced AWS Lambda in 2014. Since then, it has developed into one of their most valuable offerings. It serves as a framework for Alexa skill development and provides easy access to many of AWS's monitoring tools. Lambda natively supports Java, Go, PowerShell, Node.js, C#, Python, and Ruby code.
Alibaba Functions
Alibaba provides a robust platform for serverless computing. You may deploy and run your code using Alibaba Functions without managing infrastructure or servers. To run your code, computational resources are deployed flexibly and reliably. Dispersed clusters exist in a variety of locations. As a result, if one zone becomes unavailable, Alibaba Function Compute will immediately switch to another instance. Using distributed clusters allows any user from anywhere to execute your code faster. It increases productivity.
Microsoft
Microsoft and Azure compete with Microsoft Azure Functions. It is the biggest FaaS provider for designing and delivering event-driven applications. It is part of the Azure ecosystem and supports several programming languages, including C#, JavaScript, F#, Python, Java, PowerShell, and TypeScript.
Azure Functions provides a more complex programming style built around triggers and bindings. An HTTP-triggered function may read a document from Azure Cosmos DB and deliver a queue message using declarative configuration. The platform supports multiple triggers, including online APIs, scheduled tasks, and services such as Azure Storage, Azure Event Hubs, Twilio for SMS, and SendGrid for email.
Vercel
Vercel Functions offers a FaaS platform optimized for static frontends and serverless functions. It hosts webpages and online apps that install rapidly and expand themselves.
The platform stands out for its straightforward and user-friendly design. When running Node.js, Vercel manages dependencies using a single JSON. Developers may also change the runtime version, memory, and execution parameters. Vercel's dashboard provides monitoring logs for tracking functions and requests.
Key Technologies Powering FaaS and Their Strategic Importance
According to QKS Group and insights from the reports “Market Share: Function as a Service, 2023, Worldwide” and “Market Forecast: Function as a Service, 2024-2028, Worldwide”, organizations around the world are increasingly using Function as a Service (FaaS) platforms to streamline their IT operations, reduce infrastructure costs, and improve overall business agility. Businesses that outsource computational work to cloud service providers can focus on their core capabilities, increase profitability, gain a competitive advantage, and reduce time to market for new apps and services.
Using FaaS platforms necessitates sharing sensitive data with third-party cloud providers, including confidential company information and consumer data. As stated in Market Share: Function as a Service, 2023, Worldwide, this raises worries about data privacy and security, as a breach at the service provider's end might result in the disclosure or theft of crucial data. In an era of escalating cyber threats and severe data security rules, enterprises must recognize and mitigate the risks of using FaaS platforms. Implementing strong security measures and performing frequent risk assessments may assist in guaranteeing that the advantages of FaaS are realized without sacrificing data integrity and confidentiality.
Vendors use terms like serverless computing, microservices, and Function as a Service (FaaS) to describe similar underlying technologies. FaaS solutions simplify infrastructure management, enabling rapid application development, deployment, and scalability. Serverless computing and microservices brake systems into small, independent tasks that can be executed on demand, resulting in greater flexibility and efficiency in application development.
Conclusion
Function as a Service (FaaS) is helping businesses build and run applications more efficiently without worrying about server management. It allows companies to scale as needed, reduce costs, and focus on creating better products and services. As more sectors use FaaS, knowing how it works and selecting the right provider will be critical to keeping ahead in a rapidly altering digital landscape.
Related Reports –
https://qksgroup.com/market-research/market-forecast-function-as-a-service-2024-2028-western-europe-4684
https://qksgroup.com/market-research/market-share-function-as-a-service-2023-western-europe-5168
https://qksgroup.com/market-research/market-forecast-function-as-a-service-2024-2028-usa-4683
https://qksgroup.com/market-research/market-share-function-as-a-service-2023-usa-5167
https://qksgroup.com/market-research/market-forecast-function-as-a-service-2024-2028-middle-east-and-africa-4682
https://qksgroup.com/market-research/market-share-function-as-a-service-2023-middle-east-and-africa-5166
https://qksgroup.com/market-research/market-forecast-function-as-a-service-2024-2028-china-4679
https://qksgroup.com/market-research/market-share-function-as-a-service-2023-china-5163
https://qksgroup.com/market-research/market-forecast-function-as-a-service-2024-2028-asia-excluding-japan-and-china-4676
https://qksgroup.com/market-research/market-share-function-as-a-service-2023-asia-excluding-japan-and-china-5160
0 notes
Text
The Future of Cloud: Best Serverless Development Company Trends

Introduction
Cloud computing is evolving, and one of the most innovative advancements is serverless technology. A Serverless development company eliminates the need for businesses to manage servers, allowing them to focus on building scalable and cost-effective applications. As more organizations adopt serverless computing, it's essential to understand the trends and benefits of working with a serverless provider.
From automating infrastructure management to reducing operational costs, serverless development is revolutionizing how businesses operate in the cloud. This blog explores the role of serverless development, key trends, and how companies can benefit from partnering with a serverless provider.
Why Choose a Serverless Development Company?
A Serverless development company provides cloud-based solutions that handle backend infrastructure automatically. Instead of provisioning and maintaining servers, businesses only pay for what they use. This reduces costs, enhances scalability, and improves efficiency.
Companies across industries are leveraging serverless technology to deploy cloud applications quickly. Whether it's handling high-traffic websites, processing large-scale data, or integrating AI-driven solutions, serverless computing offers unmatched flexibility and reliability.
Latest Trends in Serverless Computing
The adoption of serverless technology is on the rise, with various trends shaping the industry. Some key developments include:
Multi-cloud serverless computing for better flexibility and redundancy.
Enhanced security frameworks to protect cloud-based applications.
Integration of AI and machine learning to automate workflows.
Low-code and no-code development enabling faster application deployment.
These trends indicate that a Serverless development company is not just about reducing costs but also about optimizing business operations for the future.
Top 10 SaaS Development Companies Driving Serverless Adoption
The SaaS industry is a significant player in the adoption of serverless computing. Many SaaS providers are integrating serverless architecture to enhance their platforms.
Here are the Top 10 SaaS Development Companies leading the way in serverless innovation:
Amazon Web Services (AWS Lambda)
Microsoft Azure Functions
Google Cloud Functions
IBM Cloud Functions
Netlify
Cloudflare Workers
Vercel
Firebase Cloud Functions
Twilio Functions
StackPath
These companies are paving the way for serverless solutions that enable businesses to scale efficiently without traditional server management.
Best SaaS Examples in 2025 Showcasing Serverless Success
Many successful SaaS applications leverage serverless technology to provide seamless experiences. Some of the Best SaaS Examples in 2025 using serverless include:
Slack for real-time messaging with scalable cloud infrastructure.
Shopify for handling e-commerce transactions efficiently.
Zoom for seamless video conferencing and collaboration.
Dropbox for secure and scalable cloud storage solutions.
Stripe for processing payments with high reliability.
These SaaS companies use serverless technology to optimize performance and enhance customer experiences.
Guide to SaaS Software Development with Serverless Technology
A Guide to SaaS Software Development with serverless technology involves several crucial steps:
Choose the right cloud provider – AWS, Azure, or Google Cloud.
Leverage managed services – Databases, authentication, and API gateways.
Optimize event-driven architecture – Serverless functions triggered by events.
Implement security best practices – Encryption, IAM policies, and monitoring.
Monitor and scale efficiently – Using automated scaling mechanisms.
These steps help businesses build robust SaaS applications with minimal infrastructure management.
Custom Software Development Company and Serverless Integration
A custom software development company can integrate serverless technology into tailored software solutions. Whether it's developing enterprise applications, e-commerce platforms, or AI-driven solutions, serverless computing enables companies to deploy scalable applications without worrying about server management.
By partnering with a custom software provider specializing in serverless, businesses can streamline development cycles, reduce costs, and improve system reliability.
How Cloud-Based Apps Benefit from Serverless Architecture
The shift towards cloud-based apps has accelerated the adoption of serverless computing. Serverless architecture allows cloud applications to:
Scale automatically based on demand.
Reduce operational costs with pay-as-you-go pricing.
Enhance security with managed cloud services.
Improve application performance with faster response times.
As more companies move towards cloud-native applications, serverless technology will continue to be a game-changer in modern app development.
Conclusion
The Serverless development company landscape is growing, enabling businesses to build scalable, cost-efficient applications with minimal infrastructure management. As serverless trends continue to evolve, partnering with the right development company can help businesses stay ahead in the competitive cloud computing industry.
Whether you're developing SaaS applications, enterprise solutions, or AI-driven platforms, serverless technology provides a flexible and efficient approach to modern software development. Embrace the future of cloud computing with serverless solutions and transform the way your business operates.
0 notes
Text
Introduction to Serverless Computing for Web Development

If you’ve ever built a website, you know how much time goes into managing servers. What if you could skip that part and focus purely on creating great designs and features? That’s the idea behind serverless computing. Let’s talk about what it is, why it matters, and how it can make life easier for developers—whether you’re working solo or with a team like a website designing company in India.
So, What’s Serverless?
The name sounds confusing, right? “Serverless” doesn’t mean there are no servers. It just means someone else (like Amazon Web Services or Google Cloud) handles them for you. Imagine ordering food delivery instead of cooking—you get the meal without worrying about the kitchen. Similarly, you write code, upload it, and the cloud provider manages the rest. No server crashes to fix, no updates to install.
How It Works
Serverless runs on triggers. Your code activates only when needed—like when a user clicks a button or uploads a file. Once the task finishes, everything quiets down. You’re billed only for the time your code runs, not for idle servers. For example, if your client’s online store gets a surge during festivals, the system scales up automatically. No manual tweaks required.
Why Try Serverless?
Save Money: Traditional servers charge you even when nobody’s using your site. With serverless, costs drop because you pay per action. This is perfect for small teams or businesses watching their budgets.
Less Hassle: Forget server setup. Just write code and push it live.
Auto-Scaling: Your site handles traffic spikes smoothly, whether 10 users or 10,000 show up.
Focus on Creativity: Spend time designing interfaces or improving user experience instead of fixing backend issues.
When to Use It
Serverless shines for tasks like:
Building APIs that adapt to user demand.
Processing data in real time (e.g., resizing images after upload).
Running automated jobs, like sending order confirmations or updating inventory.
But It’s Not Perfect
Serverless isn’t ideal for everything. Tasks that run for hours (like rendering videos) might cost more here. Debugging can also get tricky since your code runs in scattered pieces. Still, for most websites—especially those with unpredictable traffic—it’s a solid choice.
How to Get Started
Choose a Platform: AWS Lambda and Google Cloud Functions are popular picks.
Test with Simple Tasks: Move a small feature, like a newsletter signup, to serverless first.
Use Helper Tools: Frameworks like Serverless Framework cut down deployment steps.
Why Businesses Love It
For clients, serverless means faster launches and fewer upfront costs. Imagine building an app that scales during sales events without paying for idle servers the rest of the year. This efficiency is why even a website designing company in India might lean toward serverless for client projects.
Wrapping Up
Serverless computing is changing how we build websites. By handing off server management, developers can focus on what users actually see and experience. Whether you’re coding alone or collaborating with a team, trying serverless could mean fewer headaches and more time for creative work.
Next time you start a project, ask yourself: Could skipping servers make this easier? The answer might just save you time and money.
#website development company in india#web design company india#website designing company in india#best web development agencies india#digital marketing agency india#online reputation management companies in india
0 notes
Text
🚀 Integrating ROSA Applications with AWS Services (CS221)
As cloud-native applications evolve, seamless integration between orchestration platforms like Red Hat OpenShift Service on AWS (ROSA) and core AWS services is becoming a vital architectural requirement. Whether you're running microservices, data pipelines, or containerized legacy apps, combining ROSA’s Kubernetes capabilities with AWS’s ecosystem opens the door to powerful synergies.
In this blog, we’ll explore key strategies, patterns, and tools for integrating ROSA applications with essential AWS services — as taught in the CS221 course.
🧩 Why Integrate ROSA with AWS Services?
ROSA provides a fully managed OpenShift experience, but its true potential is unlocked when integrated with AWS-native tools. Benefits include:
Enhanced scalability using Amazon S3, RDS, and DynamoDB
Improved security and identity management through IAM and Secrets Manager
Streamlined monitoring and observability with CloudWatch and X-Ray
Event-driven architectures via EventBridge and SNS/SQS
Cost optimization by offloading non-containerized workloads
🔌 Common Integration Patterns
Here are some popular integration patterns used in ROSA deployments:
1. Storage Integration:
Amazon S3 for storing static content, logs, and artifacts.
Use the AWS SDK or S3 buckets mounted using CSI drivers in ROSA pods.
2. Database Services:
Connect applications to Amazon RDS or Amazon DynamoDB for persistent storage.
Manage DB credentials securely using AWS Secrets Manager injected into pods via Kubernetes secrets.
3. IAM Roles for Service Accounts (IRSA):
Securely grant AWS permissions to OpenShift workloads.
Set up IRSA so pods can assume IAM roles without storing credentials in the container.
4. Messaging and Eventing:
Integrate with Amazon SNS/SQS for asynchronous messaging.
Use EventBridge to trigger workflows from container events (e.g., pod scaling, job completion).
5. Monitoring & Logging:
Forward logs to CloudWatch Logs using Fluent Bit/Fluentd.
Collect metrics with Prometheus Operator and send alerts to Amazon CloudWatch Alarms.
6. API Gateway & Load Balancers:
Expose ROSA services using AWS Application Load Balancer (ALB).
Enhance APIs with Amazon API Gateway for throttling, authentication, and rate limiting.
📚 Real-World Use Case
Scenario: A financial app running on ROSA needs to store transaction logs in Amazon S3 and trigger fraud detection workflows via Lambda.
Solution:
Application pushes logs to S3 using the AWS SDK.
S3 triggers an EventBridge rule that invokes a Lambda function.
The function performs real-time analysis and writes alerts to an SNS topic.
This serverless integration offloads processing from ROSA while maintaining tight security and performance.
✅ Best Practices
Use IRSA for least-privilege access to AWS services.
Automate integration testing with CI/CD pipelines.
Monitor both ROSA and AWS services using unified dashboards.
Encrypt data in transit and at rest using AWS KMS + OpenShift secrets.
🧠 Conclusion
ROSA + AWS is a powerful combination that enables enterprises to run secure, scalable, and cloud-native applications. With the insights from CS221, you’ll be equipped to design robust architectures that capitalize on the strengths of both platforms. Whether it’s storage, compute, messaging, or monitoring — AWS integrations will supercharge your ROSA applications.
For more details visit - https://training.hawkstack.com/integrating-rosa-applications-with-aws-services-cs221/
0 notes
Photo

New Post has been published on https://codebriefly.com/how-to-handle-bounce-and-complaint-notifications-in-aws-ses/
How to handle Bounce and Complaint Notifications in AWS SES with SNS, SQS, and Lambda
In this article, we will discuss “how to handle complaints and bounce in AWS SES using SNS, SQS, and Lambda”. Amazon Simple Email Service (SES) is a powerful tool for sending emails, but handling bounce and complaint notifications is crucial to maintaining a good sender reputation. AWS SES provides mechanisms to capture these notifications via Amazon Simple Notification Service (SNS), Amazon Simple Queue Service (SQS), and AWS Lambda.
This article will guide you through setting up this pipeline and provide Python code to process bounce and complaint notifications and add affected recipients to the AWS SES suppression list.
Table of Contents
Toggle
Architecture Overview
Step 1: Configure AWS SES to Send Notifications
Step 2: Subscribe SQS Queue to SNS Topic
Step 3: Create a Lambda Function to Process Notifications
Python Code for AWS Lambda
Step 4: Deploy the Lambda Function
Step 5: Test the Pipeline
Conclusion
Architecture Overview
SES Sends Emails: AWS SES is used to send emails.
SES Triggers SNS: SES forwards bounce and complaint notifications to an SNS topic.
SNS Delivers to SQS: SNS publishes these messages to an SQS queue.
Lambda Processes Messages: A Lambda function reads messages from SQS, identifies bounced and complained addresses, and adds them to the SES suppression list.
Step 1: Configure AWS SES to Send Notifications
Go to the AWS SES console.
Navigate to Email Identities and select the verified email/domain.
Under the Feedback Forwarding section, set up SNS notifications for Bounces and Complaints.
Create an SNS topic and subscribe an SQS queue to it.
Step 2: Subscribe SQS Queue to SNS Topic
Create an SQS queue.
In the SNS topic settings, subscribe the SQS queue.
Modify the SQS queue’s access policy to allow SNS to send messages.
Step 3: Create a Lambda Function to Process Notifications
The Lambda function reads bounce and complaint notifications from SQS and adds affected email addresses to the AWS SES suppression list.
Python Code for AWS Lambda
import json import boto3 sqs = boto3.client('sqs') sesv2 = boto3.client('sesv2') # Replace with your SQS queue URL SQS_QUEUE_URL = "https://sqs.us-east-1.amazonaws.com/YOUR_ACCOUNT_ID/YOUR_QUEUE_NAME" def lambda_handler(event, context): messages = receive_sqs_messages() for message in messages: process_message(message) delete_sqs_message(message['ReceiptHandle']) return 'statusCode': 200, 'body': 'Processed messages successfully' def receive_sqs_messages(): response = sqs.receive_message( QueueUrl=SQS_QUEUE_URL, MaxNumberOfMessages=10, WaitTimeSeconds=5 ) return response.get("Messages", []) def process_message(message): body = json.loads(message['Body']) notification = json.loads(body['Message']) if 'bounce' in notification: bounced_addresses = [rec['emailAddress'] for rec in notification['bounce']['bouncedRecipients']] add_to_suppression_list(bounced_addresses) if 'complaint' in notification: complained_addresses = [rec['emailAddress'] for rec in notification['complaint']['complainedRecipients']] add_to_suppression_list(complained_addresses) def add_to_suppression_list(email_addresses): for email in email_addresses: sesv2.put_suppressed_destination( EmailAddress=email, Reason='BOUNCE' # Use 'COMPLAINT' for complaint types ) print(f"Added email to SES suppression list") def delete_sqs_message(receipt_handle): sqs.delete_message( QueueUrl=SQS_QUEUE_URL, ReceiptHandle=receipt_handle )
Step 4: Deploy the Lambda Function
Go to the AWS Lambda console.
Create a new Lambda function.
Attach the necessary IAM permissions:
Read from SQS
Write to SES suppression list
Deploy the function and configure it to trigger from the SQS queue.
Step 5: Test the Pipeline
Send a test email using SES to an invalid address.
Check the SQS queue for incoming messages.
Verify that the email address is added to the SES suppression list.
Conclusion
In this article, we are discussing “How to handle Bounce and Complaint Notifications in AWS SES with SNS, SQS, and Lambda”. This setup ensures that bounce and complaint notifications are handled efficiently, preventing future emails to problematic addresses and maintaining a good sender reputation. By leveraging AWS Lambda, SQS, and SNS, you can automate the process and improve email deliverability.
Keep learning and stay safe 🙂
You may like:
How to Setup AWS Pinpoint (Part 1)
How to Setup AWS Pinpoint SMS Two Way Communication (Part 2)?
Basic Understanding on AWS Lambda
0 notes
Text
Workflow Automation: A Technical Guide to Streamlining Business Processes
In an era where digital transformation is crucial for business success, workflow automation has emerged as a key strategy to enhance efficiency, eliminate manual errors, and optimize processes. This guide provides an in-depth technical understanding of automating workflows, explores the architecture of automation tools like Power Automate workflow, and highlights the benefits of workflow automation from a technical perspective.
What is Workflow Automation?
Workflow automation is the process of using software to define, execute, and manage business processes automatically. These processes consist of a sequence of tasks, rules, and conditions that dictate how data flows across systems. The goal is to reduce human intervention, improve speed, and ensure process consistency.
Automation can be applied to various workflows, including:
Document Management – Automating approvals, storage, and retrieval.
Customer Relationship Management (CRM) – Auto-updating customer data, triggering notifications, and assigning tasks.
IT Operations – Automating system monitoring, log analysis, and incident responses.
Financial Processes – Invoice processing, payment reconciliations, and fraud detection.
Key Components of Workflow Automation
A typical workflow automation system consists of:
Trigger Events – Initiate automation based on user actions (e.g., form submission, email receipt) or system changes (e.g., new database entry).
Condition Logic – Defines rules using conditional statements (IF-THEN-ELSE) to determine workflow execution.
Actions and Tasks – The automated steps executed (e.g., sending emails, updating records, triggering API calls).
Integrations – Connections with third-party applications and APIs for data exchange.
Logging and Monitoring – Capturing logs for debugging, performance monitoring, and compliance tracking.
Technical Benefits of Workflow Automation
1. API-Driven Workflows
Modern automation tools rely on RESTful APIs to integrate with external applications. For example, Microsoft Power Automate workflow uses connectors to interact with services like SharePoint, Salesforce, and SAP.
2. Event-Driven Architecture
Automation platforms support event-driven models, allowing workflows to respond to real-time changes. Technologies like AWS Lambda, Azure Logic Apps, and Kafka enable scalable automation based on event triggers.
3. RPA and AI Integration
Robotic Process Automation (RPA) enhances traditional automation by using AI-powered bots to handle tasks like document scanning, data extraction, and decision-making. AI-based automation tools leverage:
Optical Character Recognition (OCR) for processing scanned documents.
Natural Language Processing (NLP) for sentiment analysis in customer feedback.
Machine Learning (ML) for predictive analytics in workflow decision-making.
4. Security and Compliance Considerations
When implementing automating workflows, businesses must ensure:
Role-Based Access Control (RBAC) – Ensures only authorized users can modify automation rules.
Audit Trails – Logs all workflow activities for compliance and troubleshooting.
Data Encryption – Protects sensitive information during automation.
5. Serverless Automation
Serverless computing platforms like AWS Step Functions and Azure Logic Apps enable serverless workflow execution, reducing infrastructure costs while improving scalability.
How to Implement Workflow Automation?
Step 1: Process Identification
Identify repetitive and rule-based processes suitable for automation. Use process mining tools like Celonis or UIPath Process Mining to analyze workflows.
Step 2: Selecting the Right Automation Platform
Choose a tool based on business requirements:
Microsoft Power Automate workflow – Best for enterprises using Microsoft 365.
Zapier – Ideal for no-code integrations between cloud apps.
UiPath, Blue Prism – Suitable for RPA-based automation.
Step 3: Workflow Design & Configuration
Define triggers (e.g., email receipt, API call).
Configure actions (e.g., database updates, message notifications).
Set conditions (e.g., decision logic, approval steps).
Step 4: Integration with Enterprise Systems
Use APIs, Webhooks, and middleware (e.g., Mulesoft, Apache Kafka) to connect automated workflows with CRM, ERP, and HRMS systems.
Step 5: Testing & Deployment
Unit Testing – Validate each step of the workflow.
Integration Testing – Ensure proper data exchange across systems.
Performance Testing – Assess automation speed and efficiency.
Step 6: Monitoring and Optimization
Utilize monitoring tools like Splunk, ELK Stack, or Azure Monitor to analyze workflow performance and optimize automation rules.
Future of Workflow Automation
Hyperautomation – The combination of RPA, AI, and ML for end-to-end business process automation.
Blockchain for Workflow Security – Smart contracts ensuring transparent and tamper-proof workflows.
Edge Computing in Automation – Bringing automation closer to IoT devices for real-time decision-making.
Conclusion
Workflow automation is revolutionizing business operations by enabling intelligent, data-driven decision-making. Leveraging automating workflows through tools like Power Automate workflow, businesses can achieve greater efficiency, accuracy, and scalability. The benefits of workflow automation extend beyond cost savings, impacting compliance, security, and business agility.
Investing in the right automation technology will ensure a future-proof and competitive business environment. Start implementing workflow automation today to drive innovation and efficiency!
0 notes
Text
Build A Smarter Security Chatbot With Amazon Bedrock Agents

Use an Amazon Security Lake and Amazon Bedrock chatbot for incident investigation. This post shows how to set up a security chatbot that uses an Amazon Bedrock agent to combine pre-existing playbooks into a serverless backend and GUI to investigate or respond to security incidents. The chatbot presents uniquely created Amazon Bedrock agents to solve security vulnerabilities with natural language input. The solution uses a single graphical user interface (GUI) to directly communicate with the Amazon Bedrock agent to build and run SQL queries or advise internal incident response playbooks for security problems.
User queries are sent via React UI.
Note: This approach does not integrate authentication into React UI. Include authentication capabilities that meet your company's security standards. AWS Amplify UI and Amazon Cognito can add authentication.
Amazon API Gateway REST APIs employ Invoke Agent AWS Lambda to handle user queries.
User queries trigger Lambda function calls to Amazon Bedrock agent.
Amazon Bedrock (using Claude 3 Sonnet from Anthropic) selects between querying Security Lake using Amazon Athena or gathering playbook data after processing the inquiry.
Ask about the playbook knowledge base:
The Amazon Bedrock agent queries the playbooks knowledge base and delivers relevant results.
For Security Lake data enquiries:
The Amazon Bedrock agent takes Security Lake table schemas from the schema knowledge base to produce SQL queries.
When the Amazon Bedrock agent calls the SQL query action from the action group, the SQL query is sent.
Action groups call the Execute SQL on Athena Lambda function to conduct queries on Athena and transmit results to the Amazon Bedrock agent.
After extracting action group or knowledge base findings:
The Amazon Bedrock agent uses the collected data to create and return the final answer to the Invoke Agent Lambda function.
The Lambda function uses an API Gateway WebSocket API to return the response to the client.
API Gateway responds to React UI via WebSocket.
The chat interface displays the agent's reaction.
Requirements
Prior to executing the example solution, complete the following requirements:
Select an administrator account to manage Security Lake configuration for each member account in AWS Organisations. Configure Security Lake with necessary logs: Amazon Route53, Security Hub, CloudTrail, and VPC Flow Logs.
Connect subscriber AWS account to source Security Lake AWS account for subscriber queries.
Approve the subscriber's AWS account resource sharing request in AWS RAM.
Create a database link in AWS Lake Formation in the subscriber AWS account and grant access to the Security Lake Athena tables.
Provide access to Anthropic's Claude v3 model for Amazon Bedrock in the AWS subscriber account where you'll build the solution. Using a model before activating it in your AWS account will result in an error.
When requirements are satisfied, the sample solution design provides these resources:
Amazon S3 powers Amazon CloudFront.
Chatbot UI static website hosted on Amazon S3.
Lambda functions can be invoked using API gateways.
An Amazon Bedrock agent is invoked via a Lambda function.
A knowledge base-equipped Amazon Bedrock agent.
Amazon Bedrock agents' Athena SQL query action group.
Amazon Bedrock has example Athena table schemas for Security Lake. Sample table schemas improve SQL query generation for table fields in Security Lake, even if the Amazon Bedrock agent retrieves data from the Athena database.
A knowledge base on Amazon Bedrock to examine pre-existing incident response playbooks. The Amazon Bedrock agent might propose investigation or reaction based on playbooks allowed by your company.
Cost
Before installing the sample solution and reading this tutorial, understand the AWS service costs. The cost of Amazon Bedrock and Athena to query Security Lake depends on the amount of data.
Security Lake cost depends on AWS log and event data consumption. Security Lake charges separately for other AWS services. Amazon S3, AWS Glue, EventBridge, Lambda, SQS, and SNS include price details.
Amazon Bedrock on-demand pricing depends on input and output tokens and the large language model (LLM). A model learns to understand user input and instructions using tokens, which are a few characters. Amazon Bedrock pricing has additional details.
The SQL queries Amazon Bedrock creates are launched by Athena. Athena's cost depends on how much Security Lake data is scanned for that query. See Athena pricing for details.
Clear up
Clean up if you launched the security chatbot example solution using the Launch Stack button in the console with the CloudFormation template security_genai_chatbot_cfn:
Choose the Security GenAI Chatbot stack in CloudFormation for the account and region where the solution was installed.
Choose “Delete the stack”.
If you deployed the solution using AWS CDK, run cdk destruct –all.
Conclusion
The sample solution illustrates how task-oriented Amazon Bedrock agents and natural language input may increase security and speed up inquiry and analysis. A prototype solution using an Amazon Bedrock agent-driven user interface. This approach may be expanded to incorporate additional task-oriented agents with models, knowledge bases, and instructions. Increased use of AI-powered agents can help your AWS security team perform better across several domains.
The chatbot's backend views data normalised into the Open Cybersecurity Schema Framework (OCSF) by Security Lake.
#securitychatbot#AmazonBedrockagents#graphicaluserinterface#Bedrockagent#chatbot#chatbotsecurity#Technology#TechNews#technologynews#news#govindhtech
0 notes